Материалы по тегу: ии
|
22.09.2025 [11:40], Сергей Карасёв
Arista проектирует коммутаторы с СЖО для ИИ ЦОДКомпания Arista, по сообщениям интернет-источников, поделилась планами по созданию оборудования для дата-центров. В разработке в числе прочего находятся коммутаторы и серверные стойки с жидкостным охлаждением. Как рассказал соучредитель Arista Андреас Бехтольшайм (Andreas Bechtolsheim), проектируемые коммутаторы будут на 100 % использовать СЖО. Это, как ожидается, обеспечит экономию электроэнергии на системном уровне от 5 % до 10 % в зависимости от температуры и повысит надёжность из-за отсутствия вибраций, вызываемых вентиляторами. NVIDIA уже анонсировала свои коммутаторы с СЖО. Кроме того, разрабатывается серверная стойка стандарта ORv3W, поддерживающая мощность до 120 кВт. Она сможет вместить до 16 2OU-коммутаторов, а также блоки управления, силовые полки и коммутационные панели. Стойка будет оснащена специальными фитингами для развёртывания СЖО и единой шиной питания. 
Источник изображений: Arista По словам Бехтольшайма, значительная часть разработок Arista связана с новыми системами охлаждения. Применение СЖО позволит создавать конфигурации с высокой плотностью размещения коммутаторов. Это важно в свете строительства ЦОД нового поколения, ориентированных на ресурсоёмкие задачи ИИ и НРС. 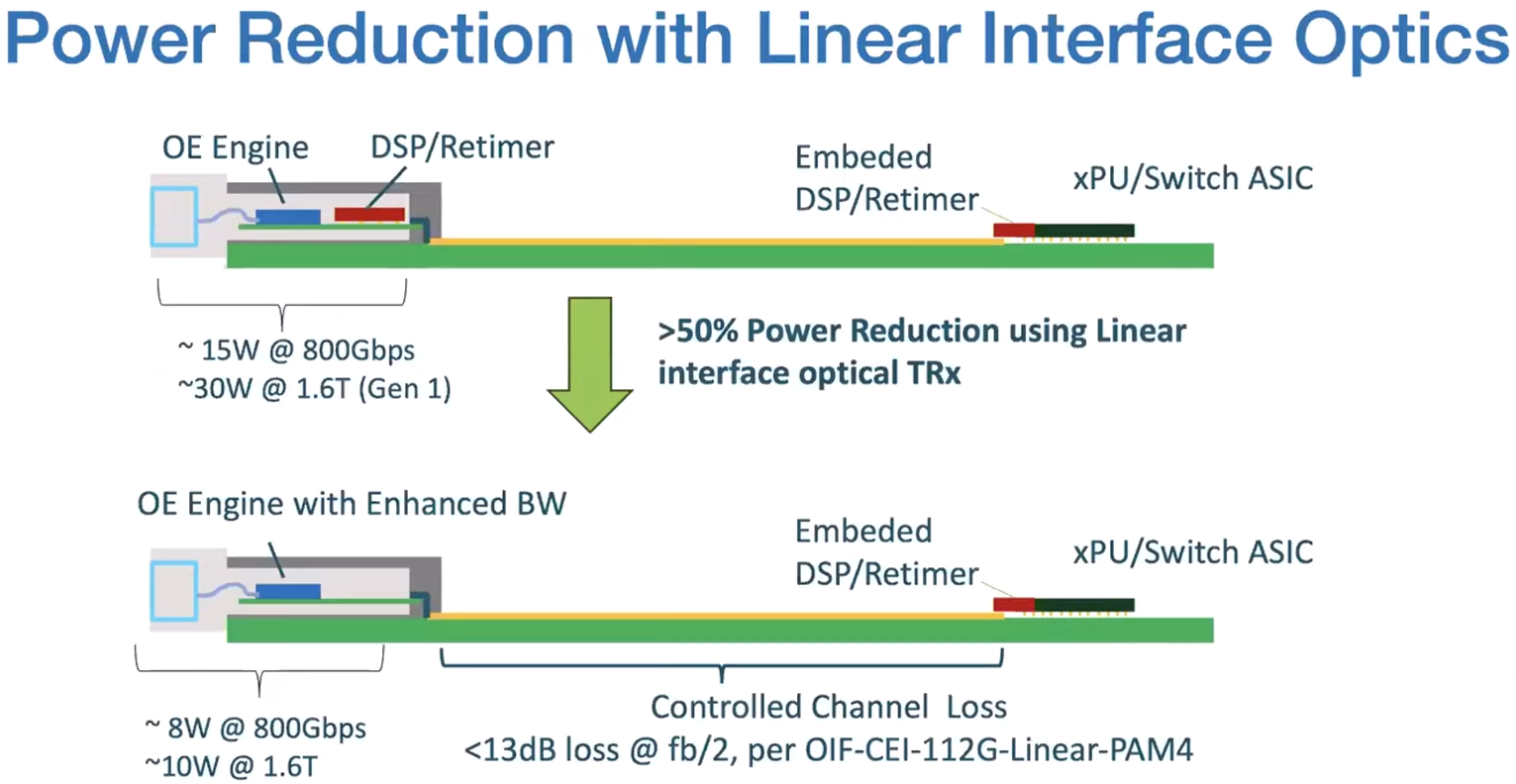 Соучредитель Arista также затронул тему LPO (Linear Pluggable Optics) — технологии, которая позволяет формировать прямые соединения между оптоволоконными модулями, устраняя необходимость в традиционных компонентах вроде цифровых сигнальных процессоров (DSP). Бехтольшайм отмечает, что LPO может обеспечить дополнительную экономию энергии на 20 % по сравнению с другими оптическими системами. По его мнению, в перспективе данная технология будет востребована в сетях, поддерживающих приложения ИИ.
22.09.2025 [11:00], Руслан Авдеев
Порт для кораблей и данных: Гибралтар одобрил создание 250-МВт ИИ ЦОДВласти заморской британской территории Гибралтар поддержали проект строительства дата-центра мощностью 250 МВт с индивидуальным питанием, получаемым независимо от местной энергосети, сообщает Computeг Weekly. Реализация проекта под управлением Pelagos Data Centres намечена в порту Гибралтара. Дата-центр, по всей вероятности, станет одним из крупнейших инфраструктурных начинаний страны. Стоимость ЦОД оценена в £1,8 млрд (более $2,4 млрд). После завершения он позволит создать более 100 постоянных рабочих мест. Само строительство запланировано в пять этапов. Первый этап намерены завершить уже к 2027 году, а на каждый последующий потребуется около 18 мес. Финансирование предусмотрено исключительно за счёт частных инвестиций и позволит преобразовать «экономический ландшафт» территории. Проект призван удовлетворить потребности Европы в мощностях ИИ ЦОД. Благодаря ему Гибралтар может стать новым значимым хабом в европейской цифровой инфраструктуре. 
Источник изображения: Petr Slováček/unspalsh.com Проект предусматривает использование возобновляемых источников энергии и СПГ, что сведёт к минимуму риски для безопасности уже имеющейся электросети Гибралтара. Также застройщики взяли на себя обязательство обеспечить работу объекта исключительно на энергии из возобновляемых источников к 2030 году, а также использовать выделяемое им тепло для других общественно значимых инициатив. По мнению местных властей, речь идёт о самых значимых инвестициях в инфраструктуру Гибралтара с 1990-х годов — тогда власти организовали строительство современных телекоммуникаций с помощью инвестиций США.
22.09.2025 [10:00], Владимир Мироненко
«Байкал Электроникс» представила универсальный микроконтроллер Baikal-U (BE-U1000)Российская компания «Байкал Электроникс» представила универсальный микроконтроллер Baikal-U (BE-U1000), который является отечественным аналогом линейки микроконтроллеров STM32F4хх–F7хх, обладая схожими техническими характеристиками. Он может использоваться на объектах КИИ в составе комплексов АСУ ТП, датчиков безопасности, приборов учёта, устройств ввода-вывода и интернета вещей (IoT), а также в системах управления беспилотными аппаратами. Baikal-U основан на открытой архитектуре RISC-V. Он использует два 32-бит ядра CloudBEAR BR-350 с максимальной рабочей частотой 200 Мгц и производительностью 3,59 CoreMark/МГц и одно 32-бит ядро CloudBEAR BM-310 с частотой до 100 Мгц и производительностью 3,42 CoreMark/МГц. Чип оснащён 192 Кбайт SRAM (в т.ч. 160 Кбайт TCM) и 256 Кбайт встроенной флеш-памяти (eFlash). Максимальный объём непосредственно адресуемой внешней флеш-памяти составляет 16 Мбайт (в XIP-режиме). 
Источник изображений: «Байкал Электроникс» Спецификации устройства включают три 12-разрядных АЦП с восемью мультиплексируемыми каналами с поддержкой дифференциальных входов, частотой дискретизации 1 МSps и функцией измерения температуры. Также сообщается о четырёх таймерах с четырьмя каналами ШИМ (PWMA), двух одноканальных таймерах общего назначения (PWMG), двух четырёхканальных таймерах общего назначения, двух сторожевых таймерах, двух DMA-контроллерах и 48 линиях GPIO.  Перечень интерфейсов также включает порт USB2.0 OTG со встроенным PHY, 8 × UART, 4 × SPI (по два ведущих и ведомых), 4 × I2C, 2 × QSPI, 2 × I2S и 2 × CAN FD. Микроконтроллер поддерживает входное напряжение 3,3 В (опционально 1,7 В и 1,2 В). Максимальный потребляемый ток — 250 мА. Заявлена встроенная поддержка MicroPython. Для разработчиков доступно две содификации варианта отладочных плат (EVU-BA и EVU-LI), а также несколько вариантов управляющих плат. Благодаря использованию в Baikal-U ядер отечественной компании CloudBEAR на открытой архитектуре RISC-V обеспечивается технологический суверенитет и независимость от иностранных разработок и ограничений, связанных с лицензионными соглашениями, говорит компания. В настоящее время устройство проходит процедуру регистрации в Реестре российской промышленной продукции. Розничная цена Baikal-U (BE-U1000) составляет 950 руб. (без НДС). Компания объявила о готовности обеспечить крупные серийные поставки со значительными скидками.
22.09.2025 [09:16], Руслан Авдеев
JLL: среднегодовой темп роста выручки неооблаков за пять лет составил 82 %По данным экспертов компании JLL, среднегодовой темп роста выручки (GAGR) неооблаков (neocloud) с 2021 года составил 82 %. В недавнем отчёте The rise of neocloud infrastructure подчёркивается, что соответствующий рынок демонстрирует значительный рост, поскольку конкуренция за ИИ-мощности и доступ к ускорителям возросли, сообщает DataCenter Knowledge. В JLL отмечают, что помимо уже хорошо известных на рынке и хорошо зарекомендовавших себя «неооблачных» операторов вроде CoreWeave, Nebius и Crusoe, имеется ещё около 190 независимых компаний того же профиля. Недавно S&P Global сообщила, что в прошлом году на этот сектор было потрачено более $10 млрд. В JLL считают, что это свидетельствует о «значительном инвестиционном импульсе». Так, акции CoreWeave с момента IPO в марте 2025 года выросли в цене почти втрое. JLL отмечает, что неооблачные провайдеры могут выбирать локации с оптимальной доступностью энергоресурсов и экономической выгодой, без привязки к традиционным хабам, необходимым гиперскейлерам. В итоге их модель развития более экономична и допускает ускоренное развёртывание мощностей. По данным Uptime Institute, неооблака обеспечивают снижение затрат примерно на 66 % в сравнении с гиперскейлерами. 
Источник изображения: venki cenation/unsplash.com По мнению экспертов, спрос на ИИ-инфраструктуру сегодня растёт исключительными темпами, а глобальный рынок ЦОД столкнулся с проблемой дефицита мощностей. Неооблачные бизнесы получили преимущество перед традиционными поставщиками облачных услуг благодаря более низким ценам, гибким условиям и некоторым другим факторам. Поскольку рынок ИИ, похоже, не намерен замедляться, инфраструктура новых облачных провайдеров в ближайшее время будет чрезвычайно востребована. Что касается возможных рисков, в JLL подчёркивают, что контракты неооблаков обычно короче, чем у традиционных облачных операторов, и составляют от двух до пяти лет — но в теории это не соответствует периодам окупаемости активов ЦОД в семь-девять лет. Кроме того, ставки у неооблаков растут из-за потребности в дефицитных ЦОД с возможностью размещения высокоплотных систем, передовыми сетевыми стеками и полами повышенной прочности, неооблачные провайдеры конкурируют за них друг с другом. JLL заявила, что более высокие требования к капиталу и более короткие сроки аренды значительно увеличивают инвестиционные риски в сравнении с традиционными ЦОД. В компании подчёркивают, что важнейшим фактором при реализации потенциала неооблаков для высоких ИИ-нагрузок станут вопросы финансирования. Для создания инфраструктуры ИИ-ускорителей требуются значительные капиталовложения — инвесторам необходимо чётко представлять, как создать жизнеспособную бизнес-модель и заручиться поддержкой клиентов прежде, чем выходить на рынок «новых облаков».
21.09.2025 [13:40], Сергей Карасёв
Schneider Electric готовит стойки NVIDIA GB300 NVL72 мощностью 142 кВтКомпания Schneider Electric анонсировала две эталонные платформы, призванные ускорить построение инфраструктур для дата-центров, ориентированных на ресурсоёмкие нагрузки ИИ и НРС. Разработка систем ведётся в партнёрстве с NVIDIA. Один из проектов предусматривает создание референсных стоек для суперускорителей NVIDIA GB300 NVL72. Такие стойки смогут обеспечивать мощность до 142 кВт. Предусмотрено использование жидкостного охлаждения. В одном машинном зале могут быть расположены три кластера GB300 NVL72, насчитывающих в общей сложности до 1152 ускорителей. Отмечается, что в основу решения положены наработки и опыт, полученные в ходе реализации аналогичного проекта для NVIDIA GB200 NVL72. Клиентам будет доступна специальная среда моделирования на базе вычислительной гидродинамики (CFD): могут применяться цифровые двойники для оценки различных конфигураций электропитания и охлаждения с целью оптимизации платформ под определённые нужды. 
Источник изображения: Schneider Electric Второй эталонный проект, как утверждается, представляет собой первую и единственную в отрасли платформу, предполагающую интеграцию систем управления питанием и жидкостным охлаждением, включая решения Motivair (контрольный пакет акций этой фирмы Schneider Electric приобрела в конце 2024 года). Для новой платформы заявлена совместимость с NVIDIA Mission Control — программным обеспечением NVIDIA для контроля производственных процессов и оркестрации работы ИИ-систем, включая управление кластерами и рабочими нагрузками. В таких системах могут применяться суперускорители GB300 NVL72 и GB200 NVL72. Подчёркивается, что новые эталонные решения являются результатом продолжающегося сотрудничества Schneider Electric и NVIDIA, которое направлено на удовлетворение растущих потребностей операторов дата-центров в области ИИ.
21.09.2025 [01:35], Владимир Мироненко
Meta✴ намерена стать энергокомпанией и продавать электричество — Amazon, Google и Microsoft уже делают то же самоеMeta✴ Platforms планирует выйти на рынок оптовой торговли электроэнергией, чтобы эффективнее управлять огромными потребностями в ней своих ЦОД, сообщил Bloomberg. По данным ресурса, Atem Energy, «дочка» Meta✴, подала заявку в Федеральную комиссию по регулированию энергетики США (FERC) с просьбой предоставить разрешение «на продажу энергии, мощности и некоторых дополнительных услуг». Компания попросила одобрить её заявку до 16 ноября. Представитель Meta✴ заявил, что выход на энергетические рынки — это вполне логичный шаг в реализации стремления компании использовать «чистую» энергию для обеспечения ведения своей деятельности. Так, компания выкупила всю энергию АЭС Clinton Clean Energy Center в Иллинойсе на 20 лет вперёд. Обеспечение электроэнергией своих объектов становится всё более актуальной задачей для технологических компаний, включая Meta✴, Microsoft и Google (Alphabet), которые разрабатывают всё более продвинутые системы и ИИ-инструменты, требующие большие объёмы электроэнергии. При этом Amazon, Google и Microsoft уже являются участниками энергетического рынка и активно торгуют электричеством, о чём свидетельствуют документы, поданным ими в регулирующие органы США. 
Источник изображения: Andrew Hall/unsplash.com Потребляя огромные объёмы энергии, эти компании также имеют контракты на продажу электроэнергии в случае необходимости и экономической целесообразности. «Появятся возможности продавать электроэнергию на оптовых рынках и немного заработать на этом», — говорит о перспективах Meta✴ Павел Молчанов (Pavel Molchanov), аналитик Raymond James. Также технологические компании, у которых есть аккумуляторы или генераторы на территории их кампусов ЦОД, могут продавать энергию обратно в сеть в случае резкого роста цен, утверждает Энди ДеВриз (Andy DeVries), аналитик CreditSights по коммунальным услугам и энергетике. Согласно прогнозам BloombergNEF, за 10 лет спрос на электроэнергию со стороны ИИ ЦОД вырастет в четыре раза. На фоне резкого роста спроса увеличиваются цены на электроэнергию. Платежи за мощность, которые получают производители на некоторых рынках США, выросли до рекордных значений. Спрос настолько высок, что некоторые технологические компании, заявлявшие о своих климатических целях, начали вновь рассматривать природный газ в качестве ключевого источника питания для ЦОД. Например, в прошлом месяце регулирующие органы Луизианы одобрили план коммунальной компании Entergy Corp. по строительству трёх электростанций, работающих на природном газе, для обеспечения ЦОД Meta✴ энергией. Ради них даже построят отдельную ЛЭП.
21.09.2025 [01:05], Владимир Мироненко
Meta✴ готова потратить $20 млрд на аренду ИИ-мощностей у OracleАгентству Bloomberg стало известно о переговорах между Oracle и Meta✴ Platforms о многолетнем соглашении на сумму $20 млрд, в рамках которого Oracle будет предоставлять гиганту социальных сетей вычислительные мощности для обучения и развертывания ИИ-моделей. Сумма сделки не окончательная, как и её условия, которые могут измениться до достижения сторонами окончательного соглашения, предупредили источники Bloomberg, знакомые с обстоятельствами ведения переговоров. Как полагает SiliconANGLE, сделка Meta✴ с Oracle в сфере облачных технологий, вероятно, является частью масштабной инициативы по созданию ЦОД, о которой компания сообщила в июле. В рамках проекта она инвестирует сотни миллиардов долларов в новую ИИ-инфраструктуру. Первые два кластера ЦОД этого проекта, Prometheus и Hyperion, потребуют по нескольку ГВт электроэнергии каждый. На прошлой неделе Oracle заключила соглашение с OpenAI на $300 млрд сроком на пять лет на предоставление вычислительный мощностей для обработки ИИ-нагрузок. Компания ранее сообщила, что в I квартале 2026 финансового года заключила многомиллиардные соглашения с тремя клиентами, в результате чего объём оставшихся обязательств по контрактам (RPO) вырос год к году на 359 % до $455 млрд. 
Источник изображения: Oracle По словам гендиректора Oracle Сафры Кац (Safra Catz, на фото выше), в ближайшие несколько месяцев у компании должно появиться еще несколько крупных клиентов с многомиллиардными контрактами, благодаря чему RPO, вероятно, превысит полтриллиона долларов. Дэйв Велланте (Dave Vellante), главный аналитик CUBE Research (SiliconANGLE Media), отметил, что эти достижения свидетельствуют о том, что Oracle вошла в число гиперскейлеров. Oracle становится ключевым поставщиком вычислительных мощностей для ИИ-нагрузок, конкурируя с лидерами рынка облачных технологий Amazon.com, Microsoft и Google. На фоне успешной работы акции техасской компании выросли в этом году на 84 %.
20.09.2025 [13:06], Сергей Карасёв
OpenAI потратит $100 млрд на аренду резервных ИИ-серверов у облачных провайдеровКомпания OpenAI, по сообщению The Information, намерена в течение пяти лет потратить до $100 млрд на аренду резервных серверов у облачных провайдеров. Эти ресурсы будут использоваться для удовлетворения спроса на вычислительные мощности в периоды пиковых нагрузок. OpenAI полагает, что быстрое развитие ИИ и внедрение новых возможностей в данной области в перспективе могут привести к более резким скачкам нагрузки на серверные платформы. Компания опасается, что нехватка мощностей в подобных ситуациях может привести к тому, что клиенты начнут обращаться к Google, Meta✴ и другим конкурирующим игрокам. 
Источник изображения: unsplash.com / Growtika Ожидается, что арендованные резервные ресурсы во время простоя будут использоваться для выполнения тех или иных научных и исследовательских задач. Кроме того, в зависимости от условий соглашения с облачным провайдером излишки вычислительных мощностей могут перепродаваться сторонним заказчикам. В целом, OpenAI намерена выделять на облачные сервисы около $85 млрд ежегодно. Недавно компания заключила пятилетнее соглашение о приобретении вычислительных мощностей у Oracle для задач ИИ: на эти цели будет выделено $300 млрд. OpenAI продолжает использовать облачную инфраструктуру Microsoft Azure, а также арендует ресурсы у CoreWeave. Ранее генеральный директор OpenAI Сэм Альтман (Sam Altman) заявлял, что со временем компания потратит на создание ИИ-инфраструктуры триллионы долларов. По словам Альтмана, доступ к передовым вычислительным мощностям является ключом к сохранению преимущества в гонке за ИИ. При этом OpenAI терпит убытки, рассчитывая выйти на прибыль в 2030 году. Компания прогнозирует, что её выручка вырастет до $200 млрд к концу текущего десятилетия против примерно $13 млрд, ожидаемых по итогам нынешнего года.
20.09.2025 [01:40], Владимир Мироненко
NVIDIA купила за $900 млн разработчика интерконнекта для ИИ-платформ EnfabricaСогласно публикациям CNBC и The Information, NVIDIA заключила сделку с разработчиком интерконнекта для ИИ-систем Enfabrica стоимостью $900 млн, чтобы лицензировать ряд его технологий, а также переманить его гендиректора и ключевых сотрудников. Оплата сделки, завершённой на прошлой неделе, производилась собственными средствами NVIDIA и её акциями. Глава Enfabrica Рочан Санкар (Rochan Sankar) уже присоединился к команде NVIDIA. Спрос на вычислительные мощности для поддержки генеративного ИИ со стороны таких компаний, как OpenAI, Anthropic, Mistral, AWS, Microsoft и Google, ставит перед NVIDIA сложную задачу: как создать унифицированный, отказоустойчивый GPU-кластер, способный справиться с такими огромными нагрузками. Решения Enfabrica, основанной в 2019 году, призваны решить эту задачу. Как пишет Network World со ссылкой на аналитиков, NVIDIA считает интеграцию технологий Enfabrica критически важной для повышения эффективности своих кластеров в обучении новейших ИИ-моделей. Во всяком случае, Enfabrica утверждает, что её технология позволяет бесшовно объединить более 100 тыс. ускорителей в единый кластер. Кроме того, к ускорителям можно добавить CXL-пулы DRAM/SSD. 
Источник изображений: Enfabrica «Используя SuperNIC и фабрику Enfabrica, NVIDIA может ускорить передачу данных в кластерах, обойти текущие ограничения масштабирования сетевых фабрик и снизить зависимость от дорогостоящей памяти HBM», — отметила Рачита Рао (Rachita Rao), старший аналитик Everest Group, имея в виду чип ACF-S, разработанный для обеспечения более высокой пропускной способности, большей отказоустойчивости, меньшей задержки и лучшего программного управления для операторов ЦОД, работающих с ресурсоёмкими ИИ-системами и HPC. Enfabrica утверждает, что ACF-S более отказоустойчив в сравнении с традиционным интерконнектом, поскольку заменяет двухточечные соединения GPU многопутевой архитектурой, которая снижает перегрузку, улучшает распределение данных и гарантирует, что сбои в работе GPU не приведут к остановке процесса вычислений. По мнению Чарли Дая (Charlie Dai), главного аналитика Forrester, для NVIDIA также представляет интерес технология EMFASYS, позволяющая дать ИИ-серверам доступ к внешним пулам памяти. По словам Дая, сочетание ACF-S и EMFASYS может помочь NVIDIA добиться более высокой загрузки GPU и снижения совокупной стоимости владения (TCO) — ключевых показателей для гиперскейлеров и разработчиков LLM. 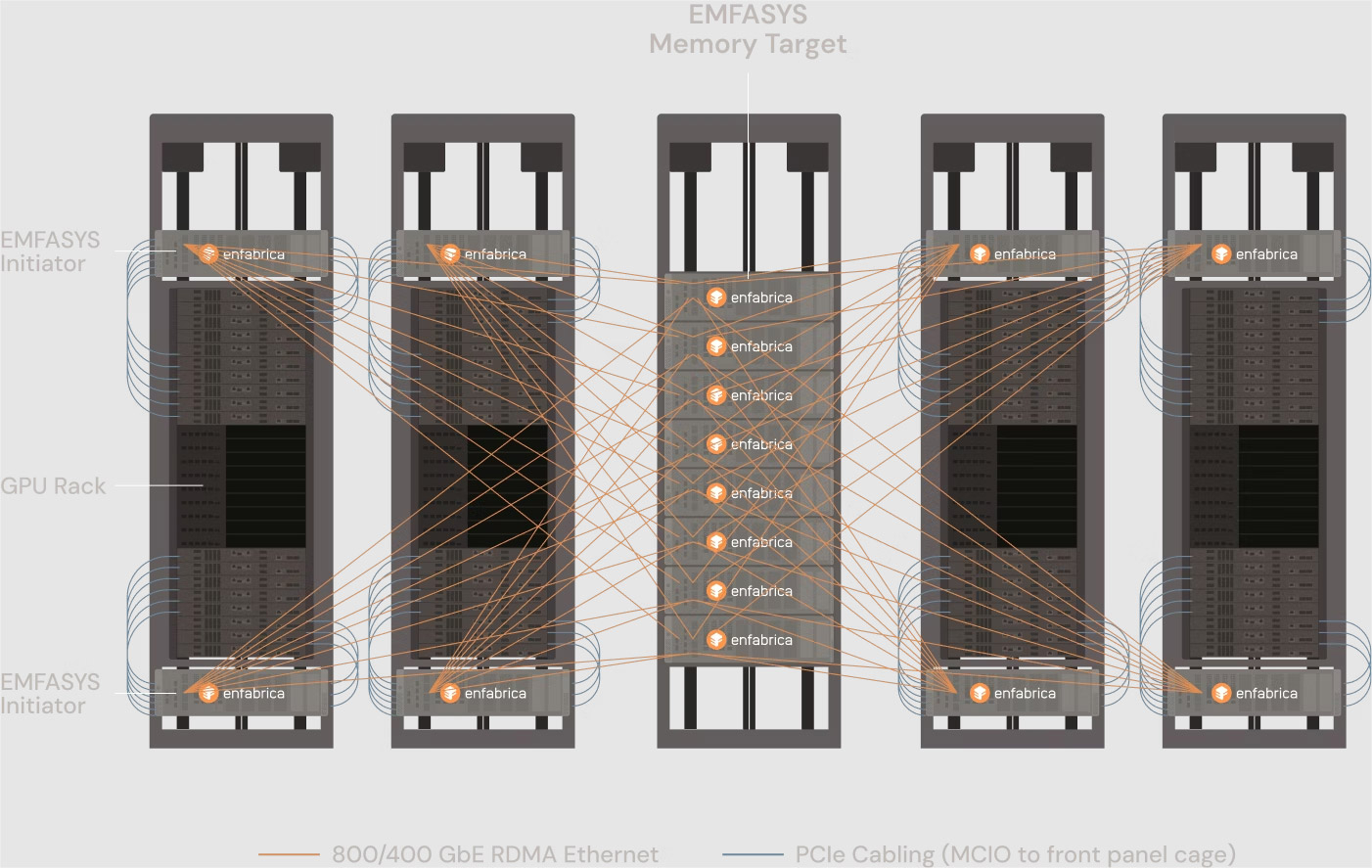 Как сообщает Blocks & Files, Enfabrica привлекла в общей сложности $290 млн венчурного финансирования: $50 млн в раунде A в размере $50 млн в 2022 году при оценке в $50 млн; $125 млн в раунде B в 2023 году с оценкой в размере $250 млн; $115 млн в раунде C в 2024 году. По данным Pitchbook, оценочная стоимость компании сейчас составляет около $600 млн. NVIDIA инвестировала в компанию в раунде B. На этой неделе NVIDIA также объявила об инвестициях в Intel в размере $5 млрд в рамках совместной разработки специализированных чипов для ЦОД и ПК. Квазислияния получили широкое распространение в Кремниевой долине, поскольку позволяют обойти препоны регуляторов. В начале этого года Meta✴ приобрела за $14,3 млрд 49 % акций Scale AI, переманив его основателя Александра Ванга (Alexandr Wang) вместе с ключевыми сотрудниками. Месяц спустя Google объявила о похожем соглашении с ИИ-стартапом Windsurf, в рамках которого его соучредитель и гендиректор Варун Мохан (Varun Mohan) перешёл вместе с рядом сотрудников в подразделение Google DeepMind. Аналогичные сделки были в прошлом году у Google с Character.AI, Microsoft с Inflection AI и у Amazon с Adept.
19.09.2025 [17:06], Руслан Авдеев
Vantage вложит €3,2 млрд в кампус ЦОД в испанской СарагосеАмериканский оператор дата-центров Vantage Data Centers выходит на рынок ЦОД Испании. Компания сообщила о намерении инвестировать в развитие кампуса в Вильянуэва-де-Гальего (Villanueva de Gállego) провинции Сарагоса (автономное сообщество Арагон) €3,2 млрд ($3,78 млрд), сообщает Datacenter Dynamics. Проект намерены реализовать совместно с арагонской Desarrollos Ecoindustriales La Cartuja. Как сообщают местные власти, проект будет реализован в пять этапов за десять лет. Дата-центр займёт 40 га неосвоенных земель промышленного назначения рядом с кампусом Университета Сан-Хорхе (USJ) напротив промзоны San Miguel. Власти Арагона одобрили проект, которому присвоен статус имеющего общерегиональное значение (DIGA, Declaración de Interés General de Aragón), что указывает на особую важность для экономического и социального развития всего региона. Проект уже обеспечен договором на поставку 90 МВт электричества от энергокомпании Endesa. Кампус разместят в экотехнопарке, поддерживаемом Vantage. Планируется интегрировать местные мощности по производству возобновляемой энергии, как ветряной, так и солнечной, с системами хранения энергии — чтобы обеспечить «климатическую нейтральность» проекта. Кроме того, ЦОД получат замкнутую систему охлаждения, чтобы гарантировать отсутствие дополнительного расхода воды. 
Источник изображения: Pedro Sanz/unsplash.com По словам представителя правительства Арагона, благодаря крупным инвестициям Vantage общий объём внешних вложений в сообщество с начала работы очередного созыва местного законодательного органа достиг €57,9 млрд ($65,5). Бизнес-инвестиции влияют на ВВП, позволяют создать тысячи рабочих мест и способствуют укреплению государственных услуг Арагона. Ожидается, что в первые три года речь кампус Vantage создат 180 постоянных рабочих мест, а в то к концу последнего года реализации — о 520 местах. Заявлено, что Арагон становится международным центром инвестиций в дата-центры. В августе правительство региона одобрило расширение ЦОД AWS в Уэске (Uesca) и Сарагосе (Zaragoza), а BlackStone попросила расширить изначальные планы строительства кампуса в Сарагосе. Также в регионе строит крупные дата-центры Microsoft. Vantage также стремится освоить азиатские рынки. Компания привлекла $1,6 млрд для расширения присутствия в Азиатско-Тихоокеанском регионе (АТР), начав с покупки кампуса Yondr Group в Джохоре (Малайзия). Кампус находится в технопарке Sedenak Tech Park и обеспечивает 72,5 МВт IT-мощностей, а к концу его строительства они должны вырасти до 300 МВт. В июне 2025 года Yondr сдала первый в кампусе ЦОД на 25 МВт, на полгода раньше расписания. Впервые анонсированный в марте 2022 года кампус получил реальный импульс к развитию двумя годами позже, и уже привлёк более $900 млн финансирования. |
|

