Материалы по тегу: разработка
|
09.06.2026 [18:19], Руслан Авдеев
NVIDIA поможет SK hynix, Naver, Doosan, SK Telecom и LG расширить ИИ-инфраструктуру Южной КореиNVIDIA анонсировала новые партнёрства с южнокорейскими технологическими гигантами. В их числе — поставщик чипов памяти SK hynix, интернет-гигант Naver, транснациональный конгломерат Doosan Group, а также SK Telecom и LG, сообщает Silicon Angle. Сделки последовали за поездкой в Южную Корею главы NVIDIA Дженсена Хуанга (Jensen Huang). Прибыв в конце прошлой недели, он провёл выходные за встречами с руководителями южнокорейских технологических компаний. SK hynix подписала с NVIDIA соглашение о многолетнем технологическом партнёрстве, основное внимание в рамках которого уделяется совершенствованию чипов памяти нового поколения для использования в передовых ИИ ЦОД. В рамках договора компания будет взаимодействовать с NVIDIA для обеспечения стабильных поставок памяти для ИИ-индустрии. Кроме того, она попытается расширить присутствие в смежных нишах «персонального ИИ» и «физического ИИ» — например, в сфере автономной робототехники и транспорта. По словам Хуанга, стабильные поставки памяти имеют ключевое значение для ускорения строительства и масштабирования ИИ-фабрик, которые возглавят новую промышленную революцию под предводительством ИИ. Также партнёры намерены сотрудничать в области «технологий симуляции» для разработки полупроводников. SK hynix будет применять библиотеку NVIDIA CUDA-X и фреймворк PhysicsNeMo для повышения скорости и эффективности симуляций, используемых при разработке и производстве передовых чипов. Это включает технологии автоматизированного проектирования (т. н. Technology Computer-Aided Design, TCAD) для анализа характеристик полупроводниковых техпроцессов и технологии вычислительной литографии для создания схем микрочипов. 
Источник изображения: NVIDIA Дополнительно родственная SK hynix компания SK Telecom рассчитывает построить в Южной Корее новое ИИ-облако гигаваттного масштаба на основе ИИ-ускорителей и инфраструктурных решений NVIDIA. Первый из нескольких ИИ ЦОД в составе этого облака должен быть введён в эксплуатацию в начале следующего года. С Naver и Doosan компания тоже договорилась о дополнительных проектах в сфере ИИ ЦОД. В случае с Naver взаимодействие стартует в Седжоне (Sejong), где расположен один из крупнейших в Азии ИИ ЦОД — Naver GAK Sejong. Компании намерены нарастить возможности объекта, а позже заняться строительством дополнительных ИИ-фабрик гигаваттного уровня, хотя будущее этих планов зависит от того, сможет ли Naver обеспечить необходимые закупки оборудования и доступ к электроэнергии. Doosan, разрабатывающая интеллектуальную робототехнику и выпускающая компоненты для GPU NVIDIA, поможет последней задействовать её энергетические решения в своих платформах для ЦОД. Doosan же рассчитывает применять технологии физического ИИ NVIDIA в своих роботах. Наконец, NVIDIA и LG Group строят ИИ-фабрику для ускорения развития нового поколения бизнесов LG, драйвером которых выступит ИИ, — от робототехники до автономного вождения, технологий ЦОД и облачных GPU-сервисов. ИИ-фабрика обеспечит LG инфраструктурой для обучения ИИ, симуляций, оценки и внедрения ИИ-приложений в ключевых сегментах бизнеса. Совместно компании объединят разработку ИИ-моделей, генерацию данных для физического ИИ, моделирование и обучение робототехники, развёртывание решений на периферии и создание цифровых двойников в масштабах целых предприятий в единый рабочий процесс для создания систем физического ИИ. Партнёрство с южнокорейскими компаниями должно помочь расширить присутствие NVIDIA в Южной Корее — одном из мировых технологических лидеров. Кстати, SK hynix и её конкурент Samsung Electronics являются двумя из трёх крупнейших производителей чипов памяти в мире, продукция которых имеет жизненно важное значение для ИИ ЦОД. В ноябре 2025 года сообщалось, что NVIDIA продаст Южной Корее 260 тыс. ускорителей для создания суверенной ИИ-инфраструктуры.
01.06.2026 [08:41], Руслан Авдеев
Наш SQL: фанаты MySQL основали фонд OurSQL Foundation, чтобы давить на OracleСообщество, выступающее от имени пользователей и разработчиков СУБД MySQL, основало фонд с говорящим названием OurSQL Foundation. Он призван помочь выступить единым фронтом против Oracle, владеющей интеллектуальной собственностью, связанной с MySQL и open source, сообщает The Register. Новая НКО намерена помочь сообществу разработчиков и пользователей MySQL получать доступ к знаниям и обеспечить прозрачную обратную связь по будущим разработкам. Организация поддержит использование MySQL как СУБД с откытым исходным кодом и рассчитывает сотрудничать со всеми участниками рынка, включая Oracle, чтобы обеспечить успех ПО на рынке. Меры вызваны опасениями того, что СУБД теряет популярность и рыночную долю в сравнении с конкурентом — PostgreSQL. Кроме того, MariaDB от автора MySQL также пользуется популярностью. 
Источник изображения: Rod Long/unsplash.com В открытом письме энтузиасты отметили, что после перехода MySQL под контроль Oracle после покупки Sun Microsystems в 2009 году разработка ведётся без необходимой прозрачности, доработки осуществляются «за закрытыми дверями», а информация о планах развития ПО и процессе принятия решений ограничена. В марте Oracle предложила новый подход к привлечению разработчиков и обещала добавить функции, обеспечивающие векторный поиск, объявив, что MySQL имеет приоритетное значение для компании. По словам представителя Percona — одной из компаний, стоящих за OurSQL Foundation, речь не идёт о попытке противостоять Oracle. В состав совета директоров также вошли представители PlanetScale, PingCAP, VillageSQL и Alibaba. Кроме того, в совет входит и независимый эксперт — Жан-Франсуа Ганье (Jean-François Gagné).
29.05.2026 [16:19], Руслан Авдеев
Project Lightwell: IBM и Red Hat предложили корпорациям скинуться на патчи безопасности для open source ПО и сами вложат $5 млрдIBM и Red Hat объявили о начале реализации Project Lightwell, в рамках которого компании инвестируют $5 млрд в развитие ПО с открытым исходным кодом. Проект станет опираться на передовые ИИ-возможности и команду из более 20 тыс. разработчиков со всего мира. Это позволит задать новую модель работы корпоративных пользователей с open source — от разработки до промышленной эксплуатации. В рамках Project Lightwell создадут доверенный «клиринговый» информационный центр, а международная сеть разработчиков поможет в устранении уязвимостей. Эта платформа станет «координационным уровнем» для обеспечения безопасности, использующим передовые ИИ-возможности для проверки и тестирования патчей для огромных объёмов открытого исходного кода. Возможности будут доступны в рамках платных подписок, что позволит корпоративным клиентам интегрировать обновления безопасности в существующие цепочки поставок ПО. При этом им будет доступен корпоративный уровень валидации и управления жизненным циклом ПО. IBM и Red Hat подчеркнули, что именно open source лежит в основе современной IT-инфраструктуры, открытый код используют более 90 % компаний из списка Fortune 500. При этом развитие передовых ИИ-технологий ускоряет как поиск, так и использование уязвимостей. Например, специальная модель Mythos Preview компании Anthropic выявила в ПО open source почти 3,9 тыс. уязвимостей высокого и критического уровней. IBM и Red Hat начали сотрудничать с Bank of America, BNY, Citi, Goldman Sachs, JPMorganChase, Mastercard, Morgan Stanley, Royal Bank of Canada, State Street, Visa и Wells Fargo — одними из первых участников Project Lightwell. Предполагается, что опыт этих структур поможет сформировать протоколы обнаружения, проверки и устранения уязвимостей в сложных цепочках поставок открытого ПО. 
Источник изображения: IBM Проект опирается на уже имеющиеся компетенции IBM и Red Hat в сфере open source, корпоративных ИИ-продуктов и кибербезопасности. Также на вооружение берётся опыт инициатив вроде Anthropic Project Glasswing и OpenAI Trust Access for Cyber. В частности, проект предусматривает использование агентных ИИ-инструментов для защиты основных компонентов open source, лежащих в основе современных корпоративных и ИИ-систем. Ключевым элементом станет создание «клирингового» центра для обеспечения безопасности open source. Модели открытого ПО компаний IBM и Red Hat расширяются за пределы их собственных платформ. IBM уже использует более 62 тыс. пакетов open source, а также имеет большой опыт, связанный с 10 тыс. из них. Компании оперируют одними из крупнейших в отрасли открытых экосистем, управляя жизненными циклами, валидацией и выпуском патчей для их компонентов, применяя технологии на базе Linux, Java, Kubernetes, Kafka, Ansible, Terraform, Flink, Cassandra и др. Теперь предполагается применять аналогичный подход при работе с открытым исходным кодом из независимых источников. Клиенты смогут сообщать об уязвимостях в активных версиях ПО для их устранения с помощью доверенного посреднического механизма, получать проверенные патчи для решений Red Hat и независимого кода, координировать раскрытие информации об устранении уязвимостей. Пока многие компании используют ИИ для сокращения своего персонала, IBM и Red Hat делают ставку на использование базы из более 20 тыс. разработчиков, усиленной ИИ-инструментами. В задачи этой международной команды войдёт сопровождение продуктов вместе с лидерами open source сообществ; анализ, сортировка и построение иерархии уязвимостей; разработка обновлений безопасности и релиз-инжиниринг. Заявлено, что Project Lightwell поддерживает государственные (естественно, американские) приоритеты по защите цифровой инфраструктуры, критически важных систем и повышению устойчивости экосистем open source в целом. Примечательно, что ещё в январе сообщалось о том, что Евросоюз делает ставку на open source, чтобы избавиться от зависимости от IT-гигантов из США. Теперь получается, что блок в некоторой степени может попасть в зависимость, но уже от других американских IT-гигантов.
26.05.2026 [09:00], Сергей Карасёв
Гибкие настройки безопасности и новые инструменты для работы с шаблонами — «Базис» обновил конструктор Basis Automation Studio до версии 2.4Компания «Базис», лидер российского рынка ПО управления динамической инфраструктурой, представила версию 2.4 конструктора платформенных сервисов Basis Automation Studio — модуля, входящего в расширенную версию облачной платформы Basis Dynamix Cloud Control. Свежий релиз предлагает интеграцию со средством защиты виртуализации Basis Virtual Security, гибкую ролевую модель и поддержку работы с внешними системами версионирования через веб-портал. Basis Automation Studio представляет собой среду автоматизации развёртывания сервисов с инструментами визуального проектирования виртуальной инфраструктуры на основе готовых компонентов и связей между ними. В состав конструктора входит расширяемый каталог шаблонов виртуальных инфраструктур и платформенных сервисов, а также расширяемая библиотека компонентов с образцами популярного ПО — ClickHouse, Consul, Docker, MariaDB, PostgreSQL и других. Алгоритм развёртывания построен на архитектуре TOSCA с использованием языков YAML, Ansible, Python и Bash. Управление правами и доступомОдной из ключевых доработок релиза стала интеграция конструктора с решением защиты Basis Virtual Security. Конструктор использует Basis Virtual Security в качестве единого провайдера идентификации, что даёт администраторам возможность централизованно управлять учётными записями и правами доступа пользователей, а также обеспечивает поддержку технологии единого входа (Single Sign-On, SSO). В результате можно централизованно применять политики безопасности, что снижает нагрузку на администраторов, а пользователей платформы избавляет от необходимости вводить учётные данные при переходе между компонентами экосистемы «Базиса». 
Источник изображений: «Базис» В Basis Automation Studio 2.4 — в дополнение к имеющейся ролевой модели — была представлена её расширенная версия, которая позволяет тонко настраивать права доступа пользователей: администратор может собирать собственные роли из атомарных разрешений и назначать их в нужном объёме конкретным пользователям. Миграция на новую модель уже выполнена на уровне архитектуры конструктора. Интеграция с внешними Git-репозиториямиВ новой версии Basis Automation Studio появилась возможность загружать компоненты и шаблоны сервисов из Git-репозиториев. Загрузка и обновление компонентов и шаблонов сервисов осуществляется, используя графический интерфейс, по выбранному Git-тегу с возможностью пакетной загрузки. Поддерживаются разные способы аутентификации (пароль, токен). Загруженный компонент шаблон сервиса поддерживает версионирование (с возможностью обновления «вперед и назад»).  Тем самым продолжается развитие веб-портала как единой точки работы с конструктором. Ранее в портал были добавлены инструменты создания и редактирования компонентов и шаблонов. В новой версии конструктора добавилась интеграция с внешними Git-репозиториями. Это позволяет встроить разработку TOSCA-шаблонов в привычные для команд процессы работы с исходным кодом, обеспечить отслеживаемость изменений и упростить совместную работу над каталогом сервисов. В новом релизе также была добавлена оценка ресурсов для развёрнутых сервисов. Это позволяет пользователям анализировать ресурсные требования сервисов и точнее планировать их эксплуатацию. «Ключевая задача, которую Basis Automation Studio решает для бизнеса — упрощение процесса развёртывания ИТ-систем и сервисов внутри виртуального ЦОД. Поэтому мы развиваем продукт сразу в нескольких направлениях, связанных с решением этой задачи. В частности, мы уже реализовали централизацию управления доступом через интеграцию с другим нашим продуктом, Basis Virtual Security, а также более гибкое разграничение прав пользователей и включение конструктора в стандартные процессы разработки через поддержку Git в веб-портале», — отметил Дмитрий Сорокин, технический директор компании «Базис».
17.05.2026 [16:24], Владимир Мироненко
Мейнфреймы тоже «поржавеют»: для IBM z готовится поддержка Rust в ядре LinuxЯн Поленски (Jan Polensky) представил первый набор патчей под названием «s390: включение поддержки Rust и добавление необходимой архитектурной привязки», позволяющих реализовать поддержку языка программирования Rust в сборке ядра Linux для мейнфреймов IBM z. Поддержка уже реализована для архитектур x86-64, ARM, ARM64, LoongArch и RISC-V, но не для s390, отметил ресурс Phoronix. И если Fujitsu готова распрощаться с мейнфреймами, то IBM это направление пока забрасывать не планирует. Она даже намерена «подружит» их с Arm. В примечаниях Ян Поленски сообщил, что поддержка Rust на s390 требует небольшого набора специфических для архитектуры компонентов, прежде чем можно будет использовать общую инфраструктуру ядра Rust: недостающие интерфейсы ассемблера, корректировка параметров сборки для избегания конфликтов и т.д. В настоящее время s390 требует «ночные» сборки rustc. Набор патчей затрагивает всего несколько десятков строк кода, поэтому есть надежда, они будут приняты уже в ядро Linux 7.2. Как отметил ресурс The Register, использование нерелизных версий компилятора Rust, включающих самые свежие изменения, экспериментальные функции и новые возможности, что предполагает нестабильную работу, вряд ли будет воспринято с энтузиазмом многими консервативными компаниями, работающими с мейнфреймами. Тем не менее, набор патчей Поленски — значительный шаг. 
Источник изображения: PalePink Green / Unsplash Когда Rust был добавлен в ядро в 2022 году, The Register упомянул проблему, которая редко поднимается где-либо ещё: хотя ядро обычно компилируется с помощью GCC, стандартный компилятор Rust — rustc — основан на LLVM. Список бэкендов LLVM хотя и растёт, но гораздо короче, чем набор из 48 компиляторов GCC. Существует экспериментальный фронтенд GCC для Rust, но он ещё не готов к полноценному использованию. Само ядро Linux поддерживает компиляцию с использованием LLVM с версии ядра 6.9, выпущенной более двух лет назад.
13.05.2026 [00:40], Владимир Мироненко
Red Hat анонсировала интегрированную ИИ-платформу Red Hat AI 3.4Red Hat представила Red Hat AI 3.4, обновлённую версию корпоративной ИИ-платформы, разработанную для поддержки крупномасштабного инференса и развёртывания агентного ИИ в гибридных облачных средах. В качестве комплексной платформы Red Hat AI 3.4 предлагает архитектурную основу и операционные инструменты, необходимые для масштабирования моделей и рабочих процессов агентов в гибридном облаке. Стратегия Red Hat в области ИИ разделена на четыре ключевых направления, заявил Джо Фернандес (Joe Fernandes), вице-президент и генеральный директор Red Hat AI. «Во-первых, мы помогаем клиентам быстро, гибко и эффективно выполнять инференс, предоставляя модели в их среде, — передаёт SiliconANGLE. — Во-вторых, мы подключаем их корпоративные данные к этим моделям и агентам. В-третьих, мы помогаем им ускорить развёртывание и управление агентами в гибридной облачной среде. В-четвёртых, мы объединяем всё это на нашей интегрированной ИИ-платформе, позволяя им запускать любую модель в любом агенте на любом оборудовании и в любой облачной среде». Как отметила компания, ключевым элементом этого релиза является предоставление модели как услуги (MaaS), которое обеспечивает единый управляемый интерфейс для разработчиков, позволяющий получать доступ к тщательно отобранным моделям, а администраторам — отслеживать их использование и применять политики. Разработчики получают доступ к моделям через стандартные OpenAI-совместимые API. Таким образом, единое управление применяется как к внутренним, так и к внешним моделям. А инструменты AutoRAG и AutoML автоматизируют сложные задачи ИИ, начиная с выбора наиболее эффективных стратегий извлечения данных для конкретных наборов и заканчивая построением и оптимизацией моделей. 
Источник изображения: Red Hat В основе системы лежит открытая библиотека vLLM. Её дополняет Kubernetes-нативный стек для инференса llm-d. Поддержка спекулятивного декодирования, которая в этом релизе стала общедоступной, повышает скорость ответа в два-три раза с минимальным влиянием на его качество и снижает стоимость взаимодействия. Кроме того, vLLM теперь поддерживает работу на CPU, что актуально для небольших языковых моделей. Для управления инструментами для агентов Red Hat представляет каталог серверов MCP и связанный с ним шлюз MCP. Новый инструментарий AgentOps даёт возможность управления агентами в масштабе, независимо от используемой платформы, на протяжении всего их жизненного цикла. Это включает в себя интегрированную трассировку вызовов LLM, вызовов инструментов и этапов рассуждений, а также управление криптографической идентификацией через SPIFFE/SPIRE. Последний позволяет организациям заменять статические, жёстко закодированные ключи кратковременными токенами. Это поддерживает операции с минимальными привилегиями для автономных агентов на всех уровнях стека и помогает подтвердить, что действия агентов связаны с проверенной личностью. Для обеспечения интеграции корпоративных данных с моделями и агентами Red Hat AI 3.4 представляет управление с помощью промптов и центр оценки точности, качества и безопасности моделей и агентов. Последний не зависит от фреймворков и заменяет разрозненные методы тестирования единым интегрированным подходом. Prompt Lab and Registry, централизованное хранилище промптов в виде полноценных информационных ресурсов, предоставляет разработчикам и администраторам единый источник достоверной информации о входных данных, управляющих моделями и агентами. 
Источник изображения: Red Hat Новые возможности трассировки построены на основе MLflow. Интеграция MLflow обеспечивает прозрачность работы агента, позволяя осуществлять сквозную трассировку вызовов LLM, этапов рассуждений, запуска инструментов, ответов модели и использования токенов через OpenTelemetry. Это создаёт прозрачный журнал аудита для всего жизненного цикла подсказок, эмбеддингов и конфигураций RAG для поддержки отладки и аудита. MLflow также обеспечивает интегрированное отслеживание экспериментов и управление артефактами для сценариев использования генеративного ИИ и прогнозного ИИ. Платформа Red Hat AI позволяет пользователям проверять безопасность моделей и агентов с помощью автоматизированного сканирования на наличие угроз, которое теперь интегрировано непосредственно в цикл разработки. Используются инструменты Chatterbox Labs и Garak. Платформа проверяет модели и агентных систем на наличие таких рисков как взлом, промпт-инъекций и предвзятость, в сочетании с NVIDIA NeMo Guardrails для обеспечения безопасности во время выполнения. Сообщается, что Red Hat AI 3.4 изначально поддерживает ускорители NVIDIA Blackwell и AMD Instinct MI325X. Расширяя эту унифицированную архитектуру платформы для работы непосредственно в управляемых облаках сторонних разработчиков, в том числе посредством Red Hat AI Inference в IBM Cloud, Red Hat обеспечивает операционную согласованность на широком спектре оборудования и облачных провайдеров.
12.05.2026 [13:24], Сергей Карасёв
Новое бизнес-подразделение OpenAI поможет клиентам во внедрении ИИГруппа OpenAI Group PBC сформировала бизнес-подразделение OpenAI Deployment Company, которое будет оказывать сторонним заказчикам услуги по внедрению ИИ-моделей и их оптимизации под конкретные задачи. Инвестиции в OpenAI Deployment Company на первом этапе составят $4 млрд при оценке этой структуры в $14 млрд. Средства поступят от самой OpenAI и более чем десяти других инвесторов, крупнейшим из которых является управляющая компания TPG. В раунде также приняли участие SoftBank Group, Bain Capital, Brookfield, Capgemini SE и McKinsey & Co. Контроль над формируемой организацией сохранит за собой OpenAI. Компания обязалась обеспечить минимальную доходность в размере 17,5% для внешних инвесторов OpenAI Deployment Company. Новая структура поможет крупным предприятиям во внедрении ИИ-моделей OpenAI. Для этого на объекты заказчиков будут направляться инженеры по развёртыванию (Forward Deployed Engineer, FDE) — специалисты, обладающие навыками разработки ПО и взаимодействия с клиентами. Такие инженеры выступают в качестве связующего звена между поставщиком продуктов и заказчиком. 
Источник изображения: unsplash.com / Growtika Внедрение ИИ-моделей на стороне клиента OpenAI намерена осуществлять в рамках многоэтапного процесса. Сначала специалисты оценят возможные варианты применения ИИ на площадке заказчика и разработают наиболее эффективные сценарии использования. Затем будет осуществлено пилотное развёртывание для «небольшого количества приоритетных рабочих процессов»: это поможет продемонстрировать отдачу от применения продуктов OpenAI. На финальном этапе произойдёт полноценное внедрение. Кроме того, по запросу клиента специалисты OpenAI Deployment Company могут осуществить сопутствующие работы, например, интегрировать ИИ-модель с существующими приложениями в IT-инфраструктуре заказчика. Для развития бизнеса OpenAI Deployment Company приобрела лондонскую фирму Tomoro AI Ltd., предоставляющую технологические услуги. В результате этой сделки, финансовые условия которой не раскрываются, OpenAI получила около 150 инженеров FDE и других технических специалистов.
12.05.2026 [12:00], Сергей Карасёв
«Базис» представил конструктор платформенных сервисов Basis Automation StudioКомпания «Базис», крупнейший российский разработчик решений для управления динамической ИТ-инфраструктурой, представила конструктор платформенных сервисов Basis Automation Studio (BAS). Решение является частью расширенной конфигурации облачной платформы Basis Dynamix Cloud Control и будет актуально в первую очередь для заказчиков, которые хотят автоматизировать развёртывание сложных ИТ-систем и платформенных сервисов, использующих виртуальную инфраструктуру. Для решения этой задачи Basis Automation Studio предоставляет системным администраторам и архитекторам заказчика инструменты для проектирования, развёртывания и сопровождения платформенных сервисов в виртуальной инфраструктуре. Конструктор позволяет визуально проектировать инфраструктуру на основе готовых компонентов и связей между ними, использовать каталог шаблонов виртуальных инфраструктур и платформенных сервисов, а также расширяемую библиотеку типовых элементов и образцов востребованного ПО, включая ClickHouse, Consul, Docker, MariaDB и PostgreSQL. 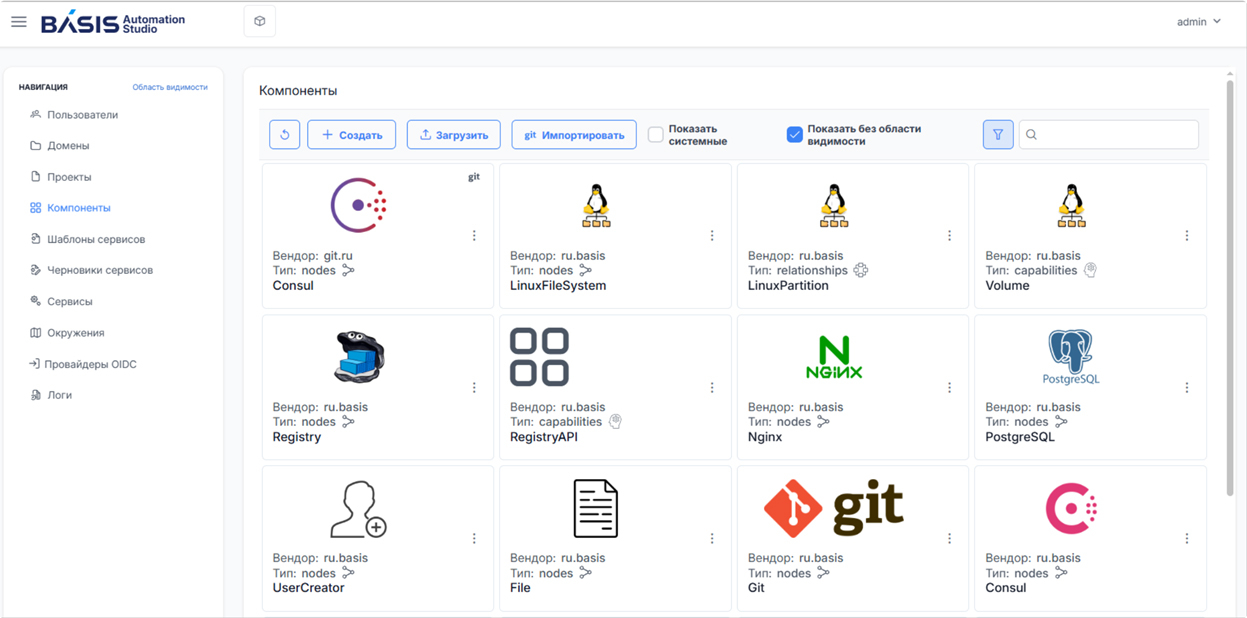
Источник изображений: «Базис» Basis Automation Studio поддерживает стандартные для облачной инфраструктуры инструменты и подходы, включая архитектуру TOSCA, формат сериализации YAML, систему управления конфигурациями Ansible, язык Python, интерпретатор Bash. Они используются для описания облачной инфраструктуры и управления её компонентами, развёртывания сервисов и их настройки. После развёртывания сервисов администраторы могут создавать day-2 операции для их сопровождения, мониторинга, обновления и поддержания работоспособности. Готовые сервисы можно публиковать на витрине портала самообслуживания, где они доступны для заказа в один клик пользователям облачной инфраструктуры. Для администрирования продукта и разработки шаблонов в BAS предусмотрен веб-интерфейс, включая визуальный редактор сервисов, а также инструменты управления правами и контроля доступа к компонентам инфраструктуры. В Basis Automation Studio реализована иерархическая мультитенантная модель, которая обеспечивает строгую логическую изоляцию ресурсов и детализированное управление доступом. На каждом уровне иерархии могут быть независимо назначены права доступа, роли и разрешения для взаимодействия с конструктором и запущенными с его помощью сервисами. Например, можно разграничить доступ между различными департаментами (или другими бизнес-единицами) одной компании, группируя принадлежащие им проекты и пользовательские учётные записи в специальные контейнеры, называемые доменами. В этом случае пользователи и ресурсы одного домена будут невидимы и недоступны для другого, что помогает заказчику обеспечивать конфиденциальность и сохранность данных в рамках масштабируемой и разветвлённой ИТ-инфраструктуры.  Дополнительно Basis Automation Studio предлагает ролевую модель управления пользователями платформы. По умолчанию доступны следующие роли: администратор с полными правами на управление конструктором, архитектор для управления компонентами и сервисами, разработчик компонентов и сервисов, администратор проектов, пользователь. При необходимости одному аккаунту внутри конструктора может быть назначено несколько ролей, в этом случае их права суммируются. В результате заказчик получает простой в то же время достаточно гибкий инструмент для обеспечения безопасности виртуальной инфраструктуры. «Интенсивное развитие облачной платформы Basis Dynamix Cloud Control и, в частности, появление конструктора платформенных сервисов Basis Automation Studio стало нашим ответом на растущий интерес рынка к облачной и гибридной инфраструктурам. Задача Basis Automation Studio — облегчить декларирование облачной инфраструктуры, а также развёртывание внутри неё необходимых для бизнеса ИТ-систем и сервисов, в первую очередь за счёт автоматизации этих процессов. Мы планируем активно развивать наш продукт под задачи российских заказчиков», — отметил Дмитрий Сорокин, технический директор компании «Базис».
08.05.2026 [14:11], Сергей Карасёв
Selectel запускает программу поддержки AI-проектов с грантом до 2 млн рублей на IT-инфраструктуруSelectel, крупнейший независимый провайдер IT-инфраструктуры в России, объявил о запуске программы поддержки для компаний, разрабатывающих решения в области искусственного интеллекта. Участники смогут получить грант до 2 000 000 руб. на использование вычислительных ресурсов Selectel, а также техническую помощь в организации IT-инфраструктуры для ML-задач от экспертов компании. В условиях растущего спроса на вычислительные мощности для обучения, инференса и запуска генеративных моделей для бизнеса крайне важен доступ к надёжной, производительной и масштабируемой IT-инфраструктуре. Для этого Selectel создал специальную программу, в рамках которой компании смогут получить поддержку для развития своих AI-проектов. После подачи заявки и прохождения интервью участникам будут доступны до 2 000 000 руб. на IT-инфраструктуру для ML-задач, включая серверы с GPU, Managed Kubernetes с GPU и Foundation Models Catalog. «Selectel последовательно развивает AI-направление, обеспечивая вычислительные мощности для бизнеса любого масштаба и создавая продуктовые решения для ML-задач. Mы строим вертикально интегрированное предложение и в этом году анонсировали сразу несколько запусков: собственный AI-сервер, обновление AI-платформы для инференса, а также интеграцию партнёрского решения с GlowByte и Data Sapience. Поэтому мы можем помочь компаниям реализовывать любые проекты на нашей инфраструктуре — и для нас это не просто поддержка, а возможность лучше понимать потребности рынка и усиливать нашу платформу», — поделился Александр Тугов, директор AI-вертикали Selectel. 
Источник изображения: Selectel Для реализации проектов с использованием ML-инструментов компаниям нужны мощные вычислительные GPU-ресурсы, гибкая архитектура и поддержка на всех этапах: от запуска MVP до вывода в продакшен и последующего масштабирования. Selectel готов взять на себя эту нагрузку, чтобы компании могли не просто запустить, а вывести свои проекты на новый уровень. При этом программа направлена не только на создание условий для технологического роста компаний, но и на популяризацию российских AI-решений. В рамках проекта планируется публикация совместных кейсов и статей с участниками, чтобы поделиться опытом и наглядным примером, как IT-инфраструктура может способствовать развитию AI-инициатив. Принять участие в программе могут новые клиенты Selectel — юридические лица или индивидуальные предприниматели. Для подачи заявки необходимо заполнить анкету на сайте программы, после чего команда Selectel выберет наиболее перспективные проекты и предложит участникам грант до 2 000 000 руб. для решения их задач. Ознакомиться с более подробными условиями участия и подать заявку можно на сайте программы.
30.04.2026 [15:41], Руслан Авдеев
VK Tech предложила бизнесу платформу VK AI Space для создания и запуска ИИ-агентовVK Tech представила платформу VK AI Space, позволяющую разрабатывать и запускать кастомных ИИ-агентов. Основой платформы стали большие языковые модели (LLM), в том числе — собственные разработки группы VK, обученные на российских данных. Кроме того, использованы популярные модели open source, а также ML-модели, предназначенные для работы систем компьютерного зрения, распознавания аудио и др. Подчёркивается, что интеграция с корпоративным ПО VK Tech позволяет быстро включать новые ИИ-сценарии в рабочую среду сотрудников компаний-клиентов, например — создавать ИИ-боты в VK WorkSpace. Платформа имеет набор уже готовых ИИ-агентов под распространённые задачи: для подготовки документов и создания протоколов встреч, перевода материалов, составления кратких резюме представленных данных, поиска по корпоративным базам знаний. Платформу протестировали на реальных внутренних ИИ-проектах VK. Особенностью платформы является возможность VK AI Space создавать изолированный контур для каждого ИИ-агента, что позволяет клиентам выбирать заранее, к каким системам агент получит доступ и что именно ему разрешено делать. После получения задачи агент самостоятельно планирует этапы её выполнения, работает с доступными инструментами и адаптируется к новым данным. Даже если принятое решение будет ошибочным, ИИ-агент не сможет выйти за пределы сферы своей ответственности и нанести ущерб смежным системам. При этом можно в любое время проверить шаги агента и наличие ошибок. 
Источник изображения: Campaign Creators/unsplash.com Изолированные контуры VK Tech позволят сокращать время от пилотного проекта до начала реальной эксплуатации, что даст возможность масштабировать применение ИИ в организациях экономически эффективно, говорит компания. Помимо возможности развернуть VK AI Space на собственных мощностях клиента, предусмотрена работа платформы в облаке VK Cloud. Кроме того, предусмотрено предоставление готового программно-аппаратного комплекса по подписке. |
|

