Материалы по тегу: cpu
|
01.08.2024 [00:53], Игорь Осколков
Ampere анонсировала 512-ядерные Arm-процессоры AmpereOne Aurora с HBM-памятью и встроенным ИИ-ускорителемAmpere Computing анонсировала процессоры AmpereOne Aurora, которые получат до 512 однопоточных Arm-ядер собственной разработки, набортную HBM-память и фирменные IP-блоки для обучения и инференса ИИ-моделей. Речь, судя по всему, идёт о чиплетной компоновке, поскольку компания говорит не только о фирменном меш-интерконнекте для вычислительных блоков, но и об объединении разных кристаллов в рамках SoC. Предполагается, что Aurora появятся где-то на рубеже 2025–2026 гг. 
Источник изображений: Ampere Computing Что интересно, для Aurora обещана возможность использования воздушного охлаждения. Для гиперскейлеров, на которых Ampere по-прежнему ориентируется, это важный пункт. Впрочем, больше никаких подробностей о новинках компания не сообщила, отметив лишь, что встроенный ускоритель сгодится для RAG и векторных баз данных. Ну и сообщив, что по количеству ядер и производительности её ещё не выпущенный чип обгоняет все остальные чипы: 144-ядерные Intel Xeon 6 (Sierra Forest), которые вскоре станут 288-ядерными (при этом все варианты без Hyper-Threading), и 128-ядерные AMD EPYC Bergamo (256 потоков), которым на смену придут 192-ядерные EPYC Turin Dense (384 потока). 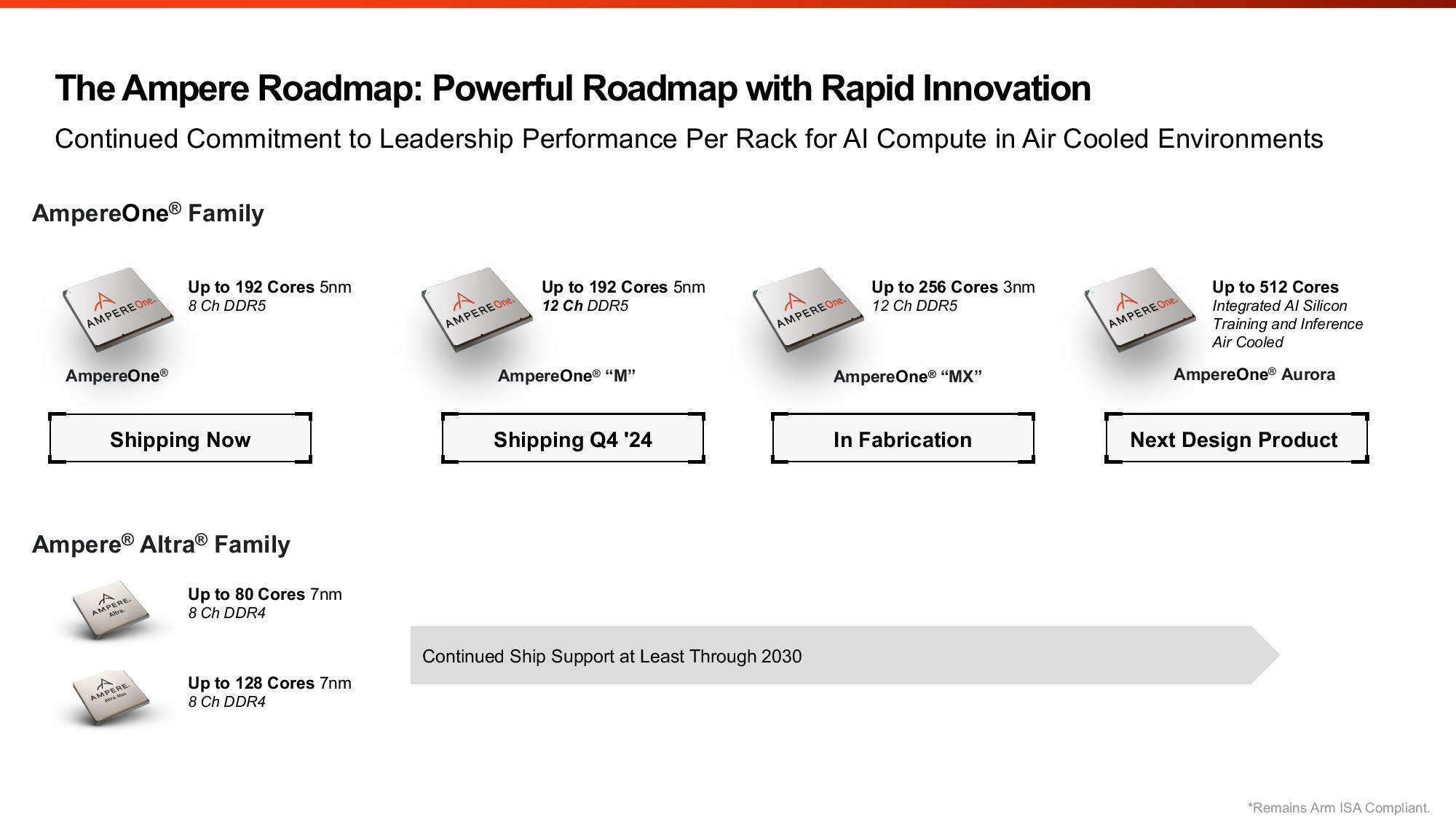 До Aurora компания выпустит ещё две серии процессоров AmpereOne: M в конце 2024 года и MX в 2025 году. 5-нм AmpereOne M получат до 192 ядер и 12-канальный контроллер памяти DDR5. 3-нм AmpereOne MX получат такой же контроллер и до 256 ядер. Заодно компания опубликовала прайс-лист актуальных CPU. В нём нет изначально заявлявшихся 136- и 172-ядерных моделей. Кроме того, остальные процессоры несколько подорожали в сравнении с прошлым поколением Altra Max, но по цене всё ещё привлекательнее решений AMD и Intel — $5555 за 192 ядра. Следует учесть, что в таблице приведён не привычный показатель TDP, а усреднённое энергопотребление чипа, из-за чего сравнивать процессоры Ampere с другими чипами затруднительно. 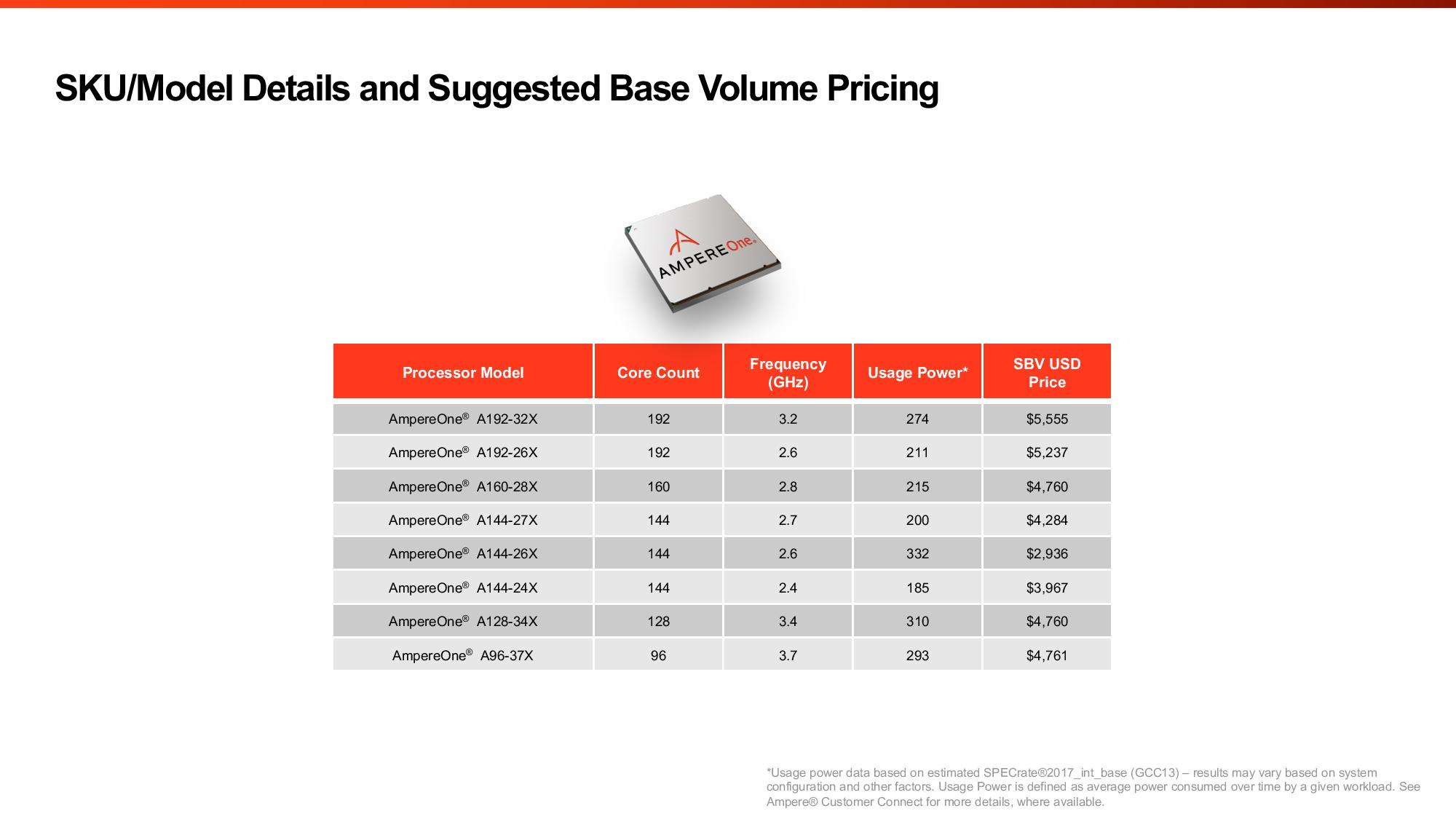 Насколько Aurora станет популярным у гиперскейлеров и других заказчиков, покажет время. У Ampere есть якорный заказчик в лице Oracle, но другие IT-гиганты уже сами разрабатывают собственные Arm-процессоры. AWS в Graviton4 довела количество ядер до 96, Microsoft анонсировала 128-ядерный Cobalt 100, Alibaba массово внедряет 128-ядерные Yitian 710, а Google готовит Axion. Fujitsu к 2027 году подготовит 144-ядерные MONAKA, которые тоже получат поддержку ИИ-нагрузок, но упор в них сделан не на HBM, а на SRAM. Собственно говоря, HBM есть только у HPC-процессоров: Fujitsu A64FX, SiPearl Rhea1 и C-DAC AUM. Даже NVIDIA Grace, которые в основном ассистируют ускорителям, обходятся LPDDR5x.
22.07.2024 [09:12], Сергей Карасёв
Intel представила чипы Raptor Lake Refresh с отключёнными E-ядрами для встраиваемых устройствКомпания Intel, по сообщению ресурса Wccftech, анонсировала процессоры Raptor Lake Refresh (Core 14-го поколения) для встраиваемых устройств. У этих чипов деактивирован кластер энергоэффективных Е-ядер (Gracemont) — они оперируют только производительными Р-ядрами (Raptor Cove). В общей сложности перечислены 11 моделей: Core i9-14901KE, Core i9-14901E, Core i9-14901TE, Core i7-14701E, Core i7-14701TE, Core i5-14501E, Core i5-14501TE, Core i5-14401E, Core i5-14401TE, Core i5-14401EF и Core i5-14401TEF. Они имеют исполнение LGA1700, а показатель TDP варьируется от 45 до 125 Вт. 
Источник изображения: Intel На вершине семейства располагается изделие Core i9-14901KE с восемью ядрами (16 потоков), базовая частота которого составляет 3,8 ГГц с возможностью динамического повышения до 5,8 ГГц. Объём кеша третьего уровня равен 36 Мбайт. Индекс «К» в обозначении указывает на возможность разгона. Возможно, данная особенность заинтересует DIY-энтузиастов. 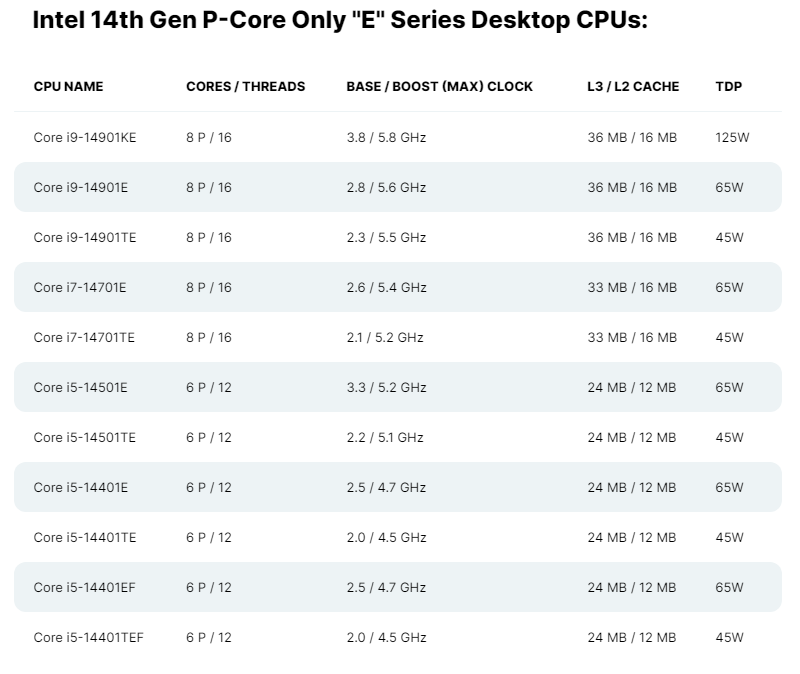
Источник изображения: Wccftech В зависимости от модификации новые процессоры насчитывают шесть или восемь Р-ядер, при этом все чипы поддерживают технологию многопоточности. Возможна работа с двухканальной оперативной памятью DDR4/DDR5. Изделия с индексом «F» не имеют встроенного графического контроллера, тогда как модели «Т» обладают повышенной энергоэффективностью. Среди прочего упомянута поддержка PCIe 5.0 x16, PCIe 4.0 x4 (NVMe) и DMI 4.0 x8.
12.07.2024 [09:09], Алексей Степин
144 ядра, чиплеты, SRAM и 3D-упаковка: Fujitsu поделилась подробностями о грядущих Arm-процессорах MONAKAОпыт японской компании Fujitsu в разработке процессоров и суперкомпьютеров велик и многогранен. Долгое время основной архитектурой для решений Fujitsu была SPARC64, но времена меняются: в 2018 году компания анонсировала разработку собственного процессора на базе архитектуры Arm. Сегодня этот чип мы знаем под именем A64FX. В 2020 году японский кластер Fugaku на основе 48-ядерных A64FX с интегрированными HBM-памятью и интерконнектом занял первое место в рейтинге TOP500 с результатом 537,2 Пфлопс. Однако эти процессоры, которые всё ещё достойно трудятся не только в Fugaku, но и в других суперкомпьютерах, трудно назвать действительно универсальным и доступным. 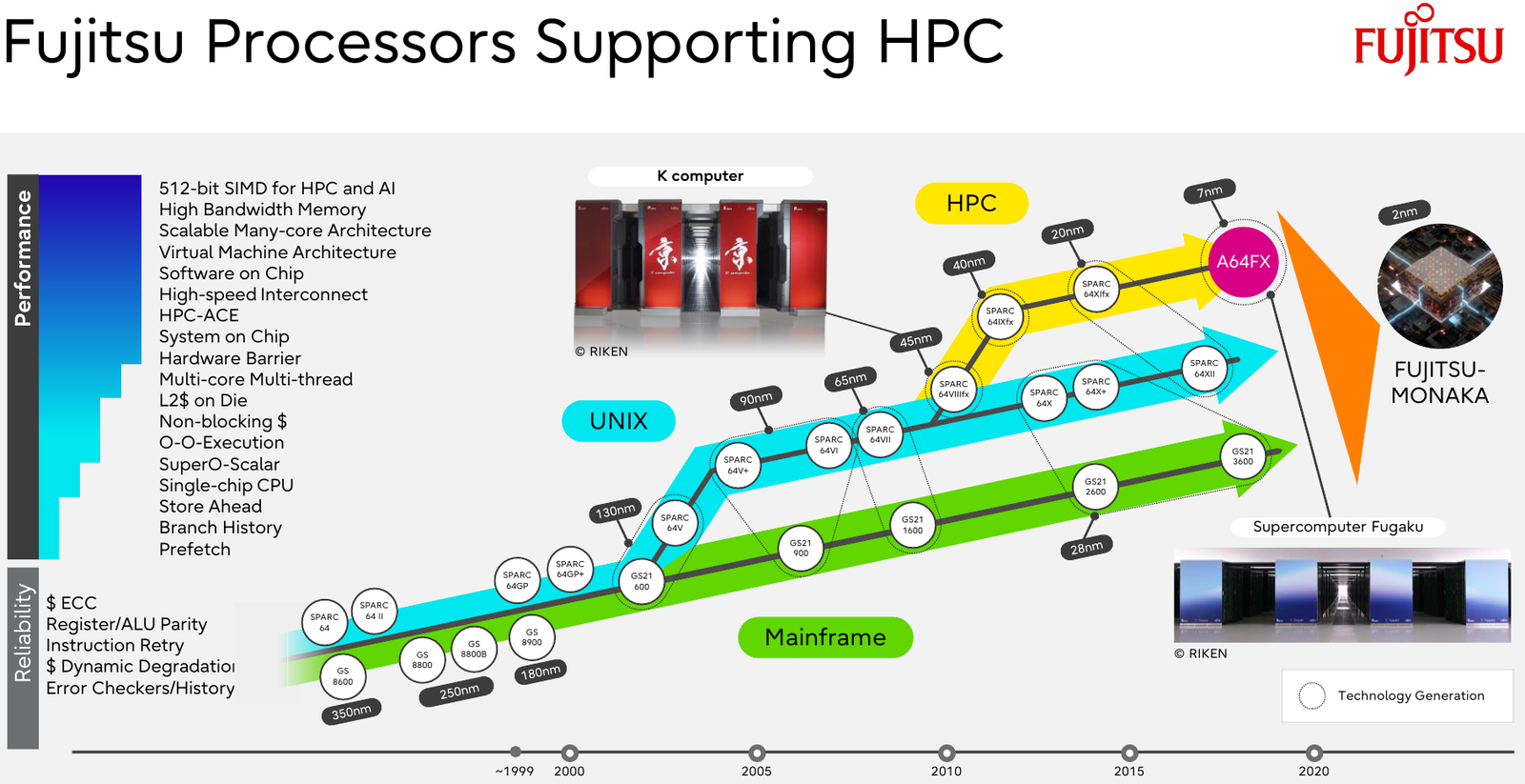
Источник изображений: Fujitsu Важность архитектурных нововведений и смену IT-ландшафта в Fujitsu прекрасно осознают. Поэтому компания объявила о разработке нового серверного процессора под кодовым именем MONAKA, для которого она намеревается вдвое увеличить показатели производительности и энергоэффективности, а также учесть растущую популярность задач класса ИИ. А совсем недавно Fujitsu впервые более детально рассказала о технических особенностях будущих CPU. 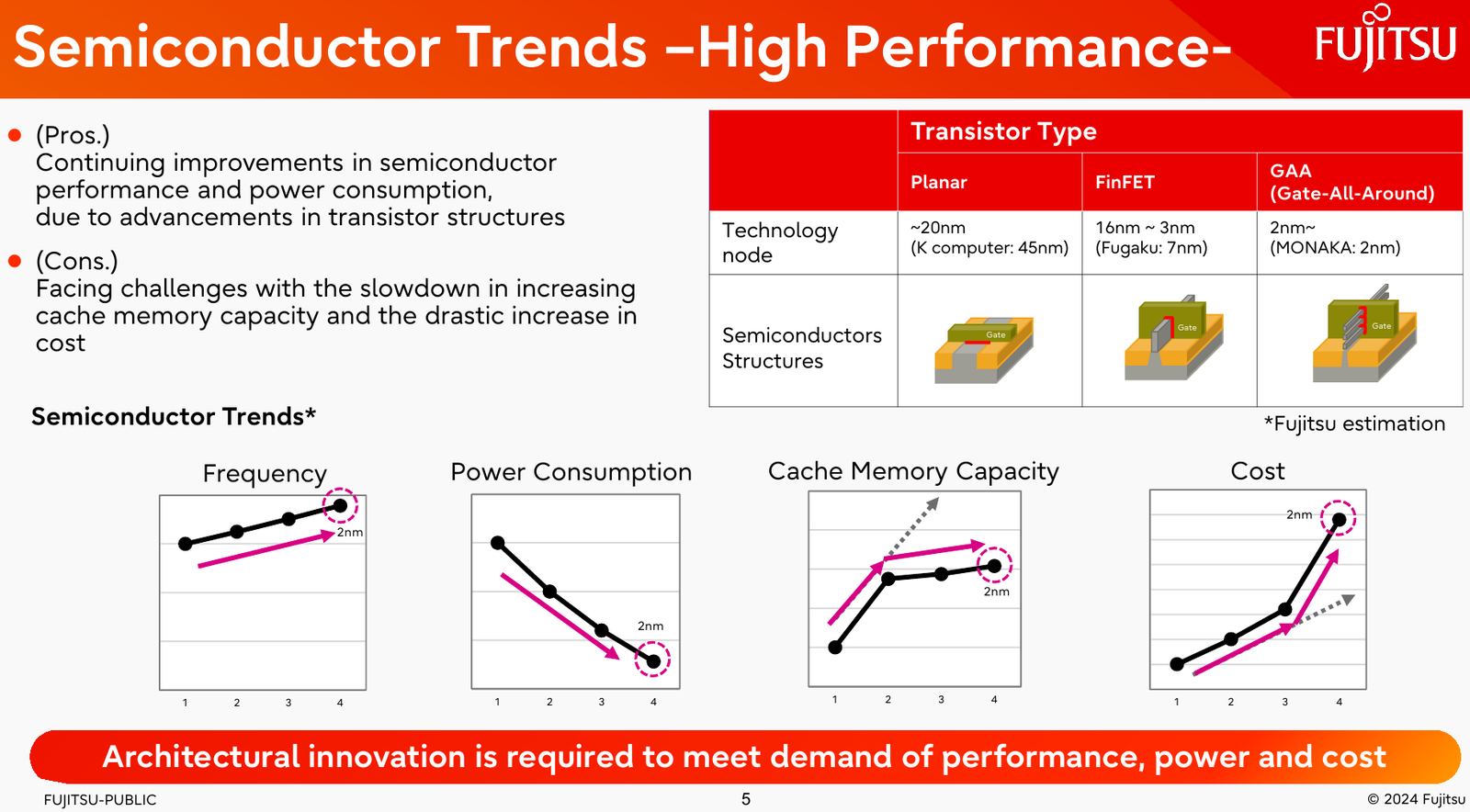 Во-первых, разработчики нового процессора хорошо осознают ограничения, накладываемые текущей транзисторной технологии. Похоже, из FinFET и её аналогов выжаты все или почти все соки и для прорывных решений нового поколения данная технология не подходит. В процессорах MONAKA будут использоваться транзисторы с затвором нового типа, так называемые GAA (Gate-all-Around). Похоже, речь идёт о технологии, которую разрабатывает и собирается внедрить в производство уже в следующем году Samsung в рамках 2-нм техпроцесса SF2. 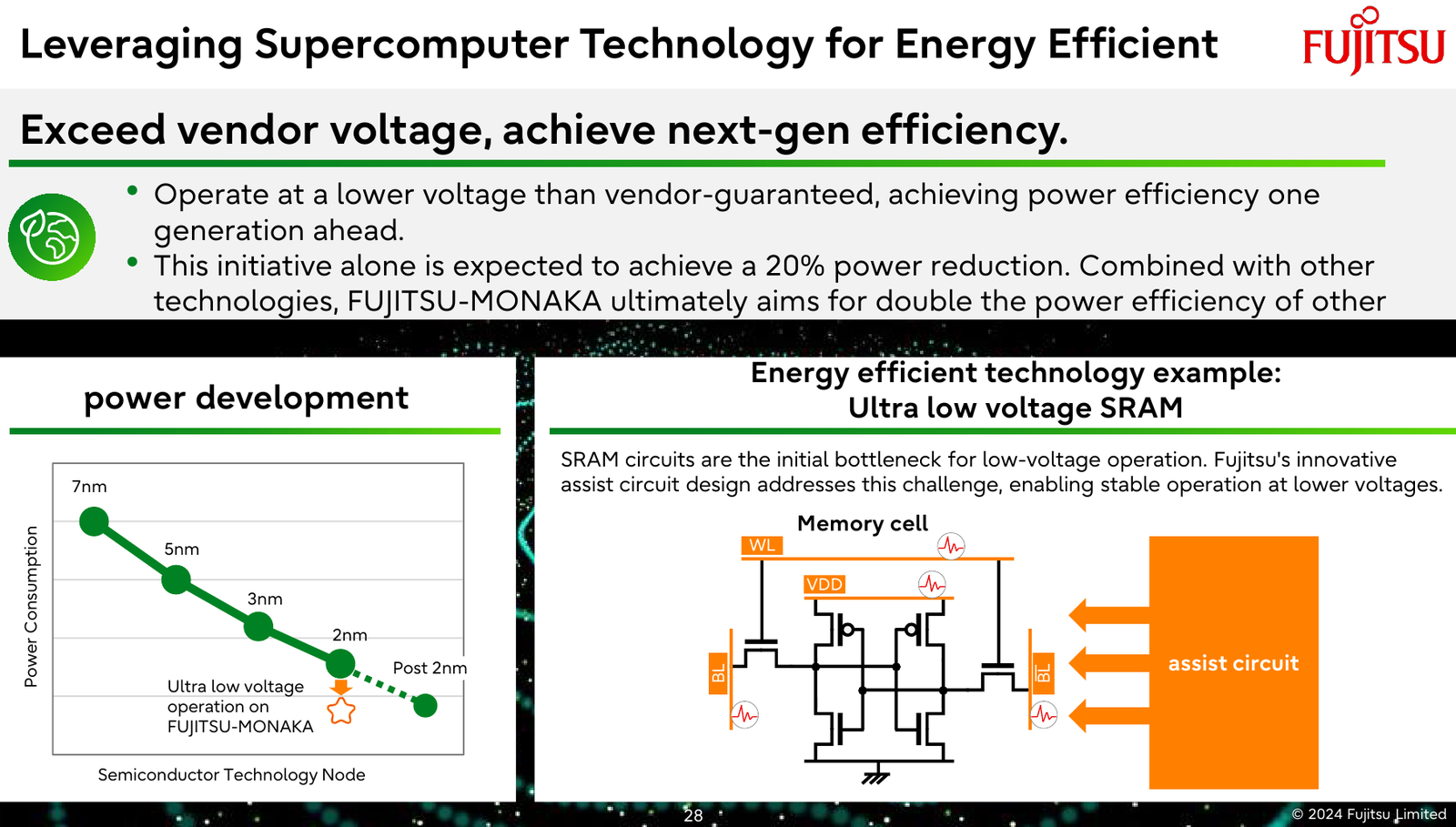 Внедрение 2-нм GAA-транзисторов позволит снизить паразитную ёмкость, а значит, добиться больших тактовых частот при меньшем напряжении питания. При этом новая технология будет применена не только в процессорных ядрах, но и в сборках кеш-памяти, также спроектированных с использованием собственного инструментария Fujitsu.  Во-вторых, MONAKA изначально проектируется как модульный процессор. В центре разместится IO-кристалл, содержащий контроллеры DDR5 (12 каналов) и PCI Express 6.0/CXL 3.0. Окружать его будут сборки из 5-нм кристаллов кеш-памяти SRAM и расположенных поверх 2-нм кристаллах с процессорными ядрами. По вертикали соединение обеспечит технология TSV, а по горизонтали — кремниевая подложка-интерпозер. Фактически речь идёт о 3D-компоновке. 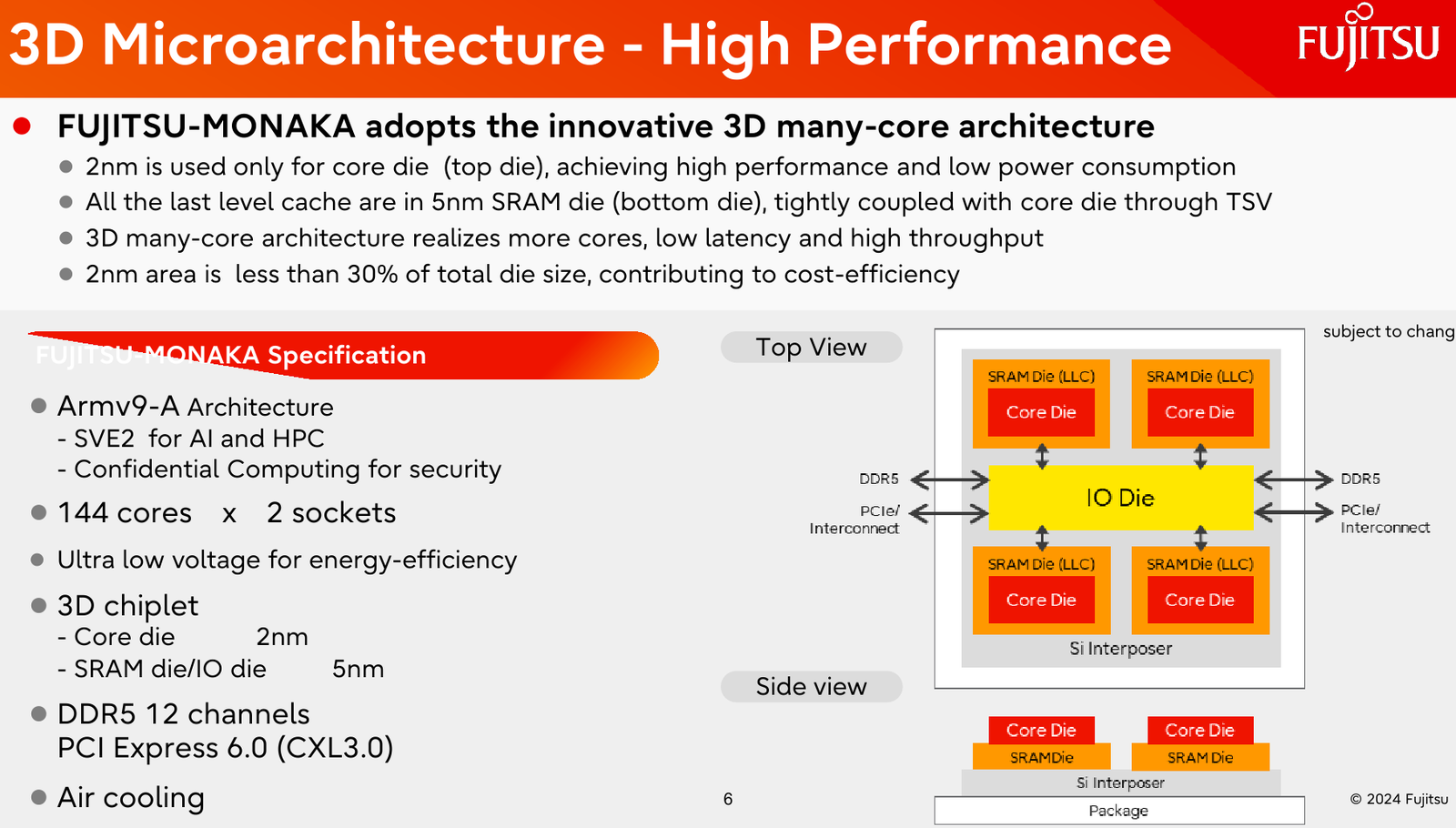 12-канальная подсистема памяти обеспечит отсутствие узких мест: у A64FX проблем с пропускной способностью благодаря использованию HBM2 не было, но объем самой памяти был ограничен 32 Гбайт. Зато у MONAKA проблем с расширением не будет — как с помощью классических модулей DIMM, так и посредством банков памяти CXL, благо, за основу сразу взята версия PCIe 6.0 с пропускной способностью 256 Гбайт/с в режиме x16. Сколько будет самих линий, пока не уточняется.  Новая платформа изначально проектируется двухсокетной, при этом в количестве ядер Fujitsu также не скромничает: процессоры MONAKA получат 144 ядра, а благодаря новому 2-нм техпроцессу они будут не такими уж горячими. Им хватит воздушного охлаждения, говорят создатели. Процессоры получат набор инструкций Armv9-A с векторными расширениями SVE2 и технологией доверенных вычислений Confidential Computing. Скорее всего, без кастомных инструкций не обойдётся и в этот раз. 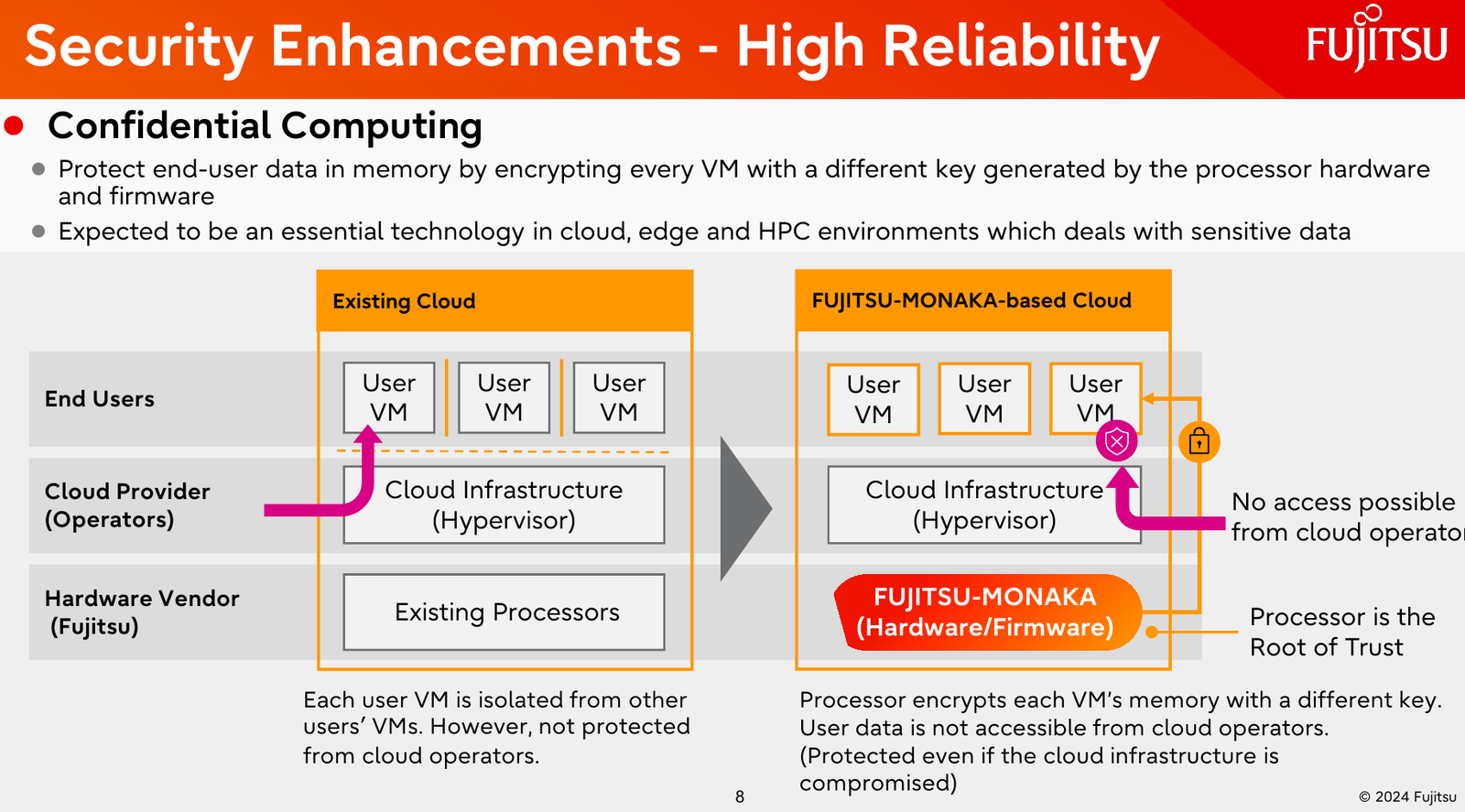 Последнее особенно важно ввиду того, что MONAKA предназначены не только для рынка HPC, но и для использования в облачных средах. Подсистема конфиденциальных вычислений позволяет шифровать содержимое каждой виртуальной машины собственным ключом, так что доступа к внутренностям ВМ не будет даже у владельцев ЦОД. Впрочем, современные HPC-комплексы всё чаще используют именно облачный подход для доступа к ресурсам. 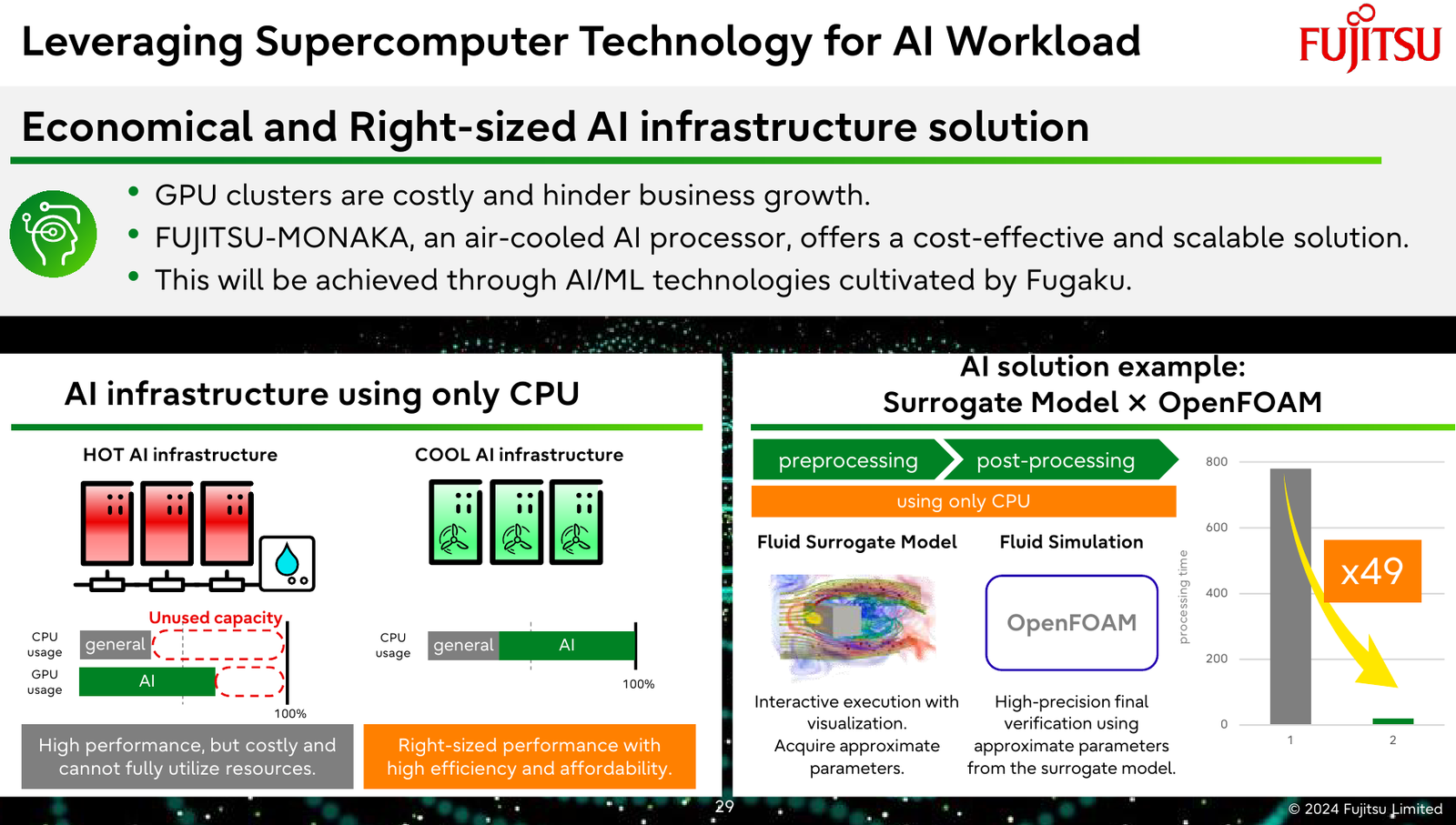 Несмотря на популярность GPU и других специализированных ускорителей, Fujitsu считает, что гетерогенная архитектура имеет существенные недостатки — она заметно дороже, особенно с учётом ценовой политики производителей, склонна к неполной утилизации ресурсов, а также не слишком экономична и зачастую требует специфических систем охлаждения. Компания полагает, что гомогенная архитектура MONAKA этих недостатков лишена и в сочетании с ПО Fujitsu может успешно обрабатывать ИИ-нагрузки.  В программной части Fujitsu активно полагается на решения с открытым кодом. Процессоры MONAKA будут отвечать стандартам Arm System Ready и получат полноценную поддержку Linux и сопутствующего инструментария, в частности, GCC, glibc, live-patch, papi и т.д. Разработка ведётся в тесном содружестве с Linaro, организацией, занимающейся консолидацией открытого ПО для Arm, а также с альянсом UXL. Для MONAKA компания подготовит, например, оптимизированную библиотеку OpenBLAS. 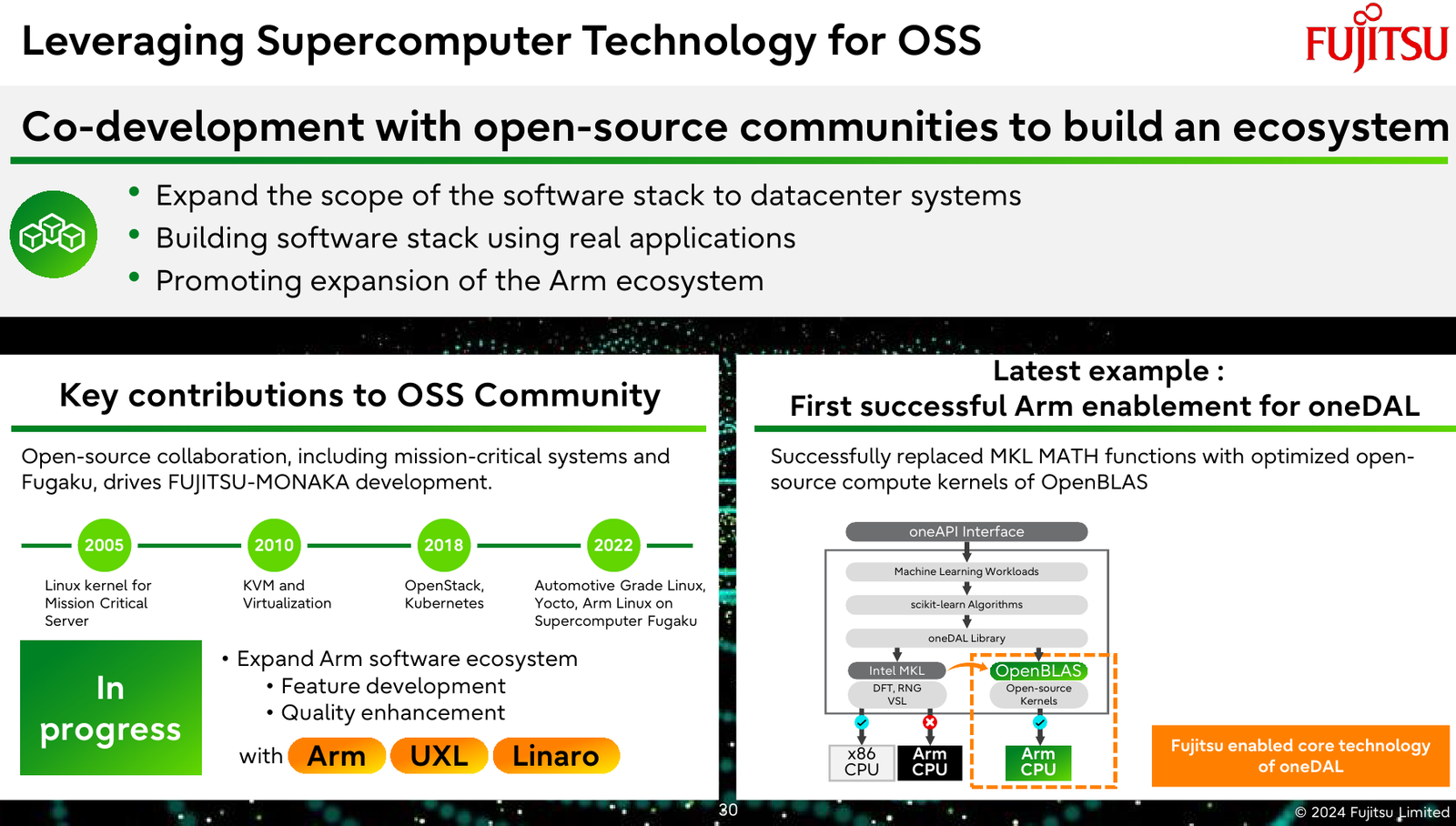 Также Fujitsu уделяет внимание экологии: напомним, одной из главных черт нового процессора будет его экономичность, что отвечает целям японской национальной программы NEDO, ставящей своей целью достижение 40 % снижения энергопотребления ЦОД к 2030 году.  Что касается начала поставок MONAKA, здесь всё идёт по плану: первые партии новых процессоров найдут своё место в серверах и вычислительных узлах уже в 2027 году. Это вполне согласуется с циклом разработки PCI Express, согласно которому появления решений PCIe 6.0 на рынке следует ожидать не ранее 2025 года.
22.06.2024 [00:05], Алексей Степин
Альянс CHERI будет продвигать технологию надёжной защиты памяти от атак — первой её могут получить процессоры RISC-VВ современных процессорах немало возможностей для атак связано с особенностями работы современных подсистем памяти. Для противостояния подобным угрозам Capabilities Limited, Codasip, FreeBSD Foundation, lowRISC, SCI Semiconducto и Кембриджский университет объявили о создании альянса CHERI (Capability Hardware Enhanced RISC Instructions). Целью новой организации должна стать помощь в стандартизации, популяризации и продвижении на рынок разработанных Кембриджским университетом совместно с исследовательским центром SRI International процессорных расширений, позволяющих аппаратно реализовывать механизмы защиты памяти, исключающие целый ряд потенциальных уязвимостей, например, переполнение буфера или некорректная работа с указателями. 
Источник: University of Cambridge Сама технология имеет «модульный» характер. Она может применяться выборочно для защиты функций от конкретных атак и требует лишь весьма скромной адаптации кода. Согласно заявлению CHERI Alliance, огромный пул уже наработанного ПО на языках семейств С и C++ может быть легко доработан для серьёзного повышения уровня безопасности. 
Источник: University of Cambridge Кроме того, данная технология позволяет реализовать высокопроизводительные и масштабируемые механизмы компартментализации (compartmentalization) и обеспечения минимально необходимых прав (least privilege). Такое «разделение на отсеки» должно защитить уже скомпрометированную систему и не позволить злоумышленнику развить атаку, даже если он воспользовался ранее неизвестной уязвимостью. 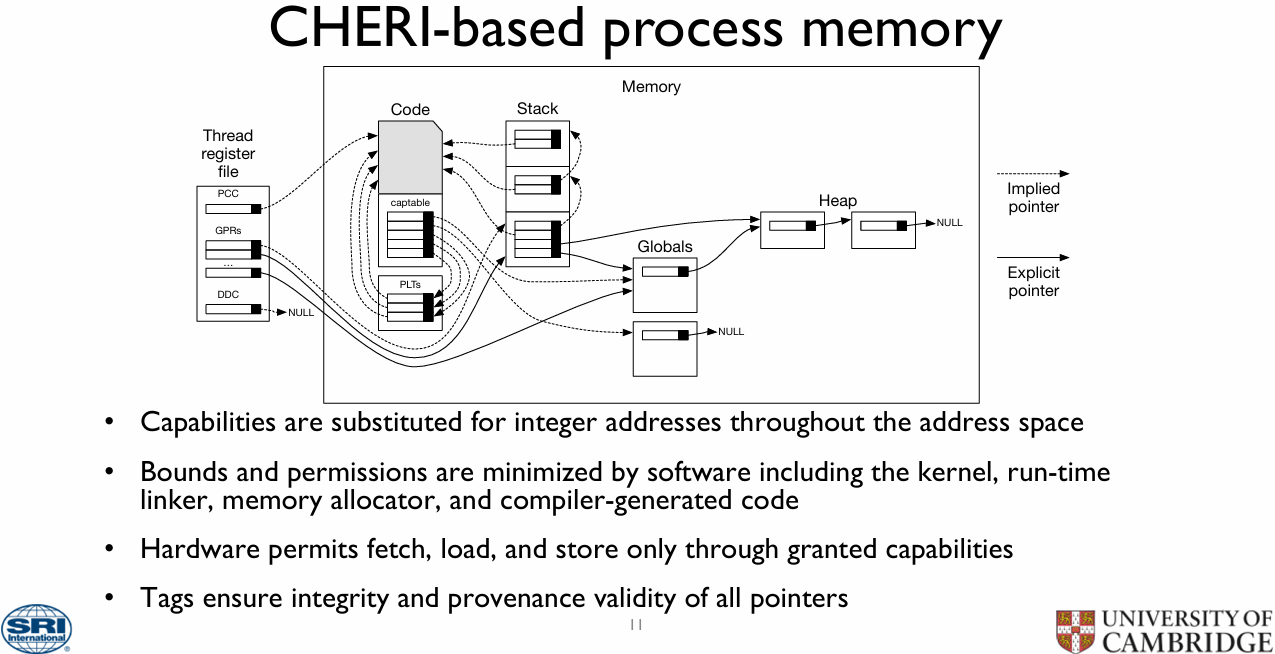
Механика работы расширений CHERI с памятью. Источник: University of Cambridge Технологии, предлагаемые альянсом CHERI, хорошо проработаны — их развитие идёт с 2010 года, а актуальность массового внедрения подобных решений за прошедшее время успела лишь назреть. Однако для успеха данной инициативы потребуется широкое содействие со стороны индустрии как аппаратного обеспечения, так и программного. 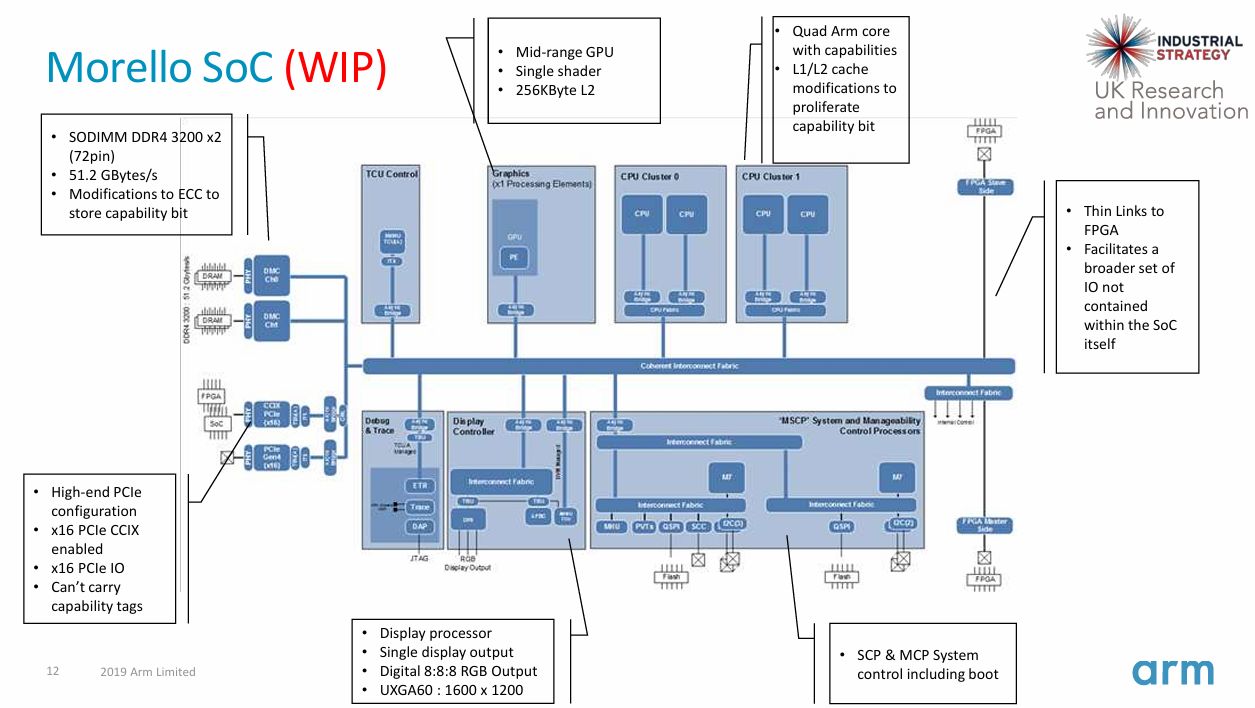
Блок-схема Arm Morello. Источник: Arm Участники альянса настроены оптимистично, однако в их число пока не входит ни один из крупных разработчиков CPU, в частности, Arm. В настоящее время главной архитектурой для приложения своих усилий они видят RISC-V, о чём свидетельствует документация на CHERI ISAv9. Впрочем, черновой вариант расширений имеется и для x86-64. Сама Arm этого оптимизма не разделяет. Компания имеет за плечами пятилетний опыт разработки проекта Morello, основанному на идеях CHERI, но, по словам представителя Arm, процесс тестирования прототипов защищённых систем выявил ряд ограничений, пока препятствующий их широкому распространению на рынке. Тем не менее, работы над платформой Morello будут продолжены. При этом буквально на днях для Arm-процессоров была выявлена атака TikTag, направленная на обход механизма защиты памяти Memory Tagging Extensions (MTE).
18.05.2024 [20:00], Алексей Степин
256 ядер и 12 каналов DDR5: Ampere обновила серверные Arm-процессоры AmpereOne и перевела их на 3-нм техпроцессВесной прошлого года компания Ampere Computing анонсировала наследников серии процессоров Altra и Altra Max — чипы AmpereOne с более высокими показателями производительности, энергоэффективности и масштабируемости. На момент анонса AmpereOne получили до 192 ядер, восемь каналов DDR5 и 128 линий PCIe 5.0. Кроме того, эти чипы могут работать и в двухсокетных платформах. Позднее AmpereOne стали доступны у нескольких облачных провайдеров, а главным бенефециаром их появления стала Oracle, когда-то инвестировавшая в Ampere Computing значительные средства. Компания перевела все свои облачные сервисы на процессоры Ampere и даже портировала на них свою флагманскую СУБД. В общем, повторила путь AWS и Alibaba Cloud с процессорами Graviton и Yitian соответственно. Но если последние являются облачным эксклюзивом, то чипы Ampere хоть и ориентированы в первую очередь на гиперскейлеров, более-менее доступны и небольшим компаниям. Поэтому в процессорной гонке останавливаться нельзя, так что на днях Ampere объявила об обновлении модельного ряда AmpereOne, запланированного к выпуску в 2025 году. Новые модели будут использовать продвинутый техпроцесс TSMC N3. 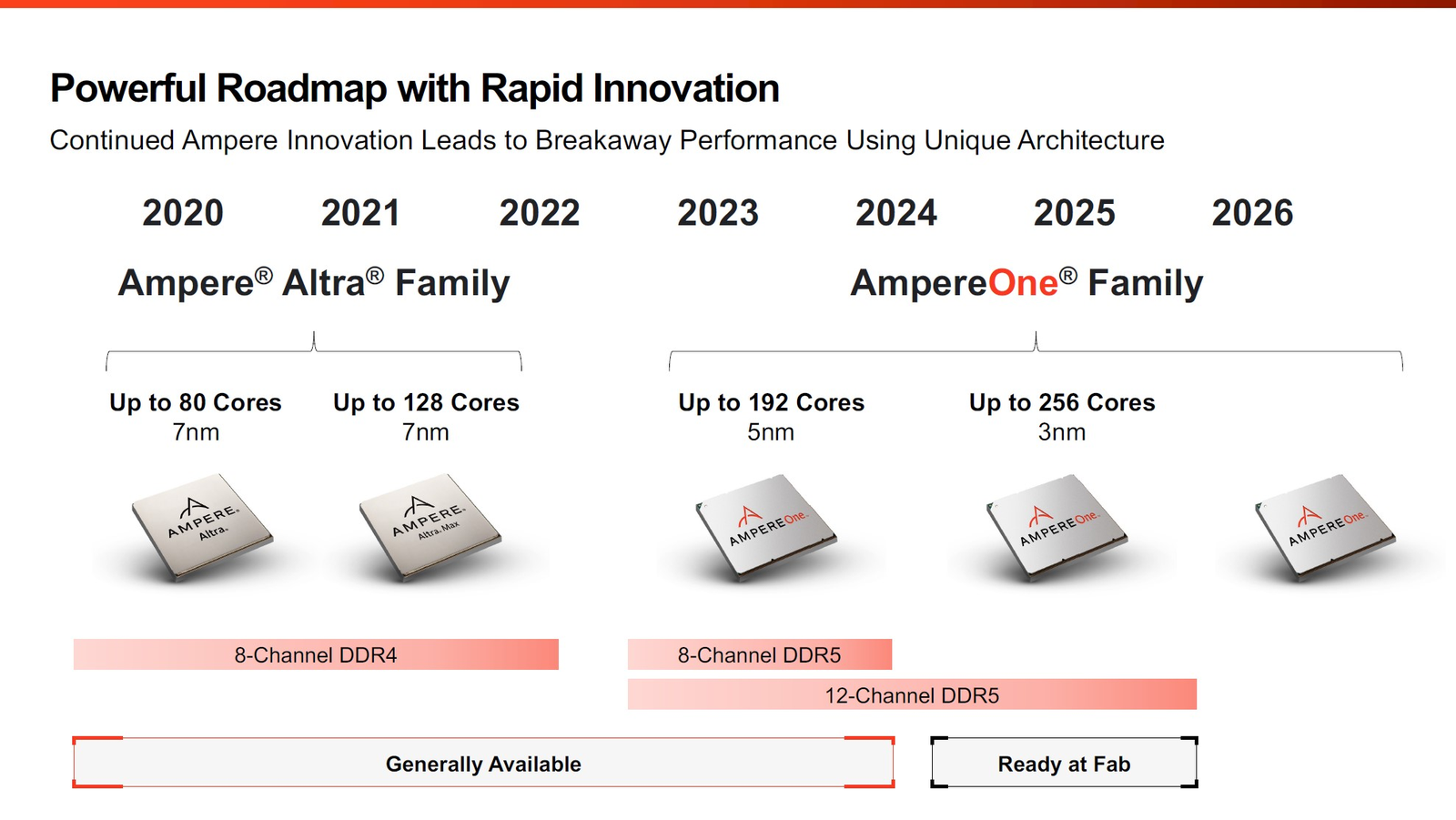
Источник здесь и далее: Ampere Computing via ServeTheHome Согласно опубликованным планам, семейство AmpereOne какое-то время будет существовать в двух ипостасях: изначальном варианте 2023 года с 8-канальным контроллером памяти и 192 ядрами в пределе, производящемся с использованием 5-нм техпроцесса, и новом 3-нм, уже готовом к массовому производству. Ожидается, что 192-ядерный вариант с 12 каналами DDR5 станет доступен в конце этого года. 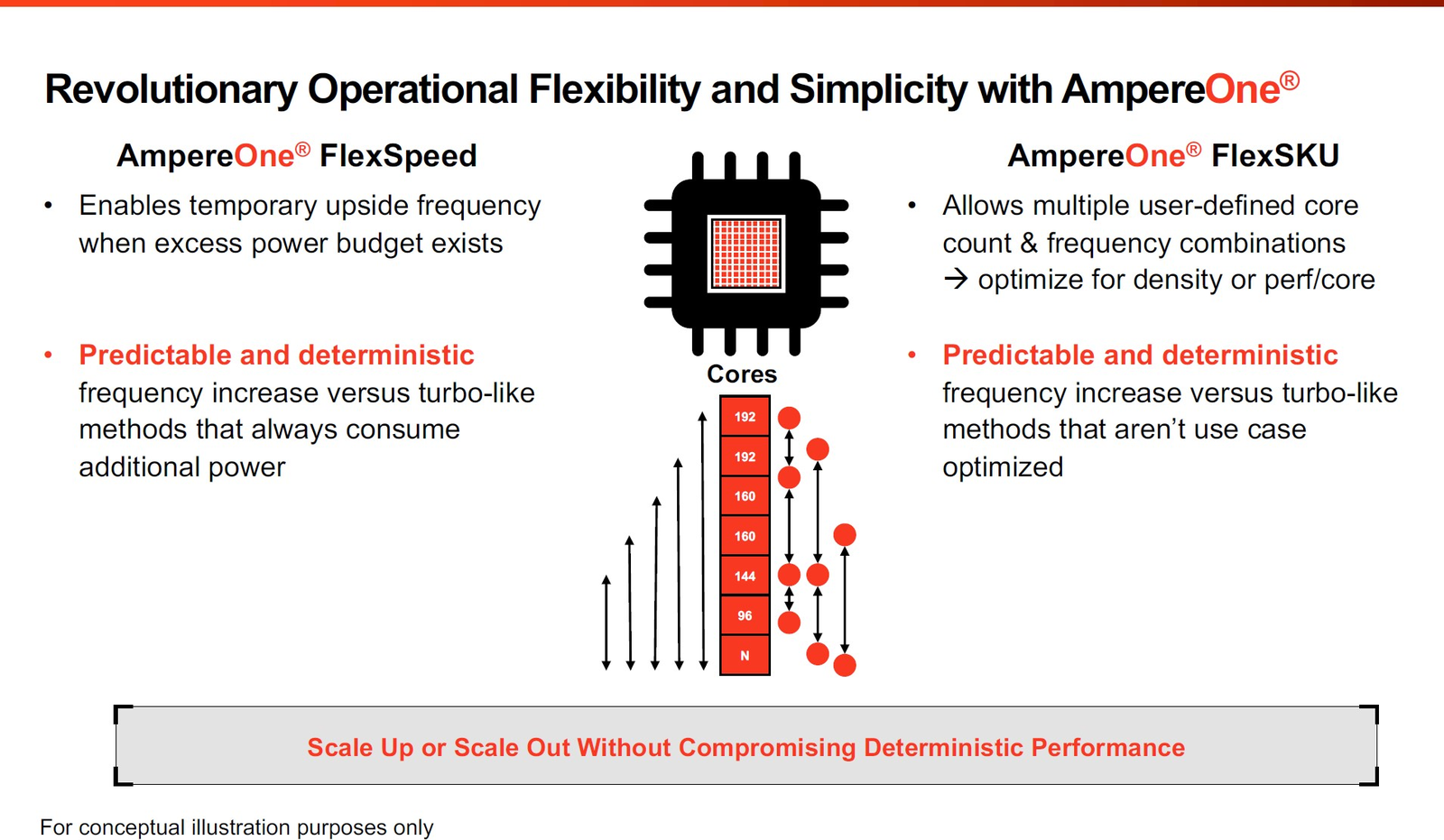
Фирменные технологии Ampere серии Flex позволят гибко управлять характеристиками платформы 3-нм вариант AmpereOne получит до 256 ядер и 12 каналов DDR5, однако отличать его будет не только это. К примеру, в нём дебютируют технологии FlexSpeed и FlexSKU, позволяющие на лету, без перезагрузок или выключения системы оперировать различными параметрами процессора — тактовой частотой, теплопакетом и даже количеством активных ядер. При этом FlexSpeed обеспечит детерминированный прирост производительности в отличие от x86-64, говорит компания. 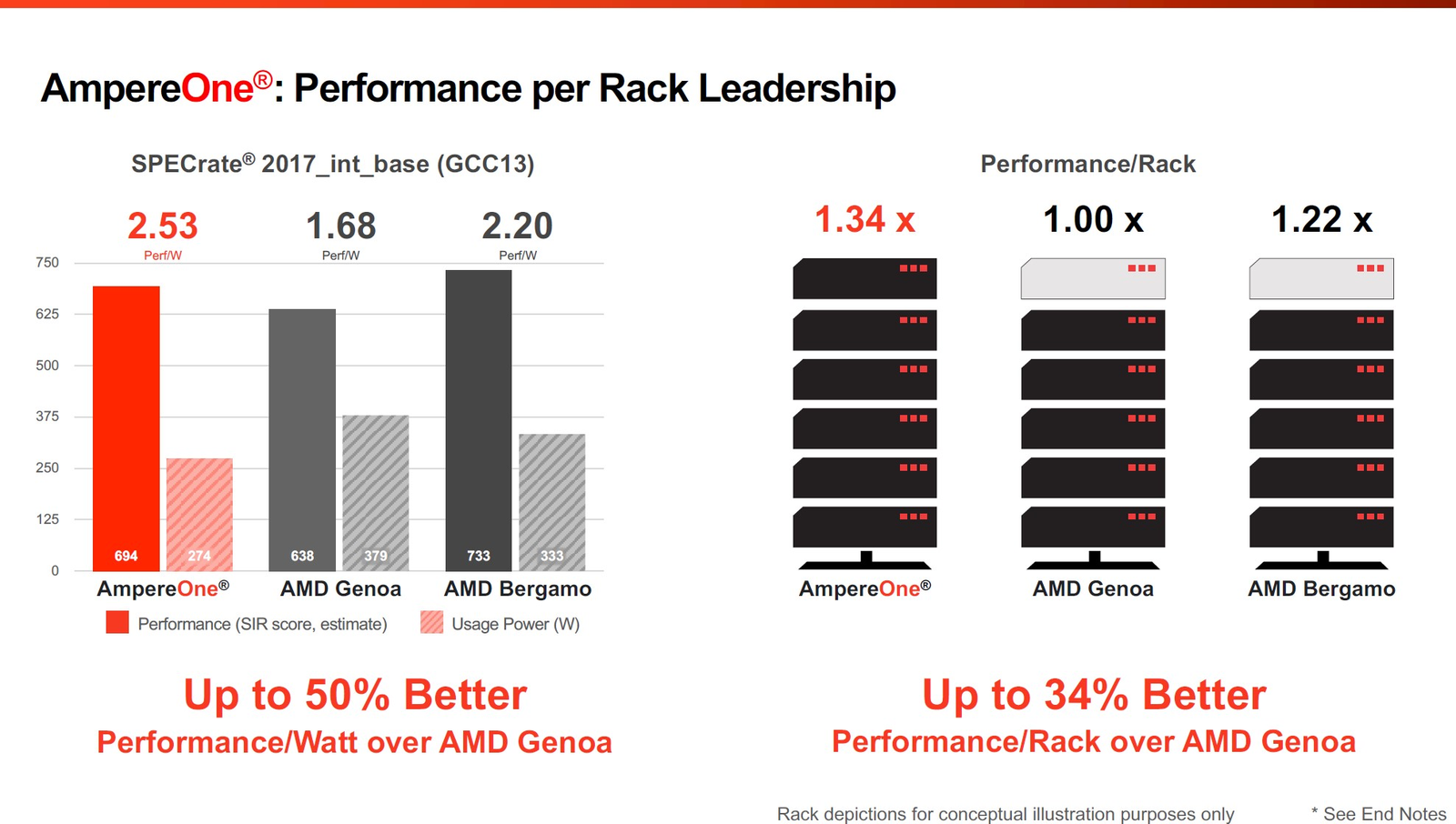 Ampere утверждает, что новые AmpereOne превзойдут в удельной производительности на Вт AMD EPYC Bergamo и обеспечат более высокую производительность в пересчёте на стойку, нежели AMD EPYC Genoa. Особенное внимание компания уделяет энергоэффективности AmpereOne, которая заключается не только в экономии электроэнергии, но и драгоценного места в ЦОД. Проще говоря, компания упирает на повышение плотности размещения вычислительных мощностей. 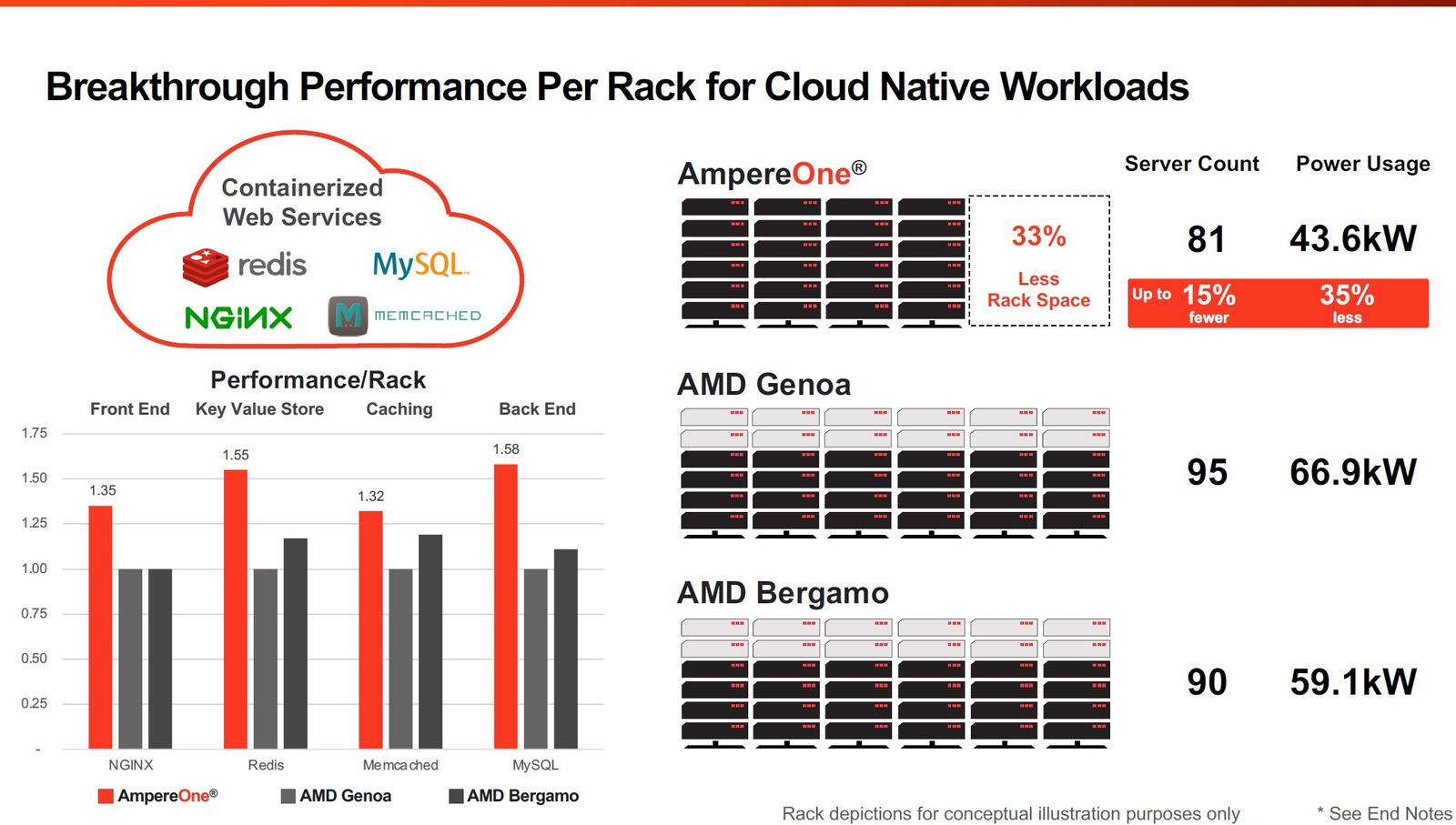 Заодно Ampere в который раз говорит, что в инференс-сценариях её процессоры сопоставимы с некоторыми ускорителями, в частности, NVIDIA A10, но при этом существенно дешевле и экономичнее. В пересчёте на токены при производительности порядка 80 токенов в секунду платформа Ampere обходится на 28% дешевле и в то же время потребляет меньше энергии на целых 67%! 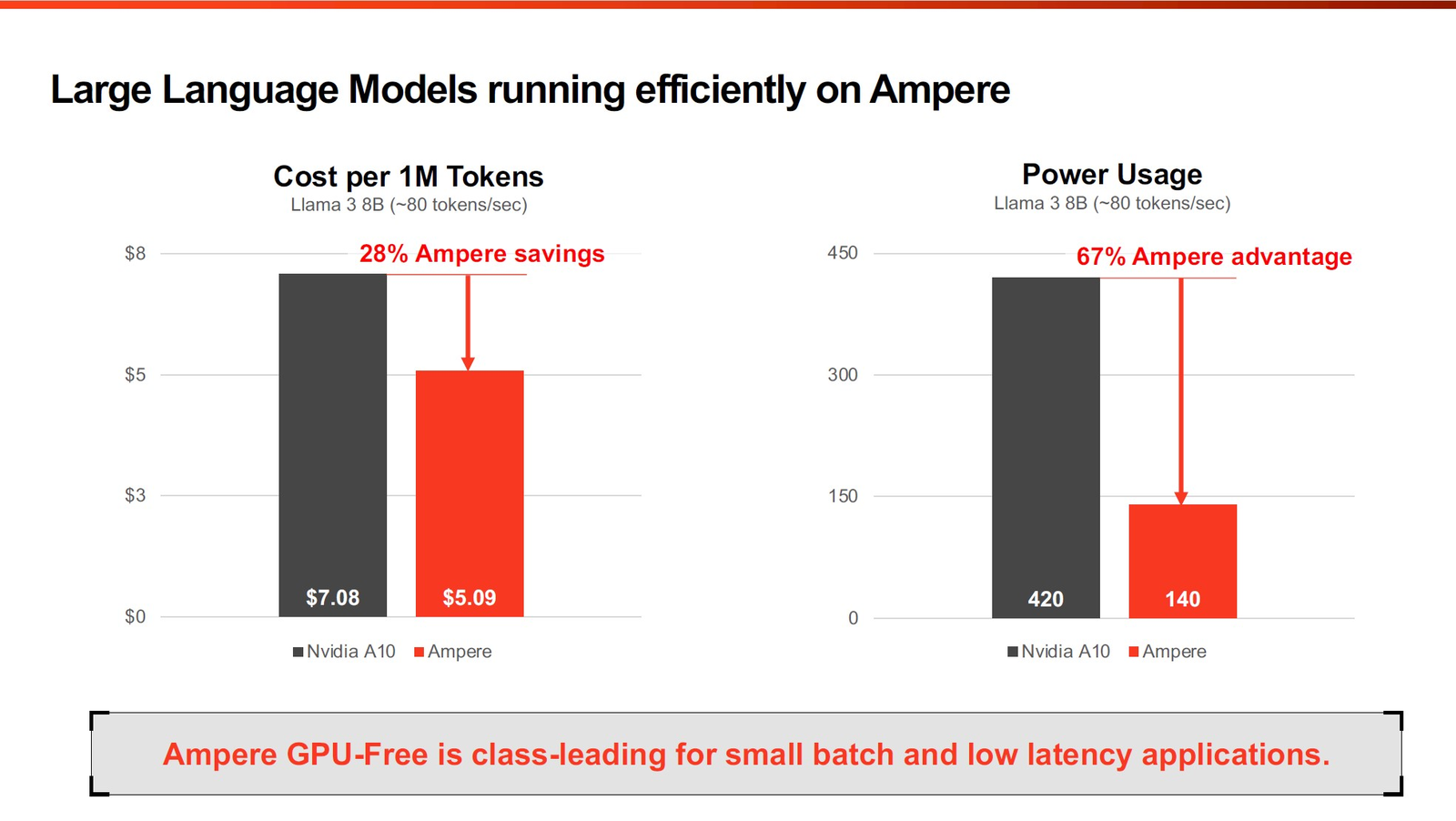 Более того, Ampere заключила союз с Qualcomm для выпуска серверной платформы, сочетающей AmpereOne в качестве процессоров общего назначения и ИИ-ускорителей Qualcomm Cloud AI 100 Ultra. Если сами процессоры успешно работают с LLM сравнительно небольшой сложности (до 7 млрд параметров), то новая платформа позволит запускать и сети с 70 млрд параметров. Кроме того, есть и готовое решение с VPU Quadra T1U.  Увидит ли свет в будущем гибридный процессор Ampere Computing с UCIe-чиплетами, будет зависеть от решений, принятых группой AI Platform Alliance, возглавленной Ampere Computing ещё осенью прошлого года. Но это вполне реальный сценарий: блоки ускорения специфических для ИИ-задач вычислений активно внедряются не только в серверных решениях, подобных Intel Xeon Sapphire/Emerald Rapids — сопроцессоры NPU уже дебютировали в потребительских и промышленных CPU Intel и AMD. При этом Ampere Computing, вероятно, придётся несколько поменять политику дальнейшего развития, поскольку основными конкурентами для неё являются не только 128-ядерные AMD EPYC Bergamo и готовящиеся 144- и 288-ядерные Intel Xeon Sierrra Forest, но и Arm-процессоры Google Axion и Microsoft Cobalt 100, которые изначально создавались гиперскейлерами под свои нужды, а потому наверняка лучше оптимизированы под их задачи и, вероятнее всего, к тому же дешевле, чем продукты Ampere.
16.05.2024 [01:05], Игорь Осколков
И для ИИ, и для HPC: первые европейские серверные Arm-процессоры SiPearl Rhea1 получат HBM-памятьКомпания SiPearl уточнила спецификации разрабатываемых ею серверных Arm-процессоров Rhea1, которые будут использоваться, в частности, в составе первого европейского экзафлопсного суперкомпьютера JUPITER, хотя основными чипами в этой системе будут всё же гибридные ускорители NVIDIA GH200. Заодно SiPearl снова сдвинула сроки выхода Rhea1 — изначально первые образцы планировалось представить ещё в 2022 году, а теперь компания говорит уже о 2025-м. При этом существенно дизайн процессоров не поменялся. Они получат 80 ядер Arm Neoverse V1 (Zeus), представленных ещё весной 2020 года. Каждому ядру полагается два SIMD-блока SVE-256, которые поддерживают, в частности, работу с BF16. Объём LLC составляет 160 Мбайт. В качестве внутренней шины используется Neoverse CMN-700. Для связи с внешним миром имеются 104 линии PCIe 5.0: шесть x16 + две x4. О поддержке многочиповых конфигураций прямо ничего не говорится. 
Источник изображения: SiPearl Очень похоже на то, что SiPearl от референсов Arm особо и не отдалялась, поскольку Rhea1 хоть и получит четыре стека памяти HBM, но это будет HBM2e от Samsung. При этом для DDR5 отведено всего четыре канала с поддержкой 2DPC, а сам процессор ожидаемо может быть поделён на четыре NUMA-домена. И в такой конфигурации к общей эффективности работы с памятью могут быть вопросы. Именно наличие HBM позволяет говорить SiPearl о возможности обслуживать и HPC-, и ИИ-нагрузки (инференс). 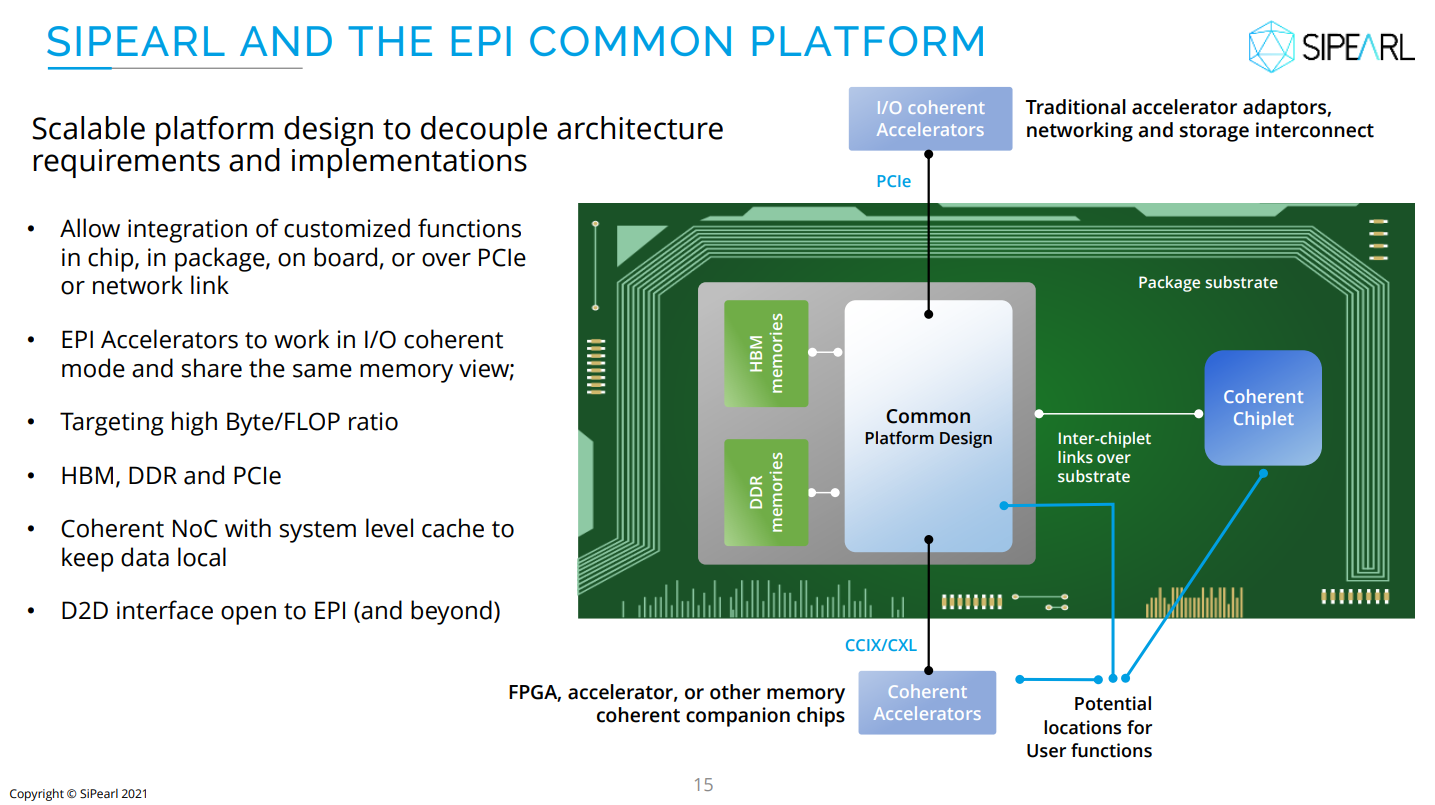
Источник изображения: SiPearl На примере Intel Xeon Max (Sapphire Rapids c 64 Гбайт HBM2e) видно, что наличие сверхбыстрой памяти на борту даёт прирост производительности в означенных задачах, хотя и не всегда. Однако это другая архитектура, другой набор инструкций (AMX), другая же подсистема памяти и вообще пока что единичный случай. С Fujitsu A64FX сравнения тоже не выйдет — это кастомный, дорогой и сложный процессор, который, впрочем, доказал эффективность и в HPC-, и даже в ИИ-нагрузках (с оговорками). В MONAKA, следующем поколении процессоров, Fujitsu вернётся к более традиционному дизайну. 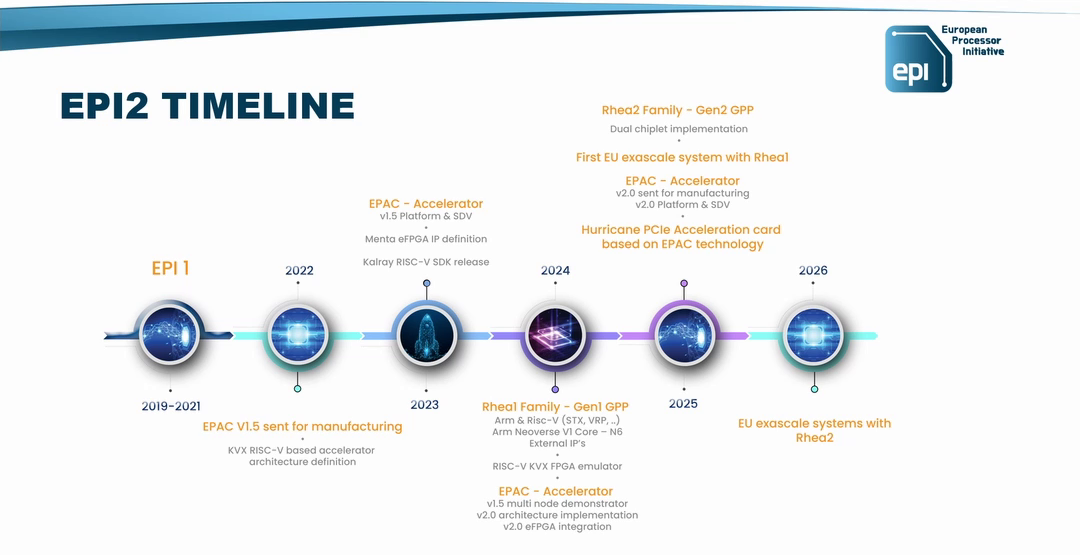
Источник изображения: EPI Пожалуй, единственный похожий на Rhea1 чип — это индийский 5-нм C-DAC AUM, который тоже базируется на Neoverse V1, но предлагает уже 96 ядер (48+48, два чиплета), восемь каналов DDR5 и до 96 Гбайт HBM3 в четырёх стеках, а также поддержку двухсокетных конфигураций. AWS Graviton3E, который тоже ориентирован на HPC/ИИ-нагрузки, вообще обходится 64 ядрами Zeus и восемью каналами DDR5. Наконец, NVIDIA Grace и Grace Hopper в процессорной части тоже как-то обходятся интегрированной LPDRR5x, да и ядра у них уже Neoverse V2 (Demeter), и своя шина для масштабирования имеется. 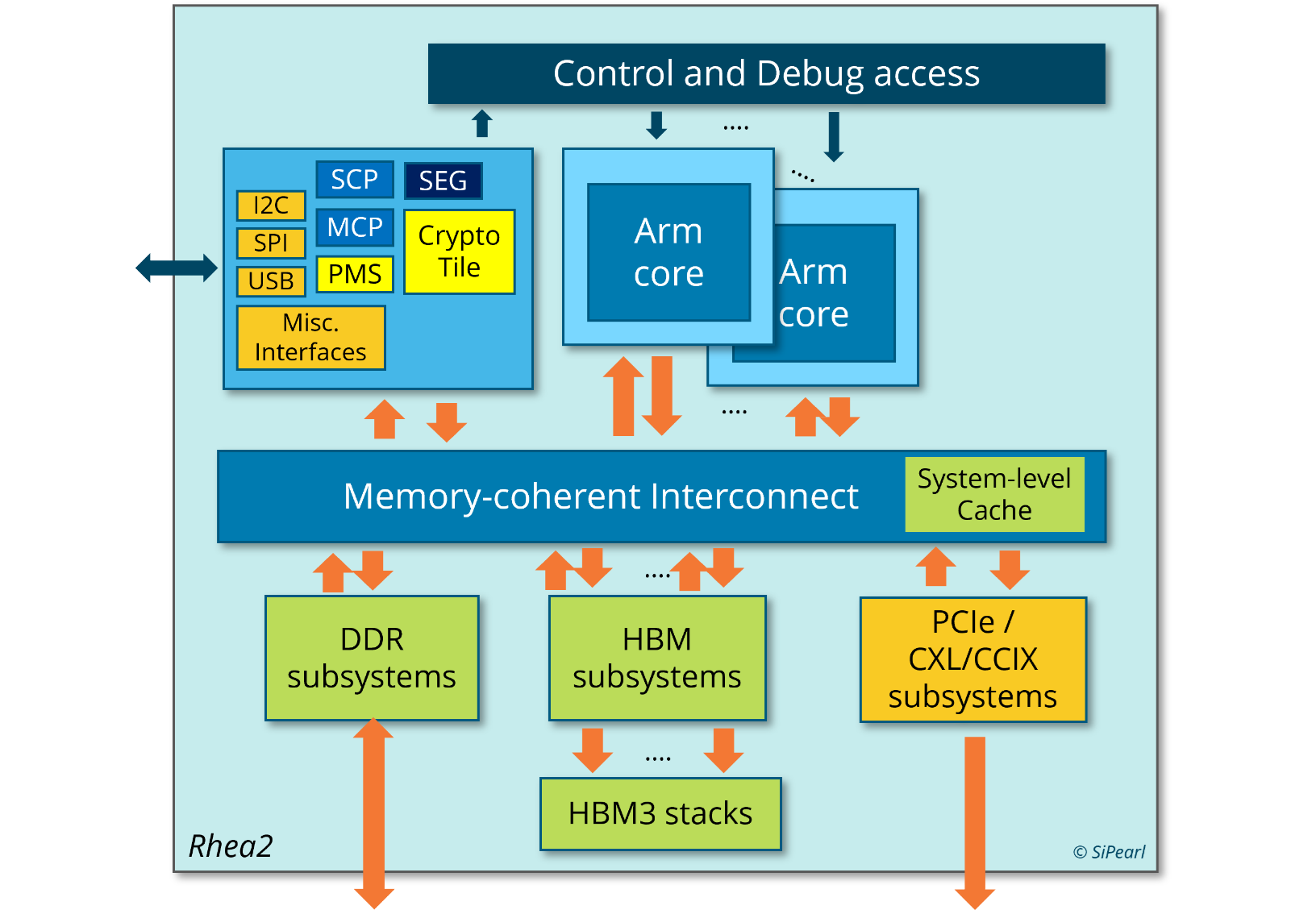
Источник изображения: EPI В любом случае в 2025 году Rhea1 будет выглядеть несколько устаревшим чипом. Но в этом же году SiPearl собирается представить более современные чипы Rhea2 и обещает, что их разработка будет не столь долгой как Rhea1. Компанию им должны составить европейские ускорители EPAC, тоже подзадержавшиеся. А пока Европа будет обходиться преимущественно американскими HPC-технологиями, от которых стремится рано или поздно избавиться.
10.04.2024 [01:30], Алексей Степин
Google анонсировала Axion, свой первый серверный Arm-процессорКомпания Google объявила о выпуске собственного процессора для своих ЦОД. В основу новинки, получившей имя Axion, легла архитектура Arm, что ставит её в один ряд с Amazon Graviton, Alibaba Yitian и Microsoft Cobalt. Это не первый процессор, разработанный Google: c 2015 года компания успела создать пять поколений ИИ-ускорителей Tensor Processing Units (TPU), а в 2018 она представила процессор Video Coding Unit (VCU) Argos для транскодирования видео. Но Axion стал первым чипом Google, который подпадает под определение «процессор общего назначения». При его создании компания сделала упор не только на энергоэффективность, но и на высокий уровень производительности, достаточный для использования в современных серверах. 
Источник изображений: Google В основу Axion легли Armv9-ядра Neoverse V2 (Demeter). Этот же дизайн используется в AWS Graviton4 и NVIDIA Grace. К сожалению, архитектурных подробностей Google пока не раскрывает, известно лишь, что ядра Neoverse V2 работают совместно с фирменными контроллерами Titanium. Последние отвечают за работу с сетью, защиту и разгрузку IO-операций при работе с блочным хранилищем Hyperdisk, то есть чем-то напоминают AWS Nitro. При этом Google вложилась в SystemReady Virtual Environment (VE), чтобы упростить перенос нагрузок на новые чипы как для себя, так и для пользователей облака. 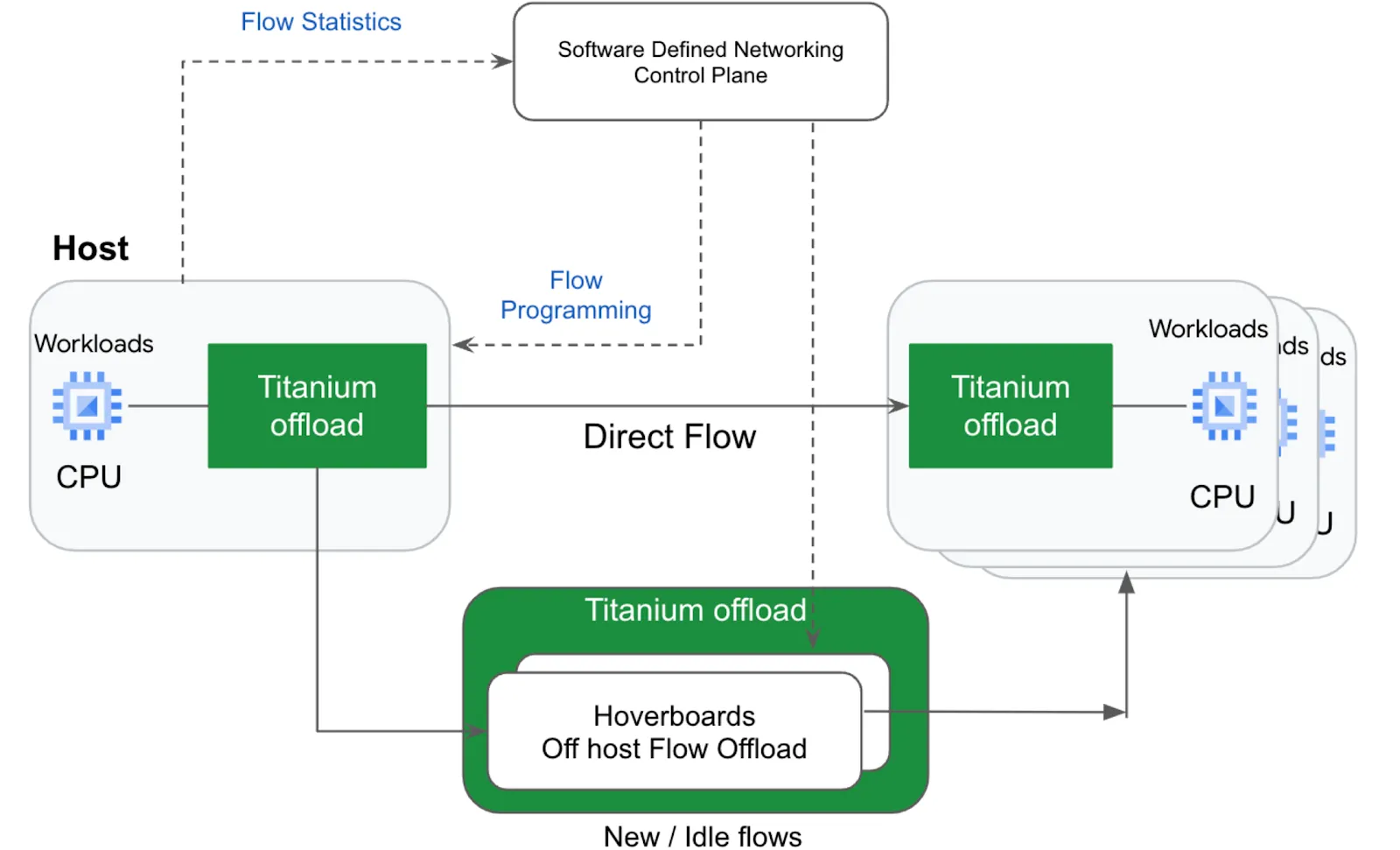 Если верить разработчикам, на момент анонса Google инстансы на базе Axion минимум на 30 % производительнее инстансов на базе самых быстрых Arm-процессоров других вендоров, а по сравнению с сопоставимыми по классу x86-процессорами преимущество может достигать и 50 % при 60 % выигрыше в энергоэффективности. Судя по всему, Axion ранее был известен под кодовым именем Cypress. А ещё один Arm-процессор Google Maple, который, по слухам, являлся наследником почивших Marvell ThunderX, в серию, видимо, не пошёл. Сама компания уже начала переводить на Axion сервисы BigTable, Spanner, BigQuery, Blobstore, Pub/Sub, Google Earth Engine и YouTube Ads. Ряд клиентов и партнёров Google уже оценили Axion по достоинству. Виртуальные машины с новыми процессорами будут доступны в ближайшие месяцы. Они же будут доступны и в Kubernetes Engine, Dataproc, Dataflow, Cloud Batch и т.д.
09.04.2024 [23:45], Сергей Карасёв
Intel представила чипы Meteor Lake PS, Raptor Lake PS и Atom x7000RE для edge-устройствКорпорация Intel анонсировала сразу три семейства процессоров для встраиваемых устройств и edge-оборудования: это чипы Core Ultra Meteor Lake PS, Core Raptor Lake PS и Atom x7000RE. Изделия серии Core Ultra PS (Meteor Lake) изготавливаются по технологии Intel 4. Они рассчитаны на установку в разъём нового поколения LGA 1851. Конструкция включает ядра P-cores и E-cores, графический блок Intel Arc GPU, а также нейропроцессорный движок (NPU), предназначенный для ускорения ИИ-операций. 
Источник изображения: Intel Семейство Core Ultra PS представлено моделями HL со стандартным значением TDP в 45 Вт и UL с базовым TDP в 15 Вт. Реализована поддержка оперативной памяти DDR5-5600 и до 20 линий PCIe 4.0. В общей сложности в серию Core Ultra PS вошли девять моделей. Количество ядер достигает 16, число одновременно обрабатываемых потоков инструкций — 22. Объём кеша L3 составляет до 24 Мбайт, тактовая частота — до 5,0 ГГц. 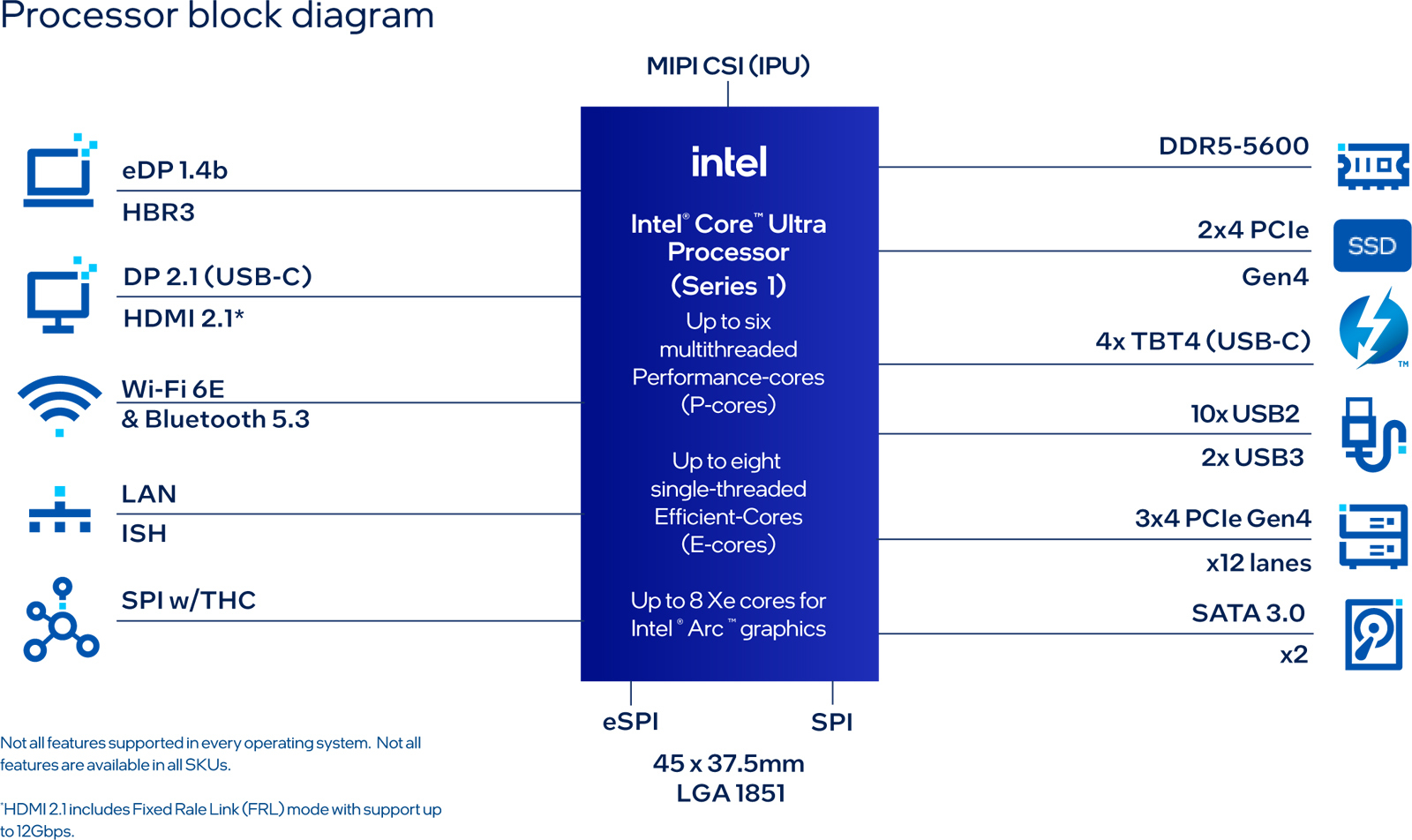
Источник изображения: Intel В свою очередь, процессоры семейства Core PS (Raptor Lake) используют сокет LGA 1700. Эти чипы также подразделяются на подсерии HL и UL с базовым TDP соответственно 45 и 15 Вт. Они содержат до 14 ядер с поддержкой до 20 потоков инструкций. Поддерживается работа с оперативной памятью DDR5–5200 и DDR4-3200. Возможно использование 8 линий PCIe 4.0 в дополнение к 12 линиям PCIe 3.0 в составе интегрированного PCH. Используется графика Intel Graphics. Объём кеша L3 достигает 24 Мбайт, тактовая частота — до 5,2 ГГц. В семейство Core PS на сегодняшний день входят 14 моделей.
Наконец, изделия Atom x7000RE (Amston Lake) выполнены по технологии Intel 7. Они насчитывают до восьми ядер E-cores, а показатель TDP варьируется от 6 до 12 Вт. Поддерживаются память LPDDR5-4800, DDR5-4800 и DDR4-3200, до девяти линий PCIe 3.0, графика Intel UHD Graphics. Максимальная тактовая частота — 3,6 ГГц.
02.04.2024 [21:13], Алексей Степин
Три в одном: AMD представила процессоры Ryzen Embedded 8000 с интегрированными NPU и GPUКомпания AMD продолжает активно развивать направление процессоров для встраиваемых систем: если в начале года она представила гибридную платформу Embedded+, сочетающую в себе архитектуру Zen и ПЛИС Versal, то сегодня анонсировала процессоры Ryzen Embedded 8000 с интегрированным ИИ-сопроцессором. Это первое решение AMD для промышленного применения, сочетающее в себе целых три архитектуры: классическую процессорную Zen 4, графическую RDNA 3 и предназначенную для ИИ-вычислений XDNA. Новые процессоры должны найти применение в системах машинного зрения, робототехнике, промышленной автоматике и многих других сценариях. 
Источник: AMD AMD говорит о производительности в ИИ-сценариях, достигающей 39 Топс, что в рамках теплопакета, не превышающего у старшей модели 54 Вт, выглядит неплохо. Но в данном случае речь идёт о совокупной производительности всех архитектур, на долю же NPU приходится только 16 Топс. В качестве памяти используется двухканальная DDR5-5600 с поддержкой ECC. Благодаря графическому ядру RDNA 3 новые Ryzen Embedded 8000 смогут выводить информацию на четыре экрана с разрешением 4K, а также обеспечивать кодирование и декодирование всех популярных видеоформатов, включая H.264, H.265 и AV1. Для связи со специфическими ускорителями или контроллерами оборудования чипы получили 20 линий PCI Express 4.0. 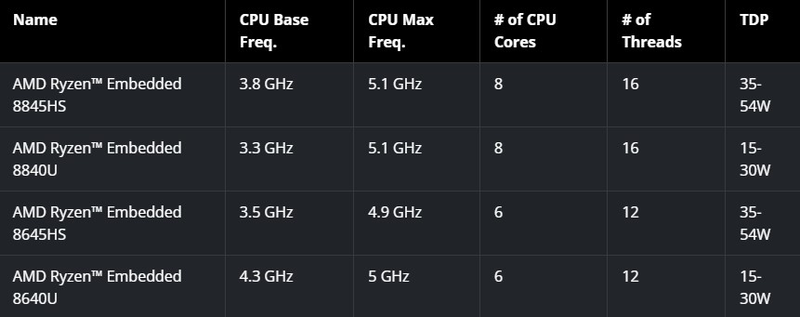 На момент анонса в серию Ryzen Embedded 8000 вошли четыре процессора — два шестиядерных (8645HS и 8640U) и два восьмиядерных (8845HS и 8840U), оба варианта поддерживают SMT и имеют тактовые частоты в диапазоне от 3,3 до 5,1 ГГц. Теплопакет у новинок конфигурируемый, в зависимости от условий охлаждения он может варьироваться либо в пределах 15–30 Вт или 35–54 Вт, что позволит обойтись пассивным теплоотводом там, где это необходимо. Новые решения AMD будут сопровождаться средствами SDK, поддерживающими Windows, а также популярные ИИ-фреймворки PyTorch и TensorFlow. В том числе анонсированы уже обученные модели, которые доступны на HuggingFace. В деле построения экосистемы для Ryzen Embedded 8000 компания тесно сотрудничает с известными производителями оборудования, в том числе с Advantech, ASRock и iBASE. Также для новых процессоров заявлен удлинённый жизненный цикл.
04.03.2024 [17:00], Руслан Авдеев
Евросоюз намерен добиться полупроводникового суверенитета, используя архитектуру RISC-VВ Евросоюзе активно инвестируют в инициативы, призванные обеспечить полупроводниковый суверенитет благодаря использованию открытой архитектуры RISC-V. EE Times сообщает, что инициативу курирует Барселонский суперкомпьютерный центр (Barcelona Supercomputing Center или BSC) — пионер в разработке европейских решений RISC-V. 
Источник изображений: European Processor Initiative (EPI) Страны ЕС беспокоит полупроводниковая зависимость от иностранных компаний, и это беспокойство усугубляется относительно недавним дефицитом чипов в мире. В то же время за использование в своих решениях архитектуры RISC-V никому не надо платить и ни у кого не нужно получать разрешений на её применение, поэтому технология так привлекательна для разработчиков. BSC представляет собой один из ведущих исследовательских центров Европы. Он играет ключевую роль в разработке чипов на архитектуре RISC-V и возглавляет несколько проектов, связанных с этой технологией, в частности, European Processor Initiative (EPI). В рамках инициативы EPI стоимостью €70 млн разрабатывается новое поколение высокопроизводительных процессоров. Связанная с BSC компания OpenChip должна найти коммерческое применение разработанным технологиям.  BSC начал создавать собственные чипы семейства Lagarto довольно давно — первые 65-нм варианты представили ещё в мае 2019 года. Сегодня речь идёт уже о четвёртом поколении, которое будет выпускаться в соответствии с 7-нм техпроцессом. Центр работает и с другими европейскими компаниями и исследовательскими организациями над созданием комплексной экосистемы RISC-V, включающей ПО, ОС и компиляторы. Подобные инициативы должны снизить зависимость Евросоюза от американских и азиатских производителей — отсутствие в ЕС зрелой индустрии высокопроизводительных чипов расценивается как значимая уязвимость. Европа считает, что RISC-V — идеальная платформа для достижения суверенитета, при этом бесплатная. Впрочем, эксперты признают, что о полной независимости не может быть речи из-за сложности экосистемы полупроводниковой индустрии. Но у Европы есть большая база знаний и потенциал разработки новых решений, предпринимаются и шаги к организации производства.  В BSC уже экспериментировали с Arm-процессорами, но после Brexit и приобретения компании Arm группой Softbank, выяснилось, что собственной региональной технологии у ЕС нет, тогда и обратили внимание на общедоступную RISC-V. В 2019 году Еврокомиссию убедили в необходимости начать выпуск чипов на этой архитектуре для суперкомпьютеров. В числе других европейских компаний, предлагающих RISC-V продукты, есть Gaiser, Esperanto Technologies, Semidynamics и Codasip, но они уделяют больше внимания процессорам и ускорителям, а не конечным готовые решения. По оценкам экспертов, в Евросоюзе компаний, работающих с RISC-V, пока недостаточно. Тем не менее, организаторы новых инициатив предостерегают от нереалистичных ожиданий и призывают к стратегическому сотрудничеству — для производства требуются не только разработки, но и сырьё, высокоточное оборудование, и др. Европа может рассчитывать на выпуск решений в пределах 7-нм, более современные техпроцессы пока слишком дороги. Впрочем, ЕС уже добился значительного прогресса в достижении полупроводникового суверенитета с помощью RISC-V. |
|


