Материалы по тегу: cpu
|
18.06.2020 [16:00], Алексей Степин
Intel представила Xeon Cooper Lake, третье поколение Scalable-процессоровКрупнейший в мире производитель процессоров с архитектурой x86, компания Intel, представила новую платформу, нацеленную на быстро растущий рынок машинного обучения, аналитики и периферийных вычислений. Хотя платформа состоит из нескольких компонентов, главным из них являются новые процессоры Intel Xeon Scalable — это уже третье поколение серии Scalable.  Первое поколение Xeon Scalable (Skylake) отличалось наличием поддержки векторных расширений с длиной 512 бит, хотя эта поддержка была наиболее полной в других процессорах с разъёмом LGA 3647, ныне почивших Xeon Phi 72xx. Во втором поколении Xeon Scalable, известном под кодовым именем Cascade Lake, появились расширения AVX-512 VNNI (Vector Neural Network Instructions, они же DL Boost), и это был первый реверанс в сторону машинного обучения со стороны Intel — расширения позволялил работать с INT8 и подходили для инференса.  Третье поколение, получившее имя Cooper Lake, ещё больше продвинулось в сторону поддержки нетипичных для традиционной архитектуры x86 форматов вычислений. Главным нововведением здесь является поддержка формата bfloat16, который часто используется в комплексах машинного обучения и системах принятия решений (инференс). Он требует меньше вычислительных мощностей, нежели традиционные форматы FP32/64, но при этом в большинстве случаев обеспечивает достаточную точность вычислений, а итоговый выигрыш в производительности может быть почти двухкратным.  Популярные фреймворки, такие как TensorFlow и Pytorch, уже давно поддерживают bfloat16, а Intel-оптимизированные версии доступны в комплекте Intel AI Analytics Toolkit. Компания также оптимизировала среды OpenVINO и ONNX с учётом возможностей новых процессоров Xeon Scalable. Собственно говоря, самое главное в Cooper Lake то, что их теперь можно использовать и для обучения нейронных сетей, а не только для инференса. Intel отдельно подчёркивает универсальность новых CPU. 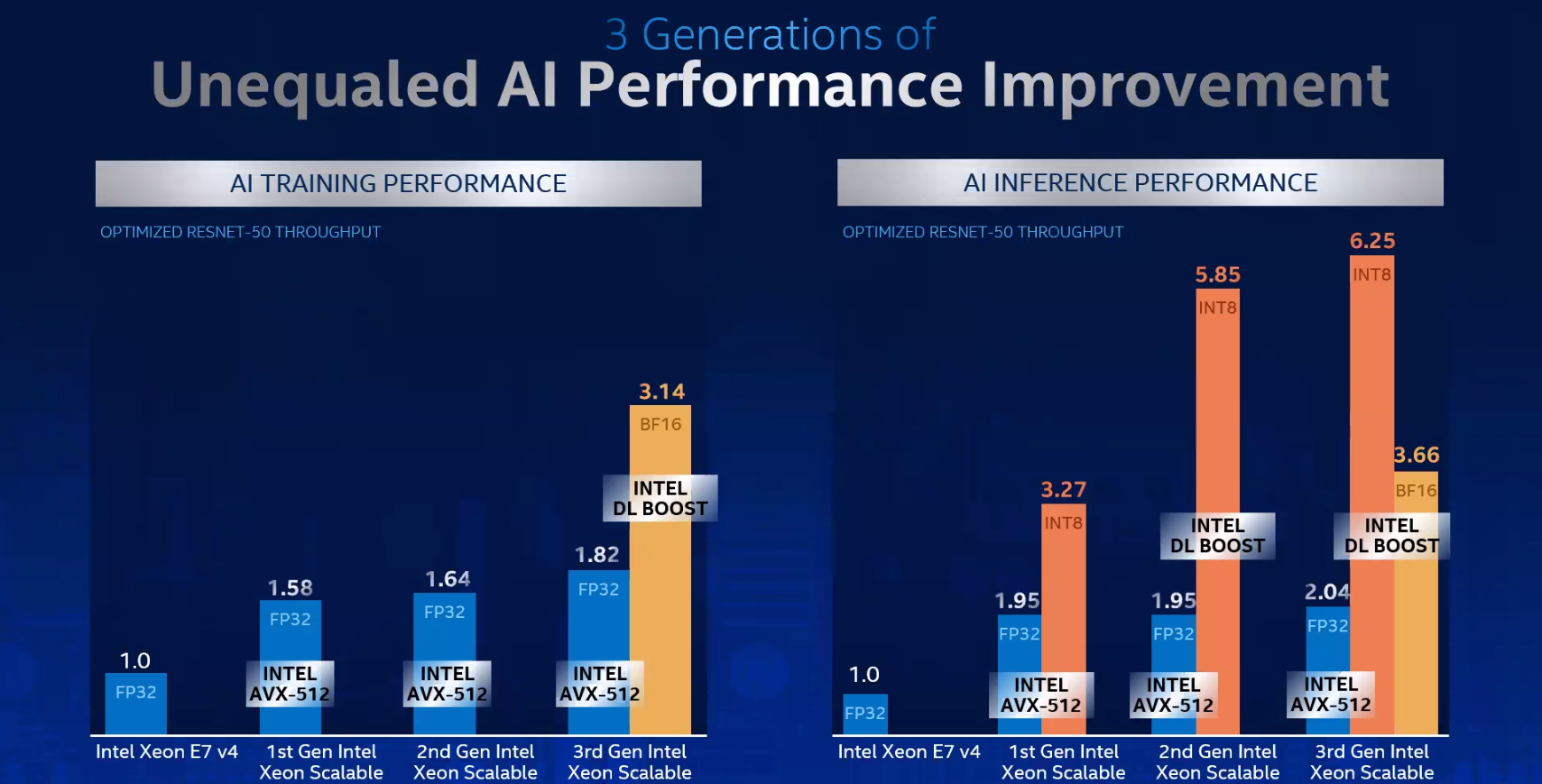 Что касается самих процессоров, то максимальное количество ядер сохранилось, их в серии Xeon Gold 53xx/63xx и Xeon Platinum 83xx по-прежнему 28 при поддержке SMT2. Однако улучшения есть, и достаточно серьёзные. Серия Xeon Platinum поддерживает память до DDR4-3200 (1DPC) и DDR4-2933 (2DPC), хотя младшие пяти- и шеститысячники так же ограничены 2666 и 2933 MT/с. Зато все они поддерживают память Intel Optane DCPMM 2-го поколения. Число каналов память осталось прежним, их шесть. Существенное отличие от Cascade Lake в том, что теперь у всех CPU есть 6 линий UPI — они могут может «бесшовно» устанавливаться в системы с четырьмя или восемью процессорными разъёмами. Другое важное отличие — серия 53xx теперь имеет два FMA-порта для AVX-512, а не один как раньше. Часть новинок поддерживает Intel Speed Select. 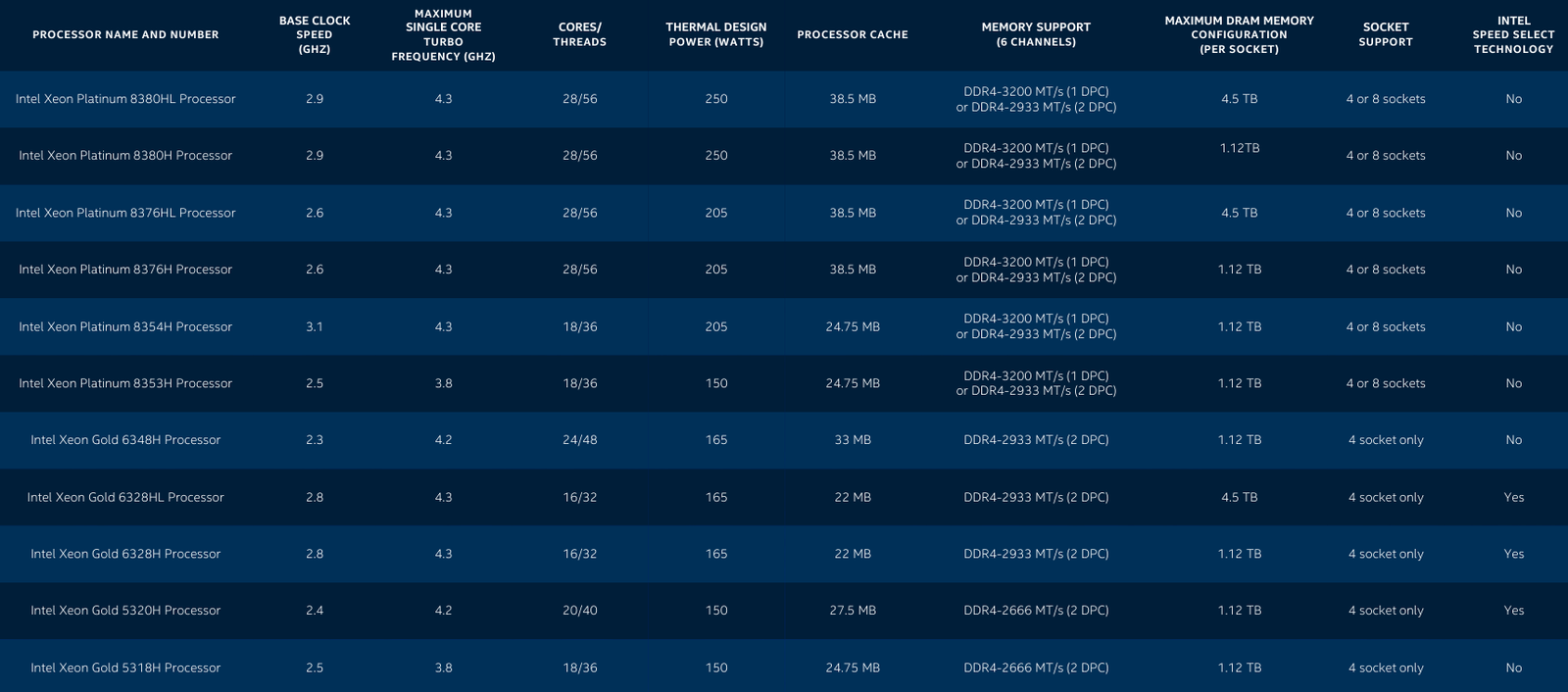 У «ёмких» моделей с суффиксом HL максимальный объём оперативной памяти достиг 4,5 Тбайт, а у базовых H — до 1,12 Тбайт. Несколько подросли тактовые частоты, в серии есть модели с частотной формулой 2,9 ‒ 4,3 ГГц, причём большая часть новинок имеет частоту в турборежиме более 4 ГГц. Исключение — модели с пониженным энергопотреблением. Всё это делает новые процессоры привлекательными для крупных предприятий, облачных провайдеров и гиперскейлеров вообще. Если даже на секунду забыть все новововведения для ИИ, Cooper Lake всё равно останется многосокетной платформой, а это значит, что он подходит для работы с большими СУБД, анализа больших объёмов данных в реальном времени, OLTP и виртуализации. В области 4S/8S-платформ у Intel давно крепкие позиции, так что новинки наверняка приглянутся определённому кругу заказчиков. Но массовыми Cooper Lake в текущем виде не станут. 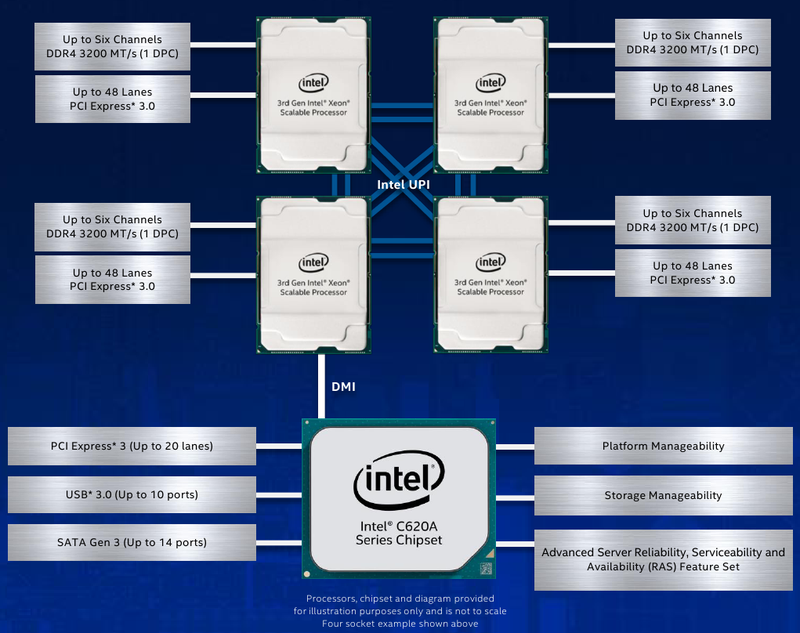 Основной системный чипсет — Intel C620A, то есть обновлённый Lewisburg. В серию пока входит всего три модели, две из которых поддерживают технологию Intel QAT, ускоряющую работы по компресии и шифрованию. Так это обновление уже имеющихся чипсетов, поддержки PCI Express 4.0 нет. Сами процессоры Xeon Scalable третьего поколения по-прежнему могут предоставить в распоряжение системы до 48 линий PCIe 3.0. С учётом того, что ориентированы они на 4-сокетные системы, этого может быть вполне достаточно.  Однако другие процессоры Xeon Scalable «Ice Lake», для одно-двухсокетных платформ Whitley, которые Intel планирует представить позднее в этом году, уже получат поддержку PCI Express 4.0. Также известно, что четвёртое поколение Xeon Scalable под именем Sapphire Rapids получит набор новых матричных расширений (Advanced Matrix Extensions, AMX), которые, вероятно, буду напоминать тензорные ядра. Она увидит свет уже в 2021 году. Для массовых одно- и двухсокетных платформ пока предлагается использовать Cascade Lake Refresh. Вместе с Intel Xeon Cooper Lake компания также анонсировала второе поколение памяти Intel Optane DCPMM 200, накопители Intel D7-P5500 и D7-5600 с интерфейсом PCIe 4.0 и новую FPGA Intel Stratix 10 NX.
24.02.2020 [17:00], Константин Ходаковский
Intel представила семейство процессоров Intel Xeon Cascade Lake RefreshВместе с серией продуктов для инфраструктуры сетей 5G, включающей систему на кристалле Atom P5900 для базовых станций, структурированную платформу ASIC Diamond Mesa для ускорения сетей 5G, серию сетевых контроллеров Ethernet 700 и программное решение OpenNESS для лёгкого развёртывания облачных периферийных микросервисов, корпорация Intel расширила и серию серверных процессоров Intel Xeon Scalable 2-го поколения.  Intel Xeon Scalable 2-го поколения являются основой платформенной инфраструктуры в центрах обработки данных. На сегодняшний день чипов Xeon Scalable продано в общей сложности более 30 миллионов. Появление этих процессоров позволило трансформировать ядро сети: сегодня на их долю приходится 50 % всех виртуализированных окружений по всему миру, а к 2023 году это число дополнительно увеличится.  Как мы уже сообщали, новая серия серверных процессоров Intel включает 18 моделей с более высокими частотами (до 4 ГГц в режиме Turbo Boost), увеличенным количеством ядер и объёмом кеша в различной комбинации этих параметров. Но главное изменение — это существенно сниженная стоимость. Например, Xeon Gold 6238R предложит 28 ядер и базовую частоту 2,2/4 ГГц, тогда как его предшественник в лице Xeon Gold 6238 использует 22 ядра с частотой 2,1/3,7 ГГц при одинаковой стоимости.  Флагманом семейства станет Xeon Gold 6258R с 28 ядрами, поддержкой Hyper-Threading, базовой частотой 2,7 ГГц и уровнем TDP не более 205 Вт. В обозначении моделей новых процессоров, как правило, присутствует литера «R», то есть Refresh. Серия оптимизированных ЦП для высочайшей производительности отдельных ядер теперь представляет собой такой перечень. Все процессоры поддерживают Intel Optane DC Persistent Memory (жирным помечены новые модели):
Серия ЦП, оптимизированных для производительности на Ватт, представляет собой такой перечень. Все процессоры Platinum и Gold поддерживают Intel Optane DC Persistent Memory, а остальные — нет (жирным помечены новые модели):
Также компания представила новый чип в семействе энергоэффективных, рассчитанных на долгий цикл процессоров, — Silver 4210T (10 ядер, 2,3/3,2 ГГц, 13,75 Мбайт, 95 Вт, $554). Как и старая 8-ядерная модель Silver 4209T, новая тоже не поддерживает Intel Optane DC Persistent Memory. И наконец для односокетных серверов, где принципиальную роль играет стоимость, представлена 16-ядерная модель Gold 6208U (2,9/3,9 ГГц, 22 Мбайт, 150 Вт, $989, поддержка Intel Optane DC Persistent Memory). Запуск новых моделей призван сделать предложения Intel более конкурентоспособными по сравнению с 7-нм чипами AMD EPYC Rome — неслучайно затронуты были наиболее ходовые процессоры. Самое производительное (и дорогое) семейство Xeon Platinum 9000 с количеством ядер от 32 до 56 обновлено не было. Повышение показателя цены/производительности — главный повод к запуску Cascade Lake R (снижение наблюдается кратное). В новой серии процессоры разделены между семействами Bronze, Silver и Gold. Неслучайно процессоров Platinum в ней нет: старшие модели, в том числе и 28-ядерный флагман, вошли в семейство Gold. Поэтому Intel законно поставила на «новинки» более низкие ценники. Ранее компания уже серьёзно пересмотрела свои серверные предложения. Она, по сути, отказалась от процессоров серии M, которые, в отличие от стандартных решений, ограниченных объёмом ОЗУ в 1,5 Тбайт, позволяют работать в системах с 2 Тбайт памяти. Клиентам, нуждающимся в таком объёме ОЗУ, теперь предлагается использовать процессоры класса выше — L, поддерживающие уже 4,5 Тбайт. Для этого компания уравняла цены моделей L с M. Впрочем, не все OEM-производители спешат обесценить свои запасы и задерживают снижение цен.  Помимо процессоров Intel также представила 17 обновлённых решений Select Solutions, в которых реализована поддержка этих новых продуктов для ускорения наиболее важных рабочих нагрузок у заказчиков. Ведущие отраслевые производители уже начинают поставки новых платформ на базе Intel Xeon 2-го поколения Refresh.
19.02.2020 [17:16], Алексей Степин
Calxeda: взлёт и падение первого разработчика серверных процессоров ARMАрхитектура ARM активно прокладывает себе путь в серверные системы и даже в суперкомпьютеры. Но судьба первой компании, рискнувшей сделать ставку на ARM, вовсе не так радужна. В 2011 году компания Calxeda опубликовала сведения о 32-бит серверном процессоре на базе ARM Cortex-A9. В 2020 году можно считать, последний гвоздь в крышку гроба этих CPU забит — в ядре Linux поддержка платформ Calxeda будет в ближайшее время прекращена. Но мы считаем, что те, кто первыми бросил вызов могуществу x86, заслуживают памяти.  Ещё первая разработка Calxeda, четырёхъядерный процессор ARM Cortex-A9, о котором мы писали в 2011 году, позволял создавать серверы формата 2U со 120 процессорами (480 ядер совокупно). Компания называла свою затею «первопроходческой инициативой» и планировала развернуть вокруг своих разработок целую экосистему — и спрос на такие решения был. 
Преимущества платформы Calxeda по мнению компании: экономичность, компактность, низкая стоимость Проект поддержал солидный список из венчурных фондов и производителей полупроводников: ARM, Advanced Technology Investment Company, Battery Ventures, Flybridge Capital Partners и Highland Capital Partners, а первым ключевым партнёром для Calxeda стала Canonical — разработчик операционной системы Ubuntu. 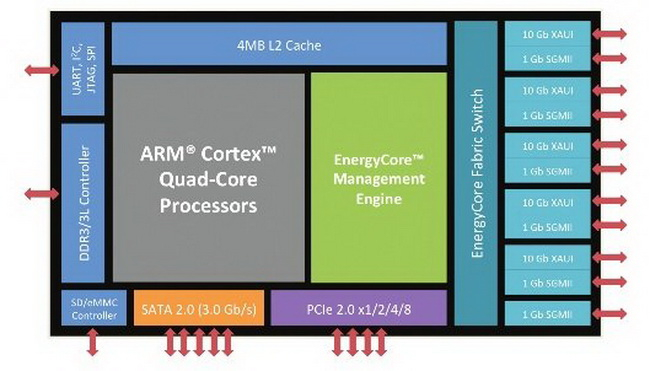
Архитектура первого серверного процессора Calxeda EnergyCore ECX-1000 К концу 2011 года проект оформился окончательно. CPU получил название EnergyCore, стали известны тактовые частоты (1,1 ‒ 1,4 ГГц) и другие подробности: наличие 4 Мбайт кеша L3, интегрированного коммутатора с производительностью 80 Гбит/с, отдельного ядра для управления энергопотребления. Энергопотребление одного узла на базе EnergyCore, в состав которого, помимо процессора, входило 4 Гбайт памяти и SSD-накопитель, могло составлять всего 5 ватт. Неудивительно, что разработкой заинтересовалась Hewlett-Packard, объявившая о намерении использовать EnergyCore в своих новых серверах. Говорилось о 4U-шасси, содержащих 288 чипов Calxeda EnergyCore. 
Эталонный дизайн вычислительного узла с четырьмя Calxeda EnergyCore К сожалению, в 2012 году было объявлено о том, что OEM-серверы на базе чипов Calxeda появятся только ближе к концу года. Но HP уже располагает такими системами под названием Redstone; они используются для разработки энергоэффективной серверной архитектуры в проекте Moonshot. 
Мини-кластер HP Redstone Осенью того же года Calxeda объявляет о выпуске новой платформы Midway. В ней используется более совершенная архитектура ARM Cortex-A15 с поддержкой аппаратных средств виртуализации. Опубликованы планы на 2014 год, в них фигурирует поддержка 64-битной архитектуры ARM v8. Наконец, на конференции Strata + HadoopWorld в Нью-Йорке компания Penguin Computing демонстрирует успешную работу Hadoop на платформе UDX1, построенной с использованием Calxeda EnergyCore. 
Типичный дизайн сервера на базе процессоров Calxeda. Производитель Boston, модель Viridis 2013 год. Intel не собирается уступать и в противовес Calxeda и AMD, работающими над созданием экономичных ARM-процессоров, выпускает первую систему на чипе на базе архитектуры Broadwell. К сожалению, это последний год деятельности Calxeda. Исчерпав резервы денежных средств, пионер на рынке ARM-серверов объявляет о прекращении своей работы. По мнению экспертов, причин краха две — компания слишком рано начала наступление на серверный рынок, ещё не готовый к пришествию ARM, а также сделала ставку на 32-битные процессоры в то время, как серверный рынок уже успел привыкнуть к 64-битным чипам, хотя бы потому, что они поддерживают большие объемы оперативной памяти. Кроме того, даже сама ARM относительно недавно, наконец, ввела спецификации ServerReady для упрощения внедрения в серверный сегмент. Крах Calxeda также негативно сказался на общее отношение к серверным ARM в индустрии, которая сама по себе всегда была консервативна. В частности, в разговоре на SC19 представитель одного из ведущих производителей серверов отметил, что неуспех первых ARM-платформ и фактически впустую потраченные средства надолго отпугнули корпорацию даже от экспериментов в этой области. 
Последние из могикан: вскоре для них не останется работы Уже выпущенные серверы с процессорами Calxeda ещё работают. Но дни их уже сочтены: на рынке серверных процессоров с архитектурой ARM появляются другие игроки, изначально сделавшие ставку на мощные 64-битные варианты. К 2020 году встретить сервер Calxeda в работе удаётся очень редко — и разработчики ядра Linux объявляют о том, что вскоре откажутся от поддержки инфраструктуры Calxeda. Будет также убрана поддержка KVM-виртуализации для всех 32-битных процессоров ARM. Это не первая история неуспеха ARM в серверном сегмента. Два крупнейших производителя SoC, Broadcom и Qualcomm, в итоге отказались от затеи. Наработки первой после долгих скитаний воплотились в ThunderX, а процессоры Centriq второй так толком и не увидели свет. Собственные CPU Marvell не снискали большой популярности, так что компания в итоге купила ThunderX. ThunderX 2 вместе с Fujitsu A64FX пока остаются единственными крупными игроками на этом рынке, если не считать ряда внутренних разработок вроде AWS Graviton, которые не предназначены для свободной продажи. Конкуренцию им в ближайшее время должны составить Ampere eMAG и Huawei KunPeng.
30.09.2019 [11:00], Андрей Созинов
Конец эпохи? Oracle сворачивает SPARC-бизнес и инвестирует в ARMКомпания Oracle объявила, что инвестировала $40 млн в компанию Ampere Computing, которая занимается разработкой 64-разрядных ARM-процессоров серверного класса. Похоже, компания потеряла интерес к SPARC, доставшейся ей при покупке Sun, так что эпоха этой архитектуры подходит к концу.  Инвестиции были произведены ещё в апреле текущего года. За сумму в примерно 40 млн долларов было приобретено около 20 % акций Ampere Computing, за счёт чего Oracle получила одно из кресел в совете директоров. Кроме того, самой Ampere управляет Рене Джеймс (Renée James), которая также занимает место в совете директоров Oracle. Помимо инвестиций Oracle заплатила Ampere около $419 000 за разработку и тестирование оборудования в 2019 финансовом году. Интересно, что сама компания об инвестициях Oracle не сообщала, отметив лишь финансирование со стороны ARM Holdings и Carlyle Group. Ampere специализируется на разработке процессоров для облачных систем и серверов, которые сочетают высокую производительность и энергоэффективность.  В то же время Oracle всё меньше внимания уделяет собственной архитектуре SPARC и разработке процессоров на её основе. Заявлений об отказе от этой архитектуры пока что не последовало. Однако в отчёте за 2019 финансовый год Сафра Кац (Safra Catz), один из генеральных директоров Oracle, заявила: «Наши высокодоходные облачные решения Fusion и NetSuite быстро растут, и мы сокращаем свой низкорентабельный бизнес устаревшего [legacy] аппаратного обеспечения». 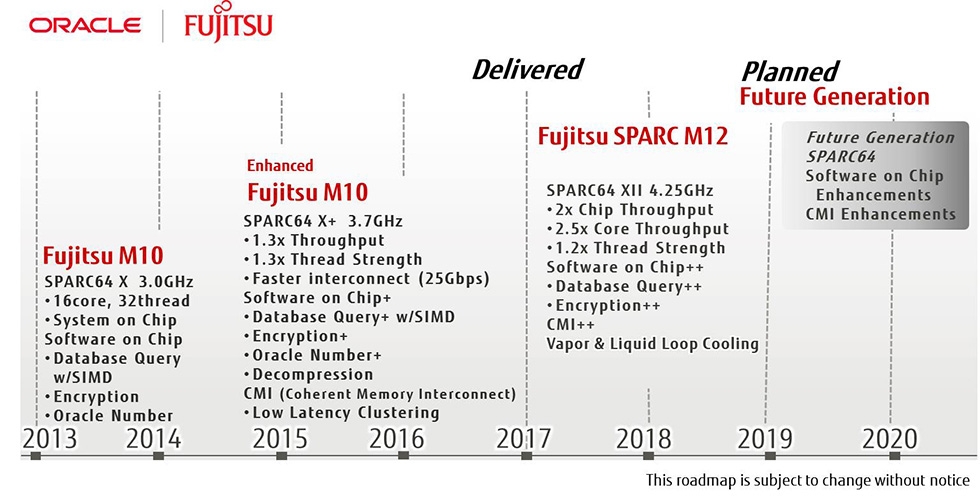 В последний раз обе компании обновляли свои SPARC-процессоры в 2017 году. После выхода M8 Oracle фактически разогнала отдел, занимавшийся разработкой CPU. Fujitsu же после выпуска SPARC64 XII говорила о намерениях выпустить следующее поколение SPARC64 в 2020 году. Формально Fujitsu остаётся последним разработчиком высокопроизводительных SPARC-процессоров серверного уровня, но у компании наверняка немало ресурсов уходит на суперкомпьютер Post-K и ARM-процессор A64FX. И несмотря на то, что лицензиями на SPARC обладает довольно много компаний, среди которых есть и отечественные разработчики, вряд ли хоть кто-то из них будет вкладываться в серьёзное развитие архитектуры.  Наконец, хотелось бы отметить, что и операционная система Solaris 11, возможно, станет последней ОС от Oracle для платформы SPARC. Первый релиз вышел 8 лет назад, и хотя Oracle постепенно вносит в неё некоторые улучшения, признаки разработки Solaris 12 отсутствуют. А на днях компания заявила, что обеспечит стандартную поддержку системы Solaris 11 до 2031 года и расширенную поддержку до 2034 года. Таким образом, Oracle исполнит свои долгосрочные обязательства по обновлению Solaris. Однако будет крайне удивительно, если мы когда-либо увидим Solaris 12.
18.09.2019 [19:50], Андрей Созинов
AMD представила EPYC 7H12: самый быстрый процессор семейства RomeСегодня в Риме компания AMD провела европейскую презентацию процессоров EPYC Rome (символично, не правда ли?), на которой неожиданно представила совершенно новый процессор — EPYC 7H12. Новинка отличается не только своим нестандартным названием, но и характеристиками, которые делают её самым мощным серверным процессором AMD на текущий момент. Процессор EPYC 7H12 обладает 64 ядрами, как и другие старшие модели семейства EPYC Rome. Базовая частота новинки составляет 2,6 ГГц, а максимальная Turbo-частота достигает 3,3 ГГц. Для сравнения — возглавлявший до этого семейство Rome процессор EPYC 7742 обладает значительно более низкой базовой частотой в 2,25 ГГц, а вот в режиме Turbo может разгоняться чуть выше — до 3,4 ГГц. Средняя же рабочая частота новинки будет выше. 
Источник изображения: AMD Базовая частота напрямую влияет на уровень TDP процессора. Поэтому показатель TDP EPYC 7H12 увеличился до 280 Вт, тогда как у EPYC 7742 он составлял 225 Вт. Из-за возросшего TDP новый процессор рекомендуется использовать в серверах с системами жидкостного охлаждения. Один из партнёров AMD, компания Atos, уже показала узел Bullsequana XH2000 с восемью процессорами EPYC 7H12 и полностью жидкостным охлаждением, высота которого составит лишь 1U. 
Источник изображения: Atos Кроме как частотами и уровнем TDP, процессоры EPYC 7H12 и EPYC 7742 ничем не отличаются друг от друга. Оба имеют 64 ядра Zen 2, 128 вычислительных потоков, 256 Мбайт кеш-памяти третьего уровня, 128 линий PCIe 4.0 и контроллер памяти с восемью каналами и поддержкой DDR4-3200. 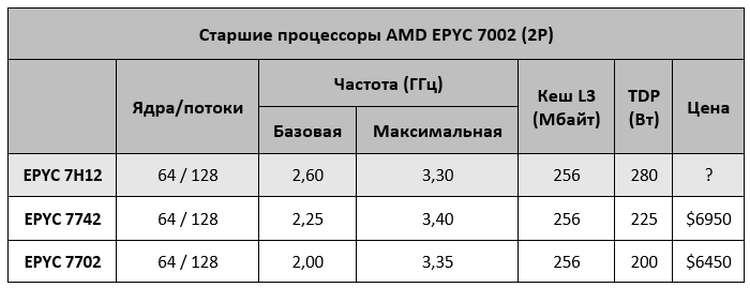 Процессор EPYC 7H12 ориентирован на использование в составе высокопроизводительных вычислительных систем и центрах обработки данных. Согласно синтетическому тесту Linpack, новый процессор обеспечивает прирост производительности до 11 % по сравнению с EPYC 7742, который мы протестировали в августе. Цена новинки пока не названа. Не исключено, что она будет заметно выше, чем у 7742. Всё-таки, это особый сегмент рынка, где даже за незначительный прирост производительности готовы платить. Аналогичную политику проводит и Intel. В семействе Xeon на базе Broadwell были модели с индексом A, которые отличались чуть более высокими частотами. А летом Intel представила процессор Xeon Platinum 8284, который в сравнении с базовой моделью 8280 также имеет повышенную частоту и возросший в полтора раза ценник.
24.08.2019 [06:14], Андрей Галадей
IBM передала наработки по архитектуре Power сообществуКорпорация IBM сообщила, что переводит архитектуру набора команд (ISA) Power в разряд открытых решений. То есть, за неё не нужно будет платить, как это было в последние 6 лет. Отмечается, что с 2013 года действовал консорциум OpenPOWER, который лицензировал связанную с Power интеллектуальную собственность. Но теперь все наработки и патенты будут переданы сообществу безвозмездно. Сама же организация OpenPOWER Foundation будет переподчинена Linux Foundation, что позволит создать площадку для развития архитектуры без привязки к чипмейкеру или иной компании. Как отмечается, OpenPOWER Foundation включает в себя более 350 компаний, а сообществу передали свыше 3 млн строк кода системных прошивок, спецификаций и схем. Всё это позволит создавать Power-совместимые чипы всем желающим. 
pixabay.com Помимо собственно процессоров, компания передала сообществу и смежные технологии для разработки расширений на основе интерфейсов OpenCAPI (Open Coherent Accelerator Processor Interface) и OMI (Open Memory Interface). Первая технология должна устранить «узкие места» во взаимодействии CPU, GPU, ASIC, а также других чипов и контроллеров. Вторая же должна ускорить оперативную память. Это позволит создавать на базе архитектуры Power специализированные чипы для искусственного интеллекта. Важно отметить, что процессоры Power позволяют создавать современные серверы и суперкомпьютеры. К примеру, суперкомпьютеры Summit и Sierra работают как раз на таких чипах. А это, на минуточку, первый и второй номера в мировом рейтинге таких систем. Напомним, на процессорах с архитектурой Power (хотя и специализированных) работали в том числе и консоли Sony PlayStation 3, Xbox 360, а также старые ПК и ноутбуки Apple.
27.07.2019 [15:15], Геннадий Детинич
Alibaba представила 16-ядерный RISC-V процессор XT 910 для «умной» периферии и edge-платформНа днях дочернее подразделение корпорации Alibaba Group компания Pingtouge Semiconductor на тематической конференции в Шанхае представила первый фирменный процессор для «умной» периферии. Китайская разработка XuanTie 910 оказалось уникальной по целому ряду причин, о которых мы поговорим ниже. Но прежде обозначим главное, на чём настаивают китайские источники. Процессор XuanTie 910 поможет китайским компаниям всех уровней сбросить зависимость от ядер ARM и других проприетарных разработок (читай ― сведут на нет опасность санкций со стороны США), поскольку ядра XuanTie 910 используют открытую архитектуру RISC-V с открытым набором команд.  Производительность моделей процессоров семейства XuanTie 910 может варьироваться в широких пределах. 64-бит ядра собираются в кластеры по четыре штуки. В процессоре может быть до четырёх таких кластеров, то есть в максимальной конфигурации XuanTie 910 имеет 16 ядер RISC-V. Больше вряд ли необходимо, но в случае надобности разработчики наверняка смогут увеличить число ядер в процессоре. Относительно небольшое число ядер в процессорах XuanTie 910 объясняется назначением платформы ― стать основой вещей с подключением к Интернету, ассистентов (умных колонок и прочего), самоуправляемых автомобилей, периферии с подключением к сетям 5G, платформ с элементами ИИ и тому подобных решений для перифейрийных (edge) вычислений и платформ. По словам разработчиков, XuanTie 910 сегодня является самым производительным решением на архитектуре RISC-V. Это решение на частоте 2,5 ГГц, изготовленное с использованием 12-нм техпроцесса, как заявлено, обеспечивает производительность на уровне 7,1 CoreMark/МГц, что на 40 % больше, чем для существующих сегодня конкурирующих процессоров на архитектуре RISC-V. Если точнее, то сравнение было с 64-бит ядром SiFive U74, которое достигает 5,1 CoreMark/МГц (на ядро). Оно тоже позиционируется как самое мощное решение RISC-V, способное исполнять полноценные ОС вроде Linux. Для сравнения — отечественный процессор Байкал-Т1, согласно нашим прошлогодним тестам, имеет производительность 5,4 CoreMark/МГц (на ядро). 
onties.com Удивительным в этом сообщении наших коллег с EE Times представляется информация о 12-нм техпроцессе, который был задействован для производства XuanTie 910. Этот техпроцесс широко использует только компания GlobalFoundries. В этом случае Alibaba 100-процентно подставляется под санкции США, что нивелирует всякий смысл выбора открытой архитектуры. Впрочем, выводы делать рано, подождём подробности. Из других интересных особенностей ядер XuanTie 910 отметим 12-уровневый конвейер с внеочередным исполнением команд. За один цикл конвейер может исполнять сразу до 8 инструкций, причём и инструкции загрузки (load), и сохранения (store). Важно, что разработчики добавили в архитектуру RISC-V и процессор 50 новых расширенных инструкций для лучшей работы арифметических операций, доступа к памяти и поддержки многоядерности. Эти инструкции и ряд других решений китайцы сделают достоянием сообщества разработчиков с открытым кодом. Всё (или почти всё) будет выложено на GitHub, вероятно, в сентябре. Компании важно получить как можно более широкую поддержку со стороны независимых программистов, чему открытость RISC-V будет только способствовать. Примечательно, что новость о выходе XT 910 исчезла с сайта RISC-V Foundation через несколько часов после выхода. Среди других заметных китайских участников RISC-V Foundation есть Huawei, MediaTek, Huami (партнёр Xiaomi), а также инвестгруппа Xiamen SIG. Сейчас Китай активно развивает импортозамещение. Согласно планам правительства, в 2020 году 40% спроса на полупроводниковую продукцию должны удовлетворить местные производители. В прошлом году, по данным TrendForce, лишь 15% пришлось на «домашние» процессоры.
16.04.2019 [17:05], Андрей Созинов
AMD Ryzen Embedded R1000: двухъядерные процессоры для встраиваемых системКомпания AMD расширила ассортимент своих продуктов для встраиваемых систем, представив новую серию процессоров Ryzen Embedded R1000. Новинки, по словам самой AMD, предлагают новый класс производительности в области встраиваемых систем, а также предлагают лучшее соотношение цены и производительности по сравнению с конкурентными решениями. 
Источник изображений: AMD Всего было представлено два процессора: Ryzen Embedded R1606G и R1505G. Новинки весьма похожи друг на друга и отличаются между собой только тактовыми частотами ядер и встроенного GPU. Оба процессора располагают парой ядер Zen с поддержкой SMT, то есть работают на четыре потока. В качестве встроенного GPU в обеих новинках выступает Vega 3. В случае процессора Ryzen Embedded R1606G частоты ядер составляют 2,6/3,5 ГГц, а GPU — 1,2 ГГц. Младший Ryzen Embedded R1505G во всём медленнее на 200 МГц, то есть предлагает 2,4/3,3 и 1 ГГц соответственно.  Объём кеша второго и третьего уровней составляет 1 и 4 Мбайт соответственно. Поддерживается оперативная память DDR4 с частотой до 2400 МГц. Также есть поддержка до двух 10-гигабитных портов Ethernet. Есть возможность подключения до трёх дисплеев. Максимальный поддерживаемый формат видео — 4K с частотой 60 FPS.  Производители систем на базе новинок AMD смогут самостоятельно настроить уровень TDP чипов в пределах от 12 до 25 Вт. Это, конечно же, будет несколько влиять на производительность, однако позволит использовать чипы как в более мощных компьютерах, так и в более экономичных, и даже безвентиляторных системах. По словам AMD, новинки могут найти применение в самых различных устройствах: от тонких клиентов до промышленных систем и игровых систем, вроде предстоящей Atari VCS.  Также AMD отмечает высокую производительность своих новинок. В качестве примера приводятся результаты тестирования в Cinebench R15 и 3DMark11. Здесь оба процессора серии Ryzen Embedded R1000 смогли опередить чипы Intel Core i3-8145U поколения Whiskey Lake и Core i3-7100U поколения Kaby Lake.
02.04.2019 [20:00], Геннадий Детинич
Intel представила процессоры Xeon D-1600: почта, телеграф, мостыВ 2015 году компания Intel представила процессоры Xeon семейства D. Первой появилась серия Xeon D-1500. Процессоры Xeon D получили архитектуру уровня Intel Core (Broadwell), став на ступеньку выше Xeon на архитектуре Atom. Целевое назначение Xeon D при этом не изменилось ― они всё так же были ориентированы на создание микросерверов, встраиваемых решений, систем для хранения данных малого и среднего уровней и сетевого оборудования. В 2018 году компания выпустила серию Xeon D-2100 на архитектуре Skylake. Тем самым в семейство Xeon D добавились решения повышенной производительности. Сегодня Intel представила третью серию Xeon D ― процессоры D-1600, которые возвращают нас к истокам семейства, главной целью которого был захват рынка производительной периферии с акцентом на плотность и сниженное потребление.  Процессоры Intel Xeon D-1600 получили меньшее число ядер, чем у их предшественников в лице Xeon D-1500. Диапазон числа физических ядер у моделей Xeon D-1600 сократился с 4–16 до 2–8. Максимальный тепловой пакет при этом остался тем же ― 65 Вт, тогда как минимальное значение TDP снизилось с 35 Вт до 27 Вт. Снижение числа ядер и сохранение максимального уровня TDP говорит о росте производительности в пересчёте на одно ядро. Во многом это достигается за счёт прироста как базовой частоты (в 1,2–1,5 раза), так и за счёт увеличения частоты при автоматическом разгоне до 3,2 ГГц, тогда как модели Xeon D-1500 в режиме турбо ограничивались частотой до 2,7 ГГц. Определённым образом Intel откатилась назад по шкале эволюции, понизив градус многоядерности в пользу наращивания однопоточной производительности. Собственно, этого требует позиционирование новой серии и активное развитие виртуализации сетевых функций (NFV). Для этого стала важнее скорость реакции сетевой платформы, что хорошо отрабатывается повышением тактовых частот.  Архитектурных изменений в моделях Xeon D-1600 не очень много, если они вообще есть (пока предполагаем, что архитектура осталась прежней ― Broadwell). Интегрированный контроллер памяти остался двухканальным с поддержкой модулей DDR4 с частотой до 2400 МГц суммарным объёмом до 128 Гбайт. Также поддерживается память DDR3L-1600. Уточним, процессоры Xeon D ― это однокристальная платформа, фактически SoC, что чрезвычайно удобно для тех областей, на которые нацелены эти решения.  Встроенные в процессоры интерфейсы представлены 24 линиями PCIe 3.0, 8 линиями PCIe 2.0, 6 портами SATA 6 Гбит/с, 4 портами USB 3.0, 4 портами USB 2.0 и 4 портами Ethernet 10 Гбит/с. Кстати, об Ethernet. На кристалл Xeon D-1600 интегрирован контроллер Intel серии Ethernet 700. На это намекают не только четыре интерфейса Ethernet 10GbE, но также поддержка технологии Intel QuickAssist.  У старшей серии Xeon D-2100 модели Xeon D-1600 взяли то, чего не было у моделей Xeon D-1500 ― это поддержка технологии Intel QuickAssist (QAT). Технология QAT поддержана в моделях Xeon D-1600 с индексом «N». Наличие QAT означает, что процессор несёт встроенный аппаратный ускоритель для работы с криптографией, компрессией и обработки сетевого трафика. Поддерживается целый ряд популярных алгоритмов, что существенно разгружает вычислительные ядра и даёт ощутимый прирост производительности. Например, обработка трафика TLS/IPSec плюс компрессия происходит со скоростью 30 Гбит/с плюс 30 000 операций в секунду, как и расшифровка ключами RSA с такой же производительностью. 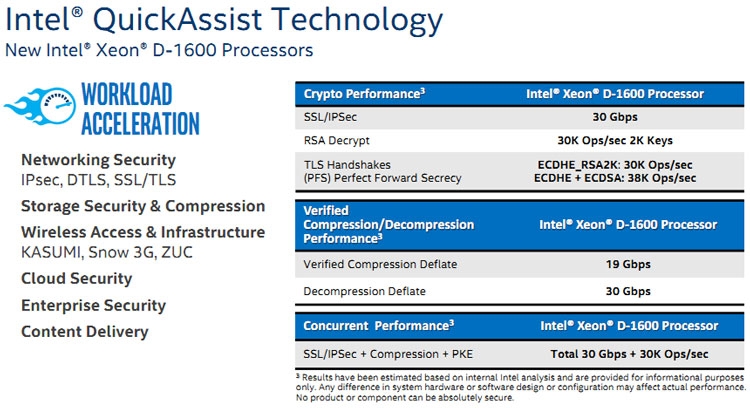 Поставки процессоров Xeon D-1600 компания Intel начнёт во втором квартале текущего года. Решения на основе новинок попадут на рынок к середине года или во второй его половине. По представлениям Intel, вычислительное и коммуникационное оборудование на базе Xeon D-1600 станет оптимальным выбором для развёртывания инфраструктуры для реализации и поддержки сотовой связи поколения 5G, а также для организации периферийных (пограничных) вычислений, когда обработка сырых данных (видео, сбор информации с датчиков, включая автомобильную электронику) происходит на месте и минимизирует пересылку в центры по обработке информации. Кроме того, они могут быть использованы в системах хранения данных. 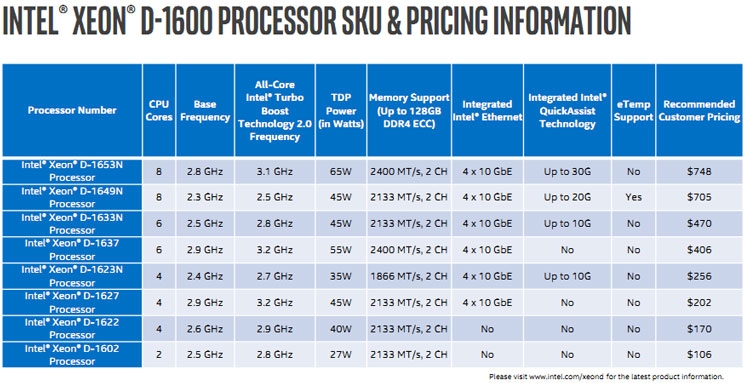 Процессоры Intel Xeon D 1600 представлены в рамках большого обновления решений для ЦОД, которое включает «взрослые» Intel Xeon Cascade Lake AP и SP с поддержкой памяти Optane в формате DDR4-модулей и новых инструкций для ИИ, модульные FPGA Agilex и сетевые контроллеры 100GbE Intel Ethernet 800. Подробности по ссылкам ниже.
23.02.2019 [20:20], Геннадий Детинич
Анонс серверных платформ ARM Neoverse E1 и N1: шах и мат, IntelУж извините за столь кричащий заголовок, но ARM давно мечтает сказать нечто подобное в отношении серверных платформ Intel. Пока получается не очень. Как говорят в самой ARM, не вышло с первого раза, попробуем во второй. Не получится во второй раз, на третий точно всё будет как надо. А сейчас и повод-то отличный! Разработчики оригинальных ядер ARM из одноимённой компании ударили сразу с двух направлений: по масштабируемым сетевым платформам (Neoverse E1) и по масштабируемым серверным (Neoverse N1). Очевидно, что пока «мата» в этой партии явно не будет. Intel крепко держится за серверные платформы и одновременно тянет руки к периферийным как в виде распределённых вычислительных ресурсов в составе базовых станций, так и в виде обычных периферийных ЦОД. Тем не менее, шансы объявить Intel «шах» у ARM определённо есть.  Рассчитанную на несколько лет вперёд стратегию Neoverse компания ARM представила в середине октября прошлого года. Она предполагает три крупных этапа, в ходе которых будут выходить доступные для широкого лицензирования 64-битные ядра ARM Ares (7 нм), Zeus (7 и 5 нм) и Poseidon (5 нм). Планируется, что каждый год производительность решений будет возрастать на 30 %. Сама компания ARM, напомним, не выпускает процессоры и SoC, а лишь продаёт лицензии на ядра и архитектуру, которые клиенты компании обустраивают нужными им контроллерами и интерфейсами. У ARM настолько многочисленная армия клиентов, что она ожидает буквально цунами из сотен и тысяч миллиардов ядер в год уже в недалёком будущем. Когда-нибудь в этот водоворот ядер будут вовлечены и серверные платформы, а затем количество перейдёт в качество.  Разработка и анонс ядер Neoverse N1 ― это явление народу 7-нм ядер Ares. Процессоры могут нести от 4 до 128 ядер, объединённых согласованной ячеистой сетью. Платформа N1 может служить периферийным компьютером с 8-ядерным процессором с потреблением менее 20 Вт, а может стать сервером в ЦОД на 128-ядерных процессорах с потреблением до 200 Вт. Степень масштабируемости должна впечатлять. Кроме этого, как сообщают в ARM, производительность ядер N1 на облачных нагрузках в 2,5 раза выше, чем у 16-нм ядер предыдущего поколения Cosmos (Cortex-A72, A75 и A53). Кстати, прошлой осенью на платформе Cosmos компания Amazon представила фирменный процессор Graviton. 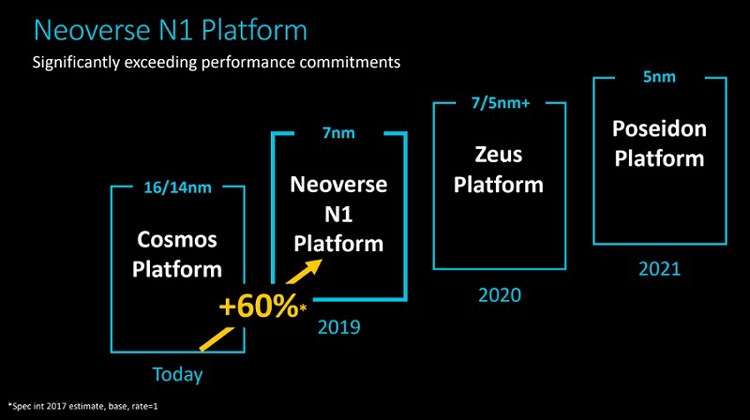 Производительность N1 при обработке целочисленных значений оказывается на 60 % больше, чем на ядрах Cortex-A72 Cosmos. При этом энергоэффективность ядер N1 также на 30 % выше, чем у ядер Cortex-A72. Как поясняют разработчики, платформа Neoverse N1 построена на «таких инфраструктурных расширениях, как виртуализация серверного класса, современная поддержка сервисов удалённого доступа, управление питанием и производительностью и профилями системного уровня». 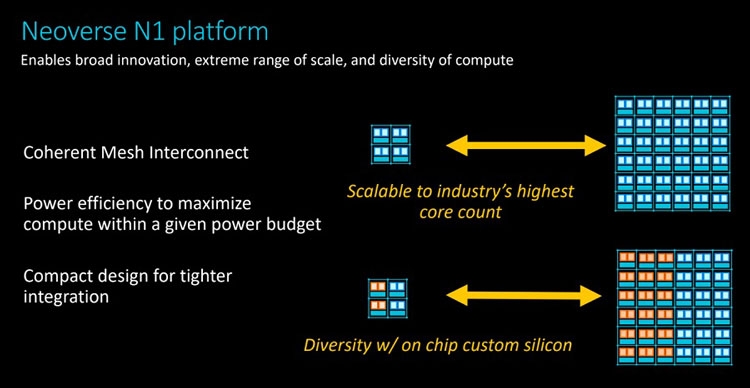 Когерентная ячеистая сеть (Coherent Mesh Network, CMN), о которой выше уже говорилось, разработана с учётом высокого соответствия вычислительным возможностям ядер. По словам ARM, сеть обменивается с ядрами такой служебной информацией, которая позволяет устанавливать объём загрузки в память данных для упреждающей выборки, распределяет кеш между ядрами и определяет, как он может быть использован, а также делает много других вещей, которые способствуют оптимизации вычислений. Интересно отметить, что в составе процессоров на платформе Neoverse N1 может быть существенно больше 128 ядер, но с оптимальной работой возникнут проблемы. Точнее, вычислительная производительность упрётся в пропускную способность памяти. Так, ARM рекомендует для CPU с числом ядер от 64 до 96 использовать 8-канальный контроллер DDR4, а для 96–128 ядерных версий ― контроллер памяти DDR5. Платформа Neoverse E1 ― это решение для сетевых шлюзов, коммутаторов и сетевых узлов, которое, например, облегчит переход от сетей 4G к сетям 5G с их возросшей требовательностью к каналам передачи данных. Так, Neoverse E1 обещает рост пропускной способности в 2,7 раза, увеличение эффективности при передаче данных в 2,4 раза, а также более чем 2-кратный рост вычислительной мощности по сравнению с предыдущими платформами (ядрами). С масштабируемостью ядер E1 тоже всё в порядке, они позволят создать решение как для базовых станций начального уровня с потреблением менее 35 Вт, так и маршрутизатор с пропускной способностью в сотни гигабайт в секунду. Что же, ARM расставила на доске новые фигуры. Будет интересно узнать, кто же начнёт игру? |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||








