Материалы по тегу: сбой
|
24.07.2024 [21:41], Руслан Авдеев
CrowdStrike обвинила в недавнем глобальном сбое ПК на Windows баг в ПО для тестирования апдейтовКомпания CrowdStrike, ставшая виновницей глобальных сбоев в работе 8,5 млн ПК с Windows, обновила страницу с инструкцией по устранению проблемы. Компания поделилась своим видением причин инцидента, а пострадавшим партнёрам она предложила купоны Uber Eats на сумму $10. При этом общий ущерб от сбоя, согласно предварительным оценкам, составил $4,5 млрд. Согласно разъяснениям, защитное ПО Falcon Sensor выпускается с набором правил Sensor Content, определяющих его функциональность. ПО также получает обновления Rapid Response Content, позволяющие своевременно распознавать новейшие угрозы и оперативно реагировать на них. Sensor Content основан на структурном коде Template Types, предусматривающем использование специальных полей, в которые вносятся данные для создания правил выявления угроз. В Rapid Response Content отмечаются конкретные варианты Template Types — Template Instances, описывающие определённые типы угроз, на которые необходимо реагировать, и их специфические признаки. В феврале 2024 года компания представила очередной вариант шаблона обнаружения угроз — IPC Template Type, специально созданный для распознавания новых методик атак, использующих т.н. «именованные каналы» (Named Pipes) в ОС. Шаблон успешно прошёл тесты 5 марта, поэтому для его использования выпустили новый вариант Template Instance. С 8 по 24 апреля компания внедрила ещё три варианта Template Instance, без малейшего видимого ущерба миллионам компьютеров на Windows — хотя в апреле отмечались проблемы с ПО компании CrowdStrike для Linux. 
Источник изображения: Johnyvino/unsplash.com 19 июля разработчик представил ещё два варианта IPC Template Instance, один из которых включал «проблемные данные». Тем не менее, CrowdStrike запустила ПО в релиз из-за «бага в Content Validator». Хотя функции Content Validator разработчиком не раскрываются, по названию можно предположить, что данный инструмент занимается валидацией готовящегося к релизу ПО. Так или иначе, валидатор не справился с фильтрацией некачественного кода и не предотвратил выпуск 19 июля фактически вредоносного Template Instance. В CrowdStrike предположили, что успешная проверка IPC Template Type мартовского образца означает, что варианты IPC Template Instance для июльского релиза тоже в порядке. Как показало время, это было трагической ошибкой — программа пыталась читать данные из области памяти, доступа к которой у неё быть не должно. В результате ошибка чтения вызвала сбой, от которого пострадало 8,5 млн компьютеров. В дальнейшем компания обещает более строго тестировать обновления Rapid Response Content и обеспечить пользователям больше контроля над процессом развёртывания обновления. Кроме того, планируется подробное описание релизов, чтобы дать пользователям возможность самостоятельно оценить риск установки обновлений. Компания обещает опубликовать полный анализ основной причины сбоя, как только расследование будет закончено. Ранее Microsoft поспешила снять с себя ответственность за инцидент, переложив вину на CrowdStrike и Евросоюз. По данным IT-гиганта именно последний ещё в 2009 году вынудил Microsoft обеспечить сторонним разработчикам антивирусного ПО вроде CrowdStrike низкоуровневый доступ к ядру операционных систем Windows.
23.07.2024 [16:32], Руслан Авдеев
Microsoft обвинила регулятора ЕС в глобальном сбое Windows — компанию вынудили открыть ядро ОС 15 лет назад
crowdstrike
microsoft
software
windows
евросоюз
закон
информационная безопасность
конкуренция
операционная система
сбой
ядро
Пока ИТ-инфраструктура по всему миру восстанавливается после критического сбоя, бизнес, эксперты и политики уже ищут виноватых в произошедшем. По данным The Wall Street Journal, в Microsoft заявили, что инцидент может оказаться результатом вынужденного соглашения 2009 года между IT-гигантом и Евросоюзом. Эксперты уже задаются вопросом, почему CrowdStrike, занимающейся решениями для обеспечения кибербезопасности, обеспечили доступ к ядру Windows на столь низком уровне, где ошибка может оказаться очень масштабной и дорого обойтись огромному числу пользователей. Хотя Microsoft нельзя напрямую обвинить в появлении дефекта после обновления ПО компании CrowdStrike, ставшего причиной хаоса во всех сферах жизнедеятельности по всему миру, программная архитектура, позволяющая третьим сторонам глубоко интегрировать своё ПО в операционные системы Microsoft, вызывает немало вопросов и требует более пристального рассмотрения. Как сообщает WSJ, в Microsoft отметили, что соглашение 2009 года компании с Еврокомиссией и стало причиной того, что ядро Windows не защищено так, как, например, ядро macOS компании Apple, прямой доступ к которому для разработчиков закрыт с 2020 года. Соглашение о совместимости фактически стало результатом повышенного внимания европейских регуляторов к деятельности Microsoft. 
Источник изображения: Sunrise King/unsplash.com В соответствии с одним из его пунктов, Microsoft обязана своевременно и на постоянной основе обеспечивать информацию об API, используемых её защитным ПО в Windows — пользовательских и серверных версиях. Соответствующая документация должна быть доступна и сторонним разработчикам антивирусного ПО для создания собственных решений, что должно способствовать честной конкуренции. Однако вместо использования API без доступа к ядру CrowdStrike и ей подобные предпочли работать напрямую с ядром ОС для максимизации возможностей своего защитного ПО. Правда, при этом велика вероятность, что в случае сбоя последствия могут быть чрезвычайно серьёзными — что и произошло. Windows — не единственная операционная система, предлагающая доступ к ядру с возможностью вывести его из строя в случае некорректной работы. Тем не менее, повсеместное присутствие продуктов Microsoft приводит в случае сбоев в сторонних приложениях к массовым проблемам и большой огласке событий, даже если прямой вины компании в произошедшем нет.
21.07.2024 [00:48], Владимир Мироненко
Глобальный сбой из-за обновления CrowdStrike затронул 8,5 млн ПК на Windows: Microsoft выпустила инструмент для починки пострадавших системMicrosoft опубликовала обновлённую информацию, касающуюся масштабного сбоя Windows-систем из-за защитного ПО CrowdStrike Falcon, и сообщила о мерах, которые были приняты для устранения последствий. Ошибка произошла из-за некорректного апдейта сведений об атаках, который приводит к краху драйвера и BSOD. Microsoft подчеркнула, что не имеет отношения к этой ошибке, но постаралась помочь клиентам и заказчикам справиться с ней. Компанией была поставлена задача — предоставить клиентам техническое руководство и поддержку для безопасного возобновления работы вышедших из строя систем. Принятые меры включали:
Работа ведётся круглосуточно с постоянным предоставлением обновлений и поддержки, сообщила компания. Кроме того, CrowdStrike помогла Microsoft разработать масштабируемое решение, которое позволит пользователям Microsoft Azure ускорить исправление проблемы. Также Microsoft работала с AWS и GCP над созданием наиболее эффективных подходов к устранению сбоя. 
Источник изображения: CrowdStrike Как отметила Microsoft, обновления ПО могут иногда вызывать сбои, но такие серьёзные инциденты, как нынешний сбой из-за обновления CrowdStrike, случаются редко. По оценкам Microsoft, фатальное обновление CrowdStrike затронуло 8,5 млн Windows-устройств или менее 1 % всех компьютеров под управлением Windows. Хотя инцидент затронул небольшой процент компьютерных систем, его широкие экономические и социальные последствия отражают широту использования CrowdStrike предприятиями, которые предоставляют множество критически важных услуг, отметила Microsoft. Этот инцидент также демонстрирует взаимосвязанный характер обширной экосистемы компании — глобальных поставщиков облачных услуг, программных платформ, поставщиков средств безопасности и других поставщиков ПО, а также клиентов. «Это также напоминание о том, насколько важно для всех нас в технологической экосистеме уделять первоочередное внимание безопасному развёртыванию и аварийному восстановлению с использованием существующих механизмов», — подчеркнула Microsoft. Некоторые апдейты от самой Microsoft тоже неоднократно вызывали сбои Windows вплоть до BSOD, равно как и обновления других продуктов, работающих на уровне ядра ОС, включая практически все антивирусы. Весеннее обновление CrowdStrike Falcon в некоторых случаях также приводило к краху ядра Linux. Кроме того, в Сети напомнили, что основатель CrowdStrike был техническим директором McAfee и именно при нём обновление баз антивируса привело к массовому отказу Windows XP SP3 в апреле 2010 года. Инцидент существенно повлиял на финансовое здоровье компании и, как предполагается, именно из-за него McAfee продала свой бизнес Intel. Обновление: Microsoft выпустила решение Microsoft Recovery Tool для создания загрузочного USB-накопителя, который поможет ИТ-администраторам ускорить процесс восстановления пострадавших ОС Windows.
19.07.2024 [13:20], Руслан Авдеев
Беда не приходит одна: многочасовой сбой Microsoft Azure совпал с неудачным обновлением CrowdStrike, приводящему к BSODМасштабный сбой в облаке Microsoft Azure, наложившийся на неудачное обновление защитного ПО компании CrowdStrike для ПК на Windows привели к нарушениям работы критически важной инфраструктуры по всему миру. По данным Datacenter Dynamics, в результате пришлось прекратить полёты некоторым авиалиниям, остановить работу банков, больниц, магазинов и других критически важных организаций и сервисов. В Сети в шутку предложили назначить 19 июля Международным днём Синего экрана смерти Windows. Эксперты уже назвали данное событие крупнейшим IT-сбоем за всю историю. В Microsoft объявили, что облачный регион Central US спустя пять часов после сбоя вернулся к работе, хотя клиентам облака на восстановление работоспособности может понадобиться больше времени. Компания CrowdStrike, занимающаяся обеспечением кибербезопасности, также подтвердила, что выпущенное её обновление вызывало появление «экранов смерти» на компьютерах или бесконечной перезагрузке, а совпадение по времени двух не связанных с собой сбоев привело к тому, что клиентам теперь трудно определить, какая именно из причин вызвала неполадки в их инфраструктуре. Возможно, в некоторых случаях оказали влияние оба фактора. 
Источник изображения: Vitaly Gariev/unsplash.com Сбои привели к тому, что авиакомпании приостановили полёты, частично прекратили функционировать аэропорты, железные дороги, банковские приложения и даже сервис Xbox Live прекратил работу на несколько часов. Пострадали и некоторые телеком-операторы и СМИ. Проблемы коснулись жителей США, Великобритании и Австралии, а также других стран, от Европы до Индии и Японии. CrowdStrike «откатила» дефектное обновление ПО Falcon Sensor, включавшее некорректный драйвер. В качестве временной меры предлагается удалить файлы вида C-00000291*.sys в директории C:WindowsSystem32driversCrowdStrike, загрузив Windows в безопасном режиме или режиме восстановления. Для облачных инстансов предлагается сделать то же самое, отмонтировав тома и сняв резервную копию. При наличии BitLocker понадобится ключ для дешифровки данных. Причём это не первая массовая проблема с ПО компании за последний месяц — более ранний апдейт приводил к 100 % загрузке одного из ядер CPU. 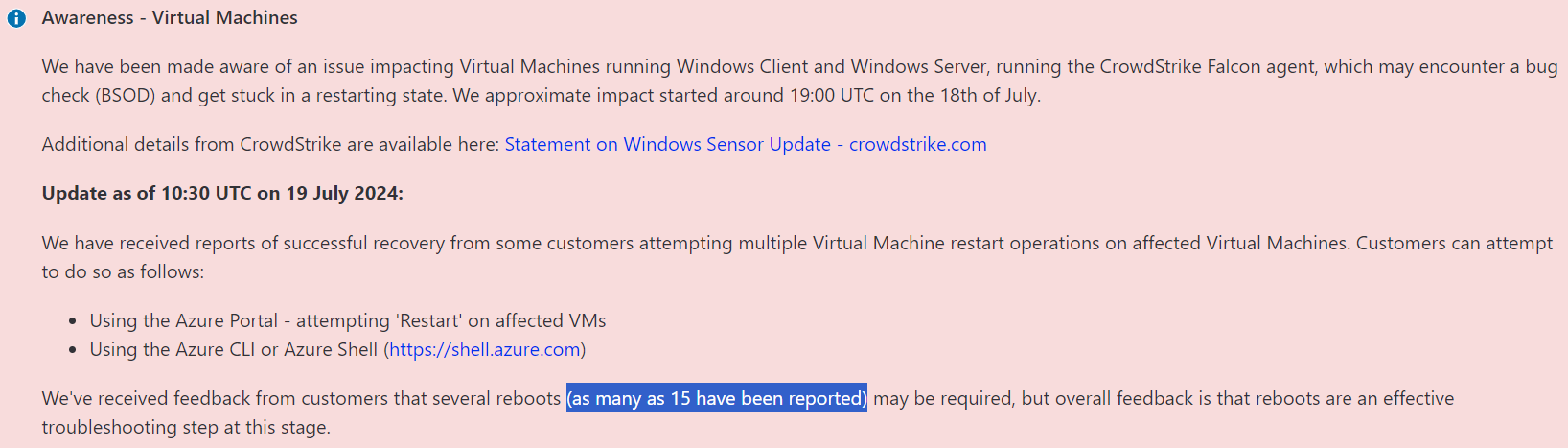
Источник изображения: Microsoft Azure Акции компании в преддверии сегодняшних торгов в США уже упали на 19 %. Аналитики полагают, что CrowdStrike в её нынешнем виде, возможно, перестанет существовать. По некоторым оценкам, поражено до 15 % корпоративных Windows-систем. Ситуация осложняется тем, что при отсутствии OOB придётся вручную исправлять проблему на каждом ПК. По неподтверждённым данным, в некоторых случаях помогает многократная последовательная перезагрузка ПК (до 15 раз подряд). Microsoft в свою очередь пояснила, что автоматизированный процесс управления внёс изменения в конфигурацию серверов, в результате чего была заблокирована связь между некоторыми хранилищами данных и вычислительными ресурсами в регионе US Central. Это привело к тому, что инстансы потеряли связь с виртуальными дисками, уходя в циклическую перезагрузку. Большинство сервисов сейчас восстановлено, но некоторые ещё испытывают «остаточное воздействие», клиенты получат поддержку на профильном портале Azure. В частности, проблемы всё ещё могут быть у пользователей и администраторов Microsoft 365.
04.07.2024 [17:12], Руслан Авдеев
Разовая акция: хакеры отдали ключи для дешифровки ЦОД властям Индонезии, но пригрозили карами, если их условия не будут выполненыГруппа хакеров-вымогателей Brain Cipher, недавно поставившая под угрозу работу индонезийского правительства, извинилась и прислала ключи для восстановления работы поражённого 20 июня ЦОД. Впрочем, напоминает The Register, $8 млн выкупа никто платить всё равно не собирался. В результате атаки посредством LockBit 3.0 была парализована работа многих правительственных служб, от миграционных до медицинских. Brain Cipher, ответственная за взлом и шифровку правительственного ЦОД PDNS, прислала ключ в виде ESXi-файла объёмом 54 Кбайт. Хакеры ждут официального подтверждения, что ключ работает и что все данные были дешифрованы. После этого они удалят ту информацию, что была скачана ими из ЦОД. Однако если будет заявлено, что данные были восстановлены при помощи и участии третьих лиц, хакеры выложат в публичный доступ украденную информацию, хотя и не уточняют, какую именно. 
Источник изображения: Mr Cup / Fabien Barral / Unsplash Согласно сообщению сингапурской Stealth Mole, команда вымогателей отправила заявление, в котором попросила прощения у граждан Индонезии. Кроме того, Brain Cipher объявила, что предоставляет файл для дешифровки по собственной воле, без давления силовых и прочих ведомств. При этом вымогатели пожелали благодарностей за своё благородное поведение и даже предоставили счёт для пожертвований. Дополнительно они рассказали о своей мотивации. Речь шла о своего рода тесте возможностей. В своём послании Brain Cipher подчеркнули, что атака наглядно продемонстрировала, насколько важно финансировать IT-индустрию и нанимать квалифицированных специалистов. В этом случае, по данным злодеев, на выгрузку и шифрование петабайт данных ушло очень мало времени. В Brain Cipher подчеркнули, что не все жертвы могут рассчитывать на подобную снисходительность. Глава одного из ведомств Министерства коммуникаций и информатизации Индонезии (Kominfo), который уже подал в отставку, подтвердил, что с помощью присланного ключа уже удалось расшифровать шесть наборов данных, но он не уверен, что ключ действительно универсальный. По словам одного из индонезийских ИБ-экспертов, это большой позор для Kominfo и страны. По его словам, при бюджете в 700 млрд рупий на защиту индонезийских данных, власти полагаются только на Windows Defender. 
Источник изображения: Dennis Schmidt/unsplash.com В последние дни в правительстве страны наблюдалась лёгкая паника, поскольку выяснилось, что многие министерства и ведомства не делали резервных копий данных. После инцидента президент страны сделал создание резервных копий обязательным и назначил аудит правительственных дата-центров. Теперь политики и общественность ищет ответственного. В частности, сформирована петиция о снятии с должности главы Kominfo. Местное издание Tempo со ссылкой на депутата Совет народных представителей (местного парламента) сообщает, что после инцидента 80 иностранных компаний начали аудит своих индонезийских подразделений. Для Индонезии, которая наряду с Малайзией стремится стать новым IT-центром Юго-Восточной Азии и пытается привлечь крупные инвестиции, взлом государственного дата-центра стал серьёзным ударом по репутации.
01.07.2024 [15:42], Руслан Авдеев
Индонезийские власти не делали резервные копии зашифрованных хакерами государственных данных, хотя такая возможность былаПрезидент Индонезии Джоко Видодо (Joko Widodo) приказал провести аудит правительственных ЦОД после того, как злоумышленники зашифровали один из них с целью получения выкупа. По данным The Register, выяснилось, что для большинства данных в стране не делалось резервных копий. Атака на национальный дата-центр Temporary National Data Center (Pusat Data Nasional, PDN), организованная 20 июня и нарушившая работу многих государственных сервисов по всей стране, показала, насколько уязвимой оказалась её информационная сеть. Выяснилось, что речь идёт о свежем варианте вредоносного ПО LockBit 3.0 — Brain Cipher. Власти сообщили, что ПО шифрует все данные на атакованных серверах. За ключи для расшифровки информации злоумышленники потребовали Rp131 млрд ($8 млн), но правительство отказалось их платить и пытается восстановить доступ к данным. Приказ об аудите, по слухам, последовал за прошедшим за закрытыми дверями совещанием, но сроки окончания проверки не называются. 
Источник изображения: Jeremy Bishop/unsplash.com В парламенте глава ведомства National Cyber and Encryption Agency (BSSN) Хинса Сибуриан (Hinsa Siburian) признал, что для 98 % данных, хранившихся в скомпрометированном ЦОД, бэкап не делался. До недавних пор в Индонезии правительственные ведомства могли делать резервные копии данных в доступных дата-центрах, но их создание было делом добровольным. Большинство структур не делали бэкапы из экономии, но в будущем это станет обязательным. Хотя отсутствие резервных копий сыграло очевидную роль в разразившемся кризисе, вице-президент Маруф Амин (Ma’ruf Amin) назвал причиной столь масштабного ущерба централизацию и унификацию IT-систем — в результате одного взлома пострадали все структуры. Чиновник заявил, что в прошлом таких серьёзных инцидентов не было.
30.06.2024 [15:08], Владимир Мироненко
Аэропорт Женевы временно не принимал и не отправлял рейсы из-за подтопления ЦОД аэронавигационной службы SkyguideШвейцарская аэронавигационная служба Skyguide на этой неделе пострадала от сбоя своего ЦОД, вызванного повреждением системы охлаждения, пишет ресурс DatacenterDynamics. 25 июня в Швейцарии прошли грозы, которые привели к наводнению в районе, где находится дата-центр Skyguide, и подтоплению ЦОД. Особенно пострадала система охлаждения, находящаяся в подвале ЦОД в Женеве. Из-за её повреждения служба Skyguide была вынуждена в этот день закрыть воздушное пространство Женевы на два с половиной часа, в связи с чем взлёт и посадка всех бортов в международном аэропорту Женевы были приостановлены. По словам представителя аэропорта Игнаса Жаннерата (Ignace Jeannerat), было отменено более 50 рейсов, более десятка было перенаправлено в другие аэропорты. 
Источник изображения: Skyguide «Был принят ряд мер, чтобы гарантировать, что системы управления воздушным движением не перегреваются, а также гарантировать охлаждение машинного зала», — указано в заявлении Skyguide. Как сообщается, к 26 июня работа системы охлаждения ЦОД была частично восстановлена, а 28 июня она уже функционировала в полном объёме. Во избежание повторения подобных сбоев Skyguide приобрела дополнительную внешнюю систему охлаждения и мобильный дизель-генератор для поддержки имеющихся изношенных генераторов. В службе отметили, что это временное решение, и для реального устранения ущерба, нанесённого затоплением помещений ЦОД, потребуется ещё некоторое время.
25.06.2024 [11:35], Руслан Авдеев
Хакеры-вымогатели заблокировали правительственный ЦОД в Индонезии и требуют $8 млн [Обновлено]Индонезийские государственные IT-сервисы пострадали от атаки хакеров-вымогателей. The Register сообщает, что местные власти сообщили о заражении национального дата-центра, из-за которого нарушено обслуживание как граждан страны, так и иностранцев. Речь идёт об управляемом Министерством связи и информационных технологий (Kominfo) ЦОД National Data Center (он же Pusat Data Nasional, PDN). Инцидент зарегистрирован 20 июня, но правительство объявило о проблеме только в понедельник. Работа PDN заблокирована, это сказалось как минимум на 210 местных организациях, серьёзно пострадали некоторые местные IT-сервисы. В частности, нарушена работа миграционной службы, из-за чего страна не может своевременно справляться с выдачей виз, паспортов и разрешений на проживание. Это уже привело к очередям в аэропортах, но власти уверяют, что автоматизированные сканеры паспортов уже вновь заработали. 
Источник изображения: Fikri Rasyid/unsplash.com Пострадала и онлайн-регистрация новых учащихся в некоторых регионах, из-за чего органы самоуправления на местах были вынуждены продлить сроки регистрации. ПО, поразившее системы PDN, представляет собой вариант LockBit 3.0 — версию Brain Cipher. В Broadcom обнаружили этот «штамм» более недели назад. Как сообщили журналистам представители властей, вымогатели требуют выкуп в размере 131 млрд местных рупий ($8 млн), но пока неизвестно, намерены ли его выплачивать. Для того, чтобы оценить значимость суммы для страны, стоит отметить, что президент Индонезии Джоко Видодо (Joko Widodo) в прошлом месяце приказал чиновникам прекратить разработку новых приложений после того, как те запросили 6,2 трлн рупий ($386,3 млн) для разработки нового софта в этом году. По словам президента, 27 тыс. приложений центральных и местных властей дублируют функции друг друга или не интегрированы должным образом. Небрежность с обеспечением устойчивости работы iT-инфраструктуры может привести к непредсказуемым последствиям. В начале июня сообщалось, что вся информационная система одного из муниципалитетов Западной Австралии зависит от одного-единственного сервера без возможности оперативной замены и в случае инцидента последствия могут оказаться катастрофическими. UPD 26.06.2024: правительство Индонезии отказалось выплачивать выкуп и попытается своими силами восстановить работу ЦОД и сервисов. Говорится об обнаружении образцов LockBit 3.0. Это самая крупная атака на госслужбы с 2017 года.
22.06.2024 [14:34], Сергей Карасёв
Галлюцинации от радиации: аппаратные сбои могут провоцировать ошибки в работе ИИ-системКомпания Meta✴, по сообщению The Register, провела исследование, результаты которого говорят о том, что ошибки в работе ИИ-систем могут возникать из-за аппаратных сбоев, а не только по причине несовершенства алгоритмов. Это может приводить к неточным, странным или просто плохим ответам ИИ. Говорится, что аппаратные сбои способны провоцировать повреждение данных. Речь идёт, в частности, о так называемом «перевороте битов» (bit flip), когда значение ячейки памяти может произвольно меняться с логического «0» на логическую «1» или наоборот. Это приводит к появлению ложных значений, что может обернуться некорректной работой ИИ-приложений. Одной из причин ошибок является космическое излучение, причём с ростом плотности размещения ресурсов его влияние нарастает. Впрочем, в современных комплексных системах такие ошибки по разным причинам могут возникать на любом из этапов хранения, передачи и обработки информации. 
Ошибка в одном бите одного параметра существенно меняет ответ ИИ (Источник: Meta✴) Такие необнаруженные аппаратные сбои, которые не могут быть выявлены и устранены «на лету», называют тихими повреждениями данных (Silent Data Corruption, SDC). Подобные ошибки могут провоцировать изменения ИИ-параметров, что, в конечном счёте, приводит к некорректному инференсу. Утверждается, что в среднем 4 из 1000 результатов инференса неточны именно из-за аппаратных проблем. «Растущая сложность и неоднородность платформ ИИ делает их всё более восприимчивыми к аппаратным сбоям», — говорится в исследовании Meta✴. При этом изменение одного бита может привести к тому, что ошибки будут расти как снежный ком. Для оценки возможных неисправностей предлагается ввести новую величину — «коэффициент уязвимости параметров» (Parameter Vulnerability Factor, PVF). PVF показывает вероятность того, как повреждение конкретного параметра в конечном итоге приведёт к некорректному ответу ИИ-модели Эта метрика, как предполагается, позволит стандартизировать количественную оценку уязвимости модели ИИ к возможным аппаратным сбоям. Показатель PVF может быть оптимизирован под различные модели и задачи. Метрику также предлагается использовать на этапе обучения ИИ и для выявления параметров, целостность которых надо отслеживать. Производители аппаратного оборудования также принимают меры к повышению надёжности и устойчивости работы своих решений. Так, NVIDIA отдельно подчеркнула важность RAS в ускорителях Blackwell. Правда, делается это в первую очередь для повышения стабильности сверхкрупных кластеров, простой которых из-за ошибок обойдётся очень дорого.
18.06.2024 [16:03], Руслан Авдеев
Интернет во Вьетнаме снова под угрозой: отказали три из пяти подводных кабелейБуквально день спустя после начала раздачи во Вьетнаме национальных доменов в зоне .VN, знаменующей укрепление цифрового суверенитета государства, там начались серьёзные неприятности со связью. По данным The Register, 15 июня отказали три из пяти морских интернет-кабелей, связывающих Вьетнам с остальным миром. По информации местного государственного агентства VNA, сбои серьёзно повлияли на связность, а к некоторым зарубежным сайтам вообще очень трудно получить доступ. Пострадал кабель Intra Asia (IA), связывавший Вьетнам с Сингапуром, цифровая магистраль Asia Pacific Gateway (APG) и Sia-Africa-Europe-1 (AAE-1). Полноценно связь до сих пор не восстановлена, так что вся нагрузка пока легла на немногочисленные наземные линии связи. Операторы не сообщают, когда связь восстановится, но в этом нет ничего удивительного, поскольку специализированные корабли для ремонта всегда в дефиците. Кроме того, довольно сложно установить точное место обрыва, а у кораблей могут уйти недели на то, чтобы добраться до него. 
Источник изображения: Guille Álvarez/unsplash.com Точная причина сбоев пока не называется, но ранее подобные инциденты обычно случались из-за естественной деградации кабелей или из-за непреднамеренного повреждения, либо, что бывало намного реже, в результате намеренного саботажа (как, вероятно, в Красном море). В начале 2023 года у Вьетнама уже были подобные проблемы, когда отказали не три, а все пять подводных ВОЛС. Тогда виноватыми назначили китайское рыболовное судно и неопознанный грузовой корабль. В целом именно якори и тралы нередко становятся причиной неумышленного повреждения подводных коммуникаций. Во Вьетнаме активно пытаются улучшить состояние морских кабельных соединений. План правительства предполагает получение ещё 60 Тбит/с через 2–4 новых подводных кабеля. С учётом того, что все пять уже имеющихся кабелей по плану должны сохранить работоспособность к 2025 году, общая пропускная способность каналов связи должна вырасти до 122 Тбит/с. Обрыв кабелей произошёл в не самое удачное время. Местное Министерство информации и коммуникаций 14 июня объявило, что бизнес-пользователи доменных имён BIZ.VN для новых сайтов получат два года бесплатного обслуживания, как и граждане страны от 18 до 23 лет, использующие домен ID.VN в личных целях. Таким образом власти пытаются привлечь к использованию домена .VN побольше местных пользователей. Сейчас национальные использует только четверть вьетнамских компаний, тогда как в развитых странах этот показатель находится на уровне 70 %. |
|

