Материалы по тегу: intel
|
06.06.2026 [11:24], Сергей Карасёв
Gigabyte показала 40-узловой сервер на платформе Intel Lunar LakeКомпания Gigabyte, по сообщению The Register, продемонстрировала на выставке Computex 2026 сервер высокой плотности R1C7-K0A-AS1. Его конструкция включает 40 компактных маломощных вычислительных узлов на аппаратной платформе Intel Lunar Lake, заключённых в корпус формата 1U. Каждый узел несёт на борту процессор Intel Core Ultra 7 258V с восемью ядрами: это четыре производительных ядра Lion Cove P с максимальной тактовой частотой 4,8 ГГц и четыре энергоэффективных ядра Skymont E с частотой до 3,7 ГГц. В состав чипа входят графический ускоритель Intel Arc 140V с восемью ядрами Xe (до 1,95 ГГц) и нейропроцессорный блок Intel AI Boost с ИИ-производительностью до 47 TOPS (INT8). Каждый процессор работает в тандеме с 32 Гбайт оперативной памяти LPDDR5Х-8533. Таким образом, вся система оперирует 320 вычислительными ядрами и 1,28 Тбайт ОЗУ. Узлы наделены двумя SSD типоразмера М.2 с интерфейсом PCIe 5.0. Общее ИИ-быстродействие достигает 1880 TOPS. Шасси сервера содержит пять несущих модулей, на которые установлены по восемь вычислительных узлов. Система располагает двумя сетевыми портами QSFP28 с пропускной способностью 100 Гбит/с. Кроме того, доступен порт CMC LAN. За питание отвечают два блока мощностью 3200 Вт с сертификатом 80 Plus Titanium. 
Источник изображения: Gigabyte Новинка позиционируется в качестве платформы для микросервисных рабочих нагрузок, таких как Kubernetes. Кроме того, сервер может стать основой VDI-инфраструктур. Наличие интегрированной графики в каждом CPU означает, что клиентам не придётся беспокоиться о стоимости лицензирования vGPU.
02.06.2026 [17:57], Владимир Мироненко
Intel с партнёрами разработает эталонный дизайн ИИ-стоек с чипами Xeon для ODM- и OEM-производителей
clearwater forest
foxconn
granite rapids
hardware
intel
nvidia
odm
oem
sambanova systems
xeon
ии
инференс
стойка
Intel совместно с SambaNova и Foxconn объявила о намерении создать референс-дизайн стоечной ИИ-инфраструктуры на базе процессоров Intel Xeon для ЦОД, гиперскейлеров и центров интеллектуального управления. Как сообщает The Register, подход основан на ранее разработанной Intel совместно с SambaNova концепции дезагрегированного ИИ. Архитектура распределяет ресурсоёмкие операции предварительного заполнения между ускорителями NVIDIA, используя чипы SambaNova для ресурсоёмких операций декодирования, что позволяет увеличить выход токенов для каждого пользователя в 2–3 раза. Генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan) представил два примера таких проектов. Один предназначен для агентных нагрузок, чувствительных к задержкам, а другой — для обеспечения максимальной плотности вычислений. Обе конфигурации поддерживают до 128 процессоров Intel: либо 128-ядерных Granite Rapids-AP, либо 288-ядерных Clearwater Forest, что в сумме составляет от 16 384 P-ядер до 36 864 E-ядер, а также до 384 Тбайт DDR5 при энергопотреблении 100 кВт. Тан сообщил, что системы на основе этого референс-дизайна будут широко доступны у ODM- и OEM-партнёров компании. В рамках сотрудничества Foxconn предоставит возможности системной интеграции для новой стоечной ИИ-инфраструктуры. Компания также планирует выпускать вариант стоечной инфраструктуры с высокой плотностью процессоров для рабочих нагрузок, не требующих дополнительного ускорения, включая оптимизированные по стоимости задачи инференса, обработку данных и гибридный ИИ. Intel объявила, что облачный провайдер Vector Core Compute, созданный Vista Equity Partners и Cambium Capital, станет одним из первых, кто развернёт эту платформу, а Together.AI — её первым коммерческим клиентом. 
Источник изображения: Intel Также на выставке Computex 2026 компании Intel, SambaNova, Vista Equity Partners и Cambium Capital представили первую реальную демонстрацию дезагрегированной системы инференса, использующей процессоры Intel Xeon 6 для оркестрации, блоки RDU SambaNova SN40 для декодирования и NVIDIA Blackwell для предварительного заполнения, работающую в ЦОД Vector Core Compute в Лос-Анджелесе. Напомним, что ранее NVIDIA объявила о запуске аналогичной стоечной платформы, включающей 256 88-ядерных процессоров Vera, ускорители Rubin и LPU Groq 3. Arm также работает над парой референс-дизайнов стоечных систем для агентных рабочих нагрузок на основе своих новых процессоров Arm AGI: 36-кВт системой с воздушным охлаждением и 8160 ядрами, а также 200-кВт системой с жидкостным охлаждением и 45 696 ядрами.
02.06.2026 [01:04], Владимир Мироненко
ИИ-ускоритель Intel Crescent Island получит до 480 Гбайт LPDDR5XIntel сообщила новые подробности о своём будущем ИИ-ускорителе для ЦОД с кодовым именем Crescent Island, который был анонсирован в прошлом году. Новый GPU основан на архитектуре Xe3P, представляющей усовершенствованную версию Xe3, которая используется в процессорах Core Ultra 300 семейства Panther Lake. Ожидается, что Xe3P также будет использоваться в GPU Intel серии Arc-C для клиентских устройств. Компания отметила, что чип разработан специально для рабочих нагрузок агентного ИИ. В то время как традиционные ИИ-ускорители от NVIDIA и AMD полагаются на дорогую память HBM, в новом чипе Intel используется LPDDR5X, и он предназначен для работы в серверах с воздушным охлаждением, а не с жидкостным. Crescent Island будет поддерживать до 480 Гбайт памяти LPDDR5X, хотя базовая эталонная конфигурация рассчитана на 160 Гбайт. Intel заявила, что Crescent Island оптимизирован по производительности на Вт — до TDP 350 Вт в версии с воздушным охлаждением и интерфейсом PCIe. 
Источник изображений: Intel Сообщается, что GPU будет поддерживать широкий спектр форматов данных от FP4 до FP64, а также полностью открытый программный стек oneAPI, что идеально подходит для поставщиков услуг «токены как услуга» и сценариев использования для инференса. Концептуально новинка напоминает Rubin CPX, от которого NVIDIA отказалась.  Intel уже оценивает свой открытый унифицированный программный стек для гетерогенных систем ИИ с помощью существующей линейки Arc Pro B-серии, поэтому будущие версии чипов получат доступ к этим оптимизациям на ранних этапах. Intel планирует начать тестирование GPU Crescent Island для клиентов во II половине 2026 года с общей доступностью в 2027 году.
01.06.2026 [21:33], Владимир Мироненко
Intel выпустит 192-ядерные процессоры Xeon Diamond Rapids на техпроцессе 18A-P в 2027 годуВместе с объявлением о выходе серии чипов Xeon 6+ (Clearwater Forest) компания Intel предоставила некоторые подробности о Xeon Diamond Rapids, выход которых намечен на 2027 год. Новый процессор будет выпускаться по техпроцессу 18A-P, усовершенствованной версии 2-нм техпроцесса. Компания сообщила, что Xeon Diamond Rapids получит на 50 % больше ядер, чем Granite Rapids-AP (6900P), т.е. 192 P-ядра. Это значительный прирост, но всё же меньше, чем у AMD, которая, как ожидается, уже в этом году предложит до 256 ядер Zen 6C в EPYC Venice. При этом Diamond Rapids не будет поддерживать Hyper-Threading (SMT). Эта технология вновь появится в Xeon Coral Rapids в 2028 году. Как сообщает The Register, на рендерах, представленных в пресс-релизе Intel, видно, что два I/O-чиплета обслуживают четыре вертикально расположенных вычислительных блока, собранных с использованием упаковки Foveros. Аналогичная компоновка используется в Clearwater Forest. Перенос L3-кеша на базовый тайл освобождает значительную площадь вычислительного чиплета. Здесь таковых четыре, по 48 ядер в каждом. The Register отметил, что в этом отношении Diamond Rapids похож на Fujitsu Monaka, который использует почти идентичную компоновку и 3.5D-упаковку Broadcom, хотя и с одним чиплетом I/O. А вот контроллеры памяти могут оказаться и на базовых тайлах, и в составе I/O-чиплетов. 
Источник изображений: Intel В отличие от Granite Rapids-SP, не стоит ожидать широкого распространения Diamond Rapids в корпоративных системах виртуализации или СХД. Как сообщила Intel, Diamond Rapids «оптимизирован для высоконагруженных IaaS-систем с высокой производительностью на поток», что ставит его в один ряд с процессорами 6900P, больше ориентированными на HPC-нагрузки. Intel уже говорила, что новинки получат 16-канальный контроллер памяти с поддержкой MRDIMM, что важно для таких задач. Чипы также будут поддерживать PCIe 6.0, предлагая высокую скорость и масштабируемость для сценариев с интенсивным использованием I/O.  Далее Intel представит Coral Rapids, вернув P-ядрам поддержку SMT. Ожидается, что линейка будет запущена в середине 2028 года с 8-канальными платформами, но, судя по недавним заявлениям генерального директора Лип-Бу Тана (Lip-Bu Tan), её выпуск, вероятно, будет ускорен из-за возросшего спроса на процессоры для рабочих нагрузок агентного ИИ.
01.06.2026 [15:26], Владимир Мироненко
Intel объявила о выходе Xeon 6+ Clearwater Forest — первых 2-нм серверных процессоровIntel объявила о выходе серии чипов Xeon 6+ (Clearwater Forest), первых процессоров для ЦОД, созданных на основе Intel 18A, самого передового технологического процесса компании. Как отметил ресурс The Register, процессоры Intel Xeon Clearwater Forest изначально были разработаны для телекоммуникационных приложений, SaaS и высокопроизводительных веб-приложений. Но с расширением использования агентных решений, как OpenClaw, роль процессоров в ИИ-инфраструктуре значительно возросла. В такой же мере вырос на них спрос. При выполнении задачи эти чипы могут отправлять множество запросов для сбора информации из интернета, запуска и отладки кода, запросов к базам данных и взаимодействия с API. Все эти запросы выполняются на ядрах CPU, количество которых у Intel Xeon 6+ составляет до 288. Это на 200 ядер больше на сокет, чем у новых процессоров NVIDIA Vera, и более чем в два раза больше, чем у недавно анонсированного Arm AGI — оба ориентированы непосредственно на агентный ИИ. 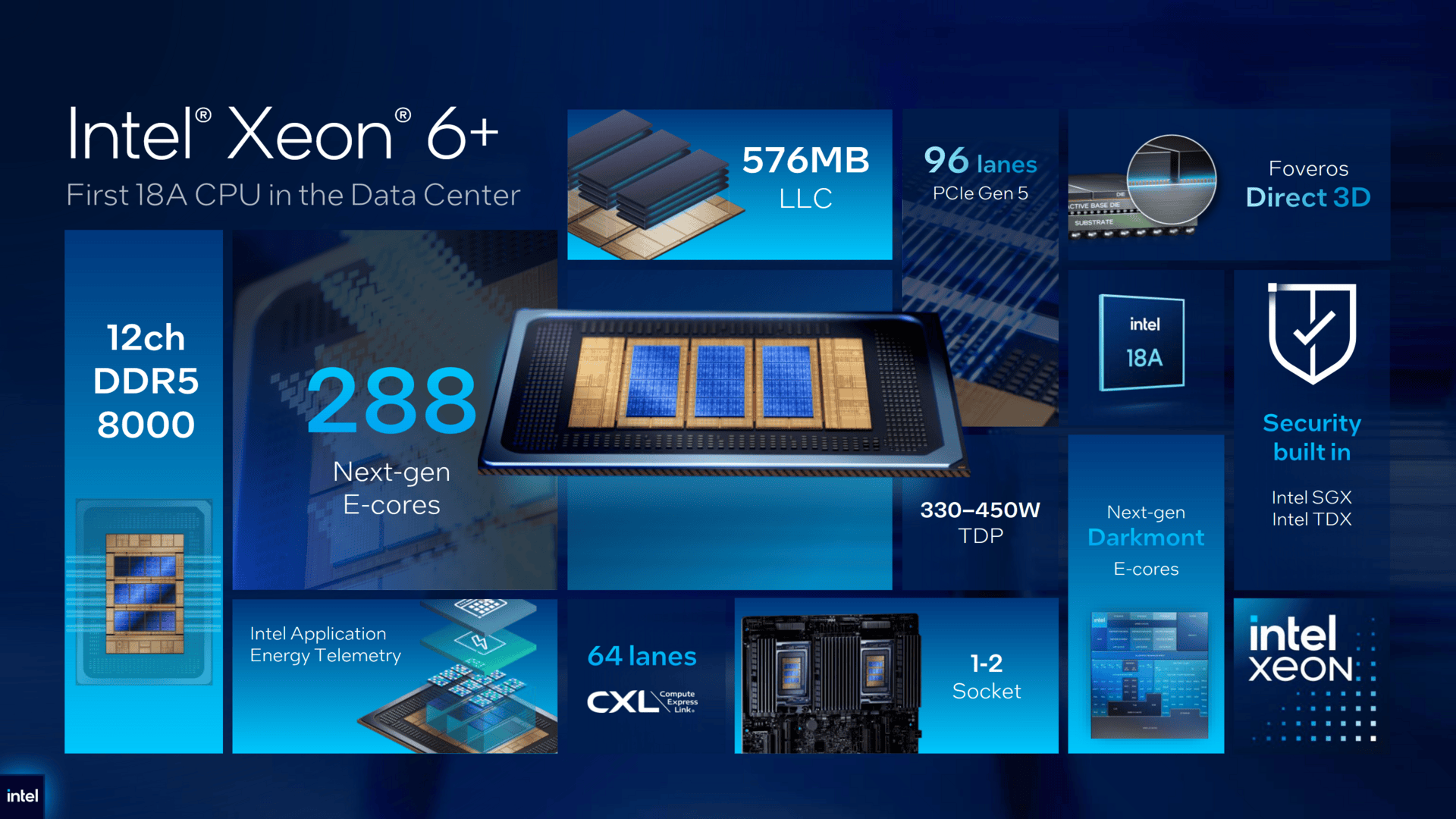
Источник изображений: Intel В максимальной конфигурации 6900E+ включает 12 чиплетов E-Core (Intel 18A с RibbonFET и PowerVia), 3 базовых тайла (Intel 3) и 2 чиплета I/O (Intel 7). 12 EMIB-тайлов объединяют все чиплеты в единую 2.5D-упаковку с использованием технологии Foveros Direct 3D, обеспечивая сверхнизкую задержку передачи данных по всему чипу. Совместимость с существующими платформами Xeon 6900P/6900E (Granite Rapids-AP/Sierra Forest-AP) означает, что Clearwater не потребует от OEM-производителей разработки совершенно новой платформы. Чип может быть установлен в существующие плат, что упрощает его внедрение. Применение архитектуры E-ядер свидетельствует о сосредоточенности Clearwater Forest на повышении энергоэффективности. Новая функция Intel AET («Телеметрия энергопотребления приложений») позволяет операторам ЦОД отслеживать энергопотребление каждого ядра и каждого приложения на аппаратном уровне. Это упрощает системным администраторам выявление проблемных рабочих нагрузок и повышение энергоэффективности путём оптимизации ПО или просто модификации окружения.  E-ядра Darkmont нового чипа работают на более низких частотах, чем P-ядра чипа Intel Xeon 6, и в отличие от них не имеют поддержки AVX-512, AMX и Hyper-Threading. Но по сравнению с первым поколением E-ядер Intel Xeon, представленных на два года назад, ядра Clearwater обеспечивают на 17 % больше инструкций за такт в дополнение к более высокой частоте в режиме Boost. Также рабочим нагрузкам агентного ИИ может пойти на пользу обилие выделенных ускорителей. В чиплеты I/O встроены 16 ускорителей (по 8 на чиплет), предназначенных для криптографических операций, перемещения данных, сжатия/распаковки, балансировки и т.д. Доступны четыре варианта Xeon 6+ в шести конфигурациях, причем две топовые модели выпускаются в конфигурациях с ограниченным энергопотреблением, более низкими базовыми и турбо-частотами всех ядер, но с идентичными характеристиками. Сравнивая новинки с процессорами Sierra Forest предыдущего поколения, Intel сообщила, что 6900E+ обеспечивают прирост производительности на 126 %. При этом производительность на Вт увеличивается на 55 %, что, по оценкам Hot Hardware, означает, что они также потребляют примерно на 46 % больше энергии. Это вполне приемлемо с учётом того, ядер стало в два раза больше, а L3-кеш вырос в пять раз. 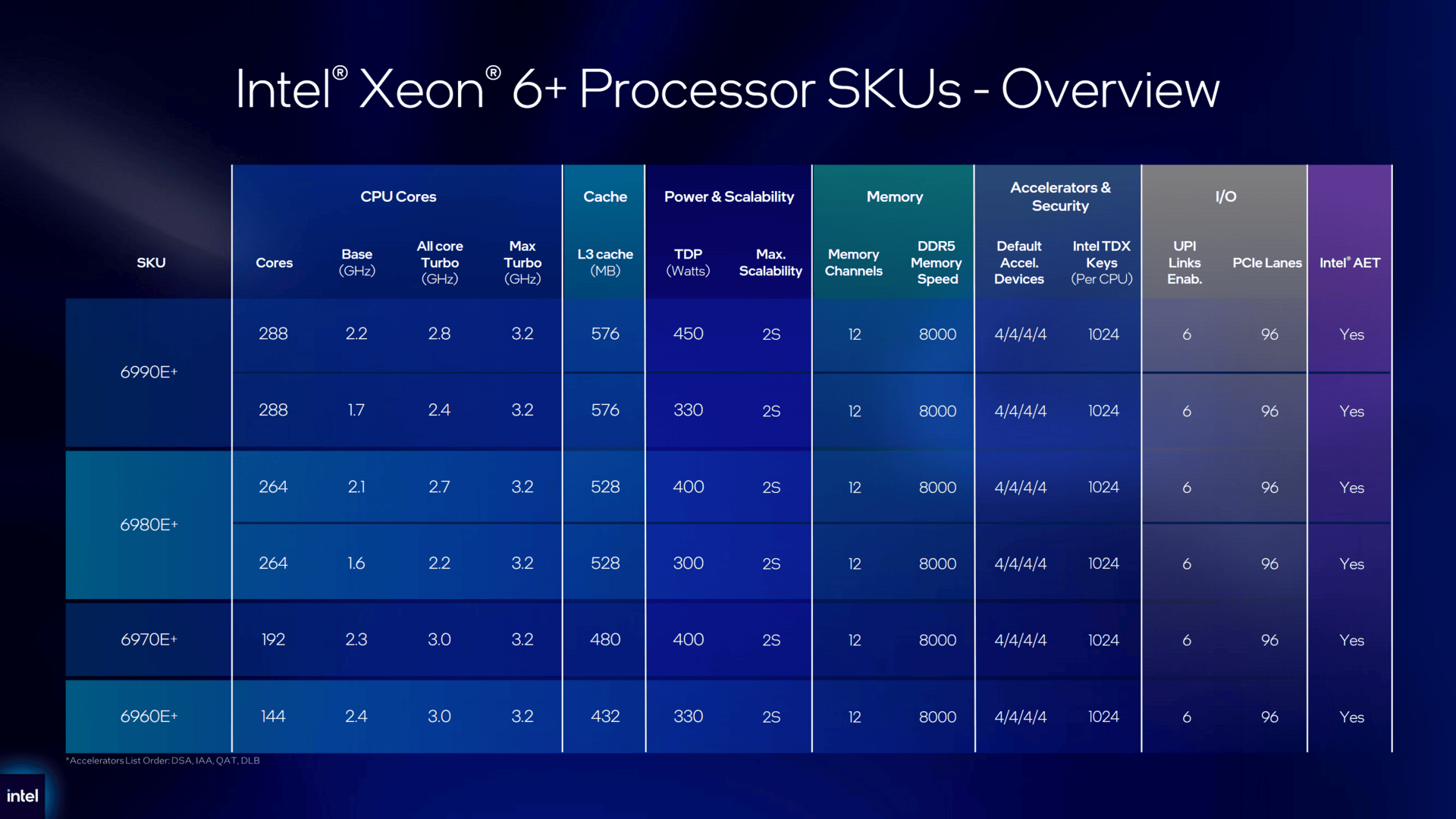 Также Intel заявила, что процессоры Xeon 6990E+ обеспечивают в 1,3 раза более высокую среднюю производительность на поток и в 1,3 раза более высокую среднюю производительность/поток/Вт по сравнению с AMD EPYC 9965 (Turin), сообщил Data Center Dynamics. Ранее Intel сообщила, что тесты Clearwater Forest в реальных условиях эксплуатации показали, что Ericsson благодаря их использованию получит 30-% увеличение производительности при том же количестве ядер, 60-% повышение производительности на Вт и 38-% снижение энергопотребления в стойке во время работы. Новые процессоры будут поддерживаться крупными производителями серверов, включая Amax, ASRock, ASUS, Dell, Foxconn, Giga Computing, Gigabyte, HPE, Inventec, Lenovo, Mitac, MSI, Pegatron, QCT и Supermicro. «Мы наблюдаем значительный спрос на все большее количество процессоров», — отметил в ходе пресс-конференции Кеворк Кечичян (Kevork Kechichian), исполнительный вице-президент и генеральный менеджер Intel Data Center Group.
31.05.2026 [11:43], Сергей Карасёв
AAEON выпустила mini-ITX-плату MIX-PTLWV1 на базе Intel Panther Lake с поддержкой четырёх 4K-дисплеевКомпания AAEON анонсировала индустриальную плату MIX-PTLWV1 в форм-факторе mini-ITX. В качестве аппаратной платформы применяется процессор Intel Core Ultra Series 3 семейства Panther Lake с графикой Intel Xe LPG, а для программной части заявлена совместимость с Windows 11 и Ubuntu 24.04. Решение имеет размеры 170 × 170 мм. Доступны два слота C/SO-DIMM для модулей оперативной памяти DDR5-6400/7200 суммарным объёмом до 128 Гбайт. Предусмотрены коннектор M.2 2280 M-Key для SSD с интерфейсом PCIe 4.0 x4 (NVMe), разъём M.2 2230 E-Key (PCIe 4.0 x1/USB 2.0/CNVi) для комбинированного адаптера Wi/Fi/Bluetooth и слот M.2 3042/3052 B-Key (PCIe x1/USB 3.0; nano-SIM) для модема 4G/5G. Допускается вывод изображения одновременно на четыре независимых дисплея 4К (4096 × 2160; 60 Гц) через интерфейсы DisplayPort 1.4. Есть четыре порта USB 3.0 Type-A и 20-контактная колодка с возможностью использования ещё двух портов USB 3.0. Кроме того, могут быть задействованы до шести последовательных портов (1 × RS-232/422/485 и 5 × RS-232). Присутствуют звуковой кодек Realtek ALC897 HD с 3,5-мм аудиогнездом, слот PCIe 5.0 x8, а также чип Infineon SLB9672 TPM 2.0 и контроллер ввода/вывода Nuvoton NCT6126D. 
Источник изображения: AAEON Новинка располагает двумя сетевыми портами 2.5GbE RJ45 на основе контроллеров Intel I226-V и Intel I226-LM. Модификация MIX-PTLWV1-A10-4L также получила два порта 10GbE на базе Intel E610-XAT2. Питание (12–24 В) подаётся через 4-контактный коннектор. Диапазон рабочих температур простирается от 0 до +60 °C. Упомянут 4-контактный разъём для вентилятора охлаждения.
26.05.2026 [11:13], Сергей Карасёв
Одноплатный компьютер ODROID-H5 получил порт 10GbE и четыре слота M.2Компания Hardkernel пополнила ассортимент одноплатных компьютеров моделью ODROID-H5 на аппаратной платформе Intel Alder Lake-N. Новинка может использоваться для создания сетевого оборудования, различных устройств с поддержкой ИИ, хранилищ данных и пр. Применён процессор Core i3-N300, который содержит восемь ядер с тактовой частотой до 3,8 ГГц и блок Intel UHD Graphics с частотой до 1,25 ГГц. Допускается использование до 64 Гбайт DDR5-4800 в виде одного модуля SO-DIMM. Реализован сетевой порт 10GbE RJ45 на основе контроллера Realtek RTL8127AT. Одноплатный компьютер располагает тремя слотами M.2 (PCIe 3.0 x2) и одним разъёмом M.2 (PCIe 3.0 x1). Это даёт возможность устанавливать дополнительные сетевые адаптеры, контроллеры Wi-Fi 6E/7, ускорители ИИ, а также NVMe SSD. Допускается вывод изображения в формате 4Kp60 одновременно на три монитора через интерфейс HDMI 2.0 и два коннектора DisplayPort. Есть порт USB 3.0 Type-A и три разъёма USB 2.0 Type-A. Реализована 24-контактная IO-колодка с поддержкой 2 × I2C, 3 × USB 2.0, 1 × UART, 1 × HDMI-CEC и пр. 
Источник изображения: Hardkernel Новинка оснащена пассивным охлаждением с довольно крупным радиатором. При этом доступен 4-контактный разъём для подключения вентилятора с ШИМ-управлением. Питание 11–20 В подаётся через DC-коннектор. Габариты составляют 120 × 120 × 44 мм, масса — 320 г с кулером. Для устройства доступны различные варианты корпусов и монтажных креплений, а также всевозможные аксессуары. Приобрести ODROID-H5 можно по ориентировочной цене $250 в виде barebone-системы (без модуля ОЗУ и накопителя).
24.05.2026 [12:26], Сергей Карасёв
Dell представила рабочую станцию Pro Precision 7 R1 формата 1U с ускорителем NVIDIA RTX Pro BlackwellКомпания Dell Technologies анонсировала рабочую станцию Pro Precision 7 R1, рассчитанную на монтаж в стойку. Новинка, построенная на аппаратной платформе Intel, предназначена для ИИ-инференса, задач визуализации, 3D-рендеринга, индустриальных приложений и пр. Устройство комплектуется «настольным» процессором Core Ultra Series 2. Объём оперативной памяти DDR5 ECC может достигать 128 Гбайт. Во фронтальной части расположены два отсека для накопителей: могут устанавливаться NVMe SSD и HDD суммарной вместимостью до 64 Тбайт. Рабочая станция несёт на борту ускоритель NVIDIA RTX PRO 6000 Blackwell Workstation Edition. Установлены два блока питания мощностью 800 Вт с резервированием. Верхняя граница заявленного диапазона рабочих температур находится на отметке +35 °C. Устройство, как отмечается, может эксплуатироваться в условиях плотной компоновки стоек, в том числе на периферии сети. Прочие технические характеристики пока не раскрываются. 
Источник изображения: Dell Technologies Ключевым преимуществом рабочей станции Pro Precision 7 R1 компания Dell называет именно стоечное исполнение. Благодаря этому могут применяться централизованные модели развёртывания, что повышает безопасность, а также улучшает управляемость и эффективность использования ресурсов. Вместо распределения компьютеров между отдельными членами команды, организации могут объединять вычислительные ресурсы в защищённых дата-центрах, предоставляя при этом пользователям удалённый доступ к необходимым мощностям. В продажу новинка поступит в июле нынешнего года.
23.05.2026 [15:49], Сергей Карасёв
Dell представила «элитные» All-Flash СХД PowerStore Elite вместимостью до 5,8 ПбайтDell Technologies анонсировала высокопроизводительные СХД нового поколения PowerStore Elite, относящиеся к классу All-Flash. Устройства выполнены на аппаратной платформе Intel, а в составе программной части используется PowerStoreOS 5.0. Дебютировали модели PowerStore 1500, 5500 и 9500. Все они выполнены в форм-факторе 3U с двумя контроллерами. Модель PowerStore 1500 комплектуется одним 24-ядерным Xeon (1,9 ГГц) и 512 Гбайт DDR5 (в расчёте на контроллер). Поддерживается до 24 NVMe-накопителей EDSFF E3.S (в перспективе — E3.L). В случае PowerStore 5500 задействованы два чипа Xeon с 24 ядрами (1,8 ГГц) и 1 Гбайт RAM на контроллер, а количество поддерживаемых E3.S достигает 40. Модификация PowerStore 9500 наделена двумя процессорами Xeon с 32 ядрами (2,2 ГГц) и 2 Гбайт RAM на контроллер; поддерживаются 40 накопителей. Все новинки допускают использование SSD типа TLC вместимостью до 15,36 Тбайт и QLC ёмкостью до 30,72 Тбайт. Могут подключаться полки расширения, поддерживающие до 44 EDSFF-накопителей. Максимальная общая вместимость достигает 5,8 Пбайт. Младшая версия использует межузловой интерконнект 100GbE RDMA, две другие — 200GbE RDMA. Могут быть использованы до пяти разъёмов OCP 3.0 (PCIe 4.0/5.0 x16). 
Источник изображения: Dell Независимо от модели, система охлаждения включает шесть вентиляторов на каждый контроллер (в сумме 12 вентиляторов на шасси). В зависимости от модификации будут доступны варианты с сетевыми портами в следующих конфигурациях: 4 × FC32/64, 4 × 1/10GbE, 4 × 10/25GbE, 2 × 100GbE. В дальнейшем появится поддержка 200/400GbE и 128Gb FC. Реализованы средства дедупликации и сжатия 6:1. Компания Dell заявляет, что новые системы можно объединять в кластеры с существующими массивами PowerStore. Продажи представленных устройств начнутся в июле.
22.05.2026 [12:00], Сергей Карасёв
Представлен российский сервер Delta Orca на базе Intel Xeon 6 для работы с неструктурированными даннымиКомпания Delta Computers анонсировала однопроцессорный сервер Delta Orca, построенный на аппаратной платформе Intel Xeon 6. Новинка ориентирована на использование в инфраструктурах Lakehouse, объединяющих гибкость «озёр данных» (Data Lake) и надёжность централизованных хранилищ (Data Warehouse). Устройство выполнено в форм-факторе 2OU для монтажа в 21″ стойку. В зависимости от модификации задействуется процессор Granite Rapids-SP (до 80 P-ядер) или Sierra Forest-SP (до 96 E-ядер) с показателем TDP до 350 Вт. Доступны восемь слотов для модулей оперативной памяти RDIMM/LRDIMM DDR5-6400 (или MCRDIMM-8000) суммарным объёмом до 2 Тбайт. Сервер допускает установку до 20 NVM-накопителей SFF U.2 (PCIe 5.0) толщиной 7 мм или до 10 устройств такого же типа толщиной 15 мм во фронтальной части. Кроме того, есть два коннектора для NVME SSD формата M2.2280. Предусмотрены слот PCIe 5.0 x16 для карты расширения HHHL, по одному порту USB 3.0 Type-A, USB Type-C (сервисный разъем) и Mini DP, сетевой порт управления 1GbE. Говорится о поддержке сетевых адаптеров 400GbE. Питание осуществляется от централизованного шинопровода OCP. Применена система гибридного охлаждения Delta Hybrid Cooling для поддержания работы процессора в режиме Turbo Boost Max в течение продолжительного времени. 
Источник изображения: Delta Computers Модель Delta Orca, по заявлениям производителя, оптимизирована для работы с неструктурированными данными и объектными хранилищами. Реализованы средства мониторинга и управления в собственной системе Delta BMC (внесено в реестр Минцифры и имеет сертификат ФСТЭК). Среди преимуществ новинки выделяются масштабируемость, высокая пропускная способность и надёжное хранение данных. Сервер уже доступен для предварительного заказа. |
|

