Материалы по тегу: ускоритель
|
16.01.2025 [16:16], Руслан Авдеев
США вводят очередные ограничения на выпуск и экспорт современных чиповМинистерство торговли США вводит новый пакет экспортных ограничений, призванных помешать Китаю и другим странам закупать передовые чипы, сообщает Silicon Angle. В частности, ограничения коснутся предприятий, выпускающих микросхемы, а также работающих по заказу других организаций. Так, новые меры коснутся TSMC и Samsung Electronics, а также упаковщиков чипов, включая ту же TSMC. Новые правила предусматривают получение производителями чипов и упаковщиками полупроводников лицензий на экспорт «определённых передовых чипов» в ряд регионов. Власти откажутся от подобных требований, если производитель чипов получит технические аттестации от доверенных участников цепочек поставок. Так, разработчики чипов могут получить от американских властей статус «одобренных» или «авторизованных». Если разработчик подтверждает, что его чипы не достигают по своим характеристикам установленных США порогов производительности, лицензионные требования к ним отменяются. То же касается фабрик и компаний-упаковщиков. Если характеристики производимых чипов не превышают определённого порога, новые экспортные ограничения не применяются. 
Источник изображения: CHUTTERSNAP/unsplash.com Объявлено и о ряде других нормативных изменений. В частности, запускается процесс утверждения компаний в перечне одобренных дизайн-центров и поставщиков чипов и услуг OSAT (Outsourced Semiconductor Assembly and Test). Также оптимизированы процедуры раскрытия информации в случаях, если производитель принимает заказ клиента, потенциально способного перенаправить продукцию в Китай. В связи с новыми правилами в чёрный список Entity List отправятся 16 новых организаций, включая некоторые ИИ-компании, поддерживающие развитие производства передовых чипов в Китае. Одной из таких компаний стала Sophgo — в прошлом году выяснилось, что она якобы передала выпущенную для неё продукцию компании Huawei, давно пребывающей в американском чёрном списке, после чего TSMC прекратила выполнение её заказов и поставки. Министерство торговли вводит новые правила всего через несколько дней после того, как администрация уходящего президента США ввела глобальные ограничения на поставки ИИ-чипов и передовых моделей ИИ. Ранее американские власти уже вводили санкции, ограничивающие возможности китайской полупроводниковой индустрии. Речь идёт о закупках чипов NVIDIA, памяти HBM и других компонентов. Не щадят и союзников. Нидерландской ASML запрещено поставлять в КНР оборудование для DUV-литографии, на котором можно изготавливать 5- и 7-нм полупроводники.
16.01.2025 [08:04], Алексей Степин
Терабайтные GPU: Panmnesia продемонстрировала CXL-память для ИИ-ускорителейКомпания Panmnesia работает в области проектирования CXL-пулов DRAM довольно давно: в 2023 году она демонстрировала систему, оставляющую позади все решения на базе RDMA и обеспечивающую доступ к 6 Тбайт оперативной памяти. Но большие объёмы памяти сегодня, в эпоху всё более усложняющихся ИИ-моделей, нужны не только и не столько процессорам, сколько ускорителям, априори лишённым возможности апгрейда набортной RAM. На выставке CES 2025 компания продемонстрировала решение данной проблемы. По мнению разработчиков Panmnesia, производительность при обучении масштабных ИИ-моделей упирается именно в объёмы набортной памяти ускорителей: вместо десятков гигабайт требуются уже терабайты, а установка дополнительных ускорителей может обходиться слишком дорого при том, что вычислительные мощности окажутся избыточными. 
Источник здесь и далее: Panmnesia Продемонстрированная на выставке CXL-система построена на базе новейшего контроллера Panmnesia с поддержкой CXL 3.1. В двунаправленном режиме латентность доступа составила менее 100 нс и находится примерно на уровне 80 нс. 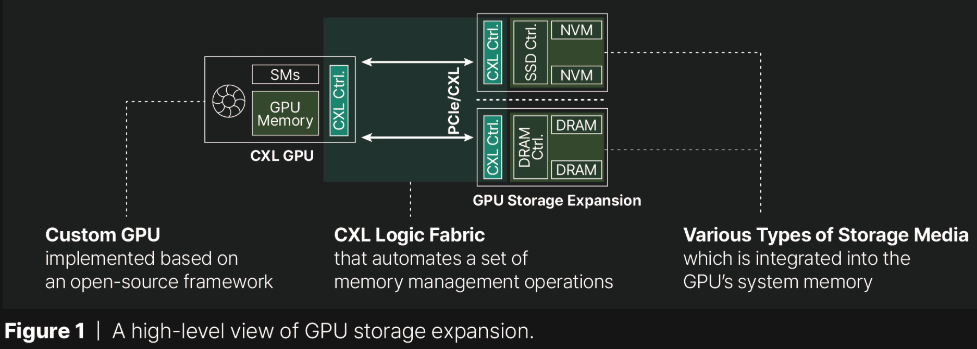 Ключ к успеху здесь кроется в фирменной реализации CXL 3.1, включая программную часть, благодаря которой GPU могут обращаться к общему пулу памяти, используя те же инструкции типа load/store, что при доступе к набортной HBM или GDDR.  Однако технология требует наличия на борту GPU фирменного контроллера CXL Root Complex, одной из важнейших частей которого является декодер HDM, отвечающий за управление адресным пространством памяти (host physical address, HPA), так что уже выпущенные ускорители напрямую работать с системой Panmnesia не смогут.  Тем не менее, технология выглядит многообещающей. Она уже привлекла внимание со стороны компаний, занимающихся ИИ, как потенциально позволяющая снизить стоимость инфраструктуры ЦОД.
13.01.2025 [23:15], Владимир Мироненко
Полупроводниковая отрасль США раскритиковала новые ограничения на экспорт ИИ-чипов и ИИ-моделейАдминистрация США объявила в понедельник о введении в действие правила AI Diffusion rule («Правило распространения ИИ»), которым теперь будет регулироваться режим экспортного контроля ИИ-технологий. 20 близким союзникам и партнерам США будет предоставлен беспрепятственный доступ к ИИ-чипам и мощным ИИ-моделям. При этом требования лицензирования теперь касаются большинства других стран, пишет Financial Times. Как сообщается, цель новых ограничений — затруднить для Китая использование других стран для обхода существующих ограничений США и получения технологий, которые могут быть использованы для укрепления военной мощи КНР — от моделирования ядерного оружия до разработки гиперзвуковых ракет. Новое правило предлагает трёхуровневую систему лицензирования для чипов, используемых в ИИ ЦОД. Верхний уровень (Tier I) включает членов G7, а также Австралию, Новую Зеландию, Южную Корею, Тайвань, Нидерланды и Ирландию, которые не будут подвергаться ограничениям. Страны Tier II, не подпадающие под контроль вооружений, смогут получить до 1700 новейших ИИ-ускорителей без специального разрешения. Если нужно больше чипов, придётся подать заявку на получение специальной лицензии. Также лицензия потребуется для получения доступа к самым мощным закрытым моделям ИИ. Для получения лицензии компании должны будут иметь адекватное обеспечение физической защиты и кибербезопасности. 
Источник изображения: silvia trigo / Unsplash Третий уровень (Tier III) включает такие страны, как Китай, Иран, Россия и Северная Корея, на которые также распространяется эмбарго на поставки оружия. Эти страны подпадают под полный запрет на поставку продвинутых технолгий ИИ. Новым правилом также впервые ограничивается их доступ к передовым ИИ-моделям. Вместе с тем правило не распространяется на деятельность в цепочке поставок, включая проектирование, производство и хранение чипов. Администрация Байдена заявила, что правило также не будет ограничивать доступ к моделям ИИ с открытым исходным кодом, таким как Llama от Meta✴. «Полупроводники, которые питают [ИИ], и мощные модели, как мы все знаем, являются технологией двойного назначения, — отметила министр торговли США Джина Раймондо (Gina Raimondo) перед объявлением нового правила. — Они используются во многих коммерческих приложениях, но также могут использоваться нашими противниками для ядерного моделирования, разработки биологического оружия и развития своих армий». Введение ограничений на международные продажи ИИ-технологий в критический момент для отрасли вызвало яростную реакцию со стороны полупроводниковой промышленности США, отметила Financial Times. На прошлой неделе Ассоциация полупроводниковой промышленности США (SIA) и Фонд информационных технологий и инноваций США (ITIF), комментируя подготовку властями этого правила с предварительным названием Export Control Framework for Artificial Intelligence Diffusion (Рамки экспортного контроля для распространения ИИ), выступили с заявлениями, в которых говорилось, что его введение даст иностранным конкурентам лишь преимущество перед американскими компаниями. 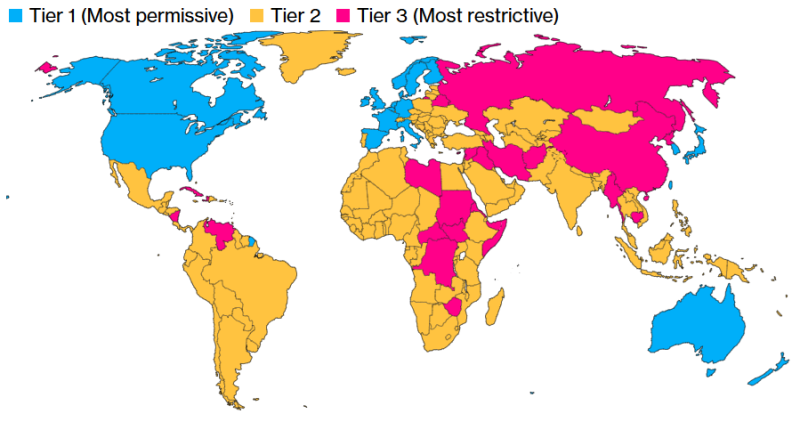
Источник изображения: Bloomberg «Отрасль по-прежнему обеспокоена настойчивостью администрации в публикации сложного и значимого правила такого рода — без каких-либо предварительных консультаций с индустрией или другими заинтересованными сторонами — в последние дни срока полномочий президента Байдена», — написал Джейсон Оксман (Jason Oxman), президент Совета индустрии информационных технологий (ITI) министру торговли Раймондо за несколько дней до публикации правила, сообщил ресурс WTTLonline. Исполнительный вице-президент Oracle Кен Глак (Ken Gluck) заявил в блоге, что новое ограничение администрации Байдена войдет в историю как «одно из самых разрушительных, когда-либо ударявших по технологической отрасли США». NVIDIA назвала новое правило «беспрецедентным и ошибочным». «Хотя эти правила и замаскированы под “антикитайские” меры, они никак не повысят безопасность США. Вместо того чтобы смягчить любую угрозу, они лишь ослабят глобальную конкурентоспособность Америки, подрывая инновации, обеспечивавшие лидерство США», — сообщила компания.
10.01.2025 [14:21], Руслан Авдеев
ИИ по квотам: США распространят ограничения на поставку ускорителей и обучение моделей почти на весь мирАдминистрация действующего президента США Джо Байдена (Joe Biden) до окончания своих полномочий намерена провести очередной раунд ограничений на экспорт ИИ-чипов. Это новая попытка перекрыть доступ к передовым технологиям Китаю, Ирану, России и другим странам, сообщает Bloomberg. После появления новостей акции NVIDIA и AMD несколько упали в цене. По данным источников, США намерены ограничить продажи ИИ-полупроводников для ЦОД как на уровне стран, так и на уровне отдельных компаний. Основная цель — обеспечить развитие передовых ИИ-систем только «дружественным» государствам и приведение мирового бизнеса в соответствие с американскими стандартами. В результате ограничения в той или иной степени распространятся почти на весь мир. Неограниченный доступ к современным технологиям сохранит только небольшая группа союзников США вроде Канады, ряда стран ЕС, Южной Кореи и Японии. Остальным доступ постараются перекрыть максимально, а большая часть мира, по мнению администрации, оказалась недостаточно благонадёжной, чтобы покупать ИИ-ускорители без ограничений. Появятся квоты, ограничивающие вычислительные способности каждой отдельной страны. Компании, базирующиеся в таких странах, могут обойти подобные ограничения — но для этого им необходимо будет привести свой бизнес в соответствие с американскими стандартами. Для этого вводится термин «проверенный конечный пользователь» (Validated End User, VEU). 
Источник изображения: Héctor J. Rivas / Unsplash Разумеется, в NVIDIA выступили против инициативы, подчеркнув, что ограничение экспорта не прекратит злоупотребления, но создаст угрозу экономическому росту и поставит под вопрос лидерство США. Пока общемировой интерес к ускоренным вычислениям в повседневной жизни — невероятная возможность для экономики Соединённых Штатов. Многолетние санкции уже ограничивают возможности NVIDIA, AMD и др. компаний поставлять передовые чипы любому заказчику. Теперь США пытаются ограничить доступ к чипам через посредников на Ближнем Востоке и в Юго-Восточной Азии. Против инициативы выступает и Ассоциация полупроводниковой промышленности (Semiconductor Industry Association). Ассоциация не одобряет принятия решения в период смены президентов, без учёта мнения отрасли — это может сказаться на конкурентоспособности США в мире. Китай имеет собственные ИИ-чипы, хотя и не такие производительные и, возможно, будет поставлять их и другим странам, усиливая своё влияние. Новые меры готовятся ввести на фоне гигантского спроса на ИИ-ускорители. Буквально каждая страна намерена использовать их в своих ЦОД, в чём и заключается «уникальная возможность» США и в политической плоскости — чтобы, по словам конгрессменов, «увести компании и страны с орбиты Пекина». 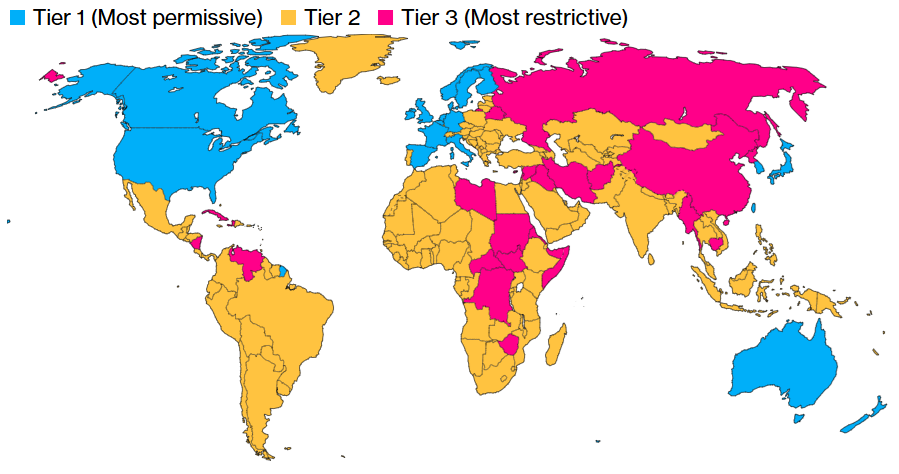
Источник изображения: Bloomberg К первому «разряду» (Tier I), по данным источников издания, отнесут США и 18 союзников, включая Канаду, Австралию, Японию, Великобританию, Германию, Францию, Южную Корею и Тайвань. Компании из этих регионов могут свободно пользоваться вычислительными ресурсами, а их штаб-квартиры в этих странах смогут получить разрешение на поставку чипов в ЦОД практически по всему миру. Однако им запрещено размещать более 25 % вычислительных мощностей за пределами стран Tier I и более 7 % — в любой из стран Tier II. Кроме того, они должны будут соблюдать требования к безопасности, выдвигаемые американским правительством. Компании со штаб-квартирами в США должны будут размещать не менее половины вычислительных мощностей на американской земле. В целом США и приближённые страны, согласно новому плану, должны располагать большими вычислительными мощностями, чем весь остальной мир. Подавляющее большинство стран относится ко второму разряду (Tier II). Каждой из них можно внедрить порядка 50 тыс. ИИ-ускорителей с 2025 по 2027 гг. При этом отдельные компании могут добиться гораздо больших лимитов, если получат статус VEU в каждой стране, где намерены оснастить ЦОД. Для этого необходимо иметь доказанную историю соблюдения американских норм и стандартов в сфере прав человека, или, как минимум, иметь убедительные планы для достижения необходимых результатов. 
Источник изображения: D A V I D S O N L U N A / Unsplash Если компания получит статус VEU, её импорт чипов не будет сказываться на общей квоте страны. Это поощряет бизнес приводить свою деятельность в соответствие с американскими стандартами. Вместе с тем накладываются и требования по физической безопасности объектов, кибербезопасности и отбору персонала. Наконец, больше всего ограничения коснутся России, Беларуси, Китая, Ирана, КНДР, а также всех стран, на которые распространяется американское эмбарго на поставки вооружений. Речь идёт приблизительно о двух дюжинах государств уровня Tier III. Поставки ИИ-ускорителей в ЦОД этих стран будут запрещены. Помимо контроля над полупроводниками, новые правила также ограничивают и экспорт закрытых ИИ-моделей. Компаниям будет запрещён их хостинг в странах Tier III, а страны Tier II должны будут выполнять ряд требований. Конечно, ограничения не распространяются на страны, получившие универсальный статус VEU. 
Источник изображения: Patrick Tomasso / Unsplash Открытых моделей эти правила не коснутся, то же касается и маломощных закрытых моделей, менее производительных, чем имеющиеся в свободном доступе. Тем не менее, если компания захочет настроить открытую модель для выполнения специальных задач и этот процесс потребует значительных вычислительных мощностей, ей также понадобится подавать заявку на получение разрешения США для выполнения подобных задач в странах Tier II. Ранее США запрещали поставки в страны вроде России на неопределённый срок. В Китай разрешено было поставлять версии с ограниченной функциональностью, а в ноябре прошлого года появилась новость, что США запретили TSMC выпускать передовые ускорители по заказу китайских компаний. На большинство стран мира ограничения не распространялись, что способствовало стремительному росту бизнеса NVIDIA.
07.01.2025 [16:10], Владимир Мироненко
NVIDIA представила «персональный ИИ-суперкомпьютер» Project DIGITS на базе гибридного ускорителя GB10Компания NVIDIA представила «персональный ИИ-суперкомпьютер» Project DIGITS — это самая компактная аппаратная платформа на базе суперчипов Grace Blackwell. Разработанная для исследователей ИИ, специалистов по данным и студентов система поставляется с полным набором ПО для создания, тюнинга и инференса ИИ-моделей. Это позволяет локально создавать и дорабатывать модели, а затем разворачивать их в облаке или ЦОД. Project DIGITS будет доступен в мае по цене от $3000. Project DIGITS оснащён чипом GB10 с FP4-производительностью до 1 Пфлопс, разработанным в партнёрстве с MediaTek. GB10 включает ускоритель Blackwell, подключённый посредством NVLink-C2C к 20-ядерному Arm-процессору Grace, 128 Гбайт унифицированной когерентной памяти LPDDR5x и 4-Тбайт NVMe SSD. В оснащение также входит адаптеры Wi-Fi, Bluetooth и Ethernet (RJ45). На задней стенке есть видеовыход HDMI и четыре разъёма USB-C. По словам компании, Project DIGITS позволит запускать модели размером до 200 млрд параметров, а при объединении двух таких систем посредством NIC ConnectX (два порта SFP28) возможен запуск моделей с 405 млрд параметров. 
Источник изображений: NVIDIA Работает новинка под управлением NVIDIA DGX OS — специализированной сборки Ubuntu Linux, оптимизированной для работы с ИИ-нагрузками. Пользователи Project DIGITS получат доступ к обширной библиотеке ПО NVIDIA AI, включая комплекты для разработки ПО, инструменты оркестрации, фреймворки и модели, доступные в каталоге NVIDIA NGC и на портале NVIDIA Developer. Разработчики смогут настраивать модели с помощью фреймворка NVIDIA NeMo, использовать в работе с данными библиотеки NVIDIA RAPIDS и задействовать популярные программные платформы, включая PyTorch, Python и Jupyter notebooks. 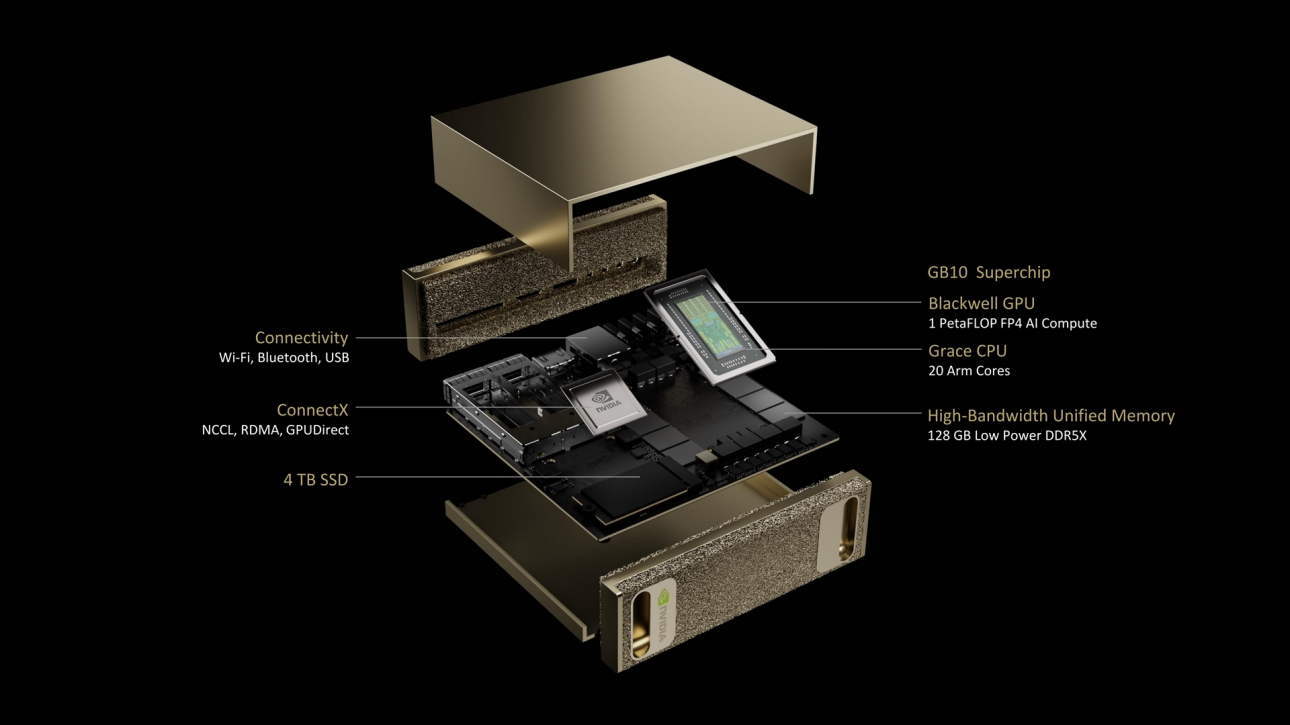 Для создания агентских приложений AI можно будет использовать NVIDIA Blueprints и микросервисы NVIDIA NIM, доступные для исследований, разработки и тестирования в рамках программы NVIDIA Developer Program. Благодаря единой архитектуре Grace Blackwell предприятия и индивидуальные исследователи смогут прототипировать, настраивать и тестировать ИИ-модели на локальных системах Project DIGITS с последующим развёртыванием в NVIDIA DGX Cloud, облачных инстансах или собственной инфраструктуре ЦОД.
31.12.2024 [14:12], Сергей Карасёв
ByteDance в 2025 году планирует потратить $7 млрд на ускорители NVIDIAКитайская холдинговая интернет-компания ByteDance, владеющая сервисом TikTok, по сообщению ресурса The Information, намерена в 2025 году закупить ИИ-продукты NVIDIA на сумму до $7 млрд. Если эти планы удастся осуществить, ByteDance получит в своё распоряжение один из самых масштабных парков ускорителей NVIDIA в мире. Приобретение передовых ИИ-решений китайскими компаниями затруднено из-за американских санкций. В 2022 году США объявили об ограничениях на экспорт определённых ИИ-чипов в КНР, и с тех пор данные меры несколько раз ужесточались. Недавно администрация президента США Джо Байдена (Joe Biden) ограничила экспорт в Китай памяти HBM, которая применяется в высокопроизводительных ИИ-ускорителях. Формально ByteDance придерживается санкционных ограничений: компания не ввозит ускорители напрямую в Китай, а использует их в дата-центрах, расположенных в других регионах, в частности, в Юго-Восточной Азии. Такая схема даёт возможность разворачивать ИИ-платформы с наиболее современными и производительными ускорителями. 
Источник изображения: ByteDance В частности, ранее сообщалось, что ByteDance реализует масштабный проект по расширению кампуса ЦОД в Малайзии: на создание хаба для ИИ-нагрузок будет потрачено свыше $2 млрд. Кроме того, ByteDance рассчитывает открыть новый дата-центр в Таиланде. Вместе с тем компания проектирует собственные ИИ-ускорители, которые, как ожидается, в перспективе помогут снизить зависимость от изделий NVIDIA. Так, ByteDance сотрудничает с Broadcom над 5-нм ИИ-решением, соответствующим всем ограничениям: производством этого чипа займётся тайваньская TSMC. По данным The Information, часть средств из $7 млрд ByteDance потратит на аренду вычислительных мощностей в американских облаках. Известно, что китайские организации нашли лазейку в законах США: они используют облачные сервисы Amazon, Microsoft и их конкурентов для доступа к передовым чипам и технологиям ИИ. Так, ByteDance остаётся остаётся крупнейшим потребителем сервисов Microsoft Azure OpenAI.
29.12.2024 [17:40], Владимир Мироненко
Конструктор вместо монолита: NVIDIA дала больше свободы в кастомизации GB300 NVL72Для новых суперускорителей (G)B300 компания NVIDIA существенно поменяла цепочку поставок, сделав её более дружелюбной к гиперскейлерам, то есть основным заказчиком новинок, передаёт SemiAnalysis. В случае GB200 компания поставляла готовые, полностью интегрированные платы Bianca, включающие ускорители Blackwell, CPU Grace, 512 Гбайт напаянной LPDDR5X, VRM и т.д. GB300 будут поставляться в виде модулей (дизайн Cordelia): SXM Puck B300, CPU Grace в корпусе BGA, HMC от Axiado (вместо Aspeed). А в качестве системной RAM будут применяться модули LPCAMM, преимущественно от Micron. Переход на SXM Puck даст возможность создавать новые системы большему количеству OEM- и ODM-поставщиков, а также самим гиперскейлерам. Если раньше только Wistron и Foxconn могли производить платы Bianca, то теперь к процессу сборки ускорителей могут подключиться другие. Wistron больше всех потеряет от этого решения, поскольку лишится доли рынка производителей Bianca. Для Foxconn же, которая благодаря NVIDIA вот-вот станет крупнейшим в мире поставщиком серверов, потеря компенсируется эксклюзивным производством SXM Puck. 
Источник изображений: NVIDIA Еще одно важное изменение касается VRM. Хотя на SXM Puck есть некоторые компоненты VRM, большая часть остальных комплектующих будет закупаться гиперскейлерами и вендорами напрямую у поставщиков VRM. Стоечные NVSwitch-коммутаторы и медный backplane по-прежнему будут поставляться самой NVIDIA. Для GB300 компания предлагает 800G-платформу InfiniBand/Ethernet Quantum-X800/Spectrum-X800 с адаптерами ConnectX-8, которые не попали GB200 из-за нестыковок в сроках запуска продуктов. Кроме того, у ConnectX-8 сразу 48 линий PCIe 6.0, что позволяет создавать уникальные архитектуры, такие как MGX B300A с воздушным охлаждением.  Сообщается, что все ключевые гиперскейлеры уже приняли решение перейти на GB300. Частично это связано с более высокой производительностью и экономичностью GB300, но также вызвано и тем, что теперь они сами могут кастомизировать платформу, систему охлаждения и т.д. Например, Amazon сможет, наконец, использовать собственную материнскую плату с водяным охлаждением и вернуться к архитектуре NVL72, улучшив TCO. Ранее компания единственная из крупных игроков выбрала менее эффективный вариант NVL36 из-за использования собственных 200G-адаптеров и PCIe-коммутаторов с воздушным охлаждением. Впрочем, есть и недостаток — гиперскейлерам придётся потратить больше времени и ресурсов на проектирование и тестирование продукта. Это, пожалуй, самая сложная платформа, которую когда-либо приходилось проектировать гиперскейлерам (за исключением платформ Google TPU), отметил ресурс SemiAnalysis.
28.12.2024 [01:55], Владимир Мироненко
Дороже, но втрое эффективнее: NVIDIA готовит ускорители GB300 с 288 Гбайт HBM3E и TDP 1,4 кВтNVIDIA выпустила новые ускорители GB300 и B300 всего через шесть месяцев после выхода GB200 и B200. И это не минорное обновление, как может показаться на первый взгляд — появление (G)B300 приведёт к серьёзной трансформации отрасли, особенно с учётом значительных улучшений в инференсе «размышляющих» моделей и обучении, пишет SemiAnalysis. При этом с переходом на B300 вся цепочка поставок меняется, и от этого кто-то выиграет, а кто-то проиграет. Конструкция вычислительного кристалла B300 (ранее известного как Blackwell Ultra), изготавливаемого с использованием кастомного техпроцесса TSMC 4NP. Благодаря этому он обеспечивает на 50 % больше Флопс (FP4) по сравнению с B200 на уровне продукта в целом. Часть прироста производительности будет получена за счёт увеличения TDP, достигающим 1,4 кВт и 1,2 кВт для GB300 и B300 HGX соответственно (по сравнению с 1,2 кВт и 1 кВт для GB200 и B200). Остальное повышение производительности связано с архитектурными улучшениями и оптимизациями на уровне системы, такими как динамическое распределение мощности между CPU и GPU. Кроме того, в B300 применяется память HBM3E 12-Hi, а не 8-Hi, ёмкость которой выросла до 288 Гбайт. Однако скорость на контакт осталась прежней, так что суммарная пропускная способность памяти (ПСП) по-прежнему составляет 8 Тбайт/с. В качестве системной памяти будут применяться модули LPCAMM. Разница в производительности и экономичности из-за увеличения объёма HBM намного больше, чем кажется. Усовершенствования памяти имеют решающее значение для обучения и инференса больших языковых моделей (LLM) в стиле OpenAI O3, поскольку более длинные последовательности токенов негативно влияют на скорость обработки и задержку. 
Источник изображения: NVIDIA На примере обновления H100 до H200 хорошо видно, как память влияет на производительность ускорителя. Более высокая ПСП (H200 — 4,8 Тбайт/с, H100 — 3,35 Тбайт/с) в целом улучшила интерактивность в инференсе на 43 %. А большая ёмкость памяти снизила объём перемещаемых данных и увеличила допустимый размер KVCache, что увеличило количество генерируемых токенов в секунду втрое. Это положительно сказывается на пользовательском опыте, что особенно важно для всё более сложных и «умных» моделей, которые могут приносить больше дохода с каждого ускорителя. Валовая прибыль от использования передовых моделей превышает 70 %, тогда как для отстающих моделей в конкурентной open source среде она составляет менее 20 %. 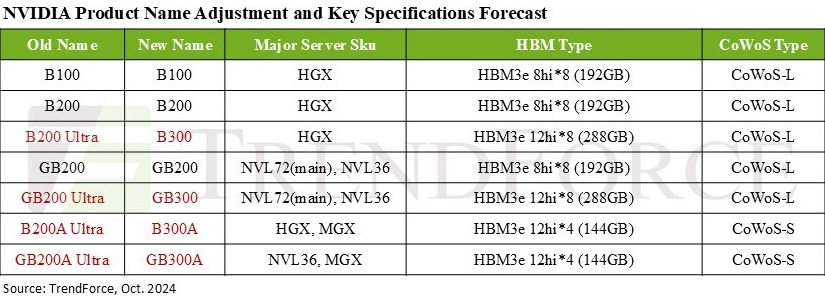
Источник изображения: TrendForce Однако одного наращивания скорости и памяти, как это делает AMD в Instinct MI300X (192 Гбайт), MI325X и MI355X (256 Гбайт и 288 Гбайт соответственно), мало. И дело не в том, что забагованное ПО компании не позволяет раскрыть потенциал ускорителей, а в особенности общения ускорителей между собой. Только NVIDIA может предложить коммутируемое соединение «все ко всем» посредством NVLink. В GB200 NVL72 все 72 ускорителя могут совместно работать над одной и той же задачей, что повышает интерактивность, снижая задержку для каждой цепочки размышлений и в то же время увеличивая их максимальную длину. На практике NVL72 — единственный способ увеличить длину инференса до более чем 100 тыс. токенов и при этом экономически эффективный, говорит SemiAnalysis. По оценкам, GB300 NVL72 обойдётся заказчиками минимум в $7,5 млн, тогда как GB200 NVL72 стоил порядка $3 млн.
26.12.2024 [18:17], Руслан Авдеев
Omdia: быстрый рост спроса на TPU Google ставит под вопрос доминирование NVIDIA на рынке ИИ-ускорителейНовейшее исследование Omdia показывает, что быстрый рост спроса на кастомные ИИ-ускорители Google (TPU) формирует особый тренд. Не исключено, что он станет достаточно сильным для того, чтобы начать процесс, способный прекратить доминирование NVIDIA на рынке ускорителей, сообщает Omdia. Результаты III квартала компании Broadcom, чьё подразделение Semiconductor Solutions выполняет аутсорс-заказы Google, Meta✴ и некоторых других IT-гигантов, дают по-новому взглянуть на рынок ускорителей. В частности, они позволяют оценить покупательские тенденции и косвенно получить информацию, которая обычно скрывается. Например, как много кастомных процессоров покупает Google. Глава Broadcom Хок Тан (Hock Tan) неоднократно пересматривал планы выручки от ИИ-полупроводников, в этом году компания намерена заработать $12 млрд. Исходя из этого ожидается, что на TPU Google придётся от $6 млрд (близко к текущим оценкам Omdia) до $9 млрд, в зависимости от распределения выручки между вычислительными и сетевыми решениями. В сумму целиком входит и выручка от чипов Meta✴ MTIA. В следующем году у Broadcom, вероятно, появится и загадочный третий заказчик. Им может стать Apple, которая сейчас активно использует для обучения моделей именно TPU. 
Источник изобраджения: Google По словам экспертов Omdia, даже с учётом того, что соотношение выручки от вычислительных и сетевых устройств точно не определено, поставки TPU даже «по нижней границе» в $6 млрд свидетельствуют о росте достаточно быстром, чтобы впервые отвоевать часть доли рынка у NVIDIA. По оценкам TechInsights, в 2023 году поставки TPU достигли 2 млн шт., а ускорителей NVIDIA для ЦОД — 3,8 млн шт. Стоит отметить, что выручка бизнеса Google Cloud Platform продолжает расти как часть выручки Google, при этом растёт и рентабельность подразделения. Это может свидетельствовать о том, что инстансы на основе TPU выступают драйверами роста Google Cloud и являются высокоприбыльными продуктами. В середине ноября Google и NVIDIA показали первые результаты TPU v6 и B200 в ИИ-бенчмарке MLPerf Training, где ускорители продемонстрировали неоднозначные результаты в разных сравнениях.
25.12.2024 [01:00], Владимир Мироненко
Гладко было на бумаге: забагованное ПО AMD не позволяет раскрыть потенциал ускорителей Instinct MI300XАналитическая компания SemiAnalysis опубликовала результаты исследования, длившегося пять месяцев и выявившего большие проблемы в ПО AMD для работы с ИИ, из-за чего на данном этапе невозможно в полной мере раскрыть имеющийся у ускорителей AMD Instinct MI300X потенциал. Проще говоря, из-за забагованности ПО AMD не может на равных соперничать с лидером рынка ИИ-чипов NVIDIA. При этом примерно три четверти сотрудников последней заняты именно разработкой софта. Как сообщает SemiAnalysis, из-за обилия ошибок в ПО обучение ИИ-моделей с помощью ускорителей AMD практически невозможно без значительной отладки и существенных трудозатрат. Более того, масштабирование процесса обучения как в рамках одного узла, так и на несколько узлов показало ещё более существенное отставание решения AMD. И пока AMD занимается обеспечением базового качества и простоты использования ускорителей, NVIDIA всё дальше уходит в отрыв, добавляя новые функции, библиотеки и повышая производительность своих решений, отметили исследователи. 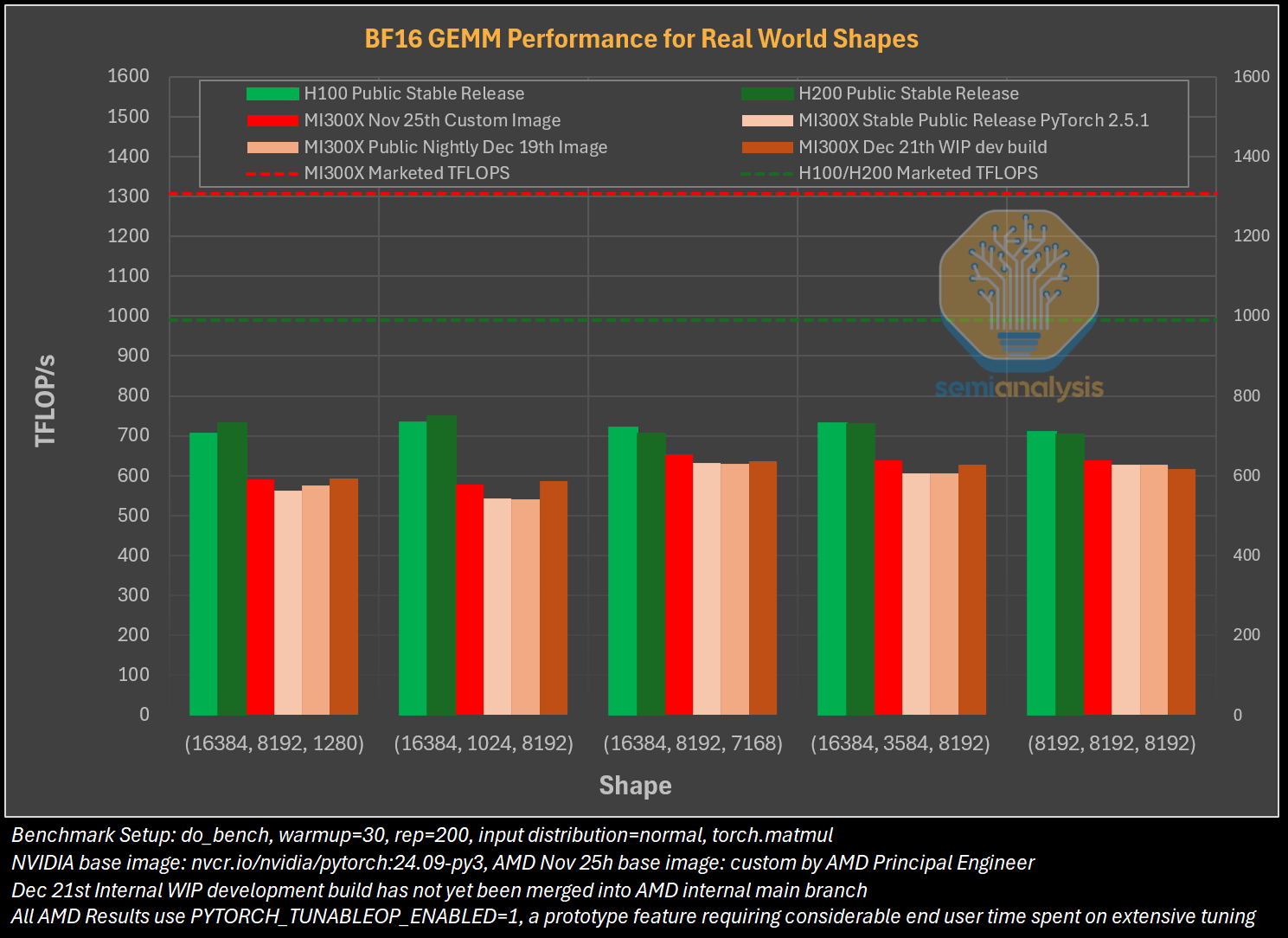
Источник изображений: SemiAnalysis На бумаге чип AMD Instinct MI300X выглядит впечатляюще с FP16-производительностью 1307 Тфлопс и 192 Гбайт памяти HBM3 в сравнении с 989 Тфлопс и 80 Гбайт памяти у NVIDIA H100. К тому же чипы AMD предлагают более низкую общую стоимость владения (TCO) благодаря более низким ценам и использованию более дешёвого интерконнекта на базе Ethernet. Но проблемы с софтом сводят это преимущество на нет и не находят реализации на практике. При этом исследователи отметили, что в NVIDIA H200 объём памяти составляет 141 Гбайт, что означает сокращение разрыва с чипами AMD по этому параметру. Кроме того, внутренняя шина xGMI лишь формально обеспечивает пропускную способность 448 Гбайт/с для связки из восьми ускорителей MI300X. Фактически же P2P-общение между парой ускорителей ограничено 64 Гбайт/с, тогда как для объединения H100 используется NVSwitch, что позволяет любому ускорителю общаться с другим ускорителем на скорости 450 Гбайт/с. А включённый по умолчанию механизм NVLink SHARP делает часть коллективных операций непосредственно внутри коммутатора, снижая объём передаваемых данных. 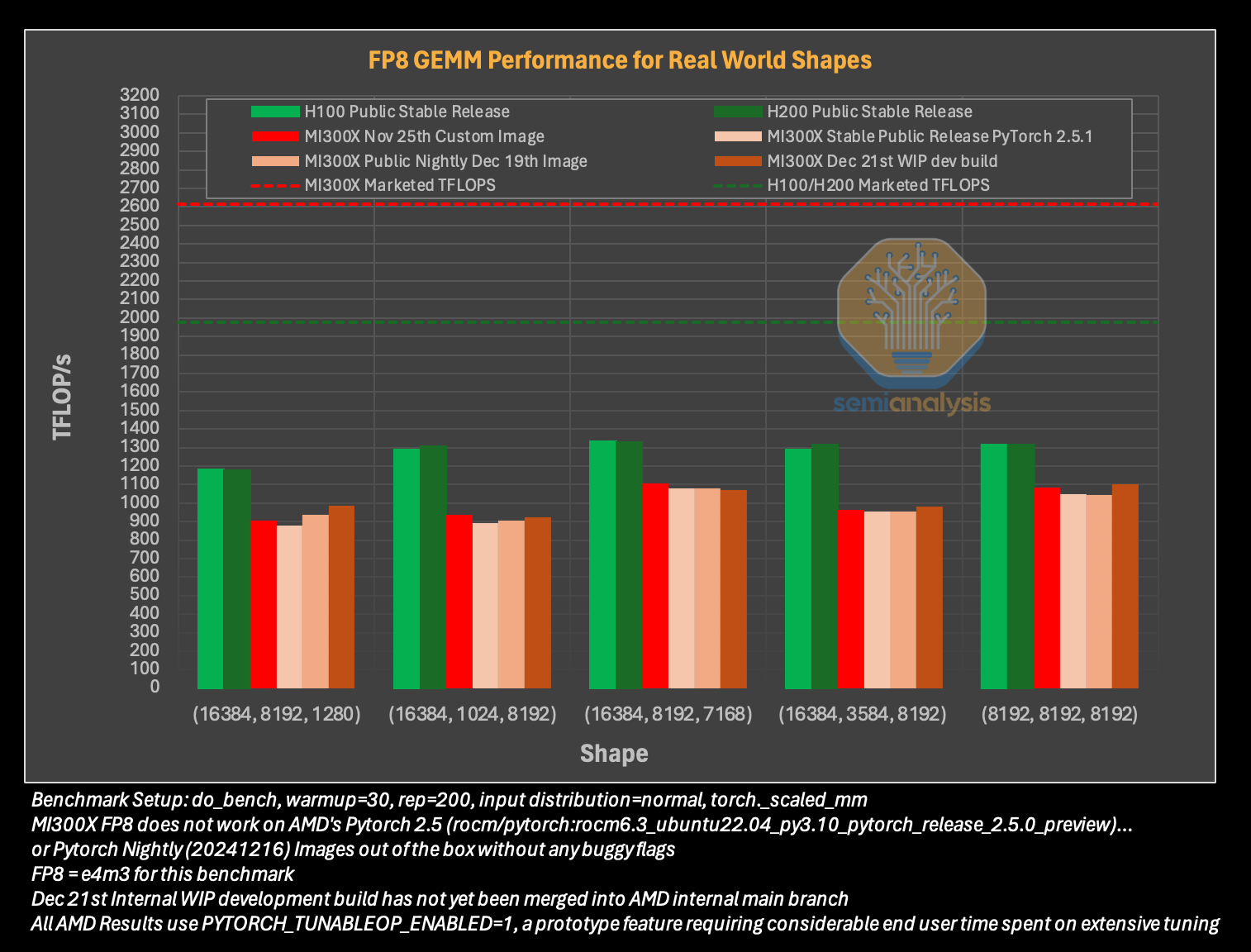 Как отметили в SemiAnalysis, сравнение спецификаций чипов двух компаний похоже на «сравнение камер, когда просто сверяют количество мегапикселей», и AMD просто «играет с числами», не обеспечивая достаточной производительности в реальных задачах. Чтобы получить пригодные для аналитики результаты тестов, специалистам SemiAnalysis пришлось работать напрямую с инженерами AMD над исправлением многочисленных ошибок, в то время как системы на базе NVIDIA работали сразу «из коробки», без необходимости в дополнительной многочасовой отладке и самостоятельной сборке ПО. В качестве показательного примера SemiAnalysis рассказала о случае, когда Tensorwave, крупнейшему провайдеру облачных вычислений на базе ускорителей AMD, пришлось предоставить целой команде специалистов AMD из разных отделов доступ к оборудованию с её же ускорителями, чтобы те устранили проблемы с софтом. Обучение с использованием FP8 в принципе не было возможно без вмешательства инженеров AMD. Со стороны NVIDIA был выделен только один инженер, за помощью к которому фактически не пришлось обращаться. 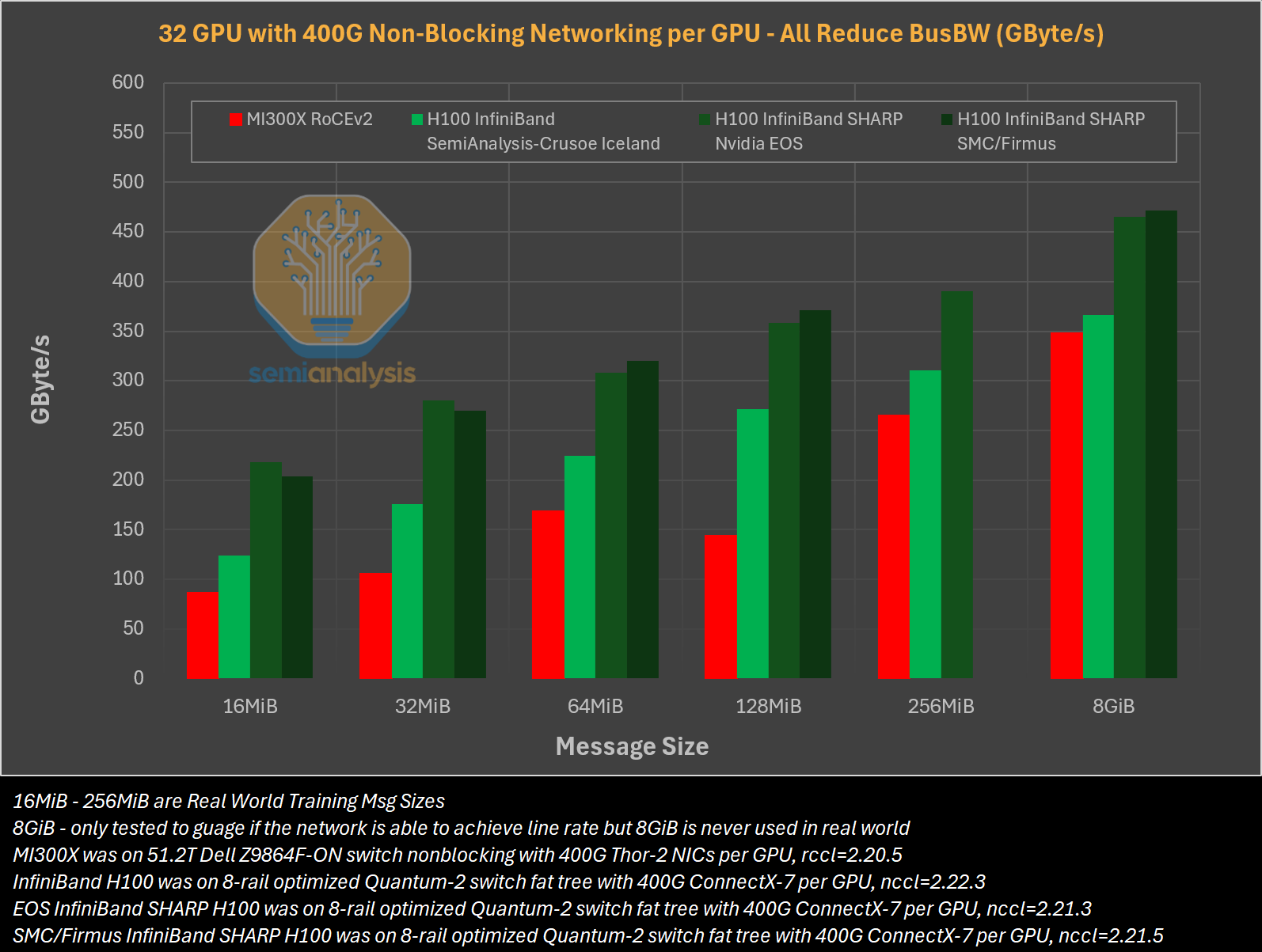 У AMD есть лишь один выход — вложить значительные средства в разработку и тестирование ПО, считают в SemiAnalysis. Аналитики также предложили выделить тысячи чипов MI300X для автоматизированного тестирования, как это делает NVIDIA, и упростить подготовку окружения, одновременно внедряя лучшие настройки по умолчанию. Проблемы с ПО — основная причина, почему AMD не хотела показывать результаты бенчмарка MLPerf и не давала такой возможности другим. В SemiAnalysis отметили, что AMD предстоит немало сделать, чтобы устранить выявленные проблемы. Без серьёзных улучшений своего ПО AMD рискует еще больше отстать от NVIDIA, готовящей к выпуску чипы Blackwell следующего поколения. Для финальных тестов Instinct использовался специально подготовленный инженерами AMD набор ПО, который станет доступен обычным пользователям лишь через один-два квартала. Речь не идёт о Microsoft или Meta✴, которые самостоятельно пишут ПО для Instinct. Один из автором исследования уже провёл встречу с главой AMD Лизой Су (Lisa Su), которая пообещала приложить все усилия для исправления ситуации. |
|

