Материалы по тегу: сбой
|
15.01.2025 [18:56], Владимир Мироненко
Из-за повреждения линии связи в Татарстане 3,8 млн россиян столкнулись с замедлением интернетаВо второй половине дня у многих россиян заметно снизилась скорость доступа в интернет. Как сообщили ТАСС в пресс-службе Роскомнадзора (РКН), в подведомственном ведомству Центре мониторинга и управления сетью связи общего пользования (ЦМУ ССОП) было зафиксировано повреждение на магистральной волоконно-оптической линии связи в Республике Татарстан. В связи с этим примерно 3,8 млн пользователей в 21 субъекте страны столкнулись с проблемами с доступом в интернет. «В связи с повреждением возможно снижение скорости работы сети Интернет и деградация сервисов для клиентов оператора связи», — предупредили в пресс-службе, не указав, о каком операторе связи идёт речь. «На участке Тюлячи – Новая Тура произошел обрыв магистрального кабеля. Повреждение кабеля привело к деградации услуг ШПД (широкополосного доступа в интернет)», — констатировали в РКН. 
Источник изображения: Shoaib Asif/unsplash.com Также сообщается, что устранением повреждения на месте уже занимаются аварийно-восстановительные бригады. По данным РКН, к 21:00 мск неисправность должна быть устранена. Это уже второй крупный инцидент за несколько дней, связанный со сбоями в работе интернета. Вчера проблемы в работе интернета наблюдались буквально у всех операторов связи и провайдеров России. Как объяснил РКН, это было вызвано «кратковременным нарушением связности», но сбой удалось быстро устранить. UPD: обрыв произошёл в результате земляных работ в посёлке Царёво; «Ростелеком» сообщил о восстановлении ВОЛС.
27.12.2024 [15:00], Руслан Авдеев
В Балтийском море порваны сразу четыре интернет-кабеля и один силовойФинские власти сообщили о высадке на нефтяной танкер, подозреваемый в умышленных обрывах нескольких кабелей в Балтийском море. 25 декабря от якоря корабля Eagle S пострадал 658-МВт подводный HVDC-кабель Estlink 2 между Финляндией и Эстонией, сообщает Datacenter Dynamics. Почти в то же время были оборваны три интернет-кабеля, связывающие две страны. Два из них принадлежат финскому оператору Elisa, а третий — китайской Citic. Кроме того, был повреждён интернет-кабель Cinia между Финляндией и Германией. Финское транспортное и коммуникационное агентство Traficom объявило, что проблемы с кабелями могут вызвать перебои со связью у клиентов. Сейчас регулятор расследует последствия инцидентов, взаимодействуя с операторами. О расследовании сообщала и финская полиция. По данным финского Национального бюро расследований (NBI), следствие рассматривает инцидент, как преступное причинение ущерба при отягчающих обстоятельствах. Местная таможенная служба ведёт предварительное расследование на борту и выясняет детали, касающиеся груза. Утверждается, что кабель Estlink 2 на 658 МВт был оборван именно в том время, когда над ним проходил нефтяной танкер Eagle S, шедший из Санкт-Петербурга (Россия) в Порт-Саид (Египет). По данным финских властей, полиция Хельсинки и местная береговая охрана провели на нём «тактическую операцию». Власти приняли меры для расследования происшествия с судном, доступ им на борт обеспечили береговая охрана и финские военные вертолёты. 
Источник изображения: Finnish Border Guard Сообщается, что ремонт силового кабеля начнётся в конце недели, но расписание, помимо прочего, зависит от погодных условий и прочих факторов. Также сообщается, что инцидент не повлиял на безопасность снабжения Финляндии и она защищена от сбоев в электроснабжении и телеком-секторе. Инцидент произошёл всего через месяц после того, как другой корабль подозревался в намеренном повреждении якорем двух ВОЛС на дне Балтийского моря. Тогда на корабль высадился датский военный десант, расследование всё ещё продолжается. Не так давно пострадала и наземная кабельная инфраструктура, связывающая Швецию и Финляндию. Финский премьер-министр Петтери Орпо (Petteri Orpo) в свете последних событий подчеркнул опасность «теневого флота» в Балтийском море.
25.12.2024 [16:50], Руслан Авдеев
От дна океана до космоса: проект НАТО HEIST занялся созданием резервного космического интернетаВ начале февраля 2024 года ракета поразила судно Rubymar в Красном море. Повреждённое судно тонуло неделями, на 70 км протащив за собой якорь, разорвавший три интернет-кабеля, на которые приходилось четверть интернет-трафика между Европой и Азией. На ремонт кабелей ушли месяцы. Теперь в рамках проекта HEIST в НАТО начали тестировать систему перенаправления трафика через околоземное пространство, сообщает IEEE Spectrum. На подводные волоконно-оптические линии связи приходится более 95 % межконтинентального интернет-трафика. Общая протяжённость 500-500 кабелей, проложенных по дну, составляет 1,2 млн км. По некоторым оценкам, ВОЛС обеспечивают финансовые транзакции более чем на $10 трлн ежедневно. Сами кабели находятся глубоко, они довольно тонкие и, по сути, не имеют никакой защиты на глубине. Если значительный ущерб может нанести повреждение одного или нескольких кабелей, то настоящая катастрофа для владельцев и пользователей может произойти, если атака произойдёт на государственном уровне. 
Источник изображения: HEIST Поэтому НАТО запустила пилотный проект HEIST (hybrid space-submarine architecture ensuring infosec of telecommunications). HEIST должен помочь в быстром определении точного местоположения повреждённого участка кабеля. Кроме того, проект направлен на создание «обходных путей» передачи данных в случае обрыва. В числе прочего предусматривается и передача информации через спутники на орбите. В 2025 году планируется начать испытания на южном побережье Швеции — интеллектуальные системы, возможно, позволят определять места разрывов с точностью до метра. Кроме того, будут вестись работы над протоколами быстрого перенаправления данных на доступные спутники. Также эксперты будут разбираться в правилах использования подводных кабелей — пока нет единого органа, контролирующего их работу. В проекте приняли участие исследователи из Исландии, Швеции, Швейцарии, США и других стран. 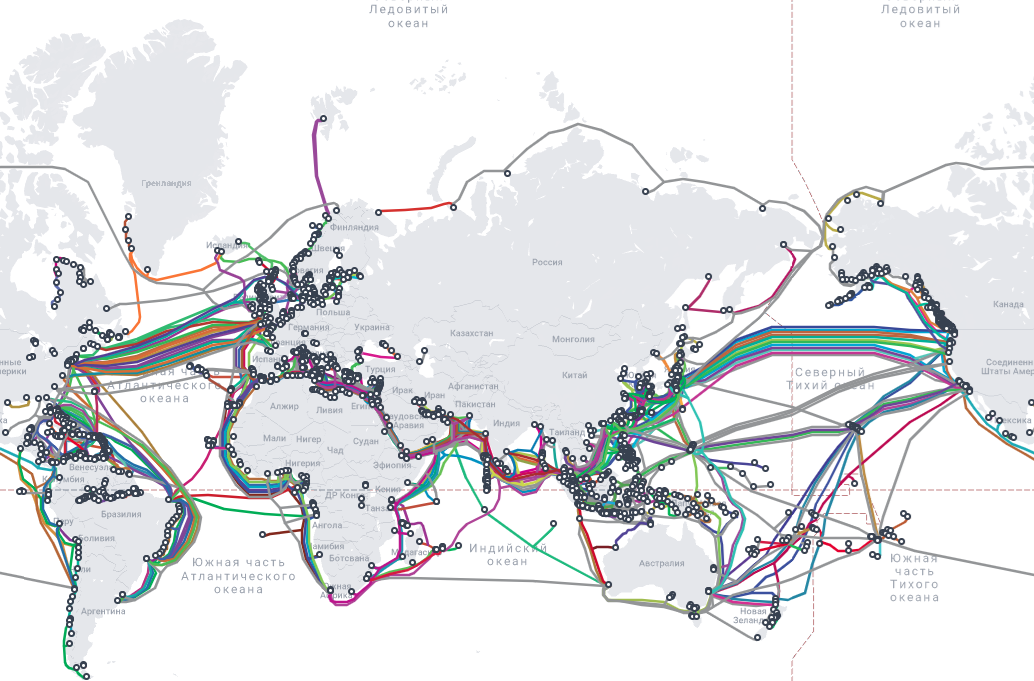
Источник изображения: Submarine Cable Map В TeleGeography напоминают, что безо всяких диверсий ежегодно происходит около 100 обрывов кабелей. Большинство из них устраняются специально оборудованными судами. На весьма дорогой ремонт может уйти от нескольких дней, недель или месяцев. В некоторых случаях речь может идти даже о годах. До сих пор у операторов связи и даже некоторых стран не было альтернатив на случай обрыва. Например, Исландию, на базе ЦОД которой работают многие финсервисы и выполняется много облачных вычислений, связывают с Европой и Северной Америкой всего четыре кабеля. Спутники способны помочь в передаче данных, но главным ограничением является их малая пропускная способность, которая на порядки меньше, чем у оптоволокна — единицы Гбит/с против десятков или сотен Тбит/с. HEIST предполагает развитие спутниковой связи, в том числе с использованием лазеров для коммуникаций. Над похожими проектами работают NASA, Starlink и Amazon. В NASA уверены, что лазеры смогут ускорить передачу минимум в 40 раз. Впрочем, это всё ещё далеко до пропускной способности кабелей, да и лазеры имеют ряд технических ограничений, мешающих повсеместному применению. Над повышением пропускной способности и сокращением времени задержки и будут работать в HEIST, хотя пока ни один из способов не является панацеей. Заявляется, что вся работа HEIST будет максимально публичной — люди смогут активно обсуждать и критиковать идеи, и способствовать его быстрому развитию.
20.12.2024 [16:10], Руслан Авдеев
Fujitsu заявила, что неоднократно предупреждала Почту Великобритании о проблемах с ПО Horizon, сломавших жизнь сотням людейВ ходе расследования Horizon Inquiry, посвящённого скандалу с британской почтовой службой, вскрылись неприглядные факты. Ошибки в ПО Horizon, из-за которых многих сотрудников несправедливо обвинили в мошенничестве, перекладываются почтой и разработчиком ПО, компанией Fujitsu, друг на друга, сообщает The Register. Fujitsu заявляет, что сообщала об ошибках в ПО, которые игнорировались ответственными лицами. Почта же утверждает, что ничего не знала и вообще зависела от японской компании. В своё время ПО Horizon стало причиной множества бухгалтерских сбоев, в результате которых сотрудники британской почтовой службы подверглись преследованию, в том числе уголовному. По словам юристов Fujitsu, поставщик IT-платформы Horizon не несёт ответственности за десятки сломанных жизней. Компания якобы в течение 25 лет сообщала почте о багах, ошибках и дефектах ПО и их влиянии на бухгалтерию государственной организации. Расследование началось в 2021 году и продолжается до сих пор. 
Источник изображения: Michael Jasmund / Unsplash Horizon представляет собой систему электронных терминалов продаж (EPOS) и финансового учёта, использующуюся Почтовой службой Великобритании. Она внедрялась компанией ICL, которую позже приобрела Fujitsu. С 1999 по 2015 гг. 736 управляющих почтовыми отделениями были неправомерно обвинены в мошенничестве — на деле причиной неточностей в бухгалтерии были ошибки ПО. В результате многие бывшие сотрудники почты стали банкротами, другие попали в тюрьму, а некоторые свели счёты с жизнью. Хотя многие обвинения сняли в судах, 60 человек по разным причинам не дожили до оправдания. Юридический представитель почты отрицает, что руководство знало о проблемах, а адвокат бывшей главы структуры Паулы Веннеллс (Paula Vennells) отрицает, что та знала о проблемах с Horizon. Представитель Fujitsu заявил, что компания установила как минимум 70 причастных, в отношении которых есть свидетельства того, что они всё время знали о проблеме. В том числе речь идёт о членах совета директоров Почтовой службы Великобритании, её топ-менеджерах и сотрудниках службы безопасности, а также командах, участвовавших в расследовании инцидентов. Утверждается, что почта пыталась замять и скрыть свою ответственность за скандал и несправедливо пытается обвинить во всём Fujitsu и другие «третьи стороны». В числе прочего почта пыталась выдать себя за «подчинённого партнёра» Fujitsu, находящегося от той в «технически зависимом» состоянии, но расследованием заявления не подтверждаются. 
Источник изображения: Joanna Kosinska / Unsplash Представитель Почтовой службы, в свою очередь, заявил, что та сожалеет о том, что положилась на японскую компанию, понадеявшись на надёжность Horizon. В результате ложное предположение об отсутствии ошибок якобы помешало вовремя принять меры — сыграло роль и желание защитить бренд и экономические интересы компании, а иерархия в организации не давала низовым сотрудникам дать делу об ошибках ход. Кроме того, руководящие должности занимали недостаточно компетентные люди, что привело к ряду управленческих ошибок. Обмена ключевой информации о Horizon в рамках почтовой структуры не происходило ни «вертикально», ни «горизонтально». Адвокат Саманта Лик (Samantha Leek), защищающая интересы непосредственно бывшей главы Почтовой службы Великобритании Веннелс, заявила, что бывшие коллеги подзащитной из числа топ-менеджеров не передали важную информацию о Horizon ни совету директоров, ни генеральному директору. Утверждается, что бывшая глава почты «опустошена» фактом того, что с ней не поделились сведениями и не имеет желания «показывать пальцами» на других или спекулировать, почему информацию не передали. Это не единственный случай в Великобритании, когда ПО проверенных компаний становится причиной катастрофических событий. В своё время ERP-система Oracle фактически довела до банкротства муниципалитет Бирмингема (крупнейший в Европе) — история не закончена до сих пор, а расходы превысили сотню миллионов фунтов.
03.12.2024 [17:10], Руслан Авдеев
Интернет-кабель между Швецией и Финляндией был повреждён сразу в двух местахКак сообщила GlobalConnect, проходящие через сухопутную шведско-финскую границу линии связи были дважды повреждены в течение очень короткого времени. Как передаёт Associated Press, соответствующая информация обнародована сегодня, хотя проблемы с кабелями начались ещё в понедельник и сразу в двух местах. Сбой затронул порядка 6 тыс. частных клиентов и 100 корпоративных пользователей. Первое повреждение уже устранено и доступ в интернет «в основном» восстановлен, а над вторым пока работают специалисты. Один обрыв был связан с земляными работами, причины второго не выяснены. При этом министр транспорта и коммуникаций Лулу Ранне (Lulu Ranne) Финляндии написала в социальной сети X, что представители властей уже ведут расследование происшествий совместно с компанией и «относятся к ситуации серьёзно». Финская полиция опубликовала краткое заявление, в котором указала, что не проводит уголовного расследования в связи с инцидентом. 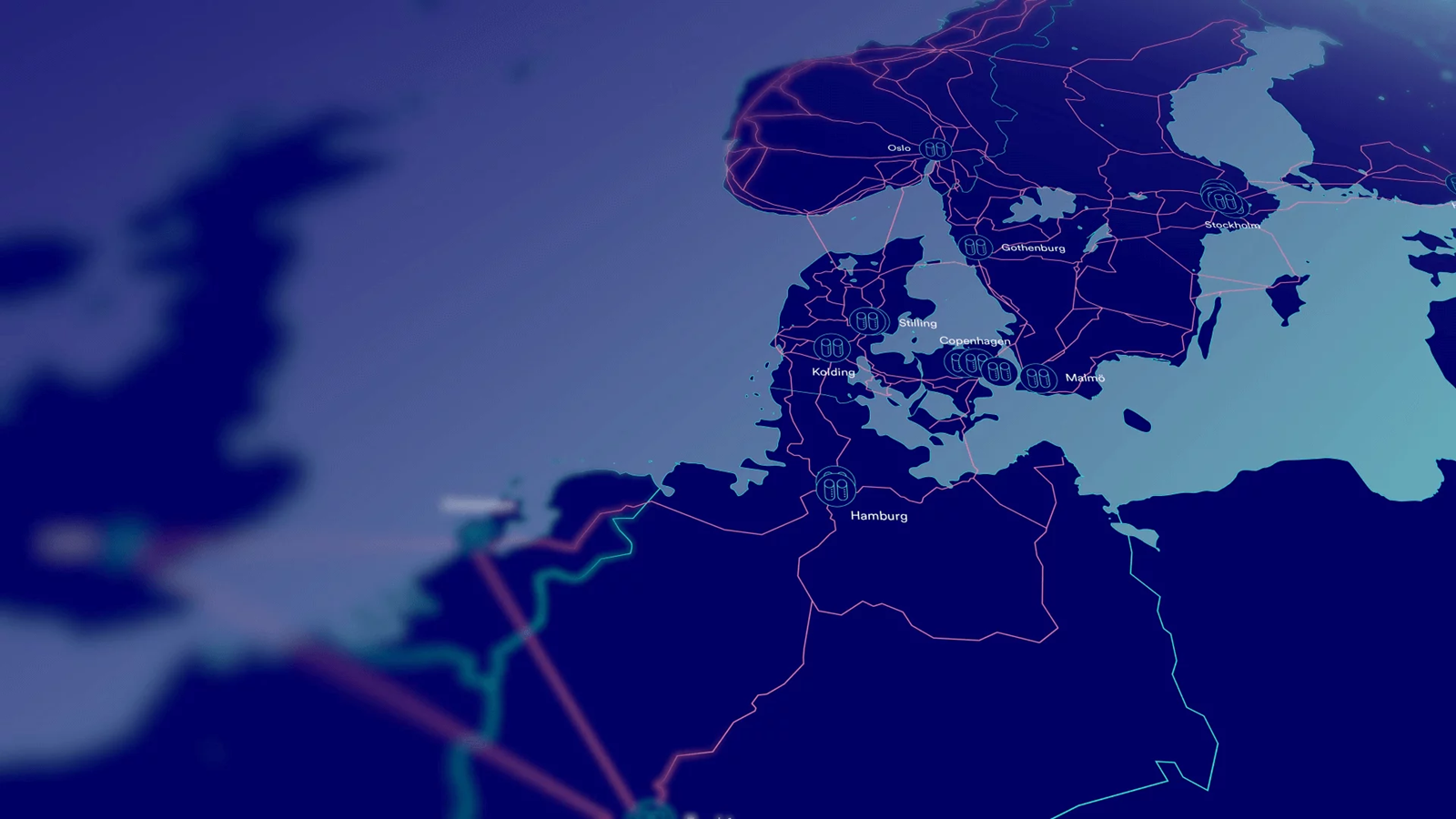
Источник изображения: GlobalConnect Балтийский регион уже оказался недавно в центре внимания в связи с повреждением кабелей стран НАТО, в том числе подводной инфраструктуры, связывающей Финляндию с Германией и Литву с Швецией. Буквально на днях Международный союз электросвязи (ITU) и Международный совет по охране кабелей (ICPC) объявили о создании совета, посвящённого обеспечению надёжности работы подводной кабельной инфраструктуры.
02.12.2024 [19:14], Руслан Авдеев
ITU и ICPC сформировали комитет по защите подводных интернет-кабелейНа днях Международный союз электросвязи (ITU) совместно с Международным советом по охране кабелей (ICPC) объявили о создании специального совета, посвящённого обеспечению надёжности работы подводной кабельной инфраструктуры. Анонс состоялся в тот же день, когда в Балтийском море была восстановлена работа ВОЛС C-Lion1 между Германией и Финляндией, сообщает The Register. Совет включает 40 членов из числа министров некоторых государств, представителей регуляторов, лидеров индустрии и экспертов. Его целью является продвижение наиболее эффективных практик, позволяющих обеспечить своевременный ремонт кабелей по всему миру и снижение рисков их повреждений. Хотя инцидент в Балтийском море некоторые считают диверсией, в большинстве случаев кабели повреждают случайно — во время вылова рыбы или при работе с якорями. Нередко причиной повреждений являются стихийные бедствия, естественный износ или отказ оборудования. По подсчётам ICPC, в среднем ежегодно происходит 150–200 инцидентов, т.е. ежендельно ремонта требуют примерно три кабеля. На первый взгляд это не так уж много, но с учётом того, что на подводные кабели приходится 99 % международного трафика, и критической важности цифровой инфраструктуры в целом, в ITU и ICPC считают жизненно необходимым создание профильного совета. 
Источник изображения: Cinia Первое официальное мероприятие Submarine Cable Resilience Summit состоится в начале 2025 года и пройдёт в Абудже (Нигерия). Собрания будут проводиться дважды в год, начиная (в виртуальном формате) с декабря 2024 года. Хотя ICPC и ITU не заявляли, что рассматривают диверсию в качестве причины недавнего повреждения кабелей, время для анонса нового совета выбрано подходящее. Сбой в работе кабеля C-Lion1 зарегистрирован 18 ноября 2024 года в 04:04 утра. Ремонтные работы в шведской исключительной экономической зоне завершились раньше, чем планировалось — 28 ноября в 21:00 по восточноевропейскому времени (EET). Ремонт выполнили довольно быстро, несмотря на необходимость переброски оборудования в Балтийское море. Cinia, оператор кабеля, говорит, что ущерб был минимальный, но инцидент свидетельствует о необходимости защиты кабелей. В компании считают, что международные правила необходимо ужесточить, чтобы увеличить риск для желающих нанести намеренный ущерб. В последнее время американская разведка предупреждала о возросшей активности российских кораблей неподалёку от европейской кабельной инфраструктуры. Не всё спокойно и в других регионах. В начале года из-за инцидентов в Красном море значительно сократился трафик между Азией и Европой. В прошлом году было повреждено сразу несколько кабелей у берегов Вьетнама и Тайваня.
27.11.2024 [19:50], Владимир Мироненко
QNAP случайно заблокировала пользователям доступ к их NAS-хранилищам с обновлением ОС QTSПосле выпуска 19 ноября компанией QNAP обновления операционной системы QTS 5.2.2.2950 build 20241114 стали поступать жалобы «от некоторых пользователей, сообщающих о проблемах с функциональностью устройства после установки», пишет Ars Technica. Как сообщила компания, обновление было отозвано, после чего она «провела всестороннее расследование» и повторно выпустила исправленную версию «в течение 24 часов». По словам QNAP, проблемы возникли лишь у ограниченного перечня моделей NAS серий TS-x53D и TS-x51, в том числе TS-453DX, TBS-453DX, TS-251D, TS-253D, TS-653D, TS-453D, TS-453Dmini, TS-451D и TS-451D2, но на форуме сообщества пишут о более широком списке устройств компании, у которых возникли проблемы после обновления ОС QTS. В числе проблем называют отказ владельцам в доступе в качестве авторизованных пользователей, сложности с загрузкой и заявления о неустановленном Python для запуска некоторых приложений и служб. 
Источник изображения: QNAP QNAP рекомендовала столкнувшимся с проблемами пользователям либо понизить версию ОС своих устройств (предположительно, чтобы затем снова обновиться до исправленного обновления), либо обратиться в службу поддержки за помощью. Как сообщают пользователи на форумах и в социальных сетях, реакция компании не соответствует серьёзности потери доступа ко всей системе резервного копирования. Обновление QTS было направлено, в частности, на устранение недавно обнаруженных уязвимостей в устройствах QNAP, которые нередко подвергаются атакам хакеров. Серьёзная уязвимость, выявленная в феврале 2023 года, позволяла выполнять удаленные SQL-инъекции и потенциально получать административный контроль над устройством. Она затронула почти 30 тыс. устройств QNAP. Ранее DeadBolt, группировка вымогателей, заразила тысячи устройств QNAP, что вынудило компанию автоматически отправлять экстренные апдейты даже клиентам с отключенными автоматическими обновлениями. Исследователи безопасности из WatchTowr сообщили, что обнаружили 15 уязвимостей в операционных системах и облачных сервисах QNAP и известили о них компанию. После того, как QNAP не смогла устранить некоторые из этих уязвимостей в течение 90-дневного периода, WatchTowr опубликовала свои выводы под названием «QNAPping at the Wheel».
19.11.2024 [12:11], Руслан Авдеев
В Балтийском море повреждены интернет-кабели, связывавшие Финляндию и Германию, а также Литву и ШвециюПодводный кабель «Хельсинки-Росток» (Helsinki-Rostock), связывавший Финляндию и Германию, а также кабель, соединявший Литву и шведский остров Готланд, повреждены. По данным Datacenter Dynamics, повреждённые участки кабелей расположены буквально в 10 м друг от друга, но их работа прекратилась в разное время. Кабель из Литвы протяжённостью 218 км, по данным телеком-компании Telia Lietuva, прекратил работу в минувшее воскресенье утром, тогда как 1200-км кабель, принадлежащий и управляющийся финской Cinia Oy, перестал работать только утром в понедельник. Хотя представители телеком-операторов заявляют об обрыве, его точные причины до сих пор не установлены. Cinia Oy заявила, что пока «нет никакой возможности» определить причину инцидента. Тем не менее утверждается, что такие повреждения не происходят без внешнего воздействия, но кто несёт ответственность за произошедшее, пока сказать трудно — в самих компаниях считают вероятным, что повреждения могут быть вызваны якорем или тралом, намеренно или случайно. Принадлежащий OMS Group корабль для прокладки и ремонта кабелей Cable Vigilance уже получил задачу на выход из французского Кале, на устранение проблемы ему понадобится 5–15 дней. В Национальном центре кибербезопасности Финляндии сообщают, что связь в стране не пострадала, поскольку имеются и другие кабельные маршруты по территории Швеции. При этом Литва разом потеряла треть пропускной способности. 
Источник изображения: Miikka Luotio/unsplash.com Кабель Helsinki-Rostock заработал в 2016 году, он предназначен для помощи центральноевропейскому бизнесу в связи с дата-центрами, расположенными в Финляндии и других североевропейских странах. Немецкое и финское министерства иностранных дел уже «выразили озабоченность» происшествием, заявив, что защита общей инфраструктуры имеет критическое значение. Балтийское море вообще довольно сурово к подводной инфраструктуре. В 2022 году от атаки пострадали ветки газопровода «Северный поток» (Nord Stream). В 2023 году были повреждены кабели, связывавшие Финляндию и Швецию с Эстонией, тогда неполадки были устранены в считаные дни. Вина возлагалась на якорь китайского корабля-контейнеровоза, хотя доказать случайный или намеренный характер происшествия и не удалось. В последнее время американская разведка предупреждала о возросшей активности российских кораблей неподалёку от европейской кабельной инфраструктуры. Впрочем, в других регионах тоже не всё спокойно. Так, буквально в начале года из-за инцидентов в Красном море значительно сократился трафик между Азией и Европой. В прошлом году было повреждено сразу несколько кабелей у берегов Вьетнама и Тайваня. Обновлено: По подозрению в повреждении кабелей в Балтийском море задержан китайский сухогруз Yi Peng 3. Как сообщает Newsweek, эксперты-юристы говорят о том, что любое расследование может «занять годы» и создать прецедент на случай будущих диверсий. В Министерстве обороны Германии инцидент назван «гибридными действиями», а его шведские и литовские коллеги заявили о том, что они «глубоко обеспокоены». По данным The Financial Times, следствие изучает историю перемещений судна, направлявшегося из российского порта Усть-Луга в египетский Порт-Саид. В социальных сетях появилась информация, что капитан судна — россиянин, но подтверждения из официальных источников пока не поступало. По данным Marine Traffic, Yi Peng 3 проходил близко от точек обрыва кабелей примерно в то время, когда те перестали работать в воскресенье и понедельник. После этого судно преследовали датские ВМС, а теперь, по имеющимся данным, оно задержано датскими военными. Сообщалось, что судно охранялось патрульным кораблём Y311 SØLØVEN, к месту событий двигался и фрегат HDMS HVIDBJØRNEN. Представитель датских ВМС подтвердил пребывание военных в районе присутствия Yi Peng 3, но отказался комментировать ситуацию.
11.11.2024 [11:59], Руслан Авдеев
Неожиданное автоматическое обновление Windows Server может привести к катастрофическим последствиям для бизнеса и сисадминов
microsoft
software
windows server
windows server 2022
windows server 2025
windows update
операционная система
сбой
В последние дни отмечены случаи неожиданного автоматического обновления систем под управлением Windows Server 2022 до Windows Server 2025. На Reddit появилась информация со ссылкой на жалобы владельцев серверов. При этом отсутствует возможность «откатить» ПО до прежней версии. Хотя с точки зрения обычного пользователя обновление с версии 2022 до 2025 может показаться хорошей новостью, для сотрудников IT-отделов и системных администраторов это обещает массу неприятностей. Обновлённые операционные системы для серверов необходимо кропотливо проверять и тестировать, чтобы убедиться, что всё ПО совместимо с новой версией ОС. По словам пользователя Reddit, системного администратора Fatboy40, все серверы на Windows Server 2022 в его ведении обновились до Windows Server 2025 или «были готовы сделать это». Примечательно, что обновление до Windows Server 2025 вообще-то требует новой лицензии, поскольку ОС позиционируется как принципиально новое поколение операционной системы. Для сравнения — новейшая ОС для ПК Windows 11 24H2 официально считается лишь новым вариантом Windows 11. 
Источник изображения: ThisisEngineering/unsplash.com Как сообщил источник в стороннем сервисе обновлений Heimdal, похоже, обновление ошибочно классифицировали в Microsoft и как «необязательное обновление», и как «обновление безопасности» для систем под управлением Windows Server 2022. По данным Tom's Hardware, в Heimdal сообщили, что проблема обнаружена в репозитории обновлений Microsoft. Уникальный идентификатор обновления (GUID) для Windows Server 2025 не соответствует обычным параметрам для обновления KB5044284, которое и вовсе связано с Windows 11. Вероятно, речь идёт об ошибке на стороне Microsoft, повлиявшей как на скорость выпуска обновления, так и на его классификацию. Проверка Heimdal показала, что номер обновления действительно относится к Windows 11, а не к Windows Server 2025. Хуже всего то, что этот тип обновления Windows Server технически вообще не поддерживается, в отличие, например, от перехода с Windows 10 на Windows 11. В результате системные администраторы не имеют официального способа вернуться к прежней ОС без использования сторонних решений, позволяющих восстановить функциональность системы из бэкапов.
18.09.2024 [17:52], Руслан Авдеев
Куда по мокрому?! Alibaba Cloud ждёт пока просохнет оборудование, пострадавшее от пожара в сингапурском ЦОД Digital RealtyКатастрофический пожар, произошедший во вторник на прошлой неделе в сингапурском дата-центре Digital Realty, всё ещё осложняет работу облачных операторов. The Register, в частности, сообщает, что к полноценной работе не может приступить облачный регион Alibaba Cloud — в компании ждут, когда просохнет оборудование, чтобы попытаться восстановить данные. Согласно данным Alibaba Cloud, миграция и восстановление данных в повреждённом ЦОД SIN11 идёт по плану. Работа облачных сервисов постепенно восстанавливается. В компании подчеркнули, что часть оборудования по-прежнему находится в небезопасной и заблокированной зоне дата-центра. О возможном затоплении ряда помещений пожарные предупредили оператора заранее. Некоторое оборудование требует тщательной просушки до того, как можно будет попытаться запустить его без дополнительной угрозы целостности данных. На их восстановление уйдёт некоторое время. Из-за сбоя Alibaba Cloud, как выяснилось, пострадали и различные сервис-провайдеры, включая Lazada и ByteDance. 
Источник изображения: Adam Wilson/unsplash.com Причиной пожара, вероятно, стало возгорание Li-Ion элементов ИБП. Сообщалось, что для тушения и охлаждения АКБ пришлось задействовать пожарного робота, поскольку аккумуляторы могли повторно воспламениться, взорваться и выделить токсичные вещества. Ситуация усугублялась тем, что АКБ находились на третьем этаже четырёхэтажного ЦОД. Хотя современные нормы Сингапура предписывают размещать ИБП на первом этаже, объект Digital Realty ввели в эксплуатацию задолго до принятия этих норм. Это единственный из трёх кампусов Digital Realty в Сингапуре, созданный на основе уже имеющейся инфраструктуры. Ещё два были возведены с нуля. 
Источник изображения: Daan Mooij / Unsplash Как сообщает Alibaba Cloud, к вечеру злополучного вторника всё ещё звучала пожарная сигнализация, а некоторое сетевое оборудование функционировало со сбоями из-за высоких температур. Клиентов предупредили о возможных сбоях во всех зонах доступности данного облачного региона. В среду большинство облачных сервисов восстановили работу в результате переноса части нагрузок. В пятницу было объявлено, что часть оборудования находится «в стадии безопасной миграции». В субботу уже проводилась подготовка к установке оборудования, включая его сушку. От грандиозного пожара в своём время пострадал ЦОД OVHCloud в Страсбурге, долгое время оператор разбирался многочисленными претензиями пользователей. В самом Сингапуре после крупного сбоя дата-центра Equinix в прошлом году власти пообещали жёстко отрегулировать деятельность ЦОД и облаков. |
|

