Материалы по тегу: hpc
|
22.10.2024 [12:49], Владимир Мироненко
В Пизанском университете установили суперкомпьютер Lenovo на базе Intel Xeon MaxКомпания Lenovo сообщила об установке в дата-центре Пизанского университета (UniPi) нового кластера, благодаря чему HPC-платформа UniPi стала крупнейшей среди университетских суперкомпьютеров в Италии. Система размещена в ЦОД Green Data Center, который включает 104 стойки, где уже размещено 700 узлов (30 тыс. ядер, более ускорителей разных поколений). 
Источник изображения: Lenovo Новая HPC-система Lenovo состоит из 16 узлов SD650 V3 с двумя процессорами Intel Xeon Max 9480 (Sapphire Rapids с HBM). Используемая СЖО Lenovo Neptune Direct Water-Cooling позволяет отводить до 98 % тепла, вырабатываемого суперкомпьютером, а также снизить энергопотребление на 40 %. Как утверждает компания, благодаря повышенной эффективности СЖО температура процессоров не достигает критических значений, что позволяет избежать снижения максимальной частоты ядер. Аналогичная платформа используется в суперкомпьютере Cassandra для Европейско-Средиземноморского центра по изменению климата (CMCC) в Лечче (Италия). Как отметил UniPi, решающим фактором при выборе решения Lenovo была адаптивность системы, поскольку проект был изначально разработан с учётом минимального воздействия на окружающую среду с целью создания экологичного ЦОД. Кроме того, стандартизированный подход Lenovo к созданию HPC-узлов упростила и ускорила её установку в ЦОД UniPi. Как ожидается, новый суперкомпьютер будет способен поддерживать рабочие нагрузки HPC и ИИ последнего поколения в течение следующих нескольких лет. UniPi имеет три ЦОД в Пизе. В 2016 году университет запустил проект строительства нового «Зелёного дата-центра» (Green Data Centre) для размещения HPC-нагрузок. По словам UniPi, новый университетский ЦОД является единственным объектом в стране, получившим классификацию «A» от AgID в начале этого года.
17.10.2024 [12:20], Сергей Карасёв
Dell представила решения AI Factory на базе NVIDIA GB200 и AMD EPYC TurinКомпания Dell Technologies анонсировала интегрированные стоечные масштабируемые системы для экосистемы AI Factory, рассчитанные на задачи НРС и ресурсоёмкие приложения ИИ. В частности, дебютировали решения Integrated Rack 7000 (IR7000), PowerEdge M7725 и PowerEdge XE9712. 
Источник изображений: Dell IR7000 — это высокоплотная 21″ стойка Open Rack Version 3 (Orv3) с поддержкой жидкостного охлаждения. Говорится о совместимости с мощными CPU и GPU с высоким значением TDP. Модификации 44OU и 50OU оснащены салазками, которые шире и выше традиционных: это гарантирует совместимость с несколькими поколениями архитектур процессоров и ИИ-ускорителей. Полки питания в настоящее время поддерживают мощность от 33 кВт до 264 кВт на стойку с последующим увеличением до 480 кВт.  Система Dell PowerEdge M7725 специально спроектирована для вычислений высокой плотности. В основу положены процессоры AMD серии EPYC 9005 (Turin), насчитывающие до 192 вычислительных ядер. Одна стойка IR7000 может вместить 72 серверных узла M7725, каждый из которых оборудован двумя CPU. Таким образом, общее количество вычислительных ядер превышает 27 тыс. на стойку. Возможно развёртывание прямого жидкостного охлаждения (DLC) и воздушного охлаждения. Доступны два IO-слота (PCIe 5.0 x16) в расчёте на узел с поддержкой Ethernet и InfiniBand.  В свою очередь, система Dell PowerEdge XE9712 разработана для обучения больших языковых моделей (LLM) и инференса в реальном времени. Эта новинка использует архитектуру суперускорителя NVIDIA GB200 NVL72. В общей сложности задействованы 72 чипа B200 и 36 процессоров Grace. Утверждается, что такая конфигурация обеспечивает скорость инференса до 30 раз выше по сравнению с системами предыдущего поколения. 
14.10.2024 [14:00], Сергей Карасёв
HPE представила архитектуру прямого жидкостного охлаждения без вентиляторовКомпания HPE анонсировала, как утверждается, первую в отрасли архитектуру прямого жидкостного охлаждения (DLC), в составе которой вообще не используются вентиляторы. Решение ориентировано на дата-центры для ресурсоёмких нагрузок ИИ и НРС. Отмечается, что эффективность ИИ-ускорителей следующего поколения повышается, но их энергопотребление продолжает расти. Поэтому ЦОД, рассчитанные на масштабные рабочие нагрузки ИИ, внедряют новые системы охлаждения. Наиболее эффективной технологией, как заявляет HPE, на сегодняшний день является DLC. Представленное решение включает жидкостное охлаждение для CPU и GPU, blade-сервера целиком, локального хранилища, сетевой фабрики, стойки, модуля/кластера и блок распределения охлаждающей жидкости (CDU). Применяется высокоплотная конструкция с интегрированной сетевой фабрикой, дополненная специальным ПО для мониторинга. При этом обеспечивается гибкость выбора ИИ-ускорителей. «Новая архитектура прямого жидкостного охлаждения обеспечивает снижение энергопотребления на 90 % по сравнению с традиционными системами воздушного охлаждения», — говорит Антонио Нери (Antonio Neri), президент и генеральный директор HPE. 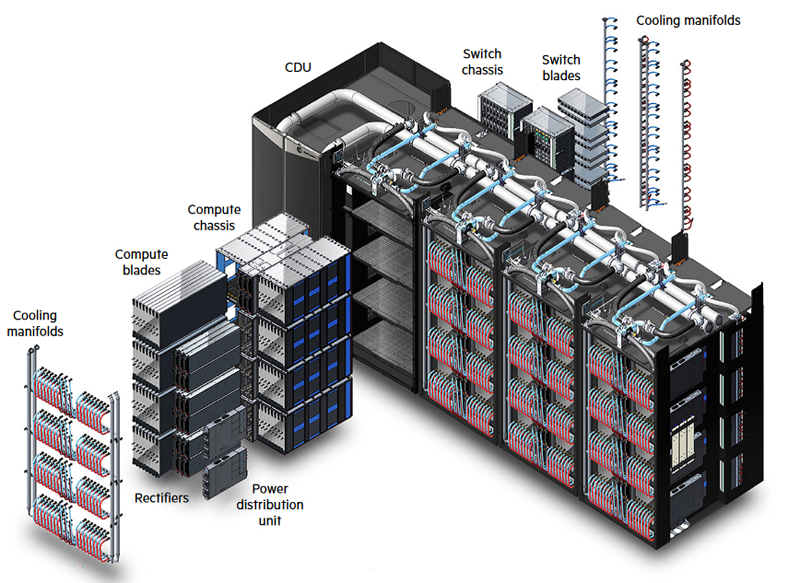
Источник изображения: HPE Полностью безвентиляторная архитектура DLC обеспечивает ряд преимуществ по сравнению с другими решениями. В частности, затраты на охлаждение «лезвия» сокращаются на 37 % по сравнению с гибридным прямым жидкостным охлаждением. Это позволяет снизить расходы на коммунальные услуги, а также уменьшить выбросы вредных газов в атмосферу. Кроме того, достигается высокая плотность монтажа оборудования, благодаря чему занимаемые площади в ЦОД могут быть уменьшены в два раза. Отметим, что российская Группа компаний РСК давно предлагает узлы (в том числе с ускорителями), СХД, коммутаторы и стойки с полностью жидкостным охлаждением.
09.10.2024 [14:43], Руслан Авдеев
Foxconn и NVIDIA построят самый быстрый на Тайване ИИ-суперкомпьютерКомпании Foxconn и NVIDIA объединили усилия для постройки крупнейшего на Тайване суперкомпьютера. По данным пресс-службы NVIDIA, проект Hon Hai Kaohsiung Super Computing Center был представлен в ходе традиционного мероприятия Foxconn — Hon Hai Tech Day, прошедшего в минувший вторник. Вычислительные мощности будут построены на основе передовой архитектуры NVIDIA Blackwell — будет использована платформа GB200 NVL72, включающая 64 стойки. С ожидаемой производительностью ИИ-вычислений более 90 Эфлопс (FP4), машина может легко считаться самой быстрой на Тайване. Foxconn намерена использовать суперкомпьютер для исследований в области медицины, разработки больших языковых моделей (LLM) и инноваций в системах умного города. Это может сделать Тайвань одним из лидеров ИИ-индустрии. В рамках стратегии «трёх платформ» Foxconn уделяет внимание умному производству, умным городам и электрическому транспорту. Новый суперкомпьютер призван сыграть ключевую роль в поддержке инициатив компании по созданию «цифровых двойников», автоматизации робототехники и созданию умной городской инфраструктуры. 
Источник изображения: NVIDIA Строительство уже началось в тайваньском муниципалитете Гаосюн, первая фаза должна заработать к середине 2025 года. Полностью работоспособным компьютер станет в 2026 году. Проект будет активно использовать технологии NVIDIA вроде робоплатформ NVIDIA Omniverse и Isaac для ИИ и «цифровых двойников». В Foxconn утверждают, что суперкомпьютер будет не только крупнейшим на Тайване, но и одним из самых производительных в мире. Каждая стойка GB200 NVL72 включает 36 CPU Grace и 72 ускорителя Blackwell, объединённых интерконнектом NVIDIA NVLink (суммарно 130 Тбайт/с). Технология NVIDIA NVLink Switch позволит системе из 72 ускорителей функционировать как единый вычислительный модуль — оптимальный вариант для обучения ИИ-моделей и инференса в режиме реального времени, с моделями на триллион параметров. Предполагается использование решений NVIDIA DGX Cloud Infrastructure и Spectrum-X для поддержки масштабируемого обучения ИИ-моделей.  Тайваньская Foxconn (официально Hon Hai Precision Industry Co.) — крупнейший в мире производитель электроники, известный выпуском самых разных устройств, от смартфонов до серверов для популярных во всём мире заказчиков. Компания уже имеет производства по всему миру и является ключевым игроком в мировой технологической инфраструктуре. При этом производитель считается одним из лидеров в организации «умного» производства, внедряющим промышленные ИИ-системы и занимающимся цифровизацией заводов с помощью NVIDIA Omniverse Cloud. Кроме того, именно она одной из первых стала пользоваться микросервисами NVIDIA NIM в разработке языковых моделей, интегрированных во многие внутренние системы и процессы на предприятиях, создании умных электромобилей и инфраструктуры умных городов. Суперкомпьютер Hon Hai Kaohsiung Super Computing Center — лишь часть растущей общемировой сети передовых проектов на основе решений NVIDIA. Сеть включает несколько значимых проектов в Европе и Азии. Сотрудничество компаний становится всё теснее. В ходе того же мероприятия объявлено о сотрудничестве Foxconn и NVIDIA в Мексике. Первая построит завод в стране для упаковки полупроводников NVIDIA.
04.10.2024 [18:31], Владимир Мироненко
Суперкомпьютеры по талонам: Минцифры намерено выделять гранты на HPC/ИИ-вычисленияМинцифры России планирует начать выделять гранты компаниям на использование мощностей суперкомпьютеров, заявил министр цифрового развития Максут Шадаев на заседании IT-комитета Госдумы 3 октября, пишет «Коммерсантъ». «Когда мы выделяем гранты на внедрение современных решений, внутри них будет возможность в том числе заказывать услуги по специализированным вычислениям у специализированных провайдеров», — рассказал глава Минцифры, добавив, что эта мера направлена на стимулирование спроса на специализированные вычисления, а выделение грантов компаниям позволит загрузить вычислительные мощности «Сбера» и «Яндекса». Насколько велики эти гранты и когда начнётся их выделение, в Минцифры не сообщили. Действительно ли указанные мощности недостаточно загружены, не уточняется. По словам источника «Коммерсанта», близкого к правительству, гранты на аренду вычислительных мощностей суперкомпьютеров планируется предоставлять с 2025 года. Речь идёт о крупных компаниях, которые внедряют «передовые решения». Источник отметил, что это позволит снять с крупных заказчиков часть рисков, связанных с внедрением инноваций. 
Источник изображения: Kvistholt Photography / Unsplash Сейчас для минимальных проектов в области ИИ требуются ускорители на сумму от 30 млн руб., говорит директор Института прикладных компьютерных наук ИТМО Антон Кузнецов. Позволить себе такие траты маленькие компании зачастую не в состоянии, хотя именно они нуждаются во внедрении современных решений для быстрого роста. Ранее в этом месяце также сообщалось о планах правительства стимулировать строительство компаниями суперкомпьютеров, оснащённых ускорителями для обучения ИИ. Как ожидается, в результате совокупная мощность всех ИИ-суперкомпьютеров вырастёт в 2027 году в три раза и в десять раз — в 2030-м. В последнем рейтинге TOP500 есть семь российских суперкомпьютеров: три принадлежат «Яндексу», два ессть у «Сбера», а ещё по одному у МГУ и МТС. Российский рейтинг ТОП50 не обновляется с 2023 года.
01.10.2024 [09:17], Сергей Карасёв
Isambard 2, один из первых Arm-суперкомпьютеров, отправился на покой30 сентября 2024 года, по сообщению Datacenter Dynamics, прекращена эксплуатация британского вычислительного комплекса Isambard 2. Это был один из первых в мире суперкомпьютеров, построенных на процессорах с архитектурой Arm. Система отправилась на покой после примерно шести лет работы. Isambard 2 назван в честь Изамбарда Кингдома Брюнеля — британского инженера, ставшего известной фигурой в истории Промышленной революции. Проект Isambard 2 реализован совместно компанией Cray, Метеорологической службой Великобритании и исследовательским консорциумом GW4 Alliance, в который входят университеты Бата, Бристоля, Кардиффа и Эксетера. Запуск суперкомпьютера состоялся в мае 2018 года. В основу Isambard 2 положены узлы Cray XC50. Задействованы 64-битные процессоры Marvell ThunderX2 с архитектурой Arm v8-A и ускорители NVIDIA P100. Общее количество вычислительных ядер — 20 992. Это одна из немногих систем на базе серии чипов ThunderX. 
Источник изображения: Marvell Technology/YouTube «После шести лет службы суперкомпьютер Isambard 2 наконец-то отправляется на пенсию. С мая 2018-го он был первым в мире серийным суперкомпьютером на базе Arm, использующим процессоры ThunderX2. Сегодня ему на смену приходит Isambard 3, содержащий Arm-чипы NVIDIA Grace», — сообщил профессор Саймон Макинтош-Смит (Simon McIntosh-Smith), руководитель проекта, глава группы микроэлектроники в Университете Бристоля. В основу Isambard 3 лягут 384 суперпроцессора NVIDIA Grace. Эта система, как ожидается, обеспечит в шесть раз более высокую производительность и в шесть раз лучшую энергоэффективность по сравнению с Isambard 2. Пиковое быстродействие FP64 у нового суперкомпьютера составит 2,7 Пфлопс при энергопотреблении менее 270 кВт. В дальнейшем вычислительные мощности Isambard 3 планируется наращивать. Комплекс будет применяться при решении сложных задач в области ИИ, медицины, астрофизики, биотехнологий и пр.
28.09.2024 [23:24], Сергей Карасёв
Индия запустила сразу пять суперкомпьютеров за два дня
a100
amd
atos
cascade lake-sp
epyc
eviden
hardware
hpc
intel
milan
nvidia
xeon
индия
метео
суперкомпьютер
Премьер-министр Индии Нарендра Моди, по сообщению The Register, объявил о вводе в эксплуатацию трёх новых высокопроизводительных вычислительных комплексов PARAM Rudra. Запуск этих суперкомпьютеров, как отмечается, является «символом экономической, социальной и промышленной политики» страны. Вдаваться в подробности о технических характеристиках машин Моди во время презентации не стал. Однако некоторую информацию раскрыли организации, которые займутся непосредственной эксплуатацией этих НРС-систем. Один из суперкомпьютеров располагается в Национальном центре радиоастрофизики Индии (NCRA). Данная машина оснащена «несколькими тысячами процессоров Intel» и 90 ускорителями NVIDIA A100, 35 Тбайт памяти и хранилищем вместимостью 2 Пбайт. Ещё один НРС-комплекс смонтирован в Центре фундаментальных наук имени С. Н. Бозе (SNBNCBS): известно, что он обладает быстродействием 838 Тфлопс. Оператором третьей системы является Межуниверситетский центр ускоренных вычислений (IUAC): этот суперкомпьютер с производительностью на уровне 3 Пфлопс использует 24-ядерные чипы Intel Xeon Cascade Lake-SP. Ёмкость хранилища составляет 4 Пбайт. Упомянут интерконнект с пропускной способностью 240 Гбит/с. The Register отмечает, что указанные характеристики в целом соответствуют описанию суперкомпьютеров Rudra первого поколения. Согласно имеющейся документации, такие машины используют:
Ожидается, что машины Rudra второго поколения получат поддержку процессоров Xeon Sapphire Rapids и четырёх GPU-ускорителей. Суперкомпьютеры третьего поколения будут использовать 96-ядерные Arm-процессоры AUM, разработанные индийским Центром развития передовых вычислений: эти изделия будут изготавливаться по 5-нм технологии TSMC. 
Источник изображения: pixabay.com Между тем компания Eviden (дочерняя структура Atos) сообщила о поставках в Индию двух новых суперкомпьютеров. Один из них установлен в Индийском институте тропической метеорологии (IITM) в Пуне, второй — в Национальном центре среднесрочного прогнозирования погоды (NCMRWF) в Нойде. Эти системы, построенные на платформе BullSequana XH2000, предназначены для исследования погоды и климата. В создании комплексов приняли участие AMD, NVIDIA и DDN. Система IITM, получившая название ARKA, обладает быстродействием 11,77 Пфлопс: 3021 узел с AMD EPYC 7643 (Milan), 26 узлов с NVIDIA A100, NVIDIA Quantum InfiniBand и хранилище на 33 Пбайт (ранее говорилось о 3 Пбайт SSD + 29 Пбайт HDD). В свою очередь, суперкомпьютер NCMRWF под названием Arunika обладает производительностью 8,24 Пфлопс: 2115 узлов с AMD EPYC 7643 (Milan), NVIDIA Quantum InfiniBand и хранилище DDN EXAScaler ES400NVX2 (2 Пбайт SSD + 22 Пбайт HDD). Кроме того, эта система включает выделенный блок для приложений ИИ и машинного обучения с быстродействием 1,9 Пфлопс (точность не указана), состоящий из 18 узлов с NVIDIA A100.
17.09.2024 [23:07], Игорь Осколков
Швейцария ввела в эксплуатацию гибридный суперкомпьютер Alps: 11 тыс. NVIDIA GH200, 2 тыс. AMD EPYC Rome и щепотка A100, MI250X и MI300AШвейцарская высшая техническая школа Цюриха (ETH Zurich) провела церемонию официального запуска суперкомпьютера Alps в Швейцарском национальном суперкомпьютерном центре (CSCS) в Лугано. Система, построенная HPE, уже заняла шестую строчку в последнем рейтинге TOP500 и имеет устоявшеюся FP64-производительность 270 Пфлопс (теоретический пик — 354 Пфлопс). К ноябрю будут введены в строй остальные модули машины, и её максимальная производительность составит порядка 500 Пфлопс. 
Источник изображений: CSCS В июньском рейтинге TOP500 участвовал раздел из 2688 узлов HPE Cray EX254n с «фантастической четвёркой» NVIDIA Quad GH200. Если точнее, это всё же «старый» вариант ускорителя с H100 (96 Гбайт HBM3), 72-ядерным Arm-процессором Grace и 128 Гбайт LPDDR5x — суммарно 10 752 Grace Hopper. Данный раздел потребляет 5,2 МВт и в Green500 находится на 14 месте. Узлы, конечно же, используют СЖО. Это основной, но не единственный раздел суперкомпьютера. Ещё в 2020 году HPE развернула 1024 двухпроцессорных узла с 64-ядерными AMD EPYC 7742 (Rome) и 256/512 Гбайт RAM. Его производительность составляет 4,7 Пфлопс. Кроме того, в состав Alps входят 144 узла с одним 64-ядерным AMD EPYC, 128 Гбайт RAM и четырьмя NVIDIA A100 (80 или 96 Гбайт HBM2e).  Наконец, машина получит 24 узла с одним 64-ядерным AMD EPYC, 128 Гбайт RAM и четырьмя AMD Instinct MI250X (128 Гбайт HBM2e) и 128 узлов с четырьмя гибридными ускорителями AMD Instinct MI300A. Большая часть узлов будет объединена интерконнектом HPE Slingshot-11: 200G-подключение на узел или ускоритель. Более точную конфигурацию системы раскроют в ноябре. Lustre-хранилище для будущей машины обновили ещё в прошлом году. Основной СХД является Cray ClusterStor E1000 с подключением Slingshot-11. Так, было добавлено 100 Пбайт полезной HDD-ёмкости (8480 × 16 Тбайт) с пропускной способностью 1 Тбайт/с (300 тыс. IOPS на запись, 1,5 млн IOPS на чтение) и 5 Пбайт SSD, а также резервные ёмкости. За архивное хранение отвечают две ленточные библиотеки объёмом 130 Пбайт каждая.  Особенностью системы является её геораспределённость (фактически узлы размещены в четырёх местах) и облачная модель использования. Так, метеослужба страны MeteoSwiss получила в своё распоряжение выделенный виртуальный кластер, что уже позволило перейти на использование метеомодели более высокого разрешения, которая лучше отражает сложный рельеф Швейцарии. Кроме того, для подстраховки часть узлов Alps размещена на территории Федеральной политехнической школы Лозанны (EPFL). Alps приходит на смену суперкомпьютеру Piz Daint (Cray XC50/40, 21,2 Пфлопс), о завершении жизненного цикла которого было объявлено в конце июля 2024 года. В CSCS пока останутся машины Arolla + Tsa (для нужд MeteoSwiss) и Blue Brain 5 (решает задачи реконструкции и симуляции мозга). Alps же помимо традиционных HPC-нагрузок, будет использоваться для разработки ИИ-решений.
16.09.2024 [14:55], Руслан Авдеев
Государство может возместить строителям суперкомпьютеров в России подключение к электросетямКомпаниям, занимающимся созданием суперкомпьютеров для обучения ИИ, возможно, будут возмещать расходы на техническое присоединение к электрическим сетям за счёт государственных средств. «Коммерсантъ» сообщает, что соответствующую меру поддержки готовятся включить в национальный проект «Экономика данных». Конечная цель госпроектов — удвоение совокупной мощности российских суперкомпьютеров к 2030 году. По оценкам, операторы дата-центров тратят до 10 % от стоимости реализации проекта на техническое присоединение. Однако в случае ИИ-суперкомпьютеров, по словам экспертов, порядка 90 % расходов приходится на приобретение ускорителей и лишь около 10 % на капитальное строительство и подведение инженерной инфраструктуры. Некоторые эксперты утверждают, что в норме стоимость технического присоединения не превышает 2–3 % от общей стоимости проекта, но для бизнеса, строящего ЦОД для сдачи в аренду, цена будет выше, на уровне 3–10 %. Некоторые эксперты уверены, что расходы будут значительными в первую очередь в том случае, если для ввода ЦОД в эксплуатацию придётся построить понижающую подстанцию. При этом подчёркивается, что ещё с 2020 года действует возмещение затрат на строительство дата-центров или их модернизацию. Речь идёт о компенсации 50 % трат на обеспечивающую инфраструктуру и до 100 % — на сопутствующую. Правда, как сообщают в Миноэкономики, никакие проекты в подобном формате сегодня не реализуются. 
Источник изображения: American Public Power Association/unsplash.com Информация о льготах представлена в предварительном варианте текста федерального проекта «Искусственный интеллект» — его предлагают включить в нацпроект «Экономика данных», который должен стартовать в следующем году. Речь идёт именно о поддержке строителей суперкомпьютеров, оснащённых ускорителями (GPU), применяемых для обучения ИИ-систем. Государственная финансовая поддержка подключения к энергосетям будет распределяться по конкурсу, а оператор дата-центра в этом случае обязуется построить суперкомпьютер. В Минцифры сообщают, что новый проект финансирования находится на межведомственном голосовании и ещё не утверждён. Предполагается, что в итоге совокупная ёмкость суперкомпьютеров для искусственного интеллекта должна достичь 300 Пфлопс (точность вычислений не указана) в 2027 году и до 1 Эфлопс — в 2030-м. Точкой отсчёта является базовое значение 2024 года, указанное на уровне 100 Пфлопс. По данным «Коммерсанта», компания Nebius AI, отделившаяся от «Яндекса», располагает суперкомпьютером ISEG с пиковой FP64-производительностью до 86,79 Пфлопс. В последнем рейтинге TOP500 машина занимает 19 место с фактической производительностью 46,54 Пфлопс. Всего же в списке есть семь российских суперкомпьютеров.
13.09.2024 [10:22], Сергей Карасёв
Некогда самый мощный в мире суперкомпьютер Summit уйдёт на покой в ноябреВысокопроизводительный вычислительный комплекс Summit, установленный в Окриджской национальной лаборатории (ORNL) Министерства энергетики США, будет выведен из эксплуатации в ноябре 2024 года. Обслуживать машину становится всё дороже, а по эффективности она уступает современным суперкомпьютерам. Summit был запущен в 2018 году и сразу же возглавил рейтинг мощнейших вычислительных систем мира TOP500. Комплекс насчитывает 4608 узлов, каждый из которых оборудован двумя 22-ядерными процессорами IBM POWER9 с частотой 3,07 ГГц и шестью ускорителями NVIDIA Tesla GV100. Узлы соединены через двухканальную сеть Mellanox EDR InfiniBand, что обеспечивает пропускную способность в 200 Гбит/с для каждого сервера. Энергопотребление машины составляет чуть больше 10 МВт. 
Источник изображения: ORNL FP64-быстродействие Summit достигает 148,6 Пфлопс (Linpack), а пиковая производительность составляет 200,79 Пфлопс. За шесть лет своей работы суперкомпьютер ни разу не выбывал из первой десятки TOP500: так, в нынешнем рейтинге он занимает девятую позицию. 
Источник изображения: ORNL Отправить Summit на покой планировалось в начале 2024-го. Однако затем была запущена инициатива SummitPLUS, и срок службы вычислительного комплекса увеличился практически на год. Отмечается, что этот суперкомпьютер оказался необычайно продуктивным. Он обеспечил исследователям по всему миру более 200 млн часов работы вычислительных узлов. В настоящее время ORNL эксплуатирует ряд других суперкомпьютеров, в число которых входит Frontier — самый мощный НРС-комплекс в мире. Его пиковое быстродействие достигает 1714,81 Пфлопс, или более 1,7 Эфлопс. При этом энергопотребление составляет 22 786 кВт: таким образом, система Frontier не только быстрее, но и значительно энергоэффективнее Summit. А весной этого года из-за растущего количества сбоев и протечек СЖО на аукционе был продан 5,34-ПФлопс суперкомпьютер Cheyenne. |
|

