Материалы по тегу: s
|
20.11.2024 [17:16], Руслан Авдеев
AWS предоставит IBM доступ к ИИ-ускорителям на $475 миллионовAWS близка к заключению сделки с компанией IBM на сумму $475 млн. По данным Business Insider, компания готовится предоставить компании IBM доступ к своим облачным ИИ-решениям. Компании ведут переговоры о пятилетнем использовании IBM ИИ-ускорителей в облаке Amazon. В частности, IBM планирует задействовать инстансы EC2 с чипами NVIDIA, что подтверждается одним из внутренних документов Amazon. По некоторым данным, сотрудничество уже началось — IBM начала обучать отдельные модели на указанных системах с использованием платформы AWS SageMaker. Однако переговоры ещё продолжаются, и подписание окончательного соглашения пока не гарантировано. Примечательно, что IBM имеет собственное облако, где так же предоставляет доступ к ускорителям. Однако, по оценкам экспертов, её доля на мировом облачном рынке не превышает 10 %. Ранее, в 2024 году, IBM анонсировала увеличение использования сервисов AWS для своей платформы Watson AI. Компании намерены интегрировать IBM watsonx.governance с платформой Amazon SageMaker, чтобы помочь клиентам эффективно управлять рисками, связанными с ИИ-моделями, и упростить их использование. 
Источник изображения: AWS Amazon активно продвигает чипы собственной разработки — Inferentia и Trainium, а ранее в этом месяце пообещала предоставить «кредиты» исследователям в сфере ИИ на сумму $110 млн для доступа к свои чипам в рамках программы Build on Trainium. Пока неизвестно, намерена ли IBM применять чипы AWS или отдаст предпочтение более популярным решениям, таким как продукты NVIDIA.
20.11.2024 [17:10], Андрей Крупин
Positive Technologies представила межсетевой экран PT NGFW для защиты бизнеса от кибератакКомпания Positive Technologies объявила о выпуске брандмауэра PT NGFW. Программный комплекс обеспечивает защиту корпоративной сети от сетевых атак и вредоносного ПО, а также управление доступом к веб‑ресурсам. В решение встроены модули контроля пользователей и приложений, система предотвращения вторжений (IPS), средства инспекции (расшифровки) TLS-трафика, механизмы URL-фильтрации и инструменты централизованного управления с поддержкой до 10 тысяч конечных устройств. PT NGFW поддерживает маршрутизацию трафика, виртуальные контексты, иерархию объектов и правил, поиск, журналирование и работу в составе отказоустойчивых кластеров. Также сообщается о возможностях интеграции с Microsoft Active Directory и экосистемой продуктов Positive Technologies. 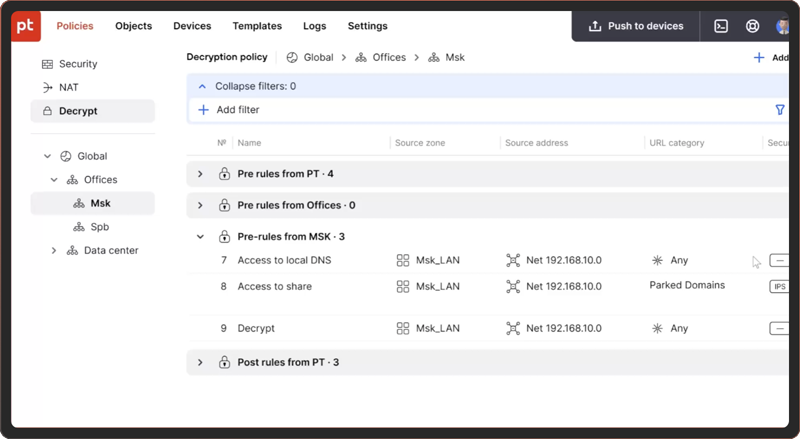
Пользовательский интерфейс PT NGFW (источник изображения: ptsecurity.com) PT NGFW доступен для приобретения как в виртуальном исполнении, так и в составе программно-аппаратных комплексов с архитектурой х86, разнящихся форм-фактором, аппаратной начинкой, набором поддерживаемых сетевых интерфейсов и производительностью в различных режимах межсетевого экрана. Самая младшая модель в линейке устройств — PT NGFW 1010 — обеспечивает производительность до 5,6 Гбит/c (режим Firewall), до 900 Мбит/с (IPS и «Инспекция приложений»), до 100 Мбит/с (NGFW) и до 100 Мбит/с (TLS Forward Proxy). Самый старший вариант — PT NGFW 3040 — позволяет обрабатывать трафик со скоростью до 300 Гбит/c (режим Firewall), до 60 Гбит/с (IPS и «Инспекция приложений»), до 10 Гбит/с (NGFW) и до 25 Гбит/с (TLS Forward Proxy). Межсетевой экран PT NGFW может применяться в организациях различного размера, в том числе в крупных со сложной сетевой инфраструктурой, а также для защиты центров обработки данных. По данным аналитиков, в 2025 году объём российского рынка сетевой безопасности достигнет 100 млрд рублей, при этом около 60 % защитных продуктов придётся на решения класса NGFW. Такие прогнозы игроки рынка связывают с требованиями правительства РФ по переводу к упомянутому сроку критической информационной инфраструктуры на преимущественное использование отечественных разработок в сфере ИБ.
20.11.2024 [12:11], Сергей Карасёв
Dell представила ИИ-серверы PowerEdge XE9685L и XE7740Компания Dell анонсировала серверы PowerEdge XE9685L и PowerEdge XE7740, предназначенные для НРС и ресурсоёмких рабочих нагрузок ИИ. Устройства могут монтироваться в 19″ стойку высокой плотности Dell Integrated Rack 5000 (IR5000), что позволяет экономить место в дата-центрах. 
Источник изображений: Dell Модель PowerEdge XE9685L в форм-факторе 4U рассчитана на установку двух процессоров AMD EPYC Turin. Применяется жидкостное охлаждение. Доступны 12 слотов для карт расширения PCIe 5.0. Говорится о возможности использования ускорителей NVIDIA HGX H200 или B200. По заявлениям Dell, система PowerEdge XE9685L предлагает самую высокую в отрасли плотность GPU с поддержкой до 96 ускорителей NVIDIA в расчёте на стойку. Новинка подходит для организаций, решающих масштабные вычислительные задачи, такие как создание крупных моделей ИИ, запуск сложных симуляций или выполнение геномного секвенирования. Конструкция сервера обеспечивает оптимальные тепловые характеристики при высоких рабочих нагрузках, а наличие СЖО повышает энергоэффективность.  Вторая модель, PowerEdge XE7740, также имеет типоразмер 4U, но использует воздушное охлаждение. Допускается установка двух процессоров Intel Xeon 6 на базе производительных ядер P-core (Granite Rapids). Заказчики смогут выбирать конфигурации с восемью ИИ-ускорителями двойной ширины, включая Intel Gaudi 3 и NVIDIA H200 NVL, а также с 16 ускорителями одинарной ширины, такими как NVIDIA L4.  Сервер подходит для различных вариантов использования, например, для тонкой настройки генеративных моделей ИИ, инференса, аналитики данных и пр. Конструкция машины позволяет эффективно сбалансировать стоимость, производительность и масштабируемость. Dell также готовит к выпуску новый сервер PowerEdge XE на базе NVIDIA GB200 NVL4. Говорится о поддержке до 144 GPU на стойку формата 50OU (Dell IR7000).
20.11.2024 [10:59], Сергей Карасёв
Nebius, бывшая Yandex, развернёт в США своей первый ИИ-кластер на базе NVIDIA H200Nebius, бывшая материнская компания «Яндекса», объявила о создании своего первого вычислительного ИИ-кластера на территории США. Система будет развёрнута на базе дата-центра Patmos в Канзас-Сити (штат Миссури), а её ввод в эксплуатацию запланирован на I квартал 2025 года. На начальном этапе в составе кластера Nebius будут использоваться ИИ-ускорители NVIDIA H200. В следующем году планируется добавить решения поколения NVIDIA Blackwell. Мощность площадки может быть увеличена с первоначальных 5 МВт до 40 МВт: это позволит задействовать до 35 тыс. GPU. По заявлениям Nebius, фирма Patmos была выбрана в качестве партнёра в связи с гибкостью и опытом в поэтапном строительстве ЦОД. Первая фаза проекта включает развёртывание необходимой инфраструктуры, в том числе установку резервных узлов, таких как генераторы. Новая зона доступности, как ожидается, позволит Nebius более полно удовлетворять потребности американских клиентов, занимающихся разработками и исследованиями в области ИИ. 
Источник изображения: Nebius Говорится, что Nebius активно наращивает присутствие в США в рамках стратегии по формированию ведущего поставщика инфраструктуры для ИИ-задач. На 2025 год намечено создание второго — более масштабного — кластера GPU в США. Кроме того, компания открыла два центра по работе с клиентами — в Сан-Франциско и Далласе, а третий офис до конца текущего года заработает в Нью-Йорке. Напомним, что ранее Nebius запустила первый ИИ-кластер во Франции на базе NVIDIA H200. У компании также есть площадка в Финляндии. К середине 2025 года Nebius намерена инвестировать более $1 млрд в инфраструктуру ИИ в Европе. А около месяца назад компания представила облачную ИИ-платформу с ускорителями NVIDIA H100 и H200.
18.11.2024 [13:38], Руслан Авдеев
Foxlink запустила мощнейший на Тайване суперкомпьютер для малого и среднего бизнесаFoxlink Group (Cheng Uei Precision Industry) открыла крупнейший на Тайване суперкомпьютерный центр Ubilink (Ubilink.AI). По данным DigiTimes, центр предназначен для обслуживания предприятий малого и среднего бизнеса (SME), которые не могут позволить себе собственных вычислительных мощностей. Хотя основной деятельностью Foxlink является производство разъёмов, компания расширяет бизнес, осваивая решения для управления электропитанием и коммуникаций, а также выпуск энергетических модулей. Центр Ubilink создан дочерней Shinfox Energy совместно с Asustek Computer и японской Ubitus, занимающейся предоставлением облачных услуг. В Ubitus сообщили, что инфраструктура Ubilink включает 128 серверов Asus, 1024 ускорителя NVIDIA H100 и интерконнект NVIDIA Quantum-2 InfiniBand. Конфигурация обеспечивает до 45,82 Пфлопс (FP64) — система занимает 31-е место в рейтинге TOP500. В будущем станут применять и более современные B100 и B200 — когда те будут доступны. Ожидается, что в 2025 году суммарно будет установлено 10 240 ускорителей H100, B100 и B200. Представители местных властей уже заявили, что Ubilink существенно улучшит позиции Тайваня на рынке ИИ-вычислений, на котором территория сегодня занимает 26-е место. В Asustek добавляют, что достигнутая производительность в 45,82 Пфлопс заметно превышает плановые 40 Пфлопс. Кроме того, центр имеет PUE на уровне 1,2 — ранее ожидалось, что удастся добиться энергоэффективности лишь на уровне 1,38. Благодаря использованию опыта Shinfox Energy в области возобновляемой энергетики, Ubilink стал первым в Азии суперкомпьютерным центром, использующим «зелёные» источники энергии — клиенты могут воспользоваться вычислениями без существенного ущерба окружающей среде. 
Источник изображения: UBITUS Предполагается, что Ubilink компенсирует отсутствие мощностей для местных малых и средних компаний, не имеющих доступа к значительным вычислительным ресурсам. Предлагая доступные вычислительные мощности, центр позволяет таким бизнесам расширить свои портфели предложений и конкурировать даже на мировом уровне. Суперкомпьютер уже востребован местными разработчиками чипов, компаний, занимающихся их упаковкой и тестированием, биотехнологическими бизнесами, а также исследовательскими институтами различной направленности. Из-за высокого спроса Foxlink уже рассматривает вторую и третью фазы расширения проекта.
18.11.2024 [10:59], Сергей Карасёв
OpenAI раздумывала, не купить ли разработчика ИИ-ускорителей Cerebras при участии TeslaКомпания OpenAI, по информации ресурса TechCrunch, изучала возможность приобретения американского стартапа Cerebras Systems, специализирующегося на разработке ИИ-ускорителей. Такие сведения вскрылись в рамках судебного процесса по иску Илона Маска (Elon Musk) против OpenAI. Маск является одним из основателей OpenAI — он покинул эту компанию в 2018 году. В начале августа нынешнего года Маск подал в суд на OpenAI и её генерального директора Сэма Альтмана (Sam Altman), обвинив их в нарушении прав и интересов, а также во введении в заблуждение. 
Источник изображения: Cerebras Как теперь сообщается, в электронном письме, адресованном Альтману и Маску, Илья Суцкевер (Ilya Sutskever), один из соучредителей OpenAI и бывший главный научный сотрудник компании, обсуждал идею покупки Cerebras через Tesla. В другом письме от июля 2017 года Суцкевер затрагивает ряд вопросов, связанных с Cerebras, таких как переговоры об условиях слияния и проверка благонадёжности финансового состояния Cerebras. «Если мы решим купить Cerebras, я твердо уверен, что это будет сделано через Tesla. Но зачем делать это таким образом, если мы могли бы провести сделку изнутри OpenAI? В частности, вызывает беспокойство то, что Tesla имеет обязательство перед акционерами максимизировать их доход, что не соответствует миссии OpenAI», — написал Суцкевер. Cerebras создаёт ИИ-суперускорители размером с целую кремниевую пластину. Флагманским продуктом стартапа является решение Wafer Scale Engine третьего поколения (WSE-3). Это гигантское изделие содержит 4 трлн транзисторов, 900 тыс. ядер и 44 Гбайт памяти SRAM. Предполагалось, что слияние с OpenAI будет выгодно обеим сторонам. В частности, Cerebras избежала бы сложного пути, связанного с IPO, тогда как OpenAI смогла бы получить в своё распоряжение мощные аппаратные ускорители для ресурсоёмких ИИ-задач. Однако сделка в итоге провалилась, хотя причины сворачивания переговоров не раскрываются.
17.11.2024 [11:32], Сергей Карасёв
NEC создаст в Японии суперкомпьютер на базе Intel Xeon 6900P и AMD Instinct MI300A для исследований термоядерного синтезаКорпорация NEC займётся созданием нового НРС-комплекса, который планируется ввести в эксплуатацию в Японии в июле 2025 года. Система, базирующаяся на компонентах AMD и Intel, будет использоваться для различных исследований и разработок в области термоядерного синтеза. Заказ на создание суперкомпьютера поступил от Национальных институтов квантовой науки и технологий Японии (QST) при Национальном агентстве исследований и разработок (ANID), а также от Национального института термоядерных наук (NIFS) в составе Национальных институтов естественных наук (NINS). Система будет установлена в Институте термоядерной энергии Rokkasho (входит в QST) в Аомори (Япония). Основой проектируемого суперкомпьютера послужат 360 узлов NEC LX 204Bin-3, в состав каждого из которых войдут два процессора Intel Xeon 6900P поколения Granite Rapids (всего 720 чипов) и память DDR5 MRDIMM. Кроме того, будут задействованы 70 узлов NEC LX 401Bax-3GA, несущих на борту по четыре ускорителя AMD Instinct MI300A (в общей сложности 280 изделий). Говорится о применении интерконнекта InfiniBand с 400G-коммутаторами NVIDIA QM9700, а также хранилища DDN EXAScaler ES400NVX2 вместимостью 42,2 Пбайт с файловой системой Lustre. Для управления рабочими нагрузками будет использоваться софт Altair PBS Professional. 
Источник изображения: NEC Ожидается, что производительность суперкомпьютера достигнет 40,4 Пфлопс. Это в 2,7 раза больше суммарных показателей двух нынешних НРС-систем, установленных в рамках независимых проектов QST и NIFS. Учёные намерены применять новый НРС-комплекс для точного прогнозирования экспериментов и создания сценариев работы для Международного экспериментального термоядерного реактора (ITER). Кроме того, мощности суперкомпьютера будут востребованы исследовательскими группами токамака Satellite Tokamak JT-60SA и электростанции DEMO (DEMOnstration Power Plant), использующей термоядерный синтез.
16.11.2024 [20:49], Сергей Карасёв
Сандийские национальные лаборатории запустили ИИ-систему Kingfisher на огромных чипах Cerebras WSE-3Сандийские национальные лаборатории (SNL) Министерства энергетики США (DOE) в рамках партнёрства с компанией Cerebras Systems объявили о запуске кластера Kingfisher, который будет использоваться в качестве испытательной платформы при разработке ИИ-технологий для обеспечения национальной безопасности. Основой Kingfisher служат узлы Cerebras CS-3, которые выполнены на фирменных ускорителях Wafer Scale Engine третьего поколения (WSE-3). Эти гигантские изделия содержат 4 трлн транзисторов, 900 тыс. ядер и 44 Гбайт памяти SRAM. Суммарная пропускная способность встроенной памяти достигает 21 Пбайт/с, внутреннего интерконнекта — 214 Пбит/с. На сегодняшний день платформа Kingfisher объединяет четыре узла Cerebras CS-3, а конечная конфигурация предусматривает использование восьми таких блоков. Узлы Cerebras CS-3 мощностью 23 кВт каждый содержат СЖО, подсистемы питания, сетевой интерконнект Ethernet и другие компоненты. 
Источник изображения: SNL Развёртывание кластера Cerebras CS-3 является частью программы Advanced Simulation and Computing (ASC), которая реализуется Национальным управлением по ядерной безопасности США (NNSA). Речь идёт, в частности, об инициативе ASC Artificial Intelligence for Nuclear Deterrence (AI4ND) — искусственный интеллект для ядерного сдерживания. Предполагается, что Kingfisher позволит разрабатывать крупномасштабные и надёжные модели ИИ с использованием защищённых внутренних ресурсов Tri-lab — группы, в которую входят Сандийские национальные лаборатории, Ливерморская национальная лаборатория имени Лоуренса (LLNL) и Лос-Аламосская национальная лаборатория (LANL) в составе (DOE).
15.11.2024 [00:25], Владимир Мироненко
Оковы окон: российские госкомпании продолжают закупать продукты Microsoft
microsoft
microsoft 365
microsoft office
software
windows
госзакупки
импортозамещение
россия
санкции
Российские госкомпании продолжали закупать в 2024 году ПО покинувшей рынок Microsoft, хотя и в меньших объёмах, пишет «Коммерсантъ». Согласно данным сервиса «Контур.Закупки», на приобретение продуктов Microsoft, включая закупки в малых объёмах, за 10 месяцев 2024 года госорганами (по 223-ФЗ и 44-ФЗ) было потрачено 24,1 млн руб., тогда как в 2023 году на эти цели израсходовали 52,5 млн руб. Закупки ОС Windows госкомпаниями и госкорпорациями (по 223-ФЗ) за этот период составили 7 млн руб., что на 69 % меньше год к году, пакетов Office — 3 млн руб. (на 75 % меньше). В «Контур.Закупках» отметили, что госкомпании не готовы полностью отказаться от продукции Microsoft, поскольку некоторые программы не импортозамещены. Поэтому они закупают «остатки» Microsoft Office и Microsoft 365 версий 2019 и 2021. Количество таких закупок малого объёма увеличилось год к году почти в два раза, хотя сумма сократилась с 3,2 млн до 2,4 млн руб. В свою очередь, электронная торговая площадка «Росэлторг» подсчитала, что по 223-ФЗ закупки ОС Windows сократились на 21 % в денежном выражении, до 35,5 млн руб., а количество тендеров уменьшилось на 5 %, до 55 единиц. По 44-ФЗ закупки уменьшились на 14 % до 22,7 млн руб. и на 12 % сократилось количество тендеров — до 99 единиц, передаёт «Коммерсантъ». 
Источник изображения: Surface / Unsplash Опрошенные «Коммерсантом» эксперты и представители отрасли предполагают, что Microsoft может не желать целиком терять рынок в РФ и снижает цены. Кроме того, даже в реестре отечественного ПО есть продукты, совместимые только Windows. В некоторых случаях на создание российских аналогов иностранных решений может уйти более 10 лет. Ещё один фактор — необходимость инвестиций, в том числе денежных, в переобучение сотрудников и развитие ПО.
13.11.2024 [22:21], Руслан Авдеев
Поработайте за нас: AWS предоставит учёным кластеры из 40 тыс. ИИ-ускорителей TrainiumAWS намерена привлечь больше людей к разработке ИИ-приложений и фреймворков, использующих разработанные Amazon ускорители семейства Tranium. В рамках нового инициативы Build on Trainium с финансированием в объёме $110 млн академическим кругам будет предоставлен доступ к кластерам UltraClaster, включающим до 40 тыс. ускорителей, сообщает The Register. В рамках программы Build on Trainium предполагается обеспечить доступ к кластеру представителям университетов, которые заняты разработкой новых ИИ-алгоритмов, которые позволяет повысить эффективность использования ускорителей и улучшить масштабирование вычислений в больших распределённых системах. На каком поколении чипов, Trainium1 или Trainium2, будут построены кластеры, не уточняется. 
Источник изображений: AWS Как поясняют в самом блоге AWS, исследователи могут придумать новую архитектуру ИИ-моделей или новую технологию оптимизации производительности, но у них может не оказаться доступа к HPC-ресурсам для крупных экспериментов. Не менее важно, что плоды трудов, как ожидается, будут распространяться по модели open source, поэтому от этого выиграет вся экосистема машинного обучения. Впрочем, со стороны AWS альтруизма мало. Во-первых, $110 млн будут выданы выбранным проектам в виде облачных кредитов, такое происходит не впервые. Во-вторых, компания фактически пытается переложить часть своих задач на других людей. Кастомные чипы AWS, включая ИИ-ускорители для обучения и инференса, изначально разрабатывались для повышения эффективности выполнения внутренних задач компании. Однако низкоуровневые фреймворки и т.п. ПО не предназначены для того, чтобы с ними мог свободно работать широкий круг лиц как, например, происходит с NVIDIA CUDA.  Иными словам, AWS для популяризации Trainium необходимо более простое в освоение ПО, а ещё лучше готовые решения прикладных задач. Неслучайно Intel и AMD склонны предлагать разработчикам готовые оптимизированные под их ускорители фреймворки вроде PyTorch и TensorFlow, а не пытаться заставить их заниматься достаточно низкоуровневым программированием. AWS занимается тем же самым, предлагая продукты вроде SageMaker. Во многом реализация проекта возможна благодаря новому интерфейсу Neuron Kernel Interface (NKI) для AWS Tranium и Inferentia, обеспечивающему прямой доступ к набору инструкций чипов и позволяющему исследователям строить оптимизированные вычислительные ядра для работы новых моделей, оптимизации производительности и инноваций в целом. Впрочем, учёным — в отличие от обычных разработчиков — часто интересно работать именно с низкоуровневыми системами. |
|

