Идея дезагрегации памяти интересует не только владельцев крупных облачных ЦОД, но и специалистов по суперкомпьютерным системам, которые также способны много выиграть от использования подобных технологий. В числе прочих, активно ведёт работы в данном направлении Корейский институт передовых технологий (KAIST), продемонстрировавший недавно работоспособный прототип технологии под названием DirectCXL, передаёт The Next Platform.

Источник: KAIST/CAMELab
Нетрудно понять из названия, что основой является протокол CXL. Основные принципы, заложенные в DirectCXL лаборатория KAIST CAMELab раскрыла ещё на мероприятии USENIX Annual Technical Conference, они изложены в брошюре, доступной для скачивания с сайта лаборатории.

Источник: KAIST/CAMELab
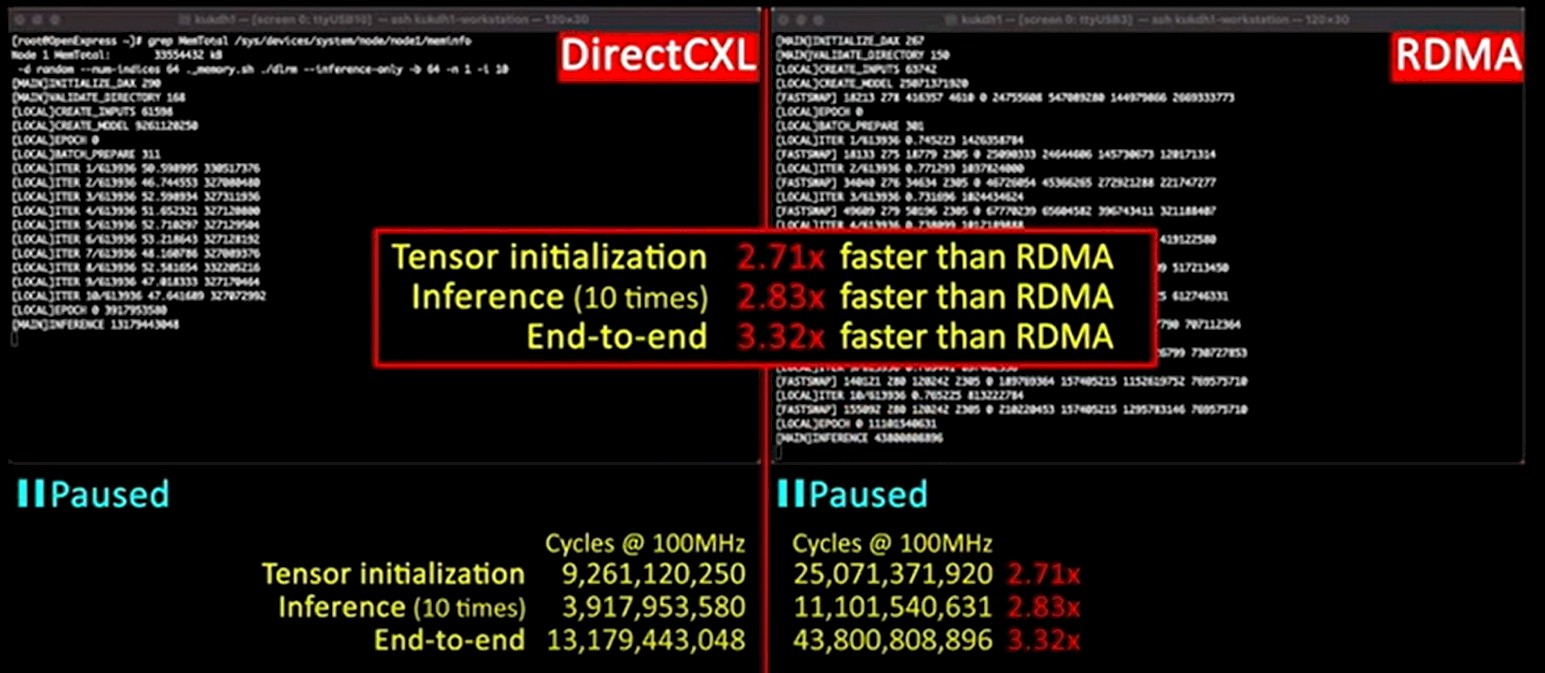
Исследователи также провели сравнительное тестирование технологий CXL и RDMA, для чего была использована не самая новая версия InfiniBand FDR (56 Гбит/с) на базе Mellanox ConnectX-3. Как выяснилось, RDMA всё ещё обеспечивает более низкие задержки, однако прогресс в этой области остановился, тогда как у CXL имеется потенциал.
Источник: KAIST/CAMELab
Избавление от «лишних» протоколов в цепочке между вычислительными узлами и узлами памяти позволило превзойти показатели RDMA over Fabrics. Прототип CXL-пула CAMELab состоял из четырёх плат с разъёмами DIMM и контроллерами на базе FPGA, отвечающими за создание линков PCIe и реализацию протокола CXL 2.0, четырёх хост-систем и коммутатора PCI Express. Для сравнения RDMA с CXL была применена система Facebook✴ DLRM.
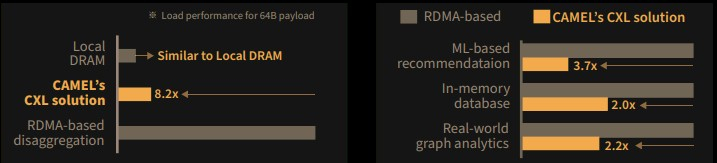
Как показали тесты, CXL-система CAMELab тратит на инициализацию существенно меньше тактов, нежели RDMA, и в некоторых случаях выигрыш составляет свыше восьми раз, но в среднем равен 2–3,7x, в зависимости от сценария. Некоторое отставание от классической локальной DRAM есть, но оно не так значительно и им в данном случае можно пренебречь, особенно с учётом всех преимуществ, обеспечиваемых CXL 2.0.
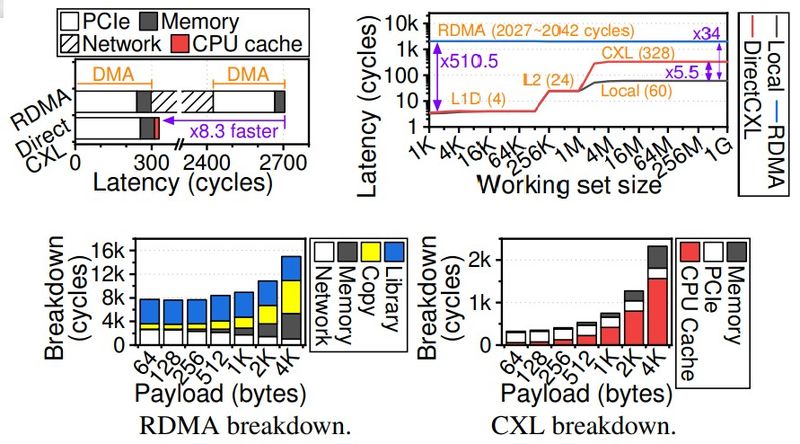
CXL тратит на пересылку пакета данных чуть более 300 циклов, RDMA — более 2700. Источник: KAIST/CAMELab
Стоит учитывать, что поддержки адресации CXL-памяти нет пока ни в одной доступной системе, и здесь CAMELab проделали серьезную работу, создав стек DirectCXL, работающий, судя по всему, непосредственно на FPGA: как и в NUMA-системах, при адресации в режиме load/store первичная обработка данных происходит «на месте», сами данные лишний раз никуда не пересылаются. Также стоит отметить, что драйвер DirectCXL существенно проще созданного Intel для пулов Optane Pmem.
Источник: KAIST/CAMELabs
Над аналогичными проектами работают также Microsoft с технологией zNUMA и Meta✴ Platforms, разрабатывающая протокол Transparent Page Placement и технологию Chameleon. А Samsung, которая первой представила CXL-модули DDR5, объединилась с Liqid и Tanzanite для развития аппаратных CXL-платформ. Ожидается, что в ближайшее время мы увдим множество разработок на тему использования технологий дезагрегации и создания унифицированных пулов памяти, подключаемых к хост-системам посредством интерконнекта CXL.
Источник:

