Материалы по тегу: qualcomm
|
07.10.2025 [23:17], Владимир Мироненко
Qualcomm купила Arduino: бренд и экосистему обещают сохранитьQualcomm объявила о приобретении Arduino, итальянской компании-разработчика, известной своей open source экосистемой решений на базе микроконтроллеров и ПО. Qualcomm отметила, что сделка позволит ускорить реализацию стратегии по расширению возможностей разработчиков за счёт упрощения доступа к её портфелю передовых технологий и продуктов, а также укрепить свои позиции в области периферийных и ИИ-вычислений. О сделке объявили через несколько дней после победы Qualcomm над Arm в суде. «Объединяя принципы open source с портфолио Qualcomm Technologies, мы помогаем миллионам разработчиков создавать интеллектуальные решения быстрее и эффективнее», — заявил Накул Дуггал (Nakul Duggal), генеральный менеджер подразделения автомобильных, промышленных и встраиваемых решений для Интернета вещей Qualcomm Technologies, передаёт TechRadar. Arduino с сообществом из более чем 33 млн активных пользователей сохранит свой бренд и продолжит поддерживать широкий спектр микроконтроллеров, а также разрабатывать решения для различных направлений: от любительских роботов и простых проектов домашней автоматизации до корпоративных платформ Интернета вещей. Финансовые подробности сделки не разглашаются. Её завершение зависит от получения одобрения регулирующих органов и других стандартных условий оформления сделки. 
Источник изображения: Qualcomm В марте 2024 года Qualcomm приобрела компанию Foundries.io, занимающуюся периферийными вычислениями, а в марте 2025 года объявила о приобретении Edge Impulse, разработчика платформы для создания периферийных ИИ-решений. Как отметил ресурс CNBC, Qualcomm стремится диверсифицировать бизнес, поскольку рынок смартфонов стагнирует, а Apple начала переход на собственные модемы. В последнем квартале на долю бизнеса Qualcomm в сфере IoT, включающем в себя многие из её текущих чипов, которые могут использоваться в промышленных или робототехнических продуктах, и автомобильного бизнеса пришлось в общей сложности 30 % от общей выручки от продажи чипов. Несмотря на то, что Qualcomm неоднократно подчёркивала, что Arduino продолжит существовать как самостоятельная экосистема, всегда существует опасение, что крупная компания, покупая любой небольшой открытый проект, в конечном итоге начнёт ограничивать экосистему, пишет Ars Technica. Это может привести к сокращению или прекращению выпуска аппаратных и программных проектов для сообщества разработчиков или снижение поддержки чипов сторонних производителей. Также это может означать перенос фокуса на крупных корпоративных клиентов Qualcomm в ущерб преподавателям и разработчикам из сообщества Arduino. Впрочем, приверженность Arduino принципам open source может стать страховкой от таких попыток Qualcomm в будущем.
17.09.2025 [11:04], Сергей Карасёв
В США появится ИИ-суперкомпьютер с Arm-процессорами AmpereOne M и ускорителями Qualcomm Cloud AIУниверситет штата Нью-Йорк в Стони-Бруке (SBU) объявил о получении гранта в размере $13,77 млн от Национального научного фонда США (NSF) на приобретение и эксплуатацию высокопроизводительного энергоэффективного суперкомпьютера для задач ИИ. Средства получит Институт передовых вычислительных наук (IACS) в составе SBU. В проекте также примет участие Университет штата Нью-Йорк в Буффало (UB). Деньги выделяются в рамках программы Sustainable Cyber-infrastructure for Expanding Participation (Устойчивая киберинфраструктура для расширенной совместной работы). В основу НРС-комплекса, который пока не получил определённого названия, лягут процессоры AmpereOne M, разработанные компанией Ampere Computing специально для ресурсоёмких ИИ-нагрузок в дата-центрах. Эти чипы насчитывают до 192 кастомизированных 64-бит ядер на базе Arm v8.6+ Реализована поддержка 12 каналов DDR5-5600 и 96 линий PCIe 5.0. Кроме того, в состав суперкомпьютера войдут ИИ-ускорители Qualcomm Cloud AI, которые несут на борту до 576 Мбайт SRAM и до 128 Гбайт памяти LPDDR4x с пропускной способностью до 548 Гбайт/с. Расчётные показатели быстродействия машины пока не раскрываются.  Ожидается, что комбинация AmpereOne M и Qualcomm Cloud AI обеспечит высокую энергоэффективность, а также значительную производительность, достаточную для работы с крупными ИИ-моделями. Доступ к ресурсам суперкомпьютера планируется предоставлять исследователям, студентам и преподавателям на всей территории США. Новый НРС-комплекс поможет ускорить открытия в области геномики, биоинформатики и в других областях. Кроме того, система будет применяться при реализации проектов в сферах машинного обучения и статистического анализа.
09.06.2025 [23:17], Владимир Мироненко
Qualcomm договорилась о покупке Alphawave за $2,4 млрдQualcomm объявила о достижении соглашения с Alphawave IP Group (Alphawave Semi) о приобретении её активов за $2,4 млрд. Как сообщила Alphawave Semi, котирующаяся на Лондонской бирже, её акционеры получат $2,48 наличными за каждую имеющуюся акцию. Цена составляет 183 пенса за акцию, что на 96 % превышает цену в размере 93,50 пенса на момент закрытия торгов на бирже 31 марта 2025 года, за день до того, как Qualcomm объявила о своей заинтересованности в покупке Alphawave Semi. До этого интерес к покупке Alphawave Semi проявила Arm, в частности, из-за её технологии создания SerDes-блоков для ускорителей в вычислительных кластерах. Как указано в пресс-релизе, приобретение Alphawave Semi направлено на дальнейшее ускорение и предоставление ключевых активов для продвижения Qualcomm на рынок ЦОД, о чём и было заявлено ранее: «Процессоры Qualcomm Oryon CPU и Hexagon NPU хорошо подходят для удовлетворения растущего спроса на высокопроизводительные энергоэффективные вычисления, который обусловлен стремительным ростом применения ИИ-инференса и переходом на кастомные процессоры для ЦОД».  Решения Alphawave Semi являются частью базовой инфраструктуры, обеспечивающей услуги следующего поколения в широком спектре быстрорастущих приложений, включая ЦОД, ИИ, сети передачи данных и хранилища данных. «Под руководством Тони Пиалиса (Tony Pialis) Alphawave Semi разработала ведущие высокоскоростные проводные подключения и вычислительные технологии, которые дополняют наши энергоэффективные CPU- и NPU-ядра, — отметил генеральный директор Qualcomm Криштиану Амон (Cristiano Amon). — Усовершенствованные кастомные процессоры Qualcomm естественным образом подходят для рабочих нагрузок ЦОД. Объединённые команды разделяют цель создания передовых технологических решений и обеспечения производительности взаимосвязанных вычислений следующего уровня в широком спектре быстрорастущих областей, включая инфраструктуру ЦОД». Ожидается, что сделка будет завершена в течение I квартала 2026 года при условии её одобрения акционерами Alphawave, а также соответствующими регулирующими органами США, Германии, Южной Кореи, Канады и Великобритании. Alphawave заявила, что её директора будут единогласно рекомендовать акционерам проголосовать за сделку. Согласно соглашению, акционеры Alphawave могут получить оплату наличными или акциями Qualcomm. Alphawave была зарегистрирована в Торонто (Канада), после чего в мае 2021 года разместила свои акции на Лондонской фондовой бирже. В ходе первичного размещения Alphawave продала акции по 410 пенсов на сумму £856 млн, получив оценку рыночной стоимости в £3,1 млрд. Предложение Qualcomm по 183 пенса за акцию составляет менее половины этой суммы, пишет The Financial Times. Как сообщает ресурс The Register, комментируя сделку, финансовая компания Jefferies Financial Group заявила, что не ожидает никаких препятствий со стороны регуляторов, поскольку Alphawave теперь избавилась от своей доли в совместном с китайцами предприятии WiseWave.
27.05.2025 [14:12], Руслан Авдеев
Sophia Space разработала «ИИ-плитки» для сборки космических ЦОД
hardware
nvidia
nvidia jetson
qualcomm
snapdragon
ии
космос
микро-цод
облако
периферийные вычисления
спутник
сша
цод
Финансирование получил очередной космический стартап, намеренный вывести на орбиту дата-центры. Sophia Space из Сиэтла (США) привлекла $3,5 млн — раунд финансирования возглавила Unlock Ventures, участие также приняли «бизнес-ангелы», заинтересованные в орбитальных периферийных вычислениях и космических ЦОД, сообщает Datacenter Dynamics. 
Источник изображений: Sophia Space В Sophia Space заявили, что мир находится на заре новой эры, в которой спрос на ИИ-технологии не должен приносить ущерба планете из-за энергетических ограничений. Компанию основали два выходца из Лаборатории реактивного движения NASA (JPL), а также ветеран Intel и Microsoft. Компания предлагает готовую, автономную, защищённую от радиации вычислительную платформу TILE, оптимизированную для ИИ-задач, в том числе в коммерческих и оборонных секторах. Каждый сервер TILE Edge представляет «плитку» размерами 1 × 1 и толщиной 1 см, оснащённую собственной солнечной панелью и пассивной системой охлаждения. Вычислительная часть представлена связкой Qualcomm Snapdragon 865 и Cloud AI 100 или NVIDIA Jetson и Blackwell. «Плитки» можно объединять друг с другом, формируя кластер необходимой мощности.  Периферийные вычисления в космосе ценятся за возможность решить проблему перегрузки спутников, генерирующих больше данных, чем когда бы то ни было. Для использования этих огромных массивов информации требуются значительные ресурсы, поэтому предварительная обработка на периферийной платформе может сослужить неоценимую службу владельцам — предназначенные для передачи на Землю данные фильтруются ещё в космосе. Тема будет становиться всё более актуальной, поскольку правительствам и военным нужны всё более сложные системы мониторинга и съёмки на орбите. Компании вроде Axiom Space, Starcloud (ранее Lumen Orbit), NTT, Lonestar, Ramon.Space и Blue Origin давно рассматривают возможность развертывания вычислительных систем на орбите. В мае уже произошли два важных события, связанных с космическими дата-центрами. Во-первых, в начале месяца Эрик Шмидт (Eric Schmidt) купил Relativity Space, чтобы заняться запуском космических ЦОД, а несколько дней назад появилась информация, что китайская ADA Space вывела на орбиту первые 13 из 2,8 тыс. спутников для создания космического ИИ ЦОД.
22.05.2025 [23:03], Владимир Мироненко
Qualcomm готовит 80-ядерный серверный Arm-процессор SD1 для ИИ-платформQualcomm провела в рамках выставки Computex 2025 мероприятие, на котором изложила свои планы на ближайшее будущее. Хотя немногим ранее компания подтвердила намерение вернуться на рынок серверных процессоров в подписанном с ИИ-стартапом Humain меморандуме о взаимопонимании, на нынешнем брифинге руководство Qualcomm лишь вскользь затронуло эту тему, уделив ей буквально считанные секунды, пишет ресурс ComputerBase. Вместе с тем на слайде, продемонстрированном в конце мероприятия, было сказано, что продвижение Qualcomm на рынке ЦОД станет следующим шагом по диверсификации компанией своей деятельности. Судя по всему, главным направлением, для которого Qualcomm займётся разработкой серверных чипов, станут ИИ-платформы. ComputerBase отметил, что генеральный директор Qualcomm Криштиану Амон (Cristiano Amon) неоднократно подчёркивал, что в ЦОД уже сейчас используется интеллектуальная собственность компании и её разработки. Лежащая в их основе технология считается «крайне революционной», предлагая высокую производительность чипа при низком энергопотреблении. Напомним, что Nuvia, которую приобрела Qualcomm, планировала выпустить «лучший в мире серверный процессор» с Arm-архитектурой и ядром Phoenix собственной разработки. Из-за этой сделки между Arm и Qualcomm начался серьёзный конфликт. Softbank же, контролирующая Arm, хочет купить производителя серверных Arm-процессоров Ampere Computing. 
Источник изображения: Qualcomm Один из инсайдеров сообщил на платформе X о свежей публикации DigiTimes, согласно которой, Qualcomm «возвращается на рынок серверов на базе Arm-архитектуры», планируя выпустить 5-нм CPU под кодовым названием SD1. По данным издания, чип будет поддерживать память HBM и PCIe 5.0 и предназначен для интеграции со стоечными системами NVIDIA, закладывая основу для энергоэффективной экосистемы CPU+GPU. Новинка получит поддержку NVLink Fusion. Вместе с тем первая информация о процессорах SD1 появилась более года назад. Тогда говорилось, что процессор получит 80 ядер Oryon, работающих на частоте до 3,8 ГГц, 16 каналов DDR5-5600, 70 линий PCIe 5.0 с поддержкой CXL 1.1. Чип будет изготавливаться на TSMC по техпроцессу N5P и получит упаковку LGA9470 (98 × 95 мм). Возможно использование в двухсокетной конфигурации. Тогда же сообщалось, что Qualcomm сообщила своим партнёрам о готовящемся чипе на рубеже 2021-2022 гг., т.е. практически сразу после приобретения Nuvia.
16.05.2025 [08:38], Владимир Мироненко
Qualcomm возвращается на рынок серверных процессоровQualcomm Technologies возвращается на рынок серверных процессоров. Это подтверждает меморандум о взаимопонимании, подписанный компанией и ИИ-стартапом Humain, принадлежащим Суверенному фонду Саудовской Аравии, с целью «запуска ИИ ЦОД, предложения гибридного ИИ на периферии и в облаке, а также сервисов “от облака до периферии” в Королевстве Саудовская Аравия и за его пределами». Меморандум о взаимопонимании был подписан в ходе Саудовско-американского инвестиционного форума в Эр-Рияде. Ранее о партнёрстве с Humain объявили NVIDIA, AMD и AWS, а также Cisco. В документе закреплено обязательство Qualcomm «разработать и поставлять современные ИИ-решения и CPU для ЦОД». Также стороны планируют интегрировать семейство арабских больших языковых моделей Humain (ALLaM, совместно разработанных с SDAIA) с широкой экосистемой периферийных ИИ-устройств на базе процессоров Qualcomm, предоставляя возможности гибридного ИИ-инференса от облака до периферии для широкого спектра устройств. В дальнейшем компании будут сотрудничать с Министерством связи и информационных технологий Саудовской Аравии (MCIT) с целью создания в Саудовской Аравии Центра проектирования полупроводниковых технологий мирового класса. 
Источник изображения: Qualcomm Согласно документу, Qualcomm и Humain намерены «разработать и построить передовые ИИ ЦОД в Саудовской Аравии, предназначенные для предоставления высокоэффективных масштабируемых гибридных решений ИИ-инференса от облака до периферии (cloud-to-edge) для местных и международных клиентов на основе решений Qualcomm». Также партнёры планируют ускорить использование инфраструктуры за счет применения процессоров Snapdragon и Dragonwing. Ранее Qualcomm и Cerebras договорились об использовании ускорителей Cloud AI для инференса, в том числе в интересах заказчиков из Саудовской Аравии. Qualcomm и Humain заявили, что их ЦОД и экосистема предназначены для предоставления как государственным, так и корпоративным организациям доступа к высокопроизводительной и энергоэффективной облачной ИИ-инфраструктуре на основе CPU, а также cloud-to-edge сервисам. Согласно пресс-релизу, эти предложения позволят развёртывать ИИ-решения, которые могут делать прогнозы и принимать решения в реальном времени, а также значительно повышать доступность и ценность передовых приложений с поддержкой ИИ. 
Источник изображения: Qualcomm Слухи о планируемом Qualcomm возврате к разработке серверных процессоров курсируют длительное время. В 2017 году компания выпустила 10-нм 48-ядерные чипы Centriq 2400, но затем отменила проект в 2019 году. Позже компания приобрела стартап Nuvia, который разрабатывал серверные Arm-процессоры. Qualcomm использовала наработки Nuvia в процессорах Snapdragon для компьютеров на базе Windows. Слухи разгорелись с новой силой, когда в начале года Qualcomm наняла Сайлеша Коттапалли (Sailesh Kottapalli) в качестве старшего вице-президента. Ранее он был главным архитектором серверных процессоров Xeon. Теперь Qualcomm не скрывает своих намерений. Она разместила на сайте вакансии, связанные с разработкой серверных процессоров, включая «архитектора управления питанием сервера», «архитектора ПО для управления питанием и температурой серверных SoC» и «архитектора серверной платформы». Причём, как отметил ресурс Computer Base, каждая вакансия сопровождается примечанием: «Команда Qualcomm Data Center разрабатывает высокопроизводительное и энергоэффективное серверное решение для ЦОД». На форуме JPMorgan финансовый директор и главный операционный директор Акаш Палхивала (Akash Palkhiwala) заявил, что у компании есть «ведущий в мире процессор» и NPU. «Изменения, которые происходят в ЦОД, очевидно, связаны с переходом к инференсу, который становится всё более важным, как и низкое энергопотребления, и именно здесь Qualcomm на высоте», — отметил Палхивала, добавив, что компания использует имеющиеся технологии в будущих серверных процессорах.
16.04.2025 [12:12], Сергей Карасёв
Одноплатный компьютер Radxa Dragon Q6A оснащён чипом Qualcomm QCS6490 с ИИ-ускорителемКомпания Radxa, по сообщению ресурса CNX-Software, готовит к выпуску одноплатный компьютер Dragon Q6A, предназначенный для построения решений с ИИ-функциями. Это могут быть робототехнические устройства, системы промышленной автоматизации, оборудование для умного города и пр. Основой новинки служит чип Qualcomm QCS6490. Он объединяет восемь вычислительных ядер Kryo 670 в конфигурации 1 × Gold Plus (Cortex-A78) с частотой 2,7 ГГц, 3 × Gold (Cortex-A78) с частотой 2,4 ГГц и 4 × Silver (Cortex-A55) с частотой до 1,9 ГГц. Предусмотрены графический ускоритель Adreno 643L (812 МГц) с поддержкой Open GL ES 3.2, Open CL 2.0, Vulkan 1.x и DX FL 12, а также VPU-блок Adreno 633 с возможностью декодирования видео 4K60 H.264/H.265/VP9 и кодирования материалов 4K30 H.264/H.265. Интегрированный движок Qualcomm AI Engine шестого поколения обеспечивает ИИ-производительность до 12 TOPS. 
Источник изображения: CNX-Software Одноплатный компьютер Radxa Dragon Q6A может нести на борту до 16 Гбайт оперативной памяти LPDDR5. Есть слот microSD, разъём M.2 M-Key для SSD, а также коннектор для флеш-модуля eMMC/UFS. В оснащение входят адаптеры Wi-Fi 6 и Bluetooth 5.4, сетевой контроллер 1GbE с опциональной поддержкой PoE. Габариты составляют 85 × 65 × 20 мм. Решение располагает интерфейсами HDMI и MIPI DSI (четыре линии), тремя коннекторами MIPI CSI (2 × 2 линии и 1 × 4 линии), аудиогнездом на 3,5 мм, разъёмом RJ45 для сетевого кабеля, тремя портами USB 2.0 Type-A, одним портом USB 3.1 Type-A OTG и одним портом USB Type-C PD. Имеется также 40-контактная колодка, совместимая с Raspberry Pi. Говорится о совместимости с Yocto Linux, Ubuntu и Android.
02.04.2025 [18:06], Руслан Авдеев
Arm собиралась купить Alphawave ради передовой технологии SerDes для выпуска ИИ-чипов — теперь её хочет купить QualcommПринадлежащий SoftBank разработчик архитектурных решений для полупроводников — компания Arm недавно собиралась приобрести британскую Alphawave для получения критически важной технологии, необходимой для создания ИИ-ускорителей. Об этом сообщили Reuters три независимых источника, «знакомых с вопросом». Теперь над покупкой Alphawave раздумывает Qualcomm, уточняет SiliconAngle. Alphawave владеет интеллектуальной собственностью, связанной с полупроводниковыми технологиями, и даже обсуждала с инвестиционными банкирами возможность продажи — после того как Arm и другие потенциальные покупатели выразили интерес к приобретению компании. Однако, по данным двух источников, в итоге было решено отказаться от сделки. На фоне новостей акции Alphawave взлетели на 21 % — рекордный рост с сентября 2021 года. По данным на конец торгов в понедельник капитализация компании составила £707 млн ($914 млн), а цена акции — 93,5 пенса. Arm рассчитывала получить от Alphawave технологию создания SerDes-блоков, которые определяют скорость передачи данных на чип и с него. Эта технология критически важна для ИИ-систем, таких как ChatGPT, где тысячи чипов должны работать согласованно. Так, SerDes является ключевым преимуществом Broadcom, помогая компании привлекать клиентов вроде Google и OpenAI. 
Источник изображения: Arm Arm с головным офисом в Великобритании на 90 % принадлежит японской SoftBank Group. Компания сама не разрабатывает чипы, а продаёт «основные строительные блоки» для их создания, а также прочую интеллектуальную собственность. Основные доходы Arm получает за счёт лицензионных отчислений от других бизнесов, а также роялти за каждый проданный чип, использующий её технологии. Недавно сообщалось, что она рассчитывает, что её архитектура займёт 50 % на рынке чипов для ЦОД уже к концу 2025 года. У AWS, Google Cloud и Microsoft Azure уже есть собственные серверные Arm-процесоры: Graviton, Axion и Cobalt 100. Конечно, компания стремилась повысить прибыль и выручку, в том числе не исключалась самостоятельная разработка чипов и прямая конкуренция с собственными клиентами. Планы покупки Alphawave частично раскрылись в декабре 2024 года в ходе судебной тяжбы с Qualcomm. Однако руководство Arm заявило, что речь шла об обычном обмене идеями между менеджерами. Тем не менее, в ходе того же процесса в феврале стало известно, что компания искала специалистов, способных вывести на рынок чип собственной разработки. Теперь же выяснилось, что Qualcomm сама не прочь приобрести Alphawave — компания должна сделать предложение до 29 апреля или полностью отказаться от сделки. У Arm нет столь передовой технологии SerDes, какой располагает Alphawave. Хотя подробностей немного, известно, что SerDes-блоки служат основой многомиллиардных полупроводниковых бизнесов Broadcom и Marvell Technology. По прогнозам Bernstein, соответствующий рынок к 2028 году вырастет до $60 млрд. NVIDIA также разработала собственный вариант SerDes и уже заявила о намерении продавать лицензии на него другим компаниям. Создание передовых решений в этой сфере критически важно для выпуска ИИ-чипов, способных выгодно отличаться от продукции конкурентов. При этом, по мнению экспертов, разработка SerDes с нуля требует специфических навыков и около двух лет. Покупка Alphawave смогла бы сэкономить Arm значительное количество времени и ресурсов.
14.01.2025 [12:23], Владимир Мироненко
Qualcomm наняла главного архитектора Intel Xeon для разработки серверных Arm-процессоровРесурсу CRN стало известно, что компания Qualcomm наняла Сайлеша Коттапалли (Sailesh Kottapalli) в качестве старшего вице-президента. Ветеран Intel с 28-летним стажем, являвшийся главным архитектором серверных процессоров Xeon, сообщил в понедельник в соцсети в LinkedIn, что он присоединился к Qualcomm после ухода из Intel, поскольку разработчик чипов формирует команду для выхода на рынок CPU для ЦОД. «Возможность внедрять инновации и расти, помогая при этом расширять горизонты, была для меня чрезвычайно привлекательной — возможность, которая выпадает раз в карьере и которую я не мог упустить», — написал Коттапалли в LinkedIn. Это не первая попытка Qualcomm выйти на рынок серверных процессоров. В 2017 году компания выпустила 10-нм 48-ядерные чипы Centriq 2400, но вскоре забросила развитие этого направления. 
Источник изображения: Intel Пост Коттапалли в LinkedIn, ранее занимавшего должность ведущего инженера по чипам Itanium и Xeon в Intel, прежде чем стать главным архитектором Xeon в компании, появился чуть более чем через месяц после того, как стало известно, что у Qualcomm есть подразделение Qualcomm Data Center, которое занимается созданием «высокопроизводительного, энергоэффективного серверного решения». Разработчик чипов раскрыл эту информацию в опубликованной в декабре вакансии архитектора безопасности серверной системы на кристалле (SoC). В ней говорилось, что команда Qualcomm Data Center сосредоточена на создании «эталонных платформ» на основе Snapdragon. Подходящий соискатель возглавит разработку «системной архитектуры для конфиденциальных вычислений в продуктах ЦОД». Конфиденциальные вычисления, позволяющие изолировать данные во время их обработки, стали стандартной функцией в Intel Xeon и AMD EPYC, отметил ресурс CRN. 
Источник изображения: Qualcomm Qualcomm разрабатывает серверные ИИ-ускорители Qualcomm Cloud AI, которые она поставляла таким компаниям, как AWS, HPE и Lenovo. Кроме того, компания сотрудничает с Cerebras, ещё одним разработчиком ИИ-ускорителей. Недавно стало известно о планах компании выпустить ускорители Cloud AI 80 (AIC080) для ИИ-задач. В 2021 году Qualcomm приобрела за $1,4 млрд стартап NUVIA, который изначально занимался серверного Arm-процессора Phoenix. Qualcomm утверждала, что будет использовать технологии NUVIA в ноутбуках, смартфонах, ADAS, AR/VR и т.п., но в прошлом году объявила, что также планирует продолжить разработку серверных процессоров. Из-за поглощения NUVIA между Arm и Qualcomm уже несколько лет идут судебные разбирательства.
06.01.2025 [19:00], Владимир Мироненко
Qualcomm представила энергоэффективные ИИ-микросерверы AI On-Prem Appliance SolutionQualcomm Technologies анонсировала Qualcomm AI On-Prem Appliance Solution — компактное энергоэффективное аппаратное решение для локальной обработки рабочих нагрузок инференса и компьютерного зрения. Также компания представила готовый к использованию набор ИИ-приложений, библиотек, моделей и агентов Qualcomm Cloud AI Inference Suite, способный работать и на периферии, в облаках. Согласно пресс-релизу, сочетание новых продуктов позволяет малым и средним предприятиям и промышленным организациям запускать кастомные и готовые приложения ИИ на своих объектах, включая рабочие нагрузки генеративного ИИ. Qualcomm отметила, что инференс на собственных мощностях позволит значительно снизить эксплуатационные расходы и общую совокупную стоимость владения (TCO) по сравнению с арендой сторонней ИИ-инфраструктуры. 
Источник изображений: Qualcomm С помощью AI On-Prem Appliance Solution совместно с AI Inference Suite клиенты смогут использовать генеративный ИИ на базе собственных данных, точно настроенные модели и технологическую инфраструктуру для автоматизации процессов и приложений практически в любой среде, например, в розничных магазинах, ресторанах, торговых точках, дилерских центрах, больницах, на заводах и в цехах, где рабочие процессы хорошо отлажены, повторяемы и готовы к автоматизации.  «Решения AI On-Prem Appliance Solution и Cloud AI Inference Suite меняют TCO ИИ, позволяя обрабатывать рабочие нагрузки генеративного ИИ не в облаке, а локально», — заявила компания, подчеркнув, что AI On-Prem Appliance Solution позволяет значительно снизить эксплуатационные расходы на приложения ИИ для корпоративных и промышленных нужд в самых разных областях. Кроме того, локальное развёртывание обеспечивает защиту от утечек чувствительных данных.  Платформа Qualcomm AI On-Prem Appliance Solution работает на базе семейства ускорителей Qualcomm Cloud AI. Сообщается, что новинка поддерживает широкий спектр возможностей, в том числе:
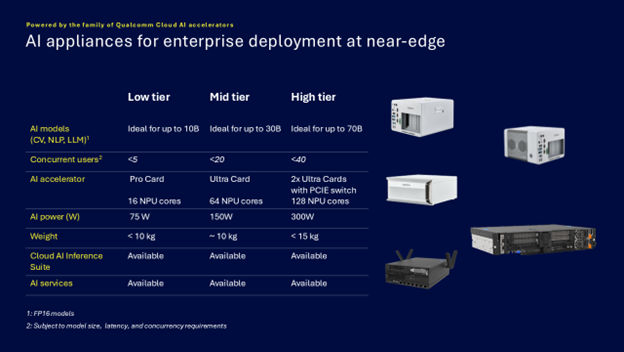 В свою очередь Qualcomm Cloud AI Inference Suite предлагает полный набор инструментов и библиотек для разработки или переноса приложений генеративного ИИ на AI On-Prem Appliance Solution или другие платформы на базе ускорителей Qualcomm Cloud AI. Набор предлагая множество API для управления пользователями и администрирования, для работы чатов, для генерации изображений, аудио и видео. Заявлена совместимость с API OpenAI и поддержка RAG. Кроме того, доступна интеграция с популярными моделями генеративного ИИ и фреймворками. Возможно развёртывание с использованием Kubernetes и bare metal. |
|

