Материалы по тегу: 24
|
19.03.2024 [01:02], Сергей Карасёв
Ускорители NVIDIA H100 лягут в основу японского суперкомпьютера ABCI-Q для квантовых вычисленийКомпания NVIDIA сообщила о том, что её технологии лягут в основу нового японского суперкомпьютера ABCI-Q, предназначенного для проведения исследований в области квантовых вычислений. Платформа, в частности, будет использоваться для тестирования гибридных систем, объединяющих классические и квантовые технологии. Развёртыванием комплекса займётся корпорация Fujitsu. Машина расположится в суперкомпьютерном центре ABCI (AI Bridging Cloud Infrastructure) Национального института передовых промышленных наук и технологий Японии (AIST). Ввод ABCI-Q в эксплуатацию намечен на начало 2025 года. В состав суперкомпьютера войдут более 500 узлов, насчитывающих в общей сложности свыше 2000 ускорителей NVIDIA H100. Говорится о применении интерконнекта NVIDIA Quantum-2 InfiniBand, а также NVIDIA CUDA Quantum — открытой платформы для интеграции и программирования CPU, GPU и квантовых процессоров (QPU). Комплекс ABCI-Q проектируется с прицелом на возможность добавления будущих аппаратных компонентов для квантовых вычислений. 
Источник изображения: NVIDIA Ожидается, что ABCI-Q позволит проводить высокоточное квантовое моделирование в рамках исследовательских проектов в различных отраслях. Учёные смогут тестировать приложения нового типа с целью ускорения их практического внедрения. Кроме того, специалисты смогут прорабатывать передовые алгоритмы для решения специфичных задач. NVIDIA и AIST также планируют сотрудничать при разработке промышленных приложений на базе ABCI-Q. В целом, ABCI-Q является частью стратегии Японии в области квантовых технологий, задачей которой является создание новых возможностей для бизнеса и общества, а также получение выгоды от квантовых технологий, в том числе посредством исследований в области ИИ, энергетики и биологии.
19.03.2024 [01:01], Сергей Карасёв
NVIDIA показала цифрового двойника нового дата-центра с ИИ-ускорителями BlackwellКомпания NVIDIA на конференции GTC 2024 приоткрыла завесу тайны над новым вычислительным кластером, предназначенным для решения ресурсоёмких задач в области ИИ. Полностью работоспособный дата-центр продемонстрирован в виде цифрового двойника на платформе Omniverse. Показанный кластер выполнен на платформе NVIDIA GB200 NVL72. Отмечается, что проектирование и создание современных ЦОД — очень трудоёмкий процесс, который требует объединения усилий самых разных команд специалистов. При этом должно учитываться огромное количество факторов, от которых зависят энергетическая эффективность, производительность, возможность масштабирования и пр. Цифровые двойники дают возможность упростить и ускорить процесс. 
Источник изображения: NVIDIA Цифровой двойник создан на платформе Cadence Reality с применением Omniverse. Для создания цифровой копии будущего ЦОД, который заменит один из устаревших дата-центров NVIDIA, компания Kinetic Vision просканировала площадку с помощью носимого сканера NavVis VLX на основе лидара. В результате были получены высокоточные данные о физических характеристиках объекта и панорамные фотографии. Далее с помощью ПО Prevu3D была сформирована реалистичная 3D-модель ЦОД. Инженеры объединили и визуализировали несколько наборов данных САПР с высокой точностью с помощью платформы Cadence Reality. 
Источник изображения: NVIDIA Программные интерфейсы Omniverse Cloud обеспечили совместимость с другими инструментами, включая Patch Manager и NVIDIA Air. С помощью Patch Manager специалисты разработали физическую схему кластера и сетевой инфраструктуры, включая необходимые кабели с расчётом их длины. Кроме того, были рассчитаны воздушные потоки и параметры СЖО от таких партнёров, как Vertiv и Schneider Electric. NVIDIA показала, что цифровые двойники позволяют проектировать, тестировать и оптимизировать ЦОД полностью в виртуальной среде. Визуализируя производительность дата-центра, команды могут изучать различные варианты компоновки и оценивать всевозможные сценарии. Таким образом, можно добиться оптимальной структуры ЦОД ещё до создания физического объекта.
19.03.2024 [01:00], Игорь Осколков
NVIDIA B200, GB200 и GB200 NVL72 — новые ускорители на базе архитектуры BlackwellNVIDIA представила сразу несколько ускорителей на базе новой архитектуры Blackwell, названной в честь американского статистика и математика Дэвида Блэквелла. На смену H100/H200, GH200 и GH200 NVL32 на базе архитектуры Hopper придут B200, GB200 и GB200 NVL72. Все они, как говорит NVIDIA, призваны демократизировать работу с большими языковыми моделями (LLM) с триллионами параметров. В частности, решения на базе Blackwell будут до 25 раз энергоэффективнее и экономичнее в сравнении с Hopper. В разреженных FP4- и FP8-вычислениях производительность B200 достигает 20 и 10 Пфлопс соответственно. Но без толики технического маркетинга не обошлось — показанные результаты достигнуты не только благодаря аппаратным улучшениям, но и программным оптимизациям. Это ни в коей мере не умаляет их важности и полезности, но затрудняет прямое сравнение с конкурирующими решениями. В общем, появление Blackwell стоит рассматривать не как очередное поколение ускорителей, а как расширение всей экосистемы NVIDIA. В Blackwell компания использует тайловую (чиплетную) компоновку — два тайла объединены 2,5D-упаковкой CoWoS-L и на двоих имеют 208 млрд транзисторов, изготовленных по техпроцессу TSMC 4NP. В одно целое со всех точек зрения их объединяет новый интерконнект NV-HBI с пропускной способностью 10 Тбайт/с, а дополняют их восемь стеков HBM3e-памяти ёмкостью до 192 Гбайт с агрегированной пропускной способностью до 8 Тбайт/с. Такой же объём памяти предлагает и Instinct MI300X, но с меньшей ПСП (5,3 Тбайт/с), хотя это скоро изменится. FP8-производительность в разреженных вычислениях у решения AMD составляет 5,23 Пфлопс, но зато компания не забывает и про FP64 в отличие от NVIDIA. 
Источник изображений: NVIDIA Одними из ключевых нововведений, отвечающих за повышение производительности, стали новые Tensor-ядра и второе поколение механизма Transformer Engine, который научился заглядывать внутрь тензоров, ещё более тонко подбирая необходимую точность вычислений, что влияет и на скорость обучения с инференсом, и на максимальный объём модели, умещающейся в памяти ускорителя. 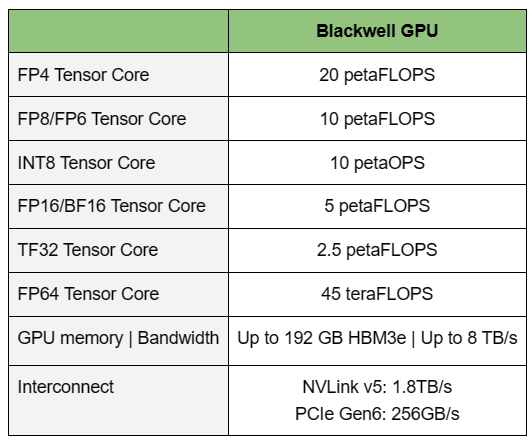 Теперь NVIDIA намекает на то, что обучение можно делать в FP8-формате, а для инференса хватит и FP4. Всё это без потери качества. Но вообще Blackwell поддерживает FP4/FP6/FP8, INT8, BF16/FP16, TF32 и FP64. И только для последнего нет поддержки разреженных вычислений. 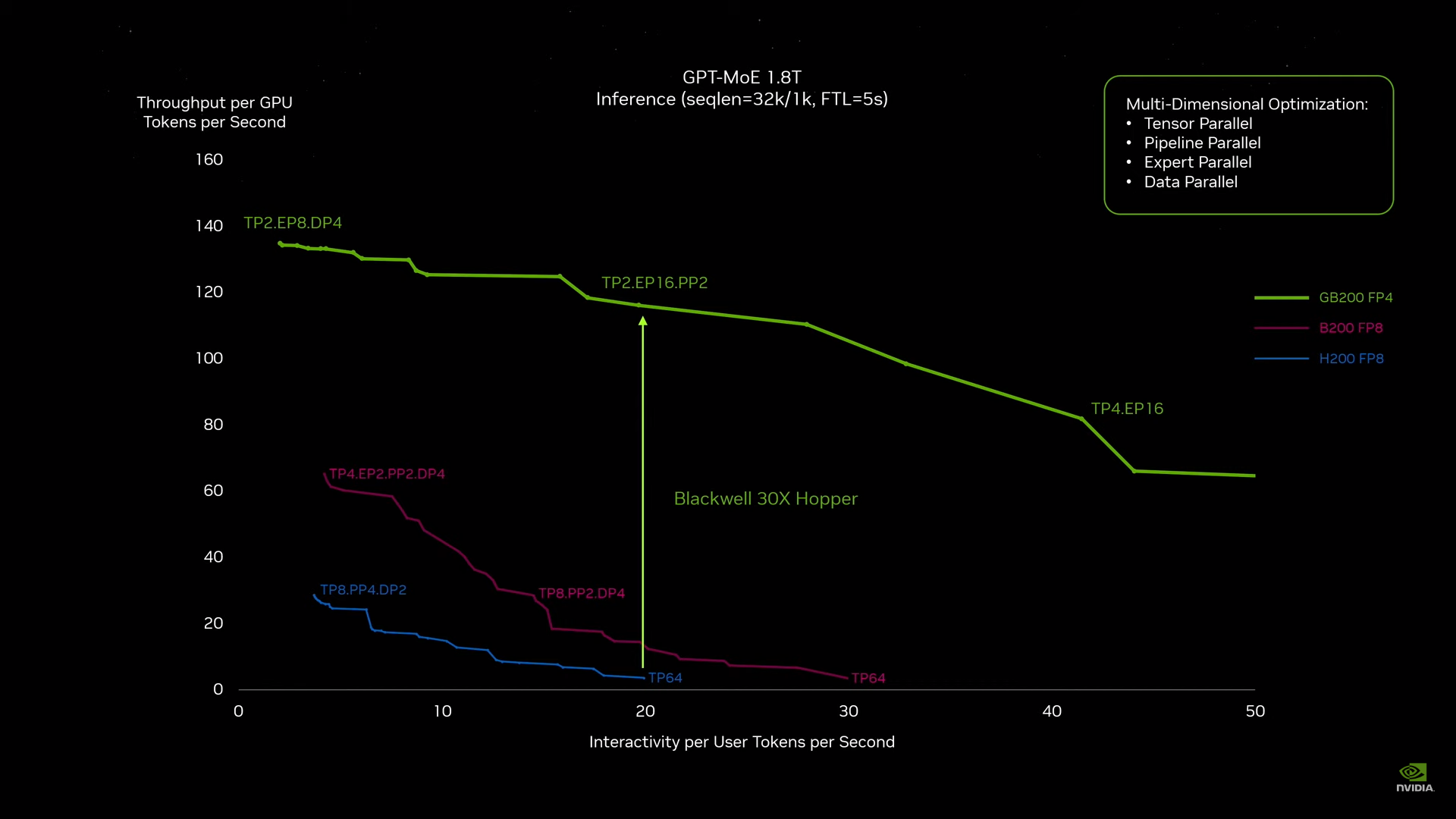 Дополнительно Blackwell обзавёлся движком для декомпрессии (в первую очередь LZ4, Deflate, Snappy) входящих данных со скоростью до 800 Гбайт/с, что тоже должно повысить производительность, т.к. теперь распаковкой будет заниматься не CPU и, соответственно, ускоритель не будет «голодать». Эта функция рассчитана в основном на Apache Spark и другие системы для аналитики больших данных. Также есть по семь движков NVDEC и NVJPEG.  Наконец, NVIDIA упоминает ещё две новых возможности Blackwell: шифрование данных в памяти и RAS-функции. В первом случае речь идёт о защите конфиденциальности обрабатываемых данных, что важно в целом ряде областей. Причём формирование TEE-анклава возможно в рамках группы из 128 ускорителей. MIG-доменов по-прежнему семь. В случае RAS говорится о телеметрии и предиктивной аналитике (естественно, на базе ИИ), которые помогут заранее выявить возможные сбои и снизить время простоя. Это важно, поскольку многие модели могут обучаться неделями и месяцами, так что потеря даже относительно небольшого куска данных крайне неприятна и финансово затратна.  Однако всё эти инновации не имеют смысла без возможности масштабирования, поэтому NVIDIA оснастила Blackwell не только интерфейсом PCIe 6.0 (32 линии), который играет всё меньшую роль, но и пятым поколением интерконнекта NVLink. NVLink 5 по сравнению с NVLink 4 удвоил пропускную способность до 1,8 Тбайт/с (по 900 Гбайт/с в каждую сторону), а соответствующий коммутатор NVSwitch 7.2T позволяет объединить до 576 ускорителей в одном домене. SHARP-движки с поддержкой FP8 дополнительно помогут ускорить обработку моделей, избавив ускорители от части работ по предобработке и трансформации данных. Чип коммутатора тоже изготавливается по техпроцессу TSMC N4P и содержит 50 млрд транзисторов.  Для дальнейшего масштабирования и формирования кластеров из 10 тыс. ускорителей и более, вплоть до 100 тыс. ускорителей на уровне ЦОД, NVIDIA предлагает 800G-коммутаторы Quantum-X800 InfiniBand XDR и Spectrum-X800 Ethernet, имеющие соответственно 144 и 64 порта. Узлам же полагаются DPU ConnectX-8 SuperNIC и BlueField-3. Правда, последний предлагает только 400G-порты в отличие от первого. От InfiniBand компания отказываться не собирается.  С базовыми кирпичиками разобрались, пора переходить к конструированию продуктов. Первым идёт HGX B100, в основе которой всё та же базовая плата с восемью ускорителями Blackwell, точно так же провязанных между собой NVLink 5 с агрегированной скоростью 14,4 Тбайт/с. Для связи с внешним миром предлагается пара интерфейсов PCIe 6.0 x16. HGX B100 предназначена для простой замены HGX H100, поэтому ускорители имеют TDP не более 700 Вт, что ограничивает пиковую производительность в разреженных FP4- и FP8/FP6/INT8-вычислениях до 14 и 7 Пфлопс соответственно, а для всей системы — 112 и 56 Пфлопс соответственно. 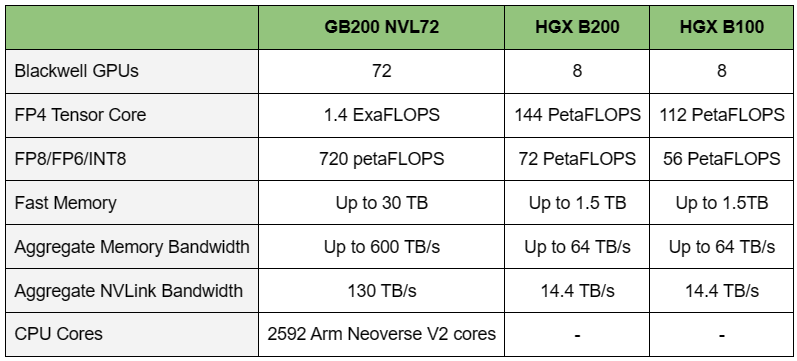 У HGX B200 показатель TDP ограничен уже 1 кВт, причём возможность воздушного охлаждения по-прежнему сохраняется. Производительность одного B200 в разреженных FP4- и FP8/FP6/INT8-вычислениях достигает уже 18 и 9 Пфлопс, а для всей системы — 144 и 72 Пфлопс соответственно. DGX B200 повторяет HGX B200 в плане производительности и является готовой системой от NVIDIA, тоже с воздушным охлаждением. В системе используются два чипа Intel Xeon Emerald Rapids. По словам NVIDIA, DGX B200 до 15 раз быстрее в задачах инференса «триллионных» моделей по сравнению с DGX-узлами прошлого поколения. 800G-интерконнект Ethernet/InfiniBand этим трём платформам не достался, только 400G.  Основным же строительным блоком сама компания явно считает гибридный суперчип GB200, объединяющий уже имеющийся у неё Arm-процессор Grace сразу с двумя ускорителями Blackwell B200. CPU-часть включает 72 ядра Neoverse V2 (по 64 Кбайт L1-кеша для данных и инструкций, L2-кеш 1 Мбайт), 144 Мбайт L3-кеша и до 480 Гбайт LPDDR5x-памяти с ПСП до 512 Гбайт/с. С двумя B200 процессор связан 900-Гбайт/с шиной NVLink-C2C — по 450 Гбайт/с на каждый ускоритель. Между собой B200 напрямую подключены уже по полноценной 1,8-Тбайт/с шине NVLink 5.  Вся эта немаленькая конструкция шириной в половину стойки имеет TDP до 2,7 кВт. 1U-узел с парой чипов GB200, каждый из которых может отъедать до 1,2 кВт, уже требует жидкостное охлаждение. FP4- и FP8/FP6/INT8-производительность (речь всё ещё о разреженных вычислениях) GB200 достигает 40 и 20 Пфлопс. И именно эти цифры NVIDIA нередко использует для сравнения новинок со старыми решениями.  18 узлов с парой GB200 (суммарно 72 шт.) и 9 узлов с парой коммутаторов NVSwitch 7.2T, которые провязывают все ускорители по схеме каждый-с-каждым (агрегированно 130 Тбайт/с, более 3 км соединений), формируют 120-кВт суперускоритель GB200 NVL72 размером со стойку, оснащённый СЖО и единой DC-шиной питания. Всё это даёт до 1,44 Эфлопс в FP4-вычислениях и до 720 Пфлопс в FP8, а также до 13,5 Тбайт HBM3e с агрегированной ПСП до 576 Тбайт/с. Ну а общий объём памяти составляет порядка 30 Тбайт. GB200 NVL72 одновременно является и узлом DGX GB200. Восемь DGX GB200 формируют DGX SuperPOD. Впрочем, будет доступен и SuperPOD попроще, на базе DGX B200.  Ускорители B200 появятся в этом году и будут стоить в диапазоне $30–$40 тыс., что ненамного больше начальной цены Hopper в диапазоне $25–$40 тыс. Глава NVIDIA уже предупредил, что Blackwell сразу будут в дефиците. Вероятно, получить доступ к ним проще всего будет в облаках Amazon, Google, Microsoft и Oracle.
04.03.2024 [09:30], Сергей Карасёв
QCT представила серверы на базе Intel Xeon для 5G-инфраструктур и ИИКомпания Quanta Cloud Technology (QCT) в ходе выставки мобильной индустрии MWC 2024, которая в конце февраля прошла в Барселоне (Испания), представила серверы нового поколения QuantaGrid, QuantaPlex и QuantaEdge. Эти системы ориентированы на 5G-инфраструктуры, ресурсоёмкие ИИ-приложения и периферийные вычисления. В частности, дебютировали модели QCT QuantaEdge EGX74I-1U и QuantaEdge EGX77B-1U на процессорах Intel Xeon Sapphire Rapids. Они отличаются небольшим энергопотреблением и сверхмалой глубиной: в случае EGX77B-1U она составляет 300 мм. По заявлениям QCT, эти машины хорошо подходят для сценариев Open RAN. Вариант EGX74I-1U поддерживает память DDR5-4800, по два накопителя M.2 2280 (NVMe или SATA-3) и SFF U.2, одну карту FHHL PCIe 5.0 x16 и две карты FH3/4L PCIe 5.0 x16. Диапазон рабочих температур простирается от -40 до +65 °C. В семействе QuantaGrid демонстрируются серверы следующего поколения на платформе Birch Stream, оснащённые чипами Intel Xeon Sierra Forest и Granite Rapids. Они предназначены прежде всего для организации ИИ-вычислений на периферии. В серию QuantaGrid вошли двухсокетные модели. Кроме того, представлено решение QCT Platform on Demand (QCT POD) с аппаратными компонентами Intel для конвергентных НРС-систем и нагрузок ИИ. 
Intel Birch Stream
В свою очередь, QCT OmniPOD Enterprise 5G Solution на платформе Intel представляет собой комплексное решение для частных сетей 5G. Оно состоит из ядра 5G, 5G RAN и системы управления сетью. Изделие может быть интегрировано с камерами видеонаблюдения, автономными мобильными роботами и другими устройствами для организации видеоаналитики, классификации изображений и моделирования.
03.03.2024 [01:02], Сергей Карасёв
ZTE представила серверный шкаф высокой плотности IceCube с СЖОКомпания ZTE на выставке MWC 2024 анонсировала серверный шкаф нового поколения IceCube, предназначенный для высокоплотного размещения оборудования. Решение, по словам компании, ориентировано на энергоэффективные и экологичные дата-центры. Говорится о показателе до 100 кВт в расчёте на стойку. Жидкостное охлаждение набирает популярность в ЦОД в связи со стремительным развитием ИИ и ресурсоёмких вычислений. СЖО позволяет обеспечить более высокие мощность и плотность размещения оборудования в стойке. Шкаф ZTE IceCube предлагает гибридный подход: вода циркулирует как через дверцу, так и через водоблоки, прилегающие к горячим компонентам. 
Источник изображения: ZTE В шкафу IceCube можно разместить до 40 серверов формата 1U благодаря монтажу «с нулевым зазором», говорит ZTE. При этом, как утверждается, можно добиться «частичного значения PUE» менее 1,1. Монтаж и замену оборудования можно осуществлять без риска утечек. Реализованы средства «слепого подключения» коммуникаций.
29.02.2024 [23:59], Алексей Степин
Intel анонсировала платформу vPro для Raptor Lake-R, Meteor Lake-U и Meteor Lake-HКак правило, Intel анонсирует новые поколения корпоративной платформы vPro уже после анонса полной серии новых процессоров. Не стал исключением и 2024 год — на MWC 2024 компания объявила о поддержке vPro процессорами 14-ого поколения. Речь идёт как о серии Core на базе микроархитектуры Raptor Lake-R, так и о новейших мобильных чипах Meteor Lake — Core Ultra-H и -U. Анонсирована поддержка как базовой версии vPro Essential, так и корпоративной vPro Enterprise. Впервые платформа vPro Essentials была анонсирована в 2022 году как подмножество более полного пакета технологий vPro, который сейчас получил приставку Enterprise к названию. Первый вариант предназначен в основном для малого бизнеса, однако обеспечивает поддержку аппаратных возможностей по обеспечению безопасности, в том числе с использованием ИИ в технологии Intel Threat Detection Technology (TDT), которая работает ниже уровня ОС. 
Источник здесь и далее: Intel via AnandTech Версия vPro Enterprise ориентирована на крупный бизнес и отличается наличием инструментов для управления большим парком ПК и ноутбуков. Это, например, поддержка out-of-band KVM, беспроводной вариант Intel AMT, улучшенная техподдержка, а также безопасное удалённое стирание информации в системах, оснащённых накопителями Intel SSD Pro.  Intel разграничила поддержку разных версий vPro в зависимости от модели процессора. К примеру, в 14-ом поколении настольных чипов Core (Raptor Lake-R) оверклокерские модели с суффиксом K поддерживают только vPro Enterprise, тогда как остальные CPU могут работать с обеими версиями vPro. Не поддерживаются лишь чипы без интегрированной графики, с суффиксами F и KF. Для работы технологии требуется системная плата с одним из двух чипсетов — либо Q670, либо W680.  С мобильными процессорами всё сложнее. Raptor Lake Refresh в список корпоративных моделей не вошли и поддержки vPro не получили. А вот мобильные Meteor Lake-U и Meteor Lake-H поддержку таковую обрели, но (в отличие от Raptor Lake-R) моделей, поддерживающих одновременно оба варианта vPro, не предусмотрено. Intel уверена в популярности новых решений и говорит о более чем 90 дизайнах коммерческих ПК на базе новых процессоров, которые поступят в продажу уже в этом квартале.
29.02.2024 [14:13], Сергей Карасёв
Lenovo представила обновлённые серверы ThinkEdge для ИИ-задач и периферийных вычисленийКомпания Lenovo на выставке MWC 2024 анонсировала новые серверы, предназначенные для решения ИИ-задач и организации периферийных вычислений. Демонстрируются модели ThinkEdge SE455 V3, ThinkEdge SE350 V2 и ThinkEdge SE360 V2. Первая из перечисленных новинок построена на платформе AMD EPYC 8004 Siena с возможностью установки одного процессора с показателем TDP до 225 Вт. Устройство выполнено в формате 2U с глубиной 438 мм. Есть шесть слотов для модулей DDR5-4800, по четыре внешних и внутренних отсека для накопителей SFF (SATA или NVMe). Доступны до шести слотов PCIe — 2 × PCIe 5.0 x16 и 4 × PCIe 4.0 x8. Предусмотрены также два коннектора для SSD типоразмера M.2. Серверы ThinkEdge SE350 V2 и ThinkEdge SE360 V2 выполнены в формате 1U и 2U соответственно. Они рассчитаны на установку одного процессора Intel Xeon D-2700 с TDP до 100 Вт. Первая из этих моделей позволяет задействовать до четырёх SFF-накопителей NVMe/SATA толщиной 7 мм и два SFF-устройства NVMe толщиной 15 мм. Слоты расширения PCIe не предусмотрены. Второй сервер может быть оборудован двум SFF-накопителями NVMe/SATA толщиной 7 мм и восемью устройствами M.2 2280/22110 (NVMe). Имеются два слота PCIe 4.0 x16.  Представлены также компьютеры небольшого форм-фактора ThinkEdge SE10 и ThinkEdge SE30 для промышленной автоматизации, IoT-приложений и пр. Эти устройства оснащаются процессорами Intel — вплоть до Atom x6425RE и Core i5-1145GRE соответственно. Первый из этих компьютеров может быть оснащён одним накопителем M.2 PCIe SSD вместимостью до 1 Тбайт, второй — двумя. Ребристая поверхность корпуса выполняет функции радиатора для отвода тепла.
29.02.2024 [12:17], Сергей Карасёв
Iceotope, HPE и Intel представили сервер KUL RAN второго поколения с СЖОКомпании Iceotope, HPE и Intel продемонстрировали на MWC 2024 ряд новинок для телекоммуникационной отрасли и edge-приложений. В частности, представлен сервер KUL RAN второго поколения с эффективной системой жидкостного охлаждения. Edge-сервер KUL RAN первого поколения дебютировал в июне 2023 года. Он предназначен для развёртывания vRAN-платформ, сетей 5G и других сервисов связи. Применена полностью автономная СЖО Iceotope Precision Liquid Cooling. Новая модель KUL RAN выполнена в форм-факторе 2U. В основу положен сервер HPE ProLiant DL110 Gen11 на базе Intel Xeon Sapphire Rapids. Iceotope заявляет, что устройство может эксплуатироваться в «самых суровых условиях». Оно имеет защиту от тепловых ударов, пыли и влаги. Диапазон рабочих температур простирается от -40 до +55 °C. Утверждается, что решение обеспечивает сокращение энергопотребления до 20 % по сравнению со стандартными телеком-серверами, тогда как частота отказов компонентов ниже на 30 %. Устройство KUL RAN второго поколения ориентировано на сети радиодоступа с низкими задержками и edge-задачи.  Iceotope также заявляет, что её технология Precision Liquid Cooling даёт возможность охлаждать процессоры с показателем TDP 1000 Вт и даже выше. Таким образом, система подходит для применения в мощных ИИ-серверах с высокой нагрузкой.
НРЕ показала на MWC 2024 и другие системы для телекоммуникационной отрасли и инфраструктур связи 5G. Это, в частности, сервер ProLiant RL300 Gen11 со 128-ядерным Arm-чипом Ampere. Устройство типоразмера 1U оборудовано десятью фронтальными отсеками для SFF NVMe SSD с интерфейсом PCIe 4.0, тремя слотами расширения PCIe 4.0 и двумя слотами OCP 3.0.
28.02.2024 [15:31], Сергей Карасёв
На MWC 2024 замечен первый образец ускорителя AMD Instinct MI300X с 12-слойной памятью HBM3EКомпания AMD готовит новые модификации ускорителей семейства Instinct MI300, которые ориентированы на обработку ресурсоёмких ИИ-приложений. Изделия будут оснащены высокопроизводительной памятью HBM3E. Работу над ними подтвердил технический директор AMD Марк Пейпермастер (Mark Papermaster), а уже на этой неделе на стенде компании на выставке MWC 2024 был замечен образец обновлённого ускорителя. На сегодняшний день в семейство Instinct MI300 входят модификации MI300A и MI300X. Первая располагает 228 вычислительными блоками CDNA3 и 24 ядрами Zen4 на архитектуре x86. В оснащение входят 128 Гбайт памяти HBM3. На более интенсивные вычисления ориентирован ускоритель MI300X, оборудованный 304 блоками CDNA3 и 192 Гбайт HBM3. Но у этого решения нет ядер Zen4.  Недавно компания Micron сообщила о начале массового производства 8-слойной памяти HBM3E ёмкостью 24 Гбайт с пропускной способностью более 1200 Гбайт/с. Эти чипы будут применяться в ИИ-ускорителях NVIDIA H200, которые выйдут на коммерческий рынок во II квартале нынешнего года. А Samsung готовится к поставкам 12-слойных чипов HBM3E на 36 Гбайт со скоростью передачи данных до 1280 Гбайт/с.  AMD подтвердила намерение применять память HBM3E в обновлённых ускорителях Instinct MI300, но в подробности вдаваться не стала. В случае использования 12-слойных чипов HBM3E ёмкостью 36 Гбайт связка из восьми модулей обеспечит до 288 Гбайт памяти с высокой пропускной способностью. Наклейка на демо-образце недвусмысленно указывает на использование именно 12-слойной памяти. Впрочем, это может быть действительно всего лишь стикер, поскольку представитель AMD уклонился от прямого ответа на вопрос о спецификациях представленного изделия.  Ожидается также, что в 2025 году AMD выпустит ИИ-ускорители следующего поколения серии Instinct MI400. Между тем NVIDIA готовит ускорители семейства Blackwell для ИИ-задач: эти изделия, по заявлениям самой компании, сразу после выхода на рынок окажутся в дефиците.
27.02.2024 [21:44], Сергей Карасёв
Gigabyte представила новые серверы для ИИ, 5G и периферийных вычисленийКомпания Gigabyte Technology на MWC 2024 анонсировала новые серверы для ИИ-задач, 5G-сетей, облачных и периферийных вычислений. Дебютировали модели на процессорах AMD и Intel, оснащённые мощными ускорителями.  В частности, представлены серверы G593-ZX1/ZX2, оборудованные восемью картами AMD Instinct MI300X для ресурсоёмких вычислений. Кроме того, демонстрируются сервер высокой плотности H223-V10 с поддержкой суперчипа NVIDIA Grace Hopper, модель G383-R80 с четырьмя APU AMD Instinct MI300A и сервер серии G593, оснащённый восемью ускорителями NVIDIA HGX H100.  Ещё одна новинка — сервер хранения S183-SH0. Он допускает использование 32 SSD формата E1.S (NVMe), благодаря чему подходит для обработки сложных рабочих нагрузок, таких как большие языковые модели (LLM). Эти серверы также могут быть интегрированы в суперкомпьютерные кластеры и инфраструктуру 5G.  На edge-сегмент рассчитан сервер E263-S30 с модульной архитектурой: он может быть адаптирован под различные сценарии использования путём установки необходимых аппаратных компонентов. А модель R163-P32 комплектуется процессором AmpereOne с архитектурой Arm (до 192 ядер Arm с частотой до 3,0 ГГц), что обеспечивает высокую энергетическую эффективность.
На ИИ-приложения и облачные периферийные вычисления ориентированы серверы R243-EG0 и R143-EG0, которые оснащены чипами AMD EPYC 8004 Siena. Для сегмента малого и среднего бизнеса Gigabyte предлагает серверы R113-C10 и R123-X00, наделённые процессорами AMD Ryzen 7000 и Intel Xeon E-2400: эти модели подходят для веб-хостинга, создания гибридных облаков и хранилищ данных. |
|


