Материалы по тегу: llm
|
21.08.2024 [11:23], Сергей Карасёв
Amazon купила разработчика ИИ-чипов Perceive за $80 млн для развития LLM на периферииКомпания Xperi объявила о заключении соглашения по продаже своего подразделения Perceive, которое занимается разработкой специализированных ИИ-чипов. Покупателем является Amazon, сумма сделки составляет $80 млн в виде денежных средств. Завершить поглощение планируется до конца 2024 года. Perceive со штаб-квартирой в Сан-Хосе (Калифорния, США) создаёт ИИ-решения для работы с большими языковыми моделями (LLM) на периферийных устройствах. Такое оборудование обычно обладает ограниченными возможностями в плане вычислительных ресурсов, средств подключения и хранения данных. Чипы Perceive проектируются с учетом особенностей edge-платформ. В частности, Perceive разработала процессор Ergo AI. Утверждается, что он позволяет запускать «нейронные сети ЦОД-класса» даже на устройствах с самыми жёсткими требованиями к энергопотреблению. Это могут быть системы конференц-связи и носимые гаджеты. Отмечается, что Ergo AI может поддерживать самые разные ИИ-нагрузки — от классификации и обнаружения объектов до обработки аудиосигналов и языка. 
Источник изображения: Perceive Как именно Amazon намерена использовать решения Perceive, не уточняется. Но известно, что Amazon приобретает разработчика ИИ-чипов через своё подразделение Devices & Services, в которое входят голосовой помощник Alexa, интеллектуальные колонки и устройства серий Echo и Fire TV. Ожидается, что сделка не потребует одобрения со стороны регулирующих органов. После поглощения большинство из 44 сотрудников Perceive присоединятся к Amazon. Perceive, которую возглавляют со-генеральные директоры Мурали Дхаран (Murali Dharan) и Стив Тейг (Steve Teig), имеет сотрудников в США, Канаде, Ирландии, Румынии и Эстонии. Лаборатория Perceive в Бойсе (Айдахо, США) продолжит функционировать. Нужно отметить, что подразделение Amazon Web Services (AWS) уже не один год разрабатывает собственные аппаратные решения для ИИ-задач и облачных платформ. Это, в частности, чипы семейства Graviton и ИИ-ускорители Trainium. В конце 2023 года дебютировало изделие Graviton4 с 96 ядрами Arm для широкого спектра нагрузок. К выпуску готовится мощный ускоритель Trainium 3, энергопотребление которого может достигать 1000 Вт.
16.08.2024 [16:56], Руслан Авдеев
Закупочная ёмкость SSD для ИИ-нагрузок превысит 45 Эбайт в 2024 годуСпрос на ИИ-системы и соответствующие серверы привёл к росту заказов на SSD корпоративного класса в последние два квартала. По данным TrendForce, производители компонентов для твердотельных накопителей налаживают производственные процессы, готовясь к массовому выпуску накопителей нового поколения, которые появятся на рынке в 2025. Увеличение заказов корпоративных SSD от пользователей ИИ-серверов привело к росту контрактных цен на эту категорию товаров на более чем 80 % с IV квартала 2023 года по III квартал 2024. При этом SSD играют ключевую роль в развитии ИИ, поскольку только они годятся для эффективной работы с моделями. Помимо собственно хранения данных модели они также нужны для создания контрольных точек во время обучения, чтобы в случае сбоев можно было быстро «откатить» модель и возобновить обучение. Благодаря высокой скорости записи и чтения, а также повышенной надёжности в сравнении с HDD, для тренировки моделей обычно выбирают TLC-накопители ёмкостью 4–8 Тбайт. Эффективность RAG и больших языковых моделей (LLM), особенно для генерации медиаконтента, зависят и от ёмкости, и от производительности накопителей, поэтому для инференса более предпочтительны TLC/QLC-накопители ёмкостью от 16 Тбайт. 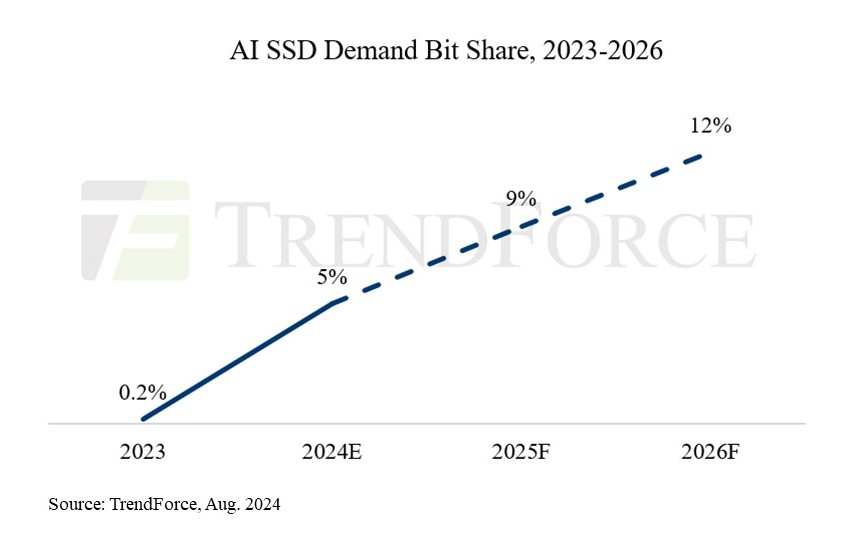
Источник изображения: TrendForce Со II квартала 2024 года спрос на SSD для ИИ-серверов ёмкостью больше 16 Тбайт значительно вырос. С повышением доступности ускорителей NVIDIA H100/H20/H200 клиенты начали наращивать спрос и на TLC SSD на 4 и 8 Тбайт. В агентстве считают, что закупочная ёмкость SSD для в 2024 году превысит 45 Эбайт, а в следующие несколько лет спрос на серверные SSD будет увеличиваться более чем на 60 % ежегодно. В частности, на SSD для ИИ-нагрузок потенциально уйдёт до 9 % всей NAND-памяти в 2025, тогда как в 2024 году этот показатель, как ожидается, составит 5 %.
06.08.2024 [16:17], Руслан Авдеев
LLM с доставкой на дом: в продаже появились жёсткие диски с комплектом открытых ИИ-моделейТо ли в шутку, то ли всерьёз компания Torrance Computer Supply (TCS) начала продажи накопителей с предзаписанными большими язковыми моделями. Доступны как HDD ёмкостью 14 Тбайт, так и карта памяти вместимостью 1 Тбайт. HDD-вариант базируется на недорогом 14-Тбайт LFF-накопителе MDD (MDD16TSATA25672E): SATA-3, 7200 RPM, кеш 256 Мбайт. Это один из самых доступных жёстких дисков такой ёмкости, поскольку MDD занимается восстановлением б/у накопителей и продажей складских остатков крупных вендоров под своим брендом. В комплекте с жёстким диском поставляется кейс Orico и адаптер USB 3.0 с внешним питанием (12 В, 24 Вт). 
Mika Baumeister / Unsplash Согласно описанию, на жёсткий диск записаны актуальные версии более двух десятков открытых больших языковых моделей (LLM), включая различные варианты Llama, Mistral, Nemotron и др. Предлагаются версии от нескольких миллиардов до почти полутриллиона параметров максимальным объёмом до 820 Гбайт. Продавцы уверяют, что постоянно меняют набор в зависимости от изменений рынка и технологий. Покупка обойдётся в $229, но если накопитель вернуть, то можно получить $125 на дальнейшие покупки в этом же магазине. На том же сайте предлагается и комплект LLM «для бедных» — желающие могут приобрести флэш-карту SanDisk 1TB Ultra microSDXC UHS-I на 1 Тбайт с адаптером в комплекте. Этот вариант стоит всего $119 и поставляется как минимум с тремя ИИ-моделями: Llama3.1 на 8, 70 и 405 млрд параметров. Практическая ценность данных предложений сомнительна, поскольку никто не мешает скачать те же самые модели и записать их на свой накопитель. Впрочем, некоторые компании предлагают услуги по оффлайн-транспортировке данных, но в этом случае речь идёт о на порядок больших объёмах.
25.07.2024 [09:59], Сергей Карасёв
OpenAI намерена потратить до $7 млрд на обучение ИИ в 2024 году, потеряв при этом $5 млрдЗатраты OpenAI на обучение ИИ-моделей и задачи инференса в 2024 году, по сообщению The Information, могут составить до $7 млрд. При этом компания может зафиксировать денежные потери в размере $5 млрд, что вынудит её искать новые возможности для привлечения инвестиций. Как рассказали осведомлённые лица, OpenAI использует мощности, эквивалентные приблизительно 350 тыс. серверов с ускорителями NVIDIA A100. Из них около 290 тыс. обеспечивают работу ChatGPT. Утверждается, что оборудование работает практически на полную мощность. В рамках обучения ИИ-моделей и инференса OpenAI получает значительные скидки от облачной платформы Microsoft Azure. В частности, Microsoft взимает с OpenAI около $1,3/час за ускоритель A100, что намного ниже обычных ставок. Тем не менее, только на обучение ChatGPT и других моделей OpenAI может потратить в 2024 году около $3 млрд. 
Источник изображения: pixabay.com На сегодняшний день в OpenAI работают примерно 1500 сотрудников, и компания продолжает расширять штат. Затраты на заработную плату и содержание работников в 2024-м могут достичь $1,5 млрд. Компания получает около $2 млрд в год от ChatGPT и может получить ещё примерно $1 млрд от взимания платы за доступ к своим большим языковым моделям (LLM). Общая выручка OpenAI, согласно недавним результатам, лежит на уровне $280 млн в месяц. В 2024 году, по оценкам, суммарные поступления компании окажутся в диапазоне от $3,5 млрд до $4,5 млрд. Таким образом, с учётом ожидаемых затрат в размере $7 млрд на обучение ИИ и инференс, а также расходов в $1,5 млрд на персонал OpenAI может потерять до $5 млрд. Это намного превышает прогнозируемые расходы конкурентов, таких как Anthropic (поддерживается Amazon), которая ожидает, что в 2024 году потратит $2,7 млрд. Не исключено, что OpenAI попытается провести очередной раунд финансирования. Компания уже завершила семь инвестиционных раундов, собрав в общей сложности более $11 млрд.
22.07.2024 [08:57], Сергей Карасёв
Mistral AI и NVIDIA представили корпоративную ИИ-модель Mistral NeMo 12B со «здравым смыслом» и «мировыми знаниями»Корпорация NVIDIA и французская компания Mistral AI анонсировали большую языковую модель (LLM) Mistral NeMo 12B, специально разработанную для решения различных задач корпоративного уровня — чат-боты, обобщение данных, работа с программным кодом и пр. Mistral NeMo 12B насчитывает 12 млрд параметров и использует контекстное окно в 128 тыс. токенов. Для инференса применяется формат данных FP8, что, как утверждается, позволяет уменьшить размер требуемой памяти и ускорить развёртывание без какого-либо снижения точности ответов. 
Источник изображения: pixabay.com При обучении модели была задействована библиотека Megatron-LM, являющаяся частью платформы NVIDIA NeMo. При этом использовались 3072 ускорителя NVIDIA H100 на базе DGX Cloud. Утверждается, что Mistral NeMo 12B отлично справляется с многоходовыми диалогами, математическими задачами, программированием и пр. Модель обладает «здравым смыслом» и «мировыми знаниями». В целом, говорится о точной и надёжной работе применительно к широкому спектру приложений. 
Источник изображения: NVIDIA Модель выпущена под лицензией Apache 2.0 и предлагается в виде NIM-контейнера. На внедрение LLM, по словам создателей, требуются считанные минуты, а не дни. Для запуска модели достаточно одного ускорителя NVIDIA L40S, GeForce RTX 4090 или RTX 4500. Среди ключевых преимуществ развёртывания посредством NIM названы высокая эффективность, низкая стоимость вычислений, безопасность и конфиденциальность. UPD 21.08.2024: компании представили Mistral-NeMo-Minitron 8B, более компактную, но не менее эффективную, по словам создателей, версию Mistral NeMo 12B, которая может работать даже на ускорителе NVIDIA RTX.
11.07.2024 [12:22], Руслан Авдеев
AMD приобрела за $665 млн финский ИИ-стартап Silo AIAMD сообщила о приобретении за $665 млн крупнейшей в Европе частной ИИ-лаборатории — Silo AI. Silo AI включает более 300 «специалистов мирового уровня» с опытом создания специализированных ИИ-моделей, платформ и решений для ведущих корпоративных клиентов, применяющих их в облачных, встраиваемых и клиентских IT-проектах. Сооснователь Silo AI и её глава Питер Сарлин (Peter Sarlin) сохранит руководящую должность в команде, которая войдёт в AMD Artificial Intelligence Group. Завершение сделки планируется на II половину 2024 года. Как отмечает AMD, предприятия каждой отрасли ищут эффективные способы разработки и внедрения ИИ-решений, а команда Silo AI уже имеет экспертов и опыт в разработке передовых ИИ-моделей и решений, включая создание больших языковых моделей (LLM) на платформах AMD. Теперь команда поможет ускорить реализацию ИИ-стратегии AMD, создание и внедрение ИИ-решений по заказу клиентов со всего мира. 
Источник изображения: Silo AI Базирующаяся в Финляндии компания действует как в Европе, так и в Северной Америке, специализируясь на комплексных решениях, которые позволяют клиентом быстро внедрять ИИ в свои продукты, сервисы и рабочие процессы. В числе клиентов — Allianz, Philips, Rolls-Royce и Unilever. Также Silo AI создаёт мультиязычные LLM, например, Poro и Viking, и предлагает платформу кастомизации LLM SiloGen. В Silo рассматривают продажу компании как очередной этап развития, который позволит масштабировать бизнес. Это последнее из серии поглощений и инвестиций AMD в области ИИ. За последние 12 месяцев компания уже инвестировала $125 млн в дюжину ИИ-компаний и приобрела стартапы Mipsology и Nod.ai для расширения своей ИИ-экосистемы. По имеющимся данным, Silo AI стала пионером в масштабировании процесса обучения LLM на суперкомпьютере LUMI — самом быстром в Европе и включающем 12 тыс. ускорителей AMD Instinct MI250X. Совместно с учёными из разных университетов специалисты Silo создали передовые модели для разных языков Евросоюза.
08.04.2024 [01:50], Владимир Мироненко
Groq больше не продаёт свои ИИ-ускорители, предлагая вместо этого совместно создавать ЦОД и облачные сервисыСтартап Groq, создавший ускоритель LPU на базе собственного массивно-параллельного тензорного процессора TSP, больше не продаёт оборудование, предлагая вместо этого воспользоваться его облачными ИИ-сервисами или стать партнёром в создании ЦОД. Об этом генеральный директор Groq Джонатан Росс (Jonathan Ross) сообщил ресурсу EE Times. Он пояснил, что для стартапа заниматься продажами чипов слишком сложно, потому что «минимальная сумма покупки, чтобы это имело смысл, высока, затраты высоки, и никто не хочет рисковать, покупая большое количество оборудования — неважно, насколько оно потрясающее». По его словам, в облаке GroqCloud для инференса больших языковых моделей (LLM) в реальном времени уже зарегистрировано 70 тыс. разработчиков и запущено более 19 тыс. новых приложений. 
Источник изображений: Groq В случае поступления заказов на поставку больших объёмов чипов для очень крупных систем Groq вместо продажи предлагает партнёрство по развёртыванию ЦОД. Groq подписала соглашение с саудовской государственной нефтяной компанией Aramco, которое предполагает масштабное развёртывание LPU. Похожее соглашение в ОАЭ подписала Cerebras, ещё один молодой разработчик ИИ-ускорителей. «Правительство США и его союзники — единственные, кому мы готовы продавать оборудование, — говорит Росс. — Для всех остальных мы лишь (совместно) создаём коммерческие облака». По его словам, в этом году Groq планирует разместить 42 тыс. LPU в GroqCloud, при этом Aramco и другие партнёры «завершают» свои сделки по получению такого же количества чипов. Компания способна выпустить 220 тыс. LPU только в этом году, а общий объём производства на ближайшее время составляет 1,5 млн ускорителей. Около 1 млн из них всё ещё не зарезверированы, но это количество быстро сокращается. Росс пообещал, что к концу 2025 году компания развернёт столько LPU, что их вычислительная мощность будет эквивалентна ИИ-мощностям всех гиперскейлерам вместе взятых.  Росс с оптимизмом смотрит на перспективы Groq, поскольку чипы TSP не используют память HBM, на которую полагаются решения конкурентов, включая NVIDIA, и поставки которой расписаны до конца 2024 года. Что касается LPU следующего поколения, то компания планирует сразу перейти с 14-нм техпроцесса (Global Foundries) на 4-нм. По словам Росса, новый чип будет оптимизирован для генеративного ИИ, но у него в силу универсальности архитектуры не будет каких-то специальных функций для обработки LLM. Будет ли новый ускоритель всё так же изготавливаться на территории США, не уточняется. Groq, похоже, достаточно уверена в своих чипах, которые в бенчмарках действительно обгоняют конкурентов. После анонса архитектуры NVIDIA Blackwell, обеспечивающей кратное увеличение производительности в задачах генеративного ИИ, компания выпустил в ответ пресс-релиз из одного предложения: «Groq всё ещё быстрее». А чуть позже даже раскритиковала NVIDIA.
20.09.2023 [20:05], Алексей Степин
SambaNova представила ИИ-ускоритель SN40L с памятью HBM3, который в разы быстрее GPUБум больших языковых моделей (LLM) неизбежно порождает появление на рынке нового специализированного класса процессоров и ускорителей — и нередко такие решения оказываются эффективнее традиционного подхода с применением GPU. Компания SambaNova Systems, разработчик таких ускорителей и систем на их основе, представила новое, третье поколение ИИ-процессоров под названием SN40L. Осенью 2022 года компания представила чип SN30 на базе уникальной тайловой архитектуры с программным управлением, уже тогда вполне осознавая тенденцию к увеличению объёмов данных в нейросетях: чип получил 640 Мбайт SRAM-кеша и комплектовался оперативной памятью объёмом 1 Тбайт. 
Источник изображений здесь и далее: SambaNova (via EE Times) Эта наработка легла и в основу новейшего SN40L. Благодаря переходу от 7-нм техпроцесса TSMC к более совершенному 5-нм разработчикам удалось нарастить количество ядер до 1040, но их архитектура осталась прежней. Впрочем, с учётом реконфигурируемости недостатком это не является. Чип SN40L состоит из двух больших чиплетов, на которые приходится 520 Мбайт SRAM-кеша, 1,5 Тбайт DDR5 DRAM, а также 64 Гбайт высокоскоростной HBM3. Последняя была добавлена в SN40L в качестве буфера между сверхбыстрой SRAM и относительно медленной DDR. Это должно улучшить показатели чипа при работе в режиме LLM-инференса. Для эффективного использования HBM3 программный стек SambaNova был соответствующим образом доработан. 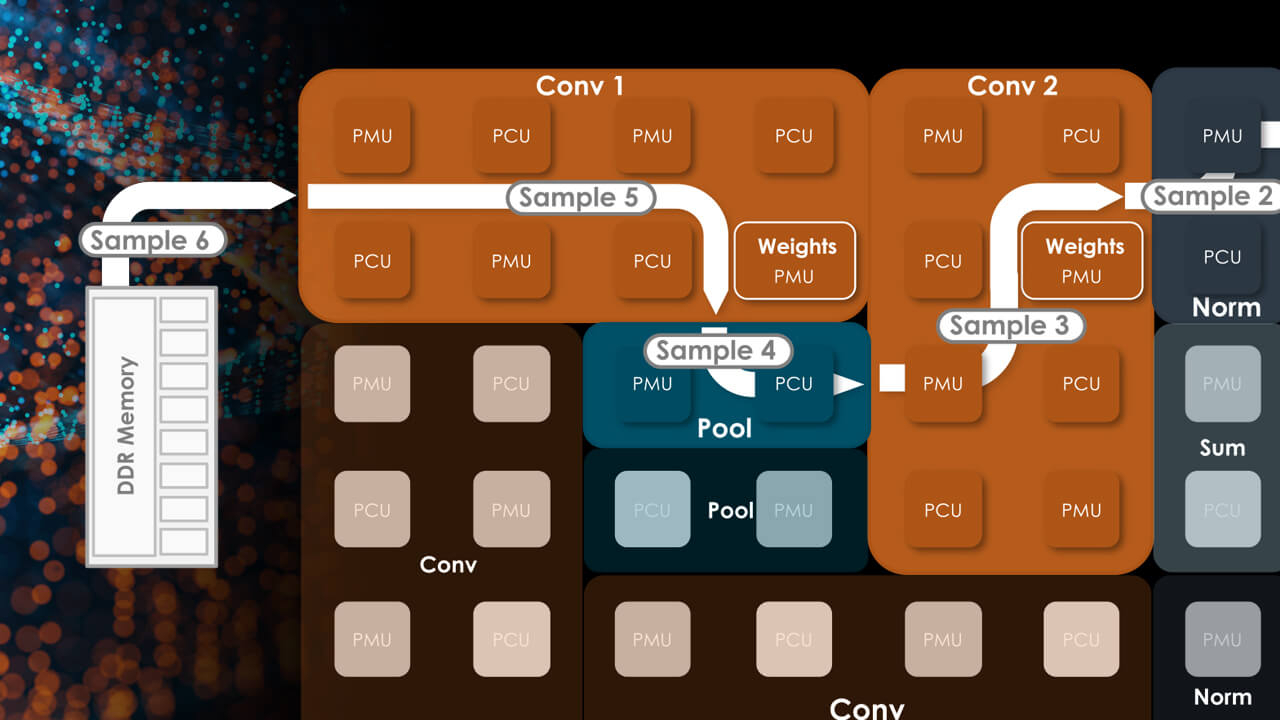
Тайловая архитектура SambaNova состоит из вычислительных тайлов PCU, SRAM-тайлов PMU, управляющей логики и меш-интерконнекта По сведениям SambaNova, восьмипроцессорная система на базе SN40L сможет запускать и обслуживать ИИ-модель поистине титанических «габаритов» — с 5 трлн параметров и глубиной запроса более 256к. В описываемой модели речь идёт о наборе экспертных моделей с LLM Llama-2 в качестве своеобразного дирижёра этого оркестра. Архитектура с традиционными GPU потребовала бы для запуска этой же модели 24 сервера с 8 ускорителями каждый; впрочем, модель ускорителей не уточняется. Как и прежде, сторонним клиентам чипы SN40L и отдельные вычислительные узлы на их основе поставляться не будут. Компания продолжит использовать модель Dataflow-as-a-Service (DaaS) — расширяемую платформу ИИ-сервисов по подписке, включающей в себя услуги по установке оборудования, вводу его в строй и управлению в рамках сервиса. Однако SN40L появится в рамках этой услуги позднее, а дебютирует он в составе облачной службы SambaNova Suite.
15.09.2023 [20:52], Алексей Степин
Groq назвала свои ИИ-чипы TSP четырёхлетней давности идеальными для LLM-инференсаТензорный процессор TSP, разработанный стартапом Groq, был анонсирован ещё осенью 2019 года и его уже нельзя назвать новым. Тем не менее, как сообщает Groq, TSP всё ещё является достаточно мощным решением для инференса больших языковых моделей (LLM). Теперь Groq позиционирует своё детище как LPU (Language Processing Unit) и продвигает его в качестве идеальной платформы для запуска больших языковых моделей (LLM). Согласно имеющимся данным, в этом качестве четырёхлетний процессор проявляет себя весьма неплохо. Groq открыто хвастается своим преимуществом над GPU, но в последних раундах MLPerf участвовать не желает. 
Источник изображений здесь и далее: Groq В своё время Groq разработала не только сам тензорный процессор, но и дизайн ускорителя на его основе, а также продумала вопрос взаимодействия нескольких TSP в составе вычислительного узла с дальнейшим масштабированием до уровня мини-кластера. Именно для такого кластера и опубликованы свежие данные о производительности Groq в сфере LLM. 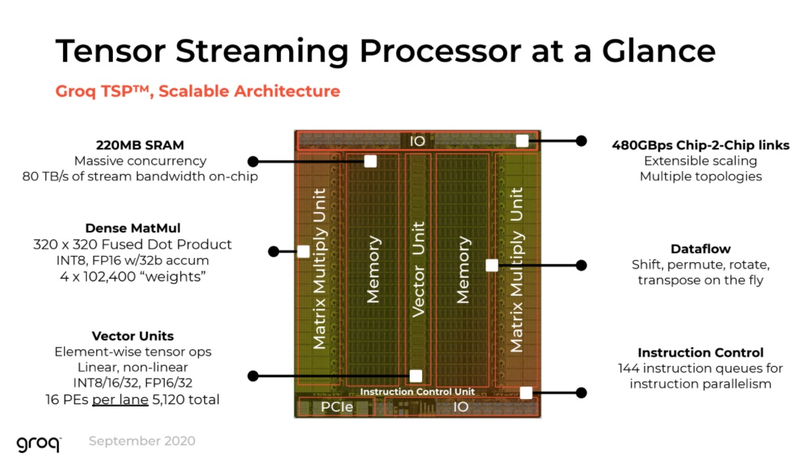 Система разработки, содержащая в своём составе 640 процессоров Groq TSP, была успешно использована для запуска модели Meta✴ Llama-2 с 70 млрд параметров. Как показали результаты тестов, модель на данной платформе работает с производительностью 240 токенов в секунду на пользователя. Для адаптации и развёртывания Llama-2, по словам создателей Groq, потребовалось всего несколько дней. В настоящее время усилия Groq будут сконцентрированы на адаптации имеющейся платформы в сфере LLM-инференса, поскольку данный сектор рынка растёт быстрее, нежели сектор обучения ИИ-моделей. Для LLM-инференса важнее умение эффективно масштабировать потоки небольших блоков (8–16 Кбайт) на большое количество чипов. 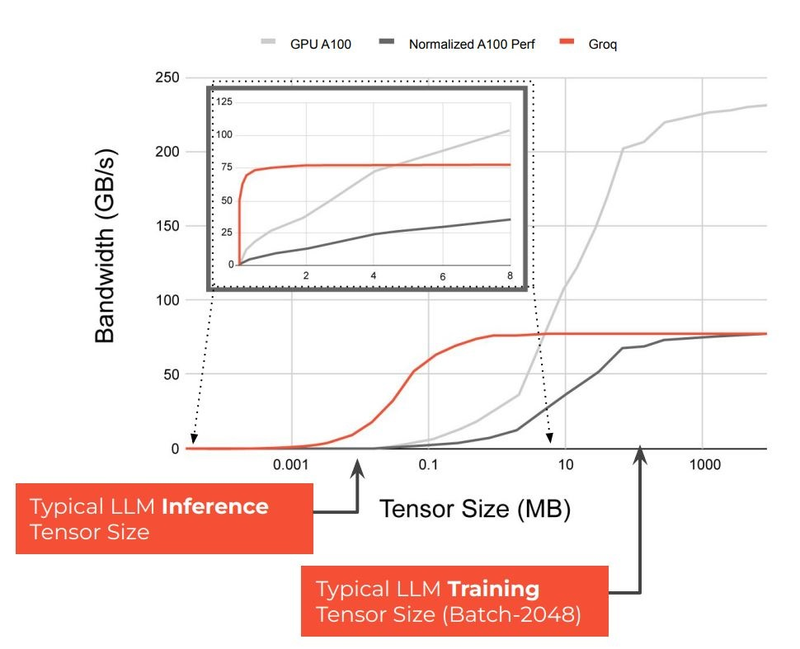 В этом Groq TSP превосходит NVIDIA A100: если в сравнении двух серверов выиграет решение NVIDIA, то уже при 40 серверах показатели латентности у Groq TSP будут намного лучше. В распоряжении Groq имеется пара 10-стоечных кластеров с 640 процессорами, один из которых используется для разработки, а второй — в качестве облачной платформы для клиентов Groq в области финансовых услуг. Работает система Groq и в Аргоннской национальной лаборатории (ALCF), где она используется для исследований в области термоядерной энергетики.  В настоящее время Groq TSP производятся на мощностях GlobalFoundries, а упаковка чипов происходит в Канаде, но компания работает над вторым поколением своих процессоров, которое будет производиться уже на заводе Samsung в Техасе. Параллельно Groq работает над созданием 8-чипового ускорителя на базе TSP первого поколения. Это делается для уплотнения вычислений, а также для более полного использования проприетарного интерконнекта и обхода ограничений, накладываемых шиной PCIe 4.0. Также ведётся дальнейшая оптимизация ПО для кремния первого поколения. 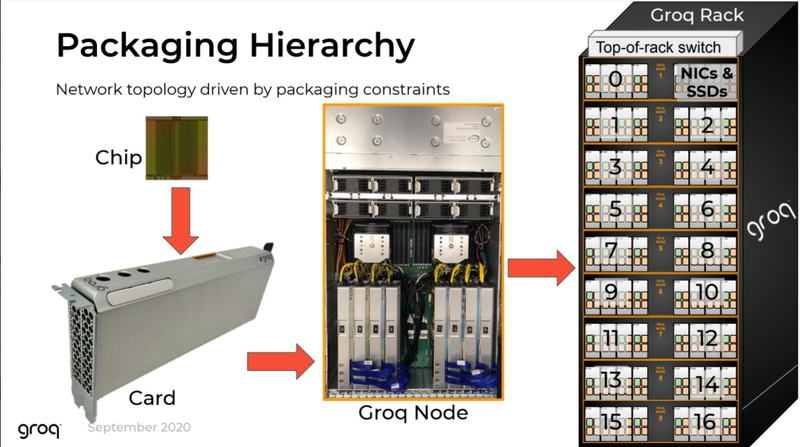 Простота и скорость разработки ПО для платформы Groq TSP объясняется историей создания этого процессора — начала Groq с создания компилятора и лишь затем принялась за проектирование кремния с учётом особенностей этого компилятора. Перекладывание на плечи компилятора всех задач оркестрации вычислений позволило существенно упростить дизайн TSP, а также сделать предсказуемыми показатели производительности и латентности ещё на этапе сборки ПО. При этом архитектура Groq TSP вообще не предусматривает использования «ядер» (kernels), то есть не требует блоков низкоуровневого кода, предназначенного для общения непосредственно с аппаратной частью. В случае с TSP любая задача разбивается на набор небольших инструкций, реализованных в кремнии и выполняемых непосредственно чипом. 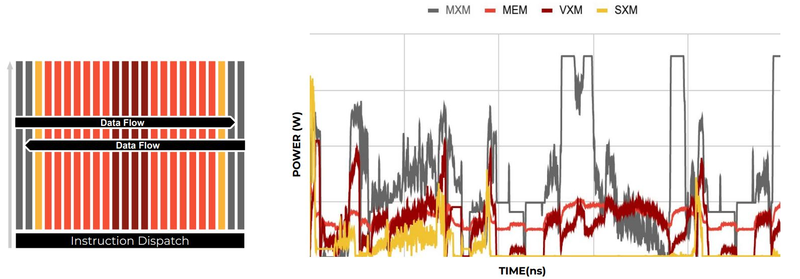
Компилятор Groq позволяет визуализировать и предсказывать энергопотребление с точностью до наносекунд. Источник: Groq Предсказуемость Groq TSP распространяется и на энергопотребление: оно полностью профилируется ещё на этапе компиляции, так что пики и провалы можно спрогнозировать с точностью вплоть до наносекунд. Это позволяет добиться от платформы более надёжного функционирования, избежав так называемой «тихой» порчи данных — сбоев, происходящих в результате резких всплесков энергетических и тепловых параметров кремния. 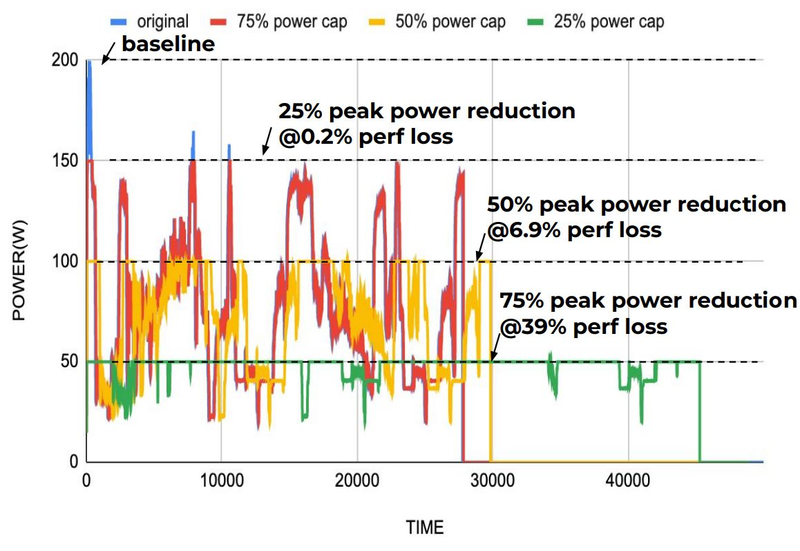
Энергопотребление Groq TSP поддаётся тонкой настройке на уровне программного обеспечения. Источник: Groq Что касается будущего LLM-инференса, то Groq считает, что этой отрасли есть, куда расти. В настоящее время LLM дают ответ на запрос сразу, и затем пользователи могут уточнить его в последующих итерациях, но в будущем они начнут «рефлексировать» — то есть, «продумывать» несколько вариантов одновременно, используя совокупный результат для более точного «вывода» и ответа. Разумеется, такой механизм потребует больших вычислительных мощностей, и здесь масштабируемая и предсказуемая архитектура Groq TSP может прийтись как нельзя более к месту. |
|

