Материалы по тегу: суперкомпьютер
|
17.03.2026 [22:28], Андрей Крупин
В России утверждён план развития высокопроизводительных вычислений и суперкомпьютерной инфраструктурыПравительство РФ утвердило план мероприятий, в рамках которого будут создаваться дополнительные условия для развития суперкомпьютерных технологий, искусственного интеллекта и вычислительных систем. Документ включает конкретные сроки мероприятий и их исполнителей, а также предполагает десятикратное увеличение совокупной мощности отечественных суперкомпьютеров к 2030 году. Согласно дорожной карте, в ближайшие несколько лет в России должна начаться реализация масштабной программы, включающей комплекс мероприятий, направленных на формирование единых требований к суперкомпьютерным центрам коллективного пользования, определение порядка предоставления доступа к ним научного сообщества и ключевых организаций промышленности, а также перспектив их дальнейшего развития и модернизации. В процессе работы по этому направлению планируется сформировать стратегию дальнейшего развития и правила функционирования национальной исследовательской компьютерной сети нового поколения, которая объединяет сотни ведущих вузов и научных организаций. Предполагается, что развитие коммуникационной инфраструктуры расширит возможности для проведения исследований, требующих обработки и передачи больших объёмов данных. 
Суперкомпьютер «Политехник РСК Торнадо» производства группы компаний РСК, установленный в Санкт-Петербургском политехническом университете Петра Великого (источник изображения: «РСК Технологии» / rscgroup.ru) Часть мероприятий дорожной карты направлена на разработку концепции профильной федеральной научно-технической программы, в рамках которой будет предусмотрено создание, развитие и внедрение отечественных алгоритмов, методов и программного обеспечения для проведения суперкомпьютерных вычислений в различных отраслях экономики. Научно-техническая программа в том числе подразумевает формирование новых и развитие имеющихся образовательных и дополнительных профессиональных программ по использованию суперкомпьютерных технологий и высокопроизводительных вычислений. По мнению «К2 НейроТех» (входит в «К2Тех»), утверждение дорожной карты — важный сигнал для всего рынка. Ключевой вызов для промышленного ИИ сегодня — не отсутствие моделей, а дефицит доступных вычислительных мощностей и зрелой инфраструктуры для их эксплуатации. При этом важно разделять два типа нагрузки: обучение моделей, требующее пиковых мощностей, и инференс — постоянную эксплуатацию, которая по мере зрелости рынка будет занимать всё большую долю вычислительных затрат. Без учёта этой специфики даже десятикратный рост мощностей может не дать ожидаемого экономического эффекта: «Особенно важно, что в дорожной карте уделено внимание подготовке кадров и развитию национальной исследовательской сети — без этого даже самые мощные суперкомпьютеры останутся невостребованными».
21.02.2026 [15:03], Сергей Карасёв
G42 из ОАЭ и Cerebras построят в Индии национальный ИИ-суперкомпьютер с царь-ускорителями WSE-3Холдинг G42 из Абу-Даби (ОАЭ) и компания Cerebras в партнёрстве с Университетом искусственного интеллекта им. Мохаммеда бин Зайеда (MBZUAI) и Индийским центром развития передовых вычислительных технологий (C-DAC) развернут в Индии национальный ИИ-суперкомпьютер. Технические подробности проекта не раскрываются. Отмечается лишь, что система обеспечит ИИ-производительность на уровне 8 Эфлопс (точность вычислений не указана). Комплекс, размещённый на территории Индии, будет эксплуатироваться в соответствии с местными требованиями к безопасности, а все обрабатываемые данные останутся в национальной юрисдикции. Иными словами, речь идёт о формировании суверенной вычислительной платформы. Как отмечает The Register, в основу суперкомпьютера лягут ускорители Cerebras WSE-3. Эти изделия содержат 4 трлн транзисторов, 900 тыс. ядер и 44 Гбайт SRAM. Суммарная пропускная способность встроенной памяти достигает 21 Пбайт/с. Производительность составляет до 125 Пфлопс на операциях FP16. Таким образом, в составе НРС-системы могут быть задействованы 64 экземпляра Cerebras WSE-3. 
Источник изображения: G42 После ввода в эксплуатацию новый суперкомпьютер станет доступен широкому кругу пользователей в Индии — от ведущих научных организаций, институтов и государственных структур до стартапов, малых и средних предприятий. Ожидается, что появление системы позволит ускорить инновации в области ИИ. «Суверенная инфраструктура ИИ становится важнейшим компонентом национальной конкурентоспособности. Новый проект предоставит Индии такую платформу, позволив местным исследователям и предприятиям внедрять ИИ, обеспечивая при этом полную безопасность данных», — заявил Ману Джайн (Manu Jain), генеральный директор G42 India. Нужно отметить, что в Индии активно развивается инфраструктуры для ИИ-вычислений. В частности, индийские Tata Group, Tata Consultancy Services (TCS) и OpenAI намерены развернуть в стране ИИ ЦОД мощностью до 1 ГВт. Вместе с тем индийский конгломерат Adani вложит $100 млрд в создание ЦОД общей мощностью 5 ГВт, снабжаемых возобновляемой энергией.
19.02.2026 [09:52], Владимир Мироненко
Американская «Миссия Генезис» будет во многом полагаться на «ненастоящие» FP64-вычисленияХотя последнее поколение GPU ориентировано на вычисления с более низкой точностью, которые предпочтительны для ИИ-задач, FP64-вычисления с более высокой точностью по-прежнему «очень важны» для «Миссии Генезис» (Genesis Mission) и её цели — ускорения научных открытий с помощью ИИ, заявил заместитель министра энергетики США по науке и инновациям Дарио Гил (Darío Gil) в интервью HPCwire. «В ходе обсуждений, которые я провел как с [генеральным директором AMD] Лизой Су (Lisa Su), так и с [генеральным директором NVIDIA] Дженсеном [Хуангом] (Jensen Huang), они выразили твёрдую приверженность FP64, подтвердив, что поддержка формата будет продолжаться, — сказал Гил. — Для нас это очень важно, потому что мы не рассматриваем это как замену. Это взаимодополняющие технологии». Он отметил, что для обеспечения вычислительных задач моделирования и симуляции, которые традиционно составляют основу научных вычислений, а также для новых методов ИИ, важно иметь высокопроизводительное оборудование. Гил добавил, что эти два типа вычислений будут работать вместе, чтобы поддержать цель миссии Genesis — расширение границ науки и техники на основе ИИ-технологий. «У вас есть высокоточные симуляционные коды, работающие с FP64. После проверки вы используете их в качестве основы для генерации примеров, на которых вы обучаете суррогатную модель, которую затем запускаете на ИИ-суперкомпьютере, — рассказал Гил. — В итоге вы получаете преимущества с точки зрения производительности и времени решения, часто в 10, 20, 100 раз». 
Источник изображений: NVIDIA Он отметил, что благодаря использованию ИИ-моделей можно получить громадное повышение производительности, но оно зависит от сохранения всего цикла работ, состоящего из экспериментов, моделирования и обучения. «Если вы разорвёте этот цикл и скажете, что у вас больше нет кодов моделирования, то возникнет проблема», — сказал Гил. «Для нас это имеет фундаментальное значение, не только для устаревших кодов, которые мы должны сопровождать и которые так важны для миссии, но и для обеспечения рабочего ИИ-процесса. Поэтому для нас очень важно поддерживать различные архитектурные подходы», — добавил он. В HPC-сообществе возникла обеспокоенность по поводу отсутствия прироста производительности для FP64 в новейших GPU. Напомним, что чип NVIDIA H100, выпущенный в 2022 году, обеспечивает 67 Тфлопс в формате FP64 на тензорных ядрах (34 Тфлопс в векторных вычислениях), в то время как B200 предлагает лишь 37 Тфлопс, а B300 — всего лишь 1,3 Тфлопс. Программная эмуляция FP64-вычислений на тензорных ядрах Blackwell позволяет получить «нечестные» 150 Тфлопс, а из новейших Rubin она позволяет «выжать» 200 Тфлопс. При этом пиковая заявленная производительность векторных FP64-вычислений у Rubin составляет лишь 33 Тфлопс, т.е. нет никакого прироста в сравнении с Hopper. 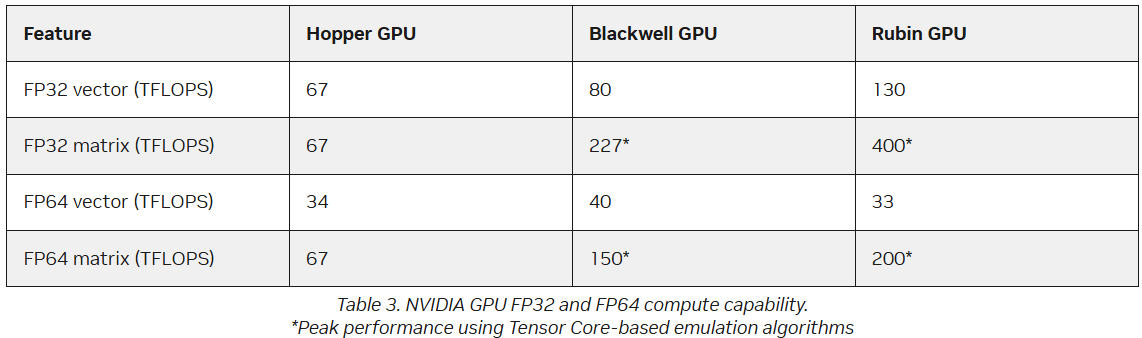 Отметим, что в AMD раскритиковали такой подход, заявив, что он эффективен не для всех сценариев и поэтому такое решение ещё не готово к широкому применению. В свою очередь, эксперты предупреждают, что смещение фокуса производителей на выпуск чипов для ИИ-нагрузок, которые отлично работают с вычислениями с низкой точностью, может привести к дефициту чипов с поддержкой FP64 для HPC, а это грозит потерей лидерства США в этом сегменте рынка. По мере того, как NVIDIA наращивает мощность для выполнения ИИ-задач с низкой точностью вычислений Rubin, компания будет всё больше полагаться на cuBLAS, библиотеку стандартных математических операций CUDA-X, которая эмулирует вычисления с двойной точностью на тензорных ядрах, чтобы постоянно наращивать показатели FP64-производительности. «Мы пытаемся предоставить эти возможности среде разработчиков, чтобы они могли… получить необходимую точность FP64», — заявил в декабре HPCwire Дион Харрис (Dion Harris), старший директор NVIDIA по ИИ/HPC-решениям для гиперскейлеров. 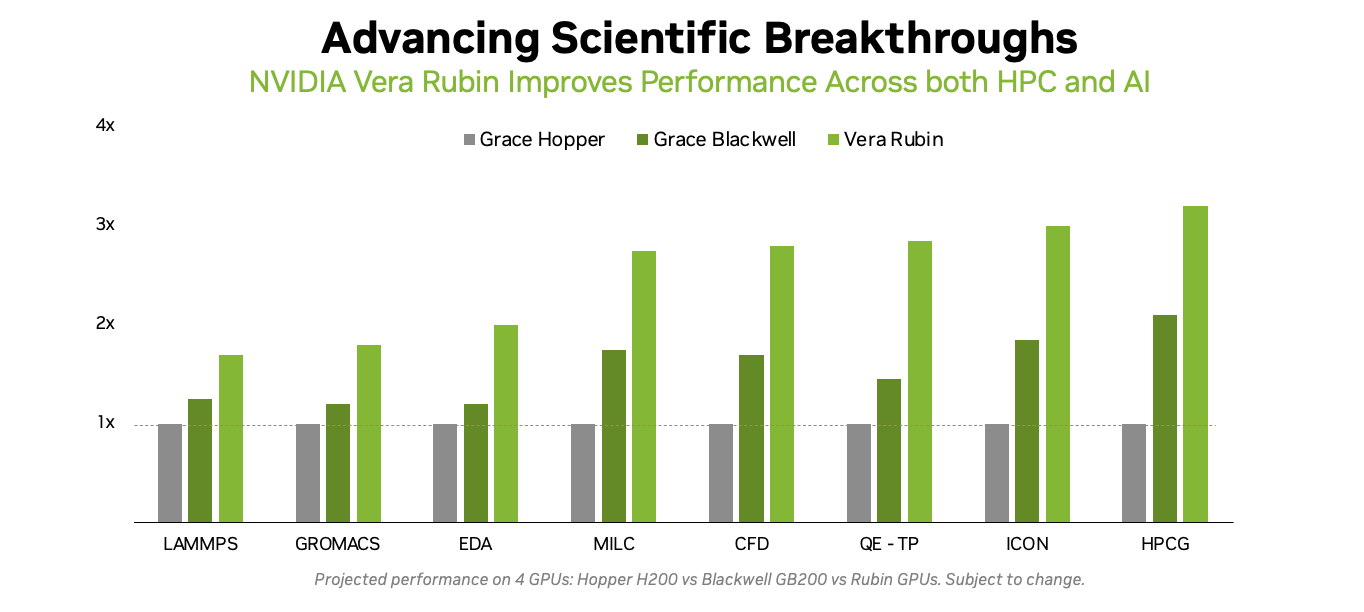
NVIDIA GPU simulation performance Методы эмуляции NVIDIA основаны на схеме Озаки (Ozaki), позволяющей выполнять умножение матриц с высокой точностью, используя многократные вычисления с низкой точностью на тензорных ядрах. NVIDIA утверждает, что использование алгоритма Озаки оправдано, поскольку увеличение производительности FP64 путём добавления большего количества ядер CUDA фактически не повысит общую производительность HPC-приложений, но сделает чипы менее гибкими. По словам компании, анализ реальных нагрузок показывает, что «наивысшая устойчивая производительность FP64 часто достигается на умножении матриц». В Hopper для этого были отдельные аппаратные блоки, но в Blackwell и в Rubin NVIDIA больше опирается на эмуляцию. В то же время, производительность векторных FP64-вычислений остаётся критически важной для научных приложений, в которых не доминируют матричные ядра, признаёт NVIDIA, однако тут же утверждает, что в этих случаях производительность ограничивается перемещением данных через регистры, кеши и HBM, а не непосредственно вычислительными ресурсами. Поэтому сбалансированная конструкция GPU «обеспечивает достаточное количество ресурсов FP64 для насыщения доступной пропускной способности памяти, избегая избыточного выделения вычислительной мощности, которая не может быть эффективно использована». Иными словам, компания ничего менять не собирается. Проект Genesis Mission, вероятно, будет создавать разнообразные ИИ-приложения для научных и инженерных задач, и каждое из них, скорее всего, будет иметь несколько иные вычислительные потребности. Достигли ли NVIDIA и AMD оптимального баланса, используя вычислительные ядра для матричных вычислений и опираясь на эмуляцию Озаки для FP64, ещё предстоит выяснить, пишет HPCwire.
09.02.2026 [13:17], Сергей Карасёв
«Ядерный» суперкомпьютер Teton производительностью 20,8 Пфлопс полагается только на AMD EPYC TurinНациональная лаборатория Айдахо (INL) в составе Министерства энергетики США (DOE) сообщила о запуске суперкомпьютера Teton. Система присоединилась к четырём другим НРС-комплексам лаборатории — Bitterroot, Hoodoo, Wind River и Sawtooth, увеличив доступные вычислительные ресурсы вчетверо. В основу Teton положена платформа HPE Cray EX 4000. Объединены 1024 вычислительных узла, каждый из которых содержит 384 ядра CPU и 768 Гбайт памяти. Задействованы процессоры AMD EPYC 9005 поколения Turin. Таким образом, в общей сложности используются около 393 тыс. CPU-ядер и 768 Тбайт памяти. Как отмечает INL, на сегодняшний день Teton — это один из самых мощных суперкомпьютеров в мире, архитектура которого базируется исключительно на CPU (без применения GPU и других специализированных компонентов). Такая конфигурация обусловлена спецификой использования системы: комплекс предназначен для сложных физических моделирований в рамках проектов по разработке передовых реакторов на быстрых нейтронах, малых модульных реакторов и микрореакторов. Утверждается, что традиционные CPU лучше подходят для подобных расчётов, нежели GPU. 
Источник изображений: INL «Teton позволит исследователям моделировать ядерные технологии следующего поколения с беспрецедентной точностью, что значительно сократит время работ от создания концепции до внедрения критически важных проектов в области ядерной энергетики», — отмечает Бренден Хайдрих (Brenden Heidrich), руководитель научной программы Nuclear Science User Facilities (NSUF), реализуемой DOE.  В рамках NSUF исследователям в области ядерной энергетики предоставляется доступ к широкому спектру ресурсов INL и других учреждений. Новый суперкомпьютер поможет учёным моделировать сложную физику реакторов, поведение перспективных материалов и процессы топливного цикла.
24.01.2026 [14:15], Сергей Карасёв
Nokia и Hypertec построили в Канаде 15-Пфлопс суперкомпьютер Nibi с погружным охлаждением
amd
emerald rapids
granite rapids
h100
hardware
hpc
intel
mi300
nokia
nvidia
ии
канада
отопление
погружное охлаждение
суперкомпьютер
Компании Nokia и Hypertec объявили о запуске суперкомпьютера Nibi, смонтированного в Университете Ватерлоо (University of Waterloo) в Канаде. Эта НРС-платформа будет использоваться для решения широкого спектра задач, в том числе в области ИИ. Проект Nibi финансируется канадским Министерством инноваций, науки и экономического развития через Канадский альянс цифровых исследований, а также Министерством колледжей, университетов, научных исследований и безопасности через некоммерческую организацию Compute Ontario. 
Источник изображения: Nokia Система насчитывает в общей сложности более 750 вычислительных узлов. Это, в частности, 700 узлов CPU, каждый из которых несёт на борту два процессора Intel Xeon 6972P поколения Granite Rapids-AP (96C/192T, до 3,9 ГГц) и 748 Гбайт оперативной памяти. Кроме того, задействованы 10 узлов с двумя чипами Xeon 6972P и 6 Тбайт памяти каждый. 
Источник изображений: Университет Ватерлоо В состав суперкомпьютера также входят 36 узлов GPU, которые содержат по два процессора Intel Xeon Platinum 8570 серии Emerald Rapids (56C/112T, до 4 ГГц), 2 Тбайт оперативной памяти и восемь ускорителей NVIDIA H100 SXM (80 GB), связанных посредством NVLink. Наконец, Nibi оперирует шестью узлами с четырьмя ускорителями AMD Instinct MI300A.  Подсистема хранения VAST Data выполнена на основе SSD суммарной вместимостью 25 Пбайт. Пропускная способность каналов передачи данных между CPU- и GPU-узлами составляет 200 Гбит/с. Подключение к хранилищу обеспечивается благодаря 24 линиям на 100 Гбит/с. Заявленная пиковая производительность Nibi достигает 15 Пфлопс. Новая НРС-платформа оборудована высокоэффективной системой погружного жидкостного охлаждения. Сгенерированное тепло используется для обогрева центра квантовых и нанотехнологий имени Майка и Офелии Лазаридис (Mike and Ophelia Lazaridis Quantum-Nano Centre).
20.01.2026 [21:58], Владимир Мироненко
Tesla возобновит строительство ИИ-суперкомпьютеров DojoГендиректор Tesla (Elon Musk) Илон Маск объявил в соцсети Х о решении компании возобновить работу над Dojo3, третьим поколением суперкомпьютерных систем, о чём сообщает Data Center Dynamics. Команда, занимавшаяся проектом Dojo, была расформирована в прошлом году в связи с тем, что компания отдала предпочтение ИИ-чипам, используемых в бортовых системах электромобилей. Также ранее было объявлено, что компания будет полагаться на чипы внешних партнёров. Вместе с тем компания возвращается к проекту Dojo, поскольку, по словам Маска, достигнуты успехи в разработке чипа AI5, что создало определённый запас прочности. Маск объявил, что однокристальный чип AI5 обеспечит производительность на уровне NVIDIA Hopper, при этом двухкристальный AI5 будет равен по мощности чипу с Blackwell. Он предложил всем заинтересованным в участии в проекте и «работе над созданием самых массово производимых в мире микросхем» отправить сообщение Tesla, указав в трёх пунктах самые сложные технические проблемы, которые они решили. Илон Маск также сообщил, что разработка чипа Tesla AI5 почти завершена, а чип AI6 находится на «ранней стадии» разработки, добавив, что компания также планирует создать чипы AI7, AI8 и AI9. По его словам, нынешний чип Tesla AI4 позволит достичь «уровня безопасности при автономном вождении, намного превышающего человеческий», а AI5 сделает электромобили Tesla «почти идеальными», также значительно улучшив функционирование человекоподобного робота Optimus. «AI6 для Optimus и ЦОД. AI7/Dojo3 будут использовать ИИ для космических вычислений», — написал Маск. В ноябре 2025 года он заявил, что существует «чёткий путь к удвоению производительности по всем показателям для AI6 в течение 10–12 мес. после выпуска AI5», а теперь он намерен сократить срок создания каждого нового поколения ИИ-чипов до 9 мес. Хотя сам миллиардер не стал называть сроки производства чипа AI5, ИИ-чат-бот Grok сообщил пользователям в ответ на запросы, что ограниченное производство AI5 ожидается в 2026 году, а массовое производство запланировано на 2027 год. 
Источник изображения: Tesla В конце прошлого года Маск заявил акционерам Tesla, что компании, вероятно, потребуется построить «гигантскую фабрику» для производства своих ИИ-чипов, чтобы хотя бы частично удовлетворить в них потребности компании. Tesla уже сотрудничает с TSMC и Samsung, которые производят чипы AI5 и AI6 на заводах в Аризоне и Тайване, а также в Южной Корее и Техасе соответственно. На том же собрании акционеров Маск сказал, что, вероятно, стоит обсудить вопрос производства и с Intel. Как отметил Techpowerup, в августе прошлого года появились сообщения о присоединении к компании Маска Intel в качестве ключевого партнёра по упаковке чипов, что ознаменовало отход Tesla от прежней зависимости от TSMC в вопросах производства. Сообщается, что Intel будет управлять сборкой и тестированием, используя свою технологию EMIB. Это лучше подходит для больших блоков Tesla Dojo, объединяющих несколько чипов площадью 654 мм² в одном корпусе. В свою очередь, Samsung будет производить обучающие чипы D3 на своем заводе в Техасе с помощью 2-нм техпроцесса, оставив Intel контроль над процессами упаковки. Такое разделение труда решает проблему ограничений производственных мощностей и предоставляет Tesla большую гибкость в настройке схем межсоединений. Для автомобильных чипов AI5 компании Samsung и TSMC создадут разные версии, хотя Tesla стремится обеспечить одинаковую производительность в обоих случаях. Предполагается, что AI5 будет потреблять 150 Вт, при этом соответствуя по производительности NVIDIA H100, у которого TDP составляет до 700 Вт. Это было достигнуто путём удаления графических подсистем общего назначения и оптимизации архитектуры специально для ИИ-алгоритмов Tesla.
22.12.2025 [12:28], Сергей Карасёв
Китайская Sugon представила ИИ-платформу ScaleX с 10 тыс. ускорителейКитайский разработчик суперкомпьютеров Sugon (Dawning Information Industry), по сообщению газеты South China Morning Post, анонсировал платформу ScaleX для решения ресурсоёмких задач в области ИИ. Система призвана составить конкуренцию продуктам NVIDIA и Huawei. По заявлениям Sugon, ScaleX представляет собой первый в КНР суперкластер, объединяющий около 10 тыс. ускорителей. ИИ-производительность превышает 5 Эфлопс (точность вычислений не называется). Платформа может применяться для работы с ИИ-моделями, насчитывающими триллионы параметров. В основу суперкластера положены 16 стоек Sugon ScaleX640, каждая из которых может нести на борту до 640 ускорителей. Таким образом, общее количество ИИ-карт в составе платформы достигает 10 240. Конструкция стоек предполагает использование иммерсионного жидкостного охлаждения с фазовым переходом и высоковольтных источников питания постоянного тока (DC). Стойки связаны друг с другом высокоскоростным интерконнектом ScaleFabric. Sugon отмечает, что для моделей ИИ с триллионами параметров ScaleX640 обеспечивает повышение производительности на 30–40 % на задачах обучения и инференса по сравнению с традиционными НРС-системами. 
Источник изображения: Sugon Предполагается, что ScaleX будет соперничать с будущими решениями Huawei, в частности, с суперкластерами Atlas 950 и Atlas 960. В их основу лягут ИИ-ускорители Ascend нового поколения, о подготовке которых стало известно в сентябре уходящего года. Система Atlas 950 SuperCluster, выход которой ожидается к концу 2026 года, будет содержать в общей сложности более 500 тыс. NPU, а Atlas 960 SuperCluster — свыше 1 млн. Сейчас у Huawei есть платформа CloudMatrix 384, которая объединяет 384 ускорителя Huawei Ascend 910C.
09.12.2025 [13:05], Сергей Карасёв
Сандийские национальные лаборатории запустили суперкомпьютер Spectra с ускорителями NextSilicon Maverick-2Сандийские национальные лаборатории (SNL) Министерства энергетики США (DOE) объявили о создании суперкомпьютера Spectra с нестандартной архитектурой. В его основу положены изделия Maverick-2 — интеллектуальные вычислительные ускорители (Intelligent Compute Accelerator, ICA), разработанные компанией NextSilicon. Система Spectra спроектирована по программе Vanguard, цель которой заключается в исследовании потенциала передовых компьютерных архитектур применительно к проектам в сфере национальной безопасности. Первой платформой Vanguard стал комплекс Astra, запущенный в 2018 году: на момент анонса это был самый быстрый в мире суперкомпьютер на базе Arm-чипов. Среди других примечательных машин SNL можно отметить Kingfisher на ИИ-чипах Cerebras WSE-3, а также две нейроморфные системы: на базе SpiNNaker2 и на базе Loihi II (Hala Point). 
Источник изображения: SNL Spectra объединяет 64 вычислительных узла, каждый из которых оснащён двумя двухкристальными ОАМ-модулями Maverick-2: эти изделия содержат 64 управляющих ядра RISC-V, 192 Гбайт памяти HBM3E и два интерфейса 100GbE. В общей сложности задействованы 128 экземпляров Maverick-2. Особенностью ускорителей является возможность динамической реконфигурации оборудования на основе данных, получаемых непосредственно во время выполнения задачи. Такой подход позволяет устранять узкие места, присущие традиционным CPU и GPU. Подробнее об архитектуре Maverick-2 можно узнать в нашем материале. За монтаж суперкомпьютера Spectra отвечала компания Penguin Solutions. Она разработала специализированный сервер, поддерживающий до четырёх ОАМ-модулей Maverick-2, хотя в текущей конфигурации используются два. Применены передовая СЖО с отрицательным давлением Chilldyne и платформа Penguin Tundra, что обеспечивает оптимизацию управления температурой и распределения питания, а также возможности масштабирования.
03.12.2025 [20:51], Владимир Мироненко
HPE одной из первых начнёт выпускать интегрированные стоечные ИИ-платформы AMD Helios AI
amd
broadcom
epyc
hardware
hpc
hpe
instinct
juniper networks
mi400
ocp
ualink
venice
германия
ии
суперкомпьютер
AMD объявила о расширении сотрудничества с HPE, в рамках которого HPE станет одним из первых поставщиков стоечных систем AMD Helios AI, которые получат коммутаторы Juniper Networking (компания с недавних пор принадлежит HPE), разработанные совместно с Broadcom, и ПО для бесперебойного высокоскоростного подключения по Ethernet. AMD Helios AI — открытая полнофункциональная ИИ-платформа на базе архитектуры OCP Open Rack Wide (ORW), разработанная для крупномасштабных рабочих нагрузок и обеспечивающая FP4-производительность до 2,9 Эфлопс на стойку благодаря ускорителям AMD Instinct MI455X, процессорам EPYC Venice шестого поколения и DPU Pensando Vulcano, работающими под управлением открытой программной экосистемы ROCm для нагрузок ИИ и HPC. Как отметил The Register, сетевая архитектура этой системы будет представлять собой масштабируемую реализацию UALink over Ethernet (UALoE) и специализированным коммутатором Juniper Networks на базе сетевого чипа Broadcom Tomahawk 6 (102,4 Тбит/с). Система разработана для упрощения развёртывания крупномасштабных ИИ-кластеров, что позволяет сократить время разработки решений и повысить гибкость инфраструктуры. В отличие от NVIDIA, AMD не выпускает коммутаторы, предлагая открытую экосистему, так что HPE и другие компании могут интегрировать собственные сетевые решения. The Register полагает, что HPE и Broadcom решили не гнаться за отдельной аппаратной реализацией UALink, если данные можно передавать поверх Ethernet. «Это первое в отрасли масштабируемое решение, использующее Ethernet, стандартный Ethernet. Это означает, что оно полностью соответствует открытому стандарту и позволяет избежать привязки к проприетарному поставщику, использует проверенную сетевую технологию HPE Juniper для обеспечения масштабируемости и оптимальной производительности для рабочих нагрузок ИИ», — заявила HPE. 
Источник изображения: HPE HPE заявила, что это позволит её стоечной системе поддерживать трафик, необходимый для обучения модели с триллионами параметров, а также обеспечить высокую пропускную способность инференса. Стоечная система HPE будет включать 72 ускорителя AMD Instinct MI455X с 31 Тбайт HBM4 с агрегиированной пропускной способностью 1,4 Пбайт/с. Агрегированная скорость интерконнекта составит 260 Тбайт/с. Новинка будет доступна в 2026 году. AMD также сообщила, что Herder, новый суперкомпьютер для Центра высокопроизводительных вычислений в Штутгарте (HLRS) (Германия), получит Instinct MI430X и EPYC Venice. Он будет построена на платформе HPE Cray Supercomputing GX5000. Поставка Herder запланирована на II половину 2027 года, а ввод в эксплуатацию — к концу 2027 года. Herder заменит используемый центром суперкомпьютер Hunter.
28.11.2025 [09:53], Руслан Авдеев
Индия построила 37 суперкомпьютеров за 10 лет, а теперь нацелилась на cоздание импортозамещённых HPC-системЗа 10 лет, прошедших с запуска в Индии Национальной суперкомпьютерной миссии (National Supercomputing Mission, NSM), страна ввела в эксплуатацию 37 суперкомпьютеров совокупной производительностью 39 Пфлопс, ещё один кластер мощностью 35 Пфлопс должен заработать в конце 2025 года. Хотя многие из машин используют технологии местного происхождения, Индии ещё далеко до роли лидера ИИ-отрасли или крупного игрока на рынке полупроводников, сообщает The Register. NSM заработала в 2015 году для обеспечения запросов правительства и исследователей. Цели, в основном, достигнуты — более 13 тыс. учёных имеют доступ к суперкомпьютерным ресурсам MSM, уровень загрузки оборудования составил 85–95 %, выполнено более 10 млн задач, опубликовано более 1,5 тыс. научных статей в рецензируемых журналах. Развитие суперкомпьютеров в Индии курирует Центр развития передовых вычислений (Centre for Development of Advanced Computing, C-DAC), в 2020 году призвавший создавать собственные, индийские компоненты для экзафлопсных суперкомпьютеров. Процесс включает проектирование чипов, плат, интерконнектов и хранилищ, в том числе с использованием технологии кремниевой фотоники. Сейчас цены на «домашнее» оборудование сопоставимы с продукцией мировых OEM-производителей, но прямые закупки и локальное производство позволяет снизить затраты минимум на 15 %. 
Источник изображения: India NSM В C-DAC утверждают, что усилия приносят успех, а уровень «индигенизации» (производства и внедрения технологий внутри страны) превысил 50 % — в числе прочего речь идёт о серверных узлах, интерконнектах и системном ПО. Узлы построены на серверной платформе Rudra на базе Intel Xeon с ускорителями AMD или NVIDIA и используют 200G-интерконнект Trinetra, который, впрочем, минимум вдвое уступает по задержкам InfiniBand. Они обеспечивают работу около трети HPC-парка. Вскоре появятся и узлы с CPU AMD. Разработку собственного Arm-процессора AUM, создаваемого при участии MosChip и Socionext, должны завершить в 2027 году, а собственных мощных GPU у Индии нет. Каждая новая система на базе Rudra оснащается СЖО (DLC) разработки C-DAC, что обеспечивает 10 % экономии энергии на уровне узла при полной нагрузке и соответствует PUE 1,20–1,25 на уровне объектов. Это приблизительно на 20 % лучше в сравнении с аналогами на воздушном охлаждении. Базовой ОС на многих кластерах NSM является Red Hat Enterprise Linux (RHEL) или его бесплатные аналоги, но всё пользовательское окружение, включая планировщики задач, менеджеры ресурсов и системы мониторинга, построена на собственных открытых разработках C-DAC. Этот подход позволяет избежать зависимости от коммерческого ПО. 
Источник изображения: India NSM Впрочем, некоторые местные эксперты уверены, что уровень локализации в рамках NSM гораздо меньше заявленных 50 %, а программно-аппаратной экосистемы, которая превращает прототипы в надёжные продукты, нет. При этом Индии фактически остаётся зависимой от глобальных игроков, что вызывает опасения относительно надёжности цепочек поставок и возможных санкций. Так, для AUM требуется 5-нм техпроцесс, но фабрик такого класса в стране нет. Впрочем, местные пользователи довольны и нынешними машинами NSM, ведь раньше у них и такого не было. Текущий этап NSM завершается 31 декабря. C-DAC уже объявила цели для NSM 2.0 — ввод 1,5 Эфлопс в течение пяти лет. В первую волну, вероятно, попадут 100-Пфлос суперкомпьютеры на оборудовании Intel и AMD. Ключевая вторая волна нацелена на достижение экзафлопсной производительности с AUM. Но C-DAC не гонится за «сырой» производительностью — важнее решение специфических для Индии задач. Кроме того, есть проект ИИ-суперкомпьютера Lenovo, которая намерена наладить здесь выпуск серверов, на базе местных ускорителей Krutrim. 
Источник изображения: India NSM Пока не хватает специалистов для разработки, эксплуатации и оптимизации HPC-систем, а также развития производства. В будущем предлагается создание крупных систем экзафлопсного класса с полной локализацией, продолжением НИОКР в области ПО и «железа». Наконец, планируется и создание HPC-маркетплейса, где предприятия любого размера смогут давать задачи, а учёные — разрабатывать решения. Достижение технологического суверенитета для Индии весьма важно. Так, в октябре сообщалось, что техногиганты США приостановили развитие ЦОД в Индии, хотя ранее обещали вложить в них миллиарды долларов, из-за некоторого охлаждения отношений Нью-Дели и Вашингтона. При этом около года назад глава NVIDIA Дженсен Хуанг заявил, что Индия должна стать одним из лидеров в области ИИ и создать собственную инфраструктуру. |
|

