Материалы по тегу: ии
|
19.06.2025 [09:27], Владимир Мироненко
ИИ — это не только GPU: Marvell проектирует полсотни кастомных чипов для ЦОДПоскольку провайдеры облачных сервисов, ИИ-стартапы и суверенные субъекты масштабируют свои ЦОД, Marvell видит растущий спрос не только на основное вычислительное оборудование, включая пользовательские CPU, GPU и ускорители, но и на широкий спектр вспомогательных полупроводниковых элементов, включая контроллеры сетевых интерфейсов, чипы управления питанием, устройства расширения памяти и т.д., пишет Converge Digest. В ходе мероприятия для инвесторов AI Investor Day 2025 гендиректор Мэтт Мерфи (Matt Murphy) обрисовал растущую роль компании в поддержке ИИ-инфраструктуры, отметив два ключевых события, формирующих рынок: рост числа новых разработчиков ИИ-инфраструктуры за пределами традиционных четырёх ведущих гиперскейлеров и быстрое появление компонентов XPU Attach как важной новой категории кастомных полупроводников. Мерфи отметил, что эти тенденции способствуют формированию гораздо более крупного и разнообразного общего целевого рынка, чем прогнозировалось ранее. 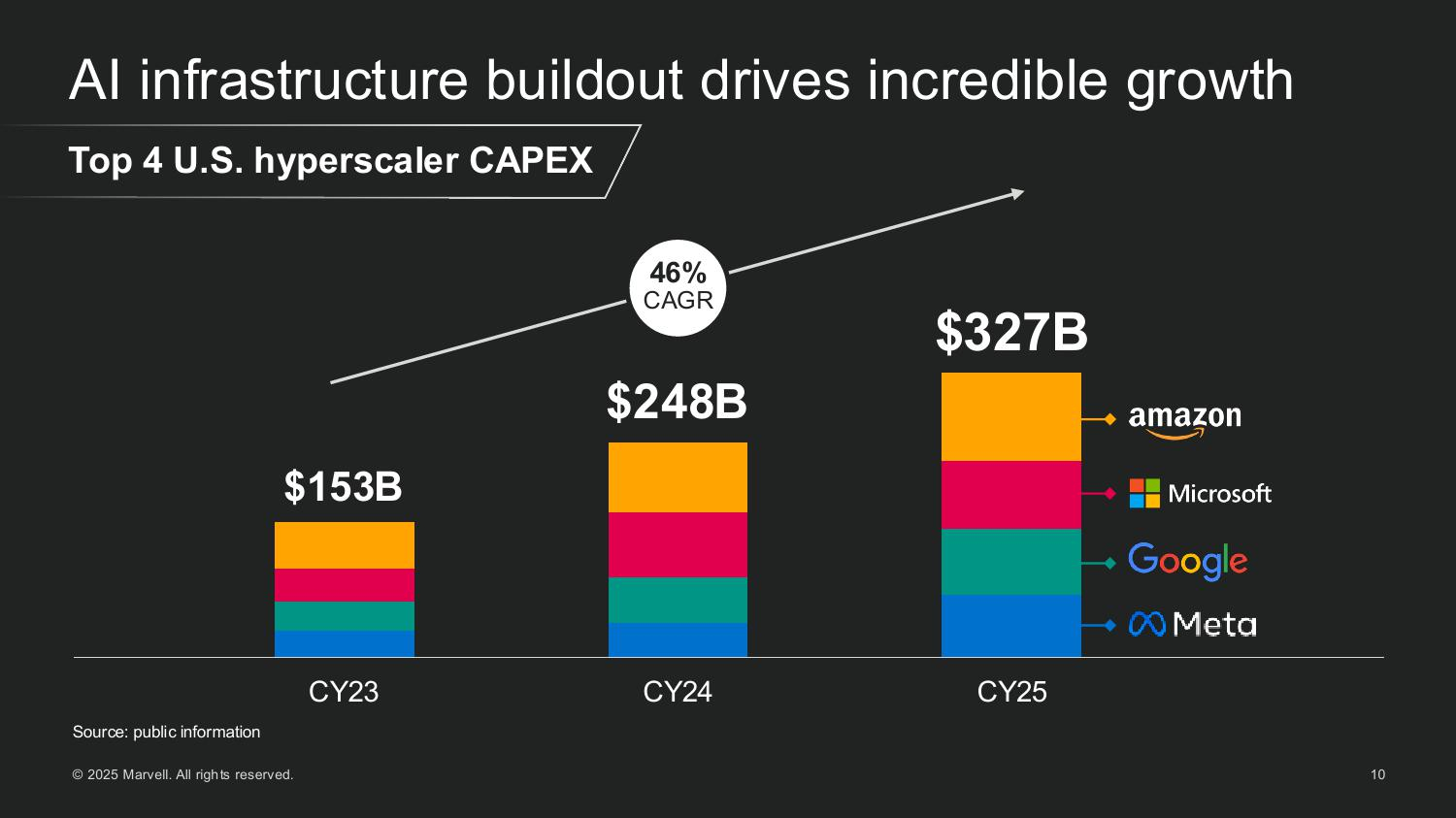
Источник изображений: Marvell Мерфи рассказал, как резко выросли глобальные капитальные затраты на ЦОД, обусловленные ростом гиперскейлеров и развитием суверенного ИИ. Ведущие американские гиперскейлеры — AWS, Microsoft, Google и Meta✴ — увеличили совокупные капитальные затраты со $150 млрд в 2023 году до более чем $300 млрд в 2025 году. По прогнозам, на глобальном уровне к 2028 году затраты превысят уже $1 трлн. Marvell считает, что значительная часть этих расходов будет направлена на кастомные полупроводниковые платформы. 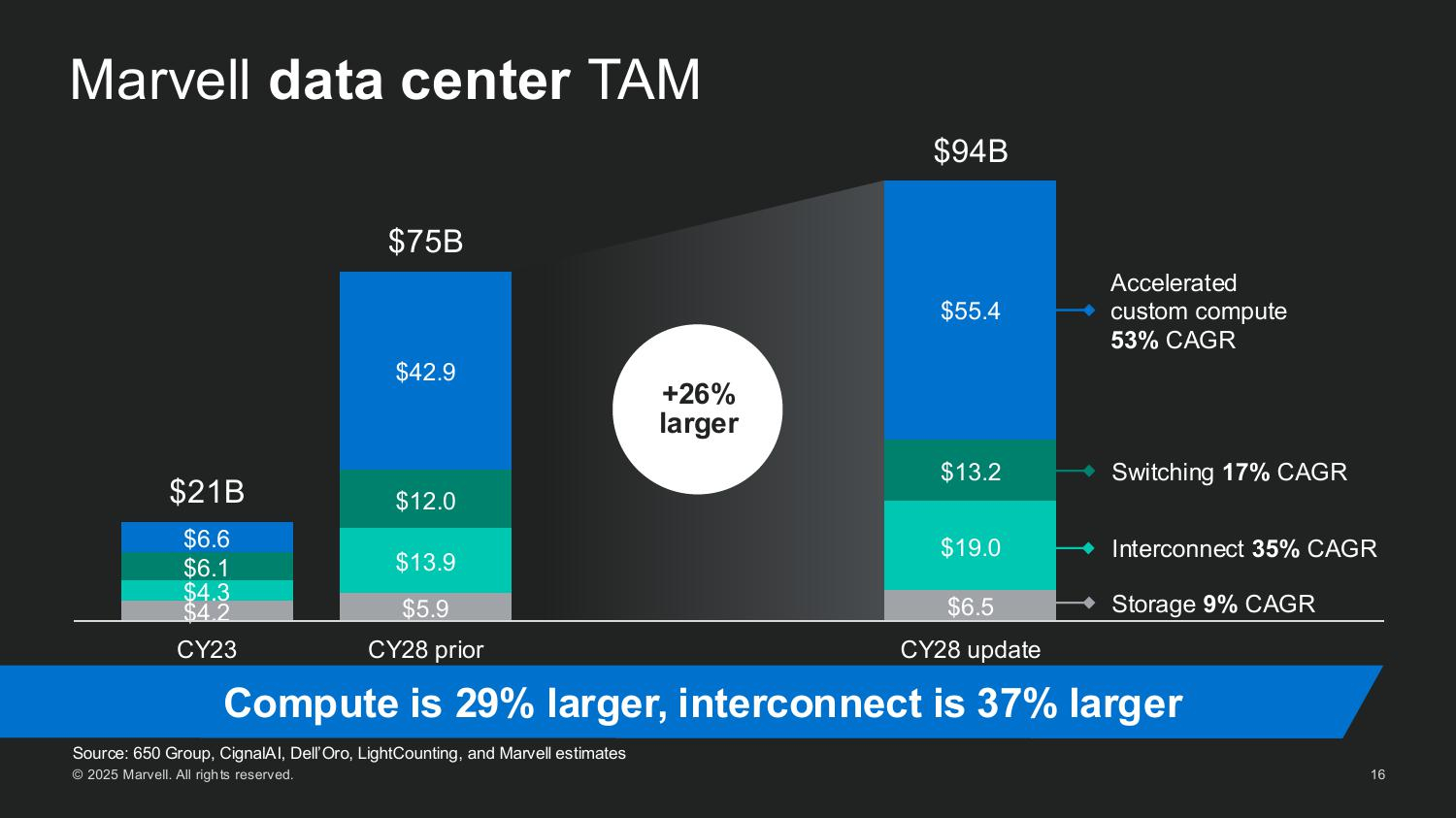 Marvell пересмотрела прогноз общего целевого рынка (TAM) в сторону увеличения до $94 млрд к 2028 году, что на 25 % больше её оценки в прошлом году. Эта сумма включает:
Мерфи подчеркнул, что XPU Attach — прорывная категория, отметив, что «вычислительные ИИ-платформы больше не определяются одним чипом. Это сложные системы с бурным ростом числа сокетов — каждый из которых представляет собой новую возможность [для компании]».  «В прошлом году у нас было три кастомных вычислительных чипа и TAM на $75 млрд. В этом году у нас 18 сокетов, TAM на $94 млрд и растущий поток из более чем 50 проектов. Рынок ИИ-инфраструктуры быстро развивается, и Marvell находится прямо в его центре», — подытожил Мерфи. 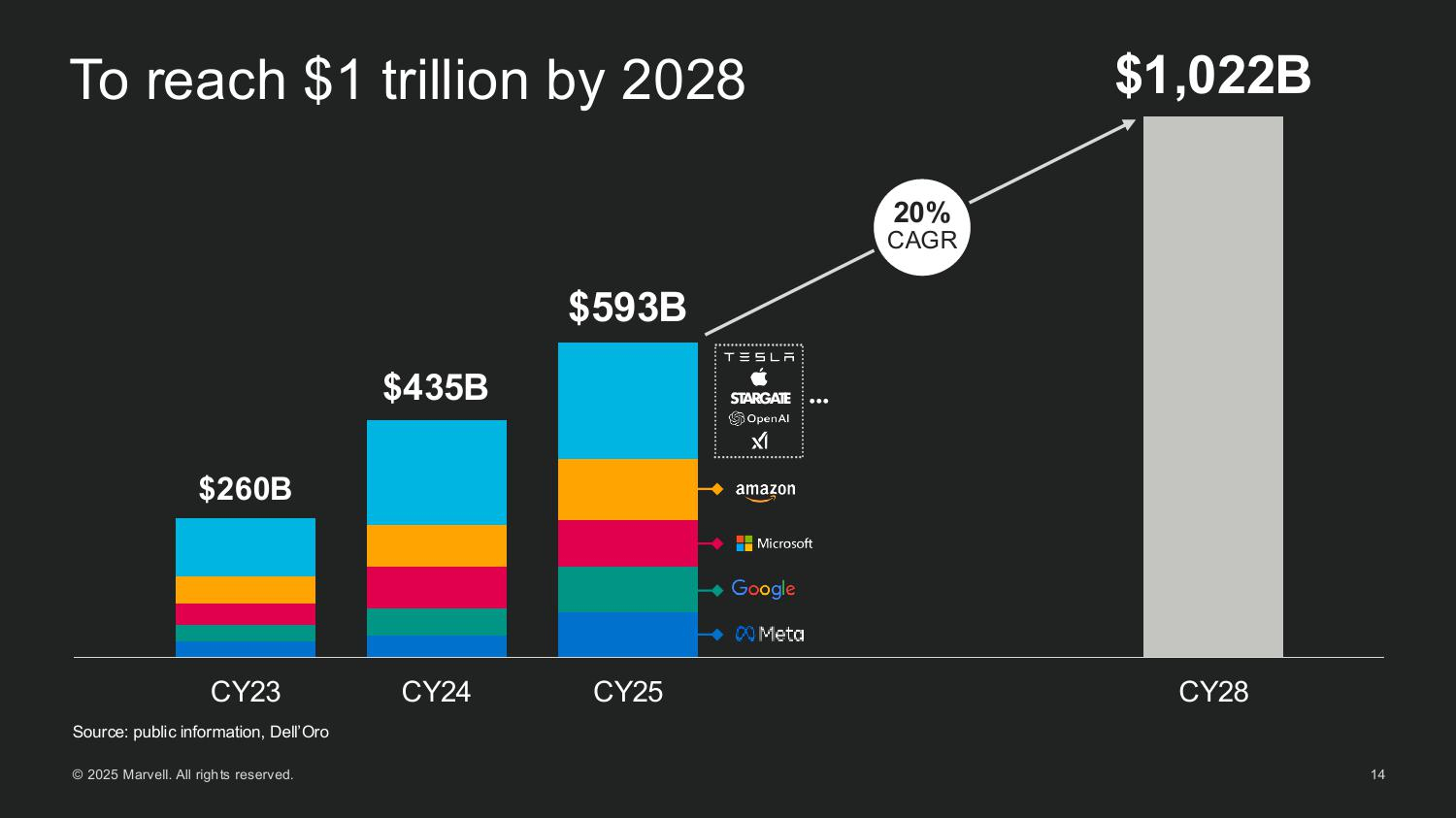 Marvell на сегодняшний день обеспечила разработку 18 кастомных чипов:
Marvell сопровождает более 50 активных кастомных полупроводниковых проектов — сочетание XPU и Attach — с более чем 10 клиентами. Среди них облачные гиперскейлеры, новые ИИ-стартапы и национальные ИИ-инициативы. По оценкам компании, эти проекты принесут $75 млрд потенциального дохода за весь срок их реализации, и это без учёта 18 уже готовых проектов. 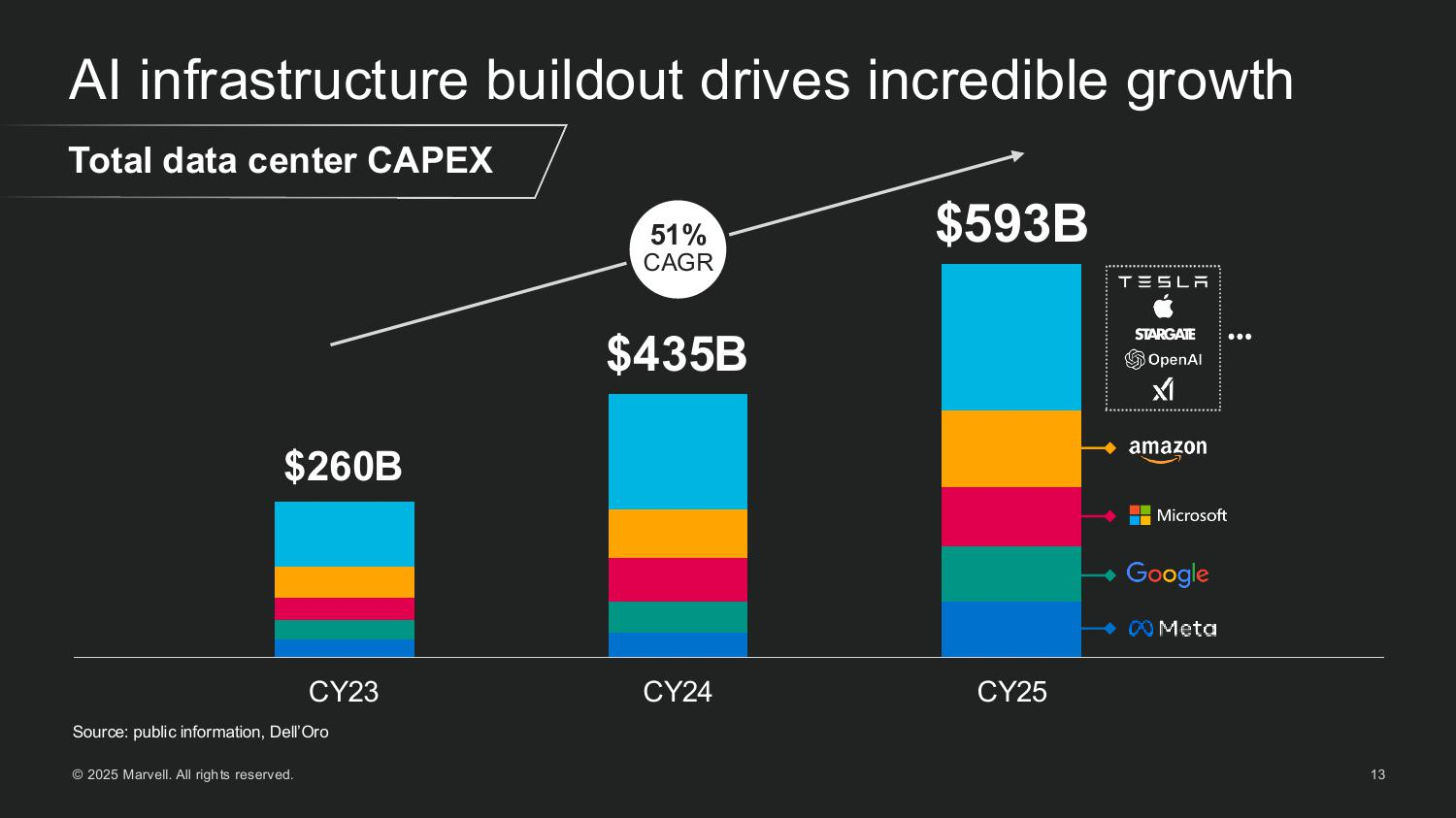 Мерфи подчеркнул, что на этом рынке больше не доминирует несколько «мегасокетов». «Ещё в 2023 году на один сокет приходилось 75 % TAM. К 2028 году ни один сокет не будет превышать 10–15 %. Это огромная диверсификация — и она отлично подходит для нас», — сообщил глава Marvell.
18.06.2025 [18:18], Руслан Авдеев
Дата-центры несут угрозу электросетям США из-за своей непредсказуемостиАмериканский регулятор North American Electric Reliability Corp. (NERC), отвечающий за надзор за электросетями и сопутствующей инфраструктурой в США, заявил, что подключение к сетям ЦОД в настоящее время весьма рискованно. Речь идёт об одной из самых серьёзных угроз надёжности сетей в краткосрочной перспективе, сообщает Bloomberg. Растущие кампусы ЦОД, занимающиеся майнингом криптовалют и ИИ-вычислениями, развиваются значительно быстрее, чем электростанции и линии электропередач, необходимые для обеспечения таких объектов электроэнергией. В результате, как заявляется в отчёте NERC, такая ситуация может привести к нарушению стабильности энергосистемы в целом. В первую очередь это связано с тем, что дата-центрам необходимо огромное количество энергии в непредсказуемые интервалы времени. Кроме того, они очень чувствительны к перепадам напряжения, что делает их главным, плохо прогнозируемым фактором влияния на энергосистемы. Они попросту не готовы к такому режиму использования. Как заявляют в NERC, в мировой «столице» ЦОД, регионе Северная Вирджиния, в июле 2024 года разом отключились дата-центры общей мощностью около 1,5 ГВт. В феврале текущего года из-за проблем с напряжением ситуация снова повторилась, затронув уже 1,8 ГВт мощностей. Считается, что отключения подобных масштабов могут иметь «волновой» эффект, распространяющийся на всю энергосеть страны. В отчёте NERC утверждается, что отключения нагрузки подобного масштаба сопоставимы с неожиданным включением в сеть крупной атомной электростанции. В результате из-за излишков энергии создаётся гигантский дисбаланс. 
Источник изображения: Matt Richmond/unsplash.com Расследование NERC показало, что в случае серии коротких сбоев в течение небольшого периода времени дата-центры не переключаются обратно на основную энергосеть — это приходится делать вручную, причём ЦОД в этом время часами питаются от резервных источников. Пока что такие резкие перепады не привели к катастрофам, но операторам энергосетей пришлось принимать меры для сокращения подачи электричества в сеть. Более того, в будущем подобные проблемы, вероятно, станут более распространёнными, поскольку спрос на электричество для ЦОД в Вирджинии только растёт. Регулятор утверждает, что необходимо срочно найти способ максимально безболезненно интегрировать дата-центры в электросети. США всё ещё находятся на ранней стадии бума ИИ, который в Вашингтоне считают необходимым для обеспечения национальной безопасности. В NERC заявили о необходимости разработки моделей, позволяющих лучше понять, как именно ЦОД используют электричество. Регулятор пришёл к выводу, что полезнее всего для обеспечения стабильности сетей будет применение аккумуляторных хранилищ. В конце прошлого года сообщалось, что в 2028 году на дата-центры США может прийтись уже 12 % энергопотребления всей страны. По данным Международного энергетического агентства (IEA), в мировом масштабе энергопотребление ЦОД к 2030 году вырастет более чем вдвое, а из-за ИИ придётся сжигать больше угля и газа.
18.06.2025 [16:03], Руслан Авдеев
Cove Architecture представили первый ЦОД, полностью спроектированный ИИКомпания Cove Architecture, вероятно, впервые в отрасли представила проект ЦОД, полностью созданный ИИ. Речь идёт об объекте площадью чуть менее 1 тыс. м2 — за 30 дней выполнено то, на что обычно уходят месяцы, сообщает Datacenter Knowledge. ИИ ЦОД стали одним из важнейших направлений работ в архитектуре — при этом операторы всё чаще используют ИИ для оптимизации систем охлаждения, управления инфраструктурой (DCIM) и выбора площадок для строительства. Представленный Cove Architecture проект ЦОД для Хартсела (Hartsel, Колорадо) пока ожидает одобрения властей. Это первый проект в отрасли, разработанный с использованием ИИ-платформы для архитекторов, утверждает компания. ИИ помог протестировать и оптимизировать различные конфигурации дата-центра, сократив время работы с недель до минут. При этом достигнут отличный показатель энергоэффективности (PUE) на уровне 1,2. 
Источник изображения: Cove Architecture Ключевые детали проекта:
ИИ меняет принципы проектирования дата-центров, позволяя комплексно оптимизировать энергопотребление и вычислительные мощности вместо использования разрозненных решений. Это не только экологично, но и экономически выгодно. Опора на ИИ, по словам представителей компании, меняет правила игры в отрасли. С использованием цифровых двойников будет гораздо дешевле проводить проверки качества, чем делать это в полевых условиях. При этом, как считают в Omdia, человеческая составляющая по-прежнему необходима и в ближайшее время это не изменится, поскольку при проектировании необходимо учитывать множество факторов. 
Источник изображения: Zan Lazarevic/unsplash.com В компании настроены оптимистично и заявляют, что ИИ-платформа позволяет учитывать местные требования к зонированию территорий, исторические данные о юридической практике одобрений таких проектов и даже климатические нюансы. Как заявляют в Cove Architecture, использование ИИ в проектировании дата-центров позволяет найти баланс для сложных, часто противоречивых требований: обеспечение доходности, соответствия стандартам, высокого качества дизайна и максимальной эффективности без ущерба экоустойчивости. Такое проектирование — лучший пример того, как технологии помогают избегать традиционных компромиссов в архитектуре, когда одним показателем приходится жертвовать в пользу другого.
18.06.2025 [14:56], Руслан Авдеев
xAI Илона Маска ежемесячно «сжигает» $1 млрд в надежде на будущие прибылиСтартап xAI Илона Маска (Elon Musk) ежемесячно тратит $1 млрд, поскольку стоимость создания компанией передовых ИИ-моделей значительно выше его доходов. Скорость трат средств компанией наглядно демонстрирует огромные финансовые потребности отрасли ИИ, сообщает Bloomberg со ссылкой на собственные источники. Для того, чтобы компенсировать дисбаланс, xAI пытается привлечь $9,3 млрд в долг и в виде акционерного капитала. При этом компания уже намерена потратить более половины из этих средств в ближайшие три месяца. Всего в 2025 году xAI, стоящая за чат-ботом Grok, рассчитывает потратить $13 млрд, но пока её усилия по сбору средств едва поспевают за расходами. Отчасти подобная ситуация обусловлена огромными расходами, с которыми столкнулись все ИИ-компании при создании современных ЦОД и покупке ускорителей для обучения LLM. По данным экспертов Carlyle Group, к 2030 году для удовлетворения спроса на ИИ-инфраструктуру будет потрачено более $1,8 трлн. В компании CreditSights тоже уверены, что разработчики «сожгут много-много денег», поскольку пространство «очень конкурентное». 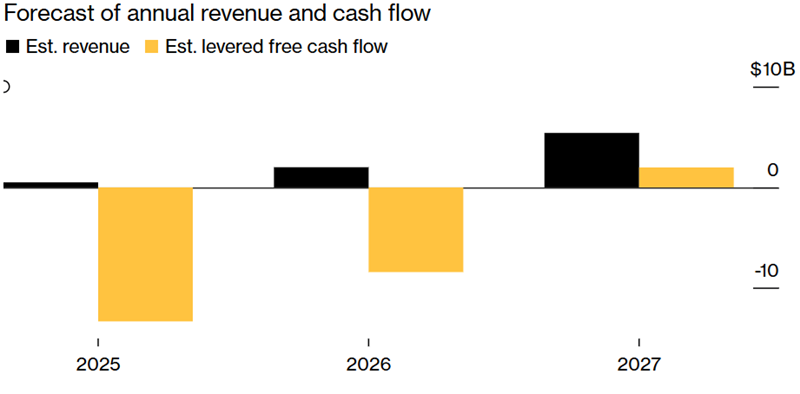
Источник изображения: Bloomberg При этом компания Маска пока не может зарабатывать столько, сколько OpenAI или Anthropic. Ни одна из этих компаний не раскрывает точных финансовых показателей, но ранее Bloomberg сообщал, что OpenAI ожидает выручить в 2025 году $12,7 млрд, тогда как xAI недавно объявила инвесторам, что в этом году её выручка составит лишь $500 млн, а в следующем — более $2 млрд. Сильная сторона xAI в том, что её глава Илон Маск, самый богатый человек в мире, не раз демонстрировал готовность тратить собственные средства на гигантские футуристические проекты задолго до того, как те начнут приносить деньги. В самой xAI, пытающейся создать «сверхразумный искусственный интеллект», способный конкурировать с людьми, считают, что компания имеет особые преимущества, которые позволят рано или поздно догнать конкурентов. Пока некоторые из компаний арендуют чипы и прочие мощности, xAI платит за большую часть инфраструктуры сама, а также пользуется ресурсами социальной сети X, которая тоже закупала ускорители. По словам Маска, xAI продолжит закупки новых чипов. После недавнего слияния xAI и X руководители ИИ-подразделения компании рассчитывают, что смогут обучать модели на архиве сообщений социальной сети, а не платить за массивы данных на стороне, как другие ИИ-компании. В результате xAI оптимистично рассчитывает стать прибыльной уже к 2027 году. Для сравнения, OpenAI предполагает «выйти в плюс» к 2029 году. 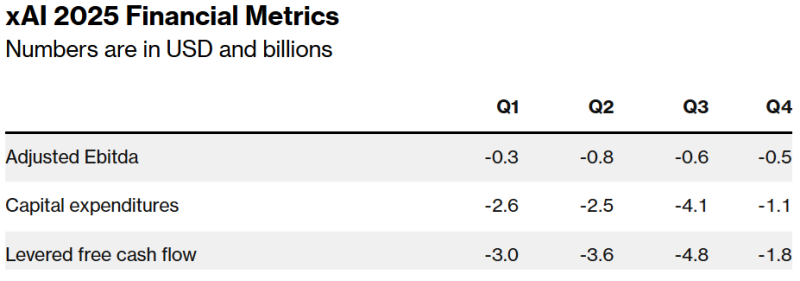
Источник изображения: Bloomberg Оптимистичные прогнозы, популярность Маска и его близость к властям в США привлекают инвесторов. Оценка xAI выросла до $80 млрд в конце I квартала, хотя в конце 2024 года она была на уровне $51 млрд. Среди инвесторов замечены Andreessen Horowitz, Sequoia Capital и VY Capital. Сейчас xAI спешит собрать достаточно денег, чтобы покрыть свои колоссальные расходы. По словам экспертов, с момента основания в 2023 году по июнь текущего компания привлекла $14 млрд акционерного капитала, из них на начало I квартала 2025 года оставалось лишь $4 млрд, оставшиеся средства компания рассчитывала потратить во II квартале. Сейчас компания завершает очередной раунд акционерного финансирования на $4,3 млрд и намерена привлечь ещё $6,4 млрд в следующем году, не считая долга в $5 млрд. Ожидается, что корпоративный долг поможет оплатить развитие ЦОД xAI. Компания также рассчитывает получить скидку в $650 млн от одного из производителей оборудования. По данным Bloomberg, уже есть первые признаки того, что xAI столкнулась с трудностями при привлечении инвестиций на первоначальных условиях. Инвесторы проявляли сдержанность, но после того, как компания изменила условия сделки в их пользу и предоставила дополнительную финансовую информацию, интерес к инвестициям вырос. Morgan Stanley, отвечающая за привлечение долговых средств xAI, отказалась от комментариев.
18.06.2025 [11:57], Руслан Авдеев
Firebird намерена построить в Армении 100-МВт ИИ ЦОДКомпания Firebird, специализирующаяся на облачных ИИ-технологиях, совместно с правительством Армении объявили о планах ввода в эксплуатацию в 2026 году ИИ ЦОД на 100 МВт. Предполагается, что он будет оснащён «тысячами» ускорителей NVIDIA Blackwell, сообщает Datacenter Dynamics. Финансирование проекта будет осуществляться в рамках государственно-частного партнёрства. Проект оценивается в $500 млн. По словам премьер-министра Армении, речь идёт о важном шаге на пути укрепления технологического сектора и глобального партнёрства в целом. Как заявил министр, правительство с радостью поддерживает инициативу, открывающую новые возможности для народа и региона. О самой компании Firebird и проекте пока известно не слишком много. По имеющимся данным, генеральным директором и соучредителем является американский бизнесмен с армянскими корнями Размик Овакимян (Razmig Hovaghimian). Он известен сотрудничеством с несколькими медийными и спортивными компаниями, включая Rakuten Viki, NBC, Hoodline и Matchday. По словам бизнесмена, компания намерена инвестировать в новые модели, робототехнику и науку, привлекая к партнёрству ведущие мировые университеты. Также планируется наращивать потенциал для взращивания нового поколения новаторов в Армении. 
Источник изображения: Ivars Utināns/unspalsh.com Ключевым инвестором Firebird выступит фонд «Афеян для Армении» (Afeyan Foundation for Armenia), а его глава Нубар Афеян (Noubar Afeyan), также являющийся руководителем компании Flagship Pioneering, получит должность стратегического консультанта и партнёра-основателя Firebird. По словам Афеяна, Армения намерена сделать ставку на глобальное сотрудничество и долгосрочные инвестиции в технологии. Развитие ИИ-инфраструктуры для страны и окружающего региона — смелый шаг, рассчитанный на превращение Армении в значимого участника «мирового ИИ-ландшафта». Развитие ИИ-инфраструктуры в Армении также поддержат Team Group, материнская компания Telecom Armenia и ирландской Imagine Broadband. Как заявил в своё время генеральный директор NVIDIA Дженсен Хуанг (Jensen Huang), «ИИ-фабрики — инфраструктура XXI века» и сотрудничество с Арменией поможет «открыть новые возможности для инноваций во всём регионе». Пока же в Армении существует небольшой рынок ЦОД. Армянская телеком-компания Ovio, принадлежащая «Ростелекому», Datacom Company и Arminco управляют ЦОД в Ереване. Небольшой объект строится местной VSDATA.
17.06.2025 [23:55], Владимир Мироненко
AMD анонсировала платформу ROCm 7.0, облако для разработчиков AMD Developer Cloud и программу Radeon Test DriveAMD вместе с ускорителями Instinct MI350X/MI355X представила 7-ю версию своего открытого программного стека ROCm (Radeon open compute). Как сообщает компания, ROCm 7.0 предназначен для удовлетворения растущих потребностей рабочих нагрузок генеративного ИИ и HPC, одновременно расширяя возможности разработчиков за счёт доступности, эффективности и активного сотрудничества сообщества. По данным AMD, платформа ROCm 7 предлагает более чем в 3,5 раза большую производительность инференса, чем ROCm 6, и в 3 раза большую эффективность обучения. Это стало возможным благодаря улучшениям производительности и поддержке типов данных с меньшей точностью, таких как FP4 и FP6. Дальнейшие улучшения в коммуникационных стеках позволили оптимизировать использование ускорителя и перемещение данных. ROCm 7 поддерживает распределённый инференс, а также фреймворки SGLang, vLLM и llm-d. Платформа ROCm 7 создавалась совместно с этими партнёрами, включая разработку общих интерфейсов и примитивов для обеспечения эффективного распределённого инференса на платформах AMD. 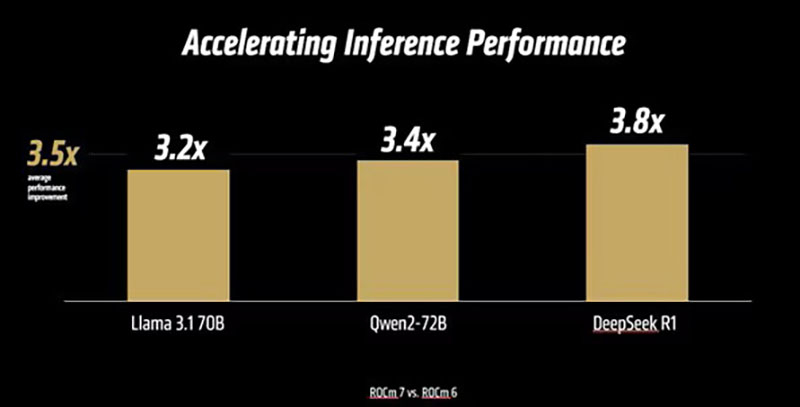
Источник изображений: AMD Вместе с ROCm 7 компания представила MLOps-платформу ROCm Enterprise AI для бесперебойных ИИ-операций в корпоративном сегменте. Платформа предлагает инструменты для тонкой настройки модели и интеграции как со структурированными, так и неструктурированными рабочими процессами. AMD заявила, что работает с партнёрами по экосистеме над созданием эталонных реализаций для таких приложений, как чат-боты и обобщение документов. 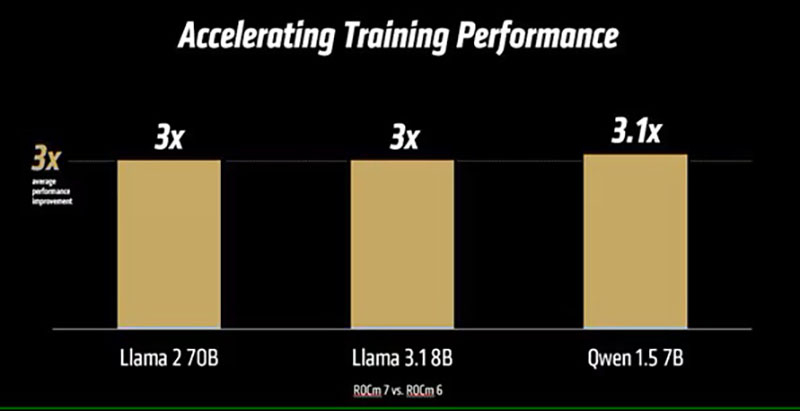 AMD отметила, что тесное партнёрство гарантирует разработчикам доступ к лучшим в своем классе инструментам, постоянному улучшению производительности и открытой среде для быстрой итерации и развёртывания. Также AMD представила партнёров экосистемы ROCm, которые используют преимущества данной платформы:
Кроме того, AMD представила «простую в использовании платформу для разработчиков» AMD Developer Cloud, обеспечивающую быстрый доступ к AMD Instinct с возможностью масштабирования от одного (192 Гбайт памяти) до восьми AMD Instinct MI300X (1536 Гбайт памяти). Сообщается, что конфигурации с одним ускорителем в основном используются для рабочих нагрузок инференса на «лёгких» моделях, тогда как максимальная конфигурация обеспечивает распределённое обучение, тонкую настройку и высокопроизводительный инференс для крупномасштабных моделей.  AMD сообщила, что платформа AMD Developer Cloud была разработана с учётом четырёх основных целей:
По словам компании, AMD Developer Cloud предполагает различные варианты использования. Решение идеально подходит для независимых разработчиков AI/ML, работающих над низкоуровневым программированием, разработкой ядер (kernel) или корпоративных приложений и проектов, нацеленных на нативную поддержку AMD. Также платформу можно использовать для мероприятий и хакатонов, обеспечивая масштабируемую поддержку образовательных и практических мероприятий с предоставлением кредитов на использование ускорителей во время семинаров, хакатонов, конкурсов и демонстраций.  Также с выходом ROCm 7 появилась поддержка ноутбуков и рабочих станциях на Windows с видеокартами Radeon и процессорами Ryzen AI. С этим связан ещё один важный анонс — компания представила программу ROCm on Radeon Test Drive, которая будет запущена этим летом партнёрстве с различными поставщиками оборудования (первыми стали Colfax и System76), чтобы упростить разработчикам возможность опробовать ROCm на GPU Radeon, передаёт Phoronix. В рамках Radeon Test Drive предоставляется возможность удалённо протестировать GPU Radeon (PRO).
17.06.2025 [15:31], Сергей Карасёв
Представлен российский OCP-сервер Delta Serval на базе Intel Xeon 6Российский разработчик и производитель IT-оборудования Delta Computers объявил о начале серийного выпуска двухпроцессорных 2OU-серверов Delta Serval. Системы предназначены для НРС-задач, виртуализации, а также использования в составе облачных инфраструктур. В основу Delta Serval положена аппаратная платформа Intel Xeon 6. При этом заказчики могут выбирать между процессорами Xeon Granite Rapids-SP (6500P/6700P) с производительными Р-ядрами и Xeon Sierra Forest с энергоэффективными Е-ядрами (6700E) с TDP 350 Вт. Поддерживается до 8 Тбайт памяти DDR5-6400 в виде 32 модулей. Возможно использование MRDIMM-8000. В зависимости от конфигурации могут быть установлены до восьми U.2 SSD (PCIe 5.0, NVMe) с толщиной 7 мм или до четырёх таких SSD с толщиной 15 мм. Кроме того, есть два коннектора для SSD формата M.2 2280 с интерфейсом PCIe. Доступны один слот OCP 3.0 PCIe 5.0 и четыре слота PCIe 5.0 x16 для карт HHHL. 
Источник изображений: Delta Computers Сервер оснащён портом USB 3.0 Type-A и интерфейсом miniDP, а также сетевым портом управления 1GbE. Задействована система гибридного охлаждения Delta Hybrid Cooling с резервированием вентиляторов по схеме N+1 (с поддержкой горячей замены). По заявлениям Delta Computers, машина может функционировать на максимальной частоте без деградации и перегрева процессоров при температуре в холодном коридоре до +45 °C. Применяется фирменное микропрограммное обеспечение Delta BIOS и Delta BMC.  Среди ключевых преимуществ новинки разработчик выделяет большое количество вычислительных ядер (до 172 P-ядер или до 288 E-ядер), возможность гибкой адаптации под требования заказчика, высокую плотность компоновки и поддержку интеграции с новыми аппаратными и программными платформами.
17.06.2025 [14:36], Владимир Мироненко
NVIDIA поможет Германии в создании индустриальных ИИ-облаков для европейских производителейNVIDIA объявила о планах по созданию первого в мире промышленного ИИ-облака для европейских производителей, базирующегося в Германии. ИИ-фабрики, которые развернут по всей стране, будут поддерживать разработку суверенных ИИ-приложений в государственном и частном секторах, в том числе для малых и средних компаний страны, известных как Mittelstand. На Mittelstand приходится 99 % всех предприятий в Германии и более половины экономического производства страны. ИИ-фабрика, построенная на системах NVIDIA DGX B200 и серверах NVIDIA RTX PRO с 10 тыс. ускорителей NVIDIA Blackwell позволит лидерам промышленности Европы ускорить работу индустриальных приложений, включая системы проектирования, инжиниринга и моделирования, цифровых двойников и робототехнику, сообщила компания. ИИ-фабрика будет построена в соответствии с концепцией NVIDIA Omniverse Blueprint. В Юлихском исследовательском центре (FZJ) в Германии идёт сборка суперкомпьютера JUPITER, который станет первой в Европе экзафлопсной системой. Благодаря 24 тыс. суперчипов GH200 с интерконнектом Quantum-2 InfiniBand JUPITER получит вдвое большую вычислительную мощность по сравнению с предыдущим самым мощным общедоступным суперкомпьютером континента. С его помощью исследователи смогут обучать большие языковые модели (LLM) с более чем 100 млрд параметров, заниматься моделированием климата, исследовать квантовых вычисления и разрабатывать лекарства. Во II половине 2026 года в Суперкомпьютерный центр Лейбница (LRZ) в Германии будет запущен суперкомпьютер Blue Lion с чипами NVIDIA Vera Rubin, предназначенный для ускорения исследований в области климата, физики и машинного обучения. NVIDIA также займётся созданием исследовательского центр в Германии в рамках программы NVIDIA AI Technology Center. Баварский ИИ-центр, который планируется создать в сотрудничестве с консорциумом BayernKI, будет продвигать исследования в таких областях, как цифровая медицина, устойчивая диффузия AI и платформы робототехники с открытым исходным кодом для содействия глобальному сотрудничеству. 
Источник изображения: NVIDIA Технологии NVIDIA широко используются немецкими компаниями всех масштабов. В частности, ИИ-компания DeepL из Кёльна развёртывает кластер на базе DGX SuperPOD GB200, который позволит ей переводить весь контент в интернете всего за 18 дней вместо нынешних 194. А модели серии FLUX от Black Forest Labs из Фрайбурга включены в NVIDIA AI Blueprint. Немецкие разработчики систем робототехники, автоматизации и сенсорных систем, включая Agile Robots, idealworks, Neura Robotics и SICK, интегрируют платформу NVIDIA Isaac. Наконец, Finanz Informatik использует инфраструктуру и ПО NVIDIA AI Enterprise для разработки ИИ-ассистента для помощи сотрудникам в обработке банковских данных. Mercedes-Benz использует Omniverse для создания цифровых двойников своих заводов и NVIDIA DRIVE AV/AGX в своих автомобилях. Технологии NVIDIA применяют BMW Group и Continental. NVIDIA также назвала в числе немецких компаний, внедряющих её ИИ-технологии, KION Group, занимающуюся решениями в сфере цепочек поставок, ИИ-стартап в сфере юриспруденции Noxtua и компанию по кибербезопасности Security Networks AG. 
Источник изображения: NVIDIA Чтобы инициировать трансформацию ИИ на всех уровнях экономики страны, необходимо обширное сообщество разработчиков в сфере ИИ, отметила NVIDIA. Поэтому Германия инвестирует в образование и повышение квалификации специалистов в области ИИ через некоммерческие организации, университеты и отраслевое сотрудничество. Одной из таких инициатив является appliedAI, крупнейшая в Европе инициатива по применению доверенного ИИ. В её рамках малым компаниям предоставляется доступ к современной инфраструктуре и ПО NVIDIA, практическому обучению и возможность подключения к экосистеме партнёров NVIDIA. Выступая на прошлом неделе с докладом на мероприятии GTC NVIDIA в Париже, гендиректор компании Дженсен Хуанг (Jensen Huang) заявил, что мощности для ИИ-вычислений в Европе вырастут в течение следующих двух лет на порядок. После фактической потери из-за санкций США доступа к рынку Китая, NVIDIA стремится расширить присутствие на новых рынках. Компания уже договорилась о сотрудничестве с французским стартапом Mistral, который построит ИИ-облако на базе 18 тыс. чипов NVIDIA Grace Blackwell. NVIDIA также объявила о запуске инфраструктурных проектов в Италии и Армении. Кроме того, компания заключила соглашения о сотрудничестве с такими телекоммуникационными компаниями, как Orange и Telefonica. В Европе компания уделяет особое внимание «суверенному ИИ», что подразумевает нахождение на территории ЕС дата-центров и серверов, предоставляющих услуги гражданам блока. NVIDIA также объявила о так называемых «технологических центрах» в Европе для передовых исследований, повышения квалификации рабочей силы и ускорении научных прорывов в таких странах, как Великобритания, Франция, Испания и Германия. NVIDIA также расширила возможности GPU-маркетплейса NVIDIA DGX Cloud Lepton.
17.06.2025 [12:27], Руслан Авдеев
AWS готовит крупнейшие в истории Австралии инвестиции в ЦОД, ИИ и облакоВ ближайшие четыре года AWS обязалась потратить AU$20 млрд (US$13 млрд) на инфраструктуру дата-центров в Австралии. Это крупнейшие инвестиции в технологическую сферу страны за всю её историю из числа заявленных публично, сообщает Tech Republic. Для того, чтобы инициативы Amazon соответствовали местным энергетическим требованиям, компания планирует реализовать три солнечных энергопроекта в провинциях Виктория и Квинсленд (Victoria и Queensland) общей мощностью более 170 МВт. Проекты будут управляться датской компанией European Energy, занимающейся «зелёной» энергетикой. Расширение инфраструктуры должно помочь удовлетворить спрос на ИИ и облачные вычисления в Австралии. По мнению экспертов, технологии автоматизации будут добавлять в австралийский ВВП к 2030 году по AU$600 млрд ежемесячно, а облачные вычисления принесут ещё AU$81 млрд в 2024–2029 гг. AWS говорит, что инвестиции в Австралии обеспечат доступ к ИИ и облачным сервисам местным компаниями, что позволит модернизировать ведение бизнеса, повысить продуктивность и т. п. с соблюдением требований местных регуляторов. Также компания продолжит поддержку образовательных программ для подготовки новых кадров для работы с ИИ и облаками. 
Источник изображения: Caleb/unspalsh.com По данным издания, несмотря на высокие позиции в глобальных рейтингах конкурентоспособности, Австралия демонстрирует низкий уровень развития предпринимательства. Эксперты связывают это с различными факторами, в том числе — довольно простой экономикой, ограниченным ассортиментом продукции и низкой «технологичностью» экспортируемых товаров. Возможно, AWS поможет стране раскрыть свой скрытый потенциал. Впрочем, не все рады попыткам компании захватить рынок. В 2023 году местные парламентарии получили жалобы на то, что доминирующее положение AWS на рынке затрудняет конкуренцию для малого бизнеса. Кроме того, AWS предлагала контракты и тарифы, усложняющие переход к другому оператору. В AWS утверждали, что на деле у неё немало соперников. По словам одного из экспертов, облака AWS «слишком дороги» — некоторые бизнесы попросту исчезли потому, что не смогли оплачивать облачные счета. 
Источник изображения: Tobias Keller/unsplash.com Дата-центры AWS также повысят нагрузку на местные электросети, что потенциально вызовет рост цен на электроэнергию. В прошлом году инвестиционный банк UBS предрекал, что к 2030 году в пиковые часы оптовые цены на электричество могут вырасти на 70 %. Проблемой также могут стать отключения электроэнергии, поэтому местный регулятор Australian Energy Market Commission формирует новые правила работы для предотвращения сбоев. Amazon же рассматривает строительство новых солнечных электростанций как способ поддержать новую инфраструктуру. Для того, чтобы компенсировать негативное влияние, Amazon намерена масштабировать своё портфолио в возобновляемой энергетике. В Новом Южном Уэльсе, Квинсленде и Виктории уже функционируют солнечные и ветряные проекты, которые вместе с тремя новыми солнечными электростанциями должны дать AWS более 1,4 ГВт∙ч ежегодно. Австралия — не единственный регион, где AWS активно занимается строительством. Новые ЦОД компания намерена строить в Южной Корее, облачный регион запущен на Тайване и ещё один планируется в Чили.
17.06.2025 [11:15], Руслан Авдеев
SK Group и AWS построят ИИ ЦОД на 60 тыс. ускорителей — крупнейший в Южной КорееКорейская SK Group и Amazon Web Services (AWS) совместно построят ИИ ЦОД в Ульсане (Ulsan, Южная Корея), в 305 км от Сеула. Дата-центр разместят в национальном промышленном комплексе Mipo, объект рассчитан на размещение 60 тыс. ИИ-ускорителей, сообщает Datacenter Dynamics. Хотя это не особенно типичная локация для размещения ЦОД, её выбрали из-за доступа к большим энергетическим мощностям. Дело в том, что поблизости находится ТЭС SK Gas, работающая на сжиженном природном газе. По данным местных СМИ, новый ЦОД будут строить поэтапно. На первом этапе, уже к ноябрю 2027 года, будет обеспечена мощность 41 МВт. К февралю 2029 года она должна вырасти до 103 МВт, а в будущем кампус должны расширить до 1 ГВт. Церемонию торжественного старта проекта запланирована на июнь, а закладка первого камня ЦОД — на август 2025 года. SK Telecom и SK Broadband намерены вложить в ИИ-инициативы ₩3,4 трлн ($2,5 млрд), причём только в совместный проект с AWS готовятся вложить триллионы. По данным СМИ, к 2028 году AWS, в свою очередь, намерена вложить в проект около $4 млрд. По данным SK Group, речь идёт о строительстве крупнейшего в стране ЦОД на сегодняшний день. 
Источник изображения: rawkkim/unsplash.com Ранее компания уже объявляла о планах строительства гигаваттных ИИ ЦОД в ключевых регионах на территории страны, но пока неизвестно, входит ли совместная инициатива в их число. Ранее южнокорейские власти объявляли о намерении создать Национальный вычислительный ИИ-центр (National AI Computing Center) на 15 тыс. ускорителей. SK Telecom (SKT) активно развивает связанный с ИИ-бизнес, делая ставку на инфраструктуру (дата-центры, GPU-as-a-Service) и ИИ-сервисы для потребителей и корпоративных клиентов. Несмотря на пока небольшой доход от ИИ-направления (около $115 млн в первом квартале), SKT сотрудничает с международными партнёрами, включая альянс Global Telecom Alliance и американские Anthropic и Lambda. Материнский холдинг SK Group обеспечивает мощную поддержку, имея $88 млрд выручки в прошлом году. В марте 2025 года сообщалось, что SK Telecom займётся созданием ИИ ЦОД совместно с Elice, Schneider Electric и Giga Computing. AWS располагает в Сеуле собственным облачным регионом с четырьмя зонами доступности, запущенными в 2016 году. Также компания строит собственный ЦОД в Согу, Инчхон (Seo-gu, Incheon). В 2021 году компания заявила, что намерена построить объект для сервиса AWS Ground Station в кампусе ЦОД в Сеуле. Также ранее компания уже сотрудничала с SK Telecom в своей зоне Wavelength. Не так давно AWS обязалась потратить $13 млрд на расширение инфраструктуры ЦОД в Австралии и запустила облачный регион на Тайване, а также готовится потратить $4 млрд на создание облачного региона в Чили. |
|

