Материалы по тегу: hgx
|
08.05.2025 [19:22], Сергей Карасёв
Cadence представила суперкомпьютер Millennium M2000 на базе NVIDIA BlackwellКомпания Cadence анонсировала суперкомпьютер Millennium M2000, спроектированный для выполнения сложного моделирования с использованием ИИ. Новая НРС-система предназначена для ускорения проектирования микрочипов, разработки лекарственных препаратов следующего поколения и пр. Суперкомпьютер построен на платформе NVIDIA HGX B200. Кроме того, задействованы карты NVIDIA RTX Pro 6000 Blackwell Server Edition, оснащённые 96 Гбайт памяти GDDR7. Применены библиотеки NVIDIA CUDA-X и специализированное ПО для решения ресурсоёмких задач. Утверждается, что Millennium M2000 обеспечивает до 80 раз более высокую производительность по сравнению с системами на базе CPU в области автоматизации проектирования электроники (EDA), создания и анализа систем (SDA) и разработки медикаментов. При этом глубоко оптимизированный программно-аппаратный стек помогает существенно сократить общее энергопотребление. В качестве примера приводится моделирование подсистемы питания на уровне полупроводниковых чипов. В случае вычислительных комплексов на основе сотен традиционных CPU на выполнение такой задачи может потребоваться около двух недель. Суперкомпьютер Millennium M2000 позволит получить результат менее чем за один день. 
Источник изображения: Cadence Генеральный директор NVIDIA Дженсен Хуанг (Jensen Huang) сообщил, что компания планирует приобрести десять суперкомпьютерных систем Millennium на базе GB200 NVL72 для ускорения проектирования собственных продуктов. Сторонние заказчики смогут получить доступ к Millennium M2000 через облако или купить устройство для установки в собственном дата-центре. Базовая конфигурация включает около 32 ускорителей и стоит $2 млн, но это не финальная цена.
13.04.2025 [23:54], Владимир Мироненко
ИИ-агенты под присмотром: Google Distributed Cloud заработает на on-premise платформах NVIDIA Blackwell DGX/HGX
b200
dgx
google cloud platform
hardware
hgx
nvidia
гибридное облако
ии
ии-агент
инференс
конфиденциальность
облако
частное облако
NVIDIA объявила о стратегическом партнёрстве с Google Cloud с целью внедрения агентного ИИ на предприятиях, которые хотели бы локально использовать семейство моделей Google Gemini с помощью платформ NVIDIA Blackwell HGX/DGX, а также функции NVIDIA Confidential Computing для повышения безопасности данных. Интеграция платформы NVIDIA Blackwell с портфелем программно-аппаратных решений Google Distributed Cloud позволяет локальным ЦОД соответствовать нормативным требованиям и законам о суверенитете данных, блокируя доступ к конфиденциальной информации, включая истории болезни пациентов, финансовые транзакции и секретную правительственную информацию. NVIDIA Confidential Computing защищает конфиденциальный код в моделях Gemini от несанкционированного доступа и утечек данных — запросы пользователя к API Gemini, а также данные, которые они использовали для тонкой настройки, остаются в безопасности и защищены от несанкционированного доступа или изменений. Сачин Гупта (Sachin Gupta), вице-президент и генеральный менеджер по инфраструктуре и решениям в Google Cloud, отметил, что партнёрство позволяет предприятиям в полной мере использовать весь потенциал агентного ИИ, внедряя модели Gemini в локальные системы, и объединяя производительность NVIDIA Blackwell и возможности конфиденциальных вычислений. Хотя многие уже могут использовать модели с мультимодальным рассуждением — интегрируя текст, изображения, код и другие типы данных для решения сложных проблем и создания облачных приложений агентного ИИ, предприятия с повышенными требованиями к безопасности или суверенитету данных столкнулись с трудностями при внедрении этих технологий. Данное партнёрство позволит решить эти проблемы, благодаря чему Google Cloud становится одним из первых поставщиков, предлагающих возможности конфиденциальных вычислений для защиты рабочих нагрузок ИИ-агентов в любой среде, как облачной, так и гибридной. 
Источник изображения: NVIDIA Масштабирование агентного ИИ требует надёжного мониторинга и безопасности для обеспечения стабильной производительности и соответствия требованиям. Google Cloud представила новый шлюз GKE Inference Gateway, созданный для оптимизации развёртывания рабочих нагрузок ИИ-агентов с расширенной маршрутизацией и масштабируемостью. Интеграция с NVIDIA Triton Inference Server и NVIDIA NeMo Guardrails обеспечивает интеллектуальную балансировку нагрузки, которая повышает производительность и снижает затраты на обслуживание, также обеспечивая централизованную безопасность и управление моделями. В дальнейшем Google Cloud планирует улучшить отслеживания рабочих нагрузок агентского ИИ, интегрировав NVIDIA Dynamo, библиотеку с открытым исходным кодом, предназначенную для обслуживания и масштабирования рассуждающих моделей. Этот перспективный подход гарантирует, что предприятия смогут уверенно масштабировать свои приложения агентского ИИ, сохраняя при этом безопасность и соответствие требованиям.
04.02.2025 [12:03], Владимир Мироненко
Google представила превью инстансов A4 на базе ускорителей NVIDIA B200Google объявила о предварительной доступности инстансов A4 на базе новых ускорителей B200 от NVIDIA с архитектурой архитектуры Blackwell. Инстанс A4 обеспечивает значительный прирост производительности по сравнению с предшественником A3. A4 используют системы NVIDIA HGX B200 с восемью ускорителями, объединёнными посредством NVIDIA NVLink. Как отметила компания, NVIDIA HGX B200 предлагает в 2,25 раза большую пиковую вычислительную мощность и в 2,25 раза большую ёмкость HBM по сравнению с инстансами A3, что делает A4 универсальным вариантом для обучения и тонкой настройки широкого спектра архитектур моделей, в то время как увеличенная вычислительная мощность и ёмкость HBM делают их подходящим вариантом для обработки нагрузок с низкой задержкой. 
Источник изображения: NVIDIA Инстансы A4 интегрируют инфраструктурные инновации Google, включая улучшенные сетевые возможности с использованием адаптеров Titanium ML, поддержку управляемой службы кластера Google Kubernetes Engine и доступ через полностью управляемую унифицированную платформу Vertex AI для разработки и использования генеративного ИИ. Также используется открытое ПО: в дополнение к использованию фреймворка МО PyTorch и CUDA компания сотрудничает с NVIDIA для оптимизации JAX и XLA. Как отметила компания, эффективное масштабирование обучения модели ИИ требует точной и масштабируемой оркестрации ресурсов инфраструктуры. При этом рабочие нагрузки часто охватывают тысячи виртуальных машин. Специализированная платформа Hypercompute Cluster позволит развёртывать и управлять большими кластерами виртуальных машин A4 с вычислениями, хранением и сетями как единым целым, обеспечивая при этом высокую производительность и устойчивость для больших распределённых рабочих нагрузок.
28.12.2024 [01:55], Владимир Мироненко
Дороже, но втрое эффективнее: NVIDIA готовит ускорители GB300 с 288 Гбайт HBM3E и TDP 1,4 кВтNVIDIA выпустила новые ускорители GB300 и B300 всего через шесть месяцев после выхода GB200 и B200. И это не минорное обновление, как может показаться на первый взгляд — появление (G)B300 приведёт к серьёзной трансформации отрасли, особенно с учётом значительных улучшений в инференсе «размышляющих» моделей и обучении, пишет SemiAnalysis. При этом с переходом на B300 вся цепочка поставок меняется, и от этого кто-то выиграет, а кто-то проиграет. Конструкция вычислительного кристалла B300 (ранее известного как Blackwell Ultra), изготавливаемого с использованием кастомного техпроцесса TSMC 4NP. Благодаря этому он обеспечивает на 50 % больше Флопс (FP4) по сравнению с B200 на уровне продукта в целом. Часть прироста производительности будет получена за счёт увеличения TDP, достигающим 1,4 кВт и 1,2 кВт для GB300 и B300 HGX соответственно (по сравнению с 1,2 кВт и 1 кВт для GB200 и B200). Остальное повышение производительности связано с архитектурными улучшениями и оптимизациями на уровне системы, такими как динамическое распределение мощности между CPU и GPU. Кроме того, в B300 применяется память HBM3E 12-Hi, а не 8-Hi, ёмкость которой выросла до 288 Гбайт. Однако скорость на контакт осталась прежней, так что суммарная пропускная способность памяти (ПСП) по-прежнему составляет 8 Тбайт/с. В качестве системной памяти будут применяться модули LPCAMM. Разница в производительности и экономичности из-за увеличения объёма HBM намного больше, чем кажется. Усовершенствования памяти имеют решающее значение для обучения и инференса больших языковых моделей (LLM) в стиле OpenAI O3, поскольку более длинные последовательности токенов негативно влияют на скорость обработки и задержку. 
Источник изображения: NVIDIA На примере обновления H100 до H200 хорошо видно, как память влияет на производительность ускорителя. Более высокая ПСП (H200 — 4,8 Тбайт/с, H100 — 3,35 Тбайт/с) в целом улучшила интерактивность в инференсе на 43 %. А большая ёмкость памяти снизила объём перемещаемых данных и увеличила допустимый размер KVCache, что увеличило количество генерируемых токенов в секунду втрое. Это положительно сказывается на пользовательском опыте, что особенно важно для всё более сложных и «умных» моделей, которые могут приносить больше дохода с каждого ускорителя. Валовая прибыль от использования передовых моделей превышает 70 %, тогда как для отстающих моделей в конкурентной open source среде она составляет менее 20 %. 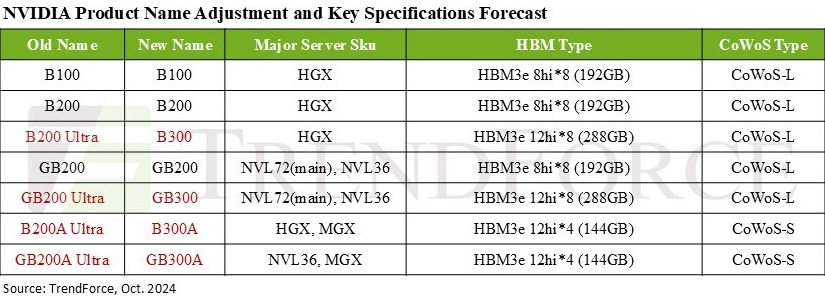
Источник изображения: TrendForce Однако одного наращивания скорости и памяти, как это делает AMD в Instinct MI300X (192 Гбайт), MI325X и MI355X (256 Гбайт и 288 Гбайт соответственно), мало. И дело не в том, что забагованное ПО компании не позволяет раскрыть потенциал ускорителей, а в особенности общения ускорителей между собой. Только NVIDIA может предложить коммутируемое соединение «все ко всем» посредством NVLink. В GB200 NVL72 все 72 ускорителя могут совместно работать над одной и той же задачей, что повышает интерактивность, снижая задержку для каждой цепочки размышлений и в то же время увеличивая их максимальную длину. На практике NVL72 — единственный способ увеличить длину инференса до более чем 100 тыс. токенов и при этом экономически эффективный, говорит SemiAnalysis. По оценкам, GB300 NVL72 обойдётся заказчиками минимум в $7,5 млн, тогда как GB200 NVL72 стоил порядка $3 млн.
31.10.2024 [11:33], Сергей Карасёв
Cisco представила ИИ-сервер UCS C885A M8 на базе NVIDIA H100/H200 или AMD Instinct MI300XКомпания Cisco анонсировала сервер высокой плотности UCS C885A M8, предназначенный для решения задач в области ИИ, таких как обучение больших языковых моделей (LLM), тонкая настройка моделей, инференс, RAG и пр. 
Источник изображения: Cisco Устройство выполнено в форм-факторе 8U. В зависимости от модификации устанавливаются два процессора AMD EPYC 9554 поколения Genoa (64 ядра; 128 потоков; 3,1–3,75 ГГц; 360 Вт) или два чипа EPYC 9575F семейства Turin (64 ядра; 128 потоков; 3,3–5,0 ГГц; 400 Вт). Доступны 24 слота для модулей DDR5-600 суммарным объёмом 2,3 Тбайт. В максимальной конфигурации могут быть задействованы восемь SXM-ускорителей NVIDIA H100, H200 или AMD Instinct MI300X. Каждый ускоритель дополнен сетевым адаптером NVIDIA ConnectX-7 или NVIDIA BlueField-3 SuperNIC. Кроме того, в состав сервера входит DPU BlueField-3. Слоты расширения выполнены по схеме 5 × PCIe 5.0 x16 FHHL плюс 8 × PCIe 5.0 x16 HHHL и 1 × OCP 3.0 PCIe 5.0 x8 (для карты X710-T2L 2x10G RJ45 NIC). 
Источник изображения: Cisco Новинка оборудована загрузочным SSD вместимостью 1 Тбайт (M.2 NVMe), а также 16 накопителями U.2 NVMe SSD на 1,92 Тбайт каждый. Установлены два блока питания мощностью 2700 Вт и шесть блоков на 3000 Вт с возможностью горячей замены. Cisco также представила инфраструктурные стеки AI POD, адаптированные для конкретных вариантов использования ИИ в различных отраслях. Они объединяют вычислительные узлы, сетевые компоненты, средства хранения и управления. Стеки, как утверждается, обеспечивают хорошую масштабируемость и высокую эффективность при решении ИИ-задач.
29.10.2024 [20:28], Сергей Карасёв
Раскрыты подробности архитектуры ИИ-кластера xAI Colossus со 100 тыс. ускорителей NVIDIA H100Портал ServeTheHome рассказал подробности об архитектуре вычислительного кластера xAI Colossus, предназначенного для обучения крупных ИИ-моделей. Эта система использует 100 тыс. NVIDIA H100, а в дальнейшем количество ускорителей планируется увеличить вдвое. Это самый крупный из известных ИИ-кластеров на текущий момент. Оборудование для него поставили компании Dell и Supermicro. Стартап xAI, курируемый Илоном Маском (Elon Musk), объявил о запуске суперкомпьютера Colossus в начале сентября нынешнего года. Утверждается, что на создание системы потребовалось всего 122 дня. Причём с момента установки первой стойки с серверами до начала обучения ИИ-моделей прошло только 19 суток. Впрочем, как отмечают эксперты, поскольку машина является «однозадачной», т.е. в отличие от традиционных суперкомпьютеров предназначенной только для работы с ИИ, ускорить строительство было не так уж сложно, хотя результат всё равно впечатляющий. Как сообщается, в составе Colossus применены серверы на платформе NVIDIA HGX H100, оборудованные системой жидкостного охлаждения. Каждый узел Supermicro серии TNHR2-LCC типоразмера 4U содержит восемь ускорителей NVIDIA H100 и два CPU. Узел разделён на две половинки, одна с CPU и PCIe-коммутаторами и одна с HGX-платой, которые могут извлекаться независимо для простоты обслуживания. CPU, коммутаторы и ускорители охлаждаются посредством СЖО. 
Источник изображения: Supermicro Вентиляторы в шасси тоже есть. Воздух от них попадает на теплообменники на задней двери, которые уносят остаточное тепло. Холодных и горячих коридоров в ЦОД нет, воздух имеет одинаковую температуру во всём зале. В нижней части стоек располагается ещё один 4U-блок Supermicro для CDU с резервированием и поддержкой горячей заменой насосов. Каждый сервер имеет четыре блока питания с резервированием и возможностью горячей замены, которые подключены к трёхфазным PDU. Одна стойка объединяет восемь узлов NVIDIA HGX H100, между которыми располагаются коллекторы СЖО в формате 1U. Таким образом, каждая стойка насчитывает 64 экземпляра H100. Стойки организованы в группы по восемь штук, которые образуют малые кластеры из 512 ускорителей H100. Они в свою очередь объединены в т.н. «острова» по 25 тыс. ускорителей, каждому из которых полагается собственный машинный зал. Общее количество стоек в составе Colossus превышает 1500.  Помимо узлов с ускорителями также есть CPU-узлы и узлы хранения All-Flash (1U). Как отмечает NVIDIA, в кластере Colossus задействована сетевая платформа Spectrum-X Ethernet. Применены коммутаторы Spectrum-X SN5600 и сетевые карты на базе чипа BlueField-3. Компания говорит об использовании трёхуровневой Ethernet-сети с 400GbE-подключением, но точная топология не указана. Судя по всему, выделенной сети для работы с хранилищем не предусмотрено. Каждом ускорителю полагается один 400GbE-адаптер SuperNIC, который и объединяет их в RDMA-сеть. Кроме того, у каждого GPU-узла есть ещё один 400GbE DPU, а также подключение к сервисной сети. Сетевые карты находятся в собственных лотках, благодаря чему их можно заменять без демонтажа шасси. По словам NVIDIA, уровень утилизации сети достигает 95 %. В качестве энергетического буфера между электросетью и суперкомпьютером используются аккумуляторные банки Tesla Megapack ёмкостью 3,9 МВт·ч каждый. Они необходимы для того, чтобы компенсировать всплески потребляемой мощности, когда нагрузка на ускорители резко возрастает в силу выполняемых ИИ-задач. Впрочем, вероятно, есть и ещё одна причина для такого решения — на первом этапе Colossus был лишён подключения к основной энергосети и в вопросе питания во многом полагался на генераторы.
19.08.2024 [10:10], Сергей Карасёв
Gigabyte представила ИИ-серверы с ускорителями NVIDIA H200 и процессорами AMD и IntelКомпания Gigabyte анонсировала HGX-серверы G593-SD1-AAX3 и G593-ZD1-AAX3, предназначенные для задач ИИ и НРС. Устройства, выполненные в форм-факторе 5U, включают до восьми ускорителей NVIDIA H200. При этом используется воздушное охлаждение. 
Источник изображений: Gigabyte Модель G593-SD1-AAX3 рассчитана на два процессора Intel Xeon Emerald Rapids с показателем TDP до 350 Вт, а версия G593-ZD1-AAX3 располагает двумя сокетами для чипов AMD EPYC Genoa с TDP до 300 Вт. Доступны соответственно 32 и 24 слота для модулей оперативной памяти DDR5.  Серверы наделены восемью фронтальными отсеками для SFF-накопителей NVMe/SATA/SAS-4, двумя сетевыми портами 10GbE на основе разъёмов RJ-45 (выведены на лицевую панель) и выделенным портом управления 1GbE (находится сзади). Есть четыре слота FHHL PCIe 5.0 x16 и восемь разъёмов LP PCIe 5.0 x16. Модель на платформе AMD дополнительно располагает двумя коннекторами М.2 для SSD с интерфейсом PCIe 3.0 x4 и x1.  Питание у обоих серверов обеспечивают шесть блоков мощностью 3000 Вт с сертификатом 80 Plus Titanium. Габариты новинок составляют 447 × 219,7 × 945 мм. Диапазон рабочих температур — от +10 до +35 °C. Есть два порта USB 3.2 Gen1 и разъём D-Sub. Массовое производство серверов Gigabyte серии G593 запланировано на II половину 2024 года. Эти системы станут временной заменой (G)B200-серверов, выпуск которых задерживается.
08.08.2024 [00:48], Сергей Карасёв
NVIDIA задержит выпуск ускорителей GB200, отложит B100/B200, а на замену предложит B200AКомпания NVIDIA, по сообщению ресурса The Information, вынуждена повременить с началом массового выпуска ИИ-ускорителей следующего поколения на архитектуре Blackwell, сохранив высокие темпы производства Hopper. Проблема, как утверждается, связана с технологией упаковки Chip on Wafer on Substrate (CoWoS) от TSMC. Отмечается, что NVIDIA недавно проинформировала Microsoft о задержках, затрагивающих наиболее продвинутые решения семейства Blackwell. Речь, в частности, идёт об изделиях Blackwell B200. Серийное производство этих ускорителей может быть отложено как минимум на три месяца — в лучшем случае до I квартала 2025 года. Это может повлиять на планы Microsoft, Meta✴ и других операторов дата-центров по расширению мощностей для задач ИИ и НРС. По данным исследовательской фирмы SemiAnalysis, задержка связана с физическим дизайном изделий Blackwell. Это первые массовые ускорители, в которых используется технология упаковки TSMC CoWoS-L. Это сложная и высокоточная методика, предусматривающая применение органического интерпозера — лимит возможностей технологии предыдущего поколения CoWoS-S был достигнут в AMD Instinct MI300X. Кремниевый интерпорзер, подходящий для B200, оказался бы слишком хрупок. Однако органический интерпозер имеет не лучшие электрические характеристики, поэтому для связи используются кремниевые мостики. В используемых материалах как раз и кроется основная проблема — из-за разности коэффициента теплового расширения различных компонентов появляются изгибы, которые разрушают контакты и сами чиплеты. При этом точность и аккуратность соединений крайне важна для работы внутреннего интерконнекта NV-HBI, который объединяет два вычислительных тайла на скорости 10 Тбайт/с. Поэтому сейчас NVIDIA с TSMC заняты переработкой мостиков и, по слухам, нескольких слоёв металлизации самих тайлов.  Вместе с тем у TSMC наблюдается нехватка мощностей по упаковке CoWoS. Компания в течение последних двух лет наращивала мощности CoWoS-S, в основном для удовлетворения потребностей NVIDIA, но теперь последняя переводит свои продукты на CoWoS-L. Поэтому TSMC строит фабрику AP6 под новую технологию упаковки, а также переведёт уже имеющиеся мощности AP3 на CoWoS-L. При этом конкуренты TSMC не могут и вряд ли смогут в ближайшее время предоставить хоть какую-то альтернативную технологию упаковки, которая подойдёт NVIDIA. Таким образом, как сообщается, NVIDIA предстоит определиться с тем, как использовать доступные производственные мощности TSMC. По мнению SemiAnalysis, компания почти полностью сосредоточена на стоечных суперускорителях GB200 NVL36/72, которые достанутся гиперскейлерам и небольшому числу других игроков, тогда как HGX-решения B100 и B200 «сейчас фактически отменяются», хотя малые партии последних всё же должны попасть на рынок. Однако у NVIDIA есть и запасной план. План заключается в выпуске упрощённых монолитных чипов B200A на базе одного кристалла B102, который также станет основой для ускорителя B20, ориентированного на Китай. B200A получит всего четыре стека HBM3e (144 Гбайт, 4 Тбайт/с), а его TDP составит 700 или 1000 Вт. Важным преимуществом в данном случае является возможность использования упаковки CoWoS-S. Чипы B200A как раз и попадут в массовые HGX-системы вместо изначально планировавшихся B100/B200.  На смену B200A придут B200A Ultra, у которых производительность повысится, но вот апгрейда памяти не будет. Они тоже попадут в HGX-платформы, но главное не это. На их основе NVIDIA предложит компромиссные суперускорители MGX GB200A Ultra NVL36. Они получат восемь 2U-узлов, в каждом из которых будет по одному процессору Grace и четыре 700-Вт B200A Ultra. Ускорители по-прежнему будут полноценно объединены шиной NVLink5 (одночиповые 1U-коммутаторы), но вот внутри узла всё общение с CPU будет завязано на PCIe-коммутаторы в двух адаптерах ConnectX-8. Главным преимуществом GX GB200A Ultra NVL36 станет воздушное охлаждение из-за относительно невысокой мощности — всего 40 кВт на стойку. Это немало, но всё равно позволит разместить новинки во многих ЦОД без их кардинального переоборудования пусть и ценой потери плотности размещения (например, пропуская ряды). По мнению SemiAnalysis, эти суперускорители в случае нехватки «полноценных» GB200 NVL72/36 будут покупать и гиперскейлеры.
19.03.2024 [01:00], Игорь Осколков
NVIDIA B200, GB200 и GB200 NVL72 — новые ускорители на базе архитектуры BlackwellNVIDIA представила сразу несколько ускорителей на базе новой архитектуры Blackwell, названной в честь американского статистика и математика Дэвида Блэквелла. На смену H100/H200, GH200 и GH200 NVL32 на базе архитектуры Hopper придут B200, GB200 и GB200 NVL72. Все они, как говорит NVIDIA, призваны демократизировать работу с большими языковыми моделями (LLM) с триллионами параметров. В частности, решения на базе Blackwell будут до 25 раз энергоэффективнее и экономичнее в сравнении с Hopper. В разреженных FP4- и FP8-вычислениях производительность B200 достигает 20 и 10 Пфлопс соответственно. Но без толики технического маркетинга не обошлось — показанные результаты достигнуты не только благодаря аппаратным улучшениям, но и программным оптимизациям. Это ни в коей мере не умаляет их важности и полезности, но затрудняет прямое сравнение с конкурирующими решениями. В общем, появление Blackwell стоит рассматривать не как очередное поколение ускорителей, а как расширение всей экосистемы NVIDIA. В Blackwell компания использует тайловую (чиплетную) компоновку — два тайла объединены 2,5D-упаковкой CoWoS-L и на двоих имеют 208 млрд транзисторов, изготовленных по техпроцессу TSMC 4NP. В одно целое со всех точек зрения их объединяет новый интерконнект NV-HBI с пропускной способностью 10 Тбайт/с, а дополняют их восемь стеков HBM3e-памяти ёмкостью до 192 Гбайт с агрегированной пропускной способностью до 8 Тбайт/с. Такой же объём памяти предлагает и Instinct MI300X, но с меньшей ПСП (5,3 Тбайт/с), хотя это скоро изменится. FP8-производительность в разреженных вычислениях у решения AMD составляет 5,23 Пфлопс, но зато компания не забывает и про FP64 в отличие от NVIDIA. 
Источник изображений: NVIDIA Одними из ключевых нововведений, отвечающих за повышение производительности, стали новые Tensor-ядра и второе поколение механизма Transformer Engine, который научился заглядывать внутрь тензоров, ещё более тонко подбирая необходимую точность вычислений, что влияет и на скорость обучения с инференсом, и на максимальный объём модели, умещающейся в памяти ускорителя. 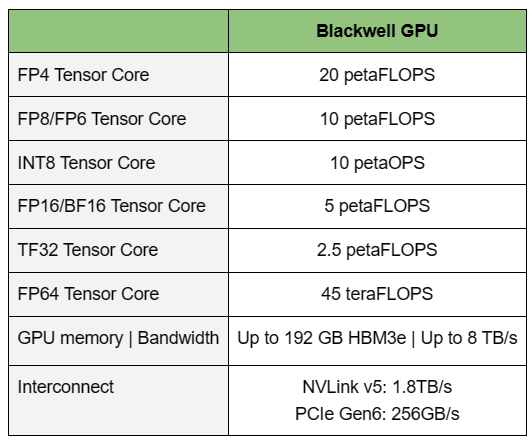 Теперь NVIDIA намекает на то, что обучение можно делать в FP8-формате, а для инференса хватит и FP4. Всё это без потери качества. Но вообще Blackwell поддерживает FP4/FP6/FP8, INT8, BF16/FP16, TF32 и FP64. И только для последнего нет поддержки разреженных вычислений. 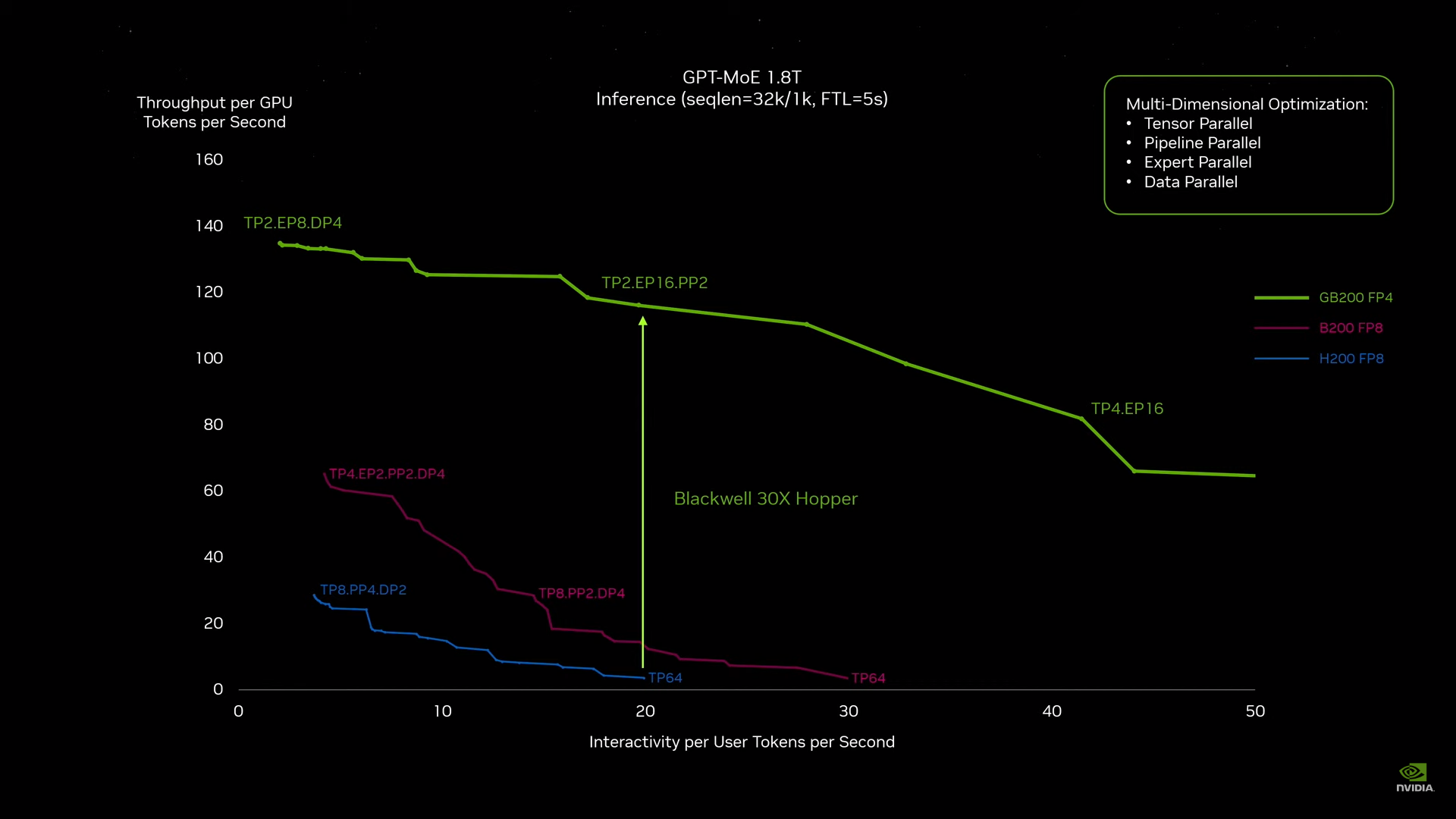 Дополнительно Blackwell обзавёлся движком для декомпрессии (в первую очередь LZ4, Deflate, Snappy) входящих данных со скоростью до 800 Гбайт/с, что тоже должно повысить производительность, т.к. теперь распаковкой будет заниматься не CPU и, соответственно, ускоритель не будет «голодать». Эта функция рассчитана в основном на Apache Spark и другие системы для аналитики больших данных. Также есть по семь движков NVDEC и NVJPEG.  Наконец, NVIDIA упоминает ещё две новых возможности Blackwell: шифрование данных в памяти и RAS-функции. В первом случае речь идёт о защите конфиденциальности обрабатываемых данных, что важно в целом ряде областей. Причём формирование TEE-анклава возможно в рамках группы из 128 ускорителей. MIG-доменов по-прежнему семь. В случае RAS говорится о телеметрии и предиктивной аналитике (естественно, на базе ИИ), которые помогут заранее выявить возможные сбои и снизить время простоя. Это важно, поскольку многие модели могут обучаться неделями и месяцами, так что потеря даже относительно небольшого куска данных крайне неприятна и финансово затратна.  Однако всё эти инновации не имеют смысла без возможности масштабирования, поэтому NVIDIA оснастила Blackwell не только интерфейсом PCIe 6.0 (32 линии), который играет всё меньшую роль, но и пятым поколением интерконнекта NVLink. NVLink 5 по сравнению с NVLink 4 удвоил пропускную способность до 1,8 Тбайт/с (по 900 Гбайт/с в каждую сторону), а соответствующий коммутатор NVSwitch 7.2T позволяет объединить до 576 ускорителей в одном домене. SHARP-движки с поддержкой FP8 дополнительно помогут ускорить обработку моделей, избавив ускорители от части работ по предобработке и трансформации данных. Чип коммутатора тоже изготавливается по техпроцессу TSMC N4P и содержит 50 млрд транзисторов.  Для дальнейшего масштабирования и формирования кластеров из 10 тыс. ускорителей и более, вплоть до 100 тыс. ускорителей на уровне ЦОД, NVIDIA предлагает 800G-коммутаторы Quantum-X800 InfiniBand XDR и Spectrum-X800 Ethernet, имеющие соответственно 144 и 64 порта. Узлам же полагаются DPU ConnectX-8 SuperNIC и BlueField-3. Правда, последний предлагает только 400G-порты в отличие от первого. От InfiniBand компания отказываться не собирается.  С базовыми кирпичиками разобрались, пора переходить к конструированию продуктов. Первым идёт HGX B100, в основе которой всё та же базовая плата с восемью ускорителями Blackwell, точно так же провязанных между собой NVLink 5 с агрегированной скоростью 14,4 Тбайт/с. Для связи с внешним миром предлагается пара интерфейсов PCIe 6.0 x16. HGX B100 предназначена для простой замены HGX H100, поэтому ускорители имеют TDP не более 700 Вт, что ограничивает пиковую производительность в разреженных FP4- и FP8/FP6/INT8-вычислениях до 14 и 7 Пфлопс соответственно, а для всей системы — 112 и 56 Пфлопс соответственно. 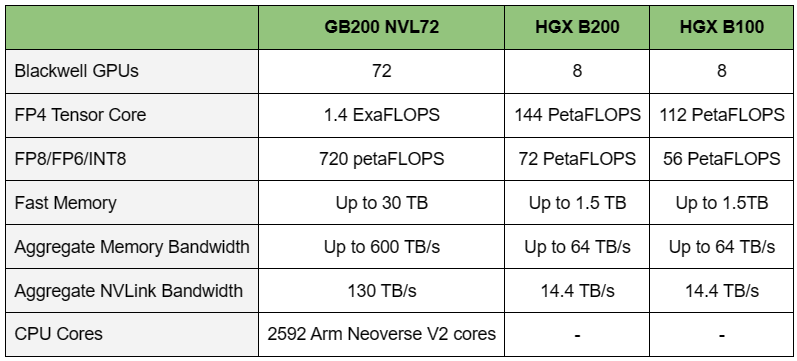 У HGX B200 показатель TDP ограничен уже 1 кВт, причём возможность воздушного охлаждения по-прежнему сохраняется. Производительность одного B200 в разреженных FP4- и FP8/FP6/INT8-вычислениях достигает уже 18 и 9 Пфлопс, а для всей системы — 144 и 72 Пфлопс соответственно. DGX B200 повторяет HGX B200 в плане производительности и является готовой системой от NVIDIA, тоже с воздушным охлаждением. В системе используются два чипа Intel Xeon Emerald Rapids. По словам NVIDIA, DGX B200 до 15 раз быстрее в задачах инференса «триллионных» моделей по сравнению с DGX-узлами прошлого поколения. 800G-интерконнект Ethernet/InfiniBand этим трём платформам не достался, только 400G.  Основным же строительным блоком сама компания явно считает гибридный суперчип GB200, объединяющий уже имеющийся у неё Arm-процессор Grace сразу с двумя ускорителями Blackwell B200. CPU-часть включает 72 ядра Neoverse V2 (по 64 Кбайт L1-кеша для данных и инструкций, L2-кеш 1 Мбайт), 144 Мбайт L3-кеша и до 480 Гбайт LPDDR5x-памяти с ПСП до 512 Гбайт/с. С двумя B200 процессор связан 900-Гбайт/с шиной NVLink-C2C — по 450 Гбайт/с на каждый ускоритель. Между собой B200 напрямую подключены уже по полноценной 1,8-Тбайт/с шине NVLink 5.  Вся эта немаленькая конструкция шириной в половину стойки имеет TDP до 2,7 кВт. 1U-узел с парой чипов GB200, каждый из которых может отъедать до 1,2 кВт, уже требует жидкостное охлаждение. FP4- и FP8/FP6/INT8-производительность (речь всё ещё о разреженных вычислениях) GB200 достигает 40 и 20 Пфлопс. И именно эти цифры NVIDIA нередко использует для сравнения новинок со старыми решениями.  18 узлов с парой GB200 (суммарно 72 шт.) и 9 узлов с парой коммутаторов NVSwitch 7.2T, которые провязывают все ускорители по схеме каждый-с-каждым (агрегированно 130 Тбайт/с, более 3 км соединений), формируют 120-кВт суперускоритель GB200 NVL72 размером со стойку (Oberon), оснащённый СЖО и единой DC-шиной питания. Всё это даёт до 1,44 Эфлопс в FP4-вычислениях и до 720 Пфлопс в FP8, а также до 13,5 Тбайт HBM3e с агрегированной ПСП до 576 Тбайт/с. Ну а общий объём памяти составляет порядка 30 Тбайт. GB200 NVL72 одновременно является и узлом DGX GB200. Восемь DGX GB200 формируют DGX SuperPOD. Впрочем, будет доступен и SuperPOD попроще, на базе DGX B200.  Ускорители B200 появятся в этом году и будут стоить в диапазоне $30–$40 тыс., что ненамного больше начальной цены Hopper в диапазоне $25–$40 тыс. Глава NVIDIA уже предупредил, что Blackwell сразу будут в дефиците. Вероятно, получить доступ к ним проще всего будет в облаках Amazon, Google, Microsoft и Oracle.
13.11.2023 [17:00], Игорь Осколков
NVIDIA анонсировала ускорители H200 и «фантастическую четвёрку» Quad GH200NVIDIA анонсировала ускорители H200 на базе всё той же архитектуры Hopper, что и их предшественники H100, представленные более полутора лет назад. Новый H200, по словам компании, первый в мире ускоритель, использующий память HBM3e. Вытеснит ли он H100 или останется промежуточным звеном эволюции решений NVIDIA, покажет время — H200 станет доступен во II квартале следующего года, но также в 2024-м должно появиться новое поколение ускорителей B100, которые будут производительнее H100 и H200. 
HGX H200 (Источник здесь и далее: NVIDIA) H200 получил 141 Гбайт памяти HBM3e с суммарной пропускной способностью 4,8 Тбайт/с. У H100 было 80 Гбайт HBM3, а ПСП составляла 3,35 Тбайт/с. Гибридные ускорители GH200, в состав которых входит H200, получат до 480 Гбайт LPDDR5x (512 Гбайт/с) и 144 Гбайт HBM3e (4,9 Тбайт/с). Впрочем, с GH200 есть некоторая неразбериха, поскольку в одном месте NVIDIA говорит о 141 Гбайт, а в другом — о 144 Гбайт HBM3e. Обновлённая версия GH200 станет массово доступна после выхода H200, а пока что NVIDIA будет поставлять оригинальный 96-Гбайт вариант с HBM3. Напомним, что грядущие конкурирующие AMD Instinct MI300X получат 192 Гбайт памяти HBM3 с ПСП 5,2 Тбайт/с.  На момент написания материала NVIDIA не раскрыла полные характеристики H200, но судя по всему, вычислительная часть H200 осталась такой же или почти такой же, как у H100. NVIDIA приводит FP8-производительность HGX-платформы с восемью ускорителями (есть и вариант с четырьмя), которая составляет 32 Пфлопс. То есть на каждый H200 приходится 4 Пфлопс, ровно столько же выдавал и H100. Тем не менее, польза от более быстрой и ёмкой памяти есть — в задачах инференса можно получить прирост в 1,6–1,9 раза.  При этом платы HGX H200 полностью совместимы с уже имеющимися на рынке платформами HGX H100 как механически, так и с точки зрения питания и теплоотвода. Это позволит очень быстро обновить предложения партнёрам компании: ASRock Rack, ASUS, Dell, Eviden, GIGABYTE, HPE, Lenovo, QCT, Supermicro, Wistron и Wiwynn. H200 также станут доступны в облаках. Первыми их получат AWS, Google Cloud Platform, Oracle Cloud, CoreWeave, Lambda и Vultr. Примечательно, что в списке нет Microsoft Azure, которая, похоже, уже страдает от недостатка H100.  GH200 уже доступны избранным в облаках Lamba Labs и Vultr, а в начале 2024 года они появятся у CoreWeave. До конца этого года поставки серверов с GH200 начнут ASRock Rack, ASUS, GIGABYTE и Ingrasys. В скором времени эти чипы также появятся в сервисе NVIDIA Launchpad, а вот про доступность там H200 компания пока ничего не говорит.  Одновременно NVIDIA представила и базовый «строительный блок» для суперкомпьютеров ближайшего будущего — плату Quad GH200 с четырьмя чипами GH200, где все ускорители связаны друг с другом посредством NVLink по схеме каждый-с-каждым. Суммарно плата несёт более 2 Тбайт памяти, 288 Arm-ядер и имеет FP8-производительность 16 Пфлопс. На базе Quad GH200 созданы узлы HPE Cray EX254n и Eviden Bull Sequana XH3000. До конца 2024 года суммарная ИИ-производительность систем с GH200, по оценкам NVIDIA, достигнет 200 Эфлопс. |
|

