Материалы по тегу: instinct
|
12.10.2024 [18:06], Сергей Карасёв
Lenovo анонсировала серверы ThinkSystem с чипами AMD EPYC Turin и ускорителями Instinct MI325XКомпания Lenovo объявила о выпуске серверов ThinkSystem на новейших процессорах EPYC 9005 Turin, которые AMD официально представила на этой неделе. Некоторые системы комплектуются мощными ИИ-ускорителями Instinct MI325X. Чипы EPYC 9005 Turin доступны для таких серверов, как ThinkSystem SR635 V3 и ThinkSystem SR645 V3 формата 1U, а также ThinkSystem SR655 V3 и ThinkSystem SR665 V3 типоразмера 2U. Все они могут работать с платформами Windows Server, SUSE Linux Enterprise Server, Red Hat Enterprise Linux и VMware vSphere. Односокетная модель ThinkSystem SR635 V3 оснащена 12 слотами для модулей памяти TruDDR5-6400 суммарным объёмом до 1,5 Тбайт. Возможна установка 12 накопителей SFF с интерфейсом SAS/SATA/NVMe или 16 устройств EDSFF. Кроме того, предусмотрены два коннектора M.2 и два отсека для системных SFF-накопителей в тыльной части. Есть четыре посадочных места для однослотовых PCIe-ускорителей. Вариант ThinkSystem SR645 V3, в свою очередь, поддерживает установку двух процессоров и 24 модулей ОЗУ суммарным объёмом до 6 Тбайт. Возможны следующие конфигурации подсистемы хранения данных: 4 × LFF, 12 × SFF или 16 × EDSFF. Упомянуты три слота PCIe 4.0, два разъёма PCIe 5.0 и слот OCP 3.0. 
Источник изображения: Lenovo Серверы ThinkSystem SR655 V3 и ThinkSystem SR665 V3 поддерживают соответственно один и два процессора EPYC 9005 и 12 и 24 модуля TruDDR5-6400. У первого устройства есть десять слотов PCIe и разъём OCP 3.0, у второго — 12 слотов PCIe (9 стандарта PCIe 5.0) и разъём OCP 3.0. Обе модели могут нести на борту до 20 накопителей LFF или до 40 накопителей SFF.
12.10.2024 [17:54], Сергей Карасёв
Giga Computing выпустила серверы с чипами AMD EPYC Turin и ускорителями Instinct MI325XКомпания Giga Computing, серверное подразделение Gigabyte, объявила о поддержке новейших процессоров AMD EPYC 9005 Turin, дебютировавших на этой неделе. Эти чипы могут использоваться с более чем 60 моделями серверов и материнских плат. Компания также сообщила о намерении использовать в некоторых своих ИИ-системах ускорители AMD Instinct MI325X. Изделия Instinct входят в состав таких машин как G593-ZX1, G383-R80, G593-SX1 и др. Кроме того, представлены полностью новые продукты, в частности, сервер XV23-ZX0. Эта система выполнена в формате 2U с габаритами 438 × 87 × 900 мм. Возможна установка двух чипов в исполнении Socket SP5 с показателем cTDP до 500 Вт. Есть 24 слота для модулей DDR5-6000. Во фронтальной части расположены отсеки для шести SFF-накопителей NVMe/SATA/SAS-4. Кроме того, предусмотрены два коннектора M.2 2280/22110 PCIe 3.0 x2 и один разъём M.2 2280/22110 PCIe 3.0 x1 для SSD. В общей сложности доступны семь слотов PCIe 5.0 x16 для карт FHFL, в том числе четыре посадочных места для двухслотовых PCIe-ускорителей. В оснащение входят два сетевых порта 10GbE на базе Intel X550-AT2, выделенный сетевой порт управления, контроллер Aspeed AST2600. Спереди и сзади находятся по два порта USB 3.2 Gen1 Type-A. Кроме того, упомянут интерфейс Mini-DP. 
Источник изображения: Giga Computing Питание обеспечивают четыре блока мощностью 2000 Вт каждый с сертификатом 80 PLUS Titanium. Применены четыре системных вентилятора охлаждения диаметром 80 мм (15 000 об/мин). Диапазон рабочих температур простирается от +10 до +35 °C.
12.10.2024 [17:51], Сергей Карасёв
Dell представила ИИ-серверы PowerEdge на базе AMD EPYC TurinКомпания Dell Technologies анонсировала обновлённые серверы PowerEdge, ориентированные на ресурсоёмкие рабочие нагрузки ИИ. В основу положены процессоры AMD серии EPYC 9005 (Turin), насчитывающие до 192 вычислительных ядер. В частности, дебютировала модель PowerEdge XE7745 для тюнинга ИИ-моделей, инференса, НРС-задач и пр. Сервер построен на шасси 4U с воздушным охлаждением. Возможна установка до восьми PCIe-ускорителей двойной ширины или до 16 ускорителей одинарной ширины. Кроме того, доступны восемь дополнительных слотов PCIe 5.0 для сетевых адаптеров. Представлены также серверы PowerEdge R6725 и PowerEdge R7725 стандарта Data Center Modular Hardware Systems (DC-MHS) с расширенными возможностями по организации воздушного охлаждения. Они могут нести на борту два чипа EPYC 9005 с показателем TDP до 500 Вт. Устройства, как утверждается, обеспечивают рекордную производительность при работе со средствами виртуализации, базами данных и ИИ-приложениями. 
Источник изображения: Dell Помимо этого, анонсированы односокетные модели PowerEdge R6715 и PowerEdge R7715, которые будут доступны в различных конфигурациях в форматах 1U и 2U. Говорится о поддержке 24 модулей DIMM (2DPC). Отмечается, что версия R6715 демонстрирует мировые рекорды производительности для задач ИИ и виртуализации. Более подробные технические характеристики всех новых серверов будут раскрыты позднее. 
Источник изображения: Dell Для клиентов, развёртывающих ИИ-системы в больших масштабах, Dell предложит поддержку новейших ускорителей AMD Instinct MI325X в серверах PowerEdge XE. Улучшенный контроллер iDRAC (Integrated Dell Remote Access Controller) благодаря более быстрому процессору, увеличенному объёму памяти и выделенному сопроцессору безопасности упрощает управление серверами и повышает уровень защиты. Решения PowerEdge R6715, R7715, R6725 и R7725 станут доступны в ноябре, тогда как PowerEdge XE7745 поступит в продажу в январе 2025 года.
12.10.2024 [17:46], Сергей Карасёв
HPE представила мощную ИИ-систему ProLiant Compute XD685 с Instinct MI325X и другие серверы на чипах AMD EPYC TurinКомпания HPE сообщила о том, что её серверы ProLiant Gen11 получили поддержку новейших процессоров AMD EPYC 9005 Turin, официально представленных на этой неделе. Кроме того, дебютировала мощная система ProLiant Compute XD685, ориентированная на наиболее сложные нагрузки ИИ. Обновлённые модели ProLiant Gen11 унаследовали ключевые характеристики у аналогичных версий на чипах AMD EPYC Genoa. При этом, как утверждает HPE, благодаря переходу на EPYC 9005 Turin прирост общей производительности достигает 35 %, а энергетической эффективности — 25 %. Эти машины установили 30 новых мировых рекордов. В семейство ProLiant Gen11 входят устройства типоразмера 1U и 2U с поддержкой одного и двух процессоров. Предлагаются гибкие возможности в плане организации подсистемы хранения данных. Серверы уже доступны для заказа в некоторых регионах. 
Источник изображения: HPE В свою очередь, новая система ProLiant Compute XD685, показанная на изображении, выполнена в формате 5U. Она комплектуется двумя чипами EPYC 9005 Turin. В оснащение могут входить до восьми ИИ-ускорителей AMD Instinct MI325X или AMD Instinct MI300X. В стандартной конфигурации используется воздушное охлаждение, а при необходимости может быть развёрнуто прямое жидкостное охлаждение. Вместе с тем HPE Services предлагает полный спектр настраиваемых услуг для развёртывания крупных кластеров ИИ. Приём предварительных заказов на ProLiant Compute XD685 уже начался; организовать поставки НРЕ планирует в I квартале 2025 года.
11.10.2024 [19:55], Алексей Степин
256 Гбайт HBM3e — это хорошо, а 288 Гбайт — ещё лучше: AMD анонсировала ускорители Instinct MI325X и MI355XВчера компания AMD анонсировала серверные процессоры EPYC 9005 (Turin) и ускорители Instinct MI325X. Если верить AMD, новинки устанавливают новые эталоны производительности в своих сферах применения. О процессорах речь пойдёт в отдельном материале, а сейчас попробуем разобраться с Instinct MI325X — чем же именно он отличается от представленного ранее MI300X, архитектура которого в своё время была разобрана достаточно подробно. Сама AMD позиционирует MI325X в качестве наследника MI300X, способного конкурировать с NVIDIA H200 и, возможно, даже с B200. В сравнении с тем, что было опубликовано ранее, характеристики новинки несколько изменились. В частности, новый ускоритель получил 256 Гбайт памяти HBM3e, а не 288 Гбайт, как было обещано ранее. 
Источник здесь и далее: AMD via WCCFTech На приведённых слайдах с изображением кристалла MI325X отчетливо видно, что количество сборок HBM по-прежнему равно восьми, однако вместо ожидаемых сборок ёмкостью 36 Гбайт использованы менее ёмкие «стопки» на 32 Гбайт. Это не позволяет говорить о 50 % приросте по объёму, только о 33 %. Но и это немало! Пропускная способность подросла с 5,3 до 6 Тбайт/с.  Последнее может быть объяснено повышением тактовой частоты, но из-за тесной интеграции HBM3e с остальными частями ускорителя должна была вырасти и производительность. Тем не менее, AMD приводит же цифры, что и для MI300X —1,3 Пфлопс в режиме FP16 и 2,6 Пфлопс в режиме FP8. По сути, улучшены только характеристики подсистемы памяти.  Архитектурно MI325X полностью подобен предшественнику, за исключением блока HBM. Он по-прежнему базируется на CDNA 3, имеет такое же количество транзисторов (153 млрд) и производится с использованием тех же техпроцессов, 5 нм для блоков XCD и 6 нм для IOD. Но теплопакет превышает 750 Вт, в то время как у MI300X данный параметр не достигал столь высокого значения. 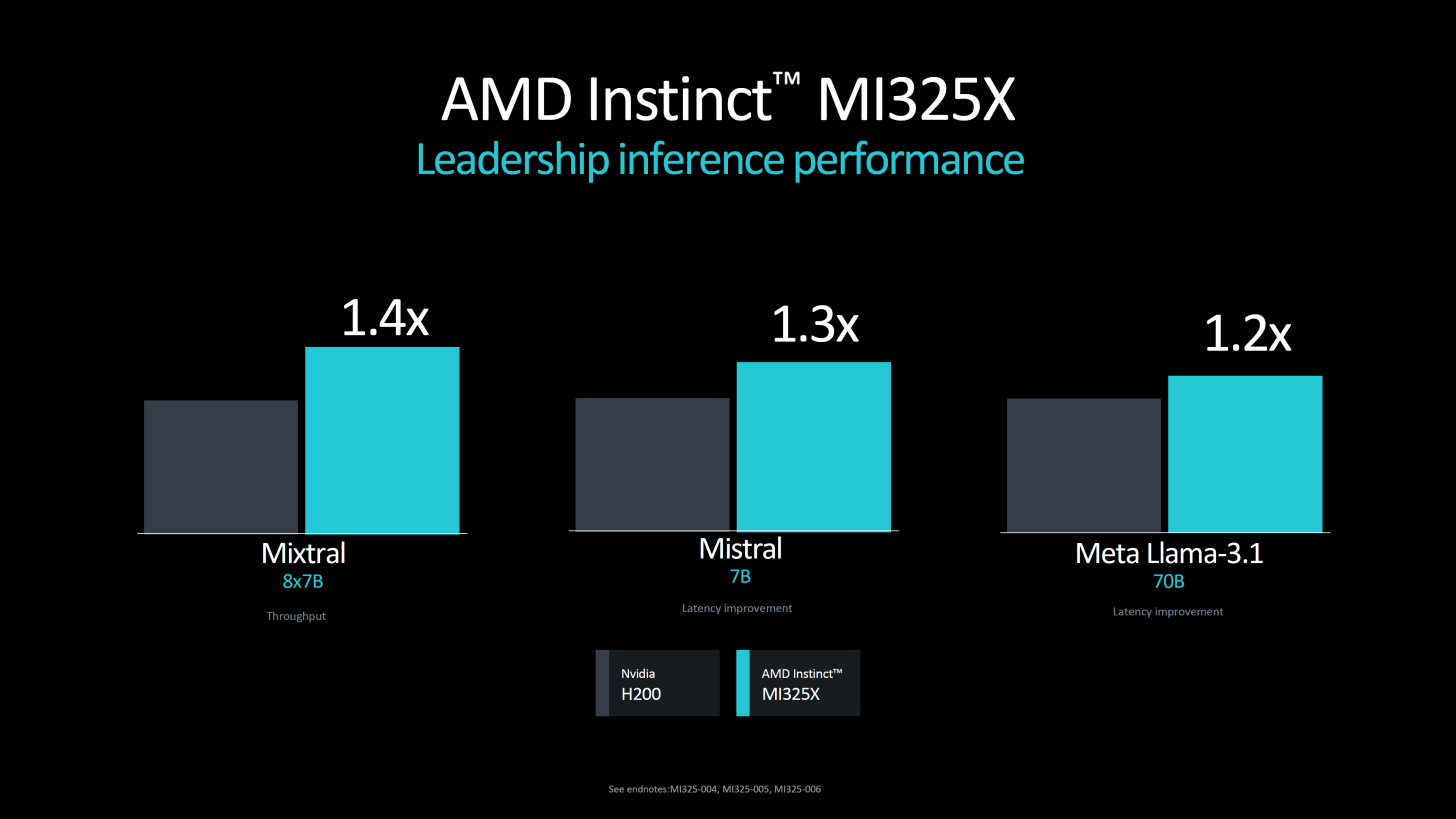 Ускорители подобного класса невозможно представить вне программной экосистемы. В настоящий момент AMD приводит данные о превосходстве MI325X над NVIDIA H200, варьирующемся в районе 20-40 % (в зависимости от нагрузки). Конечно, отчасти это заслуга памяти, но основной прирост заключается в оптимизации программной среды ROCm. По словам AMD, в задачах обучения и инференса производительность в версии 6.2 была увеличена более чем вдвое.  Для сравнения, в первых тестах MI300X в MLPerf Inference 4.1 отстал от NVIDIA H200 примерно на 50 %. Однако для полноты картины следует дождаться результатов тестов, проведённых сторонними источниками. Кроме того, H200 уже не самый совершенный ускоритель NVIDIA — в следующем году MI325X предстоит столкнуться с B200 на базе архитектуры Blackwell.  Ускорители Instinct MI325X будут доступны в I квартале 2025 года, но уже сейчас ясно, что усложнить жизнь своему главному конкуренту AMD в состоянии: так, вся обработка Llama 405B, используемой Meta✴, легла на плечи именно на MI300X. Активно используются решения AMD и в ЦОД Microsoft Azure.  Что касается следующего поколения ускорителей AMD Instinct MI355X, то оно намечено на II половину 2025 года. Оно получит обновлённую архитектуру CDNA 4, о которой пока нет никаких сведений, кроме упоминания о поддержке режимов FP6 и FP4. Вычислительные тайлы будут переведены на 3-нм техпроцесс, а их количество, как ожидается, возрастёт с 8 до 10. Тем не менее, роста тепловыделения избежать не удастся: заявлен теплопакет до 1000 Вт.  В Instinict MI355X получит дальнейшее развитие и подсистема памяти. Объём набортной HBM3e всё-таки достигнет 288 Гбайт, а пропускная способность вырастет с 6 до 8 Тбайт/с. Для связки из восьми MI355X AMD заявляет производительность в 18,5 Пфлопс в режиме FP16, что позволяет говорить о 2,31 Пфлопс для единственного ускорителя — то есть о примерно 80 % прироста в сравнении с MI325X.  Делать какие-либо далеко идущие выводы о решениях на базе CDNA 4 рано: вероятнее всего, даже лаборатории AMD ещё не располагают финальной версией MI355X, а кроме того, как уже понятно, огромную роль играет постоянно изменяющаяся и совершенствуемая программная среда, которая ко II половине 2025 года может претерпеть существенные изменения.  А вот гибридным решениям AMD планирует положить конец: преемника для Instinct MI300A, сочетающего в себе архитектуры CDNA 3 и Zen 4 не запланировано. Похоже, рынок для таких решений оказался слишком мал.
11.10.2024 [00:35], Владимир Мироненко
AMD представила серверные процессоры EPYC 9005 Turin и ускорители Instinct MI325XКомпания AMD представила ряд новых решений, включая серверные процессоры серии EPYC 9005 (Turin) и ускорители Instinct MI325X, которые, по словам компании, устанавливают новый стандарт производительности для ЦОД. Процессоры AMD EPYC 5-го поколения под кодовым названием Turin производятся с использованием техпроцесса 3 нм и 4 нм TSMC. Они предлагают тактовую частоту до 5,0 ГГц и от 8 до 192 ядер. AMD сообщила, что новая серия обеспечивает прирост показателя IPC на 17 % по сравнению с EPYC Genoa для корпоративных и облачных рабочих нагрузок и до 37 % в ИИ- и HPC-задачах по сравнению с Zen 4. Серия AMD EPYC 9005 включает 64-ядерный AMD EPYC 9575F, специально разработанный для ИИ-платформ на базе ускорителей, которым требуются максимальные возможности CPU. Турбочастота может достигать 5 ГГц, тогда как решение конкурента ограничено 3,8 ГГц — он до 28 % быстрее обрабатывает и передаёт данные ускорителям, что важно для требовательных рабочих нагрузок ИИ. 
Источник изображений: AMD В серии AMD EPYC 9005 доступны две версии чипов: 128-ядерная версия с классическими ядрами Zen5 и 192-ядерная версия с Zen5c. Оба варианта EPYC 9005 используют сокет SP5 и совместимы с некоторыми существующими платформами для Genoa (Zen4). Новинки поддерживают 12-канальную память DDR5-6400, а также предлагают полноценные обработку инструкций AVX-512 (целиком 512 бит за раз). 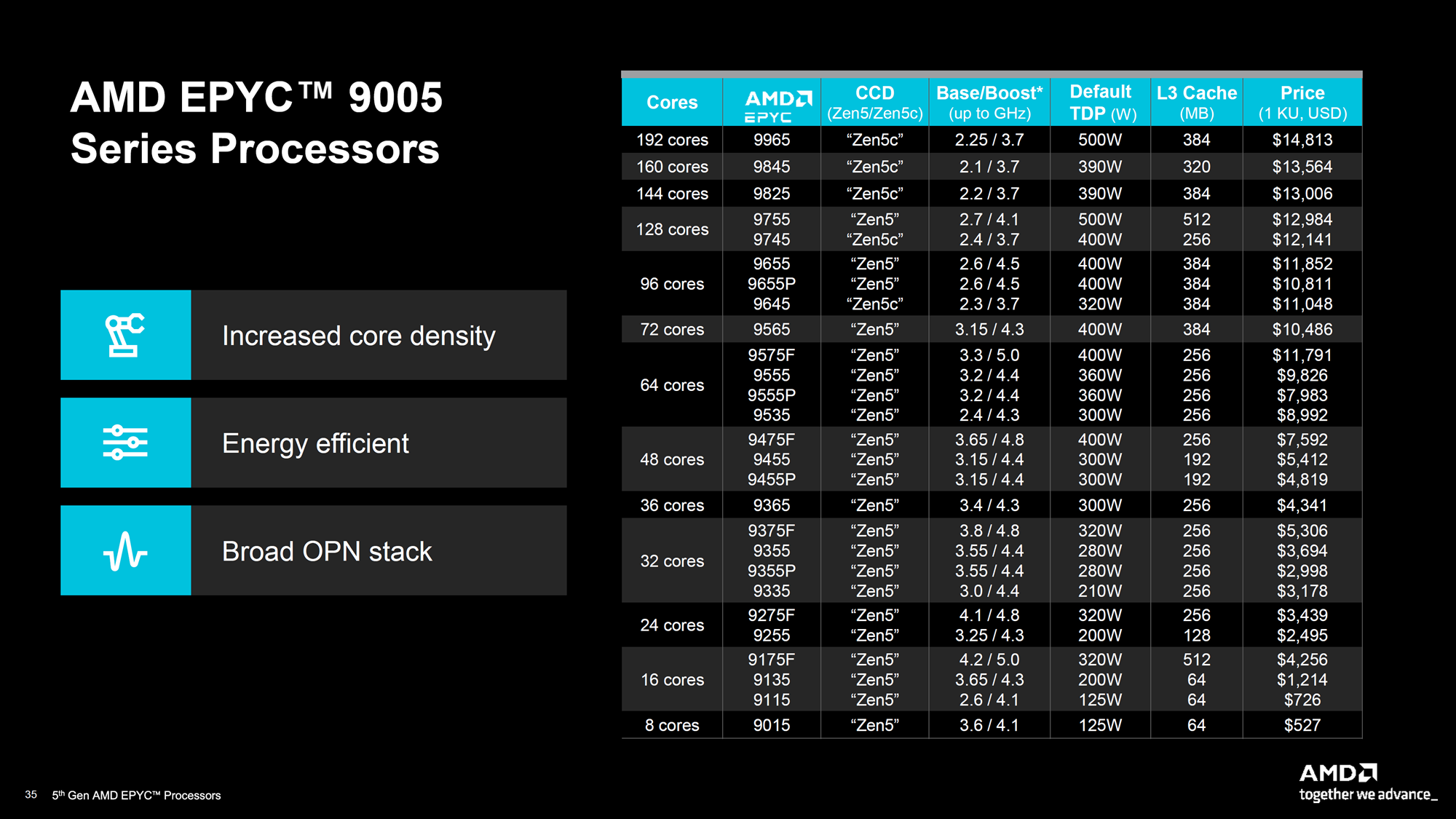 Как сообщает компания, флагманский процессор серии EPYC 9965 имеет 192 ядра Zen5c и тактовую частоту до 3,7 ГГц. Серверы на базе процессоров AMD EPYC 9965 обеспечивают по сравнению с серверами на базе процессоров Intel Xeon Platinum 8592+ (Emerald Rapids):
Также сообщается, что в сравнении с конкурентом 192-ядерный процессор EPYC 9965 обеспечивает до 3,7 раза большую производительность на end-to-end рабочих нагрузках ИИ, таких как TPCx-AI, которые имеют решающее значение для эффективного подхода к генеративному ИИ.  Что касается AMD Instinct MI325X, то новый ускоритель, построенный на архитектуре AMD CDNA 3, имеет 256 Гбайт памяти HBM3e с пропускной способностью 6,0 Тбайт/с, что соответственно в 1,8 и 1,3 раза больше, чем у NVIDIA H200. Ускоритель обеспечивает 2,6 Пфлопс производительности в режиме FP8, 1,3 Пфлопс производительности в режиме FP16.  Как утверждает AMD, по сравнению с H200 новый ускоритель в 1,3 раза быстрее в задачах инференса ИИ-модели Mistral 7B (FP16), в 1,2 раза — Llama 3.1 70B (FP8), в 1,4 раза — Mixtral 8x7B (FP16). Ускорители AMD Instinct MI325X будут доступны с I квартала 2025 года.  AMD также анонсировала следующее поколение ускорителей серии AMD Instinct MI350 на основе архитектуры AMD CDNA 4, разработанные для обеспечения 35-кратного улучшения производительности инференса по сравнению с ускорителями на базе AMD CDNA 3. Серия AMD Instinct MI350 получит до 288 Гбайт памяти HBM3e на ускоритель и поддержку форматов FP6/FP4. Новинка будет доступна во II половине 2025 года.
30.09.2024 [10:24], Сергей Карасёв
В облаке Vultr появились ускорители AMD Instinct MI300XVultr, крупнейший в мире частный облачный провайдер, объявил о том, что в составе его инфраструктуры теперь доступны ускорители AMD Instinct MI300X и открытый программный стек AMD ROCm. Клиенты могут использовать их для ресурсоёмких задач ИИ и НРС-нагрузок. Отмечается, что благодаря объединению платформы Vultr Serverless Inference с ускорителями Instinct MI300X даже небольшие предприятия получают возможность применять передовые технологии ИИ, которые ранее им были недоступны. Новое решение ориентировано на заказчиков из различных отраслей, включая здравоохранение, финансовые услуги, производство, энергетику, медиа, розничную торговлю и телекоммуникации. На сайте Vultr отмечается, что изделия Instinct MI300X обеспечивают ИИ-производительность в режиме TF32 до 653,7 Тфлопс, FP16 — 1307,4 Тфлопс, INT8 — 2614,9 TOPS, FP8 — 2614,9 Тфлопс. При НРС-нагрузках теоретическое пиковое быстродействие достигает 81,7 Тфлопс FP64 и 163,4 Тфлопс FP32. 
Источник изображения: Vultr Ускорители AMD интегрируются с Vultr Kubernetes Engine for Cloud GPU для формирования кластеров Kubernetes с ускорением на базе GPU. Компания Vultr говорит о высоком соотношении цены и производительности, гибких возможностях масштабирования и оптимизации для инференса. Нужно отметить, что ранее об использовании ускорителей Instinct MI300X в составе своей облачной инфраструктуры объявила корпорация Oracle. Новые инстансы BM.GPU.MI300X.8 могут использоваться в том числе для обработки больших языковых моделей (LLM), насчитывающих сотни миллиардов параметров.
17.09.2024 [23:07], Игорь Осколков
Швейцария ввела в эксплуатацию гибридный суперкомпьютер Alps: 11 тыс. NVIDIA GH200, 2 тыс. AMD EPYC Rome и щепотка A100, MI250X и MI300AШвейцарская высшая техническая школа Цюриха (ETH Zurich) провела церемонию официального запуска суперкомпьютера Alps в Швейцарском национальном суперкомпьютерном центре (CSCS) в Лугано. Система, построенная HPE, уже заняла шестую строчку в последнем рейтинге TOP500 и имеет устоявшеюся FP64-производительность 270 Пфлопс (теоретический пик — 354 Пфлопс). К ноябрю будут введены в строй остальные модули машины, и её максимальная производительность составит порядка 500 Пфлопс. 
Источник изображений: CSCS В июньском рейтинге TOP500 участвовал раздел из 2688 узлов HPE Cray EX254n с «фантастической четвёркой» NVIDIA Quad GH200. Если точнее, это всё же «старый» вариант ускорителя с H100 (96 Гбайт HBM3), 72-ядерным Arm-процессором Grace и 128 Гбайт LPDDR5x — суммарно 10 752 Grace Hopper. Данный раздел потребляет 5,2 МВт и в Green500 находится на 14 месте. Узлы, конечно же, используют СЖО. Это основной, но не единственный раздел суперкомпьютера. Ещё в 2020 году HPE развернула 1024 двухпроцессорных узла с 64-ядерными AMD EPYC 7742 (Rome) и 256/512 Гбайт RAM. Его производительность составляет 4,7 Пфлопс. Кроме того, в состав Alps входят 144 узла с одним 64-ядерным AMD EPYC, 128 Гбайт RAM и четырьмя NVIDIA A100 (80 или 96 Гбайт HBM2e).  Наконец, машина получит 24 узла с одним 64-ядерным AMD EPYC, 128 Гбайт RAM и четырьмя AMD Instinct MI250X (128 Гбайт HBM2e) и 128 узлов с четырьмя гибридными ускорителями AMD Instinct MI300A. Большая часть узлов будет объединена интерконнектом HPE Slingshot-11: 200G-подключение на узел или ускоритель. Более точную конфигурацию системы раскроют в ноябре. Lustre-хранилище для будущей машины обновили ещё в прошлом году. Основной СХД является Cray ClusterStor E1000 с подключением Slingshot-11. Так, было добавлено 100 Пбайт полезной HDD-ёмкости (8480 × 16 Тбайт) с пропускной способностью 1 Тбайт/с (300 тыс. IOPS на запись, 1,5 млн IOPS на чтение) и 5 Пбайт SSD, а также резервные ёмкости. За архивное хранение отвечают две ленточные библиотеки объёмом 130 Пбайт каждая.  Особенностью системы является её геораспределённость (фактически узлы размещены в четырёх местах) и облачная модель использования. Так, метеослужба страны MeteoSwiss получила в своё распоряжение выделенный виртуальный кластер, что уже позволило перейти на использование метеомодели более высокого разрешения, которая лучше отражает сложный рельеф Швейцарии. Кроме того, для подстраховки часть узлов Alps размещена на территории Федеральной политехнической школы Лозанны (EPFL). Alps приходит на смену суперкомпьютеру Piz Daint (Cray XC50/40, 21,2 Пфлопс), о завершении жизненного цикла которого было объявлено в конце июля 2024 года. В CSCS пока останутся машины Arolla + Tsa (для нужд MeteoSwiss) и Blue Brain 5 (решает задачи реконструкции и симуляции мозга). Alps же помимо традиционных HPC-нагрузок, будет использоваться для разработки ИИ-решений.
20.08.2024 [23:30], Руслан Авдеев
Суперкомпьютер с лабораторией: Пентагон создаёт новый комплекс защиты США от биологических угрозНовейший проект Министерства обороны США объединит суперкомпьютер и т.н. лабораторию быстрого реагирования (RRL, Rapid Response Laboratory). The Register сообщает, что проект призван укрепить биологическую защиту Соединённых Штатов. Расположенная на территории Ливерморской национальной лаборатории им. Э. Лоуренса (Lawrence Livermore National Laboratory, LLNL) в Калифорнии, машина строится при сотрудничестве с Национальным агентством ядерной безопасности США (National Nuclear Security Agency, NNSA) и будет основана на той же архитектуре, что и грядущий экзафлопсный суперкомпьютер El Capitan на базе ускорителей AMD Instinct MI300A. Спецификации аппаратного обеспечения и ПО не раскрываются. Машина будет использоваться как военными, так и гражданскими специалистами для крупномасштабных симуляций, ИИ-моделирования, классификации угроз, а при сотрудничестве с новой биологической лабораторией — для ускорения разработки контрмер. Некоторые из них, как ожидается, будут чрезвычайно важными, поскольку решения можно будет находить в течение дней, если не часов. Впрочем, новые вычислительные мощности военные биологи намерены использовать на регулярной основе. Конечно, как отмечает The Register, инструменты для разработки средств борьбы могут использоваться и для создания биологического оружия, хотя в самом Пентагоне о подобном применении суперкомпьютера не упоминают. 
Источник изображения: Lawrence Livermore National Laboratory Концепция биологической защиты США представляет собой комплекс мер для борьбы как с естественными, так и рукотворными биологическими угрозами военным и гражданским лицам, природным ресурсам, источникам пищи и воды и т.п., воздействие на которые может негативно сказаться на возможностях воюющей стороны. Поскольку биологические угрозы имеют важное значение для самых разных ведомств, суперкомпьютер будет доступен и прочим правительственным агентствам США, а также союзникам Соединённых Штатов, академическим исследователям и промышленным компаниям. Лаборатория RRL будет находиться буквально в «шаговой доступности» от суперкомпьютера. Она станет дополнением к проекту Пентагона Generative Unconstrained Intelligent Drug Engineering (GUIDE). GUIDE занимается разработкой медицинских и биологических контрмер с использованием машинного обучения для создания анител, структурной биологии, биоинформатики, молекулярного моделирования и т.д. Новый суперкомпьютер позволит Пентагону быстрые и многократные тесты моделируемых вакцин и лекарств. RRL автоматизирована и снабжена роботами и иными инструментами для изучения строения и свойств молекул, для редактирования структуры белков и т.д. По словам экспертов LLNL, лаборатория, подключённая к суперкомпьютеру, позволит изменить всю систему распознавания биологических угроз и ответа на них.
23.03.2022 [01:10], Алексей Степин
Анонсирован ускоритель AMD Instinct MI210: половинка MI250 в форм-факторе PCIe-картыAMD продолжает активно осваивать рынок ускорителей и ИИ-сопроцессоров. Вслед за сверхмощными Instinct MI250 и MI250X, анонсированными ещё осенью прошлого года, «красные» представили новинку — ускоритель Instinct MI210. Это менее мощная, одночиповая версия ускорителя с архитектурой CDNA 2, дополняющая семейство MI200 и имеющая более универсальный форм-фактор PCIe-карты. Если Instinct MI250/250X существует только как OAM-модуль, то новый Instinct MI210 имеет вид обычной платы расширения с разъёмом PCI Express 4.0. Это неудивительно, ведь MI250 физически невозможно уложить в тепловые и энергетические рамки, обеспечиваемые таким форм-фактором, поскольку два чипа Aldebaran требуют 560 Вт против привычных для PCIe-плат 300 Вт. Для питания MI210 используется как слот PCIe, так и 8-контактный разъём EPS12V.  Поскольку ускоритель на борту новинки только один, она вдвое уступает MI250/250X по всем параметрам, но всё равно обеспечивает весьма неплохую производительность во всех форматах вычислений. Стоит отметить, что функциональные возможности MI210 не уменьшились. Осталась, например, поддержка Infinity Fabric 3.0 — соответствующие разъёмы расположены в верхней части карты, и она поддерживает работу в кластерном режиме из двух или четырёх ускорителей. 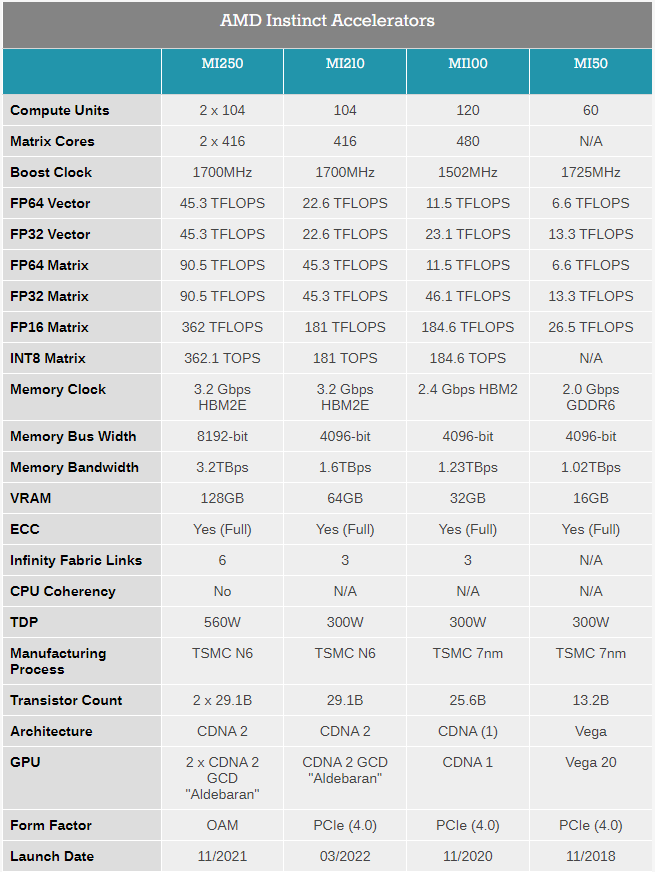
Таблица опубликована AnandTech В MI210 используется более простой вариант Aldebaran с одним кристаллом. Что интересно, по количеству вычислительных блоков этот вариант уступает более старому MI100 (104 CU против 120, 416 матричных ядер против 480). Однако последний использует первую итерацию архитектуры CDNA и работает на меньшей частоте — 1500 против 1700 МГц у новинки. В некоторых форматах вычислений MI100 может быть быстрее, но разница крайне незначительна. 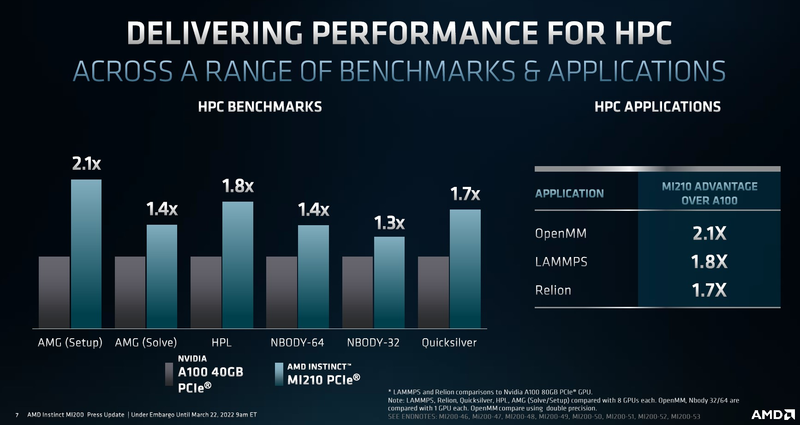
Производительность AMD Instinct MI210 в сравнении с NVIDIA A100 40GB PCIe CDNA2 позволяет использовать уникальные форматы данных, вроде packed FP32, однако это требует поддержки со стороны разработчиков, что несколько затруднит создание универсального ПО, способного полностью задействовать возможности MI210. Но в первую очередь, это ускоритель, не «зажимающий» FP64-производительность: свыше 22 Тфлопс в векторных операциях и 45 Тфлопс — в матричных. Сервер с одним или несколькими MI210 может использоваться в качестве универсальной платформы разработки ПО для суперкомпьютеров на базе более мощных ускорителей AMD Instinct MI250/250X. Новинка уже доступна у традиционных партнёров AMD по выпуску серверов, включая ASUS, Dell, HPE, Supermicro и Lenovo, которые также предлагают более мощные решения на базе MI250/250X. |
|

