Материалы по тегу: cxl
|
08.08.2025 [10:44], Сергей Карасёв
Стартап Xcena представил вычислительную память MX1 с поддержкой PCIe 6.0 и CXL 3.2Южнокорейский стартап Xcena анонсировал свой первый продукт — вычислительную память MX1. Избранные партнёры начнут получать образцы изделий с октября, тогда как массовое производство запланировано на 2026 год. Решение MX1 обладает поддержкой PCIe 6.0 и CXL 3.2. Новинка позволяет расширить основную память системы, добавив до 1 Тбайт в виде четырёх модулей DDR5 DIMM ёмкостью 256 Гбайт каждый. Реализована технология NDP (Near Data Processing), которая сводит к минимуму задержку при перемещении данных между интерфейсами и значительно снижает совокупную стоимость владения для приложений, требующих обработки больших объемов информации. Для выполнения вычислений в оперативной памяти используются «тысячи ядер» на открытой архитектуре RISC-V. Изделия MX1 позволяют существенно ускорить выполнение таких задач, как операции с векторными и графовыми базами данных, анализ информации и пр. При этом снижается нагрузка на CPU. Прототип на базе FPGA продемонстрировал сокращение времени обработки запросов при работе с базами данных на 46 % по сравнению с серверными CPU. Теоретически выигрыш может достигать 95 % при реализации в виде ASIC. 
Источник изображения: Xcena Чип задействует 4-нм техпроцесс Samsung Foundry. Упомянута поддержка ECC. Компания Xcena предоставляет полностью интегрированный комплект для разработчиков (SDK), состоящий из низкоуровневых драйверов, библиотек среды выполнения и вспомогательных инструментов, которые помогают создавать прототипы и развертывать MX1 с минимальными усилиями по интеграции.
03.08.2025 [12:14], Сергей Карасёв
Enfabrica представила технологию EMFASYS для расширения памяти ИИ-системКомпания Enfabrica анонсировала технологию EMFASYS, которая объединяет Ethernet RDMA и CXL для создания пулов памяти, предназначенных для работы с серверными ИИ-стойками на базе GPU. Решение позволяет снизить нагрузку на HBM-память ИИ-ускорителей и тем самым повысить эффективность работы всей системы в целом. Enfabrica основана в 2019 году. Стартап предлагает CXL-платформу ACF на базе ASIC собственной разработки, которая позволяет напрямую подключать друг к другу любую комбинацию GPU, CPU, DDR5 CXL и SSD, а также предоставляет 800GbE-интерконнект. Компания создала чип ACF SuperNIC (ACF-S) для построения высокоскоростного интерконнекта в составе кластеров ИИ на основе GPU. В рамках платформы EMFASYS специализированный пул памяти подключается к GPU-серверам через чип-коммутатор ACF-S с пропускной способностью 3,2 Тбит/с, который объединяет PCIe/CXL и Ethernet. Поддерживаются интерфейсы 100/400/800GbE, 32 сетевых порта и 160 линий PCIe. Могут быть задействованы до 144 линий CXL 2.0, что позволяет использовать до 18 Тбайт памяти DDR5 (в перспективе — до 28 Тбайт). Вместо копирования и перемещения данных между несколькими чипами на плате Enfabrica использует один SuperNIC, который позволяет представлять память в качестве целевого RDMA-устройства для приложений ИИ. 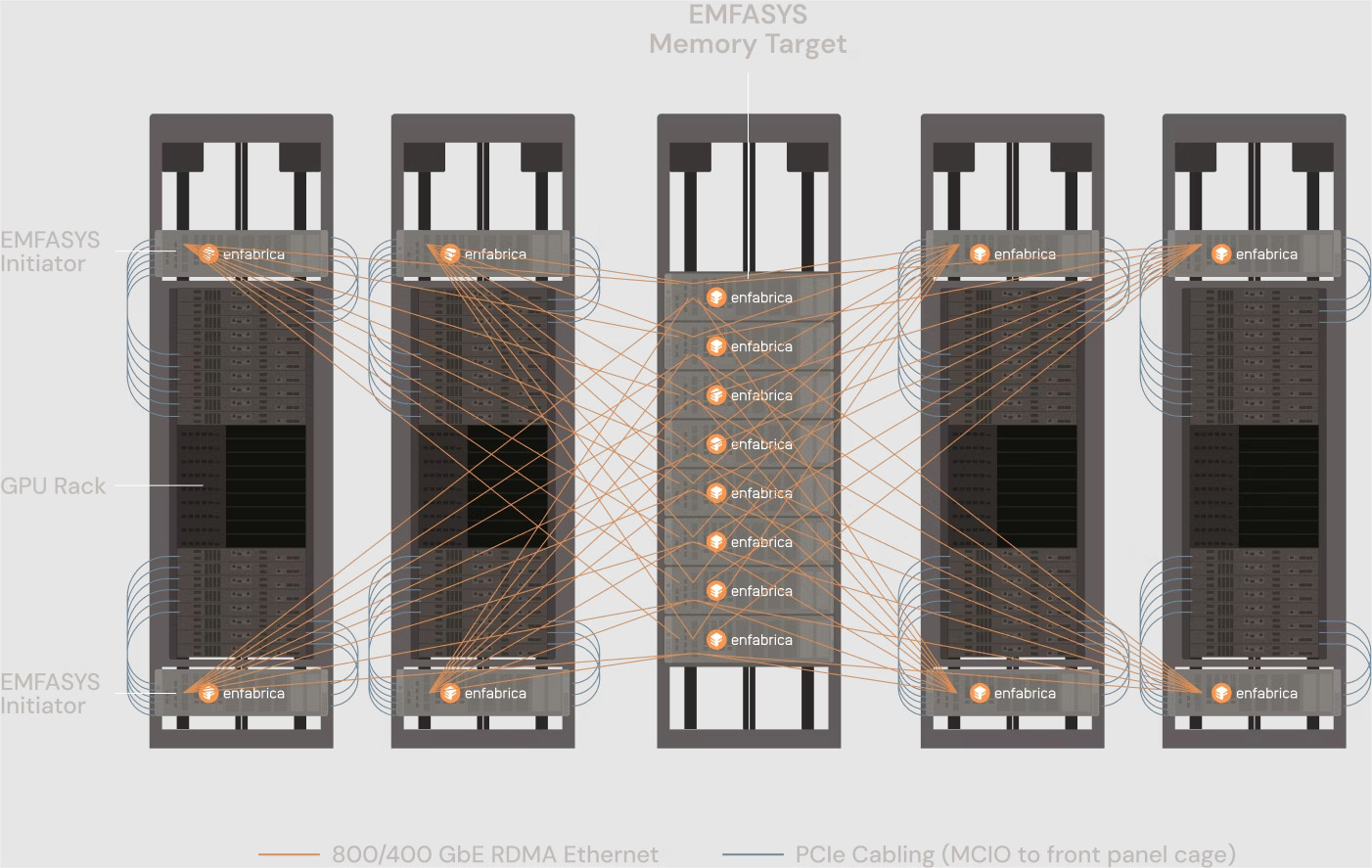
Источник изображений: Enfabrica Высокая пропускная способность памяти достигается за счёт распределения операций более чем по 18 каналам на систему. Время доступа при чтении измеряется в микросекундах. Программный стек на базе InfiniBand Verbs обеспечивает массовую параллельную передачу данных с агрегированной полосой пропускания между GPU-серверами и памятью DRAM через группы сетевых портов 400/800GbE. 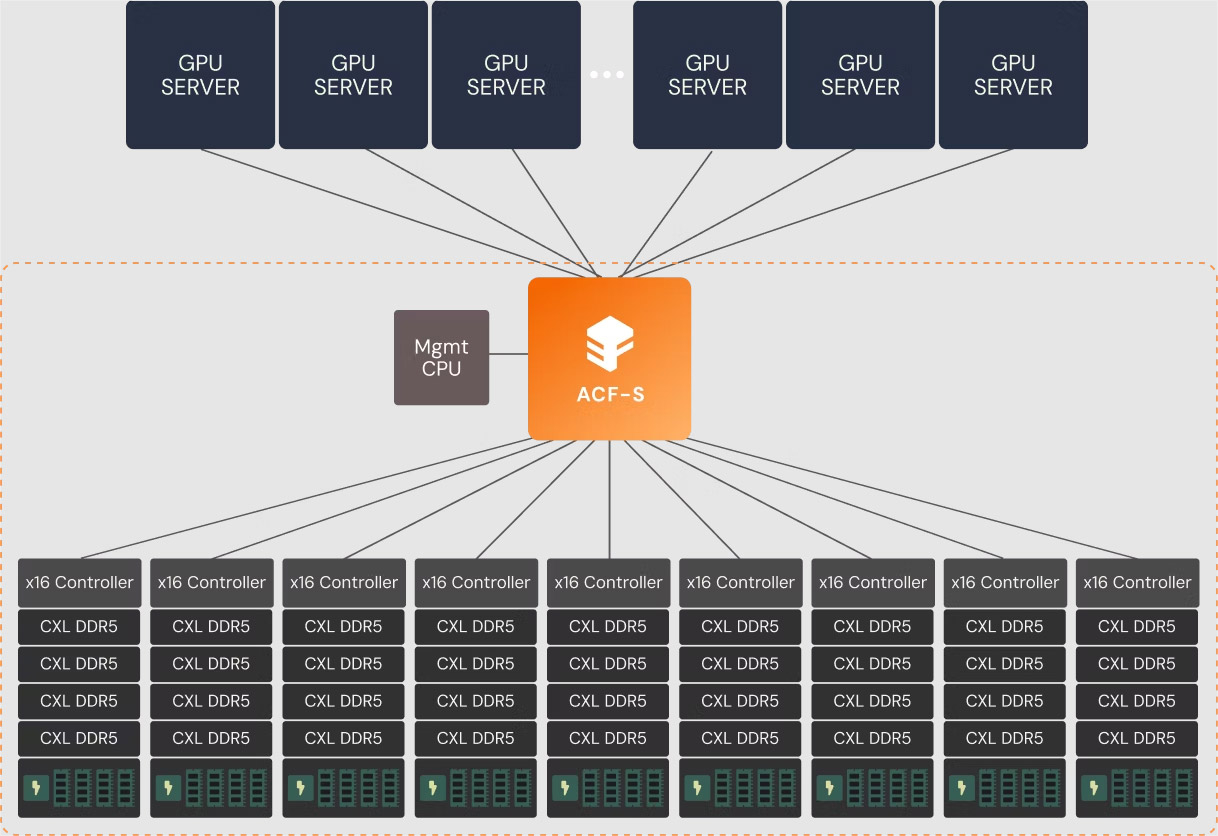 Enfabrica отмечает, что рабочие нагрузки генеративного, агентного и рассуждающего ИИ растут экспоненциально. Во многих случаях таким приложениям требуется в 10–100 раз больше вычислительной мощности на запрос, чем большим языковым моделям (LLM) предыдущего поколения. Если память HBM постоянно загружена, дорогостоящие ускорители простаивают. Технология EMFASYS позволяет решить проблему посредством расширения памяти: в этом случае ресурсы GPU используются более полно, а заявленная экономия достигает 50 % в расчёте на токен на одного пользователя.
05.07.2025 [15:16], Алексей Разин
Повальный спрос на HBM тормозит внедрение CXL- и PIM-памятиОтраслевые аналитики уже не раз отмечали, что бурное развитие отрасли искусственного интеллекта, сопряжённое с ростом спроса на память типа HBM, ограничивает ресурсы производителей памяти на других направлениях. Помимо DDR, от этого страдают и перспективные виды памяти, которые производители хотели бы вывести на рынок. Об этом сообщило издание Business Korea, приведя в пример задержки с внедрением памяти типа CXL компанией Samsung Electronics и памяти типа PIM (Processing-in-Memory) компанией SK hynix. В последнем случае речь идёт о микросхемах памяти, способных самостоятельно выполнять специфические вычисления. Оба типа памяти могли бы в известной мере дополнить HBM в сегменте систем искусственного интеллекта. 
Источник изображения: SK hynix Samsung рассчитывала приступить к продвижению CXL-памяти ещё во II половине 2024 года, но её сертификация ключевыми клиентами до сих пор не завершена. SK hynix разрабатывает GDDR6-AiM с 2022 года, но до её фактического выпуска дело так и не дошло из-за неготовности рыночной экосистемы. Кроме того, сами производители памяти ограничены в свободных ресурсах, поскольку все силы бросили на выполнение заказов по производству HBM. Всё доступное оборудование задействовано для выпуска именно HBM, не давая производителям шанса заняться подготовкой к выпуску других перспективных типов памяти. 
Источник изображения: SK hynix На этом фоне у южнокорейских игроков рынка даже возникают опасения, что китайские конкуренты быстрее справятся с выводом на рынок модулей CXL и PIM. В этой ситуации корейские производители начали всё сильнее рассчитывать на поддержку государства, причём не столько финансовую, сколько регуляторную. С технической точки зрения к выводу на рынок CXL и PIM всё уже почти готово, но по факту на память этих типов пока нет достаточного спроса.
16.05.2025 [17:20], Алексей Степин
Hygon якобы готова к выпуску 128-ядерного конкурента AMD EPYC с SMT4 и AVX-512Имя Hygon вряд ли легко найти в списке лучших серверных процессоров, однако в своё время этот китайский разработчик смог выпустить в рамках соглашения с AMD серверные чипы Hygon Dhyana, совместимые с платформой Socket SP3. В 2024 году компания похвасталась уже 64-ядерными Hygon C86-7490 для платформы Socket SP5, которые, впрочем, всё равно базировались на архитектуре Zen 1. Но амбиции китайских разработчиков отнюдь не ограничиваются устаревшими архитектурами AMD, передаёт Tom's Hardware. Недавно в социальной сети Twitter (X) был замечен слайд, на котором якобы расписаны планы Hygon в области разработки новых процессоров, и они выглядят впечатляюще. В них фигурирует новый флагман под условным именем C86-5G, способный составить конкуренцию современным многоядерным серверным процессорам Intel и AMD. Этот процессор получит до 128 ядер, причём с поддержкой SMT4, а не привычного для x86-мира SMT2, что даст ему возможность исполнять одновременно до 512 потоков. Некогда аналогичная технология уже применялась Intel в процессорах Xeon Phi Knights Landing. 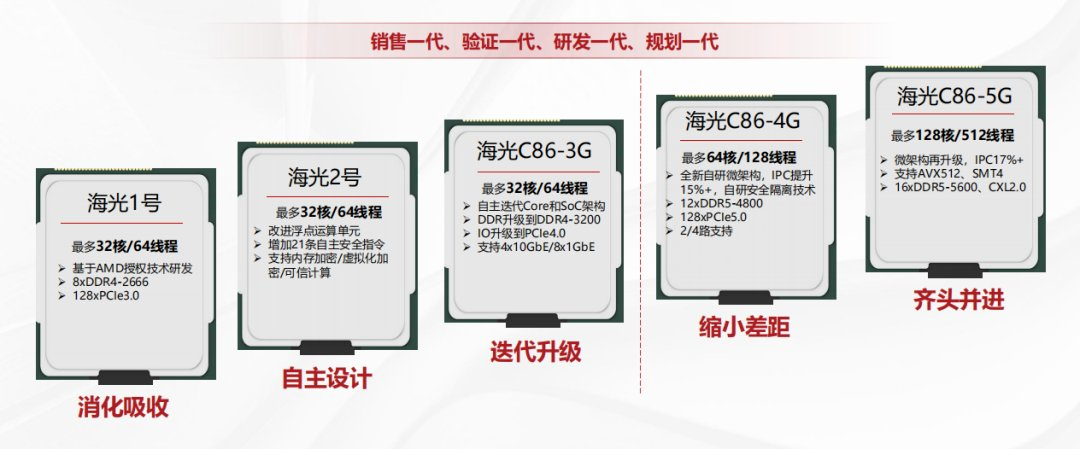
Источник: Twitter@HXL Какая микроархитектура будет стоять за новыми ядрами, пока не разглашается. Заявляется лишь, что это новая фирменная разработка Hygon, а не очередное ответвление AMD EPYC. Заявлено о как минимум 17% прироста производительности в пересчете на такт (IPC). Известно также, что C86-5G получат поддержку AVX-512. 512 потоков нуждаются в быстрой памяти — новые процессоры получат 16-канальный контроллер DDR5-5600, что является серьезным шагом вперёд от 12 каналов DDR5-4800 в предыдущем поколении. Что касается IO-подсистемы, то уже в предыдущем поколении появилась поддержка 128 линий PCI Express 5.0. Вероятнее всего, это станет минимумом для C86-5G и, хотя точных цифр компания нет, отмечается, что в новых процессорах дебютирует полноценная поддержка CXL 2.0. 
Hygon C86-7490. Источник: Twitter@YuuKi_AnS Четвёртое поколение серверных чипов Hygon доступно с прошлого года, так что можно предположить, что проектирование C86-5G находится в самом разгаре. Это один из проектов, критически важных для КНР в рамках «тарифной войны» с США и нацеленных на достижение статуса самодостаточности в сфере IT.
26.03.2025 [10:39], Сергей Карасёв
SMART Modular представила энергонезависимые CXL-модули памяти NV-CMM-E3SКомпания SMART Modular Technologies объявила о начале пробных поставок улучшенных энергонезависимых модулей памяти CXL (Non-Volatile CXL Memory Module, NV-CMM), соответствующих стандарту CXL 2.0. Изделия ориентированы на применение в дата-центрах, которые поддерживают такие нагрузки, как резидентные базы данных, аналитика в реальном времени и приложения НРС. Новинка (NV-CMM-E3S) объединяет память DDR4-3200 DRAM, флеш-память NAND и источник резервного питания в форм-факторе E3.S 2T (EDSFF). Задействован интерфейс PCIe 5.0 x8. Применяются контроллеры на базе ASIC и FPGA. Устройство NV-CMM имеет ёмкость 32 Гбайт, а максимальная пропускная способность заявлена на уровне 32 Гбайт/с. Поддерживается шифрование информации по алгоритму AES-256. Интегрированный источник аварийного питания обеспечивает сохранность критически важных данных при непредвиденных отключениях электроэнергии, что повышает надёжность и доступность системы в целом. В случае сбоя в центральной сети энергоснабжения производится копирование данных из DRAM в NAND, а после восстановления подачи энергии выполняется обратный процесс. Изделие обеспечивает более быструю перезагрузку виртуальных машин и сокращает время простоя в облачных инфраструктурах. 
Источник изображения: SMART Modular Technologies Устройство имеет размеры 112,75 × 15 × 76 мм. Эксплуатироваться модуль может при температурах окружающей среды до +40 °C. Отмечается, что внедрение NV-CMM на основе стандарта CXL знаменует собой важную веху в удовлетворении растущих потребностей платформ ИИ, машинного обучения и аналитики больших данных.
08.03.2025 [21:26], Сергей Карасёв
Team Group представила самоуничтожающиеся SSD P250Q, а также DDR5-модули памяти CU-DIMM, CSO-DIMM, (LP)CAMM и CXLКомпания Team Group 2025 анонсировала большое количество новинок для индустриального и коммерческого применения. Дебютировали SSD в различных форм-факторах, модули оперативной памяти, а также флеш-карты micro SD. В частности, представлен накопитель P250Q One-Click Data Destruction SSD, особенность которого заключается в поддержке физического уничтожения флеш-памяти с целью недопустимости извлечения информации. Эта функция дополняет традиционное программное стирание, исключая возможность восстановления конфиденциальных данных. Кроме того, анонсированы накопители RF40 E1.S Enterprise SSD в форм-факторе E1.S для дата-центров. Эти устройства допускают горячую замену, а за отвод тепла отвечает запатентованный медно-графеновый радиатор толщиной всего 0,17 мм. На промышленный сектор ориентированы изделия серий R840 и R250 типоразмера М.2, оснащённые интерфейсом PCIe 5.0 x4. В этих SSD применён контроллер, при производстве которого используется 6-нм технология TSMC. Информация о вместимости и скоростных характеристиках всех перечисленных изделий пока не раскрывается. В список новинок вошли модули оперативной памяти промышленного класса DDR5 стандартов CU-DIMM (Clocked Unbuffered DIMM) и CSO-DIMM (Clocked Small Outline DIMM). Они функционируют на частоте 6400 МГц при напряжении питания 1,1 В. Эти модули могут применяться в серверах, индустриальных ноутбуках повышенной прочности и пр. 
Источник изображения: Team Group Анонсированы также модули памяти CAMM2 и LPCAMM2 (Compression Attached Memory Module 2), рассчитанные на промышленные системы, edge-устройства и пр. Такие решения монтируются параллельно материнской плате, благодаря чему занимают меньше места в высоту. Для установки применяются резьбовые стойки. Память соответствует стандарту DDR5-6400.
В число прочих новинок вошли серверные модули памяти CXL 2.0 Server Memory Module. Плюс к этому представлены карты памяти D500R WORM Memory Card и D500N Hidden Memory Card. Первые ориентированы WORM-нагрузки (Write Once, Read Many), что предотвращает стирание или изменение данных. Карты второго типа получили встроенную функцию скрытия разделов.
03.03.2025 [08:13], Сергей Карасёв
Больше бит за те же деньги: память Sandisk 3D Matrix Memory обещает производительность на уровне DRAM при снижении цены и увеличении ёмкостиКомпания Sandisk, по сообщению TechRadar, обнародовала информацию о памяти нового типа 3D Matrix Memory, которая, как ожидается, в перспективе станет более доступной альтернативой DRAM. Работы над 3D Matrix Memory ведутся с 2017 года в сотрудничестве со специалистами международного микро- и наноэлектронного научно-исследовательского центра IMEC в Лёвене (Бельгия). 3D Matrix Memory использует архитектуру плотного массива с ячейками памяти нового типа. Говорится о совместимости с открытыми отраслевыми стандартами, такими как CXL. По утверждениям Sandisk, разрабатываемая технология позволит преодолеть ограничения в плане ёмкости и пропускной способности, с которыми столкнулись другие типы памяти на фоне стремительного развития ИИ. 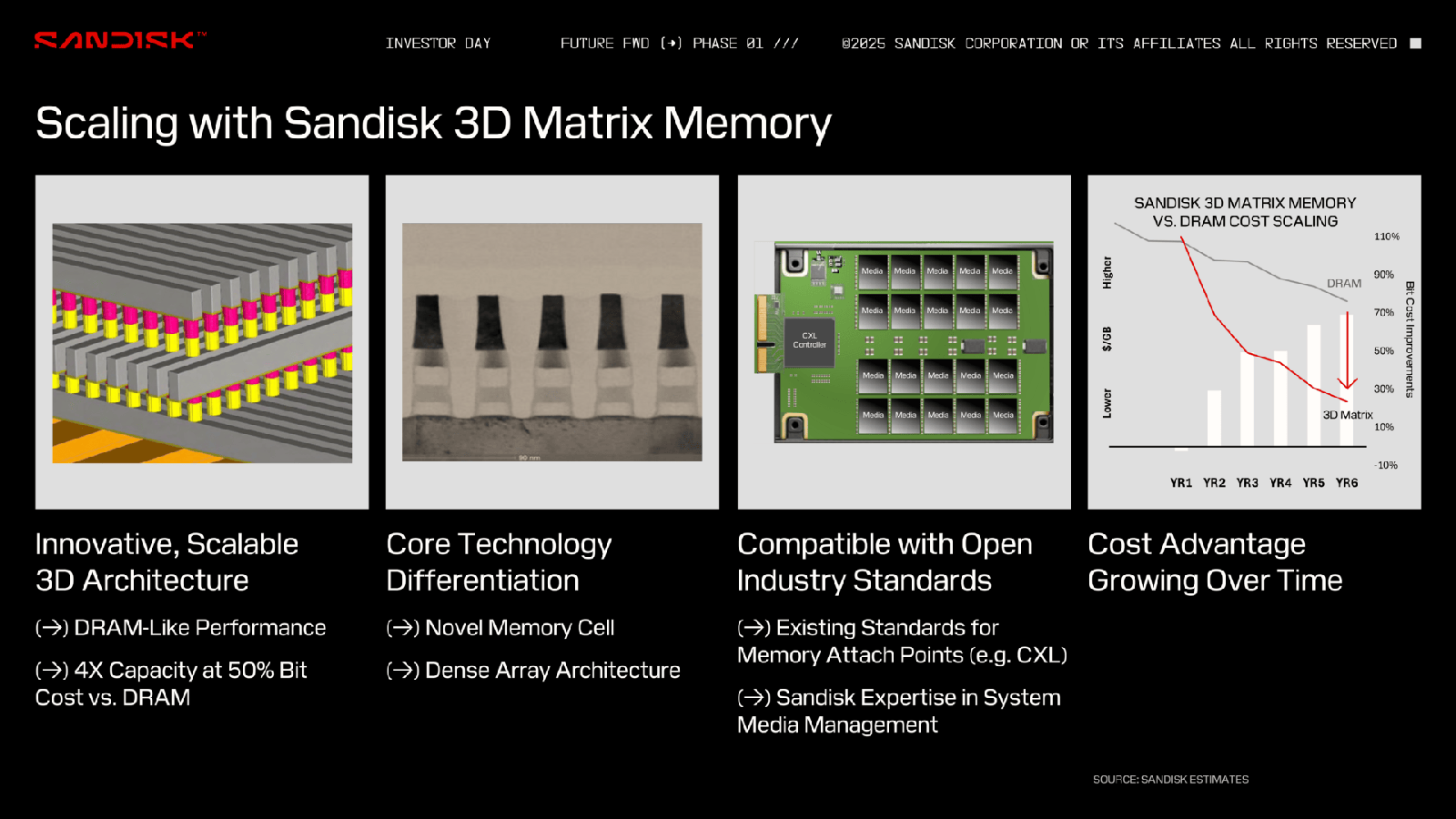
Источник изображений: Sandisk Для 3D Matrix Memory заявлен высокий уровень масштабируемости. Предполагается, что в перспективе такая память обеспечит в четыре раза большую ёмкость по сравнению с DRAM при сопоставимой производительности и двукратном снижении стоимости. Sandisk утверждает, что характеристики памяти 3D Matrix Memory с течением времени будут улучшаться, повышая её экономическую эффективность. 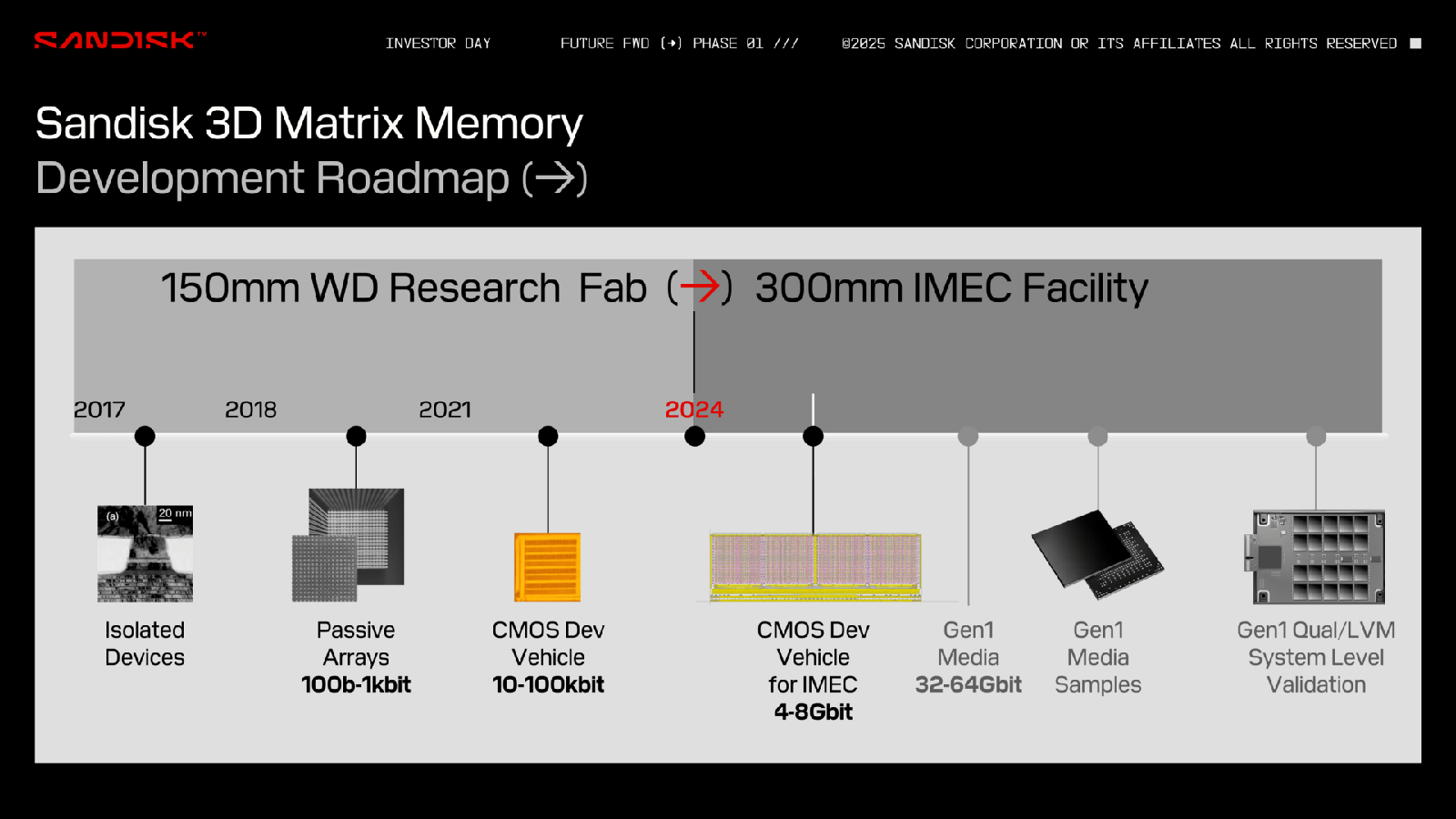 Изделия 3D Matrix Memory первого поколения будут обладать ёмкостью 32–64 Гбит. Одним из первых покупателей памяти станет Министерство обороны США, которое намерено использовать её в аэрокосмическом секторе. О сроках начала массового производства пока ничего не сообщается. Нужно отметить, что ранее Sandisk предложила технологию флеш-памяти с высокой пропускной способностью HBF (High Bandwidth Flash), которая может стать альтернативой HBM (High Bandwidth Memory) в ИИ-ускорителях при решении определённых задач, таких как инференс. По сравнению с HBM использование HBF позволит увеличить объём памяти ИИ-карт в 8 или даже 16 раз при сопоставимой цене. Кроме того, Sandisk проектирует SSD сверхвысокой вместимости для дата-центров: накопители на фирменной платформе UltraQLC смогут вмещать до 1 Пбайт информации.
28.02.2025 [12:35], Сергей Карасёв
Broadcom представила новые решения PCIe 6.0 — чип-коммутатор и ретаймерыВ марте прошлого года Astera Labs анонсировала чипы Aries 6 для PCIe 6.0. Теперь компания Broadcom объявила о доступности собственных решений PCIe 6.0: дебютировали чип-коммутатор PEX 90144, а также ретаймеры BCM85668 и BCM85667. Отмечается, что изделия с поддержкой PCIe 6.0 являются «критически важными высокопроизводительными строительными блоками», необходимыми для развёртывания передовой инфраструктуры ИИ. В тестировании продуктов приняли участие такие компании, как Micron и Teledyne LeCroy. 
Источник изображений: Broadcom Ретаймеры BCM85668 и BCM85667 поддерживают соответственно 8 и 16 линий PCIe 6. При производстве применяется 5-нм технология. Говорится об обратной совместимости с PCIe поколений 5/4/3/2/1, а также о совместимости с Compute Express Link (CXL 3.1). Возможна работа в режимах 64, 32, 16, 8, 5 и 2,5 GT/s (млрд пересылок в секунду). Изделие BCM85668 поддерживает бифуркацию x8, 2 x4 и 4 x2. В случае BCM85667 возможны конфигурации 1 x16, 4 x4 и 8 x2. Заявлена поддержка режимов с низким энергопотреблением и проприетарных режимов с малой задержкой (LL).  Чип-коммутатор PEX 90144, в свою очередь, имеет 144 линии. Изделие предназначено для координации потоков трафика. Полностью технические характеристики на данный момент не раскрываются. Год назад также упоминались чипы PEX 90104 и говорилось о разработке коммутаторов PCI Express 7.0 с поддержкой AMD AFL (Accelerated Fabric Link), коммутируемого варианта Infinity Fabric.
16.01.2025 [08:04], Алексей Степин
Терабайтные GPU: Panmnesia продемонстрировала CXL-память для ИИ-ускорителейКомпания Panmnesia работает в области проектирования CXL-пулов DRAM довольно давно: в 2023 году она демонстрировала систему, оставляющую позади все решения на базе RDMA и обеспечивающую доступ к 6 Тбайт оперативной памяти. Но большие объёмы памяти сегодня, в эпоху всё более усложняющихся ИИ-моделей, нужны не только и не столько процессорам, сколько ускорителям, априори лишённым возможности апгрейда набортной RAM. На выставке CES 2025 компания продемонстрировала решение данной проблемы. По мнению разработчиков Panmnesia, производительность при обучении масштабных ИИ-моделей упирается именно в объёмы набортной памяти ускорителей: вместо десятков гигабайт требуются уже терабайты, а установка дополнительных ускорителей может обходиться слишком дорого при том, что вычислительные мощности окажутся избыточными. 
Источник здесь и далее: Panmnesia Продемонстрированная на выставке CXL-система построена на базе новейшего контроллера Panmnesia с поддержкой CXL 3.1. В двунаправленном режиме латентность доступа составила менее 100 нс и находится примерно на уровне 80 нс. 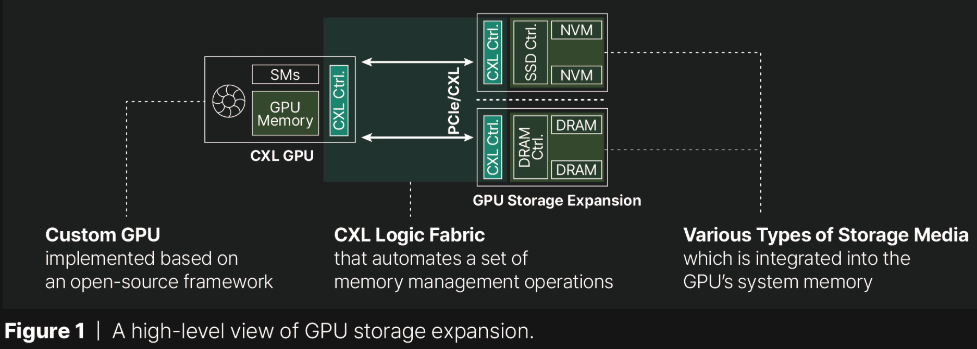 Ключ к успеху здесь кроется в фирменной реализации CXL 3.1, включая программную часть, благодаря которой GPU могут обращаться к общему пулу памяти, используя те же инструкции типа load/store, что при доступе к набортной HBM или GDDR.  Однако технология требует наличия на борту GPU фирменного контроллера CXL Root Complex, одной из важнейших частей которого является декодер HDM, отвечающий за управление адресным пространством памяти (host physical address, HPA), так что уже выпущенные ускорители напрямую работать с системой Panmnesia не смогут.  Тем не менее, технология выглядит многообещающей. Она уже привлекла внимание со стороны компаний, занимающихся ИИ, как потенциально позволяющая снизить стоимость инфраструктуры ЦОД.
04.01.2025 [15:21], Руслан Авдеев
Microsoft совместно с учёными США разработала экологичные облачные серверы GreenSKU, которые используют RAM и SSD из старых системУчёные из Microsoft, Университета Карнеги-Меллона и Вашингтонского университета разработали новый стандарт экологичных серверов GreenSKU, которые позволят снизят углеродные выбросы ЦОД, сообщает IEEE Spectrum. Кроме того, была представлена модель GreenSKU Framework для расчёта целесообразности использования подобных систем в дата-центрах гиперскейлеров и подбора оптимальных конфигураций. Созданные в рамках концепции GreenSKU прототипы серверов были протестированы в ЦОД Azure. 
Источник изображений: Microsoft Исследование, вышедшее минувшим летом, изучает возможность использования компонентов из списанных серверов. Это важно, поскольку сегодня во многих случаях при сбое одного компонента из эксплуатации выводится сервер целиком. Кроме того, Microsoft меняет серверы Azure каждые 3–5 лет для оптимизации производительности. И в этом случае работоспособные компоненты всё равно обычно не используются в других серверах. 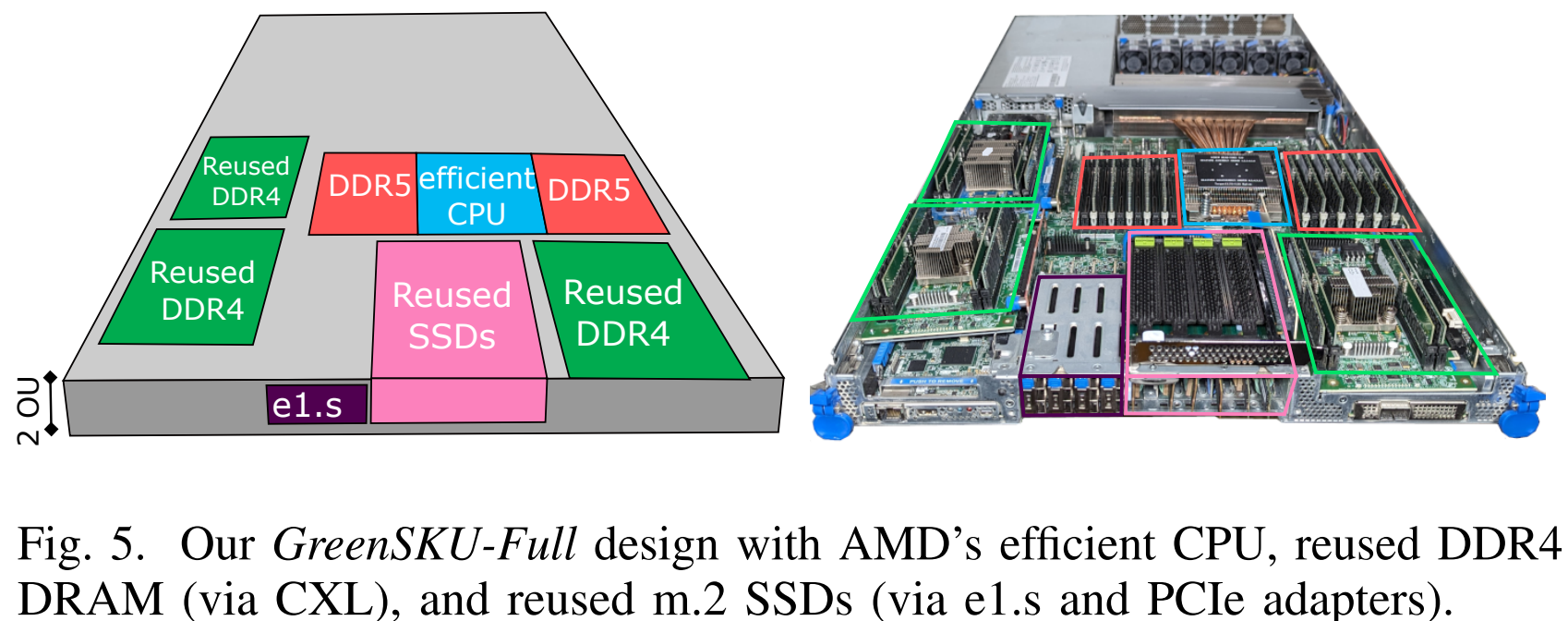 Согласно выкладкам исследователей, уровень сбоев оперативной памяти (AFR) после кратковременного всплеска вскоре после развёртывания остаётся примерно одинаковым на протяжении не менее семи лет. А износ SSD составляет около половины. Впрочем, в данном случае речь идёт об M.2-накопителях. Их надёжность и скорость работы можно повысить простым объединением в RAID-массив. А для их использования в современных платформах с E1.S-корзинами есть готовые пассивные адаптеры, благо стандарт PCIe обладает обратной совместимостью.  С памятью дело обстоит не так просто. Предыдущие поколения серверов использовали DDR4, тогда как актуальные платформы работают только с DDR5. Однако выход есть — в современных CPU появилась поддержка CXL. Точнее, CXL Type 3 (CXL.mem), что позволяет подключать по PCIe пулы DRAM. Они представлены в виде NUMA-узлов без CPU. Такое подключение памяти даёт большую задержку, но современные гипервизоры умеют работать с такими пулами, отправляя в них редко используемые массивы данных.  Старые процессоры переиспользовать не выйдет. Они гораздо менее энергоэффективны и производительны, при этом на CPU приходится основная часть энергопотребления и, соответственно, углеродных выбросов. Исследователи изучили актуальные предложения вендоров и пришли к выводу, что среди доступных на рынке процессоров наилучшим образом для GreenSKU подходят AMD EPYC Bergamo, которые предлагает большое количество ядер и потоков при сравнимом уровне TDP, пусть и при пониженной производительности каждого ядра, а также поддерживают необходимые протоколы CXL.  Для распределения нагрузок используется отдельный программный слой, определяющий, какие задачи можно выполнять на серверах GreenSKU, а какие — на стандартных серверах Azure в зависимости от требований к производительности. Как отмечают исследователи, три четверти развёрнутых в Azure инстансов в среднем используют лишь 25 % выделенных ресурсов CPU и около 15 % от доступной пропускной способности памяти. Точно так же далеко не в полной мере используются и SSD. Вместе с тем есть клиенты, которые выживают максимум из каждого инстанcа. Снижение углеродных выбросов имеет большое значение для облачных вычислений, поскольку они могут составить 20 % всех выбросов к 2030 году — об этом свидетельствуют данные НКО Ассоциация вычислительной техники. В пересчёте на ядро выбросы серверов GreenSKU на 28 % ниже, чем выбросы обычных серверов Azure. А на уровне ЦОД с учётом всех накладных расходов снижение выбросов составляет 8 %. |
|


