Материалы по тегу: s
|
29.11.2023 [01:21], Руслан Авдеев
Cerebras, критиковавшая NVIDIA за сотрудничество с Китаем, сама оказалась связана с компанией, ведущей дела с ПекиномХотя стартап Cerebras, занимающийся разработкой чипов, раскритиковал NVIDIA за попытки обойти санкционные ограничения в отношении Китая и призвал соблюдать не букву, но дух американского закона, у компании, похоже, нашлись свои скелеты в шкафу. Как сообщает The Register, сейчас в США расследуют деятельность клиента Cerebras — группы G42, возможно, помогавшей Поднебесной обходить санкционные ограничения. Американские спецслужбы подозревают, что базирующаяся в ОАЭ многопрофильная компания G42 поставляет в Китай передовые технологии. Для своих ИИ-исследований компания обратилась к Cerebras с целью постройки суперкомпьютерного кластера Condor Galaxy за $100 млн, а всего стартап намерен построить девять подобных объектов на $900 млн. При этом узлы кластера используют разработанные Cerebras чипы WSE-2, подходящие для обучения ИИ-систем. 
Источник изображения: Arthur Wang/unsplash.com Как показывают предварительные результаты расследования американских журналистов, властей и спецслужб, G42 пытается сотрудничать с Пекином и работает с китайскими компаниями вроде Huawei, давно находящимися под санкциями. В самой G42 утверждают, что принимают все меры для того, чтобы соблюдать американские ограничения. При этом, по данным журналистов, G42 считают прокси-компанией для работы в интересах КНР, помогающей Пекину получать вычислительные ресурсы и подсанкционные технологии. По словам главы Cerebras Эндрю Фельдмана (Andrew Feldman), его компания точно не будет вести бизнес с Китаем. Бизнесмен попал в неловкую ситуацию после того, как появилась информация о тесных связях G42 с Пекином. На запрос журналистов в Cerebras заявили, что кластеры Condor Galaxy находятся в США, а G42 получает к ним облачный доступ, так что любая активность контролируется и соответствует американским законам — государства-противники не имеют прямого доступа к ИИ-системам. Фельдман якобы не знал о сомнительном статусе G42, а в стартапе подчеркнули, что не комментируют слухи. Бюро промышленности и безопасности США уже обратилось к поставщикам облачных инфраструктур для консультаций о целесообразности дополнительных ограничений доступа к их услугам из некоторых стран. В частности, бюро интересует, как операторы намерены выявлять разработчиков ИИ-моделей, вызывающих обеспокоеность властей и что можно предпринять для устранения угроз. Кроме того, президент США предложил новые правила, согласно которым облакам потребуется докладывать о деятельности иностранцев, связанной с обучением больших языковых моделей (LLM).
28.11.2023 [22:20], Игорь Осколков
NVIDIA анонсировала суперускоритель GH200 NVL32 и очередной самый мощный в мире ИИ-суперкомпьютер Project CeibaAWS и NVIDIA анонсировали сразу несколько новых совместно разработанных решений для генеративного ИИ. Основным анонсом формально является появление ИИ-облака DGX Cloud в инфраструктуре AWS, вот только облако это отличается от немногочисленных представленных ранее платформ DGX Cloud тем, что оно первом получило гибридные суперчипах GH200 (Grace Hoppper), причём в необычной конфигурации. 
Изображения: NVIDIA В основе AWS DGX Cloud лежит платформа GH200 NVL32, но это уже не какой-нибудь сдвоенный акселератор вроде H100 NVL, а целая, готовая к развёртыванию стойка, включающая сразу 32 ускорителя GH200, провязанных 900-Гбайт/с интерконнектом NVLink. В состав такого суперускорителя входят 9 коммутаторов NVSwitch и 16 двухчиповых узлов с жидкостным охлаждением. По словам NVIDIA, GH200 NVL32 идеально подходит как для обучения, так и для инференса действительно больших LLM с 1 трлн параметров.  Простым перемножением количества GH200 на характеристики каждого ускорителя получаются впечатляющие показатели: 128 Пфлопс (FP8), 20 Тбайт оперативной памяти, из которых 4,5 Тбайт приходится на HBM3e с суммарной ПСП 157 Тбайтс, и агрегированная скорость NVLink 57,6 Тбайт/с. И всё это с составе одного EC2-инстанса! Да, новая платформа использует фирменные DPU AWS Nitro и EFA-подключение (400 Гбит/с на каждый GH200). Новые инстансы, пока что безымянные, можно объединять в кластеры EC2 UltraClasters.  Одним из таких кластеров станет Project Ceiba, очередной самый мощный в мире ИИ-суперкомпьютер с FP8-производительность 65 Эфлопс, объединяющий сразу 16 384 ускорителя GH200 и имеющий 9,1 Пбайт памяти, а также агрегированную пропускную способность интерконнекта на уровне 410 Тбайт/с (28,8 Тбайт/с NVLink). Он и станет частью облака AWS DGX Cloud, которое будет доступно в начале 2024 года. В скором времени появятся и EC2-инстансы попроще: P5e с NVIDIA H200, G6e с L40S и G6 с L4. 
09.11.2023 [03:15], Алексей Степин
RISC-V с приправой: модульные 192-ядерные серверные процессоры Ventana Veyron V2 можно дополнить ускорителямиВ 2022 года компания Ventana Micro Systems анонсировала первые по-настоящему серверные RISC-V процессоры Veyron V1. Анонс чипов, обещающих потягаться на равных с лучшими x86-процессорами с архитектурой x86, прозвучал громко. Популярности, впрочем, Veyron V1 не снискал, но на днях компания анонсировала второе поколение чипов Veyron V2, более полно воплотившее в себе принципы модульного дизайна и получившее ряд усовершенствований. Как и в первом поколении, компания-разработчик продолжает придерживаться концепции «процессора-конструктора» с чиплетным дизайном. В центре 4-нм Veyron V2 по-прежнему лежит I/O-хаб на базе AMBA CHI, охватывающий контроллеры памяти и шины PCI Express, а также блоки IOMMU и AIA. К нему посредством интерфейса UCIe подключаются вычислительные чиплеты. Латентность UCIe-подключения составляет менее 7 нс. 
Источник изображений здесь и далее: Ventana Micro Systems Чиплеты эти могут быть разных видов: либо с ядрами общего назначения (по 32 ядра на чиплет), образующие собственно процессор Veyron V2, либо содержащие специфические сопроцессоры под конкретную задачу (domain-specific acceleration, DSA). Последние могуть быть представлены FPGA, ИИ-ускорителями и т.д. Более того, Ventana по желанию заказчика может оптимизировать и I/O-хаб для повышения эффективности работы ядер CPU с сопроцессорами. 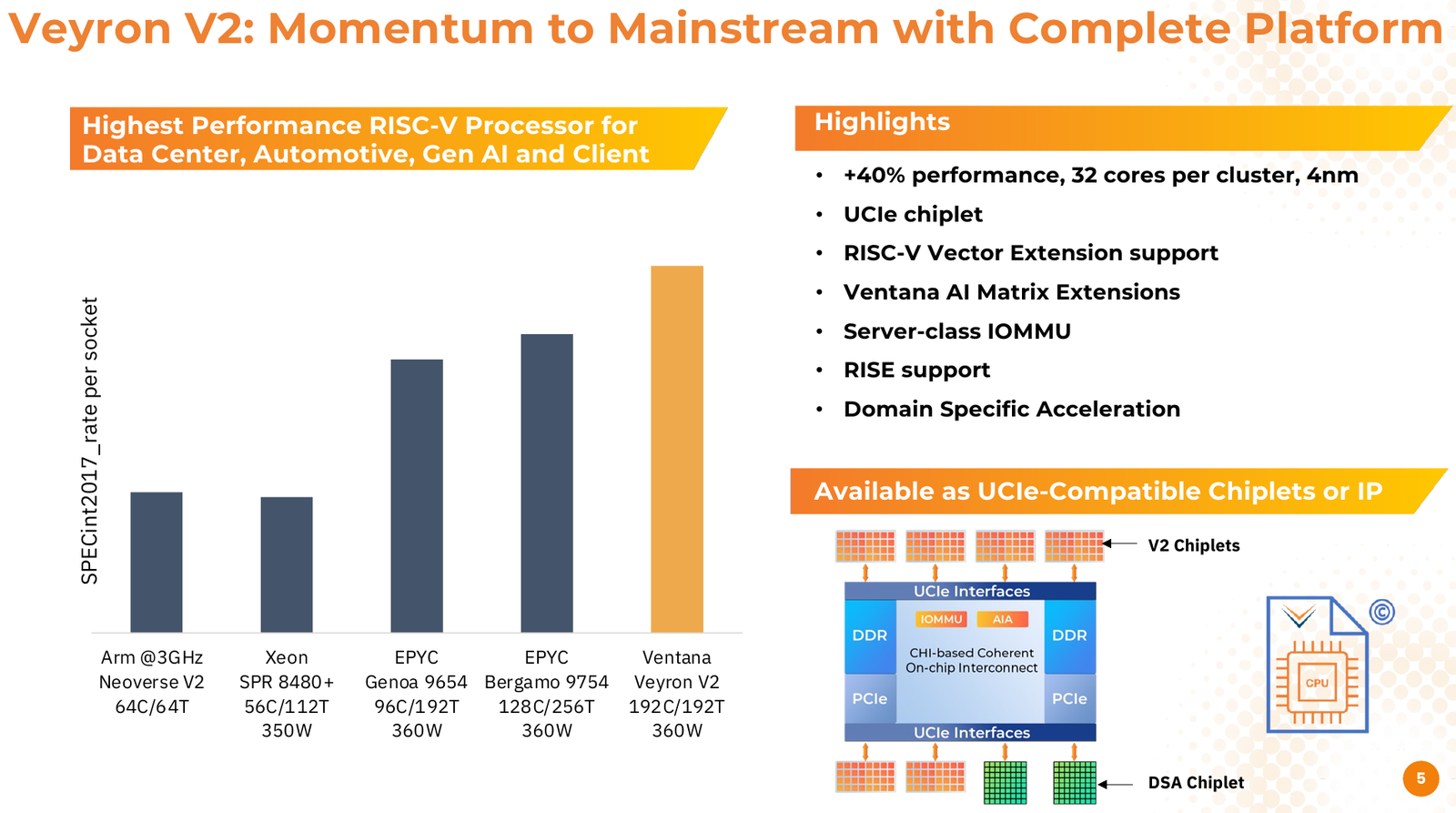 В классическом варианте Veyron V2 может иметь до шести чиплетов с RV64GC-ядрами V2, что в сумме даёт 192 ядра. Поддержка SMT отсутствует. Удельная производительность в пересчёте на ядро получается несколько ниже, чем у AMD Zen 4c, но согласно результатам тестов, предоставленных Ventana, 192-ядерный Veyron V2 заметно опережает AMD EPYC Bergamo 9754 (128C/256T) при аналогичном теплопакете в 360 Вт. 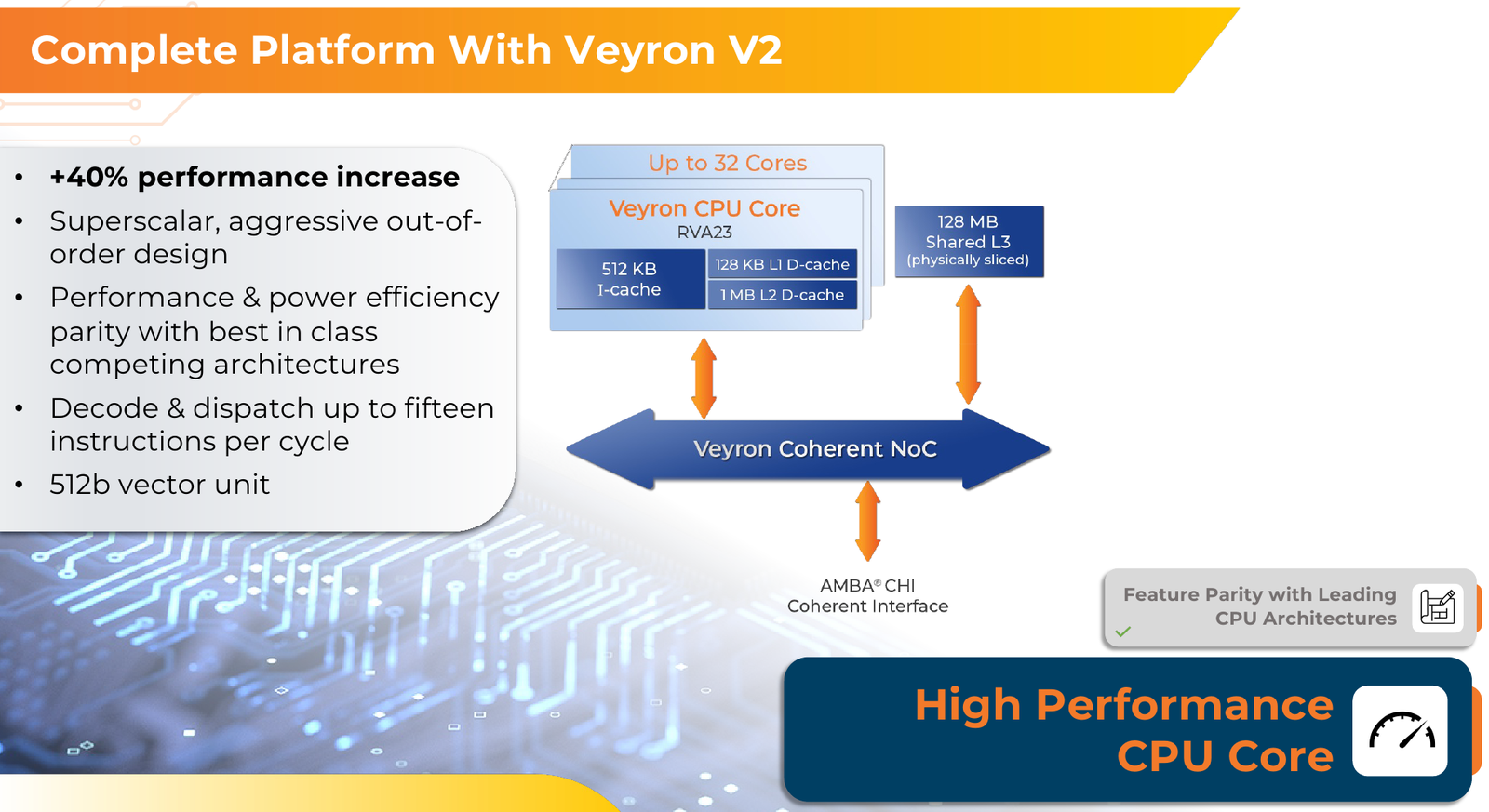 Столь неплохой результат достигнут за счёт оптимизации архитектуры Veyron: по сравнению с первым поколением говорится о 40 % прибавке производительности. Что немаловажно, во втором поколении процессоров Veyron была реализована поддержка 512-бит векторных расширений, фирменных матричных расширений, а также целого ряда других спецификаций. В целом ради совместимости разработчики предпочли остаться в рамках общего профиля RVA23. 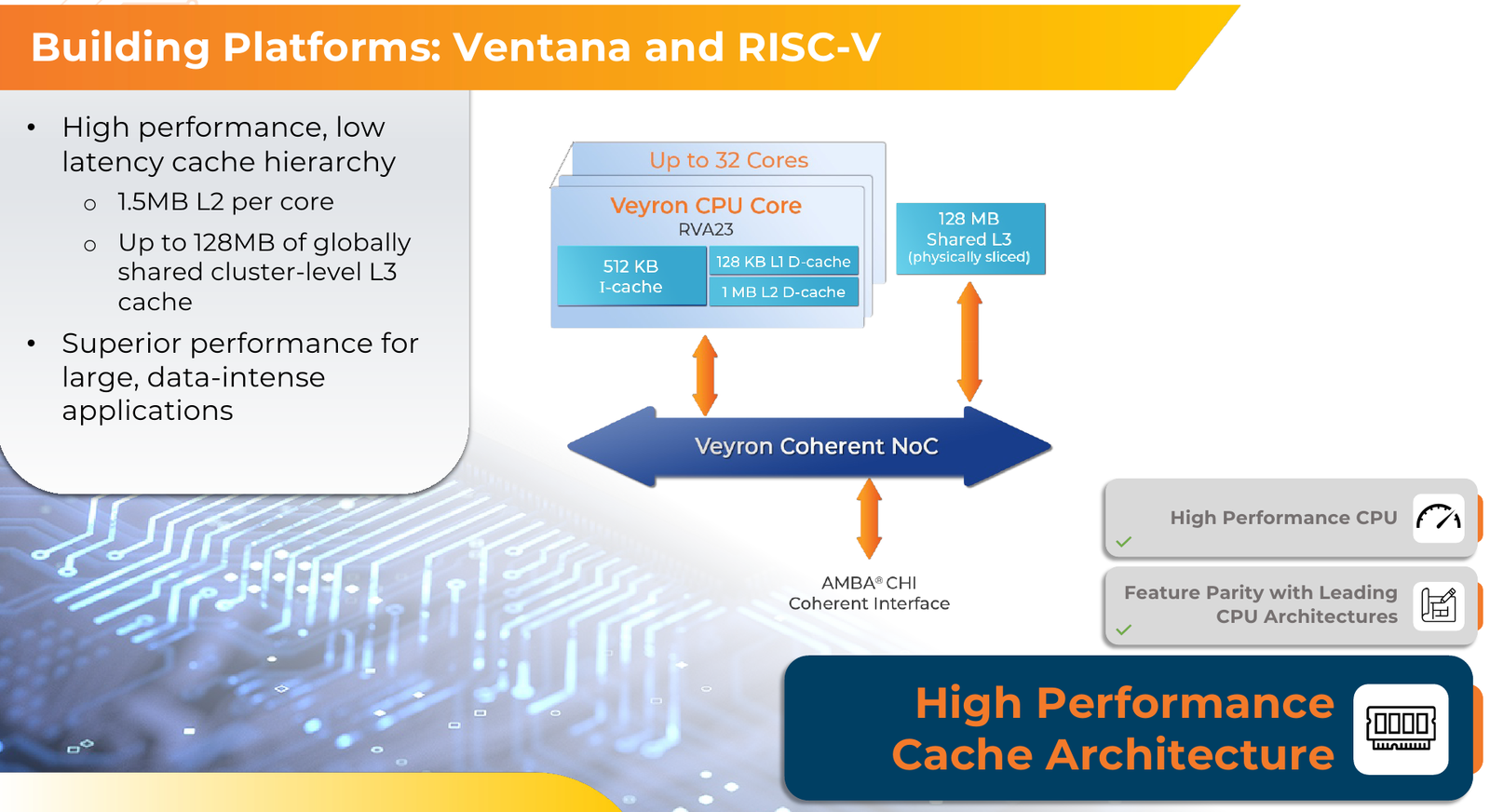 Сами ядра V2 используют суперскалярный дизайн с агрессивным внеочередным исполнением и продвинутым предсказанием ветвлений. Возможно декодирование и обработка до 15 инструкций за такт. Объём L1-кешей составляет 512 Кбайт для инструкций и 128 Кбайт для данных, дополнительно каждое ядро имеет свой кеш L2 объёмом 1 Мбайт. Общий для всего 32-ядерного чиплета L3-кеш имеет объём 128 Мбайт. Производительность внутренней когерентной шины составляет до 5 Тбайт/с. 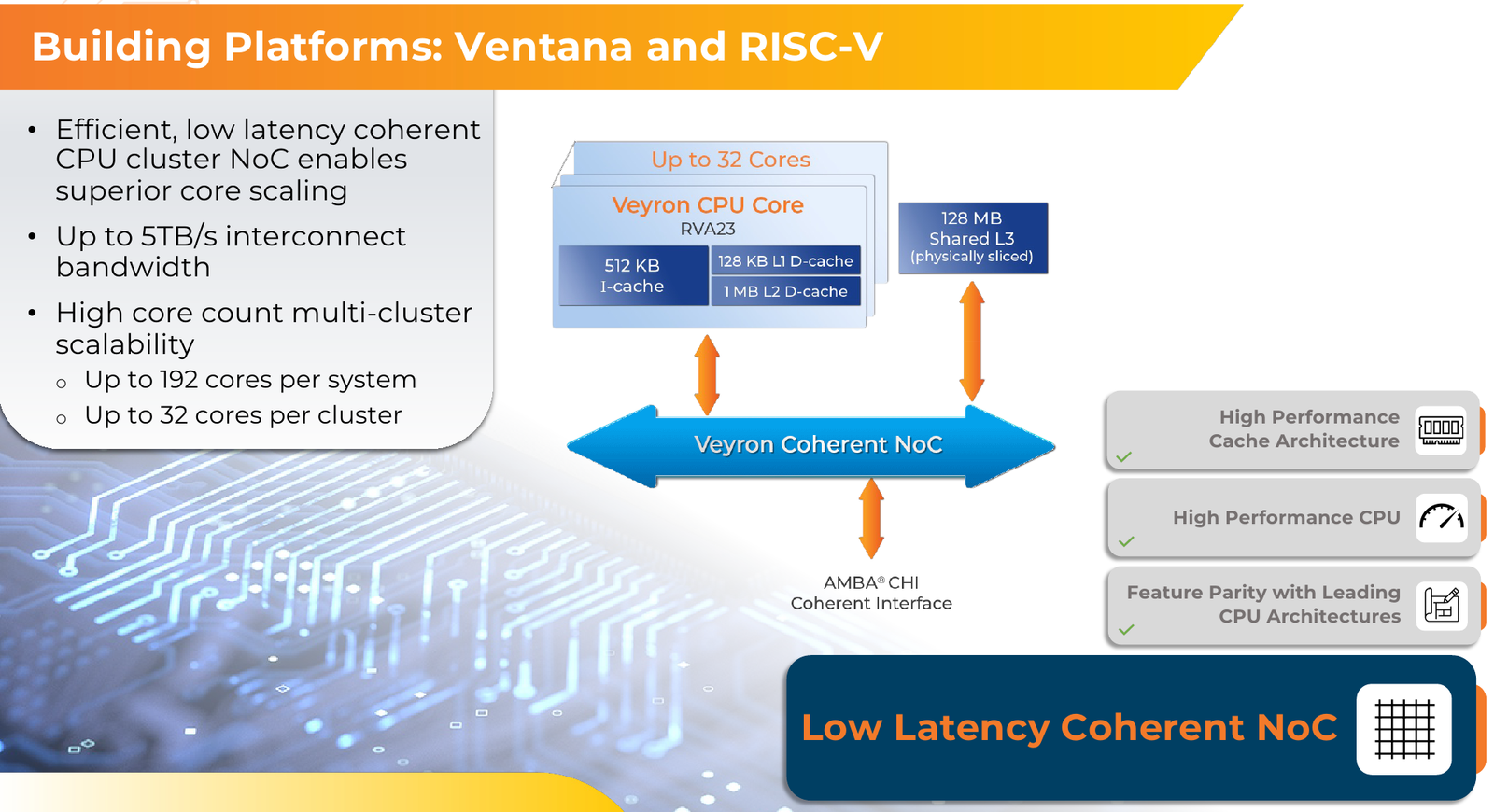 Позиционируемый в качестве решения для гиперскейлеров, крупных ЦОД и HPC, Veyron V2 имеет развитые средства предотвращения ошибок и защиты данных, от ECC-кешей и поддержки Secure Boot до аутентификации на уровне чиплета и продвинутых RAS-функций. Кроме того, реализована защита от атак по сторонним каналам. 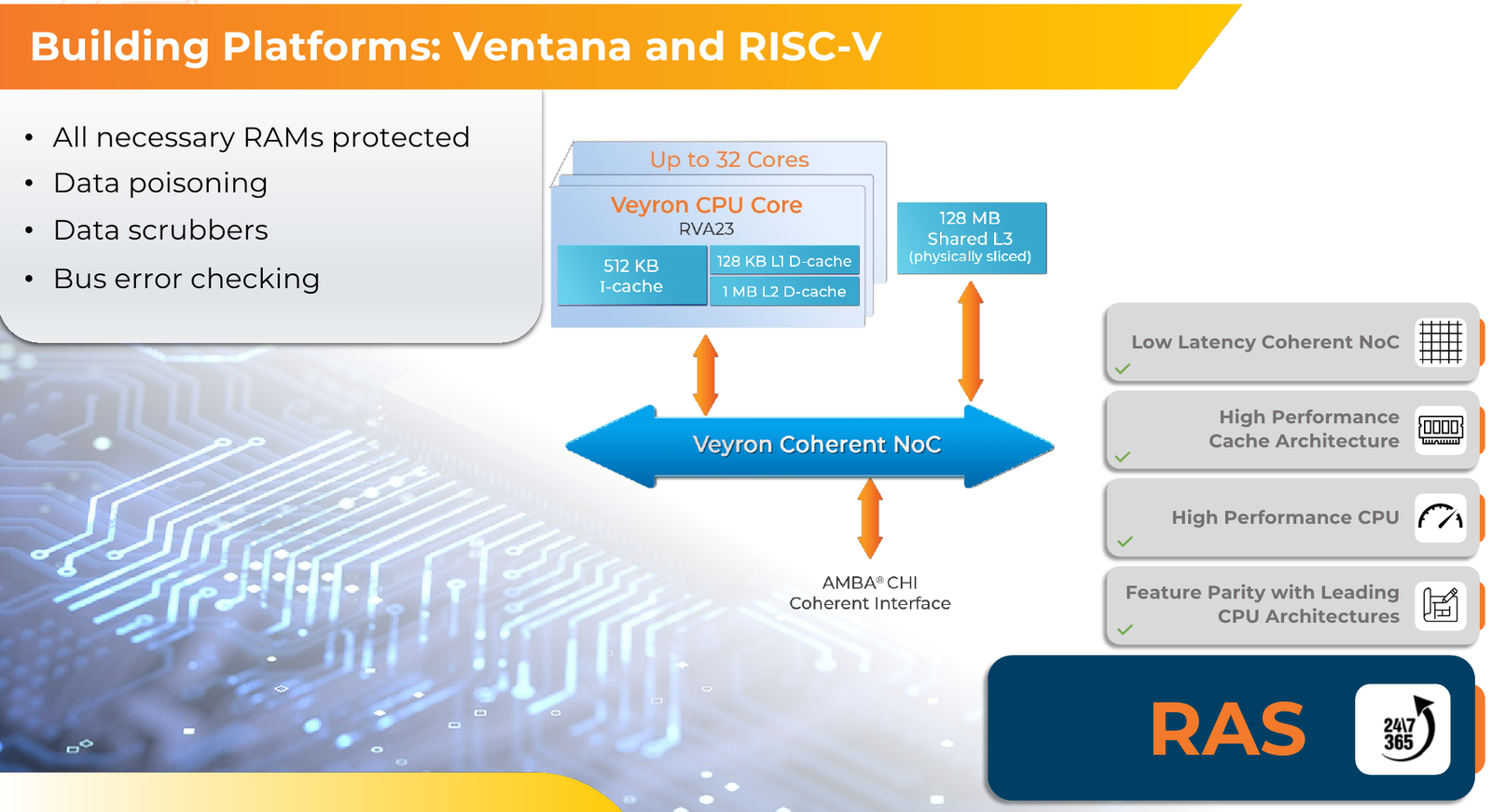 Несмотря на то, что мир RISC-V пока ещё похож на «Дикий Запад», Ventana старается опираться на развитые и популярные стандарты: в частности, это выражается в применении UCIe для подключения чиплетов, поддержку гипервизоров первого и второго типа, вложенную виртуализацию и совместимость с программной экосистемой RISC-V RISE. 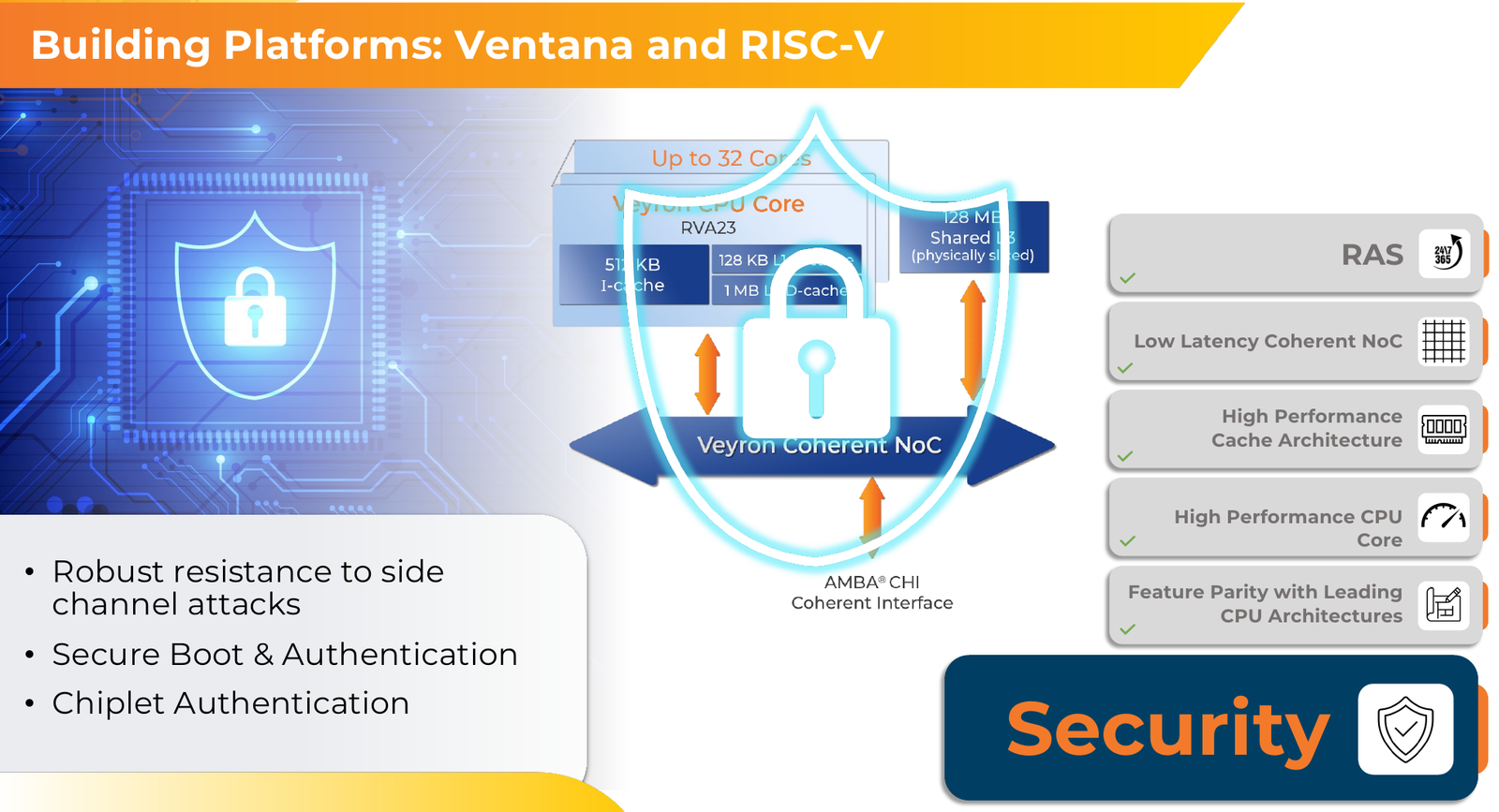 Подход Ventana позволит избежать недостатков, свойственных дискретным PCIe-ускорителям (высокая латентность, энергопотребление и стоимость) и сложным монолитным SoC (очень высокая стоимость разработки и сроки), снизить время и стоимость стоимость новых решений, а также обеспечить более низкий уровень энергопотребления. В общем, компания явно целится в гиперскейлеров. 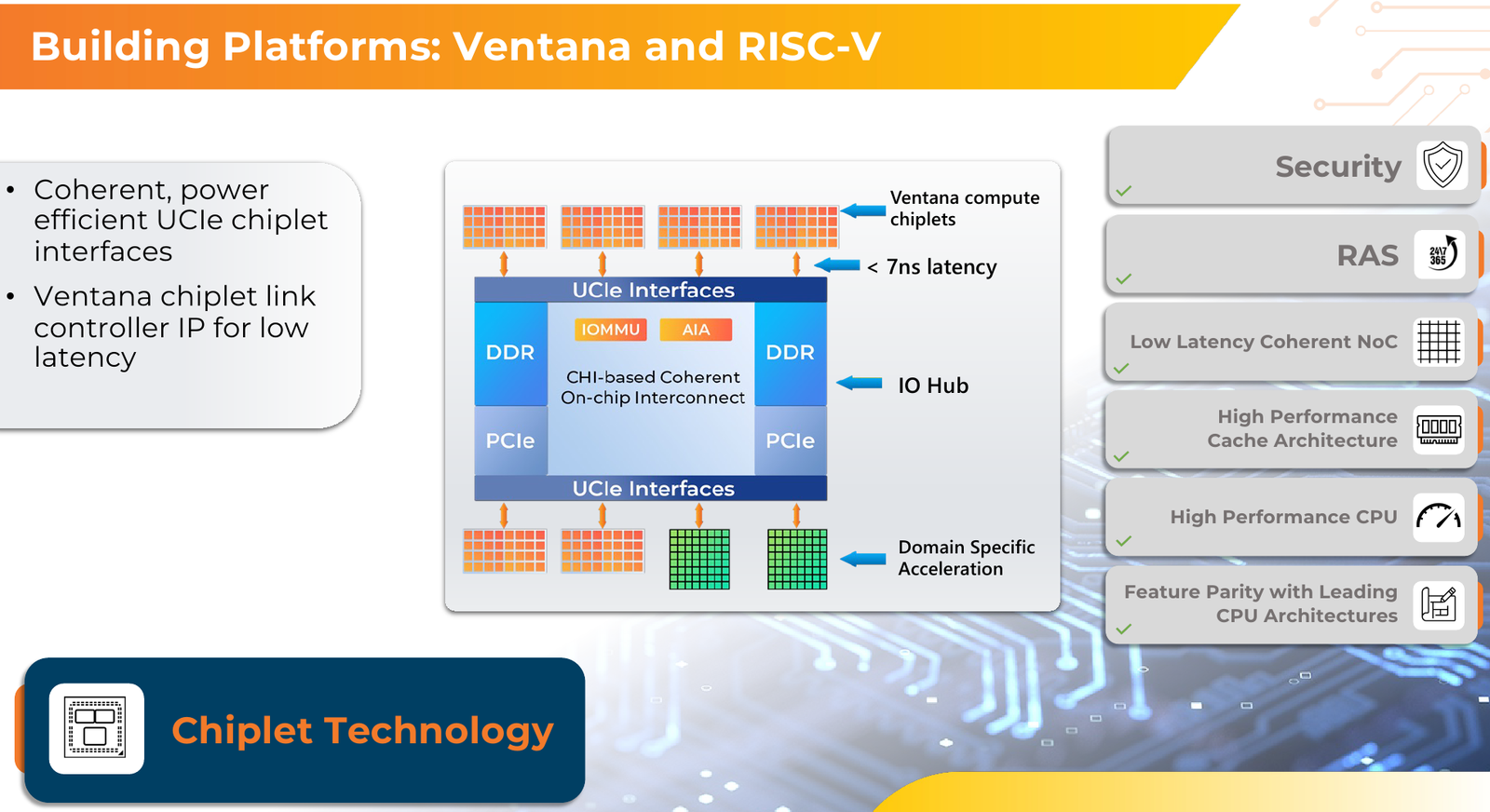 Видение сценариев применения DSA у Ventana очень широкий — от БД-ускорителей и блоков компрессии-декомпрессии данных до поддержки специфических алгоритмов в задачах аналитики и транскодеров в системах доставки контента. Также становятся ненужными дискретные DPU. Первым партнёром Ventana стала Imagination Technologies, крупный разработчик GPU. 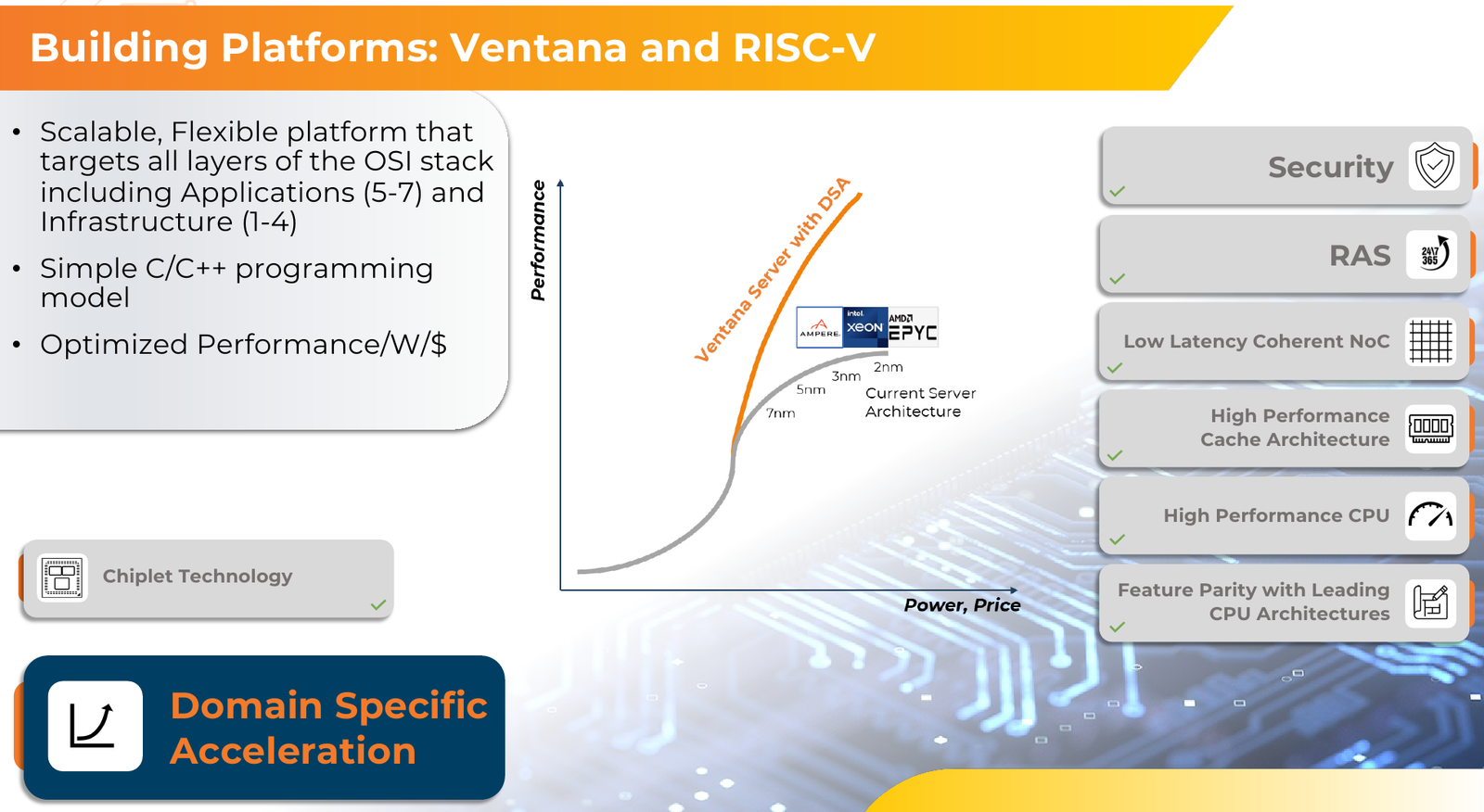 В качестве вариантов физической реализации новой платформы Ventana предлагает компактный 1U-сервер, содержащий один чип Veyron V2 со 192 ядрами, работающими на частотах до 3,6 ГГц, и 12 каналами DDR5-5600. Вероятнее всего, производителем новой платформы станет GIGABYTE. Ожидать первых поставок следует не ранее II квартала 2024 года. 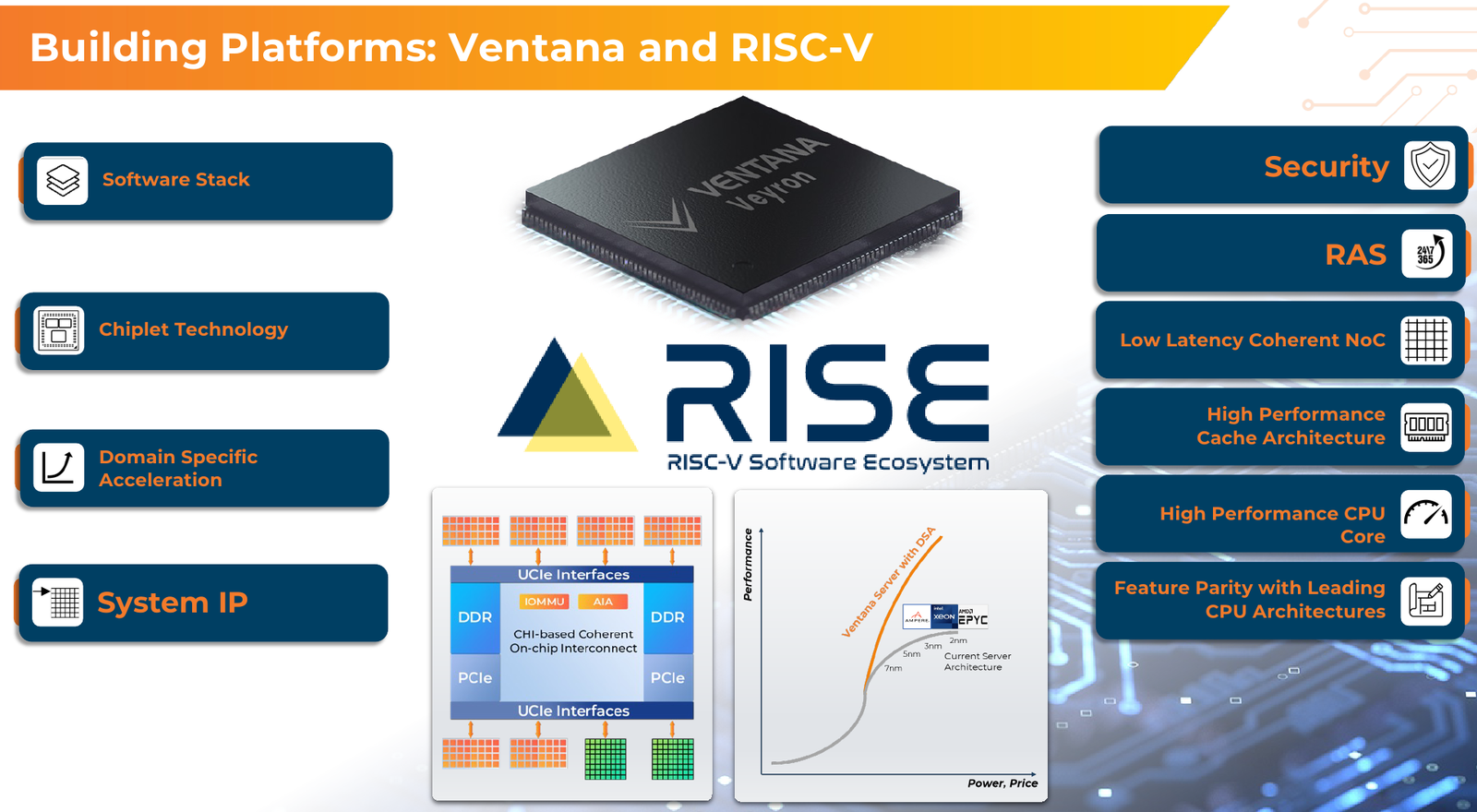 В целом, видение высокопроизводительной модульной платформы, продвигаемое Ventana, выглядит перспективно, а упор на применение DSA может выгодно отличать её большинства Arm-серверов, конкурирующих с решениями Intel/AMD лоб в лоб. Вопрос лишь в поддержке со стороны разработчиков программного обеспечения — и здесь может сыграть ставка разработчиков на максимально открытые, широкие стандарты.
20.09.2023 [20:05], Алексей Степин
SambaNova представила ИИ-ускоритель SN40L с памятью HBM3, который в разы быстрее GPUБум больших языковых моделей (LLM) неизбежно порождает появление на рынке нового специализированного класса процессоров и ускорителей — и нередко такие решения оказываются эффективнее традиционного подхода с применением GPU. Компания SambaNova Systems, разработчик таких ускорителей и систем на их основе, представила новое, третье поколение ИИ-процессоров под названием SN40L. Осенью 2022 года компания представила чип SN30 на базе уникальной тайловой архитектуры с программным управлением, уже тогда вполне осознавая тенденцию к увеличению объёмов данных в нейросетях: чип получил 640 Мбайт SRAM-кеша и комплектовался оперативной памятью объёмом 1 Тбайт. 
Источник изображений здесь и далее: SambaNova (via EE Times) Эта наработка легла и в основу новейшего SN40L. Благодаря переходу от 7-нм техпроцесса TSMC к более совершенному 5-нм разработчикам удалось нарастить количество ядер до 1040, но их архитектура осталась прежней. Впрочем, с учётом реконфигурируемости недостатком это не является. Чип SN40L состоит из двух больших чиплетов, на которые приходится 520 Мбайт SRAM-кеша, 1,5 Тбайт DDR5 DRAM, а также 64 Гбайт высокоскоростной HBM3. Последняя была добавлена в SN40L в качестве буфера между сверхбыстрой SRAM и относительно медленной DDR. Это должно улучшить показатели чипа при работе в режиме LLM-инференса. Для эффективного использования HBM3 программный стек SambaNova был соответствующим образом доработан. 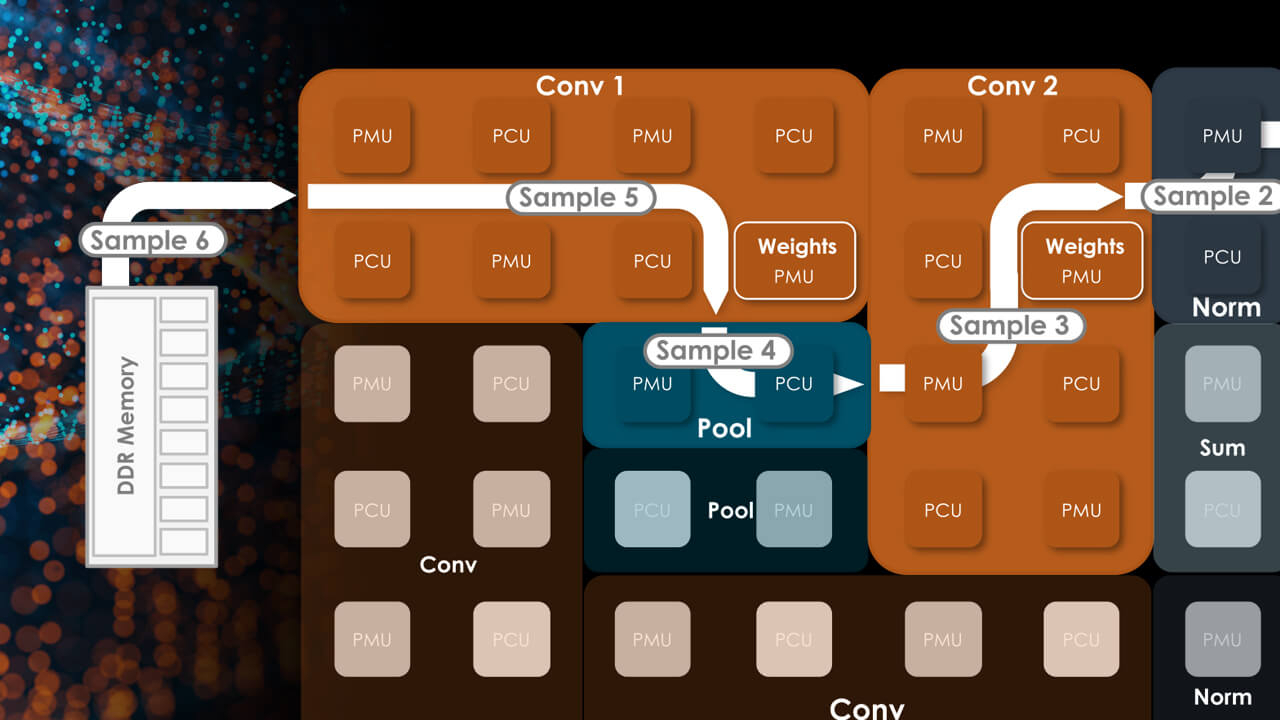
Тайловая архитектура SambaNova состоит из вычислительных тайлов PCU, SRAM-тайлов PMU, управляющей логики и меш-интерконнекта По сведениям SambaNova, восьмипроцессорная система на базе SN40L сможет запускать и обслуживать ИИ-модель поистине титанических «габаритов» — с 5 трлн параметров и глубиной запроса более 256к. В описываемой модели речь идёт о наборе экспертных моделей с LLM Llama-2 в качестве своеобразного дирижёра этого оркестра. Архитектура с традиционными GPU потребовала бы для запуска этой же модели 24 сервера с 8 ускорителями каждый; впрочем, модель ускорителей не уточняется. Как и прежде, сторонним клиентам чипы SN40L и отдельные вычислительные узлы на их основе поставляться не будут. Компания продолжит использовать модель Dataflow-as-a-Service (DaaS) — расширяемую платформу ИИ-сервисов по подписке, включающей в себя услуги по установке оборудования, вводу его в строй и управлению в рамках сервиса. Однако SN40L появится в рамках этой услуги позднее, а дебютирует он в составе облачной службы SambaNova Suite.
09.09.2023 [08:00], SN Team
Редакция ServerNews ищет авторов новостейРедакция ServerNews ищет авторов новостей. Если вы разбираетесь в мире информационных технологий для корпоративного сегмента и SMB и знаете этот рынок, умеете грамотно, быстро и интересно писать, у вас есть не менее двух-трёх часов свободного времени в день и вам нравится готовить публикации на тему IT — напишите нам! Предпочтение отдаётся кандидатам с опытом работы в сфере IT-журналистики. Если же вы имеете опыт сетевого и системного администрирования, работали с серверным «железом» и ПО или разбираетесь в инфраструктуре ЦОД и инженерных системах, не понаслышке знакомы с облаками и промышленными решениями, но никогда не работали в СМИ, то вы можете попробовать себя в новой сфере, выполнив тестовое задание. Для этого самостоятельно найдите любую свежую новость в иноязычном источнике, которая, по вашему мнению, подходит по тематике для нашего сайта, и подготовьте публикацию объёмом 1,5–2 тыс. знаков. Если вы хотите у нас работать, пишите нам на ed@servernews.ru. Тема письма: «Автор новостей ServerNews». Возможна удалённая работа. Обращения без приложенных примеров работ или выполненного тестового задания не рассматриваются. 
02.09.2023 [11:28], Сергей Карасёв
Биржа Nasdaq продолжает перенос сервисов в облако AWSАмериканская биржа Nasdaq, по сообщению ресурса Datacenter Dynamics, завершила ещё один этап переноса своих рабочих нагрузок на облачную платформу Amazon Web Services (AWS): речь идёт о системе работы с ценными бумагами Nasdaq Bond Exchange. О планах по переводу части служб на платформу AWS биржа Nasdaq объявила в конце 2021 года. Тогда сообщалось, что будет применяться решение AWS Outposts, которое позволяет развернуть локальную инфраструктуру AWS практически в любом дата-центре или на колокейшн-площадке. Это необходимо для обеспечения минимального времени отклика. Перенос системы опционов Nasdaq MRX на платформу AWS был завершен в декабре 2022 года. А сервисы Nasdaq Bond Exchange начали функционировать на базе данного облака в конце августа нынешнего года. 
Источник изображения: Nasdaq Ожидается, что полный переход Nasdaq на AWS займёт около десяти лет. Он включает в себя перемещение некоторых рабочих нагрузок в основной дата-центр Nasdaq — на площадку Equinix NY11, которая располагается в Картерете (штат Нью-Джерси). В рамках проекта предполагается модернизация ЦОД: размер нынешнего одноэтажного комплекса, обеспечивающего колокейшн-площадь около 8500 м2, будет увеличен в два раза. Объект, построенный в 2000 году, входит в число 24 центров обработки данных, купленных компанией Equinix в 2016 году у Verizon.
26.08.2023 [15:00], Руслан Авдеев
Amazon откроет фабрику по восстановлению и переработке своего серверного оборудованияКомпания Amazon намерена расширять инфраструктуры «ответственного использования» электроники, применяемой в центрах обработки данных. Как сообщает портал компании, её дочернее предприятие re:Cycle Reverse Logistics откроет в Пенсильвании (США) фабрику по оценке, ремонту и переработке электронных отходов. Объект площадью 51 тыс. м2 заработает в апреле 2024 года. Ожидается, что в переработке оборудования будут заняты от 300 до 500 человек. Само здание фабрики в некотором роде тоже относится к объектам, «бывшим в употреблении» — в компании приняли решение использовать пустующее промышленное здание для создания собственного центра переработки отходов и ремонта той электроники, которая может быть восстановлена. По данным СМИ, Пенсильванию выбрали из-за близости к объектам Amazon на восточном побережье США. А конкретное здание — потому, что оно уже зонировано для промышленных целей, поэтому бюрократические процедуры серьёзно упрощаются. 
Источник изображения: Amazon Программа работы со списанным оборудованием состоит из восьми этапов:

Источник изображения: Amazon Так называемая «обратная логистика» — это весьма распространённая практика разборки изношенного оборудования для восстановления тех комплектующих, которые ещё можно использовать, и добычи из оставшегося мусора ценного сырья. Известно, что у Amazon уже имеются соответствующие хабы, а теперь компания намерена прибегать к подобной практике более широко. Аналогичные проекты есть у Microsoft. Кроме того, б/у-оборудование гиперскейлеров нередко перепродаётся, а сами они увеличивают сроки эксплуатации «железа».
02.08.2023 [18:00], Сергей Карасёв
Светлое будущее: у PCIe появится версия с оптическими соединениями — создана рабочая группа для разработки технологииКонсорциум PCI-SIG объявил о формировании рабочей группы PCI-SIG Optical Workgroup, которая займётся реализацией интерфейса PCI Express (PCIe) по оптическим соединениям. Это, как ожидается, станет важным этапом развития соответствующей экосистемы. Внедрение оптических соединений для PCIe по сравнению с существующими решениями обеспечит более высокую пропускную способность, пониженное энергопотребление, увеличенную дальность действия и меньшие задержки. 
Источник изображения: pixabay.com Новая технология, как ожидается, будет востребована в облачных дата-центрах, системах НРС и на площадках гиперскейлеров. Речь идёт о создании системы, поддерживающей широкий спектр оптических технологий. Консорциум PCI-SIG призывает всех своих участников присоединиться к Optical Workgroup, поделиться опытом и помочь определить конкретные цели рабочей группы и требования к аппаратным компонентам. Новая рабочая группа сосредоточит усилия над тем, чтобы сделать архитектуру PCIe более подходящей для оптических сетей. Между тем, как отмечается, продолжаются работы над спецификацией PCIe 7.0, которая предусматривает увеличение производительности до 128 ГТ/с по одной линии.
21.07.2023 [15:35], Сергей Карасёв
NVIDIA, подвинься: Cerebras представила 4-Эфлопс ИИ-суперкомпьютер Condor Galaxy 1 и намерена построить ещё восемь таких жеКомпания Cerebras Systems анонсировала суперкомпьютер Condor Galaxy 1 (CG-1), предназначенный для решения ресурсоёмких задач с применением ИИ. Это одна из первых действительно крупных машин на базе уникальных чипов Cerebras. В проекте стоимостью $100 млн приняла участие холдинговая группа G42 из ОАЭ, которая занимается технологиями ИИ и облачными вычислениями. G42 является основным заказчиком комплекса. В текущем виде комплекс CG-1, расположенный в Санта-Кларе (Калифорния, США), объединяет 32 системы Cerebras CS-2 и обеспечивает производительность на уровне 2 Эфлопс (FP16). В IV квартале ткущего года будут добавлены ещё 32 системы Cerebras CS-2, что позволит довести быстродействие до 4 Эфлопс (FP16). Ожидаемый уровень энергопотребления составит порядка 1,5 МВт или более. 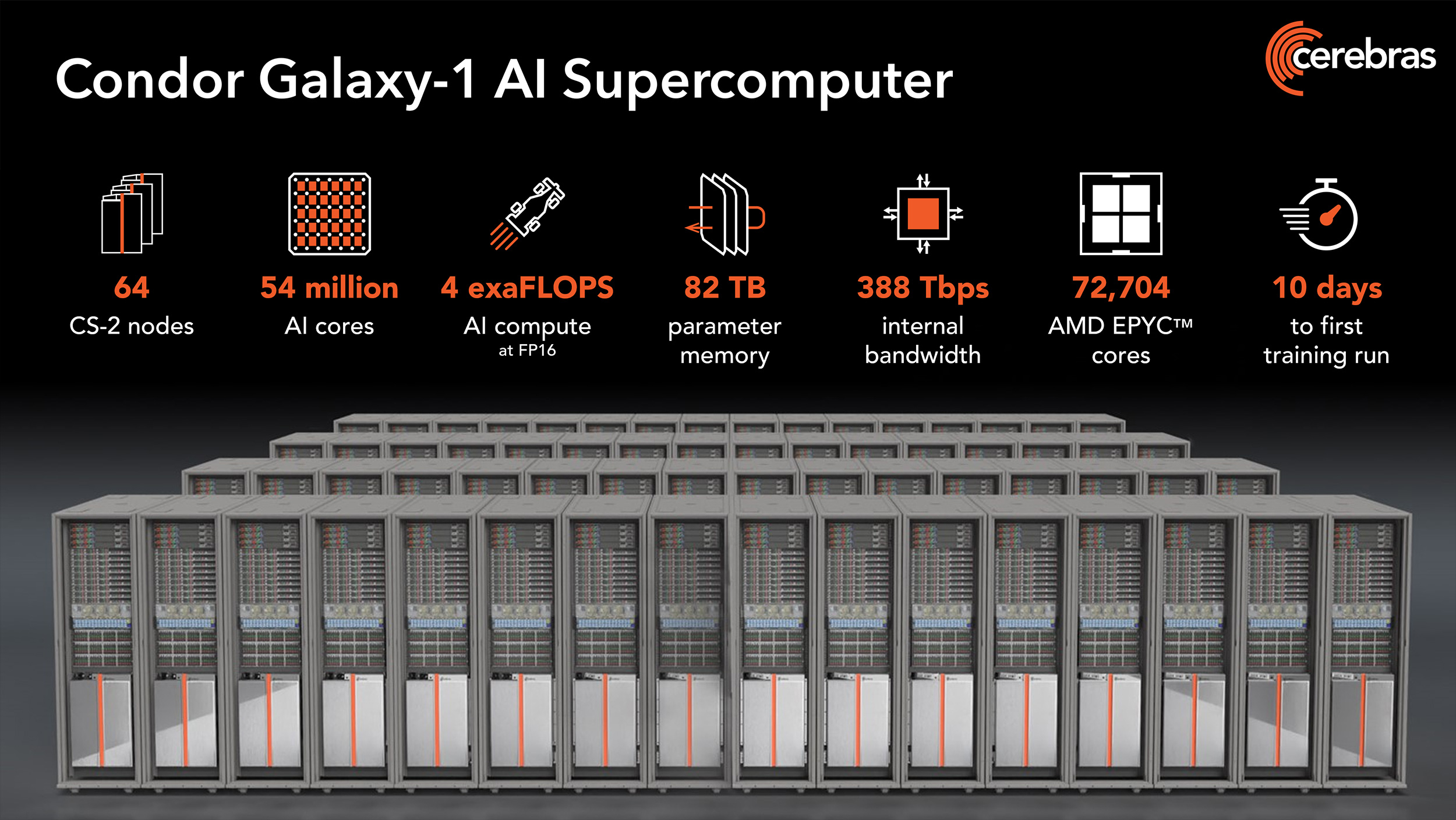
Источник изображений: Cerebras (via ServeTheHome) В системах Cerebras CS-2 применяются гигантские чипы Wafer-Scale Engine 2 (WSE-2), насчитывающие 2,6 трлн транзисторов. Такие чипы имеют 850 тыс. тензорных ядер и несут на борту 40 Гбайт памяти SRAM. Системы выполнены в формате 15 RU и укомплектованы шестью блоками питания мощностью 4 кВт каждый. Задействована технология жидкостного охлаждения. Отдельно отмечается, что программный стек позволит без проблем и существенных модификаций кода работать с ИИ-моделями.  После ввода в строй второй очереди комплекс CG-1 суммарно получит 54,4 млн ИИ-ядер, 2,56 Тбайт SRAM и внутренний интерконнект со скоростью 388 Тбит/с. Их дополнят 72 704 ядра AMD EPYC Milan и 82 Тбайт памяти для хранения параметров. По словам создателей, мощностей суперкомпьютера хватит для обучения модели с 600 млрд параметров и на очередях длиной до 50 тыс. токенов. При этом производительность масштабируется практически линейно.  Cerebras и G42 будут предоставлять доступ к CG-1 по облачной схеме, что позволит заказчикам использовать ресурсы ИИ-суперкомпьютера без необходимости управлять моделями или распределять их по узлам и ускорителям. CG-1 — первый из трёх ИИ-суперкомпьютеров нового поколения. В I полугодии 2024 года будут построены комплексы CG-2 и CG-3, полностью аналогичные CG-1, которые будут объединены в распределённый ИИ-кластер. А к концу следующего года у Cerebras будет уже девять систем CG.  Для Cerebras это означает, что компания более не является стартапом, поскольку в её решения заказчики поверили и без участия в индустриальных тестах вроде MLPerf. Кроме того, теперь компания является не просто очередным производителем «железа», а предоставляет услуги, которые и помогут ей заработать в будущем.
18.07.2023 [18:04], Сергей Карасёв
Спортивный хакинг вышел в космос — RuVDS и Positive Technologies запустили соревнования по взлому спутникаРоссийский хостинг-провайдер RuVDS и компания Positive Technologies сообщили о запуске состязания по спортивному хакингу в формате CTF (Capture the Flag). Особенность мероприятия заключается в том, что участникам предстоит взломать спутник-сервер, который начал работу на орбите Земли в текущем месяце. Пусковой контейнер со спутником RuVDS был доставлен в космос ракетой-носителем «Союз-2.1б» 27 июня. Подготовкой миссии занималась компания «Стратонавтика», которая разработала «материнский» спутник — «СтратоСат ТК-1». Космический аппарат позволит исследователям изучить работу оборудования, в условиях невесомости, высокой радиации и экстремальных температур. Анонсированные хакерские CTF-состязания включают в себя семь заданий, для выполнения которых участникам потребуется продемонстрировать знание различных аспектов информационной безопасности. Кроме того, энтузиастам предстоит взломать ИИ-систему на основе языковой модели ChatGPT. 
Источник изображения: RuVDS Участникам будут предложены задачи, разработанные специально для CTF-мероприятия, которое проходило на Positive Hack Days в мае 2023 года. Отмечается, что задания разрабатывались таким образом, чтобы объединить интересы самой разной аудитории — от радиолюбителей до опытных хакеров. Новое состязание стартовало сегодня — оно продлится приблизительно 90 часов. Для участия в хакатоне не требуется регистрация, но сам он начнется неожиданно. Победитель получит денежное вознаграждение от RuVDS, а наиболее отличившиеся участники соревнований — подарки от Positive Technologies. UPD: впоследствии выяснилось, что возник сбой, из-за которого RuVDS не полностью удалось реализовать задуманные проекты. |
|

