Материалы по тегу: сети
|
10.01.2023 [17:11], Сергей Карасёв
Microsoft подтвердила поглощение DPU-разработчика Fungible, но сумму сделки так и не назвалаКорпорация Microsoft официально объявила о заключении соглашения по покупке компании Fungible — молодого разработчика DPU (Data Processing Unit). О сумме сделки ничего не сообщается. Слухи о том, что редмондский гигант проявляет интерес к Fungible, появились в середине декабря 2022 года. Тогда говорилось, что приобретение стартапа обойдётся Microsoft приблизительно в $190 млн. Решения Fungible помогут Microsoft поднять производительность её дата-центров. По условиям соглашения, команда Fungible присоединится к подразделению разработки ЦОД-инфраструктур Microsoft. Специалисты компании сосредоточатся на создании нескольких специализированных DPU, а также на сетевых инновациях и улучшении аппаратных систем. «Технологии Fungible помогают создать высокопроизводительную, масштабируемую, дезагрегированную, горизонтально масштабируемую инфраструктуру ЦОД с высокими показателями надёжности и безопасности», — говорится в заявлении Microsoft. 
Источник изображения: Fungible Добавим, что Fungible была основана в 2015 году выходцами из Xerox PARC Прадипом Синдху (Pradeep Sindhu, сооснователь и бывший глава Juniper Networks) и Бертраном Серле (Bertrand Serlet, работал в Apple и Parallels, основал Upthere). Стартап привлёк более $300 млн инвестиций, но в последнее время дела у него шли не слишком хорошо. По слухам, после неудачной попытки продать компанию Meta✴ стартап был вынужден уволить часть сотрудников и сократить портфолио решений. Fungible, как и ряд аналогичных проектов, по мере развития перешёл от создания сверхбыстрых хранилищ к идее переноса на DPU иных инфраструктурных задач по примеру AWS Nitro (собственная разработка Amazon). Однако, как утверждают некоторые источники, сложность разработки ПО негативно сказалась на популярности решений Fungible. Например, Google пошла по другому пути и заручилась поддержкой Intel.
14.12.2022 [15:31], Сергей Карасёв
Microsoft купила разработчика необычного оптоволокна LumenisityКорпорация Microsoft объявила о заключении соглашения о покупке компании Lumenisity, базирующейся в Великобритании. Этот стартап, основанный в 2017 году, специализируется на разработке решений для высокоскоростной передачи данных с применением технологии полого оптоволокна HCF (Hollow Core Fiber). Компания Lumenisity создана как дочерняя структура Исследовательского центра оптоэлектроники (ORC) Саутгемптонского университета. Конструкцией HCF предусмотрено наличие заполненного воздухом канала, окружённого кольцом стеклянных трубок, похожим на соты. Свет проходит не через обычное волокно, а через воздушный канал, так что, по словам Lumenisity, он распространяется по HCF-кабелям примерно на 47 % быстрее, чем через волокно из кварцевого стекла. Хотя это и не новая технология, интерес к ней растёт по мере улучшения пропускной способности и надёжности. 
Источник изображения: Microsoft Такая конструкция позволяет не только повысить скорость передачи данных и снизить задержки, но и открывает путь к созданию протяжённых ВОЛС без использования репитеров благодаря более низким потерям энергии. Кроме того, Lumenisity говорит, что её решение дешевле аналогов и лучше защищено от вторжений. Microsoft заявляет, что приобретение Lumenisity расширит возможности по дальнейшей оптимизации глобальной облачной инфраструктуры Azure. Lumenisity привлекла на развитие в общей сложности около $15,5 млн, а недавно открыла производственное предприятие HCF в Ромси, Великобритания. Финансовые условия сделки не раскрываются. Важно отметить, что волокно Lumenisity не требует для развёртывания специального оборудования и работает со многими оптическими системами, которые сегодня используются в телекоммуникационных сетях. По всей видимости, Microsoft будет применять технологию Lumenisity для объединения своих ЦОД. Также Microsoft по неподтверждённым пока официально данным приобрела Fungible, разработчика DPU. Компания, судя по всему, намерена задействовать эти DPU только для собственных нужд.
25.11.2022 [16:33], Алексей Степин
Meta✴ переходит на использование протокола синхронизации времени PTPВ отличие от широко известного протокола сетевой координации времени NTP, разработанный изначально для локальных сетей, PTP (Precision Time Protocol, IEEE 1588) способен обеспечивать точность синхронизации в пределах десятков наносекунд, тогда как у NTP это значение находится в диапазоне единиц или десятков миллисекунд. С точки зрения владельцев крупных ЦОД возможность повысить точность синхронизации может представлять существенный интерес, поскольку позволяет точнее привести серверы к единому времени. И такой возможностью заинтересовалась компания Meta✴, которая в течение некоторого времени тестировала PTP локально, а в настоящее время заявила о переводе всех серверов на новый стандарт синхронизации. 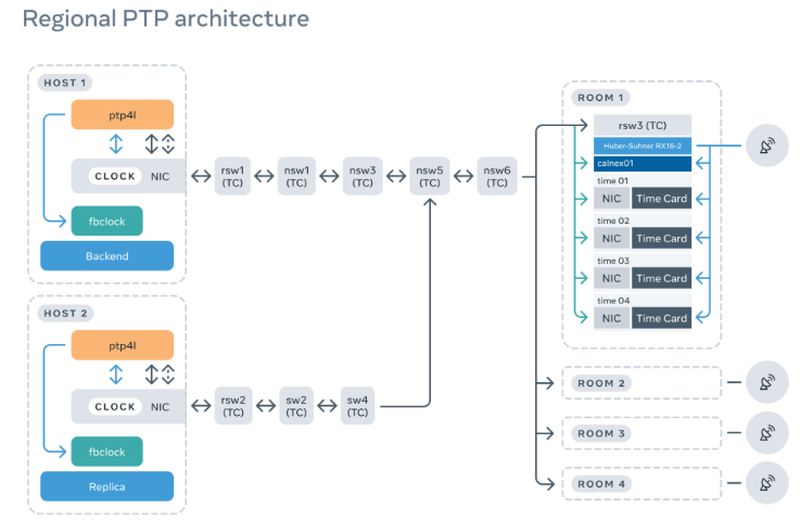 Поскольку масштабы сети серверов Meta✴ действительно велики, влияние неточностей при использовании NTP может накапливаться и приводить к задержкам, сбоям или даже сетевым отказам. Тем более сверхточная синхронизация важна для проекта метавселенной, в котором огромная виртуальная вселенная должна функционировать как единое целое. Однако внедрение PTP требует поддержки со стороны не только программного, но и аппаратного обеспечения, поэтому компания разработала в рамках OCP систему Open Time Server, в основе которой лежит плата точного времени Facebook✴ Time Card с приёмником сигналов GNSS. Требований со стороны сервера немного: использование сетевых интерфейсов с поддержкой PPS и Hardware Timestamps и процессоров с VT-d. 
Facebook✴ Time Card Программная часть состоит из ОС Linux с драйвером ocp_ptp и демонов Chrony/NTPd и ptp4u/ptp4l, работающих с устройствами dev/ptpX карты времени и сетевого адаптера. В официальном репозитории Open Time Server приведена подробная информация на этот счёт. На уровне ЦОД это означает появление выделенных стоек PTP, оснащённых соответствующим оборудованием. Подчёркивается также важность наличия качественной антенны для приёма GNSS-сигналов, гарантирующей точность позиционирования менее 10 м — лишь при такой точности можно вести речь о наносекундном уровне синхронизации. Каждая стойка PTP также содержит устройство Calnex Sentinel 2.0, ответственное за мониторинг состояния системы: расхождение между Time Card и сетевым адаптером должно укладываться в окно размером не более 50 нс.
07.10.2022 [19:02], Руслан Авдеев
Google запустила оптоволоконный подводный кабель Grace Hopper — между США и Европой появился канал на 350 Тбит/сКомпания Google ввела в эксплуатацию новый подводный оптоволоконный кабель Grace Hopper, который обеспечивает соединение сетевой инфраструктуры США, Великобритании, а также Испании. Как сообщает DataCenter Dynamics, кабель проложен от Нью-Йорка до британского города Бьюд в графстве Корнуолл, а ответвление также идёт в испанский Бильбао. Grace Hopper, названный в честь американской учёной и контр-адмирала Грейс Брюйстер Мюррей Хоппер (Grace Brewster Murray Hopper), состоит из 16 оптоволоконных пар и обеспечивает пропускную способность 350 Тбит/с по основной магистрали протяжённостью 6354 км. Как сообщают средства массовой информации, новый кабель начал работать 27 сентября, о чём Google уже оповестила Федеральную комиссию связи США (FCC). Это первый подводный кабель, построенный для связи США и Великобритании с 2003 года, дополнительно имеется ответвление в испанский Бильбао для обеспечения связи с облачным регионом в Мадриде. 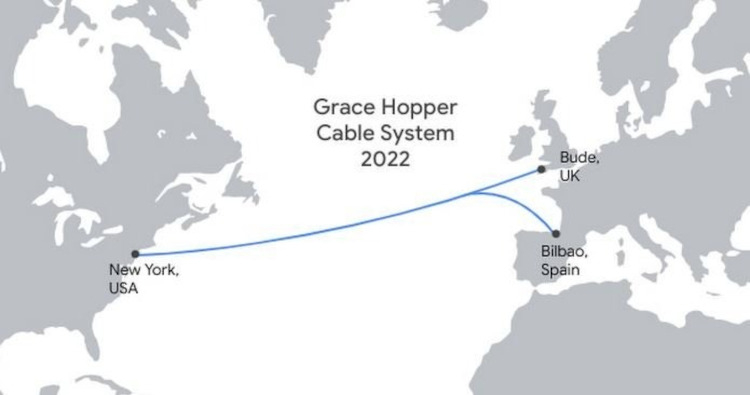
Источник изображения: Google В реализации проекта участвовала Lumen Technologies, помимо инвестиций ответственная за наземные узлы связи на обоих концах кабеля и наземную инфраструктуру. Для обеспечения оптимального качества связи при сбоях различной природы кабель Grace Hopper использует оптоволоконную коммутацию. Предусмотрена связь и с другими кабелями Google. 10 сентября прошлого года выход кабеля на сушу обеспечен в Испании, 14 сентября 2021 года — в Корнуолле.
06.09.2022 [16:16], Руслан Авдеев
Google ввела в эксплуатацию 150-Тбит/с подводный кабель Equiano длиной 15 тыс. км и стоимостью $1 млрдКомпания Google помогла повысить качество связи между Западной Европой и Южной Африкой, введя в эксплуатацию 150-Тбит/с подводный интернет-кабель Equiano стоимостью $1 млрд. Как сообщает Datacenter Dynamics, кабель назван в честь рождённого в Нигерии писателя Олауда Эквиано (Olaudah Equiano). Протяжённость кабеля, проложенного из Португалии в Южную Африку, составляет 15 тыс. км, он имеет 9 ответвлений и состоит из 12 оптоволоконных пар с поддержкой SDM (Space Division Multiplexing). Месяц назад завершилось приземление кабеля в окрестностях Кейптауна, а на прошлой неделе Google провела церемонию открытия. В Google утверждают, что его эксплуатация позволит создать 1,6 млн рабочих мест, а цена передачи данных в регионе должна упасть на 16-21 %. Проект, изначально анонсированный в 2019 году, является одним из крупнейших в портфолио подводных интернет-кабелей Google — он проложен от Португалии вдоль западного побережья африканского континента. 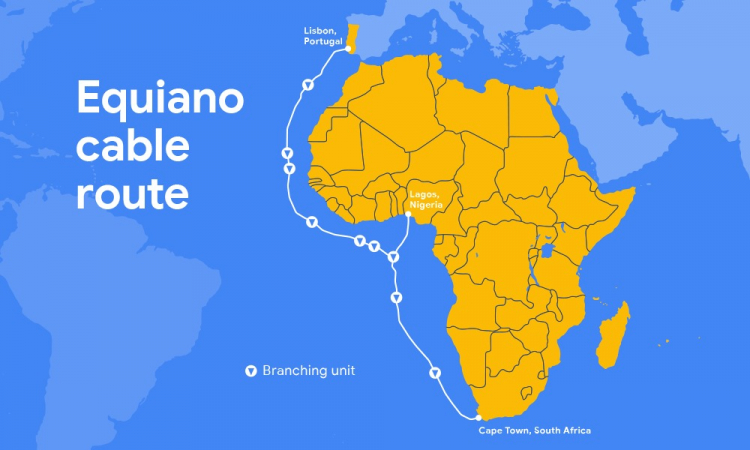
Источник изображения: Google Это один из шести кабелей, принадлежащих Google из числа уже действующих и находящихся в разработке, и девятнадцатый по счёту из тех, в создание которых Google инвестировала. В точках ответвлений к кабелю получили возможность подключиться и другие страны, включая Намибию и Того. Также планируется подключение Нигерии, Демократической республики Конго и островов Св. Елены. Весной сообщалось, что Google также намерена проложить подводный транстихоокеанский интернет-кабель Topaz от канадского Ванкувера до Миэ и Ибараки в Японии.
26.08.2022 [12:45], Алексей Степин
Интерконнект NVIDIA NVLink 4 открывает новые горизонты для ИИ и HPCПотребность в действительно быстром интерконнекте для ускорителей возникла давно, поскольку имеющиеся шины зачастую становились узким местом, не позволяя «прокормить» данными вычислительные блоки. Ответом NVIDIA на эту проблему стало создание шины NVLink — и компания продолжает активно развивать данную технологию. На конференции Hot Chips 34 было продемонстрировано уже четвёртое поколение, наряду с новым поколением коммутаторов NVSwitch. 
Изображения: NVIDIA Возможность использования коммутаторов для NVLink появилась не сразу, изначально использовалось соединение блоков ускорителей по схеме «точка-точка». Но дальнейшее наращивание числа ускорителей по этой схеме стало невозможным, и тогда NVIDIA разработала коммутаторы NVSwitch. Они появились вместе с V100 и предлагали до 50 Гбайт/с на порт. Нынешнее же, третье поколение NVSwitch и четвёртое поколение NVLink сделали важный шаг вперёд — теперь они позволяют вынести NVLink-подключения за пределы узла. 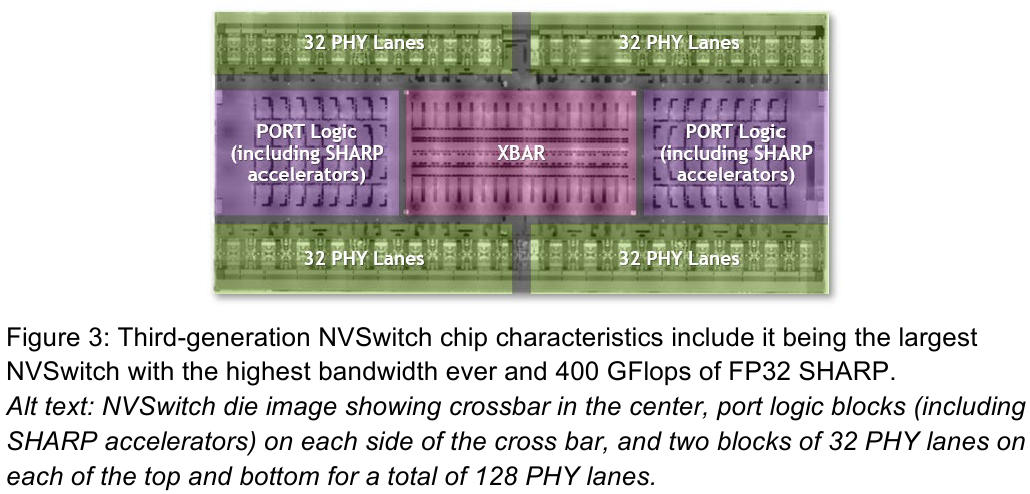 Так, совокупная пропускная способность одного чипа NVSwitch теперь составляет 3,2 Тбайт/с в обе стороны в 64 портах NVLink 4 (x2). Это, конечно, отразилось и на сложности самого «кремния»: 25,1 млрд транзисторов (больше чем у V100), техпроцесс TSMC 4N и площадь 294мм2. Скорость одной линии NVLink 4 осталась равной 50 Гбайт/с, но новые ускорители H100 имеют по 18 линий NVLink, что даёт впечатляющие 900 Гбайт/с. В DGX H100 есть сразу четыре NVSwitch-коммутатора, которые объединяют восемь ускорителей по схеме каждый-с-каждым и дополнительно отдают ещё 72 NVLink-линии (3,6 Тбайт/с). 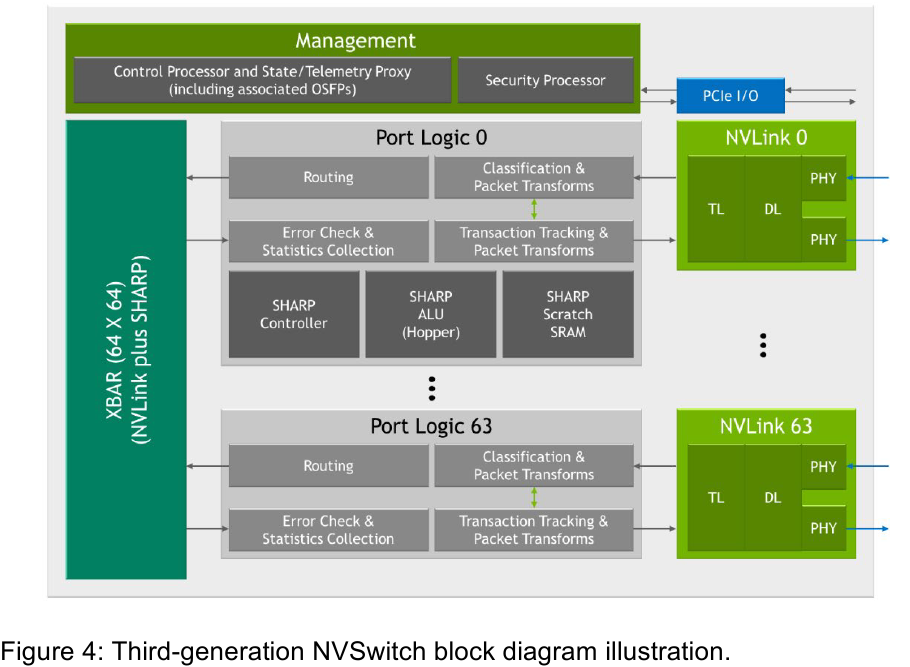 При этом у DGX H100 сохраняются прежние 400G-адаптеры Ethernet/InfiniBand (ConnectX-7), по одному на каждый ускоритель, и пара DPU BlueField-3, тоже класса 400G. Несколько упрощает физическую инфраструктуру то, что для внешних NVLink-подключений используются OSFP-модули, каждый из которых обслуживает 4 линии NVLink. Любопытно, что электрически интерфейсы совместимы с имеющейся 400G-экосистемой (оптической и медной), но вот прошивки для модулей нужны будут кастомные. 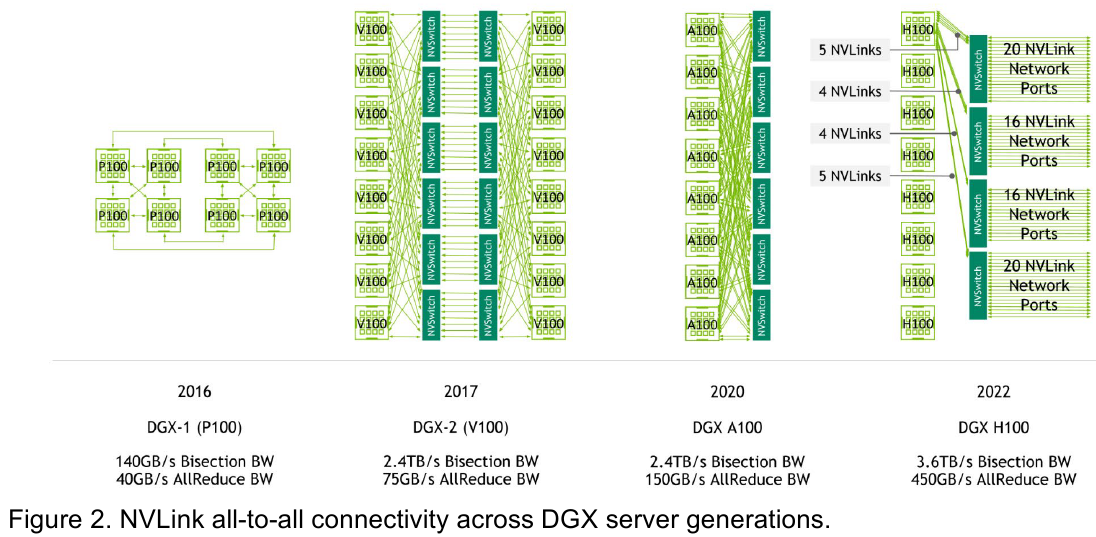 Подключаются узлы DGX H100 к 1U-коммутатору NVLink Switch, включающему два чипа NVSwitch третьего поколения: 32 OSFP-корзины, 128 портов NVLink 4 и агрегированная пропускная способность 6,4 Тбайт/с. В составе DGX SuperPOD есть 18 коммутаторов NVLink Switch и 256 ускорителей H100 (32 узла DGX). Таким образом, можно связать ускорители и узлы 900-Гбайт/с каналом. Как конкретно, остаётся на усмотрение пользователя, но сама NVLink-сеть поддерживает динамическую реконфигурацию на лету. 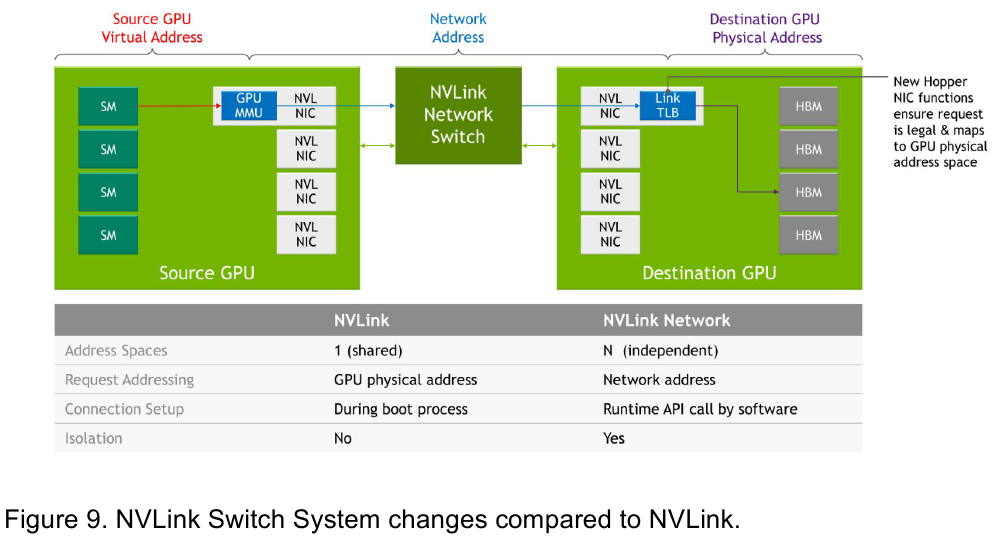 Ещё одна особенность нового поколения NVLink — продвинутые аппаратные SHARP-движки, которые избавляют CPU/GPU от части работ по подготовке и предобработки данных и избавляющие саму сеть от ненужных передач. Кроме того, в NVLink-сети реализованы разделение и изоляция, брандмауэр, шифрование, глубокая телеметрия и т.д. В целом, новое поколение NVLink получило полуторакратный прирост в скорости обмена данными, а в отношении дополнительных сетевых функций он стал трёхкратным. Всё это позволит освоить новые класса HPC- и ИИ-нагрузок, однако надо полагать, что удовольствие это будет недешёвым.
17.08.2022 [00:28], Алексей Степин
Broadcom представила 5-нм ASIC Tomahawk 5 с производительностью 51,2 Тбит/сРастущие объемы сетевого трафика, широкое распространение медиа-сервисов и видеоконференций, новые облачные услуги — всё это требует и нового сетевого «железа», способного справляться с повышающейся нагрузкой. И если не так давно для ASIC высшего класса нормой стал считаться показатель 25,6 Тбит/с, то сейчас вендоры осваивают следующий уровень производительности. Первенство в этой гонке принадлежит NVIDIA с её чипами Spectrum-4, но сейчас в игру вступила Broadcom. Компания представила пятое поколение «сетевого кремния» в серии StrataXGS Tomahawk, тоже способное осуществлять коммутацию на скоростях до 51,2 Тбит/с — 5-нм чип Tomahawk 5 (BCM78900). Появление ASIC такого класса существенно облегчает жизнь разработчикам HPС-систем для задач машинного обучения, поскольку позволит объединить в единый комплекс больше узлов без «наценки» на латентность в конфигурациях 64х800GbE, 128х400GbE или 256х100GbE. Поддерживается RoCEv2 и другие протоколы RDMA, виртуализация и сегментация сетей, VxLAN и прочие современные технологии. 
Источник: Broadcom Несколько ограничивают возможности новинки SerDes-блоки Peregrine (PAM4/106 Гбит/с). Каждые 8 таких блоков собраны в трансиверное ядро, всего ядер в новом чипе 64, что ограничивает эффективную производительность на порт именно цифрой 800 Гбит/с. Достоинством Tomahawk 5 станет его экономичность: использование 5-нм техпроцесса позволило довести удельное энергопотребление до цифры менее 1 Вт на 100 Гбит/с, то есть речь идёт о потреблении в районе 500 Вт для полной конфигурации. Цифра немалая, но всё же позволяющая сохранить воздушное охлаждение. Кроме того, новый ASIC снабжён шестью Arm-блоками для настраиваемой потоковой телеметрии. Следует отметить, что реальной потребности в таких скоростях пока очень немного: лишь 15 % (в деньгах) рынка Ethernet-устройств приходится на 400G-оборудование, но Broadcom считает, что постоянный рост аппетитов гиперскейлеров должен довести этот показатель до более чем 50 % уже к 2026 году. В случае же Tomahawk 5 пока речь идёт о первых поставках самих чипов, которые OEM-производителям ещё предстоит интегрировать в свои продукты. Они должны появиться на рынке в следующем году.
19.06.2022 [13:32], Алексей Степин
Alibaba Cloud представила свой вариант DPU — Cloud Infrastructure Processing Unit (CIPU)С учётом стремительно наступающей эры DPU/IPU не вызывает удивления, что такой китайский гигант, как Alibaba Cloud, представил своё видение «универсального сетевого сопроцессора», использовав схожий термин Cloud Infrastructure Processing Unit (CIPU). На ежегодном саммите компании Alibaba Cloud анонсировала новый чип, являющийся дальнейшим развитием идей, ранее воплощённых в умном сетевом адаптере X-Dragon, разрабатывавшемся как аналог AWS Nitro. Пока об архитектуре Alibaba CIPU известно не так много, но физически это обычная двухслотовая плата расширения с интерфейсом PCI Express. 
Источник: @ogawa_tter Судя по имеющимся данным, в основе лежит четвёртое поколение архитектуры X-Dragon, обеспечившее 20% прирост производительности в сравнении с предыдущим поколением этих процессоров. Что более интересно, в основе новой итерации X-Dragon лежит дуэт технологий Elastic RDMA (eRDMA) и Shared Memory Communications over RDMA (SMC-R). Он позволяет новому ускорителю обращаться к памяти хост-системы напрямую на уровне ядра фирменных ОС Alibaba Cloud Linux 3 и Anolis OS. Для приложений, использующих TCP, всё выглядит прозрачно, но латентность при этом удалось понизить до 5 мкс. 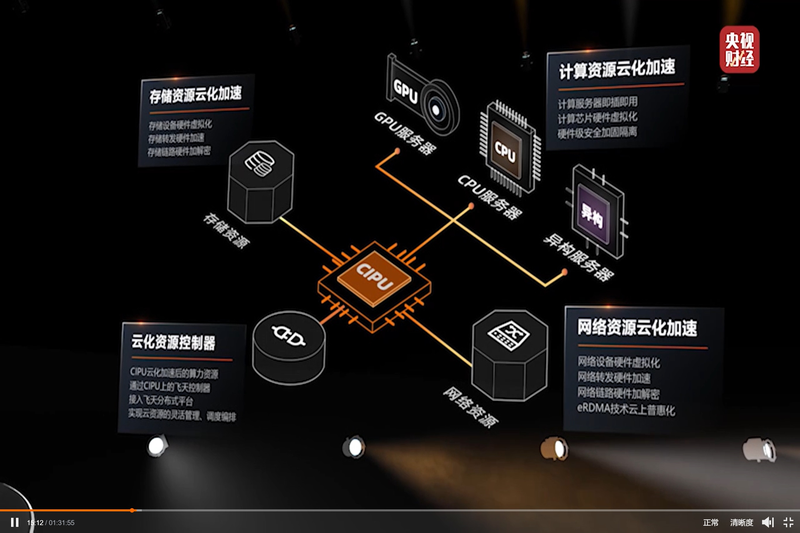
Источник: @ogawa_tter Новые сопроцессоры полностью совместимы со стеком технологий RDMA over Converged Ethernet (RoCE), причём поддерживается даже iWARP, довольно редкий вариант, встречавшийся ранее в адаптерах Intel и Chelsio. Реализации iWARP могут быть сложнее RoCE, т.к. используют многослойную архитектуру и ряд твиков, а в итоге нередко показывают менее высокую производительность. Но благодаря поддержке обеих технологий новое решение Alibaba получилось поистине универсальным. 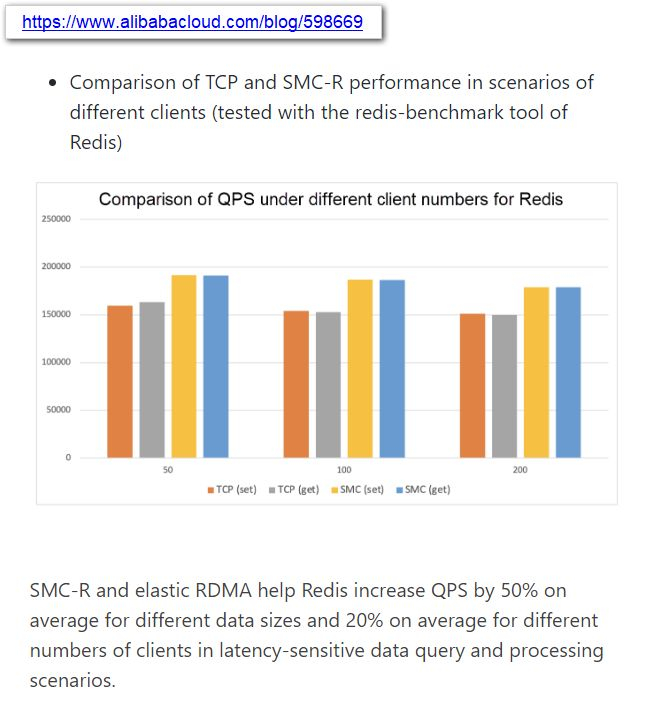
Источник: @ogawa_tter Результаты тестов весьма обнадёживают: в частности, для Redis ускорители CIPU за счёт SMC-R позволили поднять количество обрабатываемых запросов на 50%, а в сценариях с данными, чувствительными к латентности, прирост составил 20%. Исходя из опубликованных в японском блоге Tadashi Ogawa, это действительно полноценный IPU, могущий стать мостом между сетью, подсистемами хранения данных, CPU, GPU и прочими ускорителями. Компания активно развивает собственную аппаратную инфраструктуру и в прошлом году уже представила 128-ядерный 5-нм процессор Yitian 710 на базе набора инструкций Armv9 c 8 каналами DDR5, поддержкой PCIe 5.0 (96 линий) и при этом способный работать на частотах до 3,2 ГГц.
28.04.2022 [22:54], Алексей Степин
Chelsio представила седьмое поколение сетевых чипов Terminator: 400GbE и PCIe 5.0 x16Компания Chelsio Communications анонсировала седьмое поколение своих сетевых процессоров Terminator с поддержкой 400GbE. От предшественников T7 отличает более развитая вычислительная часть общего назначения, включающая в себя до 8 ядер Arm Cortex-A72, так что их уже можно назвать DPU. Всего представлено пять вариантов 5 чипов (T7, N7, D7, S74 и S72), которые различаются между собой набором движков и ускорителей. Референсная платформа T7 будет доступна в мае, первых же адаптеров на базе новых DPU следует ожидать в III квартале 2022 года. Для задач сжатия, дедупликации или криптографии есть отдельные сопроцессоры. Никуда не делся и привычный для серии Unified Wire встроенный L2-коммутатор. Для подключения к хосту T7 теперь использует шину PCIe 5.0 x16, причём он же содержит и root-комплекс. Более того, имеется и набортный коммутатор+мост PCIe 4.0, и NVMe-интерфейс, и даже поддержка эмуляции NVMe. Всё это, к примеру, позволяет легко и быстро создать NVMe-oF хранилище или мост NVMe-NVMe для компрессии и шифрования данных на лету. Новинка предлагает ускорение работы RoCEv2 и iWARP, FCoE и NVMe/TCP, iSCSI и iSER, а также RAID5/6. Сетевая часть поддерживает разгрузку Open vSwitch и Virt-IO. 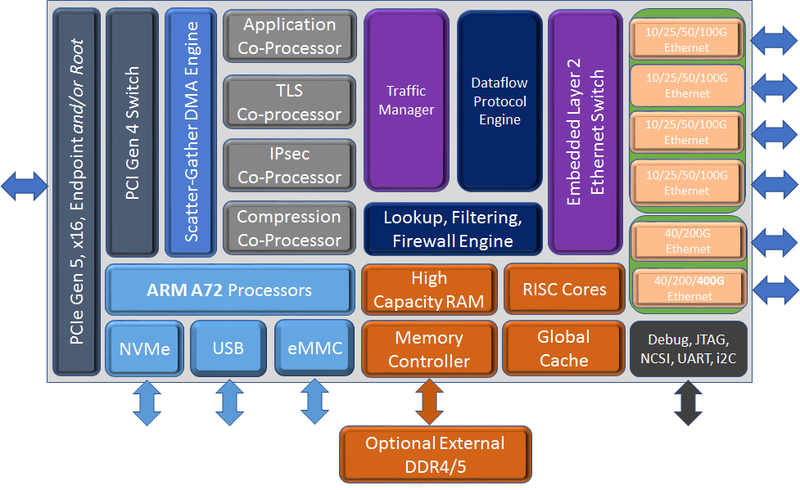
Блок-схема старшего варианта T7 (Изображения: Chelsio Communcations) Впрочем, поддержки P4 тут нет — Chelsio продолжает использовать собственные движки для обработки трафика. Но наработки, сделанные для серий T5 и T6, будет проще перенести на новое поколение чипов. Кроме того, появилась и практически обязательная нынче «глубокая» телеметрия всего проходящего через DPU трафика для повышения управляемости и его защиты. Если и этого окажется мало, то к T7 (и D7) можно напрямую подключить FPGA, а набортную память расширить банками DDR4/5. В пресс-релизе также отмечается, что T7 сможет стать достойной заменой InfiniBand в HРC-системах. 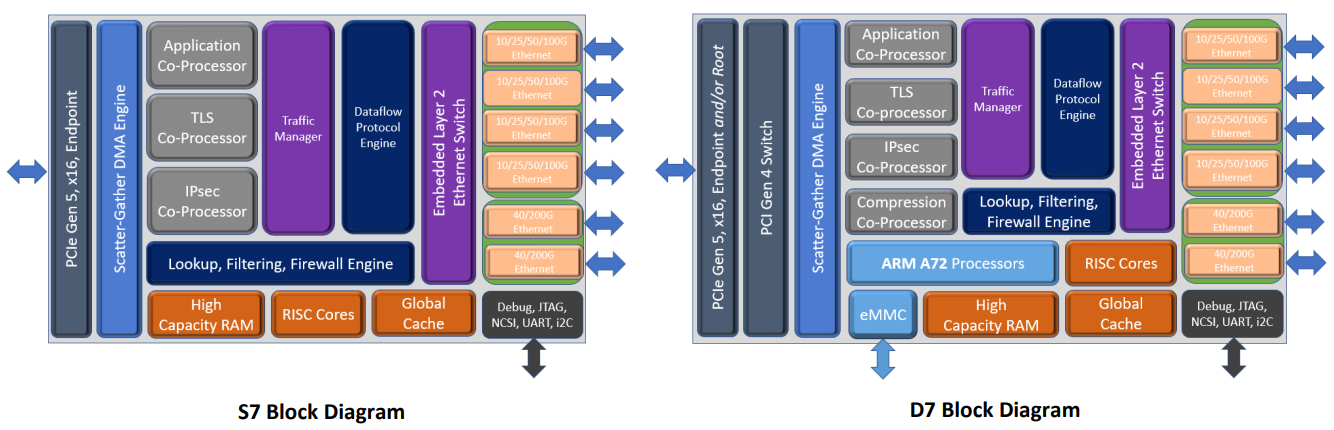 Вариант D7 наиболее близок к T7, но предлагает только 200GbE-подключение, лишён некоторых функций и второстепенных интерфейсов, да и в целом рассчитан на создание СХД. N7, напротив, лишён Arm-ядер и всех функций для работы с хранилищами, нет у него и PCIe-коммутатора и моста. Предлагает он только 200GbE-интерфейсы. Наконец, чипы серии S7 лишены целого ряда второстепенных функций и предоставляют только 100/200GbE-подключение. Они относятся скорее к SmartNIC, поскольку начисто лишены Arm-ядер и некоторых функций. Но зато они и недороги. Кроме того, в седьмом поколении Termintator появилась возможность обойтись без набортной DRAM с сохранением всей функциональности. Так что использование памяти хоста позволит дополнительно снизить стоимость конечных решений, которые будут создавать OEM-производители. Сами чипы производятся с использованием техпроцесса TSMC 12-нм FFC, так что даже у старшей версии чипов типовое энергопотребление не превышает 22 Вт.
26.04.2022 [18:53], Руслан Авдеев
Китай ускоряет внедрение IPv6 на фоне стремительного прогресса 5G-сетей и облаков, но не оставляет надежды распространить по миру свои собственные стандарты связиЦентральная администрация киберпространства КНР поделилась планами ускоренного внедрения протокола IPv6 на фоне повсеместного распространения облачных сервисов, устройств интернета вещей и 5G-сетей. Власти страны анонсировали целый ряд амбициозных целей на 2022 год. Известно, что КНР планирует полностью перейти на IPv6 к 2030 году. Так, до конца года планируется получить 700 млн активных пользователей IPv6 (при населении более 1,4 млрд человек) и 180 млн IPv6-подключений устройств Интернета вещей, причём к этому моменту 13 % трафика стационарных сетей связи и 45 % мобильного трафика тоже должно быть переведено на новый протокол. 85 % государственных, а также ключевых коммерческих онлайн-сервисов тоже должны будут освоить IPv6. 
Источник изображения: Tumisu/pixabay.com Наконец, этот протокол должен быть активирован по умолчанию во всех новых домашних роутерах. Правительство также намерено поощрять перевод на IPv6 облачных платформ, стриминговых сервисов и целый ряд ключевых отраслей вроде финансового сектора и сельского хозяйства. Отчасти это вынужденная мера, поскольку телекоммуникационный сектор страны остро нуждается в новых инструментах в связи с постоянным и довольно стремительным ростом, которому способствуют общие план по цифровизации Китая. Только в I квартале 2022 года, по данным Министерства промышленности и информатизации КНР, доходы облачных сервисов выросли на 138,1 % в сравнении с аналогичным периодом прошлого года, а секторы Big Data и IoT — на 59,1 % и 23,9 % соответственно. Очевидного прогресса страна достигла и в строительстве базовых станций 5G. К концу марта их число в КНР достигло 1,56 млн единиц, из них 134 тыс. были построены в первые три месяца года. 
Источник изображения: Huawei В этих условиях распространение IPv6 имеет критически важное значение. Новый план китайских властей предусматривает «активное участие нации» в формировании не только местных, но и международных стандартов для интернета будущего. В Китае намерены продвигать новый стандарт New IP вместо привычного стека TCP/IP. Huawei предложила его Международному союзу электросвязи (ITU), хотя разработкой соответствующих стандартов занимаются преимущественно IETF и IEEE. Впрочем, инициатива прохладно встречена этими международными институтами, поскольку новый протокол не гарантируерует обратной совместимости и фактически дублирует работы, уже проводимые IEEE и IETF. Cisco утверждает, что существующие стандарты вполне соответствуют китайским запросам. Кроме того, использование имеющихся решений позволит избежать прецедента продавливания Китаем стандарта при посредничестве ITU, который в норме не имеет к этому процессу никакого отношения. |
|

