Материалы по тегу: hbm
|
05.11.2024 [11:11], Сергей Карасёв
SK hynix представила первые в отрасли 16-ярусные чипы HBM3E ёмкостью 48 ГбайтКомпания SK hynix на мероприятии SK AI Summit в Сеуле (Южная Корея) сообщила о разработке первых в отрасли 16-ярусных чипов памяти HBM3E, ёмкость которых составляет 48 Гбайт. Клиенты получат образцы таких изделий в начале 2025 года. Генеральный директор SK hynix Квак Но-Джунг (Kwak Noh-Jung) сообщил, что компания намерена трансформироваться в поставщика ИИ-памяти «полного стека». Ассортимент продукции будет охватывать изделия всех типов — от DRAM до NAND. При этом планируется налаживание тесного сотрудничества с заинтересованными сторонами. 
Источник изображения: techpowerup.com При производстве 16-Hi HBM3E компания будет применять передовую технологию Advanced MR-MUF, которая ранее использовалась при изготовлении 12-слойных продуктов. Память рассчитана на высокопроизводительные ИИ-ускорители. Утверждается, что 16-ярусные изделия по сравнению с 12-слойными аналогами обеспечивают прирост быстродействия на 18 % при обучении ИИ-моделей и на 32 % при инференсе. SK hynix намерена предложить заказчикам кастомизируемые решения HBM с оптимизированной производительностью, которые будут соответствовать различным требованиям к ёмкости, пропускной способности и функциональности. Плюс к этому SK hynix планирует интегрировать логику непосредственно в кристаллы HBM4. Ранее говорилось, что компания рассчитывает начать поставки памяти HBM4 заказчикам во II половине 2025 года. В числе других готовящихся продуктов SK hynix упоминает модули LPCAMM2 (Compression Attached Memory Module 2) для ПК и ЦОД, решения LPDDR5 и LPDDR6 с технологией производства 1c-класса, SSD с интерфейсом PCIe 6.0, накопители eSSD и UFS 5.0 большой вместимости на основе чипов флеш-памяти QLC NAND.
23.10.2024 [16:57], Владимир Мироненко
NVIDIA переименовала будущие ИИ-ускорители Blackwell Ultra в B300Согласно данным аналитической компании TrendForce, NVIDIA решила переименовать продукты семейства Blackwell Ultra в серию B300. В связи с этим ускоритель B200 Ultra стал B300, а GB200 Ultra теперь называется GB300. Кроме того, B200A Ultra и GB200A Ultra получили имена B300A и GB300A соответственно. Серия ускорителей B300, как ожидается, выйдет в I–II квартале 2025 года, а поставки (G)B200 начнутся не позднее I квартал 2025 года. TrendForce отметила, что NVIDIA совершенствует сегментацию чипов Blackwell, чтобы лучше соответствовать требованиям по стоимости и производительности со стороны облачных провайдеров (CSP) и OEM-производителей серверов и смягчить требования к цепочкам поставок. Так, модель B300A нацелена на OEM-клиентов, её массовое производство планируется начать во II квартале 2025 года после пика поставок H200. Изначально NVIDIA хотела предложить данному сегменту упрощённый вариант B200A, но, судя по всему, спрос на него оказался более слабом, чем ожидалось. Вместе с тем переход с GB200A на GB300A для стоечных решений может привести к увеличению первоначальных затрат для корпоративных клиентов, что также может отразиться на спросе. 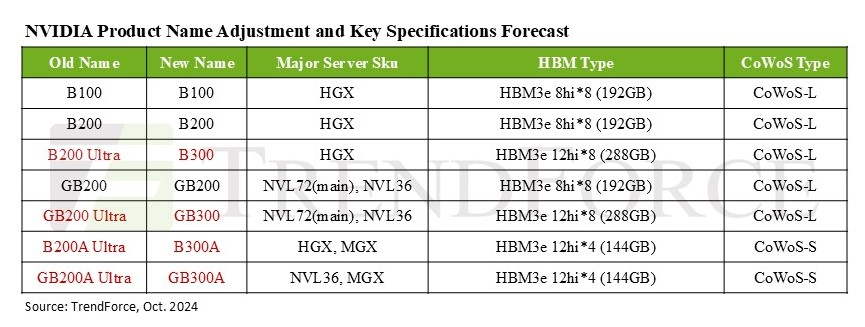
Источник изображения: TrendForce Сейчас компания вкладывает значительные средства в улучшение стоечных решений NVL, помогая поставщикам серверных систем с оптимизацией производительности и жидкостным охлаждением для систем NVL72, а AWS и Meta✴ настоятельно призывают перейти с NVL36 на NVL72. TrendForce также ожидает, что предложение топовых ускорителей NVIDIA будет расширяться, а их общая доля в поставках, как ожидается, достигнет около 50 % в 2024 году, то есть вырастет на 20 п.п. год к году. Ожидается, что выпуск ускорителей Blackwell увеличит этот показатель до 65 % в 2025 году. Аналитики также отметили роль NVIDIA в стимулировании спроса на технологию упаковки CoWoS. Благодаря Blackwell спрос на данный тип упаковки вырастет более чем на 10 п.п. в годовом исчислении. NVIDIA, скорее всего, сосредоточится на поставках чипов B300 и GB300 крупным североамериканским гиперскейлерам — оба варианта используют технологию CoWoS-L. Компания активно наращивает закупки HBM — согласно прогнозам, в 2025 году на NVIDIA придётся более 70 % мирового рынка HBM (рост на 10 п.п. год к году). TrendForce также отмечает, что все чипы серии B300 будут оснащены памятью HBM3e 12Hi, производство которой начнётся не позднее I квартал 2025 года. Но поскольку это будут первые массовые продукты с таким типом памяти, поставщикам, как ожидается, потребуется не менее двух кварталов для отработки процессов и стабилизации объёмов производства.
07.09.2024 [11:41], Сергей Карасёв
Micron представила 12-ярусные чипы HBM3E: 36 Гбайт и 1,2 Тбайт/сКомпания Micron Technology сообщила о начале пробных поставок 12-ярусных (12-Hi) чипов памяти HBM3E, предназначенных для высокопроизводительных ИИ-ускорителей. Изделия проходят квалификацию в экосистеме отраслевых партнёров, после чего начнутся их массовые отгрузки. Новые чипы имеют ёмкость 36 Гбайт, что на 50 % больше по сравнению с существующими 8-слойными вариантами HBM3E (24 Гбайт). При этом, как утверждает Micron, достигается значительно более низкое энергопотребление. Благодаря применению 12-ярусных чипов HBM3E крупные модели ИИ, такие как Llama 2 с 70 млрд параметров, могут запускаться на одном ускорителе. 
Источник изображений: Micron Заявленная пропускная способность превышает 9,2 Гбит/с на контакт, что в сумме обеспечивает свыше 1,2 Тбайт/с. Появление новой памяти поможет гиперскейлерам и крупным операторам дата-центров масштабировать растущие рабочие нагрузки ИИ в соответствии с запросами клиентов. Реализована полностью программируемая функция MBIST (Memory Built-In Self Test), которая способна работать на скоростях, соответствующих системному трафику. Это повышает эффективность тестирования, что позволяет сократить время вывода продукции на рынок и повысить надёжность оборудования. При изготовлении памяти HBM3E компания Micron применяет современные методики упаковки чипов, включая усовершенствованную технологию сквозных соединений TSV (Through-Silicon Via).  Нужно отметить, что о разработке 12-слойных чипов HBM3E ёмкостью 36 Гбайт в начале 2024 года объявила компания Samsung. Эти решения обеспечивают пропускную способность до 1,28 Тбайт/с. По данному показателю, как утверждается, чипы более чем на 50 % превосходят доступные на рынке 8-слойные стеки HBM3. Наконец, старт массового производства 12-Hi модулей HBM3E от SK hynix с ПСП 1,15 Тбайт/с намечен на октябрь.
07.08.2024 [12:28], Руслан Авдеев
Китайские компании набивают склады HBM-памятью Samsung в ожидании новых американских санкцийКитайские техногиганты, включая игроков вроде Huawei и Baidu, а также стартапы активно запасают HBM-чипы Samsung Electronics. По данным агентства Reuters, это делается в ожидании новых ограничений со стороны США на поставки в КНР чипов, использующих американские технологии. Как сообщают источники издания, компании наращивают закупки соответствующих чипов ещё с начала 2024 года, на долю китайских покупателей придётся порядка 30 % выручки Samsung от продаж HBM в I половине 2024 года. Экстренные меры наглядно демонстрируют нежелание Китая отказываться от технологических амбиций даже на фоне торговых войн с США и их союзниками. Ранее Reuters сообщало, что американские власти намерены представить новые санкционные ограничения ещё до конца текущего месяца. Они призваны ограничить возможности китайской полупроводниковой индустрии. Источники сообщают, что в документах будут заданы и параметры для ограничений на поставки HBM-памяти. Министерство торговли США отказалось от комментариев, но на прошлой неделе заявило, что постоянно обновляет правила экспортного контроля для защиты национальной безопасности США и технологической экосистемы страны. 
Источник изображения: Samsung HBM-чипы считаются критически важными компонентами при разработке передовых ИИ-ускорителей. Возможности выпуска HBM пока доступны только трём производителям: южнокорейским SK Hynix и Samsung, а также американской Micron Technology. По данным информаторов Reuters, в Китае особым спросом пользуется вариант HBM2E, который отстаёт от передового HBM3E. Глобальный бум ИИ-технологий привёл к дефициту наиболее передовых решений. По мнению экспертов, поскольку собственные китайские технологии в этой области ещё не слишком зрелые, спрос китайских компаний и организаций на сторонние HBM-чипы чрезвычайно велик, а Samsung оставалась единственной опцией, поскольку производственные мощности других производителей уже забронированы американскими ИИ-компаниями. Хотя объёмы и стоимость запасённых Китаем HBM-чипов оценить нелегко, известно, что они используются компаниями самого разного профиля, а Huawei, например, применяет Samsung HBM2E для выпуска передовых ИИ-ускорителей Ascend. Впрочем, Huawei и CXMT уже сфокусировали внимание на разработке чипов HBM2 — они на три поколения отстают от HBM3E. Тем не менее, американские санкции могут помешать новым китайским проектам. Более того, от них может больше пострадать Samsung, чем её ключевые соперники, которые меньше связаны с китайским рынком. Micron не продаёт HBM-чипы в Китай с прошлого года, а SK Hynix, чьими ключевыми клиентами являются компании вроде NVIDIA, специализируются на более современных решениях.
01.08.2024 [00:53], Игорь Осколков
Ampere анонсировала 512-ядерные Arm-процессоры AmpereOne Aurora с HBM-памятью и встроенным ИИ-ускорителемAmpere Computing анонсировала процессоры AmpereOne Aurora, которые получат до 512 однопоточных Arm-ядер собственной разработки, набортную HBM-память и фирменные IP-блоки для обучения и инференса ИИ-моделей. Речь, судя по всему, идёт о чиплетной компоновке, поскольку компания говорит не только о фирменном меш-интерконнекте для вычислительных блоков, но и об объединении разных кристаллов в рамках SoC. Предполагается, что Aurora появятся где-то на рубеже 2025–2026 гг. 
Источник изображений: Ampere Computing Что интересно, для Aurora обещана возможность использования воздушного охлаждения. Для гиперскейлеров, на которых Ampere по-прежнему ориентируется, это важный пункт. Впрочем, больше никаких подробностей о новинках компания не сообщила, отметив лишь, что встроенный ускоритель сгодится для RAG и векторных баз данных. Ну и сообщив, что по количеству ядер и производительности её ещё не выпущенный чип обгоняет все остальные чипы: 144-ядерные Intel Xeon 6 (Sierra Forest), которые вскоре станут 288-ядерными (при этом все варианты без Hyper-Threading), и 128-ядерные AMD EPYC Bergamo (256 потоков), которым на смену придут 192-ядерные EPYC Turin Dense (384 потока). 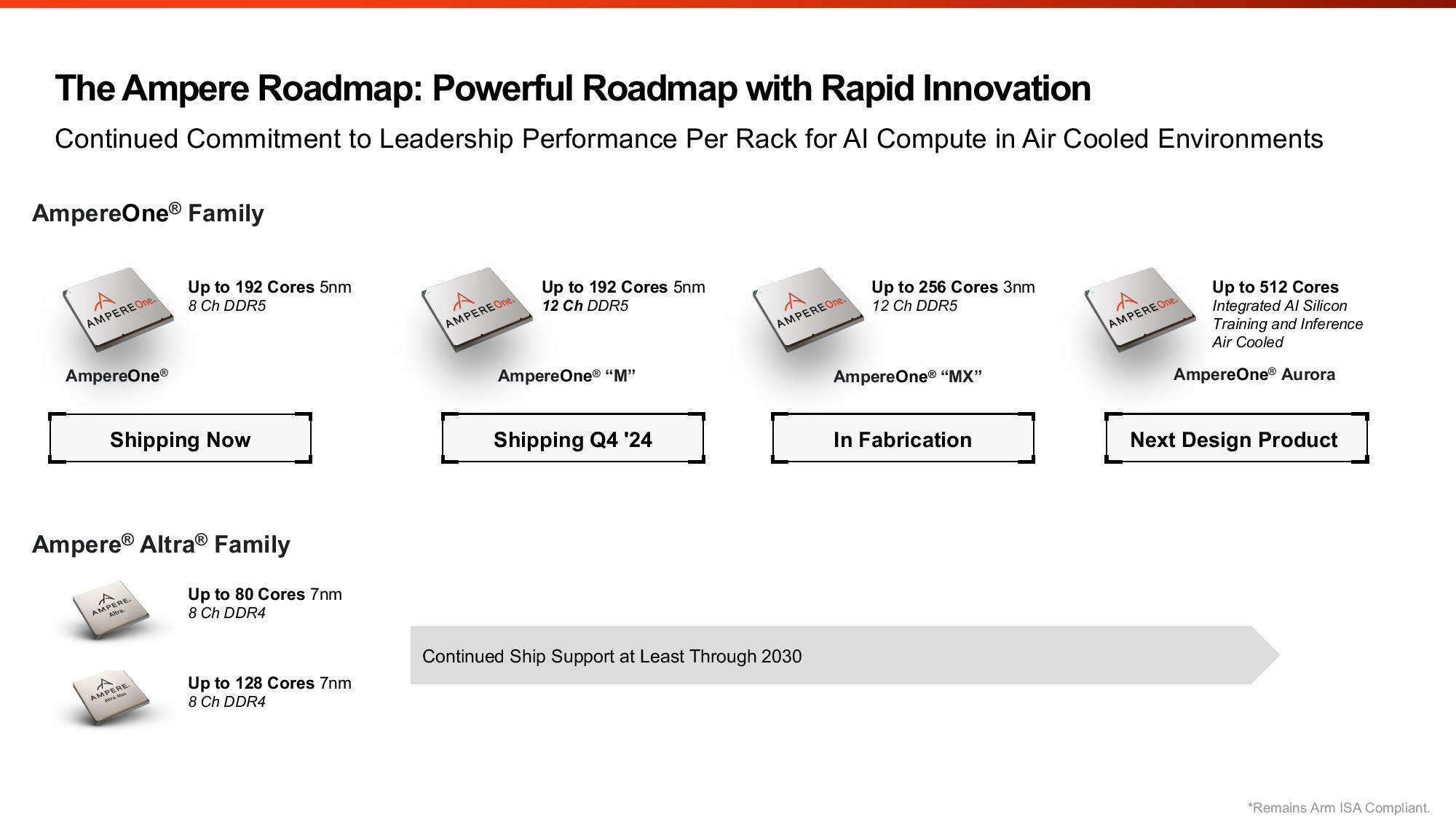 До Aurora компания выпустит ещё две серии процессоров AmpereOne: M в конце 2024 года и MX в 2025 году. 5-нм AmpereOne M получат до 192 ядер и 12-канальный контроллер памяти DDR5. 3-нм AmpereOne MX получат такой же контроллер и до 256 ядер. Заодно компания опубликовала прайс-лист актуальных CPU. В нём нет изначально заявлявшихся 136- и 172-ядерных моделей. Кроме того, остальные процессоры несколько подорожали в сравнении с прошлым поколением Altra Max, но по цене всё ещё привлекательнее решений AMD и Intel — $5555 за 192 ядра. Следует учесть, что в таблице приведён не привычный показатель TDP, а усреднённое энергопотребление чипа, из-за чего сравнивать процессоры Ampere с другими чипами затруднительно. 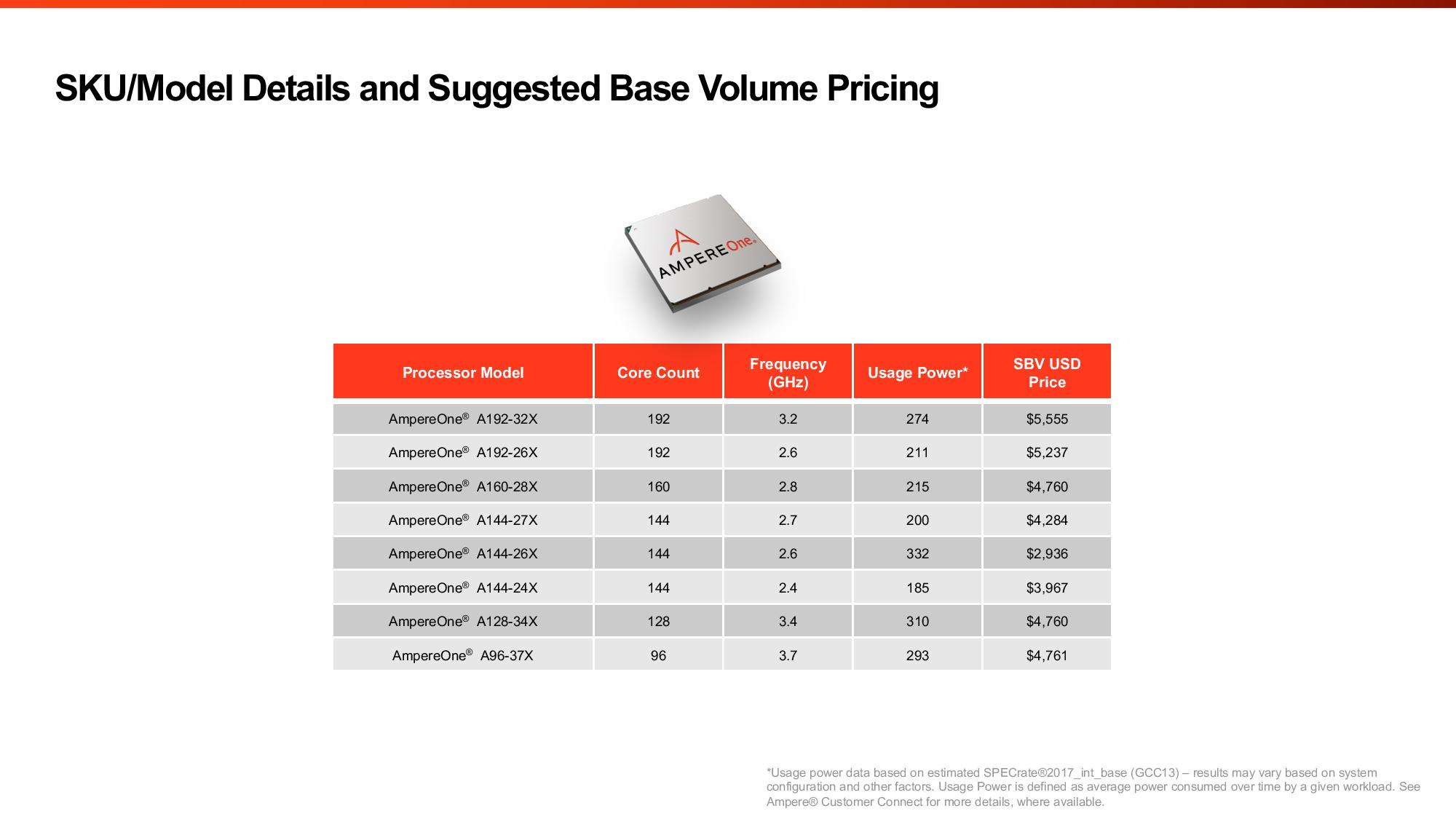 Насколько Aurora станет популярным у гиперскейлеров и других заказчиков, покажет время. У Ampere есть якорный заказчик в лице Oracle, но другие IT-гиганты уже сами разрабатывают собственные Arm-процессоры. AWS в Graviton4 довела количество ядер до 96, Microsoft анонсировала 128-ядерный Cobalt 100, Alibaba массово внедряет 128-ядерные Yitian 710, а Google готовит Axion. Fujitsu к 2027 году подготовит 144-ядерные MONAKA, которые тоже получат поддержку ИИ-нагрузок, но упор в них сделан не на HBM, а на SRAM. Собственно говоря, HBM есть только у HPC-процессоров: Fujitsu A64FX, SiPearl Rhea1 и C-DAC AUM. Даже NVIDIA Grace, которые в основном ассистируют ускорителям, обходятся LPDDR5x.
18.07.2024 [22:35], Владимир Мироненко
TrendForce прогнозирует высокий спрос на ИИ-серверы до конца 2025 годаСогласно прогнозу аналитической компании TrendForce, высокий спрос на ИИ-серверы со стороны крупных провайдеров облачных услуг и других клиентов сохранится до конца 2024 года. Постепенное расширение производства компаниями TSMC, SK hynix, Samsung и Micron позволило значительно уменьшить дефицит во II квартале и, как следствие, время выполнения заказа на NVIDIA H100 сократилось с прежних 40–50 недель до менее чем 16. По оценкам TrendForce, поставки ИИ-серверов во II квартале выросли почти на 20 % по сравнению с предыдущим кварталом. Аналитики в своём свежем отчёте пересмотрели прогноз поставок на весь год до 1,67 млн ИИ-серверов (рост на 41,5 % в годовом исчислении). Объём рынка ИИ-серверов в 2024 году в денежном выражении, как ожидают в TrendForce, превысит $187 млрд при темпах роста 69 %, что составит 65 % от рыночной стоимости всех поставленных серверов. В отчёте также отмечено, что в этом году крупные провайдеры облачных услуг продолжают концентрироваться на закупке ИИ-серверов, что негативно отражается на темпах роста поставок серверов общего назначения. У последних ежегодные темпы роста поставок составят всего 1,9 %. Как ожидают в TrendForce, доля ИИ-серверов в штучном выражении в общем объёме поставок достигнет 12,2 %, что больше на 3,4 п.п. по сравнению с 2023 годом.  Аналитики отметили, что североамериканские гиперскейлеры постоянно расширяют выпуск собственных ASIC, впрочем, как и китайские компании, такие как Alibaba, Baidu и Huawei. Ожидается, что благодаря этому доля ASIC-серверов на рынке ИИ-серверов вырастет до 26 % в 2024 году, в то время как у ИИ-серверов с ускорителями доля будет около 71 %. При этом NVIDIA сохранит абсолютное лидерство с около 90 % рынка ИИ-серверов с ускорителями, в то время как доля AMD составит лишь около 8 %. Если же учитывать вообще все чипы, используемые в ИИ-серверах (GPU, ASIC, FPGA), то доля рынка NVIDIA в этом году составит около 64 %, ожидают в TrendForce. По оценкам аналитической фирмы Tech Insights, NVIDIA в 2023 году отгрузила приблизительно 3,76 млн серверных ускорителей на базе GPU, захватив 98 % рынка GPU для ЦОД. TrendForce считает, что спрос на передовые ИИ-серверы сохранится и в 2025 году, учитывая тот факт, что NVIDIA Blackwell (включая GB200, B100/B200) заменит Hopper. Это также будет стимулировать спрос на CoWoS (2.5D-упаковка от TSMC) и память HBM. Производственная мощность TSMC в области CoWoS, по оценкам TrendForce, достигнет 550–600 тыс. единиц к концу 2025 года, при этом темпы роста достигнут 80 %. 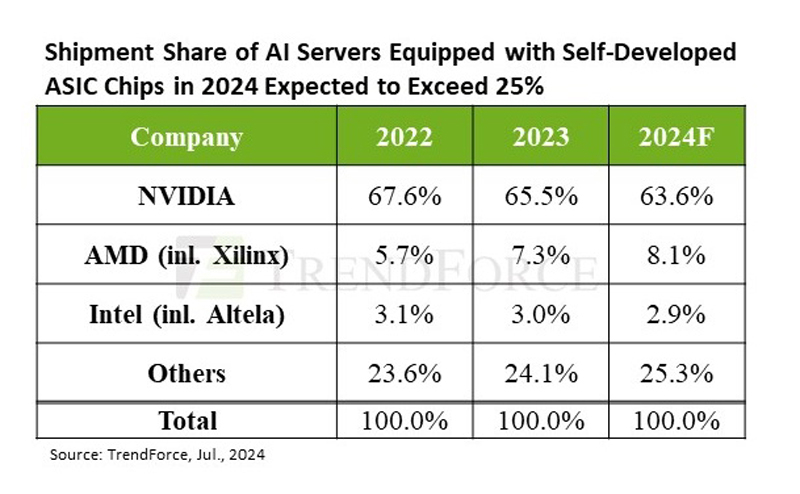
Источник изображения: TrendForce Тем не менее, ускоритель H100 получит в 2024 году наибольшее распространение. К 2025 году такие ускорители, как Blackwell Ultra от NVIDIA или MI350 от AMD, будут оснащены HBM3e ёмкостью до 288 Гбайт, что утроит количество компонентов памяти. Ожидается, что общее предложение HBM удвоится к 2025 году на фоне высокого спроса на ИИ-серверы. При этом не все уверены в светлом будущем ИИ. Так, венчурный фонд Sequoia Capital и аналитики Goldman Sachs указывают на сверхвысокие расходы на ИИ-оборудование и вместе с тем отсутсвие реальной финансовой отдачи от вложений в ИИ-решения. С другой стороны, венчурный фонд Andreessen Horowitz (a16z) уверен, что ИИ не станет очередным финансовым пузырём и сам закупает ИИ-ускорители, чтобы привлечь стартапы. А некоторые ИИ-стартапы сами приходят к крупным игрокам, поскольку не способны окупить затраты на оборудование.
16.05.2024 [01:05], Игорь Осколков
И для ИИ, и для HPC: первые европейские серверные Arm-процессоры SiPearl Rhea1 получат HBM-памятьКомпания SiPearl уточнила спецификации разрабатываемых ею серверных Arm-процессоров Rhea1, которые будут использоваться, в частности, в составе первого европейского экзафлопсного суперкомпьютера JUPITER, хотя основными чипами в этой системе будут всё же гибридные ускорители NVIDIA GH200. Заодно SiPearl снова сдвинула сроки выхода Rhea1 — изначально первые образцы планировалось представить ещё в 2022 году, а теперь компания говорит уже о 2025-м. При этом существенно дизайн процессоров не поменялся. Они получат 80 ядер Arm Neoverse V1 (Zeus), представленных ещё весной 2020 года. Каждому ядру полагается два SIMD-блока SVE-256, которые поддерживают, в частности, работу с BF16. Объём LLC составляет 160 Мбайт. В качестве внутренней шины используется Neoverse CMN-700. Для связи с внешним миром имеются 104 линии PCIe 5.0: шесть x16 + две x4. О поддержке многочиповых конфигураций прямо ничего не говорится. 
Источник изображения: SiPearl Очень похоже на то, что SiPearl от референсов Arm особо и не отдалялась, поскольку Rhea1 хоть и получит четыре стека памяти HBM, но это будет HBM2e от Samsung. При этом для DDR5 отведено всего четыре канала с поддержкой 2DPC, а сам процессор ожидаемо может быть поделён на четыре NUMA-домена. И в такой конфигурации к общей эффективности работы с памятью могут быть вопросы. Именно наличие HBM позволяет говорить SiPearl о возможности обслуживать и HPC-, и ИИ-нагрузки (инференс). 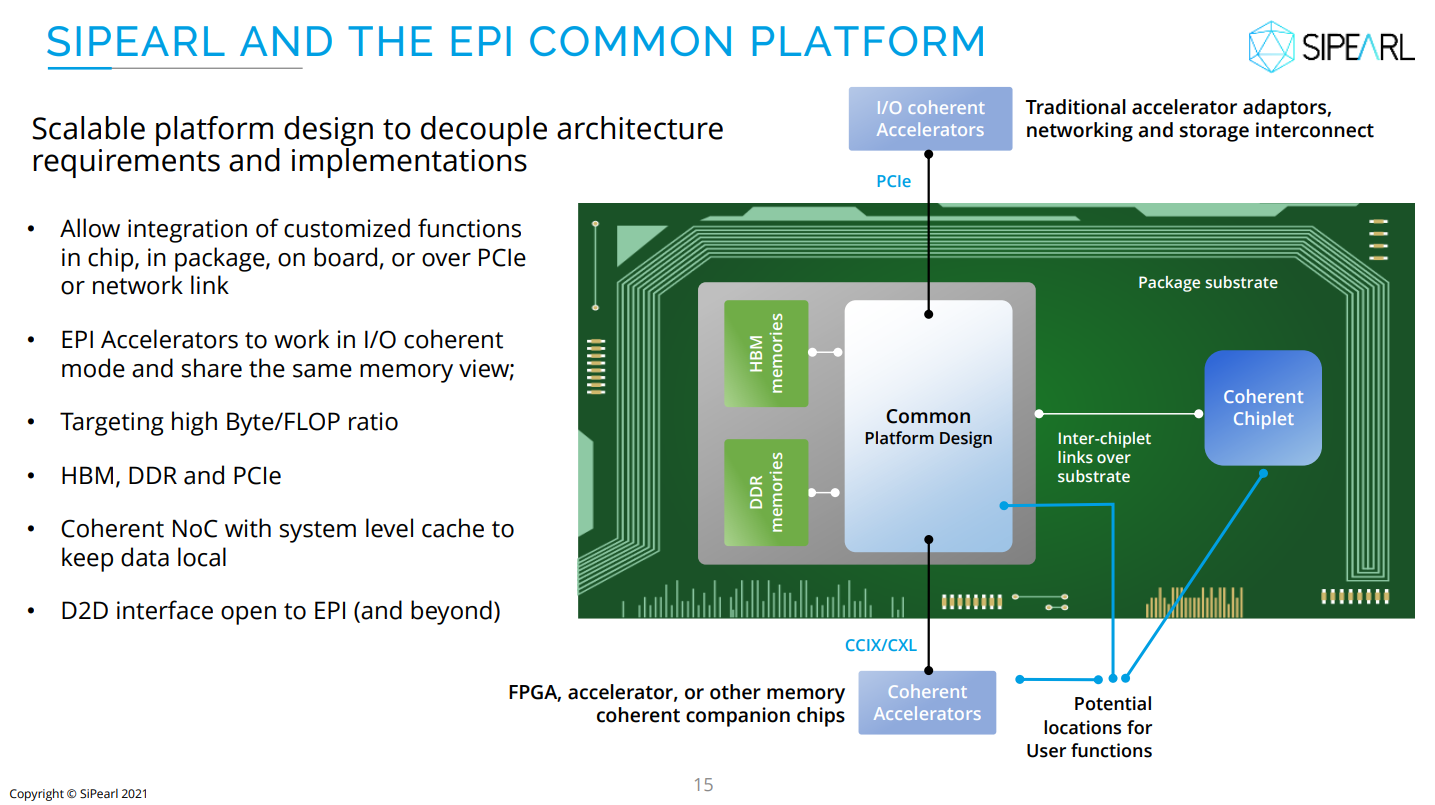
Источник изображения: SiPearl На примере Intel Xeon Max (Sapphire Rapids c 64 Гбайт HBM2e) видно, что наличие сверхбыстрой памяти на борту даёт прирост производительности в означенных задачах, хотя и не всегда. Однако это другая архитектура, другой набор инструкций (AMX), другая же подсистема памяти и вообще пока что единичный случай. С Fujitsu A64FX сравнения тоже не выйдет — это кастомный, дорогой и сложный процессор, который, впрочем, доказал эффективность и в HPC-, и даже в ИИ-нагрузках (с оговорками). В MONAKA, следующем поколении процессоров, Fujitsu вернётся к более традиционному дизайну. 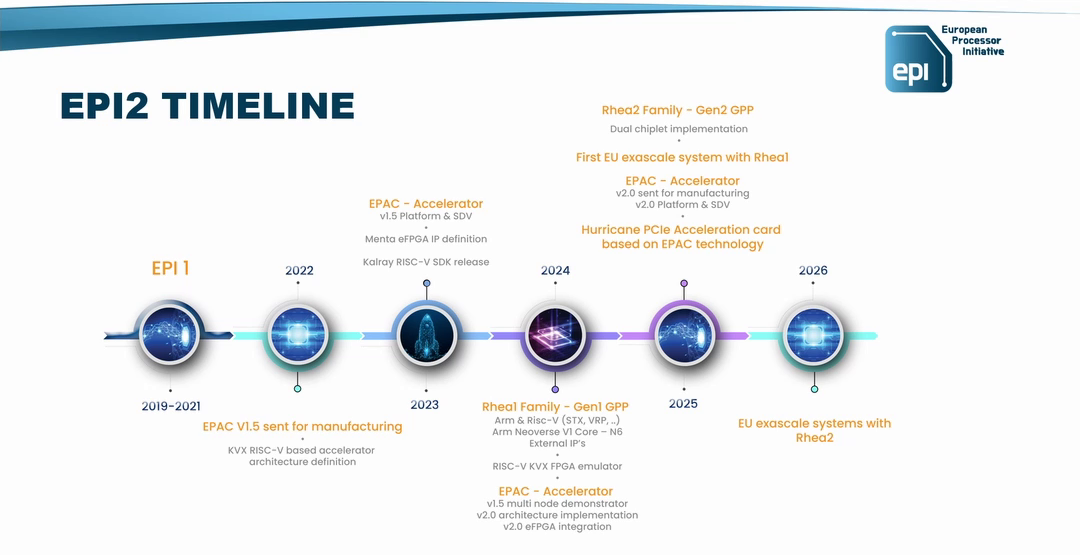
Источник изображения: EPI Пожалуй, единственный похожий на Rhea1 чип — это индийский 5-нм C-DAC AUM, который тоже базируется на Neoverse V1, но предлагает уже 96 ядер (48+48, два чиплета), восемь каналов DDR5 и до 96 Гбайт HBM3 в четырёх стеках, а также поддержку двухсокетных конфигураций. AWS Graviton3E, который тоже ориентирован на HPC/ИИ-нагрузки, вообще обходится 64 ядрами Zeus и восемью каналами DDR5. Наконец, NVIDIA Grace и Grace Hopper в процессорной части тоже как-то обходятся интегрированной LPDRR5x, да и ядра у них уже Neoverse V2 (Demeter), и своя шина для масштабирования имеется. 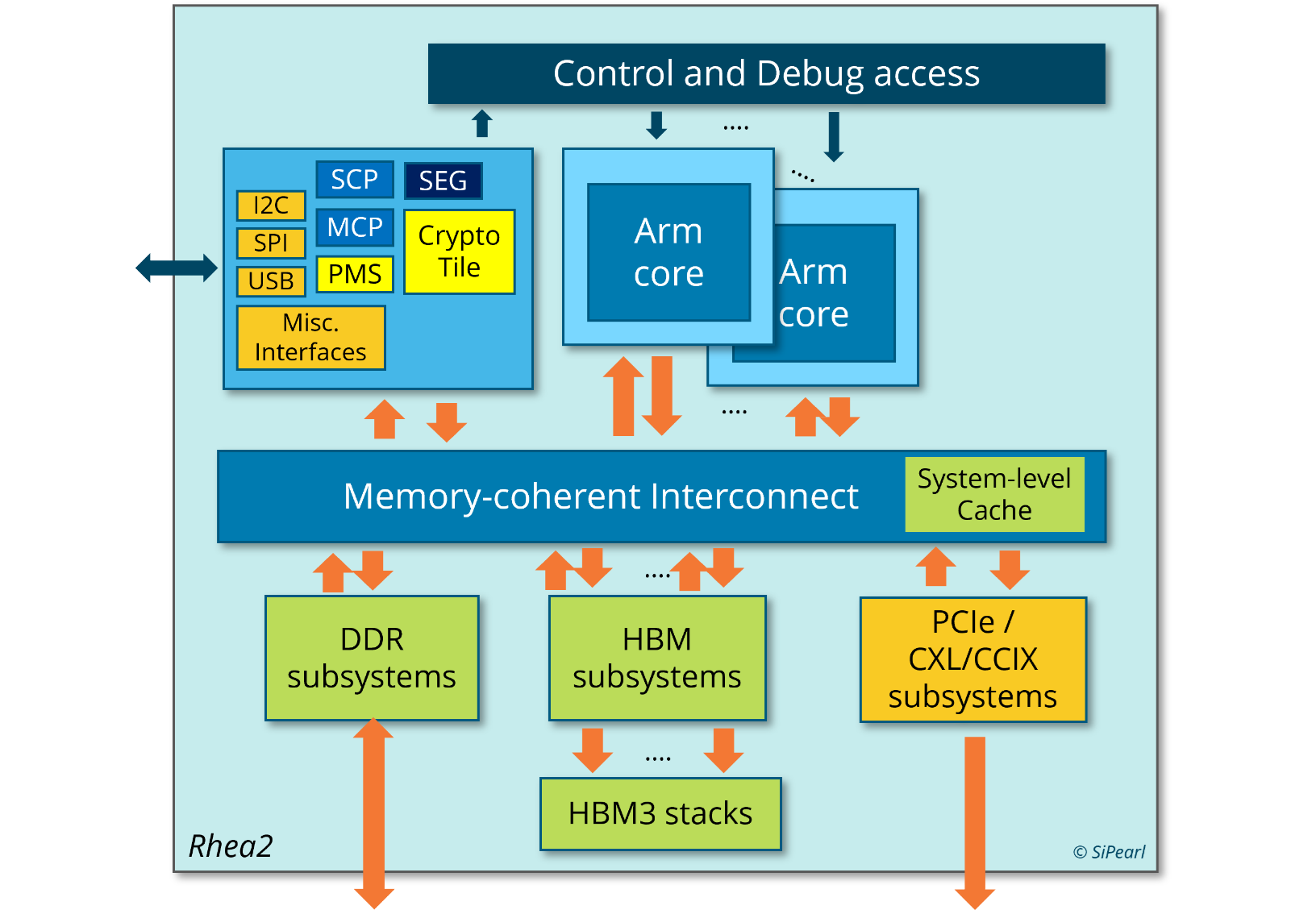
Источник изображения: EPI В любом случае в 2025 году Rhea1 будет выглядеть несколько устаревшим чипом. Но в этом же году SiPearl собирается представить более современные чипы Rhea2 и обещает, что их разработка будет не столь долгой как Rhea1. Компанию им должны составить европейские ускорители EPAC, тоже подзадержавшиеся. А пока Европа будет обходиться преимущественно американскими HPC-технологиями, от которых стремится рано или поздно избавиться. |
|

