Материалы по тегу: x
|
10.05.2024 [13:53], Владимир Мироненко
Lenovo установит в Италии 1,2-Пфлопс суперкомпьютер Cassandra на базе Intel Xeon Max для климатических исследованийКомпания Lenovo сообщила о возобновлении сотрудничества с Европейско-Средиземноморским центром по изменению климата (CMCC), базирующимся в Лечче (Италия), и подписании контракта на установку в этом году новой мощной системы высокопроизводительных вычислений (HPC) Cassandra, предназначенной для исследования изменения климата с помощью повышенных вычислительных возможностей и оптимизации использования энергии. Cassandra включает 180 узлов SD650 V3 с двумя процессорами Intel Xeon Max 9480 (Sapphire Rapids с HBM) на узел и имеет пиковую FP64-производительность 1,2 Пфлопс. Благодаря использованию технологии жидкостного охлаждения Lenovo Neptune Direct Water-Cooling, способной отводить до 98 % тепла, Cassandra потребляет на 15 % ниже электроэнергии, чем аналогичные решения с воздушным охлаждением. Благодаря повышенной эффективности СЖО температура процессоров не достигает критических значений, что позволяет избежать снижения максимальной частоты ядер процессоров, говорит Lenovo. Установкой Cassandra в суперкомпьютерном центре CMCC (SCC) будет заниматься Ricca IT, сертифицированный партнёр Lenovo. В суперкомпьютерном центре CMCC уже имеется HPC-система от Lenovo под названием Juno, установленная в 2022 году, с FP64-производительностью около 1,13 Пфлопс и построенная на базе процессоров Intel и ускорителей NVIDIA. 
Источник изображения: cmcc.it Cassandra будет использоваться для климатического моделирования системы Земли, океана, работы как глобальных, так и региональных систем сезонного прогнозирования, а также запуска приложения по исследованию изменения климата на основе ИИ. CMCC также планирует интегрировать во II полугодии в суперкомпьютер два ИИ-узла с восемью ускорителями NVIDIA H100 в каждом.
09.05.2024 [23:56], Владимир Мироненко
Red Hat представила ИИ-дистрибутив RHEL AI, который требует минимум 320 Гбайт GPU-памяти
ibm
ibm cloud
linux
llm
open source
openshift
red hat
red hat enterprise linux
software
ии
разработка
Red Hat представила Red Hat Enterprise Linux AI (RHEL AI), базовую платформу, которая позволит более эффективно разрабатывать, тестировать и запускать генеративные модели искусственного интеллекта (ИИ) для поддержки корпоративных приложений. Фактически это специализированный дистрибутив, включающий базовые модели, инструменты для работы с ними и необходимые драйверы. 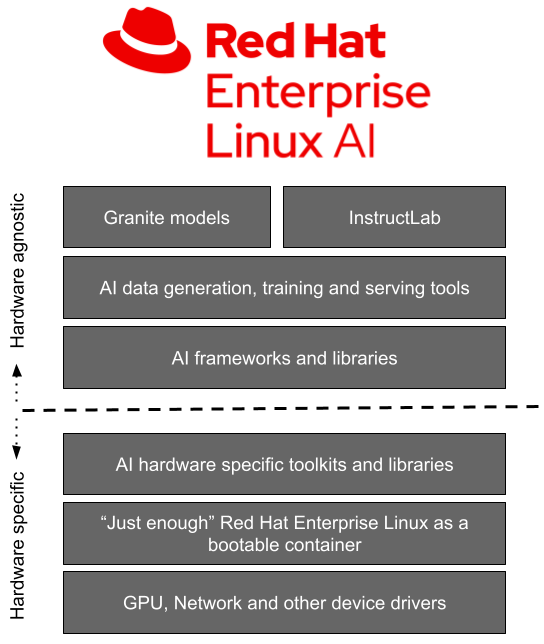
Источник изображений: Red Hat Доступная сейчас в качестве превью для разработчиков, платформа RHEL AI включает в себя семейство больших языковых моделей (LLM) IBM Granite, недавно ставших доступными под лицензией Apache 2.0, инструментом тюнинга и доработки моделей InstructLab посредством методики LAB (Large-Scale Alignment for Chatbots), а также различные библиотеки и фреймворки. Решение представляется в виде готового для развёртывания образа и является частью MLOps-платформы OpenShift AI. По словам Red Hat, RHEL AI предоставляет поддерживаемую, готовую к корпоративному использованию среду для работы с ИИ-моделями на аппаратных платформах AMD, Intel и NVIDIA. По словам компании, open source подход позволит устранить препятствия на пути реализации стратегии в области ИИ, такие как недостаток навыков обработки данных и финансовых возможностей. 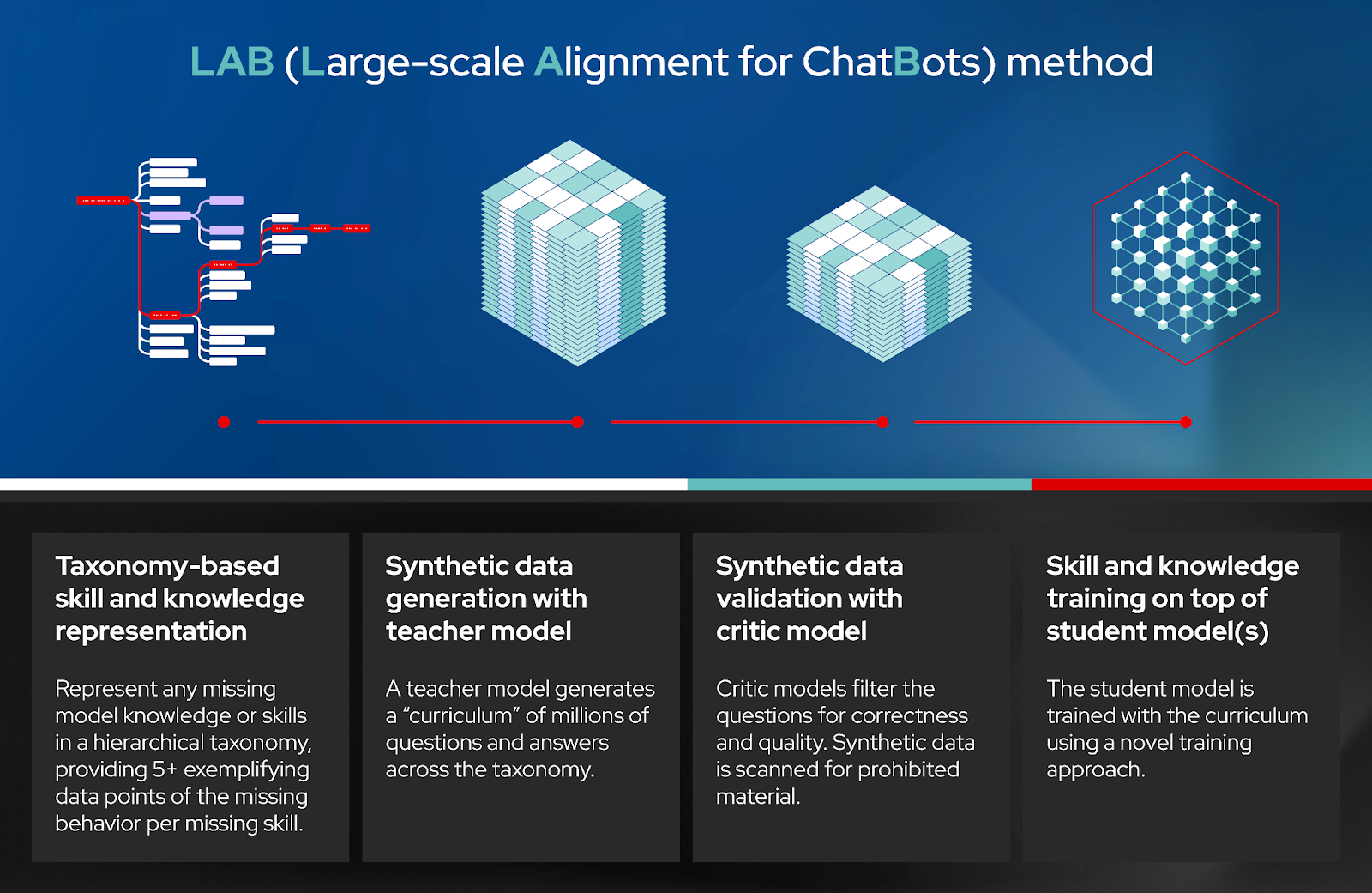 Основная цель RHEL AI и проекта InstructLab — предоставить экспертам в предметной области возможность напрямую вносить свой вклад в большие языковые модели, используя свои знания и навыки. Новая платформа позволит им более эффективно создавать приложения с использованием ИИ, например, чат-боты. Впоследствии при наличии подписки RHEL AI компания предложит поддержку корпоративного уровня на протяжении всего жизненного цикла продукта, начиная с модели Granite 7B и ПО и заканчивая возможным возмещение ущерба в отношении интеллектуальной собственности. 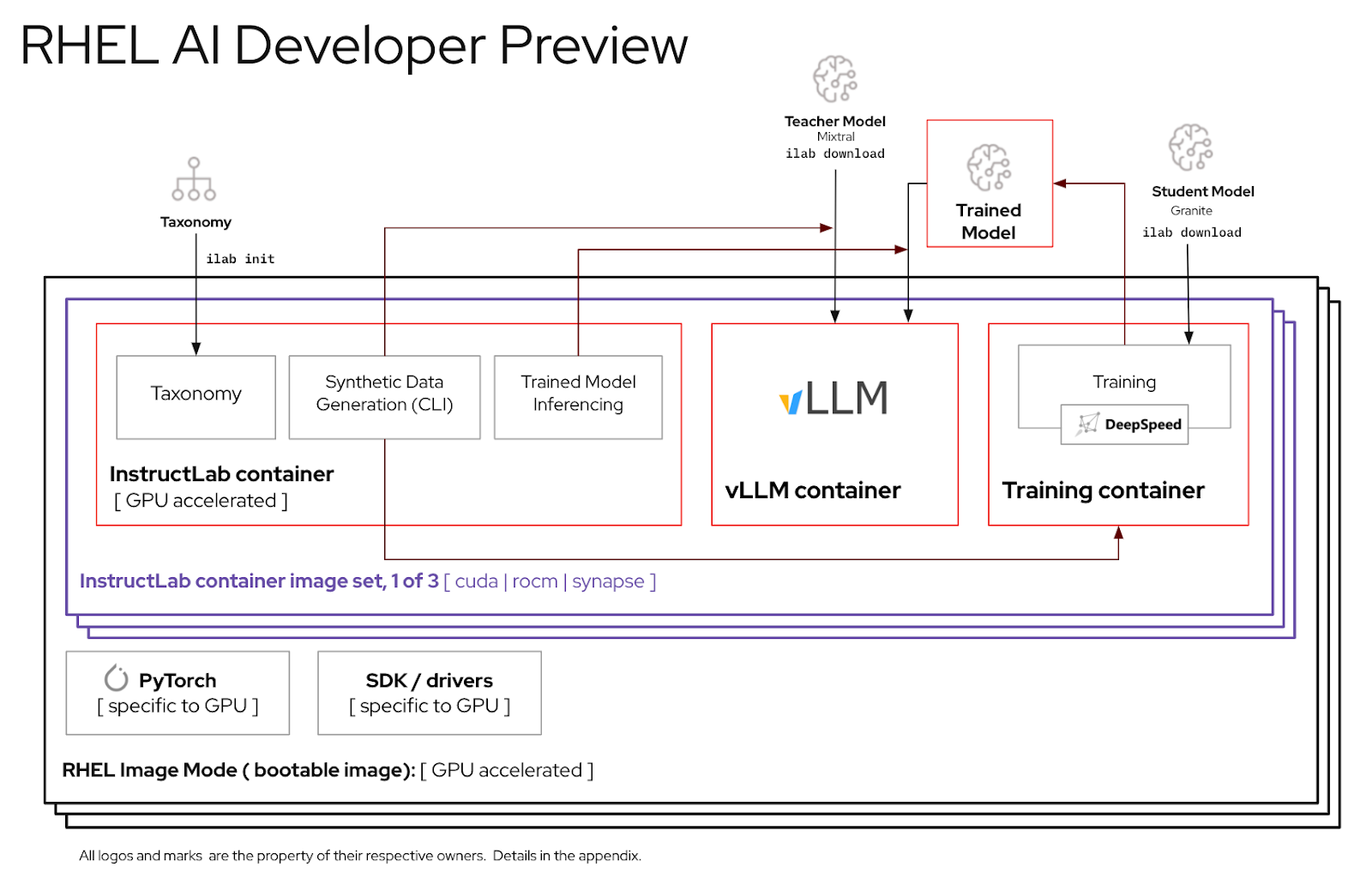 «Опираясь на инфраструктуру GPU, доступную в IBM Cloud, которая используется для обучения моделей Granite и поддержки InstructLab, IBM Cloud получит поддержку RHEL AI и OpenShift AI. Эта интеграция позволит предприятиям легче внедрять генеративный ИИ в свои критически важные приложения», — отметила компания. При этом прямо сейчас для запуска RHEL AI требуются весьма производительные сертифицированные системы с ускорителями, имеющими минимум 320 Гбайт памяти, а также хранилищем ёмкостью от 200 Гбайт. Среди протестированных указаны серверы Dell с четырьмя NVIDIA H100, Lenovo с восемью AMD Instinct MI300X, а также инстансы IBM Cloud GX3. Вскоре обещана поддержка инстансов AWS EC2 P5 с NVIDIA H100 и ускорителей Intel.
08.05.2024 [17:48], Сергей Карасёв
Одноплатный компьютер GigaIPC PICO-N97A на базе Intel Alder Lake-N выполнен в формате Pico-ITXКомпания GigaIPC, подразделение Gigabyte, представила одноплатный компьютер PICO-N97A для приложений Industry 4.0: новинка предназначена для построения различных устройств для умного города, сектора здравоохранения, ретейл-сферы и пр. В основу положена аппаратная платформа Intel Alder Lake-N. Изделие выполнено в формате Pico-ITX с размерами 100 × 72 мм. Установлен чип Intel Processor N97 (4C/4T; до 3,6 ГГц; 12 Вт), работающий в тандеме с оперативной памятью DDR5-4800, объём которой может достигать 16 Гбайт (один слот SO-DIMM). Имеется коннектор M.2 2280 для SSD с интерфейсом PCIe x2 или SATA-3. 
Источник изображений: GigaIPC Новинка оснащена двумя сетевыми портами 1GbE на базе неназванного контроллера Realtek (гнёзда RJ-45), разъёмом M.2 2230 E-Key (PCIe x1; USB 2.0) для комбинированного адаптера Wi-Fi / Bluetooth, двумя портами USB 3.0. Изображение может выводиться через интерфейсы HDMI 2.0 (4096 × 2160@60) и LVDS (1920 × 1200@60). Поддерживается подключение двух независимых дисплеев. Через коннекторы на плате можно задействовать последовательный порт RS-232/422/485, два порта USB 2.0 и пр. Напряжение питания — 12 В (подаётся через 2-контактный коннектор).  Одноплатный компьютер располагает чипом TPM 2.0 (Infineon SLB9670VQ2.0) для обеспечения безопасности. Диапазон рабочих температур простирается от 0 до +60 °C. Для изделия предусмотрено использование пассивного охлаждения.
07.05.2024 [15:01], Сергей Карасёв
Mini-ITX плата Radxa Rock 5 ITX с чипом Rockchip позволит создать NAS с двумя 2.5GbE-портамиКомпания Radxa анонсировала довольно необычную материнскую плату под названием Rock 5 ITX. Это изделие в формате Mini-ITX оснащено процессором Arm, а одной из основных сфер применения названо создание сетевых хранилищ (NAS). В качестве программной платформы применяется Roobi OS. Плата укомплектована процессором Rockchip RK3588, который часто используется в одноплатных компьютерах для индустриального применения и сферы IoT. Чип содержит четыре ядра Cortex-A76 (2,4 ГГц) и четыре ядра Cortex-A55 (1,8 ГГц), графический блок Arm Mali-G610 MC4 и нейропроцессорный модуль (NPU) с производительностью до 6 TOPS. Поддерживаются вычисления INT4/INT8/INT16/FP16/BF16/TF32. Новинка может нести на борту 4, 8, 16 или 32 Гбайт памяти LPDDR5. В оснащение входит флеш-накопитель eMMC вместимостью 8 Гбайт для Roobi OS. Дополнительно можно установить карту microSD и SSD формата M.2 (NVMe; PCIe 3.0 х2). Для подключения накопителей в рамках NAS доступны четыре порта SATA-3 на базе контроллера ASMedia ASM1164. 
Источник изображения: Radxa Плата располагает двумя сетевыми портами 2.5GbE с поддержкой PoE и коннектором M.2 E Key, которому можно подключить адаптер Wi-Fi 6. Есть два выхода HDMI (до 8Kp60), вход HDMI (до 4Kp60), два порта USB 2.0 Type-A, четыре разъёма USB 3.0 Type-A, порт USB 3.0 Type-C, набор аудиогнёзд и разъём для подачи питания (12 В). Среди прочего упомянута поддержка интерфейсов DP (через USB Type-C), MIPI DSI, eDP, MIPI CSI. Модель Radxa Rock 5 ITX имеет размеры 170 × 170 мм. Диапазон рабочих температур — от 0 до +50 °C. Может быть подключён вентилятор охлаждения с регулировкой скорости вращения посредством PWM. Стоимость модификаций с 8, 16 или 32 Гбайт ОЗУ составляет $120, $160 и $240, тогда как цена модели с 4 Гбайт памяти не раскрывается.
06.05.2024 [10:08], Сергей Карасёв
В AlmaLinux сформировано подразделение по НРС и ИИУчастники проекта AlmaLinux объявили о формировании специальной группы по интересам (SIG), которая займётся развитием направления НРС и ИИ. Подразделение под названием AlmaLinux HPC and AI SIG возглавляет Хайден Барнс (Hayden Barnes) — менеджер сообщества open source по задачам ИИ в корпорации HPE. AlmaLinux фактически заполняет пробел, оставшийся после прекращения выпуска стабильных версий CentOS Linux. Поддержка этой ОС прекратилась в конце 2021 года, а не в 2029-м, как ожидалось. Место CentOS заняла CentOS Stream, вечная бета-версия RHEL. 
Источник изображения: AlmaLinux Группа HPC and AI SIG в составе AlmaLinux, как отмечается, состоит из экспертов по HPC и ИИ, которые выбрали эту ОС в качестве программной основы для своих проектов. В их число входят специалисты компаний — поставщиков оборудования для НРС-систем, участники ИИ-проектов open source, а также администраторы, развёртывающие AlmaLinux в исследовательских организациях. Подразделение сформировано с тем, «чтобы гарантировать, что у пользователей есть ресурсы и поддержка сообщества, необходимые для максимизации преимуществ AlmaLinux» в рамках инициатив, связанных с НРС и ИИ. Участники SIG намерены взаимодействовать, внедрять инновации и обмениваться знаниями внутри сообщества AlmaLinux. За пределами экосистемы AlmaLinux специалисты новой группы намерены развивать партнёрские отношения и сотрудничать с иными заинтересованными сторонами. AlmaLinux рассчитывает «оставаться в авангарде технологических достижений» в сферах НРС и ИИ.
05.05.2024 [13:59], Сергей Карасёв
SK hynix продала всю память HBM, запланированную к выпуску в 2024–2025 гг.Компания SK hynix, по сообщению The Register, получила заказы на весь объём памяти HBM, запланированный к выпуску в 2024 году, и на основную часть этих чипов, которые будут произведены в 2025-м. Спрос на изделия HBM быстро растёт на фоне стремительного развития ИИ-рынка. SK hynix объявила на пресс-конференции в своей штаб-квартире в Ичхоне (Южная Корея) о намерении расширить производство микросхем HBM. Генеральный директор компании Квак Но-чжун (Kwak Noh-jung) заявил, что выпуск изделий данного типа удастся значительно нарастить после завершения строительства новых предприятий в Южной Корее и США. 
Источник изображения: SK hynix SK hynix является основным поставщиком памяти HBM для ускорителей NVIDIA, с поставками которых наблюдаются сложности из-за высокого спроса со стороны облачных провайдеров и операторов дата-центров, ориентированных на ИИ-нагрузки. Квак Но-чжун прогнозирует, что в среднесрочной и долгосрочной перспективе среднегодовой прирост потребности в чипах HBM будет составлять около 60 %. Это связано с увеличением объёмов генерируемых данных и повышением сложности ИИ-моделей. До конца мая SK hynix планирует предоставить клиентам образцы памяти HBM пятого поколения — 12-слойные изделия HBM3E. Массовый выпуск такой продукции компания наметила на III квартал 2024 года. Недавно SK hynix заявила, что планирует инвестировать более $14,5 млрд в новый корейский завод M15X по производству чипов памяти. Первоначально планировалось, что это предприятие будет выпускать изделия NAND, но затем было решено переориентировать его мощности под выпуск DRAM. В марте сообщалось, что компания Micron Technology, приступившая в феврале к массовому производству памяти HBM3E, уже получила контракты на весь объём поставок этих изделий до конца 2024 года, а также на большую часть поставок в 2025 году.
02.05.2024 [18:00], Сергей Карасёв
CIQ обеспечит трёхлетнюю поддержку платформы CentOS 7Компания CIQ, поддерживающая Rocky Linux, анонсировала инициативу CIQ Bridge для пользователей платформы CentOS 7, жизненный цикл которой близится к завершению. Инициатива, как ожидается, поможет клиентам поддерживать свою IT-инфраструктуру в актуальном и защищённом состоянии в рамках миграции на Rocky Linux. Поддержка CentOS, напомним, прекратилась в конце 2021 года, а не в 2029-м, как ожидалось. Место CentOS заняла CentOS Stream, вечная бета-версия RHEL. А в июне 2023 года Red Hat объявила о прекращении поддержки публикации исходного кода пакетов уже выпущенных релизов в репозитории CentOS. Впоследствии CIQ, Oracle и SUSE создали совместную торговую ассоциацию Open Enterprise Linux Association (OpenELA), чтобы противостоять политике Red Hat. Вместе с тем основатель проекта CentOS Грегори Курцер (Gregory Kurtzer) в 2020 году представил Rocky Linux — новую свободную сборку RHEL. На эту платформу предлагается перейти пользователям CentOS 7, жизненный цикл которой закончится 30 июня 2024 года. Те клиенты, которым необходимо дополнительное время для перехода на альтернативную ОС, могут воспользоваться программой CIQ Bridge. 
Источник изображения: CIQ По сути, CIQ Bridge — это расширенная поддержка CentOS 7 сроком на три года: доступ к ней предоставляется по годовой подписке с фиксированной ставкой. Клиентам будут предоставляться обновления, а также заплатки для уязвимостей, имеющих рейтинг CVSS 7 и выше. Патчи для дыр с рейтингом CVSS 5 и CVSS 6 могут распространяться на дополнительных условиях. По оценкам, на сегодняшний день более 385 тыс. компаний по всему миру применяют CentOS. Хотя многие организации успешно перешли на Rocky Linux и другие альтернативы Linux, некоторым клиентам сложно сделать это до 30 июня по ряду причин, включая проблемы с финансированием и нехватку специалистов. Таким пользователям программа CIQ Bridge даст дополнительное время для перехода на новую Linux-платформу. Сама Red Hat объявила о предоставлении дополнительной четырёхлетней поддержки пользователям Red Hat Enterprise Linux (RHEL) 7. Обычно период поддержки этой платформы составляет 10 лет, но в случае RHEL 7 он увеличен до 14 лет.
25.04.2024 [17:25], Владимир Мироненко
Из Git в RuStore: «РеСолют» интегрировала платформу GitFlic с российским магазином приложенийКомпания «РеСолют» (входит в «Группу Астра»), создатель платформы для работы с исходным кодом GitFlic, сообщила о разработке механизма, который обеспечит разработчикам приложений для RuStore возможность использования репозитория GitFlic для хранения, распространения кода и сборки бинарных пакетов. После сборки приложения будут в автоматическом режиме размещаться в магазине RuStore, используя авторизацию через API. Как сообщает компания, в настоящее время на GitFlic опубликованы все SDK для работы с RuStore. Зарегистрироваться в GitFlic и RuStore можно с помощью VK ID. Технический директор «РеСолют» сообщил, что стратегической целью сервиса, насчитывающего более 40 тыс. разработчиков, является желание стать единым центром взаимодействия для всех российских разработчиков, позволяющим управлять полным жизненным циклом разработки ПО. Сервис имеет необходимые инструменты отечественной разработки, охватывающих ключевые процессы создания и дистрибуции ПО. 
Источник изображения: GitFlic В свою очередь директор по продукту RuStore заявил, что развитие современной инфраструктуры для разработчиков — одна из главных целей RuStore. Он сообщил, что у магазина есть все необходимые SDK, включая популярные инструменты разработки и сервисы продвижения, на которые перешло уже более 1000 компаний. А сотрудничество с GitFlic обеспечит разработчикам возможность комфортной работы с SDK магазина и использования привычных решений для разработки приложений и публикации их в RuStore.
24.04.2024 [19:33], Андрей Крупин
Вышла новая версия системы резервного копирования «Кибер Бэкап Облачный» с расширенной поддержкой Linux-платформКомпания «Киберпротект» сообщила о выходе обновления системы «Кибер Бэкап Облачный» 24.03. «Кибер Бэкап Облачный» позволяет сервис-провайдерам предоставлять услуги резервного копирования и восстановления данных в облаке (BaaS), а конечным пользователям — обеспечивать непрерывность бизнес-процессов за счёт многоуровневого подхода к защите данных. Платформенная часть решения может размещаться в защищённых ЦОД «Киберпротекта», в инфраструктуре заказчика либо в облачном хранилище выбранного сервис-провайдера. Двухфакторная проверка подлинности даёт дополнительную защиту от несанкционированного доступа.  В обновлённом релизе «Кибер Бэкапа Облачного» реализована возможность работы с операционными системами на базе Linux с ядром до версии 6.2. Это позволило обеспечить совместимость решения с наиболее востребованными российскими платформами «Ред ОС» 7.2 и 7.3, Astra Linux 1.6 и 1.7, «Альт» 10, «РОСА Кобальт» 7.9, а также Debian 11, Ubuntu 22.04 и другими популярными операционными системами на этой версии ядра. Продукт зарегистрирован в реестре российского программного обеспечения Минцифры России. Его можно использовать для замещения зарубежных сервисов, прекративших свою работу и поддержку пользователей на территории РФ.
19.03.2024 [01:00], Игорь Осколков
NVIDIA B200, GB200 и GB200 NVL72 — новые ускорители на базе архитектуры BlackwellNVIDIA представила сразу несколько ускорителей на базе новой архитектуры Blackwell, названной в честь американского статистика и математика Дэвида Блэквелла. На смену H100/H200, GH200 и GH200 NVL32 на базе архитектуры Hopper придут B200, GB200 и GB200 NVL72. Все они, как говорит NVIDIA, призваны демократизировать работу с большими языковыми моделями (LLM) с триллионами параметров. В частности, решения на базе Blackwell будут до 25 раз энергоэффективнее и экономичнее в сравнении с Hopper. В разреженных FP4- и FP8-вычислениях производительность B200 достигает 20 и 10 Пфлопс соответственно. Но без толики технического маркетинга не обошлось — показанные результаты достигнуты не только благодаря аппаратным улучшениям, но и программным оптимизациям. Это ни в коей мере не умаляет их важности и полезности, но затрудняет прямое сравнение с конкурирующими решениями. В общем, появление Blackwell стоит рассматривать не как очередное поколение ускорителей, а как расширение всей экосистемы NVIDIA. В Blackwell компания использует тайловую (чиплетную) компоновку — два тайла объединены 2,5D-упаковкой CoWoS-L и на двоих имеют 208 млрд транзисторов, изготовленных по техпроцессу TSMC 4NP. В одно целое со всех точек зрения их объединяет новый интерконнект NV-HBI с пропускной способностью 10 Тбайт/с, а дополняют их восемь стеков HBM3e-памяти ёмкостью до 192 Гбайт с агрегированной пропускной способностью до 8 Тбайт/с. Такой же объём памяти предлагает и Instinct MI300X, но с меньшей ПСП (5,3 Тбайт/с), хотя это скоро изменится. FP8-производительность в разреженных вычислениях у решения AMD составляет 5,23 Пфлопс, но зато компания не забывает и про FP64 в отличие от NVIDIA. 
Источник изображений: NVIDIA Одними из ключевых нововведений, отвечающих за повышение производительности, стали новые Tensor-ядра и второе поколение механизма Transformer Engine, который научился заглядывать внутрь тензоров, ещё более тонко подбирая необходимую точность вычислений, что влияет и на скорость обучения с инференсом, и на максимальный объём модели, умещающейся в памяти ускорителя. 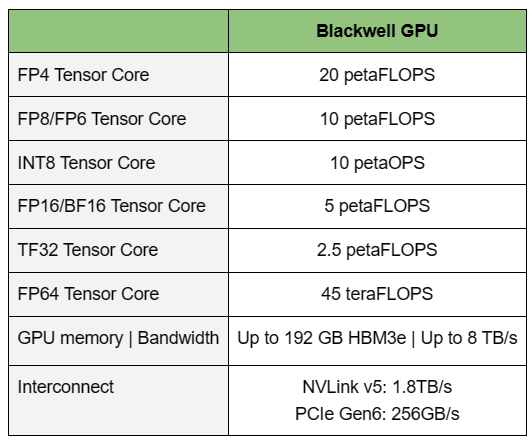 Теперь NVIDIA намекает на то, что обучение можно делать в FP8-формате, а для инференса хватит и FP4. Всё это без потери качества. Но вообще Blackwell поддерживает FP4/FP6/FP8, INT8, BF16/FP16, TF32 и FP64. И только для последнего нет поддержки разреженных вычислений. 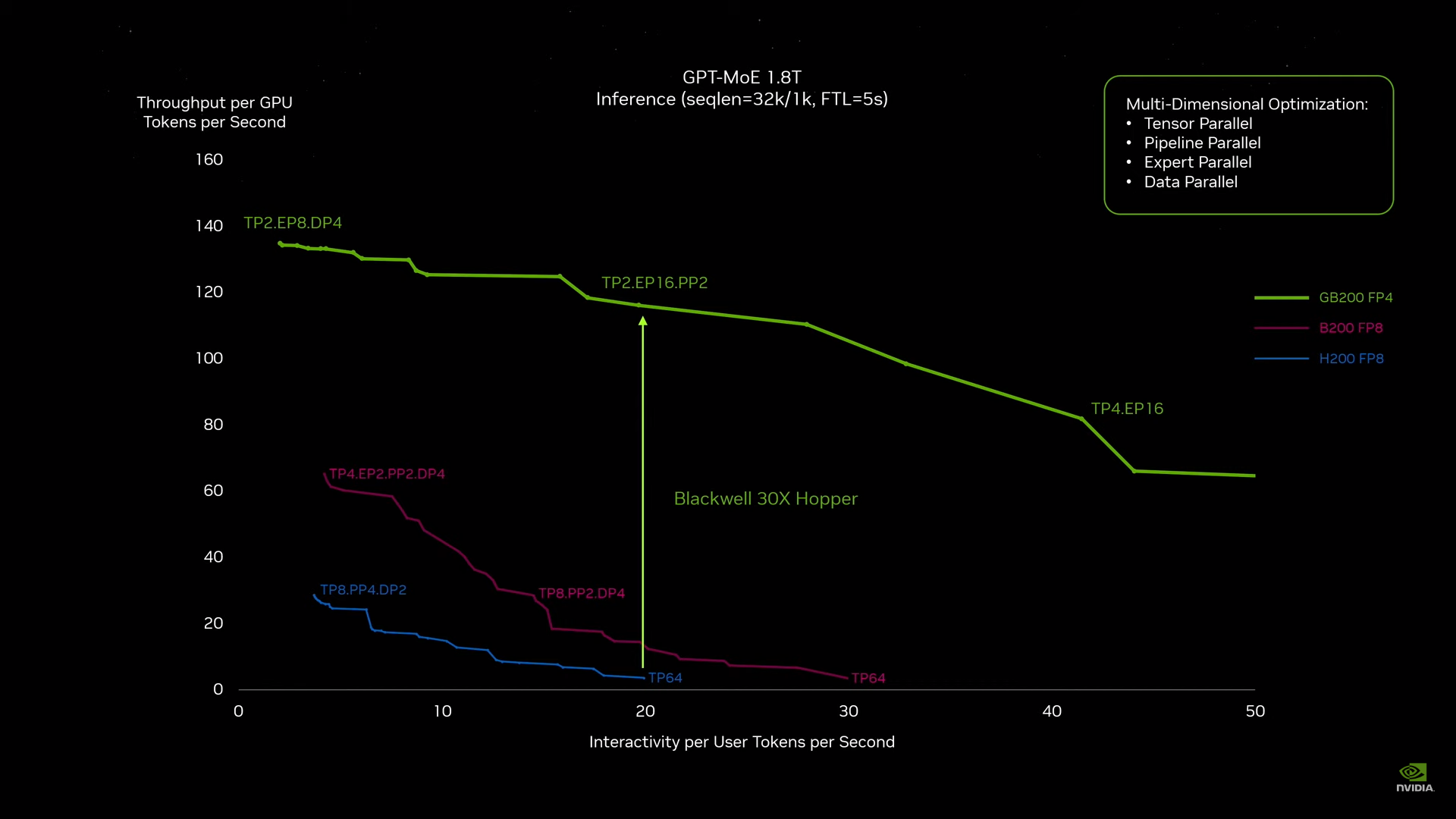 Дополнительно Blackwell обзавёлся движком для декомпрессии (в первую очередь LZ4, Deflate, Snappy) входящих данных со скоростью до 800 Гбайт/с, что тоже должно повысить производительность, т.к. теперь распаковкой будет заниматься не CPU и, соответственно, ускоритель не будет «голодать». Эта функция рассчитана в основном на Apache Spark и другие системы для аналитики больших данных. Также есть по семь движков NVDEC и NVJPEG.  Наконец, NVIDIA упоминает ещё две новых возможности Blackwell: шифрование данных в памяти и RAS-функции. В первом случае речь идёт о защите конфиденциальности обрабатываемых данных, что важно в целом ряде областей. Причём формирование TEE-анклава возможно в рамках группы из 128 ускорителей. MIG-доменов по-прежнему семь. В случае RAS говорится о телеметрии и предиктивной аналитике (естественно, на базе ИИ), которые помогут заранее выявить возможные сбои и снизить время простоя. Это важно, поскольку многие модели могут обучаться неделями и месяцами, так что потеря даже относительно небольшого куска данных крайне неприятна и финансово затратна.  Однако всё эти инновации не имеют смысла без возможности масштабирования, поэтому NVIDIA оснастила Blackwell не только интерфейсом PCIe 6.0 (32 линии), который играет всё меньшую роль, но и пятым поколением интерконнекта NVLink. NVLink 5 по сравнению с NVLink 4 удвоил пропускную способность до 1,8 Тбайт/с (по 900 Гбайт/с в каждую сторону), а соответствующий коммутатор NVSwitch 7.2T позволяет объединить до 576 ускорителей в одном домене. SHARP-движки с поддержкой FP8 дополнительно помогут ускорить обработку моделей, избавив ускорители от части работ по предобработке и трансформации данных. Чип коммутатора тоже изготавливается по техпроцессу TSMC N4P и содержит 50 млрд транзисторов.  Для дальнейшего масштабирования и формирования кластеров из 10 тыс. ускорителей и более, вплоть до 100 тыс. ускорителей на уровне ЦОД, NVIDIA предлагает 800G-коммутаторы Quantum-X800 InfiniBand XDR и Spectrum-X800 Ethernet, имеющие соответственно 144 и 64 порта. Узлам же полагаются DPU ConnectX-8 SuperNIC и BlueField-3. Правда, последний предлагает только 400G-порты в отличие от первого. От InfiniBand компания отказываться не собирается.  С базовыми кирпичиками разобрались, пора переходить к конструированию продуктов. Первым идёт HGX B100, в основе которой всё та же базовая плата с восемью ускорителями Blackwell, точно так же провязанных между собой NVLink 5 с агрегированной скоростью 14,4 Тбайт/с. Для связи с внешним миром предлагается пара интерфейсов PCIe 6.0 x16. HGX B100 предназначена для простой замены HGX H100, поэтому ускорители имеют TDP не более 700 Вт, что ограничивает пиковую производительность в разреженных FP4- и FP8/FP6/INT8-вычислениях до 14 и 7 Пфлопс соответственно, а для всей системы — 112 и 56 Пфлопс соответственно. 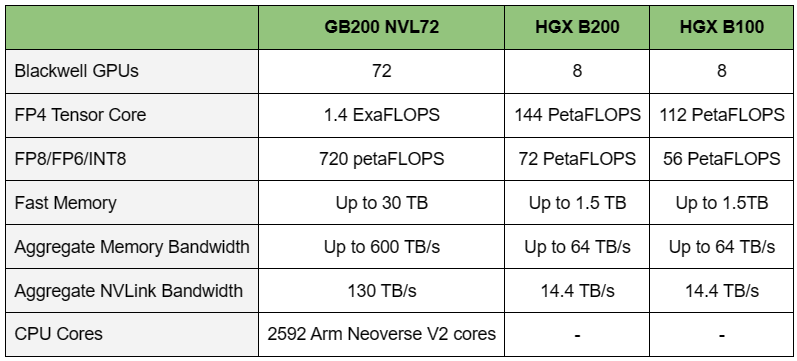 У HGX B200 показатель TDP ограничен уже 1 кВт, причём возможность воздушного охлаждения по-прежнему сохраняется. Производительность одного B200 в разреженных FP4- и FP8/FP6/INT8-вычислениях достигает уже 18 и 9 Пфлопс, а для всей системы — 144 и 72 Пфлопс соответственно. DGX B200 повторяет HGX B200 в плане производительности и является готовой системой от NVIDIA, тоже с воздушным охлаждением. В системе используются два чипа Intel Xeon Emerald Rapids. По словам NVIDIA, DGX B200 до 15 раз быстрее в задачах инференса «триллионных» моделей по сравнению с DGX-узлами прошлого поколения. 800G-интерконнект Ethernet/InfiniBand этим трём платформам не достался, только 400G.  Основным же строительным блоком сама компания явно считает гибридный суперчип GB200, объединяющий уже имеющийся у неё Arm-процессор Grace сразу с двумя ускорителями Blackwell B200. CPU-часть включает 72 ядра Neoverse V2 (по 64 Кбайт L1-кеша для данных и инструкций, L2-кеш 1 Мбайт), 144 Мбайт L3-кеша и до 480 Гбайт LPDDR5x-памяти с ПСП до 512 Гбайт/с. С двумя B200 процессор связан 900-Гбайт/с шиной NVLink-C2C — по 450 Гбайт/с на каждый ускоритель. Между собой B200 напрямую подключены уже по полноценной 1,8-Тбайт/с шине NVLink 5.  Вся эта немаленькая конструкция шириной в половину стойки имеет TDP до 2,7 кВт. 1U-узел с парой чипов GB200, каждый из которых может отъедать до 1,2 кВт, уже требует жидкостное охлаждение. FP4- и FP8/FP6/INT8-производительность (речь всё ещё о разреженных вычислениях) GB200 достигает 40 и 20 Пфлопс. И именно эти цифры NVIDIA нередко использует для сравнения новинок со старыми решениями.  18 узлов с парой GB200 (суммарно 72 шт.) и 9 узлов с парой коммутаторов NVSwitch 7.2T, которые провязывают все ускорители по схеме каждый-с-каждым (агрегированно 130 Тбайт/с, более 3 км соединений), формируют 120-кВт суперускоритель GB200 NVL72 размером со стойку (Oberon), оснащённый СЖО и единой DC-шиной питания. Всё это даёт до 1,44 Эфлопс в FP4-вычислениях и до 720 Пфлопс в FP8, а также до 13,5 Тбайт HBM3e с агрегированной ПСП до 576 Тбайт/с. Ну а общий объём памяти составляет порядка 30 Тбайт. GB200 NVL72 одновременно является и узлом DGX GB200. Восемь DGX GB200 формируют DGX SuperPOD. Впрочем, будет доступен и SuperPOD попроще, на базе DGX B200.  Ускорители B200 появятся в этом году и будут стоить в диапазоне $30–$40 тыс., что ненамного больше начальной цены Hopper в диапазоне $25–$40 тыс. Глава NVIDIA уже предупредил, что Blackwell сразу будут в дефиците. Вероятно, получить доступ к ним проще всего будет в облаках Amazon, Google, Microsoft и Oracle. |
|

