Материалы по тегу: ems
|
03.05.2023 [13:58], Сергей Карасёв
KKR купит разработчика систем прямого жидкостного охлаждения CoolITГлобальная инвестиционная компания KKR сообщила о заключении соглашения по приобретению фирмы CoolIT Systems (CoolIT) — известного канадского разработчика систем прямого жидкостного охлаждения DLC (Direct Liquid Cooling). Финансовые условия договора не раскрываются. CoolIT была основана в 2001 году. Компания занимается проектированием и производством решений жидкостного охлаждения для ЦОД и ПК. В частности, как сообщается, запатентованная DLC-технология Split-Flow повышает надёжность и срок службы оборудования, снижает эксплуатационные расходы, сокращает энергопотребление и выбросы углерода. При этом достигается возможность повышения плотности монтажа серверных компонентов по сравнению с традиционными методами воздушного охлаждения. 
Источник изображения: CoolIT Ожидается, что, получив доступ к ресурсам и капиталу KKR, компания CoolIT сможет ускорить развитие своих технологий и вывод инновационных решений на коммерческий рынок. Речь идёт о поставках продуктов для дата-центров, облачных платформ, систем НРС и пр. KKR в рамках сделки рассчитывает на дальнейшее масштабирование одного из лучших в своём классе решений DLC. Отмечается также, что KKR инвестирует в CoolIT в рамках своей стратегии Global Impact. Эта инициатива, в частности, направлена на поддержку компаний, которые вносят ощутимый вклад в достижение одной или нескольких Целей устойчивого развития ООН. Ожидается, что сделка будет закрыта во втором квартале 2023 года при условии получения необходимых разрешений со стороны регулирующих органов.
07.04.2023 [20:36], Сергей Карасёв
Google заявила, что её ИИ-кластеры на базе TPU v4 и оптических коммутаторов эффективнее кластеров на базе NVIDIA A100 и InfiniBandКомпания Google обнародовала новую информацию о своей облачной суперкомпьютерной платформе Cloud TPU v4, предназначенной для решения задач ИИ и машинного обучения с высокой эффективностью. Система может использоваться в том числе для работы с крупномасштабными языковыми моделями (LLM). Один кластер Cloud TPU Pod содержит 4096 чипов TPUv4, соединённых между собой через оптические коммутаторы (OCS). По словам Google, решение OCS быстрее, дешевле и потребляют меньше энергии по сравнению с InfiniBand. Google также утверждает, что в составе её платформы на OCS приходится менее 5 % от общей стоимости. Причём данная технология даёт возможность динамически менять топологию для улучшения масштабируемости, доступности, безопасности и производительности. Отмечается, что платформа Cloud TPU v4 в 1,2–1,7 раза производительнее и расходует в 1,3–1,9 раза меньше энергии, чем платформы на базе NVIDIA A100 в системах аналогичного размера. Правда, пока компания не сравнивала TPU v4 с более новыми ускорителями NVIDIA H100 из-за их ограниченной доступности и 4-нм архитектуры (по сравнению с 7-нм у TPU v4). 
Изображение: Google Благодаря ключевым инновациям в области интерконнекта и специализированных ускорителей (DSA, Domain Specific Accelerator) платформа Google Cloud TPU v4 обеспечивает почти 10-кратный прирост в масштабировании производительности по сравнению с TPU v3. Это также позволяет повысить энергоэффективность примерно в 2–3 раза по сравнению с современными DSA ML и сократить углеродный след примерно в 20 раз по сравнению с обычными дата-центрами.
23.02.2023 [20:32], Алексей Степин
iXsystems представила стоечное хранилище TrueNAS Mini RКомпания iXsystems, разрабатывающая системы хранения данных, объявила о новых решениях: состоялся релиз последней версии открытой платформы TrueNAS SCALE «Bluefin» 22.12.1. Также на базе этой платформы было представлено новое решение TrueNAS Mini R — это компактная СХД в корпусе высотой 2U, вмещающая до 200 Тбайт данных. TrueNAS Mini R относится к классу недорогих решений для малого бизнеса, стоимость новинки стартует с отметки $2000. Но это полноценное 2U-хранилище, позволяющее использовать до 12 полноразмерных накопителей, а при необходимости работающее и с SATA SSD объёмом до 7,6 Тбайт. Загружается система с внутреннего накопителя M.2. 
Источник изображений здесь и далее: iXsystems Сердцем Mini R является Intel Atom C3758, подходящий для задач СХД восьмиядерный процессор, дополненный 32 или 64 Гбайт RAM с поддержкой ECC. Сетевая часть представлена двумя портами 10GbE (RJ45), имеется выделенный порт 1GbE для удалённого управления, но при необходимости можно использовать опциональный сетевой адаптер с портами SFP+. 
TrueNAS Mini R рядом с настольными собратьями — Mini X и Mini XL+ Под нагрузкой потребление полностью укомплектованного дисками TrueNAS Mini R не превышает 170 Вт. В качестве ОС используется базовая версия TrueNAS CORE, но есть возможность обновления до полноценной TrueNAS SCALE. Новая СХД iXsystems органично дополняет существующий модельный ряд Mini, представленный устройствами в настольных корпусах. Сама программная платформа TrueNAS SCALE — это открытое решение на базе Linux и Kubernetes, поддерживающее файловые и объектные режимы хранения и работающее с протоколами SMB/NFS/iSCSI. Благодаря службе iX-Storj хранилище на базе TrueNAS SCALE можно сделать и распределённым.
13.12.2022 [21:52], Алексей Степин
Ventana анонсировала первый по-настоящему серверный RISC-V процессор Veyron V1: 192 ядра с частотой 3,6 ГГцАрхитектура RISC-V достаточно молода и обычно ассоциируется с экономичными чипами на платах, подобных Raspberry Pi. Однако технически она позволяет создавать и мощные процессоры, способные поспорить с лучшими решениями на базе архитектур Arm и x86. На саммите RISC-V компания Ventana Micro Systems анонсировала целое семейство высокопроизводительных процессоров, первенцем в котором стал чип Veyron V1, который, по словам разработчиков, сможет потягаться в однопоточной производительности с самыми современными CPU класса High-End. 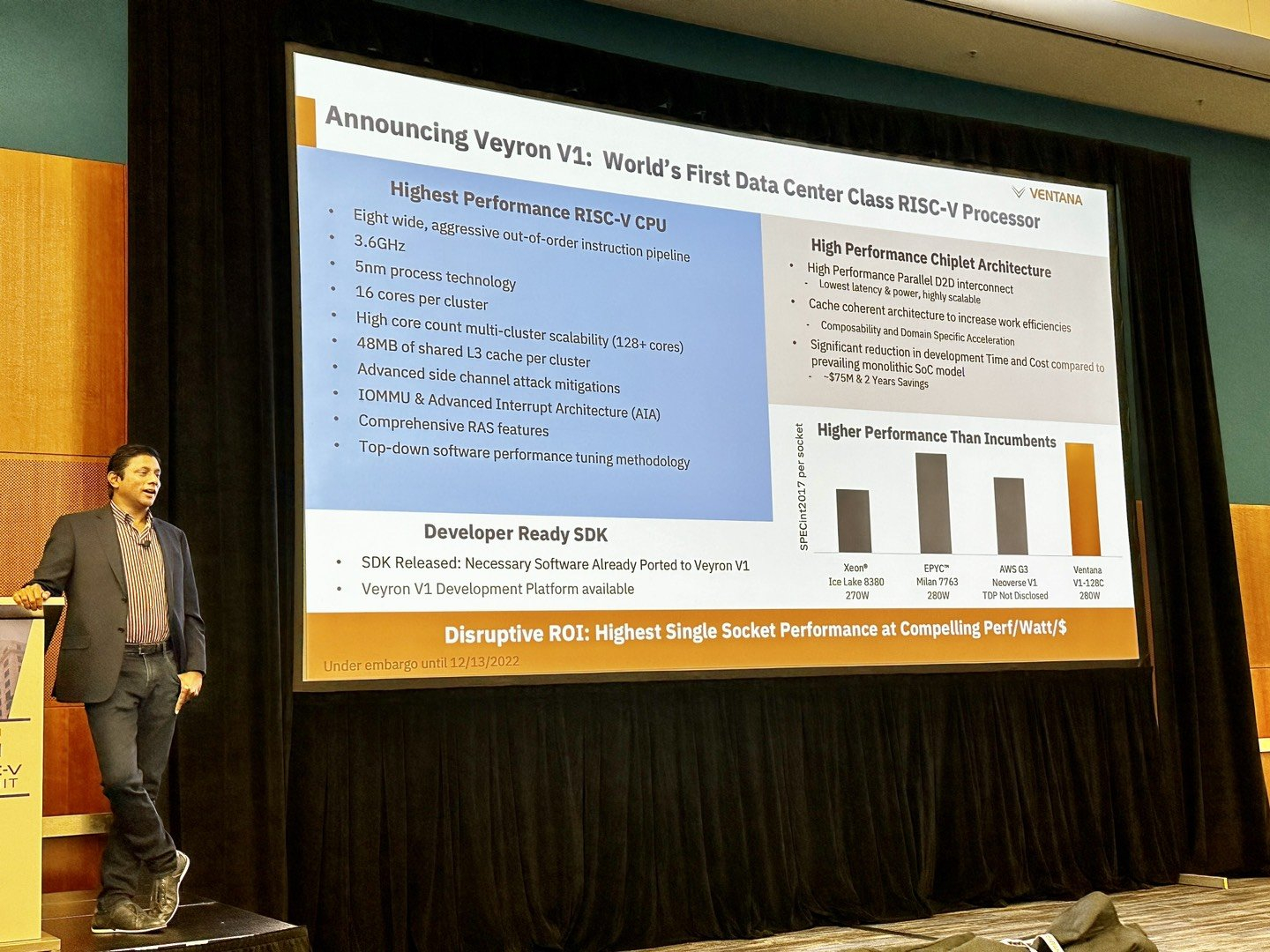
Veyron V1 должен стать самым быстрым процессором с архитектурой RISC-V. Источник: Twitter@risc_v Новинка нацелена на рынок гиперскейлеров, причём благодаря чиплетному дизайну новый процессор изначально разрабатывался как кастомизируемый под задачи заказчика. Veyron V1 будет предлагаться в виде своеобразного набора-конструктора, включающего в себя один или несколько вычислительных чиплетов Veyron, I/O-хаба и интерконнекта, позволяющего связать все компоненты воедино. Это, по словам разработчиков, должно серьёзно ускорить и удешевить процесс внедрения новой процессорной платформы, снизив расходы на разработку чипов на 75 %, а время создания — до не более чем двух лет. 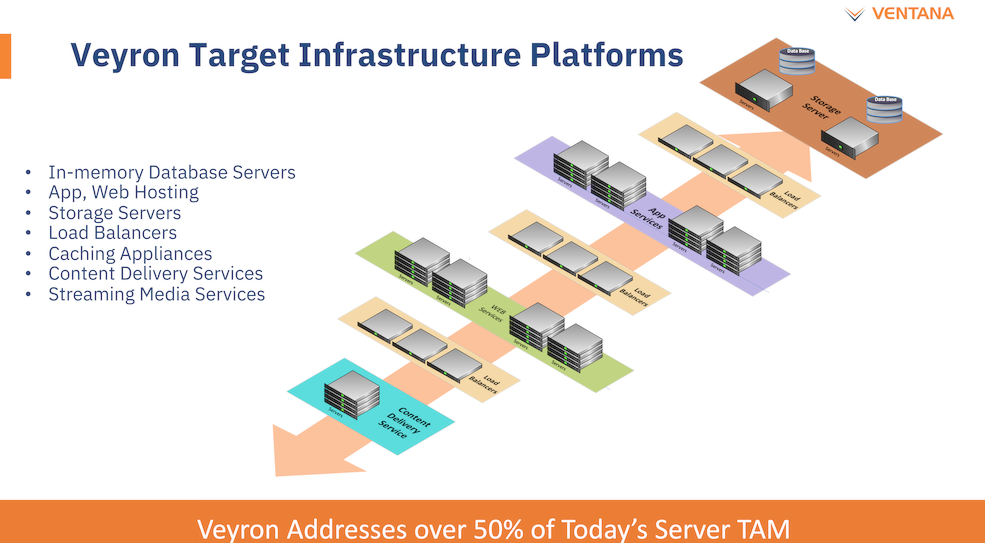
Платформа Veyron V1 универсальна и покрывает широкий спектр задач. Источник здесь и далее: StorageReview Вычислительный чиплет Veyron V1 использует продвинутые 64-битные ядра RISC-V и располагает 2 Мбайт кеша L2, а также многопоточным контроллером памяти. Предусмотрены конфигурации чиплета с 6, 8, 12 или 16 ядрами с частотой в районе 3 ГГц, что сопоставимо с решениями Google и AWS. Использоваться процессор может не только в ЦОД, но и в различных встраиваемых системах, базовых станциях 5G или даже клиентских рабочих станциях. 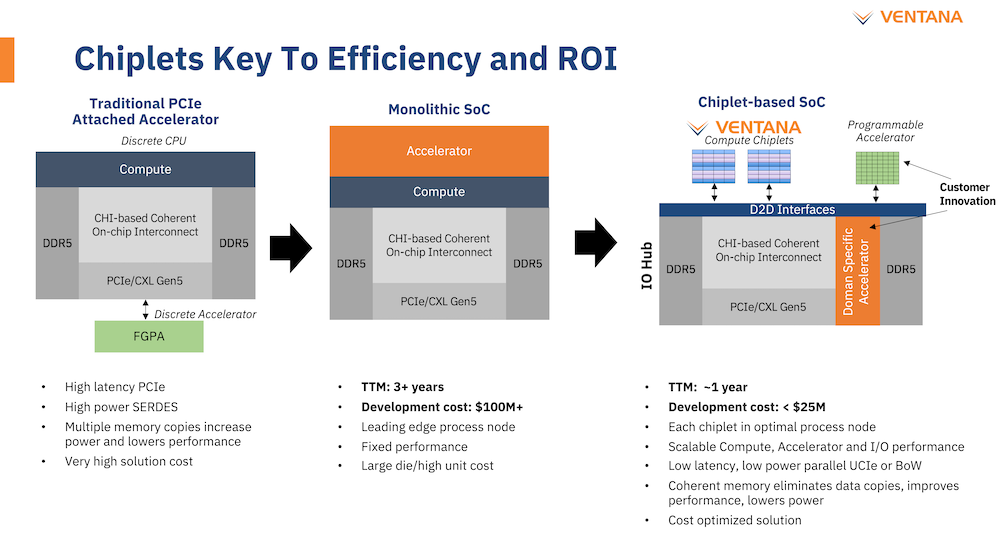
Чиплетная архитектура ускорит цикл разработки и внедрения, а также упростит задачу подключения кастомных ускорителей Архитектурно дизайн Veyron V1 использует агрессивный конвейер шириной восемь инструкций и с внеочередным исполнением. Чип способен работать на частоте до 3,6 ГГц благодаря использованию 5 нм техпроцесса TSMC. I/O-хаб может производиться с использованием более дешёвых 12 или даже 16-нм техпроцессов. Для соединения компонентов процессора разработан специальный низколатентный интерконнект D2D. 
Платформа разработки Veyron V1 и её технические характеристики Каждый чиплет включает в себя до 16 ядер, предусмотрена возможность масштабирования процессора до 192 ядер в 12 чиплетах. Общий объём разделяемого кеша L3 составляет 48 Мбайт. Заявлен высокий уровень защищённости архитектуры от атак по сторонним каналам. Разработчики заявляют о беспрецедентно низком энергопотреблении: 128 ядер V1 уложатся в 280 Вт; AMD EPYC 7763 потребляет столько же при вдвое меньшем числе ядер. 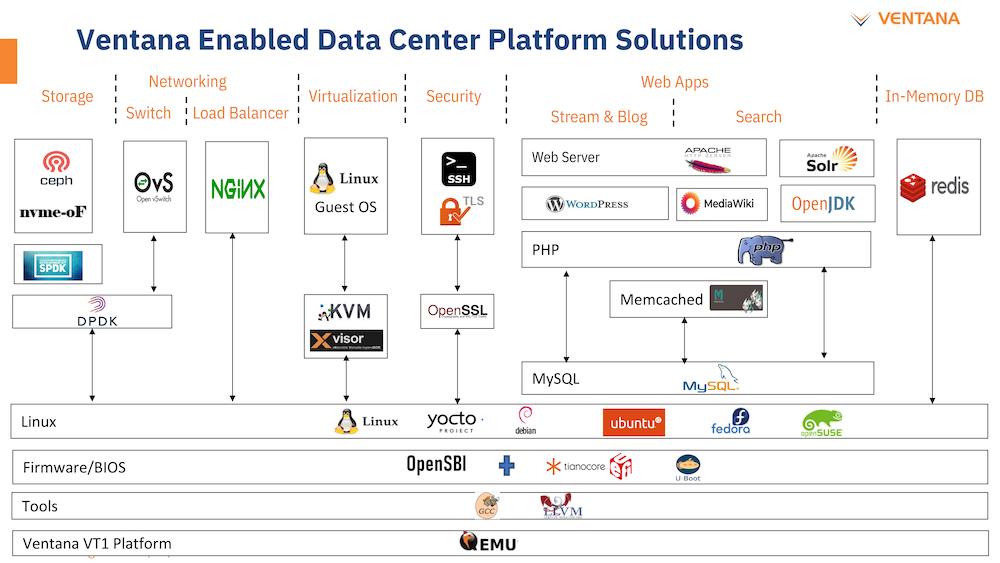
Ventana поддержит новую платформу на всех уровнях разработки системного и прикладного ПО Анонс Ventana нельзя назвать «бумажным» — компания говорит о доступности комплектов разработчика, причём сразу в двух типах шасси: в настольном и в серверном корпусе высотой 2U. Конфигурация включает в себя 16-ядерную версию V1, 128 гбайт памяти DDR5, подключенной с помощью интерфейса CXL (PCIe 5.0) x16, два свободных слота расширения PCIe 5.0 x16, загрузочный накопитель NVMe M.2 и 8 NVMe SFF SSD формата 2,5" для хранения данных. Для удалённого управления предусмотрен 1GbE-порт. 
Большая часть критически важного программного обеспечения уже портирована на архитектуру RISC-V Компания не забыла и о поддержке со стороны программного обеспечения: платформы разработчика Ventana Veyron V1 будут сопровождаться полноценным SDK с основным ПО, уже портированным на новую архитектуру. В список входят компиляторы GCC и LLVM, отладчик OpenOCD/GDB, исходные коды и бинарные файлы загрузчиков U-Boot и Tianocore UEFI EDK2.1. Поддерживается ряд дистрибутивов Linux, а также другое системное и прикладное ПО. Ожидается, что новые системы будут доступны в начале следующего года.
16.11.2022 [15:17], Сергей Карасёв
SambaNova поставит Аргоннской национальной лаборатории ИИ-систему DataScale нового поколенияСтартап SambaNova Systems сообщил о расширении сотрудничества с Аргоннской национальной лабораторией Министерства энергетики США. В рамках многолетнего соглашения компания установит вычислительную систему DataScale нового поколения. Комплекс обеспечит ускорение выполнения различных ИИ-задач, включая обработку изображений и масштабных языковых моделей. DataScale — полностью интегрированная программно-аппаратная платформа, которая позволяет компаниям и организациям переосмыслить свой подход к ИИ. Система второго поколения DataScale SN30 содержит ускоритель собственной разработки Cardinal SN30, особенностью которого является возможность реконфигурации. Решение содержит 640 Мбайт кеша SRAM и 1 Тбайт DRAM. 
Источник изображения: Аргоннская национальная лаборатория В рамках соглашения с Аргоннской национальной лабораторией комплекс DataScale будет доступен научному сообществу на базе площадки ALCF AI Testbed. Она помогает исследователям во внедрении ИИ и алгоритмов глубокого обучения в науке. Специалисты лаборатории применяли комплекс SambaNova предыдущего поколения для широкого спектра исследовательских проектов. Это, в частности, разработка суррогатных моделей для повышения точности прогнозирования погоды, ускорение моделирования гидродинамики для исследований в области двигателестроения и обработка изображений высокого разрешения для повышения эффективности экспериментальных открытий. Кроме того, система используется для проектов в области периферийных вычислений, нейтринной физики и прогнозирования злокачественных образований.
08.11.2022 [13:32], Владимир Мироненко
Американский разработчик ПО с белорусскими корнями EPAM продал все активы в РоссииАмериканский разработчик ПО с белорусскими корнями EPAM договорился о продаже всех своих активов в России третьей стороне, пишет «Интерфакс» со ссылкой на отчёт компании. Хотя об этом стало известно только сейчас, соглашение было заключено 7 сентября и для его завершения, помимо всего прочего, необходимо получить одобрение российских регулирующих органов. Сумма сделки не разглашается, как и название компании-покупателя. По данным базы «Контур.Фокус», компании и её кипрской «дочке» принадлежат в России ряд предприятий, включая ООО «ЭПАМ Решения», ООО «Эпам Системз» и ООО «Коудвеб». 
Источник изображения: EPAM О решении покинуть российский рынок в связи с событиями на Украине EPAM объявила в апреле этого года. В рамках поэтапного сокращения присутствия в России компанией было израсходовано в связи с увольнениями сотрудников за 9 месяцев $16,9 млн, а также потрачено на релокацию персонала из России, Украины и Белоруссии $37,5 млн. На поддержку сотрудников из Украины и их семей было израсходовано $38,5 млн из выделенных на эти цели $100 млн. По состоянию на конец третьего квартала большая часть активов EPAM приходится на США — 60,9 %. В странах ЕМЕА (включает Европу, в том числе Россию, Ближний Восток и Африку) размещено 35,7 % активов компании, на Центральную и Восточную Европу (регион CEE) приходится 0,8 % активов, и на Азиатско-Тихоокеанский регион (APAC) — 2,6 %. В мае EPAM потеряла крупного инвестора — американский финансовый конгломерат Morgan Stanley, который продал большую часть её акций, снизив свою долю в компании с 8,4 % до примерно 0,7 %.
06.10.2022 [21:08], Владимир Мироненко
CoolIT и Asetek договорились урегулировать все патентные споры — разбирательства шли 9 летКомпания CoolIT Systems (CoolIT), разработчик систем прямого жидкостного охлаждения DLC (Direct Liquid Cooling) из Канады, объявила о победе в последнем из серии патентных споров с датской компанией Asetek в американском суде. Сообщается, что 11 сентября 2022 года Окружной суд Северного округа Калифорнии в своём постановлении подтвердил факт отсутствия нарушений во всех вышедших ранее и текущих продуктах CoolIT в отношении патента U.S. Patent 8,240,362 компании Asetek. Суд также установил, что новейшая конструкция помпы CoolIT, которая используется в её системах жидкостного охлаждения, не нарушает патенты Asetek. Патентные разбирательства CoolIT и Asetek продолжаются как минимум с 2013 года, когда Asetek подала в суд на CoolIT. Последнее разбирательство началось с того, что Asetek 23 января 2019 года подала в суд на CoolIT, обвинив последнюю в нарушении сразу пяти патентов. В ответ CoolIT подала встречный иск, утверждая, что Asetek нарушила четыре её патента. В ходе процесса Asetek добавила в иск ещё два патента, предположительно нарушенные CoolIT. 
Источник изображения: CoolIT Systems В итоге из семи заявленных патентов Asetek шесть были отклонены судом либо их рассмотрение было отложено до получения выводов Палаты США по рассмотрению патентных споров и апелляций (PTAB). И лишь вопрос о нарушении патента 8,240,362 должен был быть рассмотрен в судебном процессе, назначенном на март 2023 года. Однако на этой неделе окружной суд вынес в упрощённом порядке решение, что продукты CoolIT не нарушают патенты Asetek. В вышедшем пресс-релизе CoolIT указала, что у Asetek не осталось претензий о нарушении прав на интеллектуальную собственность, которые можно было бы предъявить на судебном заседании в марте 2023 года. «CoolIT предъявила бы Asetek свои претензии о нарушении прав в отношении трёх патентов, связанных с технологией Split Flow», — добавила канадская компания. CooIT также сообщила, что стороны урегулировали все нерешённые между собой судебные споры, и вскоре компании представят совместное соглашение, которым аннулируются взаимные претензии без права на их возобновление. Отметим, что Asetek оказалась вынуждена уйти из HPC-сегмента, тогда как CoolIT только наращивает своё присутствие на этом рынке. Именно решения последней охлаждают Frontier, самый мощный суперкомпьютер последнего рейтинга TOP500.
16.09.2022 [22:58], Алексей Степин
SambaNova Systems представила второе поколение ИИ-систем DataScale — SN30 с 5 Гбайт SRAM и 8 Тбайт DRAMСтартап SambaNova, решивший бросить вызов NVIDIA, представил второе поколение систем машинного обучения — DataScale SN30. В основе лежит собственная разработка компании, ускоритель Cardinal SN30, для обозначения которого SambaNova использует термин Reconfigurable Data Flow Unit (RDU). На новинку уже обратили внимание такие организации, как Аргоннская национальная лаборатория (ANL) и Ливерморская национальная лаборатория им. Э. Лоуренса (LLNL). Cardinal SN30 состоит из 86 млрд транзисторов и производится с использованием 7-нм техпроцесса TSMC. Главной его особенностью является возможность реконфигурации: создатели уподобляют этот процессор сложным FPGA. Последним он уступает в степени гибкости, поскольку не может менять конфигурацию на уровне отдельных логических вентилей, зато выигрывает в скорости перепрограммирования и уровне энергопотребления. За это отвечает фирменный программный стек. 
Источник: HPCwire Большой упор SambaNova сделала на объёме локальной памяти, поскольку современные модели машинного обучения имеют тенденцию к гигантомании. Только SRAM-кеша у Cardinal SN30 640 Мбайт, а объём DRAM составляет 1 Тбайт. По своим параметрам SN30 вдвое превосходит чип первого поколения, SN10, но имеет такую же тайловую архитектуру с программным управлением. 
Здесь и далее источник изображений: SambaNova Каждый тайл содержит блоки PCU, отвечающие за вычисления, блоки PMU, содержащие SRAM и обслуживающую логику, а также mesh-интерконнект, обслуживаемый блоками коммутаторов. Такой подход к построению процессора весьма напоминает Tesla D1, у которых вычислительные блоки похожим образом чередуются с блоками быстрой SRAM-памяти. Отдельно ускорители компания не поставляет, минимальная конфигурация готовой 42U-системы DataScale включает в себя 8 чипов SN30.  Комплектация может включать в себя от одного до трёх узлов SN30. Воспользоваться возможностями DataScale можно и в виде услуги, поскольку новинка легко интегрируется в облачные среды и полностью поддерживает платформу Kubernetes. Полный список провайдеров ещё уточняется, на сегодняшний момент партнерами SambaNova являются Aicadium, Cirrascale и ORock.  Высокая производительность в режиме bfloat16 является главным достоинством новинки — по словам вице-президента SambaNova, каждый чип развивает 688 Тфлопс. Это более чем вдвое выше показателя A100, составляющего 312 Тфлопс. По словам компании, DataScale SN30 вшестеро производительнее NVIDIA DGX A100 (40 Гбайт) и эффективнее всего проявляет себя при обучении сверхбольших моделей вроде GPT-3 с её 13 млрд параметров. Однако нельзя не отметить, что, во-первых, сравнение идёт со старым продуктом NVIDIA, которая вот-вот представит DGX H100, а во-вторых, SambaNova не упоминает в явном виде энергопотребление одного узла SN30.
31.08.2022 [16:06], Алексей Степин
AMD готовит новые DPU Pensando: Giglio и SalinaКак известно, один из пионеров концепции DPU, Pensando Systems теперь принадлежит AMD. Поглощение состоялось весной этого года и обошлось «красным» в $1,9 млрд. На мероприятии VMware Explore 2022 были озвучены весьма обширные планы AMD относительно технологического наследия Pensando, передаёт ServeTheHome. Напомним, первое поколение сопроцессоров данных, разработанное Pensando, получило кодовое имя Capri, оно использовало 16-нм техпроцесс и поддерживало скорость 100 Гбит/с. Второе поколение, Elba, уже получило 7-нм «кремний», поддержку 200GbE, четыре P4-программируемых конвейера с 32 ядрами MPU для обработки сетевых пакетов, а также 16 ядер Arm Cortex-A72 для пользовательских приложений. 
Здесь и далее источник изображений: AMD (via ServeTheHome) Сопроцессоры Elba нашли своё место в коммутаторах Aruba CX 10000. Но доступны они и в виде обычных карт расширения: так, младший вариант DSC2-25G в форм-факторе HHHL имеет две корзины SFP56 и поддерживает конфигурации 2×10G или 2×25G. Старший вариант оснащён портами QSFP28 и поддерживает установку трансиверов со скоростями вплоть до 100 Гбит/с.  Но самое интересное, чем поделилась AMD на VMware Explore 2022 — планы по развитию DPU на базе наработок Pensando. Новый чип под кодовым названием Giglio должен будет увидеть свет уже в следующем, 2023 году. Относится он к поколению 2+, и является оптимизированной версией Elba. При этом в планах у AMD есть и 400G-платформа Adaptive Exotic SmartNIC. 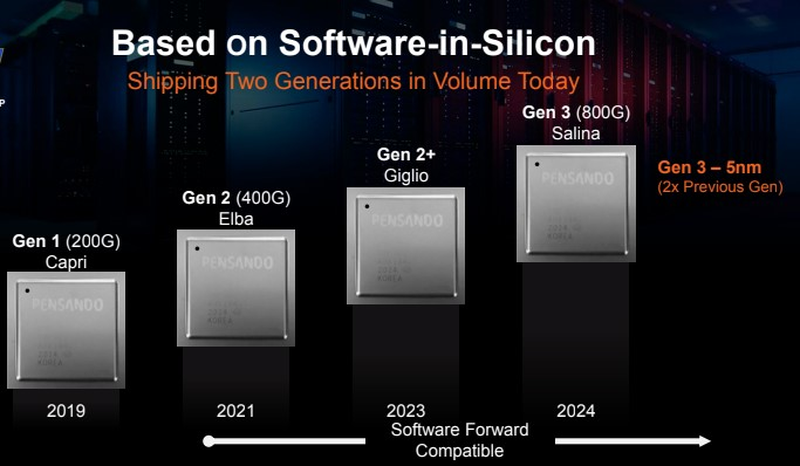 А вот на 2024 год запланирован DPU следующего поколения: 5-нм процессор под кодовым именем Salina сразу получит поддержку скорости 800 Гбит/с. При этом сохранится программная совместимость с DPU Pensando предыдущего поколения. Любопытно, что в презентации AMD присутствует упоминание «AMD EPYC Solution (Future)». Каким образом платформа Pensando будет интегрирована с EPYC, пока не уточняется.  Отметим, что AMD планирует гораздо быстрее Intel освоить 400G и 800G — первую планку «синие» собираются взять в 2023–24 гг., а вторую только двумя годами позже. И у обеих компания есть целый ряд конкурентов в лице Chelsio, Fungible, Kalray, Marvell, Nebulon, NVIDIA и др. При этом у AMD и NVIDIA уже есть важное преимущество — их решения теперь совместимы с VMware vSphere 8.
29.08.2022 [18:34], Алексей Степин
AMD представила DPU-платформу 400G Adaptive Exotic SmartNICНа конференция Hot Chips 34 AMD представила новую платформу 400G Adaptive Exotic SmartNIC. В самой концепции формально нет ничего нового, поскольку DPU уже снискали популярность в среде гиперскейлеров, но вариант AMD сочетает достоинства не двух, а трёх миров: классического ASIC, программируемой логики на базе FPGA и Arm-процессора общего назначения. На деле процессор (PSX) новинки AMD устроен ещё интереснее: он делится на два домена. В первом домене имеется шестнадцать ядер Arm Cortex-A78, организованных в четыре кластера по четыре ядра. Сюда же входят аппаратные движки для ускорения TLS 1.3. Второй домен состоит из четырёх ядер Arm Cortex-R52 и различных контроллеров низкоскоростных шин, таких как UART, USB 2.0, I2C/I3C, SPI, MIO и прочих. 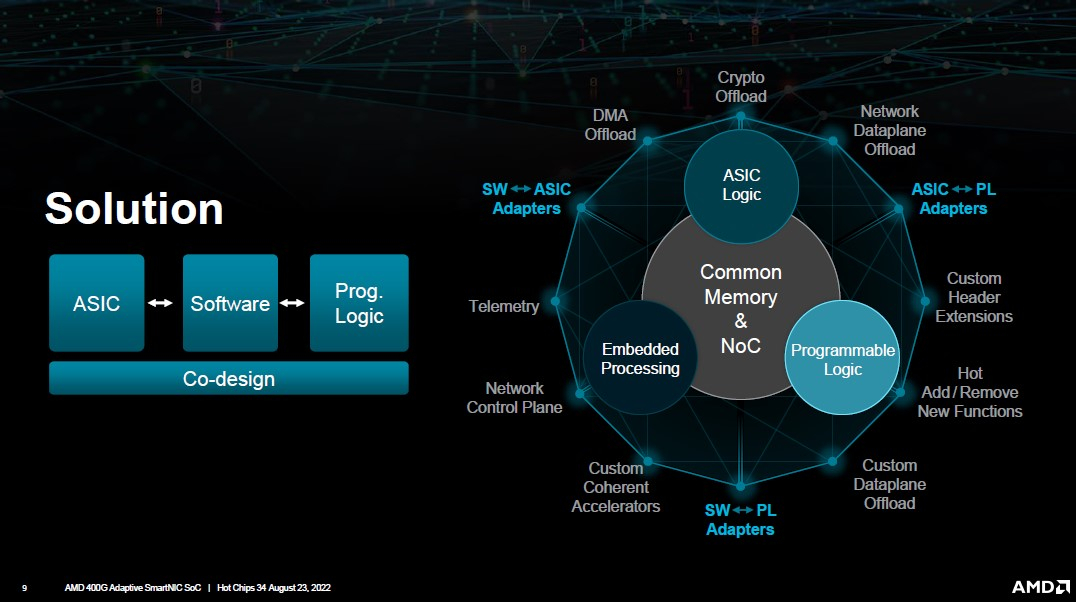
Изображения: AMD (via ServeTheHome) Посредством высокоскоростной программируемой внутренней шины блок PSX соединён с другими компонентами: модулем взаимодействия с хост-системой (CPM5N), подсистемой памяти, сетевым модулем HNICX и блоком программируемой логики. CPM5N реализует поддержку PCIe 5.0/CXL 2.0, причём доступен режим работы в качестве корневого (root) комплекса PCIe. Тут же находится настраиваемый DMA-движок. 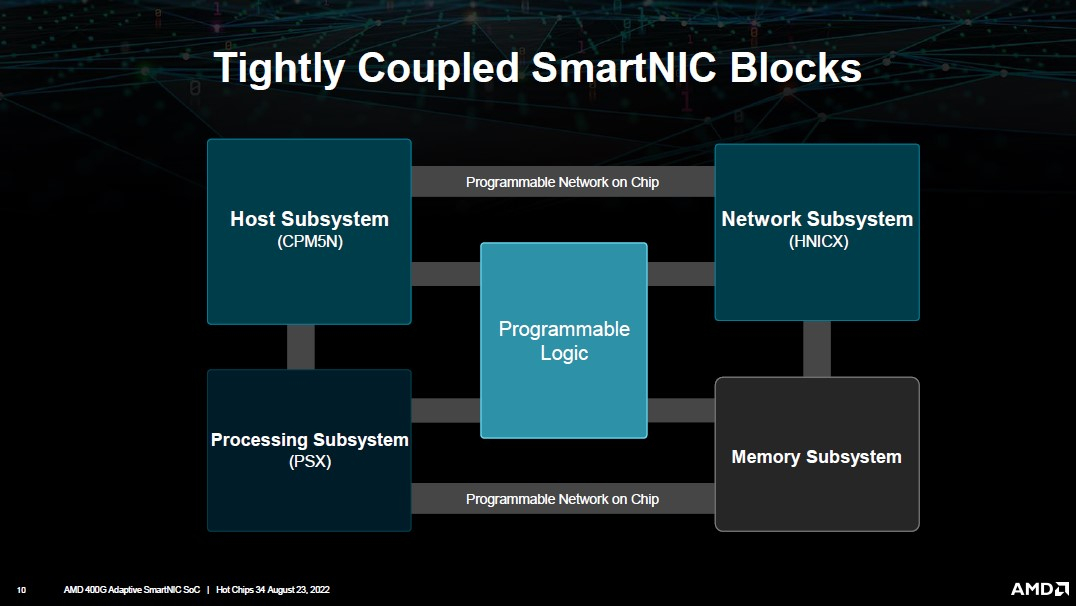 Блок фиксированных сетевых функций представляет собой классический ASIC, обслуживающий пару портов 200GbE. Подсистема памяти представлена 8 каналами DDR5/LPDDR5 с поддержкой 32-бит DDR5-5600 ECC или 160-бит LPDDR5-6400, но говорится и совместимости с другими вариантами памяти, в то числе SCM. Здесь же имеется блок шифрования содержимого памяти с поддержкой стандартов AES-GCM/AES-XTS. 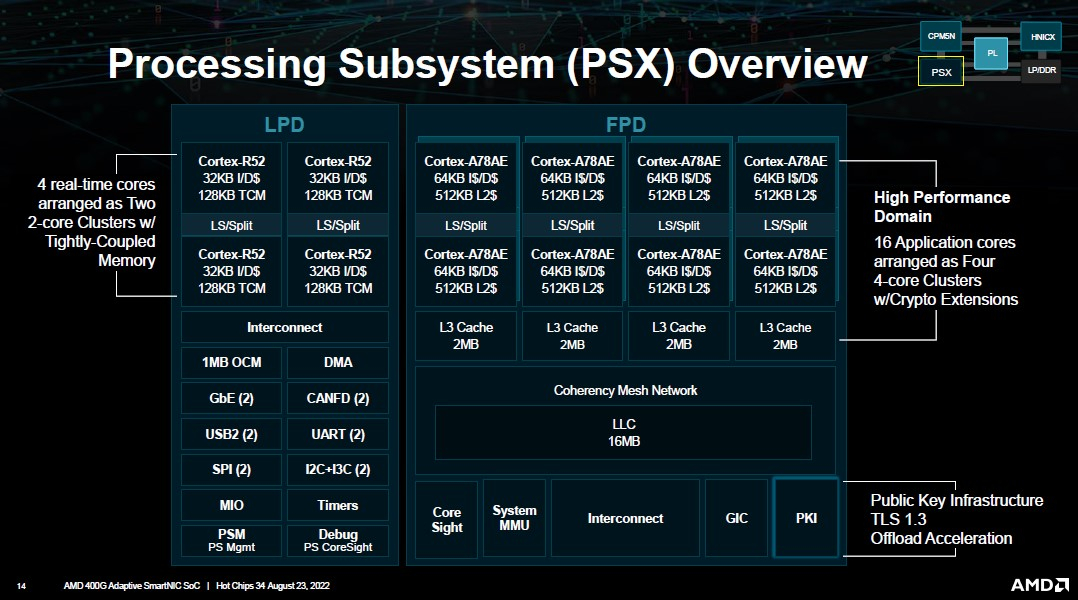 400G Adaptive Exotic SmartNIC имеет развитую поддержку VirtIO и OVS. Также поддерживается виртуализация NVMe-устройств, тоже с шифрованием. Особое внимание AMD уделила тесному взаимодействию всех частей Adaptive Exotic SmartNIC: наличие выделенных линков между блоками хост-контроллера, PSX и FPGA обеспечивает работу на полной скорости в средах, действительно требующих прокачки данных на скоростях в районе 400 Гбит/с. 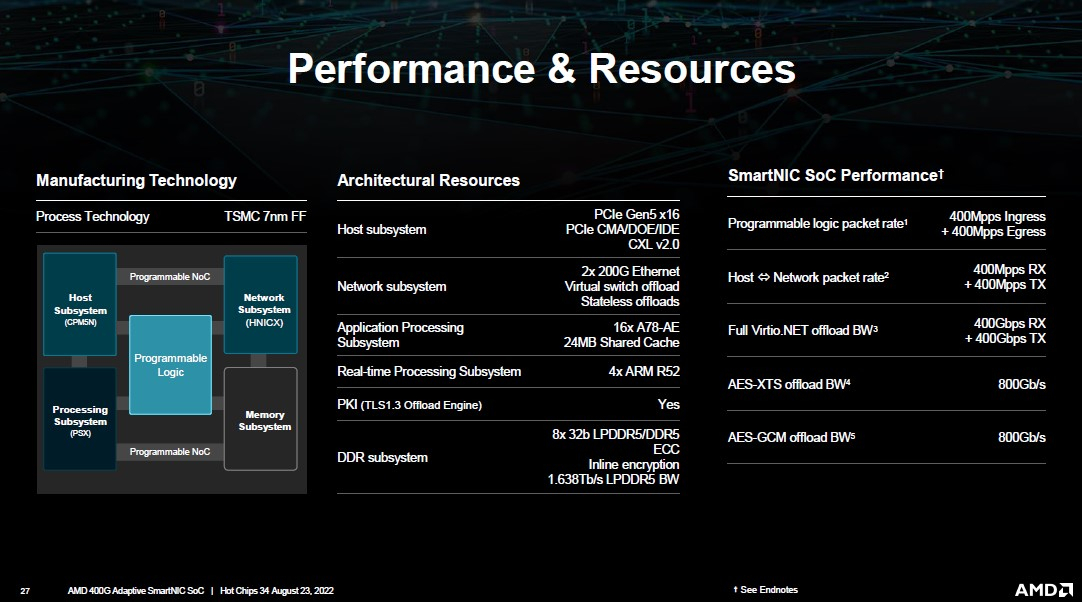 Благодаря наличию FPGA-части 400G новинка можно легко адаптировать к новым требованиям со стороны заказчиков. В частности, решения на базе ПЛИС Xilinx активно поставляются в Китай, где требования к шифрованию существенно отличаются от предъявляемых к аппаратному обеспечению в Европе или США, но наличие блока FPGA позволяет решить эту проблему. У Intel уже есть в сём-то похожая платформа, но более скромная по техническим характеристикам — Oak Springs Canyon (C6000X). |
|

