Материалы по тегу: ии
|
22.04.2025 [11:17], Сергей Карасёв
«Сигналтек» представила российский сервер SignalEdge на базе Intel Xeon Emerald RapidsКомпания «Сигналтек» сообщила о начале производства на территории России сервера SignalEdge нового поколения, ориентированного на применение в телеком-сфере и на решение задач на периферии. Устройство может использоваться, в частности, для обеспечения информационной безопасности. Сервер выполнен в форм-факторе 1U. Допускается установка двух процессоров Intel Xeon поколения Emerald Rapids или Sapphire Rapids в исполнении LGA 4677 с показателем TDP до 270 Вт. Поддерживается до 8 Тбайт оперативной памяти DDR5-4800 (32 слота). Возможна установка двух SSD стандарта M.2 SATA/NVMe и ещё двух SSD M.2 NVMe. Предусмотрены сетевой порт управления 1GbE, аналоговый разъём D-Sub и два порта USB 3.0. Во фронтальной части располагаются посадочные места для семи адаптеров: это могут быть по две карты HHHL PCIe 5.0 x16 и FHHL PCIe 5.0 x16, а также три устройства OCP 3.0. Говорится о применении инновационной системы охлаждения. За питание отвечают два блока мощностью 1200 Вт каждый с резервированием 1+1. 
Источник изображения: «Сигналтек» Особенностью новинки «Сигналтек» называет разработку собственного сетевого адаптера формата OCP 3.0 с интерфейсом PCIe 4.0 x8 на базе контроллера Intel X710. Адаптер поддерживает четыре оптических модуля 10Gb SFP+. Для управления питанием и мониторинга температуры задействован российский 32-разрядный микроконтроллер Миландр K1986BE92FI. При изготовлении изделия используется текстолит российского производства. Сборка осуществляется на собственных мощностях компании.  На основе сервера SignalEdge могут создаваться межсетевые экраны следующего поколения (NGFW) и системы глубокого анализа трафика (DPI). В настоящее время идет процесс включения новинки в реестр Минпромторга РФ.
22.04.2025 [08:45], Владимир Мироненко
Google настаивает на скорейшем переходе к 448G SerDes и готова отказаться от OSFP ради дальнейшего масштабирования ИИ-кластеровВ ходе семинара OIF 448Gbps Signaling for AI Workshop, инженер по оптическому оборудованию для систем машинного обучения Google Тэд Хофмайстер (Tad Hofmeister) привёл доводы в пользу скорейшего согласования отраслью технологий SerDes следующего поколения. Об этом пишет ресурс Converge Digest. В связи со стремительным масштабированием ИИ-нагрузок, стимулирующим беспрецедентный спрос на более высокие скорости передачи данных, Хофмайстер подчеркнул необходимость выхода за пределы возможностей 224G SerDes и начала развёртывания 448G в ИИ-системах, причём как в вертикально масштабируемых архитектурах, так и в горизонтально масштабируемых системах. Google призывает всю индустрию сфокусироваться на развитии 448G SerDes, поскольку уже сейчас возможностей 224G едва хватает — контактов на чипах скоро будет слишком мало, чтобы передавать данные. 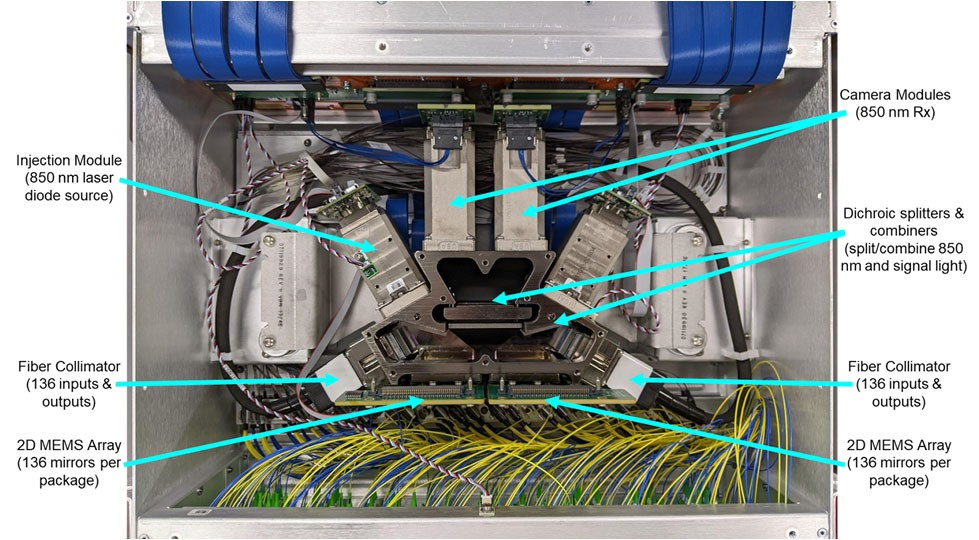
Источник изображения: Google Он отметил, что последнее поколение TPU Ironwood и суперускорителей NVIDIA GB200 расширяют требования к производительности и пропускной способности интерконнекта. И хотя медные соединения по-прежнему пригодны для топологий внутри стойки с коротким радиусом действия, оптические соединения необходимы для масштабирования ИИ-кластеров. Использование Google собственного протокола ICI для интерконнекта TPU с оптическими коммутаторами Apollo между модулями, способные объединить до 9126 ускорителей, подчеркивает важность гибких сетевых архитектур с высокой пропускной способностью. Хофмайстер также коснулся проблем, связанных с конструкцией разъёмов, целостностью сигнала и питанием. Он предположил, что отрасли, возможно, придётся отказаться от обратной совместимости с OSFP, а также объединиться для работы над модуляциями более высокого порядка — PAM6 или PAM8 вместо PAM4. Интегрированная оптика (co-packaged optics) и высокоскоростные flyover-кабели для подключения компонентов внутри узла рассматриваются как необходимые средства для обхода ограничений печатных плат и сохранения целостности сигнала 448G.
21.04.2025 [21:52], Татьяна Золотова
Arenadata приобрела у Orion soft СУБД Proxima DB и переименовала её в Arenadata Prosperity (ADP)Дочерняя компания разработчика ПО на рынке систем управления и обработки данных Arenadata ООО «Аренадата Софтвер» приобрела интеллектуальные права на продукт Proxima DB у ИТ-компании «Орион» (Orion soft). Команда разработки будет интегрирована в состав персонала «Аренадата Софтвер». Сумма сделки не разглашается. Стратегическое партнерство компаний позволит Orion soft сфокусироваться на развитии инфраструктурных продуктов, а Arenadata — расширить портфель решений для крупных организаций. Proxima DB переименован в Arenadata Prosperity (ADP). ADP построена на базе open source-технологии PostgreSQL. ADP обеспечивает оперативный мониторинг и анализ для минимизации времени простоя, совместима с платформой «1С», имеет сертификат ФСТЭК (4-й уровень доверия). В рамках партнерства предусмотрено использование продуктов Orion soft в качестве инфраструктурной основы для решений cloud-native платформы Arenadata One. Это платформа виртуализации zVirt и Kubernetes-решение для управления контейнерами Nova Container Platform. По словам генерального директора группы Arenadata, Arenadata Prosperity усилит присутствие в сегменте СУБД общего назначения для госсектора и корпоративного рынка. 
Источник: Orion soft Согласно отчету ЦСР «Рынок систем управления и обработки данных в РФ: текущее состояние и перспективы развития», рынок СУБД общего назначения составляет около 26 % от общего рынка систем управления и обработки данных, который оценивается в 95 млрд руб. на конец 2024 года.
21.04.2025 [20:31], Татьяна Золотова
R-Vision запускает линейку продуктов для цифровизации бизнеса
r-vision
software
администрирование
информационная безопасность
реструктуризация
сделано в россии
управление данными
Разработчик систем кибербезопасности R-Vision запускает новое направление, ориентированное на комплексную цифровизацию бизнеса. Компания сфокусируется на решении задач для эффективного сотрудничества ИТ и ИБ-подразделений, а также на развитии технологий для управления данными. Об этом сообщила пресс-служба R-Vision. По оценкам аналитиков, более 67 % инцидентов в сфере информационной безопасности связаны с непрозрачностью инфраструктуры и разобщенностью процессов. Невозможность эффективно управлять своими данными ведет к потерям не менее 30 % текущей выручки. Как поясняют в компании, новое ИТ-направление направлено на системное решение этих задач. Новая линейка продуктов для управления ИТ-ландшафтом, сервисом и процессами вокруг данных создается на единой платформе R-Vision EVO. Решения охватывают контроль конфигураций, инвентаризацию активов, автоматизацию совместных процессов ИТ и ИБ, а также задачи обработки и хранения данных. 
Источник изображения: R-Vision В линейку новых решений входят R-Vision CMDB (для централизованного управления базой данных об ИТ-компонентах и их конфигурациях), R-Vision ITSM (для автоматизации и управления ИТ-услугами, использующая передовые практики библиотеки ITIL), R-Vision ITAM (для управления жизненным циклом ИТ-активов компании) и R-Vision DGP (для управления данными). По информации пресс-службы, первые пилотные внедрения продуктов из ИТ-линейки уже запланированы. По оценке R-Vision, к 2028 году новое направление может приносить до 30 % общей выручки компании.
21.04.2025 [17:05], Татьяна Золотова
Для российских исследователей будут созданы суперкомпьютерный центр и роботизированные лабораторииПрезидент России поручил рассмотреть вопрос о внедрении инновационных технологий в промышленности. Для этого необходимо создать национальный суперкомпьютерный центр, роботизированные лаборатории, активнее внедрять искусственный интеллект. Об этом говорится в «Перечне поручений по итогам пленарного заседания и посещения выставки Форума будущих технологий, встречи с учеными». Как указано в документе, до 1 июня 2025 года премьер-министр РФ Михаил Мишустин должен представить предложения о создании единой межотраслевой цифровой базы данных свойств высокотехнологичных материалов и их компонентов, разработанной совместно с «Российской академией наук» и «Росатомом». В срок до 15 июля 2025 года необходимо также представить предложения о создании роботизированных лабораторий для проведения научных исследований с применением технологий ИИ. Среди поручений к середине июля 2025 года также необходимо рассмотреть вопрос о создании национального суперкомпьютерного центра. При этом доступ к его вычислительным мощностям получат все российские исследователи. 
Источник изображения: Eli Alvarez / Unsplash Кроме того, президент поручил до 1 августа 2025 года представить предложения о расширении применения технологий ИИ и компьютерного моделирования для сокращения сроков разработки и внедрения новых материалов в химической отрасли. Ожидается, что благодаря внедрению ИИ и компьютерного моделирования сроки разработки и внедрения новых материалов в России можно уменьшить до 5–10 лет, а со временем и до двух-трёх лет. К 1 сентября 2025 года Правительство РФ совместно с «Российской академией наук», «Росатомом» и «Курчатовским институтом» должно разработать предложения о создании межотраслевого центра аддитивных технологий или 3D-печати для ускорения внедрения промышленными предприятиями таких технологий.
21.04.2025 [16:13], Руслан Авдеев
«Чудо-долина» для ИИ — в Канаде построят крупнейший в мире 7,5-ГВт ЦОД с питанием от природного газаИнвестор, бизнесмен и шоумен Кевин О’Лири (Kevin O’Leary) объявил о строительстве «крупнейшего в мире» ИИ ЦОД, сообщает Tech Republic. Проект Wonder Valley (букв. «Чудо-долина» или «Долина чудес») предусматривает строительство крупного ИИ ЦОД без подключения к магистральным энергосетям в муниципальном округе Гринвью (Greenview) провинции Альберта на западе Канады. Кампус займёт территорию более 2400 га, общая мощность составит беспрецедентные 7,5 ГВт. Первую фазу на 1,56 ГВт должны закончить в 2027–2028 гг., она обойдётся в $2 млрд. По словам О’Лири, дата-центры — своеобразная «золотая лихорадка» современности. Вместе с тем получение питания для ЦОД стало большой проблемой, поскольку на присоединение может уйти пять или более лет. Он привёл пример, когда оператор ЦОД запрашивает 250 МВт сразу и ещё 250 МВт в течение двух лет, а в ответ ему предлагают 25 МВт с задержкой на три года, тогда как сейчас нужны проекты, которые будут готовы к работе уже через 24 месяца. Поэтом для питания нового кампуса будет использоваться природный газ. 
Источник изображения: Richard Hedrick/unsplash.com Wonder Valley представляет собой не просто крупнейший в мире дата-центр, но и экоустойчивый кампус на лоне дикой природы. Он сможет работать без подключения к магистральным электросетям и, более того, владельцы намерены поставлять энергию местным жителям. В регионе достаточно земли, природного газа, ВОЛС, кадров, инфраструктуры и др. По словам О’Лири, ИИ ЦОД рентабельны при реализации крупных проектов, так что теперь бизнес ищет другие площадки с государственной поддержкой и дешёвой энергией как в Альберте. По мнению О’Лири, при строительстве ИИ ЦОД надо в целом менять подход и вместо того, чтобы забирать электроэнергию из уже загруженных сетей, повышая тем самым стоимость электричества для остальных, стоит самостоятельно генерировать энергию и передавать её часть местным жителям и бизнесу. Появление кампуса в Альберте даст не только дешёвое электричество для ИИ ЦОД, но создаст рабочие места для местных, сократит вредные выбросы (за счёт утилизации попутного газа и захвата углерода), а также пополнит бюджет за счёт налоговых поступлений. Хотя газовые проекты для дата-центров в Северной Америке в последнее время очень популярны, производители газовых турбин, едва справляющиеся с заказами для дата-центров, опасаются расширять производство. А крупнейшая в США энергокомпания NextEra Energy предупреждает, что полагаться в энергетике только на газ очень опрометчиво. Что касается «крупнейшего с мире ЦОД», совсем недавно на это звание претендовал проект индийской Reliance с мощностью 3 ГВт.
21.04.2025 [12:30], Сергей Карасёв
Fujitsu, Supermicro и Nidec сообща повысят энергоэффективность ИИ ЦОДFujitsu, Supermicro и Nidec объявили об объединении усилий с целью снижения энергопотребления ЦОД. Речь идёт о создании платформы, которая поможет операторам дата-центров повысить коэффициент эффективности использования энергии (PUE). Отмечается, что стремительное внедрение ИИ приводит к быстрому росту нагрузки на ЦОД. Это, в свою очередь, провоцирует увеличение энергопотребления, что объясняется установкой мощных серверов с ускорителями на базе GPU. Тем не менее, многие дата-центры продолжают использовать воздушное охлаждение. Хотя жидкостное охлаждение обеспечивает значительно более высокую эффективность, проектирование, строительство и эксплуатация таких систем требуют высокого уровня технических знаний и навыков. В рамках нового проекта партнёры объединят ПО для мониторинга и управления жидкостным охлаждением Fujitsu, высокопроизводительные GPU-серверы Supermicro и высокоэффективную систему жидкостного охлаждения Nidec. В частности, Fujitsu намерена использовать свой 40-летний опыт в области СЖО, которые применяются в суперкомпьютерах. Supermicro предоставит высокопроизводительные серверные комплексы высокой плотности, оптимизированные для жидкостного охлаждения: такие устройства позволят сократить энергопотребление и снизить уровень шума благодаря отсутствию вентиляторов. 
Источник изображения: Nidec Nidec будет отвечать за поставки компонентов СЖО, включая блоки распределения охлаждающей жидкости (CDU), насосы и пр. Система охлаждения Nidec, как ожидается, улучшит управление температурой и снизит энергопотребление. В целом, как заявляют партнёры, новая инициатива поможет повысить общую энергоэффективность ЦОД до 40 % по сравнению с традиционными методами воздушного охлаждения. Fujitsu оценит преимущества решения в своем центре обработки данных Tatebayashi.
21.04.2025 [11:36], Сергей Карасёв
CoolIT представила 2-МВт блок распределения охлаждающей жидкости CHx2000 для ИИ и HPC ЦОДКомпания CoolIT Systems анонсировала блок распределения охлаждающей жидкости (CDU) CHx2000 для дата-центров, ориентированных на задачи ИИ и НРС. Новинка обеспечивает отвод более 2 МВт тепла: это, как утверждается, на сегодняшний день самый высокий показатель для CDU данного класса. Устройство выполнено в виде шкафа с размерами основания 750 × 1200 мм. Заявленный расход жидкости составляет 1,2 л/мин. на кВт (LPM/kW): допускается охлаждение до двенадцати стоек NVIDIA GB200 NVL72 мощностью 120 кВт. По сравнению со своим предшественником (модель CHx1500) новинка обеспечивает повышение охлаждающей способности на 66 %. При создании CHx2000 компания CoolIT Systems сделала упор на долговечность, безотказную работу и простоту обслуживания. Применены два насоса с возможностью горячей замены (N+N), обеспечивающие производительность 1500 л/мин. Трубы изготовлены из нержавеющей стали. В конструкции используются 4″ муфты Victaulic. Благодаря резервированию критически важных компонентов доступность находится на уровне 99,9999 %. 
Источник изображения: CoolIT Systems Предусмотрена интегрированная система управления и мониторинга (Redfish, SNMP, TCP/IP, Modbus, BACnet и др.). Причём допускается групповое управление одновременно до 20 экземпляров CDU. Во время обслуживания возможен доступ с лицевой и тыльной сторон с поддержкой горячей замены насосов, фильтров и датчиков. Заявленная потребляемая мощность составляет 12,24 кВт при работе одного насоса (1500 л/мин). Во фронтальной части корпуса располагается информационный дисплей. Блок CHx2000 уже доступен для заказа. CoolIT Systems предоставляет комплексную поддержку и услуги по проектированию, монтажу и обслуживанию в более чем 70 странах по всему миру.
21.04.2025 [09:13], Владимир Мироненко
«Киберпротект» представил новую версию системы резервного копирования Кибер Бэкап 17.3«Киберпротект», российский разработчик ПО для резервного копирования и восстановления данных, представил новую версию системы резервного копирования Кибер Бэкап 17.3. По словам компании, в данном релизе обеспечен рывок в производительности системы относительно максимального числа защищаемых источников данных, дальнейшего развития возможностей работы агентов в многопоточном и кластерном режимах, а также механизмов восстановления БД PostgreSQL. Также были улучшены работа с платформами виртуализации и контейнеризации, информирование и безопасность. Если предыдущая версия системы поддерживала работу с тысячами источников данных, то Кибер Бэкап 17.3 эффективно обеспечивает одновременное резервное копирование до 20 тыс. ящиков сервисов Почта VK WorkSpace и CommuniGate Pro. Как сообщает разработчик, до конца года этот показатель будет кратно увеличен. Также была добавлена возможность объединения агентов отечественных почтовых сервисов в кластер — логическую группу, выполняющую одно задание резервного копирования, автоматически балансируя нагрузку между агентами. 
Источник изображений: «Киберпротект» Росту производительности системы также способствовало расширение многозадачности агентов резервного копирования: теперь один агент способен параллельно обрабатывать разные задания резервного копирования, например, файловые и дисковые, разных экземпляров СУБД PostgreSQL и др. Таким образом, был сделан ещё один шаг в направлении развития многопоточности, обеспечивающий кратное увеличение скорости резервного копирования в ряде сценариев. Вместе с тем высокопроизводительной работе системы могут препятствовать ограничения источника данных. Например, одна из системных утилит СУБД PostgreSQL в сценариях гранулярного восстановления больших баз данных использует весь свободный объём оперативной памяти. В случае, если объём базы превышает его, возникают ошибки. Чтобы снять ограничения для PostgreSQL и отечественных СУБД на её основе при восстановлении, в Кибер Бэкап 17.3 используется собственный механизм гранулярного восстановления.  Также Кибер Бэкап 17.3 получил улучшенную защиту виртуальных машин OpenStack, поддерживаемой решением в «безагентном» режиме. А агент уровня гипервизора для OpenStack получил поддержку регионов. Это позволит полноценно реализовать защиту сложных виртуальных инфраструктур на базе OpenStack. Для VMware и решений на базе oVirt в дополнение к резервному копированию и восстановлению тегов была реализована возможность работы с тегами (поиск и группировка ВМ, применение к ним заданий резервного копирования) в самой системе резервного копирования, что поможет существенно упростить конфигурирования заданий и исключить человеческие ошибки. Кроме того, для платформы oVirt и отечественных систем доступна поддержка режиме LAN-free, в котором агент уровня гипервизора выполняет резервное копирование напрямую из SAN в обход хоста виртуализации и локальной сети, что повышает скорость резервного копирования, снижает нагрузку на хост гипервизора и сеть. Высокая скорость работы оборудования в таком режиме обеспечивает уменьшение окна резервного копирования, а изоляция трафика снижает риск перехвата данных по сравнению с использованием общей сети. 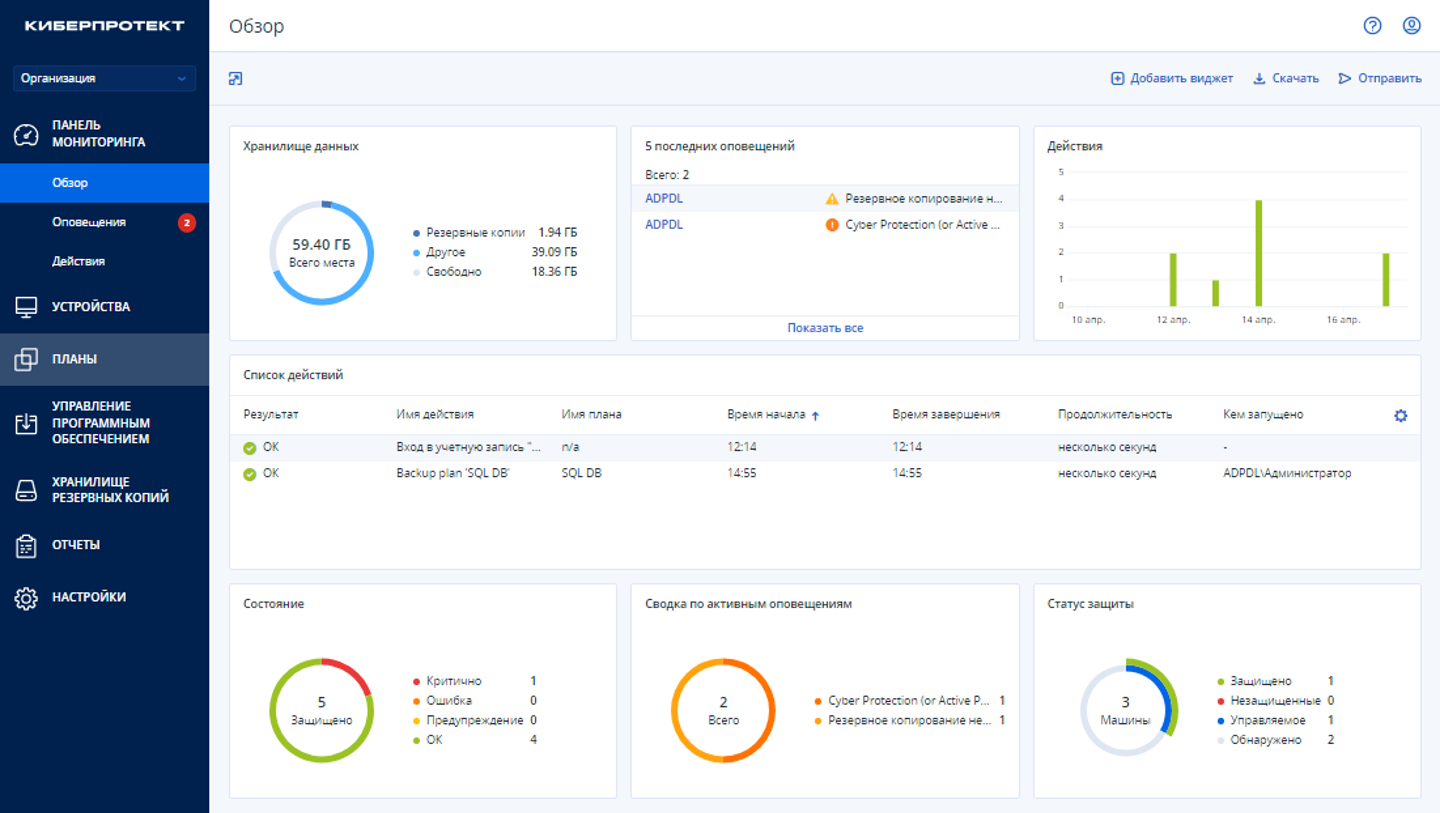 Дополнительно Кибер Бэкап 17.3 получил доработанный механизм резервного копирования и восстановления Kubernetes, позволяющий реализовать защиту постоянных томов Kubernetes собственными механизмами, обеспечивая хранение их данных во всех поддерживаемых системой резервного копирования хранилищах, дедупликацию резервных копий на уровне архива и их сжатие. Наконец, в Кибер Бэкапе 17.3 также был расширен список событий, отображаемых в Журнале аудита, представленном в Кибер Бэкап 17.2, и передаваемых в системы SIEM, за счёт десятков новых типов.
20.04.2025 [14:40], Сергей Карасёв
Sitronics Group: российским ИИ ЦОД нужны единые стандартыSitronics Group намерена принять участие в разработке и продвижении единых стандартов для рынка модульных ЦОД. Об этом в ходе конференции Data Fusion заявил директор профильного департамента компании Игорь Анисимов, призвав участников отрасли присоединиться к инициативе. В России сектор ЦОД развивается и адаптируется к новым нагрузкам, в первую очередь к ИИ. При этом возрастает нагрузка на энергетическую инфраструктуру, что потенциально может спровоцировать дефицит. По словам Анисимова, участникам рынка следует заняться решением таких вопросов, как рост плотности энергопотребления, а также стандартизация строительства и эксплуатации дата-центров, ориентированных на ИИ-нагрузки. При этом необходимо сохранить рентабельность бизнеса с учётом технологических требований для развёртывания ЦОД. Модульные дата-центры позволяют заказчикам в сжатые сроки создавать платформы для ИИ, получив мощности в аренду или же масштабировав собственные посредством типовых модулей. «Сегодня нет единого стандарта для центров обработки данных с ИИ-нагрузкой, который позволил бы снизить капитальные затраты за счёт уменьшения затрат на разработку уникальных решений для каждого ЦОД. Стандартизация позволит проработать совместимость инфраструктуры ЦОД с системами ИИ. Мы намерены активно участвовать в этом процессе, особенно в части разработки стандартов для модульных ЦОД, которые, на наш взгляд, обладают большим потенциалом для эффективного размещения систем искусственного интеллекта», — говорит Анисимов. 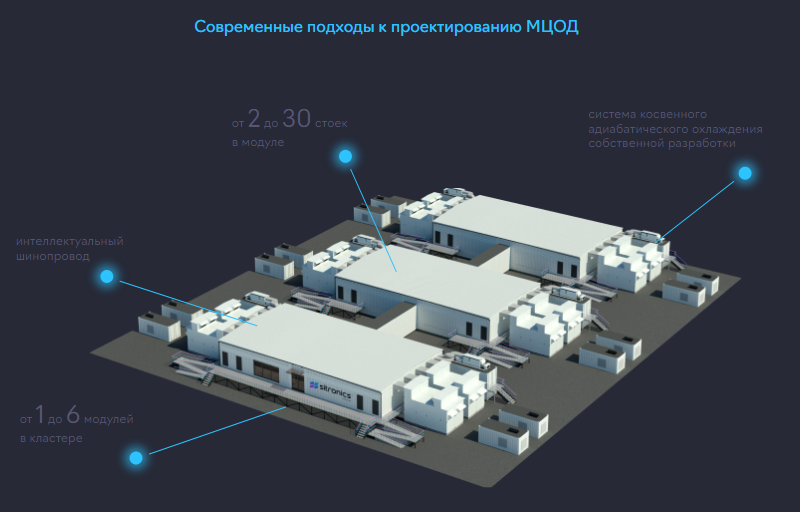
Источник изображения: Sitronics Group По его словам, при развёртывании дата-центров для ИИ прежде всего требуется бесперебойное электроснабжение и эффективное охлаждение. Сама Sitronics Group ведёт разработки в соответствующих областях: в частности, компания занимается созданием системы фрикулинга с экономайзерами. Кроме того, при стандартизации ЦОД необходимо определить форм-фактор серверов (стандартный или OCP), оптимальную температуру теплоносителя на входе в стойку и на уровне процессора, изучить вопросы совмещения зон для стандартных и ИИ-вычислений в рамках одного объекта, рассчитать мощности инженерных систем и пр. |
|

