Материалы по тегу: i
|
15.08.2024 [00:10], Владимир Мироненко
Только не упоминай VMware: Dell Technologies и Nutanix представили совместные HCI-решенияDell Technologies и Nutanix объединили усилия для повышения простоты, гибкости и масштабируемости гибридных облачных инфраструктур с помощью двух новых решений — Dell XC Plus и Dell PowerFlex with Nutanix Cloud Platform, сообщил ресурс SiliconANGLE. Новинки, как ожидается, помогут предприятиям более эффективно управлять приложениями и рабочими нагрузками в средах Nutanix. Новые программно-аппаратные комплексы будут поставляться Dell. Dell XC Plus представляет собой готовую гиперконвергентную платформу на базе программного стека Nutanix Cloud Platform и серверов Dell PowerEdge. По словам компаний, Dell XC Plus обеспечивает бесперебойное управление в рамках единой структуры, предлагая клиентам больше выбора и контроля для удовлетворения меняющихся ИТ-требований. Платформа, по словам компаний, предоставляет безопасную, устойчивую и гибкую ИТ-среду, централизованное управление гибридным облаком, автоматизацию, оптимизацию планирования ресурсов и повышение производительности посредством ИИ-алгоритмов. 
Источник изображения: Dell В свою очередь, решение Dell PowerFlex with Nutanix Cloud Platform объединяет программно-определяемую инфраструктуру Dell с гипервизором Nutanix AHV и Cloud Platform. Dell PowerFlex — масштабируемая vSAN и гиперконвергентная система с поддержкой нескольких гипервизоров. PowerFlex станет первым внешним хранилищем, поддерживаемым и интегрированным с Nutanix Cloud Platform. Ключевые атрибуты этой новой интеграции включают защиту корпоративных данных и аварийное восстановление, сетевые функции и защиту. Nutanix и Dell подписали партнёрское соглашение в мае, пытаясь побудить клиентов Broadcom VMware перейти на совместную платформу Dell-Nutanix. Dell и Nutanix сообщили, что решение Dell PowerFlex with Nutanix Cloud Platform в настоящее время находится в разработке и будет доступно для раннего доступа клиентам в конце этого года, в то время как Dell XC Plus доступно уже сейчас. Примечательно, что в анонсе новых решений имя VMware не упоминается ни разу.
13.08.2024 [20:33], Владимир Мироненко
Huawei готовит к выпуску ИИ-ускоритель Ascend 910C, конкурента NVIDIA H100Huawei Technologies вскоре представит новый ИИ-ускоритель Ascend 910C, сопоставимый по производительности с NVIDIA H100, сообщила газета The Wall Street Journal со ссылкой на информированные источники. По их словам, китайские интернет-компании и операторы в последние недели тестировали этот чип и в настоящее время ByteDance (материнская компания TikTok), поисковик Baidu и государственный оператор связи China Mobile ведут переговоры по поводу его поставок. Судя по озвученным цифрам, заказы могут превысить 70 тыс. шт. на общую сумму около $2 млрд. Huawei намерена начать поставки уже в октябре, сообщили источники, но компания не стала комментировать эти сообщения. Huawei была включена в «чёрный» список Entity List Министерства торговли США в 2019 году, что лишило её возможности производить закупки передовых чипов и оборудования для их выпуска, а также размещать заказы на производство микросхем за пределами Поднебесной. Однако благодаря многомиллиардной государственной поддержке компания стала национальным лидером во многих областях, включая ИИ, и ключевой частью усилий Пекина по «удалению» американских технологий, отметила WSJ. При этом Китай наращивает поддержку отечественного производства полупроводников и в мае выделил $48 млрд в рамках третьего транша национального инвестиционного фонда для этой отрасли. 
Источник изображения: huaweicentral.com Из-за санкций США китайским клиентам NVIDIA приходится довольствоваться ИИ-ускорителем H20, разработанным специально для Китая с учётом экспортных ограничений Министерства торговли США, в то время как американские клиенты NVIDIA, такие, как OpenAI, Amazon и Google, вскоре получат доступ к гораздо более производительным чипам, включая GB200. NVIDIA также готовит для Китая чип B20, хотя есть опасения, что и он может попасть под новые ограничения США. По оценкам аналитиков SemiAnalysis, 910C может быть даже лучше, чем B20, и если Huawei сможет наладить выпуск нового чипа, а NVIDIA по-прежнему не сможет продавать китайским клиентам передовые ускорители, то у последней все шансы быстро потерять долю рынка в стране. Согласно подсчётам SemiAnalysis, в 2025 году Huawei может произвести 1,3–1,4 млн ускорителей 910C, если не столкнётся с дополнительными ограничениями США. Аналитики ожидают, что NVIDIA продаст более 1 млн H20 в Китае в этом году на сумму около $12 млрд, т.е. в штучном выражении примерно вдове больше, чем Huawei 910B. По словам источников, в последние недели Huawei начала накапливать запасы HBM-чипов, используемых в ИИ-ускорителях, в связи с опасениями ввода США новых экспортных ограничений. На прошедшей в июне конференции, посвящённой полупроводниковой промышленности, представитель руководства Huawei сообщил, что почти половина больших языковых моделей (LLM), созданных в Китае, была обучена с помощью ускорителей компании. Он также отметил, что в этих задачах 910B превосходит по производительности NVIDIA A100.
13.08.2024 [18:43], Руслан Авдеев
Huawei Cloud построила сетевой монитор, способный быстро найти отдельный неисправный чип в целом ЦОДВ Huawei Cloud разработали собственный сверхточный инструмент сетевого мониторинга RD-Probe для обслуживания для своих облачных регионов. По данным The Register, он способен выявить проблемы, которые человек заметить не способен. В докладе Huawei и представители Пекинского университета ссылаются на данные Amazon: лишь внутри одного облачного региона AWS имеется 1087 возможных путей передачи данных и 10176 — между регионами. В ЦОД Huawei Cloud используются более 100 тыс. коммутаторов и миллион серверов. Мониторинг всей этой инфраструктуры является чрезвычайно сложной задачей. 
Источник изображения: Shivendu Shukla/unsplash.com RD-Probe отслеживает состояние всех L2-портов во всей сетевой фабрике. Исследователи отмечают, что традиционно осуществляется именно мониторинг L3, что не даёт полной картины состояния сети. При этом инструмент Huawei воспринимает коммутаторы как «чёрные ящики» и не полагается исключительно на их внутреннюю телеметрию, благодаря чему легко интегрируется с уже существующей архитектурой системы мониторинга. Инструмент сначала проводит зондирование случайным образом, потом — детерминированным. Подобная двухэтапная схема обеспечивает максимальное покрытие сети при проверках и вместе с тем не нагружает её. Для генерации трафика выделен кластер из 16 узлов, каждый из которых имеет неназванный восьмиядерный процессор с частотой 2,80 ГГц и 64 Гбайт оперативной памяти. Полученные данные в потоковом режиме обрабатывают 48 узлов (16-ядерный CPU и 32 Гбайт RAM). 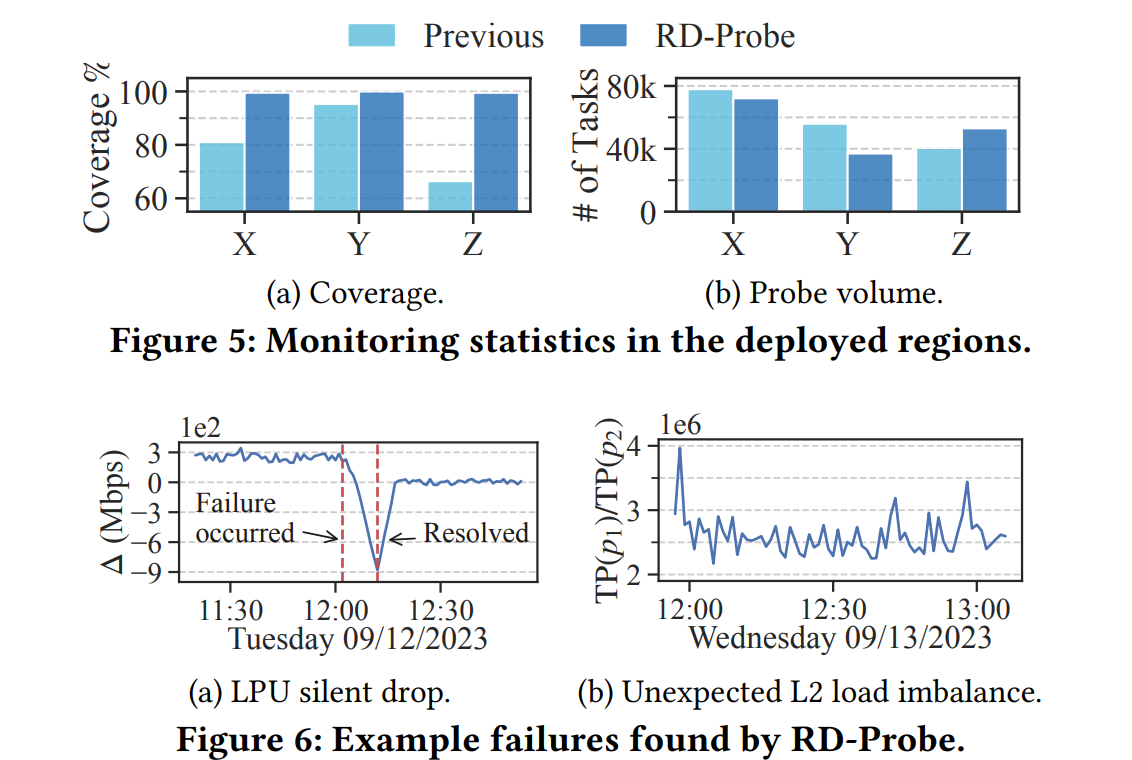
Источник изображения: Huawei Через месяц после начала использования RD-Probe в Huawei Cloud было найдено множество незамеченных ранее проблем. Конечно, большинство касалось небольших сбоев и эпизодических потерь пакетов, зато выявили их до того, как могли серьёзно пострадать пользователи. Например, инструмент помог определить сбойный чип в коммутаторе ядра сети, из-за которого периодически отбрасывался входящий трафик, но при этом отчёты об ошибках не генерировались. Также была выявлена ошибка в балансировке нагрузки, сбойное SerDes-подключение и проблема с некоторыми BGP-маршрутами. Исследователи Huawei выразили удовлетворение тем, что RD-Probe улучшило покрытие мониторингом сети с 80,9 % до 99,5 %. В скором времени решение планируется применить в других облачных регионах Huawei. При этом авторы доклада подчёркивают, что RD-Probe оценивает только внутренний трафик и не может фильтровать сбои на серверной стороне. Отмечается, что ручной мониторинг не даёт таких хороших результатов.
13.08.2024 [11:19], Сергей Карасёв
MSI представила сервер S2301 с поддержкой CXL на базе AMD EPYC TurinКомпания MSI в ходе выставки Future of Memory and Storage 2024 (FMS) анонсировала сервер S2301, предназначенный для работы с резидентными базами данных, НРС-приложениями, платформами для автоматизации проектирования электроники (EDA) и пр. Сервер поддерживает стандарт CXL 2.0 на основе интерфейса PCIe. Технология обеспечивает высокоскоростную передачу данных с малой задержкой между хост-процессором и такими устройствами, как серверные ускорители, буферы памяти и интеллектуальные IO-блоки. На основе CXL 2.0 функционирует высокопроизводительный механизм доступа к памяти, который позволяет модулям расширения напрямую взаимодействовать с иерархией памяти CPU. При этом дополнительные блоки памяти работают так, как если бы они были частью собственной памяти системы. Подключив к серверу модули расширения CXL, можно с высокой эффективностью масштабировать ресурсы для обработки сложных задач. 
Источник изображения: MSI Сервер MSI S2301 поддерживает установку двух процессоров AMD EPYC поколения Turin. Доступны 24 слота для модулей ОЗУ. Возможно применение CXL-модулей в форм-факторе E3.S 2T (PCIe 5.0 x8). Такие решения, в частности, в августе 2023 года представила компания Micron Technology. Устройства имеют вместимость 128 и 256 Гбайт. Кроме того, память DRAM с поддержкой CXL 2.0 предлагает Samsung. Во фронтальной части нового сервера располагаются отсеки для SFF-модулей. Говорится об использовании софта Memory Machine X разработки MemVerge, который оптимизирует затраты и помогает улучшить производительность ИИ-приложений и других ресурсоёмких рабочих нагрузок путём интеллектуального управления памятью.
10.08.2024 [11:52], Сергей Карасёв
Одноплатный компьютер DFI RPP051 формата Pico-ITX получил чипы Intel Raptor Lake-UКомпания DFI пополнила ассортимент одноплатных компьютеров моделью RPP051 на аппаратной платформе Intel Raptor Lake-U (Core 13-го поколения). Новинка подходит для создания edge-оборудования и устройств Интернета вещей, рассчитанных на эксплуатацию в широком температурном диапазоне — от -30 до +80 °C. Изделие выполнено в форм-факторе Pico-ITX с размерами 100 × 72 мм. В зависимости от модификации используется чип U300E (1P + 4E; шесть потоков; до 4,3 ГГц). Core i3-1315UE (2P + 4E; восемь потоков; до 4,5 ГГц), Core i5-1345UE (2P + 8E; 12 потоков; до 4,6 ГГц) или Core i7-1365UE (2P + 8E; 12 потоков; до 4,9 ГГц). Есть один слот SO-DIMM для модуля DDR5-4800 ёмкостью до 32 Гбайт. 
Источник изображения: DFI Решение DFI RPP051 располагает коннектором M.2 B key 3042/2242 (PCIe x2/USB 2.0/SATA 3.0) для SSD, разъёмом M.2 E key 2230 (PCIe x1/USB 2.0) для адаптера Wi-Fi/Bluetooth и коннектором M.2 B key 3042/2242 (PCIe x1/USB 3.2 Gen1/SATA 3.0) для модема 4G/5G (плюс слот для карты Nano SIM). В оснащение входят сетевой контроллер Intel I226IT/LM стандарта 2.5GbE и звуковой кодек Realtek ALC888S-VD2-GR. Предусмотрены два порта USB 3.2 Gen2, разъём DP++ (до 4096 × 2304 точки; 60 Гц) и гнездо RJ-45 для сетевого кабеля. Через коннекторы на плате можно задействовать два порта USB 2.0, последовательный порт RS-232/422/485, интерфейс eDP и пр. Питание (12 В) подаётся через 2-контактный коннектор. Заявлена совместимость с Windows 10 IoT Enterprise, Windows 11 и Linux. Цена одноплатного компьютера составляет $620, $891 и $1128 за версии с процессором Core i3-1315UE, Core i5-1345UE и Core i7-1365UE соответственно.
09.08.2024 [23:30], Сергей Карасёв
Представлена крошечная плата Raspberry Pi Pico 2 за $5 на чипе с ядрами RISC-V и ArmКомпания Raspberry Pi анонсировала микроплату Pico 2, в основу которого положен гибридный чип RP2350: это изделие объединяет ядра с архитектурой Arm и RISC-V. Для новинки заявлена обратная аппаратная и программная совместимость с более ранними представителями серии Pico. Оригинальная плата Raspberry Pi Pico дебютировала в январе 2021 года. Она получила микрочип собственной разработки RP2040, содержащий два ядра Cortex M0+ с базовой тактовой частотой 48 МГц и возможностью повышения до 133 МГц. Чип RP2350, в свою очередь, имеет более сложную конструкцию. 
Источник изображения: Raspberry Pi В состав RP2350 входят по два ядра Arm Cortex-M33 и RISC-V Hazard3 (RV32I с расширениями): в обоих случаях тактовая частота составляет 150 МГц. Однако использовать эти кластеры сообща нельзя — одна из двух конфигураций выбирается при инициализации устройства. Правда, при выборе RISC-V не будут работать часть функций безопасности и FP64-ускорение. Чип существует в модификациях RP2350A (QFN-60; 7 × 7 мм; 30 × GPIO) и RP2350B (QFN-80; 10 × 10 мм; 48 × GPIO). Есть 520 Кбайт памяти SRAM в обоих вариантах исполнения. Плата Raspberry Pi Pico 2 располагает 4 Мбайт флеш-памяти QSPI и портом Micro-USB 1.1. Говорится о поддержке 2 × UART, 2 × SPI, 2 × I2C, 16 × PWM, 4 × ADC. Размеры новинки равны 51 × 21 мм. Напряжение питания — от 1,8 до 5,5 В. Диапазон рабочих температур простирается от -20 до +85 °C. Плата Raspberry Pi Pico 2 предлагается как по отдельности, так и в партиях из 480 штук. Изделие будет производиться как минимум до января 2040 года, то есть жизненный цикл составляет не менее 16 лет. Приобрести новинку можно по цене $5.
09.08.2024 [11:48], Сергей Карасёв
Одноплатный компьютер Geniatech XPI-7110 в стиле Raspberry Pi получил чип RISC-VКомпания Geniatech представила одноплатный компьютер XPI-7110, предназначенный для создания различных устройств Интернета вещей. Новинка, выполненная в стиле Raspberry Pi, использует аппаратную платформу StarFive с процессором на открытой архитектуре RISC-V. Изделие имеет размеры 85 × 56 мм. Установлен чип JH7110, который содержит четыре 64-битных ядра RISC-V (SiFive U74 — RV64GC) с частотой 1 ГГц и графический блок Imagination BXE-4-32 с поддержкой OpenCL 1.2, OpenGL ES 3.2, Vulkan 1.2. Возможно декодирование видео H.264/H.265 4Kp60 и кодирование материалов H.265 1080p30. 
Источник изображения: Geniatech В базовой комплектации одноплатный компьютер несёт на борту 2 Гбайт памяти LPDDR4, в максимальной — 8 Гбайт. Есть флеш-модуль eMMC вместимостью 16 Гбайт (до 256 Гбайт), а также слот для карты microSD. В оснащение входят адаптеры Wi-Fi (2,4/5 ГГц, стандарт не указан) и Bluetooth 5.0, сетевой контроллер 1GbE. Есть выход HDMI, порт USB 3.0 и три порта USB 2.0, гнездо RJ-45 для сетевого кабеля. Кроме того, упомянуты интерфейсы MIPI DSI и MIPI CSI, а также 40-контактная колодка GPIO, совместимая с Raspberry Pi. Питание подаётся через разъём USB Type-C (5 В / 3 A). Одноплатный компьютер Geniatech XPI-7110 доступен в коммерческой и индустриальной версиях: в первом случае диапазон рабочих температур простирается от 0 до +60 °C, во втором — от -40 до +85 °C. Заявлена совместимость с Debian Linux.
01.08.2024 [16:34], Владимир Мироненко
Почти половина выручки Microsoft теперь приходится на облачные сервисы, а четверть дохода Azure OpenAI принёс TikTokMicrosoft сообщила о результатах работы в IV квартале 2024 финансового года, завершившемся 30 июня. Несмотря на то, что выручка и прибыль Microsoft превысили прогнозы аналитиков, акции компании упали более чем на 7 % после публикации отчёта из-за недовольства инвесторов замедлением темпов роста облачной платформы Azure. На облачные сервисы теперь приходится около 45 % выручки корпорации. Microsoft сообщила о прибыли (GAAP) на акцию (EPS) в размере $2,95 при выручке в $64,73 млрд, превысившей показатель аналогичного квартала годом ранее на 15 %. Чистая прибыль компании увеличилась с $20,08 до $22,04 млрд. Согласно прогнозу аналитиков, опрошенных Bloomberg, показатели по прибыли и выручке могли составить $2,94 на акцию и $64,5 млрд. В IV квартале 2023 финансового года у Microsoft была прибыль на акцию в размере $2,69 и выручка в $56,19 млрд. 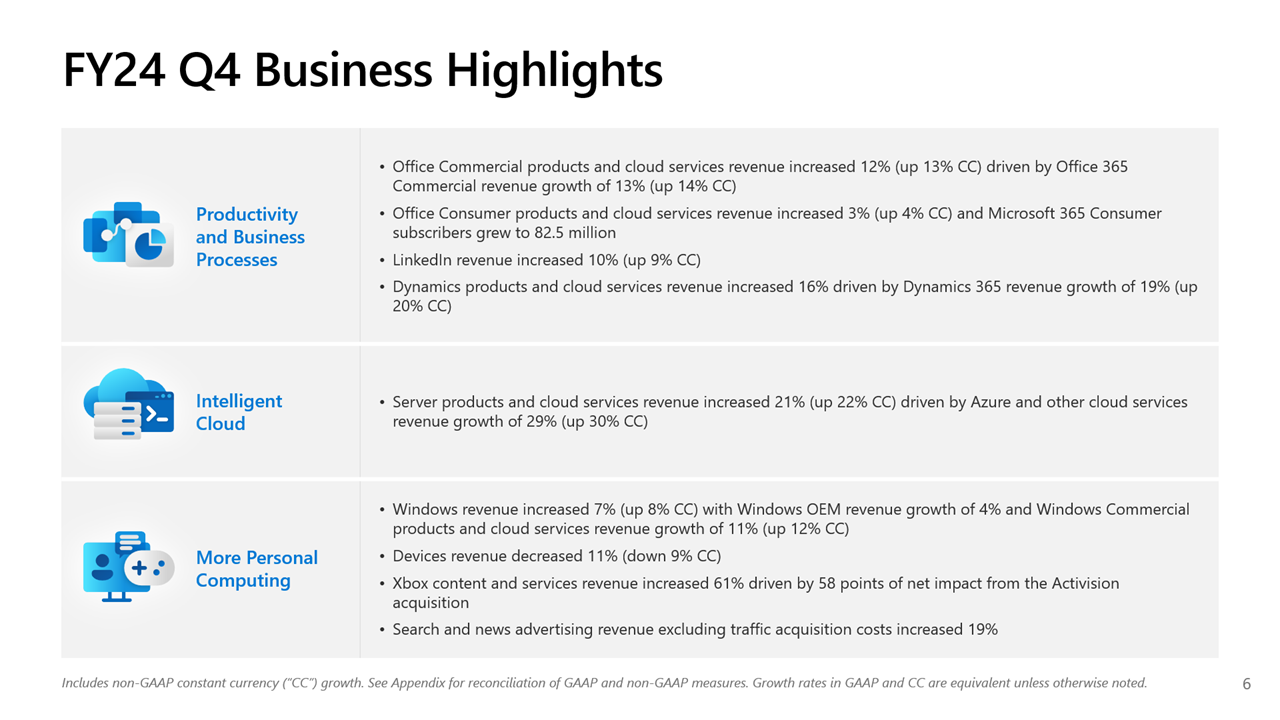
Источник изображений: Microsoft Общий доход Microsoft от облачных вычислений составил $36,8 млрд, что полностью соответствует прогнозу Уолл-стрит, но выручка подразделения Intelligent Cloud, в которое входят облачные сервисы Azure, а также Windows Server, SQL Server, GitHub, Nuance, Visual Studio и корпоративные сервисы, оказалась ниже ожиданий аналитиков, составив $28,52 млрд (рост год к году на 19 %) при консенсус-прогнозе аналитиков, опрошенных StreetAccount, в $28,68 млрд. 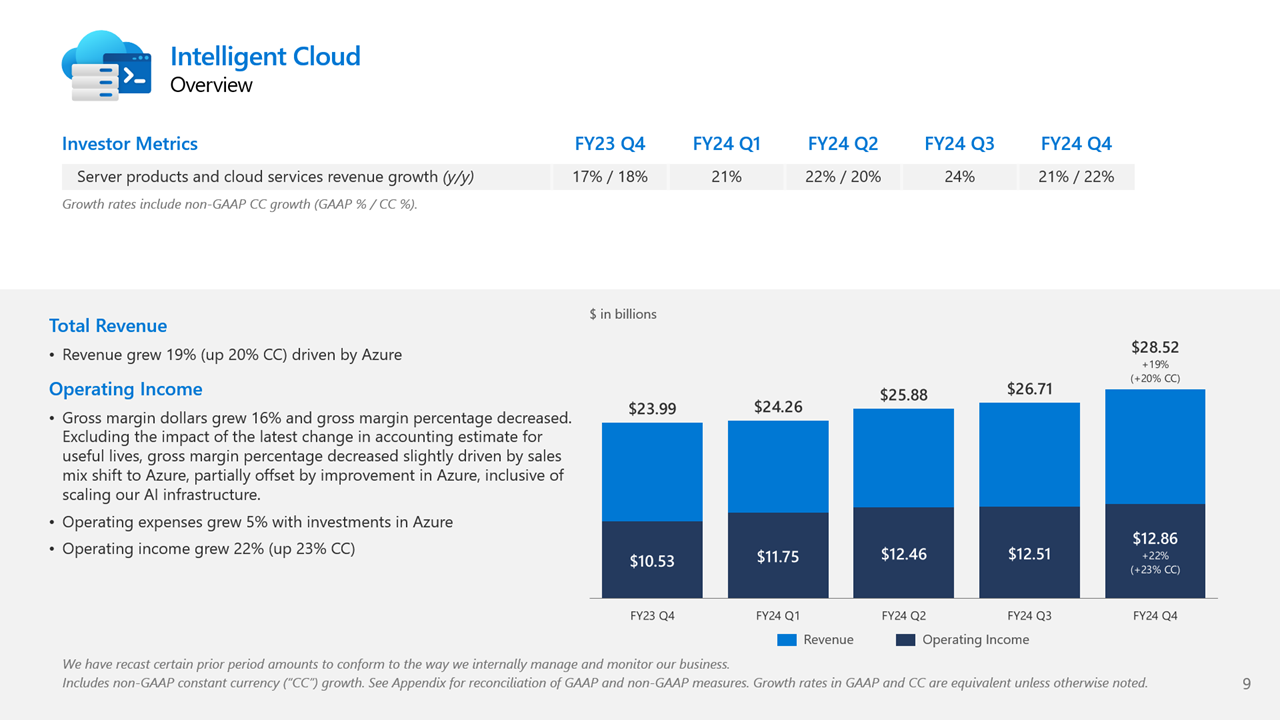 По данным Microsoft, на создание ЦОД и вычислительной инфраструктуры для обработки ИИ было израсходовано $13,9 млрд, что на 55 % больше, чем годом ранее. Компания заявила, что увеличение расходов было обусловлено более высокими доходами от ИИ, при этом спрос продолжает превышать предложение. Доход от Azure и других облачных сервисов вырос за квартал на 29 %. Аналитики, опрошенные CNBC и StreetAccount, ожидали рост на 31 %. При этом показатель Microsoft Azure не отставал от консенсус-прогноза с 2022 года. Абсолютные цифры в этой категории компания не раскрывает.  Финансовый директор Эми Худ (Amy Hood) объяснила небольшое отставание облачного сегмента «слабостью в нескольких европейских географических регионах в плане потребления сервисов без ИИ». Как ожидает компания, эта тенденция сохранится в первой половине 2025 финансового года. Генеральный директор Microsoft Сатья Наделла (Satya Nadella), что количество клиентов Azure AI выросло на 60 %, и на 50 % увеличилось числа заказчиков ИИ, которые также используют аналитические инструменты Microsoft. 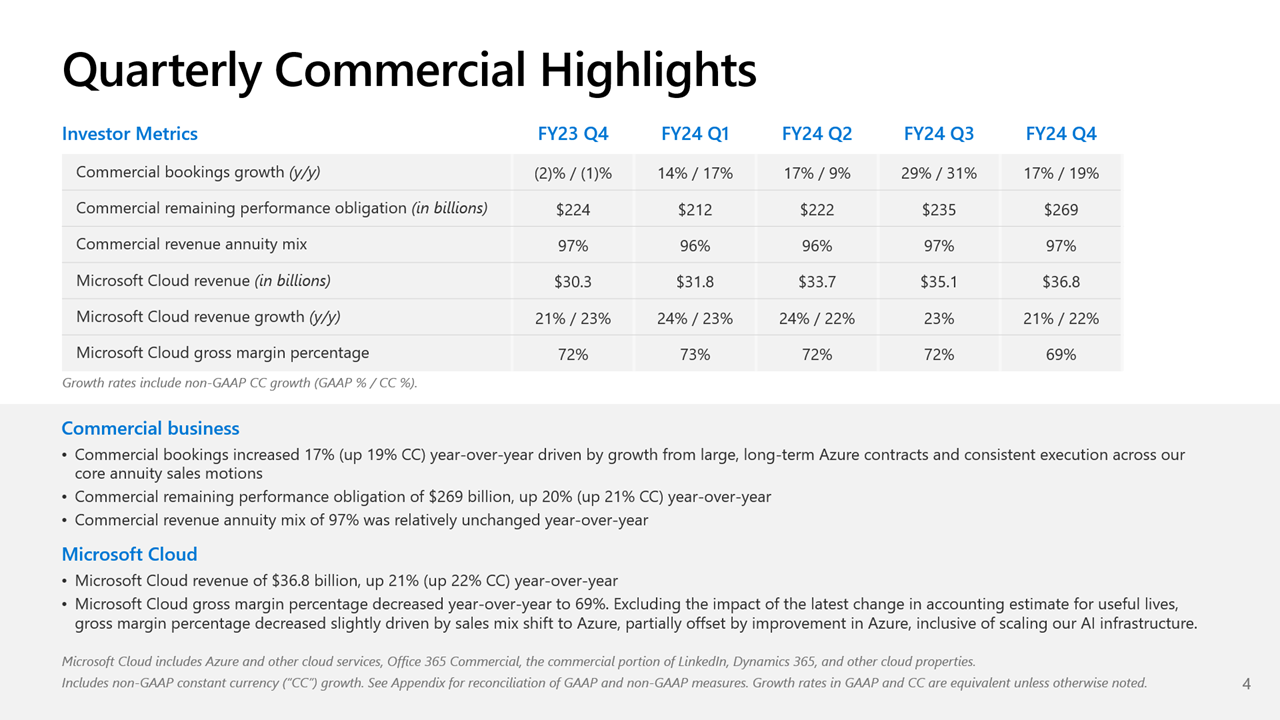 Всего более 480 000 организаций использовали возможности ИИ на платформе Microsoft. По словам Наделлы, аудитория пользователей Microsoft Copilot удвоилась по сравнению с предыдущим кварталом. Он сообщил, что с нынешними темпами роста выручка GitHub превысит $2 млрд за год, что 40 % больше, чем в прошлом году. Добавим, что согласно данным ресурса The Information, ссылающегося на внутреннюю информацию компании, примерно четверть выручки Azure OpenAI принёс сервис коротких видео TikTok, чьи ежемесячные поступления составляли около $20 млн по состоянию на март 2024 года. По оценкам, служба Azure OpenAI принесёт $1 млрд за год или $83 млн в месяц. Интересно, что теперь OpenAI с точки зрения Microsoft является конкурентом, хотя IT-гигант и владеет почти половиной ИИ-компании. 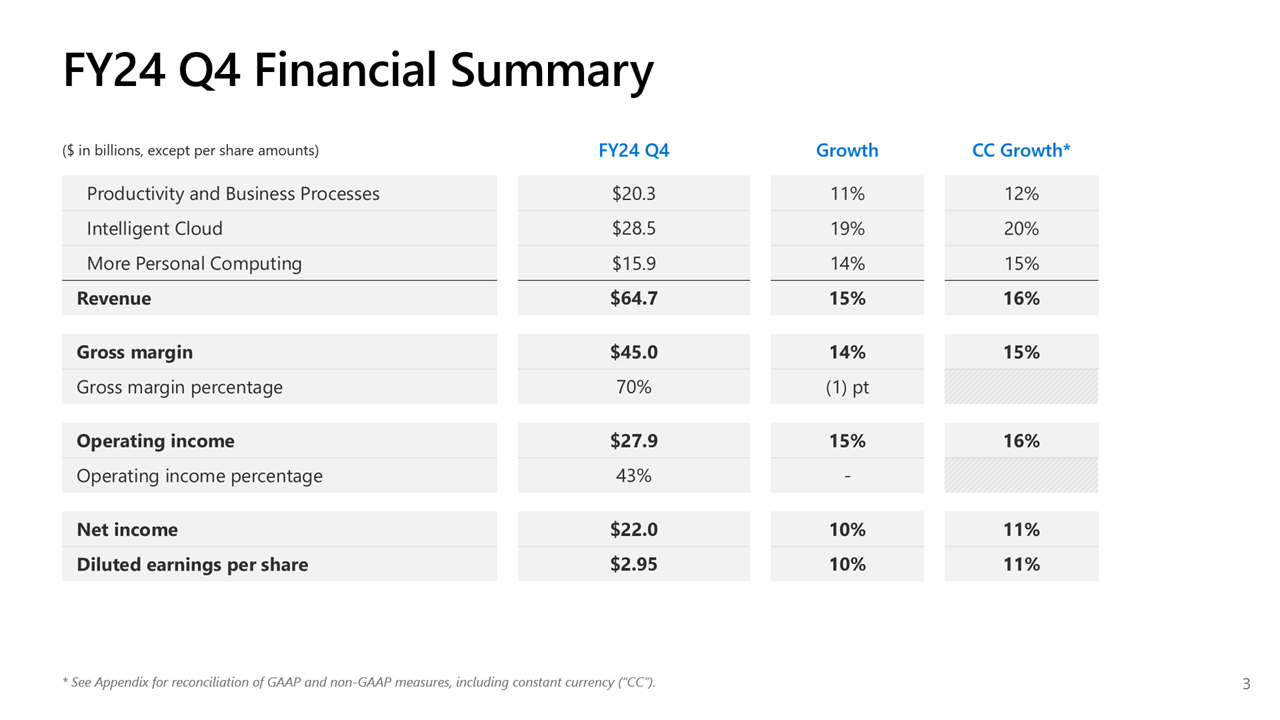 Продажи подразделения Microsoft Productivity and Business Processes выросли за отчётный квартал на 11 % до $20,3 млрд, превысив консенсус-прогноз аналитиков, опрошенных StreetAccount, в $20,13 млрд. Подразделение More Personal Computing принесло на 14 % больше дохода, составившего $15,90 млрд при консенсус-прогнозе аналитиков, опрошенных StreetAccount, в $15,49 млрд. Microsoft прогнозирует рост выручки Azure в I квартале 2025 финансового года в пределах 28–29 %, с более быстрым ростом во II половине финансового года, сообщила Худ. Согласно прогнозу Microsoft, выручка в I квартале 2025 финансового года составит от $63,8 млрд до $64,8 млрд, что подразумевает рост на 13,8 % в середине диапазона. Аналитики, опрошенные LSEG, прогнозируют $65,24 млрд дохода. Прогноз компании включает $15,25 млрд операционных расходов в середине диапазона, при консенсус-прогнозе StreetAccount в $16,10 млрд.
25.07.2024 [09:59], Сергей Карасёв
OpenAI намерена потратить до $7 млрд на обучение ИИ в 2024 году, потеряв при этом $5 млрдЗатраты OpenAI на обучение ИИ-моделей и задачи инференса в 2024 году, по сообщению The Information, могут составить до $7 млрд. При этом компания может зафиксировать денежные потери в размере $5 млрд, что вынудит её искать новые возможности для привлечения инвестиций. Как рассказали осведомлённые лица, OpenAI использует мощности, эквивалентные приблизительно 350 тыс. серверов с ускорителями NVIDIA A100. Из них около 290 тыс. обеспечивают работу ChatGPT. Утверждается, что оборудование работает практически на полную мощность. В рамках обучения ИИ-моделей и инференса OpenAI получает значительные скидки от облачной платформы Microsoft Azure. В частности, Microsoft взимает с OpenAI около $1,3/час за ускоритель A100, что намного ниже обычных ставок. Тем не менее, только на обучение ChatGPT и других моделей OpenAI может потратить в 2024 году около $3 млрд. 
Источник изображения: pixabay.com На сегодняшний день в OpenAI работают примерно 1500 сотрудников, и компания продолжает расширять штат. Затраты на заработную плату и содержание работников в 2024-м могут достичь $1,5 млрд. Компания получает около $2 млрд в год от ChatGPT и может получить ещё примерно $1 млрд от взимания платы за доступ к своим большим языковым моделям (LLM). Общая выручка OpenAI, согласно недавним результатам, лежит на уровне $280 млн в месяц. В 2024 году, по оценкам, суммарные поступления компании окажутся в диапазоне от $3,5 млрд до $4,5 млрд. Таким образом, с учётом ожидаемых затрат в размере $7 млрд на обучение ИИ и инференс, а также расходов в $1,5 млрд на персонал OpenAI может потерять до $5 млрд. Это намного превышает прогнозируемые расходы конкурентов, таких как Anthropic (поддерживается Amazon), которая ожидает, что в 2024 году потратит $2,7 млрд. Не исключено, что OpenAI попытается провести очередной раунд финансирования. Компания уже завершила семь инвестиционных раундов, собрав в общей сложности более $11 млрд.
29.06.2024 [12:52], Сергей Карасёв
ИИ-ускоритель InspireSemi Thunderbird объединяет 6144 ядра RISC-V на карте PCIeКомпания InspireSemi объявила о разработке чипа Thunderbird на открытой архитектуре RISC-V для ИИ-нагрузок. Это изделие легло в основу специализированной карты расширения с интерфейсом PCIe, которая, как утверждается, подходит для решения широкого спектра задач. Чип Thunderbird содержит 1536 кастомизированных 64-битных суперскалярных ядер RISC-V, а также высокопроизводительную память SRAM. Говорится о наличии ячеистой сети с малой задержкой для меж- и внутричиповых соединений. Кроме того, предусмотрены блоки ускорения определённых алгоритмов шифрования. 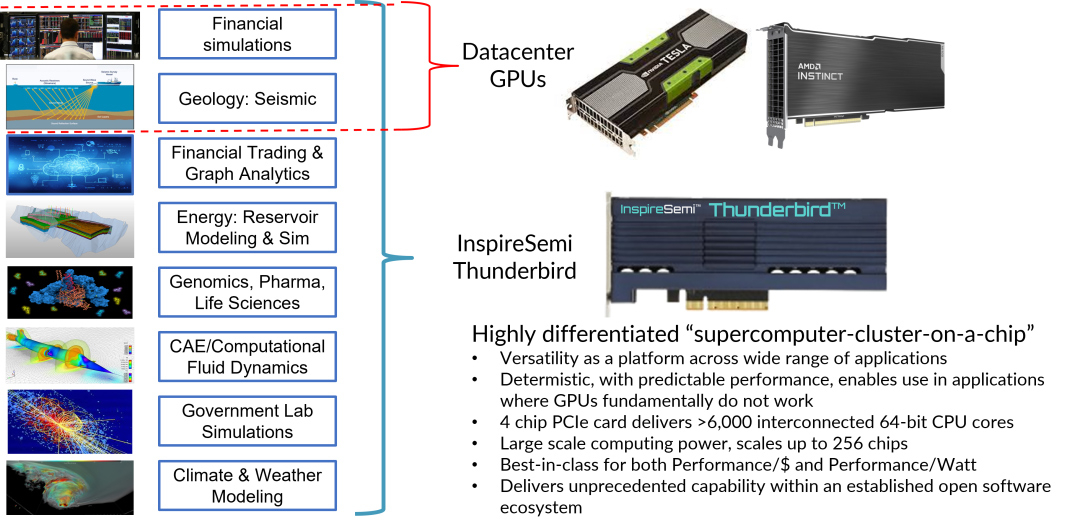
Источник изображения: InspireSemi Идея заключается в том, чтобы объединить универсальность и возможности программирования традиционных CPU с высокой степенью параллелизма GPU. Изделие ориентировано на НРС-приложения, но при этом поддерживает исполнение программ общего назначения. InspireSemi называет новинку «суперкомпьютерным кластером на кристалле». Точно так же назвала свои ИИ-ускорители Esperanto Technologies. Именно её чипы ET-SoC-1, по-видимому, впервые объединили более 1 тыс. ядер RISC-V. Впрочем, сама Esperanto позиционировала их как гибкие и энергоэффективные решения для инференса. В случае Thunderbird четыре могут быть объединены на одной карте PCIe, что в сумме даёт 6144 ядра RISC-V. Более того, заявлена возможность масштабирования до 256 чипов, связанных с помощью высокоскоростных трансиверов. Таким образом, количество ядер может быть доведено до 393 216. Чип обеспечивает производительность до 24 Тфлопс (FP64) при энергетической эффективность 50 Гфлопс/Вт. Для сравнения: NVIDIA A100 обладает быстродействием 19,5 Тфлопс (FP64), а NVIDIA H100 — 67 Тфлопс (FP64). Суперскалярные ядра поддерживают векторные и тензорные операции и форматы данных с плавающей запятой смешанной точности. Однако о совместимости с Linux ничего не говорится. Среди возможных областей применения названы ИИ, НРС, графовый анализ, блокчейн, вычислительная гидродинамика, сложное моделирование в области энергетики, изменений климата и пр. |
|

