Материалы по тегу: ff
|
21.11.2024 [17:32], Руслан Авдеев
Meta✴ планирует построить за $5 млрд кампус ЦОД Project Sucre в ЛуизианеКомпания Meta✴ намерена масштабировать свои мощности ЦОД в Луизиане. По последним данным компания планирует построить многомиллиардный дата-центр для ИИ-проектов около города Монро в Луизиане, сообщает Datacenter Dynamics со ссылкой на местные СМИ. Представитель местных властей Фостер Кэмпбелл (Foster Campbell) подтвердил информацию журналистам USA Today Network и заявил, что компания намерена вложить в проект $5 млрд. О самом проекте пока известно не очень много. Сообщается, что планы строительства кампуса поданы местным властям через дочернюю структуру Meta✴ — Laidley LLC. Проект получил имя Project Sucre. Цитируя официальное уведомление, портал Axiom сообщает, что Meta✴ рассчитывает использовать более 900 га земель сельскохозяйственного назначения за автомагистралью US 183. 
Источник изображения: Joe Lavigne/unsplash.com Как стало известно совсем недавно, именно в Луизиане компания Entergy намерена построить электростанцию на природном газе мощностью 1,5 ГВт, тоже около Холли Ридж, для некого клиента, до сих пор не названного. Предполагается, что этим клиентом и станет Meta✴. Ранее Meta✴ подписала PPA с RWE на 100 МВт энергии солнечной станции в Луизиане, которая должна заработать в 2025 году. В 2024 году компания анонсировала строительство новых объектов в Индиане, Южной Каролине, Вайоминге, Миннесоте и Алабаме. В этом году она запустила кампус в Теннеси. Также компанию связывают с проектом в Дэвенпорте (Айова), хотя об этом официально и не объявлялось.
18.11.2024 [20:15], Руслан Авдеев
Ключевыми клиентами ИИ-сервиса Microsoft Azure OpenAI стали Adobe и Meta✴, но крупнейшим заказчиком всё ещё остаётся TikTokХотя крупнейшим облачным клиентом сервисов Azure OpenAI компании Microsoft по-прежнему остаётся социальная сеть TikTok, облачный ИИ-провайдер активно диверсифицирует свой бизнес. В распоряжение The Verge попал список крупнейших клиентов Microsoft, получающих облачный доступ к большим языковым моделям (LLM) — как оказалось, более $1 млн/мес. на сервисы Azure OpenAI тратит не только TikTok. В десятку ключевых пользователей Azure OpenAI вошли Adobe и Meta✴, каждая из которых потратила более $1 млн только в сентябре 2024 года. Впрочем, компании по-прежнему отстают от TikTok, принадлежащей ByteDance. Ранее сообщалось, что TikTok платила Microsoft почти $20 млн/мес. за доступ к моделям OpenAI. По итогам IV квартале 2024 финансового года, завершившемся 30 июня, на TikTok пришлось почти четверть выручки Azure OpenAI. Теперь траты ByteDance на Azure OpenAI составляют менее 15 % всей выручки Microsoft в этом сегменте — расходы ByteDance падают, а других клиентов растут. Например, G42 из ОАЭ тратит на сервисы Azure OpenAI миллионы долларов ежемесячно, являясь вторым по величине пользователем соответствующего сервиса после ByteDance. Ранее в этом году Microsoft инвестировала $1,5 млрд в G42, поэтому, вероятно, последняя сохранит статус одного из ключевых пользователей Azure OpenAI. Ранее в этом году главным потребителем ИИ-сервисов Microsoft считалась американская торговая сеть Walmart, но теперь её нет даже в десятке. Список серьёзно меняется от месяца к месяцу, во многом потому, что клиенты Microsoft время от времени запускают или тестируют новые ИИ-проекты. Так, постоянным клиентом остаётся Intuit, хотя её расходы несопоставимы с затратами G42 или ByteDance. Компания занимается разработкой инструментов для финансового управления и обучает собственные ИИ-модели на клиентских данных. 
Источник изображения: Donald Giannatti/unsplash.com Также Microsoft удалось привлечь к сотрудничеству тесно связанную с Alibaba компанию Ant Group, которая потратила на Azure OpenAI как минимум $1 млн. Среди ключевых клиентов есть и пекинская Sankuai Technology, а всего в десятку самых «дорогих» клиентов в сентябре вошли сразу три китайские компании. В Microsoft информацию не комментируют. В компании лишь отметили, что Azure OpenAI — один из самых быстрорастущих сервисов Azure за всю историю, которым уже пользуются 60 тыс. организаций по всему миру. За последние месяцы рост сервиса удвоился. Microsoft также продаёт лицензии Copilot для бизнеса, обеспечивающие ИИ-сервисы, например, в офисных приложениях. По данным самой компании, 70 % компаний из рейтинга Fortune 500 так или иначе пользуются Microsoft 365 Copilot. Скоро выручка ИИ-бизнеса Microsoft превысит $10 млрд в год. В Microsoft утверждают, что это будет самый быстрый в истории бизнес, достигший подобного показателя. Но пока затраты довольно велики, так что инвесторы внимательно наблюдают за показателями Azure OpenAI и Microsoft 365 Copilot. Microsoft уже не хватает ресурсов для обработки ИИ, но компания готова вкладывать деньги в новые ЦОД.
14.11.2024 [15:49], Сергей Карасёв
Innodisk представила индустриальные SSD формата E1.S вместимостью до 8 ТбайтКомпания Innodisk анонсировала SSD серий 4TG2-P и 4TS2-P в форм-факторе E1.S. Устройства ориентированы на использование в корпоративном и промышленном секторах: они подходят для ИИ-приложений, периферийных вычислений, систем автоматизации, встраиваемых устройств и других нагрузок с интенсивным использованием данных. Все изделия выполнены на чипах флеш-памяти 3D TLC NAND. Для обмена данными служит интерфейс PCIe 4.0 x4 (NVMe 1.4). Заявленный показатель MTBF (средняя наработка на отказ) превышает 3 млн часов. Диапазон рабочих температур простирается от -40 до +85 °C. В семейство E1.S 4TG2-P вошли модели вместимостью от 512 Гбайт до 8 Тбайт. Скорость последовательного чтения информации достигает 6900 Мбайт/с, скорость последовательной записи — 4700 Мбайт/с. Максимальное энергопотребление равно 12 Вт. Говорится о поддержке TCG Opal. 
Источник изображения: Innodisk В свою очередь, накопители E1.S 4TS2-P доступны в модификациях ёмкостью от 400 Гбайт до 6,4 Тбайт. Максимальная скорость чтения информации составляет 6900 Мбайт/с, скорость записи — 4650 Мбайт/с. Энергопотребление не превышает 12,4 Вт. В новинках реализована фирменная технология iCell, которая гарантирует защиту критически важных данных и отсутствие потерь информации при сбоях питания. Система предусматривает размещение дополнительных буферных силовых конденсаторов на плате контроллера, которые в случае необходимости обеспечивают аварийное питание.
14.11.2024 [12:00], Сергей Карасёв
Solidigm представила PCIe 4.0 SSD серии D5-P5336 ёмкостью 122,88 ТбайтКомпания Solidigm официально представила, как утверждается, самый вместительный в мире SSD для дата-центров: устройство серии D5-P5336 имеет ёмкость 122,88 Тбайт. Покупатели смогут выбирать между модификациями в форм-факторах U.2 (толщиной 15 мм) и E1.L. Впрочем, сегодня же накопители Pascari D205V аналогичной ёмкости анонсировала и Phison. О подготовке новинок впервые сообщалось в начале августа нынешнего года. Ранее в семейство D5-P5336 входили модели ёмкостью до 61,44 Тбайт. Таким образом, анонсированные изделия по вместимости вдвое превосходят предшественников. В основу SSD положены 192-слойные чипы флеш-памяти QLC 3D NAND. Для обмена данными служит интерфейс PCIe 4.0 x4 (спецификация NVMe 2.0). Заявленная скорость последовательного чтения достигает 7400 Мбайт/с, скорость последовательной записи — 3200 Мбайт/с. Показатель IOPS (операций ввода/вывода в секунду) при произвольном чтении блоков по 4 Кбайт составляет до 930 тыс. Значение IOPS при произвольной записи блоков по 32 Кбайт — до 25 тыс. 
Источник изображения: Solidigm Показатель MTBF (средняя наработка на отказ), согласно техническим характеристикам, равен 2 млн часов. Накопители способны выдерживать до 0,6 полных перезаписи в сутки (показатель DWPD) на протяжении пяти лет. Гарантированный объём записанной информации составляет 134,3 Пбайт. Говорится о соответствии стандартам OCP 2.0 и FIPS 140-3 L2. Максимальное энергопотребление равно 25 Вт, энергопотребление в режиме простоя — менее 5 Вт. Поставки SSD вместимостью 122,88 Тбайт компания Solidigm организует в начале 2025 года. Утверждается, что для операторов ЦОД эти устройства обеспечат ряд существенных преимуществ, в частности:
14.11.2024 [12:00], Сергей Карасёв
Phison представила PCIe 5.0 SSD серии Pascari D205V ёмкостью 122,88 ТбайтКомпания Phison официально анонсировала SSD Pascari D205V вместимостью 122,88 Тбайт, о подготовке которого сообщалось в начале августа нынешнего года. Изделие ориентировано на нагрузки с высокой интенсивностью чтения данных. Solidigm сегодня тоже официально представила накопитель D5-P5336 ёмкостью 122,88 Тбайт. В основу Pascari D205V положены контроллер Phison X2 и чипы флеш-памяти 3D QLC NAND. Задействован интерфейс PCIe 5.0 (NVMe 2.0): заказчики смогут выбирать между модификациями с одним портом PCIe 5.0 x4 и двумя портами PCIe 5.0 2x2. При этом предусмотрены варианты исполнения U.2 и E3.L. Скорость последовательного чтения информации достигает 14 600 Мбайт/с, скорость последовательной записи — 3200 Мбайт/с. Показатель IOPS (операций ввода/вывода в секунду) при произвольном чтении блоков по 4 Кбайт заявлен на уровне 3 млн. Величина IOPS при произвольной записи блоков по 16 Кбайт составляет до 35 тыс. Задержка при чтении и записи — 110 и 12 мкс соответственно. 
Источник изображения: Phison Заявленное энергопотребление в активном режиме равно 25 Вт. Значение DWPD (полных перезаписей в сутки) составляет 0,3, показатель MTBF (средняя наработка на отказ) — 2,5 млн часов. Диапазон рабочих температур простирается от 0 до +70 °C. Производитель предоставляет пятилетнюю гарантию. Говорится о поддержке TCG Opal 2.0, шифрования AES-XTS 256, а также защиты от потери питания (PLP). Приём предварительных заказов на накопитель уже начался. Поставки планируется организовать во II квартале 2025 года. Кроме того, Phison предлагает накопитель D200V ёмкостью 61,44 Тбайт и высоконадёжный SSD SA50V формата SFF вместимостью 15 Тбайт с интерфейсом SATA-3.
13.11.2024 [01:45], Владимир Мироненко
Micron 6550 ION — самый быстрый в мире 61,44-Тбайт SSD в форм-факторе E3.SMicron представила SSD 6550 ION, который позиционируется как самый быстрый в мире 61,44-Тбайт накопитель для ЦОД и первый в мире накопитель стандарта PCIe 5.0 x4 (NVMe 2.0b) в форм-факторе E3.S с такой ёмкостью. Новинка подходит для растущих рабочих нагрузок ИИ, обеспечивая при этом лучшую в своем классе производительность и до 20 % более низкое энергопотребление по сравнению с накопителями конкурирующих брендов. Нюанс в том, что самым быстрым Micron 6550 ION является именно при таком сочетании ёмкости, форм-фактора и интерфейса, а сравнение делается с решениями Samsung, Solidigm и Western Digital, но не Kioxia. Типовое энергопотребление у новинок не превышает 20 Вт. Точно такой же показатель есть у одной из моделей Western Digital, но решение Micron быстрее. 6550 ION соответствует стандарту OCP 2.5 и имеет активное управление питание (ASPM). Это позволяет накопителю потреблять в режиме ожидания 4 Вт в состоянии L1 против 5 Вт в состоянии L0, что до 20 % повышает энергоэффективность в простое. 
Источник изображений: Micron 6550 ION подходят для создания озёр данных для ИИ, для приёма, подготовки данных и создания контрольных точек во время обучения, для хранения файлов и объектов, создания публичных облачных хранилищ, обслуживания аналитических баз данных, а также для систем доставки контента. Также сообщается, что 6550 ION обеспечивает ведущую в отрасли плотность хранения, позволяя клиентам сократить площадь ЦОД до 67 %, обеспечивая плотность на уровне 1,2 Пбайт/1U. 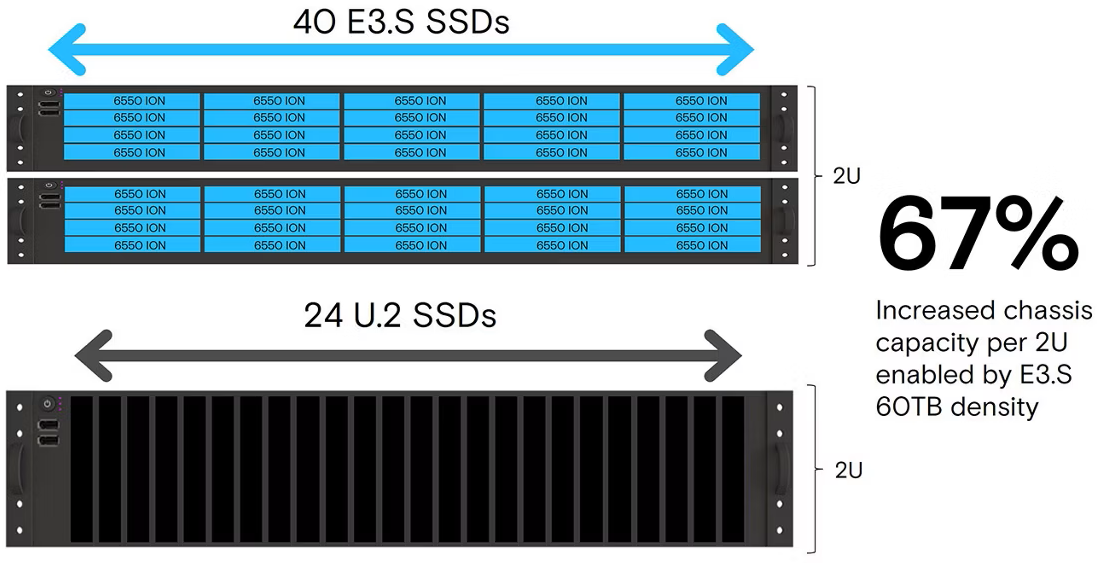 Скорость последовательного чтения/записи 6550 ION достигает 12,5/5,0 Гбайт/с. Значение IOPS при работе с блоками данных по 4 Кбайт — до 1,6 млн при произвольном чтении и до 70 тыс. при произвольной записи. 6550 ION может быть полностью записан за 3,4 часа, в то время как конкурирующие диски заполняются на 150 % дольше, отмечает компания. 
Источник: ServeTheHome Кроме того, 6550 ION также превосходит SSD аналогичной ёмкости в критических ИИ-нагрузках, включая работу с NVIDIA Magnum IO GPUDirect Storage (GDS), работу с блоками данных 4 Кбайт при обучении некоторых сетей и создание контрольных точек во время обучения ИИ. При тренировке LLM с с миллиардами параметров контрольные точки создаются довольно часто, а ускорители могут простаивать десятки минут, пока данные сбрасываются на SSD. 
Источник: ServeTheHome Micron 6550 ION доступен в форм-факторах E3.S (1T), U.2 и E1.L и имеет ёмкость 30,72 или 61,44 Тбайт. Кроме того, сообщается, что 6550 ION предлагает ведущий в отрасли набор функций безопасности, включая SPDM 1.2 для аттестации и SHA-512 для безопасной генерации подписей. Он соответствует требованиям TAA и сертифицирован по стандарту FIPS 140-3 L2. 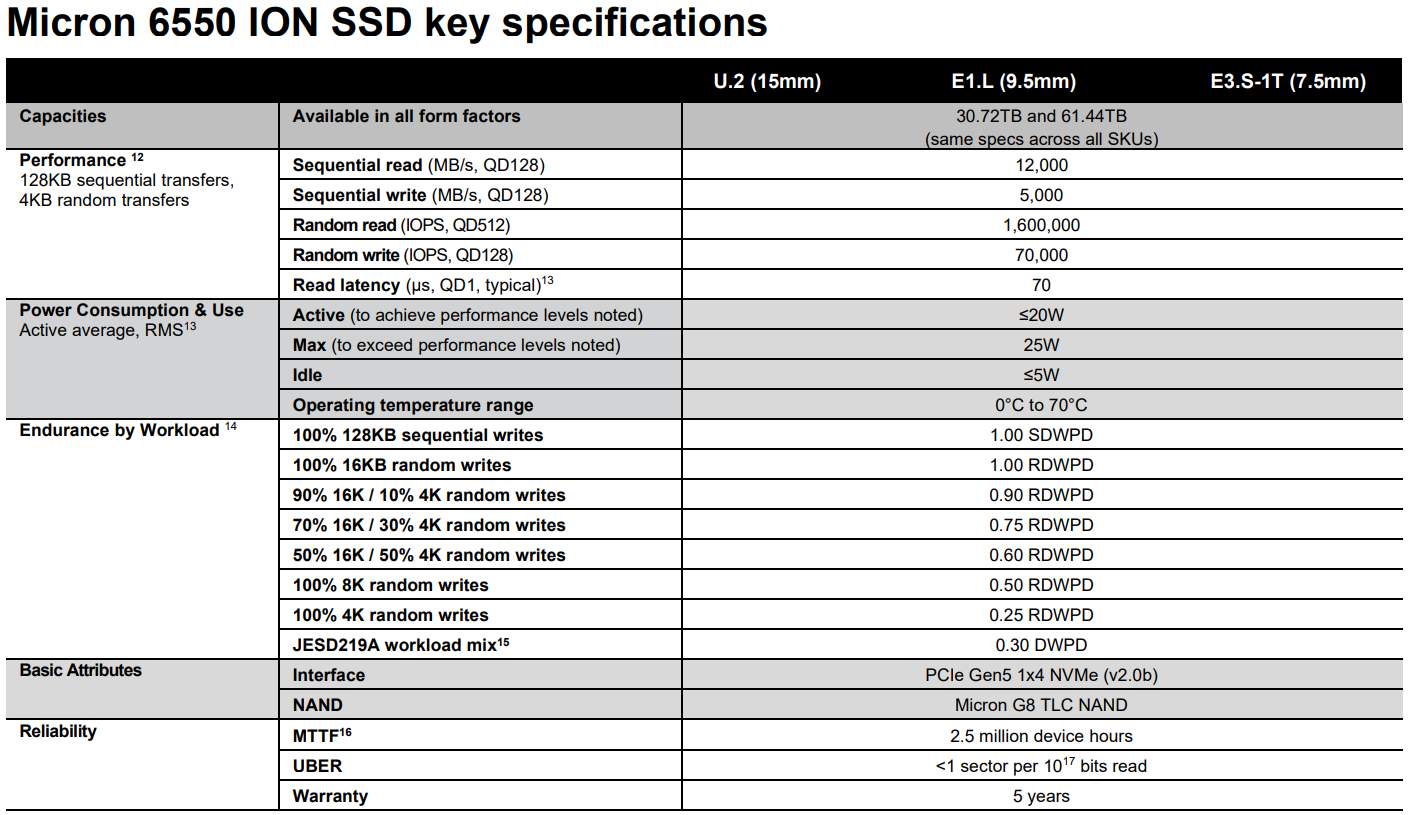 Накопитель имеет надёжность на уровне 1,0 RDWPD при записи случайных блоков на 16 Кбайт, а для 4-Кбайт блоков — 0,25 RDWPD. Диапазон рабочих температур простирается от 0 до 70 °C. Показатель MTTF составляет 2,5 млн часов. Гарантия производителя — 5 лет. Также отмечается, что 6550 ION полностью состоит из компонентов, изготовленных самой Micron.
06.11.2024 [10:22], Сергей Карасёв
SMART Modular представила индустриальные SSD серии T6EN вместимостью до 15,36 ТбайтКомпания SMART Modular анонсировала SSD семейства T6EN, предназначенные для использования в аэрокосмической и промышленной сферах, а также в оборонном секторе. В серию вошли изделия в трёх вариантах исполнения — U.2, EDSFF E1.S и M.2 2280. Все накопители выполнены на основе чипов флеш-памяти 3D TLC. Задействован интерфейс PCIe 4.0 x4. Диапазон рабочих температур простирается от -40 до +85 °C. Заявленный показатель MTBF (средняя наработка на отказ) превышает 2 млн часов. Говорится о поддержке TCG Opal 2.0 и шифрования AES-256. Устройства T6EN U.2 доступны в вариантах вместимостью 960 Гбайт, а также 1,92, 3,84, 7,68 и 15,36 Тбайт. Скорость последовательного чтения достигает 3500 Мбайт/с, скорость последовательной записи — 3000 Мбайт/с. Значение IOPS (операций ввода/вывода в секунду) при работе с блоками данных по 4 Кбайт — до 390 тыс. при произвольном чтении и до 55 тыс. при произвольной записи. 
Источник изображения: SMART Modular Решения EDSFF E1.S обладают аналогичными показателями быстродействия, но у них максимальная ёмкость составляет 7,68 Тбайт. Наконец, SSD формата M.2 2280 обеспечивают скорость последовательного чтения и записи до 3200 Мбайт/с. Величина IOPS — до 390 тыс. при произвольном чтении и до 50 тыс. при произвольной записи. Максимальная вместимость равна 7,68 Тбайт. Для всех изделий в качестве опции доступно специальное конформное покрытие, предназначенное для защиты от негативного влияния факторов окружающей среды: повышенных температур, влаги, загрязнений, химических веществ и механических воздействий.
05.11.2024 [15:51], Руслан Авдеев
Пчёлы против Meta✴: строительству «атомного» ИИ ЦОД помешали редкие насекомыеПлан компании Meta✴ по строительству дата-центра с питанием от АЭС столкнулся с неожиданным препятствием. По данным The Register, его реализации помешали насекомые, точнее — редкий вид пчёл, обосновавшийся на «спорной» территории. По словам главы компании Марка Цукерберга (Mark Zuckerberg), обнаружение редкого вида насекомых на участке будущей стройки оказало влияние на решение регуляторов, в конце концов отклонивших проект ЦОД, сообщает Financial Times. Meta✴ вела переговоры об энергоснабжении нового ИИ ЦОД с оператором действующей электростанции, рассчитывая получать безуглеродную энергию в больших объёмах. Неизвестно, где именно должны были построить ЦОД. В 2018 году Electric Power Research Institute (EPRI), занимающаяся исследованиями чистой энергетики, выступил с инициативой Power-In-Pollinators, в рамках которой энергокомпании должны были поддержать насекомых-опылителей вроде пчёл и бабочек. В частности, речь шла о восстановлении их популяций на территории бывших АЭС. Сегодня EPRI Pollinator Stewardship Dashboard включает 19 компаний-участников. 
Источник изображения: Sandy Millar/unsplash.com ИИ-вычисления требуют немало энергии, поэтому гиперскейлеры в США заинтересованы в атомных проектах для удовлетворения спроса на электричество без использования ископаемого топлива. В сентябре Microsoft заключила сделку сроком на 20 лет, связанную с возобновлением работы АЭС Three Mile Island (Crane Clean Energy Center). В прошлом месяце Google объявила о сделке с Kairos Power о покупке энергии, полученной от малых модульных реакторов (SMR). Oracle заявила, что получила разрешения на строительство трёх SMR для питания ИИ ЦОД ёмкостью более 1 ГВт. В недавнем отчёте о финансах Meta✴ подняла нижний порог капитальных затрат в 2024 году с $37 млрд до $38 млрд, верхний порог сохранился на уровне $40 млрд. Значительная часть этих расходов предназначена для строительства и обслуживания ИИ ЦОД. Впрочем, с препятствиями в попытке получить атомную энергию для своих ЦОД столкнулась и Amazon — регулятор отказал в увеличении поставок энергии кампусу AWS от АЭС Susquehanna.
01.11.2024 [11:14], Сергей Карасёв
Марк Цукерберг: для обучения ИИ-модели Llama-4 используются более 100 тыс. ускорителей NVIDIA H100Председатель правления и генеральный директор Meta✴ Марк Цукерберг (Mark Zuckerberg), по сообщению ресурса Tom's Hardware, раскрыл масштабы кластера, который используется для обучения ИИ-модели нового поколения Llama-4. По его словам, для этих целей задействованы более 100 тыс. ускорителей NVIDIA H100. Напомним, в начале сентября нынешнего года стартап xAI, курируемый Илоном Маском (Elon Musk), объявил о запуске ИИ-суперкомпьютера Colossus, в основу которого положены 100 тыс. штук H100. В дальнейшем количество ускорителей в составе Colossus планируется увеличить вдвое. Теперь об эксплуатации кластера схожего масштаба рассказал Цукерберг. Глава Meta✴ не стал вдаваться в подробности о характеристиках Llama-4, ограничившись лишь фразами вроде «новые модальности», «более сильные рассуждения» и «повышенное быстродействие». Ранее Meta✴ заявляла о намерении потратить в 2024-м от $30 млрд до $37 млрд на развитие своей инфраструктуры — прежде всего для задач ИИ. Кроме того, говорилось, что к концу текущего года компания рассчитывает оперировать мощностями, эквивалентными более чем 500 тыс. ускорителей NVIDIA H100. 
Источник изображения: Meta✴ Вместе с тем, как отмечается, возникают сложности при обеспечении питанием столь масштабных ИИ-кластеров. Дело в том, что один современный GPU может потреблять до 3,7 МВт·ч электроэнергии в год. Это означает, что массив из 100 тыс. таких ускорителей потребует не менее 370 ГВт·ч в год, чего достаточно для обеспечения энергией более 34 млн среднестатистических американских домохозяйств. Цукерберг признаёт, что трудности, связанные с доступностью энергоресурсов, в перспективе могут ограничить темпы роста отрасли ИИ. Как добавляет ComputerWeekly, Meta✴ также отказалась от практики увеличения срока службы серверов с целью сокращения расходов. Ранее компания сообщила о продлении периода эксплуатации оборудования до пяти лет вместо прежних четырёх с половиной: это, как ожидалось, даст экономию в $1,5 млрд. Однако теперь финансовый директор Meta✴ Сьюзан Ли (Susan Li) заявила, что компания в свете стремительного развития ИИ намерена применять серверы последнего поколения, чтобы максимально эффективно использовать доступную ёмкость существующих дата-центров.
31.10.2024 [20:46], Владимир Мироненко
Планы Meta✴ увеличить затраты на ИИ-инфраструктуру привели к падению акцийКомпания Meta✴ Platforms объявила результаты III квартала 2024 года, завершившегося 30 сентября. Выручка и прибыль компании, чья структура включает соцсети Facebook✴ и Instagram✴, превысили ожидания аналитиков Уолл-стрит. Тем не менее, акции компании упали после публикации результатов на 3 %, что объясняется более низким, чем ожидалось, количеством пользователей и планами по увеличению расходов на инфраструктуру в 2025 финансовом году. Выручка Meta✴ выросла на 19 % до $40,59 млрд, что выше консенсус-оценки аналитиков, опрошенных LSEG, в размере $40,29 млрд. Чистая прибыль компании составила $15,7 млрд или $6,03 на акцию, что на 35 % больше год к году, а также выше консенсус-прогноза аналитиков, ожидавших $5,25 прибыли на акцию. Несмотря на впечатляющее увеличение прибыли за квартал, это самый низкий показатель роста со II квартала 2023 финансового года. 
Источник изображения: NVIDIA Meta✴ повысила прогноз капитальных затрат на 2024 финансовый год до $38–$40 млрд с предыдущего прогноза в размере с $37–$40 млрд. Также компания заявила, что ожидает значительного роста капитальных затрат в 2025 году из-за ускорения расходов на инфраструктуру. «Наши инвестиции в ИИ по-прежнему требуют серьезной инфраструктуры, и я ожидаю, что продолжу вкладывать в неё значительные средства», — сообщил гендиректор Meta✴ Марк Цукерберг (Mark Zuckerberg) в ходе телефонной конференции с аналитиками. Цукерберг сообщил об огромных инвестициях компании в ИИ, которые включают строительство ЦОД и приобретение ускорителей NVIDIA для реализации стратегии в области ИИ и улучшения основного бизнеса компании в сфере онлайн-рекламы. По словам Цукерберга, более миллиона рекламодателей использовали рекламные инструменты на базе генеративного ИИ. Meta✴ также обновила прогноз общих расходов на 2024 финансовый год, которые будут находиться в диапазоне от $96 до $98 млрд, что ниже предыдущего прогноза в $96–$99 млрд. Что касается текущего квартала, то Meta✴ ожидает получить выручку в диапазоне от $45 млрд до $48 млрд со средней точкой выше консенсус-прогноза аналитиков в $46,3 млрд. |
|

