Лента новостей
|
24.08.2022 [21:16], Алексей Степин
Intel переименовала свои первые серверные ускорители Intel Arctic Sound-M во FlexРанее мы уже рассказывали об ускорителях Intel Arctic Sound-M, о которых впервые стало известно ещё зимой. Это универсальное решение, базирующееся на графической архитектуре Xe-HPG и предназначенное для решения широкого круга задач, от организации виртуальных рабочих мест до применения в системах машинной аналитики. Сегодня Intel официально заявила, что ускорители Arctic Sound-M теперь будут доступны под брендом Flex. В основе по-прежнему лежит микроархитектура DG2 Alchemist, и компания позиционирует Flex как решение, способное ощутимо снизить стоимость владения для серверной инфраструктуры, особенно занятой в задачах транскодирования видеопотоков. 
Источник: Intel Intel заявляет, что Flex 140 в пять раз превосходит NVIDIA A10 в задачах транскодирования видео, вдвое — в сценариях декодирования, и всё это с вдвое меньшим уровнем энергопотребления, а значит, и тепловыделения. Речь идёт о младшем решении в серии с интерфейсом PCIe 4.0 x8, которое имеет два восьмиядерных чипа Xe (1600/1950 МГц) и 12 Гбайт GDDR6-памяти (192 бит, 336 Гбайт/с). Flex 170 оснащён одним чипом, но в 32-ядерном варианте (1950/2050 МГц), и имеет вдвое более высокий теплопакет (150 против 75 Вт), а также 16 Гбайт GDDR6 (256 бит, 576 Гбайт/с) и интерфейс PCIe 4.0 x16. 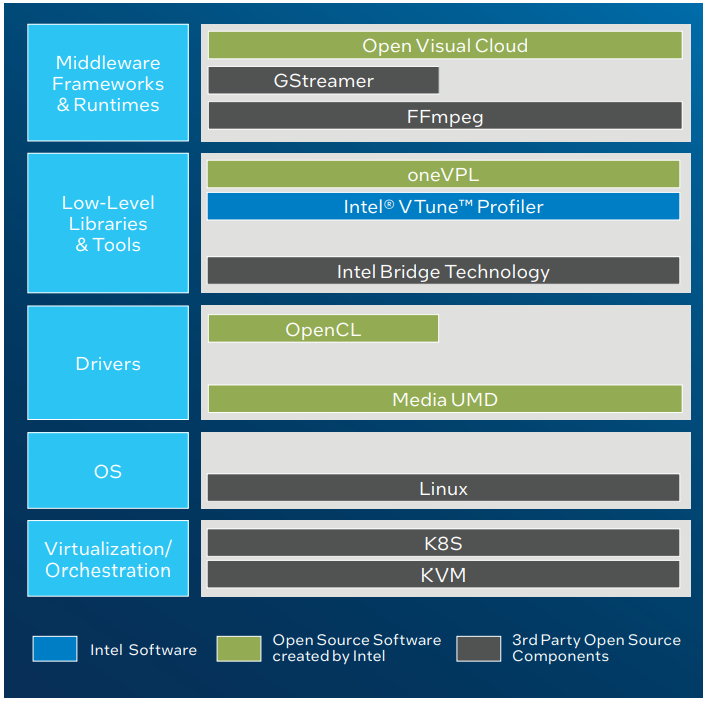
Источник: Intel До 10 ускорителей Flex 140 можно разместить в стандартном 4U-шасси, что позволит одновременно обрабатывать до 360 потоков 1080р60 HEVC. Производительность Flex 140 достаточно высока, чтобы гарантировать задержку не более 1 сек при начале транскодирования видеопотока с параметрами 8K@60 (AV1 или HEVC HDR). Intel активно делает упор на аппаратной поддержке видеостандарта AV1, но ускорители работают и с HEVC, AVC и VP9. 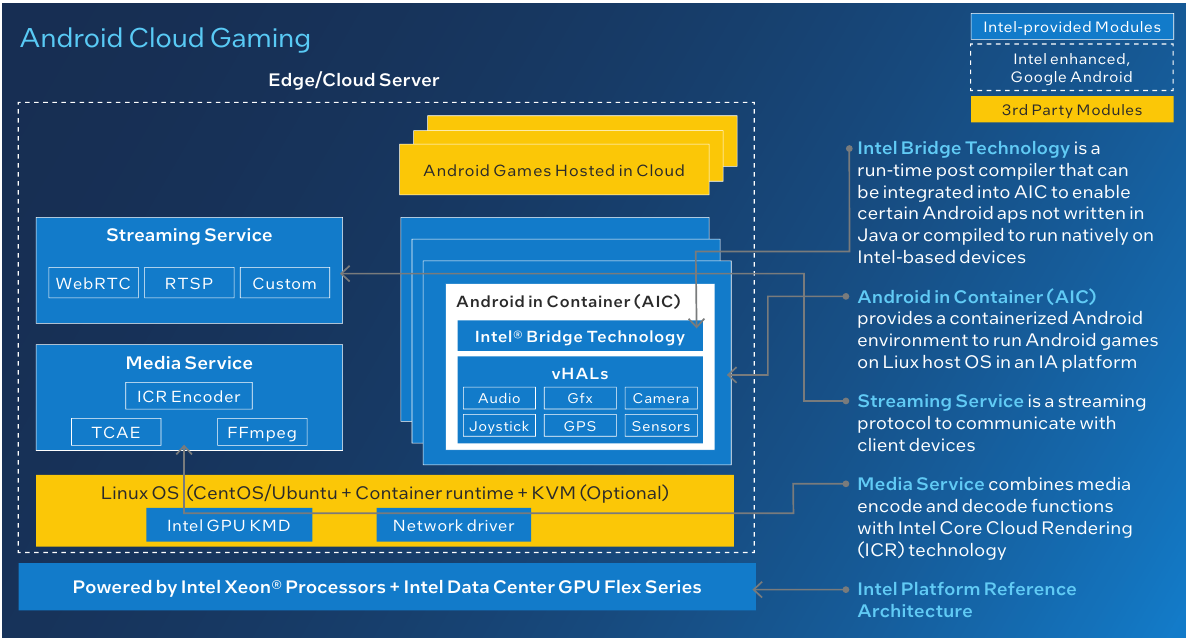
Архитектура облачного Android-гейминга Intel. Источник: Intel Также найдут своё применения ускорители Intel Flex Series и в облачных игровых платформах для Android, где единственная плата Flex 170 сможет обслуживать до 68 сессий в режиме 720p30, а шесть ускорителей Flex 140 будут в состоянии обеспечить до 216 игровых сессий с такими же параметрами. Помимо всего прочего поддерживается и аппаратное ускорение трассировки лучей. Работают новые ускорители под управлением унифицированной платформы oneAPI. 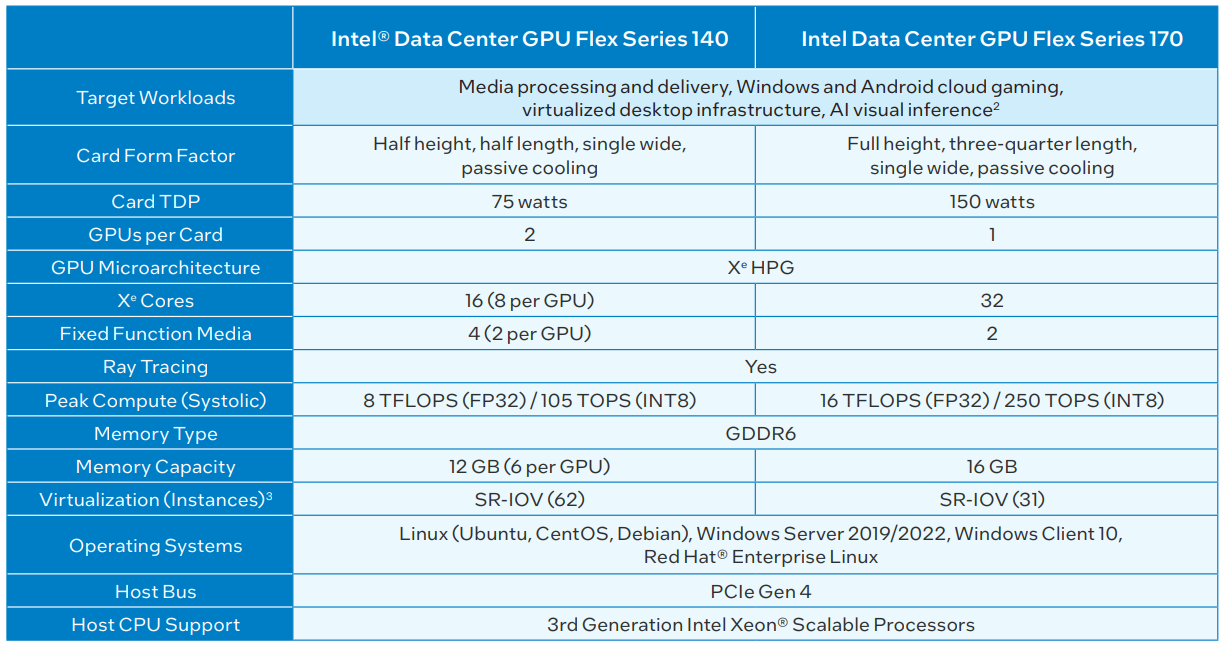 Стоимости новых ускорителей Intel пока не разглашает, но с учётом того, что компания сильно упирает на снижение стоимости владения, цена, судя по всему, будет сравнительно доступной и наверняка более привлекательной, чем у NVIDIA A10. Кроме того, Intel говорит об отсутствии необходимости докупать лицензии, чтобы воспользоваться всеми возможностями ускорителей. Но умалчивает, что производительность старшей модели Flex 170 в INT8-вычислениях совпадает с таковой у A10 (250 Топс), а в FP32-расчётах решение Intel и вовсе проигрывает. К тому же у A10 в полтора раза больше RAM.
22.08.2022 [20:55], Алексей Степин
Китайский ускоритель Birentech BR100 готов бросить вызов NVIDIA A100Как известно, Китай первым в мире успешно ввёл в эксплуатацию суперкомпьютеры экзафлопсного класса, но современная HPC-система практически немыслима без ускорителей. Однако и здесь китайские разработчики подготовили прорыв: на конференции Hot Chips 34 компания Birentech рассказала о чипе BR100, решении, которое может бросить вызов как AMD, так и NVIDIA. Новинка базируется на архитектуре собственной разработки под кодовым названием Bi Liren. Это первый китайский ускоритель общего назначения, использующий чиплетную компоновку и поддерживающий PCI Express 5.0/CXL. Новые ускорители будут сопровождаться полноценной программной поддержкой, начиная с драйверов и библиотек и заканчивая популярными фреймворками, такими, как TensorFlow и PyTorch. 
Источник: WCCFTech Сложность BR100 внушает уважение: новый чип состоит из 77 млрд транзисторов, скомпонованных воедино с использованием 7-нм техпроцесса и технологии TSMC 2.5D CoWoS. Площадь чипа составляет 1074 мм2, правда, не очень понятно, идёт ли речь исключительно о кристалле, т.н. «вычислительном тайле», или о сборке в целом, поскольку в состав BR100 входит 64 Гбайт памяти HBM2e. 
Источник: WCCFTech Среди особенностей можно отметить наличие быстрого кеша объёмом 300 Мбайт (256 Мбайт L2) — для сравнения, у NVIDIA A100 он составляет всего 40 Мбайт, и даже у новейшего H100 он увеличен лишь до 50 Мбайт. Что касается ПСП, то она составляет 1,64 Тбайт/с. 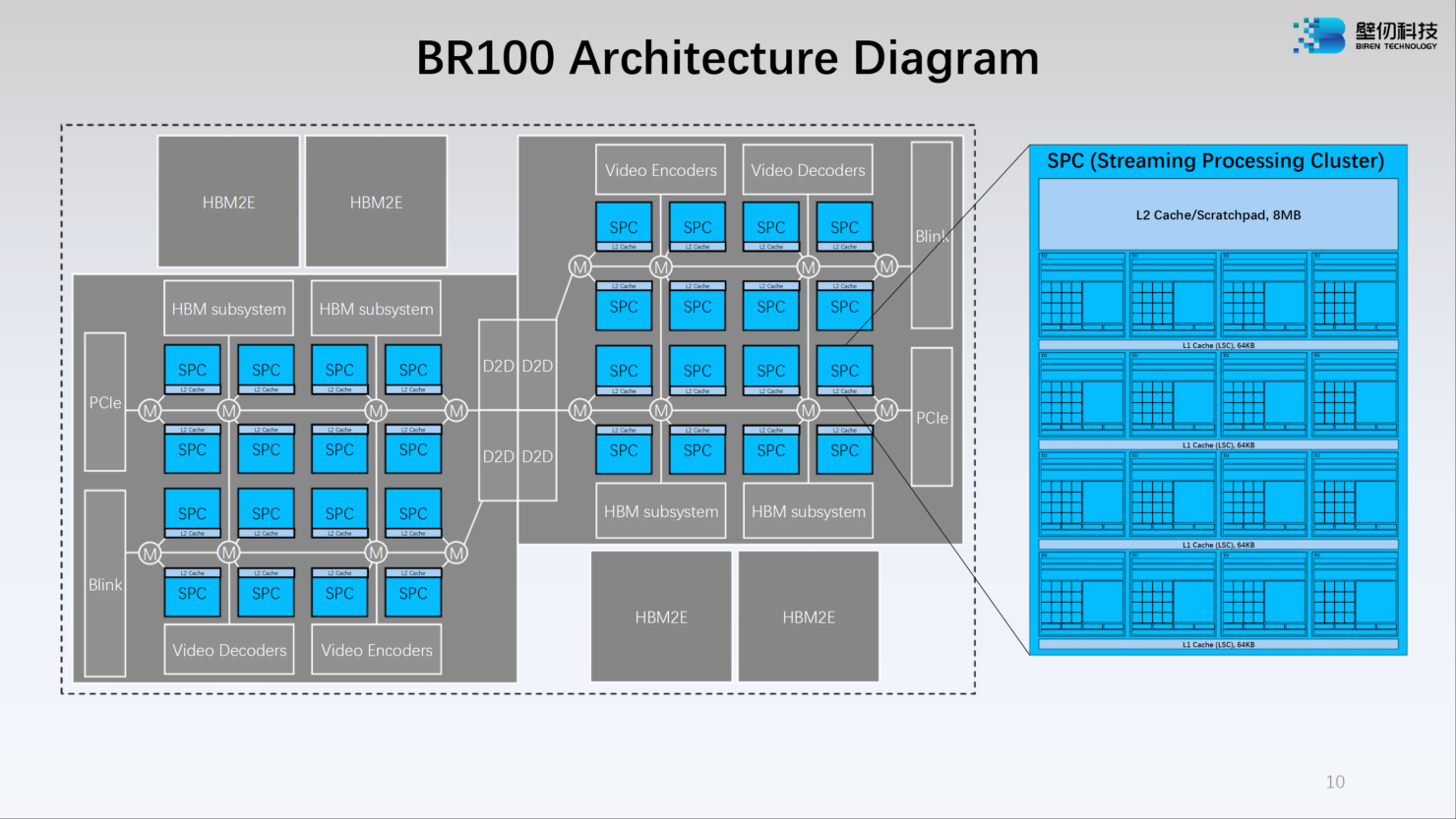
Источник: WCCFTech Модульная компоновка BR100 включает в себя два вычислительных тайла и четыре сборки HBM2e. Между собой кристаллы соединены интерконнектом с пропускной способностью 896 Гбайт/с, а для дальнейшего масштабирования в составе нового ускорителя предусмотрен фирменный интерконнект BLink (8 линий) с производительностью 2,3 Тбайт/с. 
Источник: WCCFTech Каждый из двух кристаллов несёт в себе по 16 потоковых вычислительных кластеров (SPC), а каждый такой кластер, в свою очередь, содержит 16 исполнительных блоков (EU). Каждый блок EU содержит 16 потоковых ядер V-Core и одно тензорное ядро T-Core, так что всего в составе BR100 имеется 8192 классических ядра и 512 тензорных. Каждый SPC имеет свой кеш L2 объёмом 8 Мбайт, суммарно 256 Мбайт на всю сборку BR100. 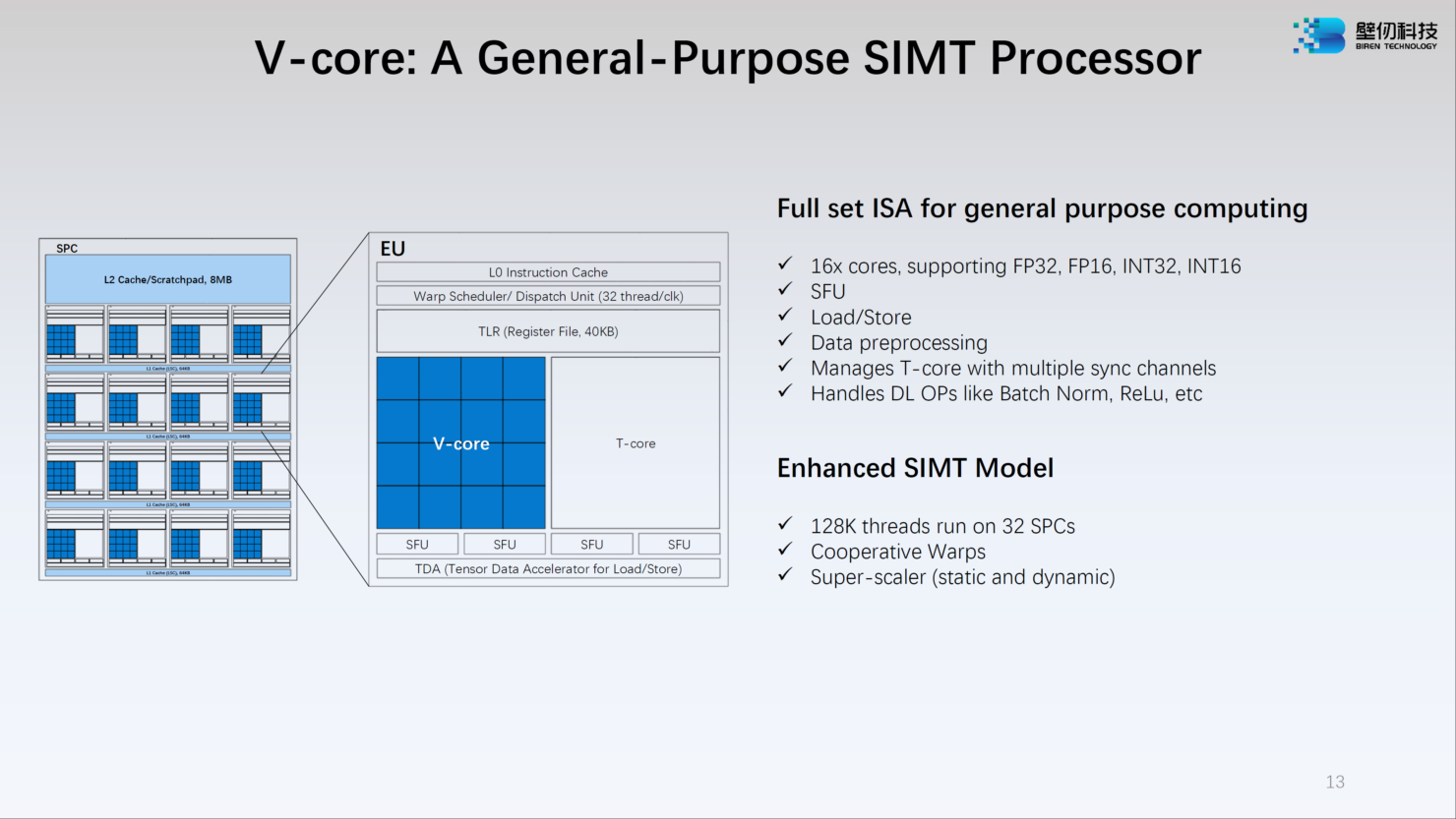
Источник: WCCFTech Ядро V-Core имеет архитектуру SIMT (Single Instructions, Multiple Thread) и поддерживает вычисления в форматах INT16/32, FP16 и FP32. Тензорные ядра T-Core предназначены для выполнения операций типа MMA, свёртки и прочих, характерных для современных задач машинного обучения. Предельное количество потоков у BR100 в суперскалярном режиме — 128 тысяч. 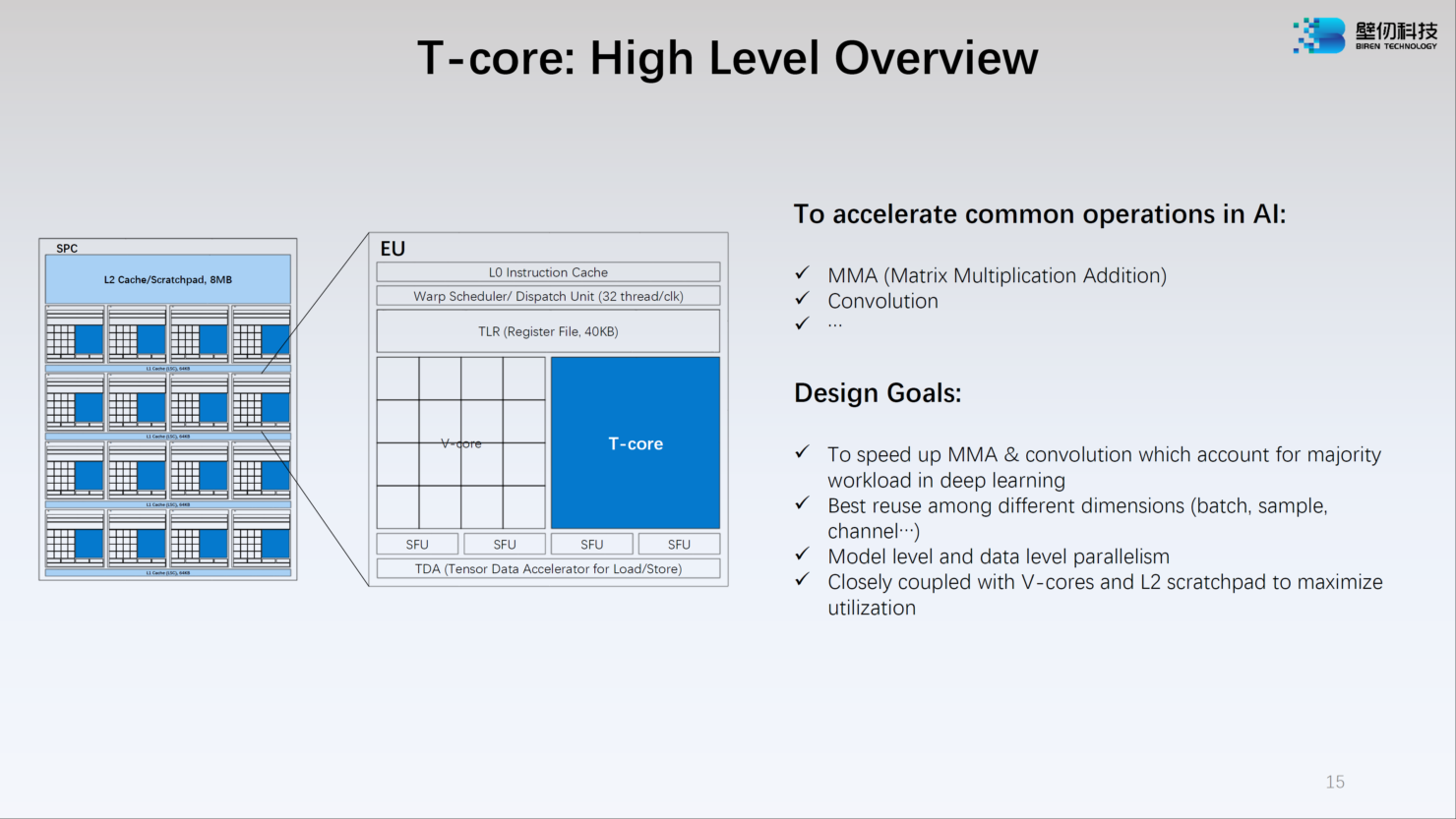
Источник: WCCFTech Компания-разработчик приводит некоторые цифры производительности для BR100: это 256 Тфлопс в режиме FP32, вдвое больше в режиме TF32+, 1024 Тфлопс в формате BF16 и целых 2048 Топс в режиме INT8. Это серьёзная заявка: с такими показателями BR100 должен опережать NVIDIA A100. Заявлено превосходство от 2,5х до 2,8х в зависимости от задачи и сценария. 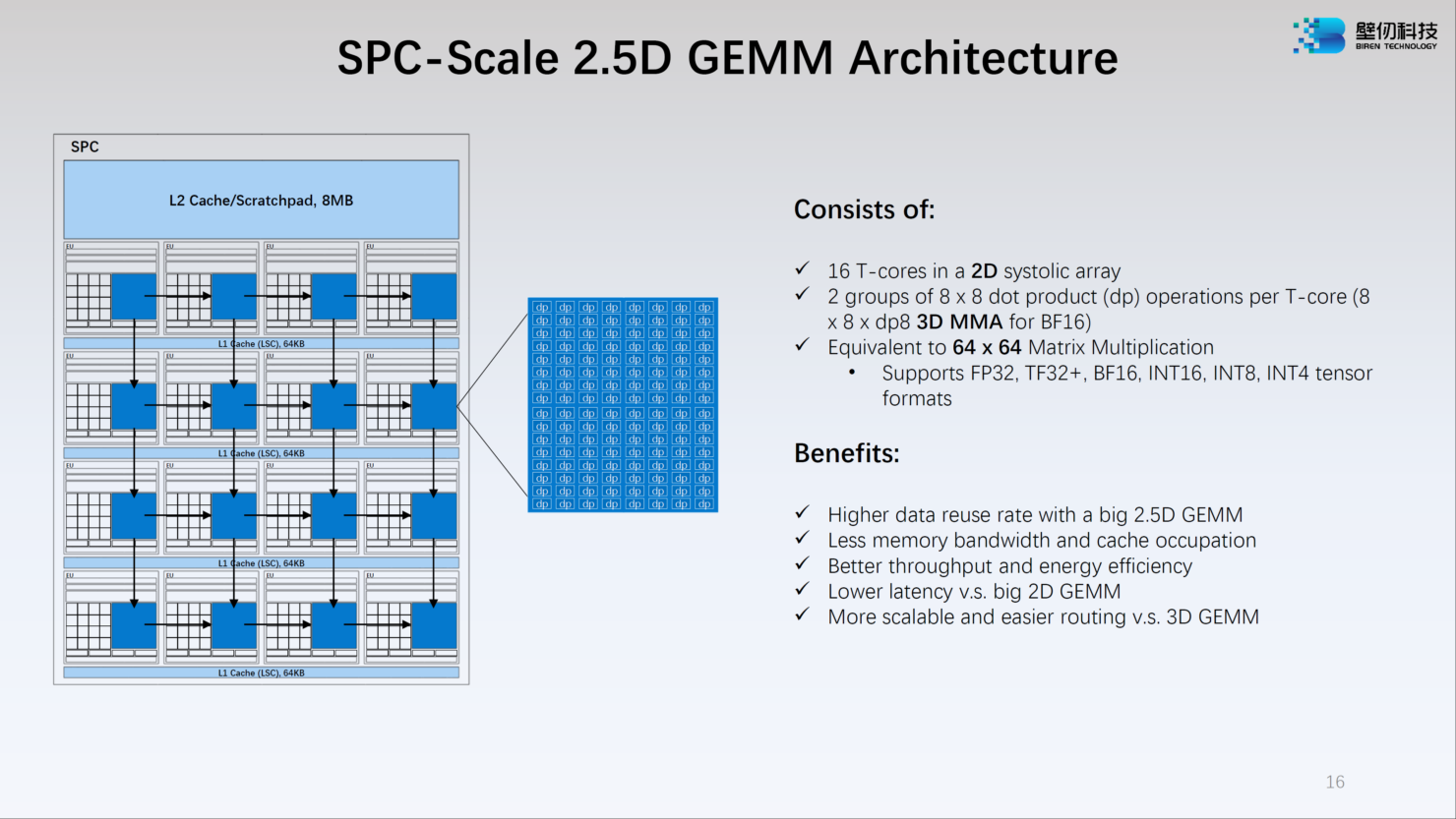
Источник: WCCFTech Любопытно, что BR100 несильно уступает NVIDIA H100 по количеству транзисторов (77 против 80 млрд), но, естественно, использование более грубого 7-нм техпроцесса против N4 у последней разработки NVIDIA означает и большее тепловыделение. Этот параметр у BR100 составляет 550 Вт в то время, как PCIe-вариант H100 укладывается в стандартные 350 Вт. 
Источник: WCCFTech Это не единственная новинка: в арсенале Birentech заявлен и менее мощный чип BR104. Он вдвое медленнее старшей модели по всем показателям и несёт 32 Гбайт памяти против 64, но в отличие от BR100, использует монолитный, а не чиплетный дизайн. На его основе будут выпущены ускорители в формате PCIe с TDP в районе 300 Вт, тогда как старшая версия будет доступна только в виде OAM-модуля.
20.08.2022 [22:30], Алексей Степин
NVIDIA поделилась некоторыми деталями о строении Arm-процессоров Grace и гибридных чипов Grace HopperНа GTC 2022 весной этого года NVIDIA впервые заявила о себе, как о производителе мощных серверных процессоров. Речь идёт о чипах Grace и гибридных сборках Grace Hopper, сочетающих в себе ядра Arm v9 и ускорители на базе архитектуры Hopper, поставки которых должны начаться в первой половине следующего года. Многие разработчики суперкомпьютеров уже заинтересовались новинками. В преддверии конференции Hot Chips 34 компания раскрыла ряд подробностей о чипах. Grace производятся с использованием техпроцесса TSMC 4N — это специально оптимизированный для решений NVIDIA вариант N4, входящий в серию 5-нм процессов тайваньского производителя. Каждый кристалл процессорной части Grace содержит 72 ядра Arm v9 с поддержкой масштабируемых векторных расширений SVE2 и расширений виртуализации с поддержкой S-EL2. Как сообщалось ранее, NVIDIA выбрала для новой платформы ядра Arm Neoverse. 
Источник: NVIDIA Процессор Grace также соответствует ряду других спецификаций Arm, в частности, имеет отвечающий стандарту RAS v1.1 контроллер прерываний (Generic Interrupt Controller, GIC) версии v4.1, блок System Memory Management Unit (SMMU) версии v3.1 и средства Memory Partitioning and Monitoring (MPAM). Базовых кристаллов у Grace два, что в сумме даёт 144 ядра — рекордное количество как в мире Arm, так и x86. 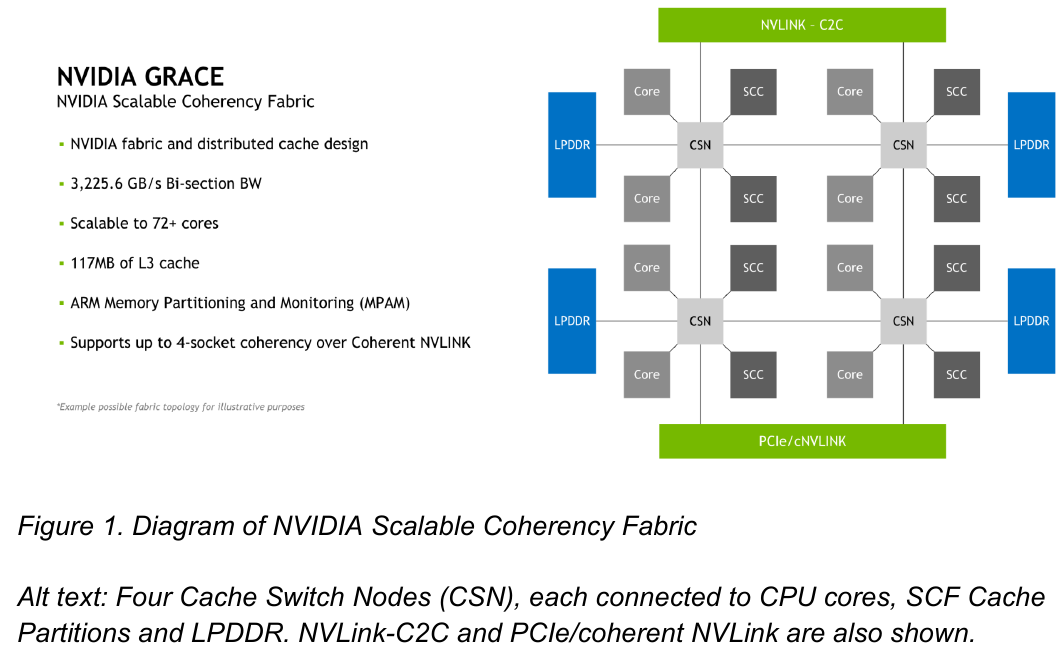
Внутренняя организация кластеров ядр в Grace. Источник: NVIDIA Внутренние блоки Grace соединяются посредством фабрики Scalable Coherency Fabric (SCF), вариации NVIDIA на тему сети CMN-700, применяемой в дизайнах Arm Neoverse. Производительность данного интерконнекта составляет 3,2 Тбайт/с. В случае Grace он предполагает наличие 117 Мбайт кеша L3 и поддерживает когерентность в пределах четырёх сокетов (посредством новой версии NVLink). Но SCF поддерживает масштабирование. Пока что в «железе» она ограничена двумя блоками Grace, а это уже 144 ядра и 234 Мбайт L3-кеша. Ядра и кеш-разделы (SCC) рапределены по внутренней mesh-фабрике SCF. Коммутаторы (CSN) служат интерфейсами для ядер, кеш-разделов и остальными частями системы. Блоки CSN общаются непосредственно друг с другом, а также с контроллерами LPDDR5X и PCIe 5.0/cNVLink/NVLink C2C. 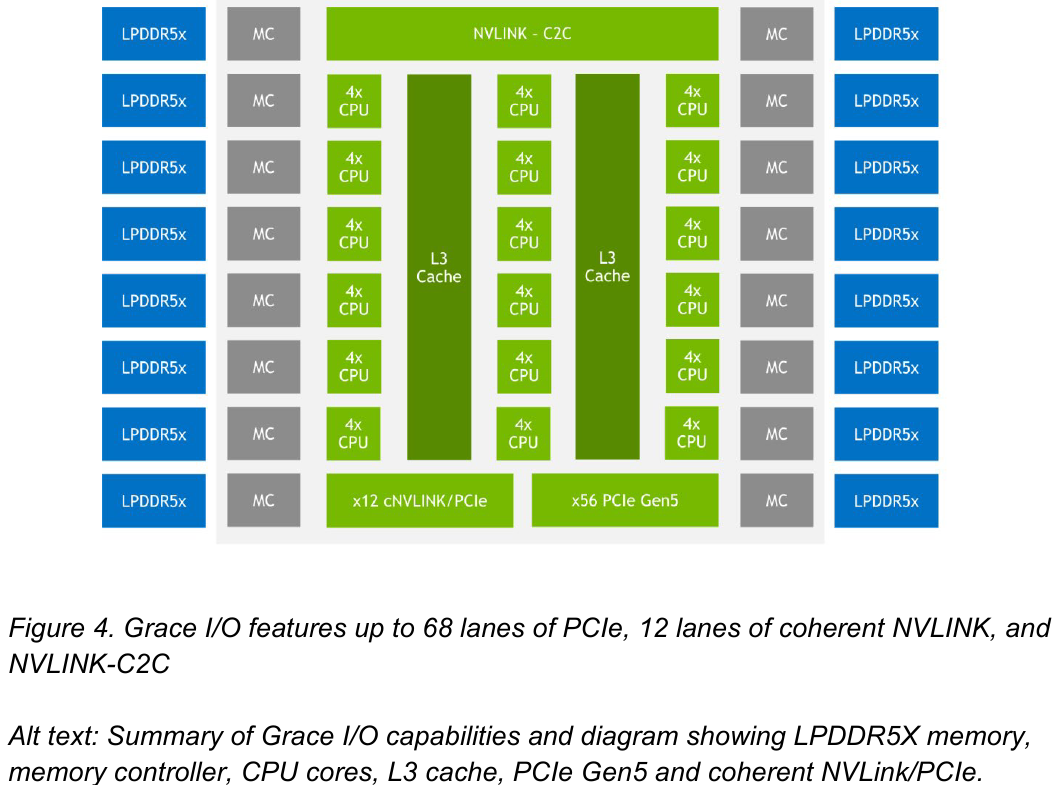
Блок-схема кристалла Grace. Источник: NVIDIA В чипе реализована поддержка PCI Express 5.0. Всего контроллер поддерживает 68 линий, 12 из которых могут также работать в режиме cNVLink (NVLink с когерентностью). x16-интерфейс посредством бифуркации может быть превращен в два x8. Также на приведённой NVIDIA диаграмме можно видеть целых 16 двухканальных контроллеров LPDDR5x. Заявлена ПСП на уровне свыше 1 Тбайт/с для сборки (до 546 Гбайт/с на кристалл CPU). 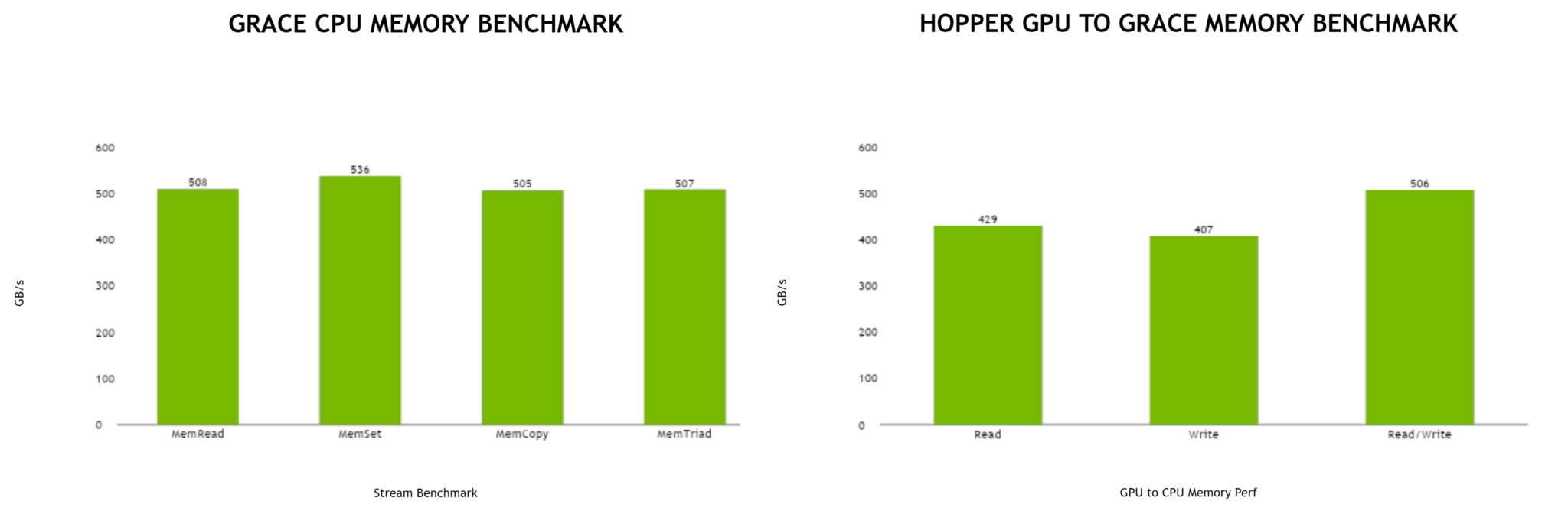
Источник: NVIDIA Основной же межчиповой связи NVIDIA видит новую версию NVLink — NVLink-C2C, которая в семь раз быстрее PCIe 5.0 и способна обеспечить двунаправленную скорость передачи данных на уровне до 900 Гбайт/с, будучи при этом в пять раз экономичнее. Удельное потребление у новинки составляет 1,3 пДж/бит, что меньше, нежели у AMD Infinity Fabric с 1,5 пДж/бит. Впрочем, существуют и более экономичные решения, например, UCIe (~0,5 пДж/бит). 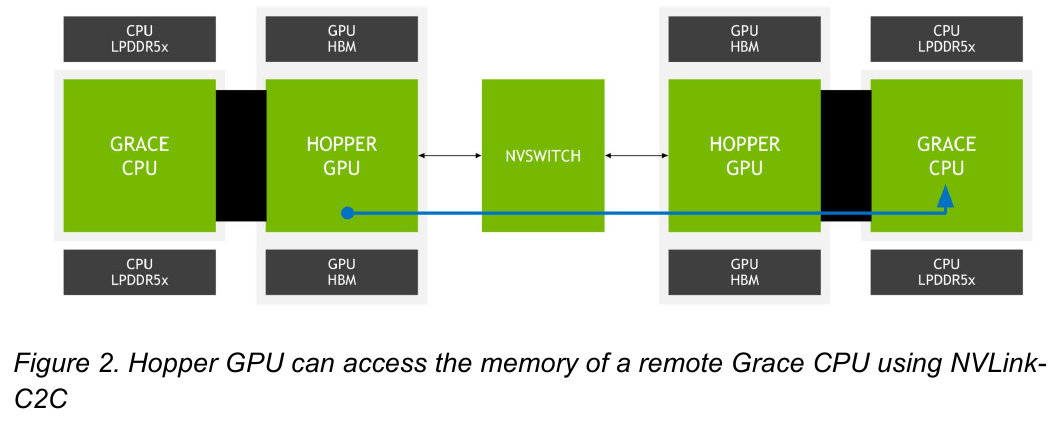
Новый вариант NVLink обеспечит кластер на базе Grace Hopper единым пространством памяти. Источник: NVIDIA NVLink-C2C позволяет реализовать унифицированный «плоский» пул памяти с общим адресным пространством для Grace Hopper. В рамках одного узла возможно свободное обращение к памяти соседей. А вот для объединения нескольких узлов понадобится уже внешний коммутатор NVSwitch. Он будет занимать 1U в высоту, и предоставлять 128 портов NVLink 4 с агрегированной пропускной способностью до 6,4 Тбайт/с в дуплексе. 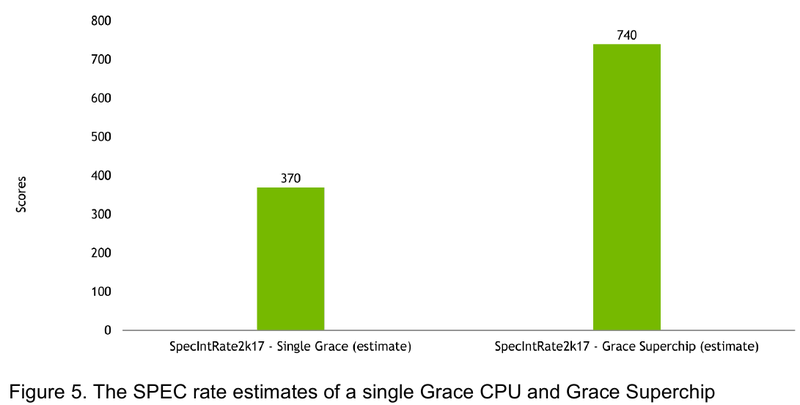
Источник: NVIDIA Производительность Grace также обещает быть рекордно высокой благодаря оптимизированной архитектуре и быстрому интерконнекту. Даже по предварительным цифрам, опубликованным NVIDIA, речь идёт о 370 очках SPECrate2017_int_base для одного кристалла Grace и 740 очках для 144-ядерной сборки из двух кристаллов — и это с использованием обычного компилятора GCC без тонких платформенных оптимизаций. Последняя цифра существенно выше результатов, показанных 128-ядерными Alibaba T-Head Yitian 710, также использующим архитектуру Arm v9, и 64-ядерными AMD EPYC 7773X.
16.08.2022 [16:14], Руслан Авдеев
ЦОД Microsoft в Нидерландах потребляют в разы больше воды, чем обещали власти и компанияКак выяснили СМИ Нидерландов, в 2021 году местный кластер дата-центров Microsoft потребовал намного больше воды, чем обещали до его строительства власти и сам техногигант. Как сообщает Data Center Dynamics, ранее говорилось, что ежегодный расход составит 12–20 тыс. м3, однако оказалось, что только в 2021 году объекты компании потребляли 84 тыс. м3. Предполагается, что в текущем году объект Microsoft в Холландс-Крон (Hollands Kroon) истратит ещё больше воды из-за засухи. Хотя проект в своё время встретил противодействие со стороны местных фермеров, строительство новых ЦОД было всё же одобрено в 2021 году рядом с уже существующим объектом. Здесь же расположены и мощности Google, тоже потребляющие огромные объёмы воды. Обычно ЦОД Microsoft довольствуются для охлаждения забортным воздухом, но когда температура превышает +25 °C, вынуждены использовать воду. В 2021 году такое случалось лишь несколько раз, однако расход воды всё равно оказался в разы выше заявленного: 75 тыс. м3 ушло на охлаждение и ещё 9 тыс. м3 — на «другие нужды». Всего расположенные в окрестностях 28 ЦОД Microsoft, Google и других компаний суммарно потребили 550 тыс. м3, т.е. 0,5 % от общего объёма поставок питьевой воды. В этом году ситуация, как ожидается, будет значительно хуже. 
Источник изображения: E Mens/unsplash.com В июне совет Холландс-Крон объявил о приостановке строительства новых ЦОД в районе. Хотя девятимесячный мораторий на строительство ЦОД пока действует по всей стране, Холландс-Крон попал в число двух исключений из общего правила для гиперскейлеров, поэтому ограничения пришлось вносить самому совету. Второй «исключительный» проект планировала реализовать Meta✴ в Зееволде, но в прошлом месяце компания окончательно отказалась от его реализации, в том числе из-за активных протестов местного населения. Ранее Microsoft под давлением местных фермеров пообещала, что будет собирать дождевую воду для использования в системах охлаждения. Однако идея пока не пошла дальше проекта и пока неизвестно приблизительно, когда начнётся хотя бы тестовый период. Кроме того, в США компания собиралась построить установку для очистки сточных вод своих дата-центров. Microsoft обещала стать «водно-положительной» к 2030 году, схожее обещание сделано и Google.
15.08.2022 [15:15], Сергей Карасёв
Капитализация китайского разработчика HPC-чипов Hygon превысила $20 млрдКитайская компания Hygon Information Technology, разработчик процессоров, осуществила первичное публичное размещение акций (IPO) на Шанхайской фондовой бирже. Стоимость ценных бумаг достигла ¥70 (приблизительно $10,34), что на 94 % больше цены начального предложения в ¥36 ($5,32). Hygon Information Technology, тесно связанная с одним из крупных китайских IT-вендоров, была основана в 2014 году. Она специализируется на создании чипов с архитектурой х86, а также ускорителей (DCU). CPU и DCU компании в настоящее время используются только в персональных компьютерах и серверах китайского производства, в которых особое внимание уделяется информационной безопасности и стоимости владения. 
Источник изображения: Hygon В активе компании имеются серверные чипы Hygon Dhyana, клоны первого поколения EPYC. Однако без сопровождения со стороны AMD, разрыв с которой произошёл в 2019 году из-за санкций США, как-либо заметно улучшить их она вряд ли сможет. Впрочем, ранее Hygon и объявляла, что планирует перевести эти чипы на 7-нм техпроцесс Samsung или TSMC. Нужно отметить, что Sugon намеревалась использовать процессоры Hygon Dhyana и ускорители DCU для создания суперкомпьютера экзафлопсного класса, который должен был составить компанию OceanLight и Tianhe-3. Однако в сложившейся ситуации этот проект оказался под угрозой срыва: пока окончательные сроки создания системы не называются. Так или иначе, но процедура размещения акций Hygon на Шанхайской фондовой бирже прошла с большим успехом: капитализация компании оценена в ¥139,6 млрд ($20,7 млрд). При этом выручка по итогам прошлого года составила 2,3 млрд юаней, из которых почти 70 % тратится на исследования и разработки.
10.08.2022 [22:05], Владимир Мироненко
На пути к Aurora: запущен «тренировочный» суперкомпьютер PolarisАргоннская национальная лаборатория (ANL) Министерства энергетики США объявила о доступности суперкомпьютера Polaris, ранний вариант которого занял 14-е место в последней версии списка TOP500. Он будет использоваться для проведения научных исследований и в качестве испытательного стенда для 2-Эфлопс суперкомпьютера Aurora, запуск которой намечен на ближайшие месяцы. Правда, аппаратно Aurora и Polaris отличаются. Созданная HPE система Polaris состоит из 560 узлов Apollo 6500, каждый из которых оснащён процессором AMD EPYC Milan, четырьмя ускорителями NVIDIA A100 (40 Гбайт) и 512 Гбайт DDR4-памяти. Эти узлы объединены в сеть интерконнектом HPE Slingshot 10 (осенью он будет обновлен до Slingshot 11) и подключены к сдвоенному 100-Пбайт Lustre-хранилищу (Grand и Eagle). Заявленная пиковая производительность должна составить 44 Пфлопс. «Polaris примерно в четыре раза быстрее нашего суперкомпьютера Theta, что делает его самым мощным компьютером в Аргонне на сегодняшний день», — отметил Майкл Папка (Michael Papka), директор Argonne Leadership Computing Facility (ALCF). Он добавил, что возможности Polaris позволят пользователям выполнять моделирование, анализ данных и ИИ-задачи с такими масштабом и скоростью, которые были невозможны с предыдущими вычислительными системами. 
Фото: ANL Помимо работы над подготовкой к запуску Aurora, суперкомпьютер Polaris будет обслуживать внутренние потребности лаборатории, например, работу с комплексом Advanced Photon Source (APS) X-ray. «Благодаря тесной интеграции суперкомпьютеров ALCF с APS, CNM и другими экспериментальными установками мы можем помочь ускорить проведение анализа данных и предоставить информацию, которая позволит исследователям управлять своими экспериментами в режиме реального времени», — заявил Майкл Папка.
09.08.2022 [18:09], Игорь Осколков
Китайская компания Biren представила ИИ-ускоритель BR100, который обгоняет по производительности NVIDIA A100Шанхайская компания Biren Technology, основанная в 2019 году и уже получившая более $280 млн инвестиций, официально представила серию ускорителей BR100, которые способные потягаться с актуальными решениями от западных IT-гигантов. Утверждается, что это первое изделие подобного класса, созданное в Поднебесной. Компания уже подписала соглашение о сотрудничестве с ведущим производителем серверов Inspur. Новинка содержит 77 млрд транзисторов, использует чиплетную компоновку, изготавливается по 7-нм техпроцессу на TSMC и имеет 2.5D-упаковку CoWoS. Для сравнения — грядущие NVIDIA H100 имеют такую же упаковку, но включают 80 млрд транзисторов и изготавливаются по более современному техпроцессу TSMC N4. При этом BR100 примерно вдвое производительнее 7-нм NVIDIA A100 и примерно вдвое же медленнее H100. Впрочем, Biren приводит только данные о вычислениях пониженной точности, да и в целом говорит о том, что новинка предназначена в первую очередь для ИИ-нагрузок. 
Изображения: Biren В серию входят два решения: BR100 и BR104. Оба варианта оснащаются интерфейсом PCIe 5.0 x16 с поддержкой CXL. Первый вариант имеет OAM-исполнение с TDP на уровне 550 Вт. Он позволяет объединить до восьми ускорителей на UBB-плате, связав их между собой фирменным интерконнектом BLink (512 Гбайт/с) по схеме каждый-с-каждым. BR100 полагается 300 Мбайт кеш-памяти и 64 Гбайт HBM2e (4096 бит, 1,64 Тбайт/c). 
BR100 Также он способен одновременно кодировать до 64 потоков FullHD@30 HEVC/H.264, а декодировать — до 512. Кроме того, доступно создание до 8 аппаратно изолированных инстансов Secure Virtual Instance (SVI) по аналогии с NVIDIA MIG. Заявленная производительность составляет 256 Тфлопс для FP32-вычислений, 512 Тфлопс для TF32+ (по-видимому, подразумевается некая совместимость с фирменным форматом NVIDIA TF32), 1024 Тфлопс для BF16 и, наконец, 2048 Топс для INT8. 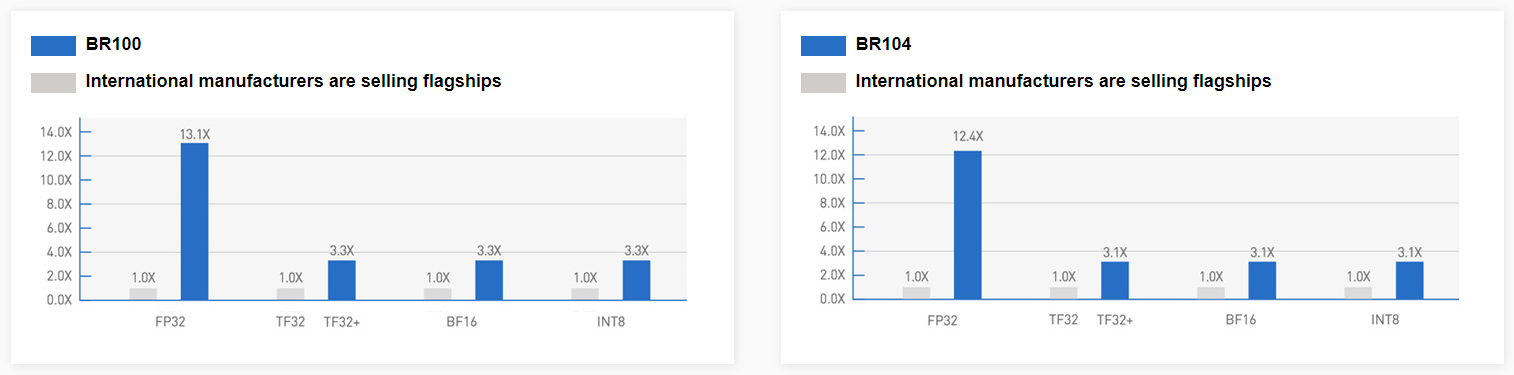 
BR104 BR104 представляет более традиционную FHFL-карту с TDP на уровне 300 Вт. По производительности она ровно вдвое медленнее старшей версии BR100, способна обрабатывать вдвое меньшее количество видеопотоков и предлагает только до 4 SVI-инстансов. BR104 имеет 150 Мбайт кеш-памяти, 32 Гбайт HBM2e (2048 бит, 819 Гбайт/c) и три 192-Гбайт/с интерфейса BLink. Для работы с ускорителями компания предлагает собственную программную платформу BIRENSUPA, совместимую с популярными фреймворками PyTorch, TensorFlow и PaddlePaddle.
04.08.2022 [15:54], Владимир Мироненко
Разработчик серверных чипов Prodigy с невероятными характеристиками обвинил в своих бедах CadenceКак сообщает The Register, cтартап Tachyum подал в суд на Cadence Design Systems, обвинив компанию в саботаже при выполнении контракта на поставку IP-блоков для будущих 5-нм серверных процессоров Prodigy. По словам Tachyum, старшие 128-ядерные CPU Prodigy с частотой 5,7 ГГц будут втрое быстрее AMD EPYC 7763 и NVIDIA H100. В иске утверждается, что заключённая в 2019 году сделка на предоставление решений Cadence для процессоров Prodigy, была сорвана, поскольку Cadence не смогла предоставить необходимые технологии для вывода продукта на рынок. Заказанные Tachyum блоки не относятся к разряду новшеств, и инженеры Cadence уверяли Tachyum, что стандартные компоненты могли быть без труда интегрированы в процессор. Однако график поставок был нарушен, и дошло даже до того, что Cadence посоветовала Tachyum не использовать её компоненты или вообще приобрести аналоги у других поставщиков. 
Источник изображения: Tachyum Стартап добавил в иске, что Cadence усугубила ущерб, прекратив доступ Tachyum к ПО eDAcard, тем самым вынудив понести расходы на лицензирование другого ПО и переобучение своих инженеров. Срыв сроков и прочие препятствия привели к задержке выхода Prodigy примерно на два года. Tachyum потребовал возместить упущенную выгоду в размере $206 млн и ещё $27 млн дополнительных затрат на поиск альтернативных решений в сжатые сроки. 
Источник изображения: Tachyum Tachyum также указала, что из-за срыва сроков она потеряла возможность получения заказов на поставку чипов для испанского суперкомпьютера MareNostrum 5 стоимостью €151,41 млн. В итоге Барселонский суперкомпьютерный центр (BSC), с которым был подписан меморандум о взаимопонимании, предпочёл компанию Atos. Последняя выбрала ускорители NVIDIA и процессоры Intel, поскольку ни одна европейская компания не могла бы поставить чипы, отвечающие ключевым критериям отбора. В иске Tachyum отмечает, что тогдашний генеральный директор Cadence Лип-Бу Тан (Lip-Bu Tan) входил в совет директоров двух конкурентов Tachyum — SambaNova и Nuvia (поглощена Qualcomm) — и активно участвовал в фондах Walden International и Walden Catalyst, которые инвестировали в другие «кремниевые» стартапы. Ещё один член совета директоров Cadence, Янг Сон (Young Sohn), также является директором одного из этих инвестфондов. По мнению Tachyum, налицо явный конфликт интересов.
02.08.2022 [16:00], Алексей Степин
Опубликованы спецификации Compute Express Link 3.0Мало-помалу стандарт Compute Express Link пробивает себе путь на рынок: хотя процессоров с поддержкой ещё нет, многие из элементов инфраструктуры для нового интерконнекта и базирующихся на нём концепций уже готово — в частности, регулярно демонстрируются новые контроллеры и модули памяти. Но развивается и сам стандарт. В версии 1.1, спецификации на которую были опубликованы ещё в 2019 году, были только заложены основы. Но уже в версии 2.0 CXL получил массу нововведений, позволяющих говорить не просто о новой шине, но о целой концепции и смене подхода к архитектуре серверов. А сейчас консорциум, ответственный за разработку стандарта, опубликовал свежие спецификации версии 3.0, ещё более расширяющие возможности CXL. 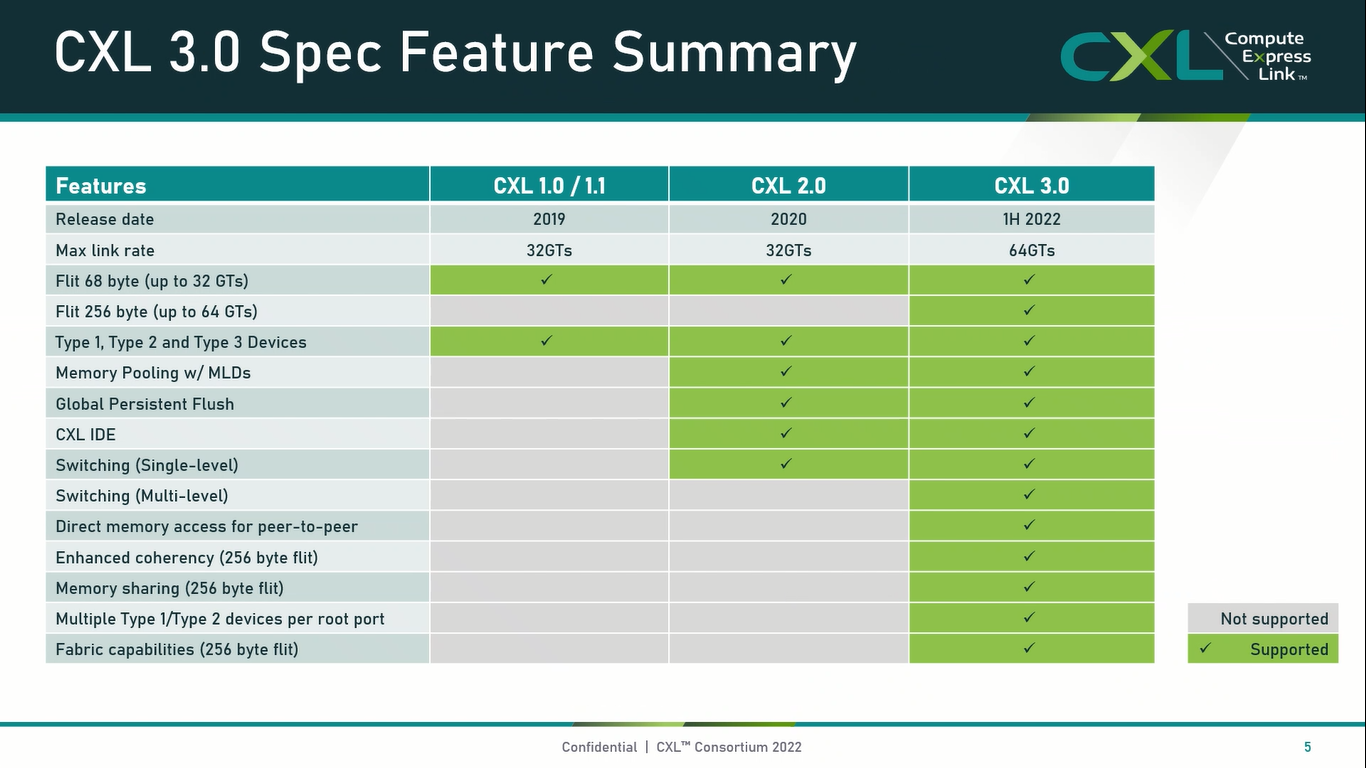
Источник: CXL Consortium И не только расширяющие: в версии 3.0 новый стандарт получил поддержку скорости 64 ГТ/с, при этом без повышения задержки. Что неудивительно, поскольку в основе лежит стандарт PCIe 6.0. Но основные усилия разработчиков были сконцентрированы на дальнейшем развитии идей дезагрегации ресурсов и создания компонуемой инфраструктуры. 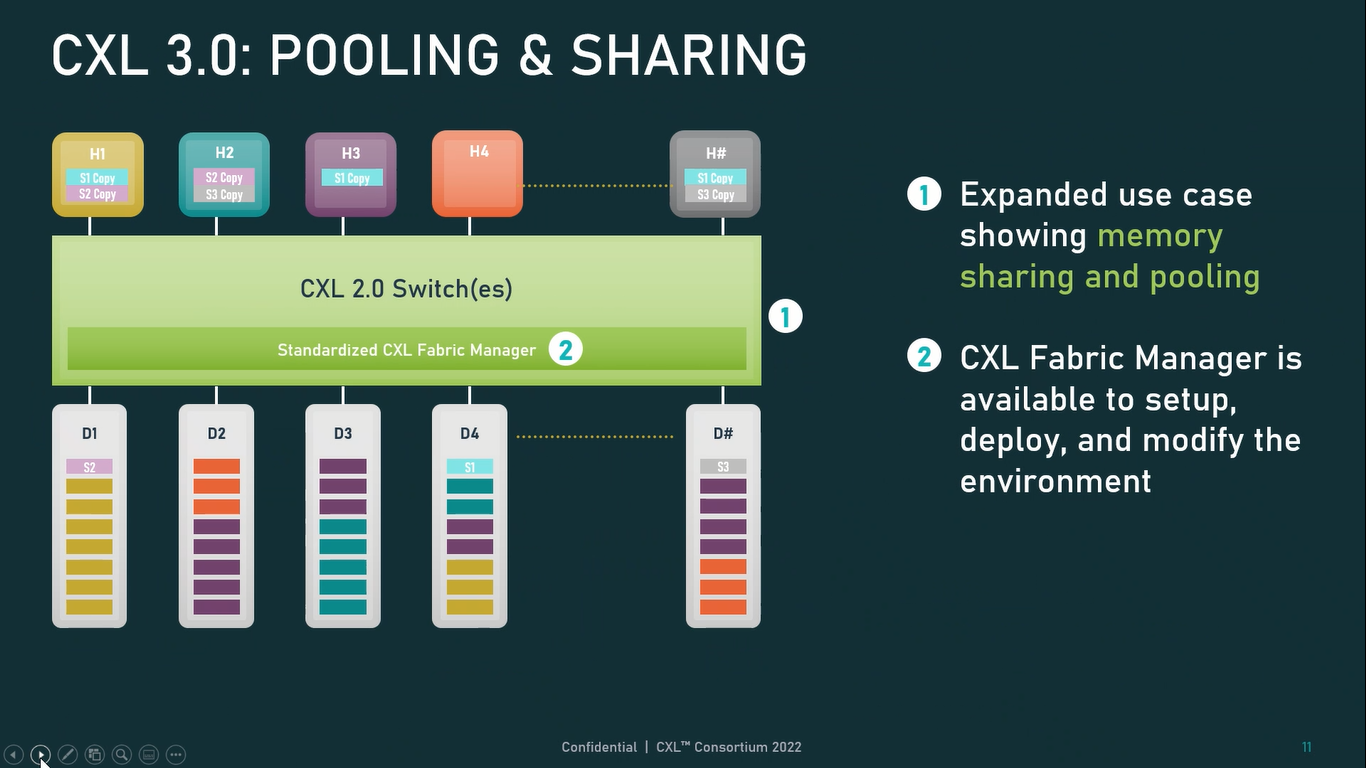 Сама фабрика CXL 3.0 теперь допускает создание и подключение «многоголовых» (multi-headed) устройств, расширены возможности по управлению фабрикой, улучшена поддержка пулов памяти, введены продвинутые режимы когерентности, а также появилась поддержка многоуровневой коммутации. При этом CXL 3.0 сохранил обратную совместимость со всеми предыдущими версиями — 2.0, 1.1 и даже 1.0. В этом случае часть имеющихся функций попросту не будет активирована. 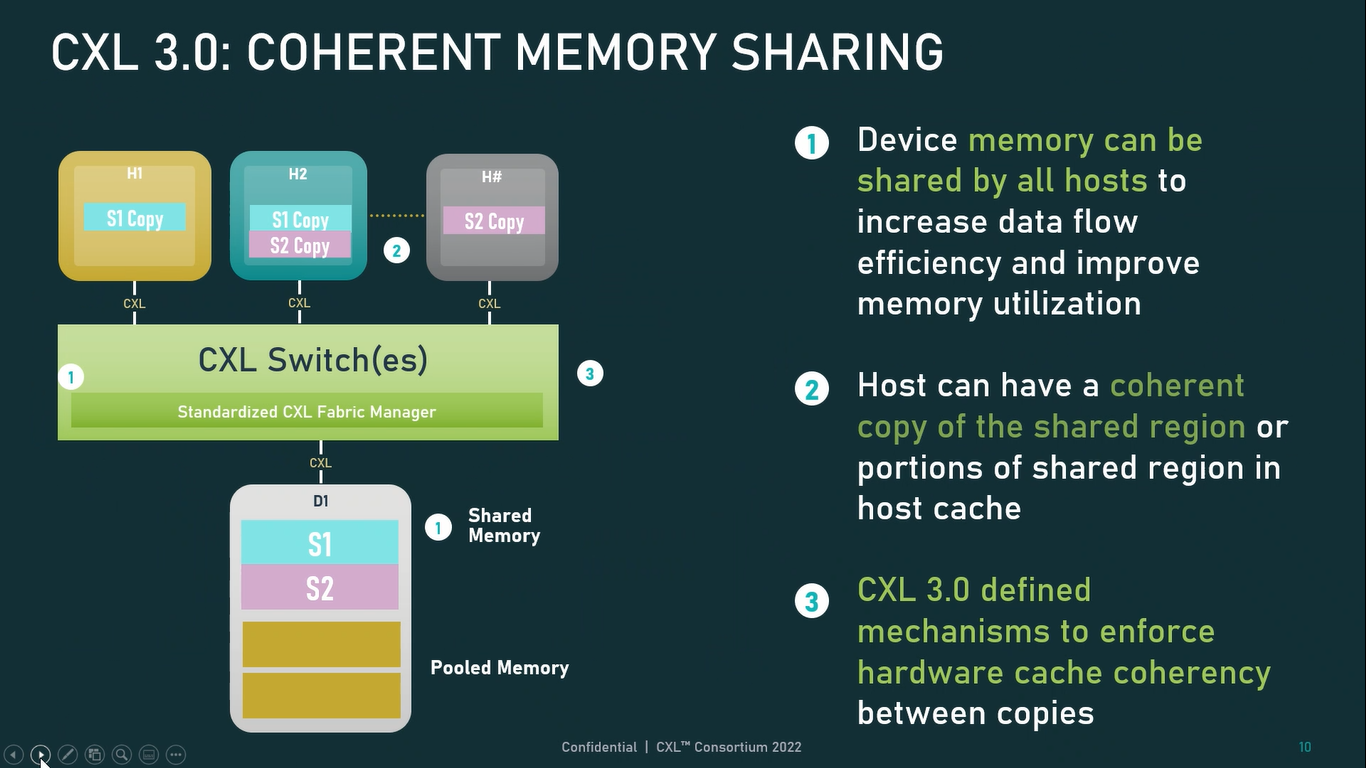 Одно из ключевых новшеств — многоуровневая коммутация. Теперь топология фабрики CXL 3.0 может быть практически любой, от линейной до каскадной с группами коммутаторов, подключенных к коммутаторам более высокого уровня. При этом каждый корневой порт процессора поддерживает одновременное подключение через коммутатор устройств различных типов в любой комбинации. 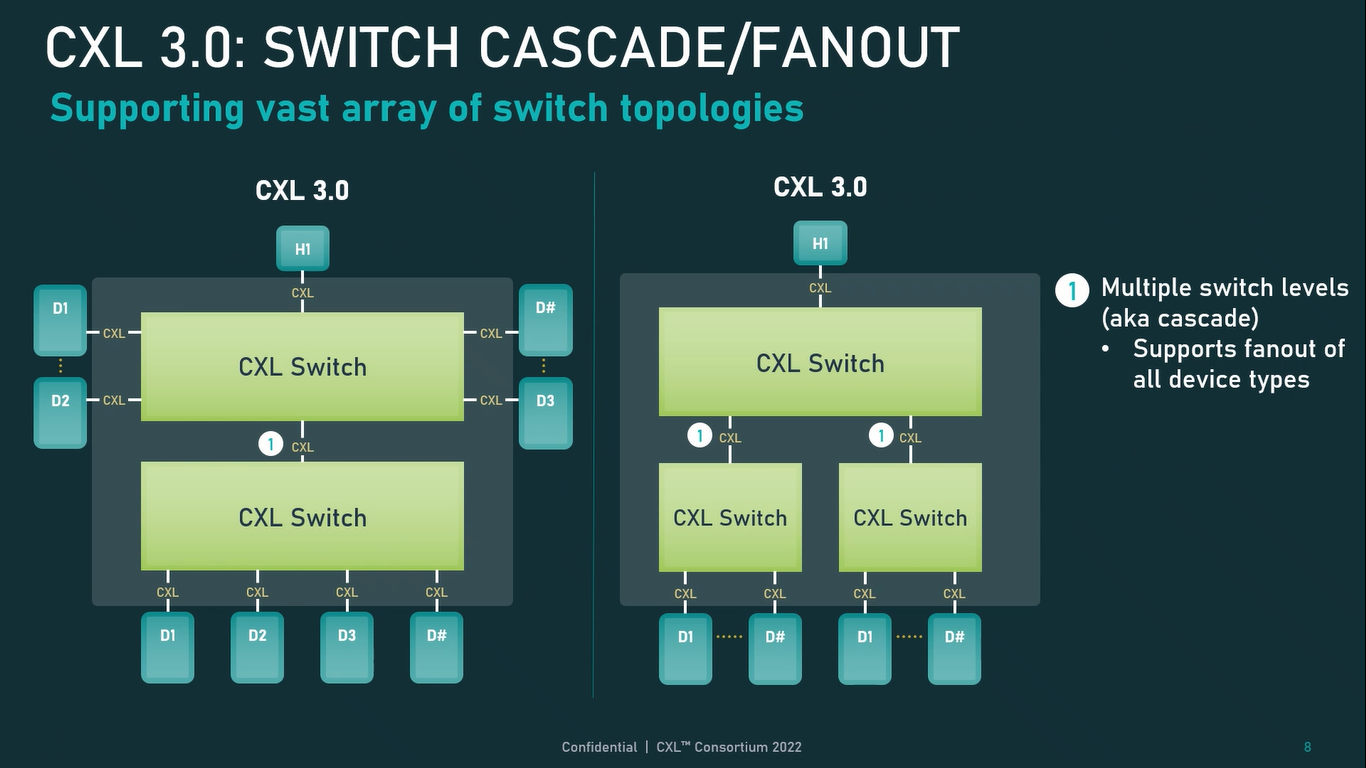 Ещё одним интересным нововведением стала поддержка прямого доступа к памяти типа peer-to-peer (P2P). Проще говоря, несколько ускорителей, расположенных, к примеру, в соседних стойках, смогут напрямую общаться друг с другом, не затрагивая хост-процессоры. Во всех случаях обеспечивается защита доступа и безопасность коммуникаций. Кроме того, есть возможность разделить память каждого устройства на 16 независимых сегментов. 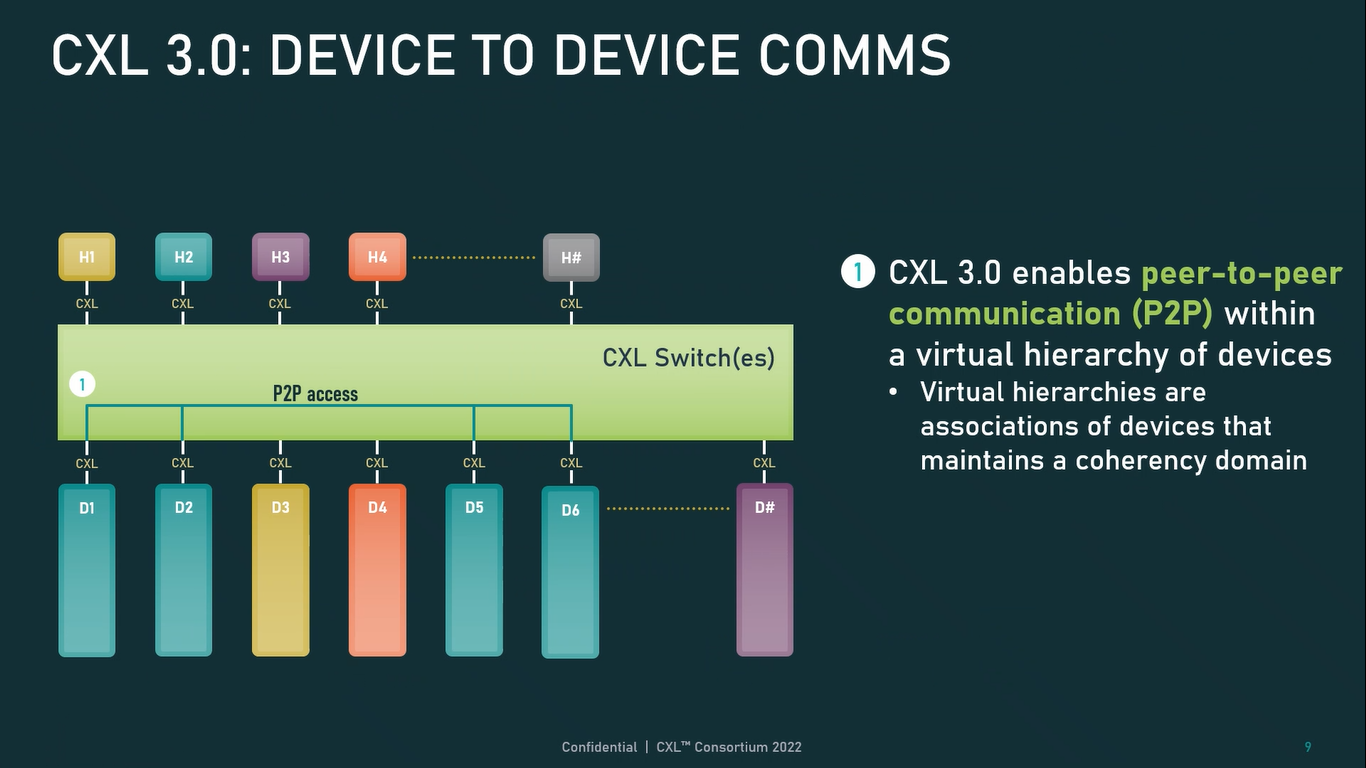 При этом поддерживается иерархическая организация групп, внутри которых обеспечивается когерентность содержимого памяти и кешей (предусмотрена инвалидация). Теперь помимо эксклюзивного доступа к памяти из пула доступен и общий доступ сразу нескольких хостов к одному блоку памяти, причём с аппаратной поддержкой когерентности. Организация пулов теперь не отдаётся на откуп стороннему ПО, а осуществляется посредством стандартизированного менеджера фабрики. 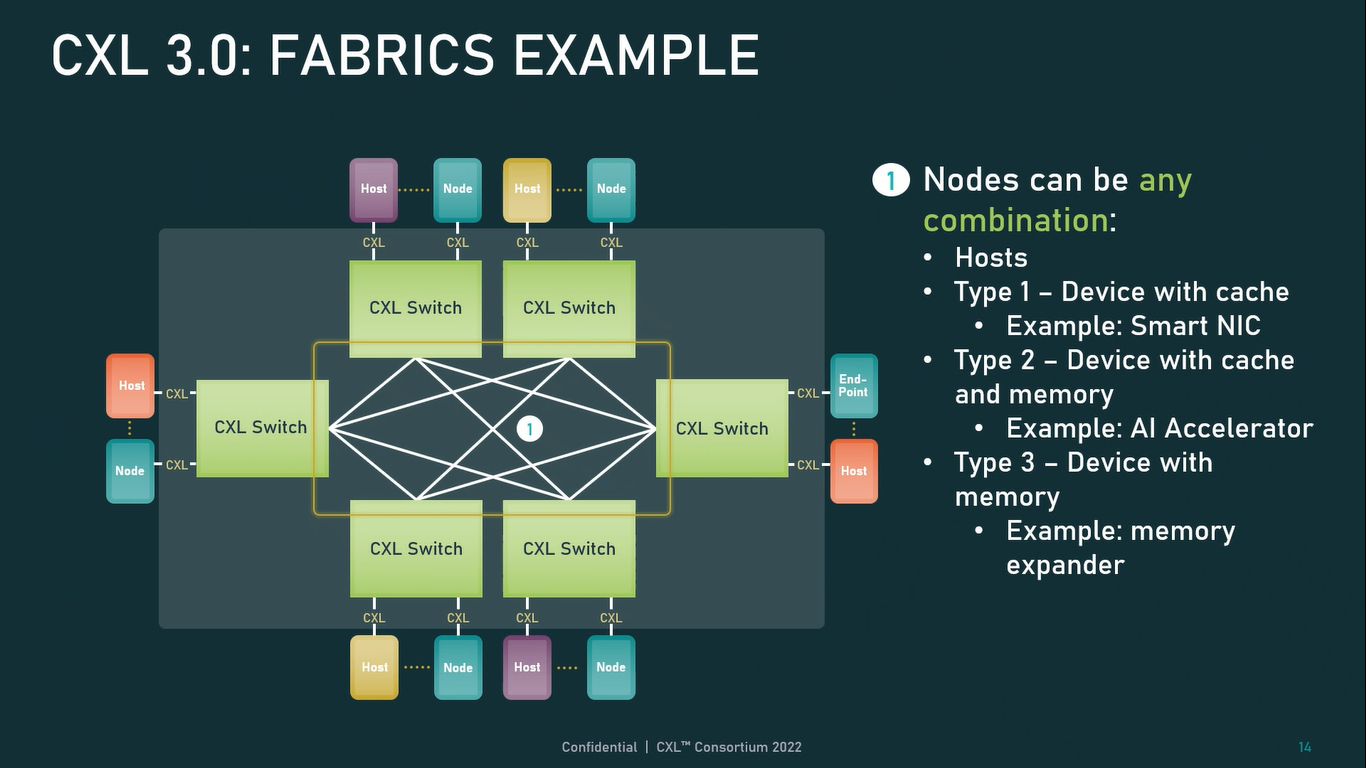 Сочетание новых возможностей выводит идею разделения памяти и вычислительных ресурсов на новый уровень: теперь возможно построение систем, где единый пул подключенной к фабрике CXL 3.0 памяти (Global Fabric Attached Memory, GFAM) действительно существует отдельно от вычислительных модулей. При этом возможность адресовать до 4096 точек подключения скорее упрётся в физические лимиты фабрики. 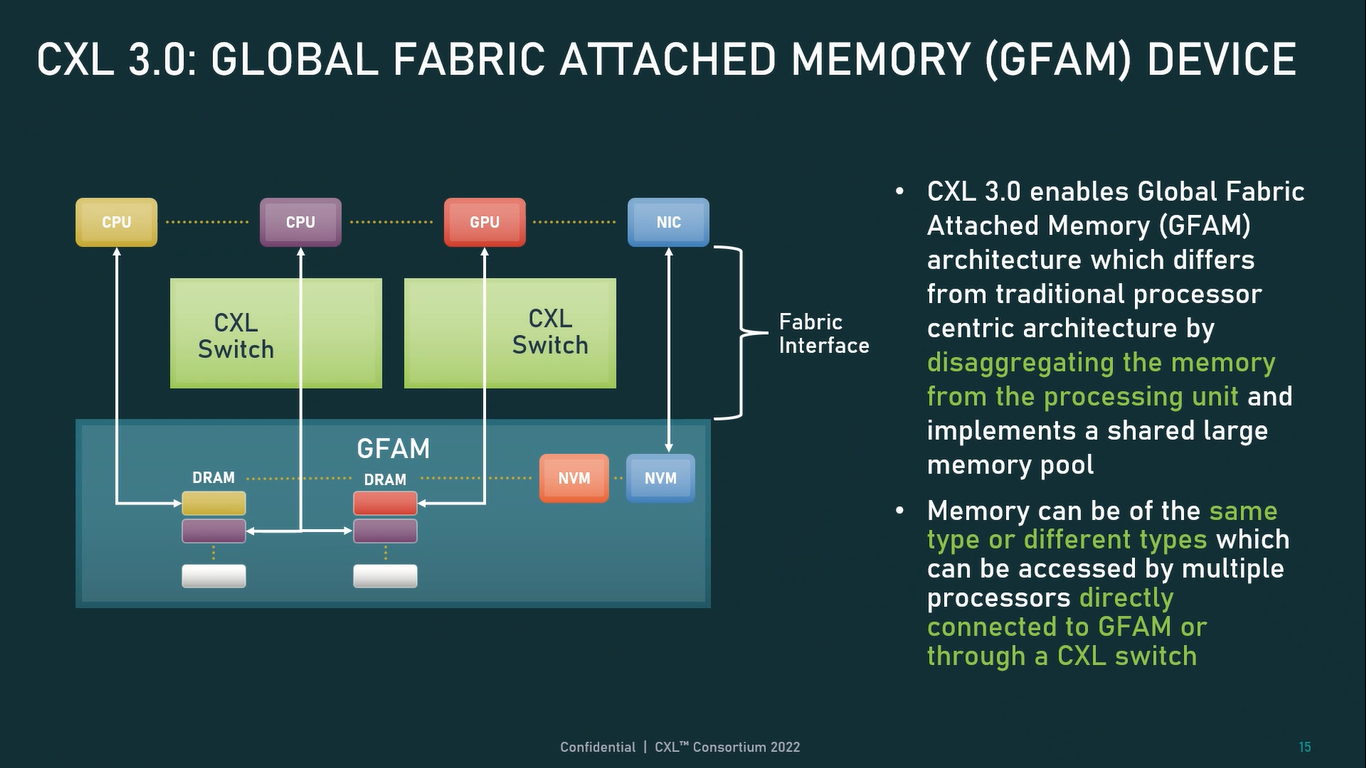 Пул может содержать разные типы памяти — DRAM, NAND, SCM — и подключаться к вычислительным мощностями как напрямую, так и через коммутаторы CXL. Предусмотрен механизм сообщения самими устройствами об их типе, возможностях и прочих характеристиках. Подобная архитектура обещает стать востребованной в мире машинного обучения, в котором наборы данных для нейросетей нового поколения достигают уже поистине гигантских размеров. 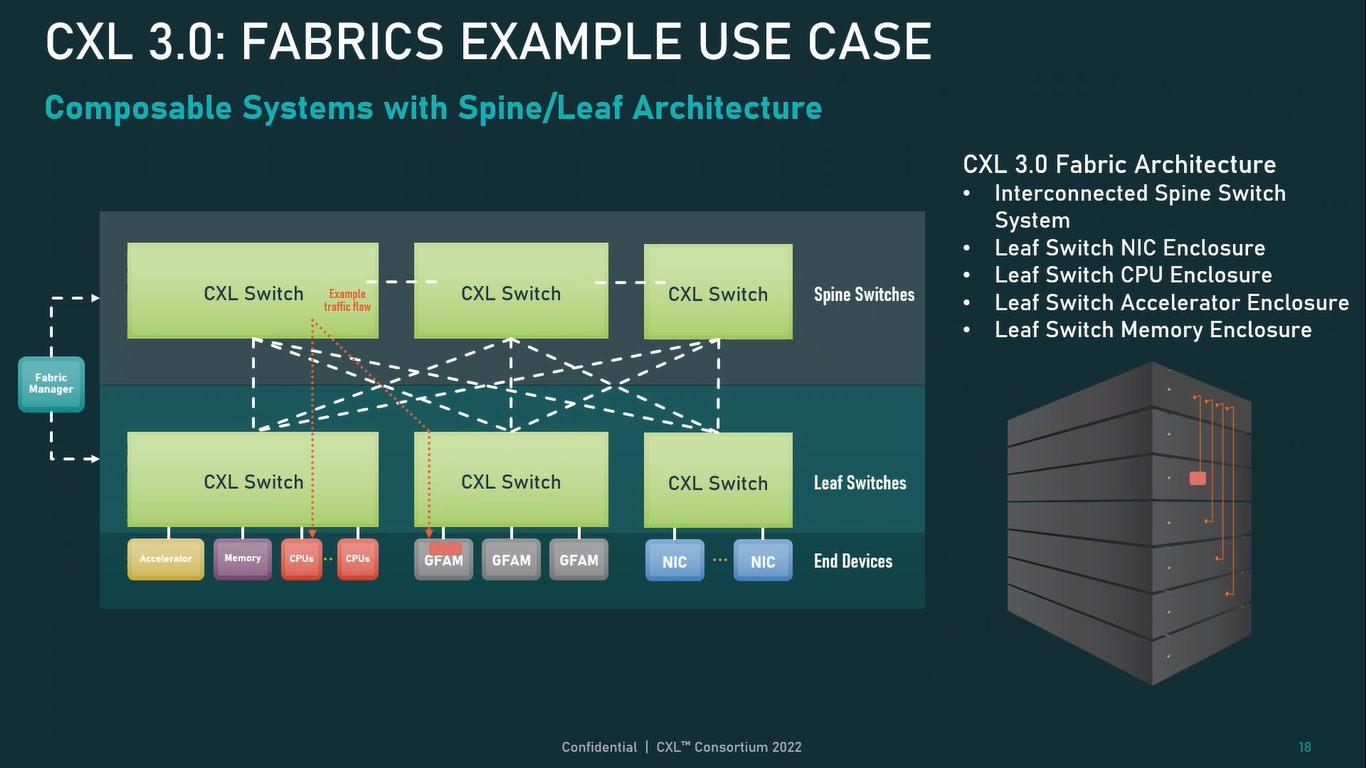 В настоящее время группа CXL уже включает 206 участников, в число которых входят компании Intel, Arm, AMD, IBM, NVIDIA, Huawei, крупные облачные провайдеры, включая Microsoft, Alibaba Group, Google и Meta✴, а также ряд крупных производителей серверного оборудования, в том числе, HPE и Dell EMC.
01.08.2022 [23:00], Игорь Осколков
Великое объединение: спецификации и наработки OpenCAPI и OMI планируется передать консорциуму CXLКонсорциумы OpenCAPI Consortium (OCC) и Compute Express Link (CXL) подписали соглашение, которое подразумевает передачу в пользу CXL всех наработок и спецификаций OpenCAPI и OMI. Если будет получено одобрения всех участвующих сторон, то это будет ещё один шаг в сторону унификации ключевых системных интерфейсов и возможности реализации новых архитектурных решений. Во всяком случае, на бумаге. Консорциумы OpenCAPI (Open Coherent Accelerator Processor Interface) был сформирован в 2016 году с целью создание единого, универсального, скоростного и согласованного интерфейса для связи CPU с ускорителями, сетевыми адаптерами, памятью, контроллерами и устройствами хранения и т.д. Причём в независимости от типа и архитектуры самого CPU. На тот момент новый интерфейс был определённо лучше распространённого тогда PCIe 3.0. С течением времени дела у OpenCAPI шли ни шатко ни валко, однако фактически его использование было ограничено только POWER-платформами от IBM. 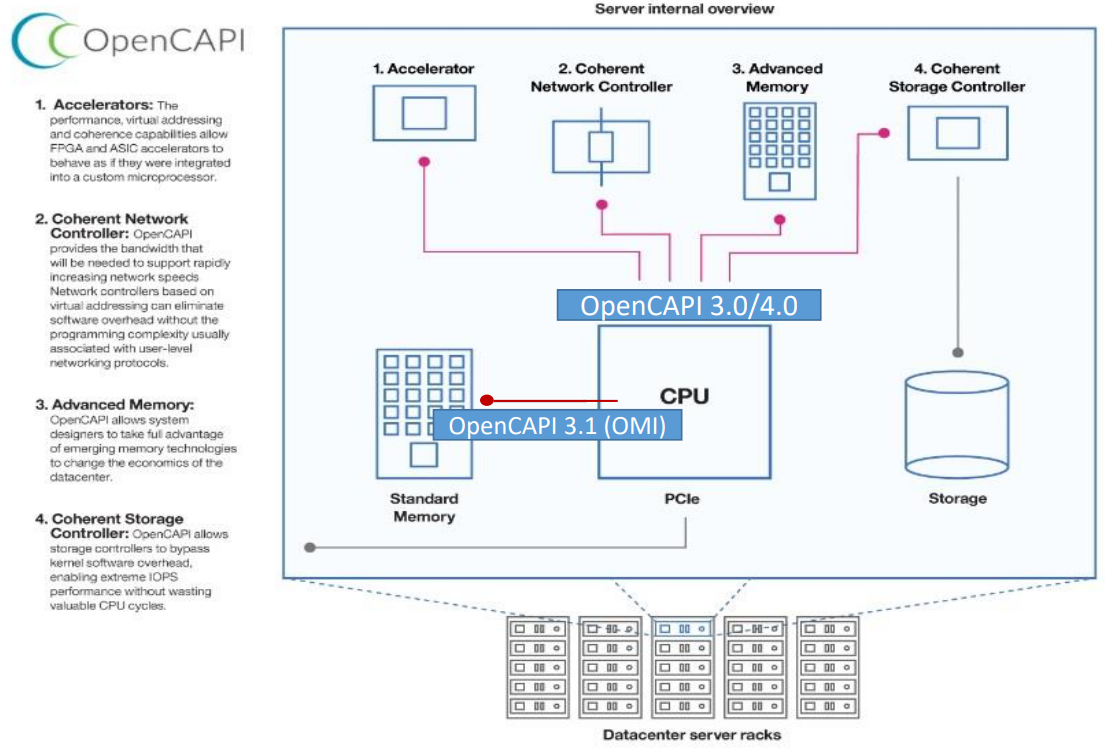
Источник: OpenCAPI Тем не менее, в недрах OpenCAPI родился ещё один очень интересный стандарт — Open Memory Interface (OMI). OMI, если коротко, предлагает некоторую дезагрегацию путём добавления буферной прослойки между CPU и RAM. С одной стороны у OMI есть унифицированный последовательный интерфейс для подключения к CPU, с другой — интерфейсы для подключения какой угодно памяти, на выбор конкретного производителя. 
Источник: Open Memory Interface (OMI) OMI позволяет поднять пропускную способность памяти, не раздувая число контактов и физические размеры и самого CPU, и модулей. Однако и в данном случае массовая поддержка OMI по факту есть только в процессорах IBM POWER10. Концептуально CXL в части работы с памятью повторяет идею OMI, только в данном случае в качестве физического интерфейса используется распространённый PCIe. 
Изображение: SK Hynix Существенная разница c OMI в том, что начальная поддержка CXL будет в грядущих процессорах AMD и Intel. А Samsung и SK Hynix уже готовят соответствующие DDR5-модули. Да и в целом поддержка CXL в индустрии намного шире. Так что консорциуму CXL, по-видимому, осталось поглотить только ещё один конкурирующий стандарт в лице CCIX, как это уже произошло с Gen-Z. Комментируя соглашение, президент консорциума CXL отметил, что сейчас наиболее удачное время для объединения усилий, которое принесёт пользу всей IT-индустрии. Участники OpenCAPI имеют богатый опыт, который поможет улучшить грядущие спецификации CXL и избежать ошибок. |
|

