Лента новостей
|
22.07.2025 [09:20], Андрей Крупин
Плохо прогнозируемый эффект от применения ИИ — один из основных барьеров, сдерживающих его использование в промышленностиСложности с расчётом и прогнозированием совокупного эффекта от применения систем искусственного интеллекта являются ключевым барьером для их повсеместного развёртывания в индустриальной среде. Об этом свидетельствует исследование, проведённое ФГАУ «Цифровые индустриальные технологии» совместно с компанией «К2Тех» в рамках проходившей в Екатеринбурге международной промышленной выставки «Иннопром-2025». Проблему с плохо прогнозируемым эффектом от применения ИИ отметили более 61 % опрошенных представителей предприятий из отраслей машиностроения, нефтегазохимии, энергетики, горной металлургии и добычи. Также среди основных барьеров респонденты выделили риски кибербезопасности (более 53 %), нехватку на рынке реальных эффективных кейсов внедрения (более 46 %), отсутствие квалифицированных кадров (более 38 %). Ещё одна проблема — неготовность IT-инфраструктуры. На 100 % готова и автоматизирована она оказалась лишь у 7 % респондентов. У остальных она не полностью готова для запуска и масштабирования нагрузок. Более 30 % промышленных предприятий назвали существенным барьером также нехватку бюджетов. 
Источник изображения: Julia Reushenova / unsplash.com Исследование показало, что более половины промышленных предприятий в перспективе ожидают, что повсеместное внедрение современных систем, построенных с использованием технологий машинного обучения и искусственного интеллекта на базе нейронных сетей, поможет увеличить эффективность планирования и прогнозирования, снизить издержки и риски аварий на производстве. «Сложно просчитать эффект от применения систем искусственного интеллекта. Самое очевидное — это сокращение трудозатрат на рутинных операциях. Но если мы копнём чуть глубже, не до конца известно, какой совокупный эффект даст нам ИИ в будущем. При этом организации, которые не начнут применять эту технологию, будут неконкурентоспособны», — прокомментировал результаты исследования директор по отраслевым решениям для машиностроения компании «К2Тех» Евгений Васильев.
21.07.2025 [20:10], Руслан Авдеев
Амстердам и Франкфурт выбыли из первой двадцатки локаций гиперскейлеровНовые данные экспертов Synergy Research Group показывают, что 62 % текущей IT-мощности ЦОД гиперскейлеров приходится всего на 20 регионов, это ряд штатов США и крупных городских агломераций. Так, только на Северную Вирджинию и «Большой Пекин» приходится 20 % от общемирового объёма. За ними следуют штаты Орегон и Айова, Дублин (Ирландия), штат Огайо, Даллас (Техас) и Шанхай (КНР). Из 20 крупнейших рынков ЦОД гиперскейлеров 14 находятся в США, 5 — в Азиатско-Тихоокеанском регионе (Китае (Пекин и Шанхай), Австралии, Японии, Сингапуре) и лишь 1 — в Европе. На вторую двадцатку рейтинга приходится ещё 17 % рынка, причём в этом случае более заметную роль играют площадки за пределами США. Так, Амстердам и Франкфурт ранее входили в первую двадцатку рынка, но недавно ослабили позиции. Лидерство США на первых 20 позициях рейтинга обусловлено тем, что 60 % мировых гиперскейлеров, включая четыре крупнейших, находятся в Штатах. Кроме того, на страну приходится почти половина всех доходов рынка облачных вычислений в нескольких ключевых сегментах. Доминировать по ключевым показателям, вероятно, продолжат США и Китай, хотя более заметную роль начинают играть и некоторые перспективные рынки «второго эшелона». Исследование основано на анализе парка дата-центров 20 крупнейших мировых компаний, стоящих за облачными и интернет-сервисами, включая крупнейших операторов SaaS/IaaS/PaaS, поиска, социальных сетей, электронной коммерции и игровой индустрии. Наиболее крупные ЦОД у Amazon, Microsoft и Google. Помимо значительного присутствия в США, каждая из компаний имеет несколько ЦОД во многих других странах мира. В целом на тройку лидеров приходится 58 % мощностей гиперскейлеров. За лидерами следуют Meta✴/Facebook✴, Alibaba, Tencent, Apple, ByteDance и иные «малые гиперскейлеры». 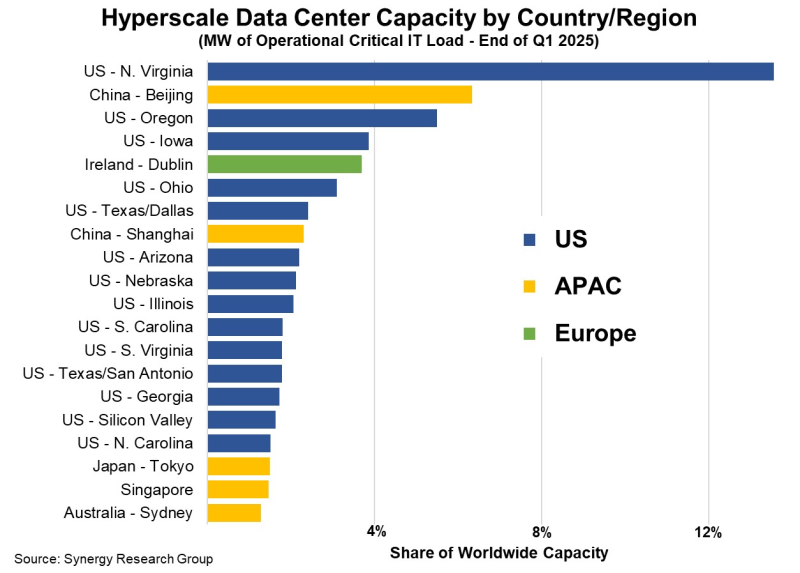
Источник изображения: Synergy Research Group Прогнозы Synergy основаны на отслеживании проектов гиперскейлеров по созданию дата-центров. Всего известно о 535 объектах, которые находятся на разных стадиях планирования, строительства или оснащения. По данным Synergy, на выбор локации для ЦОД влияет близость к клиентам, доступность и стоимость недвижимости и электроэнергии, наличие сетевой инфраструктуры, простота ведения бизнеса, местные финансовые стимулы, политическая стабильность и минимум последствий стихийных действий. По данным Synergy, в условиях стремительного роста спроса на ИИ-технологии и инфраструктуру, всё более важным критерием становится доступность электроэнергии. Это часто снижают конкурентоспособность крупных экономических мировых хабов вроде Лондона, Нью-Йорка и Франкфурта, в то время как относительно малонаселённые штаты США вроде Орегона, Айовы и Небраски выигрывают в силу местной специфики и позиции властей, желающих привлечь больше инвестиций. Хотя прогнозы компании показывают, что Северная Вирджиния останется крупнейшим рынком гиперскейлеров в США, интерес будет всё больше смещаться в сторону Юга и Среднего Запада США. За пределами США рост рынков ЦОД ожидается в Индии, Австралии, Малайзии, Испании и Саудовской Аравии. Год назад Synergy сообщала, что ключевыми рынками ЦОД гиперскейлеров остаются Северная Вирджиния, Пекин и Дублин. В конце июня 2025 года она же опубликовала исследование, согласно которому у гиперскейлеров есть уже 1,2 тыс. дата-центров, а через пять лет они будут доминировать на рынке ЦОД.
21.07.2025 [18:58], Владимир Мироненко
xAI ищет разработчиков кастомных чипов для ИИ-системИИ-стартап xAI Илона Маска (Elon Musk) разместил вакансии для разработчиков кастомных полупроводников, сообщил ресурс DataCenter Dynamics (DCD). Стартап ищет сотрудников для «создания ИИ-систем нового поколения, охватывающих весь спектр, от полупроводниковых чипов до компиляторов и моделей». Круг должностных обязанностей специалистов включает «разработку и доработку новых аппаратных архитектур для расширения границ вычислительной эффективности», а также использование ИИ в процессе проектирования оборудования. От кандидатов на должность ожидается знание инструментов для создания чипов, таких как Chisel, а также VHDL и Verilog. В идеале претенденты должны иметь опыт «симуляции обучающих рабочих нагрузок на новых аппаратных ИИ-архитектурах». Соответствующий требованиям сотрудник присоединится к команде xAI, работающей над «созданием ИИ-систем нового поколения, которые обеспечат революционную эффективность и масштабируемость на новом оборудовании, компиляторах и моделях». 
Источник изображения: xAI Как полагает DCD, команду, о которой идёт речь, возглавляет Сяо Сан (Xiao Sun), ранее работавший в Meta✴, а до этого занимавшийся разработкой аппаратного обеспечения и алгоритмов машинного обучения, а также CMOS-устройств в IBM. DCD отметил, что на данный момент неясно, сотрудничает ли xAI с другой компанией в разработке полупроводниковых чипов, как, например, Google и OpenAI, которые работают с Broadcom над созданием семейства TPU и ИИ-чипа соответственно. Компания Tesla, в которой Маск является крупнейшим акционером, также разработала собственный чип — Dojo D1, ориентированный на обработку видеоданных для обучения полуавтономных автомобилей. Однако большая часть команды, стоящей за чипом Dojo D1, покинула Tesla, и его будущее туманно. Илон Маска показал систему в 2024 году. Годом ранее Маск заявил, что чип используется из-за нехватки ускорителей NVIDIA: «Честно говоря, я не знаю, смогут ли они поставить нам достаточно графических процессоров — возможно, Dojo нам и не нужен, — но они не смогут». Как и Tesla, xAI использует значительное количество ускорителей NVIDIA для своих вычислительных задач, более 200 тыс. из них входят в состав суперкомпьютера Colossus в Мемфисе (США). Маск надеется расширить Colossus до миллиона ускорителей. В свою очередь, xAI приобрела участок под второй дата-центр в Мемфисе.
21.07.2025 [16:42], Сергей Карасёв
Запущен самый мощный в Великобритании ИИ-суперкомпьютер — комплекс Isambard-AIВ Великобритании официально введён в эксплуатацию суперкомпьютер Isambard-AI: это самый мощный в стране вычислительный комплекс, ориентированный на задачи ИИ. В июньском рейтинге TOP500 машина занимает 11-е место, а в списке наиболее энергоэффективных систем Green500 — четвёртую позицию. Суперкомпьютер назван в честь британского инженера Изамбарда Кингдома Брюнеля (Isambard Kingdom Brunel), внёсшего значимый вклад в Промышленную революцию. Проект реализован при участии компаний NVIDIA и HPE, Бристольского университета (University of Bristol) и других организаций. Создание Isambard-AI обошлось примерно в £225 млн ($302 млн). В основу комплекса положена платформа HPE Cray EX с интерконнектом Slingshot 11. Задействованы 5448 суперчипов NVIDIA GH200 Grace Hopper, которые объединяют 72-ядерный Arm-процессор NVIDIA Grace и ускоритель NVIDIA H200. Применена СХД Cray ClusterStor E1000 вместимостью 25 Пбайт. Питание полностью обеспечивается от источников энергии с нулевыми выбросами углерода. Избыточное тепло может использоваться для обогрева близлежащих зданий. Развёрнута система прямого жидкостного охлаждения HPE. 
Источник изображений: NVIDIA В тесте Linpack комплекс Isambard-AI демонстрирует FP64-быстродействие на уровне 216,5 Пфлопс, тогда как теоретический пиковый показатель составляет 278,58 Пфлопс. Производительность при решении ИИ-задач достигает 21 Эфлопс (FP8). Как отмечается, Isambard-AI более чем в 10 раз превосходит по скорости второй по быстродействию суперкомпьютер в Великобритании и предоставляет больше вычислительной мощности, чем все остальные НРС-машины страны вместе взятые.  Новый комплекс будет применяться для решения наиболее сложных и ресурсоёмких задач, таких как разработка передовых лекарственных препаратов, моделирование климата, материаловедение, большие языковые модели (LLM) и др. Доступ к ресурсам Isambard-AI регулируется Министерством науки, инноваций и технологий и Департаментом исследований и инноваций Великобритании.
21.07.2025 [16:35], Андрей Крупин
MWS Cloud запустила платформу хранения больших данных для обучения ИИКомпания MWS Cloud (входит в МТС Web Services) сообщила о запуске MWS Data Lakehouse — cloud-native-платформы для хранения и обработки данных. MWS Data Lakehouse позволяет работать с любыми типами данных — структурированными, неструктурированными и векторными, что даёт возможность создания единой среды для выполнения разного типа задач: от построения аналитических отчётов до обучения и инференса ML-моделей и LLM. В качестве инфраструктуры для развёртывания платформы могут использоваться различные решения, среди которых Kubernetes и объектное S3-совместимое хранилище. Поддерживается взаимодействие с СУБД Greenplum и Postgres. В MWS Data Lakehouse также встроены инструменты централизации контроля доступа, аудита и шифрования, динамического маскирования чувствительных данных, которые полностью соответствуют современным требованиям информационной безопасности. 
Источник изображения: Luke Peters / unsplash.com В числе особенностей MWS Data Lakehouse — поддержка широкого спектра данных (включая открытые форматы Apache Parquet и Iceberg) и возможность параллельного запуска нескольких вычислительных кластеров под разные продуктовые команды, приложения и типы запросов без дублирования данных и дополнительной репликации. Администрирование сервиса осуществляется через единый интерфейс, позволяющий централизованно управлять пользователями, кластерами и масштабированием. Поддерживается динамическое изменение ресурсов вычислительных кластеров. Платформа является частью комплекса сервисов MWS по работе с данными — MWS Data. Всего в него входят более 25 продуктов для хранения, обработки и трансформации данных, а также сервисы бизнес-аналитики и ИИ-агенты для работы с данными.
21.07.2025 [16:08], Руслан Авдеев
Samsung начал поиск альтернатив VMwareОсновные компании, входящие в Samsung Group, начали искать альтернативы VMware в связи со значительным ростом цен на продукты последней, причём ПО, похоже, будут дорожать и дальше, передаёт ETNews. Как сообщают источники издания, Samsung Electronics, Samsung Display и другие подразделения Samsung Group уже реализуют либо готовятся к реализации проектов по постепенному отказу от VMware. Так, Samsung Electronics рассматривает альтернативные варианты с прошлого года. При этом компания не намерена немедленно отказываться от продуктов, пока заключён контракт на закупку ПО на сумму ₩40 млрд (около $29 млн). Параллельно компания участвует в проектах по разработке open source ПО. Цель состоит в том, чтобы разработать облачную среду, избегая коммерческих инструментов вроде продуктов VMware. Привлечены специалисты по виртуализации и облачным технологиям. В 2026 году будут определены направление и масштаб внедрения новых продуктов. Samsung Electronics намерена самостоятельно создать частное облако. Для работы над ним привлекут как сотрудников самой Samsung, так и специализированные компании. Проект планируется завершить в течение года. Samsung Display также готовит проект снижения зависимости от VMware. Компании Samsung Group являются одними из крупнейших заказчиков VMware в Южной Корее. Однако смена политики VMware привела к росту цен, так что дочерние структуры Samsung Group посчитали затраты слишком высокими в сравнении с выгодами от использования VMware. Источник изображения: Broadcom В 2023 году VMware была куплена Broadcom, а в 2024-м компания повысила цены на свою продукцию. По мнению экспертов, в ближайшие два-три года цена может значительно увеличиться в сравнении с текущей. Уже есть примеры пятикратного роста стоимости лицензий и обслуживания. Утверждается, что цены будут формироваться в индивидуальном порядке. Кроме того, постоянно меняются условия сделок. Есть претензии и к политике продаж. Флагманский продукт VMware Cloud Foundation (VCF) включает ПО для виртуализации, сетевые решения и решения для хранения данных единым пакетом. При этом многим корейским компаниям нужны только продукты для виртуализации, а переплачивать за ненужные продукты они не хотят. По словам одного из источников, большинство крупных компаний, включая производственные и финансовые, ускорят движение к отказу от VMware.
21.07.2025 [14:05], Сергей Карасёв
NVIDIA CUDA обзавелась поддержкой RISC-VКомпания NVIDIA в ходе саммита RISC-V 2025 в Китае объявила о том, что ее платформа параллельных вычислений CUDA обзавелась поддержкой открытой архитектуры RISC-V. Это событие отражает растущий интерес к чипам RISC-V в сегменте дата-центров. Представленное решение предполагает использование типичной конфигурации: графический ускоритель обрабатывает параллельные рабочие нагрузки, тогда как CPU на основе RISC-V отвечает за функционирование системных драйверов, логики приложений и операционной системы. Такая модель позволяет CPU полностью координировать GPU-вычисления в среде CUDA. 
Источник изображения: RISC-V International (X/@risc_v) Кроме того, в дополнение к CPU с архитектурой RISC-V и ускорителю NVIDIA может быть задействован специализированный сопроцессор для обработки данных (DPU). Таким образом, могут формироваться гетерогенные вычислительные среды, в которых процессор RISC-V играет ключевую роль в управлении рабочими нагрузками. Предполагается, что чипы RISC-V будут использоваться на периферийных устройствах с поддержкой CUDA, включая решения с модулями NVIDIA Jetson. Поддержка RISC-V расширяет возможности CUDA в системах, где предпочтение отдаётся открытым наборам команд или где требуются специально оптимизированные чипы. По сути, NVIDIA создаёт мост между проприетарным стеком CUDA и открытой архитектурой RISC-V, которая активно развивается по всему миру, в том числе в Китае. 
Источник изображения: NVIDIA Ранее ряд китайских компаний, включая T-Head (принадлежит гиганту Alibaba Group Holding), Shanghai Shiqing Technology, Juquan Optoelectronics, Xinsiyuan Microelectronics и StarFive, сформировали патентный альянс в сфере RISC-V. Разработкой RISC-V-процессоров занимается научно-исследовательский институт Damo Academy (подразделение Alibaba Group Holding), Китайская академия наук, а также ряд других участников местного рынка. Не имея возможности поставлять флагманские ИИ-ускорители в Китай из-за американских санкций, NVIDIA вынуждена искать другие способы развития экосистемы CUDA в КНР.
21.07.2025 [09:27], Сергей Карасёв
10 долгих лет: состоялся официальный запуск экзафлопсного суперкомпьютера AuroraВ Аргоннской национальной лаборатории (ANL) Министерства энергетики США (DOE) в Иллинойсе состоялась церемония торжественного разрезания ленты в честь официального запуска суперкомпьютера Aurora экзафлопсного класса. В мероприятии приняли участие руководители и исследователи Intel, HPE и DOE. Церемония была скорее формальностью, поскольку Aurora стала доступна исследователям со всего мира в начале текущего года. Aurora является одним из трёх суперкомпьютеров DOE с производительностью более 1 Эфлопс. Наряду с El Capitan в Ливерморской национальной лаборатории имени Лоуренса (LLNL) и Frontier в Национальной лаборатории Оук-Ридж (ORNL) эти НРС-комплексы занимают первые три места как в списке TOP500 самых быстрых суперкомпьютеров мира, так и в бенчмарке HPL-MxP для оценки производительности ИИ. У суперкомпьютера непростая судьба. Анонс машины состоялся в 2015 году — система с FP64-производительностью на уровне 180 Пфлопс по плану должна была заработать в 2018 году. Однако планы неоднократно корректировались, а проект в конце концов был кардинально пересмотрен. Первые тестовые кластеры системы заработали более двух лет назад, а частично запущенная система попала в TOP500 в конце 2023 года. Целиком она заработала в 2024 году. 
Источник изображения: ANL / Intel В проекте по созданию Aurora принимали участие Intel и HPE. Машина построена на платформе HPE Cray EX — Intel Exascale Compute Blade: задействованы процессоры Intel Xeon CPU Max и ускорители Intel Data Center GPU Max, объединённые интерконнектом HPE Slingshot. В общей сложности применяются 63 744 ускорителей, что делает Aurora одним из крупнейших в мире суперкомпьютеров на базе GPU. 
Источник изображения: ANL / Intel Установлена ОС SUSE Linux Enterprise Server 15 SP4. Производительность в тесте Linpack составляет 1,012 Эфлопс, а теоретический пиковый показатель достигает 1,980 Эфлопс. НРС-комплекс занимает площадь около 930 м2. Развёрнута современная инфраструктура жидкостного охлаждения. Общая протяжённость соединений превышает 480 км, а количество конечных точек сети достигает 85 тыс.  Aurora останется по-своему уникальным суперкомпьютером: CPU с HBM на борту больше не планируются, от Ponte Vecchio компания отказалась в пользу Habana Gaudi и Falcon Shores. Но и последние на рынок не попадут, а будут использоваться для внутренних тестов и обкатки технологий. На смену им должны прийти Jaguar Shores, но точных дат Intel не называет.  Вычислительные мощности Aurora, как отмечается, помогают в решении сложнейших задач в самых разных областях. В биологии и медицине исследователи используют ИИ-возможности суперкомпьютера для прогнозирования эволюции вирусов, улучшения методов лечения рака и картирования нейронных связей в мозге. В аэрокосмической сфере Aurora используется для создания двигательных установок нового поколения и моделирования аэродинамических процессов. Комплекс играет важную роль в развитии технологий термоядерной энергетики, квантовых вычислений и пр.
21.07.2025 [08:52], Руслан Авдеев
Aker построит арктический ЦОД в норвежском НарвикеЗанимающаяся инвестициями в промышленность норвежская компания Aker готовится построить дата-центр в Нарвике (Narvik, Норвегия). Город и одноимённая коммуна расположены на севере страны, в 250 км от Полярного круга, сообщает Datacenter Dynamics. У площадки есть доступ к 230 МВт. Конечный пользователь объекта пока не назван. По словам Aker, дата-центр должен стать «катализатором» промышленного развития, создания рабочих мест и увеличения «экспортных доходов». В компании отмечает, что Северная Норвегия в изобилии предлагает доступную энергию ГЭС и другие источники «чистой» энергию наряду с благоприятными условиями для привлечения инвестиций и стимулирования инноваций. По данным финансового отчёта Aker за II квартал 2025 года, новый ЦОД получит финансирования от инвестиционной компании ICP Infrastructure. В реализации проекта примут участие и бывшие сотрудники дочерней компании Aker Horizons. Последняя специализировалась на «зелёной» энергетике и объединилась с материнским бизнесом в мае. 
Источник изображения: jordi/unsplash.com Ранее Aker Horizon «изучала возможности» производства «чистого» аммиака и водорода (у компании был проект с немецкой VNG), и экобезопасной стали. Однако компания пришла к выводу, что дата-центры и «ИИ-фабрики» лучше подходят для имеющихся площадок. Сейчас Aker ведёт переговоры с операторами и потенциальными клиентами ЦОД. Компания, контрольный пакет акций которой принадлежит норвежскому миллиардеру Кьеллю Инге Рекке (Kjell Inge Rokke), отчиталась о прибыли за II квартал 2025 года. Стоимость чистых активов увеличилась на 7,43 % в годовом исчислении — с NKr61,9 млрд ($6,1 млрд) до NKr66,5 млрд ($6,5 млрд). Несколько лет назад Норвегия объявила, что намерена стать «фантастической площадкой» для дата-центров. В стране много энергетических ресурсов, в том числе «зелёных» и возобновляемых, а прохладный климат позволяет экономить на охлаждении. Некоторые кластеры даже охлаждаются водой из фьорда. Вместе с тем власти неодобрительно смотрят на майнинговые ЦОД, считая, что они не приносят обществу никакой выгоды.
20.07.2025 [16:18], Руслан Авдеев
От прошлогоднего сбоя CrowdStrike пострадало не менее 750 больниц в США — разработчики попытались спихнуть часть вины на MicrosoftГод назад содержащее ошибку обновление программного обеспечения, продаваемого специалистом по кибербезопасности — компанией CrowdStrike, вывело из строя миллионы компьютеров по всему миру и отправило их в цикл постоянных перезагрузок. По эффекту сбой был сравним с одной из самых масштабных кибератак в истории, ущерб от которого исчисляется миллиардами долларов. Среди пострадавших оказались сотни больниц и их пациенты, сообщает Wired. В июле 2024 года глобальный сбой из-за обновления CrowdStrike затронул 8,5 млн ПК на Windows. В сбое Microsoft косвенно обвинила регулятора ЕС — компанию вынудили открыть ядро ОС 15 лет назад, в том числе для сторонних разработчиков. В итоге компания переработала механизм доступа к ядру. Сама CrowdStrike назвала виновником сбоя баг в ПО для тестирования апдейтов, а позже объявила, что позволит более гибко управлять обновлениями Falcon Sensor, которые стали причиной сбоя. Группа специалистов по кибербезопасности в сфере медицины провела исследование, оценив ущерб от сбоя не в долларах, а в уроне, нанесённом больницам и пациентам на территории США. Исследователи из Калифорнийского университета в Сан-Диего опубликовали статью в издании журнала Американской медицинской ассоциации (JAMA Network Open), в которой впервые предпринята попытка оценить количество пострадавших медицинских учреждений, а также выяснить, какие именно службы пострадали в больницах. 
Источник изображения: Vitaly Gariev/unspalsh.com CrowdStrike резко раскритиковала исследование, назвав данные «лженаукой». Подчёркивается, что исследователи не проверяли, действовало ли в пострадавших сетях было затронутое ПО Windows или CrowdStrike. Например, в тот же день произошёл масштабный сбой Microsoft Azure, отчего тоже могли пострадать многие больницы. Впрочем, в CrowdStrike не отрицают тяжёлых последствий сбоя и приносят извинения всем затронутым. В ответ в Калифорнийском университете в Сан-Диего (UCSD) заявили, что остаются при своих выводах — сбой Azure затронул в основном центральную часть США, а нарушения работы иного характера коснулись всей страны и начались именно тогда, когда некорректное обновление вызвало коллапс. Исследователи уверены, что дела обстоят ещё хуже, поскольку изучили лишь около трети из более 6 тыс. больниц США, а истинное число пострадавших учреждений может быть намного больше. Работа исследователей является частью более масштабного проекта по сканированию интернета под названием Ransomwhere?, который выявляет сбои в работе медучреждений, связанные с вирусами-вымогателями. В рамках проекта американские больницы уже проверялись с помощью инструментов ZMap и Censys на момент сбоя. Выяснилось, что не менее 759 из 2242 исследовавшихся больниц в США столкнулись с теми или иными проблемами из-за перебоев работы в больничных сетях в роковой день. Так, в 202 больницах нарушилась работа служб, напрямую связанных с пациентами — порталов для персонала (в т.ч. для просмотра медкарт), систем мониторинга плода, инструментов для удалённого ухода за пациентами, сервисов безопасной передачи документов и др. Например, в случае инсульта передача данных от КТ-сканера врачу значительно затруднялась. 
Источник изображения: Accuray/unspalsh.com Также выяснилось, что в 212 больницах были сбои в работе значимых систем, от платформ планирования работы персонала до систем оплаты счетов и инструментов управления временем ожидания пациентов. Что касается «релевантных для исследования» услуг, сбои наблюдались в 62 больницах. Больше всего сбоев (в 287 больницах) пришлось на категорию «прочие», включающую офлайн-сервисы. При этом отмечается, что отсутствует статистика того, как кому-либо могли быть поставлены неверные диагнозы или не вовремя назначены жизненно необходимые антибиотики. В прошлом году уже появлялась информация, что обновление ПО CrowdStrike негативно сказалось на деятельности медицинских учреждений, но теперь речь идёт о более масштабном исследовании. В нём учёные также попытались приблизительно измерить продолжительность простоя больничных служб. Около 58 % служб вновь заработали в течение шести часов, и 8 % — не менее чем через 48 часов. Это намного меньше, чем простои от реальных кибератак, однако задержка в несколько часов или даже минут может увеличить уровень смертности пациентов, считают специалисты. Команда Калифорнийского университета в Сан-Диего подчёркивает, что основная цель их исследования — показать, что с помощью правильных инструментов можно отслеживать массовые сбои в работе медицинских сетей и извлекать из них уроки. Результатом может стать более глубокое понимание того, как предотвратить или защитить больницы от подобных ситуаций в будущем. |
|

