Лента новостей
|
23.09.2024 [09:13], Руслан Авдеев
AT&T с неохотой согласилась извлечь десятки тонн свинца со дна озера ТахоАмериканский телеком-оператор AT&T согласился изъять заброшенные кабели в свинцовой оболочке, приведшие к токсичному загрязнению озера Тахо (Tahoe). По данным Datacenter Dynamics, компания достигла судебного соглашения с природоохранной группой California Sportfishing Protection Alliance (CSPA), подавшей к ней иск в 2021 году. Кабели провели в воде не менее 60 лет. AT&T извлечёт со дна озера 107 тыс. фунтов (около 48,5 тонн) свинца, общая длина кабелей составляет около 8 миль (около 12,9 км). В CSPA празднуют победу, говоря о её важности для окружающей среды, местных жителей, получающих питьевую воду из озера, а таже миллионов посетителей берегов Тахо. Проведённое CSPA расследование выявило, что заброшенные кабели действительно отравляли воду озера. В частности, свинец обнаружили в водорослях, формирующих основу пищевых цепочек для местных рыб, некоторых моллюсках и раках. Доподлинно неизвестно, как долго кабели провели в озере. Вероятно, весьма долго, поскольку применение в США содержащей свинец кабельной инфраструктуры прекратилось в 1964 году. Зато известно, что использование свинцовых оболочек для кабелей в США началось в 1880-х. Когда стало применяться оптоволокно, старые кабели обычно просто бросали там, где они были проложены, а ВОЛС тянули параллельными маршрутами. 
Источник изображения: Rodrigo Soares/unsplash.com Изначально AT&T согласилась изъять кабели со дна в 2021 году, но практически сразу приостановила процесс и наняла девять экспертов, которые в один голос заявили, что никакой угрозы нет. Но в итоге AT&T решила не связываться с защитниками природы. Её представители заявили, что хотя компания уверена в безопасности кабелей, она всё же намерена придерживаться изначальных обещаний, касающихся озера Тахо. В прошлом году издание The Wall Street Journal провело расследование, выявившее, что AT&T, Verizon и другие американские телеком-компании загрязняют воды и земли США — их кабели со свинцовыми оболочками оставлены без присмотра как на суше, так и под водой. Всего исследователи собрали около 130 образцов с мест пролегания кабелей по всей стране. Оценка состояния почв и воды проводилась несколькими независимыми лабораториями — образцы были признаны токсичными. Всего было выявлено около 2 тыс. кабелей. Сами операторы утверждали, что многие кабели до сих пор используются, в том числе экстренными службами, и их эксплуатация не противоречит местным законам. Впоследствии против Verizon и AT&T были поданы коллективные иски, где операторов обвинили в сокрытии данных о принадлежащих им токсичных кабелях. А уже в 2024 года проблемой заинтересовалось Агентство по охране окружающей среды США (EPA).
22.09.2024 [23:40], Владимир Мироненко
Amazon, Google и Microsoft снова пожаловались друг на друга британскому регулятору, который продлил антимонопольное расследование облачного рынкаУправление по конкуренции и рынкам Великобритании (CMA) продлило сроки антимонопольного расследования положения дел на облачном рынке страны на четыре месяца — до 4 августа 2025 года. Ранее планировалось завершить его до 5 апреля следующего года, пишет DataCenter Dynamics. В своём заявлении, опубликованном 19 сентября, британский регулятор сообщил, что ведущая расследование группа считает невозможным завершить его в ранее объявленные сроки. Также указано, что несмотря на перенос крайнего срока на август, группа стремится завершить расследование «как можно скорее». Как предполагает ресурс Computer Weekly, продление расследования связано с необходимостью более подробного изучения практики лицензирования продуктов и сервисов Microsoft, которая может негативно отразиться на уровне конкуренции на облачном рынке Великобритании. Расследование CMA было начато в октябре 2023 года после публикации отчёта Ofcom, телеком-регулятора страны, в котором сообщалось о препятствиях, затрудняющим клиентам переключение между облачными провайдерами и/или одновременное использование услуг нескольких поставщиков облачных сервисов: плата за перенос данных, сборы за облачную репатриацию и скидки, стимулирующие клиентов использовать только одного поставщика, и т.д. Также поступали жалобы на практику лицензирования Microsoft, взимающую повышенную плату за запуск своего ПО в облаках конкурентов. 
Источник изображения: Vitaly Gariev / Unsplash Расследование проходит на фоне взаимных обвинений облачных провайдеров в антиконкурентном поведении. В декабре прошлого года Google, по данным источников, направила в CMA жалобу по этому поводу на Microsoft. Компания Amazon тоже сочла необходимым пожаловаться регулятору на используемую Microsoft практику лицензирования, которая усложняет переход клиентов к другим облачным провайдерам. CMA объявила о продлении расследования после того, как опубликовала отчёты о слушаниях Amazon Web Services (AWS), Google и Microsoft. Во время слушаний AWS, прошедших 2 июля, компания сообщила CMA, что она «считает конкуренцию между поставщиками ИТ-услуг хорошо функционирующей и что облачные сервисы отвечают потребностям клиентов как в Великобритании, так и во всем мире с точки зрения ценообразования, инноваций, выбора продуктов, разнообразия и качества». 
Источник изображения: Vitaly Gariev / Unsplash AWS сообщила, что считает конкурентами локальные ИТ-сервисы, отметив, что облачные сервисы составляют всего 15 % рынка ИТ-услуг Великобритании, и что представление о том, что как только клиенты переходят в облако, они никогда не возвращаются к локальным сервисам, неверно. Об этом сообщается в резюме регулятора, опубликованном 16 сентября. AWS также привела примеры клиентов, возвращающихся в локальные решения, что подчёркивает гибкость её подхода, и отметила, что «приветствует возможность» обсудить практику лицензирования Microsoft. «AWS заявила, что с 2019 года Microsoft ввела лицензионные ограничения, которые не позволяют клиентам использовать ранее приобретённые лицензии Microsoft в AWS (ограничения BYOL). AWS заявила, что это имело огромные финансовые последствия для клиентов и клиенты после покупки продукты Microsoft должны навсегда сохранить к ним доступ и иметь возможность использовать их у ИТ-провайдера по своему выбору», — сообщается в резюме CMA. Что касается сегмента ИИ, AWS указала на рост количества новых игроков, которые появились и составили дополнительную конкуренцию облачным провайдерам — вероятно, имея в виду CoreWeave и других поставщиков облачных ИИ-услуг. 
Источник изображения: Vitaly Gariev / Unsplash В свою очередь, Microsoft тоже отвергла наличие проблем с конкуренцией на рынке облачных сервисов Великобритании, добавив, что «возникшие суждения CMA о конкурентной среде и конъюнктуре рынка игнорируют реальные доказательства того, что рынок очень динамичен и быстро развивается, а степень удовлетворения потребностей клиентов высока». Компания сообщила, что на рынке Великобритании работают три гиперскейлера, и что хотя Google «не добилась такого же уровня успеха, как AWS и Azure на сегодняшний день», её не следует исключать из расследования. В ходе слушаний Microsoft заявила, что лицензионные сборы за её ПО «не столь существенно увеличивают расходы для её конкурентов», добавив, что AWS и Google имеют «достаточную маржу, чтобы конкурировать с Azure», и поэтому лицензионные сборы не приводят к ограничению доступа конкурентов к ключевым ресурсам. По словам Microsoft, соглашения об облачных услугах (CSA) со скидками на основе обязательств необходимы для конкуренции, и их отмена приведёт к более высоким ценам на рынке Великобритании. 
Источник изображения: Vitaly Gariev / Unsplash Google во время слушаний, прошедших 19 июля, а также в опубликованном ранее в этом месяце заявлении сообщила, что разделяет точку зрения CMA по поводу облачного рынка страны, в частности, о «значительной рыночной власти, которой обладают AWS и Microsoft». Для гиперскейлера с наименьшей долей рынка, эта позиция неудивительна, отметил ресурс Data Center Dynamics. Google также поддержала критику AWS в отношении практики лицензирования Microsoft, добавив, что «необходимы срочные и своевременные действия для решения проблемы политики Microsoft». Как и конкуренты, Google считает, что главную роль на рынке Великобритании играют локальные ИТ-решения, а не крупные облака.
22.09.2024 [14:16], Руслан Авдеев
Reverion привлекла $62 млн на выпуск контейнерных электростанций с «отрицательным» выбросомНемецкий стартап Reverion привлёк $62 млн в раунде финансирования серии A, передаёт Datacenter Dynamics. Reverion разрабатывает контейнерные микроэлектростанции с «отрицательным» углеродным выбросом и потратит полученные средства на запуск серийного производства своих продуктов. По словам компании, у неё уже есть предварительные заказы на более чем $100 млн. В ходе раунда A компания получила больше предложений, чем планировала. В том числе получены средства т.н. неразбавляющего финансирования, не влекущего уменьшения доли существующих инвесторов. Раунд возглавила Energy Impact Partners (EIP) при участии Honda и European Innovation Council Fund (EIC Fund). Также к ним присоединились и действующие инвесторы — Extantia Capital, UVC Partners, Green Generation Fund, Doral Energy-Tech Ventures и Possible Ventures. Reverion — детище Мюнхенского технического университета, превратившееся в самостоятельную бизнес-единицу в 2022 году. Заявляется, что его электростанции на твердооксидных топливных ячейках, работающих на биогазе, обеспечивают эффективность генерации энергии до 80 %. Это заметно лучше, чем у традиционных модулей. При этом при наличии избытка энергии в сети, например, от солнечных и ветряных источников, электростанция Reverion переключается на электролиз и сама производит «зелёный» водород или метан, которые сохраняются на будущее. 
Источник изображения: Reverion Биогаз подаётся в систему, после чего из него устраняется сероводород и другие примеси. Газ предварительно нагревается и подаётся в топливную ячейку, где он окисляется для получения электроэнергии. Станция в стандартном 20-футовом контейнере обеспечивает до 100 кВт, а в 40-футовом — до 500 кВт. Параллельно она способна захватывать CO2, выделившийся в ходе генерации энергии. В Reverion заявляют, что фермеры с электростанциями на биогазе страдают от ужесточившихся требований регуляторов и ограничений, связанных с традиционными технологиями. Именно для этого сегмента рынка компания и предлагает свои решения. Некоторые эксперты предполагают, что компания способна стать лидером в своём сегменте не только в Европе, но и в мировых масштабах. Впрочем, у неё уже имеется немало конкурентов. Только в США Министерство энергетики выделило $750 млн на расширение производства водородных ячеек и электролизеров. Внедряют или намерены внедрять топливные элементы на газе многие операторы ЦОД, а некоторые компании вроде Plug Power уже занимаются их разработкой и изготовлением.
22.09.2024 [00:58], Владимир Мироненко
Linux запустили на Intel 4004 — загрузка заняла пять днейКак передаёт OpenNet, разработчик Дмитрий Гринберг сумел запустить ядро Linux с rootfs-окружением из Debian на 10-мкм 4-бит процессоре Intel 4004, вышедшем в конце 1971 года и считающемся первым в мире коммерчески доступным однокристалльным микропроцессором. У Intel 4004 всего 2300 транзисторов. Процессор имел всего 46 инструкций, а его пиковая производительность достигала примерно 93 тыс. операций в секунду. Из-за невозможности напрямую портировать ядро на Intel 4004 и из-за ограничений самого CPU автор решил написать эмулятор процессора MIPS R3000, внутри которого уже запускался Linux. Для запуска процессора автор в несколько подходов создал плату Linux/4004 на базе компонентов 1970-х годов, которые, как выяснилось, не так уж дёшевы. Естественно, плата содержит и гораздо более современные компоненты, позволяющие, к примеру, использовать SD-карту в качестве постоянной памяти. 
Источник изображения: dmitry.gr Из-за малой производительности Intel 4004 эмулятор работал медленно — на обработку каждой виртуальной секунды в эмулируемом окружении уходило почти 4 часа реального времени. После усовершенствования платы и ПО загрузка Linux сократилась с почти 9 дней до примерно 5 дней. Автор даже смог разогнать CPU с базовых 740 кГц до 790 кГц. Желающие повторить эксперимент могут воспользоваться опубликованными спецификациями и схемой платы, а также ПО.
21.09.2024 [21:02], Владимир Мироненко
AWS ищет главного инженера-атомщика, который поможет запитать ИИ ЦОД от АЭС и SMRПосле приобретения у Talen Energy Corporation кампуса ЦОД у АЭС Susquehanna в Пенсильвании (США) компания Amazon Web Services (AWS) разместила на сайте вакансию главного инженера-атомщика, который будет отвечать за развитие малых модульных реакторов и налаживание отношения с традиционными АЭС, пишет DatacenterDynamics (DCD). Претендент на эту должность должен иметь опыт проектирования и эксплуатации как АЭС для коммунальных нужд, так и малых модульных реакторов (SMR). Указано, что он будет разрабатывать «внутренние и внешние стратегические планы по ядерным продуктам и топливу» для дата-центров AWS. Также претендент должен уметь проводить комплексную проверку «конкретных энергетических проектов». В его обязанности будет входить выстраивание отношений с Министерством энергетики США и регулирующими органами, а также работа с внешними партнёрами в рамках проектирования «эксплуатационно эффективных и безопасных модульных атомных электростанций» для поддержки растущих потребностей в энергии. В связи с ростом потребности в электроэнергии для ИИ ЦОД, AWS и другие облачные провайдеры обратились к сектору атомной энергетики. 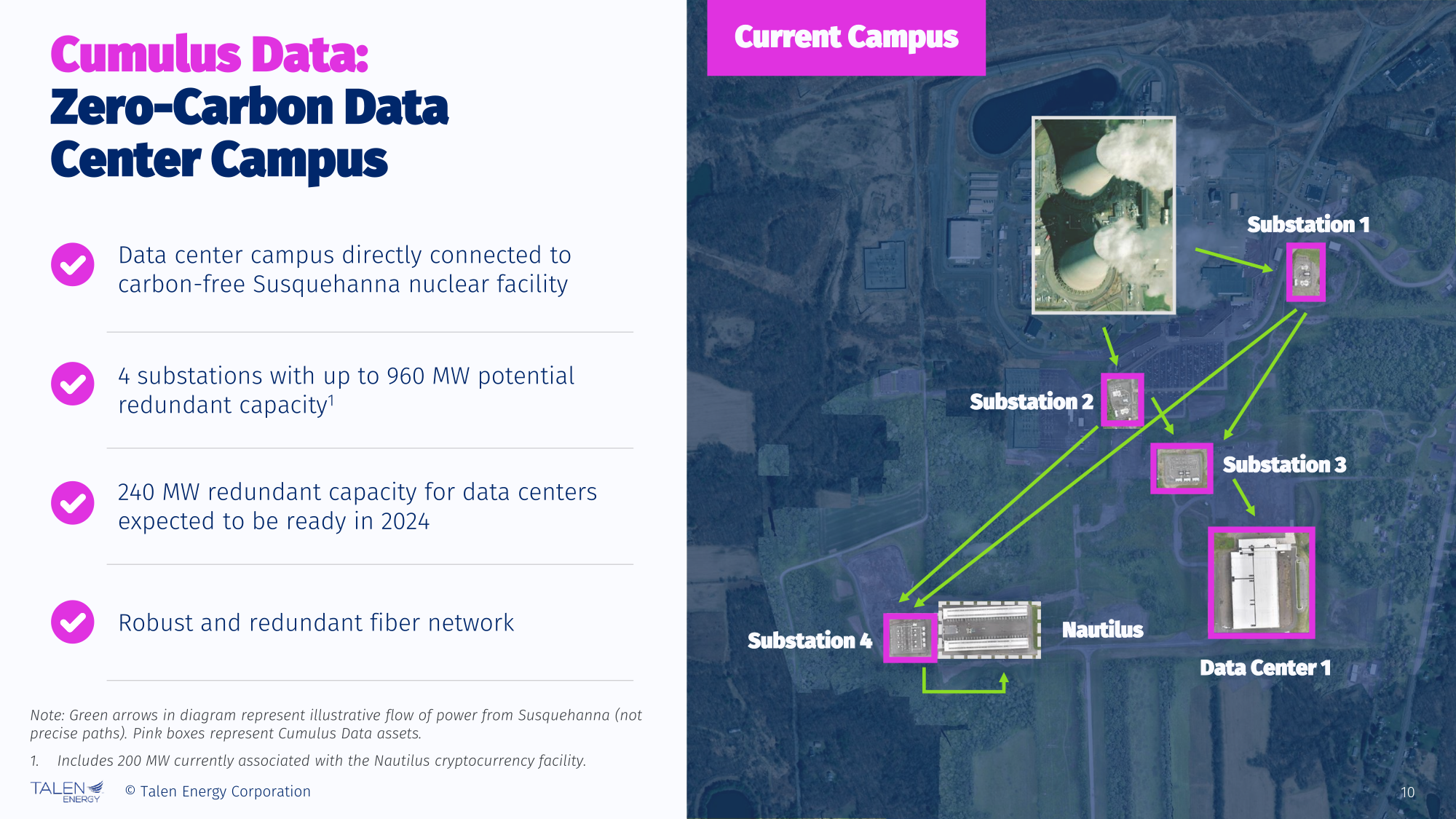
Источник: Talen Energy Как стало известно на днях, Microsoft заключила с крупнейшим оператором АЭС в США Constellation Energy 20-летний контракт на поставку электроэнергии (PPA) с АЭС Three Mile Island в Пенсильвании, которую вновь введут в эксплуатацию, а также сформировала целую команду по работе над атомной энергетикой и наняла целый ряд квалифицированных специалистов. По неофициальным данным, Microsoft будет платить за энергию порядка $800 млн/год. При этом начальные затраты только на восстановление работоспособности Three Mile Island составят $1,6 млрд. В апреле этого года Equinix подписала 20-летнее PPA-соглашение на поставку 500 МВт от модульных реакторов Oklo с возможностью его продления в дальнейшем. Спустя два месяца Wyoming Hyperscale (теперь Prometheus Hyperscale) подписала с Oklo PPA на 100 МВт. Кроме того, в этом месяце Oracle сообщила, что построит в США 1-ГВт кампус ЦОД с питанием от трёх малых модульных реакторов (SMR).
21.09.2024 [01:14], Владимир Мироненко
Microsoft перезапустит АЭС Three Mile Island, чтобы запитать свои ИИ ЦОДКомпания Constellation Energy, крупнейший оператор АЭС в США, объявила о заключении 20-летнего контракта с Microsoft на поставку электроэнергии (PPA), которая будет производиться на АЭС Three Mile Island в Пенсильвании, печально известной по аварии на втором энергоблоке в 1979 году — самом серьёзном инциденте за всю историю атомной энергетики США. В результате аварии второй энергоблок АЭС был частично разрушен, но первый энергоблок не пострадал и проработал до 2019 года. Из-за убыточности АЭС и отказа властей штата продолжать субсидировать её работу она была окончательно остановлена 20 сентября 2019 года, после чего её передали Constellation Energy, имеющей опыт ликвидации АЭС. В рамках соглашения Constellation Energy планирует вновь ввести первый энергоблок в эксплуатацию к 2028 году, если будет получено одобрение Комиссии по ядерному регулированию США после всеобъемлющей проверки безопасности и защиты окружающей среды, а также разрешения от иных государственных и местных органов. Constellation Energy будет добиваться продления лицензии, что позволит эксплуатировать АЭС как минимум до 2054 года. 
Источник изображений: Constellation Energy Планируемый к восстановлению объект был переименован в Центр чистой энергии Крейна (Crane Clean Energy Center, CCEC) в честь Криса Крейна (Chris Crane), который был гендиректором бывшей материнской компании Constellation и умер в апреле 2024 года. Хотя полные условия сделки не раскрываются, Constellation Energy объявила, что для возобновления работы необходимо около $1,6 млрд на восстановление оборудования, включая турбину, генератор, главный силовой трансформатор, а также системы охлаждения и управления. Мощность восстановленной АЭС составит 837 МВт. Вся производимая ею электроэнергия будет поступать Microsoft. Этого достаточно, чтобы обеспечить работу всех ЦОД компании в Пенсильвании, Чикаго, Вирджинии и Огайо. Согласно исследованию, которое профинансировал Совет по строительным профессиям Пенсильвании, повторное открытие АЭС создаст 3400 рабочих мест на объекте и в обслуживающих его предприятиях, а также принесёт в казну $3 млрд в виде государственных и федеральных налогов.  Сделка позволит Microsoft решить углубляющуюся энергетическую проблему, поскольку разрастающиеся ЦОД, необходимые ей для обслуживания ИИ-нагрузок, перегружают существующие в стране источники энергии. Как отмечают американские СМИ, никогда прежде атомная электростанция в США не возвращалась в строй после вывода из эксплуатации, и никогда прежде вся продукция одной коммерческой АЭС не поставлялась единственному заказчику. Срок действия соглашения с Constellation Energy значительно больше традиционных соглашений Microsoft о закупках солнечной и ветровой энергии. По всей видимости, сделка готовилась длительное время. За последние 12 месяцев Microsoft сформировала команду по работе над атомной энергетикой и наняла целый ряд опытных специалистов. Ранее Microsoft приобрела кредиты на возобновляемую энергию (CEC) у канадской энергетической компании Ontario Power Generation (OPG) и подписала соглашение с Constellation о поставке электроэнергии с АЭС для своего ЦОД в Бойдтоне. Атомная энергетика, гарантирующая в отличие от энергии ветра и солнца стабильную поставку электроэнергии вне зависимости от капризов погоды, становится всё популярнее среди гиперскейлеров. Ранее AWS приобрела за $650 млн кампус Talen Energy рядом с АЭС Susquehanna Steam Electric Station в Пенсильвании, которая обеспечит ЦОД до 960 МВт. Также в этом месяце Oracle объявила, что построит в США 1-ГВт кампус ЦОД с питанием от трёх малых модульных реакторов (SMR). А Oklo даже подписала соглашения с несколькими ЦОД.
20.09.2024 [21:51], Владимир Мироненко
Сбербанк начал переход с Citrix на отечественную VDI-платформу Termidesk
astra linux
citrix systems
software
termidesk
vdi
импортозамещение
миграция
россия
сбер
сбербанк
сделано в россии
Сбербанк приступил к внедрению отечественной платформы виртуализации рабочих мест Termidesk компании «УВЕОН — облачные технологии» (входит в состав ПАО «Группа Астра»), что позволит полностью отказаться от решений Citrix, сообщается на сайте ПАО «Группа Астра». Благодаря запуску Termidesk будет создан сервис виртуальных рабочих мест для более чем 150 тыс. сотрудников кредитного учреждения. 
Источник изображения: astragroup.ru Согласно пресс-релизу, платформа Termidesk была выбрана благодаря поддержке 100 тыс. и более пользовательских подключений, а также наличию собственного протокола доступа Tera, который оптимизирует подключения даже на слабых каналах связи. В числе преимуществ Termidesk также указаны компонент «Агрегатор», значительно упрощающий управление системой, высокая отказоустойчивость архитектуры и простота перехода на новое решение для конечных пользователей. Старший вице-президент, руководитель блока «Технологий» Сбербанка отметил, что решение от «Группы Астра» отвечает всем требованиям Сбербанка. По его словам, перевод большинства сотрудников банка на эту платформу должен завершиться в начале 2025 года.
20.09.2024 [21:27], Алексей Степин
От IoT до ЦОД: SiFive представила экономичные ИИ-ядра Intelligence XMРазработчик SiFive, известный своими процессорными ядрами с архитектурой RISC-V, решил подключиться к буму систем ИИ, анонсировав кластеры Intelligence XM — первые в индустрии RISC-V решения, оснащённые масштабируемым движком матричных вычислений для обработки ИИ-нагрузок. Как отмечает SiFive, новый дизайн должен помочь разработчикам чипов на базе RISC-V в создании кастомных ИИ-систем, в том числе для автономного транспорта, робототехники, БПЛА, IoT, периферийных вычислений и т.п., где роль таких нагрузок в последнее время серьёзно выросла, а требование к энергоэффективности никуда не делись. Но при желании можно создать и серверные ускорители, говорит компания. Каждый матричный блок в составе одного XM-кластера дополнен четырьмя ядрами X Core, каждое из которых имеет в своём составе два блока векторных вычислений и один блок скалярных вычислений. Все вместе они делят общий L2-кеш. XM-кластер располагает шиной с пропускной способностью 1 Тбайт/с и поддерживает подключение к памяти двух типов — когерентное через общую шину CHI, к которой подключается и внешняя память DDR/HBM, или высокоскоростной порт для SRAM. Производительность одного XM-кластера 8 Тфлопс в режиме BF16 и 16 Топс в режиме INT8 на каждый ГГц частоты. 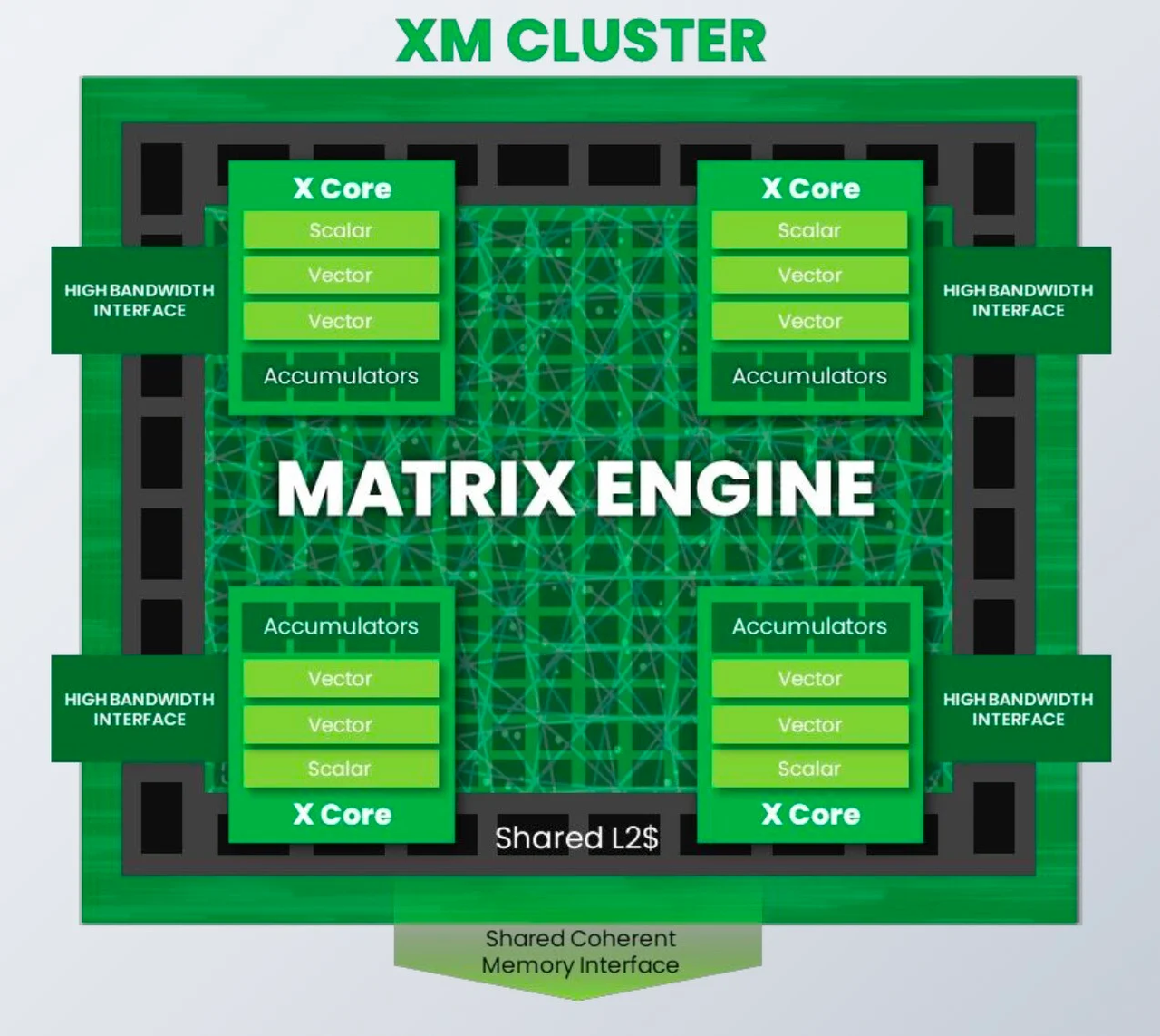
Источник здесь и далее: SiFive Тип хост-ядра не важен, это может быть RISC-V, Arm или даже x86. Впрочем, хост-ядра могут отсутствовать вовсе. Ожидается, что чипы на базе XM в среднем будут иметь от четырёх до восьми кластеров, что даст им до 8 Тбайт/с пропускной способности памяти и до 64 Тфлопс производительности в режиме BF16, и это лишь на частоте 1 ГГц при малом уровне энергопотребления. Но возможно и масштабирование до 512 XM-блоков, что даст уже 4 Пфлопс BF16. У NVIDIA Blackwell, например, в том же режиме производительность составляет 5 Пфлопс. 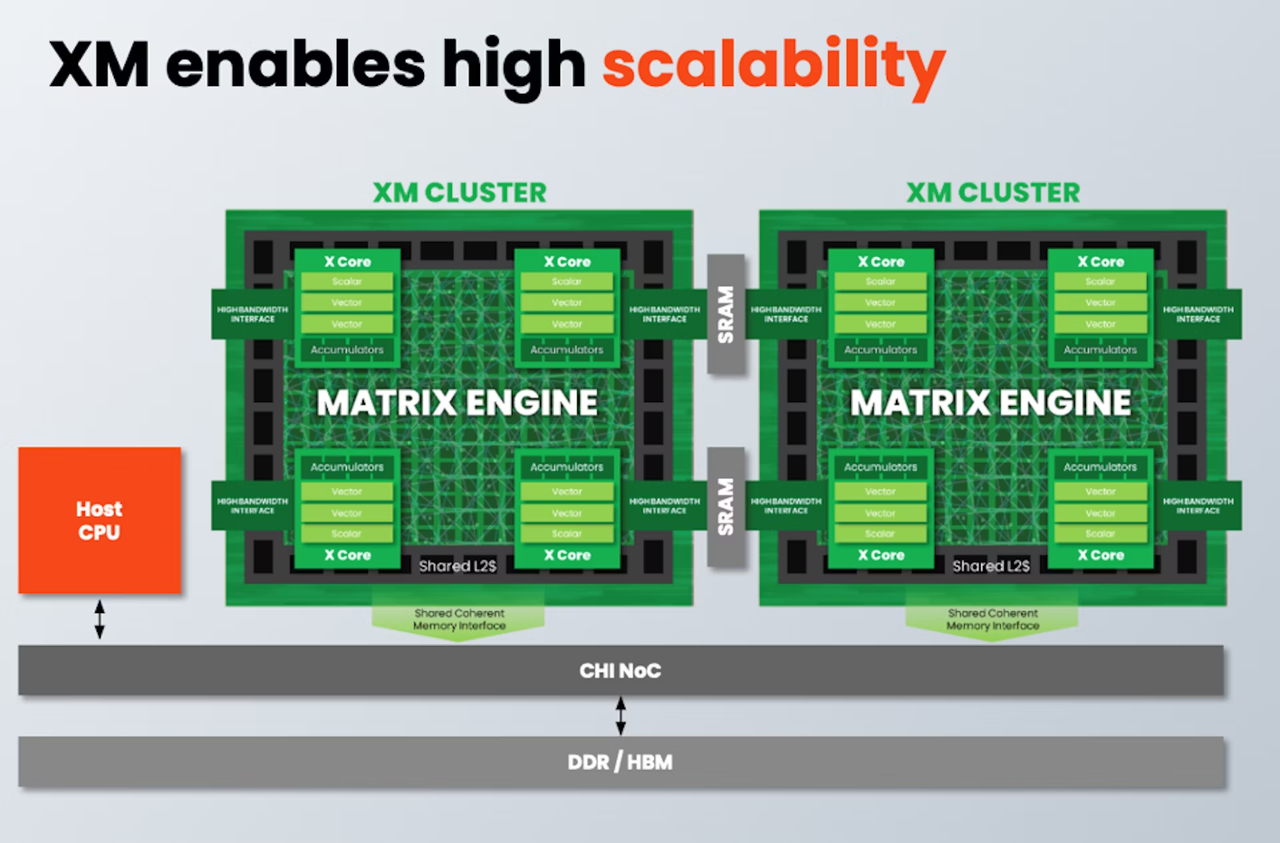 В целях дальнейшей популяризации архитектуры RISC-V компания также планирует сделать открытой (open source) референсную имплементацию SiFive Kernel Library (SKL). SKL включает оптимизированную для RISC-V ядер SiFive реализацю различных востребованных алгоритмов, в том числе для работы с нейронными сетями, обработки сигналов, линейной алгебры и т.д. 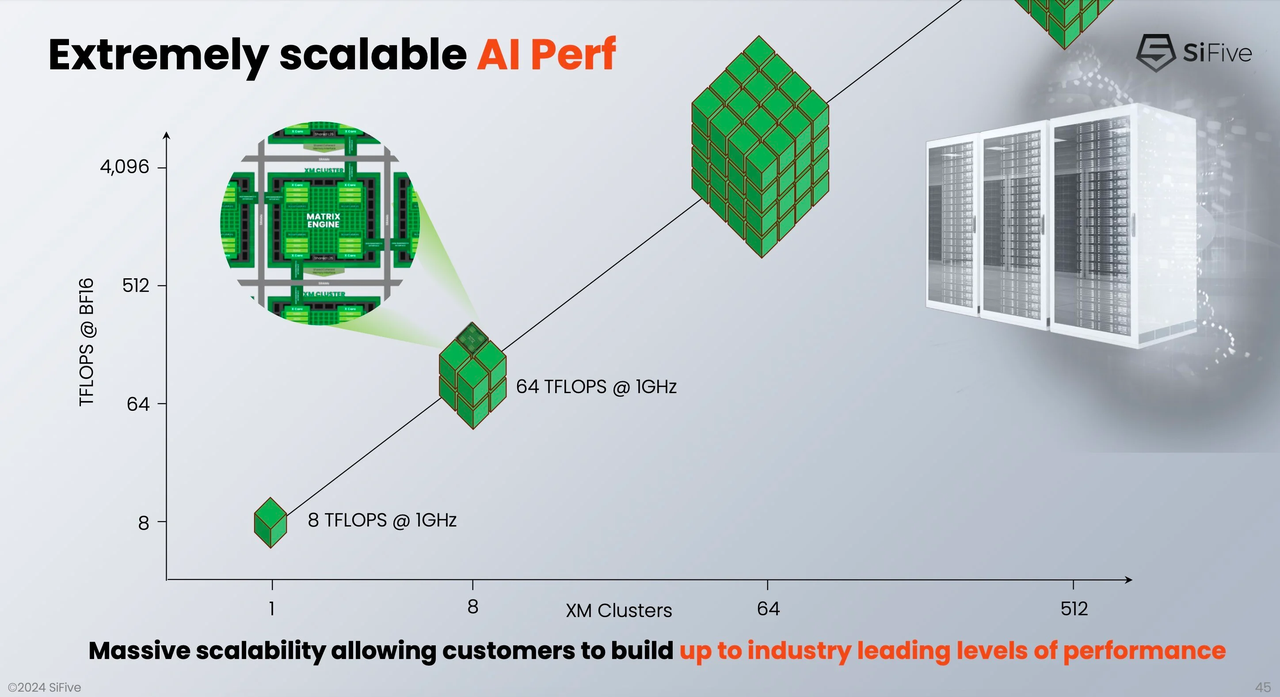 Дела у SiFive идут, судя по всему, неплохо, и, как отметил глава компании Патрик Литтл (Patrick Little), новые дизайны ядер помогут ей сохранить темпы роста и не отстать от эволюции ИИ, оставаясь в то же время поставщиком уникальных процессорных решений с открытой архитектурой. На данный момент решения SiFive уже поставляет свои решения таким гигантам, как Alphabet, Amazon, Apple, Meta✴, Microsoft, NVIDIA и Tesla.
20.09.2024 [20:25], Руслан Авдеев
20 тонн HDD в труху — накопители хранилища Alpine уходящего на покой суперкомпьютера Summit отправили в измельчительПо словам специалистов Национальной лаборатории Ок-Ридж (ORNL) Министерства энергетики США, суперкомпьютеры и их компоненты утилизируются точно так же, как и ненужная бумага — буквально отправляются в измельчитель. И совсем скоро сотрудникам лаборатории предстоит разобрать суперкомпьютер Summit, который морально устарел, хотя всё ещё входит в десятку самых производительных систем мирового рейтинга TOP500. Summit хотели вывести из эксплуатации ещё в 2023 году, но из-за довольно высокой производительности пока решено оставить его в строю почти до ноября 2024 года в рамках программы SummitPLUS. Впрочем, часть комплекса уже модернизируется. Так, на смену хранилищу Alpine придёт Alpine 2. Данные из Alpine были переданы в другие СХД суперкомпьютерного центра Oak Ridge Leadership Computing Facility (OLCF). 19 ноября Alpine2 переключат в режим «только для чтения», а потом изменят конфигурацию хранилища для использования в других проектах. Alpine, основанная на параллельной файловой системе IBM Spectrum Scale, создавалась для временного хранения данных Summit и других систем. По словам учёных, Summit строили для симуляции процессов в сверхновых и термоядерных реакторах и вряд ли где-либо ещё есть такая же концентрация жёстких дисков в одном месте, как в системах ORNL, за исключением, возможно, гиперскейлеров. Другими словами, даже разборка Alpine, которая началась ещё летом — чрезвычайно трудоёмкий процесс, поскольку накопители приходится извлекать вручную и по одному. 
Источник изображения: ORNL Alpine состояло из 40 стоек на площади около 130 м2. Хранилище суммарной ёмкостью 250 Пбайт включало 32 494 HDD. Речь идёт о почти 20 т оборудования. Чтобы обеспечить по-настоящему безопасное удаление данных, HDD отвозят для физического уничтожения. За этот процесс отвечает компания ShredPro Secure. HDD буквально крошатся металлическими зубьями до небольших фрагментов. На переработку одного диска уходит приблизительно 10 с, а за день можно уничтожить до 3,5 тыс. накопителей. Полученные остатки окончательно утилизируются в рамках программы по переработке металла ORNL, так что лаборатория ещё и получает деньги за сдачу вторичного сырья. Вывод из эксплуатации крупных вычислительных систем — постоянно совершенствуемый процесс, который с годами становится всё эффективнее. В последний раз крупное хранилище (Atlas) утилизировали в 2019 году, оно включало около 20 тыс. HDD. Утилизация своими силами заняла около 9 месяцев и оказалась очень дорогой. ShredPro Secure справилась гораздо быстрее, а сам процесс оказался гораздо дешевле. Поэтому компании в итоге отдали на уничтожение ещё около 10 тыс. HDD из других систем. Правда, теперь ORNL раздумывает над покупкой собственного измельчителя, чтобы дополнительно повысить безопасность и сэкономить ещё больше в долгосрочной перспективе.
20.09.2024 [17:05], Руслан Авдеев
На генерацию ста слов у GPT-4 уходит до трёх бутылок водыИсследование, проведённое учёными Калифорнийского университета в Риверсайде показало, что использование ИИ-технологий для экологии обходится очень дорого. The Washington Post сообщает, что ИИ ЦОД требуют очень много питьевой воды и энергии, даже когда просто генерируют только текст. Дата-центры давно считаются довольно «жадными» до воды и электричества, причём наличие ЦОД поблизости крайне негативно влияет и на счета за коммунальные услуги обычных граждан. Конкретные затраты воды и энергии отличаются от штата к штату и зависят от близости их источников к дата-центру. Так, более низкое водопотребление напрямую зависит от стоимости энергии. Если в Техасе на подготовку электронного письма из 100 слов с помощью GPT-4 потребуется 235 мл, то в Вашингтоне — уже 1408 мл. Ранее те же исследователи выяснили, что диалог из 20–50 вопросов к ChatGPT на базе GPT-3 требуется 0,5 литра, а обучение GPT-3 обошлось в 320 тыс. литров. А на обучение Meta✴ Llama-3 потребовалось уже 22 млн литров. На первый взгляд кажется, что это не очень много, но пользователи редко ограничиваются написанием одного письма или другого материала в неделю или даже в день. Кроме того, при работе с изображениями и другим контентом расход, скорее всего, ещё выше. Если один из десяти работающих американцев использует GPT-4 раз в неделю в течение года (52 запроса от 17 млн человек), энергозатраты составляют 121 517 МВт∙ч. Примерно столько же потребляют все домохозяйства Вашингтона (Округ Колумбия, 672 тыс. человек) в течение двадцати дней. На практике же целевая аудитория GPT-4 применяет модель несопоставимо активнее. 
Источник изображения: Joseph Corl/unsplash.com Представители OpenAI, Meta✴, Google и Microsoft неоднократно говорили о важности снижения экологической нагрузки своего бизнеса, но кардинальных шагов никто из них пока не совершил. Представитель Microsoft сообщил, что компания будет работать над методами охлаждения ЦОД, которые позволят полностью избавиться от потребления воды. Речь, например, об использовании воздушных систем охлаждения в сухой Аризоне. В августе сообщалось как об использовании Microsoft СЖО, так и систем на основе более прогрессивных технологий микрогидродинамики. Параллельно растут и углеродные выбросы той же Microsoft, связанные с развитием её ИИ-систем. По мнению многих экспертов, прибыль безусловно находится в приоритете в сравнении с климатическими целями, поставленными компаниями в прошлом, поэтому стоит подождать конкретных улучшений. Ранее сообщалось, что в «столице ЦОД», штате Вирджиния, дата-центры потребляют огромное количество воды, а развитие ИИ ухудшает ситуацию. Конечно, проблема актуальна не только для США. Например, в прошлом году британская коммунальная компания Thames Water пригрозила операторам ЦОД урезать подачу воды или поднять цены, если те не сократят расход этого важного ресурса. Весной 2024 года появились данные о том, что потребление воды китайскими дата-центрами удвоится к 2030 году. |
|

