Материалы по тегу: суперкомпьютер
|
07.05.2026 [15:03], Сергей Карасёв
TotalEnergies создаст суперкомпьютер Pangea 5 за €100 млнФранцузская нефтегазовая компания TotalEnergies объявила о заключении соглашения с Dell Technologies и NVIDIA на создание нового суперкомпьютера под названием Pangea 5. Ожидается, что его ввод в эксплуатацию позволит увеличить вычислительные мощности TotalEnergies в шесть раз по сравнению с нынешними показателями (точные данные не приводятся). Технические подробности о будущей НРС-системе не раскрываются. Отмечается лишь, что в составе комплекса будут применяться «специализированные процессоры, рассчитанные на массово-параллельные вычисления». Речь идёт об ускорителях NVIDIA на основе GPU, а также о решениях InfiniBand и пр. Машина получит гибридное хранилище DDN ExaScaler. Инвестиции в проект Pangea 5 оцениваются в €100 млн. Суперкомпьютер расположится в Научно-техническом центре Жана Феже в По (Jean Féger Scientific and Technical Center at Pau — CSTJF) на юго-западе Франции. Там же смонтирована нынешняя машина Pangea 4, запущенная в июле 2024 года. По сравнению с этим комплексом при сопоставимой производительности общее энергопотребление Pangea 5 будет ниже примерно на 40 %, а потребление энергии системой охлаждения — меньше в пять раз. Тепло, генерируемое новым суперкомпьютером, планируется использовать для отопления зданий CSTJF, в которых работают более 2,5 тыс. человек. 
Источник изображения: TotalEnergies Компания TotalEnergies будет использовать Pangea 5 для ресурсоёмких вычислений с применением передовых методов сейсморазведки для повышения точности визуализации недр и ускорения геологоразведочных работ. Кроме того, суперкомпьютер поможет в реализации проектов, связанных с ИИ. Запуск вычислительного комплекса намечен на следующий год.
04.05.2026 [09:52], Владимир Мироненко
Fujitsu распрощается с мейнфреймами к 2035 году — на смену придут квантовые или ИИ-суперкомпьютерыКомпания Fujitsu планирует закрыть свой бизнес в области мейнфреймов в 2035 году, пишет The Register. Об этом сообщил генеральный директор Такахито Токита (Takahito Tokita) на брифинге для инвесторов, посвящённом планам компании в среднесрочной перспективе, отметив, что в 2035 году компании исполнится 100 лет. Напомним, что в 2022 году Fujitsu сообщала о решении прекратить продажи мейнфреймов в 2030 году. Если IBM не забросит это направление, то она останется единственным поставщиком мейнфреймов. По словам главы Fujitsu, к этому времени вместо мейнфреймов компания начнёт предлагать либо ИИ-суперкомпьютеры на процессорах семейства Monaka, либо квантовые компьютеры. Гендиректор подчеркнул, что планы Fujitsu связаны с ИИ. «Мы создали глобально стандартизированную платформу данных, — сказал Токита. — Начиная с этого финансового года, на основе этой платформы данных мы ускорим полномасштабное внедрение управления на основе ИИ с использованием наших собственных разработок. Это повысит как скорость, так и качество принятия решений и управленческих оценок». 
Источник изображения: Fujitsu Компания планирует сохранить бренд Uvance, объединяющий консалтинг и ИТ-услуги, но откажется от работы по системной интеграции и почасовой оплаты в пользу «структуры прибыли, основанной на ценности и результатах». Токита сообщил компания также откажется от модели работы, что при которой выручка в значительной степени сконцентрирована в IV квартале в пользу более равномерного распределения поступлений по кварталам, что важно для повышения качества управления, добавив, что отказ будет проходить постепенно. Гендиректор отметил, что есть ещё много возможностей для дальнейшего улучшения модели ценообразования. «Я хотел бы рассмотреть подход, при котором мы будем взимать плату с клиентов на основе таких факторов, как рабочая нагрузка нашего персонала и объём данных», — рассказал он. По словам Токиты, Fujitsu Japan прекратила ежегодный набор выпускников и теперь нанимает специалистов с конкретными необходимыми навыками. Также он сообщил о планах компании сотрудничать с оборонным сектором страны.
29.04.2026 [15:34], Сергей Карасёв
Китай анонсировал 2,5-Эфлопс Arm-суперкомпьютер LineShine на домашних процессорахКитайский национальный суперкомпьютерный центр в Шэньчжэне (NSCCSZ) анонсировал проект вычислительного комплекса LineShine (LingSheng), производительность которого после полноценного ввода в эксплуатацию окажется на уровне 2 Эфлопс. Особенностью системы является то, что её конфигурация предполагает применение исключительно CPU-серверов — без ускорителей на базе GPU. Как отмечает ресурс HPC Wire, LineShine будет создаваться в несколько этапов. Одна из секций нового суперкомпьютера получит серверы Huawei Kunpeng с десятками тысяч вычислительных ядер. Предусмотрено использование 428 узлов хранения с суммарной вместимостью 650 Пбайт. Заявленная пропускная способность — 10 Тбайт/с. Вторая секция LineShine предполагает применение 20480 вычислительных узлов, каждый из которых будет оснащён двумя процессорами LX2 на архитектуре Armv9. Конструкция чипов LX2 включает два вычислительных кристалла со 152 ядрами (в сумме 304 ядра) и восемь стеков памяти HBM (32 Гбайт, 4 Тбайт/с). Каждый кристалл использует 128 Гбайт внешней памяти DDR. За обмен данными между блоками DDR и HBM отвечает специальный механизм SDMA. Каждый кристалл поделён на четыре NUMA-домена (38 ядер и 4 Гбайт HBM). Узлы соединены между собой высокоскоростным интерконнектом LingQi, обеспечивающим пропускную способность до 1,6 Тбит/с на узел. Говорится о поддержке режимов FP64/FP32/FP16/INT8. Заявленная производительность LX2 достигает 60,3 Тфлопс на операциях FP64 и 120,6 Тфлопс на операциях FP32. Таким образом, пиковая теоретическая FP64-производительность составляет 2,47 Эфлопс. 
Источник изображения: South China Morning Post Для сравнения, самый быстрый на сегодняшний день суперкомпьютер в мире по версии TOP500 — американский комплекс El Capitan — обладает быстродействием 1,809 Эфлопс с пиковым значением 2,821 Эфлопс, но в нём применяются как CPU, так и ускорители (AMD Instinct MI300A). Таким образом, LineShine станет самым мощным НРС-комплексом, построенным исключительно на базе CPU. Другой особенностью машины станет то, что в её составе будут применяться только китайские компоненты, включая процессоры, накопители и сетевое оборудование. При этом официально КНР не участвует в TOP500 уже пять лет, да и в целом не любит рассказывать о своих самых мощных суперкомпьютерах. Нужно отметить, что в Китае действует другой суперкомпьютер экзафлопсного класса — система China New-generation Intelligent Supercomputer (CNIS). Этот комплекс имеет гетерогенную конфигурацию с 5632 вычислительными узлами. Каждый из них наделён двумя 64-бит серверными процессорами на базе CISC с 64 ядрами (2,4 ГГц) и восемью ускорителями GPGPU с архитектурой SIMT с 64 Гбайт HBM (1,8 Тбайт/с). Задействованы 8-канальная подсистема памяти DDR5-6400. Каждый GPGPU обеспечивает пиковую производительность 32,7 Тфлопс в режиме FP64, 65,5 Тфлопс на операциях FP32 и 470 Тфлопс в режиме FP16, что в сумме даёт пиковую теоретическую FP64-произвоидительность на уровне 1,47 Эфлопс.
21.04.2026 [20:48], Владимир Мироненко
В ВТБ призвали к партнёрству с Китаем для развития суверенного ИИРазвивать суверенные технологий ИИ в России, включая использование больших языковых моделей (LLM) и вычислительных мощностей, необходимо в партнёрстве с дружественными странами, прежде всего, с Китаем, заявил заместитель руководителя технологического блока ВТБ. Он подчеркнул, что при этом важно учитывать необходимость защиты данных россиян, которые используются при обучении ИИ. Топ-менеджер отметил, что открытые LLM, разработанные китайскими компаниями, работают «чуть лучше», чем российские модели, но их использование несёт определенные риски для технологического суверенитета, так как они созданы за пределами России. Использование российских моделей, в частности, от «Яндекса» и Сбера, снимает часть этих рисков. Вместе с тем топ-менеджер ВТБ считает, необходимо использовать лучшие технологии, чтобы не оказаться в числе отстающих: «Для того, чтобы наши модели были не хуже, мы стараемся обучать их на обезличенных данных. И считаем, что партнёрство с Китаем — это правильный возможный вариант, они действительно сейчас по многим направлениям лидируют». Это также относится к развитию суперкомпьютеров, необходимых для ИИ: «Если взять вычислительные мощности, которые есть за рубежом и которые есть у нас, понятно, что те суперкомпьютеры, которые сейчас работают, в первую очередь в США, многократно превышают те мощности, которые есть в России. И это тоже проблема». 
Источник изображения: Hanson Lu/unsplash.com Он добавил, что в рамках кооперации уже запущены большие совместные лаборатории с китайскими коллегами. Также начинают осуществлять сборку серверов в России с китайскими GPU: «Это — будущее, так как без кооперации не обойтись. Мы большая и сильная страна, но есть другие большие и сильные страны, вместе с которыми мы достигнем больших результатов». Также было отмечено, что применение ИИ-технологий в финансовом секторе усложняется в связи с необходимостью выполнения требований по соблюдению банковской тайны и защите персональных данных. Поэтому, для того чтобы использовать самые эффективные и популярные большие языковые модели, но при этом не допустить утечку данных, в ВТБ используют их on-premise, ограничивая их применение защищённым банковским контуром. «На сегодняшний день к такому режиму работы готовы наши российские большие языковые модели, в том числе YandexGPT и GigaChat», — сообщил топ-менеджер.
20.04.2026 [19:29], Сергей Карасёв
AMD поможет в развитии экосистемы ИИ во ФранцииКомпания AMD и власти Франции объявили о расширении сотрудничества в области ИИ. Соответствующий документ подписан в Париже в Министерстве экономики, финансов, промышленности, энергетики и цифрового суверенитета. Речь идёт о реализации Национальной стратегии Франции в области ИИ. Многолетнее сотрудничество с AMD направлено на укрепление местной экосистемы ИИ посредством развития соответствующей вычислительной инфраструктуры, организации исследовательских и образовательных программ. В частности, AMD планирует предоставлять учёным, разработчикам и стартапам оборудование, необходимое ПО и экспертную поддержку в рамках своих инициатив AMD University Program, AMD AI Developer Program и AMD AI Academy. Ещё одним направлением работ станет углубление взаимодействия между AMD, французским национальным агентством высокопроизводительных вычислений (GENCI), французско-нидерландским Консорциумом Жюля Верна и Французской комиссией по альтернативным источникам энергии и атомной энергии (CEA). Стороны реализуют проект суперкомпьютера Alice Recoque — второй в Европе НРС-системы экзафлопсного класса после JUPITER. Ранее сообщалось, что в основу Alice Recoque войдут серверы с 256-ядерными процессорами AMD EPYC Venice и ускорителями Instinct MI430X (432 Гбайт HBM4). Монтаж системы стоимостью более €550 млн начнётся в 2026 году. 
Источник изображения: AMD В рамках проекта Alice Recoque планируется создание Центра передового опыта (Center of Excellence), который обеспечит экспертные знания, обучение и поддержку для максимально эффективного использования ресурсов нового суперкомпьютера. Появление центра также будет способствовать развитию более широкой экосистемы ИИ-фабрик во Франции.
20.04.2026 [09:49], Сергей Карасёв
Заработало «единое окно» для доступа к европейским суперкомпьютерам EuroHPC Federation PlatformЕвропейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) объявило о запуске системы EuroHPC Federation Platform (EFP), призванной упростить доступ к суперкомпьютерам Европы. Платформа выступает в качестве единой точки доступа к вычислительным ресурсам. EuroHPC JU активно развивает инфраструктуру НРС и ИИ: она объединяет суперкомпьютеры мирового уровня, включая первый в Европе комплекс экзафлопсного уровня — JUPITER. Каждая из этих машин имеет собственные процедуры, сервисы и технические инструменты для аутентификации и авторизации пользователей, распределения ресурсов, планирования задач и предоставления сервисов. С одной стороны, это отражает разнообразие доступных приложений и функций, но, с другой стороны, создаёт сложности для клиентов при работе с различными НРС-системами. 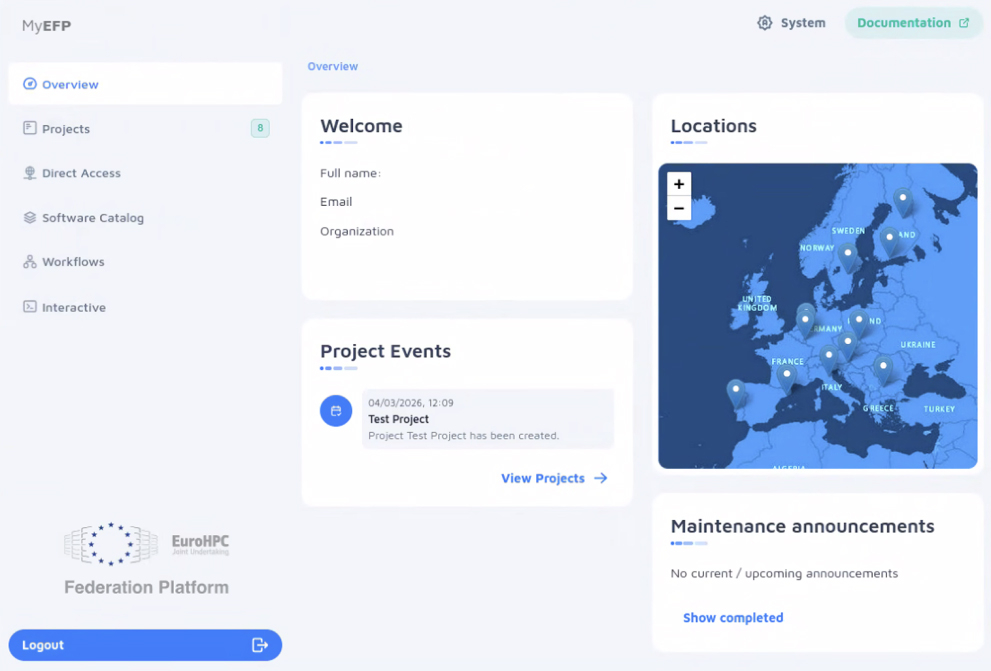
Источник изображения: EuroHPC JU EFP решает указанную проблему: платформа предоставляет единый доступ к ряду действующих суперкомпьютеров EuroHPC JU с применением унифицированного метода аутентификации, авторизации и идентификации (AAI). Иными словами, EFP выступает в качестве «единого окна» для исследователей, корпораций, малых и средних предприятий, а также государственных органов, которым требуются вычислительные мощности для реализации тех или иных проектов. Платформа устраняет фрагментацию благодаря наличию федеративного каталога ПО и упрощает межсистемные процессы, такие как выделение ресурсов и передача данных. В результате, улучшается доступность европейских суперкомпьютеров и повышается удобство их эксплуатации. «Запуск платформы знаменует собой начало пути к более взаимосвязанной и интегрированной европейской экосистеме суперкомпьютерных вычислений, расширяя возможности научного, индустриального и академического сообществ и укрепляя инновационный потенциал Европы», — говорит исполнительный директор EuroHPC JU. В перспективе в состав платформы EFP будут интегрированы европейские ИИ-фабрики, квантовые компьютеры и другие ресурсы, включая озёра данных. В целом, система EFP разработана как безопасное, масштабируемое и гибкое решение.
30.03.2026 [12:01], Сергей Карасёв
Производительность ирландского суперкомпьютера CASPIr составит 15 ПфлопсЕвропейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) объявило тендер на создание в Ирландии суперкомпьютера CASPIr (Computation Analysis and Simulation Platform for Ireland). Система будет обслуживать широкий круг пользователей в научном сообществе, промышленной сфере и государственном секторе в Европе. CASPIr — это вычислительный комплекс среднего уровня. Его технические характеристики пока не раскрываются, но известно, что производительность составит около 15 Пфлопс. Использовать суперкомпьютер планируется для решения задач в области ИИ, включая обучение моделей и инференс. Система CASPIr будет находиться в совместной собственности EuroHPC JU и Университета Голуэя (University of Galway). За управление будет отвечать Ирландский центр высокопроизводительных вычислений (ICHEC). Инвестиции в проект оцениваются в €25 млн, из которых 35% предоставит EuroHPC JU, а оставшиеся 65% — власти Ирландии через свои национальные фонды. Подрядчику предстоит осуществить поставку и монтаж вычислительного комплекса с последующим техническим обслуживанием. 
Источник изображения: EuroHPC JU Отмечается, что EuroHPC JU продолжает развивать инфраструктуру высокопроизводительных вычислений в Европе. На сегодняшний день приобретены в общей сложности 12 суперкомпьютеров, включая JUPITER — первую европейскую машину экзафлопсного класса. Кроме того, EuroHPC JU курирует развёртывание так называемых ИИ-фабрик — площадок, ориентированных на ресурсоёмкие задачи в области ИИ: такие объекты создаются в Финляндии, Германии, Греции, Италии, Люксембурге, Испании, Швеции и пр. Ещё одним направление работ является формирование инфраструктуры квантовых вычислений.
18.03.2026 [12:14], Руслан Авдеев
Великобритания выделит £45 млн на ИИ-суперкомпьютер Sunrise для моделирования физики термоядерного синтезаВласти Великобритании намерены выделить £45 млн (порядка $60 млн) на новый ИИ-суперкомпьютер Sunrise, специально предназначенный для моделирования процессов, сопутствующих термоядерному синтезу. Систему планируют ввести в эксплуатацию летом 2026 года в кампусе Управления по атомной энергии Великобритании (UKAEA), сообщает The Register. Sunrise позиционируется как самый мощный ИИ-суперкомпьютер, специально предназначенный для исследований в сфере термоядерной энергетики. Система мощностью 1,4 МВт финансируется министерским Департаментом энергетической безопасности и нулевых выбросов (Department for Energy Security and Net Zero, DESNZ). Она должна заработать в июне и станет первым элементом «Зоны роста ИИ» (AI Growth Zone) в Калхэме (Оксфордшир). Задача Sunrise — объединение HPC- и ИИ-вычислений, оптимизированных для исследования физических процессов. Это позволит более точно моделировать различные события и создавать цифровых двойников сложных термоядерных систем до проведения дорогостоящих экспериментов в реальном мире. Сообщается, что ИИ-производительность составит до 6,76 Эфлопс. Машина получит узлы Dell PowerEdge с AMD EPYC и Instinct (всего 672 шт.), а также хранилище WEKA. По данным UKAEA, за классические вычислительные мощности отвечают 192 двухпроцессорных узла с 56-ядерными Intel Xeon Max (Sapphire Rapids с HBM). Intel является одной из компаний, поддерживающих проект, наряду с образовательными и государственными структурами — Кембриджским университетом и самим UKAEA. 
Источник изображения: Kristina Gadeikyte Gancarz/unsplash.com Представители властей подчёркивают, что система поможет решать ключевые задачи, связанные с термоядерным синтезом, от моделирования турбулентности плазмы до разработки материалов для реакторов и совершенствования технологий для получения тритиевого топлива. Кроме того, предполагается создание цифровых двойников оборудования, что позволит снизить затраты и риски. Суперкомпьютер будет работать на ряд британских энергетических инициатив, включая программу LIBRTI (Lithium Breeding Tritium Innovation), призванную решить проблему производства трития, а также флагманский правительственный проект STEP, предполагающий создание прототипа электростанции на основе сферического токамака. Великобритания рассчитывает построить его в Ноттингемшире в 2040-х гг. Sunrise является частью более широкой инициативы британского правительства, предусматривающей расширение мощностей для ИИ и HPC. Ранее в 2026 году правительство страны подтвердило инвестиции £36 млн (порядка $48 млн) в суперкомпьютерный центр в Кембридже. Тем временем кампус в Калхэме, вероятно, станет центром ИИ-вычислений, связанных с исследованиями в сфере энергетики. 
Источник изображения: www.gov.uk Пока не известно, поможет ли искусственный интеллект значительно ускорить довольно медленное продвижение к созданию коммерческих термоядерных проектов. Великобритания делает ставку на то, что увеличение вычислительных мощностей поможет решить одну из ключевых задач физики, имеющих важнейшее прикладное значение. Ещё в 2025 году сообщалось, что на появление коммерческих термоядерных реакторов рассчитывает Microsoft, средства в технологию вкладывают и другие компании — например, в сентябре 2025 года Commonwealth Fusion Systems привлекла на развитие своей термоядерной программы ещё $863 млн, а NVIDIA и General Atomics создали виртуальный термоядерный реактор с помощью ИИ. Впрочем, коммерческих версий термоядерных реакторов пока не существует.
17.03.2026 [22:28], Андрей Крупин
В России утверждён план развития высокопроизводительных вычислений и суперкомпьютерной инфраструктурыПравительство РФ утвердило план мероприятий, в рамках которого будут создаваться дополнительные условия для развития суперкомпьютерных технологий, искусственного интеллекта и вычислительных систем. Документ включает конкретные сроки мероприятий и их исполнителей, а также предполагает десятикратное увеличение совокупной мощности отечественных суперкомпьютеров к 2030 году. Согласно дорожной карте, в ближайшие несколько лет в России должна начаться реализация масштабной программы, включающей комплекс мероприятий, направленных на формирование единых требований к суперкомпьютерным центрам коллективного пользования, определение порядка предоставления доступа к ним научного сообщества и ключевых организаций промышленности, а также перспектив их дальнейшего развития и модернизации. В процессе работы по этому направлению планируется сформировать стратегию дальнейшего развития и правила функционирования национальной исследовательской компьютерной сети нового поколения, которая объединяет сотни ведущих вузов и научных организаций. Предполагается, что развитие коммуникационной инфраструктуры расширит возможности для проведения исследований, требующих обработки и передачи больших объёмов данных. 
Суперкомпьютер «Политехник РСК Торнадо» производства группы компаний РСК, установленный в Санкт-Петербургском политехническом университете Петра Великого (источник изображения: «РСК Технологии» / rscgroup.ru) Часть мероприятий дорожной карты направлена на разработку концепции профильной федеральной научно-технической программы, в рамках которой будет предусмотрено создание, развитие и внедрение отечественных алгоритмов, методов и программного обеспечения для проведения суперкомпьютерных вычислений в различных отраслях экономики. Научно-техническая программа в том числе подразумевает формирование новых и развитие имеющихся образовательных и дополнительных профессиональных программ по использованию суперкомпьютерных технологий и высокопроизводительных вычислений. По мнению «К2 НейроТех» (входит в «К2Тех»), утверждение дорожной карты — важный сигнал для всего рынка. Ключевой вызов для промышленного ИИ сегодня — не отсутствие моделей, а дефицит доступных вычислительных мощностей и зрелой инфраструктуры для их эксплуатации. При этом важно разделять два типа нагрузки: обучение моделей, требующее пиковых мощностей, и инференс — постоянную эксплуатацию, которая по мере зрелости рынка будет занимать всё большую долю вычислительных затрат. Без учёта этой специфики даже десятикратный рост мощностей может не дать ожидаемого экономического эффекта: «Особенно важно, что в дорожной карте уделено внимание подготовке кадров и развитию национальной исследовательской сети — без этого даже самые мощные суперкомпьютеры останутся невостребованными».
21.02.2026 [15:03], Сергей Карасёв
G42 из ОАЭ и Cerebras построят в Индии национальный ИИ-суперкомпьютер с царь-ускорителями WSE-3Холдинг G42 из Абу-Даби (ОАЭ) и компания Cerebras в партнёрстве с Университетом искусственного интеллекта им. Мохаммеда бин Зайеда (MBZUAI) и Индийским центром развития передовых вычислительных технологий (C-DAC) развернут в Индии национальный ИИ-суперкомпьютер. Технические подробности проекта не раскрываются. Отмечается лишь, что система обеспечит ИИ-производительность на уровне 8 Эфлопс (точность вычислений не указана). Комплекс, размещённый на территории Индии, будет эксплуатироваться в соответствии с местными требованиями к безопасности, а все обрабатываемые данные останутся в национальной юрисдикции. Иными словами, речь идёт о формировании суверенной вычислительной платформы. Как отмечает The Register, в основу суперкомпьютера лягут ускорители Cerebras WSE-3. Эти изделия содержат 4 трлн транзисторов, 900 тыс. ядер и 44 Гбайт SRAM. Суммарная пропускная способность встроенной памяти достигает 21 Пбайт/с. Производительность составляет до 125 Пфлопс на операциях FP16. Таким образом, в составе НРС-системы могут быть задействованы 64 экземпляра Cerebras WSE-3. 
Источник изображения: G42 После ввода в эксплуатацию новый суперкомпьютер станет доступен широкому кругу пользователей в Индии — от ведущих научных организаций, институтов и государственных структур до стартапов, малых и средних предприятий. Ожидается, что появление системы позволит ускорить инновации в области ИИ. «Суверенная инфраструктура ИИ становится важнейшим компонентом национальной конкурентоспособности. Новый проект предоставит Индии такую платформу, позволив местным исследователям и предприятиям внедрять ИИ, обеспечивая при этом полную безопасность данных», — заявил Ману Джайн (Manu Jain), генеральный директор G42 India. Нужно отметить, что в Индии активно развивается инфраструктуры для ИИ-вычислений. В частности, индийские Tata Group, Tata Consultancy Services (TCS) и OpenAI намерены развернуть в стране ИИ ЦОД мощностью до 1 ГВт. Вместе с тем индийский конгломерат Adani вложит $100 млрд в создание ЦОД общей мощностью 5 ГВт, снабжаемых возобновляемой энергией. |
|

