Материалы по тегу: ускоритель
|
01.10.2020 [11:51], Юрий Поздеев
Hailo: новые модули ускорения ИИ для периферийных вычисленийHailo, производитель микросхем для систем искусственного интеллекта (ИИ), выпустила новые высокопроизводительные модули в форм-факторах M.2 и mini PCIe для расширения возможностей периферийных систем. 
Источник изображений: Hailo Модули на базе процессора Hailo-8 можно подключать к различным периферийным устройствам, что позволяет использовать возможности ИИ в умных домах, розничной торговле и промышленности.  Модули Hailo легко интегрируются в стандартные платформы, такие как TensorFlow и ONNX, что позволяет значительно упростить использование новинок в комплексных решениях. Заказчики могут оперативно перенести свои решения с нейронными сетями на модули Hailo-8. 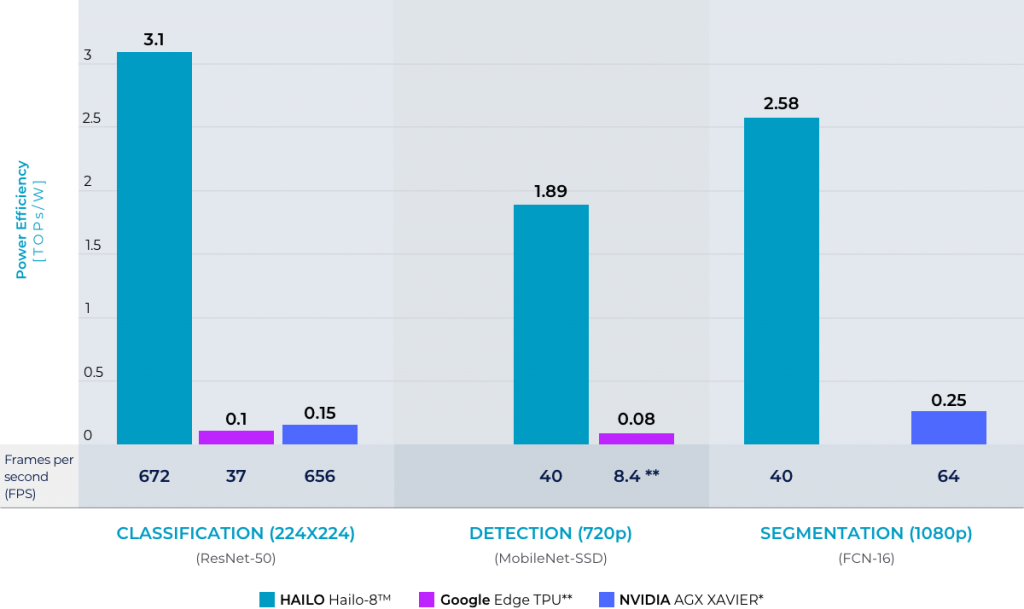 Спрос на высокопроизводительные периферийные устройства постоянно растет, поэтому безвентиляторные модули Hailo-8 будут востребованы, например, в видеоаналитике, либо для подключения большого количества внешних датчиков для сбора и обработки информации в режиме реального времени. Процессор Hailo-8 способен обеспечить 26 TOPS, при этом имеет энергоэффективность 3 TOPS/Вт.  Модуль Hailo-8 M.2 уже интегрирован в следующее поколение Foxconn BOXiedge (24-ядерный мини сервер, который потребляет всего 30 Вт, при этом обладает неплохими показателями производительности). Наличие готового продукта позволит ускорить внедрение новых модулей в периферийные вычисления и значительно упростить этот процесс для конечного заказчика.
18.09.2020 [15:55], Алексей Степин
ИИ-ускоритель Qualcomm Cloud AI 100 обещает быть быстрее и экономичнее NVIDIA T4Ускорители работы с нейросетями делятся, грубо говоря, на две категории: для обучения и для исполнения (инференса). Именно для последнего случая важна не столько «чистая» производительность, сколько сочетание производительности с экономичностью, так как работают такие устройства зачастую в стеснённых с точки зрения питания условиях. Компания Qualcomm предлагает новые ускорители Cloud AI 100, сочетающие оба параметра.  Сам нейропроцессор Cloud AI 100 был впервые анонсирован ещё весной прошлого года, и Qualcomm объявила, что этот чип разработан с нуля и обеспечивает вдесятеро более высокий уровень производительности в пересчёте на ватт, в сравнении с существовавшими на тот момент решениями. Начало поставок было запланировано на вторую половину 2019 года, но как мы видим, по-настоящему ускорители на базе данного чипа на рынке появились только сейчас, причём речь идёт о достаточно ограниченных, «пробных» объёмах поставок. 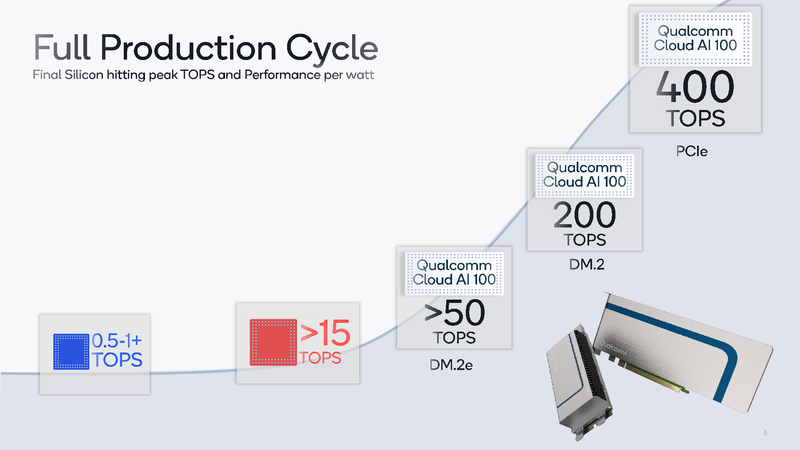 В отличие от графических процессоров и ПЛИС-акселераторов, которые часто применяются при обучении нейросетей и, будучи универсальными, потребляют при этом серьёзные объёмы энергии, инференс-чипы обычно представляют собой специализированные ASIC. Таковы, например, Google TPU Edge, к этому же классу относится и Cloud AI 100. Узкая специализация позволяет сконцентрироваться на достижении максимальной производительности в определённых задачах, и Cloud AI 100 более чем в 50 раз превосходит блок инференс-процессора, входящий в состав популярной SoC Qualcomm Snapdragon 855. 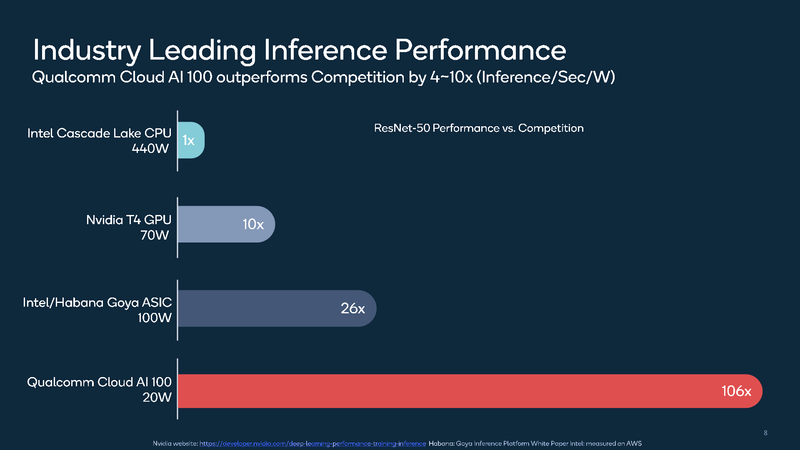 На приводимых Qualcomm слайдах архитектура Cloud AI 100 выглядит достаточно простой: чип представляет собой набор специализированных интеллектуальных блоков (IP, до 16 юнитов в зависимости от модели), дополненный контроллерами LPDDR (4 канала, до 32 Гбайт, 134 Гбайт/с), PCI Express (до 8 линий 4.0), а также управляющим модулем. Имеется некоторый объём быстрой набортной SRAM (до 144 Мбайт). С точки зрения поддерживаемых форматов вычислений всё достаточно универсально: реализованы INT8, INT16, FP16 и FP32. Правда, bfloat16 не «доложили». 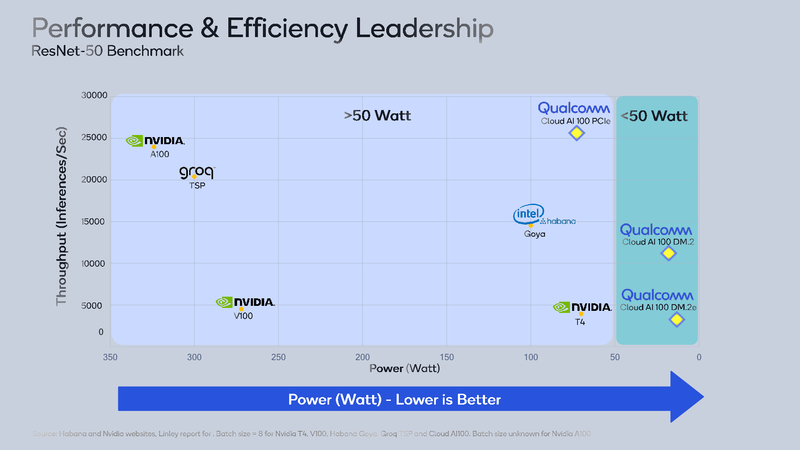 Об эффективности новинки говорят приведённые самой Qualcomm данные: если за базовый уровень принять систему на базе процессоров Intel Cascade Lake с потреблением 440 Ватт, то Qualcomm Cloud AI 100 в тесте ResNet-50 быстрее на два порядка при потреблении всего 20 Ватт. Это, разумеется, не предел: на рынок новый инференс-ускоритель может поставляться в трёх различных вариантах, два из которых компактные, форм-факторов M.2 и M.2e с теплопакетами 25 и 15 Ватт соответственно. Даже в этих вариантах производительность составляет 200 и около 500 Топс (триллионов операций в секунду), а существует и 75-Ватт PCIe-плата формата HHHL производительностью 400 Топс; во всех случаях речь идёт о режиме INT8. 
Данные для NVIDIA Tesla T4 и P4 приведены для сравнения Основными конкурентами Cloud AI 100 можно назвать Intel/Habana Gaia и NVIDIA Tesla T4. Оба этих процессора также предназначены для инференс-систем, они гибче архитектурно — особенно T4, который, в сущности, базируется на архитектуре Turing —, однако за это приходится платить как ценой, так и повышенным энергопотреблением — это 100 и 70 Ватт, соответственно. Пока речь идёт о распознавании изображений с помощью популярной сети ResNet-50, решение Qualcomm выглядит великолепно, оно на голову выше основных соперников. Однако в иных случаях всё может оказаться не столь однозначно. 
Новые ускорители Qualcomm будут доступны в разных форм-факторах Как T4, так и Gaia, а также некоторые другие решения, вроде Groq TSP, за счёт своей гибкости могут оказаться более подходящим выбором за пределами ResNet в частности и INT8 вообще. Если верить Qualcomm, то компания в настоящее время проводит углублённое тестирование Cloud AI 100 и на других сценариях в MLPerf, но в открытом доступе результатов пока нет. Разработчики сосредоточены на удовлетворении конкретных потребностей заказчиков. Также заявлено о том, что высокая производительность на крупных наборах данных может быть достигнута путём масштабирования — за счёт использования в системе нескольких ускорителей Cloud AI 100.  В настоящее время для заказа доступен комплект разработчика на базе Cloud Edge AI 100. Основная его цель заключается в создании и отработке периферийных ИИ-устройств. Система достаточно мощная, она включает в себя процессор Snapdragon 865, 5G-модем Snapdragon X55 и ИИ-сопроцессор Cloud AI 100. Выполнено устройство в металлическом защищённом корпусе с четырьмя внешними антеннами. Начало крупномасштабных коммерческих поставок намечено на первую половину следующего года.
27.08.2020 [19:13], Алексей Степин
TSMC и Graphcore создают ИИ-платформу на базе технологии 3 нмНесмотря на все проблемы в полупроводниковой индустрии, технологии продолжают развиваться. Технологические нормы 7 нм уже давно не являются чудом, вовсю осваиваются и более тонкие нормы, например, 5 нм. А ведущий контрактный производитель, TSMC, штурмует следующую вершину — 3-нм техпроцесс. Одним из первых продуктов на базе этой технологии станет ИИ-платформа Graphcore с четырьмя IPU нового поколения. Британская компания Graphcore разрабатывает специфические ускорители уже не первый год. В прошлом году она представила процессор IPU (Intelligence Processing Unit), интересный тем, что состоит не из ядер, а из так называемых тайлов, каждый из которых содержит вычислительное ядро и некоторое количество интегрированной памяти. В совокупности 1216 таких тайлов дают 300 Мбайт сверхбыстрой памяти с ПСП до 45 Тбайт/с, а между собой процессоры IPU общаются посредством IPU-Link на скорости 320 Гбайт/с. 
Colossально: ИИ-сервер Graphcore с четырьмя IPU на борту Компания позаботилась о программном сопровождении своего детища, снабдив его стеком Poplar, в котором предусмотрена интеграция с TensorFlow и Open Neural Network Exchange. Разработкой Graphcore заинтересовалась Microsoft, применившая IPU в сервисах Azure, причём совместное тестирование показало самые положительные результаты. Следующее поколение IPU, Colossus MK2, представленное летом этого года, оказалось сложнее NVIDIA A100 и получило уже 900 Мбайт сверхбыстрой памяти.  Машинное обучение, в основе которого лежит тренировка и использование нейронных сетей, само по себе требует процессоров с весьма высокой степенью параллелизма, а она, в свою очередь, автоматически означает огромное количество транзисторов — 59,4 млрд в случае Colossus MK2. Поэтому освоение новых, более тонких и экономичных техпроцессов является для этого класса микрочипов ключевой задачей, и Graphcore это понимает, заявляя о своём сотрудничестве с TSMC. 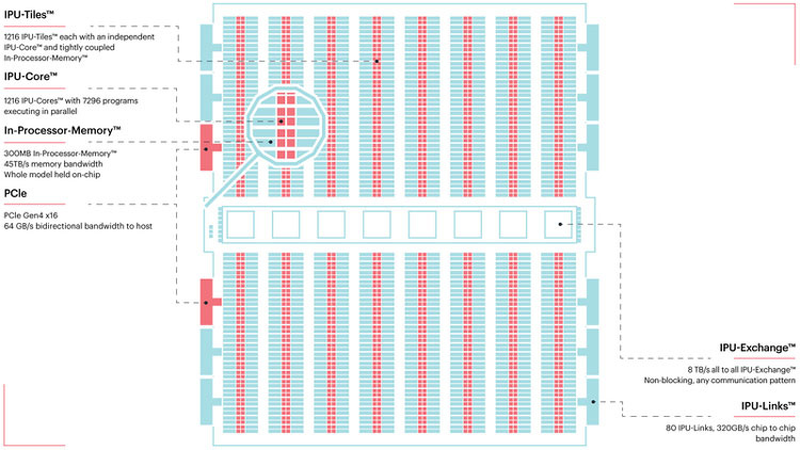
Тайловая архитектура Graphcore Colossus MK2 В настоящее время TSMC готовит к началу «рискового» производства новый техпроцесс с нормами 3 нм, причём скорость внедрения такова, что первые продукты на его основе должны увидеть свет уже в 2021 году, а массовое производство будет развёрнуто во второй половине 2022 года. И одним из первых продуктов на базе 3-нм технологических норм станет новый вариант IPU за авторством Graphcore, известный сейчас как N3. Судя по всему, использовать 5 нм британский разработчик не собирается. 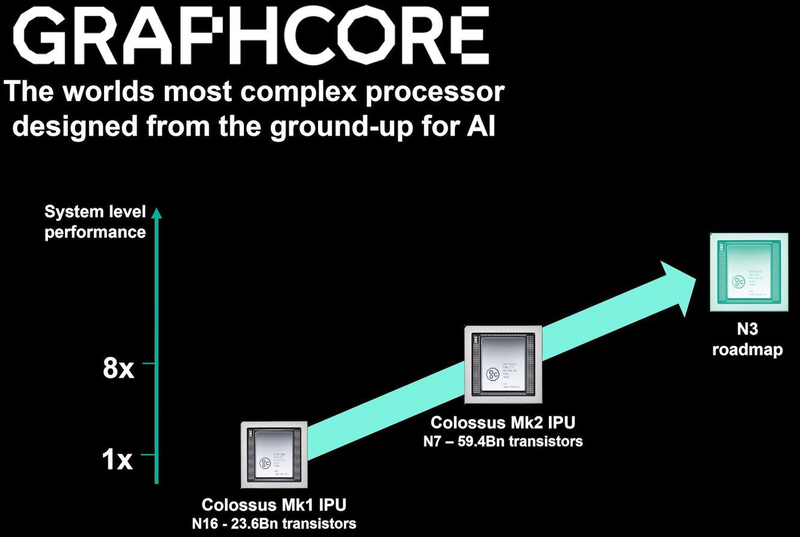
В планах компании явно указано использование 3-нм техпроцесса В настоящее время чипы Colossus MK2 производятся с использованием техпроцесса 7 нм (TSMC N7). Они включают в себя 1472 тайла и способны одновременно выполнять 8832 потока. В режиме тренировки нейросетей с использованием вычислений FP16 это даёт 250 Тфлопс, но существует удобное решение мощностью 1 Пфлопс — это специальный 1U-сервер Graphcore, в нём четыре IPU дополнены 450 Гбайт внешней памяти. Доступны также платы расширения PCI Express c чипами IPU на борту. Дела у Graphcore идут неплохо, её технология оказалась востребованной и среди инвесторов числятся Microsoft, BMW, DeepMind и ряд других компаний, разрабатывающих и внедряющих комплексы машинного обучения. Разработка 3-нм чипа ещё более упрочнит позиции этого разработчика. Более тонкие техпроцессы существенно увеличивают стоимость разработки, но финансовые резервы у Graphcore пока есть; при этом не и исключён вариант более тесного сотрудничества, при котором часть стоимости разработки возьмёт на себя TSMC.
31.07.2020 [18:37], Алексей Степин
Сопроцессор для SSD от Pliops ускорит работу с базами данных в 10 разКомпания Pliops ещё молода: она была основана в 2017 году выходцами из Samsung, M-Systems и XtremIO; все основатели являются специалистами в области СХД и энергонезависимой памяти. В 2019 году Pliops получила существенный объём инвестиций от Mellanox. А в 2020 году компания анонсирует свой новейший продукт — сопроцессор, берущий на себя тяжёлые задачи по работе с флеш-памятью. Подобные чипы разрабатывают многие, но Pliops обещает, что её решение ускорит работу с такого рода памятью более чем в 10 раз. Впервые технология была продемонстрирована на саммите Flash Memory 2019, и вот, наконец, концепция обратилась в реальный осязаемый продукт, доступный к приобретению. Решение Pliops достаточно необычное: это не контроллер NAND-массива, а именно сопроцессор-ускоритель, выполненный в виде отдельной платы с разъёмом PCI Express и берущий на себя всю работу по обслуживанию массивов SSD. И делает это новый ускоритель максимально эффективно: серьёзные флеш-СХД могут нагружать хост-процессоры весьма сильно, но решение Pliops позволяет решить эту проблему. 
Источник изображений: Pliops Особенно сильно эффект проявится в системах, используемых для работы с базами данных. Pliops объясняет это тем, что СУБД, будь то реляционные или NoSQL, традиционно разделяют непосредственно данные и ключи или индексы. А отдельная единица хранения данных имеет переменный размер, и эта структура не слишком хорошо сочетатся с традиционными устройствами хранения данных, у которых размер блока фиксирован.  Если в случае с обычными HDD вычислительная нагрузка невелика, поскольку случайных операций такие устройства выдают немного (в районе сотен), то твердотельные накопители, способные выдать 500 тысяч IOPS и более, создают и серьёзную вычислительную нагрузку, «утрамбовывая» вариабельные блоки данных в свой жёсткий формат. К этому добавляет проблем использование сжатия данных, которое тоже создаёт нагрузку. 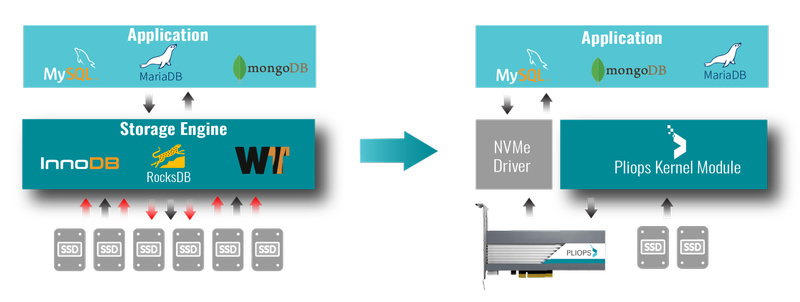 Сопроцессор, разработанный Pliops и получивший название PSP, как раз и призван взять на себя все обязанности по работе с данными в формате Key:Value (KV), что особенно важно в крупных СХД, работающих с огромными массивами БД. Немаловажно то, что сопроцессор Pliops делает свою работу полностью прозрачно и не требует модификации программного обеспечения пользователя.  Со стороны ПО он выглядит, как обычный блочный SSD, однако за счёт аппаратного акселератора работа с базами данных может ускориться более, чем в 10 раз, а время отклика — параметр также весьма немаловажный, когда речь заходит о БД — снизится еще сильнее, в 100 раз. Новинка уже прошла предварительную проверку более чем у десяти крупных провайдеров облачных и корпоративных услуг по хранению данных и запуску БД. 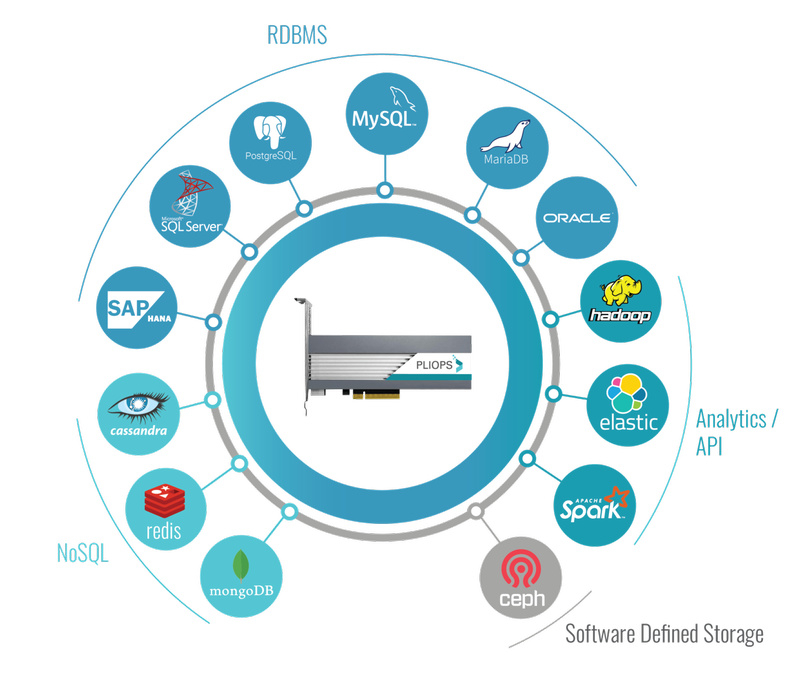 Сопроцессор PSP позволяет использовать обычные недорогие SSD (даже с QLC-памятью) а это уменьшает стоимость владения на величину до 90%, поскольку крупные специализированные твердотельные СХД всё ещё очень дороги. Pliops PSP ускоряет работу с MySQL, MariaDB, mogoDB, Redis, Oracle, Apache Spark и Cassandra и системы на его основе прекрасно масштабируются. Разработчики PSP полагают, что данного рода сопроцессоры образуют отдельный популярный класс устройств, подобно тому, как это случилось с графическими процессорами и сейчас происходит с тензорными ускорителями. Что ж, у Pliops есть все шансы стать в сфере работы с All-Flash СХД тем, чем стала NVIDIA в области ускорения машинного интеллекта. Естественно, это далеко не первый проект по ускорению работы SSD вообще и оптимизации их для СУБД в частности. Например, у Samsung есть экспериментальный продукт KV Stacks — Key:Value SSD, созданный специально для баз данных одноимённого типа. Другие проекты зачастую опираются на FPGA. Та же Samsung совместно с Xilinx представила SmartSSD, обрабатывающий часть данных непосредственно на накопителе. А SmartIOPS уже не первый год поставляет SSD с фирменным контролером на базе ПЛИС. Вероятно, следующим большим шагом станет массовое внедрение зонирования, которое подходит для HDD с SMR и уже включено в стандарт NVMe, и «вынос» FTL (Flash Translation Layer) за пределы отдельного накопителя с программной или аппаратной эмуляцией FTL на уровней всей СХД сразу.
27.06.2020 [18:54], Алексей Степин
ISC 2020: NEC анонсировала новые векторные ускорители SX-AuroraВ японском сегменте рынка супервычислений продолжает доминировать свой, уникальный подход к построению систем класса HPC. Fujitsu сделала ставку на гомогенную архитектуру A64FX с памятью HBM2 и заняла первое место в Top500, но и другая японская компания, NEC, не отказалась от своего видения суперкомпьютерной архитектуры. На предыдущей конференции SC19 NEC пополнила свой арсенал новыми ускорителями SX-Aurora 10E, которые получили более быстрые сборки HBM2. О новых ускорителях «Type 20» речь заходила ещё до начала эпидемии COVID-19; к сожалению, она внесла свои коррективы и анонс новинок состоялся лишь сейчас, летом 2020 года.  Изначально процессор SX-Aurora, используемый во всей серии ускорителей «Type 10» имеет 8 векторных блоков, каждый из которых дополнен 2 Мбайт кеша и 6 сборок памяти HBM2 общим объёмом 24 или 48 Гбайт. Из-за сравнительно грубого 16-нм техпроцесса уровень тепловыделения достаточно высок и составляет примерно 225 Ватт. В отличие от Fujitsu A64FX, NEC SX-Aurora требует для своей работы управляющего хост-процессора, и обычно компания комбинирует его с Intel Xeon, но существуют варианты и с AMD EPYC второго поколения. 
ISC 2018: HPC-модуль с восемью векторными ускорителями NEC SX-Aurora Type 10 Это роднит SX-Aurora с более широко распространёнными ускорителями на базе графических процессоров, однако позиционирование у них всё-таки выглядит иначе. ГП-ускорители, по мнению NEC, гораздо сложнее в программировании, хотя и обеспечивают высокую производительность. 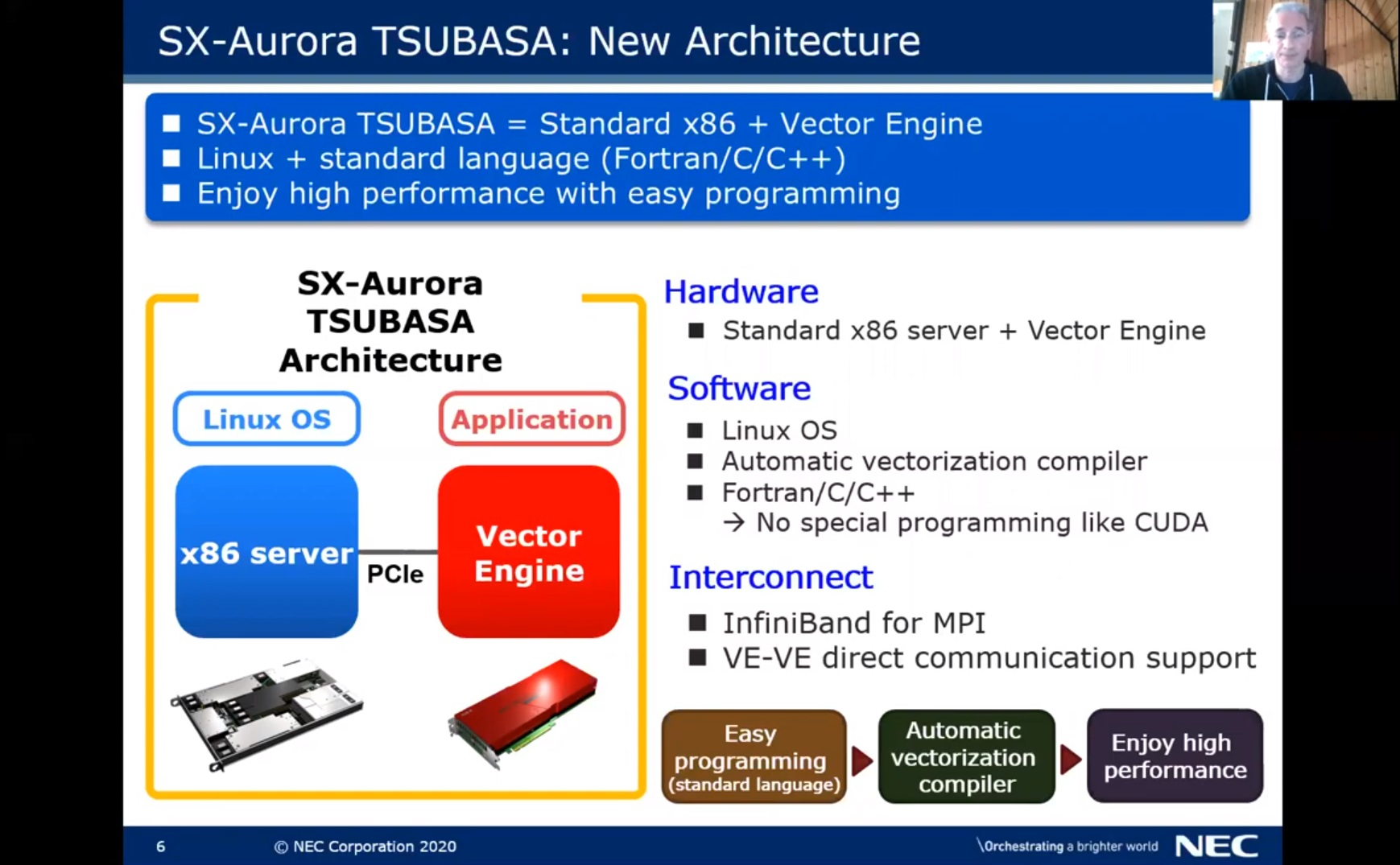 Свою же разработку компания относит к решениям с похожим уровнем производительности, но гораздо более простым в программировании. Упор также делается на высокую пропускную способность памяти, составляющую у новинок «Type 20» 1,5 Тбайт/с.  Новая версия NEC Vector Engine, VE20, структурно, скорее всего, не изменилась. Вместо восьми ядер новый процессор получил 10, и, как уже было сказано, новые сборки HBM2, в результате чего ПСП удалось поднять с 1,35 до 1,5 Тбайт/с, а вычислительную мощность с 2,45 до 3,07 Тфлопс. 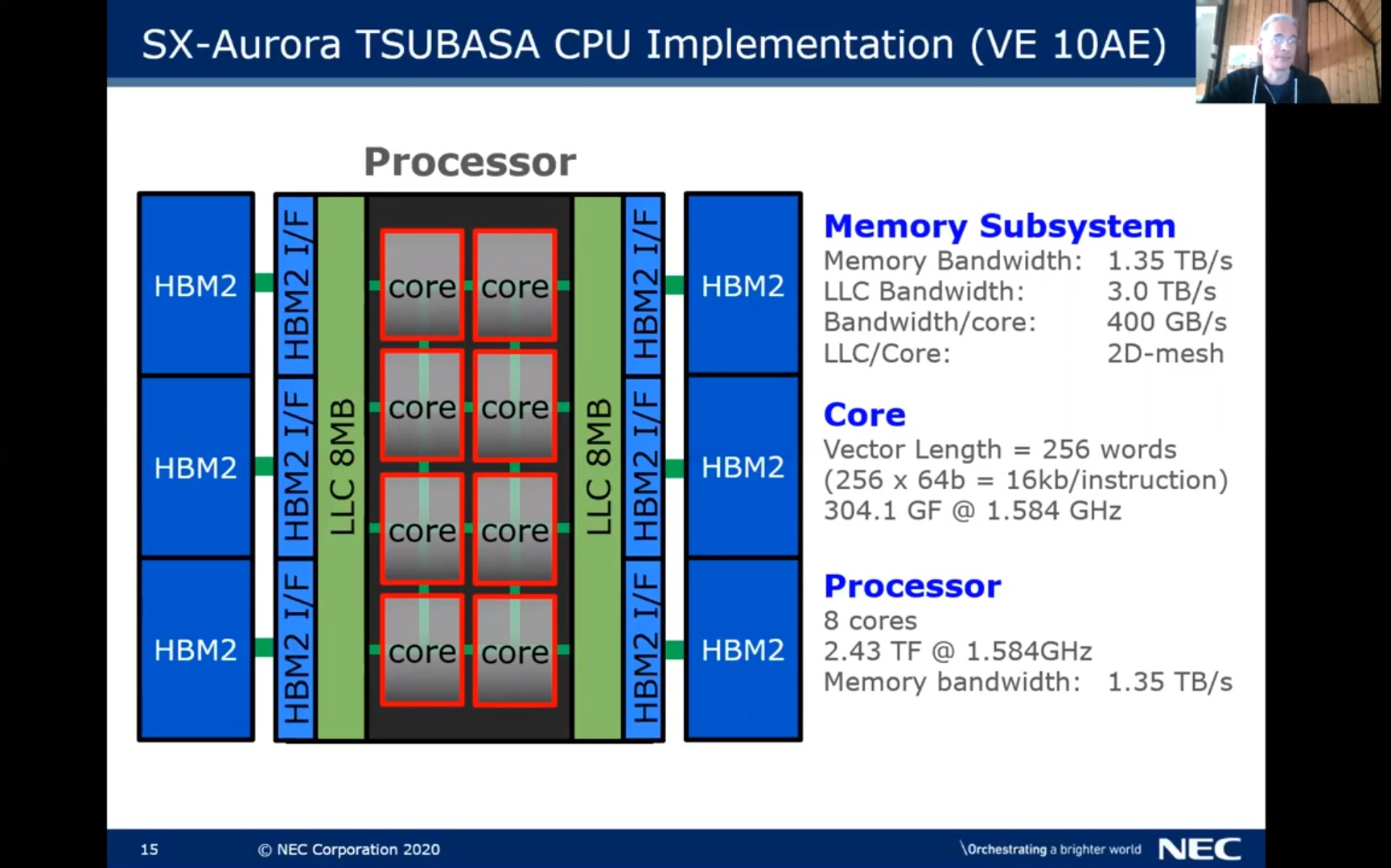 В серии пока представлено два новых ускорителя, Type 20A и 20B, последний аналогичен по конфигурации решениям Type 10 и использует усечённый вариант процессора с 8 ядрами. Говорится о неких архитектурных улучшениях, но деталей компания пока не раскрывает. Оба варианта процессора VE20 работают на частоте 1,6 ГГц, а прирост производительности в сравнении с VE10 достигается в основном за счёт повышения ПСП.  Похоже, VE20 лишь промежуточная ступень. В 2022 году планируется выпуск процессора VE30, который получит подсистему памяти с пропускной способностью свыше 2 Тбайт/с, в 2023 должен появиться его наследник VE40, но настоящий прорыв, судя по всему, откладывается до 2024 года, когда NEC планирует представить VE50, об архитектуре и возможностях которого пока ничего неизвестно. 
22.06.2020 [12:39], Илья Коваль
NVIDIA представила PCIe-версию ускорителя A100Как и предполагалось, NVIDIA вслед за SXM4-версией ускорителя A100 представила и модификацию с интерфейсом PCIe 4.0 x16. Обе модели используют идентичный набор чипов с одинаковыми характеристикам, однако, помимо отличия в способе подключения, у них есть ещё два существенных отличия. 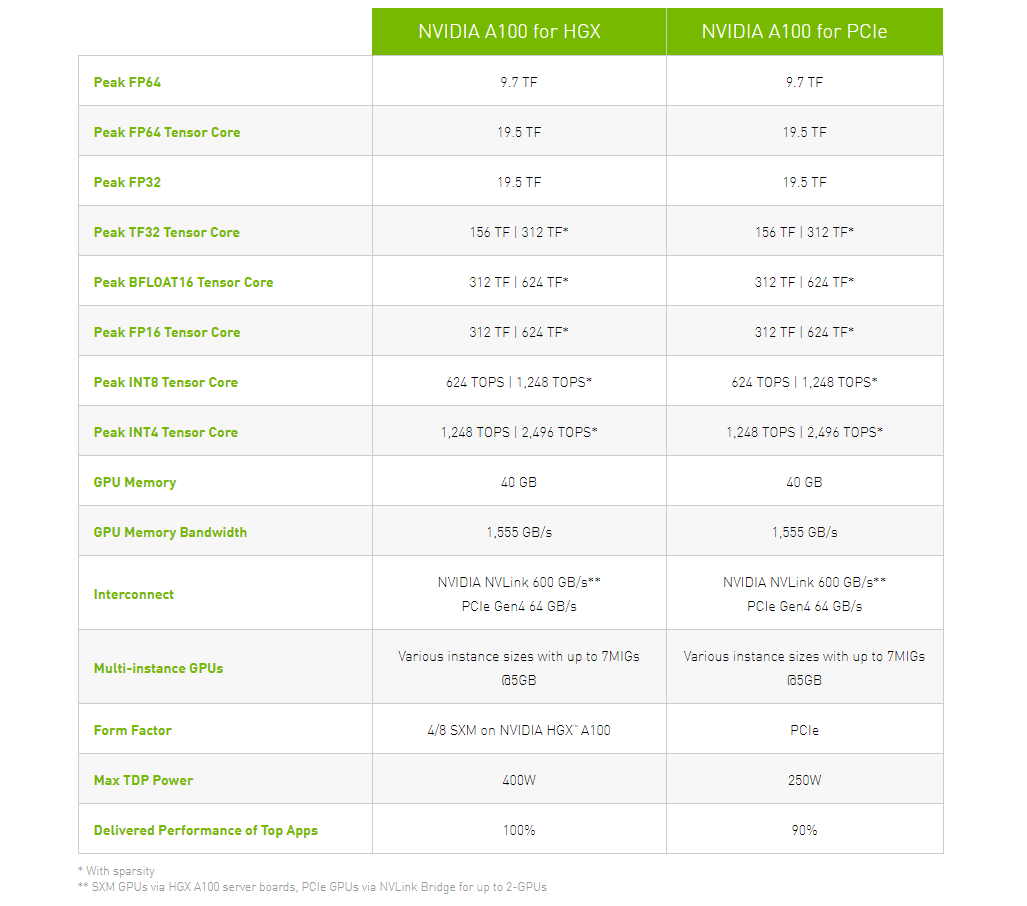 Первое — сниженный с 400 Вт до 250 Вт показатель TDP. Это прямо влияет на величину устоявшейся скорости работы. Сама NVIDIA указывает, что производительность PCIe-версии составит 90% от SXM4-модификации. На практике разброс может быть и больше. Естественным ограничением в данном случае является сам форм-фактор ускорителя — только классическая двухслотовая FLFH-карта с пассивным охлаждением совместима с современными серверами.  Второе отличие касается поддержки быстрого интерфейса NVLink. В случае PCIe-карты посредством внешнего мостика можно объединить не более двух ускорителей, тогда как для SXM-версии есть возможность масштабирования до 8 ускорителей в рамках одной системы. С одной стороны, NVLink в данном случае практически на порядок быстрее PCIe 4.0. С другой — PCIe-версия наверняка будет заметно дешевле и в этом отношении универсальнее. 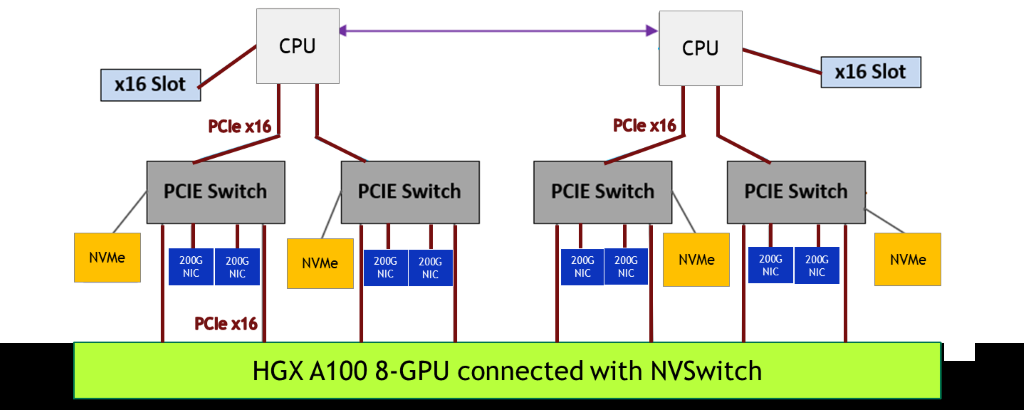 Производители серверов уже объявили о поддержке новых ускорителей в своих системах. Как правило, это уже имеющиеся платформы с возможностью установки 4 или 8 (реже 10) карт. Любопытно, что фактически единственным разумным вариантом для плат PCIe 4.0, как и в случае HGX/DGX A100, является использование платформ на базе AMD EPYC 7002.
14.05.2020 [18:52], Рамис Мубаракшин
NVIDIA представила ускорители A100 с архитектурой Ampere и систему DGX A100 на их основеNVIDIA официально представила новую архитектуру графических процессоров под названием Ampere, которая является наследницей представленной осенью 2018 года архитектуры Turing. Основные изменения коснулись числа ядер — их теперь стало заметно больше. Кроме того, новинки получили больший объём памяти, поддержку bfloat16, возможность разделения ресурсов (MIG) и новые интерфейсы: PCIe 4.0 и NVLink третьего поколения. NVIDIA A100 выполнен по 7-нанометровому техпроцессу и содержит в себе 54 млрд транзисторов на площади 826 мм2. По словам NVIDIA, A100 с архитектурой Ampere позволяют обучать нейросети в 40 раз быстрее, чем Tesla V100 с архитектурой Turing. 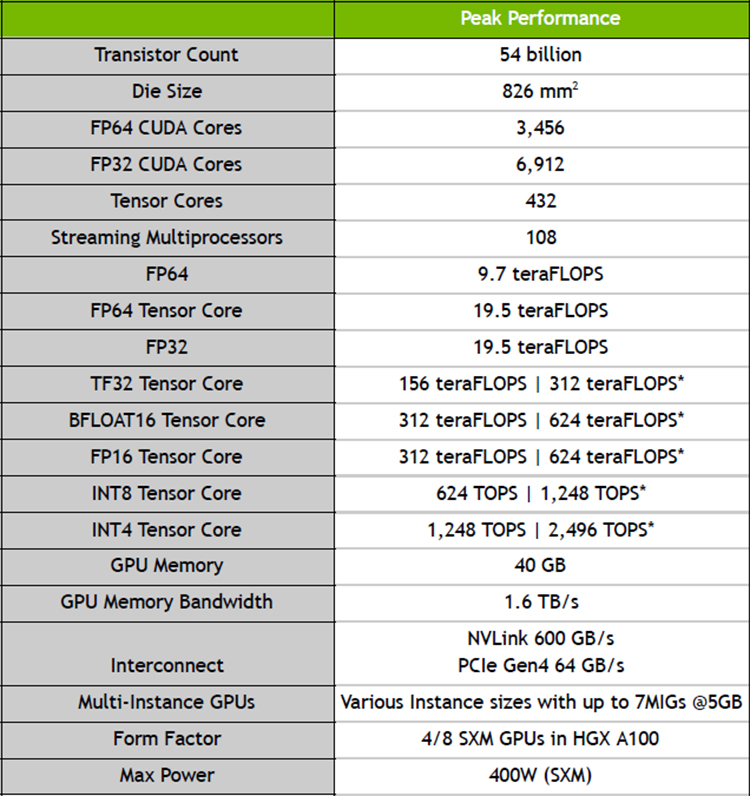
Характеристики A100 Первой основанной на ней вычислительной системой стала фирменная DGX A100, состоящая из восьми ускорителей NVIDIA A100 с NVSwitch, имеющих суммарную производительность 5 Пфлопс. Стоимость одной системы DGX A100 равна $199 тыс., они уже начали поставляться некоторым клиентам. Известно, что они будут использоваться в Аргоннской национальной лаборатории для поддержания работы искусственного интеллекта, изучающего COVID-19 и ищущего от него лекарство. Так как некоторые группы исследователей не могут себе позволить покупку системы DGX A100 из-за ее высокой стоимости, их планируют купить поставщики услуг по облачным вычислений и предоставлять удалённый доступ к высоким мощностям. На данный момент известно о 18 провайдерах, готовых к использованию систем и ускорителей на основе архитектуры Ampere, и среди них есть Google, Microsoft и Amazon. 
Система NVIDIA DGX A100 Помимо системы DGX A100, компания NVIDIA анонсировала ускорители NVIDIA EGX A100, предназначенная для периферийных вычислений. Для сегмента интернета вещей компания предложила плату EGX Jetson Xavier NX размером с банковскую карту.
02.12.2019 [14:58], Алексей Степин
NEC обновила серию ускорителей SX-Aurora и опубликовала планы относительно HPCКомпания NEC не спешит отказываться от своего уникального пути на рынке супервычислений и продолжает развивать серию векторных процессоров SX-Aurora. На конференции SC19 компания представила ряд новых решений, сочетающих в себе SX-Aurora и новейшие процессоры AMD «Rome» Intel Xeon 9200. 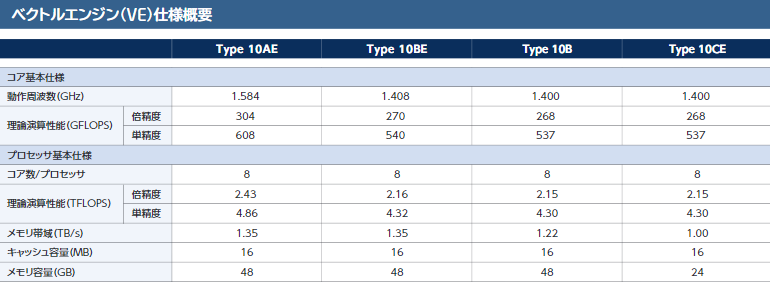
Типы ускорителей SX-Aurora Как и два года назад, основой платформы NEC является плата расширения «Type 10»; впрочем, в настоящее время производитель заменяет его на усовершенствованный «Type 10E» с более быстрыми сборками HBM2 на борту. За счёт этого ПСП удалось поднять на 10%, и даже в самом доступном варианте «Type 10CE» данный параметр теперь составляет 1 Тбайт/с против ранних 750 Гбайт/с. 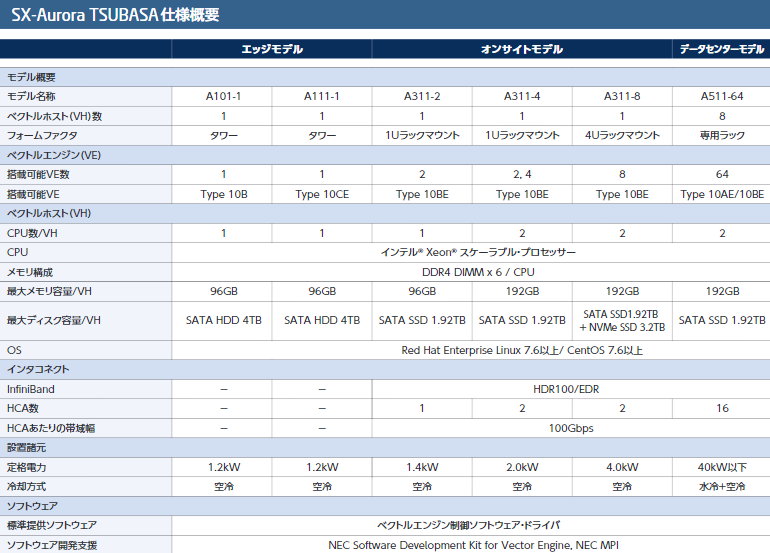
Системы NEC на базе SX-Aurora Массовый выпуск плат NEC «Type 10E» намечен на январь 2020 года. Всего в семействе будет четыре модели, отличающиеся тактовыми частотами, объёмом HBM2 и системой охлаждения. Последняя будет представлена в воздушном активном и пассивном вариантах, также будет выпускаться и вариант с жидкостным охлаждением. 
Сервер NEC A412-8 сочетает в себе SX-Aurora и AMD Rome Компания не собирается останавливаться на достигнутом и чип текущего поколения VE10 будет заменён на VE20 уже в середине или конце 2020 года. Он получит ещё более быструю память, больше векторных ядер (возможно 10 против 8 сегодняшних) и неизвестные пока новые функции. Следующее за ним поколение, VE30, должно появиться в 2022 году. Об этом поколении данных пока нет — известно лишь, что эти процессоры будут иметь новую архитектуру. 
27.09.2019 [09:36], Владимир Мироненко
LEGO для ускорителей: Inspur представила референсную OCP-систему для модулей OAMКомпания Inspur анонсировала 26 сентября на саммите OCP Regional Summit в Амстердаме новую референсую платформу с UBB-платой (Universal Baseboard) для ускорителей в форм-факторе Open Accelerator Module (OAM). OAM был представлен Facebook✴ в марте этого года. Он очень похож на слегка увеличенный (102 × 165 мм) модуль NVIDIA SXM2: «плиточка» с группами контактов на дне и радиатором на верхней крышке. 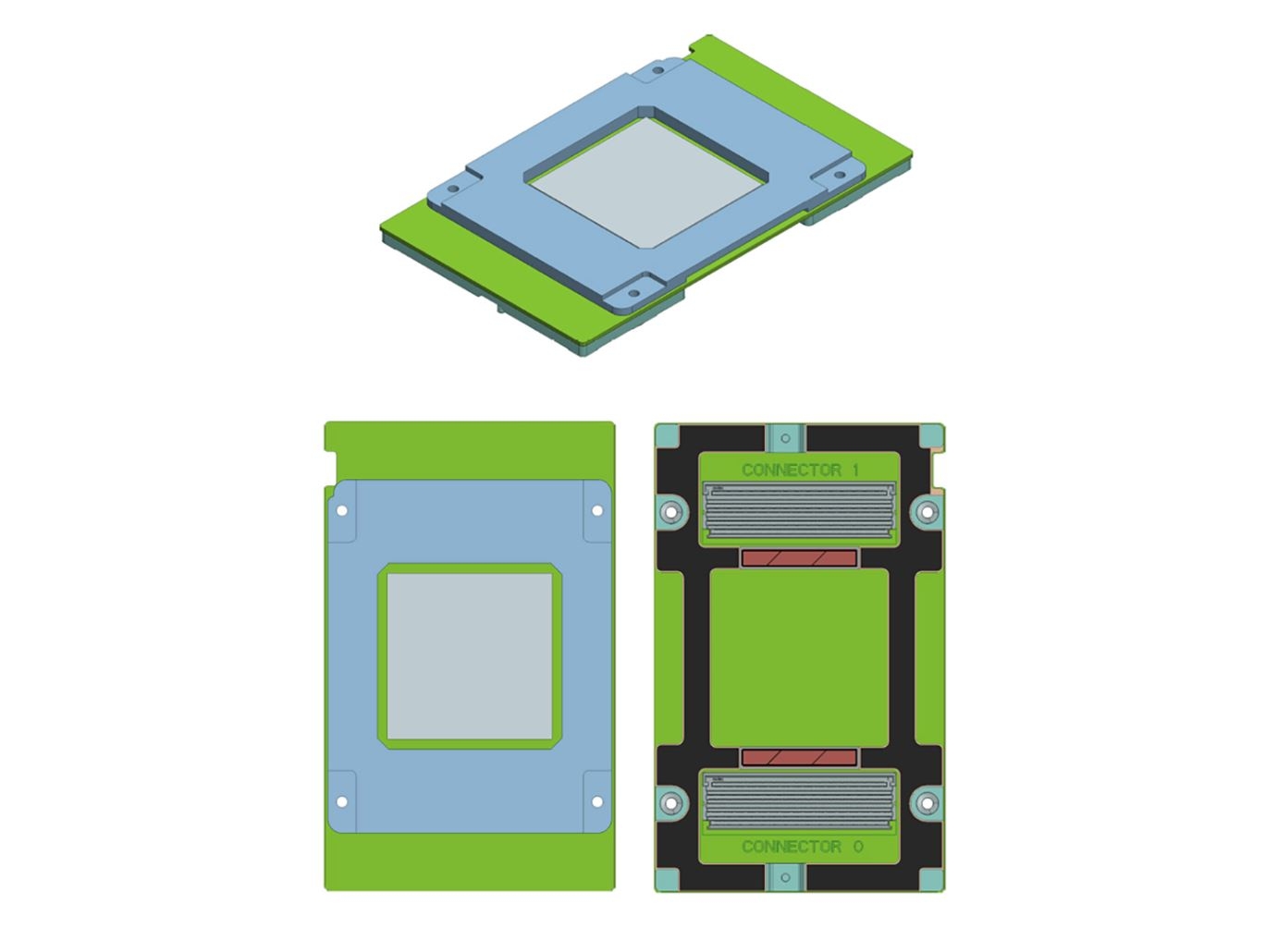 Ключевые спецификации модуля OAM:
 OAM, в отличие от классических карт PCI-E, позволяет повысить плотнсть размещения ускорителей в системе без ущерба их охлаждению, а также увеличить скорость обмена данными между модулями, благодаря легко настраиваемой топологии соединений между ними. В числе поддержавших проект OCP Accelerator Module такие компании, как Intel, AMD, NVIDIA, Google,Microsoft, Baidu и Huawei. 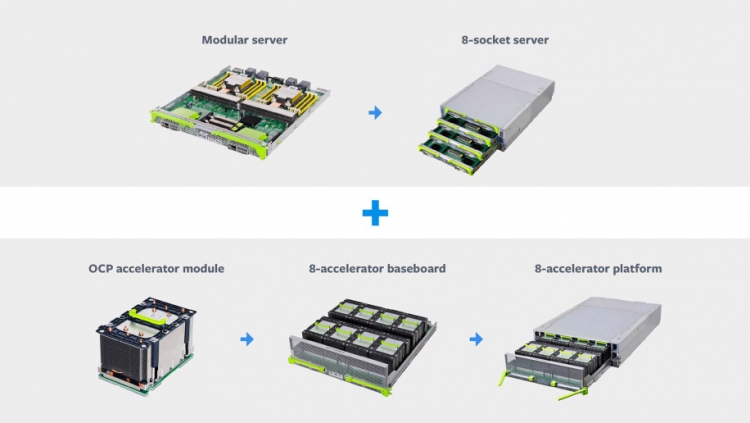 Inspur приступил к разработке референс-системы для ускорителей OAM в связи растущими требованиями, предъявляемыми к приложениям ИИ и необходимостью обеспечения взаимодействия между несколькими модулями на основе ASIC или GPU. Данная платформа представляет собой 21" шасси стандарта Open Rack V2 с BBU для восьми модулей OAM. Плата BBU снабжена восемью коннекторами QSFP-DD для прямого подключения к другим BBU. Система Inspur OAM позволяет создавать кластеры из 16, 32, 64 и 128 модулей OAM и имеет гибкую архитектуру для поддержки инфраструктур с несколькими хостами. По требованию заказчика Inspur также может поставлять 19-дюймовые системы OAM. Одной из первых преимущества новинки для задач, связанных с ИИ и машинным обучением, оценила китайская Baidu, продемонстрировавшая собственное серверное решение X-Man 4.0 на базе платформы Inspur и восьми ускорителей. 
27.08.2019 [11:00], Геннадий Детинич
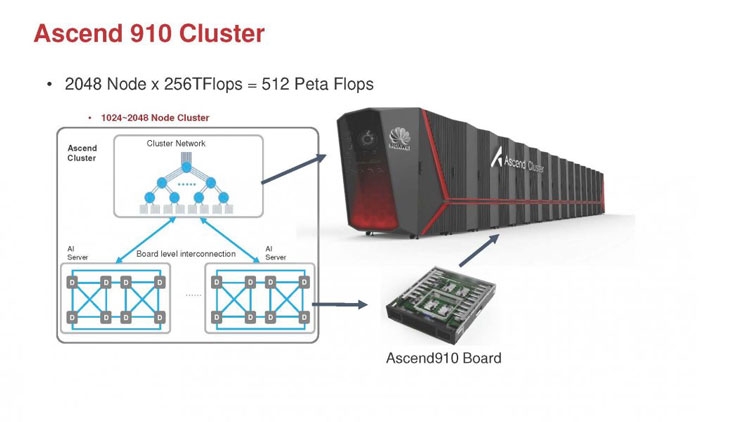
Huawei Ascend 910: китайская альтернатива ИИ-платформам NVIDIAГлубокое машинное обучение ― это сравнительно новая область приложения для вычислительных архитектур. Как всё новое, ML заставляет искать альтернативные пути решения задач. В этом поиске китайские разработчики оказались на равных и даже в привилегированных условиях, что привело к появлению в Китае мощнейших ИИ-платформ. Как всем уже известно, на конференции Hot Chips 31 компания Huawei представила самый мощный в мире ИИ-процессор Ascend 910. Процессоры для ИИ каждый разрабатывает во что горазд, но все разработчики сравнивают свои творения с ИИ-процессорами компании NVIDIA (а NVIDIA с процессорами Intel Xeon). Такова участь пионера. NVIDIA одной из первых широко начала продвигать свои модифицированные графические архитектуры в качестве ускорителей для решения задач с машинным обучением.  Гибкость GPU звездой взошла над косностью x86-совместимой архитектуры, но во время появления новых подходов и методов тренировки машинного обучения, где пока много открытых дорожек, она рискует стать одной из немногих. Компания Huawei со своими платформами вполне способна стать лучшей альтернативой решениям NVIDIA. Как минимум, это произойдёт в Китае, где Huawei готовится выпускать и надеется найти сбыт для миллионов процессоров для машинного обучения. 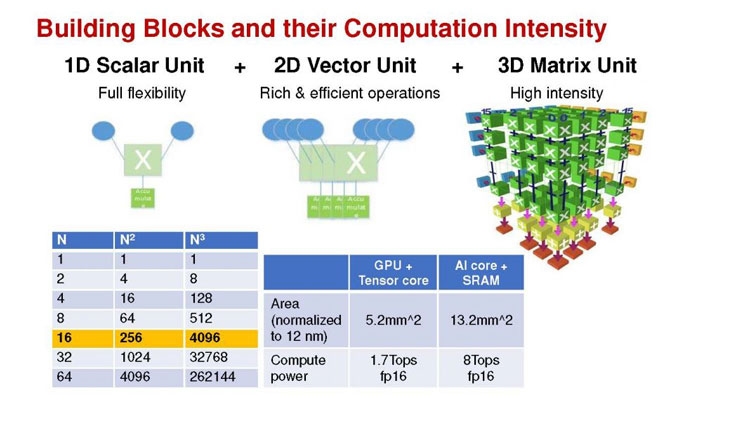 Мы уже публиковали анонс наиболее мощного ускорителя для ML чипа Huawei Ascend 910. Сейчас посмотрим на это решение чуть пристальнее. Итак, Ascend 910 выпускается компанией TSMC с использованием второго поколения 7-нм техпроцесса (7+ EUV). Это техпроцесс характеризуется использованием сканеров EUV для изготовления нескольких слоёв чипа. На конференции Huawei сравнивала Ascend 910 с ИИ-решением NVIDIA на архитектуре Volta, выпущенном TSMC с использованием 12-нм FinFET техпроцесса. Выше на картинке приводятся данные для Ascend 910 и Volta, с нормализацией к 12-нм техпроцессу. Площадь решения Huawei на кристалле в 2,5 раза больше, чем у NVIDIA, но при этом производительность Ascend 910 оказывается в 4,7 раза выше, чем у архитектуры Volta. 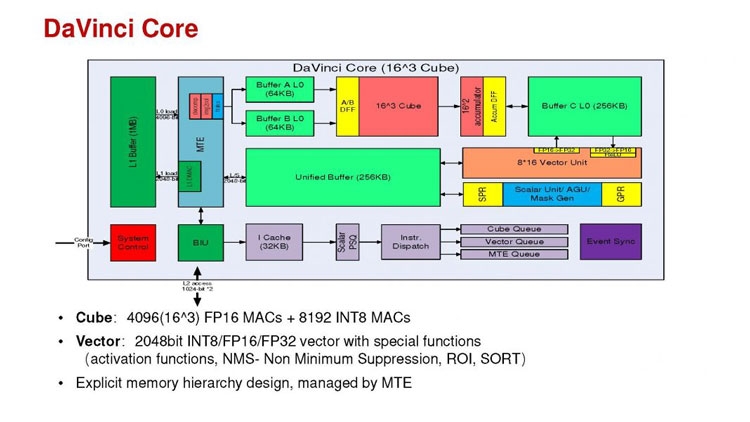 Также на схеме видно, что Huawei заявляет о крайне высокой масштабируемости архитектуры. Ядра DaVinci, лежащие в основе Ascend 910, могут выпускаться в конфигурации для оперирования скалярными величинами (16), векторными (16 × 16) и матричными (16 × 16 × 16). Это означает, что архитектура и ядра DaVinci появятся во всём спектре устройств от IoT и носимой электроники до суперкомпьютеров (от платформ с принятием решений до машинного обучения). Чип Ascend 910 несёт матричные ядра, как предназначенный для наиболее интенсивной работы. 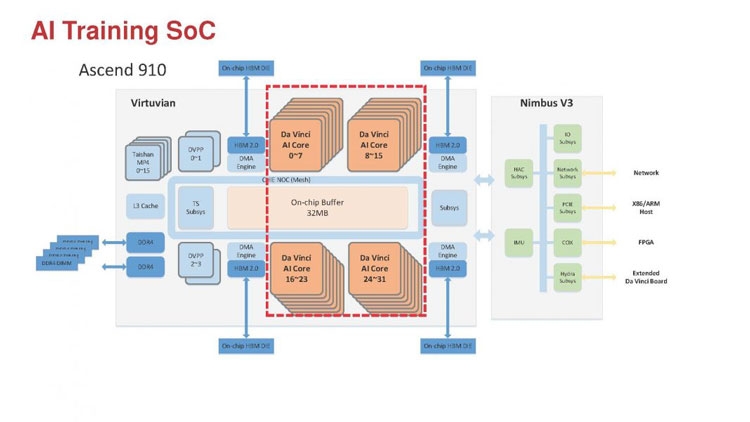 Ядро DaVinci в максимальной конфигурации (для Ascend 910) содержит 4096 блоков Cube для вычислений с половинной точностью (FP16). Также в ядро входят специализированные блоки для обработки скалярных (INT8) и векторных величин. Пиковая производительность Ascend с 32 ядрами DaVinci достигает 256 терафлопс для FP16 и 512 терафлопс для целочисленных значений. Всё это при потреблении до 350 Вт. Альтернатива от NVIDIA на тензорных ядрах способна максимум на 125 терафлопс для FP16. Для решения задач ML чип Huawei оказывается в два раза производительнее. 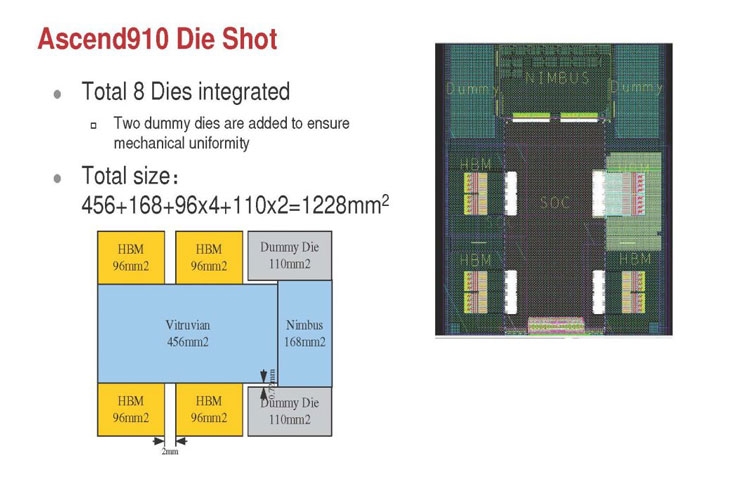 Помимо ядер DaVinci на кристалле Ascend 910 находятся несколько других блоков, включая контроллер памяти HBM2, 128-канальный движок для декодирования видеопотоков. Мощный чип для операций ввода/вывода Nimbus V3 выполнен на отдельном кристалле на той же подложке. Рядом с ним для механической прочности всей конструкции пришлось расположить два кристалла-заглушки, каждый из которых имеет площадь 110 мм2. С учётом болванок и четырёх чипов HBM2 площадь всех кристаллов достигает 1228 мм2. 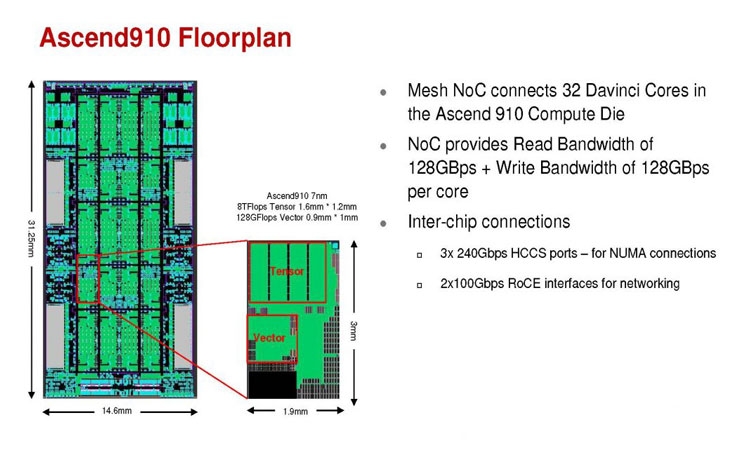 Для связи ядер и памяти на кристалле создана ячеистая сеть в конфигурации 6 строк на 4 колонки со скоростью доступа 128 Гбайт/с на каждое ядро для одновременных операций записи и чтения. Для соединения с соседними чипами предусмотрена шина со скоростью 720 Гбит/с и два линка RoCE со скоростью 100 Гбит/с. К кеш-памяти L2 ядра могут обращаться с производительностью до 4 Тбайт/с. Скорость доступа к памяти HBM2 достигает 1,2 Тбайт/с.  В каждый полочный корпус входят по 8 процессоров Ascend 910 и блок с двумя процессорами Intel Xeon Scalable. Спецификации полки ниже на картинке. Решения собираются в кластер из 2048 узлов суммарной производительностью 512 петафлопс для операций FP16. Кластеры NVIDIA DGX Superpod обещают производительность до 9,4 петафлопс для сборки из 96 узлов. В сравнении с предложением Huawei это выглядит бледно, но создаёт стимул рваться вперёд. 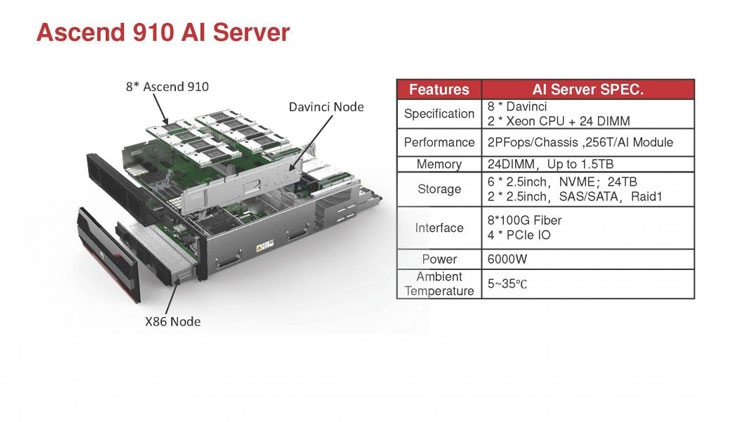
 |
|


