Материалы по тегу: cpu
|
30.06.2023 [21:39], Владимир Мироненко
Глава Oracle считает, что архитектура Intel x86 теряет актуальность для серверовВ 2023 году Oracle планирует потратить значительные средства на приобретение чипов AMD и Ampere Computing для новой инфраструктуры, отметив, что «старая архитектура Intel x86 достигает своего предела». «В этом году Oracle купит GPU и CPU у трёх компаний, — сообщил на прошедшем в среду мероприятии глава Oracle Ларри Эллисон (Larry Ellison). — Мы будем покупать GPU у NVIDIA, мы покупаем у неё на миллиарды долларов США. И потратим в три раза больше на центральные процессоры от Ampere и AMD. Мы по-прежнему тратим больше денег на традиционные чипы». Oracle сообщила, что впервые за 14 лет существования специализированных ПАК Exadata для СУБД она полностью отказалась от процессоров Intel в пользу чипов AMD. В платформе 12-го поколения Exadata X10M в рамках двух предложений Oracle Exadata Machine и управляемого решения Oracle Exadata Cloud@Customer будут использоваться AMD EPYC Genoa. Одной из причин такого перехода, пусть и далеко не самой важной, считается отказ Intel от Optane. 
Источник изображения: Oracle С момента запуска Exadata в 2008 году Oracle полагалась на процессоры Intel Xeon. Но ситуация начала меняться c выходом X9M в 2021 году. Для Oracle Exadata Machine и Oracle Exadata Cloud@Customer компания выбрала чипы Intel Xeon Ice Lake-SP, а в начале 2022 года для облачного решения Oracle Exadata Cloud Infrastructure решила использовать чипы AMD. При этом EPYC Milan использовались в серверах для обеспечения работы баз данных, а Ice Lake-SP — для СХД. Кроме того, на днях Oracle сделала важный шаг — перенесла свою флагманскую СУБД Oracle Database на архитектуру Arm, т.е. на процессоры компании Ampere Computing, в которую в своё время инвестировала. Эллисон отметил, что чипы Ampere Altra намного энергоэффективнее решений AMD и NVIDIA, что поможет ЦОД Oracle соответствовать будущим регуляциям. «Мы перешли на новую архитектуру и к новому поставщику, — сообщил Эллисон. — Мы думаем, что это будущее. Старая архитектура Intel x86 после многих десятилетий на рынке подошла к своему пределу». 
Источник изображения: Oracle Тем не менее, эксперты полагают, что ставка Oracle на архитектуру Arm не помешает её отношениям с AMD в ближайшее время, тем более что Intel и AMD планируют бороться с Arm-процессорами с помощью оптимизированных для облачных платформ чипов с высокой плотностью ядер и улучшенной энергоэффективностью: EPYC Bergamo и Xeon Sierra Forest. Кроме того, разработка, перенос и рефакторинг ПО для Arm требует времени и средств. В свою очередь, представитель Intel сообщил ресурсу CRN в четверг, что компания поставляет Oracle процессоры Xeon Sapphire Rapids «в течение многих месяцев и планирует продолжать поставки Xeon текущего и следующего поколения в будущем». Компании связывают долгие годы совместной работы над аппаратными и программными решениями для клиентов, а сейчас Intel поставляет чипы для облачной инфраструктуры Oracle OCI.
14.06.2023 [01:30], Игорь Осколков
AMD представила 128-ядерные EPYC Bergamo, а также EPYC Genoa-X с 1152 Мбайт L3-кешаAMD официально представила два новых, пока что очень небольших семейства серверных процессоров EPYC на базе архитектуры Zen 4. Это давно обещанные CPU серии EPYC 97x4, известные под кодовым именем Bergamo и рассчитанные на гиперскейлеров и облачных провайдеров, а также EPYC 9x84X Genoa-X с 3D V-Cache, которые предлагают до 1152 Мбайт L3-кеша и которые ориентированы на HPC-нагрузки. Ничего нового относительно архитектурных особенностей Bergamo компания не поведала. Более высокая плотность компоновки ядер Zen 4c достигнута, в частности, путём модификации кешей (они проще и меньше) и компромиссными решениями в отношении упаковки, частот и т.д. В итоге получается интересная картина — ядер в сравнении с EPYC Genoa (до 96 шт.) стало больше, а вот общее число транзисторов уменьшилось с 90 до 82 млрд. Показатель TDP сохранился на прежнем уровне. 
Изображения: AMD AMD говорит, что ядра Zen 4c примерно на треть меньше Zen 4: 2,48 мм2 против 3,84 мм2 (ядро + L2-кеш). Оба варианта производятся по 5-нм техпроцессу TSMC. В CCD теперь содержится 16 ядер вместо 8, а в самом процессоре теперь 8 CCD вместо 12. Центральный IO-мостик у Genoa и Bergamo предлагает одни и те же возможности: 128 линий PCIe 5.0 (CXL) и 12 каналов памяти DDR5-4800. При этом оба варианта совместимы не только на уровне сокета (SP5), но и ISA, и платформы целиком — достаточно обновления BIOS. 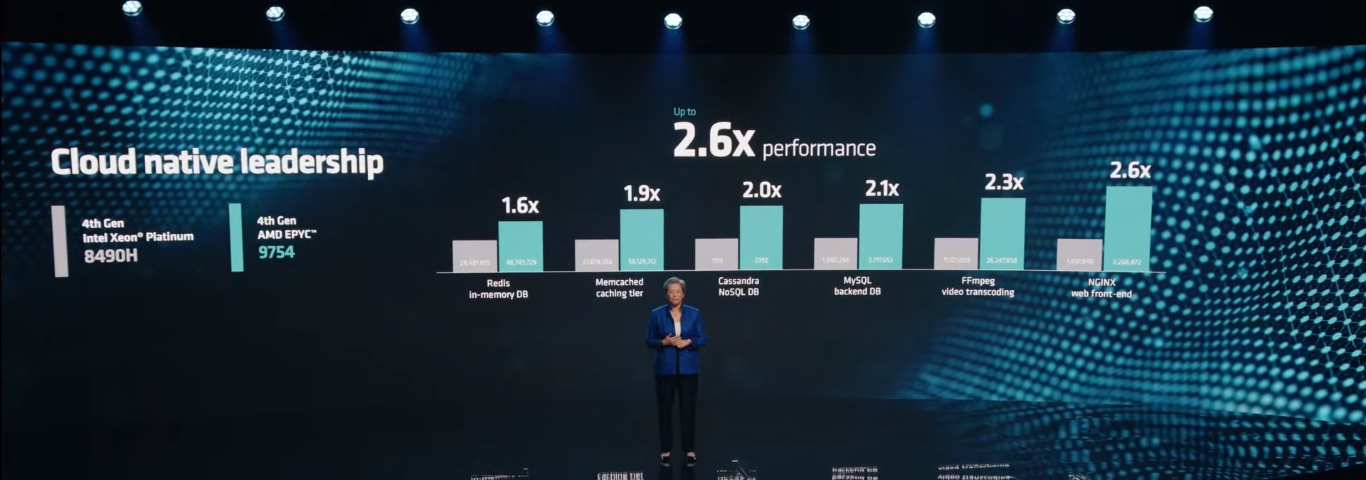 В случае Bergamo компания, как и прежде, напирает на относительно низкую совокупную стоимость владения и на ещё более высокую энергоэффективность в сравнении с Genoa. Поскольку SMT на месте, в 2U4N-шасси с двухсокетными узлами теперь можно получить 2048 vCPU. Отдельный вопрос, как это всё ещё сбалансировать с точки зрения IO. Но в любом случае такое решение должно привлечь гиперскейлеров, среди которых была упомянута Meta✴, уже использующая сотни тысяч процессоров EPYC.  Любопытно, что в пресс-релизе AMD сравнивает общую производительность Bergamo с Ampere Altra, утверждая, что в ключевых облачных нагрузках они в 3,7 раз быстрее. Кроме того, новинки в 2,7 раз энергоэффективнее конкурентов. При этом оба документа, описывающих условия тестирования, на момент написания публикации доступны не были. Возможно, как и в других тестах, речь идёт о 128-ядерных Altra Max, которые уже доступны у ключевых облачных провайдеров. 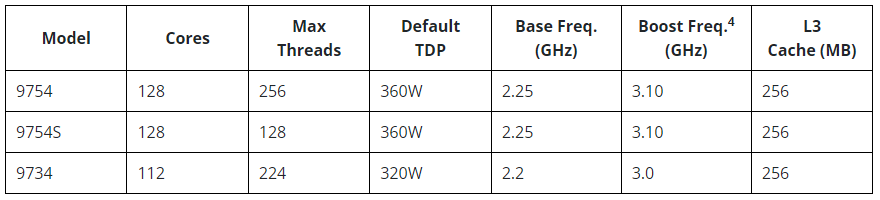 По-видимому, в этой области AMD воспринимает как важного (если не ключевого) конкурента именно Ampere, а не Intel, с продукцией которой были показаны сравнения во время презентации. Так, старший AMD EPYC 9754 до 2,6 раз быстрее старшего же Intel Xeon 8490H (Sapphire Rapids), который предлагает всего 60 ядер при сравнимом TDP. До выхода Sierra Forest с E-ядрами (до 144 шт.) в следующем году Intel отвечать AMD нечем. А вот Ampere уже представила 192-ядерные (но без SMT) AmpereOne, которые, по слухам, уже давно поставляются избранным клиентам. 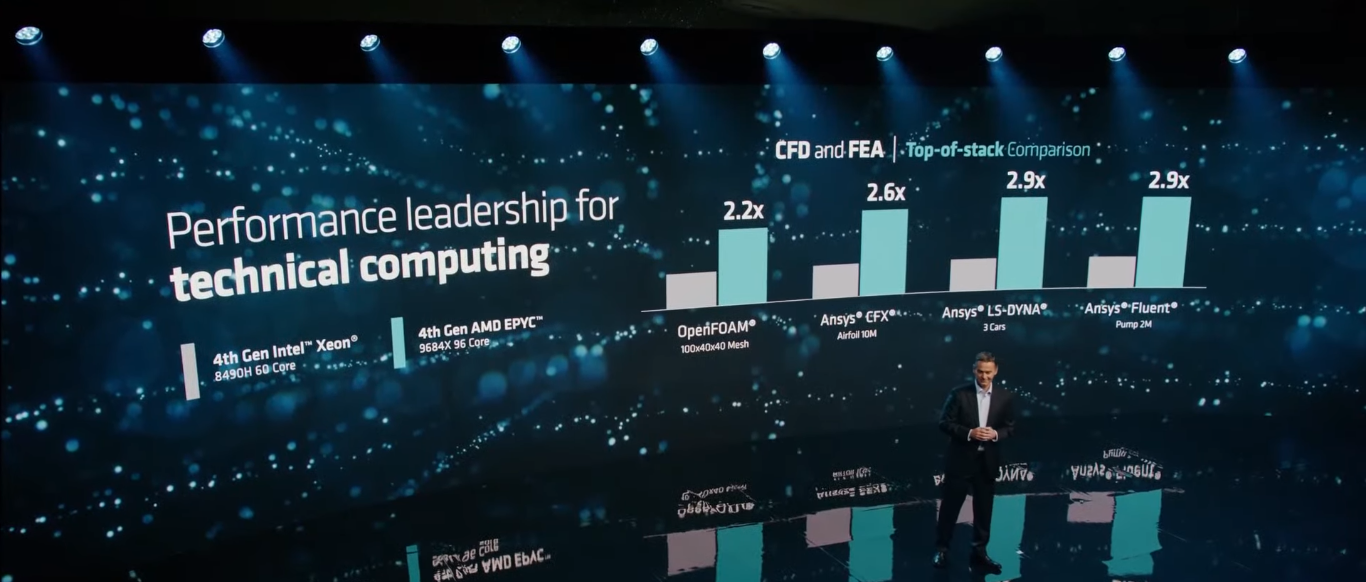 Да и сама AMD заявляет, что Bergamo тоже уже отгружаются. Заодно AMD объявила о доступности EPYC Genoa-X (9x84X). Концептуально они повторяют Milan-X, то есть поверх каждого CCD в обычном Genoa располагается плитка V-Cache с 64 Мбайт L3-кеша (с небольшим штрафом при обращении). 12 CCD дают 768 Мбайт дополнительного кеша, а суммарно выходят умопомрачительные 1152 Мбайт L3-кеша на процессор. 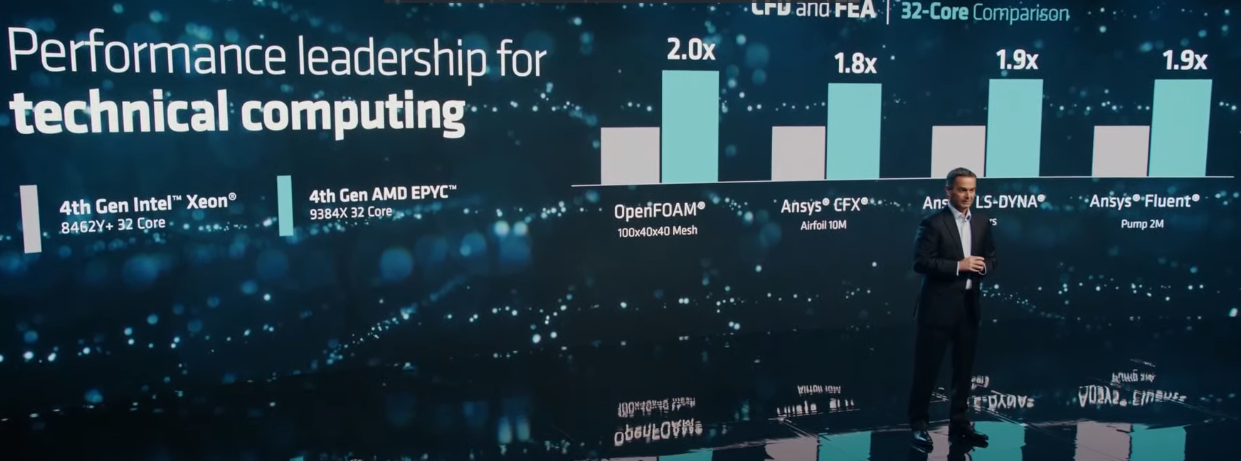 Выгоду от столь большого объёма кешей могут получить не все приложения. Речь в основном идёт об HPC, CFD, EDA и СУБД. При этом, что удивительно, AMD сравнивает новинки с «обычными» Intel Xeon Sapphire Rapids, а не с Intel Xeon Max, оснащённых 64 Гбайт набортной HBM2e-памяти (1,2 Тбайт/с) и ориентированных, в целом, на те же задачи — в таком случае они оказываются до 2,9 раз быстрее. 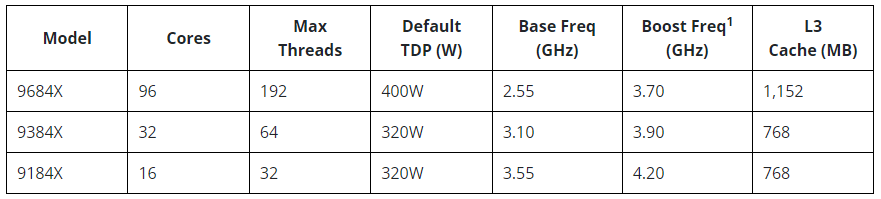
19.05.2023 [10:10], Сергей Карасёв
Ampere представила процессоры AmpereOne: до 192 ядер Arm, 8 каналов DDR5 и 128 линий PCIe 5.0Компания Ampere анонсировала процессоры серии AmpereOne, предназначенные для использования в серверах и оборудовании для дата-центров. Утверждается, что по сравнению с изделиями предыдущих поколений — Ampere Altra и Ampere Altra Max — новые чипы обеспечивают более высокие показатели производительности и энергоэффективности, а также обладают улучшенной масштабируемостью. Процессоры AmpereOne основаны на кастомизированных ядрах собственной разработки Ampere с набором инструкций Arm. Задействована чиплетная компоновка. Изготавливаются решения на предприятии TSMC на основе комбинации технологий с нормами 5 и 7 нм. 
Источник изображений: Ampere В семейство AmpereOne вошли пять моделей — со 136, 144, 160, 172 и 192 ядрами. Каждое ядро способно обрабатывать один поток инструкций. Объём кеша L2 составляет 2 Мбайт в расчёте на ядро; размер кеша L1 — 16 Кбайт для инструкций и 64 Кбайт для данных. Кроме того, есть 64 Мбайт системного кеша. Тактовая частота достигает 3,0 ГГц. 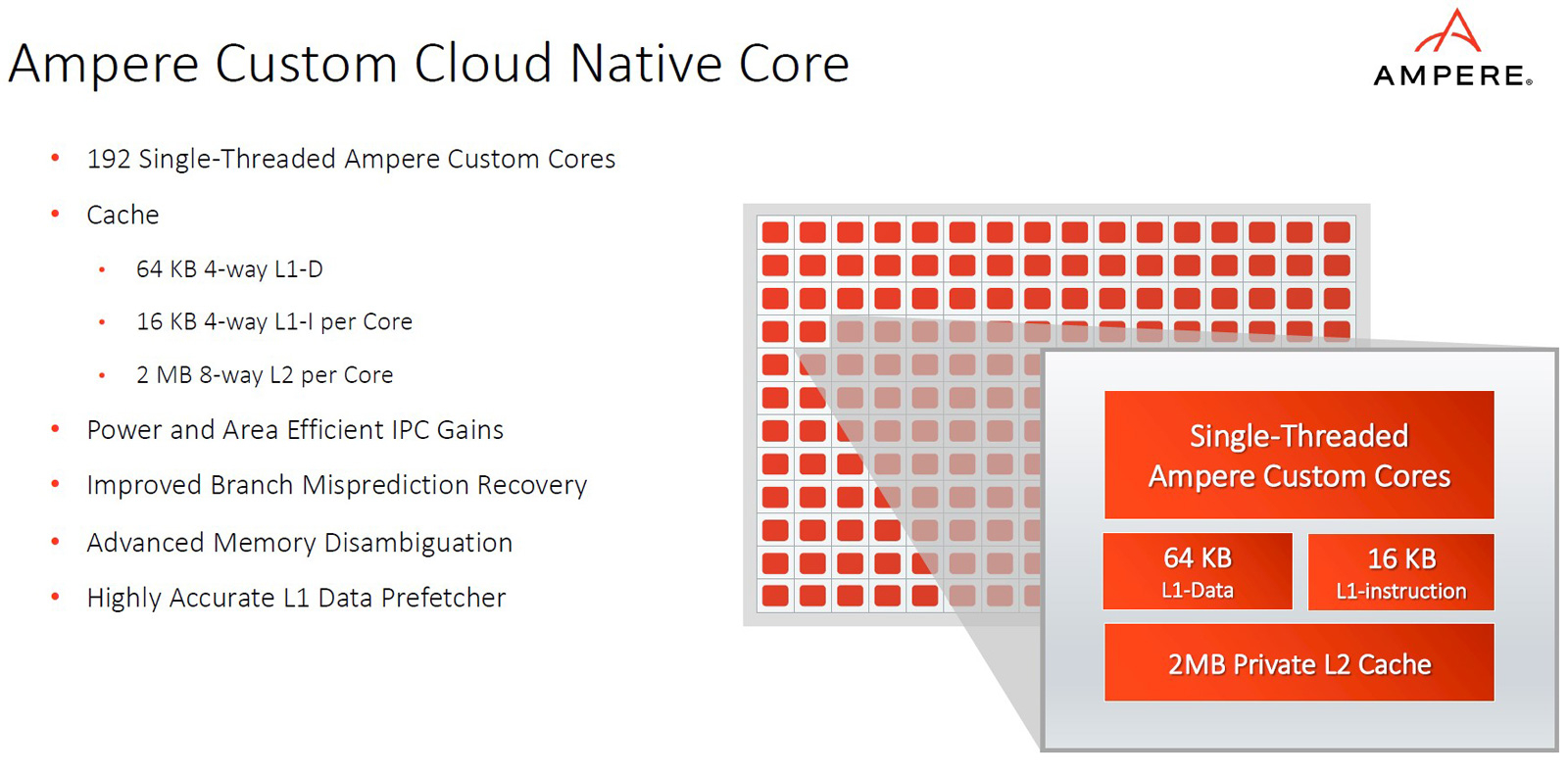
 Конструкция AmpereOne включает восемь каналов памяти DDR5 с поддержкой ECC: сервер может быть оборудован 16 слотами DIMM с возможностью использования до 8 Тбайт ОЗУ. Доступны 128 линий PCIe 5.0. Упомянута поддержка Armv8.6+ и SBSA 5. Чипы имеют исполнение FCLGA (5964-Pin).  Ampere отмечает, что процессоры AmpereOne ориентированы прежде всего на облачные платформы и среды виртуализации. Они обеспечивают высокую плотность вычислений и возможность формирования виртуальных машин, использующих от одного vCPU. Кроме того, достигается высокая производительность при ИИ-нагрузках (BF16). Заявленное энергопотребление AmpereOne составляет 1,8 Вт в расчёте на ядро, или от 200 до 350 Вт на сокет в зависимости от модификации решения. 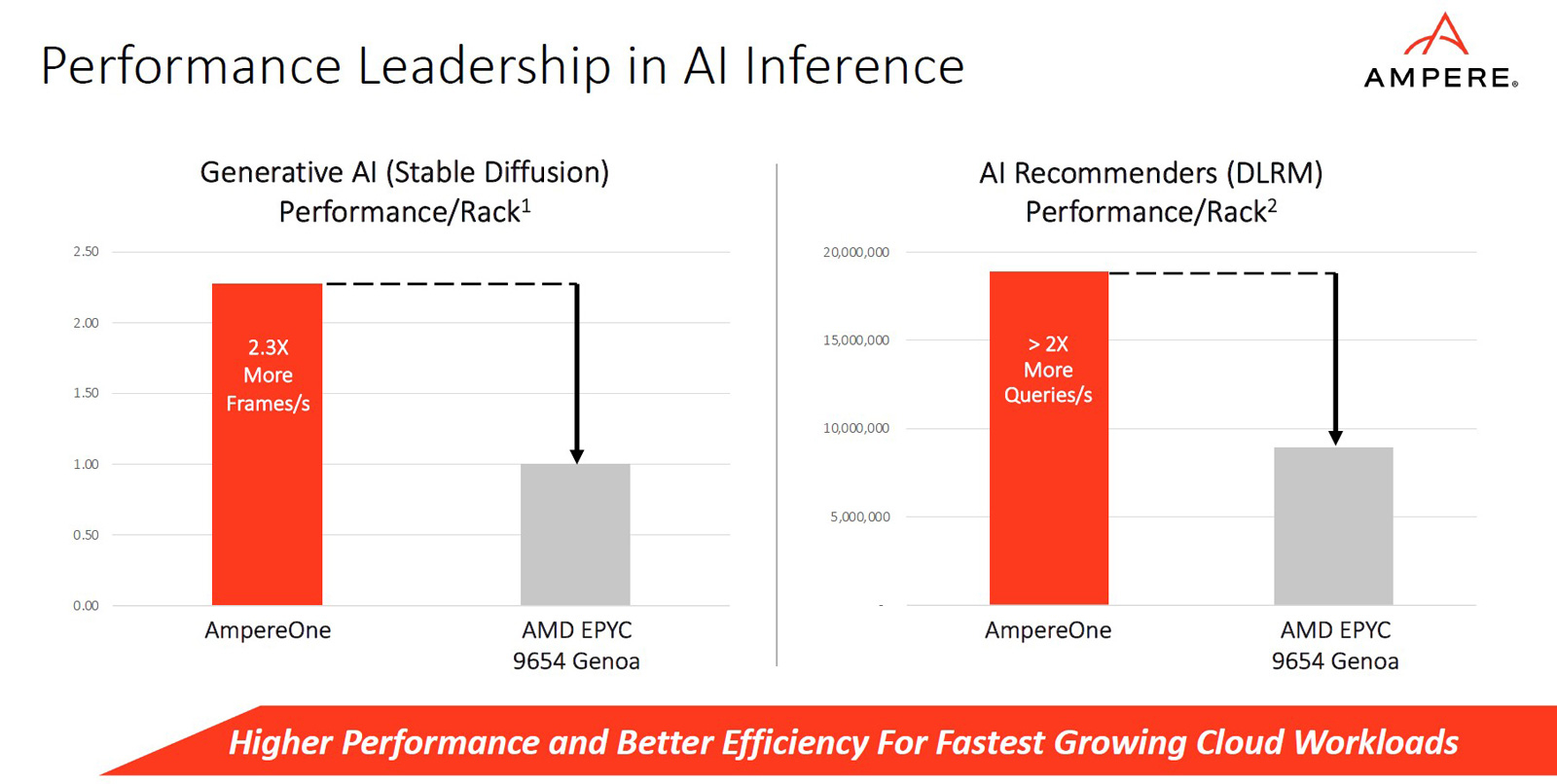
16.05.2023 [09:23], Сергей Карасёв
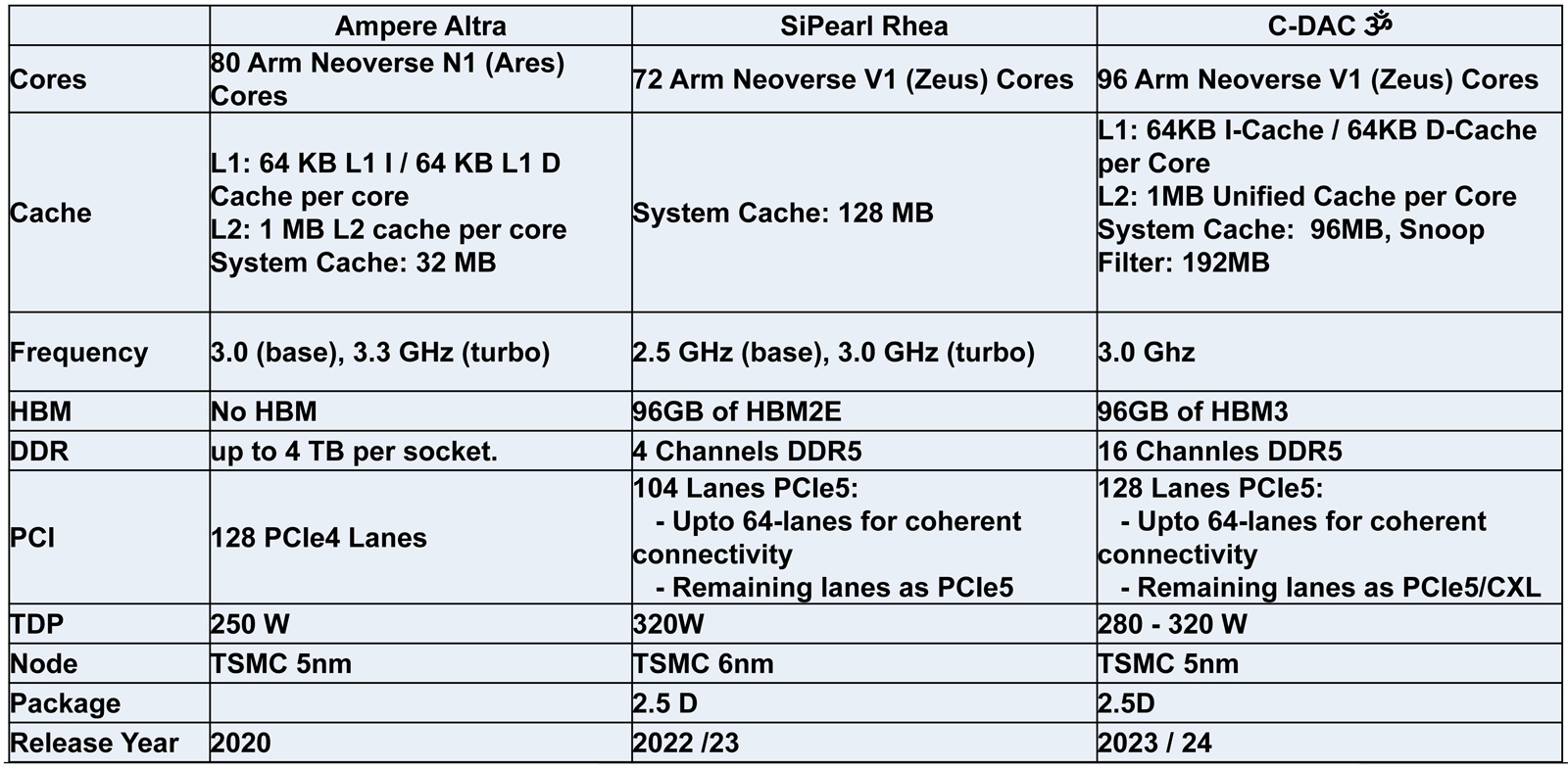
Индия представила свой первый серверный процессор AUM: 96 ядер и 96 Гбайт памяти HBM3Центр развития передовых вычислений (C-DAC) Департамента электроники и информационных технологий Министерства коммуникаций и информационных технологий Индии представил первый в стране процессор для серверов и НРС-систем. Изделие под названием AUM выйдет на коммерческий рынок в текущем или следующем году. Решение имеет чиплетную компоновку на базе двух модулей A48Z, каждый из которых насчитывает 48 вычислительных ядер Zeus с архитектурой Arm. Таким образом, суммарное количество ядер достигает 96. Тактовая частота составляет 3,0 ГГц (до 3,5 ГГц в турбо-режиме); показатель TDP варьируется от 280 до 320 Вт. 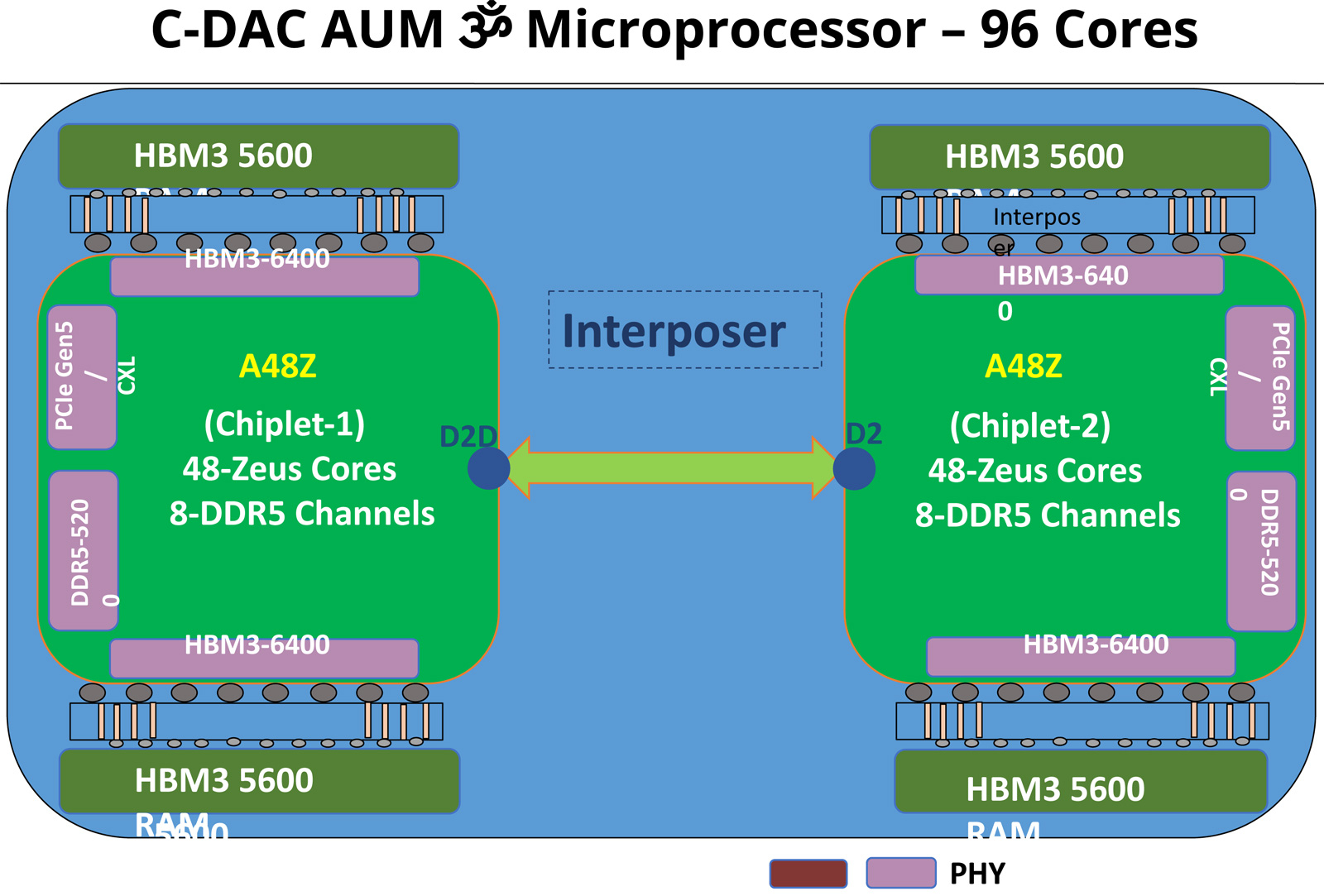
Источник изображений: C-DACC-DAC Новинка будет изготавливаться на предприятии TSMC по 5-нм технологии. Чип содержит 96 Мбайт кеша L2 и 96 Мбайт системного кеша. Изделие получило 96 Гбайт памяти HBM3 и 8-канальный контроллер DDR5-5200; кроме того, имеется доступ к 64 Гбайт памяти HBM3-5600. Таким образом, задействована трёхуровневая подсистема памяти. Упомянуты до 128 линий PCIe 5.0 с поддержкой CXL. 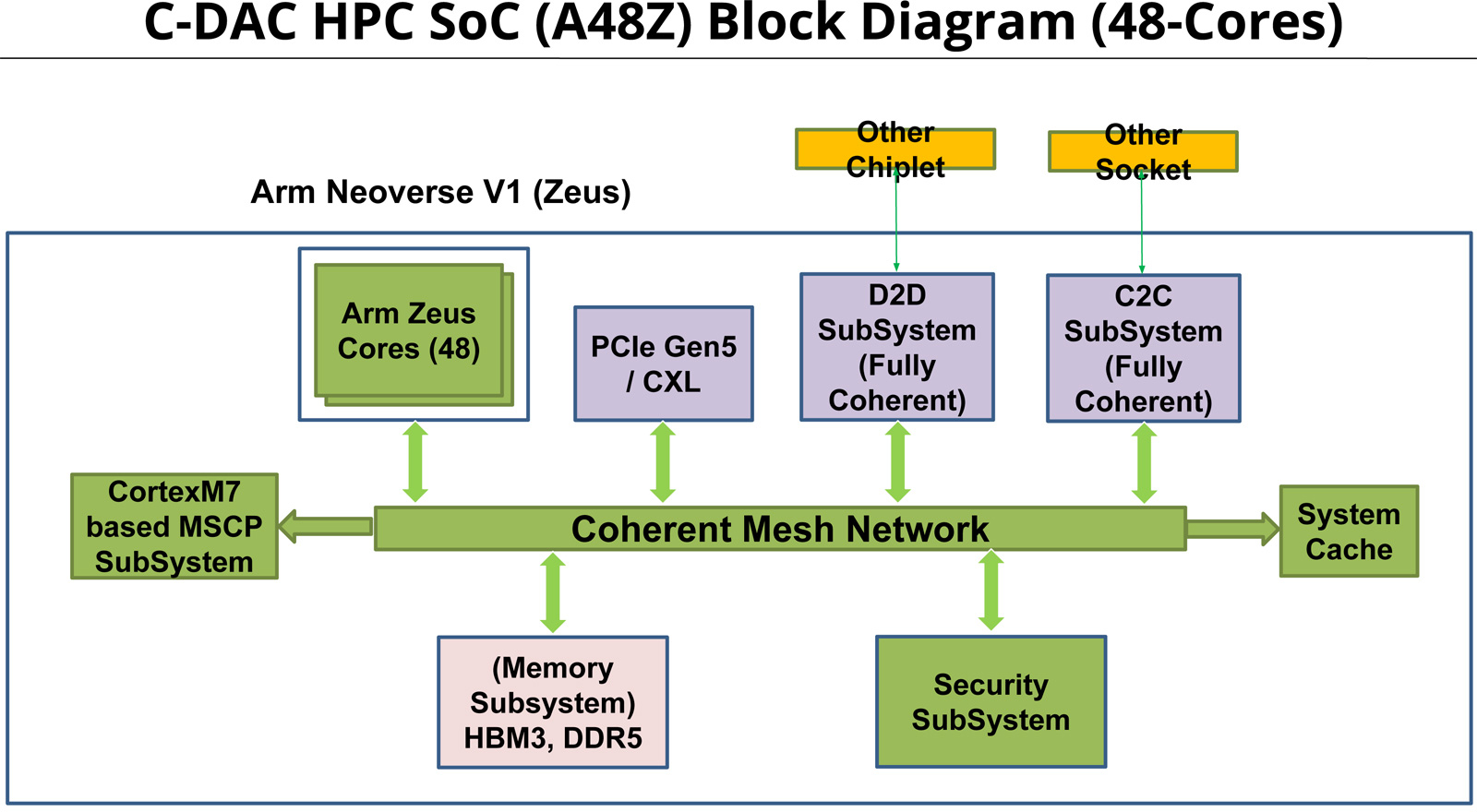 Процессор AUM может применяться в двухсокетных серверах. Заявленная производительность превышает 4,6 Тфлопс в расчёте на разъём. Реализованы различные средства обеспечения безопасности, в том числе функция Secure Boot и криптографические алгоритмы. 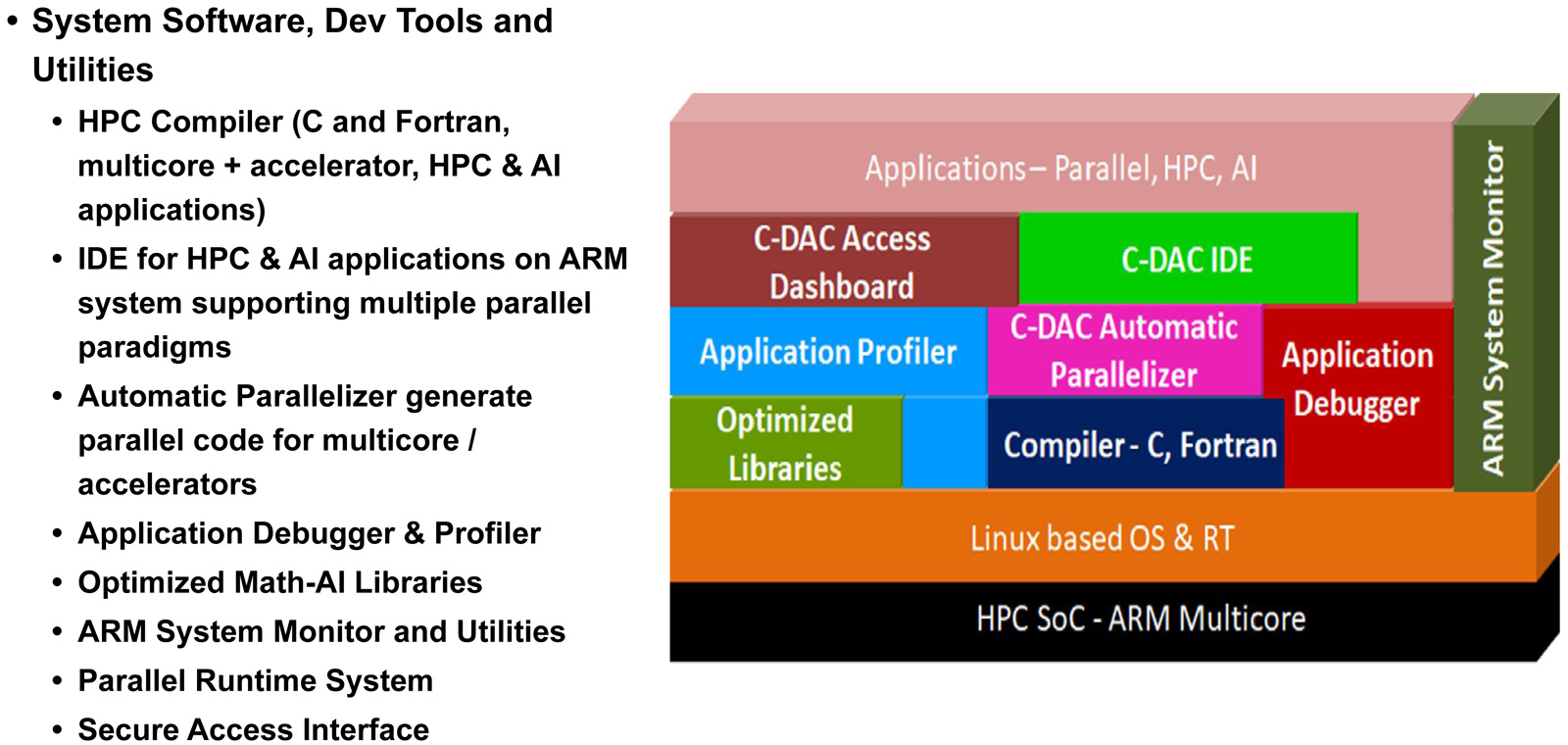
30.03.2023 [19:45], Владимир Мироненко
В 2023 году Intel выпустит Xeon Emerald Rapids и подготовит полтора десятка FPGA, а чипы Sierra Forest и Granite Rapids появятся уже в 2024 годуВ ходе мероприятия для инвесторов Intel подтвердила свои планы по противодействию процессорам AMD EPYC Bergamo, в которых будет использоваться архитектура с высокой плотностью ядер Zen4c, а также всё нарастающему давлению Arm. Intel придерживается планов по созданию собственных архитектур с производительными и энергоэффективными ядрами для чипов Xeon. Intel объявила, что рассчитывает выпустить следующее, пятое по счёту поколение процессоров Xeon Scalable под кодовым названием Emerald Rapids (EMR), преемников Sapphire Rapids (SPR), в IV квартале 2023 года. Компания также продемонстрировала чип Emeralds Rapids, состоящий из двух чиплетов (тайлов в терминологии Intel). Sapphire Rapids, напомним, имеется четыре тайла меньших размеров. Сообщается, что образцы Emerald Rapids уже доступны избранным заказчикам. Не вдаваясь особо в технические подробности, компания рассказала, что Emerald Rapids будет работать в том же диапазоне TDP, что и Sapphire Rapids, что повысит общую производительность платформы в пересчёте на Вт. 
Изображения: Intel Учитывая то, что Emerald Rapids будет использовать ту же платформу LGA 4677, что и Sapphire, заказчики смогут заменить Sapphire на Emerald в существующих решениях. Такой подход позволит легко модернизировать уже внедрённые системы, а в случае производителей оборудования — ускорить вывод Emerald Rapids на рынок. Emerald Rapids будет построен на том же техпроцессе Intel 7. Это означает, что прирост производительности должен быть обеспечен за счёт архитектурных улучшений. Intel сообщила о «повышенной плотности ядер», поэтому можно предположить, что у Emerald Rapids будет больше ядер в сравнении с Sapphire Rapids. 
Emerald Rapids Вслед за Emerald Rapids компания планирует начать в 2024 году поставки чипов следующего поколения Granite Rapids (GNR) на базе производительных P-ядер. Сообщается, что вычислительные тайлы Granite Rapids будут выпускаться с использованием техпроцесса Intel 3. Intel также впервые сообщила, что Granite Rapids будут поддерживать MCR DIMM (DDR5-8800+) и обеспечат ПСП в пределах 1,5 Тбайт/с (12 каналов памяти). Ещё одной особенностью станет полный переход на чиплетную компоновоку с независимым IO-тайлом. Первые образцы Granite Rapids уже тестируются некоторыми заказчиками. 
Emerald Rapids В первой половине 2024 года должен выйти и процессор Sierra Forest (SRF), первый Intel Xeon с энергоэффективными E-ядрами (следующее за Gracemont поколение) общим числом до 144 единиц. Сообщается, что Sierra Forest и Granite Rapids будут использовать одну и ту же платформу Birch Stream. Следует отметить, что чипы Sierra Forest появятся несколько раньше, чем Granite Rapids, и тоже будут использовать техпроцесс Intel 3, а также IO-тайлы. Отмечается, что Sierra Forest даже в текущем виде оказались на удивление стабильно работающими. Более того, их уже тестирует как минимум один заказчик Intel. 
Sierra Forest На смену Sierra Forest придут в 2025 году чипы Clearwater Forest (CWF), которые станут первыми в семействе Intel Xeon, основанными на техпроцессе Intel 18A. По словам Intel, её заказчики не хотят серверные процессоры смешанной архитектуры, то есть требуют чипы либо только с P-ядрами, либо только с E-ядрами. Sierra Forest сейчас является, пожалуй, наиболее важным продуктом для Intel и для демонстрации производственных возможностей, и для сохранения заказчиков среди гиперскейлеров. 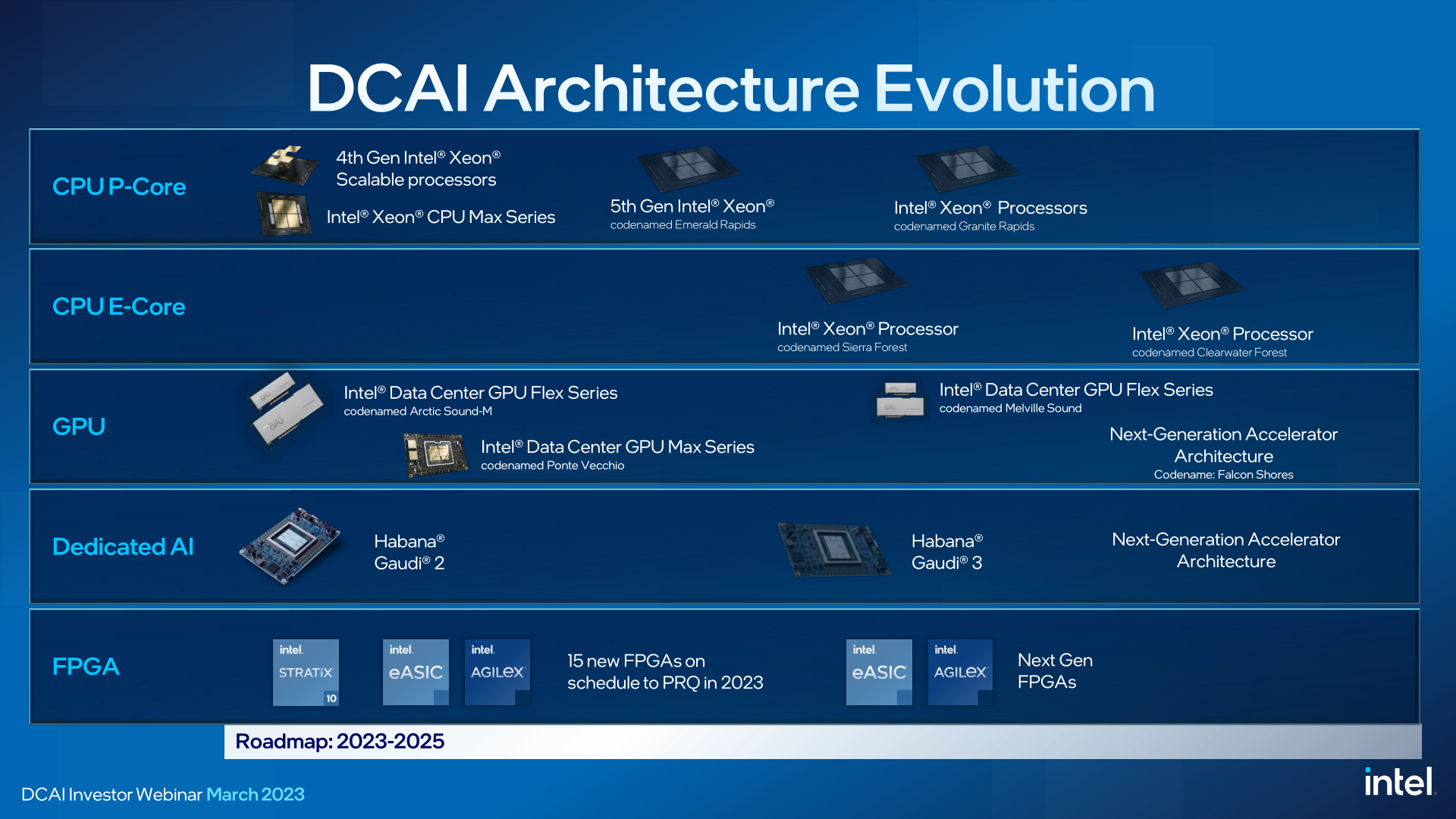 Что касается ускорителей, то компания в этом году планирует подготовить сразу 15 различных FPGA в сериях Agilex и Stratix, а также eASIC. Intel, как уже говорилось ранее, не забрасывает работу над специализированными ускорителями Habana, но грядущие Gaudi3 от нынешних Gaudi2 будут отличаться переходом с 7-нм на 5-нм техпроцесс. Отменённых Rialto Bridge в планах более нет, да и Falcon Shores тоже не упоминаются. При этом Intel считает, что к 2027 году в области ИИ-чипов соотношение между CPU и GPU будет на уровне 60/40.
22.03.2023 [00:09], Алексей Степин
NVIDIA показала сдвоенный серверный суперпроцессор Grace SuperchipПроект NVIDIA Grace весьма амбициозен: компания всерьёз намерена ворваться с его помощью на рынок высокопроизводительных серверных процессоров, где всё ещё доминируют решения Intel и AMD. Об этом чипе было объявлено ещё на конференции GTC 2022, а на GTC 2023 глава компании, наконец, показал его вживую. В рамках продолжающегося роста плотности упаковки вычислительных мощностей в современных ЦОД на первый план выдвинулась не голая производительность, а соотношение производительности к уровню энергопотребления и тепловыделения. По сочетанию этих параметров x86 далеко не оптимальна, и тут у NVIDIA есть все шансы. С анонсом Grace Superchip NVIDIA провозглашает (впрочем, уже не в первый раз) смерть «закона Мура» — пришло время оптимизации и отказа от устаревших, по мнению компании, вычислительных архитектур. 
Источник изображений здесь и далее: NVIDIA Процессор NVIDIA Grace воплощает в себе все современные тенденции, начиная с отказа от монолитного кристалла. Сборка Grace Superchip состоит из двух кристаллов, каждый из которых включает в себя 72 ядра Arm Neoverse V2 (Arm v9), поддерживающих векторные расширения SVE2 и оптимизированные для ИИ форматы BF16/INT8. Кристаллы соединены между собой шиной NVLink-C2C, обеспечивающей пропускную способность 900 Гбайт/с.  В сборку интегрированы чипы памяти LPDDR5x общим объёмом до 960 Гбайт, причём каждый кристалл имеет свою шину доступа к памяти с производительностью 500 Гбайт/с. При этом с точки зрения ПО Grace Superchip представляется единым 144-ядерным процессором с ПСП на уровне 1 Тбайт/с. 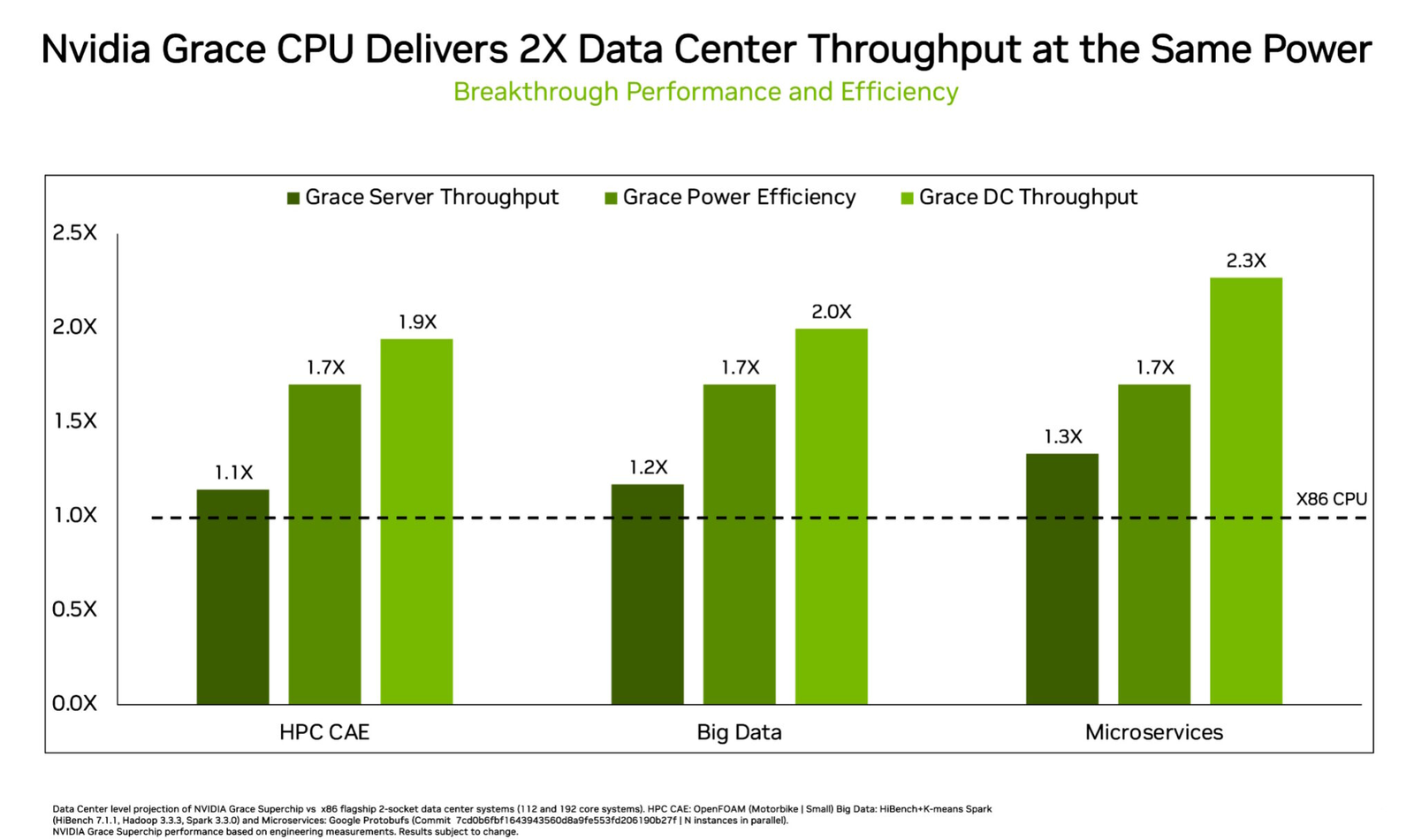 Для достижения схожих параметров в мире x86 требуется двухпроцессорная платформа AMD Genoa, куда более сложная технически и гораздо менее энергоэффективная, но при этом обладающая всеми недостатками NUMA-систем. Достаточно сравнить энергопотребление: 900 Вт против 500 у нового решения NVIDIA. 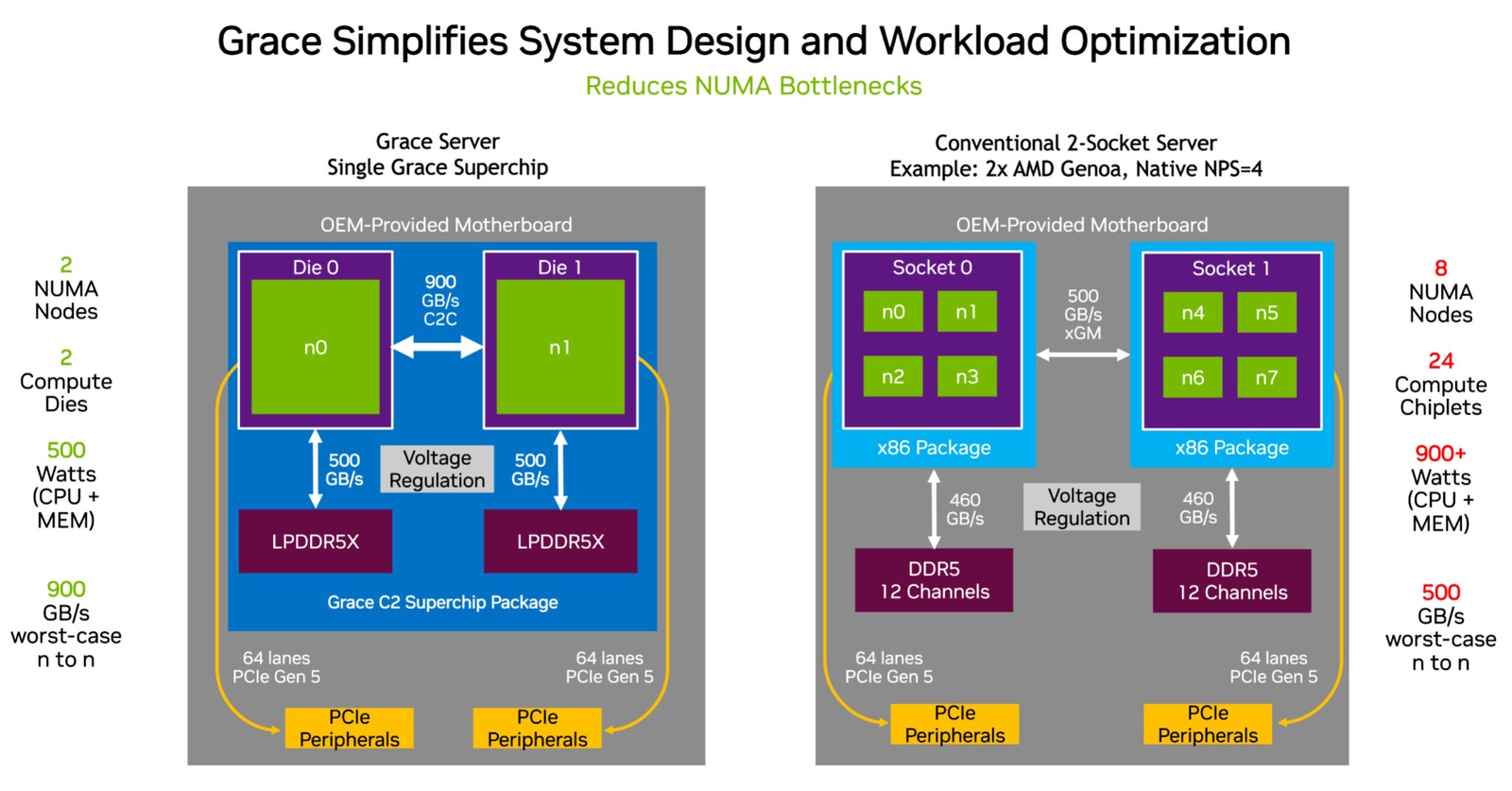 NVIDIA есть чем гордиться: при сопоставимом уровне энергопотребления Grace Superchip превосходит своих конкурентов из мира x86 в 2,3 раза при запуске микросервисов, вдвое опережает их в приложениях с интенсивным обменом данными с памятью и почти вдвое — в задачах симуляции вычислительной гидродинамики. В ряде других научно-технических задач преимущество может быть и более чем двукратным. 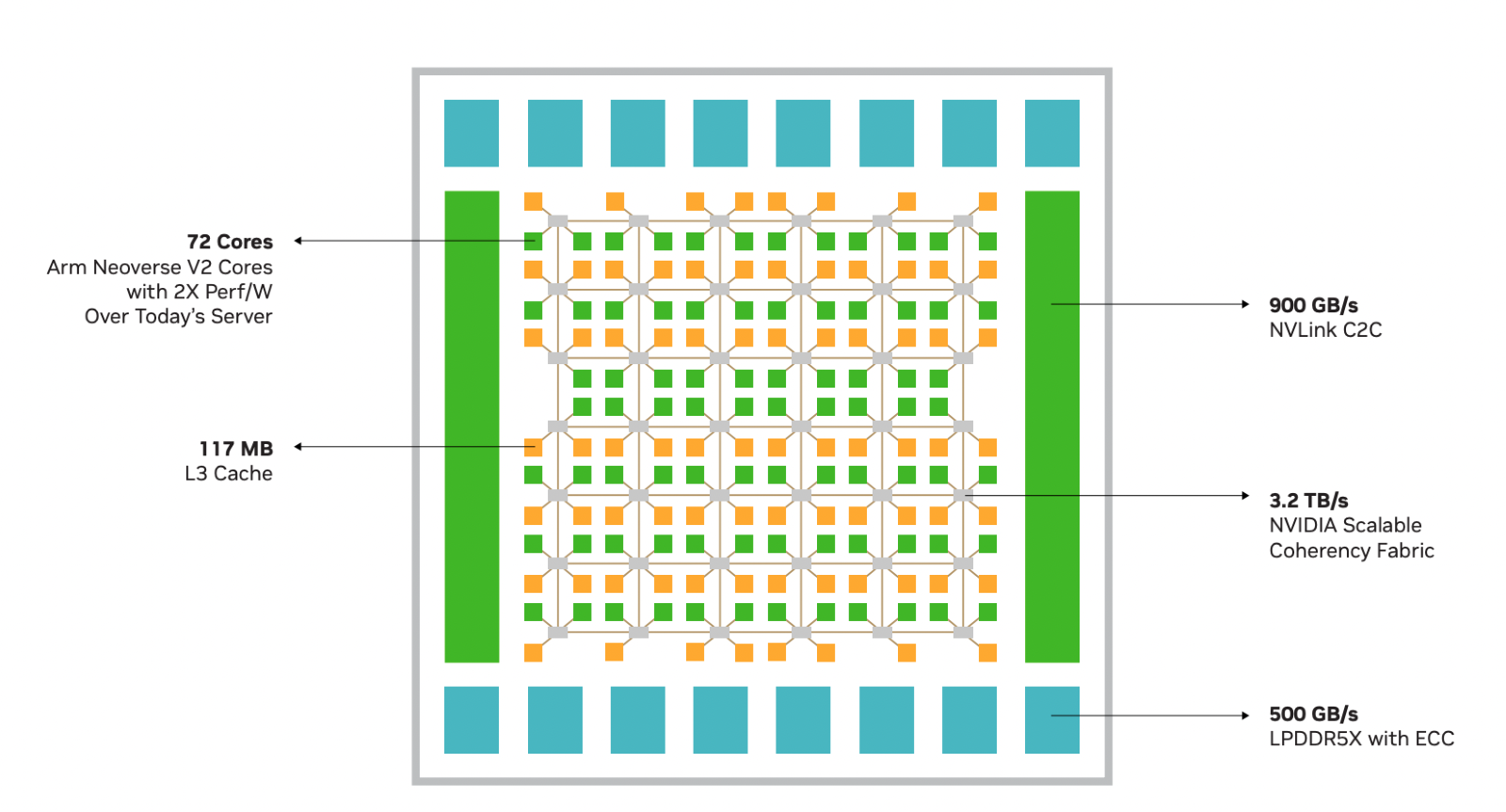 Это достигнуто в том числе благодаря изначальной оптимизации дизайна процессора с упором на максимальную производительность передачи данных. Внутренне Grace организован по принципу меш-сети с распределённой системой кеширования на базе специальных узлов коммутации CSN (Cache Switch Nodes). Называется эта сеть Scalable Coherency Fabric, она имеет пропускную способность 3,2 Тбайт/с, а объём кеша L3 составляет 117 Мбайт на кристалл и 234 Мбайт совокупно.  Сервер на базе NVIDIA Grace не только может потреблять меньше энергии, но и будет существенно проще конструктивно, поскольку модуль Grace Superchip содержит не только процессорные ядра и память, но также и регуляторы напряжения. От платформы на базе нового процессора требуется только PCIe 5.0 — у нового чипа есть два набора по 64 линии. Причём линии с поддержкой CXL 2.0, так что проблем с расширением доступного объёма памяти новинка испытывать не будет.  Даже компактные серверы высотой 1U смогут вместить две сборки Grace Superchip, что даст 288 ядер и почти 2 Тбайт оперативной памяти — труднодостижимый в таких габаритах показтель для более традиционных конструктивов процессоров и системных плат. Сравнительно невысокий теплопакет позволит таким решениям обходиться традиционным воздушным охлаждением.  При этом есть и вариант Grace Hopper, сочетающий в одном модуле кристалл Grace и новейший GPU H100, причём параметрами PCI Express последний ограничен не будет благодаря NVLink-C2C. NVIDIA уже начала первичные поставки Grace, а начало полномасштабного производства ожидается во второй половине года. Новыми процессорами заинтересовались крупные производители оборудования, включая ASUS, Atos, GIGABYTE, HPE, QCT, Supermicro, Wistron и ZT Systems.  Лос-Аламосская национальная лаборатория объявила, что использует NVIDIA Grace в новом суперкомпьютере Venado, который поможет учёным в исследованиях новых материалов и возобновляемых источников энергии. Ряд крупных европейских и азиатских ЦОД также рассматривает перспективы применения новых процессоров NVIDIA. В частности, одной из систем на базе Grace станет кластер Alps в Швейцарском национальном компьютерном центре.
14.03.2023 [15:56], Алексей Степин
AMD анонсировала процессоры EPYC Embedded 9004 для промышленных системВстраиваемые решения AMD привлекают не так много внимания как настольные или серверные, но в арсенале компании представлены широко — от экономичных Ryzen Embedded для индустриальных и встраиваемых ПК до мощных EPYC Embedded. Именно о последних сегодня пойдет речь, поскольку на выставке Embedded World 2023 компания представила новую серию процессоров EPYC Embedded 9004 (Genoa). Свою родословную новые EPYC Embedded ведут от обычных серверных чипов EPYC Genoa. AMD позиционирует новинки в качестве решений для автоматизации в промышленности, телекоммуникациях, (I)IoT и периферийных вычислениях — везде, где требуется сочетание высокой удельной производительности с энергоэффективностью. 
Источник изображений здесь и далее: AMD Новая платформа представлена в одно- и двухсокетных вариантах. Максимальное количество процессорных ядер Zen 4 составляет 96 (SMT2), а объём кеша L3 может достигать внушительных 384 Мбайт. 12-канальный контроллер памяти с поддержкой DDR5-4800 ECC (3DS) RDIMM и NV-DIMM (важно для устойчивости к потере питания и быстрого восстановления работоспособности) тоже никуда не делся. 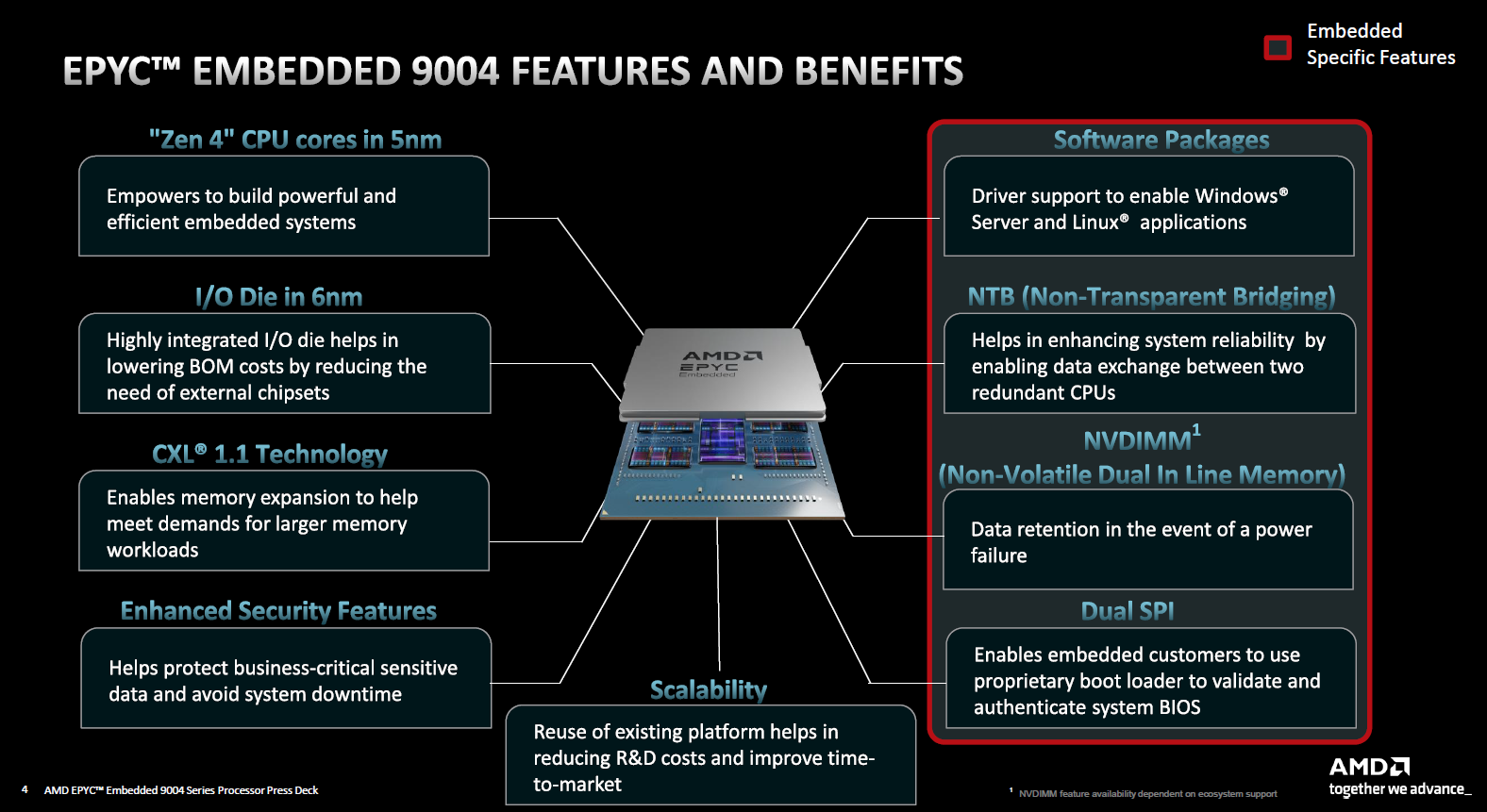 Всего в новой серии AMD представила 10 моделей EPYC Embedded 9004, с числом ядер от 16 до 96, различными частотными формулами, объёмами кеша L3 и теплопакетами в диапазоне от 200 до 360 Вт (cTDP до 400 Вт). Варианты для однопроцессорных систем располагают 128 линиями PCIe 5.0, а 2S-системы предлагают до 160 линий. Поддерживается CXL 1.1, включая устройства CXL.mem. Сокет CPU всё тот же — 6096-контактный SP5. 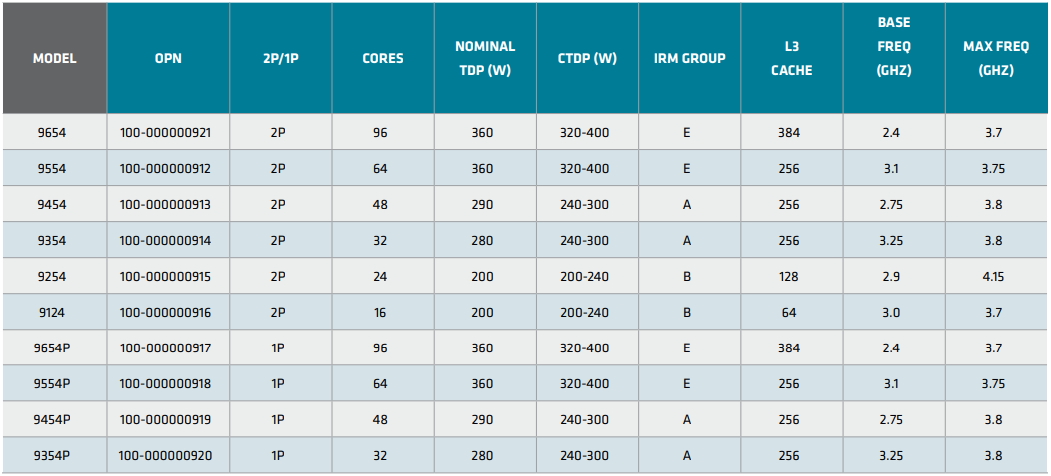 Кое-чем новые EPYC Embedded отличаются от своих обычных собратьев. В частности, отдельно отмечается поддержка Non-Transparent Bridge (NTB), что важно для формирования двухконтроллерных платформ, а также наличие технологии Scalable Control Fabric, которая позволяет более тонко конфигурировать межсоединения между чиплетами. Кроме того, например, сообщается о наличии второго канала SPI, что позволяет обеспечить дополнительную защиту и верификацию образов BIOS/UEFI. 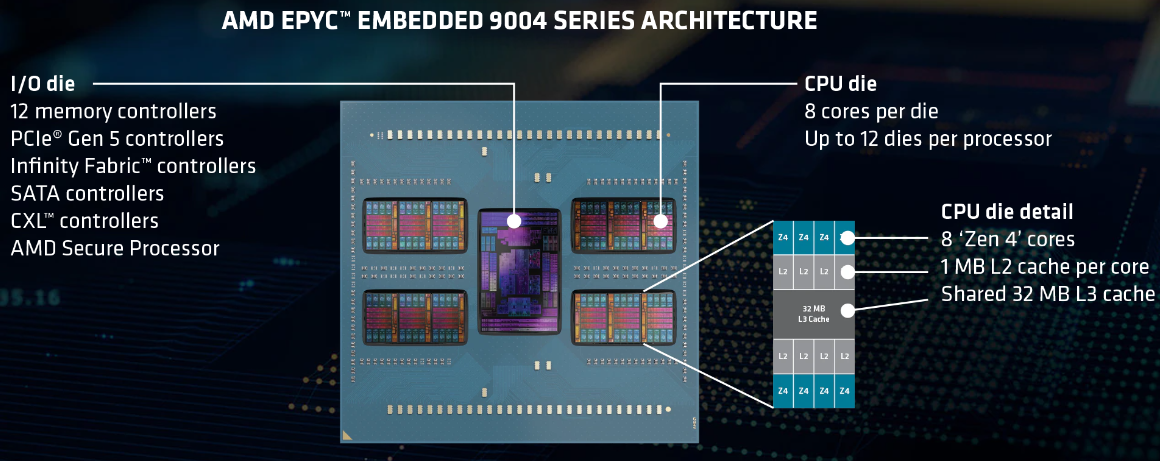 В числе главных партнёров AMD по внедрению новой платформы EPYC Embedded числятся компании Advantech и Siemens, уже анонсировавшие решения на базе новых процессоров. В качестве примера можно привести новый сервер Siemens SIMATIC IPC RS-828A или системную плату Advantech ASMB-831. Процессоры AMD EPYC Embedded 9004 уже доступны в небольших пробных партиях, но и начало массовых поставок не за горами, оно намечено уже на апрель текущего года.  В настоящее время «пробный комплект разработчика», в который входит референс-плата с процессором, полный комплект документации и программный инструментарий, доступен избранным партнёрам AMD. Также стоит отметить, что у новой платформы расширенный жизненный цикл, составляющий 7 лет, и без поддержки в ближайшее десятилетие оборудование на базе EPYC Embedded 9004 не останется.
28.02.2023 [00:08], Игорь Осколков
Xeon EE для 5G: Intel представила процессоры Sapphire Rapids со встроенным ускорителем vRAN BoostНа MWC 2023 компания Intel, как и обещала когда-то, представила специализированное решение для ускорения внедрения 5G и 4G, которое упрощает развёртывание виртуализированных сетей радиодоступа (vRAN) — процессоры Xeon Sapphire Rapids с интегрированным ускорителем vRAN Boost. Новинки, по словам компании, оптимизированы для сигнальной обработки и обработки пакетов, балансировки, ИИ и машинного обучения, а также динамического управления энергопотреблением.  Новинки позволят телеком-провайдерами консолидировать уже развёрнутые сети 4G/5G, удвоив ёмкость vRAN (по сравнению с Ice Lake-SP), а также вдвое улучшить энергоэффективность обработки L1-трафика в режиме реального времени благодаря расширенным возможностям сбора телеметрии и управления состоянием отдельных ядер (переход в сон и обратно) с низким уровнем задержки, а также гибкого перераспределения сетевых и иных нагрузок между ядрами.  Компания предложит заказчикам две серии Xeon EE (Enhanced Edge) с числом ядер до 20 или до 36 шт. и восемью каналами памяти, DDR5-4000 и DDR5-4400 соответственно. В обоих случаях речь об односокетных платформах. Некоторые модели также имеют поддержку AMX-инструкций и расширенный диапазон рабочих температур. Компанию новинкам составят FPGA Agilex 7, eASIC N5X и сетевые контроллеры E810 (Columbiaville). 
Источник: Intel Xeon EE используют расширения AVX (в частности, AVX512-FP16) для обработки сигналов и аппаратные блоки ускорения vRAN Boost для прямой коррекции ошибок (FEC, Forward Error Correction) и дискретного преобразования Фурье (DFT, Discrete Fourier Transformation), что позволяет снизить энергопотребление на величину до 20 % по сравнению с обычными Sapphire Rapids, поскольку для них и более ранних CPU требуются дискретные ускорители вроде ACC100. Для работы с новыми функциями предлагается DPDK и VPP, а драйверы совместимы с O-RAN ALLIANCE Accelerator Abstraction Layer (AAL) API. Также поддерживается и референсная платформа Intel FlexRAN.  В целом же, Intel продолжает продвигать идею замены специализированного 4G/5G-оборудования на как можно более стандартные серверы, что приводит к снижению совокупной стоимости владения (TCO) и повышает функциональность, гибкость и масштабируемость сетей нового поколения благодаря переходу к программно определяемым решениям. Среди ключевых партнёров компания называет Advantech, Capgemini, Canonical, Dell Technologies, Ericsson, HPE, Mavenir, Quanta Cloud Technology, Rakuten Mobile, Red Hat, SuperMicro, Telefonica, Verizon, VMware, Vodafone и Wind River.  На MWC 2023 также были показаны анонсированные на днях edge-серверы Dell на базе новых Xeon EE. Кроме того, Intel при сотрудничестве с SK Telecom разработала референсную программную платформу Intel Infrastructure Power Manager для ядра 5G-сети, которая позволяет ещё больше снизить (до -30 %) фактическое энергопотребление процессоров. Наконец, компания на пару с Samsung продемонстрировала работу 5G UPF (User Plane Function) на скорости 1 Тбит/с, для чего оказалось достаточно двухсокетного сервера с Sapphire Rapids, который, судя по всему, всё же был снабжён ускорителями.
20.01.2023 [15:28], Алексей Степин
NVIDIA Grace Superchip получит 144 Arm-ядра, 960 Гбайт набортной памяти LPDDR5x и 128 линий PCIe 5.0, а TDP составит 500 ВтGrace можно назвать одним из самых амбициозных проектов NVIDIA. О намерении ворваться на рынок мощных серверных процессоров компания объявила ещё на GTC 2022, но до недавних пор о чипах Grace были доступны лишь общие сведения. Однако ситуация меняется. NVIDIA явно располагает рабочим «кремнием», и на днях опубликовала пару деталей о Grace Superchip. Ожидается, что официальный анонс новинки состоится в марте этого года на GTC 2023. Эта сборка включает в себя два 72-ядерных кристалла Grace, использующих ядра Arm Neoverse V2. Данное ядро использует набор инструкций Armv9, а также имеет четыре 128-битных блока векторных расширений SVE2, блоки для работы с матрицами и поддержку BF16/INT8. Объём кеша L1 составляет по 64 Кбайт для инструкций и данных, L2 — 1 Мбайт на ядро, а общий объём L3 на сборку достигает 234 Мбайт. 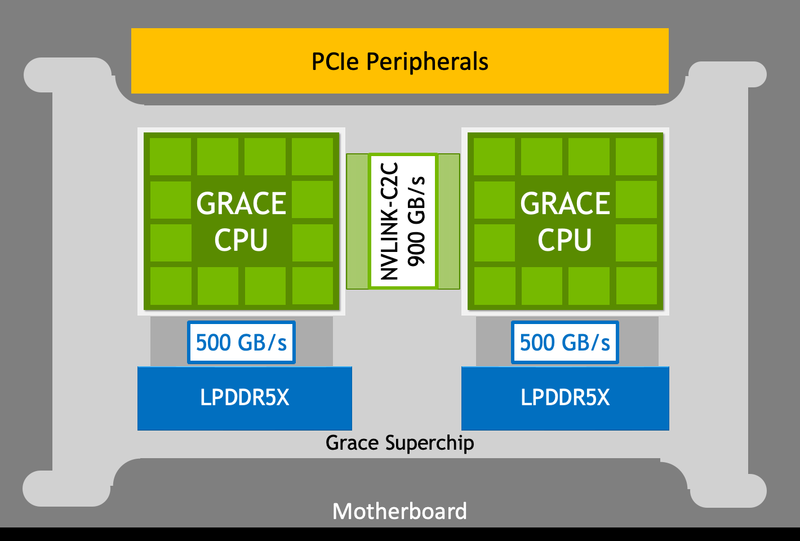
Блок-схема сборки Grace Superchip. Источник изображений здесь и далее: NVIDIA Между собой кристаллы соединены шиной NVLink C2C с пропускной способность 900 Гбайт/с, и работают они как единый 144-ядерный процессор. Но это ещё не всё: каждый из кристаллов соединен со своим банком памяти LPDDR5x ECC шиной с пропускной способностью 500 Гбайт/с (т.е. суммарно на чип получается 1 Тбайт/с). Совокупный объём памяти может достигать 960 Гбайт. 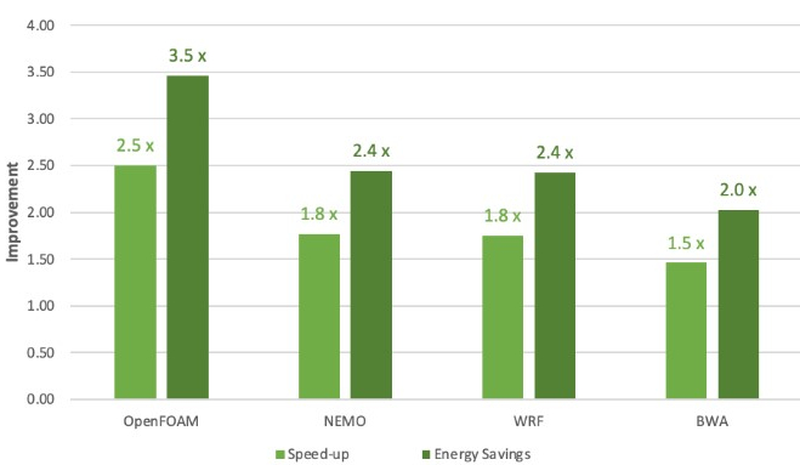
Сравнение производительности и энергоэффективности Grace Superchip с двумя AMD EPYC 7763 (Milan) Сборка Grace Superchip общается с внешним миром посредством восьми комплексов PCIe 5.0 x16 (всего 128 линий, поддерживается бифуркация). Чип при теплопакете 500 Вт (вместе с набортной памятью) способен развивать 7,1 Тфлопс на вычислениях двойной точности. С учетом интегрированной памяти это делает Grace Superchip интересной альтернативой AMD Genoa. 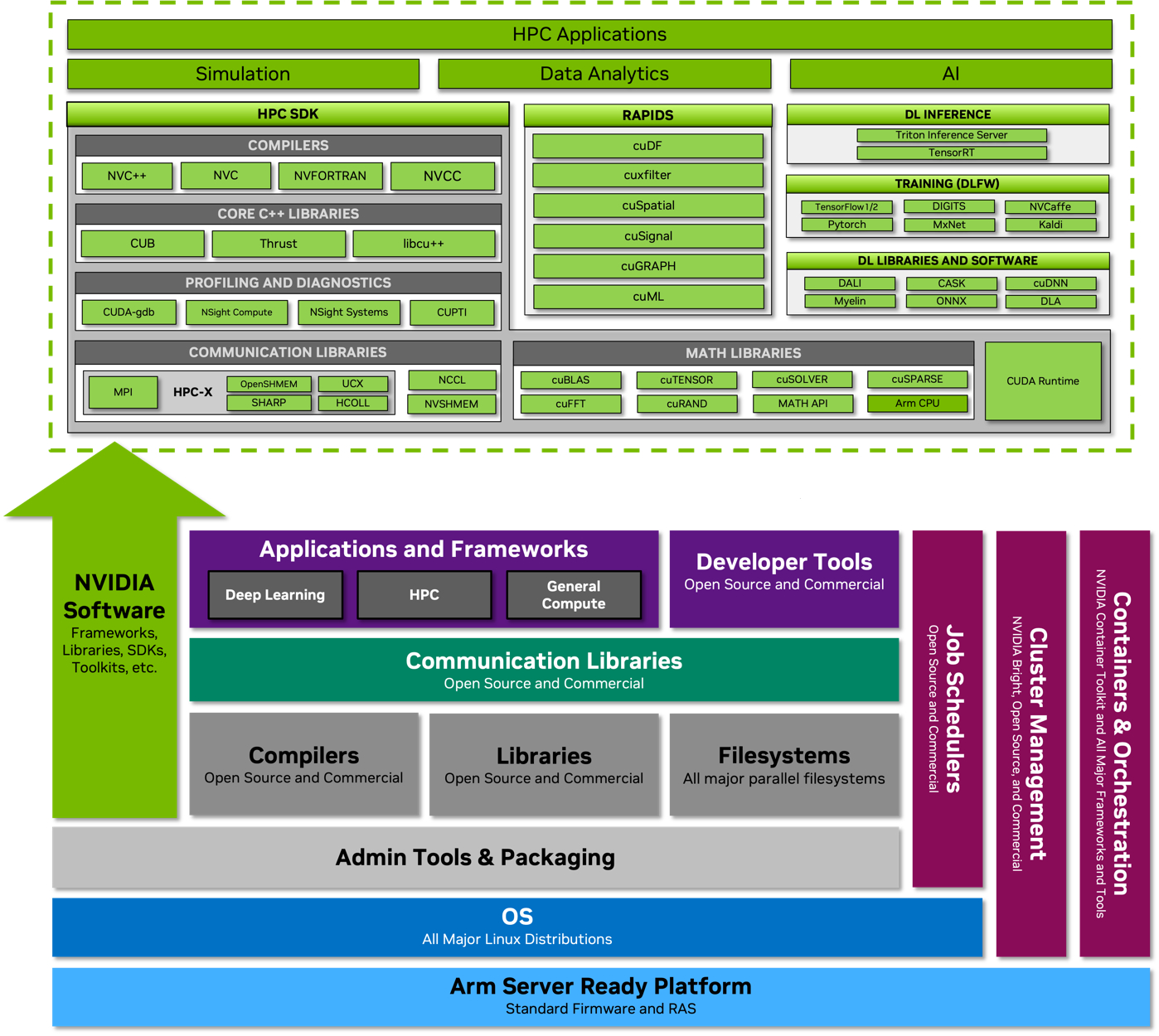
Программная экосистема платформы NVIDIA Grace. По клику открывается полноразмерная версия. Помимо данных о производительности в режиме FP64 компания уже опубликовала результаты тестов новинки в HPC-нагрузках, где сравнила своё детище с двухсокетной системой на базе AMD EPYC 7763. Выигрыш в производительности составляет от 1,5x до 2,5x, но что не менее важно — Grace Superchip намного эффективнее энергетически, здесь преимущество может достигать 3,5x. В условиях высокоплотных ЦОД или HPC-кластеров это может стать решающим.
17.01.2023 [15:33], Сергей Карасёв
Intel Xeon на китайский лад: Montage представила защищённые процессоры Jintide четвёртого поколения на базе Sapphire RapidsКитайская компания Montage Technology анонсировала процессор Jintide четвёртого поколения, рассчитанный на облачные платформы, корпоративные нагрузки, ИИ-приложения и системы НРС. В основу решения положен новейший чип Intel Xeon Sapphire Rapids, о котором можно подробно узнать в нашем материале. Ключевые отличия Jintide от стандартных Xeon заключаются в расширенных функциях безопасности. В новинках используются технологии PrC и DSC, которые обеспечивают различные уровни аппаратной защиты. Кроме того, такие чипы лучше адаптированы под потребности китайских поставщиков серверного оборудования. Решения Jintide совместимы с экосистемой x86, обладают хорошей масштабируемостью, гибкостью и удобством использования. Jintide — это комплексная платформа Montage, работающая в тандеме с фирменными гибридными модулями оперативной памяти HSDIMM, которые также обеспечивают защиту на аппаратном уровне. 
Источник изображения: Montage Technology Конфигурация Jintide четвёртого поколения включает до 48 вычислительных ядер и до 105 Мбайт кеша. Максимальная частота в турбо-режиме составляет 4,2 ГГц. Заявлена поддержка инструкций AMX (Advanced Matrix Extensions), памяти DDR5-4800 и 80 линий PCIe 5.0/CXL 1.1. Ранее Montage также представила CXL-экспандеры DDR4/DDR5. По запросу могут быть активированы дополнительные функции: Dynamic Load Balancer (DLB), Intel Data Streaming Accelerator (DSA), Intel In-Memory Analytics Accelerator (IAA), Intel In-Memory Analytics Accelerator и Intel QuickAssist (QAT). |
|

