Материалы по тегу: cpu
|
23.02.2024 [01:27], Алексей Степин
Arm представила процессорные ядра Neoverse N2 и V3: упор на ИИКомпания Arm продолжает развивать инициативу Neoverse Compute Subsystem (CSS), анонсировав два новых ядра, Neoverse N3 (Hermes) и V3 (Poseidon), рассчитанных на техпроцессы 2–5 нм. Они являются преемниками N2 (Perseus) и V2 (Demeter), а упор в их архитектуре сделан главным образом на повышении производительности в задачах ИИ. Платформа CSS представляет собой комплект IP-блоков Arm, включающий в себя помимо собственно процессорных ядер подсистемы интерконнекта, контроллеры памяти, блоки ввода-вывода и управления питанием и тому подобную «обвязку», облегчающую создание и вывод на рынок новых SoC. 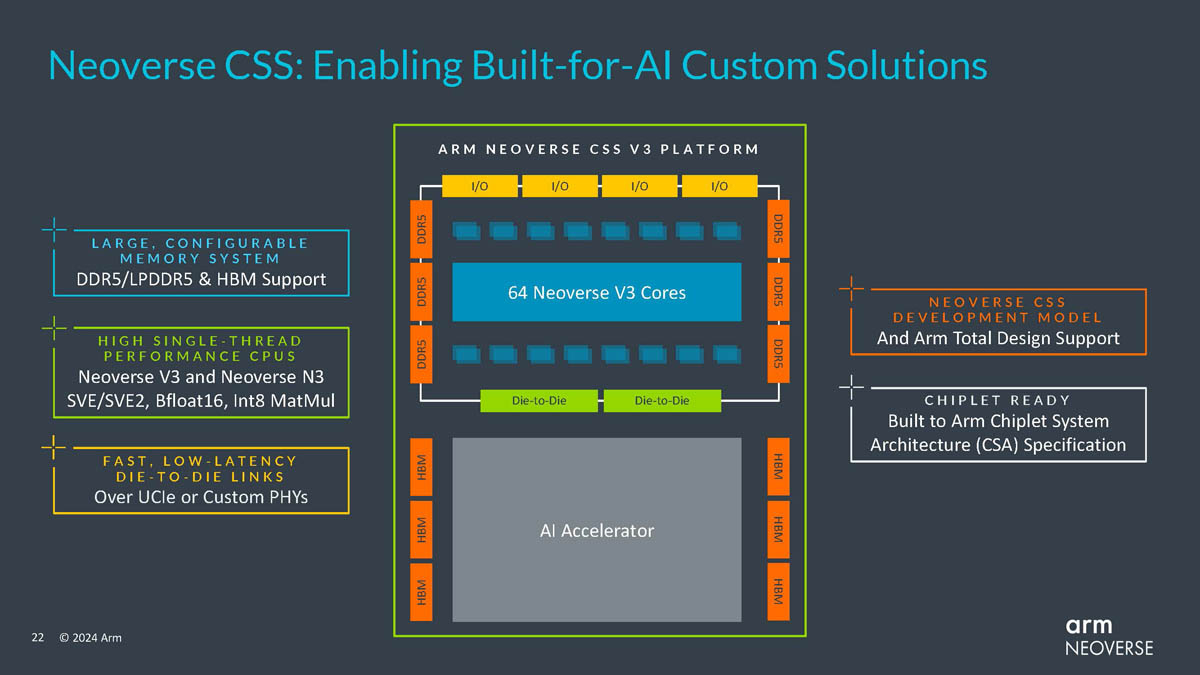
Источник изображений здесь и далее: Arm via ServeTheHome Будущие процессоры на базе Neoverse V3 получат до 64 ядер Armv9-A (v9.2) на кристалл и до 128 на сокет — в виде сборки из двух 64-ядерных кристаллов. Каждый из таких кристаллов получит шесть каналов (LP)DDR5, но также заявлена поддержка HBM3. Поддерживаются двухсокетные конфигурации. Более того, у V3 есть два блока для объедениия с чиплетами, а основным интерфейсом является UCIe 1.1, причём Arm прямо говорит о возможности подключения ИИ-ускорителя, как это сделано в NVIDIA Grace Hopper. Помимо интерконнекта для чиплетных сборок V3 будет располагать собственными контроллерами I/O с поддержкой PCIe 5.0 и CXL 3.0 — до 64 линий. 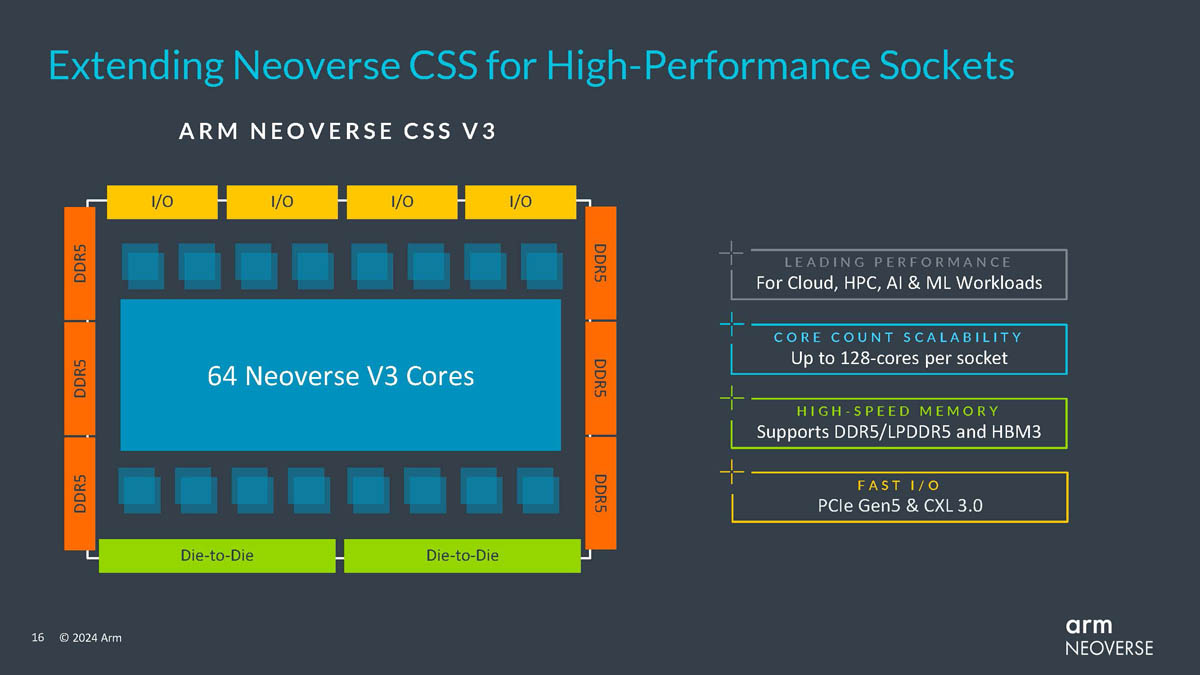 В подавляющем большинстве сценариев прирост относительно V2, обещанный Arm, не слишком велик и составляет от 9 % до 16 %, но вот производительность в ИИ-задачах подтянута аж на 84 %, что однозначно указывает на позиционирование новых ядер — это, в первую очередь, рынок гиперскейлеров, которые сегодня почти поголовно заинтересованы в применении ИИ-технологий. Сами ядра имеют по 64 Кбайт L1-кеша для инструкций и данных и до 3 Мбайт L2-кеша. Интереснее всего поддержка SVE2, но ширину и количество этих SIMD-блоков компания не раскрывает. 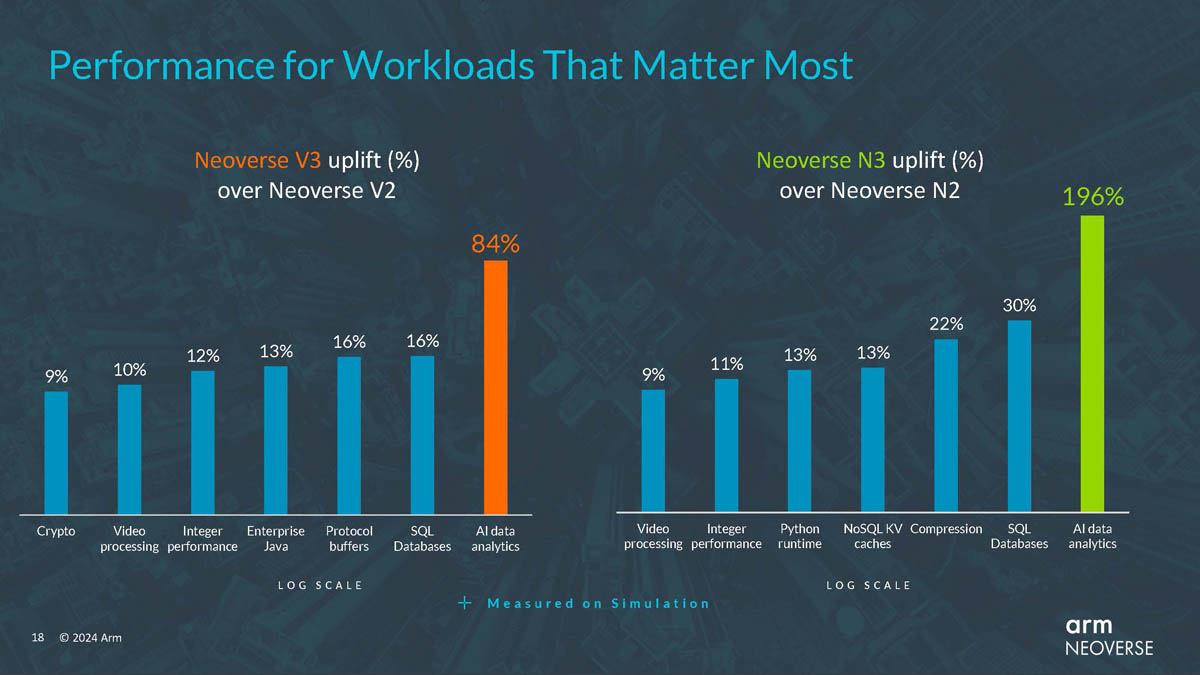 В N3 ядер меньше, от 8 до 32, а главным улучшением снова стала повышение энергоэффективности. Относительно N2 процессор N3 будет на 20 % быстрее в пересчёте на Вт. Максимальный теплопакет для 32-ядерного варианта составит всего 40 Вт. Этот дизайн должен найти своё применение в DPU и телекоммуникационных решениях. Сами ядра здесь точно такие же, что в V3, но L1-кеши можно урезать до 32 Кбайт, а L2-кеш не может быть больше 2 Мбайт. N3 также поддерживает объединение двух блоков ядер в одном чипе, двухсокетные конфигурации и UCIe-подключение стороннего чиплета, но для этого тут есть только один блок. Количество линий PCIe 5.0/CXL 3.0 вдвое меньше, до 32 шт. Каналов памяти (LP)DDR5 всего четыре.  Прирост по сценариям применения относительно N2 здесь выглядит иначе: серьёзное внимание уделено задачам сжатия и декомпрессии данных и работе с СУБД. Однако упор на ИИ-нагрузки тут даже более серьёзный, нежели у старшего собрата — прирост производительности может достигать 196 % относительно N2. Правда, в случае и N3, и V3 речь идёт о вполне конкретной библиотеке XGBoost. 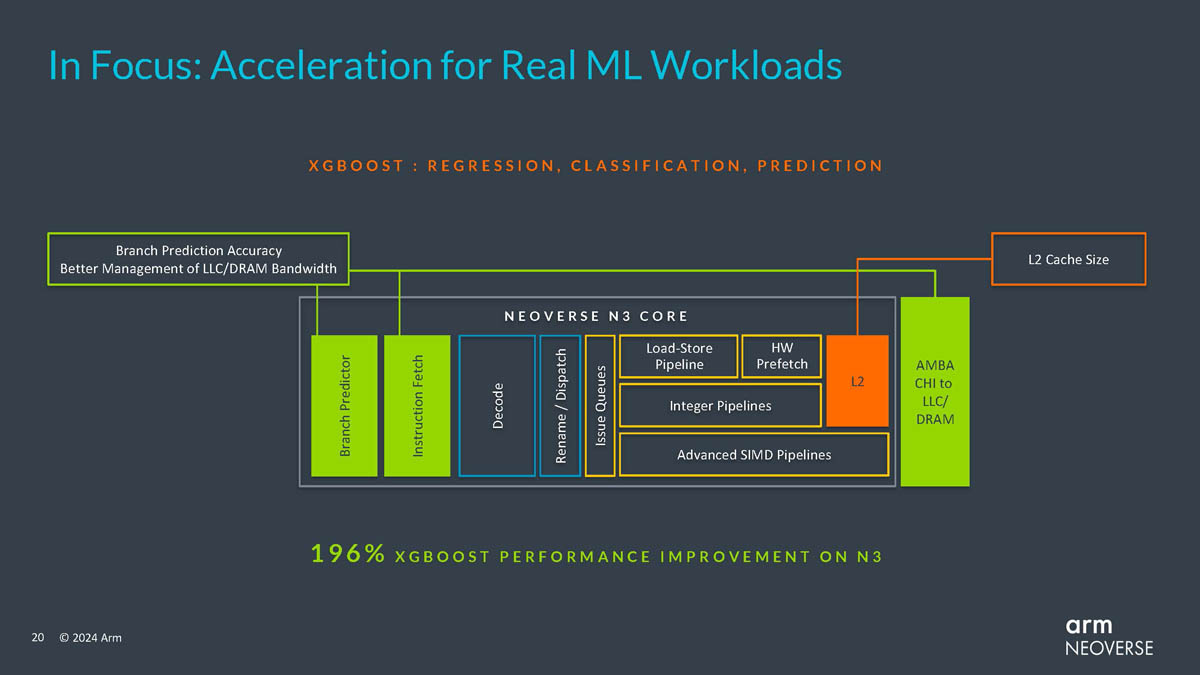 В арсенале Arm также есть ядро E3, о котором, впрочем, компания пока ничего не рассказала. Упомянуто лишь, что эта платформа ориентирована на сценарии с «прокачкой» больших объёмов данных. Заодно компания поделилась именами будущих решений четвёртого поколения. Платформа V-серии получит имя Vega с процессорными ядрами Adonis, N-серия станет называться Ranger с ядрами Dionysus, а E-серия пока никак не названа, но для ядер выбрано имя Lycius. 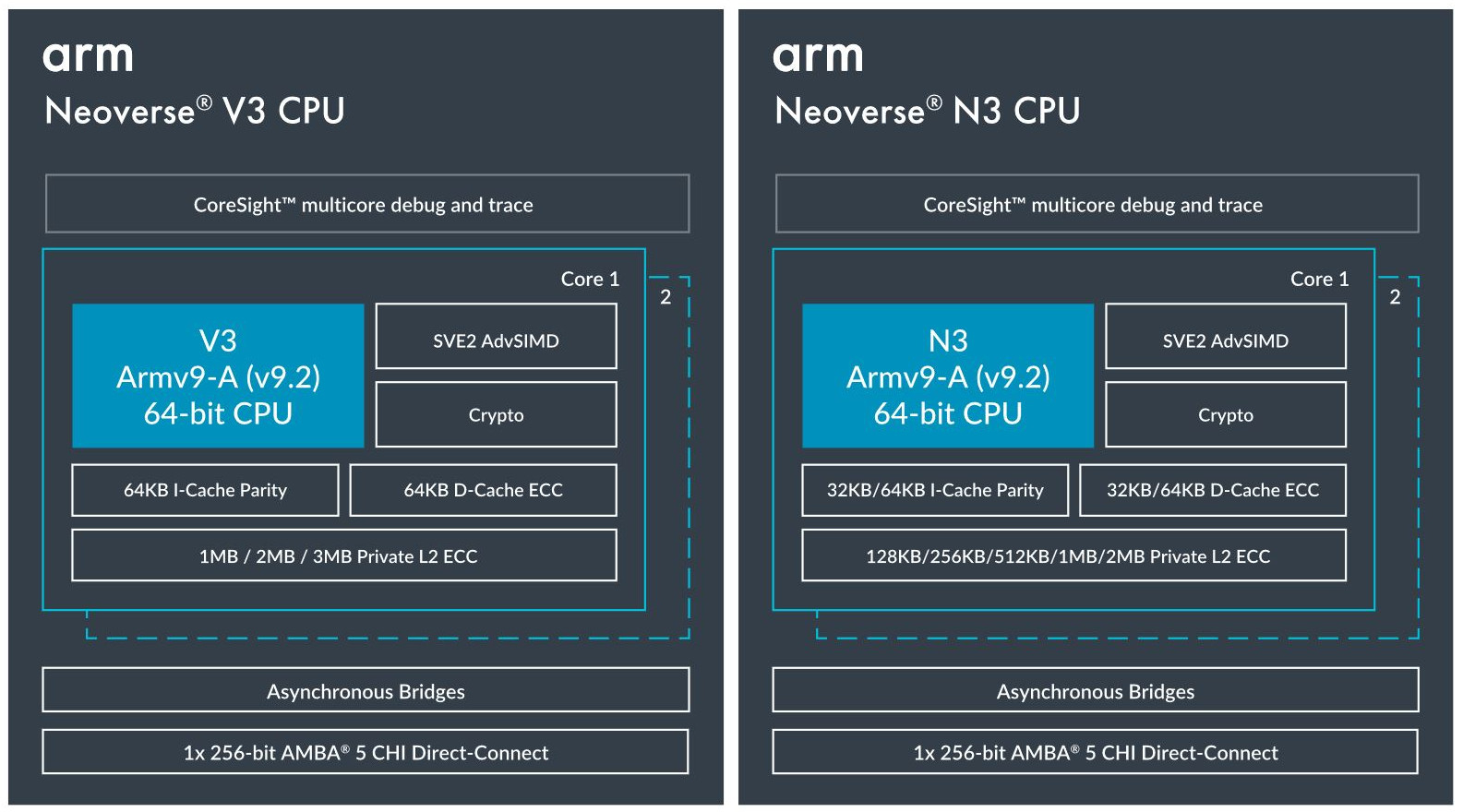 Arm не без оснований считает новые платформы и ядра лучшим поколением Neoverse на данный момент. Компания уверена в том, что за её экосистема станет основой вычислительных решений нового поколения, в том числе для ИИ. Конкурировать новым решениям предстоит, в том числе, с лучшими процессорами Intel и AMD. Сама Intel собирается поддерживать разработку технологий на базе Arm, предоставляя как интеллектуальную собственность, так и производственные мощности. 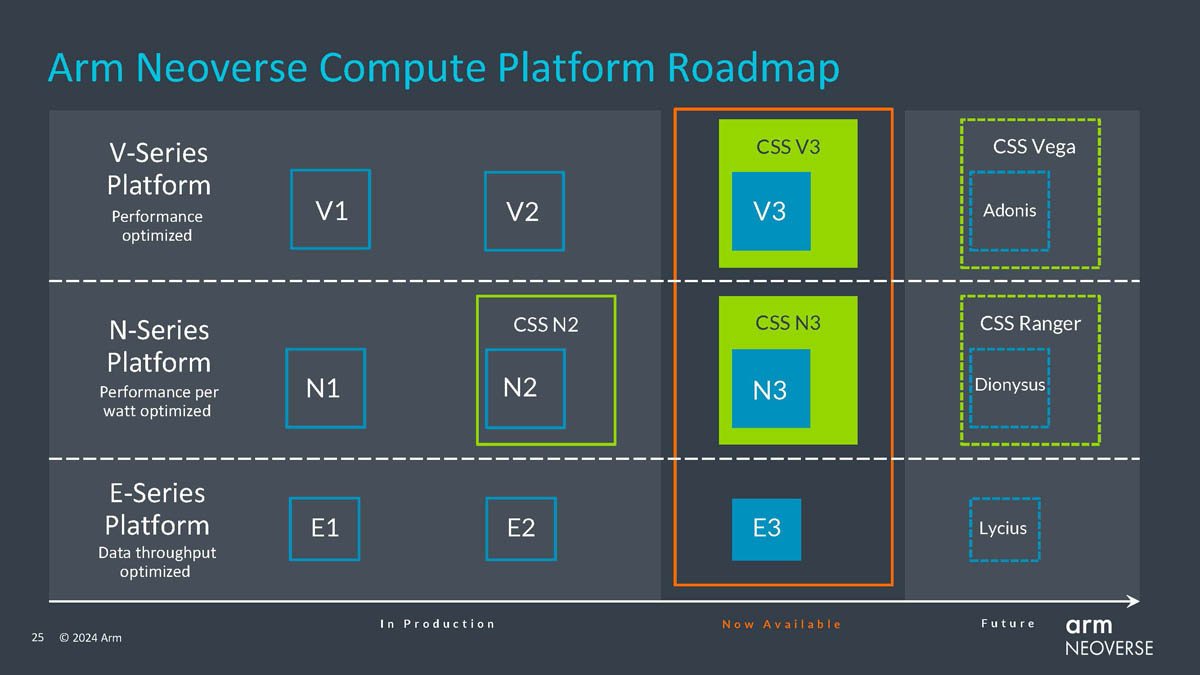 Последние два года стали для Arm весьма успешным в деле освоения рынка ЦОД. NVIDIA представила Grace и Grace Hopper, AWS создала уже четвёртое поколение собственных процессоров Graviton, Microsoft показала свой первый CPU Cobalt 100, да и Google трудится над процессорами Maple и Cypress. А основатель Oracle, которая активно перебирается на чипы Ampere, и вовсе считает, что архитектура Intel x86 теряет актуальность для серверов. Про доминирование Arm в сегменте DPU и говорить нечего.
20.12.2023 [16:13], Сергей Карасёв
Intel Xeon Emerald Rapids на китайский лад: представлены чипы Jintide 5-го поколения с 48 ядрамиКитайская компания Montage Technology, по сообщению ресурса Tom's Hardware, анонсировала процессоры Jintide 5-го поколения для местного рынка. По сути, это новейшие серверные чипы Intel Xeon Emerald Rapids с незначительно изменённой маркировкой и модифицированным набором поддерживаемых технологий. В 2016 году Intel организовала партнёрский проект с китайским университетом Цинхуа и Montage Technology Global Holdings, Ltd. для создания продуктов, ориентированных на рынок серверов и ЦОД в КНР. В рамках сотрудничества поставляются чипы Jintide на базе Xeon разных семейств. В начале 2023 года компании представили серию процессоров Jintide на базе Sapphire Rapids. В серию Jintide 5-го поколения на момент анонса вошли пять моделей: C8558P, C6548Y+, C5520+, C6542Y и C4514Y. Фактически это китайские варианты процессоров Xeon Platinum 8558P, Xeon Gold 6548Y+, Xeon Gold 5520+, Xeon Gold 6542Y и Xeon Silver 4514Y. Число вычислительных ядер составляет от 16 до 48; во всех случаях поддерживается технология многопоточности. Показатель TDP варьируется от 150 до 350 Вт (см. характеристики ниже). 
Источник изображения: Montage Technology Чипы Jintide получили дополнительные средства мониторинга и аппаратного шифрования: это технологии PrC (Pre-check) и DSC (Dynamic Security Check). От оригинальных Xeon Emerald Rapids унаследованы такие возможности, как поддержка восьми каналов памяти DDR5-5600 суммарным объёмом до 4 Тбайт и 80 линий PCIe 5.0. Изделия Jintide могут применяться в двухпроцессорных серверах. 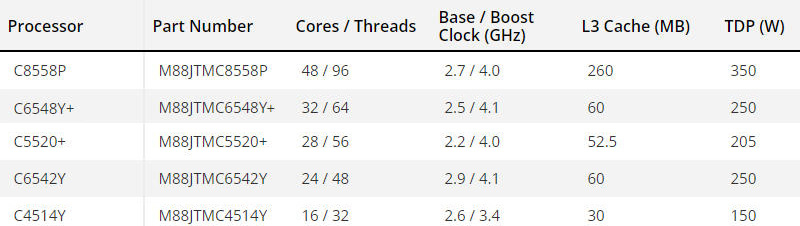
Источник изображения: Tom's Hardware На данный момент семейство Jintide 5-го поколения ограничено перечисленными моделями, и не до конца ясно, собирается ли Montage Technology выпускать другие версии. Напомним, в серии Xeon Emerald Rapids доступны процессоры с количеством ядер до 64.
17.12.2023 [17:04], Сергей Карасёв
В семейство Intel Xeon Scalable 5-го поколения вошли не только чипы Emerald Rapids, но и Sapphire RapidsНа днях корпорация Intel анонсировала процессоры Xeon Scalable 5-го поколения. Как выяснилось, в это семейство вошли не только изделия Emerald Rapids, но и чипы Sapphire Rapids. Напомним, что серия Sapphire Rapids стала основой платформы Xeon Scalable 4-го поколения. Новейшие процессоры Emerald Rapids производятся по технологии Intel 7 (10 нм ESF), насчитывают до 64 вычислительных ядер, поддерживают восемь каналов оперативной памяти DDR5-4400/5200/5600 и до 80 линий PCIe 5.0, а также CXL Type 1/2/3. Показатель TDP достигает 385 Вт. На сайте Intel говорится, что в список изделий Emerald Rapids входят 28 продуктов. Вместе с тем в перечне Xeon 5-го поколения значатся 32 процессора: сюда дополнительно входят изделия Xeon Bronze 3508U, Xeon Silver 4509Y, Xeon Silver 4510 и Xeon Silver 4510T. Все они относятся к поколению Sapphire Rapids. 
Источник изображений: Intel Перечисленные чипы также производятся по технологии Intel 7. Модели Xeon Bronze 3508U и Xeon Silver 4509Y наделены восемью ядрами, при этом второй из этих чипов поддерживает технологию многопоточности. Тактовая частота составляет соответственно 2,1–2,2 ГГц и 2,6–4,1 ГГц. Величина TDP в обоих случаях равна 125 Вт. При этом 3508U, похоже, является вообще единственным CPU в семействе, у которого есть только один FMA-порт. 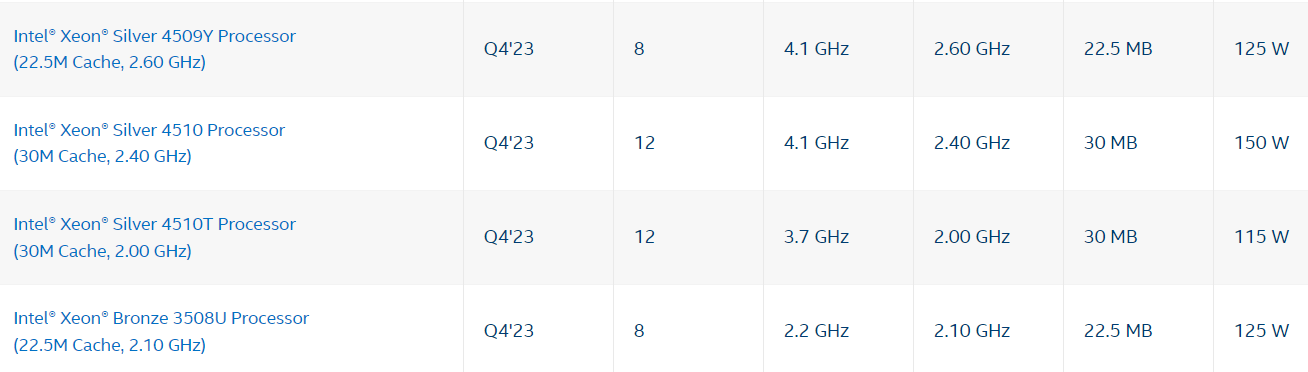 Процессоры Xeon Silver 4510 и Xeon Silver 4510T получили 12 ядер с возможностью обработки 24 потоков инструкций. Частота варьируется в диапазонах 2,4–4,1 ГГц и 2,0–3,7 ГГц. Показатель TDP — 150 и 115 Вт. Первые три из перечисленных чипов ориентированы на серверы и корпоративные системы, а четвёртый может также применяться в индустриальном оборудовании с расширенным диапазоном рабочих температур.  Иными словами, все модели Emerald Rapids относятся к Xeon Scalable 5-го поколения, но не все Xeon Scalable 5-го поколения являются изделиями Emerald Rapids. Это может создать некоторую путаницу среди потребителей.
15.12.2023 [00:30], Алексей Степин
Intel представила процессоры Xeon D-1800/2800 и E-2400 для edge-систем и серверов начального уровняНаряду с анонсом процессоров Xeon Scalable пятого поколения компания Intel обновила и модельные ряды Xeon D и Xeon E. Изменений и нововведений в представленных чипах достаточно много. Так, модельный ряд Xeon D по традиции поделён на две ветви: Xeon D-1800 и Xeon D-2800. Уже сериии Xeon D-1700 и D-2700 были адаптированы для работы в серверах периферийных вычислений и в составе сетевого оборудования. Напомним ключевые моменты:

Источник: Intel via ServeTheHome Всё это характерно и для новых Xeon D-1800 и D-2800, ведь в их основе лежит прежняя архитектура Ice Lake-D. Речь всё ещё идёт о сочетании DDR4 и PCI Express 4.0, однако улучшения всё же есть: оптимизация техпроцесса позволила довести максимальное количество ядер до 22 против 20 у предыдущих моделей при неизменном теплопакете. Небольшой прирост производительности тоже есть — примерно 1,12-1,15х у старшей модели Xeon D-2800. Кроме того, процессоры Xeon D-1800, наконец, получили поддержку двух 100GbE-портов. 
Источник: Intel Одновременно с анонсом новых Xeon D состоялся анонс серии Xeon E-2400, которая заменит Xeon E-2300. Изменений здесь существенно больше. Во-первых, платформа перебралась с LGA 1200 на LGA 1700, а на смену ядрам Cypress Cove пришли Raptor Cove. И хотя E-ядер в составе CPU нет, Intel почему-то решила не активировать поддержку AVX-512. Во-вторых, существенный апгрейд претерпела подсистема памяти: вместо двух каналов DDR4-3200 теперь доступна пара каналов DDR5-4800. Наконец, Xeon E-2400 получили поддержку PCI Express 5.0 — из 20 имеющихся процессорных линий 16 теперь способны работать именно в этом режиме. Подросла версия DMI с 3.0 до 4.0, а PCH новой платформы теперь предоставляет 20 линий PCIe 4.0 и 8 линий PCIe 3.0. Заодно с трёх до пяти выросло количество портов USB 3.2 Gen 2x2 (20 Гбит/с). 
Источник: Intel via ServeTheHome Максимальное число ядер в новой серии Xeon E осталось прежним — их всё ещё восемь, но благодаря существенно более быстрой памяти и использованию техпроцесса Intel 7 Ultra производительность новинок в среднем в 1,3 раза выше, чем у предшественников. Базовая частота подросла до 3,5 ГГц, в турборежим частота доходит до 5,6 ГГц, но при этом теплопакет не выходит за рамки 95 Вт. Нацелены Intel Xeon E-2400 на рынок серверов и облачных систем начального уровня.
29.11.2023 [03:43], Владимир Мироненко
AWS представила 96-ядерный Arm-процессор Graviton4 и ИИ-ускоритель Trainium2Amazon Web Services представила Arm-процессор нового поколения Graviton4 и ИИ-ускоритель Trainium2, предназначенный для обучения нейронных сетей. Всего к текущему моменту компания выпустила уже 2 млн Arm-процессоров Graviton, которыми пользуются более 50 тыс. клиентов. «Graviton4 представляет собой четвёртое поколение процессоров, которое мы выпустили всего за пять лет, и это самый мощный и энергоэффективный чип, который мы когда-либо создавали для широкого спектра рабочих нагрузок», — отметил Дэвид Браун (David Brown), вице-президент по вычислениям и сетям AWS. По сравнению с Graviton3 новый чип производительнее на 30 %, включает на 50 % больше ядер и имеет на 75 % выше пропускную способность памяти. 
Изображение: AWS Graviton4 будет иметь до 96 ядер Neoverse V2 Demeter (2 Мбайт L2-кеша на ядро) и 12 каналов DDR5-5600. Кроме того, новый чип получит поддержку шифрования трафика для всех своих аппаратных интерфейсов. Процессор изготавливается по 4-нм техпроцессу TSMC, включает 73 млрд транзисторов и, вероятно, имеет чиплетную компоновку. Возможно, это первый CPU компании, ориентированный на работу в двухсокетных платформах. 
Изображение: AWS Поначалу Graviton4 будет доступен в инстансах R8g (пока в статусе превью), оптимизированных для приложений, интенсивно использующих ресурсы памяти — высокопроизводительные базы данных, in-memory кеши и Big Data. Эти инстансы будут поддерживать более крупные конфигурации, иметь в три раза больше vCPU и в три раза больше памяти по сравнению с инстансами Rg7, которые имели до 64 vCPU и 512 Гбайт ОЗУ. 
Amazon Trainium2 (Изображение: AWS) В свою очередь, Trainium 2 предназначен для обучения больших языковых моделей (LLM) и базовых моделей. Сообщается, что ускоритель в сравнении с Trainium 1 вчетверо производительнее и при этом имеет в 3 раза больший объём памяти и в 2 раза более высокую энергоэффективность. Инстансы EC2 Trn2 получат 16 ИИ-ускорителей с возможностью масштабирования до 100 тыс. единиц в составе EC2 UltraCluster, которые суммарно дадут 65 Эфлопс, то есть по 650 Тфлопс на ускоритель. Как утверждает Amazon это позволит обучать LLM с 300 млрд параметров за недели вместо месяцев.  Со временем на Graviton4 заработает SAP HANA Cloud, портированием и оптимизацией этой платформы уже занимаются. Oracle также перенесла свою СУБД на Arm, а заодно перевела все свои облачные сервисы на чипы Ampere, в которую в своё время инвестировала. Microsoft же пошла по пути AWS и недавно анонсировала 128-ядерый Arm-процессор (Neoverse N2) Cobalt 100 и ИИ-ускоритель Maia 100 собственной разработки. Всё это может представлять отдалённую угрозу для AMD и Intel. С NVIDIA же все всё равно пока что продолжают дружбу — именно в инфраструктуре AWS, как ожидается, появится самый мощный в мире ИИ-суперкомпьютер на базе новых GH200.
16.11.2023 [02:43], Алексей Степин
Microsoft представила 128-ядерый Arm-процессор Cobalt 100 и ИИ-ускоритель Maia 100 собственной разработкиГиперскейлеры ради снижения совокупной стоимости владения (TCO) и зависимости от сторонних вендоров готовы вкладываться в разработку уникальных чипов, изначально оптимизированных под их нужды и инфраструктуру. К небольшому кругу компаний, решившихся на такой шаг, присоединилась Microsoft, анонсировавшая Arm-процессор Azure Cobalt 100 и ИИ-ускоритель Azure Maia 100. 
Изображения: Microsoft Первопроходцем в этой области стала AWS, которая разве что память своими силами не разрабатывает. У AWS уже есть три с половиной поколения Arm-процессоров Graviton и сразу два вида ИИ-ускорителей: Trainium для обучения и Inferentia2 для инференса. Крупный китайский провайдер Alibaba Cloud также разработал и внедрил Arm-процессоры Yitian и ускорители Hanguang. Что интересно, в обоих случаях процессоры оказывались во многих аспектах наиболее передовыми. Наконец, у Google есть уже пятое поколение ИИ-ускорителей TPU.  Microsoft заявила, что оба новых чипа уже производятся на мощностях TSMC с использованием «последнего техпроцесса» и займут свои места в ЦОД Microsoft в начале следующего года. Как минимум, в случае с Maia 100 речь идёт о 5-нм техпроцессе, вероятно, 4N. В настоящее время Microsoft Azure находится в начальной стадии развёртывания инфраструктуры на базе новых чипов, которая будет использоваться для Microsoft Copilot, Azure OpenAI и других сервисов. Например, Bing до сих пор во много полагается на FPGA, а вся ИИ-инфраструктура Microsoft крайне сложна.  Microsoft приводит очень мало технических данных о своих новинках, но известно, что Azure Cobalt 100 имеет 128 ядер Armv9 Neoverse N2 (Perseus) и основан на платформе Arm Neoverse Compute Subsystem (CSS). По словам компании, процессоры Cobalt 100 до +40 % производительнее имеющихся в инфраструктуре Azure Arm-чипов, они используются для обеспечения работы служб Microsoft Teams и Azure SQL. Oracle, вложившаяся в своё время в Ampere Comptuing, уже перевела все свои облачные сервисы на Arm.  Чип Maia 100 (Athena) изначально спроектирован под задачи облачного обучения ИИ и инференса в сценариях с использованием моделей OpenAI, Bing, GitHub Copilot и ChatGPT в инфраструктуре Azure. Чип содержит 105 млрд транзисторов, что больше, нежели у NVIDIA H100 (80 млрд) и ставит Maia 100 на один уровень с Ponte Vecchio (~100 млрд). Для Maia организован кастомный интерконнект на базе Ethernet — каждый ускоритель располагает 4,8-Тбит/с каналом для связи с другими ускорителями, что должно обеспечить максимально эффективное масштабирование.  Сами Maia 100 используют СЖО с теплообменниками прямого контакта. Поскольку нынешние ЦОД Microsoft проектировались без учёта использования мощных СЖО, стойку пришлось сделать более широкой, дабы разместить рядом с сотней плат с чипами Maia 100 серверами и большой радиатор. Этот дизайн компания создавала вместе с Meta✴, которая испытывает аналогичные проблемы с текущими ЦОД. Такие стойки в настоящее время проходят термические испытания в лаборатории Microsoft в Редмонде, штат Вашингтон.  В дополнение к Cobalt и Maia анонсирована широкая доступность услуги Azure Boost на базе DPU MANA, берущего на себя управление всеми функциями виртуализации на манер AWS Nitro, хотя и не целиком — часть ядер хоста всё равно используется для обслуживания гипервизора. DPU предлагает 200GbE-подключение и доступ к удалённому хранилищу на скорости до 12,5 Гбайт/с и до 650 тыс. IOPS.  Microsoft не собирается останавливаться на достигнутом: вводя в строй инфраструктуру на базе новых чипов Cobalt и Maia первого поколения, компания уже ведёт активную разработку чипов второго поколения. Впрочем, совсем отказываться от партнёрства с другими вендорами Microsoft не намерена. Компания анонсировала первые инстансы с ускорителями AMD Instinct MI300X, а в следующем году появятся инстансы с NVIDIA H200. 
09.11.2023 [03:15], Алексей Степин
RISC-V с приправой: модульные 192-ядерные серверные процессоры Ventana Veyron V2 можно дополнить ускорителямиВ 2022 года компания Ventana Micro Systems анонсировала первые по-настоящему серверные RISC-V процессоры Veyron V1. Анонс чипов, обещающих потягаться на равных с лучшими x86-процессорами с архитектурой x86, прозвучал громко. Популярности, впрочем, Veyron V1 не снискал, но на днях компания анонсировала второе поколение чипов Veyron V2, более полно воплотившее в себе принципы модульного дизайна и получившее ряд усовершенствований. Как и в первом поколении, компания-разработчик продолжает придерживаться концепции «процессора-конструктора» с чиплетным дизайном. В центре 4-нм Veyron V2 по-прежнему лежит I/O-хаб на базе AMBA CHI, охватывающий контроллеры памяти и шины PCI Express, а также блоки IOMMU и AIA. К нему посредством интерфейса UCIe подключаются вычислительные чиплеты. Латентность UCIe-подключения составляет менее 7 нс. 
Источник изображений здесь и далее: Ventana Micro Systems Чиплеты эти могут быть разных видов: либо с ядрами общего назначения (по 32 ядра на чиплет), образующие собственно процессор Veyron V2, либо содержащие специфические сопроцессоры под конкретную задачу (domain-specific acceleration, DSA). Последние могуть быть представлены FPGA, ИИ-ускорителями и т.д. Более того, Ventana по желанию заказчика может оптимизировать и I/O-хаб для повышения эффективности работы ядер CPU с сопроцессорами. 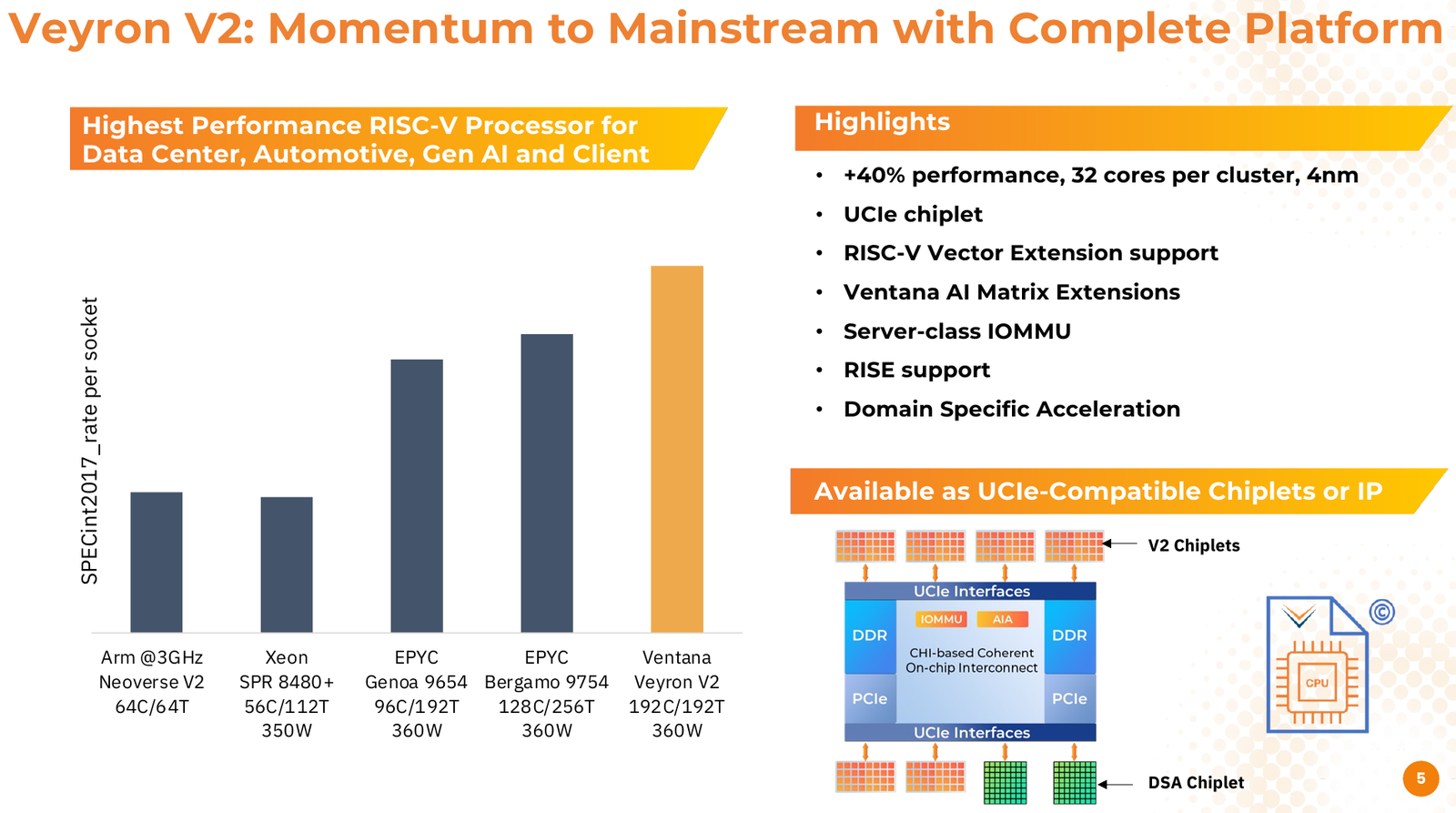 В классическом варианте Veyron V2 может иметь до шести чиплетов с RV64GC-ядрами V2, что в сумме даёт 192 ядра. Поддержка SMT отсутствует. Удельная производительность в пересчёте на ядро получается несколько ниже, чем у AMD Zen 4c, но согласно результатам тестов, предоставленных Ventana, 192-ядерный Veyron V2 заметно опережает AMD EPYC Bergamo 9754 (128C/256T) при аналогичном теплопакете в 360 Вт. 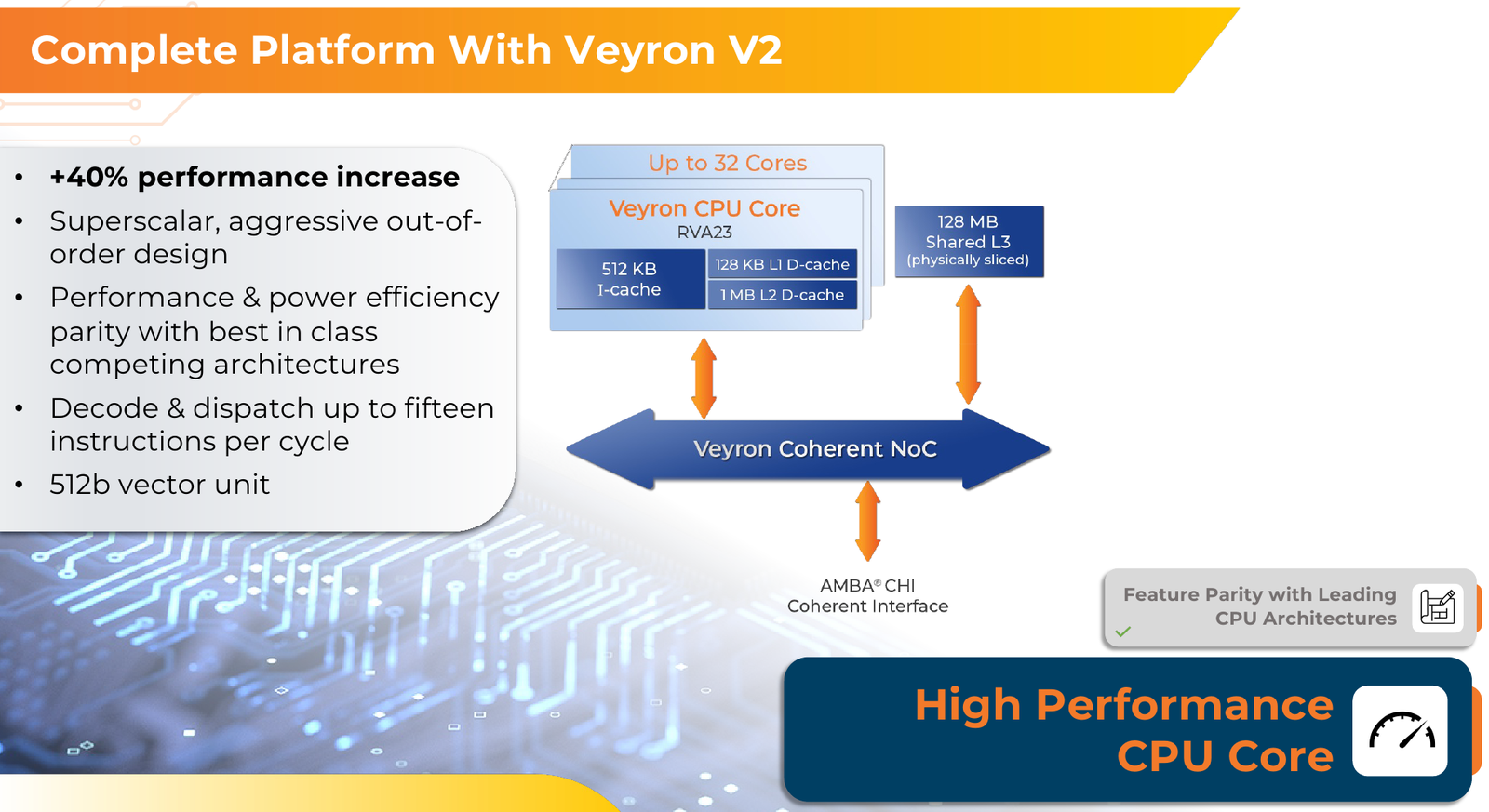 Столь неплохой результат достигнут за счёт оптимизации архитектуры Veyron: по сравнению с первым поколением говорится о 40 % прибавке производительности. Что немаловажно, во втором поколении процессоров Veyron была реализована поддержка 512-бит векторных расширений, фирменных матричных расширений, а также целого ряда других спецификаций. В целом ради совместимости разработчики предпочли остаться в рамках общего профиля RVA23. 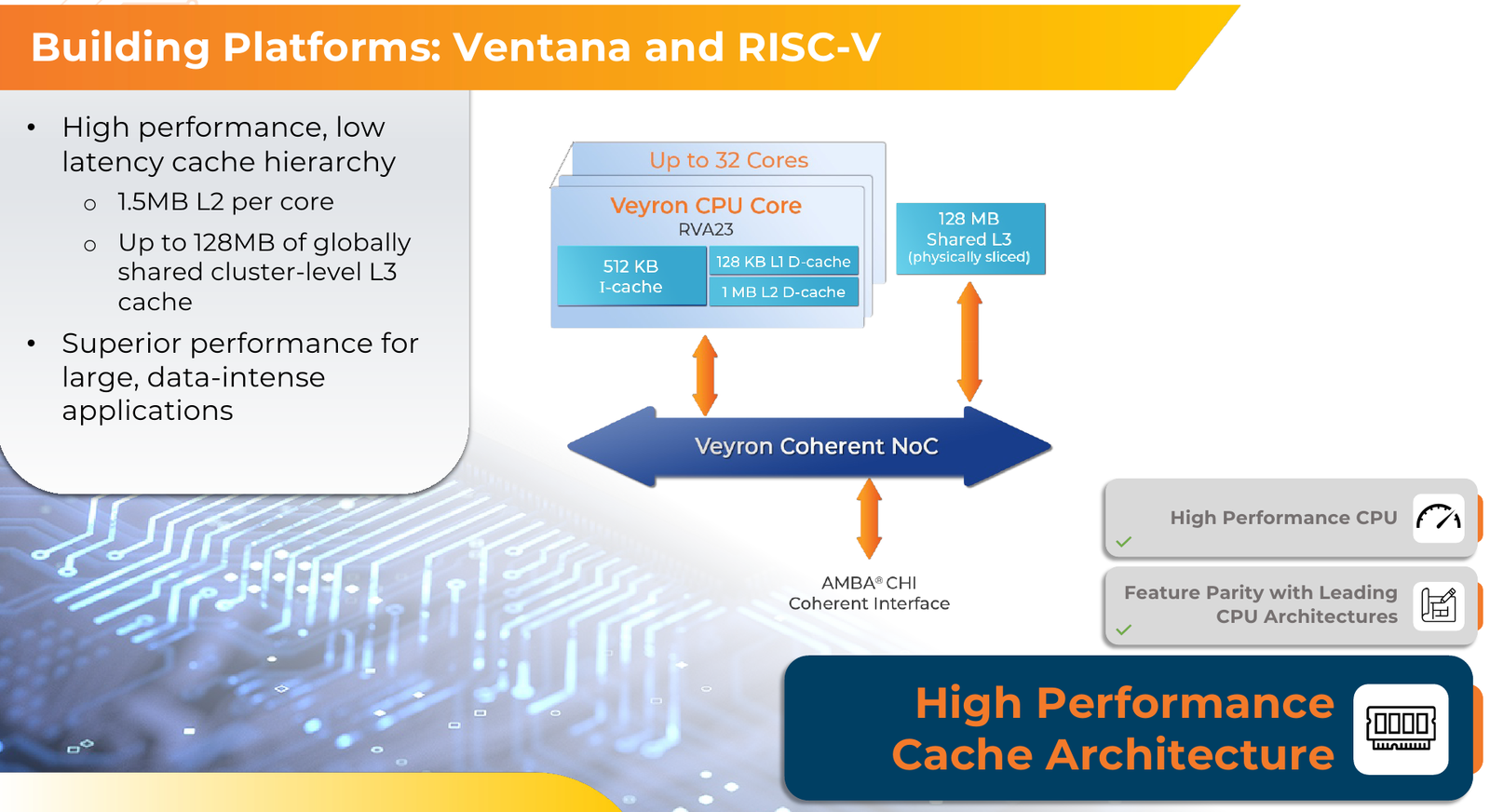 Сами ядра V2 используют суперскалярный дизайн с агрессивным внеочередным исполнением и продвинутым предсказанием ветвлений. Возможно декодирование и обработка до 15 инструкций за такт. Объём L1-кешей составляет 512 Кбайт для инструкций и 128 Кбайт для данных, дополнительно каждое ядро имеет свой кеш L2 объёмом 1 Мбайт. Общий для всего 32-ядерного чиплета L3-кеш имеет объём 128 Мбайт. Производительность внутренней когерентной шины составляет до 5 Тбайт/с. 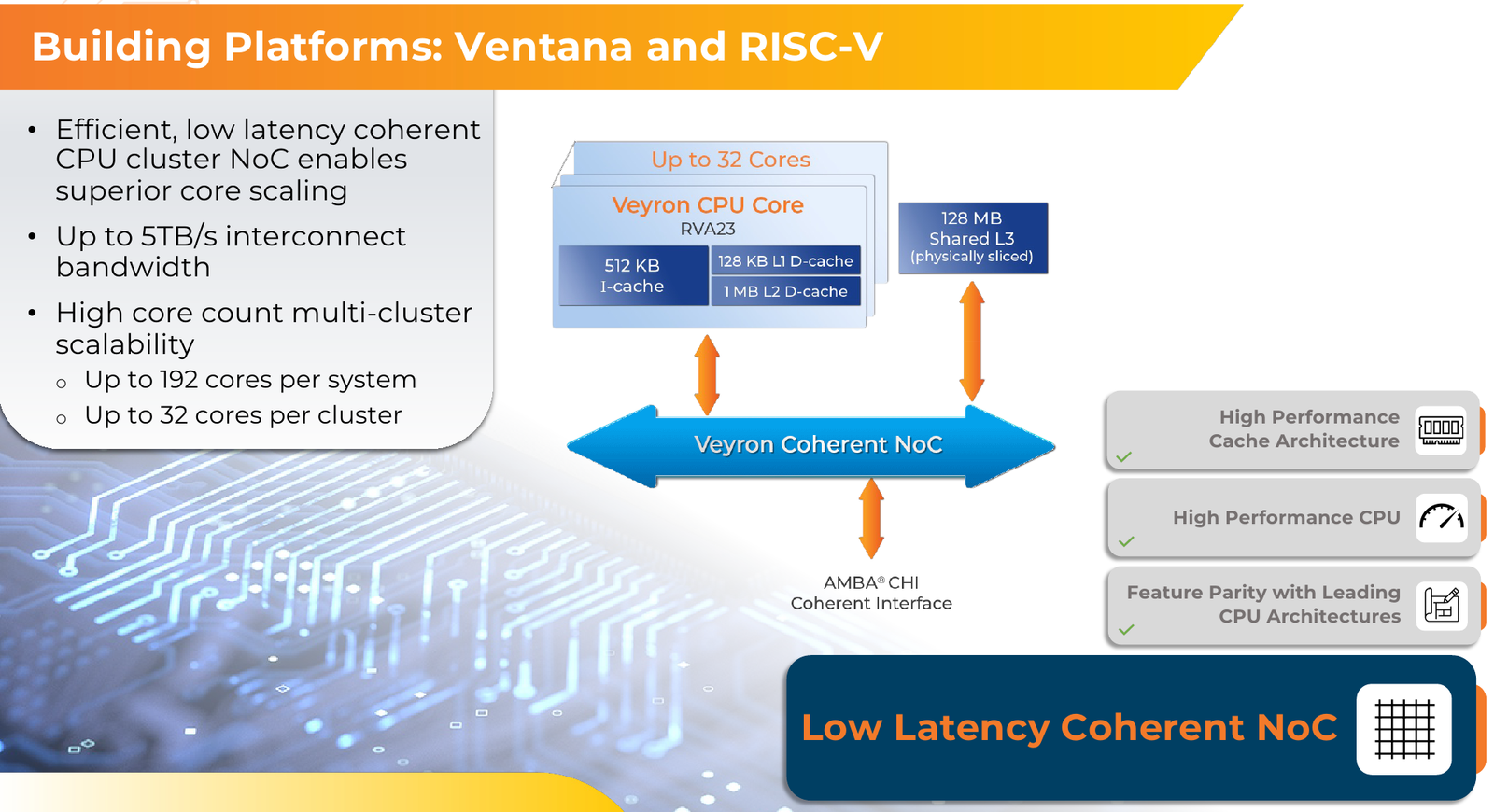 Позиционируемый в качестве решения для гиперскейлеров, крупных ЦОД и HPC, Veyron V2 имеет развитые средства предотвращения ошибок и защиты данных, от ECC-кешей и поддержки Secure Boot до аутентификации на уровне чиплета и продвинутых RAS-функций. Кроме того, реализована защита от атак по сторонним каналам. 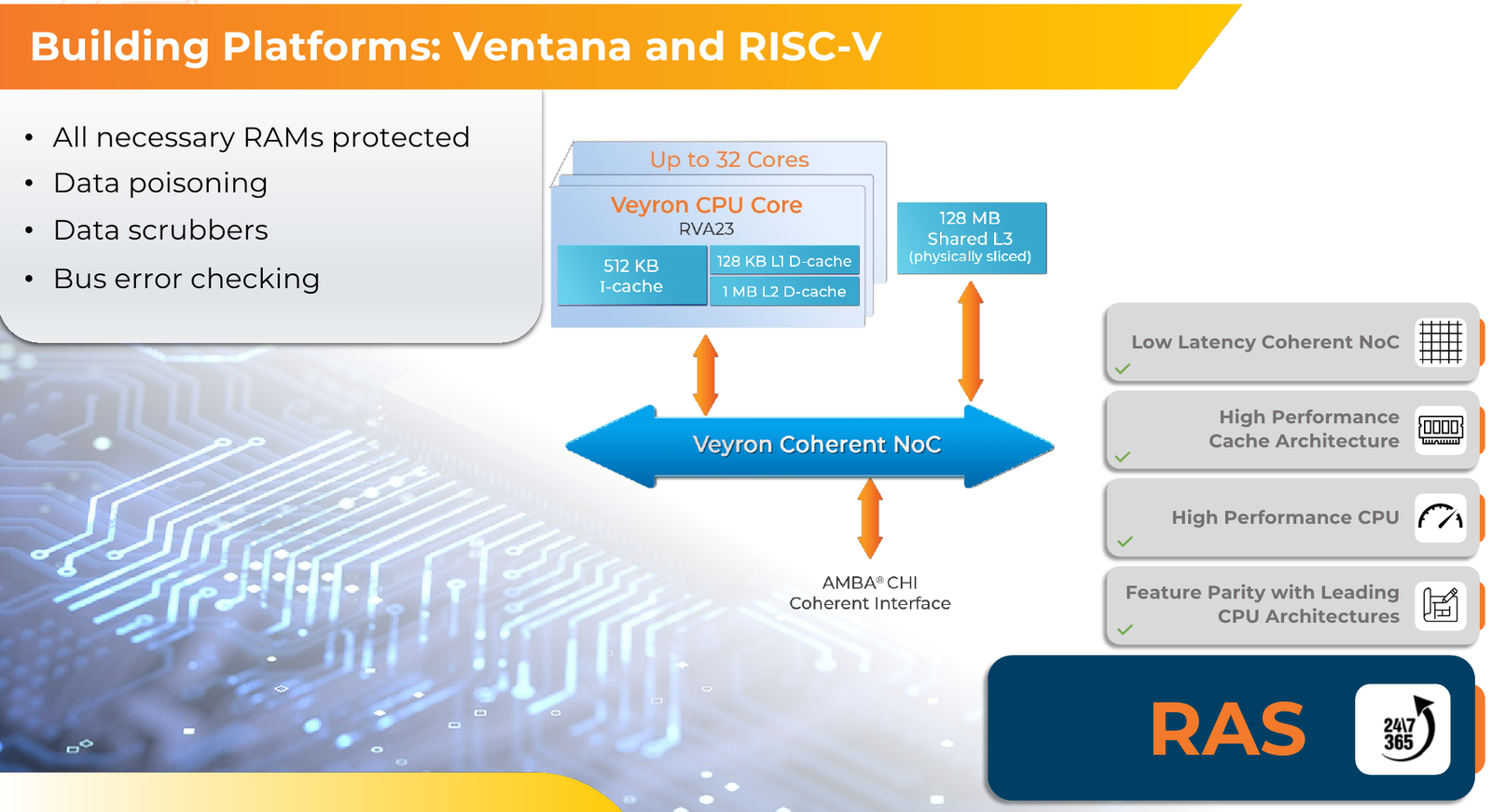 Несмотря на то, что мир RISC-V пока ещё похож на «Дикий Запад», Ventana старается опираться на развитые и популярные стандарты: в частности, это выражается в применении UCIe для подключения чиплетов, поддержку гипервизоров первого и второго типа, вложенную виртуализацию и совместимость с программной экосистемой RISC-V RISE. 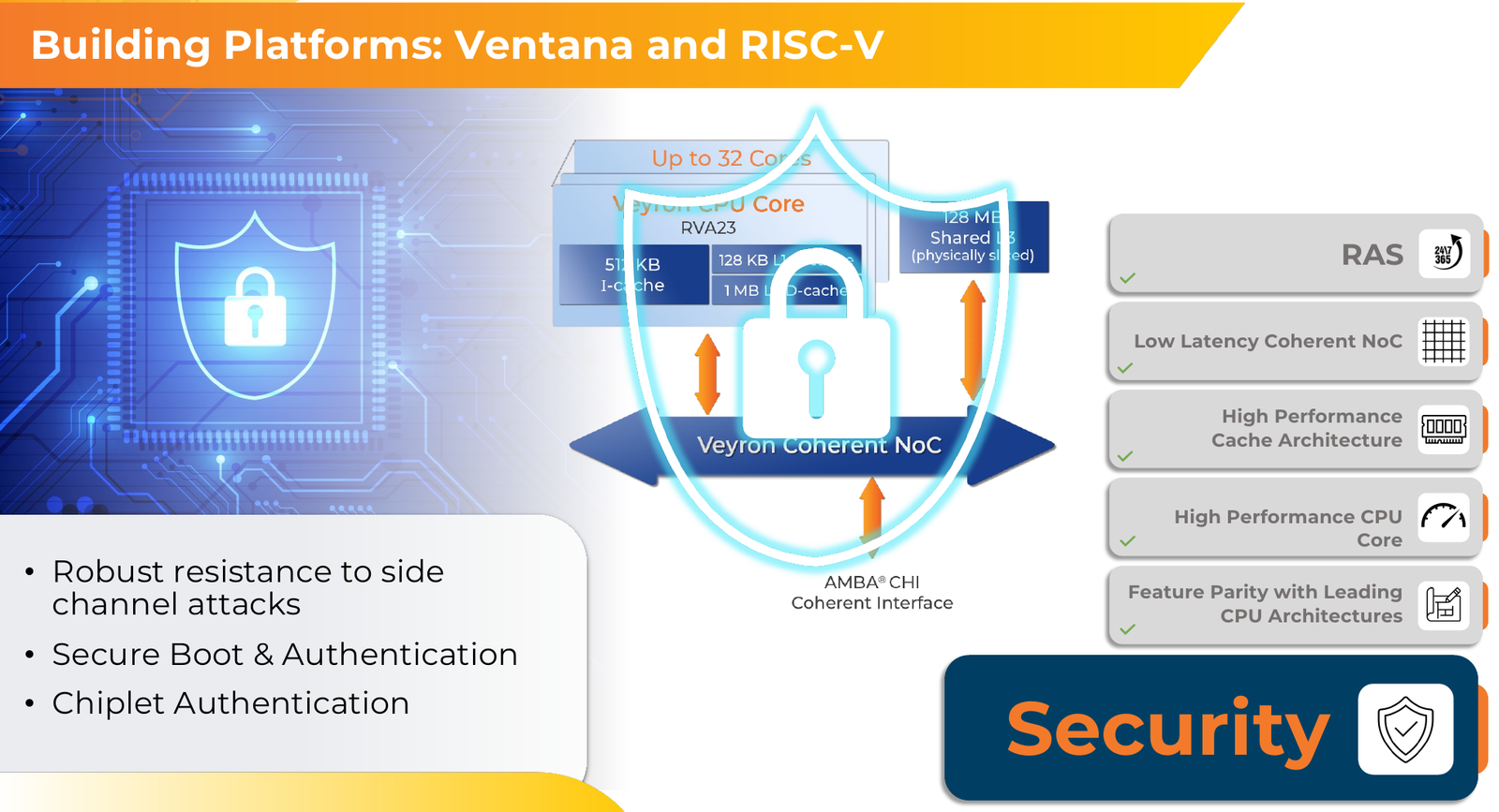 Подход Ventana позволит избежать недостатков, свойственных дискретным PCIe-ускорителям (высокая латентность, энергопотребление и стоимость) и сложным монолитным SoC (очень высокая стоимость разработки и сроки), снизить время и стоимость стоимость новых решений, а также обеспечить более низкий уровень энергопотребления. В общем, компания явно целится в гиперскейлеров. 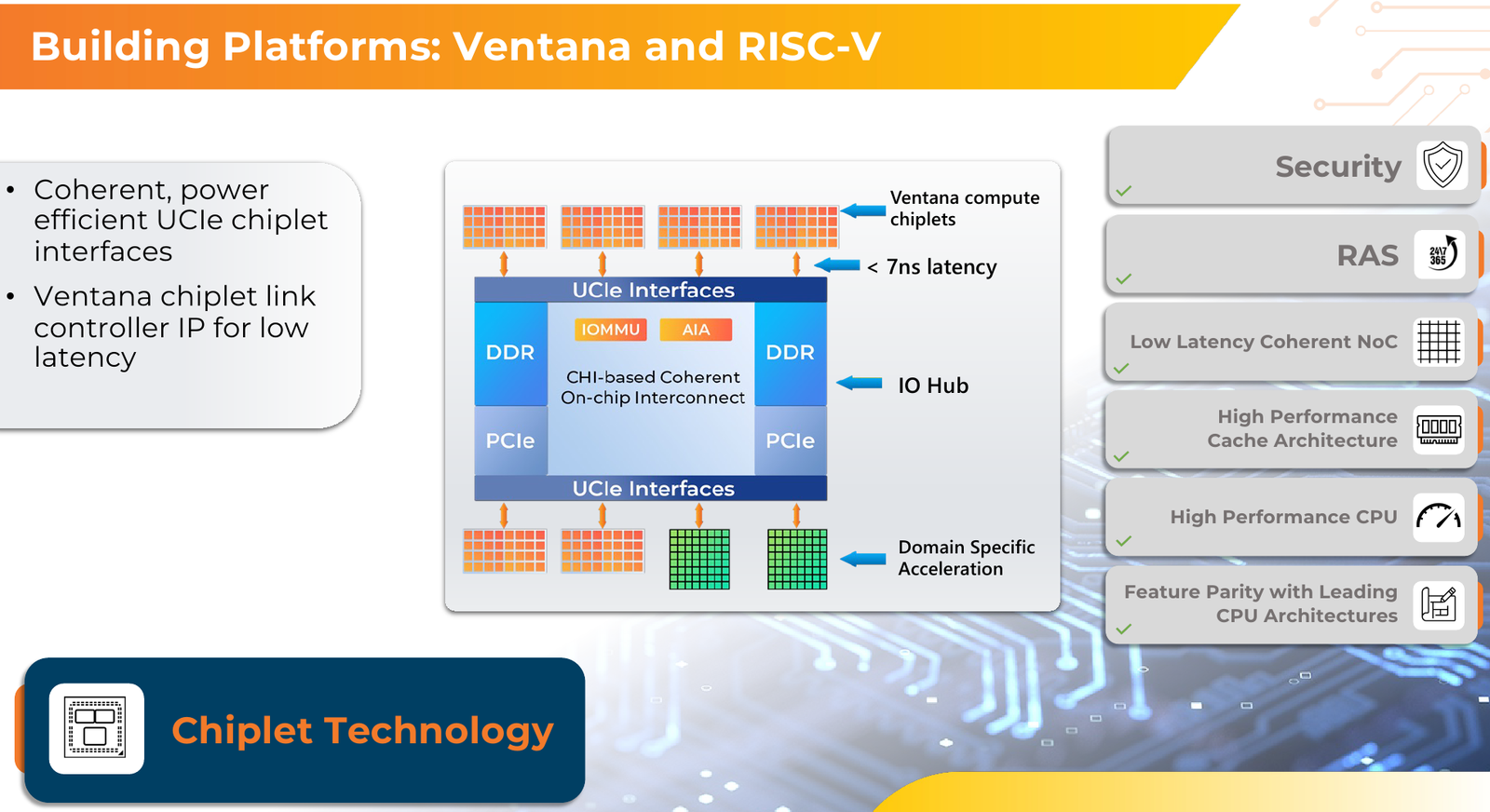 Видение сценариев применения DSA у Ventana очень широкий — от БД-ускорителей и блоков компрессии-декомпрессии данных до поддержки специфических алгоритмов в задачах аналитики и транскодеров в системах доставки контента. Также становятся ненужными дискретные DPU. Первым партнёром Ventana стала Imagination Technologies, крупный разработчик GPU. 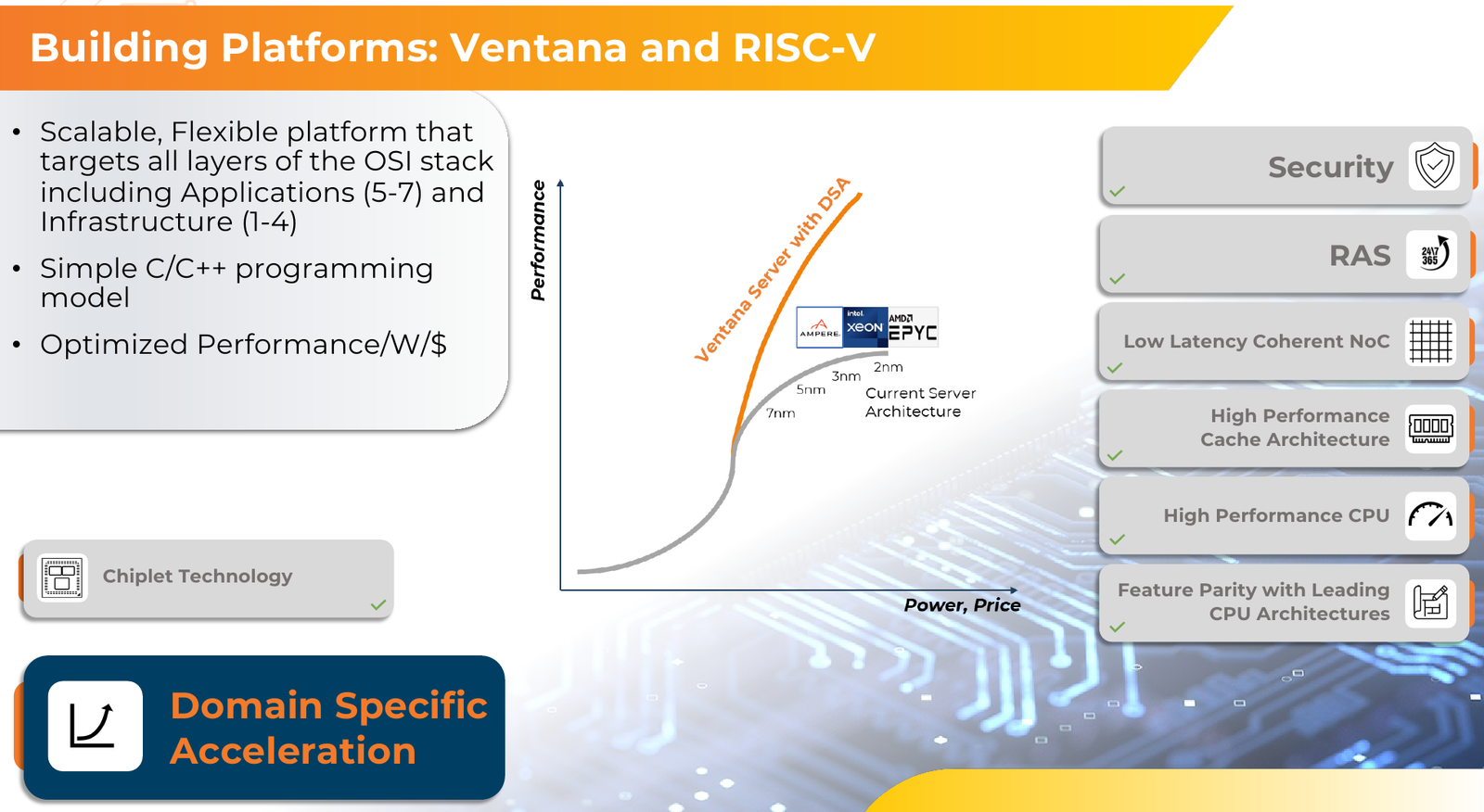 В качестве вариантов физической реализации новой платформы Ventana предлагает компактный 1U-сервер, содержащий один чип Veyron V2 со 192 ядрами, работающими на частотах до 3,6 ГГц, и 12 каналами DDR5-5600. Вероятнее всего, производителем новой платформы станет GIGABYTE. Ожидать первых поставок следует не ранее II квартала 2024 года. 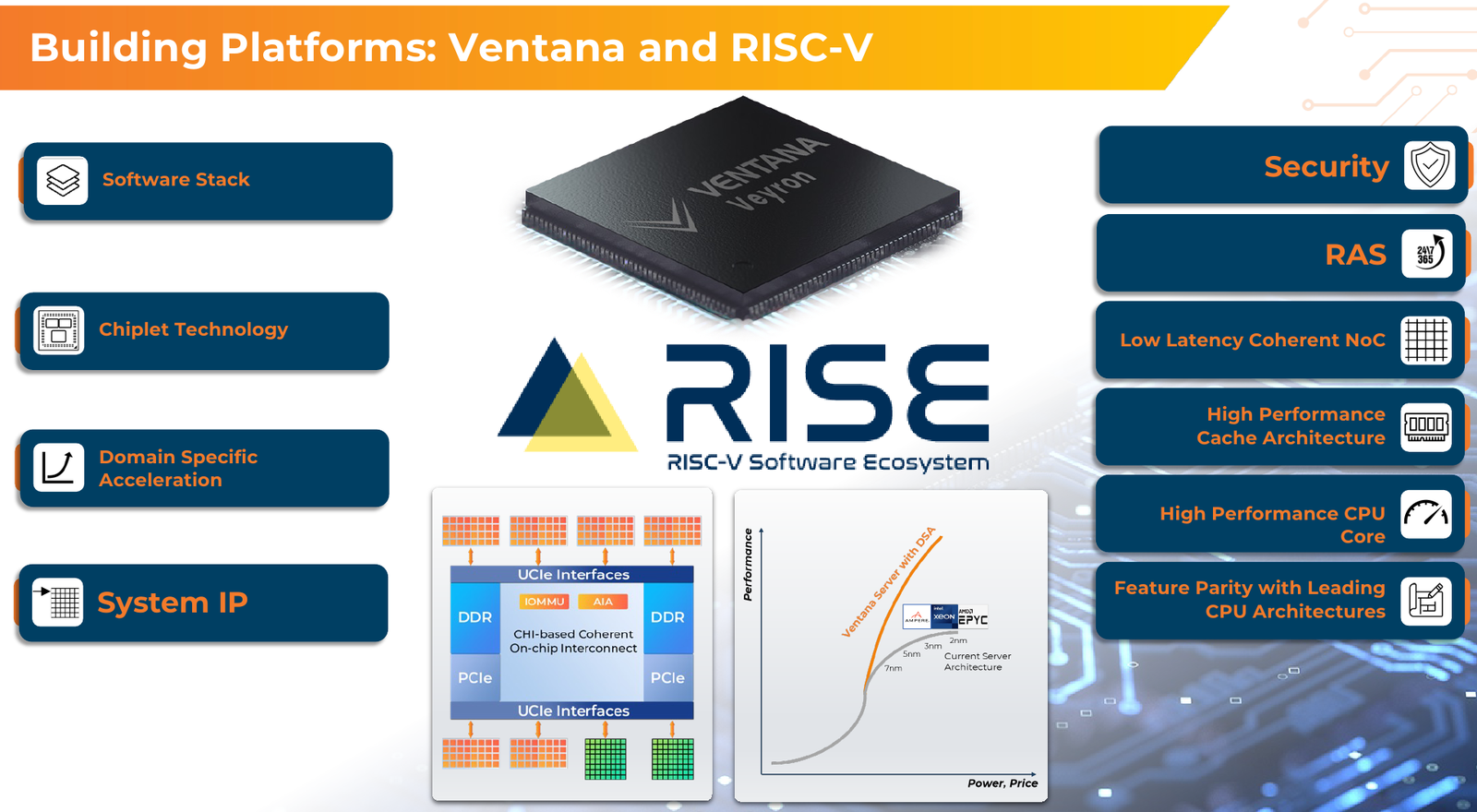 В целом, видение высокопроизводительной модульной платформы, продвигаемое Ventana, выглядит перспективно, а упор на применение DSA может выгодно отличать её большинства Arm-серверов, конкурирующих с решениями Intel/AMD лоб в лоб. Вопрос лишь в поддержке со стороны разработчиков программного обеспечения — и здесь может сыграть ставка разработчиков на максимально открытые, широкие стандарты.
21.10.2023 [01:01], Алексей Степин
Собери сам: Arm открывает эру кастомных серверных процессоров инициативой Total DesignСегодня на наших глазах в мире процессоростроения происходит серьёзная смена парадигм: от унифицированных архитектур общего назначения и монолитных решений разработчики уходят в сторону модульности и активного использования специфических аппаратных ускорителей. Разумеется Arm не осталась в стороне — на мероприятии 2023 OCP Global Summit компания рассказала о новой инициативе Arm Total Design. Эта инициатива должна помочь как создателям новых процессоров за счёт ускорения процесса разработки и снижения его стоимости, так и владельцам крупных вычислительных инфраструктур. Последние всё больше склоняются к специализации и дифференциации в процессорных архитектурах новых поколений, но ожидают также энергоэффективности, дружественности к экологии и как можно более низкой совокупной стоимости владения. 
Источник изображений здесь и далее: Arm В основе инициативы Arm лежит анонсированная ещё в августе на HotChips 2023 процессорная платформа Arm Neoverse Compute Subsystem (CSS). Neoverse CSS N2 (Genesis) представляет собой готовый набор IP-решений Arm, включающий в себя процессорные ядра, внутреннюю систему интерконнекта, подсистемы памяти, ввода-вывода, управлениям питанием, но оставляющий место для интеграции партнёрских разработок — различных движков, ускорителей и т.п. 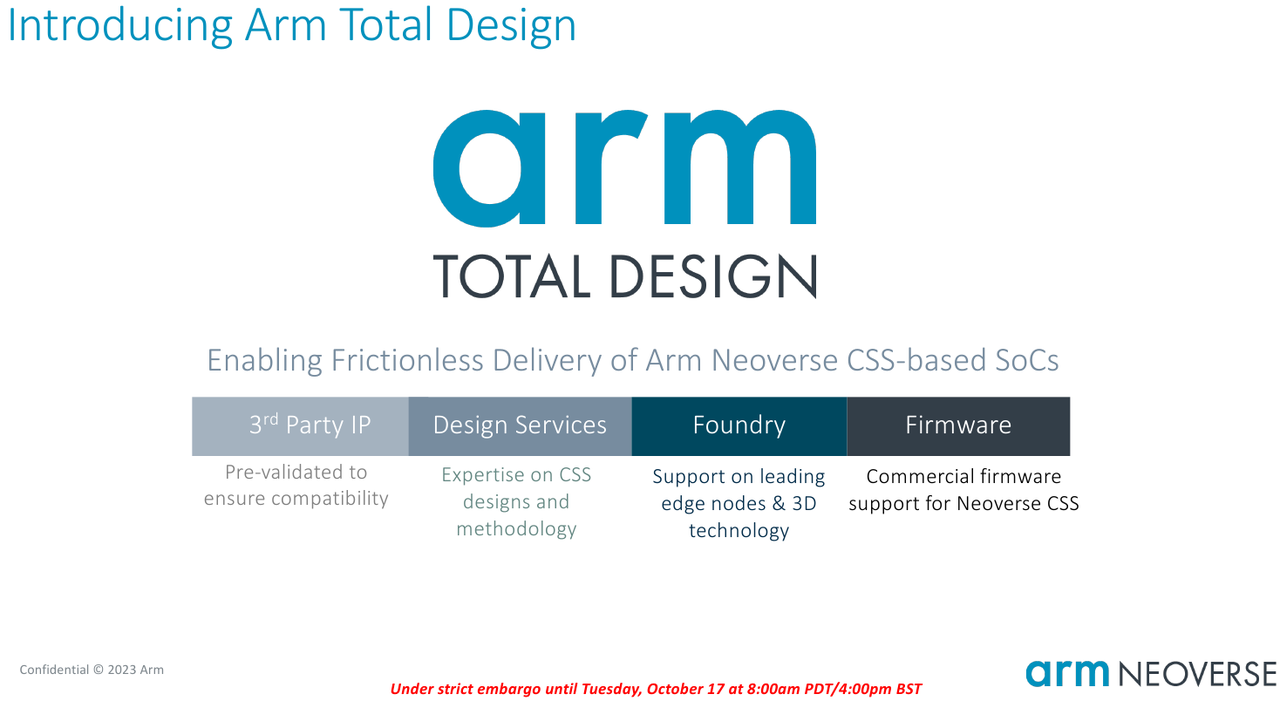 По сути, речь идёт о почти готовых процессорах, не требующих длительной разработки процессорной части с нуля и всех связанных с этим процессом действий — верификации, тестирования на FPGA, валидации дизайна и многого другого. По словам Arm такой подход позволяет сэкономить разработчикам до 80 человеко-лет труда инженеров. 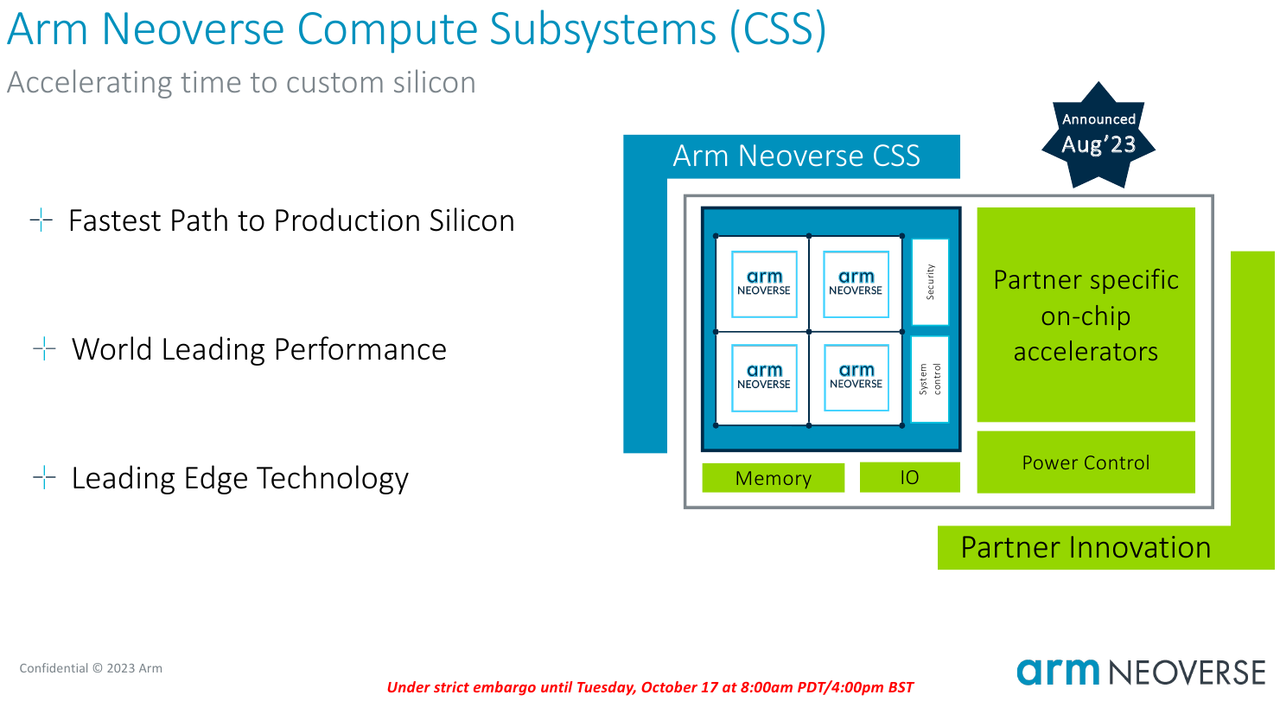 Дизайн Neoverse CSS N2 довольно гибок: финальный процессор может включать в себя от 24 до 64 ядер Arm, работающих в частотном диапазоне 2,1–3,6 ГГц. Предусмотрено по 64 Кбайт кеша инструкций и данных, а вот объёмы кешей L2 и L3 настраиваются и могут достигать 1 и 64 Мбайт соответственно. Ядра реализуют набор инструкций Arm v9 и содержат по два 128-битных векторных блока SVE2. Имеется поддержка инструкций, характерных для ИИ-задач и криптографиии. 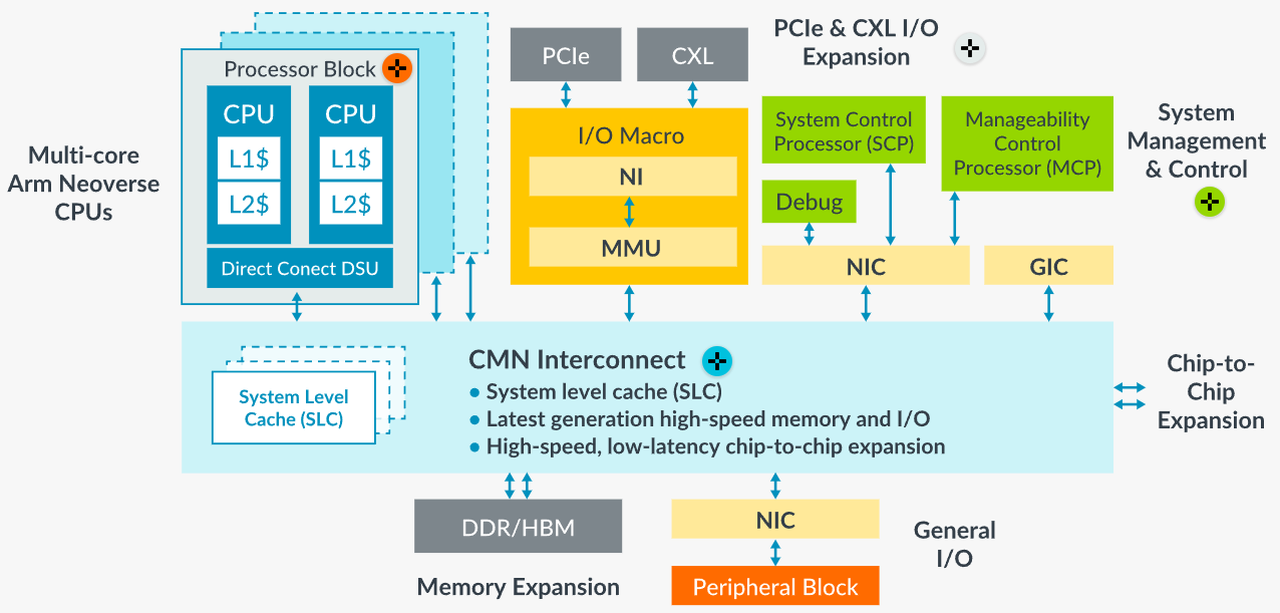 Подсистема памяти может иметь до 8 каналов DDR5, а возможности ввода-вывода включают в себя 4 блока по 16 линий PCIe или CXL. Также возможно объединение двух чипов CSS N2 в едином корпусе, что даёт до 128 ядер на чип. В качестве внутреннего интерконнекта используется меш-сеть Neoverse CMN-700. В дизайне Neoverse CSS N2 имеются и вспомогательные ядра Cortex-M7. Они работают в составе блоков System Control Processor (SCP) и Management Control Processor (MCP), то есть управляют работой основного вычислительного массива, в том числе отвечая за его питание и тактовые частоты.  Инициатива Arm Total Design расширяет рамки Neoverse Compute Subsystem: речь идёт о создании полноценной экосистемы, обеспечивающей эффективную коммуникацию между партнёрами программы Neoverse CSS и предоставление им полноценного IP-инструментария и EDA, созданных при участии Cadence, Rambus, Synopsys и др. Также подразумевается поддержка ведущих производителей «кремния» и разработчиков прошивок, в частности, AMI. В число участников проекта уже вошли такие компании, как ADTechnology, Alphawave Semi, Broadcom, Capgemini, Faraday, Socionext и Sondrel. Ожидается поддержка от Intel Foundry Services и TSMC, позволяющая говорить об эффективной реализации необходимых для мультичиповых решений технологий AMBA CHI C2C и UCIe. 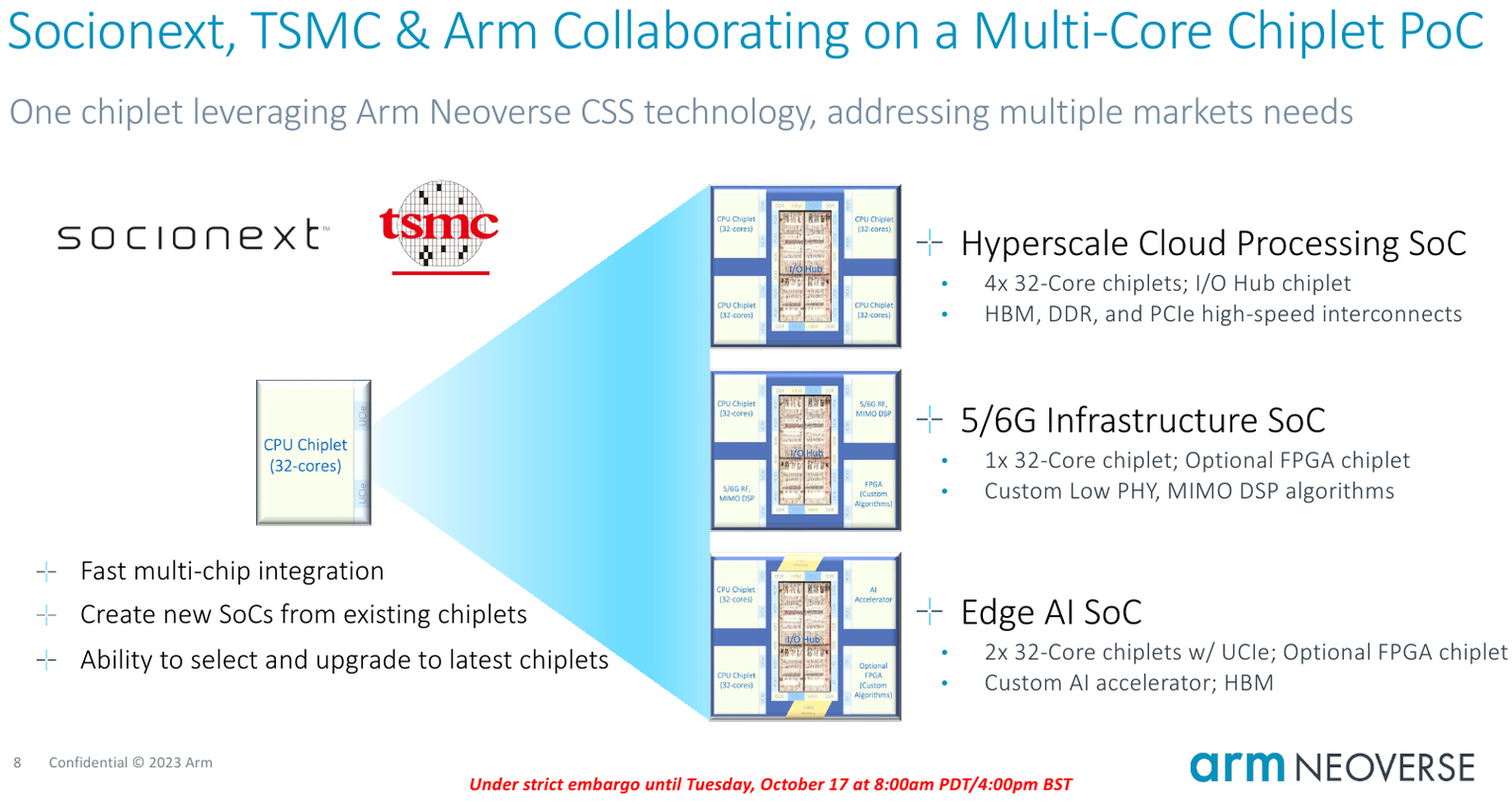 Будучи объединённым под одной крышей инициативы Arm Total Design, такой конгломерат ведущих разработчиков и производителей микроэлектроники и системного ПО для него, сможет в кратчайшие сроки не просто создавать новые процессоры, но и гибко отвечать на вызовы рынка ЦОД и HPC, наделяя чипы поддержкой востребованных технологий и ускорителей. В качестве примера можно привести совместный проект Arm, Socionext и TSMC, в рамках которого ведётся разработка универсального чиплетного процессора, который в различных вариантах компоновки будет востребован гиперскейлерами, поставщиками инфраструктуры 5G/6G и разработчиками периферийных ИИ-систем.
18.09.2023 [21:55], Алексей Степин
AMD представила процессоры EPYC 8004 Siena — Zen 4c для периферийных вычисленийКомпания AMD продолжает экспансию на серверном рынке: сегодня она анонсировала выпуск новой разновидности процессоров EPYC четвёртого поколения — чипы EPYC 8004, известные под кодовым именем Siena. Это энергоэффективные процессоры, предназначенные для применения в сфере периферийных вычислений и телекоммуникационного оборудования. Архитектурно ничего нового в EPYC 8004 нет — основе лежит тот же дизайн ядер Zen 4c, применяемый в процессорах EPYC Bergamo и позволивший создать AMD первые в мире 128-ядерные процессоры с архитектурой x86. В числе прочего, это означает и наличие поддержки AVX-512. 
Источник изображений здесь и далее: AMD Компания продолжает придерживаться уже хорошо освоенной модели создания новых процессоров путём компоновки вычислительных 5-нм чиплетов CCD вокруг унифицированного 6-нм чиплета IOD, выполняющего роль хаба ввода-вывода. Однако есть и существенные изменения. Так, в процессорах серии Siena была серьёзно усечена подсистема памяти, с 12 до 6 каналов DDR5. Также пострадала подсистема PCI Express, включающая 96 линий PCIe 5.0 вместо 128. Всё это позволило сделать процессоры компактнее, но потребовало введения нового сокета SP6 с меньшим числом контактов — 4844 против 6096 контактов у SP5. Такой ход позволит снизить себестоимость производства системных плат для EPYC 8004, тем более что поддержки двухпроцессорных конфигураций новые чипы AMD не предусматривают. 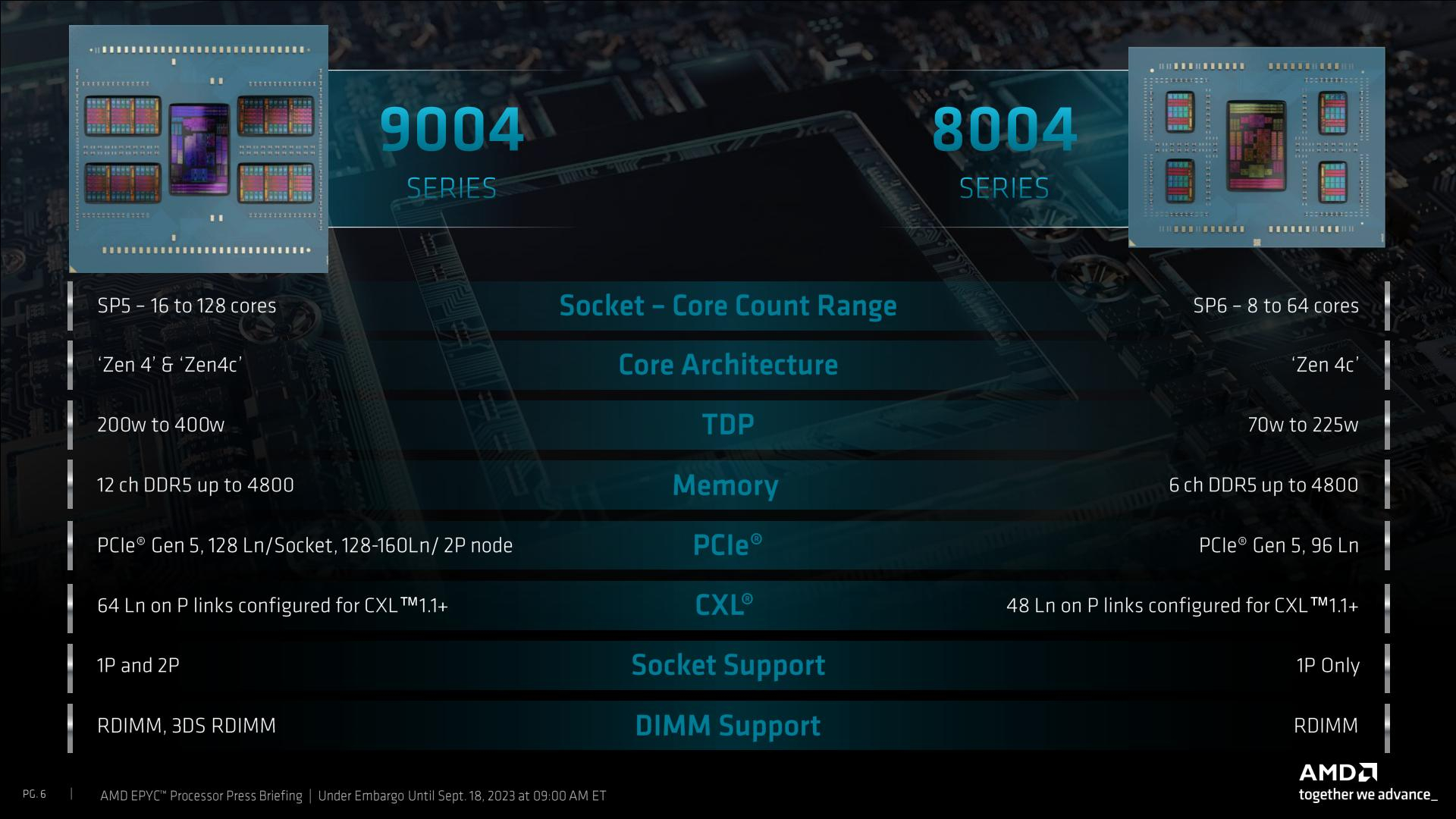 Всего в новой серии AMD анонсировала 12 процессоров, с количеством ядер от 8 до 64 (16—128 потоков), в вариациях с настраиваемым теплопакетом и фиксированным в соответствии со стандартом NEBS (Network Equipment-Building System); последний также предусматривает более широкий диапазон рабочих температур (от -5 до +85 °C). 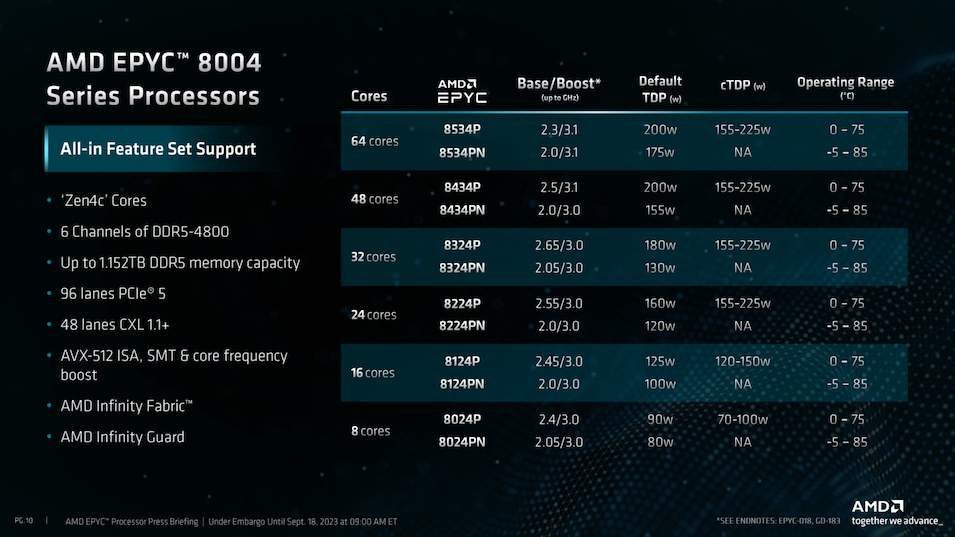 Нельзя, впрочем, сказать, что теплопакет как-то особенно низок даже у младших 8-ядерных моделей — он стартует с отметки 80 Вт (для модели с настраиваемым TDP этот показатель можно снизить до 70 Вт), а в максимальных конфигурациях система охлаждения CPU должна справляться с отводом 175–225 Ватт. Для периферийных систем и телекоммуникационного оборудования этого добиться не всегда просто.  Можно назвать и другие ограничения: так, использование прежнего дизайна IOD-чиплета означает поддержку памяти со скоростью до DDR5-4800, причём лишь при одном модуле DIMM на канал, а поддержка 3DS RDIMM отсутствует, что ограничивает максимальный объём оперативной памяти отметкой 1152 Гбайт (12 × 96 Гбайт RDIMM). Из 96 линий PCIe лишь половина может работать в режиме CXL. 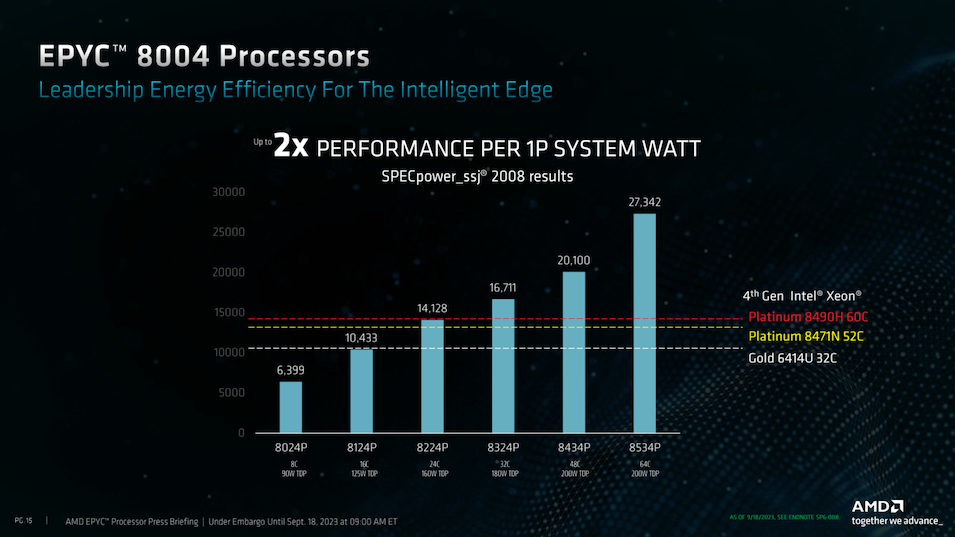 А конкуренция со стороны Intel в этом сегменте будет очень жёсткой: поскольку речь идёт о телекоммуникационном оборудовании, у «синих» имеется готовый стек решений vRAN и отлично подходящие для его запуска процессоры Xeon EE с поддержкой vRAN Boost, а также ещё более экономичные Xeon D-2700 с интегрированным 100GbE-контроллером, поддерживающие третье поколение Quick Assist и полноценные расширения AVX-512 и VNNI/DL. 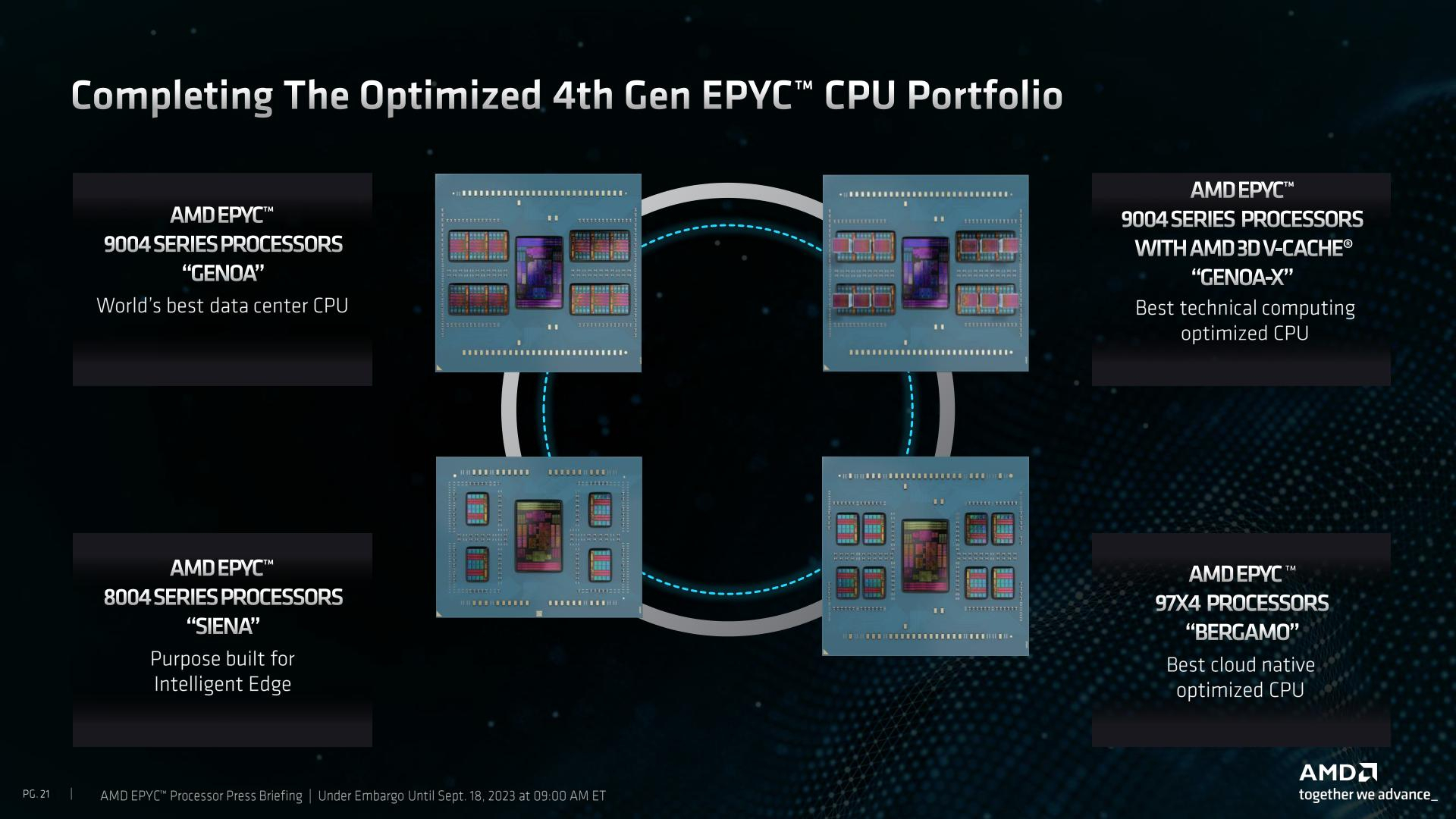 AMD хочет противопоставить этому «чистую» вычислительную мощность, достигаемую за счёт количества ядер. Это может сыграть решающую роль при использовании программного обеспечения, неспособного использовать все преимущества ускорителей в процессорах Intel. Также потенциальных заказчиков должна привлечь низкая совокупная стоимость владения для систем на базе EPYC Siena, достигаемой за счёт высокой удельной производительности новых процессоров. Компания сообщает, что процессоры EPYC 8004 уже доступны в новых периферийных серверах таких производителей, как Dell, Lenovo и Supermicro, анонсировала новые решения и Giga Computing. Также поддержали выпуск новых чипов Microsoft Azure и Ericsson. Последняя, напомним, весной этого года подписала с AMD соглашение о разработке открытого RAN-стека, что позволит ей «отвязаться» в своих продуктах от решений исключительно Intel.
01.08.2023 [10:02], Сергей Карасёв
Esperanto готовит универсальный чип ET-SoC-2 на базе RISC-V для задач НРС и ИИСтартап Esperanto Technologies, по сообщению ресурса HPC Wire, готовит новый чип с архитектурой RISC-V, ориентированный на системы высокопроизводительных вычислений (НРС) и задачи ИИ. Изделие получит обозначение ET-SoC-2. Нынешний чип ET-SoC-1 объединяет 1088 энергоэффективных ядер ET-Minion и четыре высокопроизводительных ядра ET-Maxion. Решение предназначено для инференса рекомендательных систем, в том числе на периферии. Чип ET-SoC-2 будет включать в себя новые высокопроизводительные ядра CPU на базе RISC-V с векторными расширениями. Точные данные о производительности не раскрываются, но говорится, что изделие обеспечит быстродействие с двойной точностью более 10 Тфлопс. Архитектура ET-SoC-2 предполагает совместную работу сотен и тысяч чипов для организации платформ НРС. При этом Esperanto делает упор на энергетической эффективности своих решений. 
Источник изображения: Esperanto Technologies По словам Дейва Дитцеля (Dave Ditzel), генерального директора Esperanto, чипы RISC-V смогут взять на себя функции и CPU, и GPU при обработке ресурсоёмких приложений, в частности, машинного обучения. Процессоры RISC-V отстают по производительности от чипов x86 и Arm, хотя разрыв постепенно сокращается. Дитцель сказал, что стойки с чипами ET-SoC-1 могут обеспечить производительность в петафлопсы. Однако проблема с внедрением RISC-V заключается в слабо развитой экосистеме ПО. |
|


