Материалы по тегу: hardware
|
16.07.2026 [15:50], Сергей Карасёв
NVIDIA представила модули Jetson T2000 и T3000 с GPU Blackwell для ИИ-задач на периферииКомпания NVIDIA объявила о расширении семейства вычислительных модулей Jetson Thor: дебютировали изделия T2000 и T3000, предназначенные для создания робототехнических систем и запуска ИИ-приложений на периферии сети. Обе новинки построены на архитектуре Blackwell. Младшее из двух решений, Jetson T2000, содержит шесть 64-бит вычислительных ядер Arm Neoverse-V3AE. Кроме того, задействован 1024-ядерный графический блок NVIDIA Blackwell. ИИ-производительность достигает 400 Тфлопс (FP4 Sparse). Объём памяти LPDDR5X составляет 16 Гбайт, её пропускная способность — до 137 Гбайт/с. Реализованы два сетевых интерфейса 10GbE. Энергопотребление не уточняется. В свою очередь, модуль Jetson T3000 объединяет восемь ядер Arm Neoverse-V3AE с 1 Мбайт кеша L2 каждое и 1536-ядерный GPU на базе NVIDIA Blackwell. Быстродействие на операциях ИИ составляет до 865 Тфлопс (FP4—Sparse). Это изделие располагает 32 Гбайт памяти LPDDR5X с пропускной способностью 273 Гбайт/с. Говорится о поддержке 25GbE-подключения. Энергопотребление, согласно предварительным данным, находится в диапазоне от 20 до 65 Вт. Размеры обеих новинок — примерно 50 × 87 мм. Прочие технические характеристики пока не раскрываются. 
Источник изображения: NVIDIA NVIDIA намерена начать поставки Jetson T2000 и Jetson T3000 в I квартале следующего года. Разработчики уже могут приступить к созданию продуктов на новых модулях, используя комплект Jetson AGX Thor Developer Kit. Отмечается, что в число партнёров NVIDIA по экосистеме Jetson входят такие компании, как ADLINK, Advantech, AAEON, Aetina, Auvidea, AVerMedia, Connect Tech, ForeCR, JWIPC, NEXCOM Robotic Solutions, Realtimes, Seeed Studio, Twowin, TZTEK и YUAN. Некоторые из них уже объявили о намерении выпустить решения на новых аппаратных платформах.
16.07.2026 [15:42], Сергей Карасёв
YADRO выпустила российский сервер H225 G4 на базе AMD EPYC TurinYADRO выпустила сервер H225 G4 — свою первую систему, которая может оснащаться двумя процессорами AMD EPYC 9005 Turin или EPYC 9004 Genoa. Новинка включена в Единый реестр российской радиоэлектронной продукции Минпромторга, что позволяет использовать её в проектах субъектов КИИ, государственных заказчиков и организаций регулируемых отраслей. Устройство, выполненное в форм-факторе 2U, предназначено для горизонтально масштабируемых приложений. Могут устанавливаться процессоры с TDP до 500 Вт. Доступны 24 слота для модулей оперативной памяти DDR5-6400 RDIMM/3DS-RDIMM суммарным объёмом до 6 Тбайт. Подсистема хранения данных в зависимости от конфигурации включает 12 накопителей LFF SAS/SATA/NVMe или 8/16/24 устройства SFF SAS/SATA/NVMe во фронтальной части и до четырёх устройств SFF SAS/SATA/NVMe сзади. Возможно формирование массивов RAID 0/1/5/6/10/50/60. Опционально предлагается суперконденсатор для защиты содержимого кеш-памяти при отключении питания. Для загрузки ОС служат два системных SSD формата M.2 (NVMe). 
Источник изображения: YADRO Спереди расположены по одному порту USB 3.0 Type-A и D-Sub, сзади — два разъёма USB 3.0 Type-A, интерфейс D-Sub, последовательный порт (RS-232) и выделенный сетевой порт управления 1GbE RJ45. Сервер позволяет задействовать от 4 до 11 слотов PCIe 5.0 (с учетом отсека OCP 3.0 SFF). Питание обеспечивают два блока мощностью 2700 Вт с сертификатом 80 PLUS Platinum. Габариты составляют 780 × 447 × 87,5 мм. Диапазон рабочих температур — от +10 до +35 °C. Применено воздушно охлаждение. Заявлена совместимость с Astra Linux, RedOS, Alt Linux, VMware ESXi, Windows Server, RHEL и SLES.
15.07.2026 [17:47], Руслан Авдеев
Google выкупила всю энергию 2,5-ГВт солнечной электростанции в США, которая ещё даже не построена
google
hardware
аккумулятор
возобновляемая энергия
сделка
солнечная энергия
сша
цод
экология
энергетика
Google согласилась выкупить всю энергию крупной солнечной электростанции Steel River Energy Center в Арканзасе, которая заработает в 2029 году. Считается, что это позволит компенсировать потребление компанией электричества, получаемого сжиганием ископаемого топлива, сообщает The Financial Times. Проект — крупнейший в своём роде их тех, реализация которых уже началась в США. На первом этапе мощность станции составит 1,6 ГВт, она будет дополнена аккумуляторным хранилищем на 2 ГВт∙ч. На момент ввода последней очереди в эксплуатацию мощность проекта достигнет 2,5 ГВт, а ёмкость энергохранилище увеличится до 2,9 ГВт∙ч. В случае сделки с Google речь идёт о «виртуальной» покупке энергии посредством PPA, так что ЦОД Google напрямую от электростанции запитаны не будут из-за нестабильности поставок их такого вида источников. Долгосрочные обязательства по покупке энергии позволяют девелоперам получить финансовые гарантии востребованности их «зелёной» энергии и позволят им привлекать инвестиции на строительство новых мощностей. Практики заключения PPA для формальной компенсации использования ископаемого топлива нередко критикуются, поскольку многие считают их неэффективными — операторы ЦОД всё равно забирают энергию из магистральных сетей, а «чистая» энергия, которую они оплачивают, может генерироваться в другом месте и в другое время — не там и не тогда, когда она нужна. 
Источник изображения: Markus Spiske/unspalsh.com По информации Института экологических и энергетических исследований (Environmental and Energy Study Institute, EESI), около 56 % электричества, используемого для энергоснабжения американских ЦОД, генерируется с использованием ископаемого топлива. Статистика BloombergNEF показывает, что в 2025 году выбросы Google, связанные с потреблением электроэнергии, выросли на 37 %, а на долю Google, Meta✴, Amazon и Microsoft пришлось 49 % корпоративных сделок по закупке «чистой» энергии в том же году. Ответственный за проект девелопер Cypress Creek Energy называет сделку «редким светлым пятном» в картине американской солнечной энергетики. Отрасль оказалась под давлением с приходом к власти нового президента США, отдающего явное предпочтение угольной энергетике. Вместе с тем IT-гиганты ищут крупные проекты вроде Steel River для покрытия своих растущих энергорасходов. По оценкам, в 2026–2030 гг. на долю солнечной генерации и систем хранения придётся 58 % новых вводимых в эксплуатацию энергопроектов, что объясняется относительной быстротой и дешевизной их реализации. Steel River в значительной степени опирается на комплектующие американского производства, отдавая предпочтение местным цепочкам поставок вместо китайских. Панели будет поставлять компания First Solar, заявляющая, что использует на 100 % американские материалы. Сталь будет закуплена в Арканзасе, а АКБ привезут с завода LG в Финиксе. План США, касающийся налогов и расходов, ограничил долю расходов на комплектующие из «нежелательных иностранных государств» вроде КНР. По данным Международного энергетического агентства (IEA), на долю Китая в 2025 году приходилось около 85 % в цепочке поставок солнечных панелей и более 80 % — аккумуляторов.
15.07.2026 [15:46], Руслан Авдеев
В обход FLAPD: Pure DC запустит в Финляндии 550-МВт ИИ ЦОД стоимостью €7,5 млрдКомпания Pure DC построит в Финляндии кампус ИИ ЦОД стоимостью €7,5 млрд и мощностью 550 МВт. Это весьма крупный проект за пределами рынка FLAPD, на котором царит дефицит мощностей, сообщает Computer Weekly. Кампус в Сейняйоки (Seinäjoki) станет одним из крупнейших в Европе проектов ИИ ЦОД и крупнейшей прямой инвестицией британской компании в финскую экономику. По данным Bloomberg, одним из первых клиентов дата-центра станет Microsoft. Первый этап предполагает выделение €1,5 млрд на создание 110 МВт мощностей. Для площадки (150 га) уже получено разрешение на строительство, гарантированы энергетические мощности для подключения объектов, первая подстанция построена и уже функционирует. Площадка имеет доступ к более 700 МВА возобновляемой энергии из местных источников. Для строительства используются типовые 40-МВт ИИ-модули с прямым жидкостным охлаждением замкнутого цикла. Избыточное тепло кампуса будет направляться в городскую систему отопления. Pure DC обязалась организовать подготовку кадров с местными образовательными организациями — от обучения до трудоустройства в регионе, традиционно ассоциировавшемся с деревообрабатывающей и целлюлозно-бумажной промышленностью. По данным Европейской ассоциации дата-центров (EUDCA), 67 % местных операторов ЦОД на ближайшие три года называют главной проблемой доступ к электроэнергии. Считается, что она серьёзнее, чем сложности с получением разрешений на строительство, нехватки кадров и высоких цен на электричество. Дефицит электричества острее всего наблюдается на ключевых рынках FLAPD (Франкфурта, Лондона, Амстердама, Парижа и Дублина). Там перегрузки сетей и бюрократия снизили свободные мощности до исторических минимумов. По данным EUDCA, сейчас развитие идёт в Южной Европе, Северной Европе и Восточной Европе, а также растущей группе ключевых агломераций «второго эшелона» (Tier-2). 
Источник изображения: Tapio Haaja/unsplash.com Хотя рынки FLAPD сохранят критическое значение для корпоративных задач, требующих низких задержек, масштабные ИИ-мощности смещаются на север — они лягут в основу новой волны облачных сервисов. Портфолио самой Pure DC включает также активные проекты в Мадриде и Абу-Даби, а кампус компании в Дублине обходит местные ограничения благодаря наличию собственной микросети на 110 МВт на площадке при самих ЦОД. Финляндия — лидер рейтинга Sigma Index International Data Center Authority (IDCA). Он комплексно оценивает пригодность страны к размещению дата-центров с учётом наличия резервов энергосетей, доступности водных ресурсов и «цифровой готовности». Страна набрала в нём 99 баллов из 100. Кроме того, Финляндия находится в «зелёной зоне» индекса IDCA Emissions Reduction Challenge, с показателем 2,3, один из самых низких для развитых стран. Это свидетельствует о доступности стабильной, недорогой, низкоуглеродной энергетической основы, необходимой гиперскейлерам для кластеров обучения ИИ, требующих десятки мегаватт мощностей. Интерес к региону проявляют и другие компании. Например, Nebius рассчитывает построить в Финляндии крупнейший в Европе ИИ ЦОД.
15.07.2026 [14:55], Руслан Авдеев
Google призналась, что стоит за проектом гигаваттного ИИ ЦОД в Вайоминге, который будет потреблять больше энергии, чем все дома штатаGoogle призналась, что именно она стоит за инициативой Project Jade, предусматривающей строительство 2,7-ГВт дата-центра близ Шайенна (Cheyenne) на участке площадью 290 га в технопарке Switchgrass Industrial Park в штате Вайоминг. Теперь проект сменил название, превратившись в Project Tembo, сообщает Datacenter Dynamics. Согласно доступной документации, кампус получит четыре объекта, а также офисный блок, логистические площади и здания для сетевой инфраструктуры. Строительство должно завершиться к 2031 году. Ранее за реализацию проекта отвечали Crusoe совместно с Tallgrass Energy. На момент анонса говорилось, что мощность кампуса составит 1,8 ГВт с возможностью масштабирования до 10 ГВт. Уже тогда говорилось, что ЦОД будет потреблять больше энергии, чем все дома штата. В июне Crusoe объявила, что приостановила работы «по запросу клиента». 
Источник изображения: Pete Alexopoulos/unsplash.com По информации местных СМИ, теперь строительство на территории кампуса ведётся компанией дочерней структуры Google — Jupiter Star Holdings, которая заменит Crusoe. Причины такого решения не названы. Ранее сообщалось, что участвовавшая в проекте Tallgrass Energy заявляла о том, что строительство энергогенерирующего хаба для обеспечения нужд клиента собственной энергией по принципу «принеси энергию с собой» (BYOP) всё ещё ведётся, причём работы идут «полным ходом». По данным Google, помимо локальной генерации в рамках стратегии Power First, кампус будет использовать и электричество местной компании Black Hills Energy. Шайенн является столицей Вайоминга и на его территории реализуется ряд важных проектов. Так, Meta✴ имеет в окрестностях города крупный кампус ЦОД. В августе 2025 года Microsoft начала строительство нового кампуса и намерена приобрести около 1,3 тыс. га дополнительно. В октябре 2025 года Related Digital тоже начала строительство ЦОД стоимостью $1,2 млрд в интересах CoreWeave.
15.07.2026 [14:39], Руслан Авдеев
Нью-Йорк стал первым штатом США, утвердившим временный мораторий на строительство ЦОД мощностью более 50 МВтШтат Нью-Йорк временно приостановил выдачу некоторых типов разрешений на строительство дата-центров мощностью выше 50 МВт. Губернатор Кэти Хокул (Kathy Hochul) подписала указ, обязывающий регуляторов разработать правила для штата, регламентирующие подключение к электросетям, водоснабжению и оценку воздействия на местных жителей, сообщает Datacenter Knowledge. В частности, Департаменту охраны окружающей среды штата (New York Department of Environmental Conservation) предписывается прекратить рассмотрение заявок на строительство или расширение ЦОД мощностью от 50 МВт. Исключение составляют заявки, утверждённые до вступления указа в силу. Мораторий будет действовать до тех пор, пока не будет завершена общая оценка воздействия на окружающую среду — Generic Environmental Impact Statement, или в течение одного года, в зависимости от того, что произойдёт раньше. На разрешения, выданные местными органами власти, ограничения не распространяется. В документе отмечается, что инвестиции в инфраструктуру, сделанные в ожидании роста отрасли ЦОД, создают финансовые риски — если необходимые нагрузки так и не будут востребованы. Согласно выводам авторов документа, штату нужна более комплексная нормативная база для электрической инфраструктуры, водопользования и оценки влияния на местные сообщества — прежде, чем крупные проекты можно будет реализовать снова. Указ подготовили и подписали на фоне быстрого роста объёма заявок на создание ИИ-инфраструктуры. Отмечается, что в мае в очереди на подключение к энергосистеме New York Independent System Operator насчитывалось заявок приблизительно на 12 ГВт, более 8 ГВт из них приходятся на один только 2025 год. 
Источник изображения: Othman Alghanmi/unsplash.com Департамент государственной службы (Department of Public Service) подготовит оценку воздействия на окружающую среду. Будут изучены вероятные последствия появления ЦОД на спрос на электроэнергию, на использование и качестве воды, на качество воздуха и уровень шума, на возможность негативного влияния на уязвимые группы населения и др. Кроме того, учреждается Рабочая группа по присоединению дата-центров к сети (Data Center Interconnection Working Group), призванная рекомендовать реформы для подключения новых крупных мощностей с сохранением принципа «платит бенефициар» при модернизации электросетей и затрат на необходимые ресурсы. Отдельно будет рассмотрена возможность создания специального Фонда ускорения развития энергосети Нью-Йорка (New York Grid Acceleration Fund), который сможет требовать от строителей ЦОД авансовые платежи на модернизацию электросетей, управление спросом, «зелёную» энергетику и прочие меры, призванные защитить обычных потребителей от дополнительных расходов, если реализацию проектов ЦОД отложат, сократят их масштаб или вовсе отменят. Кроме того, агентству экономического развития штата Empire State Development предписано в течение 60 дней подготовить рамочную инвестиционную программу для муниципалитетов, это должно помочь им заключать взаимовыгодные соглашения с застройщиками. Программа будет касаться вопросов создания местных инвестфондов, совершенствования инфраструктуры, развития трудовых ресурсов и обеспечения прозрачности проектов. Объединение DATA Center Coalition уже раскритиковало инициативу, заявив, что указ вынудит перенаправить инвестиции, рабочие места и налоговые поступления в другие штаты. Организация подчёркивает, что ЦОД обеспечивают в Нью-Йорке более 227 тыс. рабочих мест (по-видимому, с учётом косвенной занятости), и в 2024 году их вклад в ВВП составил $49 млрд, а ещё $5,1 млрд было получено в виде налоговых поступлений уровня штата и муниципалитетов. Указ может отпугнуть инвесторов и привести к «обесцениванию» уже вложенных средств, став сигналом о том, что Нью-Йорк «закрыт для бизнеса». 
Источник изображения: Romain Dancre/unsplash.com По словам Persistence Analytics Group, пауза в выдаче разрешений может перенаправить краткосрочные инвестиции в штаты с более лояльными к ЦОД властями, более доступной энергией или более понятными процедурами подключения к коммуникациям. При этом практика Нью-Йорка может стать примером для других штатов. По мнению экспертов группы, девелоперы давно оценивают рынки по уровню доступности энергии, ВОЛС, земли, налоговых льгот и скорости выдачи разрешений. Чёткие регуляторные стандарты позволят улучшить долгосрочные инвестиционные решения, поскольку застройщикам сегодня нужна не только скорость, но и правила, которым смогут доверять не только инвесторы, но и коммунальные службы, регуляторы и общество. При этом указ оказался не столь масштабным, как законопроект, принятый ранее в текущем году законодателями штата Нью-Йорк. Они приняли Закон об ответственном развитии дата-центров, предусматривавший введение моратория на строительство новых объектов мощностью всего лишь от 20 МВт. Одновременно ведомствам штата предписывалось изучить влияние ЦОД на электросети, водные ресурсы и близлежащие сообщества. Тем не менее, Хокул приняла собственное решение, повысив лимит мощности. Под действие нового правила подпадают объекты со специальными системами охлаждения и непрерывным циклом работы, способные потреблять не менее 50 МВт. Объектов, применяемых преимущественно для производства, исследований, образования и медицинского обслуживания, оно не касается. Ранее сообщалось, что предлагаемые штатами налоговые льготы для строителей ЦОД нередко не окупаются, но отказаться от них нелегко. В апреле сообщалось, что власти США скрывают потери от налоговых льгот для ЦОД. В штате Мэн также попытались ввести мораторий на их строительство, но подобное решение законодательной власти не одобрил губернатор.
15.07.2026 [10:51], Сергей Карасёв
IBM представила компактный сервер Power S1112 для периферийных развёртыванийIBM анонсировала компактный сервер Power S1112, ориентированный на периферийные развёртывания и локальное использование на площадках небольших заказчиков. Устройство будет предлагаться в двух вариантах исполнения — стоечном форм-факторе 2U и башенном. Новинка имеет односокетную конфигурацию на базе POWER11. Стоечный вариант может оснащаться процессором, насчитывающим до десяти ядер (3,05–4,0 ГГц), тогда как башенная модификация довольствуется четырёъядерным чипом (3,6–4,0 ГГц). Доступны четыре слота для модулей оперативной памяти DDR5-4800 суммарным объёмом до 512 Гбайт. Сервер получил по два слота PCIe 4.0 x16 и PCIe 4.0 x8 для карт расширения HHHL. Имеются четыре посадочных места для NVMe-накопителей стандарта U.2. Реализованы сетевой порт 1GbE RJ45, разъём USB 3.0 на передней панели и внутренний порт USB 3.0. Питание обеспечивают два блока мощностью 800 Вт с резервированием и сертификатом 80 PLUS Titanium. Допустимый диапазон рабочих температур — от +5 до +40 °C, рекомендованный — от +18 до +27 °C. Габариты стоечной версии составляют 223,5 × 660,4 × 88,9 мм, масса — 20,4 кг. Башенный вариант имеет размеры 210,8 × 784,8 × 411,5 мм и весит 24,5 кг. 
Источник изображения: poweribmi.fr На сервере могут использоваться ОС IBM i, AIX и Linux, в том числе с применением виртуализации IBM PowerVM. Упомянуто квантово-безопасное шифрование, обеспечивающее целостность системы и безопасность критически важных функций. Комплекс средств Power RAS (Reliability, Availability, and Serviceability) помогает минимизировать простои, повысить доступность и удобство обслуживания оборудования.
15.07.2026 [10:41], Сергей Карасёв
GPU-сервер MSI G4201-HE выполнен на платформе Intel Xeon Emerald RapidsКомпания MSI анонсировала сервер G4201-HE на аппаратной платформе Intel, подходящий для решения таких задач, как тонкая настройка больших языковых моделей (LLM), ИИ-инференс и пр. Устройство подходит для использования в инфраструктурах облачных провайдеров и в составе CDN-платформ. Новинка выполнена в форм-факторе 4U. Возможна установка двух процессоров Xeon Emerald Rapids (LGA 4677) с показателем TDP до 350 Вт. Доступны 32 слота для модулей оперативной памяти DDR5-5600 RDIMM/3DS суммарным объёмом до 8 Тбайт. Применено воздушное охлаждение. Сервер может нести на борту до восьми GPU-ускорителей в виде карт расширения FHFL с интерфейсом PCIe 5.0 x16 и максимальным энергопотреблением 600 Вт. Есть также дополнительные слоты PCIe 5.0 x16 и PCIe 4.0 x16 для карт стандарта FHFL. В оснащение входят контроллер ASPEED AST2600 и сетевой адаптер 1GbE (Intel I210AT). Во фронтальной части расположены 12 отсеков для LFF/SFF накопителей в конфигурации 2 × U.2 PCIe 4.0 (NVMe) и 10 × SATA-3. Допускается формирование массивов RAID 0/1/5/10. Кроме того, предусмотрены два внутренних коннектора для SSD M.2 2280/22110 (PCIe 3.0 x2). Опционально может быть добавлен модуль TPM 2.0 для обеспечения безопасности. 
Источник изображения: MSI На лицевую панель выведены по одному порту USB 3.0 Type-A и USB 2.0. Сзади находятся два разъёма USB 3.0 Type-A, коннектор D-Sub, последовательный порт (разъём RJ45), сетевой порт 1GbE RJ45 и выделенный сетевой порт управления. Установлены четыре блока питания мощностью 2700 Вт с резервированием и сертификатом 80 PLUS Titanium. Диапазон рабочих температур простирается от +10 до +35 °C.
15.07.2026 [01:40], Владимир Мироненко
Arm-процессоры Graviton5 оказались быстрее Intel Xeon 6, но отстали от AMD EPYC Turin в тестах инстансов AWSПосле запуска серии AWS M9g, первых инстансов на базе процессоров Graviton5, ресурс Phoronix провёл сравнительные тесты производительности процессоров Graviton4 и Graviton5. Тесты показали значительное повышение производительности новых процессоров AWS Graviton благодаря переходу от ядер Arm Neoverse-V2 к Neoverse-V3 и от памяти DDR5-5600 к DDR5-8800, а также другим улучшениям. Кроме того, для сравнения были добавлены тесты инстансов m8a.4xlarge и m8i.4xlarge на базе актуальных AMD EPYC и Intel Xeon в семействе EC2 M. Инстансы M8a используют кастомные AMD EPYC 9R45 поколения Turin с максимальной частотой 4,5 ГГц и памятью DDR5-6400. Каждый vCPU в M8a поддерживается физическим ядром CPU (без SMT). Стоимость использования m8a.4xlarge по запросу на момент тестирования составила $0,97376/час, что значительно выше, чем $0,78272/час для m8g.4xlarge на базе Graviton5. Инстансы M8i используют кастомные же Intel Xeon 6975P-C поколения Granite Rapids-AP с турбочастотой 3,9 ГГц для всех ядер и памятью DDR5-7200 (хотя сами CPU поддерживают MRDIMM-8800). В отличие от инстансов M8g/M9g и M8a, в M8i используется SMT, так что 16 vCPU являются восемью физическими ядрами с HT. Почасовая стоимость по запросу для m8i.4xlarge составила $0,84672 — дешевле m8a.4xlarge, но всё ещё дороже m9g.4xlarge, да ещё и физических ядер вдвое меньше. В общей сложности порталом Phoronix было проведено более 120 тестов производительности для четырех типов инстансов Amazon EC2. При вычислении геометрического среднего всех показателей производительности инстанс с Graviton5 превзошел экземпляр с Intel Xeon 6, в то время как инстанс с Graviton4 ему немного уступил. Инстанс m9g.4xlarge с Graviton5 оказался примерно на 19 % быстрее, чем экземпляр m8i.4xlarge, хотя важно отметить, что в случае с инстансом на Intel Xeon речь идёт об SMT (HT). Помимо того, что Graviton5 на 19 % быстрее, чем Xeon 6, в этом сравнении почасовая стоимость по запросу была примерно на 8 % ниже, чем у экземпляра на базе Granite Rapids-AP. 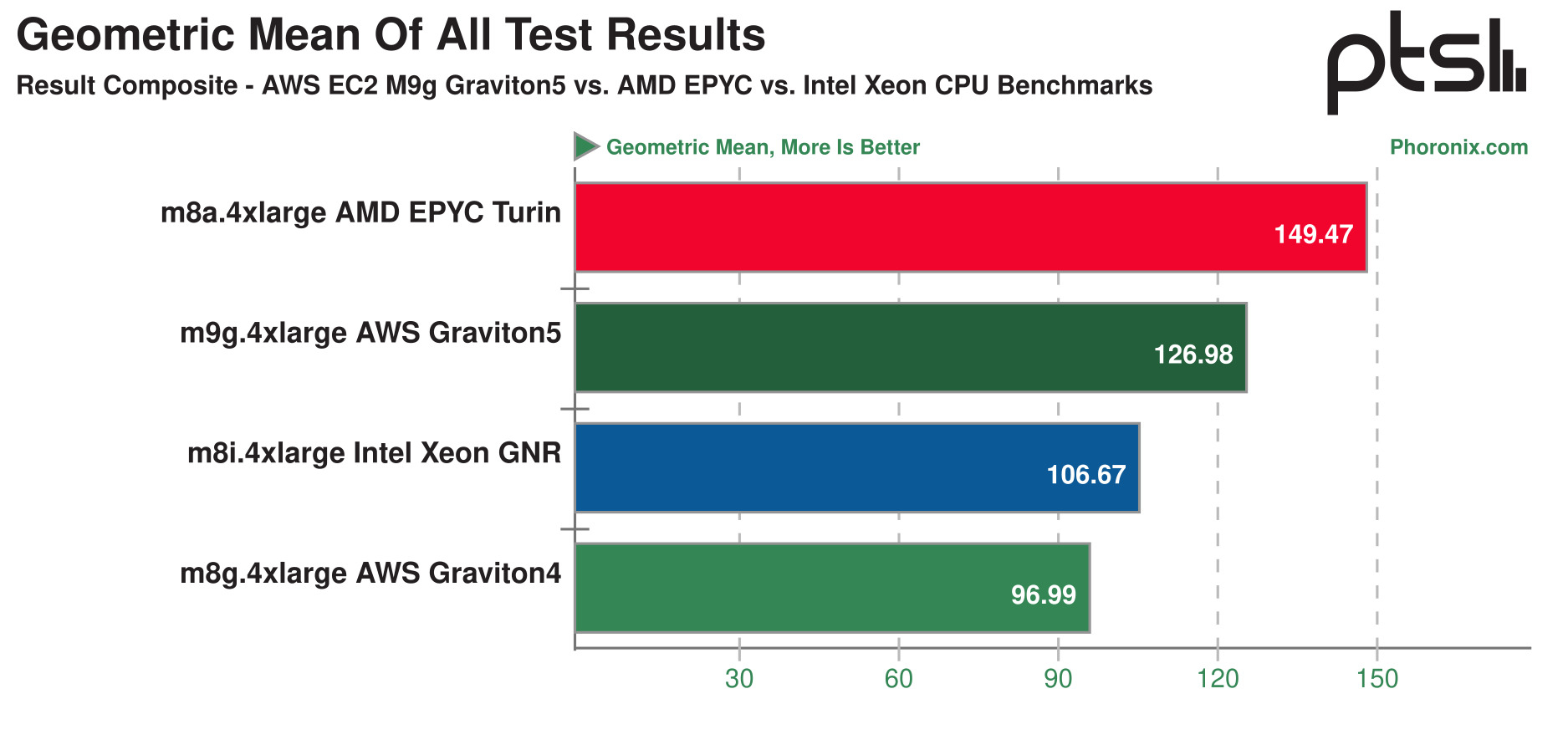
Источник изображения: phoronix.com Инстанс m8a.4xlarge на AMD EPYC Turin показал на 17 % выше производительность, чем инстанс на Graviton5 того же размера. Хотя при текущей ценовой политике по запросу инстанс m8a.4xlarge примерно на 24 % дороже в час, чем m9g.4xlarge с Graviton5, у Graviton5 всё ещё есть ценовое преимущество, поскольку это собственная разработка AWS. Однако, для некоторых рабочих нагрузок инстанс m8a.4xlarge обеспечил как лучшую производительность, так и соотношение производительности и цены, отметил Phoronix.
14.07.2026 [16:22], Руслан Авдеев
5 ГВт за $50 млрд: Meta✴ «удвоит» флагманский ИИ ЦОД HyperionКомпания Meta✴ планирует более чем удвоить мощность кампуса ЦОД в Ричленде (Richland Parish, Луизиана), доведя её 5 ГВт. Речь идёт об ИИ ЦОД Hyperion, мощность которого изначально должна была составить 2 ГВт, сообщает Datacenter Dynamics. Meta✴ анонсировала кампус Hyperion площадью 372 тыс. м2 в Ричленде в конце 2024 года. Изначально он должен был располагаться на территории площадью 910 га. В конце 2025 года компания докупила соседний участок площадью около 566 га. Изначально Hyperion должен был включать девять зданий с поэтапным вводом в эксплуатацию до 2030 года. Ранее глава Meta✴ допускал, что проект может быть расширен до 5 ГВт, а президент США уже говорил о росте стоимости кампуса до $50 млрд. По последним данным, Meta✴ намерена инвестировать в объекты в Ричленде $50 млрд, также компания обязалась потратить $1 млрд на совершенствование местной инфраструктуры, включая дороги, водные ресурсы и системы водоотведения. По словам представителя Луизианы, всего за два года штат получил обязательства по новым инвестиций на $150 млрд, создав среду, в которой компании могут реализовать масштабные проекты. 
Источник изображения: iSawRed/unsplash.com Meta✴ сообщает, что более $1,6 млрд уже законтрактовано с местными компаниями в качестве исполнителей, поддерживаются тысячи рабочих мест, помимо создания собственно ИИ-инфраструктуры, территория получает и дополнительные экономические выгоды. По данным компании, когда кампус заработает, на его обслуживание потребуется привлечь около 1 тыс. местных жителей. Также компания взаимодействует с энергетической компанией Entergy и вложит средства в семь работающих от природного газа электростанций, три аккумуляторных хранилища «сетевого» уровня, проекты увеличения мощностей АЭС, а также закупку дополнительных объёмов энергии в Луизиане. Утверждается, что благодаря этому местные потребители смогут сэкономить $2 млрд в последующие 20 лет. В целом Meta✴ имеет большие амбиции, касающиеся строительства дата-центров. В январе она создала подразделение Meta✴ Compute для строительства «сотен гигаватт» мощностей до конца текущего десятилетия и сотен гигаватт — в будущем. На днях сообщалось, что компания намерена построить кампус ЦОД за $9,17 млрд в Альберте (Канада), 33-й по счёту в её портфолио. Кроме того, компания допускает создание собственного облачного бизнеса. |
|

