Материалы по тегу: инференс
|
05.10.2024 [15:55], Сергей Карасёв
Qualcomm готовит «урезанные» ИИ-ускорители Cloud AI 80Qualcomm, по сообщению Phoronix, планирует выпустить ускорители Cloud AI 80 (AIC080) для ИИ-задач. Информация о них появилась на сайте самого разработчика, а также в драйверах Linux. Речь идёт об «урезанных» версиях изделий Cloud AI 100, уже доступных на рынке. Базовая версия Cloud AI 100 Standard выполнена в виде HHHL-карты (68,9 × 169,5 мм) с интерфейсом PCIe 4.0 х8 и пассивным охлаждением. Объём памяти LPDDR4x-2133 с пропускной способностью 137 Гбайт/с составляет 16 Гбайт. Есть также 126 Мбайт памяти SRAM. TDP равен 75 Вт. Заявленное быстродействие достигает 350 TOPS на операциях INT8 и 175 Тфлопс при вычислениях FP16. От них в своё время отказалась Meta✴, сославшись на сырость программной экосистемы и предпочтя разработать собственные ИИ-ускорители MTIA. 
Источник изображений: Qualcomm Кроме того, существует решение Cloud AI 100 Ultra в виде карты FH3/4L (111,2 × 237,9 мм). Для обмена данными служит интерфейс PCIe 4.0 х16; значение TDP равно 150 Вт. В оснащение входят 128 Гбайт памяти LPDDR4x, пропускная способность которой достигает 548 Гбайт/с. Объём памяти SRAM — 576 Мбайт. INT8-производительность составляет до 870 TOPS, FP16 — до 288 Тфлопс.  Сообщается, что к выпуску готовятся «урезанные» ускорители Cloud AI 80 Standard и Cloud AI 80 Ultra. Их характеристики в точности соответствуют таковым у Cloud AI 100 Standard и Cloud AI 100 Ultra. Отличия заключаются исключительно в пониженном быстродействии. Так, у Cloud AI 80 Standard производительность INT8 находится на уровне 190 TOPS, FP16 — 86 Тфлопс. У Cloud AI 80 Ultra значения равны 618 TOPS и 222 Тфлопс.  Нужно отметить, что в старшее семейство также входит модель Cloud AI 100 Pro в формате карты HHHL с интерфейсом PCIe 4.0 х8 и TDP 75 Вт. Она несёт на борту 32 Гбайт памяти LPDDR4x (137 Гбайт/с) и 144 Мбайт памяти SRAM. Производительность INT8 составляет до 400 TOPS, FP16 — до 200 Тфлопс. Появится ли подобная модификация в серии Cloud AI 80, пока не ясно.
12.09.2024 [21:46], Сергей Карасёв
SiMa.ai представила чипы Modalix для мультимодальных рабочих нагрузок ИИ на периферииСтартап SiMa.ai анонсировал специализированные изделия Modalix — «системы на чипе» с функциями машинного обучения (MLSoC), спроектированные для обработки ИИ-задач на периферии. Эти решения предназначены для дронов, робототехники, умных камер видеонаблюдения, медицинского диагностического оборудования, edge-серверов и пр. В семейство Modalix входя четыре модификации — М25, М50, М100 и М200 с ИИ-производительностью 25, 50, 100 и 200 TOPS соответственно (BF16, INT8/16). Изделия наделены процессором общего назначения с восемью ядрами Arm Cortex-A65, работающими на частоте 1,5 ГГц. Кроме того, присутствует процессор обработки сигналов изображения (ISP) на базе Arm Mali-C71 с частотой 1,2 ГГц. В оснащение входят 8 Мбайт набортной памяти. Изделия производятся по 6-нм технологии TSMC и имеют упаковку FCBGA с размерами 25 × 25 мм. 
Источник изображения: SiMa.ai Чипы Modalix располагают узлом компьютерного зрения Synopsys ARC EV-74 с частотой 1 ГГц. Говорится о возможности декодирования видеоматериалов H.264/265/AV1 в формате 4K со скоростью 60 к/с и кодировании H.264 в формате 4K со скоростью 30 к/с. Реализована поддержка восьми линий PCIe 5.0, четырёх портов 10GbE, четырёх интерфейсов MIPI CSI-2 (по четыре линии 2.5Gb), восьми каналов памяти LPDDR4/4X/5-6400 (до 102 Гбайт/с). Таким образом, по словам SiMa.ai, Modalix покрывает практически весь цикл работы с данными, не ограничиваясь только ускорением ИИ-задач. 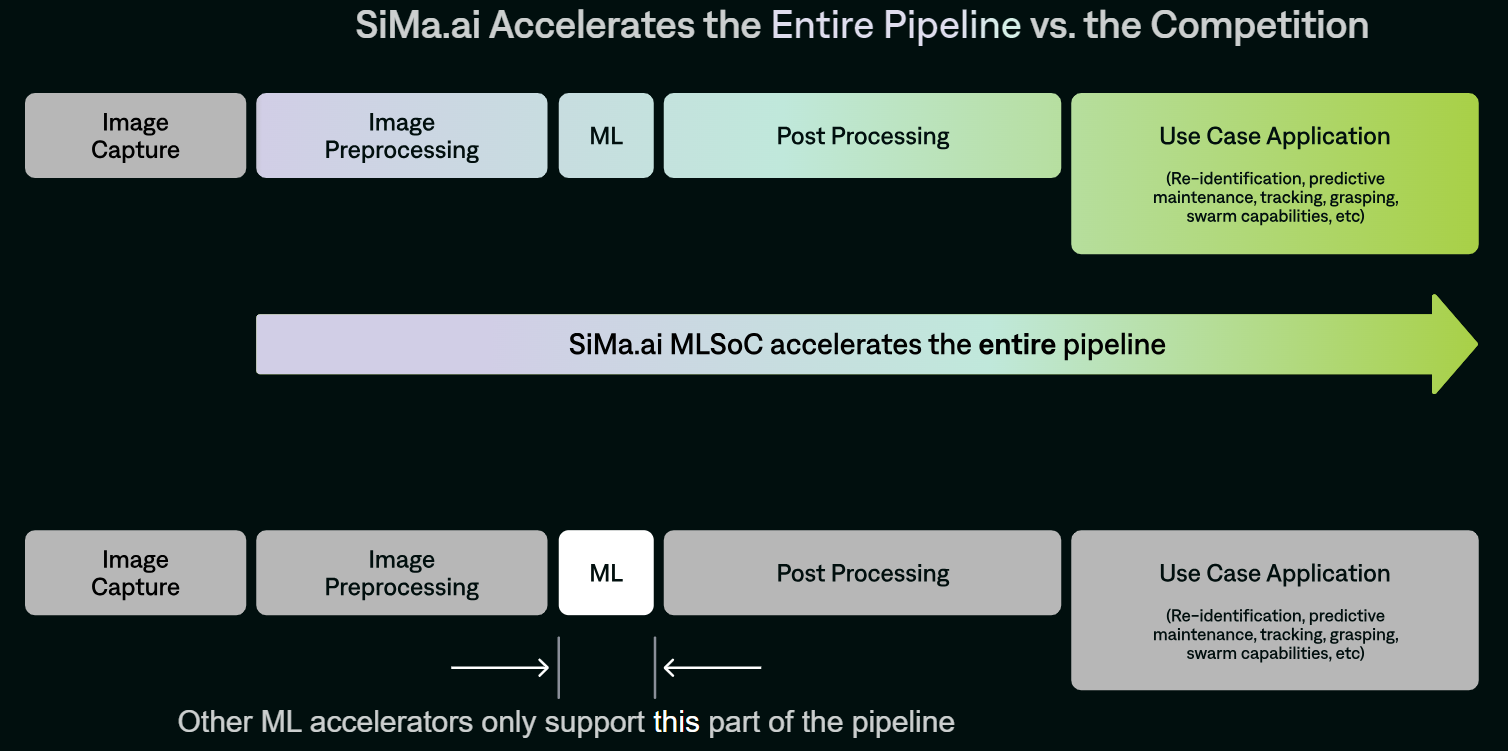
Источник изображения: SiMa.ai По заявлениям SiMa.ai, чипы Modalix можно применять для работы с большими языковыми моделями (LLM), генеративным ИИ, трансформерами, свёрточными нейронными сетями и мультимодальными приложениями. Среди возможных вариантов использования названы медицинская визуализация и роботизированная хирургия, интеллектуальные приложения для розничной торговли, автономные транспортные средства, беспилотники для инспекции зданий и пр. Есть поддержка популярных фреймворков PyTorch, ONNX, Keras, TensorFlow и т.д. Также предоставляется специализированный набор инструментов под названием Pallet, упрощающий создание ПО для новых процессоров.
11.09.2024 [18:07], Сергей Карасёв
SambaNova запустила «самую быструю в мире» облачную платформу для ИИ-инференсаКомпания SambaNova Systems объявила о запуске облачного сервиса SambaNova Cloud: утверждается, что на сегодняшний день это самая быстрая в мире платформа для ИИ-инференса. Она ориентирована на работу с большими языковыми моделями Llama 3.1 405B и Llama 3.1 70B, насчитывающими соответственно 405 и 70 млрд параметров. В основу сервиса положены ИИ-чипы собственной разработки SN40L. Эти изделия состоят из двух крупных чиплетов, оперирующих 520 Мбайт SRAM-кеша, 1,5 Тбайт DDR5 DRAM, а также 64 Гбайт высокоскоростной памяти HBM3. Утверждается, что восьмипроцессорная система на базе SN40L способна запускать и обслуживать ИИ-модели с 5 трлн параметров и глубиной запроса более 256к. 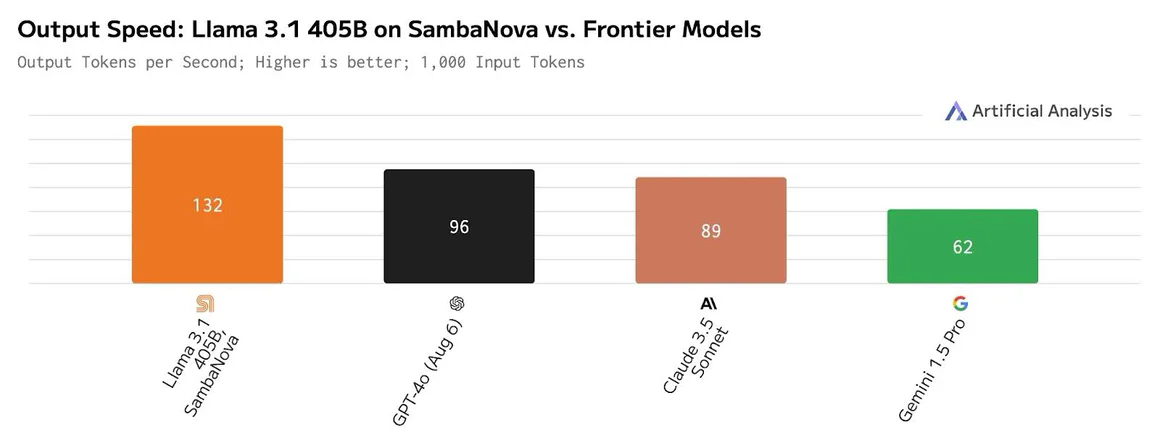
Источник изображения: SambaNova Платформа SambaNova Cloud, по заявлениям разработчиков, демонстрирует производительность до 132 токенов в секунду при работе с Llama 3.1 405B и до 461 токена в секунду при использовании Llama 3.1 70B. Для сравнения, по оценкам Artificial Analysis, даже самые мощные системы на базе GPU могут обслуживать модель Llama 3.1 405B только со скоростью 72 токена в секунду, а большинство из них намного медленнее. Подчёркивается, что SambaNova Cloud демонстрирует рекордную скорость при сохранении полной 16-битной точности. Однако без компромиссов всё же не обошлось: модель работает не в полном контекстном окне в 128k, а при 8k. Доступ к SambaNova Cloud предоставляется по трём схемам — Free, Developer и Enterprise. Первая предусматривает бесплатное базовое использование через API. Схема для разработчиков Developer (появится к концу 2024 года) позволяет работать с моделями Llama 3.1 8B, 70B и 405B с более высокими лимитами. Наконец, план Enterprise предлагает корпоративным клиентам возможность масштабирования для поддержки ресурсоёмких рабочих нагрузок. Ранее Cerebras Systems тоже объявила о запуске «самой мощной в мире» ИИ-платформы для инференса, а Groq ещё в прошлом году говорила о преимуществах своих решений и тоже переключилась на создание облачных сервисов. Впрочем, в бенчмарках MLPerf Inference по-прежнему бессменно лидируют решения NVIDIA.
31.08.2024 [14:12], Сергей Карасёв
Cerebras Systems запустила «самую мощную в мире» ИИ-платформу для инференсаАмериканский стартап Cerebras Systems, занимающийся разработкой чипов для систем машинного обучения и других ресурсоёмких задач, объявил о запуске, как утверждается, самой производительной в мире ИИ-платформы для инференса — Cerebras Inference. Ожидается, что она составит серьёзную конкуренцию решениям на основе ускорителей NVIDIA. В основу облачной системы Cerebras Inference положены ускорители WSE-3. Эти гигантские изделия, выполненные с применением 5-нм техпроцесса TSMC, содержат 4 трлн транзисторов, 900 тыс. ядер и 44 Гбайт SRAM. Суммарная пропускная способность встроенной памяти достигает 21 Пбайт/с, а внутреннего интерконнекта — 214 Пбит/с. Для сравнения: один чип HBM3e в составе NVIDIA H200 может похвастаться пропускной способностью «только» 4,8 Тбайт/с. 
Источник изображений: Cerebras По заявлениям Cerebras, новая инференс-платформа обеспечивает до 20 раз более высокую производительность по сравнению с сопоставимыми по классу решениями на чипах NVIDIA в сервисах гиперскейлеров. В частности, быстродействие составляет до 1800 токенов в секунду на пользователя для ИИ-модели Llama3.1 8B и до 450 токенов в секунду для Llama3.1 70B. Для сравнения, у AWS эти значения равны соответственно 93 и 50. Речь идёт об FP16-операциях. Cerebras заявляет, что лучший результат для кластеров на основе NVIDIA H100 в случае Llama3.1 70B составляет 128 токенов в секунду. 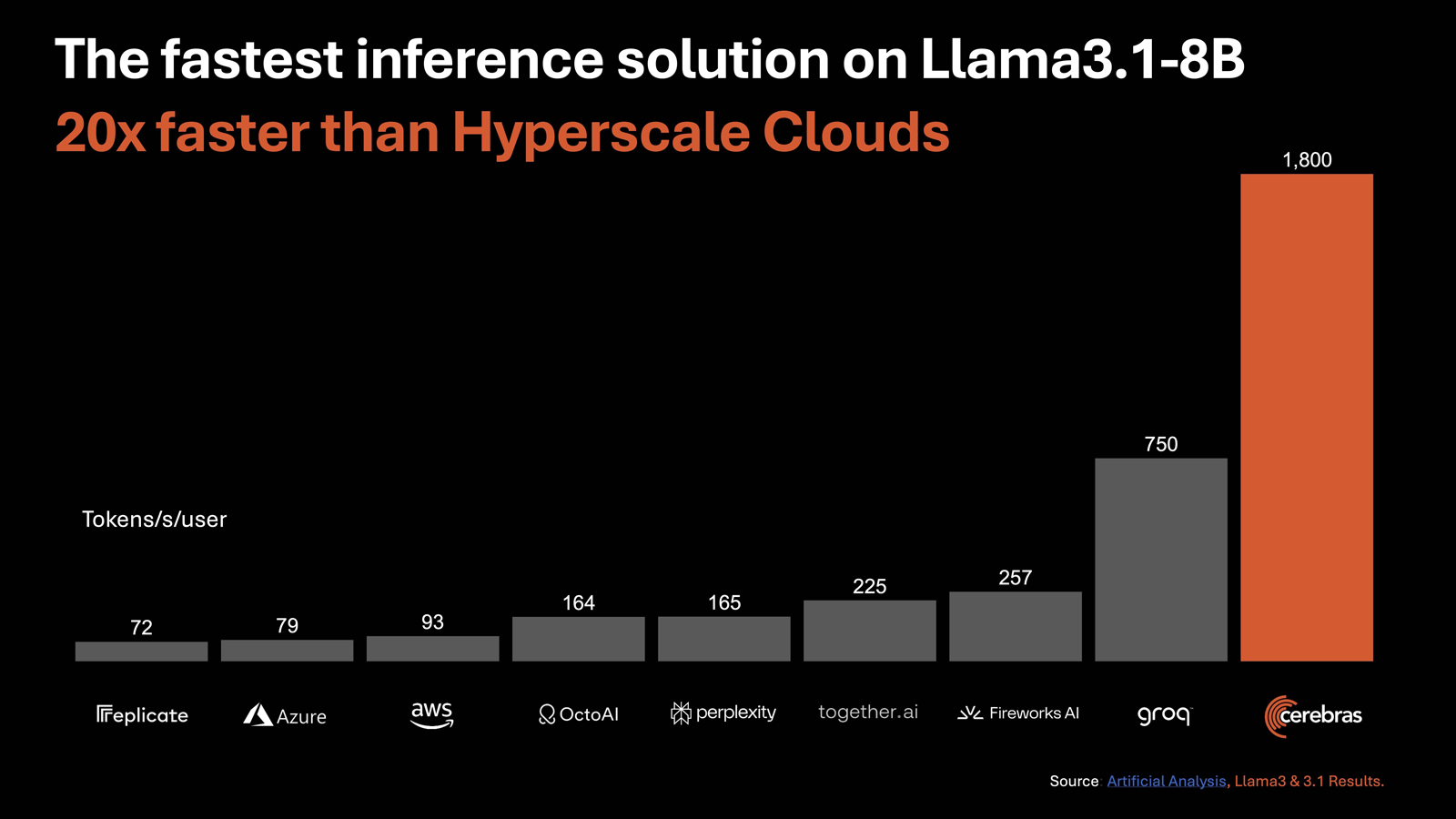 «В отличие от альтернативных подходов, которые жертвуют точностью ради быстродействия, Cerebras предлагает самую высокую производительность, сохраняя при этом точность на уровне 16 бит для всего процесса инференса», — заявляет компания. При этом услуги Cerebras Inference стоят в несколько раз меньше по сравнению с конкурирующими предложениями: $0,1 за 1 млн токенов для Llama 3.1 8B и $0,6 за 1 млн токенов для Llama 3.1 70B. Оплата взимается по мере использования. Cerebras планирует предоставлять инференс-услуги через API, совместимый с OpenAI. Преимущество такого подхода заключается в том, что разработчикам, которые уже создали приложения на основе GPT-4, Claude, Mistral или других облачных ИИ-моделей, не придётся полностью менять код для переноса нагрузок на платформу Cerebras Inference. 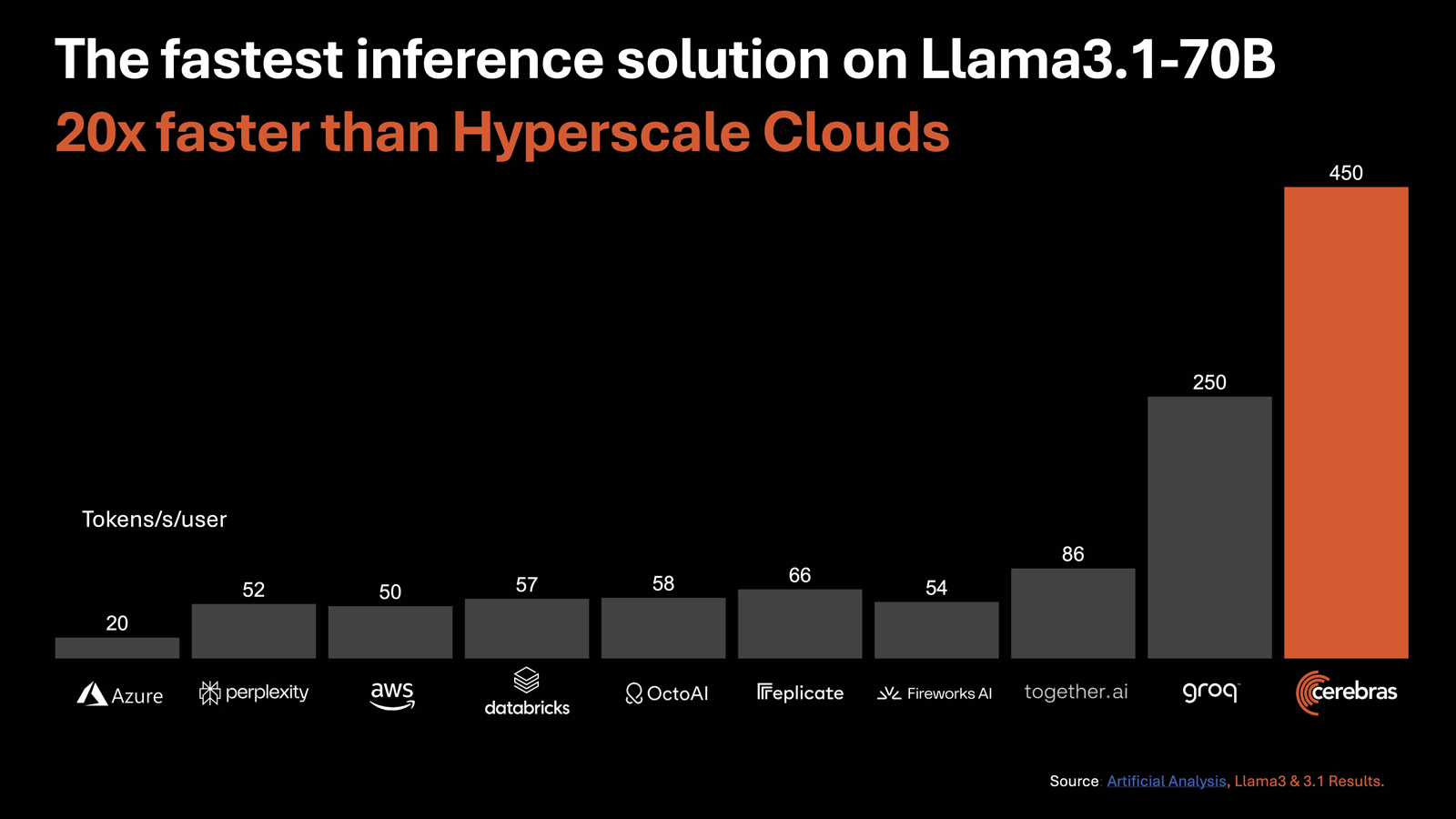 Для крупных предприятий предлагается план обслуживания Enterprise Tier, который предусматривает тонко настроенные модели, индивидуальные условия и специализированную поддержку. Стандартный пакет Developer Tier предполагает подписку по цене от $0,1 за 1 млн токенов. Кроме того, имеется бесплатный доступ начального уровня Free Tier с ограничениями. Cerebras говорит, что запуск платформы откроет качественно новые возможности для внедрения генеративного ИИ в различных сферах.
31.08.2024 [00:39], Алексей Степин
Новые мейнфреймы IBM z получат ИИ-ускорители SpyreВместе с процессорами Telum II для систем z17 компания IBM представила и собственные ускорители Spyre, ещё больше расширяющие возможности будущих мейнфреймов в области обработки ИИ-нагрузок. Они станут дополнением к встроенным в Telum ИИ-блокам. 
Источник изображений: IBM Spyre представляет собой плату расширения с интерфейсом PCIe 5.0 x16 и теплопакетом 75 Вт. Помимо самого нейропроцессора IBM на ней установлено 128 Гбайт памяти LPDDR5, а производительность в ИИ-задачах оценивается производителем в более чем 300 Топс, т.е. новинки подходят для инференса крупных моделей. Сам чип приозводится с использованием 5-нм техпроцесса Samsung 5LPE и содержит 26 млрд транзисторов, а площадь его кристалла составляет 330 мм2.  Spyre включает 32 ядра, каждое из которых дополнено 2 Мбайт быстрой скрэтч-памяти. Отдельно отмечено, что последняя не является кешем. При этом заявлена эффективность использования доступных вычислительных ресурсов — свыше 55 % на ядро. Каждое ядро содержит 78 матричных блоков и раздельные FP16-аккумуляторы, по восемь на «вход» и «выход». Интересно, что ядра Spyre и скрэтч-память используют отдельные кольцевые двунаправленные шины разной разрядности (32 и 128 бит соответственно), причём с оперативной памятью на скорости 200 Гбайт/с соединена именно вторая.  Каждый узел (drawer) на базе Telum II способен вместить восемь плат Spyre, которые формируют логический кластер, располагающий 1 Тбайт памяти с совокупной ПСП 1,6 Тбайт/с, но, разумеется, каждая плата будет ограничена 128 Гбайт/с из-за интерфейса PCIe 5.0 x16. Spyre создан с упором на предиктивный и генеративный ИИ, благо в полной комплектации новые мейнфреймы могут нести 96 таких ускорителей и развивать до 30 ПОпс (Петаопс).  Новинки рассчитаны на работу в средах zCX или Linux on Z, сопровождаются оптимизированным набором библиотек и совместимы с популярными фреймворками Pytoch, TensorFlow и ONNX. Они станут частью программных платформ IBM watsonx и Red Hat OpenShift. Новые мейнфреймы IBM z17 должны дебютировать на рынке в 2025 году. А в собственном облаке IBM будет также полагаться и на Intel Gaudi 3.
30.08.2024 [13:11], Руслан Авдеев
ИИ-ускорители Intel Gaudi 3 дебютируют в облаке IBM CloudКомпании Intel и IBM намерены активно сотрудничать в сфере облачных ИИ-решений. По данным HPC Wire, доступ к ускорителям Intel Gaudi 3 будет предоставляться в облаке IBM Cloud с начала 2025 года. Сотрудничество обеспечит и поддержку Gaudi 3 ИИ-платформой IBM Watsonx. IBM Cloud станет первым поставщиком облачных услуг, принявшим на вооружение Gaudi 3 как для гибридных, так и для локальных сред. Взаимодействие компаний позволит внедрять и масштабировать современные ИИ-решения, а комбинированное использование Gaudi 3 с процессорами Xeon Emerald Rapids откроет перед пользователями дополнительные возможности в облаках IBM. Gaudi 3 будут применяться и в задачах инференса на платформе Watsonx — клиенты смогут оптимизировать исполнение таких нагрузок с учётом соотношения цены и производительности. Для помощи клиентам в различных отраслях, в том числе тех, деятельность которых жёстко регулируется, компании предложат возможности IBM Cloud для гибкого масштабирования нагрузок, а интеграция Gaudi 3 в среду IBM Cloud Virtual Servers for VPC позволит компаниям, использующим аппаратную базу x86, быстрее и безопаснее использовать свои решения, чем до интеграции. 
Источник изображения: Intel Ранее сообщалось, что модель Gaudi 3 готова бросить вызов ускорителям NVIDIA. В своё время Intel выступила с заявлением о 50 % превосходстве новинки в инференс-сценариях над NVIDIA H100, а также о 40 % преимуществе в энергоэффективности при значительно меньшей стоимости. Позже Intel публично раскрыла стоимость новых ускорителей, нарушив негласные правила рынка.
29.08.2024 [01:00], Владимир Мироненко
NVIDIA вновь показала лидирующие результаты в ИИ-бенчмарке MLPerf InferenceNVIDIA сообщила, что её платформы показали самые высокие результаты во всех тестах производительности уровня ЦОД в бенчмарке MLPerf Inference v4.1, где впервые дебютировал ускоритель семейства Blackwell. Ускоритель NVIDIA B200 (SXM, 180 Гбайт HBM) оказался вчетверо производительнее H100 на крупнейшей рабочей нагрузке среди больших языковых моделей (LLM) MLPerf — Llama 2 70B — благодаря использованию механизма Transformer Engine второго поколения и FP4-инференсу на Tensor-ядрах. Впрочем, именно B200 заказчики могут и не дождаться. Ускоритель NVIDIA H200, который стал доступен в облаке CoreWeave, а также в системах ASUS, Dell, HPE, QTC и Supermicro, показал лучшие результаты во всех тестах в категории ЦОД, включая последнее дополнение к бенчмарку, LLM Mixtral 8x7B с общим количеством параметров 46,7 млрд и 12,9 млрд активных параметров на токен, использующую архитектуру Mixture of Experts (MoE, набор экспертов). 
Источник изображения: NVIDIA Как отметила NVIDIA, MoE приобрела популярность как способ привнести большую универсальность в LLM, поскольку позволяет отвечать на широкий спектр вопросов и выполнять более разнообразные задачи в рамках одного развёртывания. Архитектура также более эффективна, поскольку активируются только несколько экспертов на инференс — это означает, что такие модели выдают результаты намного быстрее, чем высокоплотные (Dense) модели аналогичного размера. Также NVIDIA отмечает, что с ростом размера моделей для снижения времени отклика при инференсе объединение нескольких ускорителей становится обязательными. По словам компании, NVLink и NVSwitch уже в поколении NVIDIA Hopper предоставляют значительные преимущества для экономичного инференса LLM в реальном времени. А платформа Blackwell ещё больше расширит возможности NVLink, позволив объединить до 72 ускорителей. 
Источник изображения: NVIDIA Заодно компания в очередной раз напомнила о важности программной экосистемы. Так, в последнем раунде MLPerf Inference все основные платформы NVIDIA продемонстрировали резкий рост производительности. Например, ускорители NVIDIA H200 показали на 27 % большую производительность инференса генеративного ИИ по сравнению с предыдущим раундом. А Triton Inference Server продемонстрировал почти такую же производительность, как и у bare-metal платформ. Наконец, благодаря программным оптимизациям в этом раунде MLPerf платформа NVIDIA Jetson AGX Orin достигла более чем 6,2-кратного улучшения пропускной способности и 2,5-кратного улучшения задержки по сравнению с предыдущим раундом на рабочей нагрузке GPT-J LLM. По словам NVIDIA, Jetson способен локально обрабатывать любую модель-трансформер, включая LLM, модели класса Vision Transformer и, например, Stable Diffusion. А вместо разработки узкоспециализированных моделей теперь можно применять универсальную GPT-J-6B модель для обработки естественного языка на периферии.
28.08.2024 [00:10], Владимир Мироненко
NVIDIA представила шаблоны ИИ-приложений NIM Agent Blueprints для типовых бизнес-задачNVIDIA анонсировала NIM Agent Blueprints, каталог предварительно обученных, настраиваемых программных решений, предоставляющий разработчикам набор инструментов для создания и развёртывания приложений генеративного ИИ для типовых вариантов использования, таких как аватары для обслуживания клиентов, RAG, виртуальный скрининг для разработки лекарственных препаратов и т.д. Предлагая бесплатные шаблоны для частых бизнес-задач, компания помогает разработчикам ускорить создание и вывод на рынок ИИ-приложений. NIM Agent Blueprints включает примеры приложений, созданных с помощью NVIDIA NeMo, NVIDIA NIM и микросервисов партнёров, примеры кода, документацию по настройке и Helm Chart'ы для быстрого развёртывания. Предприятия могут модифицировать NIM Agent Blueprints, используя свои бизнес-данные, и запускать приложения генеративного ИИ в ЦОД и облаках (в том числе в рамках NVIDIA AI Enterprise), постоянно совершенствуя их благодаря обратной связи. На текущий момент NIM Agent Blueprints предлагают готовые рабочие процессы (workflow) для систем обслуживания клиентов, для скрининга с целью автоматизированного поиска необходимых соединений при разработке лекарств и для мультимодального извлечения данных из PDF для RAG, что позволит обрабатывать огромные объёмы бизнес-данных для получения более точных ответов, благодаря чему ИИ-агенты чат-боты службы станут экспертами по темам компании. С примерами можно ознакомиться здесь. 
Источник изображения: NVIDIA Каталог NVIDIA NIM Agent Blueprints вскоре станет доступен у глобальных системных интеграторов и поставщиков технологических решений, включая Accenture, Deloitte, SoftServe и World Wide Technology (WWT). А такие компании как Cisco, Dell, HPE и Lenovo предложат полнофункциональную ИИ-инфраструктуру с ускорителями NVIDIA для развёртывания NIM Agent Blueprints. NVIDIA пообещала, что ежемесячно будут выпускаться дополнительные шаблоны для различных бизнес-кейсов.
27.08.2024 [17:46], Руслан Авдеев
ИИ-ускорители Rebellions Rebel Quad получат 144 Гбайт памяти Samsung HBM3eЮжнокорейский стартап Rebellions представила на днях план развития своих ИИ-ускорителей. Как сообщает Business Korea, компания ускорит выпуск ИИ-чипов нового поколения, которые получат 4-нм модули памяти HBM3e производства Samsung. Samsung же будет отвечать за объединение чипов и HBM в одной упаковке. Изначально к концу 2024 года планировалось наладить выпуск продукта Rebel Single с одним модулем памяти, но потом было решено выпустить гораздо более производительный вариант Rebel Quad с четырьмя 12-слойными (12-Hi) модулями HBM3e суммарной ёмкостью 144 Гбайт, тоже к концу текущего года. Новинка придёт на смену ускорителю ATOM, который оснащён всего лишь 16 Гбайт GDDR6. Использование ёмкой и быстрой HBM3e-памяти считается одним из главных преимуществ Rebel Quad, по этому показателю новинки сравнимы с последними ускорители NVIDIA семейства Blackwell. При этом обещано, что новинки будут значительно энергоэффективнее решений NVIDIA и даже ускорителей Groq. Это по-прежнему серверные ускорители для обработки LLM вроде ChatGPT, но подойдут ли они для обучения ИИ-моделей, пока не уточняется. 
Источник изображения: Rebellions Сейчас Rebellions ориентируется на поставки комплексных ИИ-решений «стоечного уровня». В рамках концепуии Rebellion Scalable Design (RDS) будет предложены программно-аппаратные комплексы, которые позволят органично взаимодействовать многочисленным ускорителями и серверам с максимальной производительностью и энергоэффективностью. Речь идёт о решении, теоретически способном конкурировать с NVIDIA CUDA.
27.08.2024 [12:08], Сергей Карасёв
Стартап FuriosaAI представил эффективный ИИ-ускоритель RNGD для LLM и мультимодальных моделейЮжнокорейский стартап FuriosaAI на мероприятии анонсировал специализированный чип RNGD (произносится как «Renegade»), который позиционируется в качестве альтернативы ускорителям NVIDIA. Новинка предназначена для работы с большими языковыми моделями (LLM) и мультимодальным ИИ. FuriosaAI основана в 2017 году тремя инженерами, ранее работавшими в AMD, Qualcomm и Samsung. Своё первое решение компания выпустила в 2021 году: чип Warboy представляет собой высокопроизводительный ЦОД-ускоритель, специально разработанный для рабочих нагрузок компьютерного зрения. Новое изделие RNGD, как утверждает FuriosaAI, является результатом многолетних инноваций. Чип изготавливается по 5-нм техпроцессу TSMC. ИИ-ускоритель на базе RNGD выполнен в виде карты расширения PCIe 5.0 x16. Он наделён 48 Гбайт памяти HBM3 с пропускной способностью до 1,5 Тбайт/с и 256 Мбайт памяти SRAM (384 Тбайт/с). Показатель TDP находится на уровне 150 Вт, что позволяет использовать устройство в системах с воздушным охлаждением. Для сравнения: у некоторых ускорителей на базе GPU величина TDP достигает 1000 Вт и более. 
Источник изображения: FuriosaAI Утверждается, что RNGD обеспечивает производительность до 512 Тфлопс в режиме FP8 и до 256 Тфлопс в режиме BF16. Быстродействие INT8/INT4 достигает 512/1024 TOPS. Карта позволяет эффективно запускать открытые LLM, такие как Llama 3.1 8B. Говорится, что один PCIe-ускоритель RNGD обеспечивает пропускную способность от 2000 до 3000 токенов в секунду (в зависимости от длины контекста) для моделей с примерно 10 млрд параметров. В системе можно объединить до восьми карт для работы с моделями, насчитывающими около 100 млрд параметров. RNGD основан на архитектуре свёртки тензора (Tensor Contraction Processor, TCP), которая, как отмечается, обеспечивает оптимальный баланс между эффективностью, программируемостью и производительностью. Программный стек состоит из компрессора моделей, сервисного фреймворка, среды выполнения, компилятора, профилировщика, отладчика и набора API для простоты программирования и развёртывания. Говорится, что чипы RNGD можно настроить для выполнения практически любой рабочей нагрузки LLM или мультимодального ИИ. |
|

