Материалы по тегу: ии
|
28.05.2026 [09:13], Руслан Авдеев
ИИ осветят путь: Goldman Sachs прогнозирует резкий рост рынка оптических сетейПо прогнозам Goldman Sachs, рынок оптических сетевых решений для ИИ-инфраструктуры увеличится до $154 млрд на фоне роста спроса со стороны облачных гиперскейлеров и ИИ-кластеров, сообщает блог IEEE ComSoc. Техногиганты стремятся эффективно объединить как можно больше чипов, что приведёт к росту рынка волоконно-оптических соединений в ИИ ЦОД в девять раз. В Goldman Sachs отмечают, что показатели ИИ-систем теперь зависят не только от производительности GPU и HBM, но и от того, насколько быстро данные передаются между чипами и стойками. Аналитики подчёркивают, что именно оптические сетевые решения «разблокируют» вычислительные мощности, с чем уже не особенно эффективно справляются медные интерконнекты. В докладе рынок делится на решения для вертикального (scale-up) и горизонтального (scale-out) масштабирования. Примечательно, что на первые, как ожидается, придётся около $106 млрд из $154 млрд, т.е. 69 % рынка. Рынок оптических интерфейсов CPO составит порядка $91 млрд (59 %), т.е. большая часть затрат пойдёт на сети внутри ИИ-кластеров. По прогнозам Goldman Sachs, при переходе от систем NVIDIA GB300 NVL72 к Rubin Ultra NVL576 рост долларового содержания на вычислительную единицу вырастет в 16 раз в сегменте scale-out и в 45 раз — в сегменте scale-up. Рост связан с увеличением спроса на подключаемые оптические модули, оптические «движки», медные кабели и др. Рынок подключаемых оптических модулей и оптических «движков» вырастет в 13 раз при переходе от scale-out (как в случае GB300 NVL72/Oberon) к scale-up (Rubin Ultra NVL576/Kyber) в расчёте на вычислительную единицу. 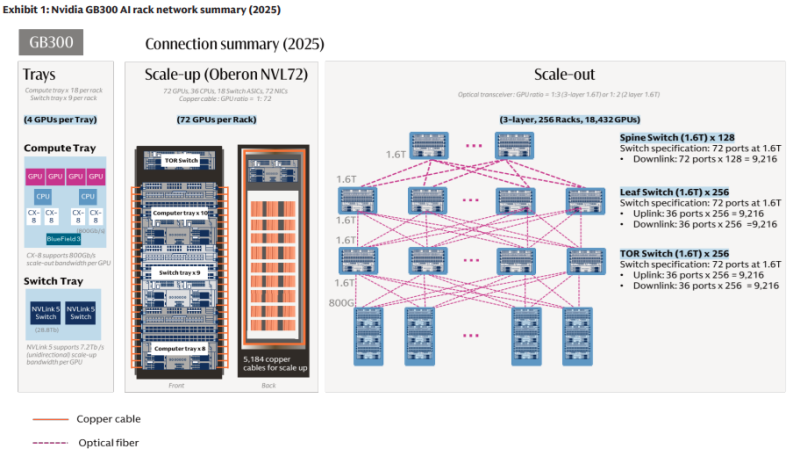
Источник изображения: Goldman Sachs Рынок подключаемых оптических модулей в сегменте scale-out вырастет в 10 раз на вычислительную единицу при переходе с GB300 NVL72 на Rubin Ultra NVL576, даже при проникновении CPO на уровне 29 %. Количество оптических модулей (в эквиваленте 1.6TbE) в одной вычислительной единице увеличится с 216 шт. в GB300 NVL72 до приблизительно 2,5 тыс. в Rubin Ultra NVL576. Банк прогнозирует, что долларовое содержание на вычислительную единицу в сегментах scale-up и scale-out увеличится в 20 раз с $315 тыс. в GB300 NVL72 до $9,4 млн в Rubin Ultra NVL576. При этом прогнозируется, что за полный жизненный цикл продукта будет поставлено 48 тыс. стоек GB300 NVL72 и 16,5 тыс. систем Rubin Ultra NVL576. Совокупный адресуемый рынок (TAM) для вертикальных и горизонтальных решений вырастет в 9 раз, с $15 млрд в случае с GB300 NVL72 (преимущественно в 2026 году) до $154 млрд для Rubin Ultra NVL576 (в основном в 2028 году). 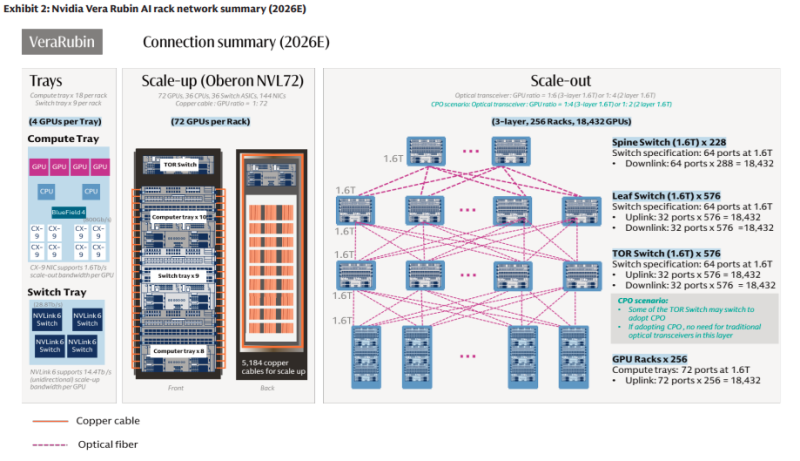
Источник изображения: Goldman Sachs Одним из ключевых выводов является то, что ИИ-кластеры становятся всё более насыщенными на разных уровнях стека оптическими системами, а не только на уровне подключения между стойками. Более всего от ситуации выиграют поставщики, способные снизить энергопотребление, повысить плотность и упростить упаковку для сверхскоростных интерконнектов. Чаще всего в числе основных бенефициаров упоминаются Coherent, Lumentum и Fabrinet, занятых в индустрии производства оптических компонентов и модулей, которое растёт вместе со спросом на ИИ-интерконнекты. Наилучшие перспективы у производителей специализированных оптических решений, а не у игроков более широкого профиля, включая Ciena, Nokia/Infinera, Cisco/Acacia, ADVA или Calix. В целом в Goldman Sachs считают, что оптические решения более не являются вспомогательным элементом инфраструктуры и становятся ключевым фактором для масштабирования инвестиций в ИИ. В результате инвесторы всё активнее интересуются производителями оптических компонентов, кремниевой фотоники, трансиверов и смежных технологий упаковки и пр. Ключевой вывод — по мере развития ИИ-кластеров сетевая инфраструктура становится одним из главных потенциальных ограничений, а оптика — наиболее вероятным решением этой проблемы.
28.05.2026 [09:00], Сергей Карасёв
«Базис» представляет Basis Workplace 3.3 с собственным протоколом доставки Basis Connect и интеграцией с Basis SDNКомпания «Базис», лидер российского рынка ПО для управления динамической инфраструктурой, выпустила обновление платформы для управления инфраструктурой виртуальных рабочих столов (VDI) — Basis Workplace 3.3. Главным событием релиза стала нативная интеграция протокола передачи данных Basis Connect, разработанного «Базис» для расширения возможностей VDI-платформы и упрощения её развёртывания. Помимо этого в версии 3.3 появились новые возможности для работы в крупных и территориально распределённых инсталляциях, добавлена поддержка программно-определяемых сетей Basis SDN при работе с Basis Dynamix Enterprise, а также реализован ряд улучшений в области администрирования, безопасности и интеграции с корпоративными системами. Собственный протокол доставкиКлючевым нововведением Basis Workplace 3.3 стала интеграция Basis Connect — собственного протокола передачи данных между клиентом и виртуальным рабочим местом. При этом «Базис» сохраняет поддержку сторонних протоколов доставки, среди которых RX и Loudplay — это одно из востребованных у заказчиков преимуществ платформы. Качество и скорость обмена данными напрямую определяют уровень комфорта пользователя при работе в виртуальной среде: сможет ли он использовать ресурсоёмкие приложения, периферийные устройства и участвовать в видеоконференциях без потерь качества. Для обеспечения необходимого уровня комфорта могут использоваться проприетарные протоколы, требующие отдельных лицензий, либо open-source протоколы, нуждающиеся в доработке и поддержке. Наличие собственного протокола передачи данных в составе Basis Workplace позволяет избежать зависимости от сторонних решений, упростить внедрение платформы и обеспечить заказчикам более предсказуемую эксплуатацию. 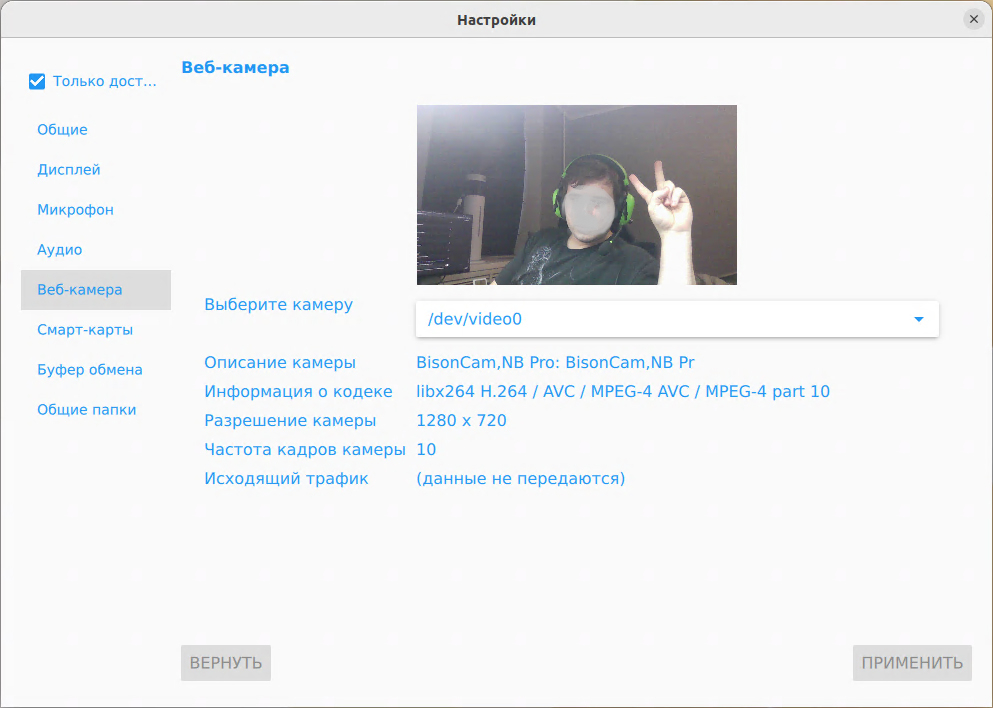
Настройки протокола Basis Connect (Источник изображений: «Базис») В первой публичной версии Basis Connect реализована передача изображения и звука, работа с буфером обмена (текст, файлы, папки, изображения), поддержка клавиатуры, мыши, принтеров, сканеров и других периферийных устройств, включая USB-токены для использования сертификатов внутри виртуального рабочего места. Нативная интеграция с Basis SDNВ новой версии продолжается развитие модульной архитектуры драйверов, которая в Basis Workplace 3.2 обеспечила нативное подключение к Basis Dynamix Enterprise и OpenStack. Теперь платформа виртуализации на основе Basis Dynamix Enterprise может работать в связке с Basis SDN — решением, отвечающим в экосистеме «Базиса» за управление сетевой инфраструктурой. Это позволяет заказчикам построить полностью отечественный стек инфраструктуры виртуальных рабочих мест на продуктах «Базис»: от серверной виртуализации и управления сетью до VDI-платформы. Усиленная отказоустойчивость крупных инсталляцийВ Basis Workplace 3.3 была реализована возможность установки резервного бэкенда: при неисправности основного, система автоматически переключается на резервный, обеспечивая непрерывность работы. Добавлена балансировка нагрузки на брокеров через механизм Global Server Load Balancing (GSLB). Появилась возможность задавать в параметрах службы каталогов сразу несколько IP-адресов и портов: при недоступности одного из них система переключается на следующий по списку, что исключает зависимость от единственного контроллера домена. 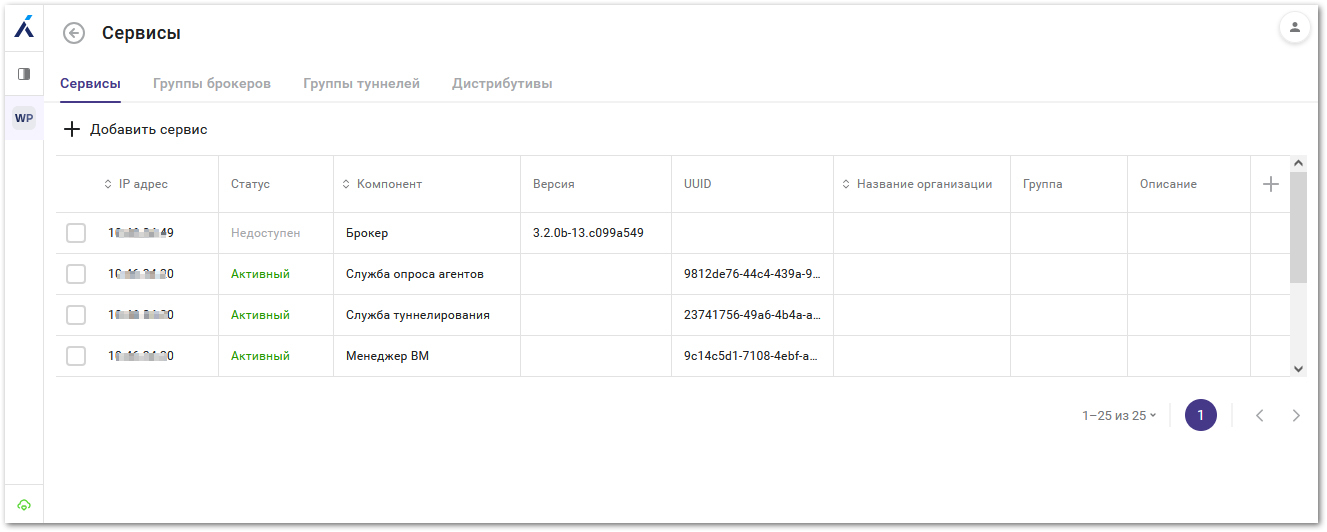
Управление сервисами и брокерами Развитие получила и реализация геораспределённой VDI. Теперь каждая площадка такой конфигурации имеет собственный сертификат для безопасного доступа, а ключи площадок генерируются непосредственно в списке площадок — это упрощает процедуру их подключения и обеспечивает изоляцию доверия между ЦОД. Дополнительный механизм надёжности — возможность отката на предыдущую версию сервиса. Если после обновления возникают непредвиденные проблемы, администратор может вернуться к работоспособной версии без сложных операций восстановления. Новые инструменты администрированияВ Basis Workplace 3.3 был расширен набор средств управления и мониторинга платформы. Появились новые инструменты для визуализации текущего состояния системы и анализа исторических данных о работе виртуальных машин, в результате администраторы получили более полную картину происходящего в инфраструктуре. Также была ускорена повседневная работа — ряд операций теперь можно выполнять над несколькими пулами и виртуальными машинами одновременно, а часть задач по управлению инфраструктурой переведена в панель управления. Дополнительно, были расширены возможности аудита: по основным сценариям работы пользователей и администраторов теперь можно формировать отчёты за произвольный период. 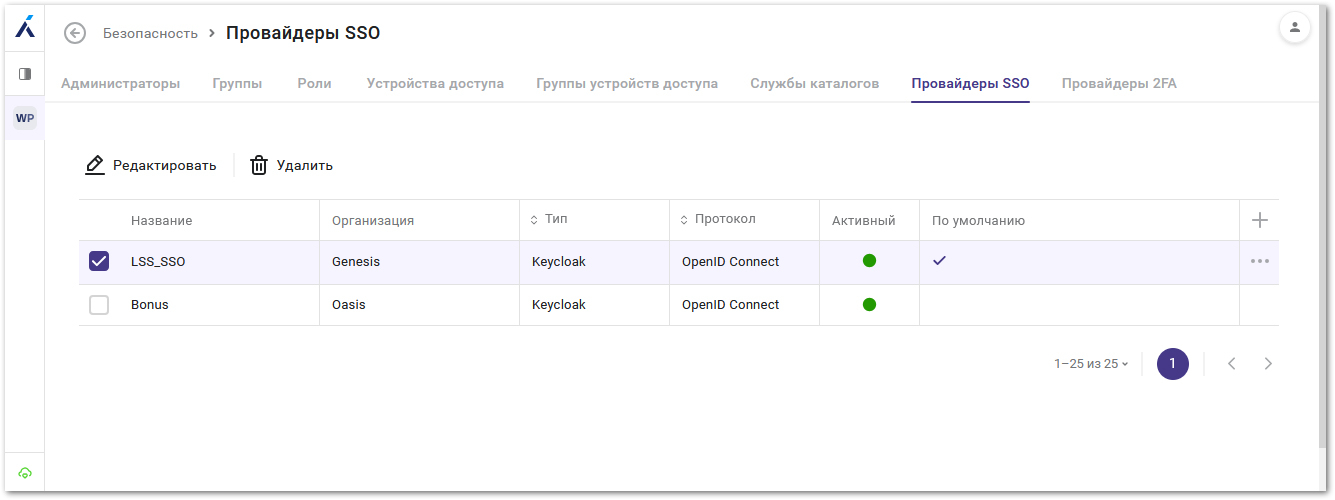
Список SSO-провайдеров В версии 3.3 расширен список поддерживаемых служб каталогов и провайдеров аутентификации, а также добавлены инструменты для интеграции с корпоративным контуром информационной безопасности. В результате повысилось удобство управления подключениями, улучшился контроль доступа администраторов и пользователей. «При создании Basis Connect мы ориентировались на запросы заказчиков на нативный протокол передачи данных в составе Basis Workplace. Он позволяет обеспечивать высокое качество работы в виртуальной среде, не требует отдельных лицензий на проприетарные протоколы и упрощает эксплуатацию платформы. Что касается интеграции с Basis SDN, то здесь мы считаем принципиально важным, чтобы возможности нашего программно-определяемого решения были доступны в других продуктах экосистемы. Для заказчиков это означает более удобное управление сетевой частью виртуальной инфраструктуры, более быстрое развёртывание рабочих мест и более высокий уровень контроля над безопасностью и сегментацией среды», — прокомментировал Дмитрий Сорокин, технический директор компании «Базис».
27.05.2026 [22:48], Владимир Мироненко
Avanpost открыла публичное тестирование облачного сервиса Avanpost Identity CloudКомпания Avanpost объявила о запуске облачного сервиса Avanpost Identity Cloud и о старте его публичного тестирования. Его участникам предоставляется пробный период с доступом ко всем функциям сервиса до 1 сентября, с неограниченным числом пользователей и возможностью выстроить защиту корпоративного доступа: от базовой многофакторной аутентификации до тарифа E-Passport. Компания отметила, что Avanpost Identity Cloud построен как продолжение on-premise практики Avanpost, при этом возможности и архитектурные принципы корпоративного решения перенесены в облако без потери уровня защиты. Для каждого клиента разворачивается независимое окружение со степенью изоляции, сопоставимой с выделенным on-premise решением. Защищённую интеграцию платформы с корпоративными системами заказчика обеспечивает компонент Access Bridge. Сервис отличается гибкостью развёртывания с возможностью адаптации под любую архитектуру. Поддержка офлайн-аутентификации обеспечивает непрерывность работы даже при сбоях связи, а централизованное управление из единой административной консоли упрощает эксплуатацию — благодаря использованию принципа plug-and-play нет надобности в ручной настройке локальных компонентов. Критически важные секреты приложений (LDAP, RADIUS) обрабатываются внутри контура заказчика, обеспечивая высокий уровень безопасности. 
Источник изображения: Towfiqu barbhuiya/unsplash.com Пользователям Avanpost Identity Cloud предлагаются четыре тарифных плана с возможностью перехода по мере расширения числа и сложности выполняемых задач: Start, Expert, E-passport и Zero Trust. С 1 сентября 2026 года будет доступна выгодная ежемесячная тарификация по уникальным пользователям с оплатой по факту использования сервиса.
27.05.2026 [17:25], Руслан Авдеев
ByteDance закупит ИИ-чипы Qualcomm и увеличит капзатраты до $70 млрдКомпания Qualcomm достигла соглашения с китайской ByteDance, предусматривающего выпуск и поставки чипов для ЦОД последней. Это важное достижение для Qualcomm, пытающейся расширить бизнес за пределы производства чипсетов для смартфонов и планшетов, сообщает Bloomberg. Кроме того, Qualcomm заключила договорилась о поставках ASIC с ещё одним неназванным американским облачным провайдером, дополняет DigiTimes. ByteDance намерена приобрести миллионы ИИ ASIC Qualcomm. По данным источников, это поможет владельцу социальной сети TikTok создавать и эксплуатировать агентный ИИ. После появления новостей акции Qualcomm подорожали на 8,3 % обновив дневной исторический максимум. Ранее компания заявила, что уже начала формировать очередь клиентов, желающих приобрести такие чипы. Qualcomm давно стремилась увеличить присутствие в индустрии ИИ-чипов, но главной проблемой был поиск клиентов на её продукцию соответствующего назначения. NVIDIA продолжает доминировать на рынке ИИ-полупроводников, хотя конкуренцию ей пытаются составить AMD, Broadcom и Google. Договор ByteDance поможет Qualcomm получить крупного покупателя и, следовательно, пропуск в один из наиболее быстро растущих сегментов полупроводниковой индустрии. 
Источник изображения: Qualcomm Сегодня американская компания предлагает чипы при посредничестве TSMC, если те соответствуют американским экспортным ограничениям — нарушать санкционный режим даже ради контракта с ByteDance в Qualcomm не будут. По словам одного из источников, новая сделка поможет ByteDance превратить уже разработанный самостоятельно дизайн чипа в готовый к производству продукт. Ещё в 2024 году сообщалось, что ByteDance проектировала собственные ускорители, хотя об отказе от продукции NVIDIA речь не шла. Тем временем ByteDance наращивает расходы. Компания увеличила увеличит капитальные затраты до порядка $70 млрд, большая часть средств пойдёт на ИИ-инфраструкту, включая ЦОД и оборудование. ПО Doubao, предлагаемое компанией, аналогично ChatGPT, Claude и Gemini. Боьшую часть прошлого года, по данным Bloomberg Intelligence, это был самый загружаемый чат-бот в Китае. Вместе с тем ByteDance стремительно осваивает и китайский рынок облачных ИИ-сервисов.
27.05.2026 [15:46], Сергей Карасёв
Broadcom представила чип-шлюз 50G PON с ИИ и постквантовой криптографиейКомпания Broadcom анонсировала систему на чипе (SoC) с обозначением BCM68850 — это высокоинтегрированное изделие 50G ITU PON/XGS-PON, предназначенное для построения производительных шлюзов в широкополосных сетях. Поставки образцов новинки уже начались. В состав BCM68850 входит многоядерный процессор с архитектурой Arm v8. Реализована поддержка памяти LPDDR, интерфейсов PCIe и USB. Возможна работа в режимах 50GbE, 25GbE и 10GbE. SoC содержит встроенный нейронный модуль (NPU), который ускоряет ИИ-инференс на периферии сети. Благодаря этому уменьшаются задержки при одновременном повышении уровня защиты конфиденциальной информации. Предусмотрены расширенные средства обеспечения безопасности, включая алгоритмы постквантовой криптографии (PQC). 
Источник изображения: Broadcom Изделие BCM68850 совместимо со стандартом Wi-Fi 8. Среди прочего упомянуты функции интеллектуального самовосстановления. Операторы смогут использовать инструменты обнаружения аномалий в режиме реального времени и средства предиктивной оптимизации полосы пропускания для снижения операционных расходов и повышения средней выручки в расчёте на абонента (ARPU). Broadcom заявляет, что новый чип обеспечивает запас пропускной способности и детерминированную задержку, необходимые для следующего этапа развития широкополосной связи. Это особенно важно в свете трансформации домохозяйств в постоянно действующие точки периферийных вычислений с возрастающим трафиком данных. Изделие допускает широкий спектр сценариев развёртывания для удовлетворения потребностей как частных пользователей, так и предприятий.
27.05.2026 [10:21], Руслан Авдеев
Безумству храбрых: французский инженер троллит IT-гигантов сатирическими ИИ-нарезками с индюкомФранцузский разработчик и SRE (Site Reliability Engineer) Амин Раити (Amine Raiti) объявил настоящую войну облачным гиперскейлерам, включая AWS, Google Cloud и Microsoft Azure. Он потребовал от них отказа от огромных комиссий за прекращение использования услуг. В противном случае гиперскейлерам грозит бесконечный поток сгенерированного ИИ сатирического музыкального контента, сообщает The Register. Раити, работающий в некой финансовой организации, находящейся под надзором европейского центробанка, выбрал оружием генерируемые ИИ песни, сатирические стихи и музыкальные пародии, от K-pop до финской польки и музыки в стиле Шопена, назвав свою кампанию «Операция индюк» (Operation Dindon). Идея появилась, когда Раити работал управленцем в одной из французских Adtech-компаний. Бизнес был связан многолетними облачными договорами, которые действовали даже на фоне падения выручки компании и сокращения штата. Хотя конкретные облачные провайдеры в тех увольнениях не обвиняются, именно тогда привязка к вендору якобы перестала быть для Раити абстрактной технической проблемой. Требования организатора интернет-протеста чрезвычайно просты: гиперскейлеры должны дать клиентам возможность отказаться от многолетних соглашений, если бизнес заходит в финансовый тупик, прекратить взимать огромные средства за выгрузку данных из своих облаков и обеспечить отказ от проприетарных сервисов гиперскейлеров без огромных трат на миграцию. Журналистам Раити привёл вопиющие примеры. По его словам, одна конфигурация AWS NAT Gateway может обойтись в €6,7 тыс. ($7777) ежегодно за функциональность, которую, по его словам, администраторы Linux-систем обеспечивали ещё в конце 1990-х гг. Управляемые Kubernetes-сервисы могут обходиться ежегодно в €14 тыс. ($16251) и более. 
Источник изображения: Amine Raiti / LinkedIn В отличие от обычных разговоров, не уходящих дальше отдельных IT-команд или публикации постов в LinkedIn, Раити превратил свой протест в настоящее представление, создав сатирический музыкальный сериал «Легенда об индюке» (The Legend of Dindon). Главный герой — вымышленный индюк, регулярно попадающий в зависимость от облачных сервисов и не способный выбраться из ловушек. Каждая серия посвящена отдельной проблеме: скрытым расходам, юридическим привязкам к вендорам или, например, завышенным тарифам. В начале мая Раити опубликовал т.н. «Железный ультиматум» (Iron Ultimatum) на 11 языках, адресовав его AWS, Google и Microsoft. Организатор музыкальных протестов готов даже выпустить хвалебный поэтический сборник с похвалами в адрес облачных компаний, если те проведут значимые реформы. Если нет — операция продлится бессрочно, благо, создание одного трека занимает около двух минут, а обойдётся это не дороже €50/мес. «Коллекция» Раити уже включает порядка 50 сгенерированных ИИ треков. Сами облачные гиганты пока не ответили на ультиматум и до объявленного «дедлайна» в сентябре остаётся довольно много времени. Впрочем, нередко они и сами обвиняют друг друга в огромных платежах за отказ от сервисов и выгрузку данных.
26.05.2026 [23:24], Руслан Авдеев
Сделка Anthropic и Microsoft расширит спрос на ИИ ASIC и повлияет на цепочки поставок для облачного рынкаКак сообщает The Information, Anthropic ведёт с Microsoft переговоры об использовании фирменных ускорителей последней для работы с ИИ-моделями Claude. Подобный шаг способен ускорить широкое внедрение Maia 200 и поддержать спрос на ASIC по всей «облачной» цепочке поставок, сообщает DigiTimes. Выиграют и поставщики компонентов для облачного рынка, от Global Unichip до Marvell с Broadcom. Как сообщают отраслевые источники, Anthropic фактически стала главным драйвером спроса на ASIC. В отличие от OpenAI, которая ранее заключала крупные долгосрочные сделки по покупке чипов, закупки Anthropic обычно соответствовали актуальному спросу на вычислительные мощности. Тем не менее, в последние месяцы она тоже повысила активность. Во-первых, компания заключила соглашение на использование ASIC с Google и (AWS), арендовала ИИ-мощности у xAI и, теперь, возможно, будет арендовать их у Microsoft. Эксперты считают, что это свидетельствует о значительном росте популярности Claude, из-за чего выросла необходимость в вычислительных ресурсах. По словам источников, Anthropic активно применяет ASIC разных поставщиков — они предпочтительнее для компании, чем более дорогие ИИ-ускорители NVIDIA, что позволяет обеспечить эффективность расходов. Подобная стратегия позволяет компании избежать зависимости от единственного поставщика, что усиливает переговорные позиции компании и снижает для неё риски, связанные с концентрацией доступных вычислительных ресурсов у одного партнёра. 
Источник изображения: Microsoft Благодаря сделке Microsoft может поддержать собственные разработки ASIC, пока уступающие по многим параметрам решениям Google и AWS. Те уже некоторое время сдают ИИ-чипы собственной разработки в аренду. Если Microsoft удастся повторить подобный успех, компания сможет сократить расходы на расширение выпуска чипов и расширить их закупки, что создаст дополнительные стимулы для фактических производителей ASIC и их партнёров. На фоне роста внимания ИИ-бизнеса к ASIC, эксперты прогнозируют увеличение соответствующего рынка. По некоторым оценкам, если их будут использовать только облачные провайдеры, закупки на рынке останутся ограниченными, но рост спроса со стороны крупных клиентов облачных платформ может существенно помочь развитию всей ниши. Текущий вектор её развития указывает на то, что спрос будет расти и дальше. В феврале сообщалось, что Anthropic планирует увеличить к 2029 году расходы на облака до $80 млрд.
26.05.2026 [23:15], Владимир Мироненко
Верховный суд РФ разрешил бывшим сотрудникам Oracle оставить себе миллионные выходные пособияВерховный суд РФ после рассмотрения кассационной жалобы бывшего сотрудника АО «Оракл компьютерное оборудование», российского подразделения Oracle Communications (CGBU), отменил решение суда первой инстанции, а также апелляционного и кассационного судов о признании выплат выходных пособий бывшим сотрудникам обанкротившейся компании незаконными. Это может стать прецедентом, который повлияет на аналогичные разбирательства в связи с банкротством других российских подразделений иностранных компаний, отметил ресурс ComNews. В августе 2024 года конкурсный управляющий по делу о банкротстве российской «дочки» Oracle подал иски с требованием признать незаконной выплату бывшим сотрудникам премий на общую сумму более 100 млн руб., а также взыскать выходные пособия, выплаченные в связи с их увольнением. Суд первой инстанции отклонил требование истца о возврате премии, поскольку она является переменной частью зарплаты, размер которой определён трудовым договором. 
Источник изображения: Wesley Tingey/unsplash.com Вместе с тем он удовлетворил иск в части взыскания выходных пособий. Это решение было отменено Верховным судом РФ. Как пояснили в Pen & Paper, банкротство не ограничивает права работников на получение всего комплекса гарантий, установленных Трудовым кодексом РФ, к которым, в том числе, относится выплата выходного пособия.
26.05.2026 [16:07], Руслан Авдеев
Выручка xFusion, отделившейся из-за санкций от Huawei, за четыре года выросла шестикратно на фоне поддержки ИИ-отрасли государствомКитайский производитель серверов xFusion, отделившийся от Huawei и получивший бизнес x86-серверов последней, объявил о выручке в объёме ¥58,2 млрд (порядка $8,6 млрд) в 2025 году. Кратный рост в сравнении с прошлыми годами связывают с курсом КНР на создание собственной цепочки поставок для ИИ-индустрии и поддержкой в стране местных вендоров, занимающихся высокопроизводительными серверами, сообщает DigiTimes. В ходе конференции, проводившейся xFusion на днях, компания представила стратегию развития, новые продукты и поделилась достижениями. По словам представителя компании, ИИ уже меняет не только цифровой, но и физический мир, а в ближайшие 3–5 лет на рынке окончательно оформится разделение на лидеров и отстающих. xFusion — один из ключевых производителей серверов в провинции Хэнань (Henan), недавно компания завершила подготовку к выходу на публичные торги. Сегодня она выпускает ИИ-серверы, СЖО для ЦОД и сдаёт вычислительные мощности в аренду. По данным IDC, в 2025 году компания, созданная в ходе реструктуризации серверного бизнеса Huawei, заняла 12,7 % доли рынка китайских серверов на архитектуре x86, уступив только Inspur с 31,3 %, но опередив H3C, Lenovo и ZTE. 
Источник изображения: xFusion В 2021 году Huawei испытывала проблемы с поставками компонентов, включая CPU производства Intel и AMD для серверов, поэтому серверное направление было решено выделить, чтобы освободить его от санкций. В ноябре 2021 года была зарегистрирована xFusion, а контроль получили инвесторы во главе с государственными структурами. Уже через 55 дней после регистрации начался выпуск серверов под брендом xFusion и было налажено массовое производство. После того, как компания отделилась от Huawei, она сосредоточила усилия на рынке вычислительных мощностей и ИИ-инфраструктуры. Её выручка выросла с ¥10 млрд в 2021 году до почти ¥60 млрд в 2025-м. Успех компании принесли высокопроизводительные серверы, поскольку она не разбрасывалась на производство относительно бюджетных вариантов — в этом сегменте и так наблюдается избыток предложения. Кроме того, компания является одним из лидеров в сфере СЖО в Китае. x86-решения xFusion совместимы с ИИ-ускорителями Huawei Ascend и соответствующей платформой в целом. Кроме того, xFusion даже входит в мировую цепочку поставок NVIDIA. По мнению экспертов, поддержка государственного сектора может превратить xFusion в одного из ключевых игроков в сфере развития собственной ИИ-инфраструктуры в Китае. Кроме того, это может помочь снизить зависимость от зарубежных технологий.
26.05.2026 [09:00], Сергей Карасёв
Гибкие настройки безопасности и новые инструменты для работы с шаблонами — «Базис» обновил конструктор Basis Automation Studio до версии 2.4Компания «Базис», лидер российского рынка ПО управления динамической инфраструктурой, представила версию 2.4 конструктора платформенных сервисов Basis Automation Studio — модуля, входящего в расширенную версию облачной платформы Basis Dynamix Cloud Control. Свежий релиз предлагает интеграцию со средством защиты виртуализации Basis Virtual Security, гибкую ролевую модель и поддержку работы с внешними системами версионирования через веб-портал. Basis Automation Studio представляет собой среду автоматизации развёртывания сервисов с инструментами визуального проектирования виртуальной инфраструктуры на основе готовых компонентов и связей между ними. В состав конструктора входит расширяемый каталог шаблонов виртуальных инфраструктур и платформенных сервисов, а также расширяемая библиотека компонентов с образцами популярного ПО — ClickHouse, Consul, Docker, MariaDB, PostgreSQL и других. Алгоритм развёртывания построен на архитектуре TOSCA с использованием языков YAML, Ansible, Python и Bash. Управление правами и доступомОдной из ключевых доработок релиза стала интеграция конструктора с решением защиты Basis Virtual Security. Конструктор использует Basis Virtual Security в качестве единого провайдера идентификации, что даёт администраторам возможность централизованно управлять учётными записями и правами доступа пользователей, а также обеспечивает поддержку технологии единого входа (Single Sign-On, SSO). В результате можно централизованно применять политики безопасности, что снижает нагрузку на администраторов, а пользователей платформы избавляет от необходимости вводить учётные данные при переходе между компонентами экосистемы «Базиса». 
Источник изображений: «Базис» В Basis Automation Studio 2.4 — в дополнение к имеющейся ролевой модели — была представлена её расширенная версия, которая позволяет тонко настраивать права доступа пользователей: администратор может собирать собственные роли из атомарных разрешений и назначать их в нужном объёме конкретным пользователям. Миграция на новую модель уже выполнена на уровне архитектуры конструктора. Интеграция с внешними Git-репозиториямиВ новой версии Basis Automation Studio появилась возможность загружать компоненты и шаблоны сервисов из Git-репозиториев. Загрузка и обновление компонентов и шаблонов сервисов осуществляется, используя графический интерфейс, по выбранному Git-тегу с возможностью пакетной загрузки. Поддерживаются разные способы аутентификации (пароль, токен). Загруженный компонент шаблон сервиса поддерживает версионирование (с возможностью обновления «вперед и назад»).  Тем самым продолжается развитие веб-портала как единой точки работы с конструктором. Ранее в портал были добавлены инструменты создания и редактирования компонентов и шаблонов. В новой версии конструктора добавилась интеграция с внешними Git-репозиториями. Это позволяет встроить разработку TOSCA-шаблонов в привычные для команд процессы работы с исходным кодом, обеспечить отслеживаемость изменений и упростить совместную работу над каталогом сервисов. В новом релизе также была добавлена оценка ресурсов для развёрнутых сервисов. Это позволяет пользователям анализировать ресурсные требования сервисов и точнее планировать их эксплуатацию. «Ключевая задача, которую Basis Automation Studio решает для бизнеса — упрощение процесса развёртывания ИТ-систем и сервисов внутри виртуального ЦОД. Поэтому мы развиваем продукт сразу в нескольких направлениях, связанных с решением этой задачи. В частности, мы уже реализовали централизацию управления доступом через интеграцию с другим нашим продуктом, Basis Virtual Security, а также более гибкое разграничение прав пользователей и включение конструктора в стандартные процессы разработки через поддержку Git в веб-портале», — отметил Дмитрий Сорокин, технический директор компании «Базис». |
|

