Материалы по тегу: сбой
|
22.04.2026 [15:37], Руслан Авдеев
Anthropic ищет аналитика для оценки геополитических рисков и угроз персоналу, офисам и дата-центрамКомпания Anthropic ищет «аналитика в области геополитической разведке» (Geopolitical Intelligence Analyst), готового оценивать риски для её сотрудников и бизнес-процессов со стороны государств, сообщает Datacenter Dynamics. Специалист войдёт в состав глобальной команды компании, занимающейся вопросами безопасности, разведки и защиты. Предполагается, что аналитик станет «проводить сбор и анализ развединформации из всех источников» — для выявления, оценки и выстраивания приоритетов в сфере геополитических рисков и угроз со стороны государственных структур «для компании Anthropic, её персонала и деятельности». В том числе речь идёт о поиске возникающих очагов напряжённости геополитического уровня, политических изменений и макро-трендов, способных повлиять на работу Anthropic или стратегическое позиционирование компании. Согласно тексту вакансии, предполагается подготовка аналитики для руководства Anthropic, от срочных сводок до стратегических оценок регионов и стран. Предусмотрен учёт международной обстановки при принятии компанией решений, мониторинг потенциальных кризисов, политических изменений и глобальных тенденций. Необходима оценка рисков для поездок сотрудников, международной экспансии, размещения объектов и др. Также потребуется взаимодействие с внешними экспертами, государственными структурами и отраслевыми партнёрами — для обмена информацией об угрозах компаниям, действующих на рынке передовых ИИ-решений. Ожидается, что соискатель будет иметь степень бакалавра в области международных отношений, политологии или смежных дисциплин, иметь 5–8 лет опыта анализа геополитических рисков, независимо действовать с минимальным контролем со стороны руководства, а также работать по гибкому графику, постоянно находясь на связи в случае международных кризисов и важных геополитических событий в целом. 
Источник изображения: mostafa meraji/unspalsh.com Сейчас компания работает из США, её штаб-квартира находится в Сан-Франциско, а дата-центры строятся по всей стране. Имеются офисы в Германии, Франции, Ирландии, Индии и Швейцарии. Дополнительно компания рассчитывает открыть региональные штаб-квартиры в Великобритании и Австралии. Также в Европе и Австралии планируется аренда ЦОД. Геополитические риски глобальной инфраструктуре ЦОД нельзя игнорировать, поскольку только в последние недели Иран поразил несколько дата-центров американских компаний в ОАЭ и Бахрейне, а также пригрозил атаковать строящийся в рамках проекта OpenAI Stargate гигантский ЦОД G42 в ОАЭ. OpenAI сталкивалась с угрозами и в США, хотя речь шла об отдельных лицах, а не собственно государстве. Так, нападению дважды подвергся дом главы компании Сэма Альтмана (Sam Altman). Сама Anthropic тоже стала жертвой угроз, но в её случае к этому приложили руку непосредственно американские власти. Пентагон назвал Anthropic угрозой для цепочки поставок после того, как компания отказалась предоставлять услуги на условиях военного ведомства, требовавшего организовать массовое наблюдение и поддержку использования полностью автономного оружия. Ситуацией попытались воспользоваться британцы, которые готовят Anthropic предложение по расширению присутствия в Соединённом Королевстве. В частности, якобы будет предложено расширение офиса Anthropic в Лондоне и «двойной листинг».
13.04.2026 [09:23], Руслан Авдеев
Не рассчитали: переход вузов Миннесоты на Workday обошёлся вдвое дороже планируемого и привёл к ошибкам в начислении зарплатВнедрение платформы управления персоналом и финансами Workday в системе университетов и колледжей Миннесоты MnSCU (Minnesota State Colleges and Universities) вместо упрощения работы привело лишь к проблемам, сообщает The Register. Выборочный аудит выявил ошибки в расчёте заработной платы преподавателям и другим сотрудникам, а также задержки с выплатами. MnSCU объединяет 54 кампуса, 270 тыс. студентов, 14,2 тыс. преподавателей и других сотрудников. В 2019 году начался процесс закупки ПО для замены устаревшей ERP-системы Integrated Statewide Record System (ISRS). Новое ПО объединяет модули учёта финансов, расчёта зарплат, управления кадрами и студентами. На практике стало ясно, что использовать единую систему для всех задач, похоже, не удастся. По словам аудиторов OLA, в MnSCU знали о проблемах с начислением заработной платы ещё до внедрения платформы Workday, но после её внедрения проблемы усугубились. Сейчас образовательная система штата вынужденно используют комбинацию Workday, устаревшей бухгалтерской системы для начисления зарплат и HR-платформу SEMA4. Согласно отчёту Office of the Legislative Auditor (OLA), выборочная проверка данных о 202 преподавателях и сотрудниках показала, что 19 из них неверно начислена зарплата. После дополнительной проверки выявлено ещё 38 пострадавших преподавателей. Попутно были выявлены и задержки с выплатами. Первоначально бюджет программы перехода на новое ПО составлял $151,1 млн. После заключения контракта с Workday в 2020 году он до $242,7 млн. Планировалось, что системы управления персоналом и начисления заработной платы заработают в июле 2023 года, а «студенческая» составляющая — осенью 2026 года. К ноябрю 2024 года бюджет проекта вырос до $290,4 млн, а сроки реализации обеих подсистем сдвинулись на июль 2024 года и осень 2029 года соответственно. 
Источник изображения: Kenny Eliason/unspalsh.com С трудностями при реализации проектов Workday столкнулись и другие. Так, в 2024 году Айова расторгла договор на поставку финансового ПО Workday из-за «проблем в реализацией». В 2021 году Мэн обвинил Workday в безответственности при неудачной замене HR-системы стоимостью $54,6 млн. Теперь штат использует гибрид системы Workday со сторонним ПО. В Вашингтонском университете проект перехода на Workday растянулся на семь лет и обошёлся в $266 млн, что вызвало массовые протесты студентов, на плечи которых фактически легла повышенная финансовая нагрузка. Workday в комментарии The Register отметила, что сотрудничала с «сотнями учреждений по всему миру» для внедрения своих облачных сервисов. Как и любой крупный технологический проект, переход от устаревших систем к современным централизованным решениям — сложный процесс. В подобных долгосрочных проектах в ходе внедрения часто изменяется объём работ, что может повлиять на стоимость и сроки. Кроме того, решение непредвиденных задач в проектах подобного масштаба — обычное дело. В декабре 2024 года Workday заявила, что более 90 % внедрений решений компании проходят успешно, а с учётом масштаба внедрений статистика для отрасли просто «беспрецедентная». Между тем цена ошибок хорошо известна в Великобритании. Внедрение ERP-системы Oracle в течение многих лет фактически превратило в банкрота Бирмингем, раздув бюджет проекта до неприличных значений в сотни миллионов фунтов — запуск системы всё ещё откладывается. Кроме того, Почта Великобритании и Fujitsu перекладывают друг на друга вину за провальное внедрение ПО Horizon, в результате сбоев в котором пострадали сотни людей, а некоторые из них даже понесли уголовную ответственность.
09.04.2026 [13:08], Руслан Авдеев
Президент Microsoft намекнул на создание защищённых ЦОД в свете войны на Ближнем ВостокеПосле начала атак США и Израиля на Иран и последовавших ответных ударов, в том числе по инфраструктуре ЦОД американских компаний, Microsoft, вероятно, пересмотрит подходы к проектированию и строительству новых дата-центров, сообщает The Register. По информации издания, президент компании Брэд Смит (Brad Smith) заявил в одном из недавних интервью, что атаки со временем окажут влияние на проектирование и строительство ЦОД, но это влияние может отличаться от региона к региону. Судя по всему, речь идёт о создании защищённой инфраструктуры. Дополнительно Смит призвал к принятию строгих международных правил, «способствующих защите гражданской инфраструктуры». По его мнению, к ней относятся и дата-центры. Microsoft привыкла к кибератакам на свою инфраструктуру, но атак на её дата-центры вне цифрового пространства пока не регистрировали. Тем временем в ходе конфликта Иран уже атаковал дата-центры как в ОАЭ, так и в Бахрейне. По данным иранских государственных СМИ, удары нанесены намеренно, атаки обоснованы тем, что ЦОД могут использоваться для поддержки как военных, так и разведывательных операций США. На днях Иран дополнительно пригрозил ударами по дата-центрам OpenAI, строящимся в Абу-Даби (ОАЭ). Это крупнейший проект в рамках Stargate за пределами США, реализуемый при участии местной компании G42. 
Источник изображения: Mario La Pergola/unsplash.com Сеть дата-центров Microsoft на Ближнем Востоке весьма развита. В управлении компании имеются объекты в ОАЭ, Катаре и Израиле. В конце 2026 года планируется начать работу в Саудовской Аравии. При этом дата-центры компании в регионе, вероятно, находятся в пределах досягаемости иранских средств поражения, но ни один из них, судя по всему, не пострадал. Ещё в 2024 году бывший глава Google Эрик Шмидт (Eric Schmidt) прогнозировал, что в будущем дата-центры США и Китая, вероятно, будут защищаться военными базами. После нападения на Иран и ответных ударов, считают эксперты, придётся пересмотреть подход к обеспечению отказоустойчивости облаков с учётом возможных атак на физическую инфраструктуру.
09.04.2026 [09:21], Руслан Авдеев
Оператор AT&T жалуется на засилье «медных ОПГ», ворующих её кабелиПо словам AT&T, в 2025 году только она одна пострадала от более 10 тыс. случаев воровства меди, общий ущерб составил $82 млн. Возможно, это послужит дополнительным стимулом для общеотраслевого перехода с медных сетей на современные ВОЛС, сообщает SDX Central. В блоге компании указывается, что к концу 2025 года регистрировалось порядка 200 инцидентов еженедельно. Подавляющее большинство пришлось на Калифорнию — 7,3 тыс. краж, ущерб $54 млн. По словам компании, кража медных элементов и кабелей влияет на связь, транспорт, освещение и доступность сервисов. Речь идёт не просто о нарушении надёжности сетей связи, но и сбоям в транспортной инфраструктуре, обесточивании целых районов и др. Впрочем, когда для самой компании избавление от старых кабелей не слишком выгодно, она всеми силами старается избежать этого. Кража меди — весьма серьёзная проблема в Калифорнии. Действуют настоящие ОПГ, привлекающие для «работы» в том числе и тяжёлую технику и совершающие одновременные кражи на одних и тех же линиях. Так, в 2025 году тысячи жителей Южной Калифорнии остались без света, в результате чего губернатор штата подписал законопроект, обязавший торговцев металлоломом и перерабатывающие компании получать подробную информацию о продавцах, запрещавший хранение лома «жизненно важной инфраструктуры» без документов о её происхождении. 
Источник изображения: Johnyvino / Unsplash Публикация в блоге AT&T появилась вскоре после того, как Федеральная комиссия по связи США (FCC) проголосовала за отмену ряда правил, усложнявших телеком-операторам отказ от медных сетей и тормозивших развёртывание современной инфраструктуры. Ранее AT&T декларировала намерение полностью вывести из эксплуатацию медные сети к 2029 году. Планируется расширение ВОЛС, а также FWA на базе 5G, в том числе в качестве временного решения на время перехода на оптоволоконные сети. Ранее AT&T сообщала, что медными подключениями пользуются всего около 3 % клиентов. Переход на оптоволокно — весьма своевременная мера. В январе сообщалось, что электрификация промышленности, транспорта и подогреваемый ИИ бум в сфере IT-инфраструктуры сказывается на спросе на медь, используемой буквально повсеместно. Исследование S&P Global позволяет предположить, что производство металла в мире достигнет пика в 2030 году. В результате возникнет дефицит в объёме порядка 10 млн т без дальнейшего существенного увеличения добычи, что может привести к стремительному росту цен на медь, из-за которого IT-оборудование значительно подорожает. Впрочем, другие операторы сами стараются не просто избавиться от медных сетей, но и отправить кабели на переработку, попутно заработав на цветмете — суммарно до $10 млрд. Одна только британская BT выручит £105 млн.
08.04.2026 [12:40], Руслан Авдеев
Иран угрожал США уничтожением ИИ ЦОД OpenAI Stargate в ОАЭВ ответ на ультиматум США, пригрозивших Ирану уничтожением электростанций и мостов, представители иранских властей пообещали сравнять с землёй один из флагманских кампусов ЦОД проекта Stargate в Абу-Даби (ОАЭ), сообщает eWeek. В соцсети X опубликовано заявление с видео скрытого на картах Google кампуса. 
Источник изображения: Malik Shibly/unsplash.com Незадолго до этого КСИР назвал 18 американских компаний, включая Apple, Microsoft, NVIDIA и Tesla законными военными целями. При этом конкретные объекты не назывались, кампус Stargate стал первым, о котором упомянули официально. При этом кампус G42, где размещаются мощности Stargate — не просто один из множества, это один из крупнейших кампусов Stargate в мире. Объект стоимостью $30 млрд по плану получит 5 ГВт мощностей и 500 тыс. ИИ-ускорителей NVIDIA. Предполагается, что кампус станет сердцем проекта за пределами США. Облачная и ИИ-инфраструктура, связанная с американскими бизнесами, уже пострадала от иранских ударов. Это коснулось мощностей AWS в ОАЭ и Бахрейне. Как сообщает Datacenter Dynamics, в начале апреля КСИР заявил об атаках на кампус Oracle, также названной в числе «законных целей». По некоторым данным, пострадало здание компании в технопарке Dubai Internet City. Впрочем, официального подтверждения Oracle пока так и не поступало.
02.04.2026 [15:52], Руслан Авдеев
Fujitsu сократит 10 % сотрудников британского подразделения, чтобы хоть как-то справиться с многолетним скандалом с Почтой ВеликобританииFujitsu объявила о намерении организовать «добровольное» увольнение в Великобритании с целью сокращения штата почти на 10 %, хотя за последние два года британское подразделение получило £280 млн от головного офиса в Японии, а на днях — ещё £80 млн. При отсутствии нужного количества добровольцев компания готова прибегнуть и к принудительным сокращениям, сообщает Computer Weekly. Дела британского подразделения Fujitsu идут неважно после обнародования информации о проблемах с ПО, поставленном Почте Великобритании. Компания лишилась значительной доли заказов в британском госсекторе и не может выиграть новые тендеры, в том числе в частном секторе. Fujitsu заявляет, что новые меры — начало трансформации компании, и она продолжит инвестиции в те области бизнеса, которые нужнее всего клиентам. Fujitsu намерена сократить 425 человек, из них 270 в подразделении UK Delivery, которое отвечает за предоставление IT-услуг и поддержку клиентов. Впрочем, увольнения коснутся всех отделов. В январе компания попросила операционного директора сократить расходы на 10 %. Ранее компания лишилась контракта с британской налоговой службой (HMRC) на £245 млн, что уже коснулось около сотни сотрудников — часть из них перейдёт к новому подрядчику Netcompany по схеме TUPE (защита прав сотрудников при смене работодателя), часть будет сокращена. 
Источник изображения: Martina Carinci/unsplash.com После появления в СМИ новостей о ПО Horizon, от ошибок которого пострадали сотни почтовых служащих в Великобритании, компания добровольно отказалась от участия в тендерах на новые госзаказы до завершения расследования. Ожидается, что главный отчёт будет опубликован не раньше конца 2026 года. Компания подверглась суровой критике британских парламентариев за то, что до сих пор не определила, какую сумму выделит на покрытие расходов, связанных со скандалом, обошедшемся налогоплательщикам в миллиарды фунтов. Некоторые уже прозвали Fujitsu «паразитом» и потребовали сотни миллионов фунтов за нанесённый ущерб. Хотя парламентарии не отрицают вины других участников, от руководства Почты до судов, подчёркивается, что именно Fujitsu фактически меняла данные в бухгалтерских отчётах сотрудников почтовых отделений, утверждая, что не делает этого, а затем фактически вступила в сговор с руководством Почты Великобритании, чтобы добиться неправосудных судебных решений. Тысячи несправедливо осуждённых британцев всё ещё не получили компенсации, пока Почта Великобритании и Fujitsu перекладывают вину друг на друга.
02.04.2026 [14:54], Руслан Авдеев
Иран нанёс новый удар по облачному ЦОД AWS в БахрейнеИран поразил ЦОД в Бахрейне, где размещены мощности AWS ME-SOUTH-1 — это стало редким случаем прямого воздействия на облачную инфраструктуру в зоне активного регионального конфликта. По информации издания Financial Times, ссылающегося на данные властей Бахрейна, удар, ответственность за который возлагается на Иран, привёл к пожару в ЦОД. Впрочем, имя оператора прямо не называлось. Инцидент случился вскоре после того, как КСИР предупредил, что связанные с США технологические компании, действующие в регионе, включая Microsoft, Apple, Google и т.д., могут стать мишенями для силовых акций. Сама Amazon ситуацию пока не комментирует. По мнению экспертов, удар наглядно демонстрирует изменение концепции современных конфликтов, в ходе которых теперь под угрозой новый вид целей — помимо объектов нефтегазового комплекса и судоходных путей, страдает и цифровая инфраструктура глобального значения. ЦОД в Бахрейне является частью широкой сети облачных регионов, обеспечивающих низкую задержку при использовании различных сервисов. Любые сбои в работе таких объектов способны повлиять на работу сервисов, включая механизмы переключения на резервные мощности. Облачные сервисы AWS в регионе обеспечивают работу в том числе банковских систем, авиаперевозчиков, логистических компаний, госаппаратов местных стран и т.д. Любые сбои подобных систем могут привести к каскадным последствиям для самых разных отраслей и регионов. 
Источник изображения: Zoltan Tasi/unsplash.com Данные о повреждениях ставят под вопрос защищённость и стабильность облачной инфраструктуры, особенно в геополитически нестабильных регионах. В отличие от физических цепочек поставок, цифровые системы считались довольно устойчивыми, но концентрация ЦОД в отдельных локациях может представлять реальную угрозу для работы всевозможных сервисов. Инцидент свидетельствует и о растущем значении гибридной войны — кибератаки на инфраструктуру применялись довольно широко, но физические удары по ЦОД и объектам связи до недавних пор считались редкостью. 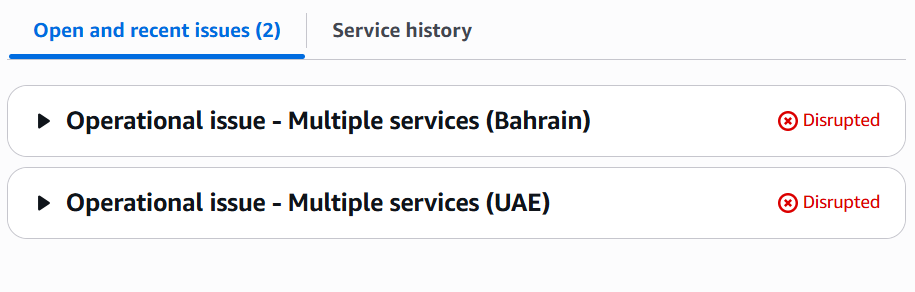 Месяц назад три дата-центра AWS в регионе уже пострадали от ударов беспилотников, но тогда сам ЦОД в Бахрейне не был повреждён — только сопутствующая инфраструктура. Оба облачных региона, в ОАЭ (ME-CENTRAL-1) и Бахрейне (ME-SOUTH-1), работали с перебоями. AWS порекомендовала пользователям по возможности перенести данные и нагрузки в другие облачные регионы, а также полностью обнулила для клиентов ME-CENTRAL-1 все счета за март и биллинговые данные. Атака на ближневосточные объекты AWS заставит пересмотреть подход к отказоустойчивости облаков, а эскалация конфликта на Ближнем Востоке угрожает буму ИИ ЦОД в регионе. UPD: Иран взял на себя ответственность за атаку на ЦОД AWS в Бахрейне. По словам КСИР, объект уничтожен.
28.03.2026 [13:40], Сергей Карасёв
В России наблюдаются массовые сбои оборудования в устаревающих ЦОДЗа последние полгода в России резко возросло количество аварий в дата-центрах, созданных 10–15 лет назад. Речь идёт, в частности, о многочисленных сбоях в небольших коммерческих ЦОД и на локальных площадках некрупных компаний. О проблеме сообщает РБК, ссылаясь на информацию, полученную от участников рынка, интеграторов и отраслевых аналитиков. «К2Теха» сообщила, что за шесть месяцев в компанию поступили более десятка обращений от владельцев дата-центров, у которых инженерная инфраструктура «находится в предсмертном состоянии». В I половине 2025-го и раньше подобных запросов вообще не фиксировалось. Об увеличении количества сбоев в устаревающих ЦОД также говорит «Ультиматек». По оценкам, с проблемой столкнулись около 20 % коммерческих дата-центров в России. Связано это с тем, что техника, которая находилась в эксплуатации более 10–15 лет, приблизилась к концу своего жизненного цикла. Из строя в массовом порядке выходят аккумуляторы в ИБП, дизель-генераторные установки, охлаждающее оборудование и другие компоненты. Наблюдающаяся ситуация может привести к крайне негативным последствиям, включая остановку конвейеров в промышленности, отключение кассовых аппаратов, нарушение логистики, а также коллапс сервисов в финансовом секторе, пишет РБК. 
Источник изображения: Evan Yang / Unsplash Проблема усугубляется из-за сформировавшейся экономической и геополитической обстановки. Из-за ухода зарубежных производителей из России отечественные компании столкнулись с трудностями при закупке необходимых запчастей и обновлении парка техники. При этом стоимость иностранной продукции растет, тогда как во многих организациях урезаны бюджеты, из-за чего средств на плановую модернизацию не хватает. Частично решить проблему можно путем замены узлов на китайские или российские альтернативы, однако такой подход возможен не во всех случаях. Некоторые участники рынка заблаговременно сформировали запас комплектующих. Так, IXcellerate сообщила, что у неё на складе есть достаточно компонентов для работы дата-центров без аварий и замены элементов инфраструктуры «в течение ближайших десяти лет». А РТК-ЦОД («Ростелеком») говорит, что нашла «доступные аналоги» и у неё нет проблем.
24.03.2026 [15:25], Руслан Авдеев
Работа облака AWS в Бахрейне снова нарушена в результате активности беспилотниковКомпания Amazon объявила, что региональное подразделение Amazon Web Services (AWS), расположенное в Бахрейне, пострадало от «нарушения работы», связанного с текущим конфликтом на Ближнем Востоке. Это уже второй случай за месяц, когда в регионе страдает инфраструктура ЦОД компании, напоминает Reuters. Сбой в работе AWS вызван активностью в районе ЦОД беспилотников. Впрочем, пока подробностей нет, а Amazon пока не ответила на запрос о том, был ли объект в Бахрейне непосредственно атакован беспилотниками или сбой вызван ударами дронов по объектам в близлежащей округе. Компания помогает клиентам перевести свои данные в другие регионы AWS, пока работа не будет восстановлена, но масштаб ущерба и вероятная продолжительность отсутствия обслуживания не разглашаются. Регион AWS в Бахрейне пострадал после начала активной фазы конфликта на Ближнем Востоке уже второй раз. Ранее в марте AWS объявила, что зоны доступности в Бахрейне и ОАЭ пострадали в результате удара БПЛА, оставшись без электроснабжения. Сообщалось, что компания работает над восстановлением работоспособности инфраструктуры, включая перенос вычислительных нагрузок в другие облачные регионы. 
Источник изображения: Afsal Shaji/unsplash.com По данным Reuters, удар по объекту в ОАЭ носит знаковый характер — это первый случай, когда военные действия нарушили работу объекта одной из крупнейших американских технологических компаний. Из-за структурных повреждений Amazon ориентировалась на «длительный» период восстановления работоспособности. Сообщается, что удары «причинили структурный ущерб, нарушили подачу электричества, а в некоторых случаях потребовалось тушение пожаров, что вызвало дополнительный ущерб от воды». На момент первых атак Amazon заявила, что расположенный в Бахрейне регион пострадал от удара беспилотника «в непосредственной близости» от одного из объектов компании.
24.03.2026 [12:03], Руслан Авдеев
Финская разведка сомневается, что Россия занимается саботажем подводных кабелей в Балтийском мореНа днях финская Полиция безопасности (SUPO), занимающаяся разведкой, охраной и пр. в Финляндии и за её пределами, опубликовала доклад 2026 National Review. В нём заявляется, что умышленное повреждение Россией подводных силовых и интернет-кабелей на Балтике маловероятно, сообщает Converge Digest. По мнению SUPO, отсутствуют какие-либо свидетельства того, что саботаж стал причиной отключений электроэнергии и обрывов ВОЛС, хотя большая часть относительно недавних повреждений в Балтийском регионе пришлась именно на финскую инфраструктуру. Агентство отметило, что саботаж не отвечает интересам самой России, поскольку способен поставить под угрозу свободу судоходства в акватории Балтийского моря. По оценкам SUPO, Россия прилагает все усилия для сохранения свободы судоходства в своих интересах. Кроме того, Балтийское море является и цифровым подводным «окном» для передачи трафика на Запад и обратно, большая часть данных в этом направлении передаётся по кабелям в Балтийском море. Как считают представители спецслужбы, действия на государственном уровне всегда имеют цель и мотив, они всегда должны приносить выгоду исполнителю. Простое внесение толики хаоса в этой акватории навредило бы в том числе и России. Кроме того, в ходе последних инцидентов на Балтике с кораблями, обрывавшими кабель якорями, пострадала не только западная, но и российская инфраструктура. Кроме того, по тем же западным интернет-кабелям действительно направляется и российский трафик — большинство российских операторов используют Хельсинки в качестве телекоммуникационного узла. 
Источник изображения: John/unsplash.com Считается, что для РФ важно сохранение свободы передвижения т.н. «теневого флота», который, по оценкам SUPO резко нарастил грузоперевозки. При этом относящиеся к нему корабли часто находятся в плохом состоянии, а Балтийское море само по себе мелководно. В то же время за последние пять лет количество кабелей на его дне удвоилось. Другими словами, SUPO предполагает, что количество обрывов увеличилось по «естественным» причинам из-за роста количества кораблей на мелководье, но резкого увеличения количества обрывов нет. Указывается и на высокую устойчивость балтийской телеком-сети. На состояние интернета в регионе мало влияют даже многочисленные одновременные сбои в кабельной инфраструктуре. Например, несколько обрывов кабелей между Финляндией и Европой лишь несколько замедлят соединение. Более того, на деле инциденты с кабелями происходят на Балтике десятилетиями. SUPO отмечает, что последние инциденты стали заметны в основном благодаря СМИ. Так, в конце января 2025 года зафиксировано повреждение подводного оптоволоконного кабеля компании LVRTC, соединяющего Латвию и Швецию. Ещё раньше получили повреждения четыре интернет-кабеля и один силовой. А ещё раньше, в ноябре 2024 года, были повреждены интернет-кабели, связывающие Финляндию и Германию, Литву и Швецию. Хотя данных об умышленных повреждениях инфраструктуры нет и причиной обрывов названа низкая квалификация экипажей кораблей, НАТО анонсировала программу Baltic Sentry по защите кабелей, а Швеция направила в Балтийское море три корабля и самолёт для патрулирования. В дополнение Германия начала патрулирование акватории Балтийского моря с использованием подводного беспилотного аппарата израильской Elta Systems. В минувшем январе Финляндия задержала судно Fitburg в связи с повреждением подводного интернет-кабеля в Балтийском море. Позже сообщалось, что судно было отпущено, но часть команды была задержана властями. |
|

