Материалы по тегу: ускоритель
|
13.06.2025 [00:15], Владимир Мироненко
Ускорители AMD Instinct MI355X с архитектурой CDNA 4 потребляют 1400 ВтAMD представила ускоритель Instinct MI355X для ИИ- и HPC-нагрузок, демонстрирующий значительный рост производительности в задачах инференса, но вместе с тем почти удвоенное энергопотребление по сравнению с MI300X 2023 года выпуска, сообщил ресурс ComputerBase. Есть и чуть более простая версия MI350X, менее требовательная к питанию и охлаждению. AMD Instinct MI350X (Antares+) основан на оптимизированной архитектуре CDNA 4, отличающейся эффективной поддержкой новых форматов вычислений, в чём AMD ранее не была сильна. В дополнение к FP16 новый ускоритель поддерживает не только FP8, но также FP6 и FP4, которые актуальны для ИИ-нагрузок, особенно инференса. AMD во многом позиционирует Instinct MI350X как ускоритель для инференса, что имеет смысл, поскольку масштабирование MI350X по-прежнему ограничено лишь восемью ускорителями (UBB8), что снижает их конкурентоспособность по сравнению с ускорителями NVIDIA. Впрочем, для т.н. думающих моделей масштабирование тоже важно, что уже сказалось на продажах MI325X. 
Источник изображений: AMD via ServeTheHome Серия ускорителей AMD Instinct MI350X включает две модели: стандартный ускоритель Instinct MI350X мощностью 1000 Вт, который всё ещё можно использовать с системами воздушного охлаждения, а также более производительный Instinct MI355X до 1400 Вт, рассчитанный исключительно на работу с СЖО. Впрочем, AMD считает, что некоторые из её клиентов смогут использовать воздушное охлаждение для MI355X, пишет Tom's Hardware. В случае СЖО в одну стойку можно упаковать до 16 узлов (128 ускорителей MI355X), а в случае воздушного охлаждения — до 8 узлов (64 ускорителя MI350X). Для вертикального масштабирования предполагается использование UALink, для горизонтального — Ultra Ethernet.  Оба ускорителя будут поставляться с 288 Гбайт памяти HBM3E с пропускной способностью до 8 Тбайт/с. Сообщается, что ускоритель MI350X обладает максимальной производительностью в операциях FP4/FP6 в размере 18,45 Пфлопс, тогда как MI355X — до 20,1 Пфлопс. То есть обе модели серии Instinct MI350X превосходят ускоритель NVIDIA B300 (Blackwell Ultra), который с производительностью 15 FP4 Пфлопс. Что интересно, для векторных FP64-вычислений AMD сохранила тот же уровень производительности, что был у MI300X, а матричные FP64-вычисления стали почти вдвое медленнее. Тем не менее, это всё равно лучше, чем почти 30-кратное снижение скорости FP64-расчётов при переходе от B200 к B300. 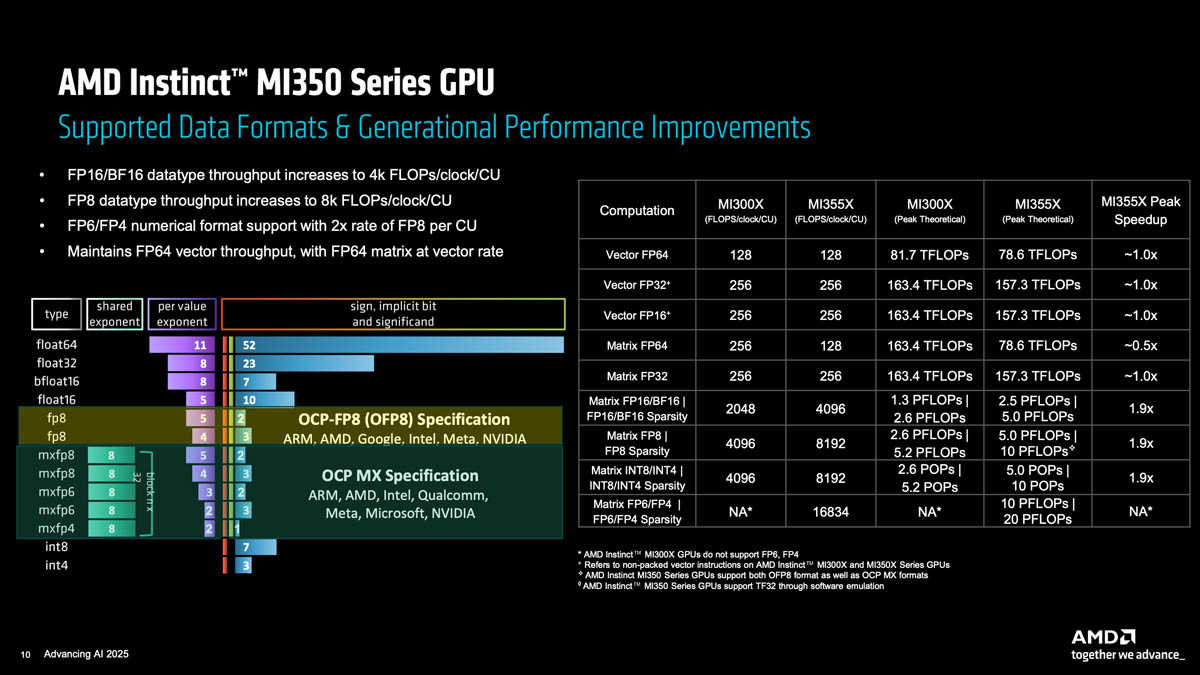 Если сравнивать производительность новых чипов с предшественником, то производительность MI350X в вычислениях с точностью FP8 составляет около 9,3 Пфлопс, в то время как у MI355X, как сообщается, этот показатель составляет 10,1 Пфлопс, что значительно выше, чем 5,22 Пфлопс у Instinct MI325X (во всех случаях речь идёт о разреженных вычислениях). MI355X также превосходит NVIDIA B300 на 0,1 Пфлопс в вычислениях FP8. Формально разница между MI350X и MI355X не так велика, но на практике она может достигать почти 20 % из-за возможности более долго поддерживать частоты при наличии СЖО. В целом, по словам AMD, в ИИ-тестах MI350X/MI355X быстрее MI300X в 2,6–4,2 раза в зависимости от задачи и до 1,3 раз быстрее (G)B200, но при этом значительно дешевле последних.  Компоновка MI350X/MI355X напоминает компоновку MI300X. Есть восемь 3-нм (TSMC N3P) XCD-чиплетов, лежащих поверх двух 6-нм (N6) IO-тайлов (IOD) и обрамлённых восемью стеками HBM3E. Переход к двум IOD повлиял и на NUMA-домены, поскольку теперь память можно поделить только пополам. А вот вычислительных инстансов может быть до восьми.  Используется комбинированная 3D- и 2.5D-компоновка чиплетов, причём для связи IOD, т.е. двух половинок всего чипа, используется шина Infinity Fabric AP с пропускной способностью 5,5 Тбайт/с. Каждый XCD содержит 36 CU, из которых активно только 32 (для повышения процента годных чипов), и общий L2-кеш объёмом 4 Мбайт. Все XCD подключены к Infinity Cache объёмом 256 Мбайт. Для связи с внешним миром есть один интерфейс PCIe 5.0 x16 (128 Гбайт/с) и семь линий Infinity Fabric (1075 Гбайт/с), которые как раз и позволяют объединить восемь ускорителей по схеме каждый-с-каждым.  Технический директор AMD Марк Пейпермастер (Mark Papermaster) заявил, что отрасль продолжит разрабатывать всё более мощные процессоры и ускорители для суперкомпьютеров, чтобы достичь производительности зеттафлопсного уровня примерно через десятилетие. Однако этот рост будет достигаться ценой резкого увеличения энергопотребления, поэтому суперкомпьютер с производительностью такого уровня будет потреблять примерно 500 МВт — половину того, что вырабатывает средний реактор АЭС.  Для поддержания роста производительности пропускная способность памяти и масштабирование мощности тоже должны расти. Согласно расчётам AMD, пропускная способность памяти ускорителя должна более чем удваиваться каждые два года, чтобы сохранить соотношение ПСП к Флопс. Это потребует увеличения количества стеков HBM на один ускоритель, что приведёт к появлению более крупных и более энергоёмких ускорителей и модулей.  Instinct MI300X имел пиковую мощность 750 Вт, Instinct MI355X имеет пиковую мощность 1400 Вт, в 2026–2027 гг., по словам Пейпермастера, нас ждут ускорители мощностью 1600 Вт, а в конце десятилетия — уже 2000 Вт. У чипов NVIDIA энергопотребление ещё выше — ожидается, что у ускорителей Rubin Ultra с четырьмя вычислительными чиплетами энергопотребление составит до 3600 Вт. На фоне растущего энергопотребления суперкомпьютеры и ускорители также быстро набирают производительность. Согласно презентации AMD на ISC 2025, эффективность производительности увеличилась с примерно 3,2 ГФлопс/Вт в 2010 году до примерно 52 Гфлопс/Вт к моменту появления экзафлопсных систем, таких как Frontier.  Поддержание такого темпа роста производительности потребует удвоения энергоэффективности каждые 2,2 года, пишет Tom's Hardware. Прогнозируемая система зетта-класса потребует эффективность на уровне 2140 Гфлопс/Вт, т.е. в 41 раз выше, чем сейчас. AMD считает, что для значительного повышения производительности суперкомпьютеров через десятилетие потребуется не только ряд прорывов в архитектуре чипов, но и прорыв в области памяти и интерконнектов.
09.06.2025 [14:02], Руслан Авдеев
Перегрев, плохое ПО и сила привычки: китайские компании не горят желанием закупать ИИ-ускорители HuaweiНесмотря на дефицит передовых ИИ-ускорителей на китайском рынке, китайская компания Huawei, выпустившая модель Ascend 910C, может столкнуться с проблемами при её продвижении. Она рассчитывала помочь китайскому бизнесу в преодолении санкций на передовые полупроводники, но перспективы нового ускорителя остаются под вопросом, сообщает The Information. Китайские гиганты вроде ByteDance, Alibaba и Tencent всё ещё не разместили крупных заказов на новые ускорители. Основная причина в том, что экосистема NVIDIA доминирует во всём мире (в частности, речь идёт о программной платформе CUDA), а решения Huawei недостаточно развиты. В результате компания продвигает продажи государственным структурам (при поддержке самих властей КНР) — это косвенно свидетельствует о сложности выхода на массовый рынок. Китайский бизнес годами инвестировал в NVIDIA CUDA для ИИ- и HPC-задач. Соответствующий инструментарий, библиотеки и сообщество разработчиков — настолько развитая экосистема, что альтернатива в лице Huawei CANN (Compute Architecture for Neural Networks) на её фоне выглядит весьма слабо. У многих компаний всё ещё хранятся огромные запасы ускорителей NVIDIA, накопленные в преддверии очередного раунда антикитайских санкций, поэтому у их владельцев нет стимула переходить на новые и незнакомые решения. Они скорее предпочтут оптимизировать программный стек, как это сделала DeepSeek, чтобы повысить утилизацию имеющегося «железа». Если бы, например, та же DeepSeek перешла на ускорители Huawei, это подтолкнуло бы к переходу и других разработчиков, но пока этого не происходит. Кроме того, некоторые компании вроде Tencent и Alibaba не желают поддерживать продукты конкурентов, что усложняет Huawei продвижение её ускорителей. 
Источник изображения: Huawei Есть и технические проблемы. Самый передовой ускоритель Huawei Ascend 910C периодически перегревается, поэтому возникла проблема доверия к продукции. Поскольку сбои во время длительного обучения модели обходятся весьма дорого. Кроме того, он не поддерживает ключевой для эффективного обучения ИИ формат FP8. Ascend 910С представляет собой сборку из двух чипов 910B. Он обеспечивает производительность на уровне 800 Тфлопс (FP16) и пропускную способность памяти 3,2 Тбайт/с, что сопоставимо с параметрами NVIDIA H100. Также Huawei представила кластер CloudMatrix 384. Наконец, проблема в собственно американских санкциях. В мае 2025 года Министерство торговли США предупредило, что использование чипов Huawei без специального разрешения может расцениваться, как нарушение экспортных ограничений — якобы в продуктах Huawei незаконно используются американские технологии. Такие ограничения особенно важны для компаний, ведущих международный бизнес — даже если они китайского происхождения. Хотя NVIDIA ограничили продажи в Китае, она по-прежнему демонстрирует рекордные показатели. По данным экспертов UBS, у компании есть перспективные проекты суммарной мощностью «десятки гигаватт» — при этом, каждый гигаватт ИИ-инфраструктуры, по заявлениям NVIDIA, приносит ей $40–50 млрд. Если взять вероятную очередь проектов на 20 ГВт с периодом реализации два-три года, то только сегмент ЦОД может обеспечить NVIDIA около $400 млрд годовой выручки. Это подчеркивает доминирующее положение компании на рынке аппаратного обеспечения для ИИ.
02.06.2025 [22:50], Руслан Авдеев
NVIDIA якобы разрабатывает для Китая «антисанкционный» ИИ-ускоритель B30 с возможностью объединения в кластерыПосле запрета США на экспорт в Китай ИИ-ускорителей H20 NVIDIA занялась разработкой альтернативного продукта на базе Blackwell. Ранее уже появилась информация о имеется модели B40 на основе видеокарты RTX Pro 6000D. Тогда же упоминалось, что компания ведёт разработку ещё одного чипа. Теперь источники The Information сообщили о модели B30, причём с возможностью объединения в кластеры. По имеющимся данным, модель будет использовать память GDDR7 и GB20x — те же, что лежат в основе игровых видеокарт серии RTX 5000. Хотя многие предполагают, что B30 получат поддержку NVLink, в потребительских продуктах последнего поколения поддержка этого интерконнекта не предусмотрена. С другой стороны, у компании теперь есть серверы на основе RTX Pro Blackwell, которые объединяют до восьми GPU посредством платы с адаптерами ConnectX-8 SuperNIC со встроенными коммутаторами PCIe 6.0 для связи между ускорителями. Аналогичная конфигурация применяется для связи систем DGX Spark. В своё время глава NVIDIA Дженсен Хуанг (Jensen Huang) прямо заявил, что возможности архитектуры Hopper в плане её ослабления исчерпаны, и компания больше не будет использовать её для выпуска ослабленных ускорителей для Китая. При этом американские власти своими санкциями специально нацелились на снижение пропускной способности памяти и интерконнектов чипов для КНР.  Хотя NVIDIA соблюдает санкционные требования, компания давно находится в оппозиции к американским регуляторам — сам Хуанг недавно раскритиковал экспортные ограничения, заявив, что те только помогают Китаю нарастить собственные компетенции в сфере ИИ. NVIDIA уже потеряла $4,6 млрд из-за запрета на экспорт H20 в Китай, а в перспективе потеряет более $15 млрд. AMD после запрета на экспорт чипов MI308 сообщила о вероятных потерях $800 млн. По словам Хуанга, США, вводя новые меры, США рискуют потерять конкурентные преимущества в сфере ИИ, если китайские конкуренты вроде Huawei будут вынуждены форсировать инновации из-за отсутствия доступа к передовому оборудованию. В результате новые китайские продукты, возможно, не только смогут конкурировать с продукцией NVIDIA, но и начнут задавать будущие мировые стандарты в сфере ИИ-полупроводников.
02.06.2025 [09:02], Сергей Карасёв
EnCharge AI представила аналоговые ИИ-ускорители EN100Компания EnCharge AI анонсировала изделия семейства EN100 — аналоговые ИИ-ускорители для in-memory вычислений. Дебютировали устройства в форм-факторе M.2 для ноутбуков и карты расширения PCIe для настольных рабочих станций. Стартап EnCharge AI, основанный в 2022 году, разрабатывает чипы, которые дают возможность перенести ИИ-нагрузки из облака на локальные платформы. Для этого применяется концепция вычислений в оперативной памяти, позволяющая увеличить эффективность и устранить узкие места, связанные с перемещением данных. NPU-ядра EnCharge AI, как утверждает сам разработчик, обеспечивают производительность на уровне 40 Топс/Вт (8-бит точность). Ускоритель EN100 для ноутбуков имеет типоразмер M.2 2280. В оснащение входят 32 Гбайт памяти с пропускной способностью до 68 Гбайт/с. Быстродействие превышает 200 Топс при общем энергопотреблении не более 8,25 Вт. Для оркестрации задействована многопоточная архитектура RISC-V. 
Источник изображений: EnCharge AI На рабочие станции ориентированы ускорители EN100 в виде карт расширения PCIe HHHL. Они несут на борту 128 Гбайт памяти с суммарной пропускной способностью 272 Гбайт/с. Производительность составляет около 1 Попс. Изделия обоих типов изготавливаются с применением 16-нм CMOS-технологии. 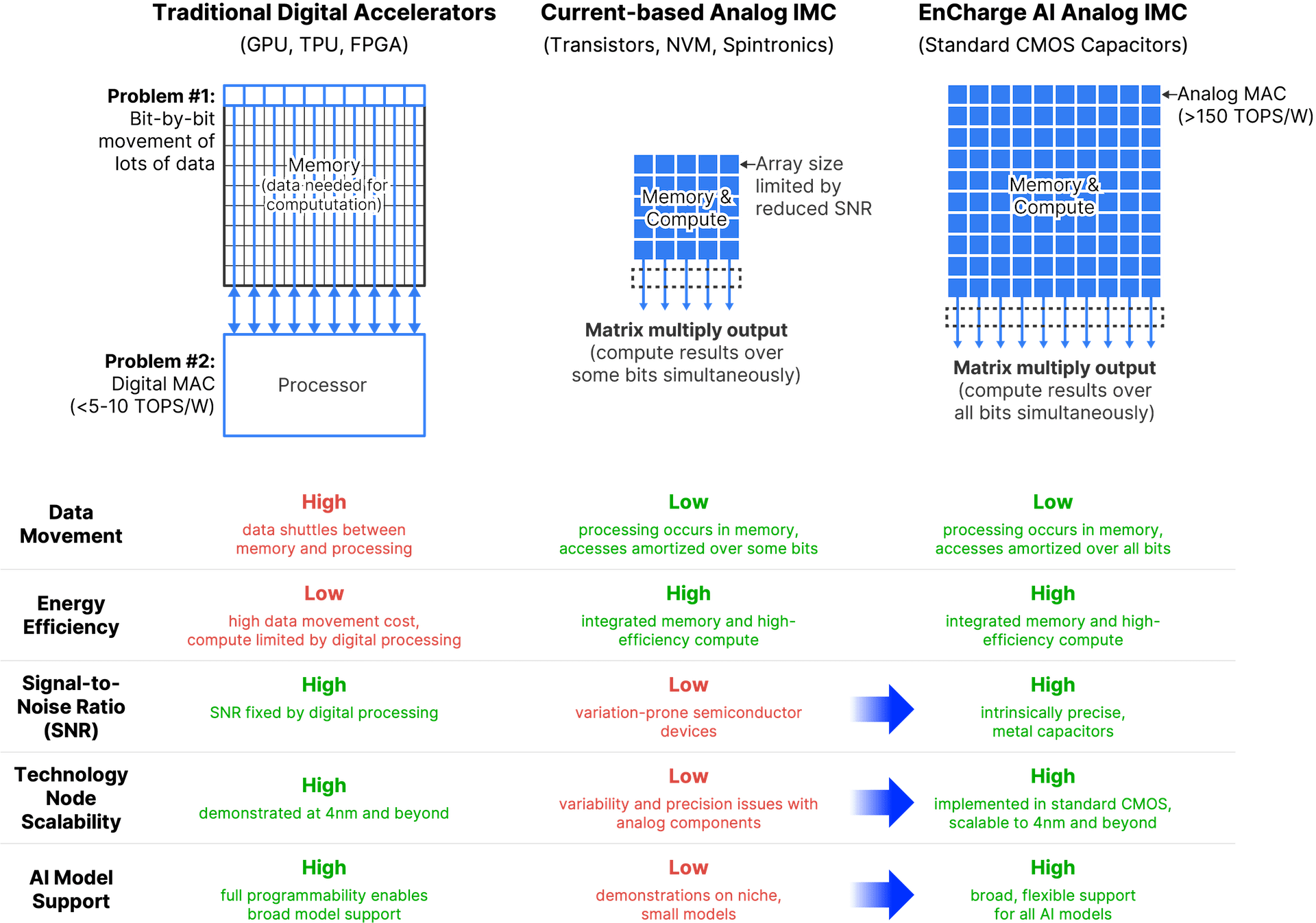 Навин Верма (Naveen Verma), генеральный директор EnCharge AI, заявляет, что решения компании позволят выполнять ресурсоёмкие задачи ИИ локально, не полагаясь на облачную инфраструктуру. Утверждается, что такие устройства по сравнению с современными ИИ-ускорителями обеспечат в 20 раз более высокую энергоэффективность (Топс/Вт) и в 9 раз более высокую плотность вычислений (Топс/мм2) при 10-кратном снижении совокупной стоимости владения (TCO).
30.05.2025 [10:19], Руслан Авдеев
Япония планирует крупные закупки ИИ-чипов для сокращения торгового дефицита с СШАВ преддверии переговоров Японии и США относительно американских пошлин, японские власти предложили закупить в Соединённых Штатах полупроводники на несколько миллиардов долларов. Предполагается, что это поможет «задобрить» США и сократить торговый дефицит с Японией, сообщает Digitimes. Источники в японском правительстве сообщили, что в ходе последних обсуждений тарифной политики Япония предложила планы закупок полупроводников, основным поставщиком в которых рассматривается американская NVIDIA — речь идёт о «многомиллиардных» закупках. Японское правительство намерено поощрять и субсидировать телекоммуникационные и IT-компании, чтобы те выступили операторами новых дата-центров и закупали больше ИИ-ускорителей. Если инициатива будет успешно реализована, импорт из США увеличится на сумму от сотен миллиардов до триллиона японских иен (около $7 млрд), что потенциально компенсирует дефицит приблизительно на 10 %. Торговый дефицит с Японией в 2024 году для США составлял $68,5 млрд. 
Источник изображения: JJ Ying/unsplash.com Помимо закупок чипов, Япония также предложила поддержать поставки ключевых материалов для производства полупроводников, таких как пластины и химические компоненты, в США. Совместное укрепление цепочки поставок должно усилить и экономическую безопасность стран. По имеющимся данным, США не намерены менять позицию и готовы только к переговорам о дополнительных дифференцированных пошлинах (помимо единой 10 % пошлины для всех). При этом они не хотят «оптимизировать» ставки на отдельные группы товаров, например — автомобили. Япония же настаивает, что пошлины на автомобили, на которые приходится около 30 % местного экспорта в США, должны быть снижены, поэтому позиции двух стран пока не меняются. Рёсей Аказава (Ryosei Akazawa), в 2024 году получивший в японском правительстве сразу несколько министерских портфелей, связанных с экономикой и развитием, должен был посетить США 29 мая для четвёртого раунда переговоров с министром финансов США Скоттом Бессентом (Scott Bessent) и другими представителями федеральных американских властей. Переговоры посвящены импортно-экспортным пошлинам двух стран. Весьма вероятно, что цель правительства несколько другая. В феврале сообщалось, что SoftBank Group и OpenAI объединились для продвижения ИИ-сервисов среди японских корпоративных клиентов, а в марте появились данные о том, что SoftBank купит за $676 млн заброшенный объект Sharp для строительства ИИ ЦОД, вероятно, в интересах OpenAI. Кроме того, SoftBank участвует в создании двух крупных платформ на базе DGX B200 и GB200 NVL72. Сейчас американскими властями очень много внимания уделяется ИИ-проекту Stargate, в котором японская SoftBank является одним из ключевых игроков наряду с OpenAI. Не исключено, что очередной кампус Stargate по результатам переговоров появится именно в Японии. Расширение проекта за пределы США уже началось, OpenAI и G42 построят 5-ГВт кампус в Абу-Даби.
29.05.2025 [13:18], Руслан Авдеев
Перегрев, протечки и нестабильность затормозили массовый выпуск NVIDIA GB200 NVL72, но теперь все проблемы решеныПоставщики ИИ-серверов на базе NVIDIA GB200 NVL72, включая Dell, Foxconn, Inventec и Wistron, увеличили выпуск серверов. Для этого им пришлось решить ряд технических проблем, которые ранее привели к задержкам поставок продуктов клиентам, сообщает The Financial Times. Компании совершили «серии прорывов», что позволило им начать своевременные поставки серверов GB200 NVL72. Как сообщил один из инженеров неназванного производственного партнёра NVIDIA, внутренние тесты выявили «проблемы с подключением» в серверах, но поставщики организовали совместную работу с NVIDIA, и вопрос был решён два или три месяца назад. Впрочем, это не первая проблема с чипами семейства Blackwell. В конце 2024 года стало известно о перегреве суперускорителей NVL72. По слухам, разработчику чипов пришлось просить производителей внести немало изменений в эталонный вариант стоек, чтобы решить проблему. Также поступала информация о проблемах межчипового интерконнекта, программных багах и протечках охлаждающих жидкостей. В результате поставщикам пришлось увеличить число протоколов проверки — оборудование стали тестировать намного внимательнее перед поставками клиентам. При этом производителям уже нужно готовиться к выпуску систем на базе GB300. NVIDIA GB300 NVL72 всё так же использует полностью жидкостное охлаждение. Суперускоритель оснащён 72 чипами Blackwell Ultra и 36 процессорами Grace. В продажу решение должно поступить в III квартале 2025 года. 
Источник изображения: NVIDIA Впрочем, как сообщают журналисты, чтобы ускорить внедрение GB300-серверов, NVIDIA отказалась от более совершенного дизайна платы Cordelia позволявшего заменять отдельные компоненты, в пользу текущей версии Bianca, применяемой для GB200. Это решение может усложнить ремонт, но ускорит развёртывание систем. По словам трёх источников, знакомых с вопросом, NVIDIA сообщила поставщикам, что намерена перейти дизайн Cordelia в следующем поколении ИИ-продуктов.
26.05.2025 [14:38], Руслан Авдеев
NVIDIA выпустит для Китая дешёвый ускоритель семейства BlackwellNVIDIA намерена выпустить новый ИИ-ускоритель для Китая, который будет значительно дешевле недавно запрещённой к продаже в КНР модели H20. По данным источников Reuters, начало массового производства запланировано на июнь. Новинка войдёт в серию Blackwell и будет стоить $6,5–$8 тыс., т.е. намного меньше, чем H20, которые продавались по $10–$12 тыс. Вероятное название новинки — B40. Ускоритель предположительно получит чип от NVIDIA RTX Pro 6000D, будет использовать память GDDR7 вместо HBM и лишится поддержки NVLink. Кроме того, модель не будет использовать передовую технологию упаковки TSMC CoWoS (Chip-on-Wafer-on-Substrate). Представитель NVIDIA заявил, что компания всё ещё оценивает урезанные варианты ускорители — до того, как компания утвердит новый дизайн продукта и получит одобрение американских регуляторов, она фактически изолирована от китайского рынка объёмом $50 млрд. В TSMC слухи не комментируют. Китай долго оставался огромным рынком для NVIDIA, на который пришлось 13 % всех продаж за прошлый финансовый год. Уже в третий раз NVIDIA вынуждена ухудшать свои ИИ-ускорители из-за американских санкций, пытающихся замедлить технологическое развитие КНР (ранее пришлось выпустить A800, H800, H20 и др.). Запрет на продажи H20 фактически заставил NVIDIA списать $5,5 млрд и упустить $15 млрд потенциальных продаж. При этом дальнейшее ухудшение характеристик H20 невозможно. 
Источник изображения: NVIDIA Новый ускоритель хотя и намного слабее H20, должен помочь сохранить конкурентоспособность NVIDIA на китайском рынке, несмотря на значительные потери выручки из-за торговых ограничений со стороны США. Основным конкурентом компании является Huawei, выпускающая чипы Ascend. По словам экспертов Oak Capital Partners, производительность китайских ускорителей достигнет показателей ослабленных моделей NVIDIA в течение года-двух, но NVIDIA сохранит преимущество благодаря программной экосистеме CUDA, сопоставимых альтернатив которой у Huawei пока нет. До 2022 года, т.е до ввода серьёзных экспортных ограничений со стороны США, доля NVIDIA на китайском рынке ускорителей составляла 95 %, а сейчас она упала до 50 % — об этом сообщил глава компании Дженсен Хуанг (Jensen Huang). Он также предупредил об неэффективности санкций и заявил, что продолжение ограничений приведёт к тому, что чипов Huawei будут покупать всё больше, а вместо того, чтобы замедлить развитие ИИ-индустрии Китая, американские власти способствуют её прогрессу. Новейшие экспортные ограничения в очередной раз коснулись пропускной способности памяти и интерконнекта, этот показатель чрезвычайно важен для ИИ-чипов. По оценкам инвестиционного банка Jefferies новые правила ограничивают пропускную способность на уровне 1,7–1,8 Тбайт/с. H20 обеспечивает 4 Тбайт/с. GF Securities прогнозирует, что GDDR7 позволит получить допустимые 1,7 Тбайт/с. По словам двух источников Reuters, NVIDIA создаёт ещё один чип на архитектуре Blackwell для Китая, производство которого должно начаться в сентябре, но его характеристики пока неизвестны.
19.05.2025 [08:49], Владимир Мироненко
На одном ИИ не выедешь: США рискуют потерять лидерство в HPC
hardware
hpc
top500
государство
дефицит
ии
кадры
квантовые вычисления
обучение
прогноз
разработка
суперкомпьютер
сша
ускоритель
финансы
энергоэффективность
Проблемы, связанные с высокопроизводительными вычислениями (HPC), угрожают инновациям в США, утверждает Джек Донгарра (Jack Dongarra), лауреат премии А. М. Тьюринга и один создателей рейтинга самых мощных суперкомпьютеров в мире TOP500, чьи разработки и реализации многих библиотек, включая EISPACK, LINPACK, BLAS, LAPACK и ScaLAPACK, сыграли важную роль в продвижении HPC. В статье, опубликованной The Conversation, Донгарра рассказал о прогрессе HPC и проблемах с инновациями в США. Учёный отметил, что HPC являются одной из самых важных технологий в современном мире, позволяющей решать различные задачи — от прогнозирования погоды до поиска новых лекарств и обучения ИИ-моделей, которые слишком сложны или слишком велики для обычных компьютеров. Сейчас HPC находятся на переломном этапе, и выбор, который правительство США, исследователи и технологическая отрасль делают сегодня, может повлиять на будущее инноваций, национальной безопасности и мирового лидерства, предупреждает Донгарра. Используя тысячи и даже миллионы чипов с передовыми системами памяти и хранения для быстрого перемещения и сохранения огромных объёмов данных, HPC-платформы позволять выполнять чрезвычайно подробные симуляции и вычисления, говорит Донгарра. Важность HPC ещё больше возросла с развитием ИИ-технологий, требующих огромных вычислительных мощностей для обучения. «В результате ИИ и HPC теперь тесно сотрудничают, подталкивая друг друга вперёд», — отметил учёный. По словам Донгарра, сегмент HPC находится под большим давлением, чем когда-либо, с более высокими требованиями к системам по скорости, данным и энергопотреблению. Также он отметил, что HPC сталкиваются с некоторыми серьёзными техническими проблемами. Донгарра назвал одной из ключевых проблем разрыв между производительностью чипов и подсистем памяти. «Представьте себе, что у вас есть сверхбыстрый автомобиль, но вы застряли в пробке — мощность бесполезна, если дорога не может с ней справиться», — говорит учёный. Точно так же подсистемы памяти не способны «прокормить» вычислительные блоки, которые простаивают, что отражается на эффективности всей вычислительной системы. 
Источник изображения: OLCF Ещё одна проблема HPC — энергопотребление. Закон масштабирования Деннарда, согласно которому с уменьшением размеров транзистора уменьшается и энергопотребление при росте производительности, прекратил своё действие в 2006 году. Теперь, чем мощнее компьютеры, тем больше они потребляют энергии. Чтобы исправить это, исследователи ищут новые способы проектирования как аппаратного, так и программного обеспечения HPC. Также существует проблема с типами производимых чипов, отметил учёный. Сейчас индустрия чипов в основном сосредоточена на ИИ, который отлично работает с вычислениями с низкой точностью. Однако для многих научных приложений по-прежнему требуется FP64-вычисления. В частности, NVIDIA сделала ставку исключительно на ИИ, поэтому FP64-производительность новейших GB300 почти в 30 раз меньше, чему GB200. У AMD, по слухам, в следующем поколении Instinct будет сразу два варианта ускорителей MI430X с поддержкой FP64 и MI450X, полностью лишённый тензорных ядер с FP64. Но и она может сделать ставку только на ИИ. Если производители прекратят выпускать чипы, которые требуются учёным, это негативно отразится на выполнении важных исследований. Таким образом тенденции в производстве полупроводников и коммерческие приоритеты могут разниться с потребностями научного сообщества, а отсутствие специализированного оборудования может помешать прогрессу в исследованиях. Можно попытаться создавать специализированные чипы для HPC, но это дорого и сложно. Исследователи, тем не менее, изучают возможность применения новых конструкций для изготовления чипов, включая чиплеты, чтобы сделать их более доступными. В прошлом у США было преимущество в области HPC благодаря государственному финансированию, поддержке и открытости разработок, но теперь многие страны вкладывают значительные средства в HPC в стремлении снизить зависимость от иностранных технологий и выйти на лидирующие позиции в таких областях, как моделирование климата и персонализированная медицина. В Европе развивают программу EuroHPC, у Японии есть собственный суперкомпьютер Fugaku (а скоро будет ещё один), а у Китая — целая серия «автохтонных» машин. 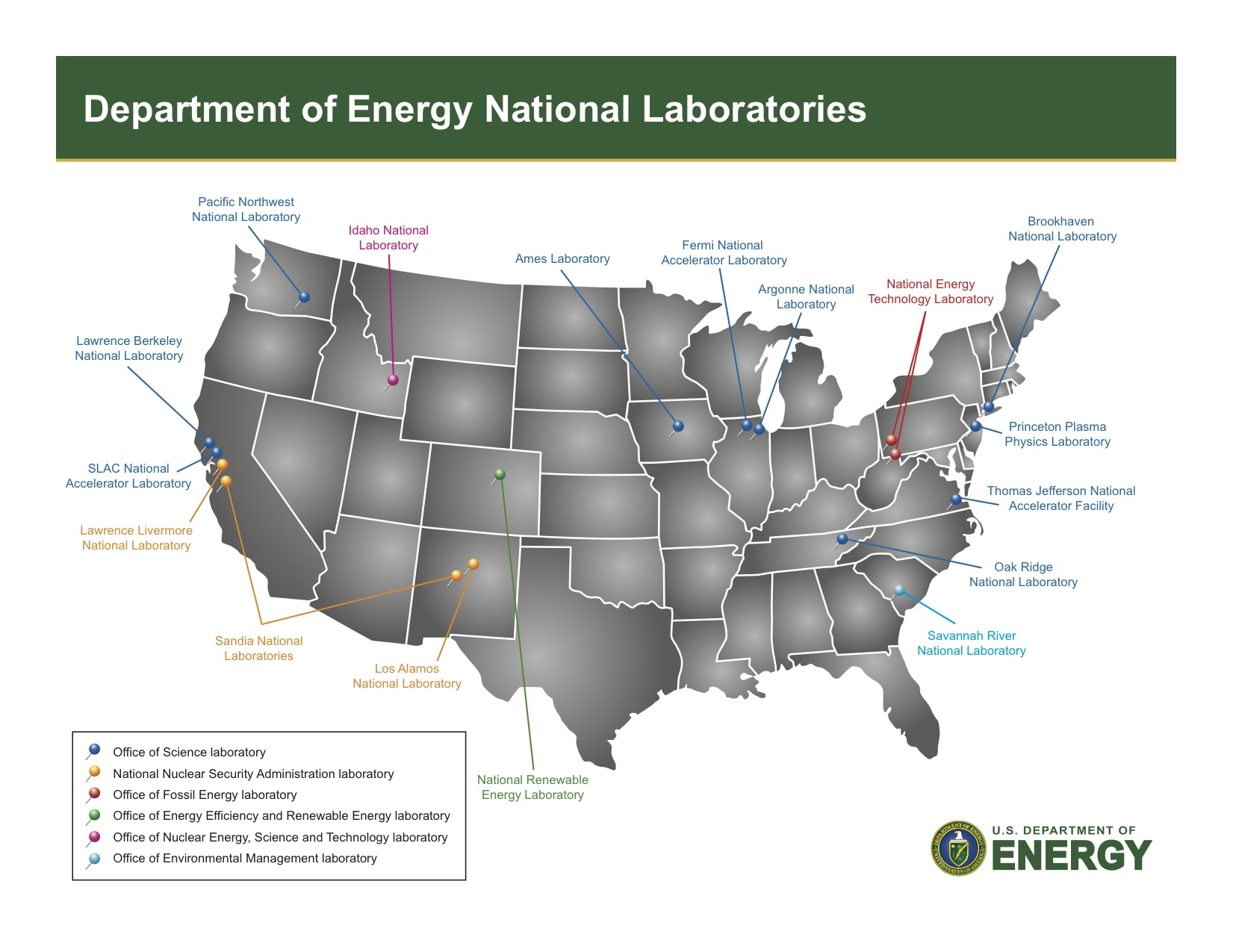
Источник изображения: WIkipedia / DoE Правительства стран понимают, что HPC являются ключом к их национальной безопасности, экономической мощи и научному лидерству, отметил Донгарра, подчеркнув, что у США всё ещё нет чёткого долгосрочного плана на будущее. Другие страны развивают это направление быстро, а без национальной стратегии США рискуют отстать, предупредил он: «Национальная стратегия США должна включать финансирование создания новых машин и обучение людей их использованию. Она также должна включать партнёрство с университетами, национальными лабораториями и частными компаниями. Самое главное, что план должен быть сосредоточен не только на оборудовании, но и на ПО и алгоритмах, которые делают HPC полезными», — заявил учёный. Он отметил, что некоторые шаги в этом направлении уже предприняты, включая принятие в 2022 году «Закона о чипах и науке» (CHIPS and Science Act) и создание управления, которое поможет превратить научные исследования в реальные продукты. В 2025 году также была сформирована целевая группа Vision for American Science and Technology, призванная объединить некоммерческие организации, академические круги и промышленность для помощи правительству в принятии решений. Кроме того, получили развитие квантовые вычисления. Но они пока находятся на ранних стадиях и, скорее всего, будут дополнять, а не заменять традиционные HPC. Поэтому важно продолжать инвестировать в оба вида вычислений. Донгарра назвал это правильными шагами, но они не решат проблему поддержки HPC в долгосрочной перспективе. Помимо краткосрочного финансирования и инвестиций в инфраструктуру, учёный предложил:
Донгарра отметил, что HPC — это больше, чем просто быстрые суперкомпьютеры. Это основа научных открытий, экономического роста и национальной безопасности. Если США примут предложенные меры, то можно гарантировать, что HPC продолжат поддерживать инновации в течение десятилетий.
16.05.2025 [14:13], Руслан Авдеев
Tencent санкциями не напугать: китайский IT-гигант накопил достаточно ИИ-ускорителей для обучения моделей в течение многих летКитайский IT-гигант Tencent уверен, что накопил достаточно высокопроизводительных ускорителей для обучения новых ИИ-моделей в течение многих лет. Отчасти это объясняют тем, что в КНР нашли более эффективные способы работы с ИИ-нагрузками, чем в США, сообщает The Register. В ходе подведения финансовых итогов I квартала 2025 года президент Tencent Мартин Лау (Martin Lau), объявил, что у компании «довольно большой запас чипов», которые компания успела приобрести до новых ограничений со стороны Соединённых Штатов. Часть будет использоваться для приложений, которые принесут «немедленную прибыль» — вроде рекламных и рекомендательных систем. Часть пойдёт на обучение ещё нескольких поколений LLM с использованием передовых методов, позволяющих использовать минимально возможное количество ускорителей. Сообщается, что в последние месяцы в КНР стали отходить от американской концепции «масштабирования», согласно которой обучающий кластер надо постоянно увеличивать — хороших результатов можно добиться и без этого, в том числе на этапе пост-обучения. По словам Лау, агентный и рассуждающий ИИ требуют больше ускорителей сам по себе, но оптимизация ПО поможет ещё больше повысить эффективность инференса. Поэтому Tencent намерена вкладываться в повышение эффективности использования доступных ресурсов — например, обучение более мелких моделей для более узких задач, требующих меньше мощностей. 
Источник изображения: chen zy/unsplash.com Как заявил Лау, компания рассматривает и альтернативы недоступным более ускорителям NVIDIA. Потенциально компания может использовать и другие ускорители и аппаратные решения, включая ASIC-модули и даже обычные GPU в некоторых случаях, в том числе для более мелких моделей. Высказывания Лау предполагают, что попытки США заблокировать экспорт высокопроизводительных ускорителей в Китай не принесли ожидавшихся результатов — вместо этого Tencent добилась прогресса в оптимизации и инновациях. Несколько противоречат оптимистичным заявлениям Лау высказывания генерального директора Tencent Пони Ма (Pony Ma), который подчеркнул, что облачный бизнес фактически подразумевает перепродажу мощностей ускорителей, поэтому сейчас для компании, на фоне дефицита, это направление стало менее приоритетным. Другими словами, дефицит всё же имеется. В любом случае на данный момент компания находится в превосходном состоянии. За I квартал выручка выросла на 13 % год к году до $25,1 млрд, а валовая прибыль — на 20 % до $14 млрд. Компания насчитывает 1,4 млрд активных пользователей Weixin и WeChat ежемесячно, а новая рекламная платформа на базе ИИ только улучшает показатели. Компания является не только рекламным посредником, но и активно занимается стримингом видео и аудио, а доходы от её игр в последнее время резко выросли. 
Источник изображения: Donald Wu/unsplash.com Пока торговая война между США и Китаем смешала планы многих бизнесов, но Лау предлагает подождать и посмотреть на результаты в следующем квартале. По его словам, правительство оказывает большую поддержку, что компенсирует новые высокие тарифы. В своё время китайский стартап DeepSeek сумел доказать, что в мире ИИ можно добиться больших результатов относительно малыми средствами. Хотя позже выяснилось, что экономичность его моделей не так высока, как утверждалось, американское технологическое превосходство всё равно было поставлено под вопрос.
15.05.2025 [13:51], Владимир Мироненко
Спрос на AMD Instinct MI325X со стороны крупных компаний оказался ниже ожиданий из-за ограниченных возможностей масштабированияОдно из последних предложений AMD для рынка ЦОД — ускоритель AMD Instinct MI325X — не вызвал большого интереса у крупных заказчиков, отдавших предпочтение чипам NVIDIA Blackwell из-за лучшего соотношения цены и производительности, сообщили аналитики SemiAnalysis. После тестовых закупок чипа в 2024 году Microsoft не стала размещать заказы на дальнейшие поставки. Пытаясь привлечь интерес других крупных клиентов, AMD снизила цены на Instinct MI325X. После этого чипы приобрела Oracle и ещё несколько гиперскейлеров, но объёмы закупок не идут ни в какое сравнение с продажами ускорителей NVIDIA. 
Источник изображения: AMD Отсутствие интереса крупных компаний связано с ограничением MI325X в возможности масштабирования лишь до восьми ускорителей, объединённых быстрым интерконнектом, тогда как суперускоритель GB200 NVL72 размер со стойку поддерживает объединение 72 ускорителей. Когда дело касается крупномасштабных рабочих нагрузок ИИ-инференса и рассуждений на on-premise уровне, такая разница имеет решающее значение, отметил ресурс SemiAnalysis. AMD позиционировала MI325X в качестве альтернативы NVIDIA HGX B200 (NVL8) и HGX B300 (NVL16), но даже в этом сегменте NVIDIA имеет преимущество как в чистой производительности, так и в совокупной стоимости владения. Вместе с тем, у MI325X имеются перспективы для менее масштабных развёртываний, не требующих больших кластеров ускорителей, например, для инференса небольших моделей, когда требуется много памяти с большой пропускной способностью. AMD продолжает совершенствовать свою программную экосистему, с которой у неё были очень большие проблемы, и MI325X при условии конкурентоспособной цены может вызвать интерес у компаний, разрабатывающих ИИ-модели среднего размера, считают в SemiAnalysis. |
|

