Материалы по тегу: инференс
|
23.02.2026 [23:22], Владимир Мироненко
Astera Labs по-тихому купила PliopsAstera Labs приобрела Pliops, сообщил ресурс StorageNewsletter со ссылкой на заявление Мариуса Тудора (Marius Tudor), бывшего директора по развитию бизнеса Pliops, подтвердившего факт сделки на своей странице в соцсети LinkedIn. Финансовых подробностей о сделке не сообщается. Ресурс допустил, что компания приобрела Pliops для своего первого научно-исследовательского центра в Израиле. О создании своего передового R&D-центра в Израиле Astera Labs сообщила в начале февраля. Предполагается, что новый центр с офисами в Тель-Авиве и Хайфе ускорит разработку масштабируемых сетей следующего поколения для протоколов высокоскоростной связи, а также будет способствовать техническим исследованиям и разработкам, направленным на решение проблем с памятью в приложениях для обучения и инференса ИИ. Руководителем центра назначен ветеран полупроводниковой индустрии Гай Азрад (Guy Azrad), старший вице-президент по проектированию и генеральный директор Astera Labs Israel, а его помощником станет Идо Букспан (Ido Bukspan), вице-президент по проектированию ASIC, имеющий 20-летний стаж работы в Mellanox и NVIDIA, где он дошёл до должности старшего вице-президента по проектированию микросхем, разрабатывая высокопроизводительные решения InfiniBand, Ethernet и NVLink. 
Источник изображения: Pliops «Новый израильский дизйн-центр будет стремиться использовать лучшие в регионе инженерные таланты, чтобы сосредоточиться на полном цикле проектирования микросхем — от архитектуры до производства, включая ПО и системное проектирование для передовых ИИ-платформ и новых приложений для инференса», — заявил Азрад. Разработанная Pliops PCIe-карта расширения XDP LightningAI с программным стеком FusIOnX функционирует как ещё один уровень памяти для GPU-серверов. Она работает на базе ASIC, которая «раскладывает» KV-кеш на SSD с доступом через NVMe-oF (RDMA) и горизонтальным масштабированием. Стек Pliops FusIOnX снижает стоимость, энергопотребление и вычислительные затраты путём оптимизации рабочих процессов инференса LLM. 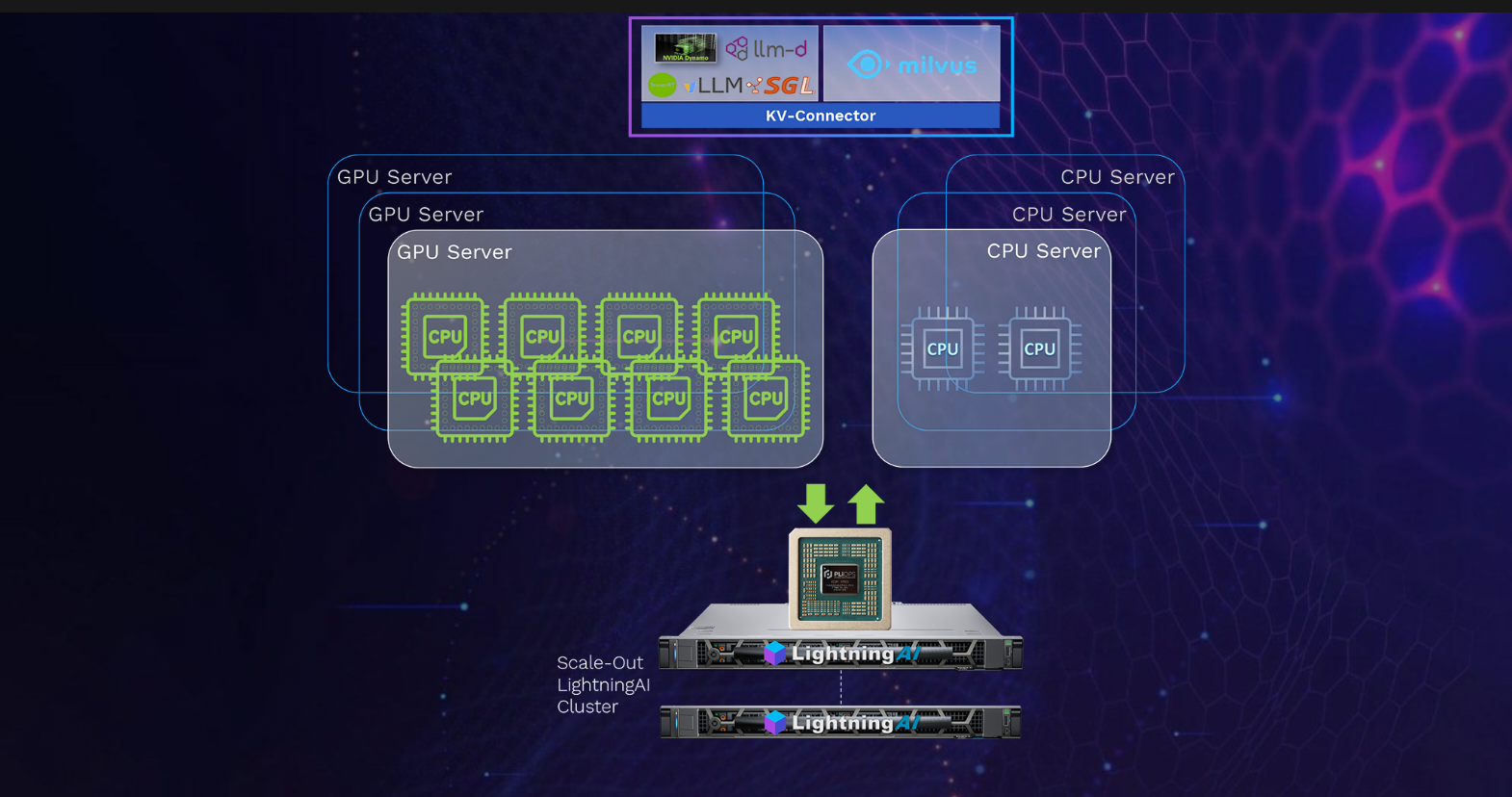
Источник изображения: Pliops «Сочетание нашего оборудования LightningAI с ПО FusIOnX устраняет узкое место, связанное с памятью GPU, обеспечивая до восьми раз более быструю обработку данных и экономию энергии на уровне стойки. И это работает от начала до конца: на любом GPU, любой LLM, любом ПО для обработки данных и любой сетевой инфраструктуре», — заявил Идо Букспан. По данным компании, Pliops XDP LightningAI вместе с ПО расширяют возможности высокоскоростной памяти (HBM) для серверов с GPU и ускоряют работу vLLM на NVIDIA в 2,5 раза.
23.02.2026 [22:57], Владимир Мироненко
Чипы AMD прожорливы, NVIDIA — дороги, а Intel — ненадёжны: Ericsson остаётся верна кастомным ASICEricsson представила свой первый набор продуктов AI-RAN, подчеркнув приверженность стратегии, основанной на собственных ASIC для повышения производительности сетей радиодоступа (RAN). В то время как беспроводная индустрия всё чаще обращается к виртуализированным/облачным RAN с использованием универсальных процессоров (GPP) Intel, Ericsson защищает свои продолжающиеся инвестиции в кастомные чипы для высокопроизводительных задач, отметил ресурс IEEE ComSoc Technology Blog. Впрочем, Intel остаётся ключевым партнёром Ericsson, а вот с AMD и NVIDIA у компании не заладилось. Портфель решений Ericsson для RAN базируется на двух основных архитектурах. Большая часть основана на ASIC, разработанных как собственными силами, так и в партнёрстве с Intel. Также портфель включает Cloud RAN, которая объединяет программный стек Ericsson с процессорами Intel Xeon EE. Несмотря на надежды отрасли, что виртуализация позволит отделить аппаратное обеспечение от программного, Intel остаётся единственным партнером Ericsson по поставке микросхем для массового развёртывания, что создаёт некоторые риски. Фактически Ericsson подтвердила «коммерческую поддержку» исключительно решений Intel, в то время как в случае AMD, Arm и NVIDIA всё по-прежнему ограничивается «поддержкой прототипов». Несмотря на многолетние заявления отрасли о необходимости разнообразия микросхем в экосистеме vRAN, прогресс, похоже, застопорился. Кроме того, интеграция ИИ в ПО RAN добавляет новые уровни сложности, которые могут ещё больше укрепить зависимость компании от «железа» одного вендора. 
Источник изображений: Ericsson Отраслевые наблюдатели по-прежнему скептически относятся к стремлению Ericsson к «единому программному стеку» для гетерогенных аппаратных платформ. Хотя аппаратная и программная дезагрегация достижима на более высоких уровнях (L2/L3), PHY-уровень L1 — наиболее ресурсоёмкая часть стека — остаётся сильно оптимизированным для конкретного «кремния». Первоначально Ericsson рассчитывала на переносимость L1-кода между x86 (в т.ч. AMD) и Arm SVE2 (NVIDIA Grace) для соответствия возможностям Intel AVX-512. Однако достижение высокой производительности на этих платформах без существенного рефакторинга остается серьёзной инженерной проблемой. 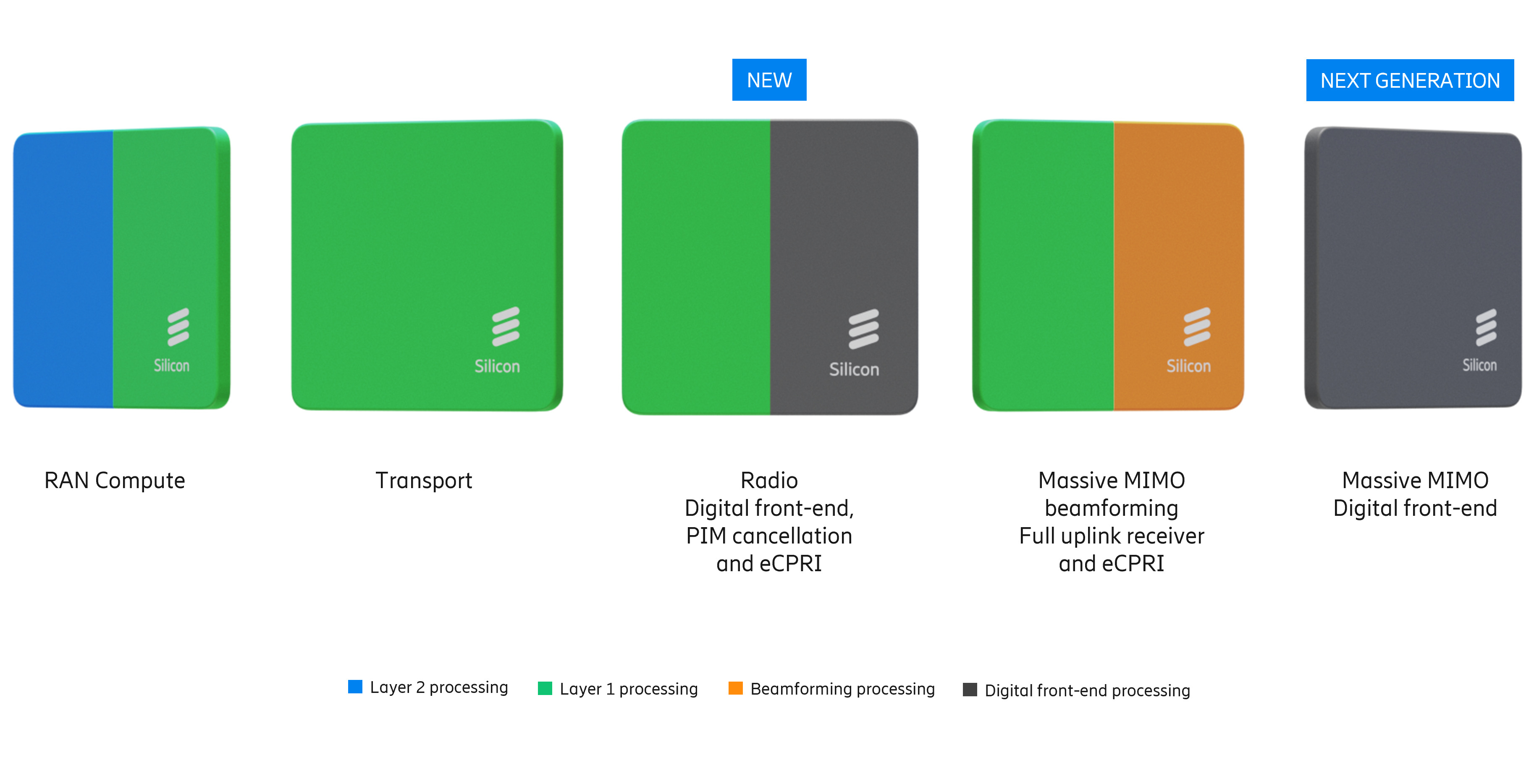 Критическим узким местом в обработке L1-трафика является коррекция ошибок (Forward Error Correction), которая традиционно требует выделенного аппаратного ускорения. Ericsson первоначально полагалась на разгрузку с переносом задач FEC на дискретные PCIe-ускорители Intel. Затем Intel внедрила ускорение FEC в Xeon EE в рамках vRAN Boost. Попытки использовать FPGA AMD показали их невысокую энергоэффективность, а GPU NVIDIA оказались слишком дороги для такой задачи.  Однако развитие AI-RAN изменило экономику, поскольку теперь ускорители можно использовать как для RAN, так и для ИИ-задач. Так, Ericsson заинтересовали тензорные процессоры Google (TPU). Тем не менее, несмотря на стремление к созданию «единого ПО», планы Ericsson подтверждают существование проблем в реализации этой идеи. В то время как уровни L2 и выше используют универсальную кодовую базу для всех аппаратных платформ, уровень L1 требует адаптации под конкретные чипы. Чтобы избежать зависимости от одного поставщика чипов, компания уделяет приоритетное внимание развитию HAL (Hardware Abstraction Layers), что позволит портировать ПО на разные аппаратные платформы с минимальными изменениями. Основные инициативы включают внедрение интерфейса BBDev (Baseband Device) для отделения ПО RAN от базового аппаратного обеспечения. Рассматривается даже возможность интеграции с NVIDIA CUDA, но здесь многое зависит от более широкой отраслевой стандартизации. Что касается радиосвязи, менее подверженной полной виртуализации, Ericsson встраивает процессоры Neural Network Accelerators (NNA) непосредственно в радиомодули. Эти программируемые матричные ядра оптимизированы для обработки данных в системах Massive MIMO, обеспечивая формирование луча и оценку канала за доли миллисекунды при соблюдении строгих ограничений по мощности. Новые AI-радиомодули оснащены ASIC Ericsson с NNA. Утверждается, что они расширяют возможности локального инференса в радиосистемах Massive MIMO, обеспечивая оптимизацию в реальном времени.
20.02.2026 [15:59], Сергей Карасёв
Узкие специалисты: Talaas, разрабатывающая оптимизированные под конкретные ИИ-модели ускорители, получила на развитие $169 млнСтартап Taalas, разрабатывающий чипы, специально оптимизированные для работы с конкретными ИИ-моделями, провел раунд финансирования на сумму в $169 млн. В число инвесторов вошли Quiet Capital и Fidelity, а также венчурный капиталист Пьер Ламонд (Pierre Lamond). Таким образом, на сегодняшний день компания получила на развитие в общей сложности более $200 млн. Фирма Taalas вышла из крытого режима (stealth mode) в марте 2023 года. Стартап занимается созданием чипов, предназначенных для определённых LLM. Первым продуктом компании стало изделие, ориентированное на ИИ-модель Llama 3.1 8B. Утверждается, что этот процессор способен генерировать до 17 тыс. выходных токенов в секунду, что в 73 раза больше по сравнению с NVIDIA H200. При этом решение Taalas потребляет в 10 раз меньше энергии. 
Источник изображения: Taalas Оптимизация аппаратных ускорителей под конкретную ИИ-модуль повышает производительность и эффективность благодаря отказу от избыточных компонентов. Однако разработка таких узкоспециализированных изделий представляет собой сложный и дорогостоящий процесс. Компании Taalas удалось решить проблему, создав архитектуру, при которой для «тонкой» настройки требуется кастомизация только двух из более чем 100 слоев, из которых состоят её чипы. Кроме того, Taalas не использует в своих изделиях дорогостоящую память HBM. Это также упрощает конструкцию, позволяя упразднить компоненты, которые необходимы для обеспечения взаимодействия с HBM-модулями. В настоящее время Taalas работает над чипом, предназначенным для запуска ИИ-модели Llama с 20 млрд параметров: выпуск этого решения намечен на лето нынешнего года. Затем появится более мощный чип, ориентированный на LLM высокого уровня.
19.02.2026 [12:50], Сергей Карасёв
Впятеро энергоэффективнее H100: HyperAccel разработала экономичный чип Bertha 500 для ИИ-инференсаЮжнокорейский стартап HyperAccel, по сообщению EETimes, готовится вывести на рынок специализированный чип Bertha 500, предназначенный для ИИ-инференса. Утверждается, что благодаря особой архитектуре изделие способно генерировать в пять раз больше токенов в секунду по сравнению с решениями на основе GPU при том же уровне TOPS. В Bertha 500 упор сделан на экономическую эффективность. С этой целью используется память LPDDR вместо дорогостоящей HBM. При этом благодаря отказу от традиционной иерархии памяти достигается утилизация пропускной способности LPDDR на 90 %. Дальнейшее повышение эффективности обеспечивается путём оптимизации архитектуры именно для задач инференса. Для сравнения, как утверждает HyperAccel, в случае GPU при инференсе используется только около 45 % пропускной способности памяти и 30 % вычислительных ресурсов. Иными словами, немного жертвуя производительностью, чип Bertha 500 позволяет достичь значительного снижения стоимости. Изделие Bertha 500 будет производиться по 4-нм техпроцессу Samsung. В состав чипа входят 32 ядра LPU (LLM Processing Unit), четыре ядра Arm Cortex-A53 и 256 Мбайт SRAM. Подсистема памяти LPDDR5x использует восемь каналов; пропускная способность достигает 560 Гбайт/с. Заявленная ИИ-производительность на операциях INT8 составляет 768 TOPS. Кроме того, поддерживаются другие 16-, 8- и 4-бит форматы, включая FP16. В целом, по заявлениям HyperAccel, пропускная способность Bertha 500 в расчёте на доллар примерно в 20 раз выше по сравнению с NVIDIA H100, тогда как энергоэффективность больше в пять раз. Чип Bertha 500 будет потреблять около 250 Вт. 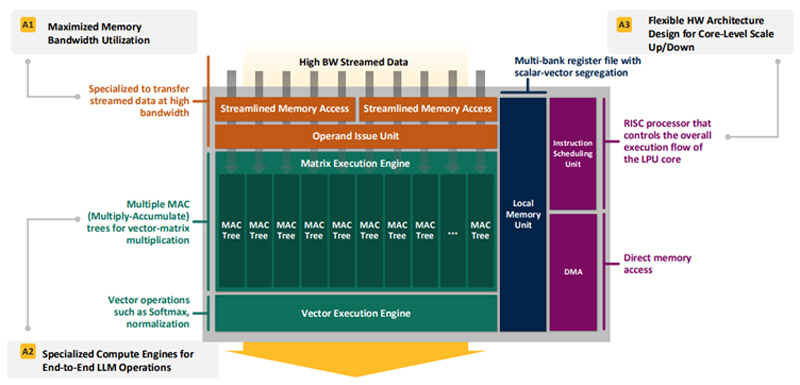
Источник изображения: EETimes Программный стек HyperAccel поддерживает все модели из репозитория HuggingFace. Кроме того, компания работает над предметно-ориентированным языком (DSL) под названием Legato, который предоставит разработчикам низкоуровневый доступ к системе. Образцы Bertha 500 появятся к концу I квартала 2026 года, а серийное производство планируется организовать в начале 2027 года. Отмечается также, что совместно с LG стартап разрабатывает «урезанную» версию Bertha 500 для периферийных устройств — Bertha 100. Эта SoC получит ядра Arm Cortex-A55 и отдельные компоненты LG, а также два канала памяти LPDDR5x. Среди возможных сфер применения названы автомобильная промышленность, бытовая электроника и робототехника. Bertha 100 планируется выпускать в виде модулей M.2: первые изделия выйдут в IV квартале текущего года. Решение сможет, например, осуществлять преобразование текста в речь или речи в текст. Стартап HyperAccel основан профессором Корейского института передовых технологий (KAIST) Джуёном Кимом (Jooyoung Kim) вместе с группой его студентов в начале 2023 года. На сегодняшний день компания привлекла $45 млн инвестиций, а её рыночная стоимость оценивается в $200 млн. Штат насчитывает около 80 человек. Первым продуктом HyperAccel стал специализированный сервер Orion на базе FPGA, предназначенный для решения ИИ-задач.
17.02.2026 [14:22], Руслан Авдеев
Индийские NeevCloud и Agnikul Cosmos тоже готовы развернуть в космосе сотни дата-центровИндийская аэрокосмическая компания Agnikul Cosmos совместно с облачным ИИ-провайдером NeevCloud планируют развернуть в космосе сотни небольших дата-центров, сообщает Datacenter Dynamics. Первый дата-центр должен заработать на орбите к концу 2026 года. NeevCloud развернёт облачный дата-центр и запустит приложения для ИИ-инференса в режиме реального времени на патентованной платформе, разработанной и построенной Agnikul. Последняя известна напечатанными на 3D-принтере ракетами для запуска малых спутников. Если пилотный запуск окажется удачным, компании намерены вывести на орбиту более 600 дата-центров Orbital Edge в следующие три года. NeevCloud заявляет, что речь идёт не только о простом строительстве дата-центров в космосе, но и полностью новом уровне инфраструктуры для орбитального инференса. По словам представителя Agnikul, технология ступени-трансформера позволяет сохранять её функциональность. Фактически речь идёт о превращении ступени в «полезные активы», в которых может размещаться оборудование и программное обеспечение, включая данные и вычислительные мощности. Это новый этап для аэрокосмической компании, позволяющий снизить цены эксплуатации и капитальные издержки, используя размещённое в многоразовых ступенях оборудование. 
Источник изображения: Agnikul Помимо SpaceX, попросившей разрешение на запуск сразу миллиона спутников, с проектами космических ЦОД выступают и другие компании, например, масштабная инициатива исходит от Google и др., хотя реальная практика внедрения, вероятно, будет довольно сложной. На днях Starcloud также подала заявку на запуск 88 тыс. спутников. Это меньше, чем мегапроект SpaceX, но тоже вполне крупный проект. Помимо этих компаний, над собственными космическими проектами работают Amazon, Blue Origin, Axiom Space, NTT, Ramon.Space, Sophia Space и др.
17.02.2026 [11:08], Сергей Карасёв
SK hynix предлагает гибридную память HBM/HBF для ускорения ИИ-инференсаКомпания SK hynix, по сообщению ресурса Blocks & Files, разработала концепцию гибридной памяти, объединяющей на одном интерпозере HBM (High Bandwidth Memory) и флеш-чипы с высокой пропускной способностью HBF (High Bandwidth Flash). Предполагается, что такое решение будет подключаться к GPU для повышения скорости ИИ-инференса. Современные ИИ-ускорители на основе GPU оснащаются высокопроизводительной памятью HBM. Однако существуют ограничения по её ёмкости, из-за чего операции инференса замедляются, поскольку доступ к данным приходится осуществлять с использованием более медленных SSD. Решить проблему SK hynix предлагает путём применения гибридной конструкции HBM/HBF под названием H3. Архитектура HBF предусматривает монтаж кристаллов NAND друг над другом поверх логического кристалла. Вся эта связка располагается на интерпозере рядом с контроллером памяти, а также GPU, CPU, TPU или SoC — в зависимости от предназначения конечного изделия. В случае H3 на интерпозере будет дополнительно размещён стек HBM. Отмечается, что время доступа к HBF больше, чем к HBM, но вместе с тем значительно меньше, нежели к традиционным SSD. Таким образом, HBF может служить в качестве быстрого кеша большого объёма. 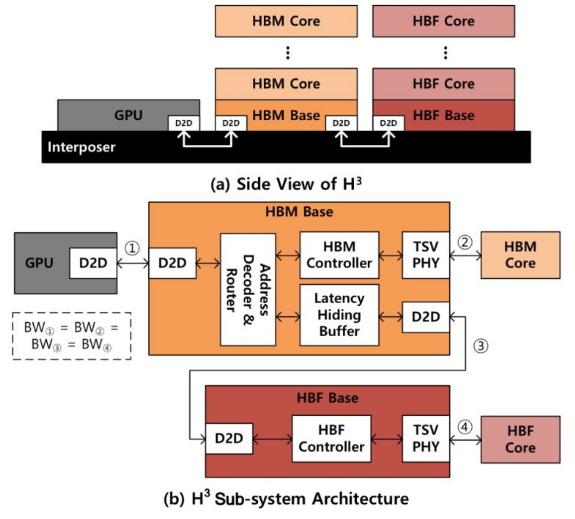
Источник изображения: SK hynix По заявлениям SK hynix, стеки HBF могут иметь до 16 раз более высокую ёмкость по сравнению с HBM, обеспечивая при этом сопоставимую пропускную способность. С другой стороны, HBF обладает меньшей износостойкостью при записи, до 4 раз более высоким энергопотреблением и большим временем доступа. HBF выдерживает около 100 тыс. циклов записи, а поэтому лучше всего подходит для рабочих нагрузок с интенсивным чтением. В результате, как утверждается, гибридная конструкция сможет эффективно решать задачи инференса при использовании больших языковых моделей (LLM) с огромным количеством параметров. В ходе моделирования работы H3, проведенного специалистами SK hynix, рассматривался ускоритель NVIDIA Blackwell B200 с восемью стеками HBM3E и таким же количеством стеков HBF. В пересчете на токены в секунду производительность системы с памятью H3 оказалась в 1,25 раза выше при использовании 1 млн токенов и в 6,14 раза больше при использовании 10 млн токенов по сравнению с решениями, оборудованными только чипами HBM. Более того отмечено 2,69-кратное повышение производительности в расчёте на 1 Вт затрачиваемой энергии по сравнению с конфигурациями без HBF. К тому же связка HBM и HBF может обрабатывать в 18,8 раз больше одновременных запросов, чем только HBM.
13.02.2026 [13:18], Руслан Авдеев
ECL представила всеядную энергетическую архитектуру для периферийных ИИ ЦОДКомпанией ECL (EdgeCloudLink) анонсирована платформа FlexGrid. Речь идёт об энергетической архитектуре, позволяющей развёртывать ИИ ЦОД высокой плотности в локациях с ограниченными возможностями питания. Решение предлагается как способ масштабирования инфраструктуры инференса за пределы крупных кампусов, в которых осуществляется обучение ИИ-моделей — в городские агломерации, периферийные локации и промзоны, где зачастую доступно не более 50–100 МВт, сообщает Converge Digest. FlexGrid обеспечивает модульное развёртывание на площадках мощностью от 2–10 МВт с возможностью масштабировать подключение до 20–25 МВт на объект с помощью интеграции дополнительных, локальных источников энергии различного происхождения. Основа платформы — патентованная система управления питанием ECL, позволяющая объединять несколько источников энергии, включая классические электросети, водородные топливные элементы, генераторы на природном газе, возобновляемые источники и дизельные генераторы. В результате обеспечивается унифицированная подача постоянного или переменного тока. В отличие от традиционных дата-центров, в норме использующих один тип источников энергии, FlexGrid позволяет менять источники энергии или добавлять к ним новые без изменения базовой энергетической инфраструктуры объектов. 
Источник изображения: ECL ECL утверждает, что это позволяет оперативно реагировать на региональные энергетические ограничения, изменения политики энергоснабжения на местах и дефицит топлива, при этом сохраняя стабильное качество электропитания ИИ-инфраструктуры. ECL подчёркивает, что FlexGrid разработана для «нормализации» подачи энергии из любых локальных источников и надёжного энергоснабжения ИИ-объектов в условиях ограничений сетевой энергоинфраструктуры. Пока конкуренты стремятся обеспечить себе мощности от 50 МВт для обучения, ECL работает на обозримую перспективу, делая ставку на периферийные объекты, где жизненно важным становится возможность агрегации и управления питанием таким образом, чтобы обеспечить гибкий выбор площадок и быстрый ввод объектов в эксплуатацию. Летом 2026 года сообщалось, что ECL напечатала свой первый модульный дата-центр, работающий от водородных элементов питания. В сентябре того же года появилась информация, что компаняи построит гигантский «зелёный» ЦОД TerraSite-TX1, а первым арендатором станет ИИ-облако Lambda. Годом позже вышла новость о том, что Lambda и ECL впервые запитали NVIDIA GB300 NVL72 от водорода, но теперь стартап перешёл к более универсальным решениям.
06.02.2026 [10:53], Владимир Мироненко
Без дефицитной HBM: Positron AI готовит ИИ-ускоритель Asimov с терабайтами LPDDR5xКомпания Positron AI сообщила о привлечении $230 млн инвестиций в рамках переподписанного раунда финансирования серии B, в результате которого оценка её рыночной стоимости превысила $1 млрд. Раунд возглавили ARENA Private Wealth, Jump Trading и Unless при участии новых инвесторов Qatar Investment Authority (QIA), Arm и Helena, а также существующих инвесторов Valor Equity Partners, Atreides Management, DFJ Growth, Resilience Reserve, Flume Ventures и 1517. Объявление было сделано на мероприятии Web Summit Qatar, что подчеркивает растущий международный авторитет компании, отметил ресурс eWeek. На то, чтобы перейти в категорию единорогов, Positron AI потребовалось 34 месяца. Positron AI отметила решение Jump Trading стать одним из лидеров раунда после того, как эта компания стала её клиентом. «Для рабочих нагрузок, которые нас интересуют, узкими местами всё чаще становятся память и энергопотребление, а не теоретические вычисления», — сказал технический директор Jump Trading. — В ходе наших тестов Positron Atlas показал примерно в три раза меньшую сквозную задержку, чем сопоставимая система на базе NVIDIA H100, при оценке рабочих нагрузок инференса, в готовом к производству корпусе с воздушным охлаждением и цепочкой поставок, которую мы можем спланировать». 
Источник изображения: Positron AI Полученные инвестиции позволят ускорить выход платформы следующего поколения Asimov, разработанной на заказ. Компания планирует завершить тестирование Asimov к концу III квартала, а пробные версии появятся в конце I квартала 2027 года. В Asimov будет использоваться память LPDDR (без HBM), но возможность приблизиться к теоретической пиковой пропускной способности памяти означает, что компании и не нужно полагаться на HBM для быстрой генерации токенов, сообщил ресурсу EE Times технический директор Positron. Вычислительные элементы Asimov — это эволюция блоков Atlas с добавлением ядер Arm и улучшенным интерконнектом. Расширить память LPDDR5x в Asimov можно с помощью CXL — с 864 Гбайт до 2,3 Тбайт на чип. Чип позволяет создать два независимых домена памяти, чтобы лучше утилизировать её. Хосит-интерфейс чипа — PCI 6.0 x32. Хотя LPDDR5x дешевле и ёмче HBM, она значительно уступает ей по пропускной способности. Если ускорители Rubin от NVIDIA оснащены 288 Гбайт памяти HBM4 с пиковой пропускной способностью 22 Тбайт/с, то для Asimov, по-видимому, потолок составляет около 3 Тбайт/с, пишет The Register (в спецификациях указано 2,76 Тбайт/с). По словам Positron, разница в том, что её чипы действительно могут использовать 90 % этой пропускной способности, в то время как GPU на базе HBM в реальных условиях едва достигают 30 % пиковой пропускной способности, хотя память Rubin даже в этом случае примерно в 2,4 раза быстрее, чем у Asimov. 
Источник изображения: Positron AI Компания сообщила, что 400-Вт чип оснащён систолической матрицей 512×512, работающей на частоте 2 ГГц и поддерживающей типы данных TF32, FP16/BF16, FP8, NVFP4 и INT4. Эта матрица управляется рядом ядер Armv9 и может быть переконфигурирована, например, в 128×512 (GEMV) или 512×128 (GEMM), в зависимости от того, какой вариант более выгоден для решения конкретной задачи. Четыре чипа Asimov образуют 4U-платформу Titan с воздушным охлаждением и пропускной способностью между чипами 16 Тбит/с. Компания отметила, что Asimov рассчитан на поддержку 2 Тбайт памяти на ускоритель и 8 Тбайт памяти на систему Titan с аналогичной пропускной способностью памяти, как у ускорителя NVIDIA Rubin. В масштабе стойки это означает объём памяти более 100 Тбайт. До 4096 систем Titan (16384 ускорителя) могут быть объединены в единый масштабируемый домен с более чем 32 Пбайт памяти. Это достигается с помощью чистого межчипового интерконнекта, а не коммутируемых масштабируемых сетей, как в стоечных архитектурах NVIDIA или AMD. Positron подчеркнула, что её архитектура, ориентированная на память, открывает доступ к высокоэффективным задачам инференса, включая большие языковые модели с длинным контекстом, агентные рабочие процессы и модели медиа и видео следующего поколения.
03.02.2026 [17:15], Руслан Авдеев
OpenAI не устроили чипы NVIDIA для инференса, теперь она ищет альтернативыПо данным многочисленных отраслевых источников, компания OpenAI недовольна некоторыми ИИ-чипами NVIDIA и с прошлого года ищет им альтернативы. Потенциально это усложнит отношения между крупнейшими игроками рынка на фоне бума ИИ, сообщает Reuters. Изменения стратегии OpenAI связаны с усилением акцента на инференсе. NVIDIA доминирует в нише ускорителей для обучения ИИ-моделей, но теперь инференс стал отдельным рынком с сильной конкуренцией. Решение OpenAI — вызов доминированию NVIDIA в сфере ИИ и препятствие $100-млрд сделки между компаниями, обеспечивающей разработчику чипов долю в ИИ-стартапе в обмен на доступ к передовым ускорителям. Предполагалось, что сделка будет закрыта за недели, но вместо этого переговоры ведутся месяцами. В то же время OpenAI заключила соглашение с AMD и Cerebras (её в своё время даже хотели купить) для получения «альтернативных» чипов, а также разрабатывает собственный ИИ-ускоритель при участии Broadcom. Amazon тоже не прочь предоставить OpenAI собственные ускорители, равно как и Google. Изменение планов OpenAI изменило и потребности в вычислительных мощностях и замедлило переговоры с NVIDIA. 
Источник изображения: Robin Jonathan Deutsch / Unsplash В минувшую субботу глава NVIDIA Дженсен Хуанг (Jensen Huang) опроверг слухи о проблемах с OpenAI, назвав их «чепухой» и подчеркнув, что клиенты продолжают выбирать NVIDIA для инференса, поскольку компания обеспечивает наилучшее соотношение производительности и совокупной стоимости владения, причём в больших масштабах. Отдельно представитель OpenAI заявлял, что компания полагается на NVIDIA для поставок большинства чипов для инференса, причём именно NVIDIA обеспечивает наилучшую производительность на каждый вложенный доллар. Глава OpenAI Сэм Альтман (Sam Altman) отметил, что NVIDIA выпускает «лучшие чипы в мире» и есть надежда, что OpenAI останется её «гигантским» клиентом очень долгое время. При этом, как сообщает Reuters со ссылкой на семь источников, OpenAI не удовлетворена производительностью инференса, на которую способны чипы NVIDIA. В частности, речь идёт о специализированных задачах вроде разработки ПО с помощью ИИ и коммуникаций ИИ с другим ПО. По данным одного из источников, компании понадобится новое аппаратное обеспечение, которое в конечном счёте обеспечит в будущем порядка 10 % вычислительных мощностей для инференса. 
Источник изображения: OpenAI OpenAI обсуждала возможности работы с ИИ-стартапами, включая Cerebras и Groq для обеспечения чипов с более быстрым инференсом, но NVIDIA фактически поглотила Groq на $20 млрд, что привело к прекращению переговоров с компанией. Хотя формально речь идёт неэксклюзивном лицензировании технологий Groq, что в теории позволяет сторонним компаниям получить доступ к решениям Groq, фактически все разработчики перешли в NVIDIA, а оставшаяся небольшая команда отвечает за выполнение облачных контрактов с имеющимися заказчиками. Чипы NVIDIA хорошо подходят для обработки больших объёмов данных при обучении больших ИИ-моделей вроде тех, что стоят за ChatGPT. Тем не менее прогресс требует массового использования уже обученных моделей для дальнейшего инференса и ИИ-рассуждений. Как сообщается, OpenAI с 2025 года ищет альтернативы ускорителям NVIDIA с упором на компании, создающие чипы с большими объёмами интегрированной SRAM. Maia 200 от Microsoft, по-видимому, компании не очень подходит. 
Источник изображения: Hermann Wittekopf - kmkb / Unsplash Инференс моделей более требователен к памяти, чем обучение, а вычислительная нагрузка, наоборот, не так велика. В тоге нередко на доступ к данным уходит больше времени, чем на расчёты. NVIDIA и AMD полагаются на внешнюю память, что замедляет соответствующие процессы общения с чат-ботами. В OpenAI проблемы отметили при эксплуатации системы Codex, активно продвигаемой компанией для создания кода. В компании считают, что некоторые слабости системы связаны именно с оборудованием NVIDIA. Конкуренты OpenAI полагаются на альтернативное оборудование. Anthropic активно использует AWS Trainium и Google TPU, а Google уже много лет использует свои TPU, которые с недавних пор готова отдавать на сторону. TPU оптимизированы в том числе для инференса и в некоторых отношениях более производительны, чем GPU общего назначения AMD и NVIDIA. Когда OpenAI недвусмысленно выразила отношение к технологиям NVIDIA, та предложила компаниям, создающим ускорители с упором на SRAM, включая Cerebras и Groq, купить их бизнес. Cerebras отказалась и заключила прямую сделку с OpenAI. Groq вела переговоры с OpenAI о предоставлении вычислительных мощностей, что вызвало интерес у инвесторов, оценивших капитализацию компании на уровне $14 млрд.
01.02.2026 [11:55], Сергей Карасёв
Южнокорейский стартап FuriosaAI начал массовое производство ИИ-ускорителей RNGDЮжнокорейский стартап FuriosaAI объявил о начале серийного выпуска ИИ-ускорителей RNGD и серверов NXT RNGD на их основе. Отмечается, что благодаря тесному партнёрству с TSMC, SK hynix и другими отраслевыми игроками, включая ASUS, сформирована стабильная производственная и логистическая цепочка, а новые продукты доступны корпоративным заказчикам по всему миру. ИИ-ускоритель RNGD выполнен в виде карты расширения PCIe 5.0 x16: он оснащён 48 Гбайт HBM3 с пропускной способностью до 1,5 Тбайт/с и 256 Мбайт SRAM с пропускной способностью 384 Тбайт/с. Показатель TDP не превышает 180 Вт. Заявленная производительность достигает 512 Тфлопс на операциях INT8. В свою очередь, система NXT RNGD формата 4U несёт на борту восемь карт RNGD. Энергопотребление находится на уровне 3 кВт. Утверждается, что в стандартную серверную стойку с воздушным охлаждением можно установить пять экземпляров NXT RNGD, что обеспечит ИИ-быстродействие до 20 Пфлопс (INT8). 
Источник изображений: FuriosaAI Как подчёркивает FuriosaAI, современные ИИ-модели требуют колоссальных вычислительных мощностей, но подавляющее большинство корпоративных дата-центров имеют воздушное охлаждение, а их мощность ограничена 15 кВт на стойку. Поэтому для использования огромного количества GPU-ускорителей с показателем TDP до 600 Вт и более требуется дорогостоящая и трудоёмкая модернизация инфраструктуры. Применение изделий RNGD позволяет решить проблему. По заявлениям FuriosaAI, её решения обеспечивает в 3,5 раза большую вычислительную плотность, чем системы на базе NVIDIA H100 в стандартных средах.  Для ускорителей RNGD доступен полнофункциональный комплект разработки SDK. Говорится о поддержке популярных ИИ-моделей, таких как Qwen 2 и Qwen 2.5. Объём первой изготовленной партии изделий составил 4000 единиц. |
|

