Материалы по тегу: ии
|
28.01.2025 [00:14], Владимир Мироненко
Дороговизна и высокое энергопотребление ИИ-ускорителей NVIDIA открыли новые горизонты для Marvell и BroadcomВзрывной рост популярности ChatGPT и других решений на базе генеративного ИИ вызвал беспрецедентный спрос на вычислительные мощности, что привело к дефициту ИИ-ускорителей, пишет DIGITIMES. NVIDIA занимает львиную долю рынка ИИ-чипов, а ведущие поставщики облачных услуг, такие как Google, Amazon и Microsoft, активно занимаются проектами по разработке собственных ускорителей, стремясь снизить свою зависимость от внешних поставок. Всё большей популярностью у крупных облачных провайдеров пользуются ASIC, поскольку они стремятся оптимизировать чипы под свои конкретные требования, отметил DIGITIMES. ASIC обеспечивают высокую производительность и энергоэффективность в узком спектре задач, что делает их альтернативой универсальным ускорителям NVIDIA. Несмотря на доминирование NVIDIA на рынке, высокое энергопотребление её чипов в сочетании с высокой стоимостью позволило ASIC занять конкурентоспособную нишу. Особенно хорошо ASIC подходят для обучения и инференса ИИ-моделей, предлагая значительно более высокие показатели производительности в пересчёте на 1 Вт по сравнению с GPU общего назначения. Также ASIC предоставляют заказчикам больший контроль над своим технологическим стеком. На рынке разработки ASIC основными конкурентами являются Broadcom и Marvell, которые используют разные технологии и стратегические подходы. 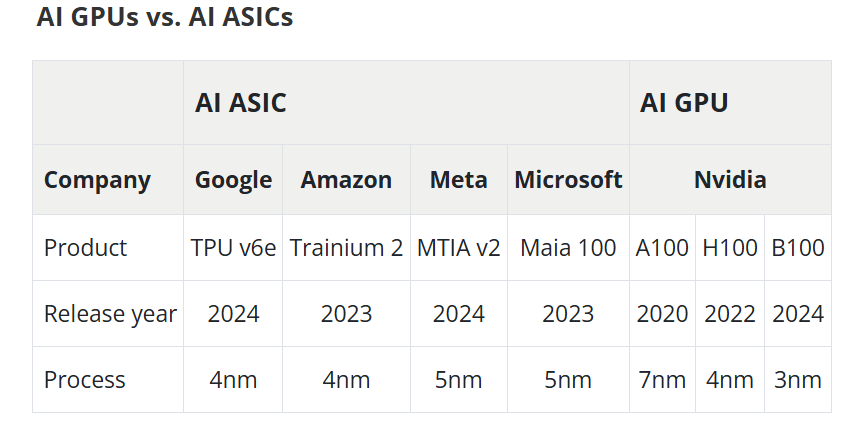
Источник изображений: DIGITIMES Marvell укрепила свои позиции на рынке, в частности, благодаря партнёрству с Google в разработке серверных Arm-чипов, расширив при этом стратегическое сотрудничество со своим основным клиентом — Amazon. TPU v6e от Google представляет собой самую передовую ASIC ИИ среди чипов, разработанных четырьмя ведущими облачными провайдерам, приближаясь по производительности к H100. Однако она всё ещё отстает от ускорителей NVIDIA примерно на два года, утверждает DIGITIMES. Созданный Marvell и Amazon ускоритель Trainium 2 по производительности находится между NVIDIA A100 и H100. В ходе последнего отчёта о финансовых результатах Marvell поделилась прогнозом значительного роста выручки от ASIC, начиная с 2024 года (2025 финансовый год), обусловленного Trainium 2 и Google Axion. В частности, совместный с Amazon проект Marvell Inferential ASIC предполагается запустить в массовое производство в 2025 году (2026 финансовый год), в то время как Microsoft Maia, как ожидается, начнет приносить доход с 2026 года (2027 финансовый год). 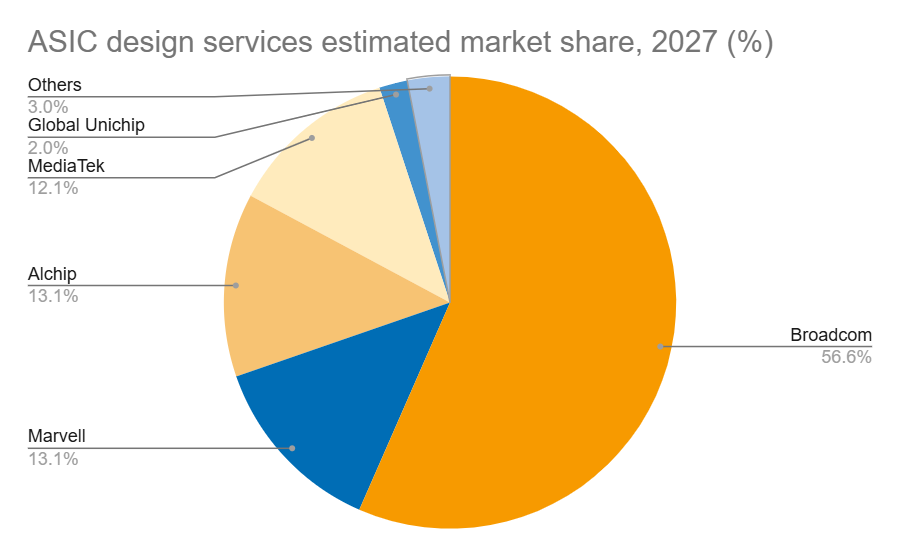 Как утверждают в Morgan Stanley, хотя бизнес Marvell по производству кастомных чипов является ключевым драйвером роста его подразделения по разработке решений для ЦОД, он также несёт в себе значительную неопределённость. Краткосрочные прогнозы Morgan Stanley для продуктов Marvell/Trainium положительны, что подтверждается возросшими мощностями TSMC по упаковке чипов методом CoWoS, планами Amazon по расширению производства и уверенностью Marvell в рыночном спросе. Однако в долгосрочной перспективе конкурентная среда создает проблемы. Появление компаний вроде WorldChip Electronics в секторе вычислительных чипов может заставить Marvell переориентироваться на сетевые решения. Кроме того, потенциальное снижение прибыли от Trainium после 2026 года означает, что Marvell нужно будет обеспечить запуск новых проектов для поддержания динамики роста, говорят аналитики. Broadcom и Marvell являют собой примеры разных стратегий развития в секторе ASIC, отмечает DIGITIMES. Broadcom отдаёт приоритет крупномасштабной интеграции и проектированию платформ, подкрепляя свой подход значительными инвестициями в НИОКР и сложной технологической интеграцией. В свою очередь, Marvell развивается за счёт стратегических приобретений, например, Cavium, Avera и Innovium, благодаря чему расширяет своё портфолио технологий.
27.01.2025 [22:17], Руслан Авдеев
Южная Каролина заинтересовалась достройкой «скандальной» АЭС Virgil C Summer из-за спроса на ИИ ЦОДГосударственная коммунальная компания Santee Cooper, отвечающая в Южной Каролине (США) за электро- и водоснабжение проявила официальный интерес к разморозке строительства двух частично возведённых энергоблоков атомной электростанции Virgil C Summer в Южной Каролине в связи с ростом спроса на ИИ ЦОД и безуглеродную энергетику, сообщает Datacenter Dynamics При этом в пресс-релизе указывается, что компания не намерена напрямую владеть новыми объектами или управлять ими. С учётом длительных сроков ввода в эксплуатацию новых энергоблоков у Santee Cooper появилась уникальная возможность достаточно быстрого запуска для энергоблоков Unit 2 и 3, которые смогут обеспечить 2,2 ГВт. Поскольку АЭС VC Summer уже имеет сертификаты безопасности, а также достаточно земли, воды и инфраструктуры для передачи энергии, сроки ввода в эксплуатацию существенно сокращаются. Сейчас единственный действующий энергоблок (973 МВт), запущенный в 1984 году, обеспечивает электричеством клиентов компаний Santee Cooper и Dominion Energy. Расширение площадки началось в 2008 году, тогда South Carolina Electric & Gas (позже сменившая имя на Santee Cooper), подала заявку на строительство двух новых 1,1-ГВт реакторов Westinghouse AP1000 на той же площадке. Годом позже с Westinghouse был подписан контракт на проектирование, закупки и строительство реакторов. Стоимость строительства оценивалась в $9,8 млрд. 
Источник изображения: DJSlawSlaw / Wikipedia Новые блоки начали строить в 2013 году, однако к 2017 году оценочная стоимость проекта выросла до $25 млрд, в том числе из-за ошибок при производстве оборудования, а в 2017 года Westinghouse подала заявление о банкротстве. В июле того же года принято решение отказаться от дальнейшей реализации проекта. Ситуация привела к крупному политическому скандалу. Рост спроса на электричество со стороны ЦОД привёл к возвращению интереса к ядерной энергетике, поскольку та считается надёжным и низкоуглеродным источником энергии. Так, AWS почти год назад приобрела кампус ЦОД, расположенный в непосредственной близости от 2,5-ГВт АЭС Susquehanna Steam Electric Station в Пенсильвании. В ноябре 2024 года Федеральная комиссия по регулированию энергетики США (FERC) отклонила наращивание поставок электроэнергии кампусу, но Amazon сдаваться не собирается. В сентябре 2024 года Microsoft подписала соглашение сроком на 20 лет о закупке энергии у восстановленной АЭС Three-Mile Island. Владеющая мощностями Constellation Energy рассчитывает запустить объект на 837 МВт, закрытый в 2019 году из-за высоких капитальных затрат, в 2028 году. В декабре Meta✴ заявила, что не прочь получить в США до 4 ГВт от АЭС. Наконец, с идеей восстановления реакторов ради ЦОД выступили и некоторые другие операторы страны. Например, в октябре NextEra объявила, что допускает возможность перезапуска АЭС Duane Arnold (Айова).
27.01.2025 [18:43], Руслан Авдеев
Индийская Reliance заявила, что построит «крупнейший ЦОД в мире» мощностью 3 ГВтИндийская Reliance Industries намерена построить «крупнейший в мире» дата-центр в городе Джамнагар (штат Гуджарат, Индия). Планы реализации проекта в штате впервые обнародовали в сентябре 2024 года, теперь ожидается, что Reliance закупит для него ускорители NVIDIA, сообщает Datacenter Dynamics. Ранее компании объявили о совместной разработке ИИ-суперкомпьютеров в Индии и создании больших языковых моделей (LLM) на разных языках страны. В планы входит совместная постройка ИИ-инфраструктуры на территории всей страны. Для запланированного ЦОД гигаваттного уровня NVIDIA готова была поставлять чипы семейства Blackwell. Правда, пока непонятно, как план будет реализован на фоне введённых США ограничений. Индийскую инициативу поддержал глава NVIDIA Дженсен Хуанг (Jensen Huang), заявивший, что стране не стоит «экспортировать муку, чтобы импортировать хлеб». Другими словами, нужно создавать собственные ИИ-мощности. Параллельно NVIDIA сотрудничает с другим индийским гигантом — Tata Group. Недавно пообещало поддержать развитие ИИ в стране и правительство Индии, выделив около ₹100 млрд ($1,16 млрд) на ИИ-стартапы и проекты. 
Источник изображения: Olha Kolesnyk/Unsplash.com Впрочем, это далеко не единственный крупный проект в Индиии. В штате Телингана планируется создать несколько ЦОД в Хайдарабаде. Так, Blackstone намерена построить объект на 150 МВт за ₹45 млрд ($521 млн), Ursa Clusters — на 100 МВт за ₹50 млрд ($580 млн), а Tillman Global Holdings — на 300 МВт за ₹150 млрд рупий ($1,7 млрд) в Хайдарабаде. При полной загрузке он обеспечит мощность в 300 МВт. Власти Телинганы заявляют, что инвестиции компании сами по себе свидетельствуют о дружественной политике штата по отношению к бизнесу. В Мумбаи свой многомиллиардный вклад сделает и AWS. Хайдарабад с недавних пор превращается в хаб для ЦОД с присутствием таких компаний, как Iron Mountain, AdaniConneX, Nxtra, Microsoft и Tata Communications. AWS также располагает в Хайдарабаде облачным регионом, в прошлом году она даже объявила о планах по расширению ЦОД в городе. Наконец, в январе 2025 года STT GDC и CtrlS представили планы создания кампусов ЦОД в Хайдарабаде. Хотя Reliance и утверждает, что её ЦОД будет крупнейшим в мире, в это трудно поверить. Так, в США проект Stargate стоимостью до $500 млрд намерен построить не один гигаваттный дата-центр. Китай готов выделить на развитие ИИ в стране $138 млрд. Впрочем, даже одиночные компании инвестируют в дата-центры немалые суммы. Так, Meta✴ в этом году выделит до $65 млрд на развитие ИИ-инфраструктуры и уже начала строительство первого 2-ГВт кампуса, а Microsoft и вовсе готова потратить на ИИ ЦОД $80 млрд.
27.01.2025 [15:35], Руслан Авдеев
До 2030 года AWS вложит $8,3 млрд в облачную инфраструктуру в МумбаиAmazon Web Services (AWS) намерена инвестировать $8,3 млрд в развитие облачной инфраструктуры в регионе AWS Asia Pacific (Мумбаи), расположенном в индийском штате Махараштра (Maharashtra). По оценкам Amazon, её инвестиции приведут к увеличению ВВП страны на $15,3 млрд к 2030 году. Ещё в 2024 году появилась информация, что AWS купила участок площадью около 15,5 га в Палаве недалеко от Мумбаи. Впервые AWS вышла на рынок Индии в 2016 году, запустив регион Мумбаи. По 2022 год было инвестировано $3,7 млрд, а позднее в 2022 году AWS запустила и облачный регион в Хайдарабаде (Hyderabad). Кроме того, с 2017 года компания обучила 5,9 млн человек навыкам работы с облаками. Новые инвестиции в облачный регион Мумбаи в объёме $8,3 млрд являются частью более масштабного плана. Всего AWS рассчитывает потратить в Индии $12,7 млрд, об этом сообщалось ещё в мае 2023 года. 
Источник изображения: Amazon Также планируется открытие локальных зон в Ченнаи, Бангалоре, Дели и Калькутте. Как сообщает ряд изданий, в ходе Всемирного экономического форума в Давосе AWS обещала потратить $6,95 млрд на регион в Хайдарабаде в штате Телингана (Telangana). В 2024 году сообщалось о готовности вложить в штат $2 млрд. В начале 2025 года Microsoft заявила, что инвестирует $3 млрд в ИИ и облачные вычисления в Индии.
27.01.2025 [15:01], Сергей Карасёв
Китайский ответ Stargate: КНР вложит в развитие ИИ 1 трлн юанейВласти Китая, по сообщениям сетевых источников, разработали программу AI Industry Development Action Plan, направленную на комплексное развитие инфраструктуры и сервисов ИИ в стране. На эти цели в течение следующих пяти лет планируется направить не менее ¥1 трлн, или около $138 млрд. Отмечается, что инициатива AI Industry Development Action Plan является ответом КНР на масштабный проект Stargate по развитию ИИ в США. В случае Stargate речь идёт о создании совместного предприятия OpenAI, Softbank и Oracle, которое займётся развитием «физической и виртуальной инфраструктуры для поддержки следующего поколения ИИ». В проекте примут участие Microsoft, Arm и Nvidia, а также фонд MGX с Ближнего Востока. Общий объём вложений, как ожидается, достигнет $500 млрд. Программу AI Industry Development Action Plan, как сообщается, будет поддерживать Банк Китая (Bank of China). План включает четыре основных направления. Первое — укрепление национальной технологической независимости: это особенно важно в условиях усиливающихся санкций со стороны США. Банк Китая будет оказывать всестороннюю поддержку предприятиям, занимающимся инновационными технологиями, включая ИИ. 
Источник изображения: unsplash.com / Dominic Kurniawan Suryaputra Вторым направлением является развитие ИИ-инфраструктуры, включая наращивание вычислительных мощностей, строительство новых дата-центров и вспомогательных объектов. Третьей стратегической задачей названо ускорение инноваций в области ИИ, что предусматривает разработку специализированных приложений. Четвёртое направление — продвижение использования ИИ в различных сценариях, в том числе в области робототехники, передовых материалов, биопроизводства и пр. Конечной целью инициативы AI Industry Development Action Plan названо создание финансовой экосистемы, ориентированной на ИИ, для ускорения инноваций, обеспечения промышленного развития и устойчивой разработки. Стоит отметить, что китайский ИИ-стартап DeepSeek на днях устроил переполох в Кремниевой долине: компания выпустила «рассуждающую» модель ИИ R1 и сделала её полностью бесплатной для использования всеми желающими. Более того, DeepSeek опубликовала инструкции, как с минимальными затратами построить модель, способную самостоятельно обучаться и совершенствоваться без контроля со стороны человека. Это бросило вызов многим западным конкурентам, включая OpenAI.
26.01.2025 [13:05], Сергей Карасёв
В Великобритании появится крупнейший в Европе дата-центр, который построят для неназванного гиперскейлераСовет округа Хертсмер, по сообщению The Register, одобрил строительство мегацентра обработки данных в Хартфордшире (Великобритания). Ожидается, что объекты будут введены в эксплуатацию ориентировочно к 2030 году. Речь идёт о проекте компании DC01 UK Ltd., информация о котором появилась в сентябре 2024 года. Общая площадь сооружений дата-центра составит примерно 186 тыс. м2, площадь территории кампуса — около 34 га. Участок земли находится недалеко от трассы M25 и автодороги A1 и примыкает к автомагистрали South Mimms. Предполагается, что будущая площадка станет самым крупным в Европе дата-центром для ИИ и облачных сервисов. Земельный участок для ЦОД имеет близость к национальным и международным оптоволоконным маршрутам. Предусмотрена резервная мощность в 400 МВА от Национальной энергосистемы. На этапе строительства будут обеспечены как минимум 500 рабочих мест, а после ввода в эксплуатацию появятся 200 постоянных рабочих мест. 
Источник изображения: DC01 UK Утверждается, что проект не только удовлетворит национальную потребность в мощностях дата-центров, но и будет способствовать развитию местной инфраструктуры. В частности, финансовые взносы пойдут на улучшение автобусного сообщения и велосипедных дорожек. Тепло, генерируемой оборудованием ЦОД, будет использоваться для отопления новых домов и предприятий. Реализация проекта оценивается в £3,75 млрд ($4,9 млрд). При этом DC01 UK не будет заниматься строительством или эксплуатацией зданий: роль компании заключается в получении прав на планирование и подготовке к возведению объектов. Конечным пользователем ЦОД выступит некий «известный гиперскейлер», имя которого не раскрывается. The Register обратился с вопросами к AWS, Google, Microsoft и Meta✴, но эти компании от комментариев отказались. «С момента анонса проекта в сентябре прошлого года мы получили широкий отклик от участников рынка. На данный момент ведутся активные переговоры, которые будут завершены в ближайшем будущем. Мы сделаем дополнительное объявление в надлежащее время», — сообщил представитель DC01 UK. Нужно отметить, что многие компании изъявляют желание развивать дата-центры на территории Великобритании. В частности, Cloud HQ, CyrusOne, CoreWeave и ServiceNow намерены инвестировать £6,3 млрд ($8,22 млрд) в британскую инфраструктуру ЦОД. Американская инвестиционная компания Blackstone собирается вложить до £10 млрд ($13,4 млрд) в масштабный ИИ ЦОД в этой стране. AWS готова потратить £8 млрд ($10,45 млрд) на расширение облачного бизнеса в Великобритании. Вместе с тем власти самой страны отнесли дата-центры к элементам критически важной национальной инфраструктуры (CNI).
25.01.2025 [23:05], Владимир Мироненко
Microsoft ищет директора по ЛЭП и энергетиковMicrosoft приступила к созданию команды, которая займётся вопросами совершенствования энергетической инфраструктуры с целью обеспечения питанием растущего количества ЦОД в условиях усиливающихся ограничений поставок электричества, пишет DataCenter Dynamics. Microsoft опубликовала вакансию директора по технологиям электропередачи в Северной Америки, а также старшего менеджера программы по глобальным технологиям энергопередачи в странах Азиатско-Тихоокеанского региона (APAC), Европы, Ближнего Востока и Африки (EMEA). Обе должности относятся к офису технического директора подразделения Microsoft по облачным операциям и инновациям (CO+I) в США. Новые сотрудники должны заняться «разработкой технологического плана внедрения новых технологий для глобальных рынков», определять готовность технологий к внедрению и определять стратегию развития компании в этой области. Претендент на первую вакансию должен «обладать знаниями в области разработки стратегий передачи энергии для рынка Соединённых Штатов в соответствии с бизнес-целями Microsoft». Его задача — совместно с партнёрами разработать инновационные решения для обеспечения достаточными энергетическими мощностями растущий парк дата-центров Microsoft. В свою очередь, старший менеджер должен будет «разрабатывать инновационные решения для поддержки энергетической инфраструктуры, а также оказывать поддержку в разработке стратегии внедрения новых технологий». 
Источник изображения: American Public Power Association/unsplash.com Компания также разместила вакансию менеджера по программам в области энергетических технологий. На него будет возложена задача «поддержки технической оценки передовых энергетических и инфраструктурных технологий для обеспечения ЦОД, в которых облака Microsoft». В вакансии указано, что менеджер также «будет нести ответственность за поддержку команды, отвечающей за исследования и разработку различных энергетических технологий на докоммерческих этапах». Все три должности новые — ранее таких в штатном расписании не было. Специалисты будут работать в сотрудничестве с Эрин Хендерсон (Erin Henderson), директором по ускорению развития ядерной энергетики, принятой на работу в прошлом году, и П. Тоддом Ноэ (P. Todd Noe), директором по инновациям в ядерной и энергетической сферах. Хендерсон и Ноэ сыграли важную роль в заключении сделки Microsoft с Constellation по возрождению 837-МВт АЭС Three Mile Island, которая запитает ЦОД компании. Microsoft также намерена задействовать термоядерные реакторы Helion, но пока не объявила о каких-либо крупных сделках по малым модульным реакторам (SMR). По оценкам Министерства энергетики США, к 2028 году на дата-центры может прийтись уже 12 % энергопотребления всей страны. Эта оценка была сделана до анонса проекта Stargate стоимостью $500 млрд, который окажет значительное давление на энергетическую структуру США. Microsoft планирует инвестировать в этом году $80 млрд в ИИ ЦОД. В прошлом году компания в партнёрстве с Brookfield вложила $10 млрд в строительство в 2026–2030 гг. крупных ветряных и солнечных электростанций суммарной мощностью до 10,5 ГВт в США и Европе.
25.01.2025 [00:59], Владимир Мироненко
Meta✴ выделит $60–65 млрд на развитие ИИ в 2025 годуMeta✴ Platforms планирует в 2025 году выделить на капитальные затраты $60–65 млрд. Эти средства будут направлены в основном на строительство ЦОД и серверы, а также на «значительное» расширение команды ИИ-специиалистов. Об этом сообщил гендиректор Meta✴ Марк Цукерберг (Mark Zuckerberg) в своём аккаунте в соцсети Facebook✴. С учётом того, что в прошлом году капиталовложения Meta✴ составили от $35 до $40 млрд, это представляет собой значительный рост расходов, отметил DataCenter Dynamics. Для сравнения, Microsoft заявила, что потратит в этом году $80 млрд на ИИ ЦОД. В своём сообщении Цукерберг подтвердил планы Meta✴ инвестировать $10 млрд в строительство гигантского ЦОД в Луизиане. Meta✴ сообщила, что специально спроектированный кампус площадью 1,2 млн м2 станет крупнейшим дата-центром компании. «Meta✴ строит ЦОД мощностью более 2 ГВт, который будет настолько большим, что покроет значительную часть Манхэттена», — сказал Цукерберг. На строительной площадке уже начались подготовительные работы, а строительство кампуса будет продолжаться до 2030 года. 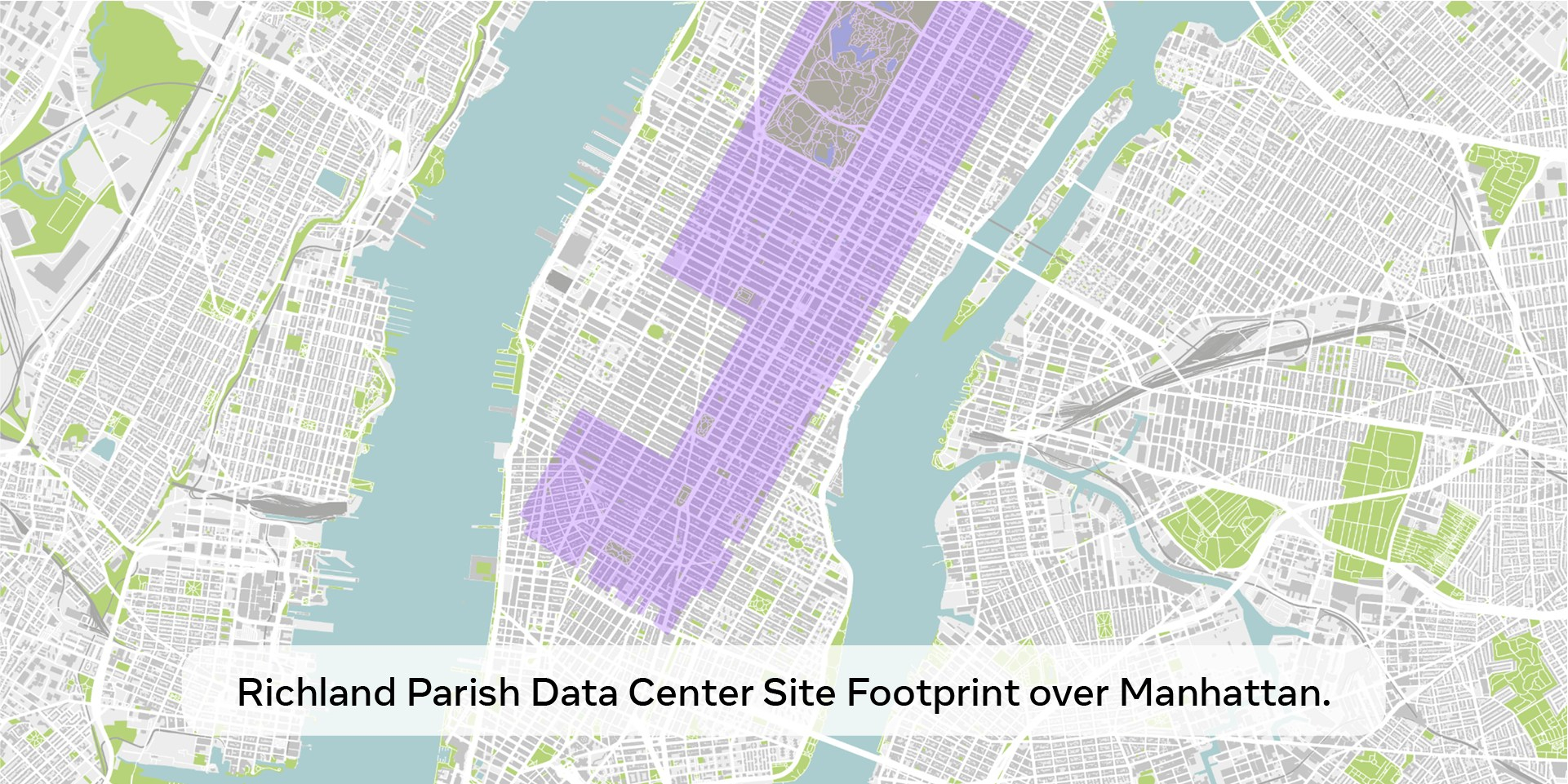
Источник изображения: Mark Zuckerberg/Facebook✴ Цукерберг отметил, что этот год будет определяющим для ИИ. Meta✴ планирует ввести в 2025 году в эксплуатацию около 1 ГВт мощностей и иметь к концу года парк из более чем 1,3 млн ускорителей. Он также добавил, что у компании есть «капитал для продолжения инвестиций в ближайшие годы», что может быть отсылкой к критике Илоном Маском (Elon Musk) проекта Stargate, усомнившегося в том, что на его реализацию у SoftBank, OpenAI и остальных найдётся заявленная сумма в $500 млрд. Масштаб и сравнения, которые использовал Цукерберг, могут иметь более глубокий смысл: согласно документации, с которыми ознакомился Bloomberg, первый кампус Stargate будет размером с Центральный парк в Нью-Йорке, который сам по себе является всего лишь частью Манхэттена.
24.01.2025 [23:38], Владимир Мироненко
Платформа GenAI от DigitalOcean упростит создание ИИ-агентовОблачный провайдер DigitalOcean представил платформу GenAI, которая позволяет использовать базовые модели от сторонних поставщиков для создания и развёртывания агентов ИИ за считанные минуты без необходимости глубоких знаний в области ИИ или машинного обучения. Как сообщает DigitalOcean, интуитивно понятная работа в GenAI позволяет клиентам вне зависимости от уровня подготовки настраивать агентов с доступом к надёжным конвейерам данных и многоагентным командам. DigitalOcean GenAI позволяет компаниям создавать чат-боты на основе базовых моделей сторонних поставщиков (Anthropic, Meta✴, Mistral и др.) для анализа документов, семантического поиска, создания изображений и т.д. Платформа создана так, чтобы быть независимой от фреймворков. Платформа упрощает и создание агентов, специфичных для конкретных вариантов использования, привнося контекстные данные в базовые LLM. Клиенты смогут не только извлекать неструктурированные данные из файлов, но и структурированные данные из баз данных или обращаясь к API, чтобы дополнять подсказки и задействовать Retrieval Augmented Generation (RAG), обеспечивая агентам доступ к точной и актуальной информации. С помощью вызываемых функций можно дописать кастомный код, чтобы расширить возможности своего агента. 
Источник изображения: DigitalOcean Встроенные ограничители (guardrails) позволяют повысить достоверность ответов агента, помогая отфильтровывать неправильные или ненадлежащие результаты. А возможность частных подключений и наличие готового интерфейса для чат-ботов упрощают запуск этих агентов на веб-сайте клиента. В будущем появится возможность обращаться к источникам данным по URL, поддержка конвейеров AgentOps и CI/CD, тонкая настройка моделей и многое другое.
24.01.2025 [15:23], Руслан Авдеев
Microsoft и OpenAI останутся партнёрами до 2030 годаКомпания Microsoft объявила о новом этапе сотрудничества с OpenAI. В числе прочего пресс-служба IT-гиганта упомянула о взаимодействии в рамках проекта Stargate. По данным Microsoft, партнёрство, развивавшееся с 2019 года, перешло в новую фазу. Не исключено, что публичное заявление компании — ответ на волну слухов, появившихся после изменения политики использования OpenAI облачных ресурсов. Многие буквально уверены, что Редмонд теряет хватку и упускает OpenAI из сферы своего влияния. Возможно, поэтому компания сама спешит сообщить, что если раньше партнёрское соглашение об использовании облаков было эксклюзивным и OpenAI могла пользоваться только ресурсами Microsoft (в одном случае Oracle с оговорками), то теперь она сможет прибегать к помощи сторонних облачных провайдеров чаще. У Microsoft сохранится право «первого отказа» и сначала OpenAI по-прежнему должна обращаться за облачными ресурсами именно к ней, и лишь в случае их недоступности — к другим провайдерам. При этом Microsoft подчёркивает, что OpenAI недавно вновь обязалась использовать Azure в ещё больших масштабах для поддержки своих продуктов и обучения моделей. Также компания напоминает, что ключевые элементы партнёрского соглашения не изменятся до окончания договора в 2030 году. Гиперскейлер сохранит доступ к интеллектуальной собственности OpenAI, предполагается обмен выручкой в соответствии с существующими договорённостями и сохранятся эксклюзивные права Microsoft на API ИИ-стартапа. 
Источник изображения: Microsoft В частности, Microsoft сохраняет право использовать интеллектуальную собственность OpenAI, включая ИИ-модели, в продуктах вроде Copilot. API OpenAI будут эксклюзивно использоваться в облаке Azure и доступны посредством Azure OpenAI Service. Соглашение означает, что клиенты будут получать доступ к самым передовым моделям на платформе Microsoft напрямую от OpenAI. А выручкой компании будут обмениваться в двухстороннем порядке, это будет на руку обеим благодаря росту использования новых и уже существующих моделей. Наконец, Microsoft подчеркнула, что остаётся главным инвестором OpenAI, обеспечивая компанию средствами и облачными ресурсами для поддержки развития — одной из ключевых выгод самой Microsoft является поступательный рост стоимости ИИ-стартапа. Сейчас OpenAI участвует в многомиллиардном американском ИИ-проекте Stargate совместно с Oracle и SoftBank (помимо Microsoft), поэтому дополнительные ресурсы ей, безусловно, понадобятся. |
|

