Материалы по тегу: инференс
|
10.11.2025 [12:05], Сергей Карасёв
Фабрика токенов: Nebius, бывшая Yandex NV, запустила платформу Token Factory для инференса на базе открытых ИИ-моделейКомпания Nebius (бывшая материнская структура «Яндекса») представила платформу Nebius Token Factory для инференса: она позволяет разворачивать и оптимизировать открытые и кастомизированные ИИ-модели в больших масштабах с высоким уровнем надёжности и необходимым контролем. Nebius отмечает, что применение закрытых ИИ-моделей может создавать трудности при масштабировании. С другой стороны, открытые и кастомизированные модели позволяют устранить эти ограничения, но управление ими и обеспечение безопасности остаются технически сложными и ресурсоёмкими задачами для большинства команд. Платформа Nebius Token Factory призвана решить существующие проблемы: она сочетает гибкость открытых моделей с управляемостью, производительностью и экономичностью, которые необходимы организациям для реализации масштабных проектов в сфере ИИ. Nebius Token Factory базируется на комплексной ИИ-инфраструктуре Nebius. Новая платформа объединяет высокопроизводительный инференс, пост-обучение и управление доступом. Обеспечивается поддержка более 40 open source моделей, включая новейшие версии Deep Seek, Llama, OpenAI и Qwen. 
Источник изображения: Nebius Среди ключевых преимуществ Nebius Token Factory заявлены соответствие требованиям корпоративной безопасности (HIPAA, ISO 27001 и ISO 27799), предсказуемая задержка (менее 1 с), автоматическое масштабирование пропускной способности и доступность на уровне 99,9 %. Инференс выполняется в дата-центрах на территории Европы и США без сохранения данных на серверах Nebius. Задействована облачная экосистема Nebius AI Cloud 3.0 Aether, что, как утверждается, обеспечивает безопасность корпоративного уровня, проактивный мониторинг и стабильную производительность. Отмечается, что Nebius Token Factory может применяться для решения широкого спектра ИИ-задач: от интеллектуальных чат-ботов, помощников по написанию программного кода и генерации с дополненной выборкой (RAG) до высокопроизводительного поиска, анализа документов и автоматизированной поддержки клиентов. Интегрированные инструменты тонкой настройки и дистилляции позволяют компаниям адаптировать большие открытые модели к собственным данным. При этом достигается сокращение затрат на инференс до 70 %. Оптимизированные модели затем можно быстро разворачивать без ручной настройки инфраструктуры.
07.11.2025 [14:16], Владимир Мироненко
Google объявила о доступности фирменных ИИ-ускорителей TPU Ironwood и кластеров на их основеGoogle объявила о доступности в ближайшие недели ИИ-ускорителя седьмого поколения TPU v7 Ironwood, специально разработанного для самых требовательных рабочих нагрузок: от обучения крупномасштабных моделей и сложного обучения с подкреплением (RL) до высокопроизводительного ИИ-инференса и обслуживания моделей с малой задержкой. Google отметила, что современные передовые ИИ-модели, включая Gemini, Veo, Imagen от Google и Claude от Anthropic, обучаются и работают на TPU. Многие компании смещают акцент с обучения этих моделей на обеспечение эффективного и отзывчивого взаимодействия с ними. Постоянно меняющаяся архитектура моделей, рост агентных рабочих процессов и практически экспоненциальный рост спроса на вычисления определяют новую эру инференса. В частности, ИИ-агенты, требующие оркестрации и тесной координации между универсальными вычислениями и ускорением машинного обучения, создают новые возможности для разработки специализированных кремниевых процессоров и вертикально оптимизированных системных архитектур. TPU Ironwood призван обеспечить новые возможности для инференса и агентных рабочих нагрузок. 
Источник изображений: Google TPU Ironwood был представлен в апреле этого года. По данным Google, он обеспечивает десятикратное увеличение пиковой производительности по сравнению с TPU v5p и более чем четырёхкратное увеличение производительности на чип как для обучения, так и для инференса по сравнению с TPU v6e (Trillium), что делает Ironwood самым мощным и энергоэффективным специализированным кристаллом компании на сегодняшний день. Ускорители объединяются в «кубы» — 64 шт. TPU в 3D-торе, объединённых интерконнектом Inter-Chip Interconnect (ICI) со скоростью 9,6 Тбит/с на подключение.  Google сообщила, что на базе Ironwood можно создавать кластеры, включающие до 9216 чипов (42,5 Эфлопс в FP8), объединённых ICI с агрегированной скоростью 88,5 Пбит/с с доступом к 1,77 Пбайт общей памяти HBM, преодолевая узкие места для данных даже самых требовательных моделей. Компания отметила, что в таком масштабе сервисы требуют бесперебойной доступности. Её гарантирует технология оптической коммутации (OCS), которая реализуется как динамическая реконфигурируемая инфраструктура. А если клиенту требуется больше мощности, Ironwood масштабируется в кластеры из сотен тысяч TPU.  Своим клиентам, пользующимся решениями на TPU, компания предлагает возможности Cluster Director в Google Kubernetes Engine. Это включает в себя расширенные возможности обслуживания и понимания топологии для интеллектуального планирования и создания высокоустойчивых кластеров. 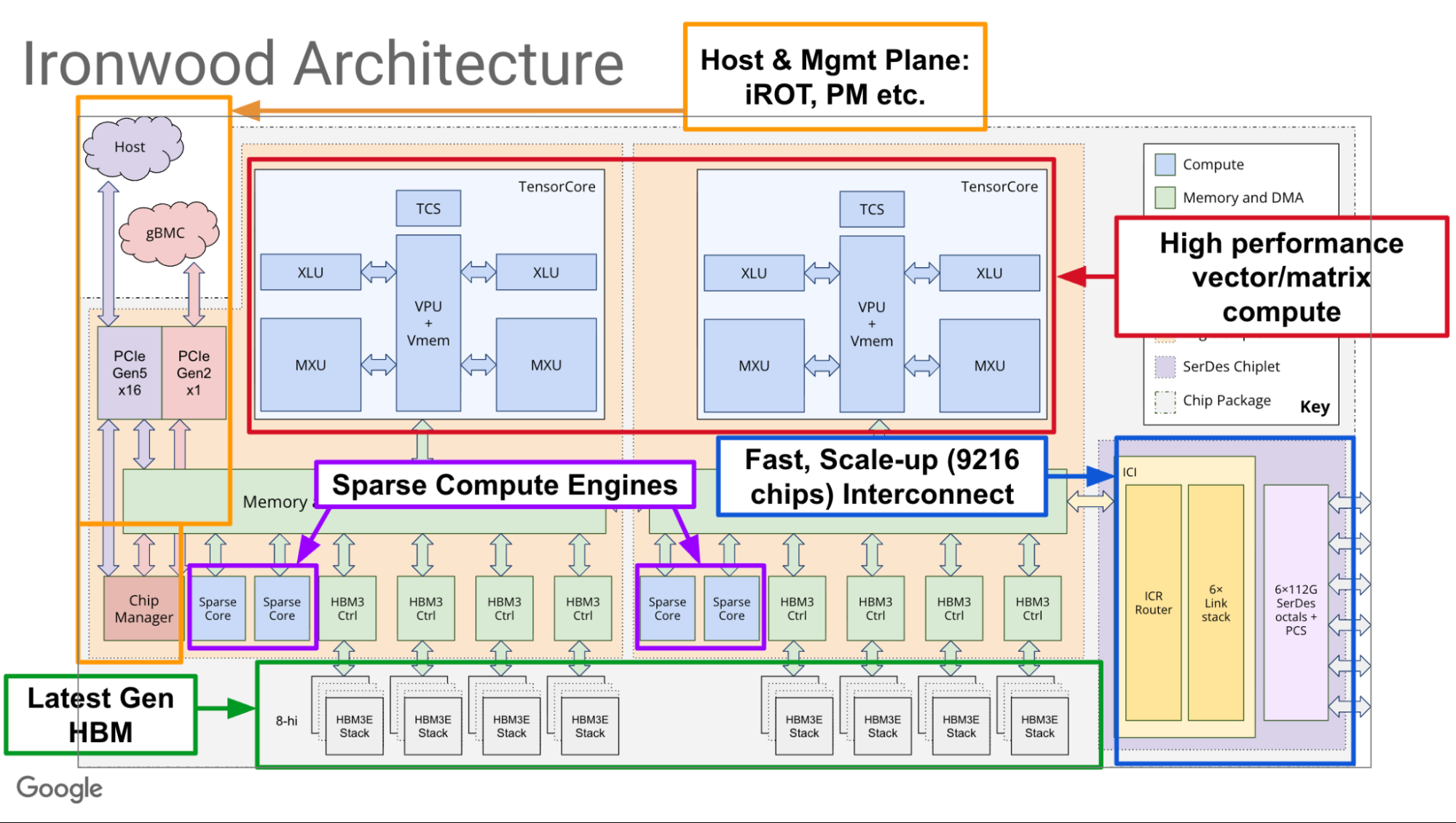 Для предобучения и постобучения компания предлагает новые улучшения MaxText, высокопроизводительного фреймворка LLM с открытым исходным кодом, которые упрощают внедрение новейших методов оптимизации обучения и обучения с подкреплением, таких как контролируемая тонкая настройка (SFT) и оптимизация политики генеративного подкрепления (GRPO) — алгоритм обучения с подкреплением (RL). Также улучшена поддержка vLLM, что позволит с минимальными усилиями перенести инференс с GPU на TPU. А GKE Inference Gateway позволит снизить задержку выдачи первого токена (TTFT). Никуда не делась и поддержка JAX с PyTorch.
06.11.2025 [22:34], Владимир Мироненко
Qualcomm и Arm разошлись во мнениях по поводу развития ИИ-вычисленийQualcomm и Arm опубликовали в среду квартальные отчёты, дав разные прогнозы относительно рынка процессоров для инференса, пишет The Register. Генеральный директор Qualcomm Криштиану Амон (Cristiano Amon) сообщил аналитикам в ходе телефонной конференции, посвященной квартальным финансовым результатам о том, что его компания выйдет на рынок ЦОД с чипами, предназначенными для выполнения задач инференса и потребляющими меньше энергии, чем «железо» конкурентов. Амон рассказал, что Qualcomm разрабатывает SoC и плату для неё, поскольку «рост ИИ-ЦОД смещается от обучения к специализированным рабочим нагрузкам инференса, и ожидается, что эта тенденция усилится в ближайшие годы». Вместе с тем он отметил, что Qualcomm не сможет отчитаться о «существенной» выручке в сегменте ЦОД до 2027 года. Генеральный директор Arm Рене Хаас (Rene Haas) тоже придерживается мнения, что энергопотребление является «узким местом» в ЦОД, и что спрос сместится с обучения на инференс, вместе с тем считая, что такого рода задачи будут выполняться и за пределами дата-центров. Он отметил растущий спрос на различные архитектуры и вычислительные решения, позволяющие выполнять инференс не в облаке. «Очевидно, что вы не будете полностью полагаться на что-то, что находится на периферии. Но сегодня всё наоборот. Всё на 100 % зависит от облака. И мы думаем, что это изменится», — заявил Хаас во время телефонной конференции с аналитиками, посвящённой финансовому отчёту Arm. 
Источник изображения: BoliviaInteligente / Unsplash Qualcomm анонсировала новую серию чипов для ИИ ЦОД AI200/AI250, заявив, что ИИ-стартап Humain, основанный суверенным фондом Саудовской Аравии, станет одним из их заказчиков. В ходе телефонной конференции Амон сообщил, что Qualcomm ведёт переговоры с другим крупным заказчиком-гиперскейлером, отметив, что они проходят успешно, пишет Reuters. Выручка Qualcomm в IV квартале 2025 финансового года, завершившемся 28 сентября 2025 года, составила $11,27 млрд, что на 10 % больше, чем годом ранее, и выше консенсус-прогноза аналитиков, опрошенных LSEG, в размере $10,79 млрд. В полупроводниковом сегменте (QCT) выручка компании составила $9,82 млрд, превысив результат годичной давности на 13 %. При этом выручка в автомобильном сегменте выросла на 17 % до $1,05 млрд, в сегменте Интернета вещей — на 7 % до $1,81 млрд. 
Источник изображения: Qualcomm Скорректированная прибыль на акцию составила $3,00 при прогнозе от LSEG в размере $2,88. Из-за единовременной налоговой выплаты в размере $5,7 млрд компания завершила квартал с чистым убытком в $3,12 млрд, или $2,89 на акцию, тогда как годом ранее у неё была чистая прибыль в размере $2,92 млрд, или $2,59 на акцию. Выручка Qualcomm за 2025 финансовый год составила $44,3 млрд, что на 14 % больше показателя предыдущего финансового года. Чистая годовая прибыль снизилась на 45 % до $5,5 млрд. В I квартале 2026 финансового года Qualcomm прогнозирует выручку в размере $11,8–$12,6 млрд, что соответствует среднему значению в $12,2 млрд. По данным LSEG, это превышает консенсус-прогноз аналитиков в $11,62 млрд. Скорректированная прибыль на акцию, согласно ожиданиям компании, составит $3,30–$3,50 при прогнозе Уолл-стрит в размере $3,31 на акцию. 
Источник изображения: Qualcomm Arm объявила о выручке во II квартале 2026 финансового года в размере $1,14 млрд, что на 34 % больше, чем годом ранее, а также больше прогноза аналитиков в размере $1,06 млрд, пишет Reuters. Третий квартал подряд выручка компании превышает $1 млрд. Выручка компании от роялти выросла год к году на 21 % до рекордных $620 млн, а от лицензирования — на 56 % до $515 млн благодаря новым крупным соглашениям в сфере вычислительных технологий нового поколения. Скорректированная операционная прибыль (Non-GAAP), достигла $467 млн, а скорректированная прибыль на акцию (Non-GAAP), составила $0,39, что в обоих случаях превышает прогноз, отметил ресурс Converge! Network Digest. Финансовый директор Джейсон Чайлд (Jason Child) сообщил инвесторам, что наибольший вклад в рост выручки внесли смартфоны, но «более высокие ставки роялти за чип в ЦОД, где мы по-прежнему наблюдаем рост доли кастомных чипов для гиперскейлеров», безусловно, не были помехой. Arm отметила, что набирает обороты вклад своей архитектуры в развитие облачного ИИ: более 1 млн ядер Arm Neoverse уже развёрнуто в инфраструктуре гиперскейлеров. Ожидается, что доля процессоров Arm в установленных ведущими гиперскейлерами чипах в этом году достигнет почти 50 %. 
Источник изображения: Arm Среди новых игроков на этом рынке компания отметила Google, которая уже перенесла более 30 тыс. облачных приложений на Arm-чипы Axion, включая Gmail и YouTube, и намерена перенести большую часть из более чем 100 тыс. своих приложений. Также в минувшем квартале Microsoft расширила использование процессоров Cobalt 100 на базе Arm до 29 регионов по всему миру. «Открытие пяти новых ЦОД Stargate AI, все из которых основаны на Arm как стратегической вычислительной платформе, подчёркивает роль Arm в обеспечении масштабируемого ИИ», — отметила компания. Доля Arm на рынке серверных процессоров действительно достигла 25 %, но во многом благодаря внедрению интегированных в суперчипы NVIDIA процессорам Grace.
27.10.2025 [22:50], Владимир Мироненко
Qualcomm анонсировала ИИ-ускорители AI200 и AI250 — прошлое поколение чипов популярным не стало, но компания обещала исправитьсяQualcomm Technologies представила решения нового поколения для ЦОД, оптимизированные для ИИ-инференса — стоечные суперускорители Qualcomm AI200 и AI250. После их анонса акции Qualcomm подскочили на 15 %, показав самый большой внутридневной рост за более чем шесть месяцев, сообщил Bloomberg. Ожидается, что новые решения станут новой точкой роста компании. Она демонстрировала уверенный рост прибыли в течение последних двух лет, но инвесторы отдавали предпочтение акциям других технологических компаний. Qualcomm AI200 — специализированное стоечное решение для ИИ-инференса, обеспечивающее низкую совокупную стоимость владения (TCO). Платформа оптимизирована для инференса больших языковых и мультимодальных моделей (LLM, LMM) и других ИИ-нагрузок. AI200 включает карты с 768 Гбайт LPDDR. Чип основан на NPU Hexagon, которые используются в последних поколениях Snapdragon. Qualcomm AI250 получил инновационную архитектуру, построенную на принципах предельно близкого расположения быстрой памяти к вычислительным ядрам (Near-Memory Computing, NMC), что обеспечит качественно новый уровень эффективности и производительности ИИ-инференса. По словам Qualcomm, новая архитектура обеспечивает более чем десятикратный прирост эффективной пропускной способности памяти и значительное снижение энергопотребления. Это позволит проводить дезагрегированный ИИ-инференс для более эффективного использования оборудования. 
Источник изображений: Qualcomm Оба продукта будут предлагаться отдельно и в составе стоек с полным жидкостным охлаждением, PCIe-коммутаторами для вертикального масштабирования и Ethernet — для горизонтального, а также поддержкой конфиденциальных вычислений. Энергопотребление стойки составит 160 кВт, что ставит новинки в один ряд с GB200 NVL72. Компания отметила, что её программный ИИ-стек гиперскейл-класса, охватывающий все этапы — от прикладного уровня до системного ПО — оптимизирован для ИИ-инференса. Стек поддерживает ведущие фреймворки машинного обучения, механизмы инференса, фреймворки генеративного ИИ и методы оптимизации инференса LLM/LMM, такие как дезагрегированное обслуживание. Обещаны бесшовный перенос моделей и развёртывание моделей платформы Hugging Face в один клик посредством библиотеки Efficient Transformers и пакета Qualcomm AI Inference Suite от Qualcomm. Qualcomm отметила, что её ПО предоставляет готовые к использованию приложения и ИИ-агенты, комплексные инструменты, библиотеки, API и сервисы. Прошлое поколение ускорителей CloudAI 100 не снискало успеха во многом из-за слабой программной экосистемы. От этого же страдала и AMD, которая ускоренными темпами навёрстывает упущенное.  Qualcomm AI200 и AI250 поступят в продажу в 2026 и 2027 годах соответственно. Qualcomm также сообщила, что придерживается ежегодного плана развития направления ЦОД, ориентированного на достижение лидирующей в отрасли производительности ИИ-инференса, энергоэффективности и минимальной совокупной стоимости владения (TCO). Кроме того, компания решила вернуться на рынок серверных процессоров. Первым заказчиком анонсированных решений Qualcomm станет саудовский государственный ИИ-стартап Humain, который планирует развернуть 200 МВт ИИ ЦОД на базе новых чипов, начиная с 2026 года. Ранее было заключено соглашение с Cerebras, в рамках которого планировалось использовать для инференса именно чипы Qualcomm, в том числе в Саудовской Аравии. Ещё одним крупным игроком в ИИ-сделках здесь является Groq. Qualcomm запоздало пытается занять заметную долю рынка ИИ-оборудования. Компания считает, что новые решения в области памяти и энергоэффективности, основанные на технологиях для мобильных устройств, привлекут клиентов, несмотря на относительно поздний выход на рынок. Под руководством Криштиану Амона (Cristiano Amon) компания стремится диверсифицировать бизнес, больше не полагаясь на смартфоны, рост продаж которых замедлился. Qualcomm «занимала эту нишу, не торопясь и наращивая мощь», — заявил Дурга Маллади (Durga Malladi), старший вице-президент компании. По его словам, Qualcomm ведёт переговоры со всеми крупнейшими заказчиками о развёртывании стоек на базе своего оборудования.
27.10.2025 [11:16], Сергей Карасёв
Axelera AI представила ИИ-чип Europa с производительностью 629 TOPSНидерландский стартап Axelera AI анонсировал ИИ-ускоритель (AIPU) под названием Europa, предназначенный для таких задач, как генеративные сервисы и приложения компьютерного зрения. По заявлениям разработчиков, чип может использоваться в оборудовании разного класса — от периферийных устройств до корпоративных серверов. В состав Europa AIPU входят восемь «ядер ИИ второго поколения», которые используют векторные движки и технологию цифровых вычислений в оперативной памяти (D-IMC), разработанные специалистами Axelera. Заявленная ИИ-производительность достигает 629 TOPS на операциях INT8. Кроме того, чип содержит 16 специализированных векторных ядер с архитектурой RISC-V, сгруппированных в два кластера: они предназначены для операций пред- и постобработки, не связанных с ИИ. Пиковая производительность блока RISC-V достигает 4915 GOPS (млрд операций в секунду). Интегрированный декодер H.264/H.265 ускоряет выполнение медиазадач. 
Источник изображения: Axelera AI Процессор располагает 256-бит интерфейсом памяти LPDDR5 с пропускной способностью 200 Гбайт/с и 128 Мбайт памяти L2 SRAM. Новинка будет предлагаться в различных форм-факторах, включая компактное исполнение с размерами 35 × 35 мм и карты расширения PCIe 4.0 х4 в различных конфигурациях, в частности, с одним чипом и 16 Гбайт памяти, а также с четырьмя чипами и 256 Гбайт памяти. Разработчикам предоставляет комплект Voyager SDK, который позволяет полностью раскрыть потенциал процессора. В целом, как утверждается, новинка обеспечивает в 3–5 раз более высокую производительность в расчёте на 1 Вт и $1 по сравнению с ведущими отраслевыми решениями в той же категории. Поставки Europa AIPU и PCIe-карт начнутся в I половине 2026 года.
26.10.2025 [14:20], Сергей Карасёв
d-Matrix представила систему SquadRack для ИИ-инференса со сверхнизкой задержкойКомпания d-Matrix анонсировала систему SquadRack — стоечное решение для пакетного инференса со сверхнизкой задержкой. Это, как утверждается, первый в отрасли продукт данного класса. В его разработке приняли участие специалисты Arista, Broadcom и Supermicro. В основу SquadRack положена серверная платформа Supermicro X14 AI. Судя по изображениям, используется модель SYS-522GA-NRT, которая допускает установку двух процессоров Intel Xeon 6900 (Granite Rapids) и 24 модулей оперативной памяти DDR5-8800. Доступны 24 фронтальных отсека для SFF-накопителей U.2/U.3 (NVMe). Устройство выполнено в форм-факторе 5U. Система SquadRack предусматривает использование ускорителей d-Matrix Corsair. Их архитектура основана на модифицированных ячейках SRAM для вычислений в памяти (DIMC), работающих на скорости около 150 Тбайт/с. По заявлениям d-Matrix, решение обеспечивает непревзойдённую производительность ИИ-инференса: быстродействие достигает 2,4 Пфлопс (8-бит вычисления). Кроме того, задействованы IO-карты d-Matrix JetStream, предназначенные для распределения нагрузок инференса. Одна такая карта может обслуживать до четырёх экземпляров Corsair, обеспечивая сетевую задержку на уровне 2 мкс. 
Источник изображения: d-Matrix Решение SquadRack также оборудовано PCIe-коммутаторами Broadcom для масштабирования в пределах одного узла. В свою очередь, связь между узлами обеспечивают коммутаторы Arista Leaf Ethernet, подключённые к картам JetStream. Применяется программный стек d-Matrix Aviator. В одну стойку могут быть установлены до восьми экземпляров SquadRack, что позволяет с высокой скоростью обрабатывать модели ИИ, насчитывающие до 100 млрд параметров. В целом, возможно масштабирование до сотен узлов в нескольких серверных стойках.
21.10.2025 [00:35], Владимир Мироненко
Ещё одна альтернатива платформам NVIDIA — IBM объединила усилия с GroqIBM и Groq объявили о стратегическом партнёрстве с целью предоставления клиентам возможностей высокоскоростного ИИ-инференса по доступной цене путём объединения watsonx Orchestrate от IBM с аппаратными решениями Groq, что позволит ускорить развёртывание агентных систем ИИ. В рамках партнёрства Groq и IBM планируют интегрировать и усовершенствовать технологию Red Hat vLLM с архитектурой LPU Groq. Ожидается, что совместное решение позволит клиентам использовать возможности watsonx Orchestrate привычным образом и с привычными инструментам в инференс-платформе GroqCloud, предоставляющей разработчикам доступ к высокоскоростной и недорогой обработке LLM. Эта интеграция позволит удовлетворить ключевые потребности разработчиков ИИ-решений, включая оркестрацию инференса, балансировку нагрузки и аппаратное ускорение, что в конечном итоге оптимизирует сам процесс инференса. Также планируется поддержка моделей IBM Granite в GroqCloud для клиентов IBM. IBM отметила, что предприятия при переводе ИИ-агентов из пилотной версии в промышленную эксплуатацию продолжают сталкиваться с проблемами обеспечения скорости, стоимости и надёжности. Партнёрство IBM и Groq позволяет объединить скорость инференса Groq, экономическую эффективность и доступ к новейшим open source моделям с оркестрацией агентского ИИ IBM, предоставляя клиентам инфраструктуру, необходимую для их масштабирования, говорит компания. 
Источник изображения: Groq IBM сообщила, что LPU обеспечивают минимум в пять раз более быстрый и экономичный инференс, чем системы на ускорителях конкурентов, имея, по всей видимости, в виду NVIDIA. Это позволяет обеспечить стабильно низкую задержку и производительность при масштабировании нагрузок, что особенно важно для ИИ-агентов в регулируемых отраслях. В качестве примера IBM привела деятельность клиентов из сферы здравоохранения, которые одновременно получают тысячи сложных вопросов пациентов. Благодаря Groq ИИ-агенты IBM смогут анализировать информацию в режиме реального времени и мгновенно предоставлять точные ответы, позволяя организациям в этой сфере принимать более оперативные и обоснованные решения. В нерегулируемых отраслях клиенты IBM с помощью платформы GroqCloud смогут ускорить работу ИИ-агентов и повысить автоматизацию кадровых процессов и производительность сотрудников. IBM объявила, что сразу же предоставит клиентам доступ к возможностям GroqCloud, а совместные с Groq команды сосредоточатся на предоставлении заказчикам IBM следующих возможностей:
Groq привлекла инвестиции в размере $1,8 млрд, включая раунд финансирования на сумму $750 млн в прошлом месяце с оценкой в $6,9 млрд. В числе её инвесторов — Cisco и Samsung. Также Groq сотрудничает с саудовской Aramco Digital. По данным WSJ, компания развернула в этом году 12 ЦОД и намерена развернуть как минимум ещё 12 в 2026 году. В 2024 году Groq сменила модель работы — с тех пор она больше не продаёт свои ИИ-ускорители, предлагая вместо этого создание ЦОД или облака.
20.10.2025 [12:13], Сергей Карасёв
ИИ-ускоритель Huawei Atlas 300I Duo получил однослотовое исполнениеВ распоряжении сетевых источников оказалась информация о необычном ускорителе Atlas 300I Duo, разработанном компанией Huawei для решения задач в области ИИ: это двухпроцессорное изделие, оснащенное пассивной системой охлаждения. Карта получила однослотовое исполнение. В оснащение входят два GPU серии Ascend 310 и 96 Гбайт памяти LPDDR4X, пропускная способность которой достигает 408 Гбайт/с. Используется интерфейс PCIe 4.0 х16. Утверждается, что Atlas 300I Duo может декодировать до 256 потоков видео в формате Full HD со скоростью 30 к/с или 32 потока 4K со скоростью 60 к/с. Возможно кодирование 48 видеопотоков Full HD со скоростью 30 к/с. ИИ-производительность на операциях INT8 достигает 280 TOPS. При этом показатель TDP находится на отметке 150 Вт. 
Источник изображений: Gamers Nexus via YouTube Применённая пассивная система охлаждения предусматривает использование радиаторов в области каждого GPU, соединённых тепловыми трубками. Кроме того, имеется металлическая пластина для рассеяния тепла. Для подачи дополнительного питания используется специальный 8-контактный разъём, не совместимый со стандартными гнёздами. Стоимость Huawei Atlas 300I Duo составляет около $1600.  Между тем Huawei продолжает развивать семейство ИИ-ускорителей Ascend. В I квартале 2026 года компания намерена представить ускоритель Ascend 950PR, который обеспечит производительность до 1 Пфлопс на операциях FP8. После этого последуют устройства Ascend 950DT, Ascend 960 и Ascend 970.
20.10.2025 [01:23], Владимир Мироненко
Ускорителей хватит на всех — Alibaba Aegaeon оптимизировал обработку ИИ-нагрузок, снизив использование дефицитных NVIDIA H20 на 82 %Alibaba Cloud представила Aegaeon, систему пулинга вычислений, позволяющую сократить количество ускорителей NVIDIA, необходимых для обслуживания ИИ-моделей, на 82 %, пишет ресурс SCMP. По словам разработчиков, благодаря Aegaeon количество ускорителей NVIDIA H20, необходимых для обслуживания десятков моделей с 72 млрд параметров, удалось сократить с 1192 до 213 единиц. «Aegaeon — это первое решение на рынке, которое выявило чрезмерные затраты, связанные с обслуживанием параллельных рабочих нагрузок LLM», — сообщили исследователи из Пекинского университета и Alibaba Cloud. Провайдеры облачных сервисов, такие как Alibaba Cloud и ByteDance Volcano Engine, предоставляют пользователям одновременно тысячи ИИ-моделей — множество вызовов API обрабатывается одновременно. Однако на практике для инференса чаще всего используются лишь несколько моделей, таких как Qwen и DeepSeek, а большинство других моделей применяются лишь эпизодически. Это приводит к неэффективному использованию вычислительных ресурсов: исследователи обнаружили, что 17,7 % ускорителей выделяется на обслуживание лишь 1,35 % запросов в Alibaba Cloud. Aegaeon выполняет «автоматическое масштабирование» на уровне токенов, обеспечивая переключение ускорителей между обслуживанием различных моделей в процессе генерации. В рамках системы один ускоритель поддерживает обработку до семи моделей по сравнению с двумя-тремя моделями в альтернативных системах. При этом задержка, связанная с переключением между моделями, снижена на 97 %, заявили исследователи. Alibaba Cloud сообщила, что решение уже используется на её торговой площадке моделей Bailian. 
Источник изображения: Alibaba Глава NVIDIA Дженсен Хуанг (Jensen Huang) объявил, что из-за экспортных ограничений доля компании на рынке передовых чипов в Китае сократилась с 95 % до нуля. Этому также способствовала стратегия Пекина, направленная на самообеспечение местного рынка. В связи с этим планы NVIDIA возобновить отгрузки ИИ-ускорителей H20, на которые ранее были установлены ограничения правительством США, встретили в Китае довольно прохладно. Более того, в Китае вынесли запрет местным компаниям на покупку разработанного специально для местного рынка ускорителя NVIDIA RTX Pro 6000D, поскольку пришли к выводу, что китайские ИИ-чипы не уступают продукции NVIDIA, разрешённой к экспорту в Китай.
16.10.2025 [15:53], Руслан Авдеев
NVIDIA поможет Starcloud отправить в космос первый ИИ-спутник с H100Появление массовых космических дата-центров уже не за горами. В скором времени вывести на орбиту ИИ-спутник намерен стартап Starcloud (ранее Lumen Orbit), участвующий в грантовой программе NVIDIA Inception. В Starcloud заявляют, что в космосе доступна практически неограниченная возобновляемая энергия, которая даже с учётом расходов на запуск на порядок дешевле, чем на Земле. При этом постоянное нахождение Солнца в «пределах прямой видимости» позволяет отказаться от мощных резервных источников питания. Затраты ожидаются в основном до вывода в космос, а после предполагается десятикратная «экономия» углеродных выбросов в течение всего жизненного цикла в сравнении с ЦОД на Земле. Охлаждение в космосе тоже практически «бесплатное» и «безлимитное». Запуск спутника запланирован на ноябрь 2025 года. Речь идёт о дебютном использовании ИИ-ускорителей NVIDIA H100 в космосе. 60-килограммовый спутник Starcloud-1 размером с небольшой холодильник должен обеспечить в 100 раз более эффективные вычисления, чем любой предыдущий космический проект аналогичного назначения. 
Источник изображения: Starcloud На начальном этапе космические дата-центры будут применяться для анализа данных наблюдений за земной поверхностью. Обработка данных в режиме реального времени в космосе обеспечивает огромные преимущества в критических ситуациях — при распознавании лесных пожаров, получении сигналов о бедствии и др. Инференс в космосе, т.е. там же, где будут собираться данные, позволяет выдавать результаты практически немедленно, снижая задержки с часов до минут. Методы наблюдения за Землёй включают съёмки камерами в нескольких диапазонах и радарами с синтезированной апертурой (SAR) для создания трёхмерных карт с высоким разрешением. SAR, в частности, генерируют около 10 Гбайт данных в секунду, поэтому обрабатывать информацию на месте намного выгоднее, чем отправлять её на Землю. 
Источник изображения: Starcloud В Starcloud подчёркивают необходимость быть конкурентоспособными на фоне наземных ЦОД, поэтому компания выбрала ИИ-ускорители NVIDIA. Вместе с тем Starcloud — недавний «выпускник» программы Google for Startups Cloud AI Accelerator, поэтому для тестов будет использоваться LLM Gemma. Что касается будущих запусков, в перспективе Starcloud рассчитывает перейти на платформу NVIDIA Blackwell. Ещё осенью 2024 года сообщалось, что Lumen Orbit проектирует на орбите гигантские гигаваттные дата центры. Идея популярна — основатель Amazon Джефф Безос (Jeff Bezos) в начале октября заявлял, что в космосе скоро появится множество ЦОД гигаваттного масштаба. |
|

