Материалы по тегу: s
|
17.10.2024 [15:56], Руслан Авдеев
AWS запитает свои ЦОД от модульных реакторов X-energyПо данным пресс-службы Amazon (AWS), компания готовится к инвестициям в атомную энергетику. Она анонсировала три новых энергетических проекта, предполагающих постройку нескольких малых модульных реакторов (SMR). Компания уже заявила о переходе на 100 % возобновляемую электроэнергию — на семь лет раньше, чем планировалось. Атомные проекты — часть плана по переходу на полностью безуглеродную энергетику. AWS объявила о подписании как минимум трёх соглашений для поддержки развития атомных проектов, включая помощь в строительстве новых SMR. Гиперскейлер утверждает, что такие решения помогут удовлетворить спрос клиентов и добиться нулевого выброса CO2 в ходе всех операций к 2040 году. Кроме того, инвестиции помогут и в разработке новых атомных технологий, которые обеспечат генерацию энергии в ближайшие десятилетия. AWS делает ставку на решения компании X-energy. IT-гигант является одним из ключевых инвесторов раунда финансирования серии C, в ходе которого планируется привлечь $500 млн. Благодаря поддержке AWS консорциумом Energy Northwest (шт. Вашингтон) получит четыре малых модульных реактора X-energy Xe-100 мощностью 80 МВт каждый, которые используют топливо TRISO-X, разработанное совместно с Министерством энергетики США (DoE). В дальнейшем мощность планируется довести до 960 МВт, но не факт, что вся она достанется AWS. Всего к 2039 году X-energy рассчитывает построить 5 ГВт мощностей. 
Источник изображения: Amazon В Вирджинии AWS подписала соглашение с Dominion Energy. Вместе компании изучат возможность строительства SMR рядом с принадлежащей Dominion атомной станцией North Anna, которые добавят не менее 300 МВт мощностей. Ранее AWS купила за $650 млн кампус Cumulus Data, запитанный напрямую от действующей АЭС Susquehanna. В рамках сделки будет обеспечен доступ к 480–960 МВт для питания 15 дата-центров. Инвестиции в атомные проекты, помимо сохранения прежних реакторов и создания новых, будут способствовать экономическому развитию местных сообществ, говорит AWS. 
Источник изображения: Amazon AWS не единственный гиперскейлер, желающий использовать атомную энергию. Microsoft наняла специалиста для контроля разработки SMR для своих ЦОД, до этого было подписано PPA с поддерживаемым Сэмом Альтманом (Sam Altman) энергетическим стартапом Helion. Дополнительно компания заключила PPA на 20 лет с Constellation Energy, которое позволит «оживить» реактор АЭС Three Mile Island, заглушенный в 2019 году из-за нехватки финансирования. В сентябре Oracle анонсировала получение разрешений на строительство трёх SMR для питания ЦОД ёмкостью более 1 ГВт. Собственные амбиции в этой сфере имеются и у Google, которая объявила о намерении покупать энергию от SMR Kairos Power. Впрочем, рабочих реакторов у Kairos пока нет, а коммерческие модели, вероятно, не появятся до 2035 года.
17.10.2024 [14:36], Руслан Авдеев
Nebius, бывшая Yandex, представила облачную ИИ-платформу с ускорителями NVIDIA H100 и H200ИИ-компания Nebius, сформированная из бывшей Yandex N.V., представила облачную платформу с современными ускорителями NVIDIA. Как уточняет Datacenter Dynamics, речь идёт о моделях NVIDIA H100 и H200, а также L40S. В скором будущем компания рассчитывает добавить и новейшие суперускорители GB200 NVL72. 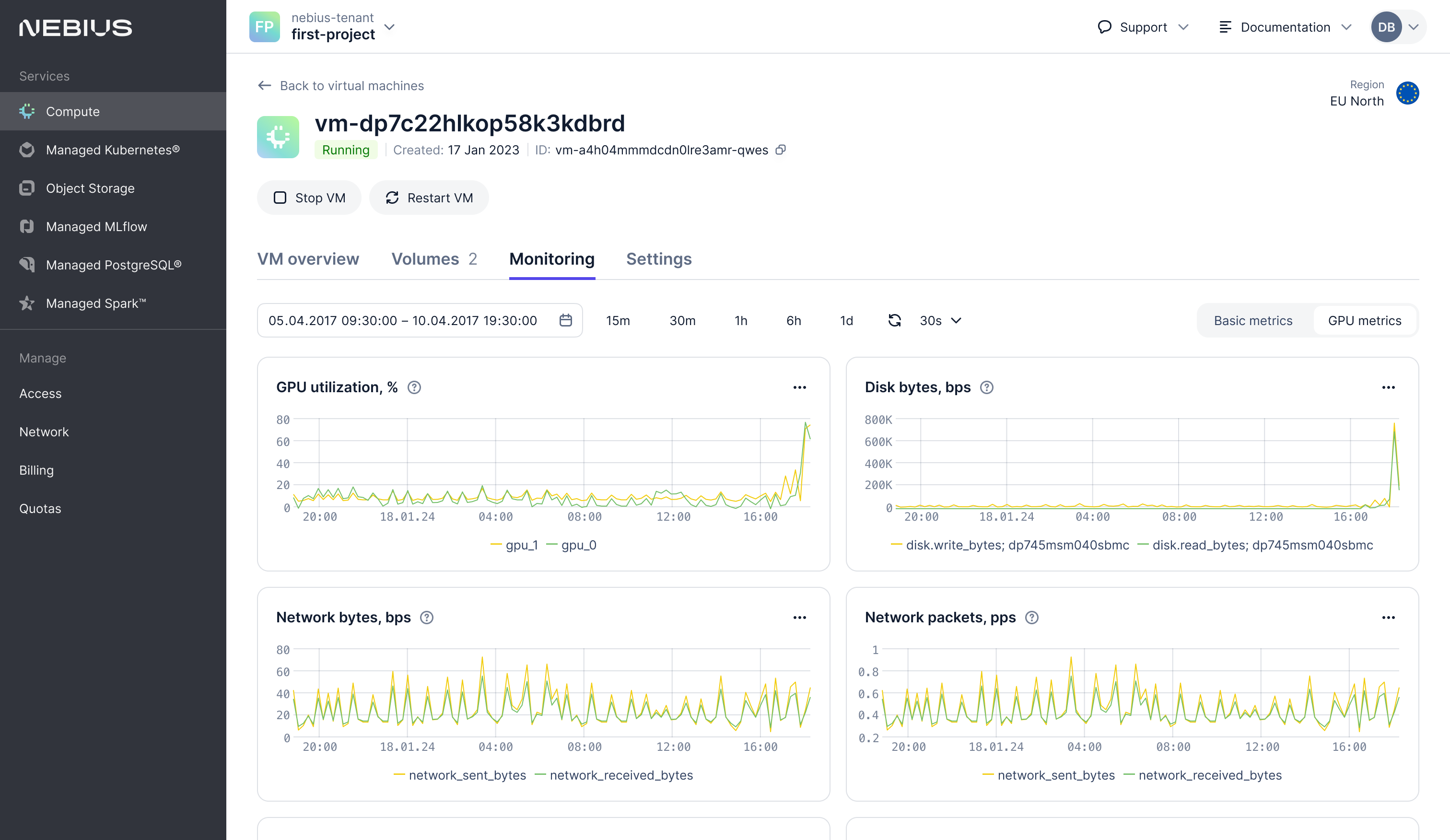
Источник изображения: Nebius Облачное хранилище обеспечивает агрегированную скорость чтения до 100 Гбайт/с и 1 млн IOPS. Платформа также предлагает управляемые Apache Spark и MLFlow, а ВМ по умолчанию включают ИИ-библиотеки и драйверы. По словам компании, она прислушалась к запросам клиентов, нуждавшихся в самостоятельном доступе и инфраструктуре, отлично от просто «базовой». Речь идёт о крупномасштабных кластерах с InfiniBand-подключением на базе эталонной архитектуры NVIDIA, но с кастомизированным оборудованием и проприетарной программной облачной платформой. После введения антироссийских санкций Nebius дистанцировалась от «Яндекса», основная часть активов которого была продана группе российских инвесторов. У Nebius остался дата-центр в Финляндии, ёмкость которого она намерена утроить в обозримом будущем. Там разместятся более 60 тыс. ускорителей. В августе сообщалось, что компания увеличила облачную выручку на 60 % год к году во II квартале.
16.10.2024 [18:44], Руслан Авдеев
У семи CEO Atos без глазу: тонущий французский IT-гигант назначил очередного гендиректораИспытывающая немалые проблемы с бизнесом компания Atos привлекла к руководству нового генерального директора. Datacenter Dynamics напоминает, что речь идёт о назначении уже седьмого главы бизнеса за последние три года. На пост Жана-Пьера Мюстье (Jean-Pierre Mustier) придёт новый CEO Филипп Салль (Philippe Salle), который приступит к работе 1 февраля 2025 года. А прямо сейчас он займёт пост президента компании. Мюстье стал CEO Atos в июле 2024 года, но к компании он присоединился ещё в прошлом октябре. У Салля богатый опыт работы в сфере IT-консалтинга, в своё время бизнесмен был главой Altran Group (позже ставшей Capgemini). Его предшественник Мюстье стал генеральным директором Atos после Пола Салеха (Paul Saleh), работавшего в должности с января 2024 года. Тот, в свою очередь, сменил Ива Бернера (Yves Bernaert), проработавшего CEO чуть более года. Наконец, до него директорами были Нурдин Бихман (Nourdine Bihmane), Филипп Олива (Philippe Oliva) и Диана Гальб (Diane Galbe). 
Источник изображения: Brooke Cagle/unsplash.com Последняя вступила в должность, когда от руководства отстранили Родольфа Бельмера (Rodolphe Belmer), не сумевшего продержаться в должности и года. Примечательно, что в первые 20 лет деятельности у Atos было всего четыре генеральных директора. Мюстье сообщил, что решение о выборе нового CEO принято с учётом его «обширного послужного списка». Правда, не последнюю роль, вероятно, сыграл и тот факт, что Салль сам намерен инвестировать в Atos €9 млн ($9,8 млн). Предлагающая локальную и облачную инфраструктуру, услуги консалитинга и IT-сервисы компания Atos годами стремилась справиться с долгами, но в итоге её акции значительно упали в цене на фоне массы иных финансовых проблем. Сейчас в Atos работают над планом реструктуризации, который, как ожидается, позволит контролировать задолженность бизнеса и решит вопрос с многолетней финансовой неопределённостью. Компания предложила и утвердила с кредиторами ряд мер по выходу из кризиса — облигации и долг в объёме €2,9 млрд ($3,1 млрд) будут конвертированы в капитал. Также компании дадут в долг ещё €1,68 млрд ($1,81 млрд) и вольют €233 млн ($250,7 млн) новых инвестиций в капитал. Ранее французские власти намеревались выкупить часть бизнеса за €1 млрд ($1,09 млрд), чтобы сохранить критически важные для страны технологии, но теперь сделка, похоже, не состоится. В сентябре Atos опубликовала отчёт, в котором сообщалось о сокращении прогнозируемой выручки в ближайшие три года из-за не лучших результатов работы в I половине 2024 года.
16.10.2024 [14:20], Руслан Авдеев
Blackstone потратит €15 млрд на ЦОД в испанском АрагонеКомпания Blackstone готова построить в муниципалитете Калаторао в Арагоне (Испания) кампус ЦОД ёмкостью 300 МВт. По данным Datacenter Dynamics, объектом будет управлять подконтрольный Blackstone оператор дата-центров QTS. Как заявляют представители властей Арагона, регион находится на пути к тому, чтобы стать Северной Вирджинией Южной Европы — именно в этом штате США сконцентрированы мощности ЦОД не только страны, но даже мира. Blackstone намерена инвестировать €7,5 млрд ($8,2 млрд) в строительство в рамках инициативы Project Rodes — проект будет реализован на участке площадью 224 га. Сначала застроят около половины участка, позже на освоение второй половины потратят ещё €7,5 млрд. Blackstone приобрела QTS в 2021 году за $10 млрд, в июле 2023 года компания взяла на себя обязательство потратить дополнительные $8 млрд на ЦОД в связи с бумом ИИ, поскольку события такого масштаба случаются «раз в поколение». При этом компания действует и на других европейских рынках. Так, Blackstone вложит £10 млрд в создание крупнейшего ЦОД в Европе ЦОД в Великобритании. 
Источник изображения: Des Mc Carthy/unsplash.com QTS активно ведёт бизнес в США, но также управляет европейским кампусом в Гронингене (Нидерланды). Ранее Blackstone и QTS также объявили о намерении построить кампус на 1,1 ГВт в Нортумберленде (Великобритания). Первые данные о том, что Blackstone и подконтрольная ей QTS оценивают целесообразность расширение парка дата-центров в Испании, появились ещё в 2022 году. В Арагоне активно строятся новые кампусы ЦОД. В частности, Microsoft вложит в дата-центры в регионе около €8,6 млрд, AWS — €15,7 млрд, а Oracle — €0,9 млрд.
16.10.2024 [10:30], Сергей Карасёв
Western Digital представила жёсткий диск Ultrastar DC HC690 SMR ёмкостью 32 ТбайтКомпания Western Digital анонсировала, как утверждается, самые вместительные на рынке HDD, построенные по технологии энергосберегающей перпендикулярной магнитной записи (ePMR). Накопители Ultrastar DC HC690 SMR, рассчитанные на дата-центры и гиперскейлеров, имеют ёмкость 32 Тбайт. В устройствах применена технология черепичной магнитной записи нового поколения UltraSMR. Она повышает плотность хранения данных на 20 % по сравнению с методикой традиционной магнитной записи (CMR). Конструкция Ultrastar DC HC690 SMR включает 11 пластин, а скорость вращения шпинделя составляет 7200 об/мин. Заказчикам будут предлагаться модификации с интерфейсом SATA-3 и SAS-3. Размер буфера составляет 512 Мбайт. Заявленная установившаяся скорость передачи данных при чтении достигает 269 Мбайт/с, при записи — 257 Мбайт/с. Устройства, выполненные в LFF-формате, рассчитаны на круглосуточную эксплуатацию. Величина MTBF (среднее время безотказной работы) достигает 2,5 млн часов. Энергопотребление в активном режиме не превышает 9,7 Вт. Производитель предоставляет на диски пятилетнюю гарантию. HDD построены с применением фирменной технологии OptiNAND, которая использует встроенную флеш-память iNAND для выполнения основных функций по обслуживанию: это позволяет повысить надёжность, оптимизировать производительность и энергопотребление. Функция ArmorCache обеспечивает повышенное быстродействие и защиту систем от сбоев электропитания. 
Источник изображения: Western Digital Кроме того, Western Digital представила накопитель Ultrastar DC HC590 CMR вместимостью 26 Тбайт на основе CMR. Он также доступен в вариантах с интерфейсом SATA-3 и SAS-3. Ёмкость буфера равна 512 Мбайт, скорость вращения шпинделя — 7200 об/мин. Устройство может считывать данные со скоростью до 302 Мбайт/с и записывать со скоростью 288 Мбайт/с. Новые HDD семейства Ultrastar интегрируются в гибридные платформы хранения данных Ultrastar Data60 и Data102 JBOD, которые подходят для современных дата-центров, частных облаков и платформ аналитики больших данных. Системным интеграторам и реселлерам Western Digital предложит накопители WD Gold SATA ёмкостью 26 Тбайт. Они, как утверждается, обеспечивают максимальную производительность, надёжность и долговечность (значение MTBF равно 2,5 млн часов).
15.10.2024 [19:43], Николай Хижняк
Rambus представила полный набор компонентов для выпуска DDR5-памяти MRDIMM-12800 и RDIMM-8000Компания Rambus объявила о выпуске наборов электронных SMD-компонентов, необходимых для производства модулей ОЗУ RDIMM и MRDIMM нового поколения для серверов. Наборы включают тактовые генераторы, драйверы для управления питанием и некоторые другие компоненты. В представленный Rambus набор вошли следующие базовый компоненты:
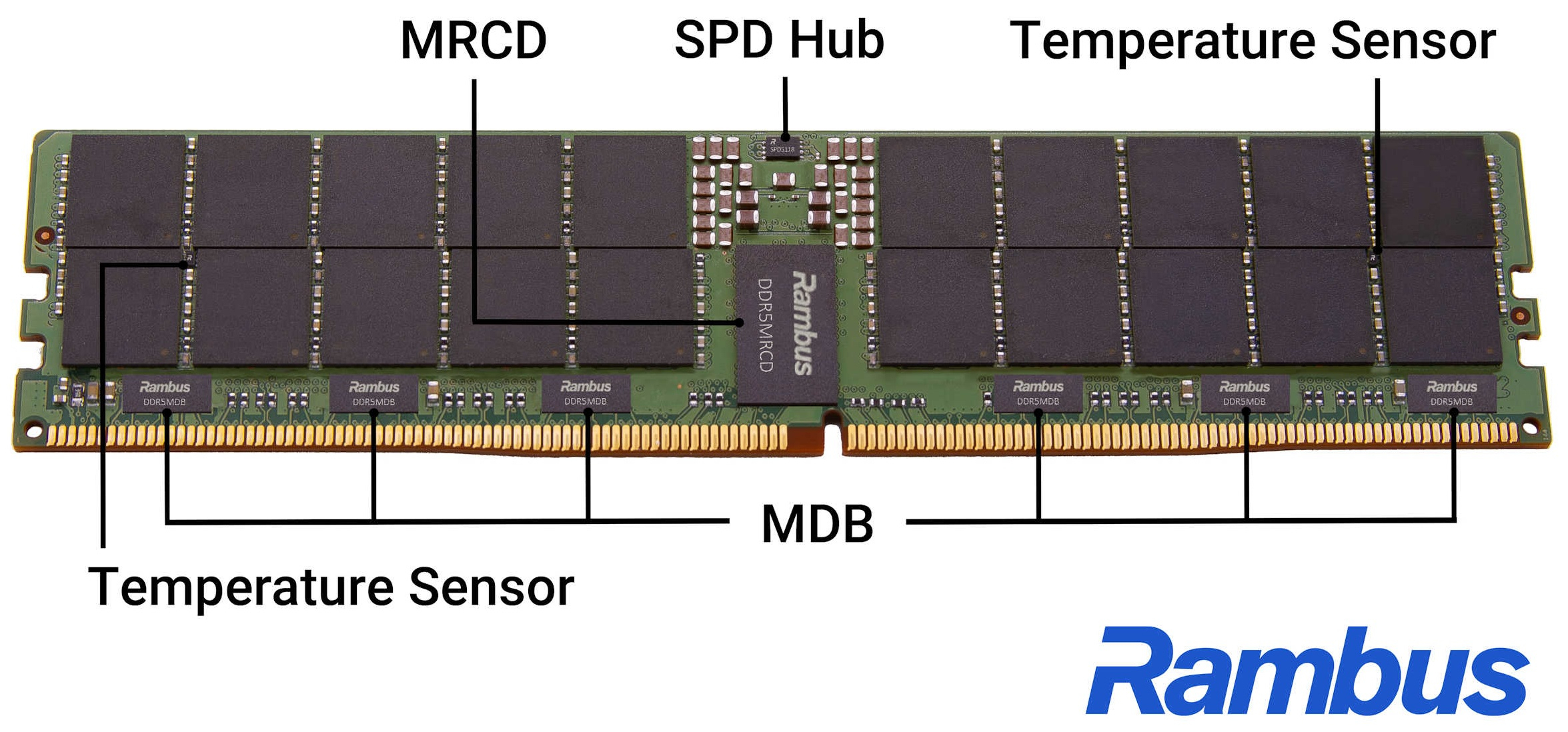
Источник изображения: Rambus Компания поясняет, что DDR5 MRDIMM-12800 использует новую конструкцию модуля, которая повышает скорость передачи данных и производительность системы за счёт мультиплексирования двух рангов, эффективно чередуя два потока данных. Это позволяет шине памяти хоста удвоить скорость передачи данных в сравнении с традиционными модулями при использовании тех же физических соединений DDR5 RDIMM. Для этого требуется чип MRCD, который может адресовать два ранга DRAM в чередующихся тактовых циклах, а также чипы MDB для управления потоками данных к микросхемам DRAM и от них. Для каждого модуля DDR5 MRDIMM-12800 требуется один MRCD и десять чипов MDB. MRCD и MDB также будут поддерживать формфактор Tall MRDIMM с четырьмя рангами.
15.10.2024 [14:03], Руслан Авдеев
Российская «Аквариус» намерена поставлять серверы во Вьетнам — но её ждёт жёсткая конкуренция с китайским бизнесомУже с 2025 года российская «Акавариус» намерена наладить поставки серверов во Вьетнам, сообщают «Ведомости» со ссылкой на главу компании Алексея Калинина. Компания также ведёт переговоры с бизнес-структурами в Нигерии, на Филиппинах, в Конго и других странах. По словам бизнесмена, первые контракты, вероятно, будут заключены с предприятиями государственного сектора. Директор Института устойчивого развития и цифровой экономики Вьетнама подтвердил журналистам сам факт переговоров — власти страны заинтересованы в сотрудничестве и намерены внедрять российские решения, в том числе серверы, в местную инфраструктуру. Кто именно может выступить контрагентом российской компании, не говорится. 
Источник изображения: Jonathan Ouimet/unsplash.com У «Аквариуса» широкий спектр продуктов корпоративного класса. Само производство находится в Твери и Шуе. В 2023 году сообщалось, что ещё до 2026 года компания готовится вложить 40 млрд руб. на создание новых продуктов и расширение бизнеса. Некоторые источники уверены, что шансы преуспеть на азиатских рынках у компании невелики, поскольку страны открыты для китайского бизнеса. Однако появление на вьетнамском рынке может сыграть положительную роль — компания может получить доступ к азиатским производствам и микроэлектронике. По данным агентства UnivDatos, серверный рынок Вьетнама оценивался в 2022 году в $165 млн. Ожидается, что он будет устойчиво развиваться, прирастая в среднем на 14 % в год до 2030 года. Главным препятствием к успешному выходу на этот рынок для российской компании является конкуренция со стороны китайских поставщиков. По мнению отраслевых экспертов, шансы «Аквариуса» в Азии будут зависеть от точной оценки рынков отдельных стран региона и местных условий работы, например — будут ли привлекаться к делу местные партнёры. В конце 2023 года появилась информация о запуске шоурума «Акавариус» в соседней Мьянме. О планах выхода на рынки дружественных стран рассуждают и в Fplus, сообщают «Ведомости». А в том же Вьетнами российская ГК Softline недавно открыла представительство для продвижения своих решений в стране и регионе.
14.10.2024 [18:25], Руслан Авдеев
Postgres Professional инвестирует 3 млрд рублей в развитие экосистемы Deckhouse
deckhouse
kubernetes
open source
postgres professional
software
инвестиции
россия
сделано в россии
сделка
финансы
Российские разработчики ПО Postgres Professional и АО «Флант» объявили о стратегическом партнёрстве для развития экосистемы решений Deckhouse. По данным пресс-службы АО «Флант», в рамках партнёрства Postgres Professional инвестирует 3 млрд руб. АО «Флант», по данным самой компании, является одним из ведущих контрибьюторов Kubernetes и лидеров DevOps в России, а Postgres Professional — это крупный и известный отечественный разработчик СУБД. Сегодня экосистема Deckhouse включает платформу контейнеризации Deckhouse Kubernetes Platform, платформу виртуализации Deckhouse Virtualization Platform, систему мониторинга Deckhouse Observability, менеджер кластеров Deckhouse Commander и другое ПО. Флагманом является продукт Deckhouse Kubernetes Platform. Платформа управляет более чем 600 кластерами в банковских структурах, ретейле, финтех- и нефтегазовых компаниях, а также других отраслях. Сотрудничество на стратегическом уровне обеспечит компаниям развитие ПО, экспертизу в области Cloud Native и технологиях больших данных. Условия партнёрства предусматривают получение Postgres Professional миноритарной доли «Фланта» до 2028 года, при этом действующие акционеры сохранят контроль над компанией. Доля будет определена с учётом финансовых показателей «Фланта» в последующие три года. За это время компания намерена увеличить портфолио заказчиков и выручку, а также втрое увеличить присутствие на рынке. 
Источник изображения: Alex Kotliarskyi/unsplash.com Во «Фланте» заявляют, что партнёрство с крупными игроками вроде Postgres Professional открывает новые возможности для развития бизнеса. Партнёры заняты разработкой ПО с открытым кодом и заинтересованы в развитии сообщества. Инвестиции будут направлены на улучшение продуктов и оптимизацию клиентских сервисов. В Postgres Professional отметили, что поддерживают IT-бизнесы, не только предлагающие качественные продукты, но и отдающие разработки для свободного использования в соответствии с принципами open source. Утверждается, что сотрудничество поможет совершенствованию Cloud Native-технологий и предложить клиентам инструменты для удобной и надёжной работы с данными.
11.10.2024 [12:21], Сергей Карасёв
Квартальные поставки HDD превысили 325 ЭбайтКомпания TrendFocus, по сообщению ресурса Storage Newsletter, подвела предварительные итоги развития мирового рынка HDD в III квартале 2024 года. Общие отгрузки накопителей составили от 30,8 млн до 32,6 млн ед., тогда как их суммарная вместимость превысила 325 Эбайт. Продажи растут на фоне хорошего спроса на Nearline-решения. Отмечается, что в годовом исчислении поставки HDD в штуках поднялись на 7,4–13,7 %. В сегменте жёстких дисков LFF и SFF корпоративного класса отгрузки составили около 15,3 млн шт. при суммарной ёмкости 275 Эбайт. При этом было реализовано около 0,8 млн производительных HDD. 
Источник изображения: Barez Omer / Unsplash Крупнейшим игроком является Seagate с долей 40,6–40,8 %: в течение III квартала эта компания реализовала 12,5–13,3 млн накопителей, продемонстрировав рост на 3,9–10,6 % в годовом исчислении. На втором месте в рейтинге располагается Western Digital, занимающая 40,2–40,3 % мирового рынка: компания продала 12,4–13,1 млн устройств, что на 19,1–25,8 % больше по сравнению с III четвертью 2023-го. Замыкает тройку Toshiba, удерживающая 19,0–19,2 % отрасли: у этой компании поставки за год снизились на 5,3–0,5 %, оказавшись на уровне 5,9–6,2 млн ед. В исследовании сказано, что квартальные отгрузки LFF-изделий для настольных ПК и потребительской электроники (включая решения для систем видеонаблюдения) составили около 9 млн штук. Поставки SFF-устройств для ноутбуков и электроники зафиксированы на уровне 6,4 млн шт.
11.10.2024 [11:55], Сергей Карасёв
DPU + UEC: AMD представила 400G-адаптеры Pensando Salina и PollaraКомпания AMD анонсировала сетевой сопроцессор (DPU) третьего поколения Pensando Salina 400, а также сетевую карту Pensando Pollara 400, ориентированную на применение в составе ИИ-систем. Образцы изделий станут доступны заказчикам в текущем квартале, тогда как массовые продажи начнутся в I половине 2025 года. Решение Pensando Salina 400, рассчитанное на сетевые кластеры гиперскейлеров, обеспечивает пропускную способность до 400 Гбит/с. Утверждается, что по сравнению с DPU предыдущего поколения производительность увеличилась в два раза. Устройство Pensando Salina 400 выполнено в виде карты PCIe 5.0 с двумя портами 400GbE. Задействованы 16 ядер Arm Neoverse-N1 и 232 ядра P4 MPU. Объём памяти DDR5 достигает 128 Гбайт, её пропускная способность — 102 Гбайт/с. Новинка будет применяться в том числе в интеллектуальных коммутаторах, предназначенных для решения различных задач во внешней зоне: это может быть распределение данных, балансировка нагрузки, обеспечение безопасности, шифрование и пр. 
Источник изображений: AMD В свою очередь, Pensando Pollara 400 представляет собой интеллектуальный сетевой адаптер с одним портом 400 Гбит/с. Изделие выполнено на том же чипе, что и Pensando Salina 400. Компания AMD называет Pensando Pollara 400 первой в мире сетевой картой для приложений ИИ, соответствующей стандартам, которые определяет консорциум Ultra Ethernet (UEC). Примечательно, что первые спецификации консорциум намерен представить не раньше конца текущего года.  Цель UEC — разработка основанной на Ethernet открытой высокопроизводительной архитектуры с полным коммуникационным стеком, отвечающей задачам современных рабочих нагрузок ИИ и НРС. Благодаря программируемой архитектуре P4 адаптер можно настраивать с учётом конкретных требований. В целом, как утверждается, новинка является мощным решением для повышения производительности рабочих нагрузок ИИ и улучшения надёжности сети.
|
|


