Материалы по тегу: вычисления
|
01.03.2021 [15:09], Сергей Карасёв
Microsoft Azure MDC: мобильное облако в 40-футовом контейнереКорпорация Microsoft начала поставки любопытного серверного решения — центра обработки данных Azure Modular Data Center (MDC), все составляющие которого заключены в стандартный 40-футовый контейнер. Такое исполнение позволяет перевозить систему на различных видах транспорта и быстро вводить в эксплуатацию. ЦОД может быть развёрнут в любом месте, где есть подходящая площадка для установки контейнера и электрическая сеть необходимой мощности. Более того, питание может подаваться от дизельных генераторов. ЦОД и всё его оборудование сконструированы так, чтобы пережить и транспортировку, и эксплуатацию в не самых благоприятных условиях.  Система позволяет получить доступ к вычислительным мощностям облака Azure. Контейнерный ЦОД может функционировать в суровом климате, обеспечивая бесперебойную работу критически важной инфраструктуры. Платформа MDC может использоваться, к примеру, в центрах гуманитарной помощи, передвижных пунктах управления, а также на территориях предприятий добывающей промышленности.  MDC может работать как полностью автономно, так и в связке с «большим» облаком Azure. Причём предусмотрена возможность использования спутниковых средств связи — на случай перебоев в основном интернет-канале. Собственно говоря, именно в рамках совместного со SpaceX проекта Azure Space и были анонсированы эти ЦОД.  Внутри контейнера размещены три серверных блока, каждый из которых содержит две стойки 42U с коммутаторами и контроллерами. На каждый блок приходится 8 серверов и 48 узлов хранения. Все они работают под управлением Azure Stack Hub. Доступ к такому ЦОД предоставляется на условиях аренды, как и в случае более простых и компактных устройств серии Azure Stack Edge.
12.02.2021 [00:58], Владимир Мироненко
Oracle RED — компактное мобильное облако с защитойOracle объявила о пополнении своего облачного портфолио платформой Oracle Roving Edge Infrastructure, которая позволяет создавать безопасные масштабируемые облачные сервисы даже в самых удалённых регионах мира. Новое решение выводит основные инфраструктурные услуги на периферию с помощью Roving Edge Devices (RED) — надёжных, портативных, серверных узлов. RED позволяет организациям использовать преимущества Oracle Cloud для создания и запуска периферийных центров обработки данных в удалённых или труднодоступных местах. Как утверждает компания, с помощью RED предприятия и правительственные учреждения смогут использовать свои приложения и данные в Oracle Cloud Infrastructure (OCI) и безопасно развёртывать их на периферии — от военных самолётов до нефтяных танкеров и полярных станций. 
Источник изображений: Oracle RED работают даже при периодических подключениях к интернету или когда вовсе отключены от него. Сценарии использования включают рабочие нагрузки машинного обучения, хранилища данных с интенсивными запросами, а также приём и обработку данных датчиков Интернета вещей. Клиенты смогут синхронизировать и выгружать данные в облако, когда подключение доступно. Новые периферийные устройства заполнят брешь в портфеле продуктов Oracle для гибридного облака. Узел Oracle RED включает 2U-сервер, который имеет 40 OCPU (т.е. 40 процессорных ядер), ускоритель NVIDIA T4, 512 Гбайт ОЗУ, NVMe-хранилище ёмкостью 61 Тбайт, по два порта 100 GbE (QSFP28) и 10GbE (RJ45), а также TPM-модуль. Сервер упакован в защитный кейс. Система соответствует стандарту MIL-STD-810, то есть, к примеру, её можно уронить 26 раз с высоты 1,2 м без потери работоспособности.  Устройства Oracle RED могут быть объединены в группы от 5 до 15 узлов в одном кластере. Стоимость аренды начинается с отметки в $160 за узел в день, а минимальный срок аренды составляет 30 дней. Устройства Oracle RED уже доступны для правительственных учреждений США, бизнес-пользователи смогут получить их ближе к лету. Похожие продукты уже давно есть у конкурентов. AWS предлагает аналогичное по формату решение Snowball Edge, компактные Snowcone, а с недавних пор 1U/2U-узлы Outposts на базе Graviton2 и Intel Xeon. Microsoft имеет серию продуктов Azure Stack Edge, среди которых также есть как компактные, так и защищённые решения.
23.11.2020 [23:34], Владимир Мироненко
Б/У серверы Facebook✴ и Microsoft будут отапливать теплицы с помидорами
ff
hardware
itrenew
microsoft
ocp
микро-цод
нидерланды
отопление
периферийные вычисления
сельское хозяйство
сжо
экология
Производитель OCP-систем ITRenew объединил усилия с голландским облачным хостинг-провайдером Blockheating, чтобы предложить контейнеризированные дата-центры «всё-в-одном», которые поставляют ненужное тепло в теплицы. Blockheating производит микро-ЦОД с жидкостным охлаждением, благодаря чему «мусорное» тепло может передаваться с водой (t°=65 °C) в близлежащие теплицы. В рамках партнёрства контейнеры будут укомплектованы стоечными серверами и системами хранения Sesame от ITRenew. Согласно совместному заявлению компаний, в Нидерландах имеется более 3700 га коммерческих теплиц. Один микро-ЦОД может обогревать два гектара теплиц летом и полгектара зимой. Этого, по словам Blockheating, достаточно для выращивания тонны помидоров в год. Что более важно, тепло, выделяемое в виде отходов ЦОД, обходится намного дешевле природного газа, сжигаемого фермерами для обогрева теплиц. Blockheating заявила о разработке «нового способа водяного охлаждения серверов», который делает его рентабельным. В 2019 году компания провела испытания тестового ЦОД мощностью 60 кВт в Венло, недалеко от границы с Германией (на фото выше). Сейчас решения Blockheating имеют мощность 200 уже кВт. Поскольку они охлаждаются жидкостью, это устраняет потребность в установке оборудования для кондиционирования воздуха и повышает энергоэффективность. 
Blockheating В свою очередь системы ITRenew Sesame, устанавливаемые в микро-ЦОД, используют б/у-оборудование гиперскейлеров вроде Facebook✴ и Microsoft. Таким образом, снижается стоимость покупки и владения, почти на четверть сокращаются выбросы CO2 и объёмы электронного мусора, связанные с ИТ-индустрией.
01.10.2020 [11:51], Юрий Поздеев
Hailo: новые модули ускорения ИИ для периферийных вычисленийHailo, производитель микросхем для систем искусственного интеллекта (ИИ), выпустила новые высокопроизводительные модули в форм-факторах M.2 и mini PCIe для расширения возможностей периферийных систем. 
Источник изображений: Hailo Модули на базе процессора Hailo-8 можно подключать к различным периферийным устройствам, что позволяет использовать возможности ИИ в умных домах, розничной торговле и промышленности.  Модули Hailo легко интегрируются в стандартные платформы, такие как TensorFlow и ONNX, что позволяет значительно упростить использование новинок в комплексных решениях. Заказчики могут оперативно перенести свои решения с нейронными сетями на модули Hailo-8. 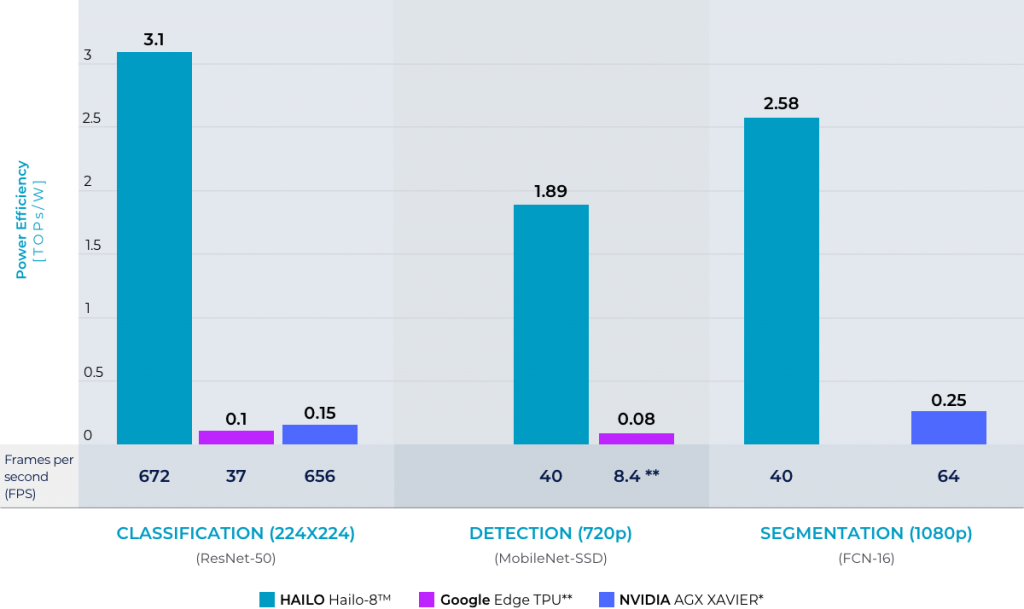 Спрос на высокопроизводительные периферийные устройства постоянно растет, поэтому безвентиляторные модули Hailo-8 будут востребованы, например, в видеоаналитике, либо для подключения большого количества внешних датчиков для сбора и обработки информации в режиме реального времени. Процессор Hailo-8 способен обеспечить 26 TOPS, при этом имеет энергоэффективность 3 TOPS/Вт.  Модуль Hailo-8 M.2 уже интегрирован в следующее поколение Foxconn BOXiedge (24-ядерный мини сервер, который потребляет всего 30 Вт, при этом обладает неплохими показателями производительности). Наличие готового продукта позволит ускорить внедрение новых модулей в периферийные вычисления и значительно упростить этот процесс для конечного заказчика.
23.09.2020 [16:00], Алексей Степин
Intel представила новые 10-нм индустриальные процессоры: от Atom x6000E до Core i7 Tiger LakeНа мероприятии Intel Industrial Summit компания показала новые решения для периферийных вычислений и промышленных систем: платформу Atom x6000E, а также новые процессоры Pentium и Celeron серий N/J и индустриальные версии Core i3/i5/i7 11-го поколения известного как Tiger Lake. Для x6000E, Pentium и Celeron используется классический, «старый» 10 нм, а кристаллы Tiger Lake производятся с использованием «нового» 10 нм, так называемого SuperFIN. Платформа Intel Atom x6000E (Elkhart Lake) универсальна и позволяет решать широкий круг задач. Она может применяться в производящей промышленности и энергетике, в системах управления «умного города», в здравоохранении и медицине и во многих других отраслях, где требуется обработка достаточно серьёзных входных потоков данных в реальном времени. При этом платформа отвечает самым строгим требованиям безопасности.  По сравнению с предыдущими процессорами Atom аналогичного назначения в серии x6000E однопоточная производительность возросла в 1,7 раза, многопоточная — в 1,5 раза, а производительность графической подсистемы вдвое. Для повышенной временной точности в новинках реализована поддержка технологий Intel Time Coordinated Computing (TCC) и Time-Sensitive Networking (TSN).  Как и полагается современной SoC для периферийных вычислений, в составе x6000E имеются блоки критографических ускорителей, а для IoT имеется интегрированный микроконтроллер ARM Cortex-M7, отвечающий за работу Intel Programmable Services Engine (Intel PSE). Он работает независимо от остальных блоков и предоставляет возможности удалённого управления SoC, обработки низкоскоростного ввода-вывода от различных сенсоров, запуск приложений реального времени и синхронизацию. Есть также и чисто аппаратные средства обеспечения ИТ-безопасности, объединённые под именем Intel Safety Island. 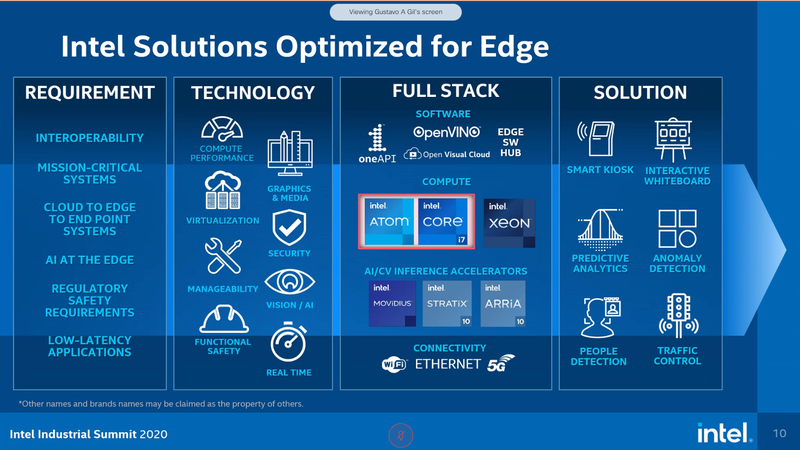 Также в целях обеспечения надёжности реализован широкий спектр средств удалённого мониторинга и управления, как в режиме in-band, так и в out-of-band. Включение, выключение, сброс и перезагрузку можно выполнять даже если система в целом не отвечает. Модели Atom x6427FE и x6200FE отвечают стандартам функциональной безопасности IEC 61508 и ISO 13849, они прошли соответствующую сертификацию, так что использовать их можно и в системах жизнеобеспечения, в комплексах управления АЭС или нефтеперабатывающего предприятия. 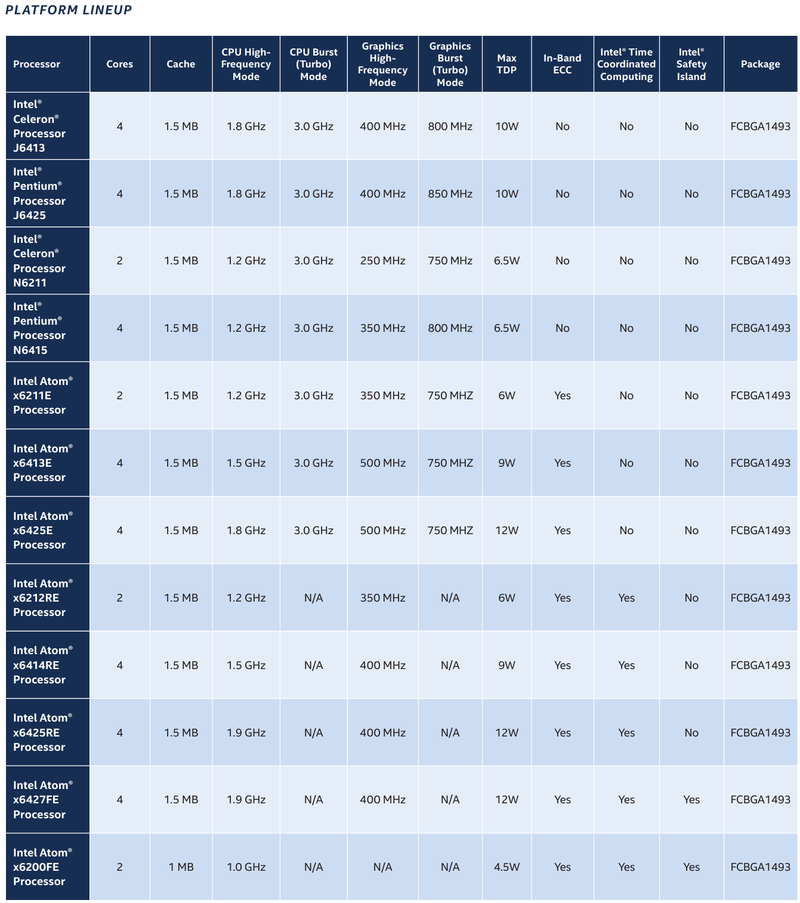 Серия Intel Atom x6000E включает в себя процессоры с двумя или четырьмя ядрами, их частотный диапазон составляет от 1,0 до 1,9 ГГц, в турборежиме частота может временно увеличиваться до 3,0 ГГц. Аналогичные частотные формулы имеют и Pentium/Celeron, базирующиеся на ядрах Tiger Lake (11 поколение). Контроллер памяти может работать либо с LPDDR4x (4×32 бита, максимум 4267 Мт/с, 16 Гбайт при 3200 МГц, всего до 64 Гбайт) или DDR4 (2×64 бита, 3200 Мт/с, максимум 32 Гбайт, всего до 64 Гбайт), есть поддержка in-band ECC для обычных модулей без ECC. Объём кеша составляет 1 Мбайт у самой младшей модели, во всех остальных случаях он равен 1,5 Мбайт. 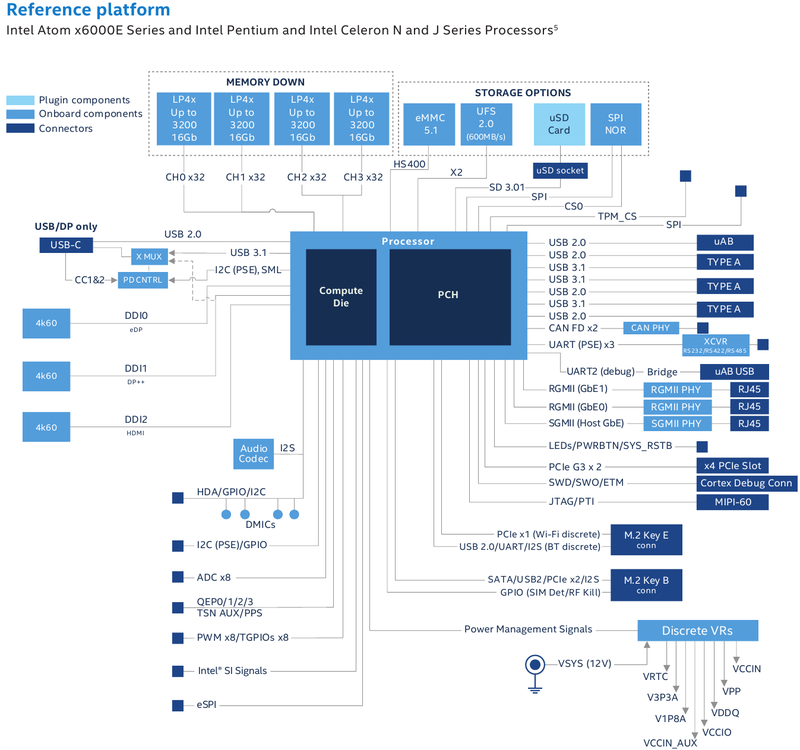 В соответствии с современными требованиями к графике, новинки Atom поддерживают подключение до трёх независимых дисплеев с разрешением 4K при 60 Гц, для этого служат интерфейсы Display Port 1.3 и HDMI 2.0b. Также поддерживается подключение экранов по eDP или MIPI DSI. Сам графический движок Intel UHD Graphics может иметь конфигурацию с 16 или 32 исполнительными блоками, работающими на частоте до 400 МГц, а в турборежиме — и до 800 МГц. Они поддерживают различные режимы вычислений для работы в качестве инференс-системы. Новые SoC Intel выполнены в едином корпусе FCBGA1493, однако под крышкой скрываются два кристалла — вычислительный и PCH. 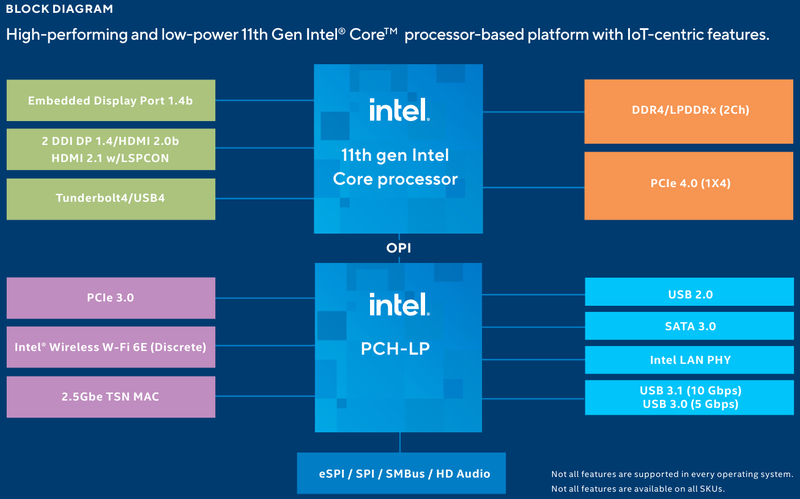 У более мощных процессоров с ядрами Tiger Lake графика тоже намного мощнее, она представлена блоками Iris Xe, которых в составе чипа может быть до 96, к тому же новая графическая архитектура лучше подходит для систем принятия решений (инференс) и задач машинного зрения. Такая графическая подсистема может одновременно обрабатывать до 40 потоков видео в формате 1080p при 30 кадрах в секунду, а выводить — либо четыре потока 4K, либо два, но уже в 8K. Подобные мощности позволяют использовать Tiger Lake в системах, для которых требуется детерминированная, строго синхронизированная по времени работа, либо в гибких системах машинного зрения с ИИ-компонентами. Безопасности способствует возможность полного шифрования содержимого оперативной памяти. 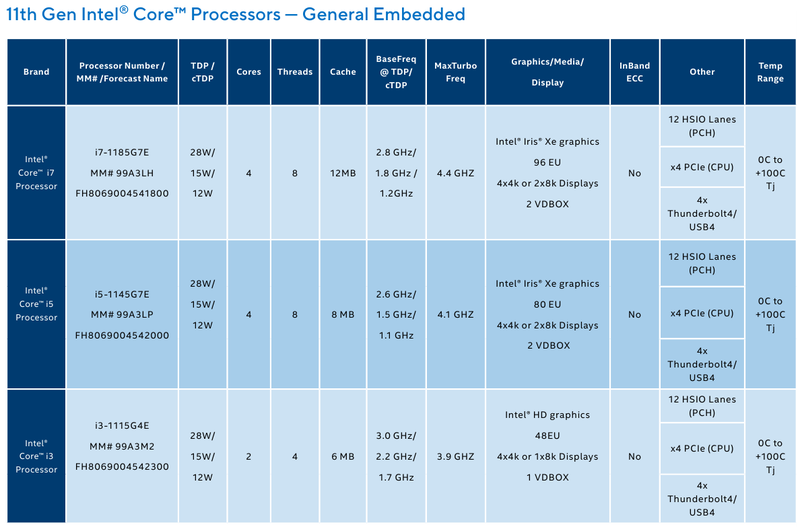 Коммуникационные возможности новых промышленных процессоров Intel также соответствуют требованиям времени: новые SoC несут на борту три MAC-контроллера, способных работать на скорости 2,5 Гбит/с, причём, в моделях с поддержкой TSN обеспечивается режим реального времени с минимальными задержками. Также общение «с внешним миром» происходит посредством 8 линий PCI Express 3.0, четырех портов USB 3.1 и 10 портов USB 2.0. Имеется два порта для подключения флеш-накопителей с интерфейсом UFS 2.0. В референсной платформе Intel реализована и поддержка UART и JTAG (разъём MIPI-60). 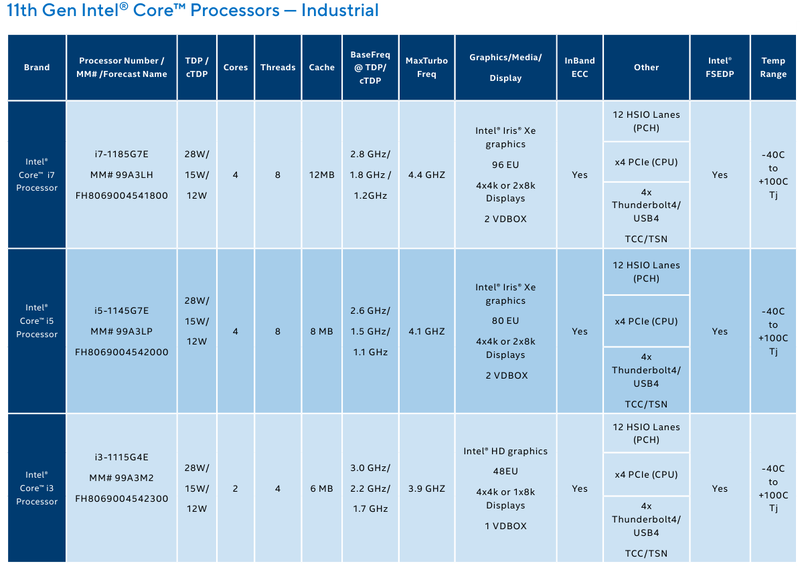 У более мощных Tiger Lake из серий i3/i5/i7 возможности несколько иные: встроенных MAC два, один из которых работает в режиме 1GbE, другой поддерживает cкорость 2,5GbE, в некоторых моделях дополнен поддержкой Time-Sensitive Networking. Поддерживается подключение дискретного сетевого контроллера I225LM/IT. Что касается беспроводной части, то имеется поддержка Wi-Fi со скоростями до 1,73 Гбит/с, а также Bluetooth 5.0. Для расширения инференс-способностей поддерживается подключение дополнительного ускорителя Intel из серии Movidius. Также реализованы стандарты PCIe 4.0 (четыре линии) и Thunderbolt/USB 4 (четыре порта).  Теплопакеты достаточно скромные: от 4,5 до 12 Ватт у Atom, до 28 Ватт у Tiger Lake. Улучшенный техпроцесс позволяет последним быть существенно быстрее аналогичных Core 8 поколения, в зависимости от характера нагрузки это до 23% (однопоточная) или до 19% (многопоточная), а графическая подсистема и вовсе практически в три раза быстрее за счёт новой архитектуры.  Новые процессоры имеют широкий спектр программной поддержки. В первую очередь, это, естественно, Microsoft Windows 10 IoT Enterprise и Yocto Project Linux, разрабатываемая сообществом Yocto совместно с Intel. Поддерживается также запуск Ubuntu, Wind River Linux LTS и Android 10 (только 64-битная версия). Для Tiger Lake также заявлена совместимость с Wind River VxWorks. 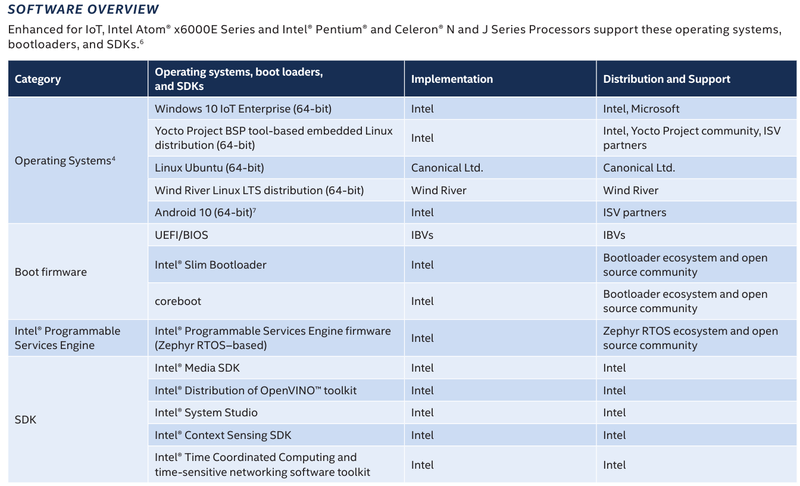 В качестве загрузчика может использоваться как обычный BIOS/UEFI, так и открытые Intel Slim Bootloader и coreboot. Часть, отвечающая за подсистемы безопасности и реального времени, работает под управлением Zephyr RTOS, также открытой. В число партнёров Intel, отвечающих за код BIOS, входят American Metatrends, Thundersoft, Byosoft, Insyde и Phoenix.  Для создания ПО компания предлагает расширенный комплект разработчика: инструменты для реализации Time Coordinated Computing, Intel Media SDK, набор Intel для OpenVINO, Intel System Studio и Intel Context Sensing SDK. Intel понимает всю важность рынка периферийных вычислений, за которым, судя по всему, будущее промышленности: любая производственная задача будет неизбежно порождать серьёзные потоки данных и требовать от системы управления минимальных задержек. Именно поэтому периферийные вычислительные устройства, к которым относятся и новые процессоры Intel, столь важны. Неудивительно, что компания уделяет много внимания как аппаратным возможностям, так и программным компонентам в новой платформе.
15.09.2020 [19:33], Алексей Степин
Microsoft Natick может стать будущим периферийных ЦОД, надёжность доказанаЛюбой современный ЦОД — это не только помещение, занимающее определённую площадь, но ещё и серьёзные системы питания и, особенно, охлаждения. Ряд компаний считает, что с точки зрения последнего фактора имеет смысл рассмотреть возможность размещения ЦОД под водой, на дне моря, где температура постоянна и достаточно низка. В их числе Microsoft со своей разработкой Project Natick. Первый прототип Natick, доказавший работоспособность концепции, успешно проработал 105 дней в водах Калифорнийского залива, однако действительно серьёзная мощность была достигнута лишь во второй фазе, о которой и идёт речь в данной заметке. Второй прототип Natick являет собой 12,2-метровый цилиндрический контейнер стандарта ISO 40, внутри размещено 12 стоек с 864 серверами Microsoft (в составе присутствуют ПЛИС-ускорители) и СХД общим объёмом 27,6 Пбайт. Система охлаждения во втором варианте была разработана французской группой Naval Group на основе теплообменников, использующихся в современных подводных лодках.  На этот раз местом размещения подводного ЦОД был выбран район Оркнейских островов в 193 километрах (120 миль) от берега, глубина погружения составляла примерно 35 метров. Для питания и данных использовался общий кабель, содержащий как силовые линии, способные передать около четверти мегаватта, так и оптические волокна. Проект создавался с прицелом на пятилетний срок работы без обслуживания, с прицелом на 20 лет в будущем. Для обеспечения повышенной надёжности внутреннее пространство контейнера заполнено азотом, который практически инертен и способствует уменьшению износа оборудования.  14 сентября Microsoft сообщила об окончании второй фазы Project Natick, которая продлилась два года. Сам контейнер был извлечён из моря ещё летом, и специалисты и эксперты занялись изучением состояния аппаратного обеспечения, входившего в состав второго прототипа автономного ЦОД. Результат проекта признан очень успешным, возглавляющий Project Natick Бен Катлер (Ben Cutler) заявил, что «дело сделано, и второй вариант Natick можно с полным правом назвать подходящим строительным блоком». Согласно статистике, около 50% населения планеты проживает недалеко от берега моря, поэтому размещение подводных ЦОД в прибрежных областях вполне оправдано, а Европейский центр морской энергетики (Europetn Marine Energy Centre) вообще говорит о возможности использования для питания таких ЦОД приливных турбин и волновых конвертеров, что сделает их практически автономными, не считая оптоволоконного подключения. 
Часть системы охлаждения Natick Тонкости функционирования Natick ещё предстоит изучить, но предварительные результаты оказались несколько обескураживающими: ЦОД в герметичном контейнере, покоившийся на дне моря, и, естественно, лишённый обслуживания, оказался в восемь раз надёжнее, нежели его копия, расположенная на суше. Причины примерно ясны: стабильные температуры, отсутствие окисляющей атмосферной среды, а также каких-либо серьёзных вибраций. Компания считает, что эти данные могут помочь и в проектировании более надёжных наземных ЦОД.  Microsoft признала, что проект всё ещё далёк от завершения, но считает, что стандартный ЦОД Azure в подводном варианте уже может быть создан. Вице-президент отдела Azure по системам класса mission critical Вильям Чэппел (William Chappell) отметил, что его команда особенно заинтересована в пост-квантовых методах шифрования, критичных для такого рода периферийных центров обработки данных. Также заявлено, что Natick успешно может служить в качестве периферийного ЦОД или ЦОД с повышенной безопасностью; последнее достаточно очевидно — получить доступ к оборудованию, находящемуся под водой, намного сложнее, нежели в обычном ЦОД. Надёжнее в этом плане может быть только сервер на орбите, но по понятным причинам такое решение намного дороже и сложнее, нежели Natick, оно менее мощное, а также не гарантирует постоянной низкой латентности, которая может быть критичной в edge-сценариях использования.
18.06.2020 [19:38], Владимир Мироненко
AWS Snowcone — мини-облако в дорогуКомпания Amazon анонсировала AWS Snowcone, нового представителя семейства устройств AWS Snow, предназначенных для периферийных вычислений, хранения и передачи данных из удалённых сред или мест, где отсутствует подключение к сети. Snowcone весит всего 2,1 кг и имеет габариты 227 × 148,6 × 82,65 мм.  Мини-облако поддерживает запуск малых инстансов Amazon EC2:
Внутри у него неназванный x86-процессор c минимум двумя ядрами и 4 Гбайт оперативной памяти. Также у устройства имеется хранилище ёмкостью 8 Тбайт. AWS Snowcone можно подключать как к проводным, так и беспроводным сетям — у него есть два порта 1/10GbE и адаптер Wi-Fi 802.11a/b/g/n/ac. Питается устройство от порта USB Type-C (мин. 61 Вт), возможно подключение внешнего аккумулятора. Устройство защищено от внешнего воздействия согласно стандарту IP65. Диапазон рабочих температур: 0°...38° C. Максимальный расчётный срок службы составляет 4 года.  Перед отправкой клиенту Amazon загрузит в устройство желаемый образ AMI, в том числе с IoT Greengrass. Для обмена данными с внешним миром используется NFSv4. Устройство можно использовать с существующими локальными серверами и файловыми приложениями для чтения и записи данных. Как и в случае других решений семейства Snow, Snowcone с загруженными клиентом данными можно отправить назад в Amazon, чтобы они были перемещены в S3-хранилище в выбранном клиентом облачном регионе. В настоящий момент AWS Snowcone можно арендовать лишь в США: $60 за заказ + $6 за каждый день использования. В дальнейшем AWS будет предлагать эту услугу в других регионах.
02.04.2019 [20:00], Геннадий Детинич
Intel представила процессоры Xeon D-1600: почта, телеграф, мостыВ 2015 году компания Intel представила процессоры Xeon семейства D. Первой появилась серия Xeon D-1500. Процессоры Xeon D получили архитектуру уровня Intel Core (Broadwell), став на ступеньку выше Xeon на архитектуре Atom. Целевое назначение Xeon D при этом не изменилось ― они всё так же были ориентированы на создание микросерверов, встраиваемых решений, систем для хранения данных малого и среднего уровней и сетевого оборудования. В 2018 году компания выпустила серию Xeon D-2100 на архитектуре Skylake. Тем самым в семейство Xeon D добавились решения повышенной производительности. Сегодня Intel представила третью серию Xeon D ― процессоры D-1600, которые возвращают нас к истокам семейства, главной целью которого был захват рынка производительной периферии с акцентом на плотность и сниженное потребление.  Процессоры Intel Xeon D-1600 получили меньшее число ядер, чем у их предшественников в лице Xeon D-1500. Диапазон числа физических ядер у моделей Xeon D-1600 сократился с 4–16 до 2–8. Максимальный тепловой пакет при этом остался тем же ― 65 Вт, тогда как минимальное значение TDP снизилось с 35 Вт до 27 Вт. Снижение числа ядер и сохранение максимального уровня TDP говорит о росте производительности в пересчёте на одно ядро. Во многом это достигается за счёт прироста как базовой частоты (в 1,2–1,5 раза), так и за счёт увеличения частоты при автоматическом разгоне до 3,2 ГГц, тогда как модели Xeon D-1500 в режиме турбо ограничивались частотой до 2,7 ГГц. Определённым образом Intel откатилась назад по шкале эволюции, понизив градус многоядерности в пользу наращивания однопоточной производительности. Собственно, этого требует позиционирование новой серии и активное развитие виртуализации сетевых функций (NFV). Для этого стала важнее скорость реакции сетевой платформы, что хорошо отрабатывается повышением тактовых частот.  Архитектурных изменений в моделях Xeon D-1600 не очень много, если они вообще есть (пока предполагаем, что архитектура осталась прежней ― Broadwell). Интегрированный контроллер памяти остался двухканальным с поддержкой модулей DDR4 с частотой до 2400 МГц суммарным объёмом до 128 Гбайт. Также поддерживается память DDR3L-1600. Уточним, процессоры Xeon D ― это однокристальная платформа, фактически SoC, что чрезвычайно удобно для тех областей, на которые нацелены эти решения.  Встроенные в процессоры интерфейсы представлены 24 линиями PCIe 3.0, 8 линиями PCIe 2.0, 6 портами SATA 6 Гбит/с, 4 портами USB 3.0, 4 портами USB 2.0 и 4 портами Ethernet 10 Гбит/с. Кстати, об Ethernet. На кристалл Xeon D-1600 интегрирован контроллер Intel серии Ethernet 700. На это намекают не только четыре интерфейса Ethernet 10GbE, но также поддержка технологии Intel QuickAssist.  У старшей серии Xeon D-2100 модели Xeon D-1600 взяли то, чего не было у моделей Xeon D-1500 ― это поддержка технологии Intel QuickAssist (QAT). Технология QAT поддержана в моделях Xeon D-1600 с индексом «N». Наличие QAT означает, что процессор несёт встроенный аппаратный ускоритель для работы с криптографией, компрессией и обработки сетевого трафика. Поддерживается целый ряд популярных алгоритмов, что существенно разгружает вычислительные ядра и даёт ощутимый прирост производительности. Например, обработка трафика TLS/IPSec плюс компрессия происходит со скоростью 30 Гбит/с плюс 30 000 операций в секунду, как и расшифровка ключами RSA с такой же производительностью. 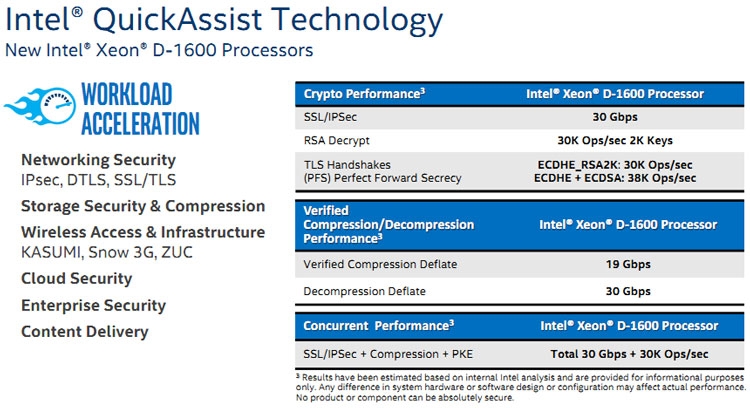 Поставки процессоров Xeon D-1600 компания Intel начнёт во втором квартале текущего года. Решения на основе новинок попадут на рынок к середине года или во второй его половине. По представлениям Intel, вычислительное и коммуникационное оборудование на базе Xeon D-1600 станет оптимальным выбором для развёртывания инфраструктуры для реализации и поддержки сотовой связи поколения 5G, а также для организации периферийных (пограничных) вычислений, когда обработка сырых данных (видео, сбор информации с датчиков, включая автомобильную электронику) происходит на месте и минимизирует пересылку в центры по обработке информации. Кроме того, они могут быть использованы в системах хранения данных. 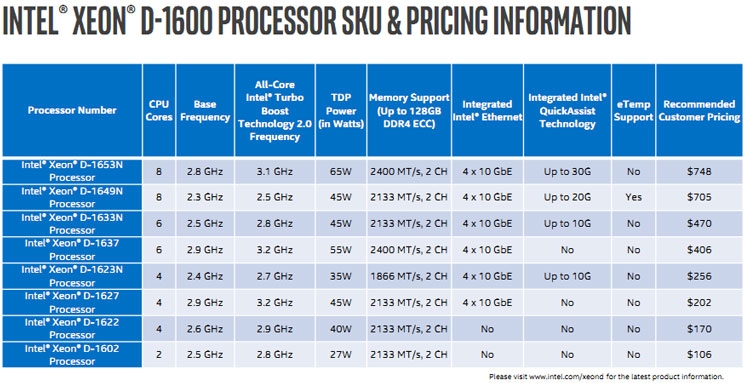 Процессоры Intel Xeon D 1600 представлены в рамках большого обновления решений для ЦОД, которое включает «взрослые» Intel Xeon Cascade Lake AP и SP с поддержкой памяти Optane в формате DDR4-модулей и новых инструкций для ИИ, модульные FPGA Agilex и сетевые контроллеры 100GbE Intel Ethernet 800. Подробности по ссылкам ниже.
29.06.2018 [13:00], Геннадий Детинич
Опубликованы финальные спецификации CCIX 1.0: разделяемый кеш и PCIe 4.0Чуть больше двух лет назад в мае 2016 года семёрка ведущих компаний компьютерного сектора объявила о создании консорциума Cache Coherent Interconnect for Accelerators (CCIX, произносится как «see six»). В число организаторов консорциума вошли AMD, ARM, Huawei, IBM, Mellanox, Qualcomm и Xilinx, хотя платформа CCIX объявлена и развивается в рамках открытых решений Open Compute Project и вход свободен для всех. В основе платформы CCIX лежит дальнейшее развитие идеи согласованных (когерентных) вычислений вне зависимости от аппаратной реализации процессоров и ускорителей, будь то архитектура x86, ARM, IBM Power или нечто уникальное. Скрестить ежа и ужа — вот едва ли не буквальный смысл CCIX. 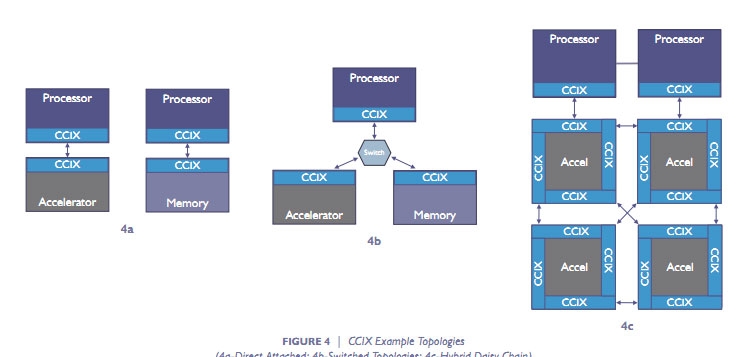
Варианты топологии CCIX На днях консорциум сообщил, что подготовлены и представлены финальные спецификации CCIX первой версии. Это означает, что вскоре с поддержкой данной платформы на рынок может выйти первая совместимая продукция. По словам разработчиков, CCIX позволит организовать новый класс подсистем обмена данными с согласованием кеша с низкими задержками для следующих поколений облачных систем, искусственного интеллекта, больших данных, баз данных и других применений в инфраструктуре ЦОД. Следующая ступенька в производительности невозможна без эффективных гетерогенных (разнородных) вычислений, которые смешают в одном котле исполнение кода общего назначения и спецкода для ускорителей на базе GPU, FPGA, «умных» сетевых карт и энергонезависимой памяти. 
Решение CCIX IP компании Synopsys Базовые спецификации CCIX Base Specification 1.0 описывают межчиповый и «бесшовный» обмен данными между вычислительными ресурсами (процессорными ядрами), ускорителями и памятью во всём её многообразии. Все эти подсистемы объединены разделяемой виртуальной памятью с согласованием кеша. В основе спецификаций CCIX 1.0, добавим, лежит архитектура PCI Express 4.0 и собственные наработки в области быстрой коррекции ошибок, что позволит по каждой линии обмениваться данными со скоростью до 25 Гбайт/с. 
Тестовая платформа с поддержкой CCIX Synopsys на FPGA матрице Но главное, конечно, не скорость обмена, хотя это важная составляющая CCIX. Главное — в создании программируемых и полностью автономных процессов по обмену данными в кешах процессоров и ускорителей, что реализуется с помощью новой парадигмы разделяемой виртуальной памяти для когерентного кеша. Это радикально упростит создание программ для платформ CCIX и обеспечит значительный прирост в ускорении работы гетерогенных платформ. Вместо механизма прямого доступа к памяти (DMA), со всеми его тонкостями для обмена данными, на платформе CCIX достаточно будет одного указателя. Причём обмен данными в кешах будет происходить без использования драйвера на уровне базового протокола CCIX. Ждём в готовой продукции. Кто первый, AMD, ARM или IBM? 
Тестовый набор CCIX 
Рабочая демо-система с неназванным CPU и FPGA, соединённых шиной CCIX |
|
|||||||||||||








