Материалы по тегу: ии
|
11.12.2025 [14:15], Руслан Авдеев
OpenAI заключила с Deutsche Telecom соглашение о многолетнем сотрудничестве в сфере ИИDeutsche Telecom (DT) заключила стратегическое многолетнее соглашение о партнёрстве с OpenAI. Компании намерены внедрять передовые ИИ-технологии в экосистеме компании, включая внутренние процессы и клиентские сервисы. Пилотные программы стартуют в I квартале 2026 года, сообщает блог IEEE ComSoc. DT намерена внедрить ChatGPT Enterprise в масштабах всей компании, используя ИИ для оптимизации ключевых функций, включая:
Партнёрство способно подкрепить стремление DT стать одним из лидеров европейской облачной ИИ-инфраструктуры, особое внимание уделяется достижению цифрового суверенитета. В числе предыдущих инициатив компании можно отметить создание Sovereign Cloud в 2021 году силами подразделения T-Systems и Google Cloud. В начале 2025 года был предложен пакет T Cloud Suite, обеспечивавший доступ к суверенным публичным, частным и ИИ-облакам с использованием гибридной инфраструктуры. При поддержке NVIDIA начато строительство Industrial AI Cloud в Мюнхене, запуск которого запланирован на I квартал 2026 г. По мнению экспертов, интеграция ИИ-технологий OpenAI усилит позиции DT в роли поставщика полного стека решений для корпоративных клиентов, от связи и ЦОД до специализированного ПО. Эксперты подчёркивают, что ИИ ЦОД в Германии и Европе не особенно много, благодаря чему операторы уровня DT и другие компании могут развиваться в этой нише, не опасаясь сильной конкуренции. В США ИИ ЦОД значительно больше, но попытки телеком-операторов конкурировать с гиперскейлерами на рынке ЦОД провалились. При этом масштаб проектов в США значительно больше. 
Источник изображения: Deutsche Telekom По словам представителя Tekonyx, интеграция продуктов OpenAI позволит использовать инструменты разработки на основе ChatGPT для создания проприетарных информационных систем — Operational Support Systems (OSS) и Business Support Systems (BSS), связанных с техническим обеспечением работы сети и бесперебойности бизнес-процессов. Ожидается, что это откроет новые источники дохода, благодаря предложению edge-вычислений корпоративным клиентам, отраслевых ИИ-решений для медицины, ретейла и производства, интегрированных частных 5G-сетей и ИИ-пакетов для промышленных логистических хабов. Подчёркивается, что телеком-операторы могут сыграть значительную роль в организации инференса на периферии, а также хостинге специализированных моделей, которые стоит эксплуатировать поблизости от источника пользовательских данных. Более того, такие операторы будут обеспечивать связью неооблачных провайдеров уровня CoreWeave, Lambda Labs, Digital Ocean, Vast.AI и др. Поэтому OpenAI стремится заранее занять нишу сотрудничества с телеком-бизнесом. По словам других экспертов, такая модель партнёрства особенно перспективна для европейских операторов: Orange, Telefonica и др. При этом воспроизведение модели требует крупных инвестиций и масштабов развёртывания. Новое сотрудничество переводит DT из статуса пользователя ИИ в статус партнёра по разработке. В то же время OpenAI организует взаимодействие и с другими операторами — в Евросоюзе, США, Индии, Южной Корее и др. Например, компания имеет соглашения различного рода с T-Mobile US, SK Telecom, Circles, Rakuten, Orange, Jio и Airtel. Имея более 261 млн клиентов мобильных сервисов по всему миру, Deutsche Telekom имеет мощную основу для масштабного внедрения ИИ. Новое партнёрство с OpenAI знаменует переход компании от пилотных проектов к крупномасштабным продуктам, приносящим пользу всем абонентам.
11.12.2025 [14:05], Руслан Авдеев
Microsoft инвестирует в Индию $17,5 млрд для масштабирования ИИ-инфраструктурыКомпания Microsoft заявила о крупных инвестициях в ИИ-инфраструктуру в размере $23 млрд, большая часть из этих средств предназначена Индии — IT-гигант делает ставку на один из самых быстрорастущих рынков цифровых проектов в мире, сообщает Reuters. Доля индийских инвестиций составит $17,5 млрд — это крупнейшие вложения компании в азиатском регионе. Они станут развитием двухлетнего инвестиционного проекта объёмом $3 млрд. Новый, четырёхлетний план вступает в силу в 2026 году и обеспечит Microsoft самое масштабное присутствие на местном рынке облачных вычислений. Хотя момент не самый удачный из-за некоторой напряжённости между Нью-Дели и Вашингтоном, возникшей из-за торговых пошлин и зашедших в тупик переговорах о торговой сделке. Благодаря наличию в стране порядка 1 млрд интернет-пользователей и обилию IT-специалистов высокой квалификации Индия стала ключевым регионом для американских капиталовложений, техногиганты охотно инвестируют миллиарды долларов в развитие ИИ в стране. Соответствующие ЦОД стали для Индии шансом воспользоваться экономическим бумом на рынке высоких технологий, учитывая то, что её возможности по производству полупроводников пока ограничены. Так или иначе, Microsoft заявила, что новый кампус ЦОД в Хайдарабаде (Hyderabad) станет крупнейшим облачным регионом компании в Индии, включающим три зоны доступности. Как ожидается, его введут в эксплуатацию в середине 2026 года. Также компания расширит три действующих региона в Ченнаи, Хайдарабаде и Пуне. Правда, по данным Datacenter Dynamics, регион в Мумбаи переведён в статус т.н. «reserved access region» с ограниченным доступом. Дополнительно она удвоила январское обещание обучить 20 млн жителей Индии навыкам работы с ИИ до конца десятилетия. Компания интегрирует возможности Azure OpenAI в местные платформы e-Shram и National Career Service (NCS), оптимизируя подбор вакансий, способствуя развитию навыков и др. для более чем 310 миллионов работников. Microsoft также заявила, что инвестирует CA$7,5 млрд ($5,42 млрд) в Канаду в следующие два года. Новые облачные мощности должны ввести в эксплуатацию во II половине 2026 года. Это часть общего плана инвестиций Microsoft в Канаду в объёме CA$19 млрд в 2023–2027 гг. В частности, компания намерена расширить предложение Azure Local в стране. Кроме того, Microsoft взаимодействует с ИИ-стартапом Cohere для предложения передовых ИИ-моделей компании на платформе Azure. В ноябре сообщалось о планах компании инвестировать $10 млрд в ИИ-инфраструктуру в Португалии, а также $15 млрд в ОАЭ. Как прогнозирует консалтинговая компания Colliers, к 2030 году общая мощность ЦОД в Индии вырастет более чем втрое и составит порядка 4,5 ГВт. В Индии на Microsoft работает более 22 тыс. человек, в Канаде — около 5,3 тыс. В октябре Google объявила о намерении инвестировать в строительство ИИ ЦОД в штате Андхра-Прадеш (Andhra Pradesh) $15 млрд за пять лет, это станет крупнейшим вложением гиганта в стране. В январе AWS объявила о намерении вложить в страну $8,3 млрд, а теперь Amazon увеличила инвестиции до $30,5 млрд. В целом, как сообщает Reuters, ожидается, что Microsoft и другие американские облачные провайдеры только в 2025 году более $400 млрд на ИИ-проекты и ЦОД по всему миру.
11.12.2025 [14:05], Руслан Авдеев
Amazon инвестирует $35 млрд в Индию к 2030 году для инноваций в сфере ИИ и создания рабочих местAmazon объявила о намерении вложить более $35 млрд в индийские подразделения компании до 2030 года в дополнение к уже потраченным здесь $40 млрд. Новые инвестиции направят на масштабирование активности и три стратегически важных направления: цифровизацию на основе ИИ, рост экспорта и создание рабочих мест. В отчёте Keystone Strategy говорится, что инвестиции $40 млрд (в т.ч. выплаты сотрудникам и деньги на развитие инфраструктуры) сделали компанию крупнейшим зарубежным инвестором в стране, крупнейшим «катализатором» экспорта с помощью электронной торговли, и одним из ключевых создателей рабочих мест в Индии. Значительные средства затрачены на создание физической и цифровой инфраструктуры, в т.ч. пунктов обслуживания, логистических сетей, дата-центров и инфраструктуры цифровых платежей. По данным Keystone, Amazon оцифровала более 12 млн малых предприятий, помогла увеличению объёма экспорта с помощью электронной коммерции на сумму $20 млрд, а в 2024 году обеспечила порядка 2,8 млн прямых и косвенных рабочих мест в различных отраслях индийской экономики, включая технологическую сферу, логистику, службы поддержки и др. с медицинским страхованием и обучением. В Amazon утверждают, что влияние компании в стране выходит за рамки прямого трудоустройства сотрудников, она обеспечивает рабочие места в сфере упаковки, логистики и сопутствующих технологий, а также даёт возможность развития на своей торговой площадке тысячам малых предприятий. В 2030 году количество прямых и косвенных рабочих мест увеличится до 3,8 млн благодаря расширению бизнеса как самой Amazon, так и растущих сетей пунктов обслуживания и сервисов доставки — одновременно поддерживаются и смежные отрасли. Совокупный объём экспорта, связанный с электронной коммерцией, к 2030 году должен вырасти в четыре раза до $80 млрд. 
Источник изображения: pavan gupta/unsplash.com Благодаря дополнительным вложениям $35 млрд Amazon намерена ускорить цифровую трансформацию в стране, укрепить местную инфраструктуру и поддержать инновации. Инвестиции соответствуют приоритетам Индии и направлены на расширение возможностей ИИ, улучшение логистики, поддержку роста малого бизнеса и создание новых рабочих мест. Программа Amazon по внедрению ИИ во все сферы жизни должна помочь преобразовать цифровое пространство страны, поддерживая заявленную государством концепцию «ИИ для всех». К 2030 году Amazon намерена обеспечить преимущества ИИ 15 млн малых предприятий — продавцы на платформе Amazon.in уже используют ИИ-инструменты Seller Assistant, Next Gen Selling и др. Опыт покупок для сотен миллионов покупателей планируется улучшить с помощью инструментов Lens AI (визуальный поиск), интерактивных покупок с помощью Rufus и многоязычных интерфейсов. Также планируется предоставить 4 млн школьников возможности обучиться навыкам работы с ИИ и познакомить их с карьерными возможностями в технологической сфере. Программа включает разработку учебной программы, посвящённой ИИ, экскурсии в технологические компании, практические занятия в «ИИ-песочнице» и обучение самих преподавателей. Инициатива напрямую поддерживает цели Национальной образовательной политики Индии от 2020 года. 
Источник изображения: Varun Gaba/unspalsh.com О том, сколько именно средств выделят на ИИ-инфраструктуру, включая ЦОД AWS, не сообщается. В начале 2025 года AWS выделила $8,3 млрд только на строительство одного облачного региона — AWS Asia-Pacific в Мумбаи (Mumbai). Регион работает с 2016 года, к 2022 году компания инвестировала в него $3,7 млрд. В 2022 году она запустила облачный регион в Хайдарабаде (Hyderabad). Обязательство потратить $8,3 млрд на ЦОД в Мумбаи — часть более обширного инвестиционного плана, в рамках которого AWS намеревалась потратить в Индии $12,7 млрд. Также компания планирует инвестировать $7 млрд в течение 14 лет в облачный регион в Хайдарабаде. Последние новости об Amazon появились вскоре после того, как Microsoft объявила о планах потратить $17,5 млрд на ИИ-инфраструктуру в Индии к 2030 году. В октябре 2025 года Google подтвердила о реализации проекта по строительству кампуса ЦОД в штате Андхра-Прадеш (Andhra Pradesh), планируется потратить $15 млрд за пять лет.
11.12.2025 [12:38], Сергей Карасёв
«Карманный ИИ-суперкомпьютер» Tiiny AI Pocket Lab справляется с LLM, насчитывающими до 120 млрд параметровАмериканский стартап Tiiny AI представил устройство AI Pocket Lab: это, как утверждается, самый компактный в мире персональный суперкомпьютер для задач ИИ. Он способен работать с большими языковыми моделями (LLM), насчитывающими до 120 млрд параметров: при этом не требуется подключение к облачным сервисам. Устройство заключено в корпус с размерами 142 × 80 × 25,3 мм, а вес составляет около 300 г. Применён процессор с 12 вычислительными ядрами на архитектуре Armv9.2. Кроме того, задействован нейромодуль dNPU. Общий объём памяти LPDDR5X составляет 80 Гбайт, из которых 32 Гбайт приходится на CPU и 48 Гбайт — на dNPU. В оснащение входит SSD вместимостью 1 Тбайт. Типовое энергопотребление находится на уровне 65 Вт. 
Источник изображений: Tiiny AI Суммарная заявленная ИИ-производительность достигает 190 TOPS: из них примерно 30 TOPS обеспечивает CPU, ещё 160 TOPS — блок dNPU. Компьютер ориентирован прежде всего на локальную работу с моделями, насчитывающими от 10 до 100 млрд параметров: подобные решения, как утверждается, удовлетворяют более чем 80% реальных потребностей. Устройство может поддерживать такие функции, как многоэтапное рассуждение, глубокое понимание контекста, агенты ИИ, генерация контента и безопасная обработка конфиденциальной информации без необходимости подключения к удалённым серверам.  Tiiny AI Pocket Lab поддерживает быструю установку популярных открытых ИИ-моделей, включая OpenAI GPT-OSS, Llama, Qwen, DeepSeek, Mistral и Phi. При этом могут развертываться различные ИИ-агенты, например, OpenManus, ComfyUI, Flowise, Presenton, Libra, Bella и SillyTavern. Среди потенциальных пользователей компьютера названы разработчики, исследователи, создатели контента, учащиеся и пр. Новинка будет демонстрироваться в следующем месяце на выставке электроники CES 2026.
10.12.2025 [23:59], Андрей Крупин
МГТУ им. Н. Э. Баумана запустил производство специального оптического волокнаМосковский государственный технический университет имени Н. Э. Баумана сообщил о запуске на территории вуза производственной площадки по серийному выпуску специального оптического волокна — ключевого материала для сенсорных, лазерных и высокоточных измерительных систем. Специализированное оборудование для производства оптического волокна размещено в корпусе «Квантум-парк». Ключевым элементом комплекса является башня вытяжки — вертикальная установка высотой 15 метров, в которой преформа нагревается до температуры размягчения, после чего вытягивается в волокно толщиной до сотен микрон. В процессе контролируются температура, скорость вытяжки, геометрия волокна и параметры защитного покрытия. В вытяжной системе МГТУ им. Н. Э. Баумана задействованы автоматизированные системы управления, обеспечивающие стабильность параметров и высокую точность изготовления продукции. 
Источник изображения: пресс-служба МГТУ им. Н. Э. Баумана / bmstu.ru Пусконаладочные работы по запуску производственной площадки были выполнены при участии специалистов Института радиотехники и электроники РАН им. В. А. Котельникова, что обеспечило формирование необходимых компетенций для создания отечественных аппаратных и программных решений в волоконно-оптической области. Что касается размещённой в Бауманке вытяжной системы, то она, по заверениям конструкторов и разработчиков, по техническим характеристикам не уступает зарубежным аналогам. Специальное оптическое волокно в коммерческих объёмах сегодня производят лишь несколько российских организаций. Появление собственной башни вытяжки в МГТУ им. Н. Э. Баумана позволит ежегодно выпускать несколько тысяч километров специального волокна, говорится в заявлении пресс-службы технического университета.
10.12.2025 [20:02], Владимир Мироненко
Intel договорилась о покупке разработчика ИИ-ускорителей SambaNova за $1,6 млрд, но не окончательноРесурсу Wired стало известно о подписании Intel соглашения о покупке ИИ-стартапп SambaNova Systems. Финансовые условия соглашения, которое носит предварительный характер и не имеет обязательной силы, не разглашаются. Впервые о заинтересованности Intel в приобретении стартапа сообщил Bloomberg в конце октября. На тот момент переговоры находились на ранней стадии. Согласно данным ресурса, сумма предполагаемой сделки составляла менее $5 млрд. Что примечательно, генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan) в настоящее время является исполнительным председателем и инвестором SambaNova Systems, сообщили источники The New York Times, знакомые с ситуацией. И он рассказывал о предложениях SambaNova на встречах как минимум с одним крупным клиентом Intel, компанией Dell. Intel Capital, которую сейчас выделяют в отдельную компанию, также инвестировала в SambaNova Systems. Ещё один инвестор SambaNova, японская SoftBank Group, также является крупным инвестором Intel. 
Источник изображения: SambaNova Systems SambaNova Systems была основана в 2017 году в Пало-Альто (Palo Alto, Калифорния, США) Кунле Олукотуном (Kunle Olukotun), Родриго Ляном (Rodrigo Liang) и Кристофером Ре (Christopher Ré). Олукотун и Ре — профессора Стэнфордского университета. Лян ранее был топ-менеджером в Oracle. По данным PitchBook, к началу 2025 года компания привлекла $1,14 млрд инвестиций. В частности, в 2020 году она получила $250 млн от BlackRock, Intel Capital, венчурной фирмы GV и других инвесторов, а её оценка выросла до $2,5 млрд. В 2021 году SambaNova была оценена в $5 млрд после раунда финансирования в размере $676 млрд, возглавляемого фондом SoftBank Vision Fund 2. С тех пор предполагаемая оценка стартапа снизилась. По данным The Information, BlackRock снизила стоимость своих акций SambaNova на 17 % за последний год. Это, вероятно, сделало компанию целью для Intel, наряду с тем фактом, что Intel отстаёт от остальной части индустрии чипов в производстве ИИ-чипов, отметил Wired. Разработки купленной когда-то Habana едва продаются, а после отказа от Ponte Vecchio, проблем с запуском Falcon Shores и неопределённостью относительно Jaguar Shores у Intel практически не осталось «больших» ускорителей. О сделке с Nervana в компании предпочитают не вспоминать. SambaNova разрабатывает ИИ-ускорители на основе реконфигурируемого блока обработки данных (Reconfigurable Dataflow Unit, RDU). 5-нм ускоритель SN40L, представленный более двух лет назад, имеет 1040 ядер RDU, обеспечивающих производительность до 653 Тфлопс в режиме BF16. Он оснащён 520 Мбайт SRAM, 64 Гбайт HBM3 с внешним DDR5-массивом объёмом 1,5 Тбайт для размещения LLM. Компания фактически отказалась от попыток конкурировать с NVIDIA в задачах обучения ИИ. Вслед за Groq она переключилась на инференс и поставку готовых ИИ-платформ вместо продажи ускорителей. UPD 13.12.2025: по данным Bloomberg, переговоры между компаниями значительно продвинулись — Intel готова приобрести SambaNova за $1,6 млрд с учётом долгов последней. Если сделка состоится, она станет первой крупной покупкой «синих» под руководством Лип-Бу Тана.
10.12.2025 [18:14], Руслан Авдеев
Omdia: капитальные затраты на ЦОД вырастут до $1,6 трлн к 2030 году — если раньше не лопнет ИИ-пузырьСогласно прогнозам аналитиков Omdia, капитальные затраты на дата-центры будут расти на 17 % ежегодно до 2030 года. В итоге они достигнут $1,6 трлн, а ограничения в цепочках поставок вызовут рост цен на компоненты вычислительной инфраструктуры. В своём последнем обзоре рынка облаков и дата-центров (Cloud and Data Center Market Snapshot) компания сообщила, что инвестиции в ИИ-инфраструктуру продолжают расти быстрыми темпами, хотя разговоры о том, что на рынке формируется готовый лопнуть пузырь, не утихают. Впрочем, уровень внедрения ИИ пока остаётся относительно низким, в будущем ожидается, что вырастет как количество пользователей, так и средняя интенсивность использования ими ИИ-инструментов. В то же время ИИ-модели становятся всё более громоздкими и используют больше вычислительных ресурсов для инференса. В результате операторы наращивают производительность инфраструктуры. Вместе с этим растёт потребление электроэнергии, увеличивается энергетическая плотность серверов, стоек и самих дата-центров. Окупятся ли все эти гигантские инвестиции, никто пока точно сказать не может. Bain & Company полагает, что к 2030 году доходы отрасли должны вырасти до $2 трлн/год, чтоб окупить прогнозируемый уровень инвестиций. Окупаемость затрат под вопросом как для поставщиков услуг, так и для пользователей. Как сообщает The Register, на днях представители ряда технологических компаний заявили, что ИИ — не пузырь, не находя аналогий с крахом «доткомов». 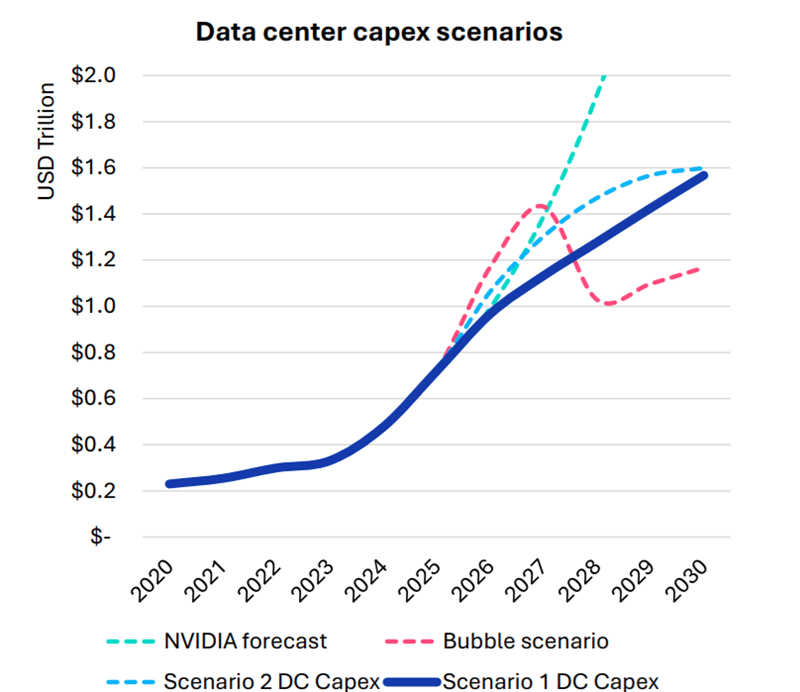
Источник изображения: Omdia Omdia рассмотрела четыре сценария развития рынка:
Рост расходов на ЦОД обусловлен и увеличением поставок серверов, цикл обновления которых начался в 2025 году и продолжится 6–8 кварталов. Ранее Omdia сообщала, что крупные операторы ЦОД, в основном гиперскейлеры, откладывали замену серверов разных типов. Новые серверы способны заменить оборудование сразу нескольких поколений. При этом ожидается, что к 2030 году серверы с Blackwell будут ещё в ходу. Рост инвестиций ожидается во всех сегментах, включая ниши неооблаков (CoreWeave, Nebius, xAI и др.), колокейшн-провайдеров первого и второго уровней, гиперскейлеров и корпоративных пользователей. 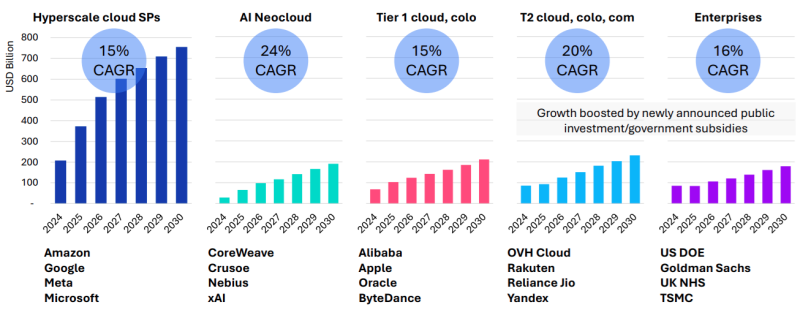
Источник изображения: Omdia Ограничения в цепочках поставок ведут к росту стоимости некоторых компонентов, например, памяти. По данным источников The Register, это, вероятно, приведёт к росту цен на серверы на 15 %. Omdia утверждает, что новые ЦОД, вероятно, будут проектироваться не так, как сегодня — спрос на ИИ приводит к быстрой смене внутренней инфраструктуры. Это касается всех компонентов, от микросхем до серверов и стоек, систем терморегуляции, распределения энергии, резервного питания и др. В докладе имеются рекомендации на будущее как для вендоров, так и для пользователей. Кроме того, Omdia прогнозирует, что, несмотря на спекуляции относительно ИИ-пузыря, быстрое внедрение ИИ-технологий и инвестиции продолжатся, а мощности по-прежнему будут в дефиците.
10.12.2025 [14:27], Руслан Авдеев
«Сверхзвуковая» газовая турбина Boom Superpower запитает ИИ ЦОДBoom Supersonic, занимающаяся строительством коммерческих сверхзвуковых самолётов, представила газовую турбину Superpower мощностью 42 МВт. Она предназначена для генерации электроэнергии для дата-центров, а первым покупателем стала Crusoe, строящая ИИ ЦОД для проекта OpenAI Stargate, которая заказала 29 турбин Superpower общей мощностью 1,22 ГВт. По имеющимся данным, портфолио заказов на Superpower превышает $1,25 млрд. Дополнительно Boom привлекла $300 млн новых инвестиций в ходе раунда серии B, возглавленного Darsana Capital Partners. Также в нём приняли участие Altimeter Capital, ARK Invest, Bessemer Venture Partners, Robinhood Ventures и Y Combinator. Boom Supersonic объявила, что выручка от продажи турбин Superpower поможет профинансировать сертификацию сверхзвукового пассажирского самолёта Overture, а также разработку двигателя Symphony. Он будет использоваться как в самолёте, так и в генераторах. Сегодня портфолио заказов Boom на пассажирские самолёты составляет 130 ед., в т.ч. для United, American и Japan Airlines. Испытания ключевых компонентов двигателя начнутся в 2026 году на площадке Boom в Колорадо. В компании подчёркивают, что сверхзвуковые технологии стали не только решением для быстрых полётов, но и «ускорителем» ИИ-решений. В турбине Superpower применяются те же ключевые решения, что и в двигателе Symphony. В том числе применяются материалы, готовые работать в экстремальных режимах, и архитектура высокого давления, доработанная для стабильной работы даже во время пиковых температурных нагрузок. В отличие от многих других турбин авиационного типа, Superpower обеспечивает мощность 42 МВт даже при температуре окружающей среды выше 43,3 °C, говорит компания. Турбина работает без воды и может быть размещена в контейнере, что позволяет эксплуатировать её в удалённых регионах. Boom рассчитывает выйти к концу десятилетия на выпуск турбин общей мощностью более 4 ГВт/год. По данным Converge! Digest, Boom Supersonic занимается разработкой сверхзвуковых пассажирских самолетов с 2014 года. Она начинала с концепт-проектов Overture и создания демонстрационного образца XB-1. После того, как традиционные поставщики силовых установок отказали в разработке двигателя под требования компании, она начал реализацию собственной программы Symphony в 2022 год. Superpower — попытка монетизировать «ядро» своего высокотемпературного двигателя на раннем этапе его разработки, тем самым снизив зависимость от внешнего финансирования. 
Источник изображений: Boom Supersonic Если компании удастся масштабировать поставки турбин и выдержать график испытаний авиадвигателя Symphony в 2026 году, стратегия создания двигателя двойного назначения может стать промежуточным этапом на пути окончательной сертификации авиалайнера Overture. Благодаря этому Boom Energy сможет войти в число немногих компаний, одновременно пытающихся создать и коммерческий самолёт нового поколения, и развивать масштабируемый бизнес по созданию энергетических решений для промышленности и ЦОД. Crusoe работает и с другими компаниями, применяющими сходные технологии. Ещё в июле появилась новость, что она заказала у GE Vernova 29 газовых турбин LM2500XPRESS для ИИ ЦОД Stargate. Они построены на основе авиационных двигателей General Electric LM2500, адаптированных для наземного использования. ProEnergy поступает ещё проще, адаптируя десятки старых авиадвигателей к работе на земле.
10.12.2025 [13:37], Руслан Авдеев
Экоактивисты призвали США немедленно остановить строительство всех ИИ ЦОДАктивисты более 230 организаций из США подписали воззвание к местным конгрессменам, призывая ввести мораторий на строительство дата-центров. Они утверждают, что нынешний бум представляет огромную экологическую и социальную угрозу, сообщает The Register. В открытом письме Конгрессу США активистами Food & Water Watch выражено недовольство тем, что расширение ЦОД, вызванное ростом интереса к ИИ, требует большего количества энергии. Это ведёт к росту выбросов парниковых газов, истощению водных ресурсов и росту цен на электричество для рядовых потребителей. Представители организаций, оставивших подписи под письмом, утверждают, что совокупно представляют интересы миллионов жителей 50 штатов США. Конгресс призывают приостановить строительство новых дата-центров до тех пор, пока не примут адекватные меры по защите населения и окружающей среды от уже наносимого ущерба. Сегодня инвестиции в ЦОД достигли исторического максимума, их основным драйвером является ИИ. По оценкам Omdia, к концу 2025 года мировые затраты на дата-центры превысят $657 млрд, это почти вдое больше, чем два года назад — лидером остаются США. В одной только Вирджинии мощность ЦОД гиперскейлеров превышает мощность дата-центров всего Китая или Европы целиком. Во II половине 2024 года эти ЦОД потребовали вдвое больше энергии, чем в предыдущие шесть месяцев. Потребление воды ЦОД за последние пять лет выросло почти на ⅔. 
Источник изображения: Ella Ivanescu/unsplash.com За дополнительные генерирующие мощности и сопутствующую инфраструктуру придётся платить простым американцам. Ранее эксперты уже предупреждали о том, что к 2030 году счета на электричество в США могут вырасти на 70 %. Кроме того, в ноябре выяснилось, что некоторые штаты не сообщают своим гражданам о субсидиях, выделяемых для привлечения новых ИИ-компаний, т.е. фактически финансирование осуществляется за счёт налогоплательщиков. Более того, строительство новых ЦОД ведёт к увеличению выбросов парниковых газов — Microsoft и Google открыто признают, что за последние десять лет уровень загрязнения атмосферы вырос несмотря на обещания добиться нулевых выбросов к концу десятилетия. Спрос на электричество уже спровоцировал возрождение интереса к угольной энергетике — не самого экобезопасного способа получать электричество. Кроме того, проблему усугубляют ЦОД с собственными генерирующими мощностями, например, кластеры xAI. И таких объектов будет всё больше и больше. 
Источник изображения: Jan Kopřiva/unsplash.com В Food & Water Watch подчёркивают, что взрывной рост индустрии больших данных является по-настоящему экзистенциальной угрозой для сообществ, не готовых справиться с колоссальными экологическими и экономическими трудностями, создаваемыми дата-центрами. Единственным разумным действием называется остановка бесконтрольного расширения отрасли ЦОД, чтобы сделать передышку и оценить потенциальный вред. Тем временем американские власти соревнуются с Китаем за первенство в сфере ИИ и победить в гонке США смогут, только если будут инвестировать в вычислительные мощности ещё больше. Некоторые политики прямо заявляют, что настоящая экзистенциальная угроза — не изменение климата, а возможность проиграть в «гонке вооружений» в сфере ИИ, если мощностей будет недостаточно. США пообещали устранить препятствия для подключения ЦОД к источникам электроэнергии, а в октябре экономисты отмечали, что инвестиции в ИИ — единственное, что удерживает экономику США от рецессии. При этом в индустрии ЦОД прекрасно осознают, что гигантские проекты по нраву далеко не всем. Впрочем, участники индустрии согласны не в том, что отрасли нужны перемены, а в том, что общественность стоит лучше информировать о настоящей работе дата-центров, отраслях, зависящих от ИИ и др. — люди должны воспринимать ЦОД как объекты, необходимые как вода или электричество.
10.12.2025 [13:18], Сергей Карасёв
«Гравитон» представил SmartNIC SNC-QSFP2-SH01 с FPGA, 100GbE-портами и слотом SO-DIMMКомпания «Гравитон», российский производитель вычислительной техники, анонсировала сетевой адаптер SNC-QSFP2-SH01 класса SmartNIC, предназначенный для использования в дата-центрах. Устройство обеспечивает аппаратное ускорение различных сетевых функций. В основу решения положена неназванная ПЛИС, которая насчитывает свыше 1 млн логических ячеек и содержит более 50 Мбит встроенной блочной памяти. Адаптер может нести на борту до 32 Гбайт оперативной памяти DDR4. Также упоминается отечественный центральный микроконтроллер первого уровня. Карта оснащена двумя 100GbE-портами QSFP28, что, впрочем, видится избыточным, поскольку используемое подключение PCIe 3.0 x8 не способно «прокачать» столько трафика. За охлаждение отвечают радиатор и вентилятор тангенциального типа. Заявлена поддержка библиотек DPDK и совместимость с платформами Linux и Windows Благодаря возможности реконфигурирования FPGA адаптер может использоваться для решения широкого спектра задач. Среди них названы ускорение работы облачных сервисов, виртуализация, проверка сетевых пакетов по их содержимому (DPI) для регулирования и фильтрации трафика, межсетевые экраны нового поколения (NGFW). Изделие также может применяться в комплексных решениях в сфере кибербезопасности для поиска и устранения угроз в сетевом трафике. 
Источник изображения: «Гравитон» «Использование архитектуры на базе ПЛИС позволило нам создать устройство, которое не просто передаёт пакеты, а берёт на себя ресурсоёмкие вычисления: от балансировки нагрузки до глубокой инспекции пакетов. Мы предлагаем рынку мощный инструмент, который поможет оптимизировать работу облачных сервисов и систем информационной безопасности, высвобождая ресурсы CPU для прикладных задач», — говорит «Гравитон». |
|

