Материалы по тегу: ии
|
03.02.2024 [23:45], Владимир Мироненко
В 2023 году Alphabet сэкономил $3,9 млрд, продлив срок службы серверов, но увеличил расходы на ИИ-инфраструктуруХолдинг Alphabet сообщил результаты работы в IV квартале и 2023 году, завершившемся 31 декабря. Выручка облачного подразделения Google Cloud составила около $9,2 млрд, увеличившись год к году на 25,66 %. Что примечательно, подразделение сработало с операционной прибылью в размере $864 млн, в то время годом ранее у него были убытки в $186 млн. Выручка всего Alphabet в IV квартале составила $86,31 млрд по сравнению с $76,048 млрд годом ранее. Выручка за весь 2023 год — $307,394 млрд, что значительно превышает результат 2022 года, равный $282,836 млрд. Чистая прибыль холдинга выросла в 2023 году до $73,795 млрд с $59,972 млрд годом ранее, отчасти благодаря решению компании продлить срок службы серверов и сетевого оборудования. Alphabet впервые продлил срок службы своего оборудования в 2021 году, увеличив продолжительность работы серверов с трёх до четырёх лет, а сетевого оборудования — с четырёх до пяти. В 2023 году Alphabet вновь продлил срок эксплуатации оборудования, на этот раз — до шести лет. Благодаря этому только в IV квартале 2023 года расходы компании на амортизацию оборудования упали на $983 млн, а чистая прибыль увеличилась на $765 млн. За весь год амортизация оборудования Alphabet снизилась на $3,9 млрд, а чистая прибыль увеличилась на $3 млрд. 
Изображение: Google При этом компания вложила значительные средства в новую инфраструктуру. В IV квартале общие капитальные затраты составили $11 млрд, что, по словам президента и главного инвестиционного директора Alphabet и Google Рут Порат (Ruth Porat), было обусловлено «инвестициями в техническую инфраструктуру, причём самый крупный компонент — серверы, за которыми следуют ЦОД». В предыдущем квартале капзатраты составили $7,6 млрд. Резкое увеличение капзатрат обусловлено «перспективами создания уникальных приложений ИИ для пользователей, рекламодателей, разработчиков, облачных корпоративных клиентов и правительств во всем мире, а также возможностями долгосрочного роста, которые они предлагают». Порат добавила, что компания будет придерживаться этой политики и в 2024 году. «Мы ожидаем, что капитальные затраты в 2024 году будут значительно больше, чем в 2023 году», — отметила она. Порат также подчеркнула, что фактором роста Google Cloud Platform (GCP) является ИИ. Гендиректор Сундар Пичаи (Sundar Pichai) заявил, что компания продолжит инвестировать в инфраструктуру, как в ЦОД, так и в вычислительную технику, чтобы поддержать рост возможностей ИИ-технологий. 
Изображение: Google Подразделение Google Cloud снова стало самым быстрорастущим сегментом. После значительного замедления роста с +28 % год к году во II квартале до +22 % в III квартале рост облака вновь ускорился до +26 %. Более того, в этот раз ускорение темпов роста было сильнее, чем у AWS и Azure. Рост доходов от облачных технологий вновь ускорился на 4 п. п. Также резко выросла операционная маржа Google Cloud — последовательно на 6 п.п. до 9 %. Компания объяснила замедление темпов роста в III квартале проведением оптимизации рабочей нагрузки. В ходе нынешнего отчёта Сундар Пичаи сообщил, что этот вопрос «в основном был проработан». Темпы роста Google Cloud по-прежнему опережают рынок: по оценкам Synergy Research Group, общемировой прирост рынка облаков составил +20 % в годовом исчислении до $74 млрд в IV квартале, ускорившись с 18 % в годовом исчислении в III квартале. Доминирует Amazon (31 % рынка), за ним следуют Microsoft (24 %) и Google (11 %). Большая тройка занимает 67 % рынка. Причём Microsoft и Google нарастили свои доли, а AWS — снизила.
17.01.2024 [08:08], Владимир Мироненко
300 кВт на стойку: Aligned представила СЖО DeltaFlow~ для своих дата-центровКомпания Aligned представила новую систему жидкостного охлаждения DeltaFlow~, которая позволяет увеличить плотность размщения вычислительных мощностей 300 кВт на стойку, сообщил ресур Datacenter Dynamics. DeltaFlow~ — это готовое решение, поддерживающее текущие и будущие технологии жидкостного охлаждения, включая прямое охлаждение direct-to-chip с CDU, охлаждение с использованием теплообменника на задней дверце (Rear-door Heat Exchanger, RDHx) и иммерсионное охлаждение. Решение опирается на систему с замкнутым контуром без использования наружного воздуха или воды. По словам Alidned, новая СЖО позволяет клиентам по-максимуму использовать современные чипы и ускорителя, сокращая время выхода на рынок, затраты и риски. 
Фото: Aligned DeltaFlow~ также интегрируется с технологией воздушного охлаждения Delta3 (Delta Cube) без изменений в подаче электроэнергии или существующей температуры в машинных залах. Delta3 вместо традиционного холодного коридора использует вентиляторы и теплообменники, расположенные непосредственно за стойками и подключённые к водяному контуру, уходящему к чиллерам. Delta3 позволяет добиться плотности до 50 кВт на стойку. Aligned стала одной из последних компаний, анонсировавшей платформу для оборудования высокой плотности, основанное на жидкостном охлаждении. Ранее в этом месяце Stack представила решение с использованием погружного охлаждения, которое позволяет поддерживать мощность 300 кВт или выше на стойку. Летом прошлого года CyrusOne анонсировала новую архитектуру ЦОД для ИИ-нагрузок, где тоже используется погружное охлаждение и тоже можно получить 300 кВт на стойку. Тогда же Digital Realty запустила услугу колокации с поддержкой размещений до 70 кВт на стойку, а в декабре Equinix объявила о планах по расширению поддержки передовых технологий СЖО в значительной части своих ЦОД, хотя и не указала предельную плотность. DataBank также переработала конструкцию машинных залов для поддержки размещений высокой плотностью с использованием жидкостного охлаждения.
07.12.2023 [21:04], Сергей Карасёв
Google представила Cloud TPU v5p — свой самый мощный ИИ-ускорительКомпания Google анонсировала свой самый высокопроизводительный ускоритель для задач ИИ — Cloud TPU v5p. По сравнению с изделием предыдущего поколения TPU v4 обеспечивается приблизительно 1,7-кратный пророст быстродействия на операциях BF16. Впрочем, для Google важнее то, что она наряду с AWS является одной из немногих, кто при разработке ИИ не зависит от дефицитных ускорителей NVIDIA. К этому же стремится сейчас и Microsoft. Решение Cloud TPU v5p оснащено 95 Гбайт памяти HBM с пропускной способностью 2765 Гбайт/с. Для сравнения: конфигурация TPU v4 включает 32 Гбайт памяти HBM с пропускной способностью 1228 Гбайт/с. 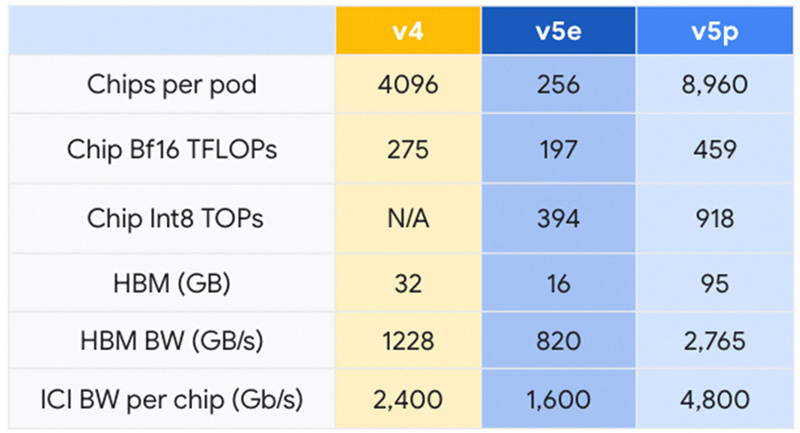
Источник изображений: Google Кластер на базе Cloud TPU v5p может содержать до 8960 чипов, объединённых высокоскоростным интерконнектом со скоростью передачи данных до 4800 Гбит/с на чип. В случае TPU v4 эти значения составляют соответственно 4096 чипов и 2400 Гбит/с. Что касается производительности, то у Cloud TPU v5p она достигает 459 Тфлопс (BF16) против 275 Тфлопс у TPU v4. На операциях INT8 новинка демонстрирует результат до 918 TOPS. 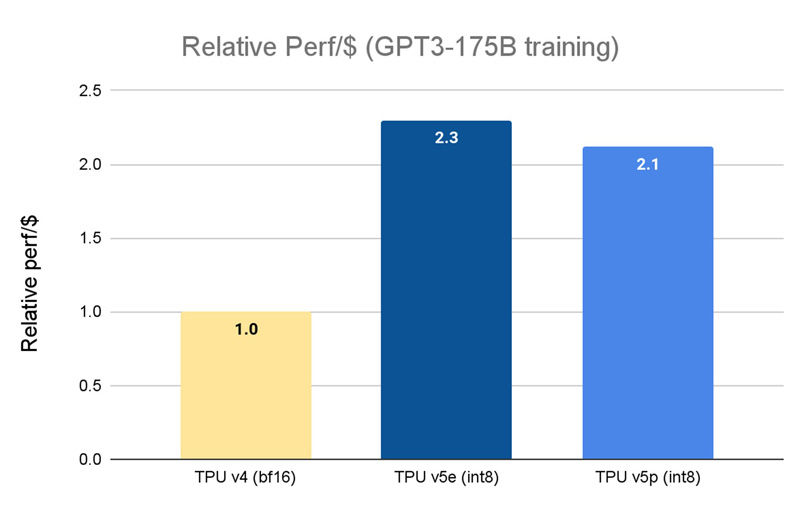 В августе нынешнего года Google представила ИИ-ускоритель TPU v5e, созданный для обеспечения наилучшего соотношения стоимости и эффективности. Это изделие с 16 Гбайт памяти HBM (820 Гбит/с) показывает быстродействие 197 Тфлопс и 394 TOPS на операциях BF16 и INT8 соответственно. При этом решение обеспечивает относительную производительность на доллар на уровне $1,2 в пересчёте на чип в час. У TPU v4 значение равно $3,22, а у новейшего Cloud TPU v5p — $4,2 (во всех случаях оценка выполнена на модели GPT-3 со 175 млрд параметров). 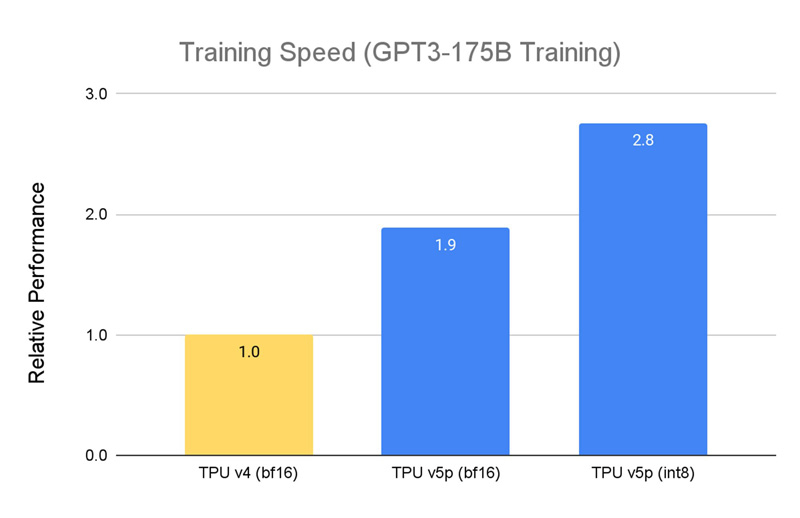 По заявлениям Google, чип Cloud TPU v5p может обучать большие языковые модели в 2,8 раза быстрее по сравнению с TPU v4. Более того, благодаря SparseCores второго поколения скорость обучения моделей embedding-dense увеличивается приблизительно в 1,9 раза. На базе TPU и GPU компания предоставляет готовый программно-аппаратный стек AI Hypercomputer для комплексной работы с ИИ. Система объединяет различные аппаратные ресурсы, включая различные типы хранилищ и оптический интерконнект Jupiter, сервисы GCE и GKE, популярные фреймворки AX, TensorFlow и PyTorch, что позволяет быстро и эффективно заниматься обучением современных моделей, а также организовать инференс.
29.11.2023 [03:43], Владимир Мироненко
AWS представила 96-ядерный Arm-процессор Graviton4 и ИИ-ускоритель Trainium2Amazon Web Services представила Arm-процессор нового поколения Graviton4 и ИИ-ускоритель Trainium2, предназначенный для обучения нейронных сетей. Всего к текущему моменту компания выпустила уже 2 млн Arm-процессоров Graviton, которыми пользуются более 50 тыс. клиентов. «Graviton4 представляет собой четвёртое поколение процессоров, которое мы выпустили всего за пять лет, и это самый мощный и энергоэффективный чип, который мы когда-либо создавали для широкого спектра рабочих нагрузок», — отметил Дэвид Браун (David Brown), вице-президент по вычислениям и сетям AWS. По сравнению с Graviton3 новый чип производительнее на 30 %, включает на 50 % больше ядер и имеет на 75 % выше пропускную способность памяти. 
Изображение: AWS Graviton4 будет иметь до 96 ядер Neoverse V2 Demeter (2 Мбайт L2-кеша на ядро) и 12 каналов DDR5-5600. Кроме того, новый чип получит поддержку шифрования трафика для всех своих аппаратных интерфейсов. Процессор изготавливается по 4-нм техпроцессу TSMC, включает 73 млрд транзисторов и, вероятно, имеет чиплетную компоновку. Возможно, это первый CPU компании, ориентированный на работу в двухсокетных платформах. 
Изображение: AWS Поначалу Graviton4 будет доступен в инстансах R8g (пока в статусе превью), оптимизированных для приложений, интенсивно использующих ресурсы памяти — высокопроизводительные базы данных, in-memory кеши и Big Data. Эти инстансы будут поддерживать более крупные конфигурации, иметь в три раза больше vCPU и в три раза больше памяти по сравнению с инстансами Rg7, которые имели до 64 vCPU и 512 Гбайт ОЗУ. 
Amazon Trainium2 (Изображение: AWS) В свою очередь, Trainium 2 предназначен для обучения больших языковых моделей (LLM) и базовых моделей. Сообщается, что ускоритель в сравнении с Trainium 1 вчетверо производительнее и при этом имеет в 3 раза больший объём памяти и в 2 раза более высокую энергоэффективность. Инстансы EC2 Trn2 получат 16 ИИ-ускорителей с возможностью масштабирования до 100 тыс. единиц в составе EC2 UltraCluster, которые суммарно дадут 65 Эфлопс, то есть по 650 Тфлопс на ускоритель. Как утверждает Amazon это позволит обучать LLM с 300 млрд параметров за недели вместо месяцев.  Со временем на Graviton4 заработает SAP HANA Cloud, портированием и оптимизацией этой платформы уже занимаются. Oracle также перенесла свою СУБД на Arm, а заодно перевела все свои облачные сервисы на чипы Ampere, в которую в своё время инвестировала. Microsoft же пошла по пути AWS и недавно анонсировала 128-ядерый Arm-процессор (Neoverse N2) Cobalt 100 и ИИ-ускоритель Maia 100 собственной разработки. Всё это может представлять отдалённую угрозу для AMD и Intel. С NVIDIA же все всё равно пока что продолжают дружбу — именно в инфраструктуре AWS, как ожидается, появится самый мощный в мире ИИ-суперкомпьютер на базе новых GH200.
29.11.2023 [01:21], Руслан Авдеев
Cerebras, критиковавшая NVIDIA за сотрудничество с Китаем, сама оказалась связана с компанией, ведущей дела с ПекиномХотя стартап Cerebras, занимающийся разработкой чипов, раскритиковал NVIDIA за попытки обойти санкционные ограничения в отношении Китая и призвал соблюдать не букву, но дух американского закона, у компании, похоже, нашлись свои скелеты в шкафу. Как сообщает The Register, сейчас в США расследуют деятельность клиента Cerebras — группы G42, возможно, помогавшей Поднебесной обходить санкционные ограничения. Американские спецслужбы подозревают, что базирующаяся в ОАЭ многопрофильная компания G42 поставляет в Китай передовые технологии. Для своих ИИ-исследований компания обратилась к Cerebras с целью постройки суперкомпьютерного кластера Condor Galaxy за $100 млн, а всего стартап намерен построить девять подобных объектов на $900 млн. При этом узлы кластера используют разработанные Cerebras чипы WSE-2, подходящие для обучения ИИ-систем. 
Источник изображения: Arthur Wang/unsplash.com Как показывают предварительные результаты расследования американских журналистов, властей и спецслужб, G42 пытается сотрудничать с Пекином и работает с китайскими компаниями вроде Huawei, давно находящимися под санкциями. В самой G42 утверждают, что принимают все меры для того, чтобы соблюдать американские ограничения. При этом, по данным журналистов, G42 считают прокси-компанией для работы в интересах КНР, помогающей Пекину получать вычислительные ресурсы и подсанкционные технологии. По словам главы Cerebras Эндрю Фельдмана (Andrew Feldman), его компания точно не будет вести бизнес с Китаем. Бизнесмен попал в неловкую ситуацию после того, как появилась информация о тесных связях G42 с Пекином. На запрос журналистов в Cerebras заявили, что кластеры Condor Galaxy находятся в США, а G42 получает к ним облачный доступ, так что любая активность контролируется и соответствует американским законам — государства-противники не имеют прямого доступа к ИИ-системам. Фельдман якобы не знал о сомнительном статусе G42, а в стартапе подчеркнули, что не комментируют слухи. Бюро промышленности и безопасности США уже обратилось к поставщикам облачных инфраструктур для консультаций о целесообразности дополнительных ограничений доступа к их услугам из некоторых стран. В частности, бюро интересует, как операторы намерены выявлять разработчиков ИИ-моделей, вызывающих обеспокоеность властей и что можно предпринять для устранения угроз. Кроме того, президент США предложил новые правила, согласно которым облакам потребуется докладывать о деятельности иностранцев, связанной с обучением больших языковых моделей (LLM).
28.11.2023 [22:20], Игорь Осколков
NVIDIA анонсировала суперускоритель GH200 NVL32 и очередной самый мощный в мире ИИ-суперкомпьютер Project CeibaAWS и NVIDIA анонсировали сразу несколько новых совместно разработанных решений для генеративного ИИ. Основным анонсом формально является появление ИИ-облака DGX Cloud в инфраструктуре AWS, вот только облако это отличается от немногочисленных представленных ранее платформ DGX Cloud тем, что оно первом получило гибридные суперчипах GH200 (Grace Hoppper), причём в необычной конфигурации. 
Изображения: NVIDIA В основе AWS DGX Cloud лежит платформа GH200 NVL32, но это уже не какой-нибудь сдвоенный акселератор вроде H100 NVL, а целая, готовая к развёртыванию стойка, включающая сразу 32 ускорителя GH200, провязанных 900-Гбайт/с интерконнектом NVLink. В состав такого суперускорителя входят 9 коммутаторов NVSwitch и 16 двухчиповых узлов с жидкостным охлаждением. По словам NVIDIA, GH200 NVL32 идеально подходит как для обучения, так и для инференса действительно больших LLM с 1 трлн параметров.  Простым перемножением количества GH200 на характеристики каждого ускорителя получаются впечатляющие показатели: 128 Пфлопс (FP8), 20 Тбайт оперативной памяти, из которых 4,5 Тбайт приходится на HBM3e с суммарной ПСП 157 Тбайтс, и агрегированная скорость NVLink 57,6 Тбайт/с. И всё это с составе одного EC2-инстанса! Да, новая платформа использует фирменные DPU AWS Nitro и EFA-подключение (400 Гбит/с на каждый GH200). Новые инстансы, пока что безымянные, можно объединять в кластеры EC2 UltraClasters.  Одним из таких кластеров станет Project Ceiba, очередной самый мощный в мире ИИ-суперкомпьютер с FP8-производительность 65 Эфлопс, объединяющий сразу 16 384 ускорителя GH200 и имеющий 9,1 Пбайт памяти, а также агрегированную пропускную способность интерконнекта на уровне 410 Тбайт/с (28,8 Тбайт/с NVLink). Он и станет частью облака AWS DGX Cloud, которое будет доступно в начале 2024 года. В скором времени появятся и EC2-инстансы попроще: P5e с NVIDIA H200, G6e с L40S и G6 с L4. 
19.11.2023 [03:00], Сергей Карасёв
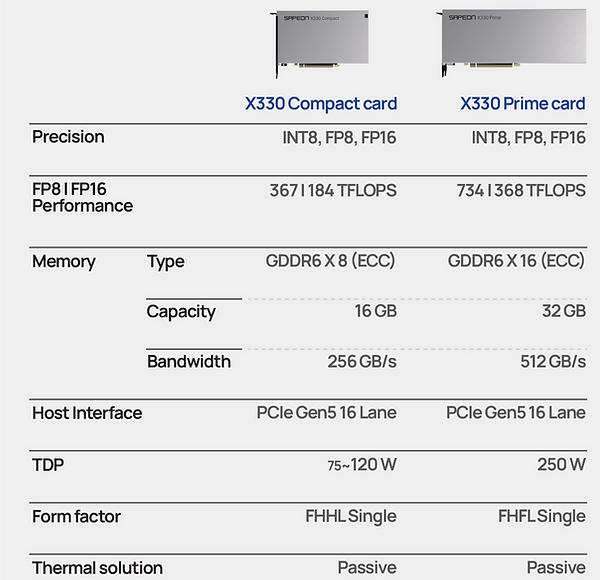
Южнокорейский стартап Sapeon представил 7-нм ИИ-чип X330ИИ-стартап Sapeon, поддерживаемый южнокорейским телекоммуникационным гигантом SK Group, анонсировал чип X330, предназначенный для инференса и обслуживания больших языковых моделей (LLM). Изделие ляжет в основу специализированных ускорителей для дата-центров. Sapeon заявляет, что новый нейропроцессор (NPU) обеспечивает примерно вдвое более высокую производительность и в 1,3 раза лучшую энергоэффективность, чем продукты конкурентов, выпущенные в этом году. По сравнению с предыдущим решением самой компании — Sapeon X220 — достигается увеличение быстродействия в четыре раза и повышение энергоэффективности в два раза. 
Изображения: Sapeon Новинка будет изготавливаться на TSMC по 7-нм технологии. Массовое производство запланировано на I полугодие 2024 года. На базе чипа будут предлагаться два ускорителя — X330 Compact Card и X330 Prime Card. Оба имеют однослотовое исполнение и оснащаются системой пассивного охлаждения. Для подключения применяется интерфейс PCIe 5.0 х16. Карты могут осуществлять вычисления INT8, FP8 и FP16.  Модель X330 Compact Card уменьшенной длины несёт на борту 16 Гбайт памяти GDDR6 с пропускной способностью до 256 Гбайт/с. Заявленная производительность на операциях FP8 и FP16 достигает соответственно 367 и 184 Тфлопс. Энергопотребление варьируется в диапазоне от 75 до 120 Вт. Полноразмерная модификация X330 Prime Card получила 32 Гбайт памяти GDDR6 с пропускной способностью до 512 Гбайт/с. Заявленное быстродействие FP8 и FP16 составляет до 734 и 368 Тфлопс. Энергопотребление — 250 Вт. 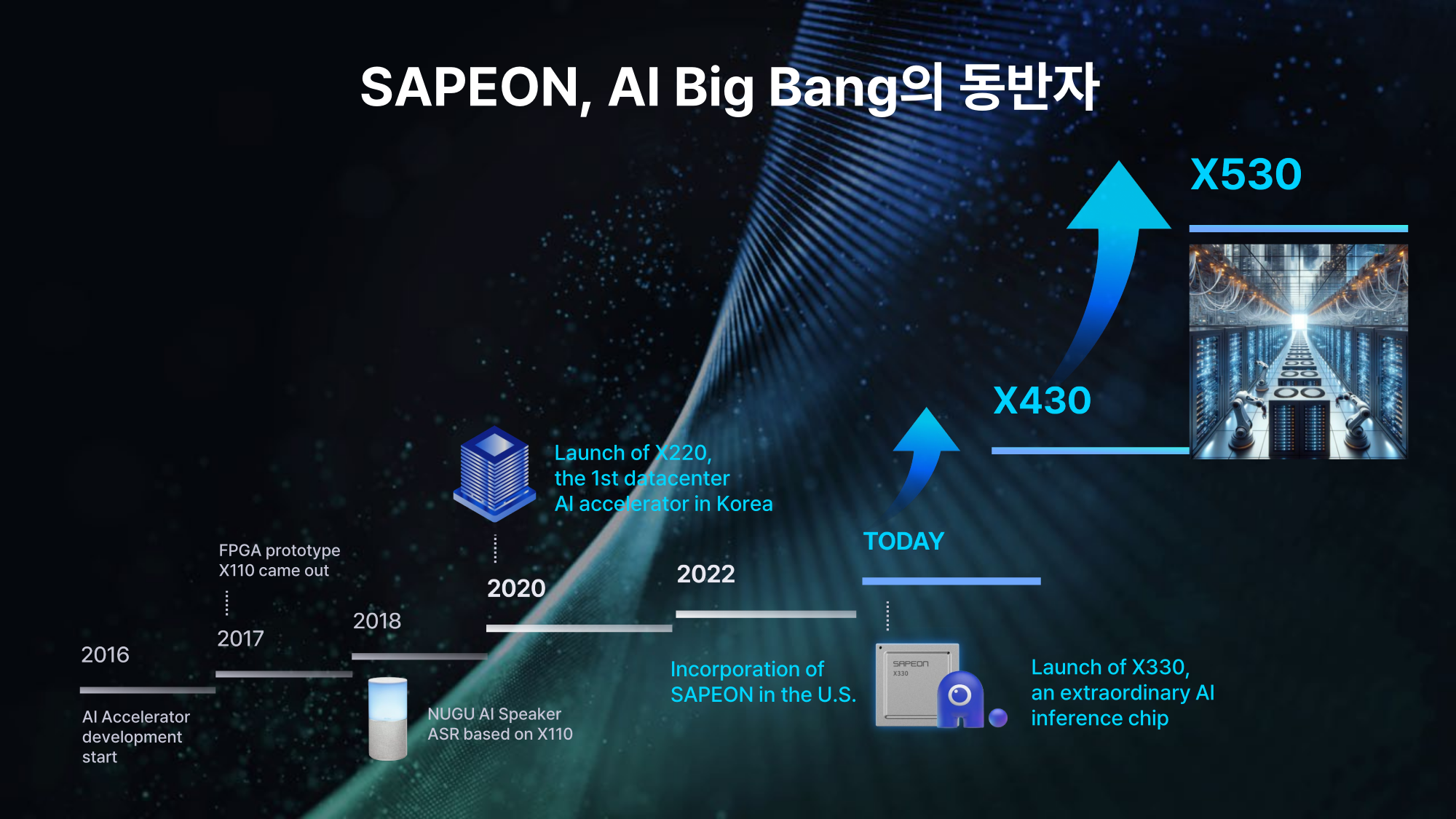 Группа SK в последнее время активно вкладывается в развитие ИИ, инвестируя напрямую или через дочерние структуры как в софт, так и в железо. С ней, в частности, связан ещё один южнокорейский разработчик ИИ-чипов Rebellions, также поддерживаемый правительством страны, которое намерено к 2030 году довести долю отечественных ИИ-чипов в местных дата-центрах до 80 %. Делается это для того, чтобы снизить зависимость от иностранных решений и избежать дефицита. Сама же Sapeon готовит ещё минимум два поколения своих чипов.
16.11.2023 [02:43], Алексей Степин
Microsoft представила 128-ядерый Arm-процессор Cobalt 100 и ИИ-ускоритель Maia 100 собственной разработкиГиперскейлеры ради снижения совокупной стоимости владения (TCO) и зависимости от сторонних вендоров готовы вкладываться в разработку уникальных чипов, изначально оптимизированных под их нужды и инфраструктуру. К небольшому кругу компаний, решившихся на такой шаг, присоединилась Microsoft, анонсировавшая Arm-процессор Azure Cobalt 100 и ИИ-ускоритель Azure Maia 100. 
Изображения: Microsoft Первопроходцем в этой области стала AWS, которая разве что память своими силами не разрабатывает. У AWS уже есть три с половиной поколения Arm-процессоров Graviton и сразу два вида ИИ-ускорителей: Trainium для обучения и Inferentia2 для инференса. Крупный китайский провайдер Alibaba Cloud также разработал и внедрил Arm-процессоры Yitian и ускорители Hanguang. Что интересно, в обоих случаях процессоры оказывались во многих аспектах наиболее передовыми. Наконец, у Google есть уже пятое поколение ИИ-ускорителей TPU.  Microsoft заявила, что оба новых чипа уже производятся на мощностях TSMC с использованием «последнего техпроцесса» и займут свои места в ЦОД Microsoft в начале следующего года. Как минимум, в случае с Maia 100 речь идёт о 5-нм техпроцессе, вероятно, 4N. В настоящее время Microsoft Azure находится в начальной стадии развёртывания инфраструктуры на базе новых чипов, которая будет использоваться для Microsoft Copilot, Azure OpenAI и других сервисов. Например, Bing до сих пор во много полагается на FPGA, а вся ИИ-инфраструктура Microsoft крайне сложна.  Microsoft приводит очень мало технических данных о своих новинках, но известно, что Azure Cobalt 100 имеет 128 ядер Armv9 Neoverse N2 (Perseus) и основан на платформе Arm Neoverse Compute Subsystem (CSS). По словам компании, процессоры Cobalt 100 до +40 % производительнее имеющихся в инфраструктуре Azure Arm-чипов, они используются для обеспечения работы служб Microsoft Teams и Azure SQL. Oracle, вложившаяся в своё время в Ampere Comptuing, уже перевела все свои облачные сервисы на Arm.  Чип Maia 100 (Athena) изначально спроектирован под задачи облачного обучения ИИ и инференса в сценариях с использованием моделей OpenAI, Bing, GitHub Copilot и ChatGPT в инфраструктуре Azure. Чип содержит 105 млрд транзисторов, что больше, нежели у NVIDIA H100 (80 млрд) и ставит Maia 100 на один уровень с Ponte Vecchio (~100 млрд). Для Maia организован кастомный интерконнект на базе Ethernet — каждый ускоритель располагает 4,8-Тбит/с каналом для связи с другими ускорителями, что должно обеспечить максимально эффективное масштабирование.  Сами Maia 100 используют СЖО с теплообменниками прямого контакта. Поскольку нынешние ЦОД Microsoft проектировались без учёта использования мощных СЖО, стойку пришлось сделать более широкой, дабы разместить рядом с сотней плат с чипами Maia 100 серверами и большой радиатор. Этот дизайн компания создавала вместе с Meta✴, которая испытывает аналогичные проблемы с текущими ЦОД. Такие стойки в настоящее время проходят термические испытания в лаборатории Microsoft в Редмонде, штат Вашингтон.  В дополнение к Cobalt и Maia анонсирована широкая доступность услуги Azure Boost на базе DPU MANA, берущего на себя управление всеми функциями виртуализации на манер AWS Nitro, хотя и не целиком — часть ядер хоста всё равно используется для обслуживания гипервизора. DPU предлагает 200GbE-подключение и доступ к удалённому хранилищу на скорости до 12,5 Гбайт/с и до 650 тыс. IOPS.  Microsoft не собирается останавливаться на достигнутом: вводя в строй инфраструктуру на базе новых чипов Cobalt и Maia первого поколения, компания уже ведёт активную разработку чипов второго поколения. Впрочем, совсем отказываться от партнёрства с другими вендорами Microsoft не намерена. Компания анонсировала первые инстансы с ускорителями AMD Instinct MI300X, а в следующем году появятся инстансы с NVIDIA H200. 
13.11.2023 [17:00], Игорь Осколков
NVIDIA анонсировала ускорители H200 и «фантастическую четвёрку» Quad GH200NVIDIA анонсировала ускорители H200 на базе всё той же архитектуры Hopper, что и их предшественники H100, представленные более полутора лет назад. Новый H200, по словам компании, первый в мире ускоритель, использующий память HBM3e. Вытеснит ли он H100 или останется промежуточным звеном эволюции решений NVIDIA, покажет время — H200 станет доступен во II квартале следующего года, но также в 2024-м должно появиться новое поколение ускорителей B100, которые будут производительнее H100 и H200. 
HGX H200 (Источник здесь и далее: NVIDIA) H200 получил 141 Гбайт памяти HBM3e с суммарной пропускной способностью 4,8 Тбайт/с. У H100 было 80 Гбайт HBM3, а ПСП составляла 3,35 Тбайт/с. Гибридные ускорители GH200, в состав которых входит H200, получат до 480 Гбайт LPDDR5x (512 Гбайт/с) и 144 Гбайт HBM3e (4,9 Тбайт/с). Впрочем, с GH200 есть некоторая неразбериха, поскольку в одном месте NVIDIA говорит о 141 Гбайт, а в другом — о 144 Гбайт HBM3e. Обновлённая версия GH200 станет массово доступна после выхода H200, а пока что NVIDIA будет поставлять оригинальный 96-Гбайт вариант с HBM3. Напомним, что грядущие конкурирующие AMD Instinct MI300X получат 192 Гбайт памяти HBM3 с ПСП 5,2 Тбайт/с.  На момент написания материала NVIDIA не раскрыла полные характеристики H200, но судя по всему, вычислительная часть H200 осталась такой же или почти такой же, как у H100. NVIDIA приводит FP8-производительность HGX-платформы с восемью ускорителями (есть и вариант с четырьмя), которая составляет 32 Пфлопс. То есть на каждый H200 приходится 4 Пфлопс, ровно столько же выдавал и H100. Тем не менее, польза от более быстрой и ёмкой памяти есть — в задачах инференса можно получить прирост в 1,6–1,9 раза.  При этом платы HGX H200 полностью совместимы с уже имеющимися на рынке платформами HGX H100 как механически, так и с точки зрения питания и теплоотвода. Это позволит очень быстро обновить предложения партнёрам компании: ASRock Rack, ASUS, Dell, Eviden, GIGABYTE, HPE, Lenovo, QCT, Supermicro, Wistron и Wiwynn. H200 также станут доступны в облаках. Первыми их получат AWS, Google Cloud Platform, Oracle Cloud, CoreWeave, Lambda и Vultr. Примечательно, что в списке нет Microsoft Azure, которая, похоже, уже страдает от недостатка H100.  GH200 уже доступны избранным в облаках Lamba Labs и Vultr, а в начале 2024 года они появятся у CoreWeave. До конца этого года поставки серверов с GH200 начнут ASRock Rack, ASUS, GIGABYTE и Ingrasys. В скором времени эти чипы также появятся в сервисе NVIDIA Launchpad, а вот про доступность там H200 компания пока ничего не говорит.  Одновременно NVIDIA представила и базовый «строительный блок» для суперкомпьютеров ближайшего будущего — плату Quad GH200 с четырьмя чипами GH200, где все ускорители связаны друг с другом посредством NVLink по схеме каждый-с-каждым. Суммарно плата несёт более 2 Тбайт памяти, 288 Arm-ядер и имеет FP8-производительность 16 Пфлопс. На базе Quad GH200 созданы узлы HPE Cray EX254n и Eviden Bull Sequana XH3000. До конца 2024 года суммарная ИИ-производительность систем с GH200, по оценкам NVIDIA, достигнет 200 Эфлопс.
09.11.2023 [16:15], Сергей Карасёв
NVIDIA готовит для Китая три новых ускорителя взамен подпавших под санкции: H20, L20 и L2Компания NVIDIA, по сообщению Reuters, планирует выпустить три новых ИИ-ускорителя, модифицированных специально для Китая с учётом дополнительных санкций со стороны США. Изделия фигурируют под обозначениями HGX H20 (SXM), L20 (PCIe) и L2 (PCIe), а их официальная презентация состоится не раньше 16 ноября. Напомним, в середине октября 2023 года США ввели новые ограничения на поставку передовых чипов NVIDIA в Китай: они затронули решения A800 и H800 — модифицированные версии A100 и H100, созданные специально для рынка КНР с учетом ранее действовавших американских ограничений. После этого NVIDIA пришлось искать новые регионы сбыта для «урезанных» ускорителей, предназначавшихся для Поднебесной. Как теперь сообщается, NVIDIA снова нашла возможность поставлять ускорители на китайский рынок, который потенциально может обеспечить значительную выручку. Решения H20, L20 и L2 не подпадают ни под одно из действующих экспортных ограничений. Обратной стороной медали является то, что производительность у них серьёзно снижена (см. характеристики в таблице выше), передаёт SemiAnalysis. 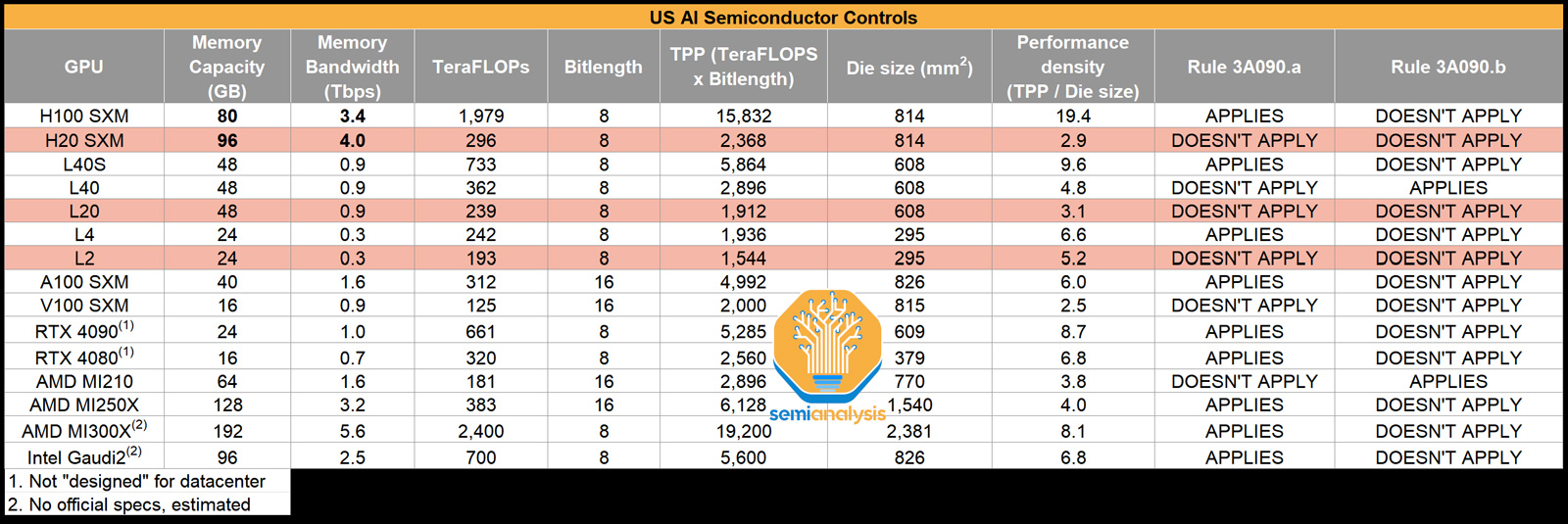
Источник: SemiAnalysis Отмечается, что у NVIDIA уже готовы образцы новых ускорителей для китайского рынка, а их массовое производство будет организовано в течение следующего месяца. Сама компания какие-либо комментарии по поводу обнародованной в интернете информации не даёт. |
|



{kind=link}