Материалы по тегу: ускоритель
|
14.05.2025 [23:27], Руслан Авдеев
США отменили спорные ограничения на экспорт ИИ-ускорителей в другие страны, но запретили им покупать ускорители HuaweiВызвавшие немало споров «Правила распространения ИИ» (AI Diffusion rules), которые должны были ограничить продажу американских ускорителей уже на этой неделе, официально отменены президентом США Дональдом Трампом (Donald Trump), сообщает The Register. Министерство торговли США выполнило данное ранее обещание отменить экспортный контроль для большинства стран на том основании, что он «подавлял бы американские инновации и обременял бы компании новыми нормативными требованиями». В заявлении министерства также подчёркивалось, что новые правила подорвали бы дипломатические отношения Соединённых Штатов с десятками стран. Рамочную программу опубликовали в последние дни правления администрации Байдена — она была направлена на ограничение продаж ИИ-чипов буквально большинству стран мира, за исключением нескольких избранных союзников — в число счастливчиков не вошли даже многие страны НАТО. Предполагалось, что новые ограничения заставят «пострадавшие» страны серьёзно относиться к контролю возможного реэкспорта или контрабанды ИИ-чипов и оборудования в недружественные страны. 
Источник изображения: Greg Bulla / Unsplash Хотя некоторые приветствовали ограничения, многие американские технологические компании выступили резко против новых правил, заявив, что страны, не получив ИИ-инфраструктуру от США, смогут получить её от Китая. В администрации Трампа разрабатывают собственный подход. Политики обещают защитить национальные интересы США, но подробностей пока очень мало. Ранее Министерство торговли также выпустило документ, в котором предупредило об опасностях IaaS — многие компании закрывают глаза на то, что китайские разработчики ИИ-моделей работают со своими проектами в их облаках. Хотя покупать передовые чипы структурам из КНР давно запрещено, им никто не мешает арендовать ИИ-инфраструктуру, в том числе в США. Во вторник Бюро промышленности и безопасности (BIS) Министерства торговли США также выпустило разъяснение к Правилам экспортного контроля (EAR), в котором предупредило, что производители чипов могут подпадать под экспортные ограничения при продажах иностранным облачным провайдерам. В этих правилах уже предусмотрен запрет гражданам США, а также поставщикам облачных услуг и операторам ЦОД без разрешения и сознательно предоставлять сервисы или заключать контракты, которые будут способствовать разработке ИИ-решений недружественным странами для целей военной разведки или создания оружия. 
Источник изображения: Dario Daniel Silva / Unsplash В частности, в разъяснении указывается, что производителям также потребуется разрешение США на продажу чипов иностранным IaaS-провайдерам, если известно, что ускорители могут использоваться противниками США. Фактически поставщикам напомнили, что если таких провайдеров поймают на помощи в обучении моделей для китайских военных, за этим последует суровое наказание. Более того, США ужесточают контроль не только над новыми чипами для ИИ, но и над теми, что уже есть у иностранных компаний, если они могут быть использованы для разработки «враждебного» ИИ. Наконец, в BIS зашли настолько далеко, что ограничили использование в любой точке мира ускорителей Huawei — наиболее производительной альтернативы чипам NVIDIA в Китае, поскольку, якобы, есть высокая вероятность того, что такие чипы сделаны с использованием американских технологий, но без лицензии.
10.05.2025 [09:45], Руслан Авдеев
NVIDIA ослабит и без того урезанные ускорители H20, чтобы вернуть возможность поставок в КитайNVIDIA планирует представить искусственно ухудшенные версии ИИ-ускорителей H20 для Китая в ближайшие пару месяцев. Это позволит обойти экспортные ограничения, введённые в отношении исходной модели, сообщает Reuters со ссылкой на три источника, знакомых с вопросом. По информации двух из них, американский производитель чипов уведомил ключевых китайских покупателей, включая ведущих облачных провайдеров, что намерен представить модифицированную версию H20 в июле. Это последняя из попыток NVIDIA сохранить присутствие на китайском рынке, являющемся для компании одним из ключевых — при этом официальный Вашингтон всеми силами стремится ограничить доступ Поднебесной к передовым полупроводниковым технологиям. До недавнего времени H20 были самыми производительными ИИ-чипами, допущенными американскими властями к продаже в Китай, но в прошлом месяце компанию уведомили, что на их поставки в страну потребуется специальная экспортная лицензия, что фактически означает запрет массовых продаж. Правда, многие компании из КНР успели сделать большие запасы H20. 
Источник изображения: NVIDIA NVIDIA уже подготовила новое техническое задание на новую версию чипов. В результате H20 будут значительно ослаблены, в частности, по словам одного из источников, новинкам уменьшат ёмкость памяти. Правда, один из источников сказал, что потребители смогут перенастраивать модули для изменения производительности чипа. В самой NVIDIA новость не комментируют, как и в Министерстве торговли США. В минувшем фискальном году, закончившемся 26 января, на рынок Китая приходилось $17 млрд или 13 % общей выручки NVIDIA, а в прошлом году глава компании Дженсен Хуанг (Jensen Huang) лично засвидетельствовал важность китайского рынка, нанеся в страну визит — всего через несколько дней после того, как американские власти анонсировали новые торговые ограничения, касавшиеся поставок H20. В ходе встреч с китайскими чиновниками он подчеркнул важность рынка страны для компании. Стоит отметить, что это не первое искусственное ухудшение чипов, инициированное американскими властями. Ранее NVIDIA пришлось представить модели A800 и H800 вместо A100 и H100, а позже, в октябре 2023 года их тоже посчитали слишком производительными и появилась модель H20. На фоне роста спроса на ИИ-решения ключевые китайские IT-гиганты вроде Tencent, Alibaba и ByteDance нарастили закупки для использования эффективных ИИ-моделей компаний вроде DeepSeek. По данным Reuters, с января NVIDIA получила заказы на H20 на сумму $18 млрд. Впрочем, в марте сообщалось, что H20 не соответствуют новым китайским требованиям к энергоэффективности ИИ-ускорителей и местные бизнесы негласно вынуждают применять отечественные, китайские решения вроде Ascend 910B. Для Huawei это шанс закрепиться на рынке, компания уже готовит ускорители Ascend 910D и 920.
28.04.2025 [12:32], Сергей Карасёв
Huawei готовится к тестированию своего самого мощного ИИ-ускорителя — Ascend 910DКомпания Huawei, по сообщению газеты The Wall Street Journal, готовится к выводу на рынок своего самого производительно ИИ-ускорителя — изделия Ascend 910D. Ожидается, что новинка сможет составить конкуренцию решениям NVIDIA, которые китайские заказчики не могут приобретать в связи с американскими санкциями. Первые образцы Ascend 910D, как предполагается, будут изготовлены к концу мая. Huawei уже ведёт переговоры с рядом китайских технологических компаний по вопросу тестирования ускорителя. Испытания необходимы для оценки производительности новинки и подготовки к массовому производству. Huawei рассчитывает, что в плане быстродействия Ascend 910D сможет превзойти NVIDIA H100. В семейство Ascend 910 также входят модели 910B и 910C. Причём версия Ascend 910С позиционируется в качестве китайской альтернативы NVIDIA H100. Однако независимые тесты, проведённые сторонними специалистами, показали, что по производительности это изделие Huawei уступает продукту конкурента. 
Источник изображения: Huawei Тем не менее, некоторые заказчики уже ведут переговоры с Huawei об увеличении объёмов закупок Ascend 910C. Связано это с новыми санкциями со стороны США, которые запрещают поставлять в КНР даже специально ослабленные ускорители NVIDIA H20. Сама Huawei в текущем году намерена отгрузить более 800 тыс. изделий Ascend 910B и 910C клиентам в различных отраслях, включая государственных операторов связи и частных ИИ-разработчиков, таких как ByteDance (родительская компания TikTok). Ранее также сообщалось, что Huawei готовит ИИ-ускорители следующего поколения — 6-нм решения Ascend 920 и Ascend 920C. По имеющейся информации, Ascend 920C сможет демонстрировать BF16-производительность на уровне 900 Тфлопс против 780 Тфлопс у Ascend 910C. Новинка получит память HBM3 с пропускной способностью до 4 Тбайт/с, поддержку интерфейса PCIe 5.0 и интерконнекта с высокой пропускной способностью. Начало массового производства ожидается во II половине 2025 года.
23.04.2025 [16:15], Руслан Авдеев
GPU под роспись: Amazon резко ужесточила использование дефицитных ИИ-ускорителей внутри компании в рамках Project GreenlandВ прошлом году ретейл-бизнес Amazon столкнулся с острой нехваткой ИИ-ускорителей для внутреннего пользования. Это привело к задержкам при реализации ключевых проектов. На фоне глобального бума ИИ-технологий и дефицита чипов NVIDIA компания вынужденно пересмотрела принципы доступа к ускорителям для собственных нужд, сообщает Business Insider. В июле 2024 года началась реализация т. н. Project Greenland. Фактически речь идёт о платформе для централизованного распределения ресурсов ускорителей. Платформа позволяет отслеживать их использование, перераспределяет мощности в случае простоя и даёт возможность оперативно реагировать на изменения спроса. Теперь все заявки на доступ к ускорителям подаются только через Greenland, а приоритет получают проекты с высоким уровнем возврата инвестиций (ROI), чётким графиком и заметным влиянием на снижение затрат или рост выручки. У проектов с низкой эффективностью доступ к вычислительным мощностям могут вообще отозвать в пользу более перспективных инициатив. Amazon выделила восемь принципов распределения ускорителей среди сотрудников компании:

Источник изображения: Centre for Ageing Better/unsplash.com Amazon уже активно использует искусственный интеллект в различных проектах. В числе ключевых инициатив:
По оценкам Amazon, ИИ-проекты розничного подразделения в 2024 году принесли $2,5 млрд операционной прибыли, попутно сэкономив $670 млн. В 2025 году ретейл-подразделение Amazon намерено вложить $1 млрд в ИИ-проекты розничного сегмента и увеличить расходы на облако AWS до $5,7 млрд (с $4,5 млрд в 2024 году). Если во II полугодии 2024 года розница Amazon нуждалась в более 1 тыс. дополнительных инстансов P5 с NVIDIA H100, то в 2025 году ситуация, как свидетельствуют внутренние прогнозы, должна стабилизироваться. А к концу года внутренние запросы полностью удовлетворят с помощью чипов собственной разработки Amazon Tranium, «но не раньше». Тем не менее, в Amazon не теряют бдительности, постоянно задаваясь вопросом: «Как получить больше ускорителей?».
22.04.2025 [13:10], Сергей Карасёв
Huawei готовит 6-нм ИИ-ускоритель Ascend 920 с производительностью 900 ТфлопсКомпания Huawei, по сообщениям сетевых источников, готовит ускорители Ascend 920 и Ascend 920C для ИИ-задач. Эти изделия, как ожидается, станут альтернативой картам NVIDIA H20, поставки которых в Китай оказались под запретом в связи с новыми санкциями со стороны США. По имеющейся информации, при производстве изделий семейства Ascend 920 будет применяться 6-нм технология китайской компании SMIC. Ускорители будут оснащаться памятью HBM3 с пропускной способностью до 4 Тбайт/с. Для сравнения: память HBM2E в составе решений Ascend 910C обеспечивает скорость до 3,2 Тбайт/с. По имеющейся информации, модель Ascend 920C, ориентированная на обучение ИИ-моделей, сможет демонстрировать BF16-производительность на уровне 900 Тфлопс. У Ascend 910C быстродействие достигает 780 Тфлопс. В целом, как утверждается, общая эффективность ИИ-обучения у Ascend 920C улучшится на 30–40 % по сравнению с предшественником. Новые ускорители получат поддержку интерфейса PCIe 5.0 и интерконнекта с высокой пропускной способностью следующего поколения. Говорится об использовании архитектуры на основе чиплетов. Реализуемые улучшения призваны сократить разницу в производительности на ватт затрачиваемой энергии по сравнению с решениями конкурентов. Массовое производство ускорителей серии Ascend 920 запланировано на II половину 2025 года. 
Источник изображения: Huawei Сетевые источники отмечают, что возможности Huawei по выпуску Ascend 920 будут отчасти зависеть от того, сможет ли компания получить доступ к высококачественной памяти HBM в нужных объёмах. Ранее сообщалось, что на китайском рынке ИИ-ускорителей, предназначенных для обучения моделей, доминирует NVIDIA. Вместе с тем Huawei со своими изделиями Ascend рассчитывает укрепить позиции в области инференса.
17.04.2025 [13:31], Руслан Авдеев
Сначала NVIDIA, потом AMD: США не позволили продать в Китай ускорители Instinct на $800 млнNVIDIA оказалась не единственным разработчиком чипов, который пострадает от новых торговых санкций, введённых в отношении Китая администрацией США. В минувшую среду AMD заявила, что ожидает «списания» $800 млн — около 16 % выручки серии Instinct за 2024 финансовый год, сообщает The Register. Причина — ограничения на экспорт, введённые США, которые блокируют поставки её ИИ-ускорителей Instinct MI308 в Китай и другие страны, вызывающие «обеспокоенность». Как и в случае с NVIDIA, велика вероятность, что американские власти могут пересмотреть запреты, рассматривая партии поставок в индивидуальном порядке и выдавая экспортные лицензии для MI308 в Китай. При этом AMD отмечает в документе, поданном в Комиссию по ценным бумагам и биржам (SEC), что подать заявки на лицензии компания намерена, но нет никаких гарантий, что они будут одобрены в итоге. Пока же AMD в том же положении, что и NVIDIA, не успевшая распродать запасы ослабленных ускорителей H20 и теперь ожидающая изменения ситуации со складами, полными их запасов. Хотя потенциальные убытки AMD выглядят весьма скромно в сравнении с $5,5 млрд, которые потеряет NVIDIA в результате запрета продаж H20 в Китай и некоторые другие страны без специального разрешения, для AMD в этом приятного всё равно мало. Бизнес рос хорошими темпами со времени дебюта ускорителей MI300X в конце 2023 года. 
Источник изображения: AMD Ранее AMD заявляла, что производительность MI300X до 32 % выше в сравнении с NVIDIA H100 в некоторых задачах. Как и NVIDIA, AMD рассчитывала разработать собственную версию ослабленного ускорителя для китайского рынка по аналогии c A800 и H800, а позже H20. Речь шла именно о серии MI308 — правда, о ней практически ничего не известно. Год назад говорилось, что некие урезанные версии Instinct MI309 оказались недостаточно слабы для экспорта в Китай. По-видимому, AMD в MI308 пришлось ещё сильнее снизить производительность и пропускную способность интерфейсов. Хотя возможности NVIDIA и AMD вести дела с Китаем будут серьёзно ограничены в обозримом будущем, компании, возможно, снова смогут доработать существующие модели, дополнительно снизив производительность для обхода ограничений, введённых Министерством торговли США. Intel также готовила отдельную серию ИИ-ускорителей Habana Gaudi3 — к обычным HL-325L, HL-335 и HL-338 были добавлены урезанные HL-328 и HL-388. Впрочем, продажами Habana компания и так не может похвастаться. Также не исключено, что AMD начнёт продвигать MI308 в качестве ускорителя для инференса в странах, куда продавать их по американским законам всё ещё можно. Это позволит хотя бы вернуть часть инвестиций. Нечто подобное произошло с NVIDIA A800. В Китай они не попали, но NVIDIA смогла продать их HP для установки в рабочии станции. Заинтересованность в A800 и H800 также выражала Индия, на которую на тот момент ограничения в основном не распространялись.
17.04.2025 [00:10], Владимир Мироненко
Суперускоритель Huawei CloudMatrix 384 оказалася быстрее NVIDIA GB200 NVL72, но значительно прожорливееHuawei анонсировала на конференции Huawei Cloud Ecosystem Conference 2025 собственный суперускоритель CloudMatrix 384, который позиционируется в качестве отечественной альтернативы системы NVIDIA GB200 NVL72. Решение Huawei отличается более высокой общей производительностью — 300 Пфлопс против 180 Пфлопс. Но в то же время оно уступает решению NVIDIA по производительности на чип и имеет значительно более высокое энергопотребление, пишет SemiAnalysis. Система Huawei CloudMatrix 384 использует 384 ускорителя Huawei Ascend 910C, в то время как в GB200 NVL72 задействовано 36 процессоров Grace в сочетании с 72 ускорителями B200 (Blackwell). То есть, чтобы вдвое превзойти по производительности GB200 NVL72, потребовалось примерно в пять раз больше ускорителей Ascend 910C, что не очень хорошо с точки зрения использования самих ускорителей, но отлично на уровне развёртывания системы, отметил ресурс SemiAnalysis. Как утверждает SemiAnalysis, Huawei отстает от NVIDIA на поколение по производительности чипов, но опережает в проектировании и развёртывании масштабируемых систем. 
Источник изображения: TechPowerUp Если сравнивать отдельные ускорители, то NVIDIA GB200 явно превосходит Huawei Ascend 910C, обеспечивая более чем в три раза большую производительность в вычислениях в формате BF16 (2500 против 780 Тфлопс) и больший HBM на чипе (192 против 128 Гбайт) с более высокой пропускной способностью памяти (ПСП, 8 против 3,2 Тбайт/с). Другими словами, у NVIDIA есть преимущество в чистой мощности и на уровне чипа. Но на уровне системы эффективность CloudMatrix CM384 выходит вперёд. Он выдаёт в 1,7 раза больше Пфлопс, имеет в 3,6 раз больше HBM, обеспечивает в 2,1 раза большую ПСП и объединяет более чем в пять раз больше ускорителей, чем GB200 NVL72. Однако эта масштабируемость имеет обратную сторону, поскольку система Huawei потребляет почти в четыре раза больше энергии — 145 кВт против ~560 кВт. Для Huawei CloudMatrix 384 требуется в 3,9 раза больше энергии, чем для GB200 NVL72: в 2,3 раза больше энергии на 1 флопс, в 1,8 раза — на 1 Тбайт/с ПСП и в 1,1 раза — на 1 Тбайт HBM. SCMP со ссылкой на данные самой Huawei сообщает, что CloudMatrix CM384 показал производительность на уровне 800 Пфлопс в BF16-вычислениях без разреженности или 1920 токенов/с на модели DeepSeek-R1. Суперускоритель размещается в 16 стойках, из которых четыре отведено только под интерконнект — всего 6912 400G-порта. Остальные стойки содержат по 32 ускорителя Ascend 910C в четырёх узлах (8×4) и ToR-коммутатор. Как отметил SemiAnalysis, было бы заблуждением говорить, что Ascend 910C и CloudMatrix 384 производятся в Китае: HBM в них от Samsung, пластины от TSMC, а само оборудование из США, Нидерландов и Японии. Хотя у китайской SMIC уже есть 7-нм техпроцесс, подавляющее большинство Ascend 910B/910C было втайне сделано по 7-нм технологии TSMC. Предполагается, что Huawei смогла обойти санкции США, заказав чипы на $500 млн при посредничестве Sophgo. Сама TSMC прекратила поставки Huawei в 2020 году.
16.04.2025 [12:26], Руслан Авдеев
США запретили продавать Китаю даже ослабленные ускорители NVIDIA H20Очередным шагом в американо-китайской торговой войне стало введение администрацией Дональда Трампа (Donald Trump) запрета на поставки в КНР специально ослабленных ускорителей NVIDIA H20. По последним данным, это может стоить NVIDIA $5,5 млрд, сообщает The Register. Деталей пока немного, но уже известно, что новые экспортные ограничения предусматривают ограничение поставок H20 не только в материковый Китай, но и Гонконг, а также другие регионы, вызывающие сомнения у американских властей. Возможность продаж не закрыта полностью — но для этого потребуется получить специальную экспортную лицензию. NVIDIA узнала об этом 9 апреля, а позже ей сообщили, что требование о получении экспортной лицензии останется в силе «на неопределённый период времени». Согласно данным, поданным американскому регулятору — Комиссии по ценным бумагам и биржам (SEC), контроль должен предотвратить использование чипов Китаем в своих суперкомпьютерах. NVIDIA сообщила SEC, что ожидает убытков до $5,5 млрд в I квартале финансового года из-за затрат, связанных с H20, в т.ч. со списанием запасов, обязательствами по закупкам и связанными резервами. Другими словами, у NVIDIA, похоже, останется огромная партия ускорителей H20, которые она не успела продать в Китай, а теперь они будут занимать место на складах, пока Трамп не решит, стоит ли намерение NVIDIA инвестировать в производство ИИ-решений на территории США разрешения на поставки H20 в Китай. С учётом того, что глава NVIDIA встречался с Дональдом Трампом ранее в этом месяце, вероятно, он не рассчитывал на столь суровые встречные меры. По слухам, именно после совместного обеда администрация Трампа «поставила на паузу» планы по ужесточению экспортного контроля относительно ускорителей H20. Источник изображения: NVIDIA С учётом того, что NVIDIA совсем недавно выразила готовность расширять производство на территории США наряду с TSMC, Wistron, Foxconn и другими компаниями, вполне возможно, со временем Белый дом всё-таки разрешит поставки H20 в Китай, хотя бы в некоторых объёмах. США уже не впервые ограничивают поставки ускорителей NVIDIA в Китай. С конца 2022 года администрация Байдена вводила ограничения на всё новые типы ускорителей, и каждый раз NVIDIA ослабляла свои решения специально для китайского рынка для того, чтобы те соответствовали техническим требованиям для свободного экспорта. Теперь, как сообщают в SEC, этот порог поднят до такой степени, что под запрет попали как H20 (и без того в разы более слабые в сравнении с современными решениями), но и другие ускорители с аналогичными характеристиками. После новостей о запрете акции NVIDIA упали более, чем на 6 %. Удар для Китая может оказаться болезненным. В конце февраля триумф ИИ-моделей DeepSeek подстегнул спрос на ускорители H20 в Китае, а чуть более недели назад сообщалось, что NVIDIA может переключиться на выполнение заказов только из Китая в преддверии усиления санкций США.
11.04.2025 [11:00], Сергей Карасёв
NTT представила ИИ-чип для обработки видео на периферииКомпания NTT объявила о создании ИИ-чипа, предназначенного для задач инференса на периферии. Изделие может применяться для обработки видео высокой чёткости, в том числе в формате 4K, в реальном времени на устройствах со строгими ограничениями по мощности. В качестве сфер применения новинки NTT выделяет беспилотные летательные аппараты и камеры видеонаблюдения. Например, благодаря представленному чипу дроны могут использоваться для обнаружения прохожих и объектов, таких как автомобили, с высоты до 150 м. Для повышения эффективности инференса при одновременном снижении энергопотребления задействованы специальные алгоритмы. Входное изображение высокого разрешения сегментируется на фрагменты, после чего производится независимая обработка каждого из них. Это позволяет обнаруживать объекты небольшого размера. 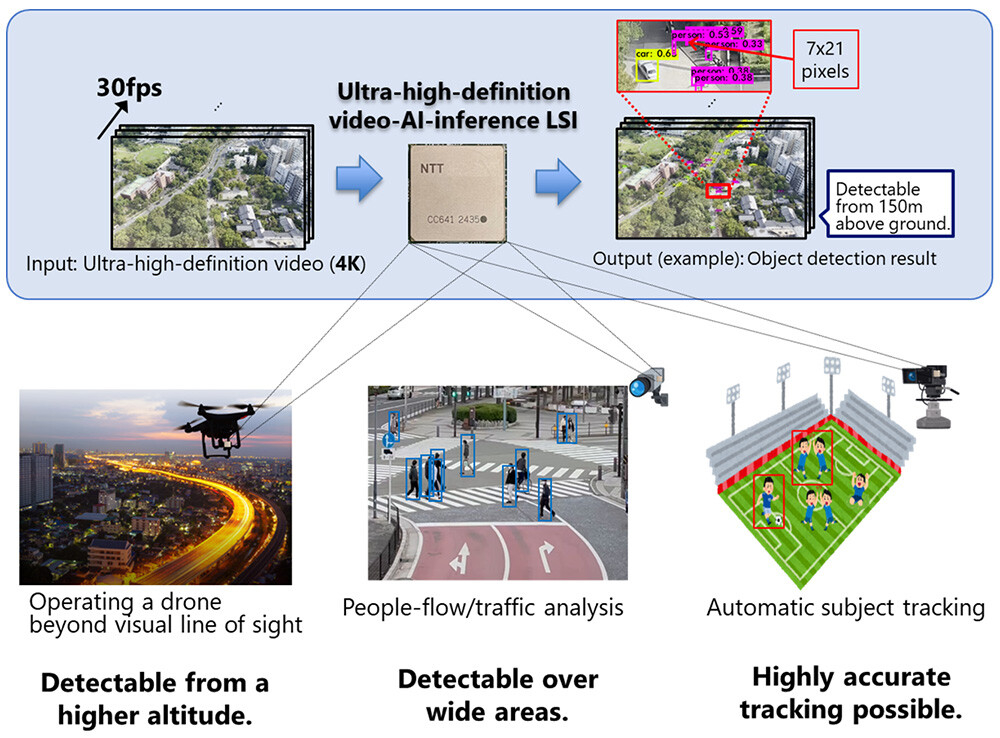
Источник изображений: NTT Параллельно с этим выполняется анализ целого изображения в сжатом виде для обнаружения крупных объектов. После этого полученные результаты объединяются: таким образом, могут быть идентифицированы как небольшие, так и крупные детали. При этом все операции могут выполняться независимо друг от друга, что обеспечивает высокую эффективность. 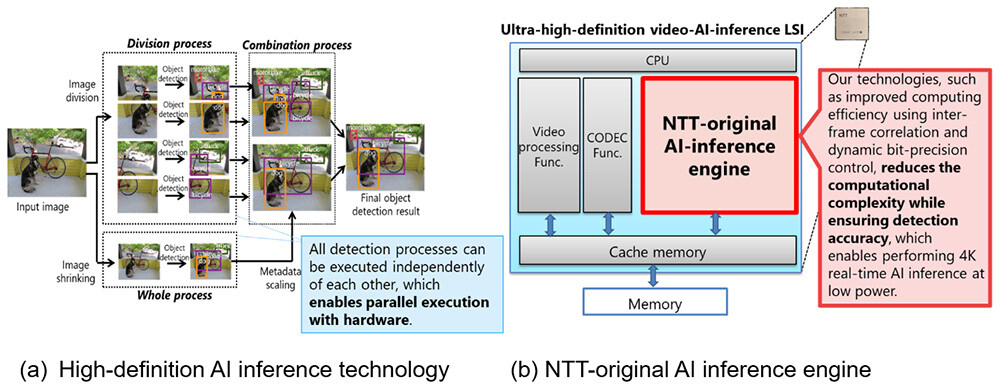 По заявлениям NTT, в случае нового изделия обнаружение объектов в реальном времени при разрешении 4K (30 к/с) возможно с тем же или более низким энергопотреблением (менее 20 Вт), что и при выполнении задачи с пониженным разрешением — 608 × 608 пикселей. Повышение эффективности вычислений достигается с помощью межкадровой корреляции и динамического управления точностью вычислений. Это позволяет добиться ИИ-инференса в реальном времени при низкой затрачиваемой мощности. На коммерческий рынок изделие планируется вывести в течение 2025 года через операционную компанию NTT Innovative Devices Corporation. Отмечается также, что NTT продолжат разработку дополнительных технологий, связанных с новым чипом.
10.04.2025 [09:14], Владимир Мироненко
ZeroPoint Technologies и Rebellions займутся разработкой ИИ-ускорителей со «сжимаемой» памятьюШведская компания ZeroPoint Technologies, специализирующаяся на создании решений для оптимизации памяти, объявила о стратегическом альянсе с южнокорейским разработчиком ИИ-чипов Rebellions с целью разработки ИИ-ускорителей для инференс. Компании планируют представить новые продукты в 2026 году, обещая «беспрецедентную производительность в пересчёте на токены в секунду на Вт (TPS/W)», пишет EE Times. Компании планируют увеличить эффективную пропускную способность и ёмкость памяти для нагрузок инференса, используя технологии сжатия, уплотнения и управления памятью от ZeroPoint Technologies. По словам генерального директора ZeroPoint Technologies Класа Моро (Klas Moreau), аппаратная оптимизация работы с памятью на уровне ЦОД позволит увеличить адресуемую ёмкость с ускорением работы почти в 1000 раз по сравнению с использованием программного сжатия. Компании планируют улучшить показатели токенов в секунду на Вт без ущерба для точности, используя сжатие модели без потерь для уменьшения её размера и сокращения использования энергии, необходимой для перемещения компонентов модели. Гендиректор Rebellions Сонхён Пак (Sunghyun Park) указал, что партнёрство позволит компаниям переопределить возможности инференса, предоставляя более умную, экономичную и устойчивую ИИ-инфраструктуру. 
Источник изображения: ZeroPoint Technologies Моро ранее заявил, что более 70 % данных, хранящихся в памяти, являются избыточными, что позволяет полностью избавиться от них, добившись сжатия без потерь полезной информации. Такая технология сжатия должна выполнять ряд специфических действий в пределах наносекунды, т.е. всего нескольких тактов: «Во-первых, она должна отрабатывать сжатие и распаковку. Во-вторых, она должна уплотнять полученные данные, собирая небольшие фрагменты в единичную линию кеша, чтобы значительно улучшить видимую пропускную способность памяти, и, наконец, она должна бесперебойно управлять данными, отслеживая все фрагменты. Чтобы минимизировать задержку, такой подход должен работать с гранулярностью линий кеша — сжимая, уплотняя и управляя данными в 64-байт фрагментах — в отличие от гораздо больших блоков 4–128 Кбайт, используемых традиционными методами сжатия вроде ZSTD и LZ4». По словам Моро, благодаря этой технологии, для базовых рабочих нагрузок в ЦОД гиперскейлера адресуемая ёмкость памяти и пропускная способность могут быть увеличены в два-четыре раза, производительность на Вт может увеличиться на 50 %, а совокупная стоимость владения (TCO) может быть значительно снижена. А для специализированных нагрузок, таких как большие языковые модели (LLM), интеграция программного сжатия в сочетании с встроенной аппаратной декомпрессией (что минимизирует любую дополнительную задержку) уже продемонстрировала прирост примерно на 50 % в адресуемой ёмкости памяти, пропускной способности и токенах в секунду. Моро утверждает, что грядущая интеграция аппаратной (де-)компрессии обещает ещё более существенные улучшения. Например, для базовых ИИ-нагрузок кластер со 100 Гбайт физической памяти благодаря использованию этой технологии будет функционировать так, как если бы у него было 150 Гбайт памяти. «Это не только представляет собой миллиарды долларов потенциальной экономии, но и может повысить производительность сложных ИИ-моделей», — заявил Моро. «Эти достижения обеспечивают надёжную основу для компаний, производящих чипы ИИ, позволяя бросить вызов доминированию таких гигантов отрасли, как NVIDIA», — добавил он. |
|

