Материалы по тегу: hardware
|
05.02.2026 [11:35], Сергей Карасёв
AMD представила FPGA серии Kintex UltraScale+ Gen 2 с поддержкой PCIe 4.0 и LPDDR5XКомпания AMD анонсировала FPGA серии Kintex UltraScale+ Gen 2, относящиеся к среднему классу. Эти изделия могут использоваться в разных сферах, включая здравоохранение (эндоскопия, машинное зрение, роботизированная хирургия), промышленный сектор (системы автоматизации и инспекции, периферийные платформы), вещание (видеозахват, производство материалов), среды тестирования и пр. Решения выполнены по 16-нм технологии FinFET. Реализована поддержка памяти LPDDR4X, LPDDR5 и LPDDR5X, интерфейса PCIe 4.0, а также двух блоков 100G CMAC. Упомянуты средства постквантовой криптографии в соответствии с алгоритмами, одобренными Национальным институтом стандартов и технологий США (NIST). 
Источник изображений: AMD В семейство Kintex UltraScale+ Gen 2 вошли три модели — 2KU030P, 2KU040P и 2KU050P. Первый из перечисленных чипов содержит 328 тыс. логических элементов, 150 тыс. CLB LUT (Configurable Logic Block Look-Up Table), четыре контроллера LPDDR4X/5/5X, а также в общей сложности 33,9 Мбайт памяти. Конфигурация включает два интерфейса PCIe 4.0 x8. В свою очередь, решение 2KU040P насчитывает 410 тыс. логических элементов и 187 тыс. CLB LUT, имеет шесть контроллеров LPDDR4X/5/5X, 42,4 Мбайт памяти и два интерфейса PCIe 4.0 x8. Старший вариант, 2KU050P, получил 491 тыс. логических элементов, 225 тыс. CLB LUT, шесть контроллеров LPDDR4X/5/5X, 50,9 Мбайт памяти, два интерфейса PCIe 4.0 x8 и один интерфейс PCIe 4.0 x4. 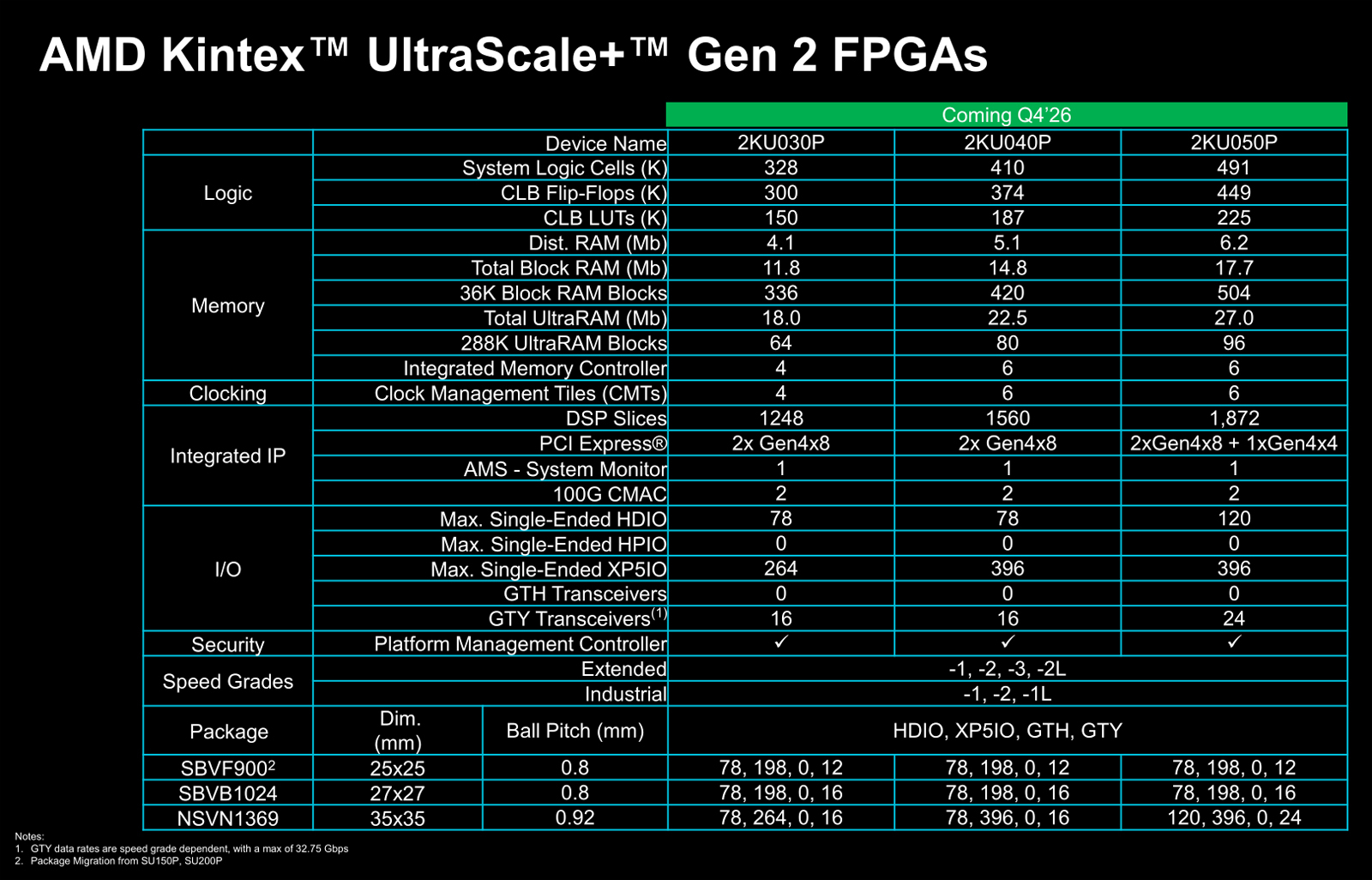 Первые инженерные образцы решений Kintex UltraScale+ Gen 2 начнут поступить заказчикам в IV квартале текущего года, тогда как серийное производство чипов должно начаться в I половине 2027-го. Компания AMD гарантирует доступность изделий как минимум до 2045 года, что должно сделать новые FPGA особенно привлекательными для отраслей с длительным жизненным циклом продукции, таких как аэрокосмическая и оборонная промышленность.
04.02.2026 [22:39], Владимир Мироненко
Western Digital готовит жёсткие диски для эпохи ИИ: ёмкостью 100+ Тбайт и кратно быстрее нынешнихКомпания Western Digital (WD), представила план дальнейшего развития своих решений для хранения данных, ориентированный на клиента и призванный переосмыслить использование жёстких дисков для инфраструктуры эпохи ИИ. Его анонс знаменует собой важную веху в продолжающейся трансформации WD в компанию, специализирующуюся исключительно на HDD и ориентированную на гиперскейлров и провайдеров облачных платформ, отметил ресурс SiliconANGLE. Многолетняя стратегия компании направлена на масштабирование ёмкости, повышение производительности, снижение энергопотребления и упрощение развёртывания СХД, поскольку рабочие ИИ-нагрузки приводят к стремительному росту объёмов данных в облачной инфраструктуре. План включает в себя выпуск HDD объёмом более 100 Тбайт, внедрение новых архитектур, оптимизированных по производительности и энергопотреблению, а также интеллектуальной платформы, разработанной для повышения экономической эффективности хранения данных и сокращения времени окупаемости инвестиций. 
Источник изображений: Western Digital WD сообщила, что её 40-Тбайт жёсткий диск UltraSMR ePMR, в настоящее время являющийся самым ёмким накопителем в мире, уже проходит квалификацию у двух крупных клиентов, и его серийное производство запланировано на II половину 2026 года. WD также проводит квалификацию своих HAMR-накопителей у двух крупных облачных провайдеров, а их серийное производство начнётся в 2027 году. Компания утверждает, что может увеличить ёмкость своих ePMR-накопителей до 60 Тбайт «за счёт использования инноваций HAMR без увеличения энергопотребления», пишет ресурс Blocks & Files. Накопители HAMR и ePMR построены на общей архитектуре и могут быть объединены в одном шасси, поскольку их интерфейсы одинаковы. WD также представила две новые технологии, разработанные с целью удовлетворения растущих требований к производительности жёстких дисков в ИИ-эпоху. Т.н. технология высокоскоростных накопителей (High Bandwidth Drive, HBD) позволяет одновременно считывать и записывать данные на нескольких головках и дорожках, обеспечивая первоначально до двух раз большую пропускную способность по сравнению с обычными жёсткими дисками, а в планах — до 4, 6 и 8 раз. Клиенты уже подтверждают эффективность этой технологии, сообщил ресурс StorageReview.  Ещё одна новая разработка под названием Dual Pivot добавляет второй независимо работающий привод внутри стандартного 3,5″ накопителя. В отличие от более ранних конструкций с двумя приводами, этот подход сохраняет ёмкость и позволяет избежать изменений в ПО, обеспечивая при этом до двух раз больше последовательных операций I/O. При этом приложениям нужно управлять одним устройством хранения, что значительно улучшает совместимость. Уменьшение расстояния между пластинами позволит повысить плотность хранения данных. В настоящее время WD использует в накопителях 11 пластин, в то время как Seagate — 10, а Toshiba продемонстрировала технологию с 12 пластинами. Ожидается, что жёсткие диски с технологией Dual Pivot появятся в продаже в 2028 году. Компания утверждает, что использование HBD и Dual Pivot в конечном итоге может обеспечить до четырёх раз больше последовательных операций I/O, сохраняя при этом относительную скорость I/O на 1 Тбайт по мере увеличения ёмкости. Также ожидается, что технология HBD и конструкция Dual Pivot позволят значительно сократить разрыв в производительности жёстких дисков с флеш-памятью QLC, сохраняя при этом их преимущество в стоимости.  Компания также уделила внимание энергоэффективности, представив новый класс оптимизированных по энергопотреблению жёстких дисков, предназначенных для хранения «холодных» данных, к которым должен быть обеспечен быстрый доступ. Ожидается, что эти накопители обеспечат снижение энергопотребления примерно на 20 %, уменьшив разрыв между уровнями «тёплого» и «холодного» хранения и обеспечив более низкую совокупную стоимость владения для хранения больших объёмов данных ИИ. Выпуск оптимизированных по энергопотреблению накопителей запланирован на 2027 год. WD также объявила о расширении своего бизнеса Platforms. В 2027 году компания представит интеллектуальный программный слой, предоставляемый через открытый API. Программный слой призван обеспечить экономическую эффективность гиперскейл-хранилищ для организаций, управляющих 200 Пбайт и более. Платформа призвана значительно упростить квалификацию и сократить время до начала производства жёстких дисков и флеш-памяти WD. Не требуя изменений в архитектуре, ПО предназначено для работы поверх существующей инфраструктуры, помогая клиентам среднего масштаба достичь эффективности хранения данных, близкой к средам гиперскейлеров. WD отметила, что примерно 90 % ее выручки теперь поступает от клиентов, использующих ИИ и облачные технологии. По словам WD, операционные улучшения более чем вдвое увеличили валовую прибыль по сравнению с прошлым годом, что способствовало включению компании в Nasdaq 100 и в число лучших компаний S&P 500 в 2025 году. WD также представила новую финансовую модель, в которой изложены прогнозы на следующие три-пять лет.
04.02.2026 [18:37], Сергей Карасёв
«Рикор» выпустил российские 2U-серверы на базе Intel Xeon Emerald RapidsКомпания «Рикор» анонсировала российские серверы Rikor 7212DSP5 и Rikor 7225DSP5, построенные на аппаратной платформе Intel Xeon Emerald Rapids. Устройства, как утверждается, подходят для решения широко спектра задач, включая виртуализацию, гиперконвергентную инфраструктуру, облачные сервисы, анализ данных, машинное обучение и приложения ИИ. Новинки выполнены в форм-факторе 2U. Допускается установка двух процессоров Xeon и 32 модулей оперативной памяти DDR5 суммарным объёмом до 8 Тбайт. Реализована поддержка интерфейса PCIe 5.0. Серверы различаются конфигурацией подсистемы хранения данных: модель Rikor 7212DSP5 рассчитана на 12 накопителей с доступом через фронтальную панель, а модификация Rikor 7225DSP5 — на 25. Прочие технические характеристики пока не раскрываются. 
Источник изображения: «Рикор» Одним из ключевых преимуществ решений производитель называет использование корпусов собственной разработки. Это, как утверждается, обеспечивает контроль качества металла и сборки, а также ускоряет процесс выпуска систем. Кроме того, «Рикор» может предлагать заказчикам уникальные решения по оптимизации внутреннего пространства. В результате, клиенты получают «более гибкие, технологичные и экономически выгодные серверы, наиболее полно соответствующие требованиям по локализации и технологической независимости». Производство серверов осуществляется на роботизированном заводе. «Рикор» уже принимает заказы на новые модели, а их отгрузки начнутся в ближайшее время. Компания гарантирует стабильность поставок.
04.02.2026 [14:11], Владимир Мироненко
Акции AMD упали из-за слабого прогноза, даже несмотря на рекордные квартальные результатыAMD сообщила финансовые результаты IV квартала и всего 2025 финансового года, завершившегося 27 декабря 2025 года. Объявленные показатели превысили ожидания Уолл-стрит, но прогноз компании на I квартал 2026 финансового года не оправдал ожиданий некоторых аналитиков на фоне бума расходов на ИИ, что вызвало опасения по поводу её способности эффективно конкурировать с NVIDIA, в связи с чем акции упали во вторник на 8 % на внебиржевых торгах, отметил Reuters. Выручка AMD за IV квартал достигла рекордных $10,27 млрд, что больше результата аналогичного квартала годом ранее на 34 %, а также выше консенсус-прогноза аналитиков, опрошенных LSEG, в размере $9,67 млрд (по данным CNBC). Скорректированная прибыль (Non-GAAP) на разводнённую акцию составила $1,53, превысив на 40 % прошлогодний показатель и прогноз от LSEG в $1,32. Чистая прибыль (GAAP) AMD увеличилась за квартал в годовом исчислении на 213 % до $1,51 млрд, или $0,92 на разводнённую акцию, с $482 млн, или $0,29 на разводнённую акцию годом ранее. 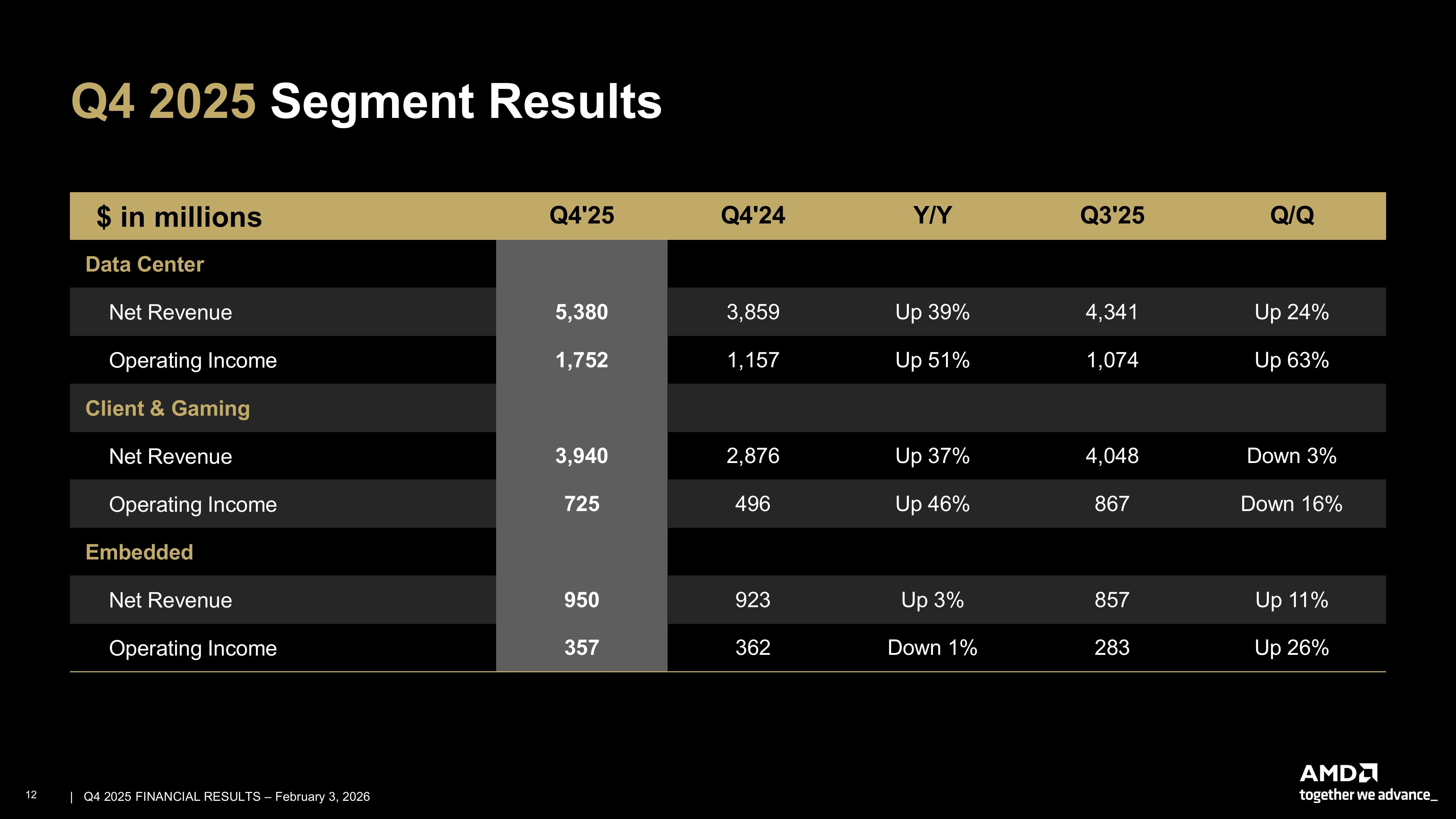
Источник изображений: AMD В I квартале AMD прогнозирует получить выручку в размере $9,8 млрд ± $300 млн, против ожиданий в $9,38 млрд. Прогноз включает $100 млн выручки от продаж в Китай ускорителей AMD Instinct MI308. Однако некоторые аналитики ожидали, что AMD представит более оптимистичный прогноз, а не снижение выручки, поскольку клиенты продолжают наращивать расходы на чипы, необходимые для работы ИИ-моделей. Тем более, что администрация Трампа одобрила лицензию на заказы, которые AMD получила в начале 2025 года от китайских компаний. Выручка от продаж MI308 в Китай в IV квартале составила около $390 млн. AMD сообщила о рекордной выручке за весь 2025 год в размере $34,64 млрд (рост 34 %), валовой марже в 50 % (рост 1 п.п.), операционной прибыли в $3,69 млрд (рост 94 %), чистой прибыли в $4,34 млрд (рост — 164 %) и прибыли на разводнённую акцию в $2,65 (рост — 165 %). 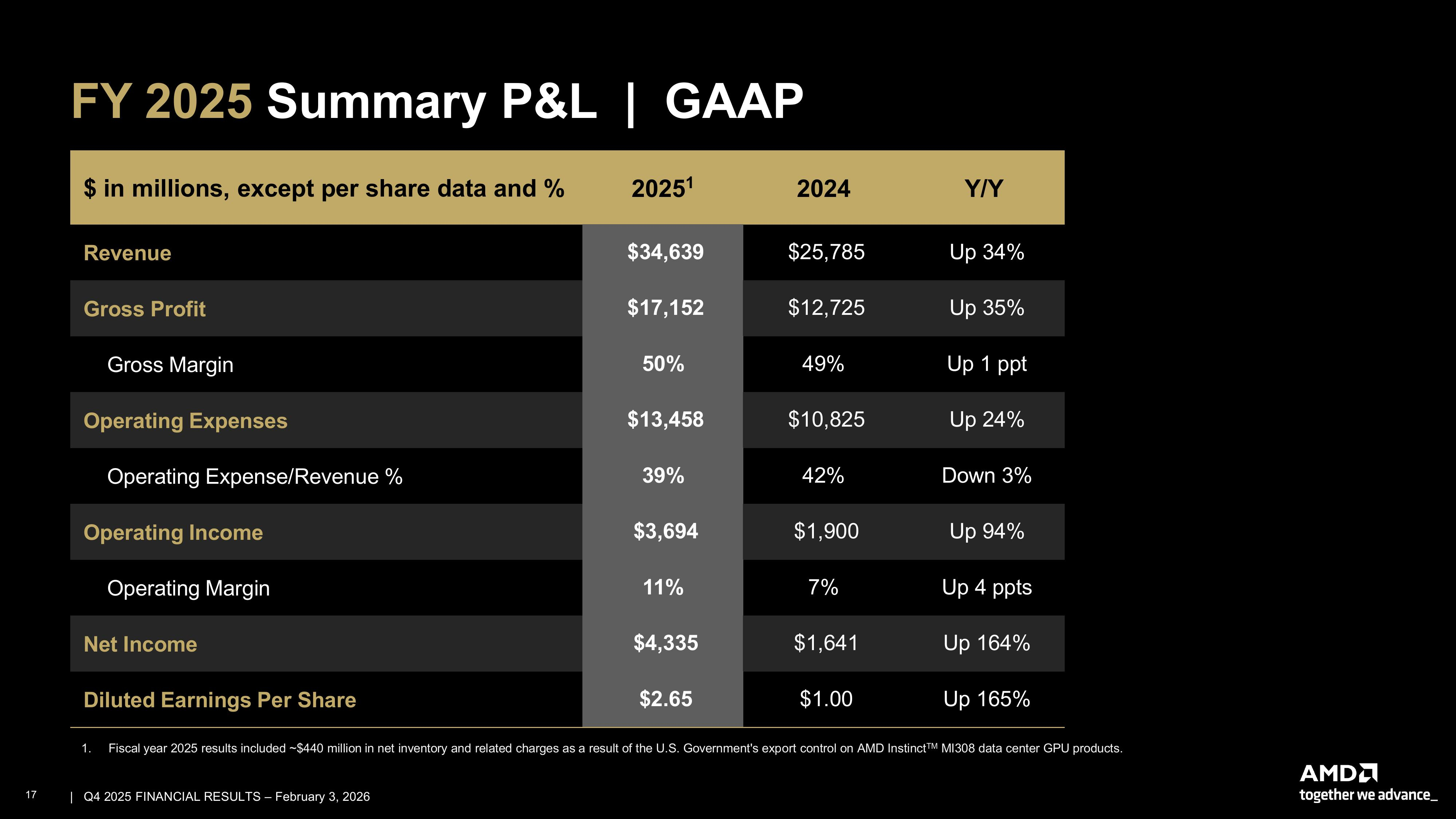 «2025 год стал определяющим для AMD, с рекордными показателями выручки и прибыли, обусловленными эффективной реализацией проектов и широким спросом на наши высокопроизводительные платформы и платформы искусственного интеллекта», — отметила Лиза Су (Lisa Su), председатель совета директоров и генеральный директор AMD. Подразделение ЦОД AMD, которое поставляет CPU и ИИ-ускорители, принесло рекордную выручку в $5,38 млрд (рост — 39 %), что выше прогноза аналитиков в $4,97 млрд (по данным finance.yahoo.com) благодаря высокому спросу на процессоры AMD EPYC и продолжающемуся наращиванию поставок ускорителей AMD Instinct. Операционная прибыль подразделения составила $1,75 млрд, что значительно выше показателя годом ранее в размере $1,07 млрд. За весь 2025 год выручка сегмента ЦОД достигла рекордных $16,6 млрд, что на 32 % больше, чем годом ранее. 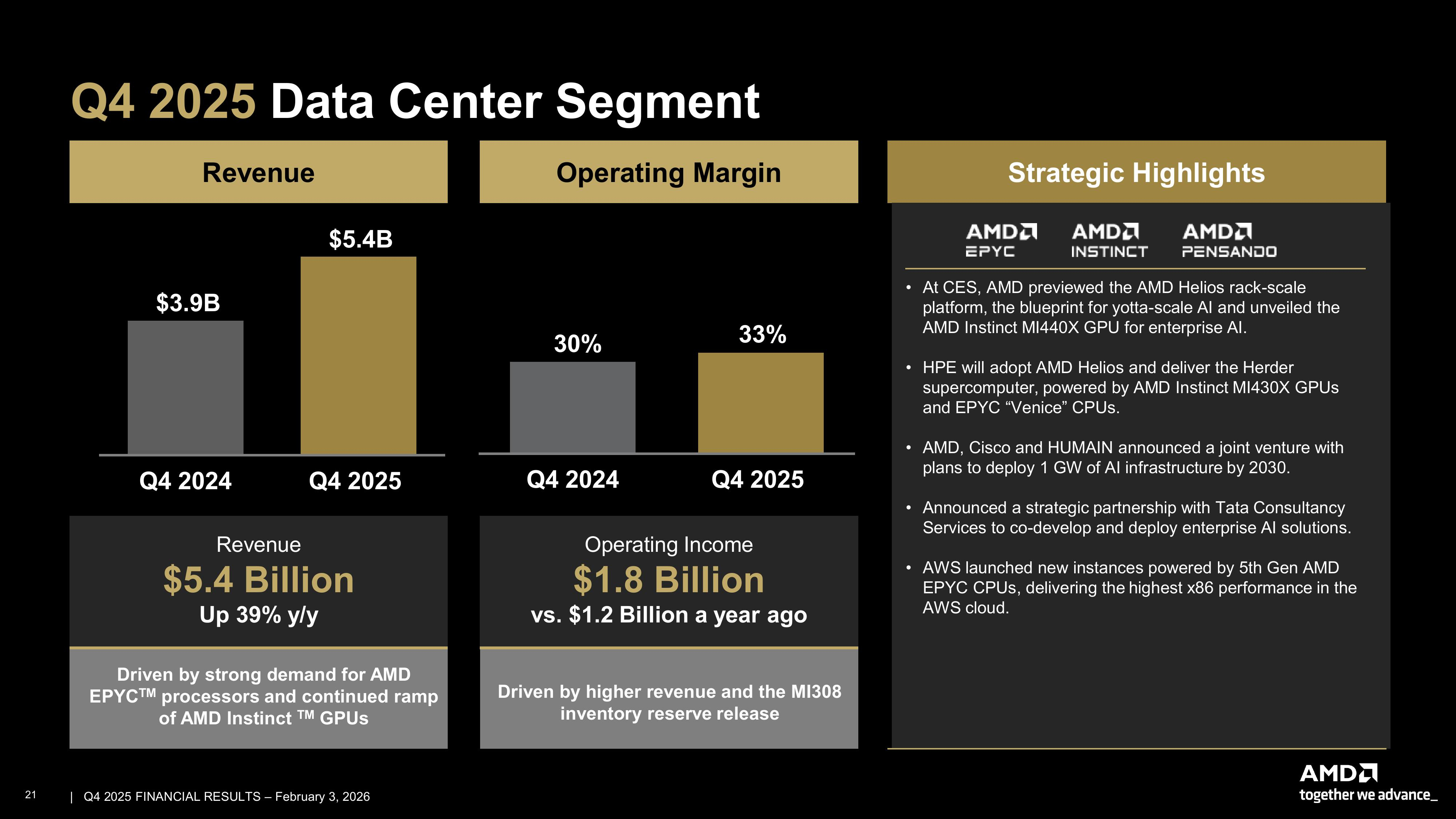 Су отметила, что бум ИИ стимулирует также продажи CPU компании, а не только GPU. «Спрос на серверные процессоры остается очень высоким, — сказала Су. — Крупные компании расширяют свою инфраструктуру, чтобы удовлетворить растущий спрос на облачные сервисы в области ИИ, в то время как крупные предприятия модернизируют свои ЦОД, чтобы обеспечить наличие необходимых вычислительных мощностей для реализации новых рабочих ИИ-процессов». Сегмент клиентских и игровых решений AMD вырос на 37 % в годовом исчислении до $3,94 млрд с $2,88 млрд годом ранее. За весь 2025 год выручка сегмента достигла рекордных $14,6 млрд, увеличившись на 51 %. 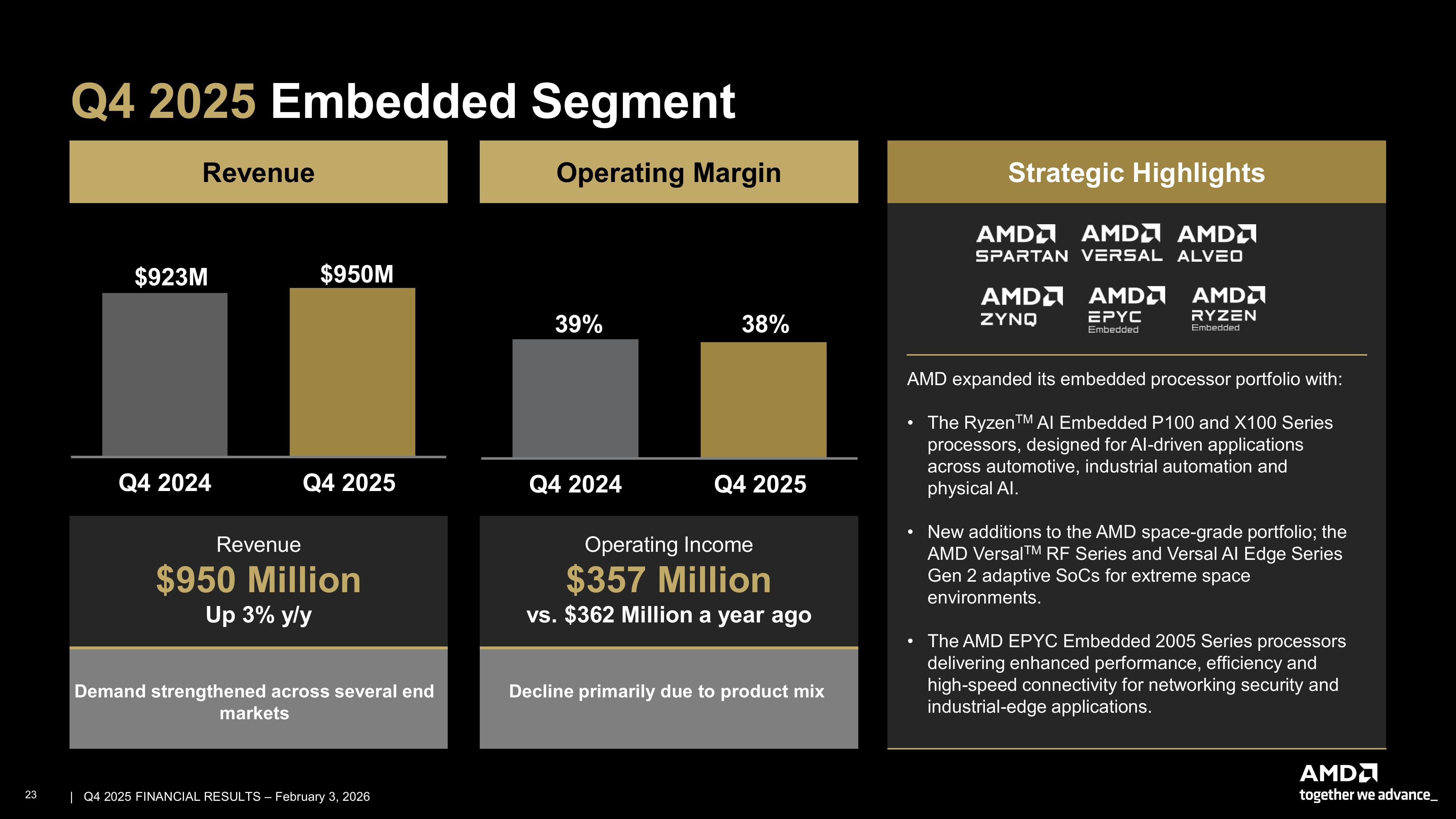 Сегмент встраиваемых систем увеличился на 3 % в годовом исчислении до $950 млн. Операционная прибыль осталась почти на том же уровне — $357 млн против $362 млн годом ранее. За весь 2025 год выручка сегмента встраиваемых систем составила $3,5 млрд (падение на 3 %), что, как утверждает компания, отражает влияние корректировок уровня запасов у клиентов, произведенных ранее в этом году. AMD ускорила запуск своих продуктов и переходит к продаже полноценных ИИ-систем Helios, чтобы лучше конкурировать с NVIDIA, которая предлагает стоечные системы, объединяющие GPU, CPU и сетевое оборудование. Компания ожидает, что к 2027 году ежегодный рост продаж подразделения ЦОД превысит 60 %. Это принесёт компании десятки миллиардов долларов. Су сообщила, что компания ожидает быстрого роста продаж нового флагманского ИИ-сервера компании OpenAI и другим компаниям во II половине этого года, отметив, что глобальный дефицит микросхем памяти не замедлит её планы. «Я не думаю, что мы столкнёмся с ограничениями поставок в плане наращивания объёмов производства», — заявила гендиректор AMD.
04.02.2026 [12:11], Руслан Авдеев
Датские исследователи напечатали в 3D испарительную камеру для пассивной двухфазной СЖОГруппа учёных создала один из ключевых компонентов системы жидкостного охлаждения (СЖО) дата-центров с использованием 3D-печати. В проекте приняли участие исследователи и специалисты практики из Дании, Бельгии и Германии, сообщает Datacenter Dynamics. Датский технологический институт (Danish Technological Institute) совместно с компанией Heatflow (Дания), бельгийской Open Engineering и занимающимся прикладными исследованиями немецким институтом Fraunhofer IWU разработали, напечатали на 3D-принтере и протестировали компонент системы охлаждения для дата-центров и высокопроизводительных компьютеров. В новом решении охлаждающая жидкость испаряется на горячей поверхности. Пар, отводя тепло, поднимается, а потом конденсируется и под действием силы тяжести возвращается к источнику тепла. Ключевой компонент — испарительная камера — изготовлена с помощью 3D-печати компанией Heatflow и Датским технологическим институтом. в ходе испытаний достигнута мощность охлаждения 600 Вт, это на 50 % больше, чем планировалось (400 Вт). Насосы этим элементом системы не используются, что снижает энергопотребление. 
Источник изображения: Danish Research Institute Как заявили представители Датского технологического института, благодаря 3D-печати можно интегрировать необходимые функции в единую деталь. Благодаря этому отпадает надобность в узлах соединения, снижается риск протечек и повышается надёжность компонента. Кроме того, используется только один материал, поэтому переработка упрощается. Проект — часть европейской исследовательской инициативы AM2PC. Он поддерживается европейской сетью M-ERA.NET за счёт средств гранта Датского инновационного фонда (Danish Innovation Fund). Основной задачей проекта была разработка и производство испарительной камеры, а также проверка его рабочих характеристик. По словам Heatflow, наблюдается тенденция к беспрецедентному росту удельной мощности серверов, поэтому классического воздушного охлаждения уже недостаточно, а новое двухфазное решение позволяет пассивно отводить тепло без использования насосов и вентиляторов, это значительно снижает энергопотребление. 
Источник изображения: Danish Research Institute Основанная в 2018 году Heatflow является поставщиком систем охлаждения для электроники. Компания специализируется на двухфазном охлаждении. Испарительная камера изготовлена благодаря лазерному спеканию порошковых слоёв (PBF-LB). При этом методе лазер используется для формирования металлических заготовок. Решение отводит тепло при температурах 60–80 °C и потенциально применимо в системах централизованного теплоснабжения, применяющих отработанное тепло дата-центров. Учёные подчёркивают, что не уделяли особого внимания интеграциям с системами центрального отопления, но наглядно продемонстрировали, что подобная технология обеспечивает такую возможность. Утверждается, что речь идёт о важном шаге на пути создания более энергоэффективных дата-центров, способных внести позитивный вклад в общий энергетический баланс. Развитие технологий охлаждения особенно важно, поскольку, по данным исследования Rest of World, около 80 % всех дата-центров мира построены в неподходящих климатических условиях, речь идёт о почти 7 тыс. объектов.
04.02.2026 [11:00], Руслан Авдеев
Volvo Penta представила 450-кВт газовый генератор G17 для ЦОДНа фоне стремительного роста спроса на электроэнергию во всём мире, особенно в индустрии ЦОД, потребность в масштабируемых и экологически чистых источниках питания становится всё выше, говорит Volvo Penta. Поэтому компания предложила газовый электрогенератор G17, специально разработанный с учётом требований современного рынка. G17 — 16-литровый 6-цилиндровый двигатель с искровым зажиганием — представляет собой аналог проверенного решения D17 того же производителя. G17 призван обеспечить около 450 кВт (60 Гц) при 1,8 тыс. об/мин, предлагая довольно высокую мощность при компактных размерах. Способность к быстрому принятию нагрузок и незамедлительной подаче питания обеспечивает работу во время пиковых нагрузок или перебоев электроснабжения. G17 обеспечивает дополнительную гибкость в выборе топлива, работая как на обычном природном газе «трубопроводного» качества, так и на газе из «возобновляемых» источников. Двигатель готов к подключению к трубопроводу без использования дополнительных систем подготовки топлива и является более экологичной альтернативой вариантам на дизельном топливе в тех областях, где критически важна бесперебойная работа, устойчивость и хорошие экологические показатели, говорит Volvo Penta. G17 разработан для уменьшения выбросов оксидов азота и твёрдых частиц. Соответствие стандартам Агентства по охране окружающей среды США (EPA) для стационарных энергетических установок, а также усовершенствованная система управления сгоранием, рециркуляции отработанных газов низкого давления (EGR) и трёхкомпонентный каталитический нейтрализатор делает новинку подходящим вариантом для компаний с жёсткими обязательствами в области ESG или работающих в зонах со строгими требованиями к качеству воздуха. 
Источник изображения: Volvo Penta Компактная, штабелируемая платформа, по данным разработчика, идеально подходит для ограниченных пространств вроде дата-центров. Работающий на природном газе двигатель также можно интегрировать в системы, сочетающие ДВС с возобновляемым топливом и аккумуляторными энергохранилищами. Модульная архитектура позволяет создавать довольно гибкие энергосистемы, способные развиваться с учётом изменения спроса. Затраты на топливо потенциально ниже в сравнении с дизельными вариантами, а конструкция, обеспечивающая снижение уровня шума, обеспечивает ещё большую привлекательность для потребителей. Размеры и система охлаждения G17 эквивалентны двигателям D16 и D17, что упрощает установку и модернизацию. Новый вариант поставляется в виде полностью интегрированного OEM-решения. Оптимизация компоновки компонентов и уменьшение числа цилиндров повышает ремонтопригодность и способствуют снижению общей стоимости владения на протяжении срока службы двигателя. Это не единственные современные решения на рынке двигателей для генерации энергии. Например, Boom Supersonic, занимающаяся строительством сверхзвуковых самолётов коммерческого назначения, представила газовую турбину Superpower мощностью 42 МВт. Более того, Управление энергетической информации США (EIA) представило доклад, в котором предлагает применять списанные авиационные двигатели военных самолётов для снабжения электричеством дата-центров, таких двигателей на «кладбищах» самолётов можно найти буквально тысячи.
04.02.2026 [10:12], Сергей Карасёв
Intel и SoftBank займутся разработкой памяти Z-Angle Memory (ZAM) — альтернативы HBM для ИИ-системКорпорации Intel и SoftBank объявили о сотрудничестве в рамках проекта по разработке высокопроизводительной памяти нового типа Z-Angle Memory (ZAM), ориентированной на ИИ-системы. Предполагается, что в перспективе такие решения составят конкуренцию HBM. В инициативе принимает участие Saimemory — дочернее предприятие SoftBank, сформированное в декабре 2024 года. Речь идёт о разработке многослойной архитектуры DRAM с вертикальной компоновкой. Цель заключается в увеличении ёмкости чипов памяти и их пропускной способности по сравнению с HBM при одновременном снижении энергопотребления. Проект ZAM основан на результатах исследований, полученных по программе передовых технологий памяти AMT (Advanced Memory Technology), которая управляется Министерством энергетики США (DOE) и Администрацией по национальной ядерной безопасности США (NNSA). В данной программе участвуют Сандийские национальные лаборатории (SNL), Ливерморская национальная лаборатория имени Лоуренса (LLNL) и Лос-Аламосская национальная лаборатория (LANL) в составе DOE. Планируется использование технологии сборки Intel Next Generation DRAM Bonding (NGDB), которая, как утверждается, значительно повышает производительность DRAM, снижает энергопотребление и оптимизирует затраты на память. 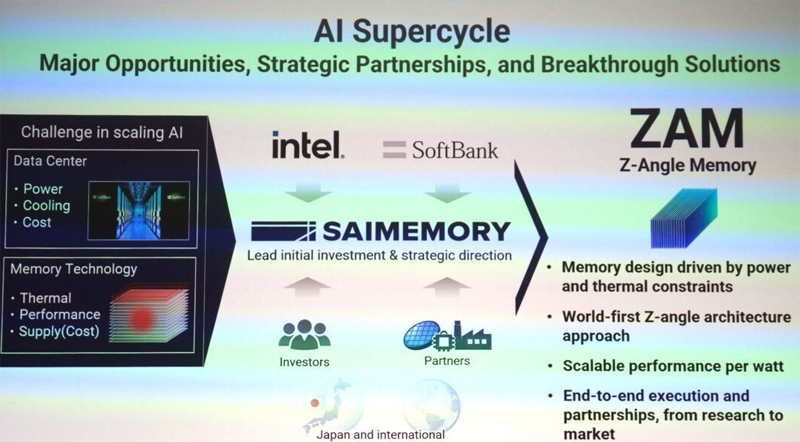
Источник изображения: TechPowerUp В целом, в рамках нового проекта Intel и Saimemory планируют увеличить ёмкость модулей памяти в два–три раза по сравнению с современными HBM, снизить энергопотребление на 40–50 % и при этом сохранить конкурентоспособную стоимость. Предполагается, что появление ZAM позволит устранить ключевые узкие места при масштабировании высокопроизводительных систем ИИ. Работы над памятью нового типа начнутся в текущем квартале. Демонстрация прототипов запланирована на 2027 год, а коммерциализация технологии — на 2030-й.
03.02.2026 [17:15], Руслан Авдеев
OpenAI не устроили чипы NVIDIA для инференса, теперь она ищет альтернативыПо данным многочисленных отраслевых источников, компания OpenAI недовольна некоторыми ИИ-чипами NVIDIA и с прошлого года ищет им альтернативы. Потенциально это усложнит отношения между крупнейшими игроками рынка на фоне бума ИИ, сообщает Reuters. Изменения стратегии OpenAI связаны с усилением акцента на инференсе. NVIDIA доминирует в нише ускорителей для обучения ИИ-моделей, но теперь инференс стал отдельным рынком с сильной конкуренцией. Решение OpenAI — вызов доминированию NVIDIA в сфере ИИ и препятствие $100-млрд сделки между компаниями, обеспечивающей разработчику чипов долю в ИИ-стартапе в обмен на доступ к передовым ускорителям. Предполагалось, что сделка будет закрыта за недели, но вместо этого переговоры ведутся месяцами. В то же время OpenAI заключила соглашение с AMD и Cerebras (её в своё время даже хотели купить) для получения «альтернативных» чипов, а также разрабатывает собственный ИИ-ускоритель при участии Broadcom. Amazon тоже не прочь предоставить OpenAI собственные ускорители, равно как и Google. Изменение планов OpenAI изменило и потребности в вычислительных мощностях и замедлило переговоры с NVIDIA. 
Источник изображения: Robin Jonathan Deutsch / Unsplash В минувшую субботу глава NVIDIA Дженсен Хуанг (Jensen Huang) опроверг слухи о проблемах с OpenAI, назвав их «чепухой» и подчеркнув, что клиенты продолжают выбирать NVIDIA для инференса, поскольку компания обеспечивает наилучшее соотношение производительности и совокупной стоимости владения, причём в больших масштабах. Отдельно представитель OpenAI заявлял, что компания полагается на NVIDIA для поставок большинства чипов для инференса, причём именно NVIDIA обеспечивает наилучшую производительность на каждый вложенный доллар. Глава OpenAI Сэм Альтман (Sam Altman) отметил, что NVIDIA выпускает «лучшие чипы в мире» и есть надежда, что OpenAI останется её «гигантским» клиентом очень долгое время. При этом, как сообщает Reuters со ссылкой на семь источников, OpenAI не удовлетворена производительностью инференса, на которую способны чипы NVIDIA. В частности, речь идёт о специализированных задачах вроде разработки ПО с помощью ИИ и коммуникаций ИИ с другим ПО. По данным одного из источников, компании понадобится новое аппаратное обеспечение, которое в конечном счёте обеспечит в будущем порядка 10 % вычислительных мощностей для инференса. 
Источник изображения: OpenAI OpenAI обсуждала возможности работы с ИИ-стартапами, включая Cerebras и Groq для обеспечения чипов с более быстрым инференсом, но NVIDIA фактически поглотила Groq на $20 млрд, что привело к прекращению переговоров с компанией. Хотя формально речь идёт неэксклюзивном лицензировании технологий Groq, что в теории позволяет сторонним компаниям получить доступ к решениям Groq, фактически все разработчики перешли в NVIDIA, а оставшаяся небольшая команда отвечает за выполнение облачных контрактов с имеющимися заказчиками. Чипы NVIDIA хорошо подходят для обработки больших объёмов данных при обучении больших ИИ-моделей вроде тех, что стоят за ChatGPT. Тем не менее прогресс требует массового использования уже обученных моделей для дальнейшего инференса и ИИ-рассуждений. Как сообщается, OpenAI с 2025 года ищет альтернативы ускорителям NVIDIA с упором на компании, создающие чипы с большими объёмами интегрированной SRAM. Maia 200 от Microsoft, по-видимому, компании не очень подходит. 
Источник изображения: Hermann Wittekopf - kmkb / Unsplash Инференс моделей более требователен к памяти, чем обучение, а вычислительная нагрузка, наоборот, не так велика. В тоге нередко на доступ к данным уходит больше времени, чем на расчёты. NVIDIA и AMD полагаются на внешнюю память, что замедляет соответствующие процессы общения с чат-ботами. В OpenAI проблемы отметили при эксплуатации системы Codex, активно продвигаемой компанией для создания кода. В компании считают, что некоторые слабости системы связаны именно с оборудованием NVIDIA. Конкуренты OpenAI полагаются на альтернативное оборудование. Anthropic активно использует AWS Trainium и Google TPU, а Google уже много лет использует свои TPU, которые с недавних пор готова отдавать на сторону. TPU оптимизированы в том числе для инференса и в некоторых отношениях более производительны, чем GPU общего назначения AMD и NVIDIA. Когда OpenAI недвусмысленно выразила отношение к технологиям NVIDIA, та предложила компаниям, создающим ускорители с упором на SRAM, включая Cerebras и Groq, купить их бизнес. Cerebras отказалась и заключила прямую сделку с OpenAI. Groq вела переговоры с OpenAI о предоставлении вычислительных мощностей, что вызвало интерес у инвесторов, оценивших капитализацию компании на уровне $14 млрд.
03.02.2026 [15:23], Руслан Авдеев
Сделка на триллион с четвертью: SpaceX приобрела xAIКомпания SpaceX Илона Маска (Elon Musk) приобрела основанный им же ИИ-стартап xAI. Рекордная сделка позволит реализовать амбиции мультимиллиардера в сфере освоения космоса и искусственного интеллекта. По данным Reuters, это одно из самых амбициозных слияний в технологическом секторе. По словам Маска, речь идёт не просто об очередной главе, а об очередном томе в истории SpaceX и xAI: «создать разумное солнце, чтобы понять Вселенную и распространить свет сознания до звёзд». По словам источника Reuters, в ходе сделки стоимость SpaceX оценивалась в $1 трлн, а xAI — $250 млрд. Сообщается, что инвесторы xAI получат акции SpaceX в обмен на акции xAI, по 0,1433 акции за каждую. Не исключается, что некоторые топ-менеджеры предпочтут обменять имеющиеся у них ценные бумаги на наличные, по $75,46 за акцию. Сделка ставит новый рекорд на рынке слияний и поглощений. Прежний более 25 лет удерживала Vodafone, в 2000 году купившая Mannesmann, тогда поглощение оценивалось в $203 млрд. Акции объединённой компании, согласно ожиданиям некоторых источников, будут оценены в $527/шт. Последние оценки капитализации SpaceX и xAI до сделки составляли $800 млрд и $230 млрд соответственно. По словам источников, знакомых с ситуацией, в этом году объединённая компания планирует IPO, и её оценка может составить по его результатам $1,5 трлн. 
Источник изображения: xAI Сделка — очередной шаг Маска на пути создания мегакорпорации-экосистемы, также включающей Tesla, Neuralink и Boring Company. У Маска уже есть опыт объединения подконтрольных ему предприятий: в 2025 году xAI поглотила социальную сеть X, в результате ИИ-стартап получил доступ к данным и медиаресурсам социальной платформы. В 2016 году акции Tesla использовались для покупки компании SolarCity, занимавшейся солнечной энергетикой. Конечно, сделка может привлечь пристальное внимание регуляторов и инвесторов, учитывая то, что Маск занимает руководящие роли в нескольких связанных компаниях. Кроме того, не исключено перемещение из компании в компанию специалистов, патентованных технологий и даже контрактов. SpaceX имеет контракты на миллиарды долларов с NASA, Министерством обороны США и другими американскими спецслужбами, которые в той или иной мере имеют полномочия по проверке подобных сделок на предмет угрозы национальной безопасности и других рисков. Стоит отметить, что слияние SpaceX и xAI происходит весьма своевременно. На днях появилась новость, что SpaceX попросила разрешение на запуск до 1 млн спутников для формирования космических ЦОД мощностью в сотни гигаватт. Компетенции xAI в этой сфере окажутся весьма кстати.
03.02.2026 [14:51], Андрей Крупин
«Байкал Электроникс» открыл свободный доступ к документации на серийный микроконтроллер Baikal-UРоссийский разработчик микропроцессоров «Байкал Электроникс» запустил публичный портал, содержащий полный комплект документации на серийный микроконтроллер Baikal-U (BE-U1000). На площадке представлены сведения технического характера, принципиальные схемы, чертежи печатных плат, SDK, API и прочая информация для разработчиков устройств на базе упомянутого изделия. BE-U1000 представляет собой трёхъядерный 32-бит микроконтроллер общего назначения, в основу которого положена архитектура RISC-V. Характеристики устройства позволяют применять его в индустрии интернета вещей, автоматизированных системах управления технологическими процессами, машиностроении, робототехнике, промышленной автоматике, управлении электродвигателями и других отраслях. Изделие включено в реестр Минпромторга РФ и подходит для программ импортозамещения, а также государственных закупок. 
Микроконтроллер Baikal-U (источник изображения: baikalelectronics.ru) По словам компании «Байкал Электроникс», размещённая в открытом доступе документация призвана упростить процесс разработки аппаратных решений на базе отечественного микроконтроллера Baikal-U, сократить время интеграции и сделать работу удобной для инженерных команд, технологических партнёров, сообществ разработчиков и образовательных проектов.  Портал будет регулярно обновляться и дополняться — планируется публикация новых практических примеров применения Baikal-U и прикладных заметок, а также дальнейшее улучшение пользовательского опыта при работе с продуктами компании. |
|

