Лента новостей
|
18.06.2024 [17:43], Сергей Карасёв
Microsoft свернула проект подводного дата-центра Natick, хотя он доказал свою надёжностьКорпорация Microsoft, по сообщению Datacenter Dynamics, прекратила развитие проекта Natick по созданию подводного ЦОД. Причины данного решения не уточняются. Но редмондский гигант говорит, что полученные наработки и знания в перспективе найдут применение в других областях. Microsoft запустила инициативу Natick ещё в 2013 году, а в 2018-м развернула тестовую платформу у побережья Шотландии. Идея подводного дата-центра заключается в том, что оборудование функционирует на дне моря, где температура постоянна и достаточно низка. Концепция Natick доказала свою надёжность. В рамках тестирования только шесть серверов из 855 столкнулись со сбоями. Для сравнения: на суше в кластере из 135 машин из строя вышли восемь за аналогичный период эксплуатации. Более низкий процент отказов серверов в подводном ЦОД может объясняться стабильной температурой окружающей среды. Другая причина заключается в том, что Natick был заполнен инертным азотом, а не кислородом. 
Источник изображения: Microsoft В 2020 году Microsoft продемонстрировала Natick третьего поколения, но после этого корпорация практически не делилась информацией о проекте. И вот теперь Ноэль Уолш (Noelle Walsh), глава облачного подразделения Microsoft Cloud Operations + Innovation (CO+I), заявила, что компания пока не собирается строить подводные дата-центры. «Моя команда работала над проектом, и он подтвердил жизнеспособность. Мы узнали много нового о работе ниже уровня моря, вибрации и воздействиях на серверы. В дальнейшем мы применим эти знания в других областях», — сказала Уолш. В 2021 году Microsoft открыла некоторые из запатентованных технологий, которые были применены в Natick. Компания подчёркивает, что продолжит использовать проект в качестве исследовательской платформы «для изучения, тестирования и проверки новых концепций, касающихся надёжности и устойчивости ЦОД». Вместе с тем фактическая эксплуатация таких объектов прекращена. Нужно отметить, что идею дата-центров на морском дне развивают и другие компании. Это, в частности, китайская HiCloud Data Center Technology (подразделение Highlander), которая создаёт коммерческий подводный ЦОД у побережья города Санья (о. Хайнань). А Subsea Cloud занимается разработкой глубоководных дата-центров.
18.06.2024 [17:43], Руслан Авдеев
Проект Martoc разработает глубоководный подводный дрон для инспекции интернет-кабелейПо данным Datacenter Dynamics, RTSys, Orange Marine, Mappem Geophysics и ENSTA Bretagne в рамках совместного проекта Martoc займутся созданием морских подводных дронов для мониторинга кабелей. Разрабатываемый компаниями автономный дрон Comet-3000 сможет выявлять проблемы на глубинах до 3000 м. Машина оснащена магнитометром, камерами, электромагнитными сенсорами, фронтальным сонаром и другими датчиками. В Martoc Project заявляют, что дрон будет запускаться с надводного судна в рамках картографических миссий и мониторинга угроз. Кроме того, ведётся разработка систем запуска и извлечения беспилотника для установки, например, на судах, прокладывающих кабели. Martoc Project стартовал в феврале 2024 года. Компания RTSys, занимающаяся разработкой подводных роботов и акустических технологий, расположена во Франции, но владеет базой и в Сингапуре. Orange Marine, подразделение оператора связи Orange, владеет более 15 % мирового флота судов для прокладки и починки кабелей. Компания уже проложила 264 тыс. км подводных оптоволоконных кабелей. 
Источник изображения: RTSys Французская же Mappem Geophysics специализируется на исследовании дна с помощью электромагнетизма, а ENSTA Bretagne представляет собой инженерную школу и исследовательский центр, базирующийся во французском Бресте. Там ведётся обучение и исследовательские работы, связанные с морскими прикладными задачами, оборонными проектами, транспортом, аэрокосмическими и цифровыми исследованиями. Ранее в этом году итальянский сетевой оператор Terna и американская Terradepth уже запустили проект использования подводных дронов для инспекции морского дня с помощью подводных дронов для последующей прокладки морских кабелей.
18.06.2024 [16:03], Руслан Авдеев
Интернет во Вьетнаме снова под угрозой: отказали три из пяти подводных кабелейБуквально день спустя после начала раздачи во Вьетнаме национальных доменов в зоне .VN, знаменующей укрепление цифрового суверенитета государства, там начались серьёзные неприятности со связью. По данным The Register, 15 июня отказали три из пяти морских интернет-кабелей, связывающих Вьетнам с остальным миром. По информации местного государственного агентства VNA, сбои серьёзно повлияли на связность, а к некоторым зарубежным сайтам вообще очень трудно получить доступ. Пострадал кабель Intra Asia (IA), связывавший Вьетнам с Сингапуром, цифровая магистраль Asia Pacific Gateway (APG) и Sia-Africa-Europe-1 (AAE-1). Полноценно связь до сих пор не восстановлена, так что вся нагрузка пока легла на немногочисленные наземные линии связи. Операторы не сообщают, когда связь восстановится, но в этом нет ничего удивительного, поскольку специализированные корабли для ремонта всегда в дефиците. Кроме того, довольно сложно установить точное место обрыва, а у кораблей могут уйти недели на то, чтобы добраться до него. 
Источник изображения: Guille Álvarez/unsplash.com Точная причина сбоев пока не называется, но ранее подобные инциденты обычно случались из-за естественной деградации кабелей или из-за непреднамеренного повреждения, либо, что бывало намного реже, в результате намеренного саботажа (как, вероятно, в Красном море). В начале 2023 года у Вьетнама уже были подобные проблемы, когда отказали не три, а все пять подводных ВОЛС. Тогда виноватыми назначили китайское рыболовное судно и неопознанный грузовой корабль. В целом именно якори и тралы нередко становятся причиной неумышленного повреждения подводных коммуникаций. Во Вьетнаме активно пытаются улучшить состояние морских кабельных соединений. План правительства предполагает получение ещё 60 Тбит/с через 2–4 новых подводных кабеля. С учётом того, что все пять уже имеющихся кабелей по плану должны сохранить работоспособность к 2025 году, общая пропускная способность каналов связи должна вырасти до 122 Тбит/с. Обрыв кабелей произошёл в не самое удачное время. Местное Министерство информации и коммуникаций 14 июня объявило, что бизнес-пользователи доменных имён BIZ.VN для новых сайтов получат два года бесплатного обслуживания, как и граждане страны от 18 до 23 лет, использующие домен ID.VN в личных целях. Таким образом власти пытаются привлечь к использованию домена .VN побольше местных пользователей. Сейчас национальные использует только четверть вьетнамских компаний, тогда как в развитых странах этот показатель находится на уровне 70 %.
18.06.2024 [15:21], Сергей Карасёв
Квартальные убытки ИБ-стартапа Rubrik выросли в восемь разАмериканский стартап Rubrik, специализирующийся на решениях в области информационной безопасности, отчитался о работе в I четверти 2025 финансового года, которая была закрыта 30 апреля 2024-го. Это первый отчёт компании после IPO. Выручка компании в годовом исчислении поднялась на 38 %, достигнув $187,3 млн. Отмечается, что годовой периодический доход от подписок (ARR) вырос на 46 % и составил $856,1 млн. В течение отчётного периода подписки принесли Rubrik приблизительно $172,2 млн, что на 59 % больше результата за I квартал 2024 финансового года, когда было получено $108,4 млн. 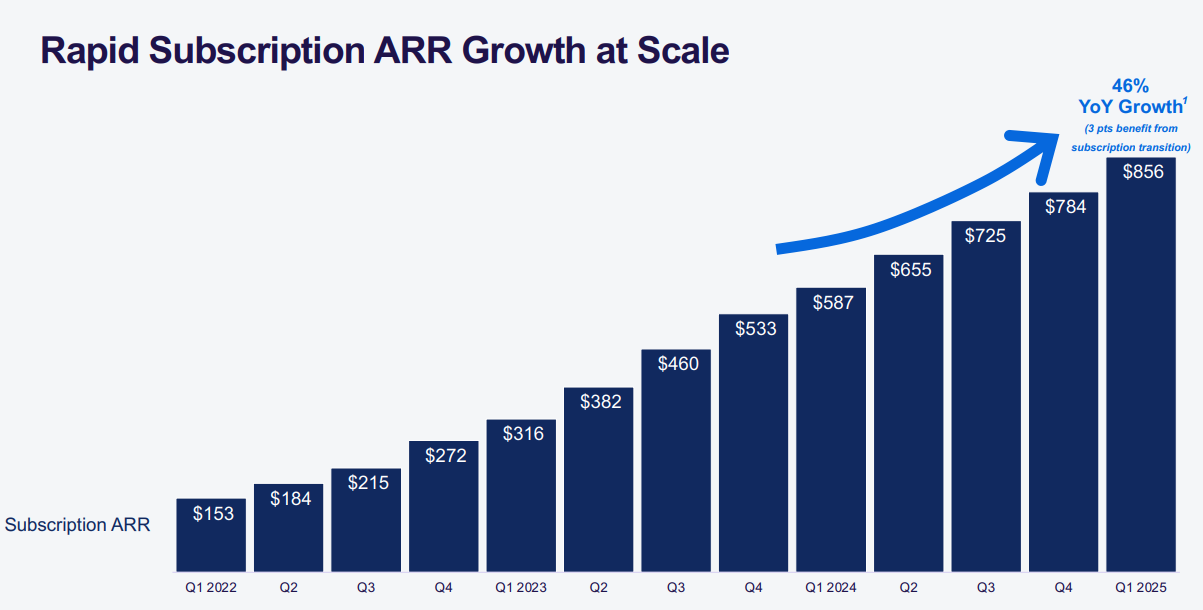
Источник изображения: Rubrik Вместе с тем стартап продолжает нести убытки, которые в годовом исчислении увеличились более чем в восемь раз. Если в I четверти 2024 финансового года компания потеряла $89,3 млн, или $1,49 в пересчёте на одну ценную бумагу, то теперь — $732,1 млн, или $11,48 на акцию. В отчёте сказано, что по состоянию на 30 апреля 2024 года у Rubrik насчитывалось 1859 клиентов, у которых величина ARR на подписки составляла $100 тыс. или более. Это на 41 % больше по сравнению с результатом годичной давности. В апреле нынешнего года Rubrik провела процедуру первичного публичного размещения ценных бумаг (IPO), получив $752 млн при оценке в $5,6 млрд. Отмечается, что Microsoft инвестировала в эту компанию в 2021 году. Во II четверти 2025 финансового года стартап рассчитывает получить выручку от $195 млн до $197 млн, а по итогам года в целом показатель ожидается в диапазоне $810–$824 млн. При этом годовой периодический доход от подписок прогнозируется в размере $983–$997 млн.
18.06.2024 [10:54], Владимир Мироненко
В подмосковной Дубне начали строительство 8-МВт ЦОДВ подмосковной Дубне начали строительство ЦОД по проекту компании WildTeam. Как сообщила компания в своём Telegram-канале, одноэтажное здание площадью 15,8 тыс. м2 будет построено на территории Российского центра программирования, где находятся научно-производственные комплексы. В качестве заказчика выступил крупнейший маркетплейс России. На данный момент уже завершены земляные работы и сейчас строители занимаются возведением фундамента здания. Ввод в эксплуатацию ЦОД с максимальной мощностью 8 МВт запланирован на апрель 2025 года. 
Источник изображения: WildTeam Новый ЦОД предназначен для размещения и хостинга серверного и сетевого оборудования, подключения к интернет-каналам. Согласно проекту, он будет включать пять IT‑модулей с машинными залами, силовыми электрическими блоками и помещениями для дизель-генераторных установок. В здании будет также находиться инженерный технологический модуль со складскими помещениями и административно-бытовая часть. По словам гендиректора проектной компании WildTeam, благодаря использованию принципа модульности здание ЦОД в дальнейшем можно будет расширить, добавив ещё ряд модулей: «ЦОД — автономная система, где нет необходимости в постоянном пребывании людей, кроме административно-бытовой части. В здании появятся системы бесперебойного питания, а система управления дизель-генераторных установок будет работать полностью в автоматическом режиме».
18.06.2024 [10:52], Сергей Карасёв
AMD: дата-центры остаются для компании основным источником прибылиФинансовый директор AMD Жан Ху (Jean Hu) в ходе конференции для инвесторов Nasdaq в Лондоне сообщила о том, что решения для ЦОД остаются для компании основным источником прибыли, несмотря на бум ИИ. По её словам, для многих рабочих нагрузок ключевым аппаратным ресурсом являются ядра CPU. Ху отметила, что в I четверти 2024 года направление продуктов для дата-центров демонстрировало значительно более высокие темпы роста, нежели другие сегменты бизнеса AMD. Вместе с тем были отмечены некоторые сложности в области встраиваемых продуктов. «Основным драйвером повышения валовой прибыли по-прежнему остаются ЦОД, и я думаю, что в следующем году будет наблюдаться аналогичная картина», — подчеркнула Жан Ху. 
Источник изображения: AMD Вместе с тем финдиректор AMD признаёт, что ИИ является «горячей темой». На этом фоне Ху рассказала о разработках компании в соответствующей сфере. Она напомнила, что на выставке Computex 2024 дебютировали чипы для ноутбуков Ryzen AI 300 с NPU, а также настольные процессоры Ryzen 9000. На серверный сегмент ориентированы мощные ускорители Instinct MI325X и MI350X. Отмечается, что изделие MI350X, продажи которого начнутся в 2025 году, будет конкурировать с NVIDIA Blackwell B200. А в 2026-м AMD выпустит ускоритель Instinct MI400 в качестве конкурента будущим решениям NVIDIA Rubin. При этом NVIDIA продаёт ускорители миллионами, а AMD и Intel в сумме смогли продать и 100 тыс. шт. в 2023 году. Что касается сегмента традиционных серверов (без средств ИИ), то финансовый директор AMD указала на его сокращение по итогам 2023 года. Ху сказала, что данный сектор остаётся «довольно смешанным». В области серверных процессоров компания укрепляет позиции благодаря своим чипам EPYC, в том числе поколения Siena. По словам Ху, доля AMD в соответствующей области в I квартале 2024 года достигла 33 %. Новейшие серверные платформы AMD позволяют предприятиям уменьшить количество серверов на 40 % при сохранении прежнего уровня производительности.
18.06.2024 [10:47], Сергей Карасёв
H3C в партнёрстве с Foxconn откроет завод в Малайзии, а затем выйдет в США и ЕвропуКомпания H3C Technologies, базирующаяся в Китае, по информации ресурса DigiTimes, заключила соглашение о сотрудничестве с Foxconn с целью открытия своего первого зарубежного завода. Предприятие расположится в Малайзии: выпуск продукции на нём планируется начать в сентябре нынешнего года. H3C, принадлежащая Tsinghua Unigroup и HPE, является крупнейшим в Китае поставщиком серверов и памяти HPE, а также технических услуг. По оценкам IDC, H3C занимала второе место в рейтинге производителей серверов x86 в КНР в течение трёх лет подряд — с 2021-го по 2023 год: доля этой компании оценивалась в 15,8 %. Кроме того, H3C удерживала в Китае первое место (51,7 %) в сегменте блейд-серверов с 2019-го по 2023 год и второе место (20,5%) в области GPU-серверов с первой половины 2020-го по 2023 год. Партнёрство с Foxconn является частью стратегии H3C по выходу на международный рынок. В течение следующих двух-трёх лет H3C намерена запустить производственные мощности в США, Мексике и Европе. План состоит в том, чтобы использовать передовые технологии Тайваня для развития бизнеса в других регионах. В частности, в Малайзии H3C намерена предоставлять цифровые решения и техническую поддержку, используя свой опыт в области ИИ, IoT, облачных вычислений, больших данных и информационной безопасности. Предполагается, что это будет способствовать цифровой трансформации страны. 
Источник изображения: H3C H3C планирует задействовать мощности Foxconn по производству чипов в Малайзии. Последняя приобрела примерно 5,03 % акций малазийской компании Dagang Nexchange Bhd (DNex), которой принадлежит доля в размере 60 % в SilTerra — местном производителе полупроводниковой продукции. Между тем HPE намерена избавиться от оставшейся доли в совместном китайском предприятии H3C. Недавно Tsinghua Unigroup приобрела у НРЕ 30 % акций H3C примерно за $2,14 млрд, увеличив свою долю с 51 % до 81 %. В дальнейшем Tsinghua Unigroup может купить оставшиеся 19 % бумаг H3C.
18.06.2024 [00:18], Владимир Мироненко
С чистого листа: VMware возобновила сотрудничество с Dell и подписала OEM-соглашения с Lenovo и HPEVMware, поглощённая Broadcom в результате сделки на $69 млрд, переподписала OEM-соглашения с тремя ключевыми поставщиками оборудования: Dell, HPE и Lenovo. Это, в частности, позволит им и дальше продавать гиперконвергентные системы и серверы с предустановленным стеком ПО VMware. Сообщивший об этом ресурс The Register утверждает, что это большое достижение для VMware, поскольку гиперконвергентная инфраструктура, сочетающая в себе вычислительные мощности, СХД и сетевую виртуализацию, являются популярным способом комплектации ИТ-продуктов для корпоративного сегмента, и теперь к их продаже присоединились три крупнейших производителя соответствующего оборудования. Все три компании имеют значительную клиентскую базу, поэтому сделка с VMware тоже пойдёт им на пользу. Ранее Dell сообщила Комиссии по ценным бумагам и биржам США (SEC), что с 25 января перестали работать дистрибуторские соглашения, заключённые с VMware, когда та входила в состав Dell. В свою очередь, Broadcom объявила в феврале, что уравнивает правила игры для OEM-партнёров VMware, включая Dell, HPE, Lenovo и т.д. 
Источник изображения: VMware После заключения нового соглашения с VMware компания Dell опубликовала заявление, в котором заявила: «Новое соглашение основано на более чем 20-летнем сотрудничестве Dell и VMware и позволяет компаниям продолжать предоставлять совместно разработанные решения, которые помогают организациям внедрять современные приложения и оптимизировать свои ЦОД». В заявлении указано, что сделка охватывает HCI-платформы Dell VxRail и Dell vSAN Ready Nodes, серверы Dell PowerEdge и системы Dell PowerFlex. Подписание новых соглашений произошло спустя после того, как Intel и AMD анонсировали новые линейки серверных процессоров. Виртуализация только выигрывает от многоядерности, поскольку позволяет обеспечить ещё большую консолидацию мощностей. По мнению The Register, это хорошая новость для Broadcom, которая изменила политику лицензирования продуктов VMware, что многие связали с повышением цен, хотя чипмейкер утверждает, что на самом деле новое предложение является более выгодными для клиентов.
17.06.2024 [22:49], Илья Коваль
Три квантовых компьютера, NVIDIA DGX Quantum, немножко HPC и облако: в Израиле открыт уникальный центр квантовых вычислений IQCC
aws
gh200
grace
hardware
hpc
nvidia
quantum machines
израиль
квантовые вычисления
квантовый компьютер
облако
разработка
Стартап Quantum Machines, разработчик систем управления квантовыми компьютерами, открыл Израильский центр квантовых вычислений (Israeli Quantum Computing Center, IQCC). Площадка, создание которой было частично профинансировано правительством страны, располагается в Тель-Авивском университете. По словам основателей, это первый в мире центр, располагающий квантовыми компьютерами разных типов, которые интегрированы с системой NVIDIA DGX Quantum, HPC-инфраструктурой и облаком. 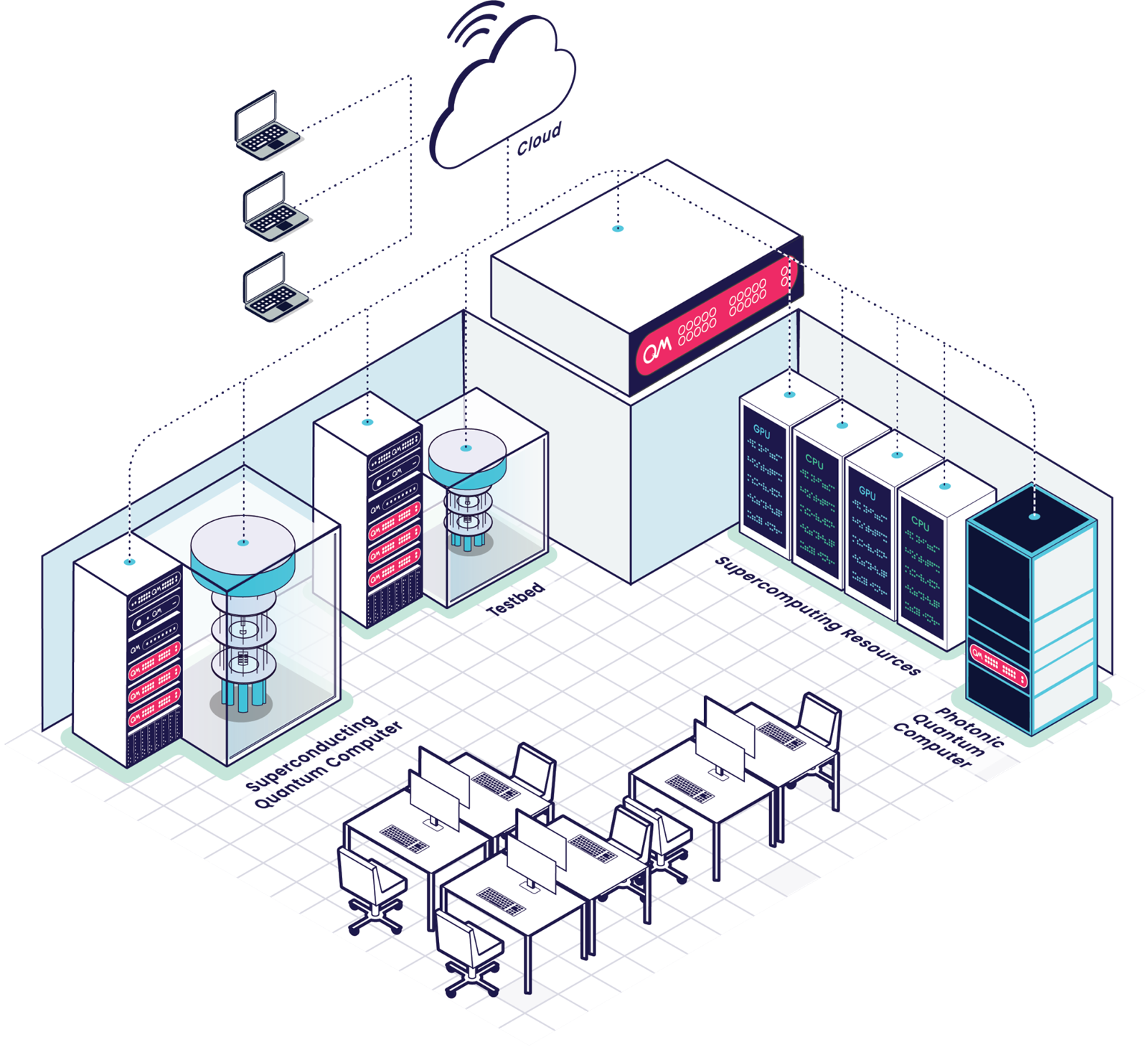
Источник изображений: Quantum Machines Приоритетный доступ со скидкой получат исследовательские организации Израиля, но в целом центр будет открыт для компаний со всего света. Как говорят создатели, IQCC — это лучший в мире полигон для создания новых технологий в области квантовых вычислений, а открытая архитектура площадки позволяет регулярно проводить обновления и упрощает дальнейшее масштабирование возможностей и вычислительных мощностей. Сейчас в IQCC установлены 21-кубитный компьютер Galilee от Quantware на сверхпроводящих кубитах (ещё один такой же используется в качестве тестовой платформы) и фотонный компьютер Negev от ORCA (8 кумод). Системы управляются контроллерами OPX1000 от самой Quantum Machines. HPC-инфраструктура представлена DGX A100, четырьмя GH200 и 128 vCPU на базе AMD EPYC 9334 (Genoa). Дополнительные ресурсы можно арендовать в облаке AWS.  Для Galilee и Negev доступна интеграция с DGX Quantum, платформой для гибридных квантово-классических вычислений, которая была создана NVIDIA и Quantum Machines и впервые в мире развёрнута именно в IQCC. Управлять компьютерами и разрабатывать ПО можно с использованием Qiskit, QUA, OpenQASM3, QBridge, а также Classiq. К системе организован облачный доступ. В ближайшие месяцы в IQCC будут развёрнуты ещё несколько квантовых компьютеров и QPU.
17.06.2024 [13:09], Сергей Карасёв
Rambus представила набор решений PCIe 7.0, включая высокопроизводительный контроллерКомпания Rambus анонсировала пакет IP-блоков для создания различных продуктов стандарта PCI Express (PCIe) 7.0. В частности, представлен высокопроизводительный контроллер для систем, ориентированных на решение задач в области ИИ и НРC. Предварительная версия спецификации PCIe 7.0 была обнародована в апреле нынешнего года. Стандарт предусматривает скорость передачи данных до 128 ГТ/с, что обеспечивает до 512 Гбайт/с в двустороннем режиме в конфигурации x16. Ожидается, что PCIe 7.0 найдёт применение в 800GbE-решениях, системах ИИ, платформах квантовых вычислений и ЦОД нового поколения. 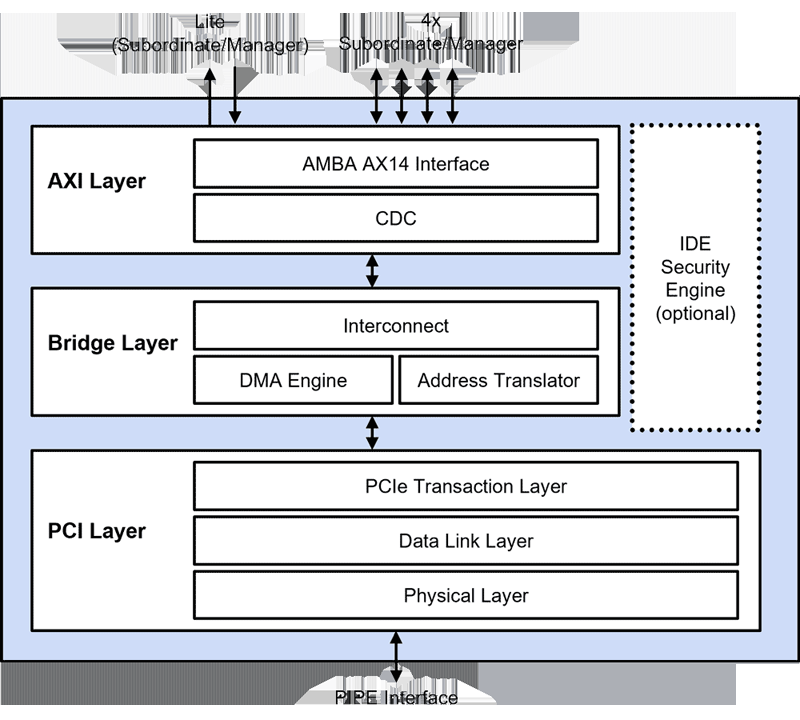
Источник изображения: Rambus Контроллер Rambus стандарта PCIe 7.0 поддерживает максимально предусмотренную спецификацией скорость работы — 128 ГТ/с. Реализованы средства коррекции ошибок (Forward Error Correction, FEC) с малой задержкой. Среди прочего упомянуты обратная совместимость со стандартами PCIe предыдущих поколений (PCIe 6.0, 5.0, 4.0 и пр.), поддержка шины AMBA AXI, а также развитые инструменты обеспечения безопасности. «Контроллер PCIe 7.0 обеспечивает высокую пропускную способность, низкую задержку и надёжность, необходимые для приложений ИИ и НРС нового поколения», — заявляет разработчик. Кроме того, Rambus представила ретаймер PCIe 7.0 с поддержкой конфигураций от x2 до x16, высокопроизводительный коммутатор PCIe 7.0 Switch с возможностью использования до 32 портов и другие решения. |
|

