Материалы по тегу: инференс
|
10.01.2026 [09:18], Руслан Авдеев
Не «пузырь», а «суперцикл» — к 2030 году на ЦОД будет потрачено $3 трлнСогласно докладу JLL 2026 Global Data Center Outlook, до 2030 года на ЦОД потребуется $3 трлн вложений. Это крупнейший инвестиционный «суперцикл» в истории. В докладе учитываются данные рынка, региональные прогнозы и стратегические сдвиги в индустрии ЦОД. По оценкам JLL, в 2025–2030 гг. появятся ЦОД общей мощностью около 97 ГВт. Общая мощность ЦОД достигнет примерно 200 ГВт, т.е. фактически удвоится, что потребует значительных инвестиций. Как считают в JLL, такой рост приведёт к созданию активов коммерческой недвижимости в объёме $1,2 трлн, что потребует около $870 млрд нового долгового финансирования. Кроме того, пользователи ЦОД потратят $1–$2 трлн на обновление парка ИИ-ускорителей и сетевой инфраструктуры. В совокупности инвестиции достигнут приблизительно $3 трлн к 2030 году. Как сообщает Datacenter Dynamics, в рамках прогноза JLL среднегодовой темп прироста глобального сектора ЦОД (CAGR) составит 14 % до 2030 года. Но, например, оценка Omdia на тот же период более консервативна. Несмотря на опасения экспертов, допускающих появление «ИИ-пузыря», в JLL утверждают, что существующие метрики не свидетельствуют о его возможном формировании. JLL утверждает, что сектор сохраняет здоровые фундаментальные показатели — глобальную загрузку мощностей на уровне 97 %, а 77 % строящихся уже объектов забронированы арендаторами. 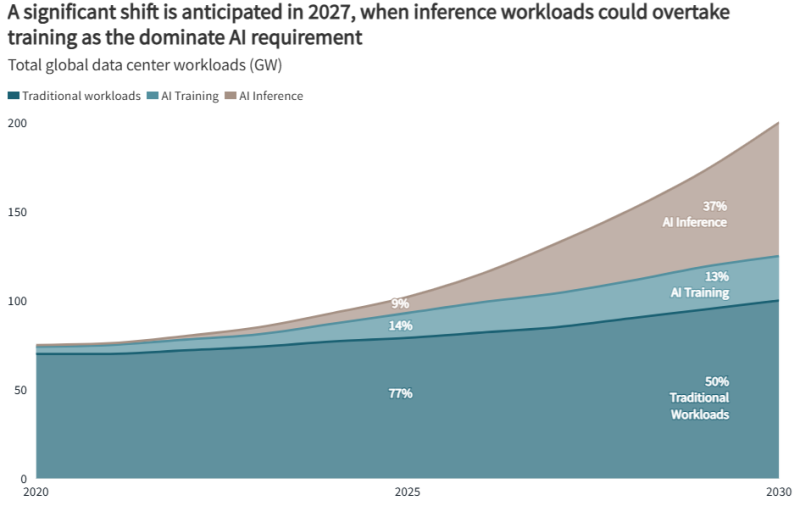
Источник изображения: JLL Research Впрочем, есть и некоторые проблемы, негативно влияющие на мировой рынок ЦОД. Например, ограничения в цепочках поставок ведут к задержкам сроком выполнения заказов на оборудование по всему миру. По данным компании, среднее время выполнения достигает 33 недель, что на 50 % дольше в сравнении с 2020 годом. Кроме того, проблемы с цепочками отражаются на стоимости строительства, CAGR в этом секторе составляет 7 % ежегодно. По прогнозам JLL, в 2026 году стоимость строительства увеличится на 6 %, до $11,3 млн/МВт. Тем не менее, аналитики JLL подчёркивают, что увеличение сроков выполнения заказов свидетельствует о росте уверенности в рынке, а не о потенциальном спаде на нём. 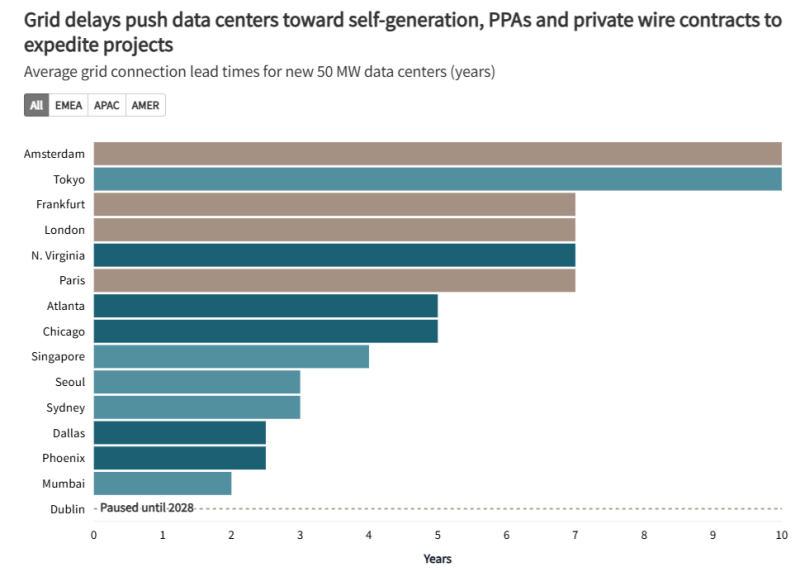
Источник изображения: JLL Research Ключевой проблемой остаются ограничения, связанные с энергетикой. Прогнозируется рост соответствующей индустрии, связанный с энергоёмкими ИИ-сервисами. В частности, время присоединения ЦОД к энергосетям на основных рынках превышает четыре года, поэтому придётся прибегнуть к «энергетическим инновациям», а некоторые операторы дата-центров стремятся организовать локальные мощности для генерации энергии. JLL ожидает, что ключевую роль в масштабировании поставок энергии в США будет играть газовая энергетика, причём и как временное, и как постоянное решение для получения энергии непосредственно на территории кампусов. Впрочем, отмечается, что для APAC и EMEA такие решения менее привлекательны, поскольку не являются «устойчивыми». Потенциальным надёжным источником электричества называется и атомная энергетика, но в JLL признают малую вероятность того, что до 2030 года появятся новые значительные мощности АЭС. 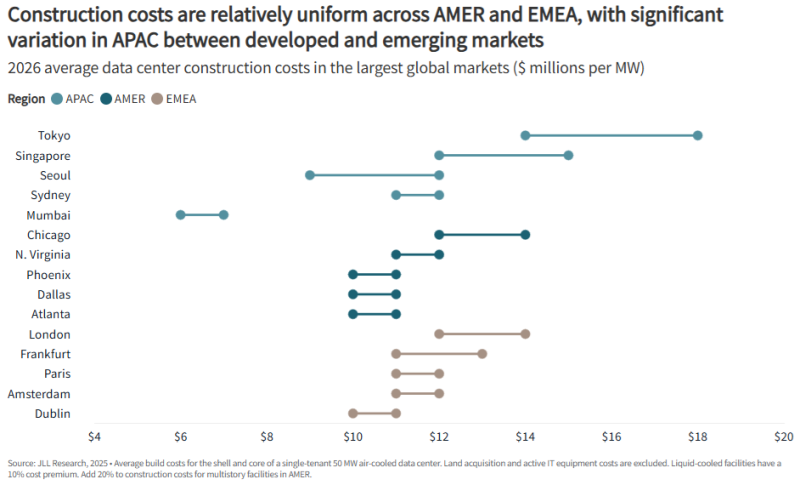
Источник изображения: JLL Research По данным JLL, на ИИ-нагрузки к 2030 году, возможно, будет приходиться половина всех мощностей ЦОД, т.е. их доля увеличится вдвое по сравнению с 2025 годом. Также прогнозируется, что к 2027 году затраты на инференс будут больше, чем на обучение, благодаря чему спрос может сместиться с централизованных кластеров на распределённые региональные центры. До 2030 года на американские проекты будет приходиться около половины всех новых мощностей ЦОД, там же будут отмечаться и самые высокие темпы прироста рынка. В Азиатско-Тихоокеанском регионе мощности почти удвоятся, с 32 ГВт до 57 ГВт к 2030 году, а EMEA прирастёт на скромные 13 ГВт. 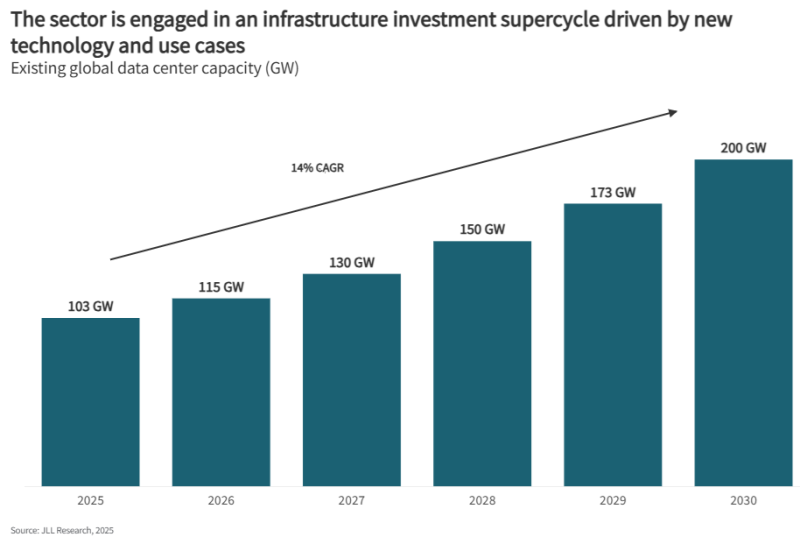
Источник изображения: JLL Research В докладе также анализируется быстрый рост на связанных с сектором рынках капитала. На базовые, с низким уровнем риска инвестиционные стратегии теперь приходится около 24 % активности по привлечению средств на ЦОД. За последние пять лет объём слияний и поглощений на рынке составил более $300 млрд и ожидается, что в будущем инвестиции сместятся в сторону рекапитализации и совместных предприятий. В компании уверены, что стремительное появление крупных сделок в сфере ИИ и неооблачного сектора определило 2025 год, как год трансформации сектора ЦОД и инфраструктуры. Структурирование капитала для новых компаний может оказаться сложным, поскольку кредиторы и партнёры по акционерному капиталу требуют надлежащих механизмов обеспечения защиты многомиллиардных инвестиций. Масштаб и особые требования к инфраструктуре сделок требуют инноваций при финансировании, позволяющих обеспечить баланс роста технологий ИИ и неооблачных проектов с надлежащим снижением рисков. Стоит отметить, что в сентябре 2025 года Bain Global Technology Report прогнозировала, что расходы ИИ-отрасли к 2030 году могут оказаться на $800 млрд больше её доходов.
25.12.2025 [02:15], Игорь Осколков
NVIDIA купит за $20 млрд активы разработчика ИИ-ускорителей Groq — это самая дорогая покупка в истории компанииNVIDIA приобретёт активы Groq, своего конкурента в области ИИ-ускорителей, за $20 млрд, передаёт CNBC. Сама Groq заявила, что «заключила неисключительное лицензионное соглашение с NVIDIA на технологии инференса» и что основатель и генеральный директор Groq Джонатан Росс (Jonathan Ross), а также президент компании Санни Мадра (Sunny Madra) и другие высокопоставленные сотрудники «присоединятся к NVIDIA, чтобы помочь продвижению и масштабированию лицензированной технологии». При этом Groq продолжит свою деятельность как независимая компания под руководством Саймона Эдвардса (Simon Edwards). Финансовый директор Nvidia Колетт Кресс (Colette Kress) отказалась комментировать сделку. По-видимому, речь фактически идёт о поглощении Groq, а столь необычная форма сделки выбрана, по примеру других, в попытке снизить внимание к ней регулирующих органов. Стоимость сделки официально не называется, однако Алекс Дэвис (Alex Davis), глава Disruptive, которая инвестировала в Groq более $500 млн, называет сумму в $20 млрд, причём «живыми» деньгами. Дэвис сообщил CNBC, что NVIDIA получит все активы Groq, за исключением её облачного бизнеса. Groq заявила, что «GroqCloud продолжит работать без перебоев». В электронном письме сотрудникам, полученном CNBC, глава NVIDIA Дженсен Хуанг (Jensen Huang) заявил, что сделка расширит возможности NVIDIA: «Мы планируем интегрировать ускорители Groq в архитектуру NVIDIA AI Factory, расширив платформу для обслуживания ещё более широкого спектра задач инференса и рабочих нагрузок в реальном времени». Хуанг добавил: «Хотя мы пополняем наши ряды талантливыми сотрудниками и лицензируем интеллектуальную собственность Groq, мы не приобретаем Groq как компанию». 
Источник изображения: Groq Эта сделка является крупнейшей покупкой NVIDIA за всю историю. До этого самой крупной сделкой была покупка Mellanox почти за $7 млрд в 2019 году. В конце октября у NVIDIA было $60,6 млрд наличных средств и краткосрочных инвестиций, что на $13,3 млрд больше, чем в начале 2023 года. По схожей с Groq схеме была организована и сделка c Enfabrica, в рамках которой NVIDIA заплатила $900 млн деньгами и акциями за лицензирование технологий и переход главы Enfabrica Рочана Санкара (Rochan Sankar) и других ключевых в NVIDIA. Всего три месяца назад Groq, основанная в 2016 году разработчиками ИИ-ускорителей Google TPU, привлекла $750 млн при оценке примерно в $6,9 млрд. Раунд возглавила Disruptive, к которой присоединились Blackrock, Neuberger Berman, Deutsche Telekom Capital Partners, Samsung, Cisco, D1, Altimeter, 1789 Capital и Infinitum. Повлияло ли на решение NVIDIA слухи о намерении Intel купить разработчика ИИ-ускорителей для инференса SambaNova, который наряду с Cerebras является одним из немногих стартапов, способных составить хоть какую-то серьёзную конкуренцию NVIDIA, не уточняется. Сама Groq планировала достичь выручки в $500 млн в этом году. По словам Дэвиса, компания не планировала продажу, когда к ней обратилась NVIDIA. В сентябре NVIDIA объявила о намерении вложить $5 млрд в Intel, а также инвестировать до $100 млрд в OpenAI. Впрочем, последняя сделка носит циклический характер и пока далеко не продвинулась.
16.12.2025 [17:50], Владимир Мироненко
Универсальный ИИ-процессор Electron E1 в 100 раз энергоэффективнее традиционных CPUСтартап из Питтсбурга (Pittsburgh) Efficient Computer выпустил оценочный набор универсального процессора Electron E1 (EVK). Как сообщает компания, Electron E1 представляет собой настоящую альтернативу чипам с использованием традиционной архитектуры фон Неймана, способную обеспечить значительно более высокую энергоэффективность, в 100 раз превышающую показатели обычных маломощных процессоров, таких как Arm Cortex-M33 и Cortex-M85. Electron E1 предназначен для выполнения сложных задач обработки сигналов и инференса. Он основан на т.н. Efficient Fabric, разработанной компанией запатентованной архитектуре пространственного потока данных, которая позволяет снизить «чрезмерное» энергопотребление, связанное с перемещением данных между памятью и вычислительными ядрами, характерное для традиционных систем фон Неймана. При этом «разработчики по-прежнему получают привычный опыт программирования, но с существенно более высокой энергоэффективностью». Генеральный директор Efficient Брэндон Лючия (Brandon Lucia) в интервью EE Times заявил, что предыдущие попытки отойти от подхода фон Неймана так и не были полностью реализованы: «Были мимолётные альтернативы, которые появлялись и исчезали». Он отметил, что одним из ограничений во многих альтернативах был отказ от универсальности вычислений: «Это действительно критически важно». Нечто похожее предлагает и NextSilicon Maverick. 
Источник изображения: Efficient Computer Процессор включает 128 Кбайт сверхэкономичной кеш-памяти, 3 Мбайт SRAM и 4 Мбайт энергонезависимой MRAM, а его производительность может достигать 21,6 GOPS (млрд операций в секунду) при 200 МГц в высоковольтном режиме и 5,4 GOPS при 50 МГц в низковольтном режиме. Архитектура Fabric коренным образом переосмысливает способ выполнения вычислений, уменьшая необходимость в перераспределении данных между памятью и процессорами, говорит Лючия. Это достигается за счёт пространственного отображения операций по сетке вычислительных элементов, каждый из которых активируется только тогда, когда доступны его входные данные в отличие от непрерывного цикла инструкций и косвенной адресации данных, которые доминируют в традиционных конвейерах CPU. Лючия отметил, что универсальный процессор важен для ИИ-технологий, поскольку он представляет собой нечто гораздо большее, чем просто алгоритмы в физическом мире — он обеспечивает, в том числе, интеграцию данных с датчиков, цифровую обработку сигналов, шифрование и преобразование: «Если ваша архитектура специализируется только на одном типе вычислений, все остальные функции остаются невостребованными». 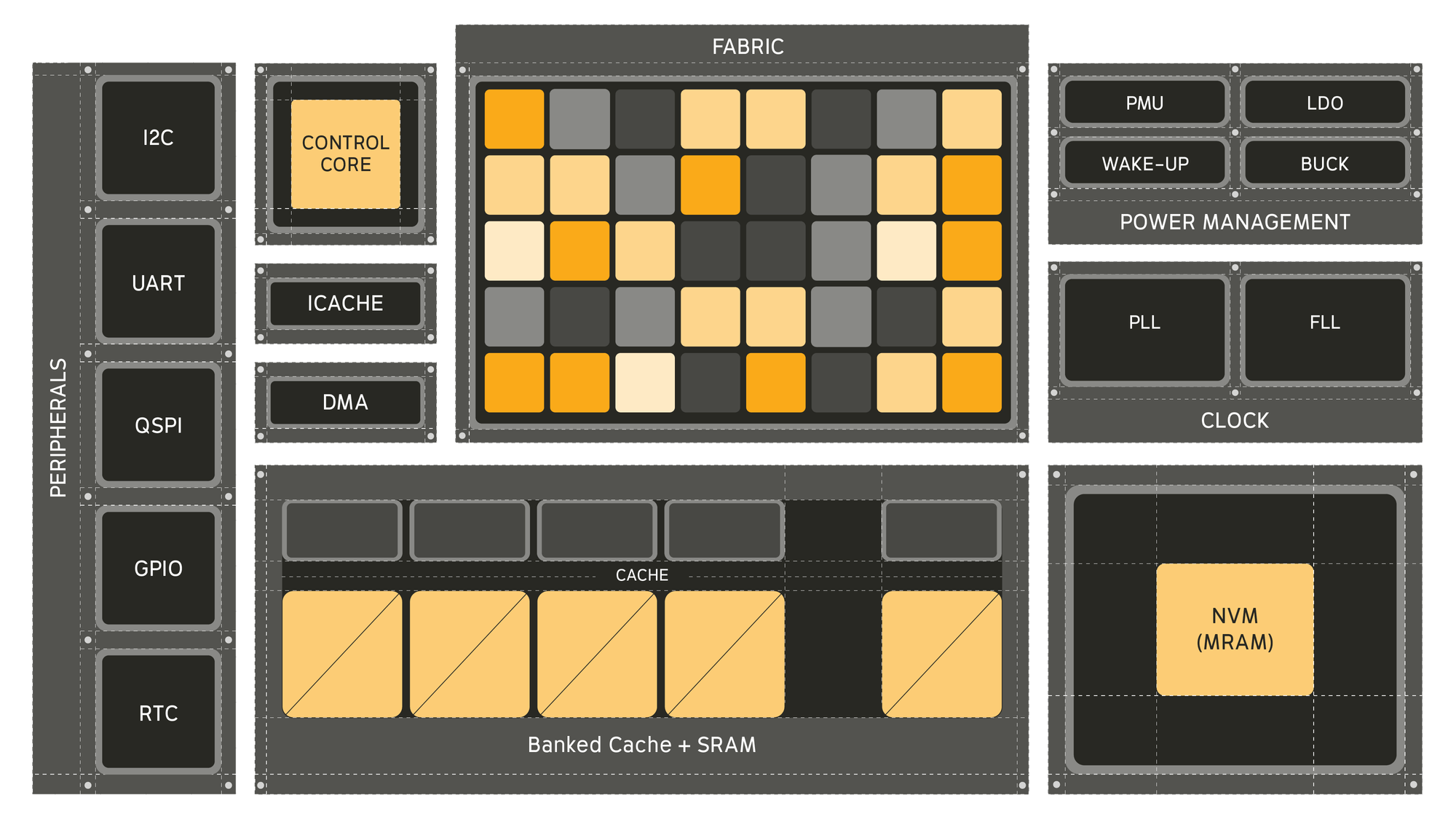
Источник изображения: Efficient Computer По словам главы Efficient, Electron E1 разработан для поддержки всего кода, необходимого для работы приложения, что делает его идеальным для периферийных вычислений, встроенных систем и ИИ-приложений: «Разработчики могут использовать уже имеющийся у них код». Лючия отметил, что процессор лучше всего подходит для устройств, требующих длительного времени автономной работы, а также условий ограниченного энергопотребления, например, для использования в дронах и промышленных датчиках. Чип уже используется в устройствах партнёра Efficient, компании BrightAI, позволяя обрабатывать ИИ-нагрузки в реальном времени на периферии и снижая потребность в энергоемких облачных вычислениях для таких задач, как обработка сигналов и инференс. Лючия сообщил, что компания видит большие перспективы для использования чипа в робототехнике, автомобилестроении, космосе и оборонных приложениях, которые имеют ограничения по размерам и мощности. Что касается E1 EVK, то он, по словам компании, разработан для того, чтобы максимально упростить изучение потенциала нового процессора. Независимо от того, разрабатываете ли вы новое ПО, проводите анализ энергопотребления или портируете существующее ПО, EVK предоставляет:
В случае отсутствия оборудования можно использовать решение Electron E1 Cloud EVK, которое предоставляет размещённую среду со всеми возможностями физической платы. Как физический EVK, так и облачный EVK доступны в рамках программы раннего доступа Efficient Computer.
08.12.2025 [08:49], Сергей Карасёв
Японские Arm-процессоры Fujitsu MONAKA пропишутся в «зелёном» европейском ИИ-облаке ScalewayЯпонская корпорация Fujitsu и французский облачный провайдер Scaleway объявили о заключении соглашения о стратегическом сотрудничестве, направленном на формирование в Европе устойчивой ИИ-платформы с прицелом на суверенитет данных. Стороны намереные использовать будущие CPU Fujitsu для инференса. Речь идёт о Fujitsu Monaka, выход которых запланирован на 2027 год. Эти 2-нм чипы с 3.5D-упаковкой получат до 144 вычислительных ядер с архитектурой Arm, а также 12 каналов оперативной памяти DDR5, интерфейс PCIe 6.0 с CXL 3.0. Для систем на базе Monaka предусмотрено воздушное охлаждение. Отмечается, что в настоящее время многие организации используют ИИ-модели в своих операциях и производственных процессах на постоянной основе. Это порождает потребность в предсказуемой производительности и контролируемых эксплуатационных расходах при одновременном снижении негативного воздействия на окружающую среду. Архитектуры на базе CPU способствуют решению подобных задач, поскольку обеспечивают стабильное быстродействие, более низкое по сравнению с GPU энергопотребление и простую интеграцию в существующие окружения. 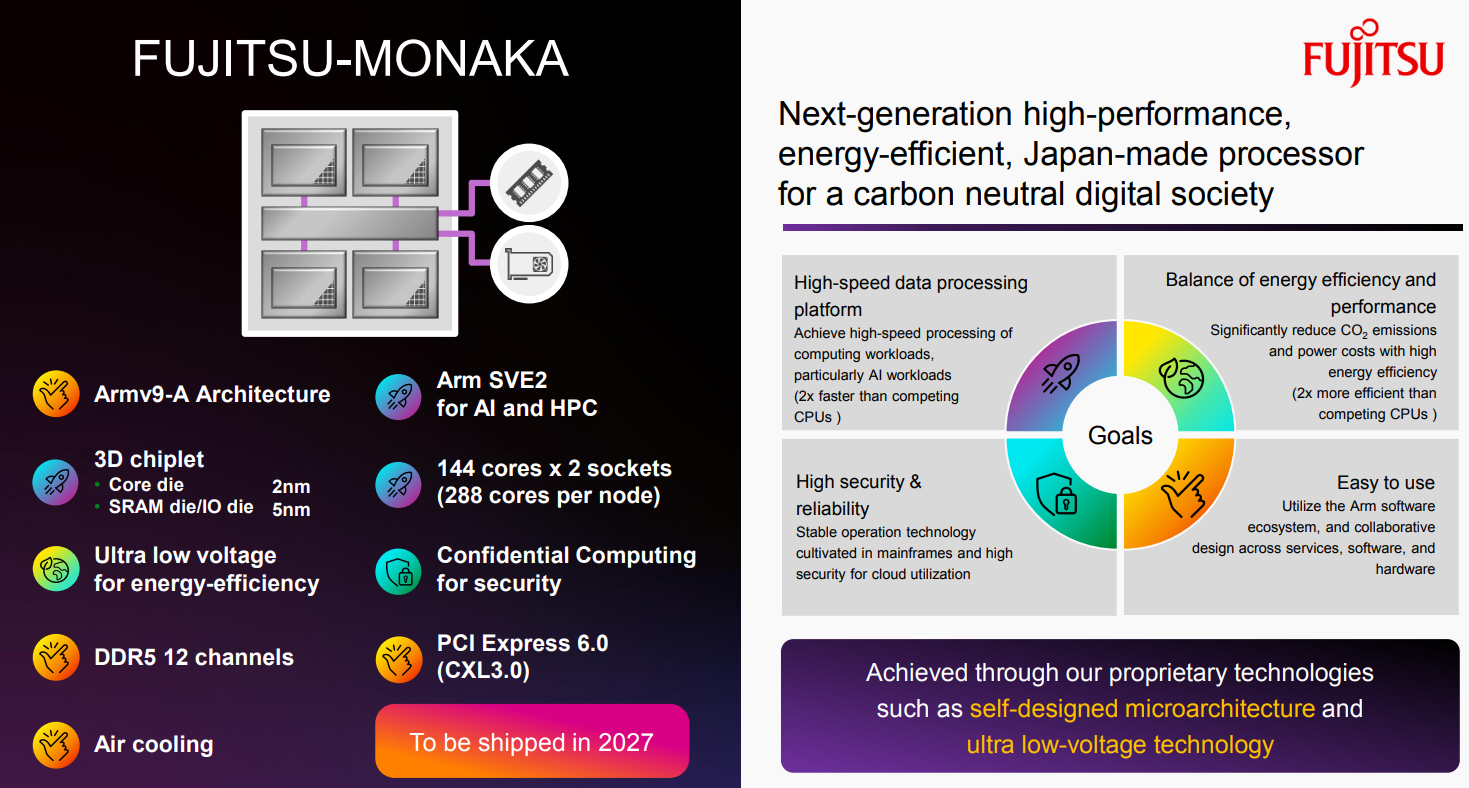
Источник изображения: Fujitsu В рамках партнёрства Fujitsu и Scaleway проведут совместное тестирование CPU-платформ для задач ИИ: цель заключается в создании оптимальных инфраструктурных решений, адаптированных к конкретным рабочим нагрузкам. В результате, заказчики смогут выбрать наиболее подходящую систему с учётом своих потребностей и бюджета. В целом, платформы на базе Monaka станут дополнением к GPU-системам. Предварительные результаты испытаний, предоставленные Fujitsu, говорят о повышении энергоэффективности в 1,9 раза и снижении затрат в 1,7 раза в случае определённых нагрузок, связанных с инференсом. Платформы с чипами Monaka, как утверждается, могут поддерживать ИИ-модели, насчитывающие до 70 млрд параметров.
02.12.2025 [09:39], Владимир Мироненко
Миллионы IOPS, без посредников: NVIDIA SCADA позволит GPU напрямую брать данные у SSDNVIDIA разрабатывает SCADA (Scaled Accelerated Data Access, масштабируемый ускоренный доступ к данным) — новую IO-архитектуру, где GPU инициируют и управляют процессом работы с хранилищами, сообщил Blocks & Files. SCADA отличается от существующего протокола NVIDIA GPUDirect, который, упрощённо говоря, позволяет ускорить обмен данными с накопителями, напрямую связывая посредством RDMA память ускорителей и NVMe SSD. В этой схеме CPU хоть и не отвечает за саму передачу данных, но оркестрация процесса всё равно ложится на его плечи. SCADA же предлагает перенести на GPU и её. Обучение ИИ-моделей обычно требует передачи больших объёмов данных за сравнительно небольшой промежуток времени. При ИИ-инференсе осуществляется передача небольших IO-блоков (менее 4 Кбайт) во множестве потоков, а время на управление каждой передачей относительно велико. Исследование NVIDIA показало, что инициирование таких передач самим GPU сокращает время и ускоряет инференс. В результате была разработана схема SCADA. NVIDIA уже сотрудничает с партнёрами по экосистеме хранения данных с целью внедрения SCADA. Так, Marvell отмечает: «Потребность в ИИ-инфраструктуре побуждает компании, занимающиеся СХД, разрабатывать SSD, контроллеры, NAND-накопители и др. технологии, оптимизированные для поддержки GPU, с акцентом на более высокий показатель IOPS для ИИ-инференса. Это будет принципиально отличаться от технологий для накопителей, подключенных к CPU, где главными приоритетами являются задержка и ёмкость». 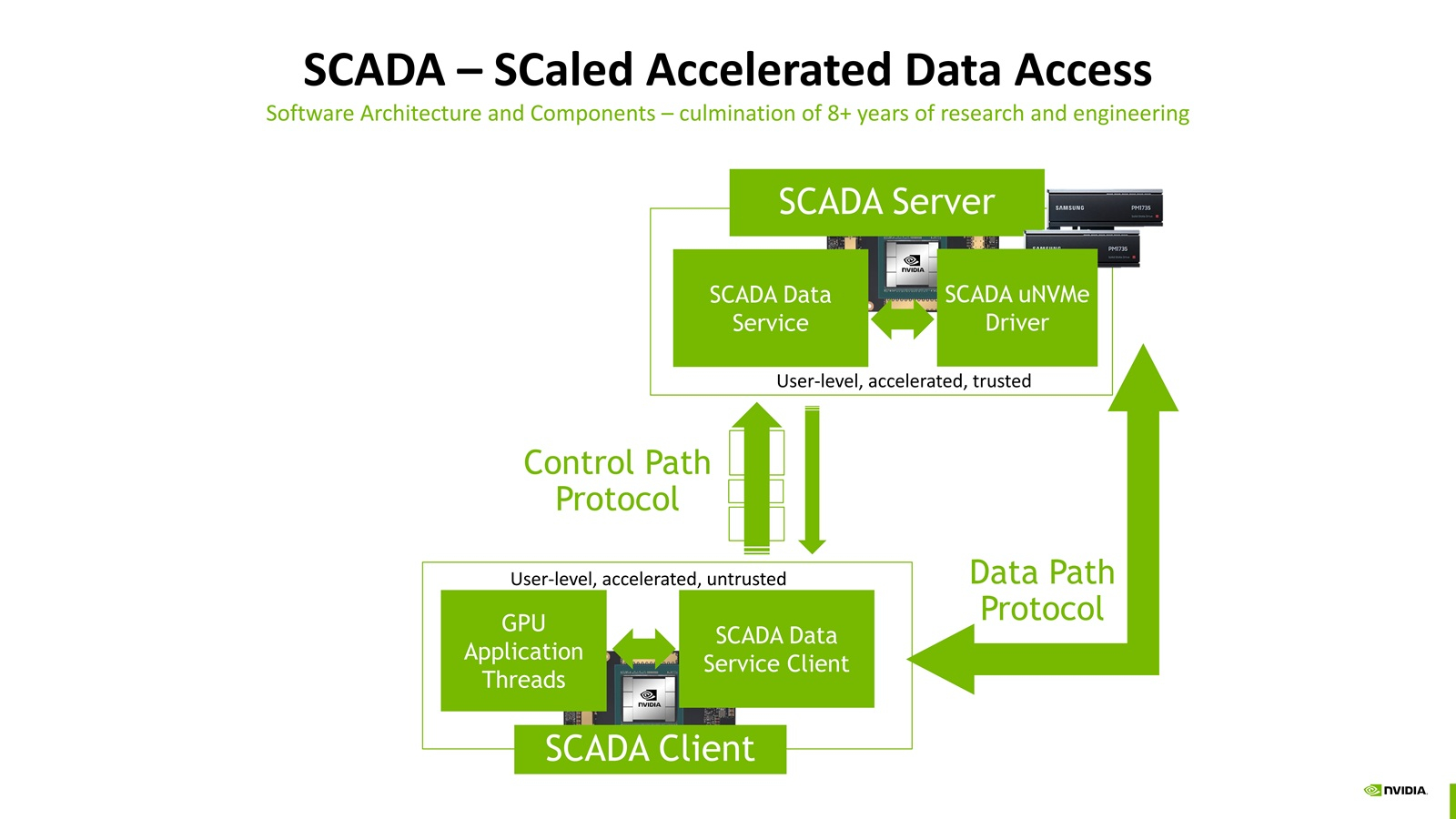
Источник изображения: NVIDIA По словам Marvell, в рамках SCADA ускорители используют семантику памяти при работе с накопителями. Однако сами SSD мало подходят для таких задач, поскольку не могут обеспечить необходимый уровень IOPS, когда во время инференса тысячи параллельных потоков запрашивают наборы данных размером менее 4 Кбайт. Это приводит к недоиспользованию шины PCIe, «голоданию» GPU и пустой трате циклов. В CPU-центричной архитектуре, которая подходит для обучения моделей, параллельных потоков данных десятки, а не тысячи, а блоки данных крупные — от SSD требуется высокие ёмкость и пропускная способность, а также малая задержка, поскольку свою задержку в рамках СХД также внесут PCIe и Ethernet. Внедрение PCIe 6.0 и PCIe 7.0, конечно, само по себе ускорит обмен данными, но контроллеры SSD также нуждаются в обновлении. Они должны уметь использовать возможности SCADA, иметь оптимальные схемы коррекции ошибок для малых блоков данных и быть мультипротокольными (PCIe, CXL, Ethernet). Компания Micron также участвует в разработке SCADA. 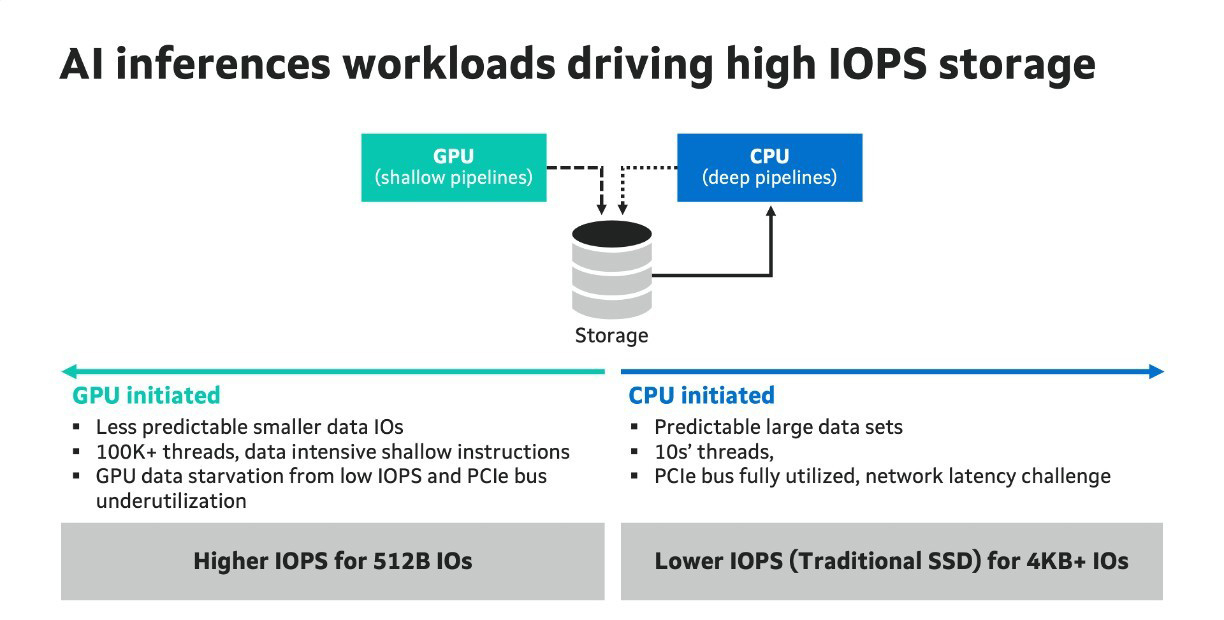
Источник изображения: Micron В рамках SC25 Micron показала прототип SCADA-хранилища на базе платформы H3 Platform Falcon 6048 с PCIe 6.0 (44 × E1.S NVMe SSD + 6 × GPU/DPU/NIC), оснащённой 44 накопителями Micron 9650 (7,68 Тбайт, до 5,4 млн на случайном чтении 4K-блоками с глубиной очереди 512, PCIe 6.0), тремя коммутаторами Broadcom PEX90000 (144 линии PCIe 6.0 в каждом), одним процессором Intel Xeon (PCIe 5.0) и тремя ускорителями NVIDIA H100 (PCIe 5.0). Micron заявила, что система «демонстрирует линейное масштабирование производительности от 1 до 44 SSD», доходя до 230 млн IOPS, что довольно близко к теоретическому максимуму в 237,6 млн IOPS. «В сочетании с PCIe 6.0 и высокопроизводительными SSD архитектура [SCADA] обеспечивает доступ к данным в режиме реального времени для таких рабочих нагрузок, как векторные базы данных, графовые нейронные сети и крупномасштабные конвейеры инференса», — подытожила Micron.
25.11.2025 [16:24], Руслан Авдеев
Нехватка ИИ-мощностей и проблемы с производительностью вынудили многих клиентов AWS обратиться к конкурентамЛетом 2025 года облачный бизнес Amazon (AWS) с трудом справлялся с растущим спросом на ИИ и упустил часть доходов. Сервис Bedrock занимает ключевое место в развитии ИИ-проектов компании. Однако летом Bedrock столкнулся с нехваткой мощностей, из-за чего некоторые клиенты ушли к конкурентам, в том числе к Google, сообщает Business Insider. Это привело к потерям десятков миллионов долларов и отложенной выручки. Например, проект Fortnite стоимостью $10 млн достался Google Cloud после того, как AWS не смогла выделить ей необходимые квоты (лимит на токены или вызовы API). Согласно внутреннему документу AWS, попавшему в распоряжение журналистов, нефтетрейдер Vitol также перенёс проекты из AWS, а некоторые крупные клиенты, включая Atlassian и GovTech Singapore, летом были вынуждены ожидать увеличения квот, что привело к «отсроченным продажам» минимум на $52,6 млн. Более того, задержки с одобрением выделения мощностей и отказ в обработке нерегулярных, вынудили Stripe, Robinhood и Vanguard отказаться от переноса нагрузок в Bedrock. Подчёркивается, что проблемы Bedrock потенциально ведут к потерям выручки и проблемам с клиентами. Это объясняет, почему облачные компании стремятся построить как можно больше ИИ ЦОД. Высокий спрос хорош только тогда, когда можно его удовлетворить и удержать клиентов от перехода к конкурентам. Бывшие и действующие сотрудники AWS отмечают, что проблемы с вычислительными мощностями были одними из наиболее значимых для компании в сентябре. AWS и раньше испытывала проблемы с нехваткой мощностей даже для собственных нужд, но сейчас ситуация обострилась. 
Источник изображения: LARAM/unsplash.com Тем временем в Amazon утверждают, что Bedrock быстро растёт, а AWS стремительно наращивает мощности для удовлетворения спроса, за 12 месяцев добавив 3,8 ГВт. Это больше, чем смогу получить любой другой облачный провайдер. AWS удвоила мощность с 2022 года и намерена сделать то же самое к 2027 году. Компания и далее намерена быть «очень агрессивной» в деле масштабирования вычислительных мощностей, причём AWS может монетизировать новые мощности «практически незамедлительно», а Bedrock имеет не меньший потенциал роста, чем EC2. Частично проблемы с Bedrock могут быть связаны с тем, что компания отдаёт предпочтение крупным клиентам. В октябре заявлялось, что большинство задач Bedrock выполняется с помощью «доморощенных» ИИ-чипов Trainium, но в основном нагрузки приходятся на нескольких очень крупных клиентов, которые, по-видимому, готовы вкладываться в развитие инструментов на не самой популярной платформе. Ожидается, что компании среднего размера в ближайшие месяцы тоже начнут использовать Trainium нового поколения. Впрочем, последние иногда всё ещё не могут конкурировать с чипами NVIDIA. Впрочем, помешала Bedrock не только нехватка мощностей. Так, Figma, Intercom и Wealthsimple предпочли использовать LLM Claude в Google Cloud или на платформе самой Anthropic из-за недостатка функций и высокой задержки в Bedrock. Британская госслужба Government Digital Service рассматривала переход в Microsoft Azure только потому, что Claude 3.7 Sonnet работала медленнее на платформе Bedrock. Thomson Reuters также выбрала Google Cloud для своего ИИ-продукта CoCounsel, поскольку сервис AWS оказался на 15–30 % медленнее и не имел ключевых правительственных сертификатов. 
Источник изображения: Vitaly Gariev/unspalsh.com В документе AWS отмечается, что платформа Bedrock уступает Google. Для моделей Gemini квоты в пять-шесть раз выше, а Gemini Pro побеждает Claude в Bedrock во многих бенчмарках. Хуже того, Gemini Flash обеспечивает сравнимое качество при кратно меньших затратах. Некоторые стартапы буквально «сбежали» по этой причине. TainAI перенесла 40 % задач на Gemini Flash, отказавшись от Claude в Bedrock и экономя тем самым $85 тыс./день, а Hotel Planner намеревалась перейти в Google Cloud или к OpenAI. Всё это было ещё до запуска Gemini 3. Ещё более важная проблема, согласно документу, заключается в том, что у AWS нет целостного видения ИИ-инференса, хотя это ключевой сервис Bedrock. Это сыграло на руку не только гиперскейлерам, но и компаниями поменьше. Без чёткой стратегии AWS рискует упустить одну из самых привлекательных возможностей на рынке ИИ. Но этим проблемы не ограничиваются. Октябрьский сбой AWS продемонстрировал зависимость мировой Сети от лидера облачного рынка, так что многие задумались о переносе хотя бы части нагрузок на другие платформы, а Евросоюз рассматривает необходимость ограничения возможностей американских облачных гигантов. В последние недели инвесторы обеспокоены расходами на ИИ, опасаясь возникновения очередного пузыря на рынке IT. В этом контексте дефицит мощностей для Amazon играет двоякую роль. Это свидетельствует, что спрос со стороны клиентов до сих пор высок. С другой стороны, дефицит — ещё одна причина тратить больше денег в развитие инфраструктуры, что повышает риск возникновения пузыря. Amazon утверждает, что намерена выделить $125 млрд на капитальные затраты в текущем году, и ещё больше — в 2026-м.
25.11.2025 [11:24], Сергей Карасёв
Стартап Kneron представил чип KL1140 для работы с ИИ-моделями на периферииАмериканский стартап Kneron, по сообщению ресурса SiliconANGLE, разработал ИИ-чип KL1140, предназначенный для запуска больших языковых моделей (LLM) на периферийных устройствах. Утверждается, что изделие обеспечивает ряд существенных преимуществ перед облачными развёртываниями. Kneron, основанная в 2015 году, базируется в Сан-Диего (Калифорния, США). Стартап проектирует чипы для всевозможного оборудования с ИИ-функциями: это могут быть роботы, подключённые автомобили и пр. Ранее Kneron представила решение KL730, которое объединяет четырёхъядерный CPU на архитектуре Arm и акселератор для задач инференса. В 2023 году компания привлекла на развитие $49 млн от Foxconn and HH-CTBC Partnership (Foxconn Co-GP Fund), Alltek, Horizons Ventures, Liteon Technology Corp, Adata и Palpilot. В общей сложности на сегодняшний день Kneron получила более $200 млн от различных инвесторов. 
Источник изображения: Kneron Характеристики нового чипа KL1140 полностью пока не раскрываются. Kneron заявляет, что это первый нейронный процессор, способный полноценно работать с сетями-трансформерами на периферии. Связка из четырёх чипов KL1140, как утверждается, обеспечивает производительность на уровне GPU при работе с ИИ-моделями, насчитывающими до 120 млрд параметров. При этом энергопотребление сокращается на 50–66 %. Суммарные затраты на оборудование могут быть снижены в 10 раз по сравнению с существующими облачными решениями. Среди других преимуществ запуска LLM на периферийных устройствах названы уменьшение задержки, отсутствие необходимости отправки конфиденциальных данных на внешние серверы и возможность использования даже без подключения к интернету. Чип KL1140 ориентирован на такие задачи, как обработка естественного языка в реальном времени, голосовые интерфейсы, системы машинного зрения, интеллектуальные платформы видеонаблюдения и др. Разработчики могут применять изделие для безопасного локального развёртывания приложений ИИ без необходимости использования облачных ресурсов.
24.11.2025 [15:14], Сергей Карасёв
Технологии тысячеядерного RISC-V-ускорителя Esperanto будут переданы в open sourceСтартап Ainekko, специализирующийся на разработке аппаратных и программных решений в сфере ИИ, по сообщению EE Times, приобрёл интеллектуальную собственность и некоторые активы компании Esperanto Technologies. Речь идёт о дизайне чипов, программных инструментах и фреймворке. Фирма Esperanto, основанная в 2014 году, специализировалась на создании высокопроизводительных ускорителей с архитектурой RISC-V для задач НРС и ИИ. В частности, было представлено изделие ET-SoC-1, объединившее 1088 энергоэффективных ядер ET-Minion и четыре высокопроизводительных ядра ET-Maxion. Основной сферой применения чипа был заявлен инференс для рекомендательных систем, в том числе на периферии. Однако в июле нынешнего года стало известно, что Esperanto сворачивает деятельность и ищет покупателя на свои разработки — ключевых инженеров переманили крупные компании. А продать чипы Meta✴, в чём, по-видимому, и заключался изначальный план, не удалось. Как рассказала соучредитель Ainekko Таня Дадашева (Tanya Dadasheva), её компания работает с чипами Esperanto в течение примерно полугода. Изначально компания планировала использовать чипы Esperanto для запуска своего софтверного стека. В частности, удалось перенести llama.cpp up и tinygrad. Когда стало понятно, что Esperanto вряд ли выживет, было принято решение выкупить разработки стартапа. Во всяком случае, это лучше, чем просто закрыть компанию, оставив её заказчиков ни с чем, как поступила AMD с Untether AI. 
Источник изображения: Esperanto Ainekko планирует передать сообществу open source технологии Esperanto, связанные с многоядерной архитектурой RISC-V, включая RTL, референсные проекты и инструменты разработки. Предполагается, что решения Esperanto будут востребованы прежде всего в области периферийных устройств, где большое значение имеет энергоэффективность. Архитектура Esperanto, как утверждается, подходит для таких задач, как робототехника и дроны, системы безопасности, встраиваемое оборудование с ИИ-функциями и пр. Второй соучредитель Ainekko Роман Шапошник (Roman Shaposhnik) добавляет, что многоядерная архитектура Esperanto подходит не только для разработки ИИ-чипов, но и для создания «универсальной вычислительной платформы». Сама Ainekko намерена выпустить чип с восемью ядрами Esperanto и 16 Мбайт памяти MRAM, разработанной стартапом Veevx. Отмечается, что соучредитель и генеральный директор Veevx, ветеран Broadcom Даг Смит (Doug Smith), является ещё одним сооснователем Ainekko. В дальнейшие планы входит разработка процессора с 256 ядрами: по производительности он будет сопоставим с чипом Broadcom BCM2712 (4 × 64-бит Arm Cortex-A76), лежащим в основе Raspberry Pi 5, но оптимизирован для инференса.
18.11.2025 [16:55], Владимир Мироненко
d-Matrix привлекла ещё $275 млн и объявила о разработке первого ИИ-ускорителя с 3D-памятью Raptord-Matrix сообщила о завершении раунда финансирования серии C, в ходе которого было привлечено $275 млн инвестиций с оценкой рыночной стоимости компании в $2 млрд. Общий объём привлечённых компанией средств достиг $450 млн. Полученные средства будут направлены на расширение международного присутствия компании и помощь клиентам в развёртывании ИИ-кластеров на основе её технологий. Раунд C возглавил глобальный консорциум, включающий BullhoundCapital, Triatomic Capital и суверенный фонд благосостояния Сингапура Temasek. В раунде приняли участие Qatar Investment Authority (QIA) и EDBI, M12, венчурный фонд Microsoft, а также Nautilus Venture Partners, Industry Ventures и Mirae Asset. Сид Шет (Sid Sheth), генеральный директор и соучредитель d-Matrix, отметил, с самого начала компания была сосредоточена исключительно на инференсе. «Мы предсказывали, что когда обученным моделям потребуется непрерывная масштабная работа, инфраструктура не будет готова. Последние шесть лет мы потратили на разработку решения: принципиально новой архитектуры, которая позволяет ИИ работать везде и всегда. Это финансирование подтверждает нашу концепцию, поскольку отрасль вступает в эпоху ИИ-инференса», — добавил он. d-Matrix разработала ускоритель инференса Corsair на базе архитектуры с вычислениями в памяти DIMC (digital in-memory computing) — процессорные компоненты в нём встроены в память. Ускоритель предлагается вместе с сетевой картой JetStream. Также предлагается референсная архитектура SquadRack, которая упрощает создание ИИ-кластеров на базе Corsair. Она поддерживает до восьми серверов в стойке, каждая из которых содержит восемь ускорителей Corsair. Шасси SquadRack позволяет запускать ИИ-модели размером до 100 млрд параметров, хранящиеся полностью в SRAM. По данным d-Matrix, такая конфигурация обеспечивает на порядок большую производительность по сравнению с чипами с HBM. Вместе с оборудованием компания предлагает программный стек Aviator, который автоматизирует часть работы, связанной с развертыванием ИИ-моделей на ускорителе. Aviator также включает набор инструментов для отладки моделей и мониторинга производительности. 
Источник изображения: d-Matrix В следующем году d-Matrix планирует выпустить более производительный ускоритель инференса Raptor. Это первый в мире ускоритель на базе 3D DRAM. Решение разрабатывается в партнёрстве с Alchip, известной разработками в области ASIC. Благодаря сотрудничеству уже реализована ключевая технология d-Matrix 3DIMC, представленная в тестовом кристалле d-Matrix Pavehawk. По словам компаний, новинка обеспечит до 10 раз более быстрый инференс по сравнению с решениями на базе HBM4, что позволит повысить эффективность генеративных и агентных рабочих ИИ-нагрузок. Также в Raptor будет использоваться процессор AndesCore AX46MPV от Andes Technology. Компании заявили, что их сотрудничество представляет собой конвергенцию вычислений, ориентированных на память, и инноваций в области процессоров на основе открытых стандартов для рабочих ИИ-нагрузок в масштабах ЦОД. Andes AX46MPV будет отвечать за оркестрацию наргрузок, распределение памяти, векторные вычисления и функции активации. AX46MPV — 64-бит многоядерный RISC-V-процессор с поддержкой Linux. Он включает 2048-бит блок векторной обработки (RVV 1.0), высокоскоростную векторную память (HVM) и ряд других аппаратных блоков для работы с массивными вычислениями. В совокупности эти функции обеспечивают запас производительности и гибкость ПО, необходимые для систем инференса уровня ЦОД. Референсные ядра, являющиеся ключевыми для рабочих нагрузок ИИ-трансформеров и LLM, демонстрируют прирост производительности до 2,3 раза по сравнению с предшественником AX45MPV.
11.11.2025 [19:36], Руслан Авдеев
AMD приобрела ИИ-стартап MK1, созданный ветеранами NeuralinkКомпания AMD объявила о покупке ИИ-стартапа MK1 для наращивания своих комптенций в сфере ИИ, сообщает CRN. MK1 занимается созданием ПО для инференса и корпоративного ИИ. MK1 основали соучредитель Neuralink Пол Меролла (Paul Merolla), который руководил проектированием чипов и разработкой алгоритмов для декодировки мозговой активности, а также бывший тимлид в Neuralink Тонг Вэй Ко (Thong Wei Koh). Также в команду входят бывшие разработчики Neuralink, Meta✴, Tesla и Apple. MK1 сосредоточена на «высокоскоростных» технологиях инференса и «рассуждений», оптимизированных для крупномасштабных проектов на базе оборудования AMD. Решения уже обрабатывают более 1 трлн токенов ежедневно. Технологии разработаны для использования преимуществ архитектуры памяти ускорителей AMD Instinct. Последние становятся всё популярнее на рынке ИИ-инфраструктуры — AMD заключила с OpenAI сделку о развёртывании на базе Instinct мощностей на 6 ГВт в рамках стратегического партнёрства. 
Источник изображения: Arlington Research/unsplash.com Сочетание ПО MK1 и ускорителей AMD позволит, как ожидается, обеспечить «точные, полностью отслеживаемые рассуждения в любом масштабе». Вместе AMD и MK1 ускорят появление следующего поколения корпоративного ИИ, это позволит клиентам автоматизировать даже сложные бизнес-процессы и др. AMD объявила о покупке MK1 после отчёта о потраченных на покупку других компаний $36 млн, помимо нашумевшей сделки с ZT Systems на $4,9 млрд, заключённую ранее в этом году. Ранее компания приобрела стартап Enosemi, занимающийся кремниевой фотоникой, стартап Brium, специализировавшийся на инструментах разработки и оптимизации ИИ ПО, а также команду стартапа Untether AI, занимавшуюся разработкой ИИ-ускорителей. Ранее портал CRN сообщал, что в последние годы AMD активно занималась покупками бизнесов для расширения возможностей ИИ-ускорителей, оборудования и ПО в условиях растущей конкуренции с NVIDIA в сфере искусственного интеллекта. ZT Systems уже используется для разработки стоечных ИИ-решений на базе ускорителей Instinct, это очень помогло AMD получить контракты с крупными клиентами, включая OpenAI. В октябре компания продала производственный сегмент ZT Systems американской Sammina за $3 млрд, сохранив проектно-конструкторское и сервисное клиентское подразделения компании. |
|

